

このシステムはリアルタイムのウェブインテリジェンスで新規リードを発見し、購買シグナルを自動検知、実際のビジネスイベントに基づくパーソナライズされたアプローチを生成します。GitHubでアクションを即座に開始。
学習内容:
- CrewAIを用いた専門的な見込み客開拓タスク向けマルチエージェントシステムの構築方法
- Bright Data MCPを活用したリアルタイム企業・コンタクト情報取得手法
- 採用・資金調達・経営陣変更などのトリガーイベントを自動検知する方法
- ライブビジネスインテリジェンスに基づくパーソナライズされたアウトリーチ生成方法
- 見込み客発見からCRM連携までの自動化パイプライン構築方法
さあ始めましょう!
現代のセールス開発が直面する課題
従来の販売開発は手動調査に依存しており、見込み客を特定するためにLinkedInプロフィール、企業サイト、ニュース記事を飛び回る必要があります。この手法は時間がかかり、ミスが発生しやすく、連絡先リストが古くなったり、ターゲットを絞ったコミュニケーションが困難になることがよくあります。
CrewAIとBright Dataの統合により、見込み客開拓ワークフロー全体が自動化され、数時間かかっていた手作業がわずか数分に短縮されます。
構築するシステム:インテリジェント営業開発システム
理想的な顧客プロファイルに合致する企業を発見するマルチエージェントAIシステムを構築します。購買意欲を示すトリガーイベントを追跡し、意思決定者に関する検証済み情報を収集し、実際のビジネスインテリジェンスを活用したパーソナライズされたアウトリーチメッセージを作成します。このシステムはCRMに直接接続し、質の高いパイプラインを維持します。
前提条件
以下の要件を満たす開発環境を構築してください:
- Python 3.11+のインストール
- MCPアクセス権限付きBright Dataアカウント
- AI生成用OpenAI APIキー
- パイプライン統合用のHubSpot CRM認証情報
環境設定
プロジェクトディレクトリを作成し、依存関係をインストールします。他のPythonプロジェクトとの競合を避けるため、クリーンな仮想環境を設定することから始めます。
python -m venv ai_bdr_env
source ai_bdr_env/bin/activate # Windows: ai_bdr_envScriptsactivate
pip install crewai "crewai-tools[mcp]" openai pandas python-dotenv streamlit requests環境設定ファイルを作成:
BRIGHT_DATA_API_TOKEN="your_bright_data_api_token"
OPENAI_API_KEY="your_openai_api_key"
HUBSPOT_API_KEY="your_hubspot_api_key"AI BDRシステムの構築
それでは、AI BDRシステム用のAIエージェント構築を始めましょう。
ステップ1: Bright Data MCPの設定
複数のソースからリアルタイムでデータを収集するウェブスクレイピングインフラの基盤を作成します。MCPクライアントはBright Dataのスクレイピングネットワークとのすべての通信を処理します。
プロジェクトルートディレクトリにmcp_client.py ファイルを作成し、以下のコードを追加します:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call, deduplicate_by_key, extract_domain_from_url
class CompanyDiscoveryInput(BaseModel):
industry: str = Field(description="企業発見の対象業界")
size_range: str = Field(description="企業規模範囲 (スタートアップ, 小規模, 中規模, 大企業)")
location: str = Field(default="", description="地理的位置または地域")
class CompanyDiscoveryTool(BaseTool):
name: str = "discover_companies"
description: str = "ウェブスクレイピングを用いてICP基準に合致する企業を検索"
args_schema: type[BaseModel] = CompanyDiscoveryInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, industry: str, size_range: str, location: str = "") -> list:
companies = []
search_terms = [
f"{industry} companies {size_range}",
f"{industry} startups {location}",
f"{industry} technology companies"
]
for term in search_terms:
results = self._search_companies(term)
for company in results:
enriched = self._enrich_company_data(company)
if self._matches_icp(enriched, industry, size_range):
companies.append(enriched)
return deduplicate_by_key(companies, lambda c: c.get('domain') or c['name'].lower())
def _search_companies(self, term):
"""Bright Dataを介した実際のウェブ検索を使用して企業を検索します。"""
try:
companies = []
search_queries = [
f"{term} directory",
f"{term} list",
f"{term} news"
]
for query in search_queries:
try:
results = self._perform_company_search(query)
companies.extend(results)
if len(companies) >= 10:
break
except Exception as e:
print(f"検索クエリ '{query}' でエラー: {str(e)}")
continue
return self._filter_unique_companies(companies)
except Exception as e:
print(f" '{term}' の企業検索でエラー: {str(e)}")
return []
def _enrich_company_data(self, company):
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
website_data = safe_mcp_call(self.mcp, 'scrape_company_website', company.get('domain', ''))
employee_count = linkedin_data.get('employee_count') or 150
return {
**company,
'linkedin_intelligence': linkedin_data,
'website_intelligence': website_data,
'employee_count': employee_count,
'icp_score': 0
}
def _matches_icp(self, company, industry, size_range):
score = 0
if industry.lower() in company.get('industry', '').lower():
score += 30
if self._check_size_range(company.get('employee_count', 0), size_range):
score += 25
if company.get('name') and company.get('domain'):
score += 20
company['icp_score'] = score
return score >= 20
def _check_size_range(self, count, size_range):
ranges = {'startup': (1, 50), 'small': (51, 200), 'medium': (201, 1000)}
min_size, max_size = ranges.get(size_range, (0, 999999))
return min_size <= count <= max_size
def _perform_company_search(self, query):
"""Bright Data MCPを使用して企業検索を実行します。"""
search_result = safe_mcp_call(self.mcp, 'search_company_news', query)
if search_result and search_result.get('results'):
return self._extract_companies_from_mcp_results(search_result['results'], query)
else:
print(f"{query} の MCP 結果はありません")
return []
def _filter_unique_companies(self, companies):
"""重複する企業をフィルタリングします。"""
seen_names = set()
unique_companies = []
for company in companies:
name_key = company.get('name', '').lower()
if name_key and name_key not in seen_names:
seen_names.add(name_key)
unique_companies.append(company)
return unique_companies
def _extract_companies_from_mcp_results(self, mcp_results, original_query):
"""MCP検索結果から企業情報を抽出する。"""
companies = []
for result in mcp_results[:10]:
try:
title = result.get('title', '')
url = result.get('url', '')
snippet = result.get('snippet', '')
company_name = self._extract_company_name_from_result(title, url)
if company_name and len(company_name) > 2:
domain = self._extract_domain_from_url(url)
industry = self._extract_industry_from_query(original_query)
companies.append({
'name': company_name,
'domain': domain,
'industry': industry
})
except Exception as e:
print(f"MCP結果から企業名を抽出中にエラー: {str(e)}")
continue
return companies
def _extract_company_name_from_result(self, title, url):
"""検索結果のタイトルまたはURLから企業名を抽出する。"""
import re
if title:
title_clean = re.sub(r'[|-—–].*$', '', title).strip()
title_clean = re.sub(r's+(Inc|Corp|LLC|Ltd|Solutions|Systems|Technologies|Software|Platform|Company)$', '', title_clean, flags=re.IGNORECASE)
if len(title_clean) > 2 and len(title_clean) < 50:
return title_clean
if url:
domain_parts = url.split('/')[2].split('.')
if len(domain_parts) > 1:
return domain_parts[0].title()
return None
def _extract_domain_from_url(self, url):
"""URLからドメインを抽出する。"""
return extract_domain_from_url(url)
def _extract_industry_from_query(self, query):
"""検索クエリから業界を抽出する。"""
query_lower = query.lower()
industry_mappings = {
'saas': 'SaaS',
'fintech': 'FinTech',
'ecommerce': 'E-commerce',
'healthcare': 'Healthcare',
'ai': 'AI/ML',
'machine learning': 'AI/ML',
'artificial intelligence': 'AI/ML'
}
for keyword, industry in industry_mappings.items():
if keyword in query_lower:
return industry
return 'Technology'
def create_company_discovery_agent(mcp_client):
return Agent(
role='企業発掘スペシャリスト',
goal='ICP基準に合致する高品質な見込み客の発見',
backstory='リアルタイムWebインテリジェンスを活用した潜在顧客の特定に精通。',
tools=[CompanyDiscoveryTool(mcp_client)],
verbose=True
)このMCPクライアントは、Bright DataのAIインフラストラクチャを使用してすべてのウェブスクレイピングタスクを管理します。LinkedInの企業ページ、企業ウェブサイト、資金調達データベース、ニュースソースへの信頼性の高いアクセスを提供します。クライアントは接続プーリングを担当し、自動でボット対策機能を回避します。
ステップ2: 企業発見エージェント
理想的な顧客プロファイル基準を、特定の要件に合致する企業を発見するスマートなシステムに変換します。エージェントは複数のソースを検索し、ビジネスインテリジェンスで企業データを強化します。
まず、プロジェクトルートにagents フォルダを作成します。次にagents/company_discovery.py ファイルを作成し、以下のコードを追加します:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call, deduplicate_by_key, extract_domain_from_url
class CompanyDiscoveryInput(BaseModel):
industry: str = Field(description="企業発見の対象業界")
size_range: str = Field(description="企業規模範囲 (スタートアップ, 小規模, 中規模, 大企業)")
location: str = Field(default="", description="地理的位置または地域")
class CompanyDiscoveryTool(BaseTool):
name: str = "discover_companies"
description: str = "ウェブスクレイピングを用いてICP基準に合致する企業を検索"
args_schema: type[BaseModel] = CompanyDiscoveryInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, industry: str, size_range: str, location: str = "") -> list:
companies = []
search_terms = [
f"{industry} companies {size_range}",
f"{industry} startups {location}",
f"{industry} technology companies"
]
for term in search_terms:
results = self._search_companies(term)
for company in results:
enriched = self._enrich_company_data(company)
if self._matches_icp(enriched, industry, size_range):
companies.append(enriched)
return deduplicate_by_key(companies, lambda c: c.get('domain') or c['name'].lower())
def _search_companies(self, term):
"""Bright Dataを介した実際のウェブ検索を使用して企業を検索します。"""
try:
companies = []
search_queries = [
f"{term} directory",
f"{term} list",
f"{term} news"
]
for query in search_queries:
try:
results = self._perform_company_search(query)
companies.extend(results)
if len(companies) >= 10:
break
except Exception as e:
print(f"検索クエリ '{query}' でエラー: {str(e)}")
continue
return self._filter_unique_companies(companies)
except Exception as e:
print(f" '{term}' の企業検索でエラー: {str(e)}")
return []
def _enrich_company_data(self, company):
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
website_data = safe_mcp_call(self.mcp, 'scrape_company_website', company.get('domain', ''))
employee_count = linkedin_data.get('employee_count') or 150
return {
**company,
'linkedin_intelligence': linkedin_data,
'website_intelligence': website_data,
'employee_count': employee_count,
'icp_score': 0
}
def _matches_icp(self, company, industry, size_range):
score = 0
if industry.lower() in company.get('industry', '').lower():
score += 30
if self._check_size_range(company.get('employee_count', 0), size_range):
score += 25
if company.get('name') and company.get('domain'):
score += 20
company['icp_score'] = score
return score >= 20
def _check_size_range(self, count, size_range):
ranges = {'startup': (1, 50), 'small': (51, 200), 'medium': (201, 1000)}
min_size, max_size = ranges.get(size_range, (0, 999999))
return min_size <= count <= max_size
def create_company_discovery_agent(mcp_client):
return Agent(
role='企業発見スペシャリスト',
goal='ICP基準に合致する高品質な見込み客を発見する',
backstory='リアルタイムWebインテリジェンスを活用した潜在顧客の特定に精通。',
tools=[CompanyDiscoveryTool(mcp_client)],
verbose=True
)ディスカバリーエージェントは複数のデータソースを検索し、理想的な顧客プロファイルに合致する企業を見つけます。各企業についてLinkedInや企業ウェブサイトからのビジネス情報を追加します。その後、設定可能なスコアリング基準に基づいて結果をフィルタリングします。重複排除プロセスにより見込み客リストをクリーンに保ち、重複エントリを回避します。
ステップ3: トリガー検出エージェント
購買意図や最適なアプローチ時期を示すビジネスイベントを監視します。エージェントは採用動向、資金調達発表、経営陣変更、事業拡大の兆候を分析し、見込み客の優先順位付けを行います。
agents/trigger_detection.py ファイルを作成し、以下のコードを追加します:
from crewai import Agent, Task
from crewai.tools import BaseTool
from datetime import datetime, timedelta
from typing import Any, List
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call
class TriggerDetectionInput(BaseModel):
companies: List[dict] = Field(description="分析対象企業のリスト(トリガーイベント用)")
class TriggerDetectionTool(BaseTool):
name: str = "detect_triggers"
description: str = "採用動向、資金調達ニュース、経営陣変更を検出"
args_schema: type[BaseModel] = TriggerDetectionInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, companies) -> list:
companies = validate_companies_input(companies)
if not companies:
return []
for company in companies:
triggers = []
hiring_signals = self._detect_hiring_triggers(company)
triggers.extend(hiring_signals)
funding_signals = self._detect_funding_triggers(company)
triggers.extend(funding_signals)
leadership_signals = self._detect_leadership_triggers(company)
triggers.extend(leadership_signals)
expansion_signals = self._detect_expansion_triggers(company)
triggers.extend(expansion_signals)
company['trigger_events'] = triggers
company['trigger_score'] = self._calculate_trigger_score(triggers)
return sorted(companies, key=lambda x: x.get('trigger_score', 0), reverse=True)
def _detect_hiring_triggers(self, company):
"""LinkedInデータを用いて採用トリガーを検出する。"""
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
triggers = []
if linkedin_data:
hiring_posts = linkedin_data.get('hiring_posts', [])
recent_activity = linkedin_data.get('recent_activity', [])
if hiring_posts:
triggers.append({
'type': 'hiring_spike',
'severity': 'high',
'description': f"{company['name']}で活発な採用活動を検出 - {len(hiring_posts)}件の求人募集",
'date_detected': datetime.now().isoformat(),
'source': 'linkedin_api'
})
if recent_activity:
triggers.append({
'type': 'company_activity',
'severity': 'medium',
'description': f"{company['name']} における LinkedIn アクティビティの増加",
'date_detected': datetime.now().isoformat(),
'source': 'linkedin_api'
})
return triggers
def _detect_funding_triggers(self, company):
"""ニュース検索を用いて資金調達トリガーを検出する。"""
funding_data = safe_mcp_call(self.mcp, 'search_funding_news', company['name'])
triggers = []
if funding_data and funding_data.get('results'):
triggers.append({
'type': 'funding_round',
'severity': 'high',
'description': f"{company['name']}で最近の資金調達活動が検出されました",
'date_detected': datetime.now().isoformat(),
'source': 'news_search'
})
return triggers
def _detect_leadership_triggers(self, company):
"""ニュース検索を用いて経営陣の変更を検知する。"""
return self._detect_keyword_triggers(
company, 'leadership_change', 'medium',
['ceo', 'cto', 'vp', 'hired', 'joins', 'appointed'],
f"{company['name']}で経営陣の変更を検出しました"
)
def _detect_expansion_triggers(self, company):
"""ニュース検索を用いて事業拡大を検出する。"""
return self._detect_keyword_triggers(
company, 'expansion', 'medium',
['expansion', 'new office', 'opening', 'market'],
f"{company['name']}で事業拡大を検出しました"
)
def _detect_keyword_triggers(self, company, trigger_type, severity, keywords, description):
"""ニュース内のキーワードに基づくトリガーを検出する汎用メソッド。"""
news_data = safe_mcp_call(self.mcp, 'search_company_news', company['name'])
triggers = []
if news_data and news_data.get('results'):
for result in news_data['results']:
if any(keyword in str(result).lower() for keyword in keywords):
トリガ.append({
'type': trigger_type,
'severity': severity,
'description': description,
'date_detected': datetime.now().isoformat(),
'source': 'news_search'
})
break
return triggers
def _calculate_trigger_score(self, triggers):
severity_weights = {'high': 15, 'medium': 10, 'low': 5}
return sum(severity_weights.get(t.get('severity', 'low'), 5) for t in triggers)
def create_trigger_detection_agent(mcp_client):
return Agent(
role='トリガーイベントアナリスト',
goal='購買シグナルと最適なアプローチタイミングの特定',
backstory='購買意欲を示すビジネスイベントの検知に精通。',
tools=[TriggerDetectionTool(mcp_client)],
verbose=True
)トリガー検知システムは、購買意図と最適なアプローチ時期を示す様々なビジネスシグナルを監視します。LinkedInの求人投稿から採用動向を分析し、ニュースソースで資金調達発表を追跡し、経営陣の異動を監視し、事業拡大活動を特定します。各トリガーには深刻度スコアが割り当てられ、緊急性と商機規模に基づいて見込み客の優先順位付けを支援します。
ステップ4: コンタクトリサーチエージェント
意思決定者の連絡先情報を検索・検証し、複数のデータソースからの信頼度スコアを考慮します。エージェントは役職とデータの品質に基づき連絡先を優先順位付けします。
agents/contact_research.py ファイルを作成し、以下のコードを追加します:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any, List
from pydantic import BaseModel, Field
import re
from .utils import validate_companies_input, safe_mcp_call, validate_email, deduplicate_by_key
class ContactResearchInput(BaseModel):
companies: List[dict] = Field(description="調査対象企業のリスト")
target_roles: List[str] = Field(description="調査対象役職のリスト")
class ContactResearchTool(BaseTool):
name: str = "research_contacts"
description: str = "MCPを使用して意思決定者の連絡先情報を検索・検証する"
args_schema: type[BaseModel] = ContactResearchInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, companies, target_roles) -> list:
companies = validate_companies_input(companies)
if not companies:
return []
if not isinstance(target_roles, list):
target_roles = [target_roles] if target_roles else []
for company in companies:
contacts = []
for role in target_roles:
role_contacts = self._search_contacts_by_role(company, role)
for contact in role_contacts:
enriched = self._enrich_contact_data(contact, company)
if self._validate_contact(enriched):
contacts.append(enriched)
company['contacts'] = self._deduplicate_contacts(contacts)
company['contact_score'] = self._calculate_contact_quality(contacts)
return companies
def _search_contacts_by_role(self, company, role):
"""MCPを使用して役職別に連絡先を検索する。"""
contacts = []
search_query = f"{company['name']} {role} LinkedIn contact"
search_result = safe_mcp_call(self.mcp, 'search_company_news', search_query)
if search_result and search_result.get('results'):
contacts.extend(self._extract_contacts_from_mcp_results(search_result['results'], role))
if not contacts:
contact_query = f"{company['name']} {role} email contact"
contact_result = safe_mcp_call(self.mcp, 'search_company_news', contact_query)
if contact_result and contact_result.get('results'):
contacts.extend(self._extract_contacts_from_mcp_results(contact_result['results'], role))
return contacts[:3]
def _extract_contacts_from_mcp_results(self, results, role):
"""MCP検索結果から連絡先情報を抽出する"""
contacts = []
for result in results:
try:
title = result.get('title', '')
snippet = result.get('snippet', '')
url = result.get('url', '')
names = self._extract_names_from_text(title + ' ' + snippet)
for name_parts in names:
if len(name_parts) >= 2:
first_name, last_name = name_parts[0], ' '.join(name_parts[1:])
contacts.append({
'first_name': first_name,
'last_name': last_name,
'title': role,
'linkedin_url': url if 'linkedin' in url else '',
'data_sources': 1,
'source': 'mcp_search'
})
if len(contacts) >= 2:
break
except Exception as e:
print(f"結果から連絡先を抽出中にエラー: {str(e)}")
continue
return contacts
def _extract_names_from_text(self, text):
"""テキストから可能性の高い名前を抽出する"""
import re
name_patterns = [
r'b([A-Z][a-z]+)s+([A-Z][a-z]+)b',
r'b([A-Z][a-z]+)s+([A-Z].?s*[A-Z][a-z]+)b',
r'b([A-Z][a-z]+)s+([A-Z][a-z]+)s+([A-Z][a-z]+)b'
]
names = []
for pattern in name_patterns:
matches = re.findall(pattern, text)
for match in matches:
if isinstance(match, tuple):
names.append(list(match))
return names[:3]
def _enrich_contact_data(self, contact, company):
if not contact.get('email'):
contact['email'] = self._generate_email(
contact['first_name'],
contact['last_name'],
company.get('domain', '')
)
contact['email_valid'] = validate_email(contact.get('email', ''))
contact['confidence_score'] = self._calculate_confidence(contact)
return contact
def _generate_email(self, first, last, domain):
if not all([first, last, domain]):
return ""
return f"{first.lower()}.{last.lower()}@{domain}"
def _calculate_confidence(self, contact):
score = 0
if contact.get('linkedin_url'): score += 30
if contact.get('email_valid'): score += 25
if contact.get('data_sources', 0) > 1: score += 20
if all(contact.get(f) for f in ['first_name', 'last_name', 'title']): score += 25
return score
def _validate_contact(self, contact):
required = ['first_name', 'last_name', 'title']
return (all(contact.get(f) for f in required) and
contact.get('confidence_score', 0) >= 50)
def _deduplicate_contacts(self, contacts):
unique = deduplicate_by_key(
contacts,
lambda c: c.get('email', '') or f"{c.get('first_name', '')}_{c.get('last_name', '')}"
)
return sorted(unique, key=lambda x: x.get('confidence_score', 0), reverse=True)
def _calculate_contact_quality(self, contacts):
if not contacts:
return 0
avg_confidence = sum(c.get('confidence_score', 0) for c in contacts) / len(contacts)
high_quality = sum(1 for c in contacts if c.get('confidence_score', 0) >= 75)
return min(avg_confidence + (high_quality * 5), 100)
def create_contact_research_agent(mcp_client):
return Agent(
role='コンタクトインテリジェンススペシャリスト',
goal='MCPを使用して意思決定者の正確な連絡先情報を発見する',
backstory='高度なMCP検索ツールを用いた連絡先情報の発見と検証の専門家。',
tools=[ContactResearchTool(mcp_client)],
verbose=True
)コンタクトリサーチシステムは、LinkedInや企業ウェブサイト上の役職を検索することで意思決定者を特定します。一般的な企業パターンを用いてメールアドレスを生成し、様々な検証方法を通じて連絡先情報を確認します。システムはデータソースの品質に基づいて信頼度スコアを割り当てます。重複排除プロセスにより連絡先リストをクリーンに保ち、検証信頼度に基づいて優先順位付けを行います。
ステップ5:インテリジェントメッセージ生成
ビジネスインテリジェンスを、特定のトリガーイベントに言及し調査結果を示すパーソナライズされたアウトリーチメッセージに変換します。ジェネレーターは異なるチャネル向けに複数のメッセージ形式を生成します。
agents/message_generation.py ファイルを作成し、以下のコードを追加します:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any, List
from pydantic import BaseModel, Field
import openai
import os
class MessageGenerationInput(BaseModel):
companies: List[dict] = Field(description="メッセージ生成対象の連絡先を持つ企業リスト")
message_type: str = Field(default="cold_email", description="生成するメッセージの種類 (cold_email, linkedin_message, follow_up)")
class MessageGenerationTool(BaseTool):
name: str = "generate_messages"
description: str = "企業情報に基づくパーソナライズされたアウトリーチを作成"
args_schema: type[BaseModel] = MessageGenerationInput
client: Any = None
def __init__(self):
super().__init__()
self.client = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def _run(self, companies, message_type="cold_email") -> list:
# companiesがリストであることを確認
if not isinstance(companies, list):
print(f"警告: 企業のリストを期待しましたが、{type(companies)}が渡されました")
return []
if not companies:
print("メッセージ生成用の企業が提供されていません")
return []
for company in companies:
if not isinstance(company, dict):
print(f"警告: 会社辞書が期待されましたが、{type(company)} が取得されました")
continue
for contact in company.get('contacts', []):
if not isinstance(contact, dict):
continue
message = self._generate_personalized_message(contact, company, message_type)
contact['generated_message'] = message
contact['message_quality_score'] = self._calculate_message_quality(message, company)
return companies
def _generate_personalized_message(self, contact, company, message_type):
context = self._build_message_context(contact, company)
if message_type == "cold_email":
return self._generate_cold_email(context)
elif message_type == "linkedin_message":
return self._generate_linkedin_message(context)
else:
return self._generate_cold_email(context)
def _build_message_context(self, contact, company):
triggers = company.get('trigger_events', [])
primary_trigger = triggers[0] if triggers else None
return {
'contact_name': contact.get('first_name', ''),
'contact_title': contact.get('title', ''),
'company_name': company.get('name', ''),
'industry': company.get('industry', ''),
'primary_trigger': primary_trigger,
'trigger_count': len(triggers)
}
def _generate_cold_email(self, context):
trigger_text = ""
if context['primary_trigger']:
trigger_text = f"{context['company_name']} 様の {context['primary_trigger']['description'].lower()} に気づきました。"
prompt = f"""パーソナライズされたコールドメールを作成してください:
連絡先: {context['contact_name']}, {context['contact_title']} (所属: {context['company_name']})
業界: {context['industry']}
背景: {trigger_text}
要件:
- トリガー事象を参照する件名
- ファーストネームを用いた個人宛の挨拶
- 事前調査を示した導入文
- 簡潔な価値提案
- 明確な行動喚起
- 最大120語
フォーマット:
件名:[件名]
本文:[メール本文]"""
response = self.client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=300
)
return self._parse_email_response(response.choices[0].message.content)
def _generate_linkedin_message(self, context):
prompt = f"""LinkedInのコネクションリクエストを作成(最大300文字):
連絡先: {context['contact_name']}({context['company_name']})
背景: {context.get('primary_trigger', {}).get('description', '')}
プロフェッショナルな態度で、相手の会社活動に言及し、直接的な営業トークは避けてください。"""
response = self.client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=100
)
return {
'subject': 'LinkedIn Connection Request',
'body': response.choices[0].message.content.strip()
}
def _parse_email_response(self, response):
lines = response.strip().split('n')
subject = ""
body_lines = []
for line in lines:
if line.startswith('SUBJECT:'):
subject = line.replace('SUBJECT:', '').strip()
elif line.startswith('BODY:'):
body_lines.append(line.replace('BODY:', '').strip())
elif body_lines:
body_lines.append(line)
return {
'subject': subject,
'body': 'n'.join(body_lines).strip()
}
def _calculate_message_quality(self, message, company):
score = 0
body = message.get('body', '').lower()
if company.get('name', '').lower() in message.get('subject', '').lower():
score += 25
if company.get('trigger_events') and any(t.get('type', '') in body for t in company['trigger_events']):
score += 30
if len(body.split()) <= 120:
score += 20
if any(word in body for word in ['call', 'meeting', 'discuss', 'connect']):
score += 25
return score
def create_message_generation_agent():
return Agent(
role='パーソナライゼーションスペシャリスト',
goal='返信が得られる説得力のあるパーソナライズされたアウトリーチを作成する',
backstory='調査を示し価値を提供するメッセージ作成の専門家。',
tools=[MessageGenerationTool()],
verbose=True
)メッセージ生成システムはビジネスインテリジェンスをパーソナライズされたアウトリーチに変換します。特定のトリガーイベントを参照し、詳細な調査結果を示します。文脈に合った件名、パーソナライズされた挨拶、各見込み客の状況に合致する価値提案を作成します。システムは異なるチャネルに適した様々なメッセージ形式を生成し、パーソナライゼーションの品質を一貫して維持します。
ステップ6:リードスコアリングとパイプライン管理
様々なインテリジェンス要素を用いて見込み客をスコアリングし、適格リードを自動的にCRMシステムへエクスポートします。マネージャーは適合度、タイミング、データ品質に基づきリードの優先順位付けを行います。
agents/pipeline_manager.py ファイルを作成し、以下のコードを追加します:
from crewai import Agent, Task
from crewai.tools import BaseTool
from datetime import datetime
from typing import List
from pydantic import BaseModel, Field
import requests
import os
from .utils import validate_companies_input
class LeadScoringInput(BaseModel):
companies: List[dict] = Field(description="スコアリング対象企業リスト")
class LeadScoringTool(BaseTool):
name: str = "score_leads"
description: str = "複数の知能要素に基づいてリードをスコアリングする"
args_schema: type[BaseModel] = LeadScoringInput
def _run(self, companies) -> list:
companies = validate_companies_input(companies)
if not companies:
return []
for company in companies:
score_breakdown = self._calculate_lead_score(company)
company['lead_score'] = score_breakdown['total_score']
company['score_breakdown'] = score_breakdown
company['lead_grade'] = self._assign_grade(score_breakdown['total_score'])
return sorted(companies, key=lambda x: x.get('lead_score', 0), reverse=True)
def _calculate_lead_score(self, company):
breakdown = {
'icp_score': min(company.get('icp_score', 0) * 0.3, 25),
'trigger_score': min(company.get('trigger_score', 0) * 2, 30),
'contact_score': min(company.get('contact_score', 0) * 0.2, 20),
'timing_score': self._assess_timing(company),
'company_health': self._assess_health(company)
}
breakdown['total_score'] = sum(breakdown.values())
return breakdown
def _assess_timing(self, company):
triggers = company.get('trigger_events', [])
if not triggers:
return 0
recent_triggers = sum(1 for t in triggers if 'high' in t.get('severity', ''))
return min(recent_triggers * 8, 15)
def _assess_health(self, company):
score = 0
if company.get('trigger_events'):
score += 5
if company.get('employee_count', 0) > 50:
score += 5
return score
def _assign_grade(self, score):
if score >= 80: return 'A'
elif score >= 65: return 'B'
elif score >= 50: return 'C'
else: return 'D'
class CRMIntegrationInput(BaseModel):
companies: List[dict] = Field(description="CRMにエクスポートする企業のリスト")
min_grade: str = Field(default="B", description="エクスポートするリードの最低グレード (A, B, C, D)")
class CRMIntegrationTool(BaseTool):
name: str = "crm_integration"
description: str = "見込み顧客をHubSpot CRMにエクスポート"
args_schema: type[BaseModel] = CRMIntegrationInput
def _run(self, companies, min_grade='B') -> dict:
companies = validate_companies_input(companies)
if not companies:
return {"message": "CRMエクスポート用の企業が指定されていません", "success": 0, "errors": 0}
qualified = [c for c in companies if isinstance(c, dict) and c.get('lead_grade', 'D') in ['A', 'B']]
if not os.getenv("HUBSPOT_API_KEY"):
return {"error": "HubSpot APIキーが設定されていません", "success": 0, "errors": 0}
results = {"success": 0, "errors": 0, "details": []}
for company in qualified:
for contact in company.get('contacts', []):
if not isinstance(contact, dict):
continue
result = self._create_hubspot_contact(contact, company)
if result.get('success'):
results['success'] += 1
else:
results['errors'] += 1
results['details'].append(result)
return results
def _create_hubspot_contact(self, contact, company):
api_key = os.getenv("HUBSPOT_API_KEY")
if not api_key:
return {"success": False, "error": "HubSpot API key not configured"}
url = "https://api.hubapi.com/crm/v3/objects/contacts"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
trigger_summary = "; ".join([
f"{t.get('type', '')}: {t.get('description', '')}"
for t in company.get('trigger_events', [])
])
email = contact.get('email', '').strip()
if not email:
return {"success": False, "error": "連絡先メールアドレスが必要です", "contact": contact.get('first_name', '不明')}
properties = {
"email": email,
"firstname": contact.get('first_name', ''),
"lastname": contact.get('last_name', ''),
"jobtitle": contact.get('title', ''),
"company": company.get('name', ''),
"website": f"https://{company.get('domain', '')}" if company.get('domain') else "",
"hs_lead_status": "NEW",
"lifecyclestage": "lead"
}
if company.get('lead_score'):
properties["lead_score"] = str(company.get('lead_score', 0))
if company.get('lead_grade'):
properties["lead_grade"] = company.get('lead_grade', 'D')
if trigger_summary:
properties["trigger_events"] = trigger_summary[:1000]
if contact.get('confidence_score'):
properties["contact_confidence"] = str(contact.get('confidence_score', 0))
properties["ai_discovery_date"] = datetime.now().isoformat()
try:
response = requests.post(url, json={"properties": properties}, headers=headers, timeout=30)
if response.status_code == 201:
return {
"success": True,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"hubspot_id": response.json().get('id')
}
elif response.status_code == 409:
既存コンタクト = response.json()
return {
"success": True,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"hubspot_id": 既存コンタクト.get('id'),
"note": "コンタクトは既に存在します"
}
else:
error_detail = response.text if response.text else f"HTTP {response.status_code}"
return {
"success": False,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"error": f"API エラー: {error_detail}"
}
except requests.exceptions.RequestException as e:
return {
"success": False,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"error": f"Network error: {str(e)}"
}
except Exception as e:
return {
"success": False,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"error": f"予期しないエラー: {str(e)}"
}
def create_pipeline_manager_agent():
return Agent(
role='Pipeline Manager',
goal='見込み客のスコアリングと、適格な見込み客に対するCRM統合の管理',
backstory='見込み客の品質評価と営業パイプライン管理の専門家。',
tools=[LeadScoringTool(), CRMIntegrationTool()],
verbose=True
)リードスコアリングシステムは、見込み客を複数の領域で評価します。これには、理想的な顧客プロファイルへの適合度、トリガーイベントの緊急性、連絡先データの品質、タイミング要因などが含まれます。詳細なスコア内訳を提供することでデータ駆動型の優先順位付けを可能にし、迅速な見込み客選定のために自動的に文字評価を割り当てます。CRM統合ツールは、選定済みリードをHubSpotに直接エクスポートし、営業チームがフォローアップするためにすべてのインテリジェンスデータが適切にフォーマットされることを保証します。
ステップ6.1: 共有ユーティリティ
メインアプリケーション作成前に、全エージェントで共通利用するユーティリティ関数を格納するagents/utils.py ファイルを作成します:
"""
全エージェントモジュール共通のユーティリティ関数
"""
from typing import List, Dict, Any
import re
def validate_companies_input(companies: Any) -> List[Dict]:
"""全エージェント共通の企業名入力の検証と正規化"""
if isinstance(companies, dict) and 'companies' in companies:
companies = companies['companies']
if not isinstance(companies, list):
print(f"警告: 企業のリストを期待しましたが、{type(companies)} を受け取りました")
return []
if not companies:
print("企業が提供されていません")
return []
valid_companies = []
for company in companies:
if isinstance(company, dict):
valid_companies.append(company)
else:
print(f"警告: 企業の辞書が期待されましたが、{type(company)} が取得されました")
return valid_companies
def safe_mcp_call(mcp_client, method_name: str, *args, **kwargs) -> Dict:
"""MCPメソッドを一貫したエラー処理で安全に呼び出す"""
try:
method = getattr(mcp_client, method_name)
result = method(*args, **kwargs)
return result if result and not result.get('error') else {}
except Exception as e:
print(f"MCP {method_name} の呼び出しエラー: {str(e)}")
return {}
def validate_email(email: str) -> bool:
"""メールアドレスの形式を検証します。"""
pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}$'
return bool(re.match(pattern, email))
def deduplicate_by_key(items: List[Dict], key_func) -> List[Dict]:
"""キー関数を使用して辞書のリストから重複を削除します。"""
seen = set()
unique_items = []
for item in items:
key = key_func(item)
if key and key not in seen:
seen.add(key)
unique_items.append(item)
return unique_items
def extract_domain_from_url(url: str) -> str:
"""フォールバックパース付きでURLからドメインを抽出する。"""
if not url:
return ""
try:
from urllib.parse import urlparse
parsed = urlparse(url)
return parsed.netloc
except:
if '//' in url:
return url.split('//')[1].split('/')[0]
return ""また、agentsフォルダをPythonパッケージ化するために、空のagents/__init__.pyファイルを作成する必要があります。
ステップ7: システムオーケストレーション
インテリジェントなワークフローで全エージェントを調整するメインの Streamlit アプリケーションを作成します。このインターフェースはリアルタイムフィードバックを提供し、ユーザーが様々なプロスペクティングシナリオ向けにパラメータをカスタマイズできるようにします。
プロジェクトルートディレクトリにai_bdr_system.pyファイルを作成し、以下のコードを追加します:
import streamlit as st
import os
from dotenv import load_dotenv
from crewai import Crew, Process, Task
import pandas as pd
from datetime import datetime
import json
from mcp_client import Bright DataMCP
from agents.company_discovery import create_company_discovery_agent
from agents.trigger_detection import create_trigger_detection_agent
from agents.contact_research import create_contact_research_agent
from agents.message_generation import create_message_generation_agent
from agents.pipeline_manager import create_pipeline_manager_agent
load_dotenv()
st.set_page_config(
page_title="AI BDR/SDR システム",
page_icon="🤖",
layout="wide")
st.title("🤖 AI BDR/SDR エージェントシステム")
st.markdown("**マルチエージェントインテリジェンスとトリガーベースのパーソナライゼーションによるリアルタイム見込み顧客開拓**")
if 'workflow_results' not in st.session_state:
st.session_state.workflow_results = None
with st.sidebar:
try:
st.image("bright-data-logo.png", width=200)
st.markdown("---")
except:
st.markdown("**🌐 Bright Data 提供**")
st.markdown("---")
st.header("⚙️ 設定")
st.subheader("理想的な顧客プロファイル")
industry = st.selectbox("業界", ["SaaS", "FinTech", "Eコマース", "ヘルスケア", "AI/ML"])
size_range = st.selectbox("企業規模", ["スタートアップ", "小規模", "中規模", "大企業"])
location = st.text_input("所在地 (任意)", placeholder="サンフランシスコ、NYなど")
max_companies = st.slider("対象企業数", 5, 50, 20)
st.subheader("ターゲット意思決定者")
all_roles = ["CEO", "CTO", "VP Engineering", "Head of Product", "VP Sales", "CMO", "CFO"]
target_roles = st.multiselect("役職", all_roles, default=["CEO", "CTO", "VP Engineering"])
st.subheader("アウトリーチ設定")
message_types = st.multiselect(
"メッセージタイプ",
["cold_email", "linkedin_message", "follow_up"],
default=["cold_email"]
)
with st.expander("高度なインテリジェンス"):
enable_competitive = st.checkbox("競合情報", value=True)
enable_validation = st.checkbox("マルチソース検証", value=True)
min_lead_grade = st.selectbox("最小CRMエクスポートグレード", ["A", "B", "C"], index=1)
st.divider()
st.subheader("🔗 API Status")
apis = [
("Bright Data", "BRIGHT_DATA_API_TOKEN", "🌐"),
("OpenAI", "OPENAI_API_KEY", "🧠"),
("HubSpot CRM", "HUBSPOT_API_KEY", "📊")
]
for name, env_var, icon in API:
if os.getenv(env_var):
st.success(f"{icon} {name} 接続済み")
else:
if name == "HubSpot CRM":
st.warning(f"⚠️ {name} CRMエクスポートに必須")
elif name == "Bright Data":
st.error(f"❌ {name} 不足")
if st.button("🔧 設定ヘルプ", key="bright_data_help"):
st.info("""
**Bright Data 設定必須:**
1. Bright Data ダッシュボードから認証情報を取得
2. .env ファイルを以下で更新:
```
BRIGHT_DATA_API_TOKEN=your_password
WEB_UNLOCKER_ZONE=lum-customer-username-zone-zonename
```
3. 詳細な手順はBRIGHT_DATA_SETUP.mdを参照
**現在のエラー**: 407 無効な認証 = 認証情報が間違っています
""")
else:
st.error(f"❌ {name} 不足")
col1, col2 = st.columns([3, 1])
with col1:
st.subheader("🚀 AI見込み顧客開拓ワークフロー")
if st.button("マルチエージェント開拓を開始", type="primary", use_container_width=True):
required_keys = ["BRIGHT_DATA_API_TOKEN", "OPENAI_API_KEY"]
missing_keys = [key for key in required_keys if not os.getenv(key)]
if missing_keys:
st.error(f"必須のAPIキーが不足しています: {', '.join(missing_keys)}")
st.stop()
progress_bar = st.progress(0)
status_text = st.empty()
try:
mcp_client = BrightDataMCP()
discovery_agent = create_company_discovery_agent(mcp_client)
trigger_agent = create_trigger_detection_agent(mcp_client)
contact_agent = create_contact_research_agent(mcp_client)
message_agent = create_message_generation_agent()
pipeline_agent = create_pipeline_manager_agent()
status_text.text("🔍 ICPに合致する企業を検索中...")
progress_bar.progress(15)
discovery_task = Task(
description=f"{location} において {industry} 分野の {size_range} 規模の企業を {max_companies} 社検索",
expected_output="ICP スコアとインテリジェンス付き企業リスト",
agent=discovery_agent
)
discovery_crew = Crew(
agents=[discovery_agent],
tasks=[discovery_task],
process=Process.sequential
)
companies = discovery_agent.tools[0]._run(industry, size_range, location)
st.success(f"✅ {len(companies)} 社を発見しました")
status_text.text("🎯 トリガーイベントと購買シグナルを分析中...")
progress_bar.progress(30)
trigger_task = Task(
description="採用急増、資金調達ラウンド、経営陣変更、拡大シグナルを検出",
expected_output="トリガーイベントとスコアを持つ企業",
agent=trigger_agent
)
trigger_crew = Crew(
agents=[trigger_agent],
tasks=[trigger_task],
process=Process.sequential
)
companies_with_triggers = trigger_agent.tools[0]._run(companies)
total_triggers = sum(len(c.get('trigger_events', [])) for c in companies_with_triggers)
st.success(f"✅ {total_triggers} 件のトリガーイベントを検出しました")
progress_bar.progress(45)
status_text.text("👥 意思決定者の連絡先を検索中...")
contact_task = Task(
description=f"役職: {', '.join(target_roles)} の検証済み連絡先を検索",
expected_output="意思決定者の連絡先情報を持つ企業",
agent=contact_agent
)
contact_crew = Crew(
agents=[contact_agent],
tasks=[contact_task],
process=Process.sequential
)
companies_with_contacts = contact_agent.tools[0]._run(companies_with_triggers, target_roles)
total_contacts = sum(len(c.get('contacts', [])) for c in companies_with_contacts)
st.success(f"✅ 確認済み連絡先 {total_contacts} 件を発見")
progress_bar.progress(60)
status_text.text("✍️ パーソナライズされた連絡メッセージを生成中...")
message_task = Task(
description=f"トリガーインテリジェンスを使用して各コンタクト向けに{', '.join(message_types)}を生成",
expected_output="パーソナライズされたメッセージ付き企業",
agent=message_agent
)
message_crew = Crew(
agents=[message_agent],
tasks=[message_task],
process=Process.sequential
)
companies_with_messages = message_agent.tools[0]._run(companies_with_contacts, message_types[0])
total_messages = sum(len(c.get('contacts', [])) for c in companies_with_messages)
st.success(f"✅ {total_messages} 件のパーソナライズドメッセージを生成しました")
progress_bar.progress(75)
status_text.text("📊 リードのスコアリングとCRM更新中...")
pipeline_task = Task(
description=f"リードをスコアリングし、Grade {min_lead_grade} 以上のものを HubSpot CRM にエクスポート",
expected_output="スコアリング済みリードと CRM 連携結果",
agent=pipeline_agent
)
pipeline_crew = Crew(
agents=[pipeline_agent],
tasks=[pipeline_task],
process=Process.sequential
)
final_companies = pipeline_agent.tools[0]._run(companies_with_messages)
qualified_leads = [c for c in final_companies if c.get('lead_grade', 'D') in ['A', 'B']]
crm_results = {"success": 0, "errors": 0}
if os.getenv("HUBSPOT_API_KEY"):
crm_results = pipeline_agent.tools[1]._run(final_companies, min_lead_grade)
progress_bar.progress(100)
status_text.text("✅ ワークフローが正常に完了しました!")
st.session_state.workflow_results = {
'companies': final_companies,
'total_companies': len(final_companies),
'total_triggers': total_triggers,
'total_contacts': total_contacts,
'qualified_leads': len(qualified_leads),
'crm_results': crm_results,
'timestamp': datetime.now()
}
except Exception as e:
st.error(f"❌ ワークフロー失敗: {str(e)}")
st.write("API設定を確認し、再度お試しください。")
if st.session_state.workflow_results:
results = st.session_state.workflow_results
st.markdown("---")
st.subheader("📊 ワークフロー結果")
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("分析済み企業数", results['total_companies'])
with col2:
st.metric("トリガーイベント", results['total_triggers'])
with col3:
st.metric("検出されたコンタクト", results['total_contacts'])
with col4:
st.metric("見込み顧客", results['qualified_leads'])
if results['crm_results']['success'] > 0 or results['crm_results']['errors'] > 0:
st.subheader("🔄 HubSpot CRM 統合")
col1, col2 = st.columns(2)
with col1:
st.metric("CRMへエクスポート", results['crm_results']['success'], delta="contacts")
with col2:
if results['crm_results']['errors'] > 0:
st.metric("エクスポートエラー", results['crm_results']['errors'], delta_color="inverse")
st.subheader("🏢 企業インテリジェンス")
for company in results['companies'][:10]:
with st.expander(f"📋 {company.get('name', 'Unknown')} - グレード {company.get('lead_grade', 'D')} (スコア: {company.get('lead_score', 0):.0f})"):
col1, col2 = st.columns(2)
with col1:
st.write(f"**Industry:** {company.get('industry', 'Unknown')}")
st.write(f"**Domain:** {company.get('domain', 'Unknown')}")
st.write(f"**ICPスコア:** {company.get('icp_score', 0)}")
triggers = company.get('trigger_events', [])
if triggers:
st.write("**🎯 トリガーイベント:**")
for trigger in triggers:
severity_emoji = {"high": "🔥", "medium": "⚡", "low": "💡"}.get(trigger.get('severity', 'low'), '💡')
st.write(f"{severity_emoji} {trigger.get('description', 'Unknown trigger')}")
with col2:
contacts = company.get('contacts', [])
if contacts:
st.write("**👥 Decision Makers:**")
for contact in contacts:
confidence = contact.get('confidence_score', 0)
confidence_color = "🟢" if confidence >= 75 else "🟡" if confidence >= 50 else "🔴"
st.write(f"{confidence_color} **{contact.get('first_name', '')} {contact.get('last_name', '')}**")
st.write(f" {contact.get('title', 'Unknown title')}")
st.write(f" 📧 {contact.get('email', 'No email')}")
st.write(f" Confidence: {confidence}%")
message = contact.get('generated_message', {})
if message.get('subject'):
st.write(f" **件名:** {message['subject']}")
if message.get('body'):
preview = message['body'][:100] + "..." if len(message['body']) > 100 else message['body']
st.write(f" **プレビュー:** {preview}")
st.write("---")
st.subheader("📥 エクスポート & アクション")
col1, col2, col3 = st.columns(3)
with col1:
export_data = []
for company in results['companies']:
for contact in company.get('contacts', []):
export_data.append({
'Company': company.get('name', ''),
'Industry': company.get('industry', ''),
'Lead Grade': company.get('lead_grade', ''),
'リードスコア': company.get('lead_score', 0),
'トリガーカウント': len(company.get('trigger_events', [])),
'コンタクト名': f"{contact.get('first_name', '')} {contact.get('last_name', '')}",
'役職': contact.get('title', ''),
'メールアドレス': contact.get('email', ''),
'確信度': contact.get('confidence_score', 0),
'件名': contact.get('generated_message', {}).get('subject', ''),
'本文': contact.get('generated_message', {}).get('body', '')
})
if export_data:
df = pd.DataFrame(export_data)
csv = df.to_csv(index=False)
st.download_button(
label="📄 完全レポートをダウンロード (CSV)",
data=csv,
file_name=f"ai_bdr_prospects_{datetime.now().strftime('%Y%m%d_%H%M')}.csv",
mime="text/csv",
use_container_width=True
)
with col2:
if st.button("🔄 HubSpot CRMに同期", use_container_width=True):
if not os.getenv("HUBSPOT_API_KEY"):
st.warning("HubSpot APIキーが必要です(CRMエクスポート用)")
else:
with st.spinner("HubSpotへの同期中..."):
pipeline_agent = create_pipeline_manager_agent()
new_crm_results = pipeline_agent.tools[1]._run(results['companies'], min_lead_grade)
st.session_state.workflow_results['crm_results'] = new_crm_results
st.rerun()
with col3:
if st.button("🗑️ Clear Results", use_container_width=True):
st.session_state.workflow_results = None
st.rerun()
if __name__ == "__main__":
passStreamlitオーケストレーションシステムは、リアルタイム進捗追跡とカスタマイズ可能な設定を備えた効率的なワークフローで全エージェントを調整します。メトリクス付きの結果表示、詳細な企業情報、エクスポートオプションを提供します。直感的なダッシュボードにより、技術スキルがなくても営業チームが複雑なマルチエージェント操作を容易に管理できます。
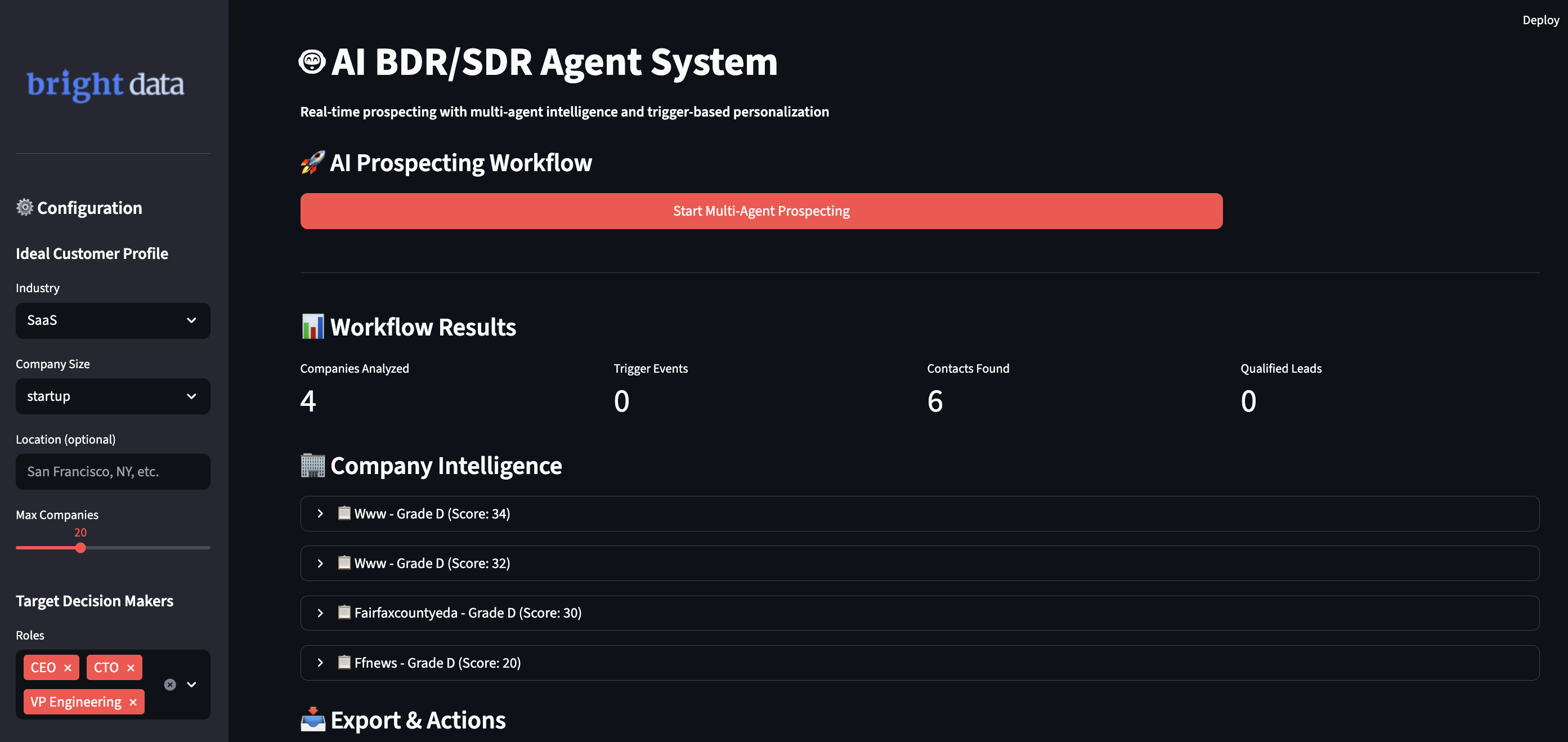
AI BDRシステムの実行
アプリケーションを実行してインテリジェントな見込み顧客開拓ワークフローを開始します。ターミナルを開き、プロジェクトディレクトリに移動します。
streamlit run ai_bdr_system.py
システムが要件を処理するスマートワークフローが確認できます:
- リアルタイムデータチェックにより、理想的な顧客プロファイルに合致する企業を発見します。
- 様々なソースからのトリガーイベントを追跡し、最適なタイミングを見つけます。
- 複数の情報源から意思決定者の連絡先を検索し、信頼性スコアを算出します。
- 特定のビジネスインサイトを盛り込んだパーソナライズドメッセージを作成します。
- 自動的にリードをスコアリングし、見込み顧客をCRMパイプラインに追加します。
まとめ
このAI BDRシステムは、自動化が見込み客開拓とリード評価をいかに効率化できるかを示しています。営業パイプラインをさらに強化するには、正確な連絡先・企業データを提供する当社のLinkedInデータセットをはじめ、BDRおよび営業チーム向けに構築されたその他のデータセットや自動化ツールなど、Bright Data製品のご利用をご検討ください。
Bright Dataのドキュメントでさらに多くのソリューションを探索してください。
自動化されたBDRワークフローの構築を開始するには、無料のBright Dataアカウントを作成してください。





