

このガイドでは以下を学びます:
- モデルコンテキストプロトコル(MCP)とは何か、そしてAIエージェントにとってなぜ重要なのか
- – Bright DataのMCPサーバーをAugment Codeで設定する方法
- – Web検索、Markdownスクレイピング、SERP APIツールの使用方法
- スクレイピングブラウザを使用した動的ウェブサイトの操作方法
- AIコーディングとライブWebデータを組み合わせた実用的なワークフローの構築方法
設定に入る前に、接続する2つの技術を理解しておくと役立ちます。
モデルコンテキストプロトコル(MCP)とは?
MCPは、AIモデルが外部ツールやデータソースに接続するための標準化された方法です。MCPをLLMのUSB-Cポートと考えてください。USB-Cが単一の標準であらゆる周辺機器をあらゆるデバイスに接続できるように、MCPは統一プロトコルを通じてAIモデルがあらゆるデータソースやツールに接続することを可能にします。
MCPが登場する前は、LLMを外部ツールに接続するには、組み合わせごとにカスタム統合を構築する必要がありました。Claude搭載エージェントにウェブ検索をさせたい?統合を構築。GPTに切り替える?再構築。新しいデータソースを追加?さらにカスタムコードが必要。
MCPはこの複雑さを解消します。AIモデルが外部ツールを発見し、呼び出し、結果を受け取る標準的な方法を定義します。MCPサーバーを一度構築すれば、MCP互換のあらゆるクライアントが利用可能です。
より深い技術的解説については、ウェブスクレイピング向けMCPサーバーのガイドをご覧ください。
ツール接続を標準化するMCPの仕組みを理解したところで、ウェブアクセス機能で強化するAIコーディングアシスタントを見ていきましょう。
Augment Codeとは?
Augment Codeは、大規模で複雑なコードベース向けに設計されたAIコーディングアシスタントです。行単位の自動補完に焦点を当てるツールとは異なり、Augment Codeはプロジェクト全体をインデックス化し、ファイル間の依存関係を理解します。
最大の差別化要素は「コンテキストエンジン」と呼ばれる機能です。単なる大規模コンテキストウィンドウ(20万トークン以上)を提供するだけでなく、コードベースを積極的にインデックス化し、プロジェクトのアーキテクチャを常に把握します。関数のリファクタリングを依頼すると、その関数をインポートしている他のファイルを特定し、更新が必要な箇所を認識します。
主な機能
- コードベース全体のインデックス化。複数のリポジトリにまたがる依存関係を含め、プロジェクト全体をインデックス化。質問に対してコードベース内のあらゆる場所から関連コンテキストを抽出。
- エージェントモード。チャットや自動補完に加え、Augmentは自律的に複数ステップのタスクを実行可能。全API呼び出しにエラー処理を追加するよう指示すれば、ファイル単位でコードベース全体に適用します。
- IDE対応の柔軟性。VS Code、JetBrains製全IDE(IntelliJ、PyCharm、WebStorm)、Vim/Neovimに対応。ターミナルワークフロー向けCLIツール「Auggie」を提供。
- セキュリティ認証。SOC 2 Type II認証取得、ISO/IEC 42001準拠。
Augment Codeはコードベースの理解に優れていますが、1つの大きな制限があります:ライブウェブ上で何が起きているかを見ることができません。そこでBright Dataの出番です。
Bright Data MCPとAugment Codeを組み合わせる理由

Augment Codeのコンテキストウィンドウとエージェント機能は、複雑な多段階タスクに効果的です。しかし単独ではライブウェブにアクセスできません。APIエンドポイントが先週変更されたか確認したり、ライブラリの最新版を検証したり、競合情報を収集したりすることはできません。
Bright DataのMCPサーバーがこのギャップを埋めます。MCPサーバーは60以上のウェブアクセスツールを提供します。Bright Dataのドキュメントによれば、195カ国にまたがる1億5000万以上のレジデンシャルIPへのアクセスが含まれます。
これらを接続すると、以下の機能が得られます:
| カテゴリー | 機能 | 例となるツール |
|---|---|---|
| Web検索 | プログラムで検索エンジンをクエリ | search_engine, search_engine_batch |
| ページスクレイピング | 任意のURLからコンテンツを抽出 | scrape_as_markdown, scrape_as_html |
| ブラウザ自動化 | ナビゲート、クリック、入力、スクロール | scraping_browser_navigate, scraping_browser_click_ref |
| 構造化抽出 | 60以上のプラットフォームからクリーンなJSONを取得 | web_data_amazon_product, web_data_linkedin_profile |
スクレイピングブラウザツールは注目に値する。単純なフェッチリクエストとは異なり、これらのツールはJavaScriptレンダリング、ログインフロー、無限スクロール、複数ステップのナビゲーションを処理する実ブラウザを制御する。これは現代的なウェブアプリケーションと対話する必要がある能動的システムにとって重要だ。
この設定を初めてテストした際、AugmentにOpenAI APIのレート制限に関する最新変更を確認させました。約8秒で最新のドキュメントを取得し、ローカルにキャッシュした内容と比較。GPT-4 Turboエンドポイントの分単位トークン制限が変更されたことを指摘しました。この単一のクエリが、本番環境でレート制限に抵触するコードのデプロイを防いでくれました。
メリットが明確になったところで、実際の設定手順を見ていきましょう。
Bright DataとAugment Codeの連携
前提条件
開始前に、以下の環境が整っていることを確認してください:
- Node.js 18以上がインストールされている
- VS Code(またはお好みのIDE)にAugment Code拡張機能がインストールされている
- Bright Dataアカウント(設定方法は後述)
Bright Data API トークンがまだない場合もご安心ください。次のセクションで作成方法を説明します。
ステップ1: Bright Dataアカウントの作成とAPIトークンの取得
開始するには、Bright DataアカウントとMCPサーバー認証用のAPIトークンが必要です(所要時間約2分)。
- brightdata.com にアクセスし、「無料トライアル」をクリックしてアカウントを作成します。
- ダッシュボードにログイン後、左サイドバーの「設定」(歯車アイコン)に移動し、「APIトークン」をクリックします。
- 「トークンを作成」をクリックし、「Augment Code MCP」などわかりやすい名前を付けます。
- 新規トークンをコピーし、安全に保管してください。次のステップで必要になります。
ステップ2: Augment CodeでBright Data MCPを設定する
このチュートリアルでは、Visual Studio Code用Augment Code拡張機能を使用します。
AugmentではMCPサーバーの追加に3つの方法を提供しています:Easy MCP(ワンクリック設定)、設定パネルGUI、JSONインポートです。設定オプションを完全に制御できるため、ここではJSONインポートを使用します。
- VS Codeを開き、アクティビティバー(左サイドバー)のAugment Codeアイコンをクリックします。
- Augmentパネルで、右上隅にある歯車アイコン(設定)をクリックします。これにより、新しいタブでAugmentの設定ページが開きます。
- 「MCP サーバー」セクションをクリックします。
- 「JSONからインポート」をクリックします。
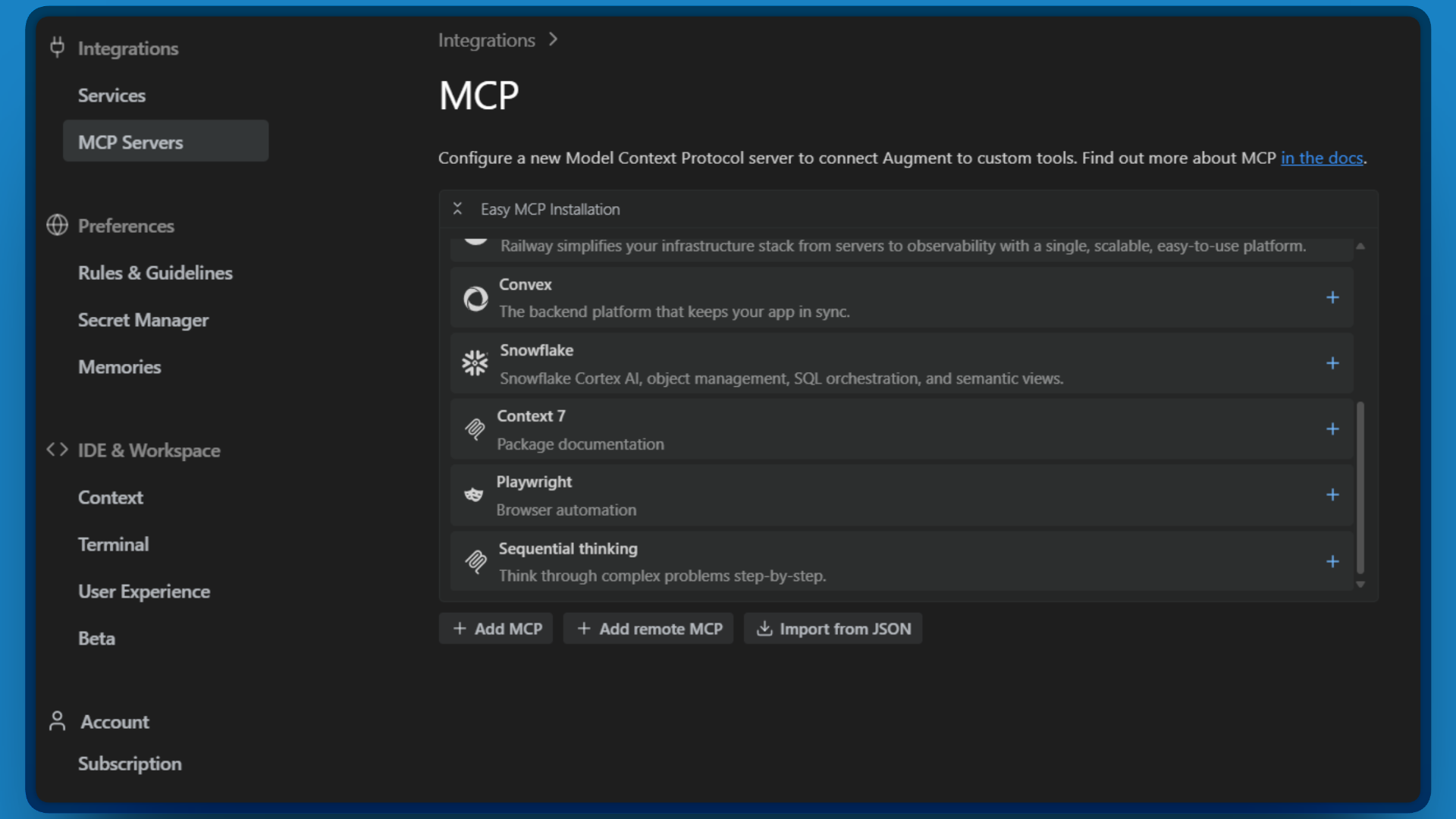
設定を貼り付ける準備が整いました。以下のJSONをコピーし、<YOUR_API_TOKEN>をステップ1で作成したBright Dataトークンに置き換えてください:
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": ""
}
}
}
}VS Codeを再起動してMCPサーバーが正しく初期化されることを確認すると、AugmentがBright Dataのウェブスクレイピングインフラに完全にアクセスできるようになります。
代替方法: リモートサーバー設定
ローカルで何も実行したくない場合は、SSE(サーバー送信イベント)を使用してBright Dataのホストサーバーに直接接続できます:
{
"mcpServers": {
"Bright Data": {
"url": "https://mcp.brightdata.com/sse?token=&pro=1",
"type": "sse"
}
}
}このリモート方式ではローカル設定が一切不要です。MCPサーバーは完全にBright Dataのインフラ上で動作するため、npmパッケージをインストールできない環境やローカル依存関係を最小限に抑えたい場合に有用です。
ステップ3: 接続の確認
接続を確認するため、高度な機能に進む前にすべてが正常に動作していることを確認しましょう。
- VS CodeのアクティビティバーにあるAugmentアイコンをクリックして、Augmentコードパネルを開きます。
- 新規チャットを開始し、Webアクセスを必要とする簡単なリクエストを入力します。例:
“Search the web for ‘Python 3.13 new features’ and summarize the top results.”
- Augment
Codeがsearch_engineツールを呼び出し、最新の検索結果を返す様子を確認してください。
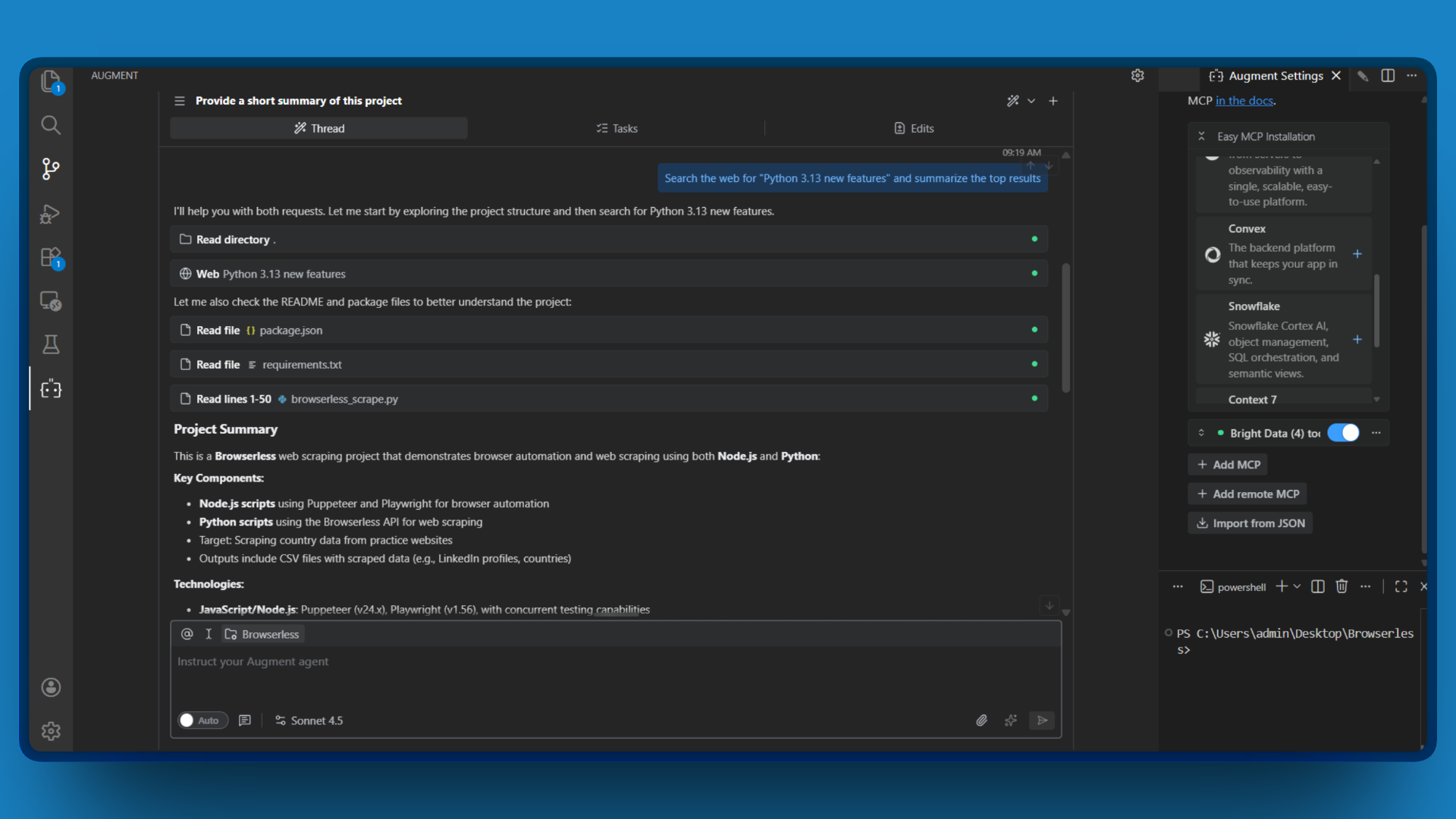
ライブウェブから取得された検索結果が表示されたら、おめでとうございます!Bright Data MCP接続が正常に機能しています。
Augment Codeにウェブ検索を依頼すると、以下の流れで処理されます:
- Augment Codeがリクエストを解析し、ウェブデータが必要と判断
- MCPクライアント(Augmentに組み込み済み)がBright Data MCPサーバーに利用可能なツールを問い合わせ
- MCPサーバーがsearch_engineを含むツールリストを返す
- Augment Codeが検索クエリと共にsearch_engineを呼び出します
- BrightDataはSERP APIを使用して検索を実行し、地域ターゲティングとボット対策機能を自動的に処理します
- 結果はMCP経由でAugmentコードに戻り、フォーマット処理されます
この一連のプロセスは数秒で完了します。IDEを離れる必要はありません。
接続が確認されれば、これらのツールが実際に何ができるのかを探索する準備が整います。
クラシック版Bright Data MCPツールの使用
接続が確立されたので、Rapid Mode(無料)とPro Modeの両方で動作する基本ツールを探ってみましょう。
search_engineによるWeb検索
search_engineツールはGoogle、Bing、Yandexにクエリを送信し、構造化された結果を返します。以下に最適です:
- 最新のエンドポイントが必要な場合の現行APIドキュメント調査
- 未知のライブラリに関する最新のチュートリアルやStack Overflowの回答を探す場合
- 依存関係を追加する前にパッケージの最新版を確認する
- 類似製品・サービスに関する競合情報収集
例えば、Augmentに次のように指示すると:
最新のNext.js 15の互換性のない変更点を検索し一覧表示する
Augment Codeはsearch_engineを呼び出し、結果を処理して、ソース付きの互換性のない変更点の要約を提供します。タブを切り替える必要はありません。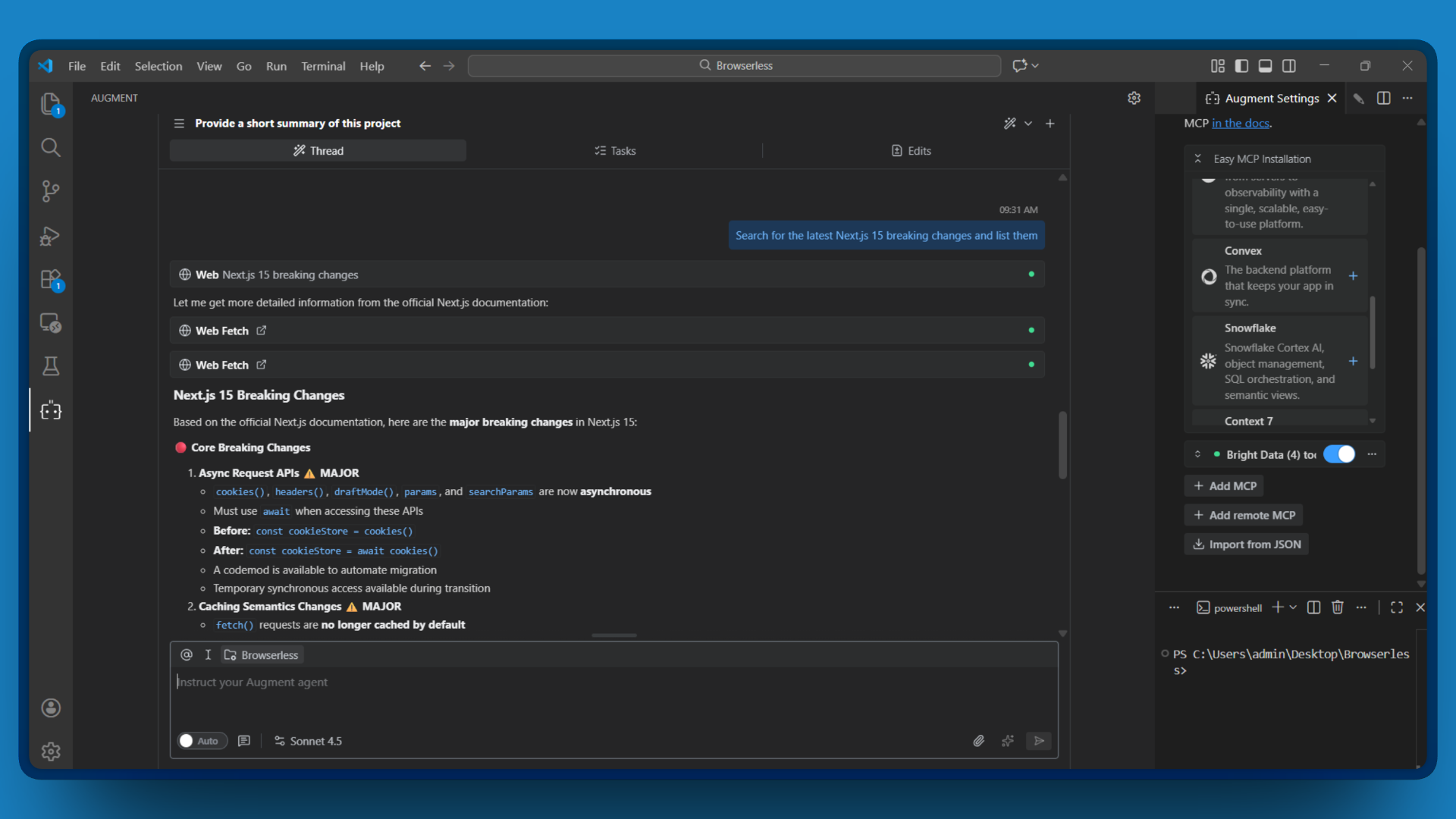
一括検索(最大10クエリ同時実行)には、Proモードでsearch_engine_batchが利用可能になります。
scrape_as_markdownによるページスクレイピング
特定のページの完全なコンテンツが必要な場合、scrape_as_markdownがHTMLを取得し、クリーンなMarkdownに変換します。このツールはWeb Unlocker技術を使用して、CAPTCHAやボット対策機能を自動的に回避します。
例:
https://stripe.com/docs/api の Stripe API ドキュメントをスクレイピングし、認証方法を解説してください
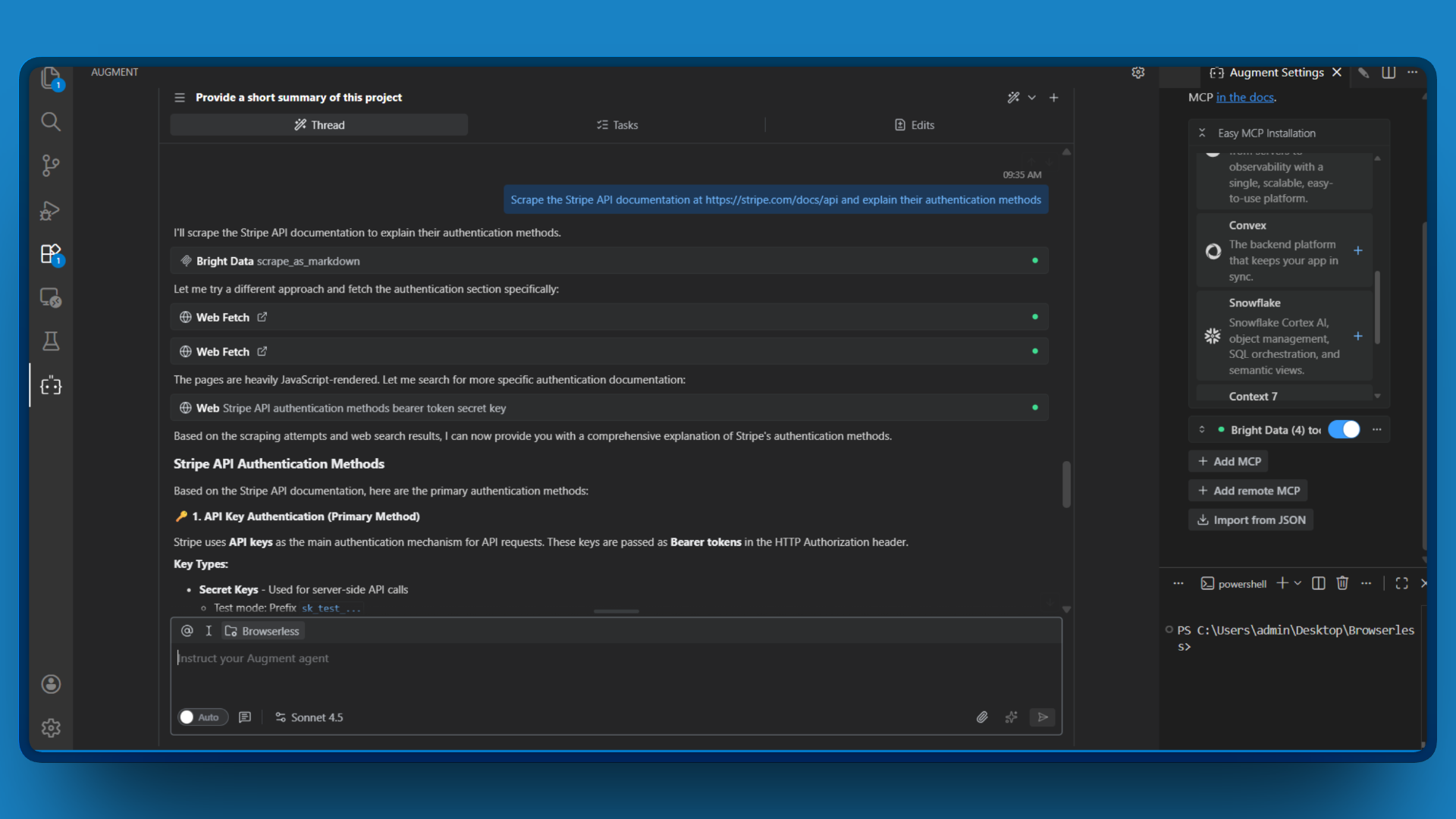
ツールはページ内容をMarkdown形式で返却し、Augment Codeがこれを解析・要約します。煩雑なドキュメントを手動で読み込むことなく、必要な情報を取得できます。
Web Data APIによる構造化データ
主要プラットフォームでは、HTMLを手動でパースする必要はありません。プロモードには、クリーンで構造化されたJSONを返す事前構築済み抽出ツールが含まれます。
例:
このAmazon商品ページの詳細を取得: https://www.amazon.com/dp/B0CHX3QBCH
web_data_amazon_productツールは、タイトル、価格、評価、レビュー、仕様などの構造化データを返します。パースコードは不要です。
利用可能な抽出ツールは60以上のプラットフォームをカバー:
- Eコマース:Amazon、Walmart、eBay、Etsy、Best Buy、Google Shopping
- ソーシャル: LinkedIn、Instagram、Facebook、TikTok、X/Twitter、YouTube、Reddit
- ビジネス:Crunchbase、ZoomInfo、Zillow、Google Maps
- 金融:Yahoo Finance、Reuters
完全なリストはMCPツールのドキュメントでご確認ください。
複数のツールが利用可能な状況では、状況に応じてどのツールを活用すべきかを知ることが、作業効率向上につながります。
適切なツールの選択
状況によって適したツールは異なります。適切なツールを選ぶために、以下の表をご活用ください:
| 状況 | 推奨ツール | 理由 |
|---|---|---|
| 事実の迅速な検索 | 検索エンジン |
高速、構造化された結果を返す、低コスト |
| ページ全体のコンテンツが必要 | scrape_as_markdown |
ボット対策に対応、クリーンなテキストを返す |
| ページにJavaScriptが必要 | scraping_browser_navigate |
JSをレンダリングし、動的コンテンツを待機 |
| ログインまたは複数ステップフロー | スクレイピングブラウザツール | クリック、入力、認証処理が可能 |
| Amazon、LinkedInなど | web_data_* API |
構造化されたJSONを返すため、パース不要 |
| 複数の検索を同時実行 | search_engine_batch |
最大10件のクエリを効率的に処理 |
基本原則:まず最も単純で機能する可能性のあるツールから始める。より単純な方法が失敗した場合にのみブラウザ自動化に移行する。
適切なツールを選択しても、時折問題が発生することがあります。最も一般的な問題の診断と修正方法をご紹介します。
よくある問題のトラブルシューティング
問題が発生しましたか?最も一般的な問題への解決策をご紹介します:
「ツールが見つかりません」エラー
Augment CodeがBright Dataツールを検出できない場合、まずAPIトークンが正しく有効期限切れでないかを確認してください。次に、MCP設定が正しく保存されていることを確認し、Augment Codeを再読み込みではなく完全に再起動してみてください。問題が解決しない場合は、Augmentのログで接続エラーを確認してください。
応答が遅い
ブラウザ自動化は単純なスクレイピングよりも時間がかかるため、応答が遅い場合は以下の点を考慮してください。JavaScriptレンダリングには時間がかかります。スクレイピングブラウザはページとやり取りする前に完全にレンダリングする必要があるためです。インタラクティブな要素が多い複雑なページでは、より大きなスナップショットが必要となり、処理時間も増加します。
インタラクションを必要としないシンプルなページでは、より高速な代替手段としてscrape_as_markdownの使用を検討してください。
レート制限
レート制限に抵触した場合は、まずBright Dataダッシュボードで利用状況を確認してください。設定ファイルのRATE_LIMIT環境変数を調整してリクエスト頻度を管理することも可能です。より高い制限が必要な大規模プロジェクトでは、プランのアップグレードをご検討ください。
技術的な問題に加え、AIエージェントをウェブに接続する際には、留意すべきセキュリティ上の考慮事項があります。
セキュリティのベストプラクティス
AIエージェントをウェブに接続する際は、セキュリティが重要です。以下の原則を心に留めてください:
- スクレイピングしたコンテンツは信頼できないものとして扱ってください。スクレイピングしたページからのコード実行や、生のコンテンツをeval()に渡すことは絶対に避けてください。
- 可能な場合は構造化抽出を使用してください。web_data_*ツールは検証済みJSONを返すため、生のHTMLパースに比べて注入リスクが低減されます。
- APIトークンは安全に保管してください。コードベースにハードコードした値ではなく、環境変数を使用してください。
- エージェントの動作をレビューする。特に本番環境では、エージェントの動作を監視してください。
これらの対策を実施すれば、開発を開始する準備が整います。
結論
Bright DataのMCPサーバーは、Augment Codeをコード中心のアシスタントから、リアルタイム情報を収集できるWeb対応エージェントへと変革します。検索、スクレイピングブラウザ、ブラウザ自動化、構造化抽出のための60以上のツール(1億5000万以上のレジデンシャルIPと99.95%の成功率を基盤)により、AIコーディングアシスタントは以下が可能になります:
- 最新のドキュメントやライブAPIを調査
- 競合情報を自動収集
- 複雑なデータ収集ワークフローの自動化
- 多段階操作を伴う動的ウェブサイトのナビゲーション
スクレイピングブラウザツールは特にエージェント型システムで威力を発揮します。ARIAスナップショットと安定した要素参照を活用し、ログインフロー、多段階フォーム、単純なスクレイピング手法では対応困難な動的コンテンツをエージェントが処理します。
AIコーディングアシスタントにリアルタイムWebアクセスを実装する準備はできていますか?
より高度な手法については、LlamaIndexを用いたAIエージェント構築ガイドやCrewAIとのMCP連携ガイドをご参照ください。





