

本ガイドでは以下の内容を確認できます:
- AG2の定義、シングルエージェントおよびマルチエージェントシステム開発への支援方法、Bright Dataによる拡張の利点。
- 本連携を開始するための前提条件。
- カスタムツールを介してBright DataでAG2マルチエージェントアーキテクチャを強化する方法。
- AG2をBright DataのWeb MCPに接続する方法。
それでは始めましょう!
AG2(旧称AutoGen)の概要
AG2は、複雑なタスク解決のために自律的に連携するAIエージェントおよびマルチエージェントシステムを構築するためのオープンソースAgentOSフレームワークです。単一エージェントのワークフロー作成、複数の専門エージェントのオーケストレーション、外部ツールのモジュール化された実運用環境対応パイプラインへの統合を可能にします。
AG2(旧称AutoGen)はMicrosoft AutoGenライブラリの進化形です。元のアーキテクチャと後方互換性を維持しつつ、マルチエージェントワークフロー、ツール統合、ヒューマン・イン・ザ・ループAIを実現します。Pythonで記述され、GitHubで4,000以上のスターを獲得しています。
(Bright DataとAutoGenの統合方法については、 専用ブログ記事をご参照ください)
AG2は、エージェント型AIプロジェクトを実験段階から本番環境へ移行させるために必要な柔軟性と高度なオーケストレーションパターンを提供します。
主なコア機能には、マルチエージェント会話パターン、ヒューマン・イン・ザ・ループ対応、ツール統合、構造化されたワークフロー管理が含まれます。最終目標は、最小限のオーバーヘッドで高度なAIシステムを構築することです。
こうした優れた機能にもかかわらず、AG2エージェントは依然としてLLMの根本的な制限に直面しています:トレーニングデータからの静的知識と、ライブウェブ情報へのネイティブアクセスがないことです!
Bright DataのようなウェブデータプロバイダーとAG2を統合することで、これらの課題はすべて解決されます。ウェブスクレイピング、検索、ブラウザ自動化のためのBright DataのAPIにAG2エージェントを接続することで、リアルタイムで構造化されたウェブデータが利用可能になり、エージェントの知能、自律性、実用性が向上します。
前提条件
本ガイドを実践するには以下が必要です:
- ローカルマシンにインストールされたPython 3.10以上
- Web Unlocker API、SERP API、および設定済みのAPIキーを備えたBright Dataアカウント(本チュートリアルで必要な設定をすべてガイドします)。
- OpenAI APIキー(またはAG2がサポートする他のLLMのAPIキー)。
Bright Dataの製品・サービスに関する基礎知識、およびAG2ツールシステムの動作原理に関する基本的な理解があると便利です。
Bright DataをAG2マルチエージェントワークフローに統合する方法
このステップバイステップセクションでは、Bright Dataサービスに基づくマルチエージェントAG2ワークフローを構築します。具体的には、ウェブデータ取得専用のエージェントがカスタムAG2ツール関数経由でBright DataのWeb UnlockerおよびSERP APIにアクセスします。
このマルチエージェントシステムは、食品業界におけるTwitchなどのプラットフォーム上のトップインフルエンサーを特定し、新種のハンバーガーのプロモーションを支援します。この例は、AG2がデータ収集の自動化、構造化されたビジネスレポートの作成、情報に基づいた意思決定の実現を、すべて手動作業なしで可能にする方法を示しています。
実装方法をご覧ください!
ステップ #1: AG2プロジェクトの作成
ターミナルを開き、AG2プロジェクト用の新規フォルダを作成します。例として「ag2-bright-data-agent」と命名します:
mkdir ag2-bright-data-agentag2-bright-data-agent/ には、Bright Data 機能と連携する AG2 エージェントの実装とオーケストレーションを行う Python コードが含まれます。
次に、プロジェクトディレクトリに移動し、その中に仮想環境を作成します:
cd ag2-bright-data-agent
python -m venv .venvプロジェクトルートにagent.pyという新しいファイルを追加します。プロジェクト構造は次のようになります:
ag2-bright-data-agent/
├── .venv/
└── agent.py # <----agent.pyファイルにはAG2エージェントの定義とオーケストレーションロジックが含まれます。
お好みのPython IDE(Python拡張機能付きのVisual Studio CodeやPyCharm Community Editionなど)でプロジェクトフォルダを開きます。
次に、作成した仮想環境をアクティブ化します。LinuxまたはmacOSでは以下を実行:
source .venv/bin/activateWindowsでは同等の操作として以下を実行します:
.venv/Scripts/activate仮想環境が有効化された状態で、必要なPyPI依存関係をインストールします:
pip install ag2[openai] requests python-dotenvこのアプリケーションは以下のライブラリに依存しています:
ag2[openai]: OpenAIモデルを活用したマルチエージェントAIワークフローの構築とオーケストレーション。requests: カスタムツールを通じてBright DataサービスへのHTTPリクエストを実行します。python-dotenv:.envファイルで定義された環境変数から必要なシークレットを読み込むため。
完了!これでAG2を用いたマルチエージェントAI開発用のPython環境が使用可能になりました。
ステップ #2: LLM 統合の設定
次のステップで構築するAG2エージェントには、LLMが提供する「頭脳」が必要です。各エージェントは独自のLLM設定を使用できますが、簡素化のため、すべてのエージェントを同じOpenAIモデルに接続します。
AG2には、専用の設定ファイルからLLM設定を読み込む組み込みメカニズムが備わっています。これを行うには、agent.pyに以下のコードを追加してください:
from autogen import LLMConfig
# OpenAI設定リストファイルからLLM設定を読み込み
llm_config = LLMConfig.from_json(path="OAI_CONFIG_LIST")このコードはOAI_CONFIG_LIST.json というファイルから LLM 設定を読み込みます。プロジェクトのルートディレクトリにこのファイルを作成してください:
ag2-bright-data-agent/
├── .venv/
├── OAI_CONFIG_LIST.json # <----
└── agent.py次に、OAI_CONFIG_LIST.jsonに以下の内容を記述します:
[
{
"model": "gpt-5-mini",
"api_key": "<YOUR_OPENAI_API_KEY>"
}
]<YOUR_OPENAI_API_KEY>プレースホルダーを実際の OpenAI API キーに置き換えてください。この設定により、AG2 エージェントはGPT-5 Miniモデルを使用して動作しますが、必要に応じて他のサポートされている OpenAI モデルに切り替えることもできます。
llm_config変数はエージェントとグループチャットオーケストレーターに渡されます。これにより、設定されたLLMを使用して推論、コミュニケーション、タスク実行が可能になります。素晴らしい!
ステップ #3: 環境変数読み取りの管理
AG2エージェントはOpenAIに接続可能になりましたが、別のサードパーティサービスであるBright Dataへのアクセスも必要です。OpenAIと同様に、Bright Dataも外部APIキーを使用してリクエストを認証します。
セキュリティリスクを回避するため、APIキーをコードに直接ハードコードしてはいけません。代わりに、環境変数から読み込むことがベストプラクティスです。これが、先にpython-dotenvをインストールした理由です。
まず、agent.pyで python-dotenvをインポートします。load_dotenv()関数を使用して.envファイルから環境変数をロードします:
from dotenv import load_dotenv
import os
# .envファイルから環境変数をロード
load_dotenv()次に、プロジェクトのルートディレクトリに.envファイルを追加します。内容は以下の通りです:
ag2-bright-data-agent/
├── .venv/
├── OAI_CONFIG_LIST.json
├── .env # <----
└── agent.py.envファイルにシークレット値を追加すると、コード内でos.getenv()を使用してそれらにアクセスできるようになります:
ENV_VALUE = os.getenv("ENV_NAME")これでスクリプトは環境変数からサードパーティ連携のシークレットを安全に読み込めます。
ステップ #4: Bright Data サービスの設定
導入部で述べた通り、WebデータエージェントはBright DataのSERP APIとWeb Unlocker APIに接続し、Web検索とWebページからのコンテンツ取得を処理します。これらのサービスを組み合わせることで、エージェントはエージェント型RAGスタイルのデータ取得レイヤーでライブWebデータを取得する能力を獲得します。
これら2つのサービスと連携するには、後ほど2つのカスタムAG2ツールを定義する必要があります。その前に、Bright Dataアカウントで全てを設定してください。
まず、Bright Dataアカウントをお持ちでない場合は新規作成してください。お持ちの場合はログインし、ダッシュボードにアクセスします。そこから「プロキシ&スクレイピング」ページに移動し、プロファイルで設定済みのサービスを一覧表示する「マイゾーン」テーブルを確認します: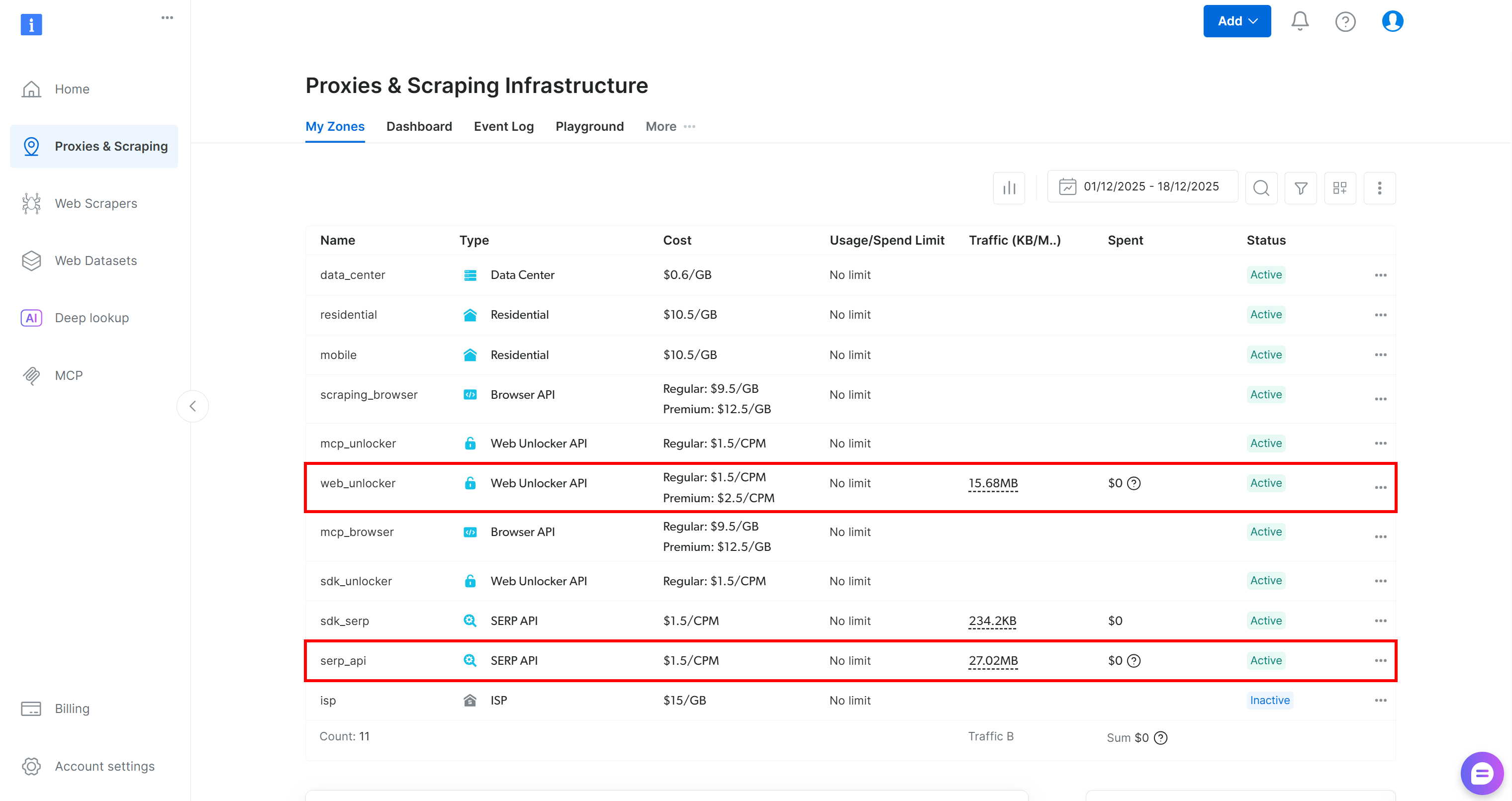
上記のように、テーブルにWeb Unlocker APIゾーン(この例ではweb_unlocker)とSERP APIゾーン(この例ではserp_api)が既に存在する場合、準備は完了です。これらの2つのゾーンは、カスタムAG2ツールが必要なBright Dataサービスを呼び出す際に使用されます。
いずれか一方または両方のゾーンが欠けている場合は、下にスクロールして「アンブロッカーAPI」と「SERP API」カードを見つけ、それぞれに対して「ゾーンを作成」をクリックしてください。セットアップウィザードに従って両方のゾーンを作成します: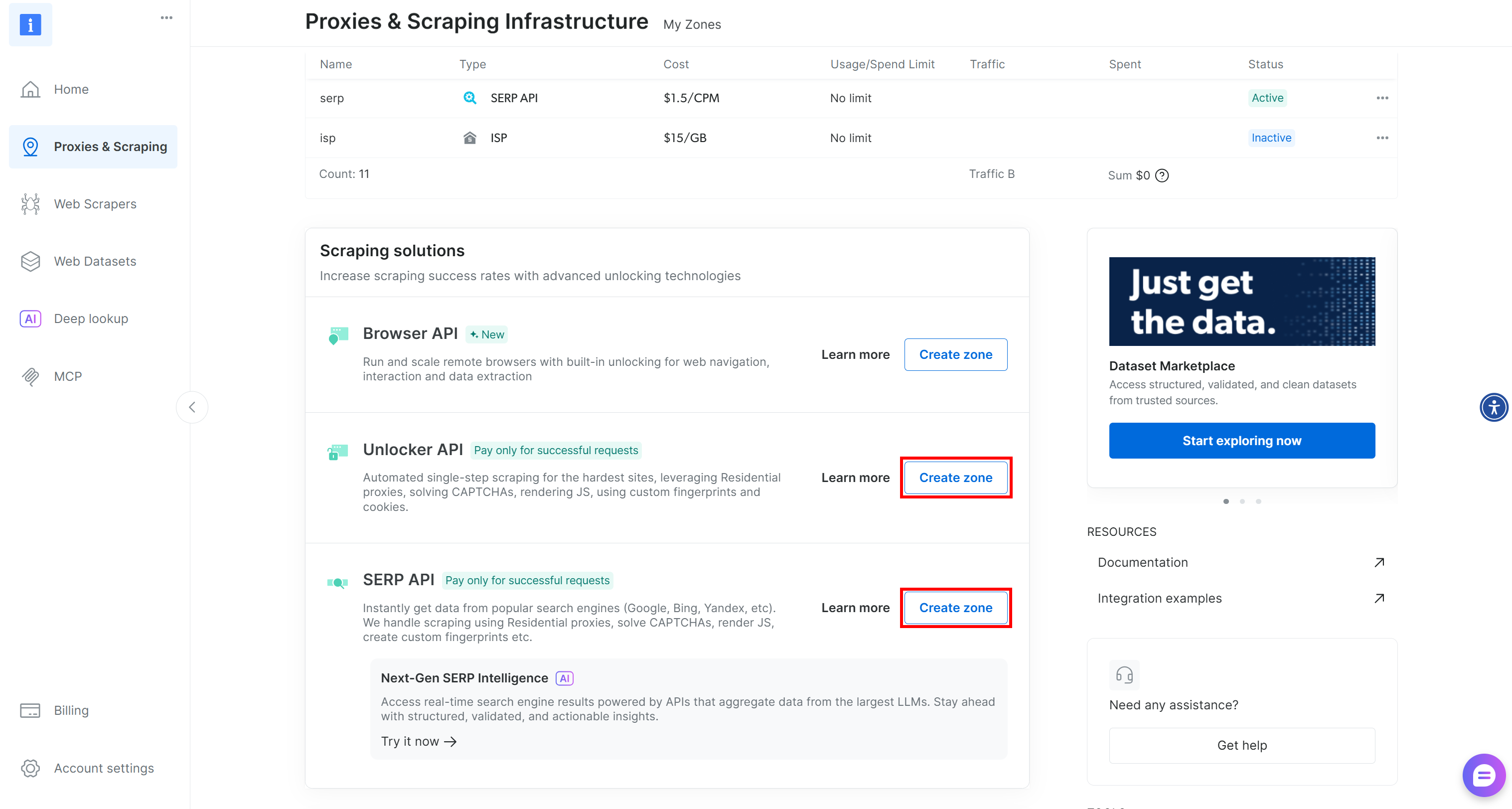
詳細な手順については、公式ドキュメントを参照してください:
重要:以降、ゾーン名はそれぞれ「serp_api」と「web_unlocker」と仮定します。
ゾーンの準備が整ったら、Bright Data APIキーを生成します。これを.envファイルの環境変数として保存してください:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"次に、agent.pyで以下のように読み込みます:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")これで、カスタムツールを通じてAG2エージェントをBright DataのSERP APIおよびWeb Unlockerサービスに接続するための基盤が整いました。
ステップ #5: AG2エージェント向けBright Dataツールの定義
AG2では、ツールはエージェントがアクションを実行し意思決定を行うために呼び出せる特殊な機能を提供します。内部的には、ツールは単にAG2が構造化された方法でエージェントに公開するカスタムPython関数です。
このステップでは、agent.pyに2つのツール関数を実装します:
serp_api_tool(): Bright Data SERP APIに接続し、Google検索を実行します。web_unlocker_api_tool(): Bright Data Web Unlocker APIに接続し、すべてのボット対策システムをバイパスしてウェブページコンテンツを取得します。
両ツールとも、ドキュメントに基づきRequests Python HTTPクライアントを使用してBright Dataへの認証済みPOSTリクエストを実行します:
2つのツール関数を定義するには、agent.pyに以下のコードを追加します:
from typing import Annotated
import requests
import urllib.parse
def serp_api_tool(
query: Annotated[str, "Google検索クエリ"],
) -> str:
payload = {
"zone": "serp_api", # Bright Data SERP APIゾーン名に置き換えてください
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw",
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers,
)
response.raise_for_status()
return response.text
def web_unlocker_api_tool(
url_to_fetch: Annotated[str, "取得対象ページURL"],
data_format: Annotated[
str | None,
"出力ページ形式 (例: 'markdown'、省略時は生のHTML)"
] = "markdown",)
-> str:
payload = {
"zone": "web_unlocker", # Bright Data Web Unlocker のゾーン名に置き換えてください
"url": url_to_fetch,
"format": "raw",
"data_format": data_format,
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers
)
response.raise_for_status()
return response.text2つのツールは、Bright Data APIキーを使用してリクエストを認証し、Bright Data APIエンドポイントにPOSTリクエストを送信します:
serp_api_tool() はGoogle をクエリし、brd_json=1パラメータを有効化することで構造化された JSON 形式の検索結果を取得します。web_unlocker_api_tool() は任意のウェブページを取得し、その内容をMarkdown形式(または必要に応じて生のHTML)で返します。
重要: JSONとMarkdownはどちらも、AIエージェントにおけるLLMの取り込みに最適な形式です。
両関数は引数の記述にPython型指定とAnnotatedを使用しています。型指定はこれらの関数を適切なAG2ツールに変換するために必須であり、アノテーション記述はエージェント内部からツールを呼び出す際にLLMが各引数をどのように設定すべきかを理解する助けとなります。
素晴らしい!これでAG2アプリケーションに2つのBright Dataツールが組み込まれ、AIエージェントによる設定と利用が可能になりました。
ステップ #6: AG2 エージェントの実装
ツールの準備が整ったところで、導入部で説明したAIエージェント構造を構築します。この構成は3つの補完的なエージェントで構成されます:
user_proxy: 実行層として機能し、ツール呼び出しを安全に実行し、人間の入力なしにワークフローを調整します。これはUserProxyAgentのインスタンスであり、ユーザーのプロキシとして機能する特別なAG2エージェントです。コードを実行し、必要に応じて他のエージェントにフィードバックを提供します。web_data_agent: ウェブデータの発見と取得を担当します。このエージェントはBright Data SERP APIを使用してウェブを検索し、Web Unlocker API経由でページコンテンツを取得します。ConversableAgentとして、他のエージェントや人間とのコミュニケーション、情報処理、システムメッセージで定義された指示の追従などが可能です。reporting_agent: 収集したデータを分析し、意思決定者向けに構造化されたビジネス対応のMarkdownレポートに変換します。
これらのエージェントが連携し、Twitchストリーマーの特定と対象製品のプロモーションを目的とした完全自律型マルチエージェントパイプラインを構成します。
agent.pyでは、以下のコードで3つのエージェントを全て指定します:
from autogen import (
UserProxyAgent,
ConversableAgent,)
# ツール呼び出しを実行し、人間の介入なしにワークフローを調整
user_proxy = UserProxyAgent(
name="user_proxy",
code_execution_config=False,
human_input_mode="NEVER",
llm_config=llm_config,
)
# ウェブデータの検索と取得を担当
web_data_agent = ConversableAgent(
name="web_data_agent",
code_execution_config=False,
llm_config=llm_config,
system_message=(
"""
あなたはウェブデータ取得エージェントです。
Bright Data SERP APIツールを使用してウェブを検索し、
Web Unlocker APIツールを使用してページコンテンツを取得します。
"""
),
)
# 収集したデータを分析し構造化されたレポートを生成する
reporting_agent = ConversableAgent(
name="reporting_agent",
code_execution_config=False,
system_message=(
"""
あなたはマーケティングアナリストです。
意思決定者向けに、構造化されたビジネス対応のMarkdownレポートを
作成します。
"""
),
llm_config=llm_config,
# 「report」という単語が出現したら会話を自動的に終了
is_termination_msg=lambda msg: "report" in (msg.get("content", "") or "").lower()
)上記のコードでは、以下の点に注意してください:
- AG2エージェントはメッセージ内のコード(コードブロックなど)を実行し、結果を次のエージェントに渡せます。本設定ではセキュリティ
のためcode_execution_config=Falseでコード実行を無効化しています。 - 全エージェントはステップ#2でロードされた
llm_configで動作します。 reporting_agentにはis_termination_msg関数が含まれており、メッセージに「report」という単語が含まれると自動的にワークフローを終了させます。これは最終出力が生成されたことを示すシグナルです。
次に、BrightDataツールをweb_data_agentに登録し、ウェブ取得を有効化します!
ステップ #7: AG2 Bright Data ツールの登録
Bright Data関数をツールとして登録し、register_function() を通じてweb_data_agentに割り当てます。AG2のアーキテクチャ要件に従い、user_proxyエージェントがこれらのツールの実行担当となります:
from autogen import register_function
# Webデータエージェント向けSERP検索ツールを登録
register_function(
serp_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Bright DataのSERP APIを使用してGoogle検索を実行し、生の結果を返す。"
)
# 保護されたページ取得用 Web Unlocker ツールの登録
register_function(
web_unlocker_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Bright Data の Web Unlocker API を使用して、一般的なボット対策機能を回避しウェブページを取得します。",
)各関数には簡潔な説明が含まれており、LLMがその目的を理解し、いつ呼び出すべきかを判断するのに役立ちます。
これらのツールを登録することで、web_data_agentはウェブ検索とページアクセスを計画できるようになり、user_proxyが実行を担当します。
これで、AG2マルチエージェントパイプラインはBright DataのAPIを使用した自律的なデータ発見とスクレイピングを完全に実行可能になりました。ミッション完了!
ステップ #8: AG2 マルチエージェントオーケストレーションロジックの導入
AG2は複数のエージェントをオーケストレーション・管理する複数の方法をサポートしています。この例ではGroupChatパターンを紹介します。
AG2グループチャットの中核は、全てのエージェントが単一の会話スレッドに貢献し、同じコンテキストを共有することです。このアプローチは、当パイプラインのように複数エージェント間の連携を必要とするタスクに最適です。
次に、GroupChatManagerがグループチャット内のエージェント調整を処理します。次の実行エージェントを選択する様々な戦略をサポートしています。ここでは、マネージャーのLLMを活用して次に発言するエージェントを決定するデフォルトの自動戦略を設定します。
マルチエージェントオーケストレーションのための全体を以下のように統合します:
from autogen import (
GroupChat,
GroupChatManager,)
# マルチエージェントグループチャットの定義
groupchat = GroupChat(
agents=[user_proxy, web_data_agent, reporting_agent],
speaker_selection_method="auto",
messages=[],
max_round=20
)
# エージェント間の相互作用を調整するマネージャー
manager = GroupChatManager(
name="group_manager",
groupchat=groupchat,
llm_config=llm_config
)注: 以下のいずれか早い時点でワークフローは終了します: –reporting_agentがis_termination_msgロジックをトリガーするメッセージを生成した場合 – エージェント間の往復やり取りが20ラウンドに達した場合 (max_round引数による)
さあ始めましょう!エージェント定義とオーケストレーションロジックは完了しました。最後のステップはワークフローを開始し、結果をエクスポートすることです。
ステップ #9: Agentic ワークフローを起動し結果をエクスポート
Twitchストリーマーインフルエンサー検索タスクを詳細に記述し、ユーザープロキシエージェントにメッセージとして渡して実行します:
prompt_message = """
シナリオ:
---------
食品飲料ブランドが新種のハンバーガーをプロモーションしたい。
目標:
- TwitchMetricsの「Food & Drink」カテゴリページを検索
- SERPから取得したTwitchMetricsカテゴリページの内容を取得し、上位5人のストリーマーを選定
- 各ストリーマーのTwitchMetricsプロフィールページを訪問し関連情報を取得
- 構造化されたMarkdownレポートを作成(以下を含む)
- チャンネル名
- 推定リーチ
- コンテンツの焦点
- 視聴者層との適合性
- ブランドアプローチの実現可能性
"""
# マルチエージェントワークフローを開始
user_proxy.initiate_chat(recipient=manager, message=prompt_message)ワークフロー完了後、出力(Markdownレポート)をディスクに保存:
with open("report.md", "w", encoding="utf-8") as f:
f.write(user_proxy.last_message()["content"])素晴らしい!AG2とBright Dataを活用したマルチエージェントワークフローが完全に稼働し、Twitchインフルエンサーデータの収集・分析・レポート作成の準備が整いました。
ステップ #10: 全てを統合する
agent.pyファイルの最終コードは以下のようになります:
from autogen import (
LLMConfig,
UserProxyAgent,
ConversableAgent,
register_function,
GroupChat,
GroupChatManager,)
from dotenv import load_dotenv
import os
from typing import Annotated
import requests
import urllib.parse
# OpenAI設定リストファイルからLLM設定を読み込み
llm_config = LLMConfig.from_json(path="OAI_CONFIG_LIST")
# .envファイルから環境変数を読み込み
load_dotenv()
# 環境変数からBright Data APIキーを取得
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Bright Dataツールを実装する関数を定義
def serp_api_tool(
query: Annotated[str, "Google検索クエリ"],)
-> str:
payload = {
"zone": "serp_api", # Bright Data SERP APIゾーン名に置き換えてください
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw",
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers,
)
response.raise_for_status()
return response.text
def web_unlocker_api_tool(
url_to_fetch: Annotated[str, "取得対象ページURL"],
data_format: Annotated[
str | None,
"出力ページ形式 (例: 'markdown'、省略時は生のHTML)"
] = "markdown",)
-> str:
payload = {
"zone": "web_unlocker", # Bright Data Web Unlocker のゾーン名に置き換えてください
"url": url_to_fetch,
"format": "raw",
"data_format": data_format,
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers
)
response.raise_for_status()
return response.text
# ツール呼び出しを実行し、人間の介入なしにワークフローを調整する
user_proxy = UserProxyAgent(
name="user_proxy",
code_execution_config=False,
human_input_mode="NEVER",
llm_config=llm_config,
)
# ウェブデータの検索と取得を担当
web_data_agent = ConversableAgent(
name="web_data_agent",
code_execution_config=False,
llm_config=llm_config,
system_message=(
"""
あなたはウェブデータ取得エージェントです。
Bright Data SERP APIツールを使用してウェブを検索し、
Web Unlocker APIツールを使用してページコンテンツを取得します。
"""
),
)
# 収集したデータを分析し構造化されたレポートを生成する
reporting_agent = ConversableAgent(
name="reporting_agent",
code_execution_config=False,
system_message=(
"""
あなたはマーケティングアナリストです。
意思決定者向けに、構造化されたビジネス対応のMarkdownレポートを
作成します。
"""
),
llm_config=llm_config,
# "report"という単語が出現したら会話を自動的に終了
is_termination_msg=lambda msg: "report" in (msg.get("content", "") or "").lower()
)
# Webデータエージェント向けにSERP検索ツールを登録
register_function(
serp_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Bright DataのSERP APIを使用してGoogle検索を実行し、生の検索結果を返す。"
)
# 保護されたページ取得用 Web Unlocker ツールを登録
register_function(
web_unlocker_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Bright Data の Web Unlocker API を使用して、一般的なボット対策機能を回避しウェブページを取得します。",
)
# マルチエージェントグループチャットの定義
groupchat = GroupChat(
agents=[user_proxy, web_data_agent, reporting_agent],
speaker_selection_method="auto",
messages=[],
max_round=20
)
# エージェント間の連携を調整するマネージャー
manager = GroupChatManager(
name="group_manager",
groupchat=groupchat,
llm_config=llm_config)
prompt_message = """
シナリオ:
---------
飲食ブランドが新種のハンバーガーを宣伝したい。
目標:
- TwitchMetricsの「Food & Drink」カテゴリページを検索
- SERPから取得したTwitchMetricsカテゴリページの内容を取得し、上位5人のストリーマーを選定
- 各ストリーマーのTwitchMetricsプロフィールページを訪問し関連情報を取得
- 構造化されたMarkdownレポートを作成(以下を含む):
- チャンネル名
- 推定リーチ
- コンテンツの焦点
- 視聴者層との適合性
- ブランドアプローチの実現可能性
"""
# マルチエージェントワークフローを開始
user_proxy.initiate_chat(recipient=manager, message=prompt_message)
# 最終レポートをMarkdownファイルに保存
with open("report.md", "w", encoding="utf-8") as f:
f.write(user_proxy.last_message()["content"])強力なAG2 APIのおかげで、わずか約170行のコードで、複雑なエンタープライズ対応のBright Data搭載マルチエージェントワークフローを構築できました!
ステップ #11: マルチエージェントシステムのテスト
ターミナルで、AG2エージェントアプリケーションが動作することを確認します:
python agent.py期待される出力は以下のようになります: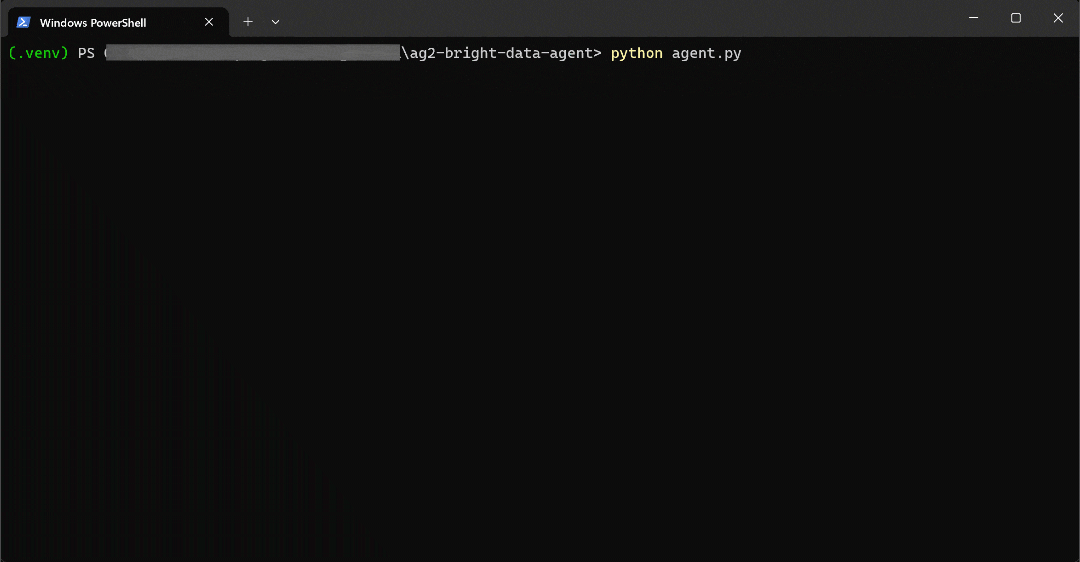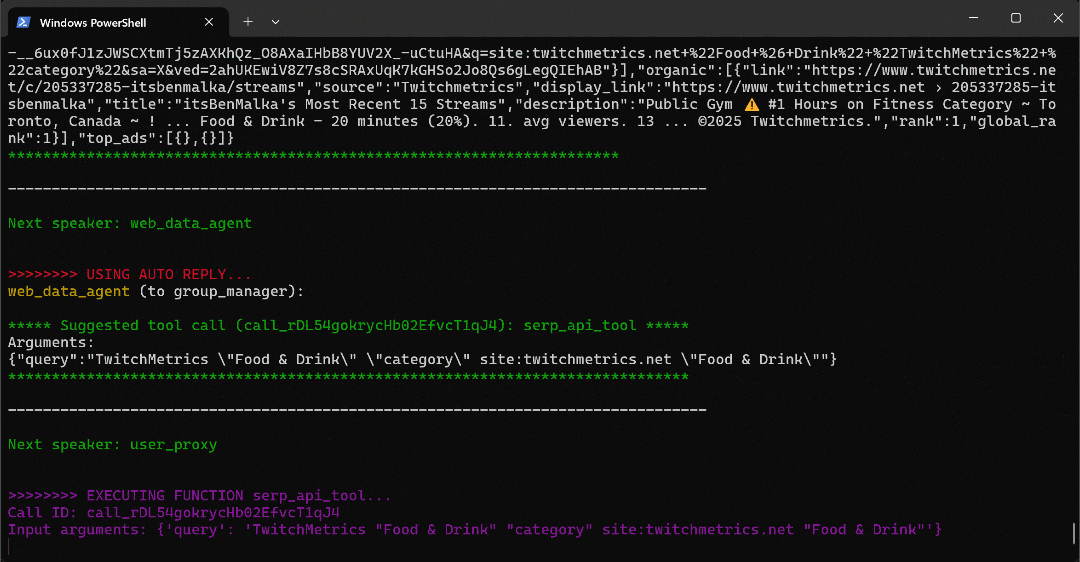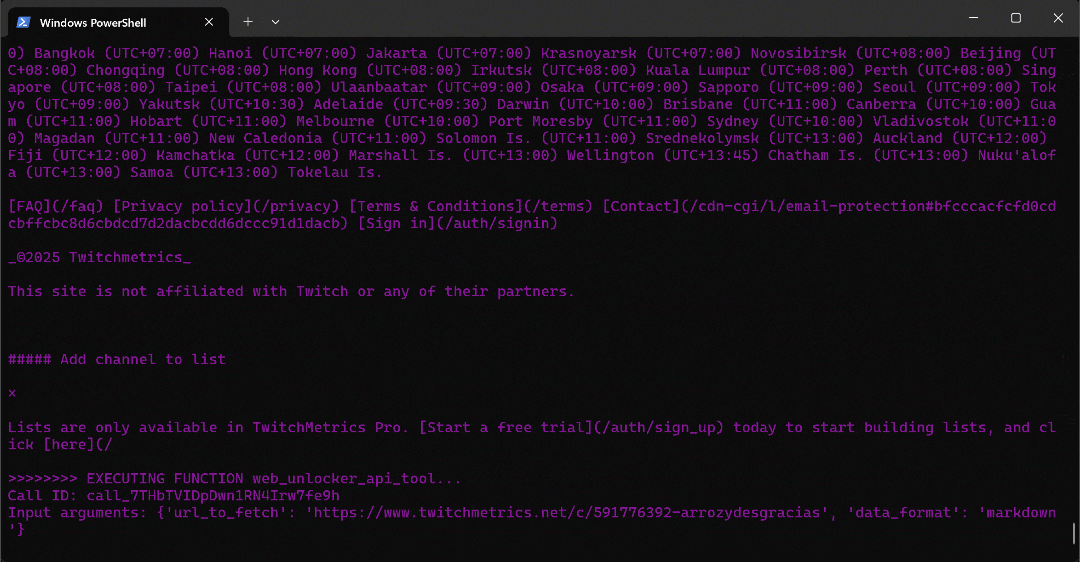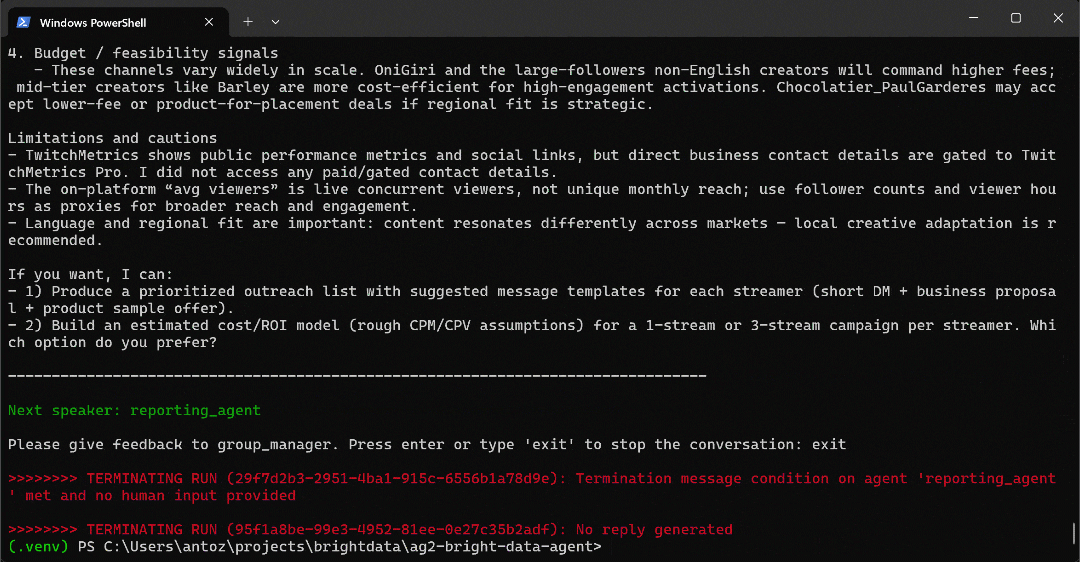
詳細には、マルチエージェントワークフローが段階的に進行する様子に注目してください:
web_data_agentは、必要な TwitchMetrics の「Food & Drink」カテゴリページを見つけるためにserp_api_toolを呼び出す必要があることを判断します。user_proxyエージェントを介して、このツールは複数の検索クエリを実行します。- 正しい TwitchMetrics カテゴリページが特定されると、
web_unlocker_api_toolを呼び出して Markdown 形式でコンテンツをスクレイピングします。 - Markdown出力から、「Food & Drink」カテゴリにおける上位5人のインフルエンサーのTwitchMetricsプロフィールURLを抽出します。
web_unlocker_api_toolが再度呼び出され、各プロフィールページのコンテンツを Markdown で取得します。- 収集された全データは
reporting_agentに渡され、分析を経て最終レポートが生成されます。
この最終レポートはコードで指定された通りreport.md としてディスクに保存されます: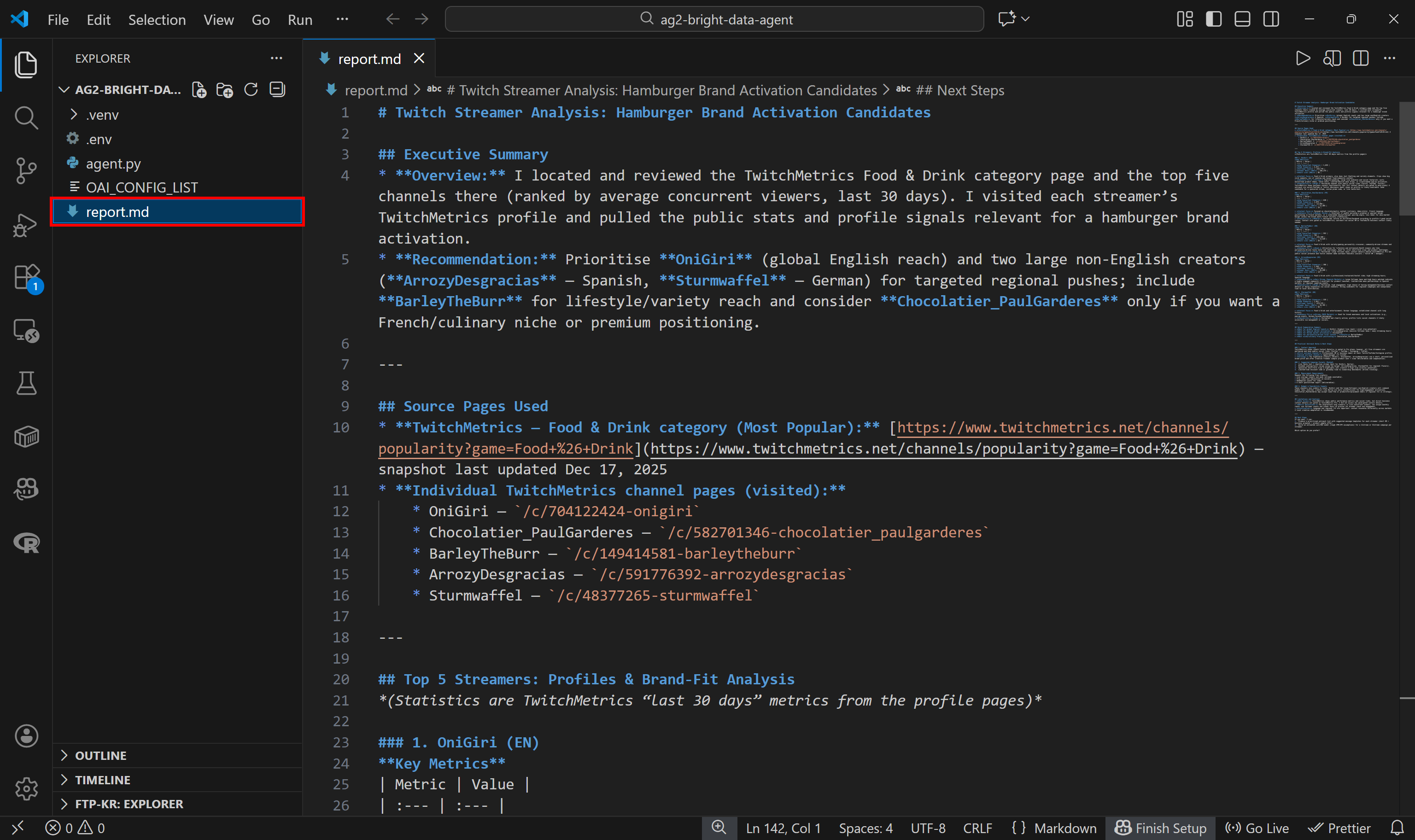
VS CodeのMarkdownプレビューで表示し、レポートの詳細さと情報量の豊富さを確認してください: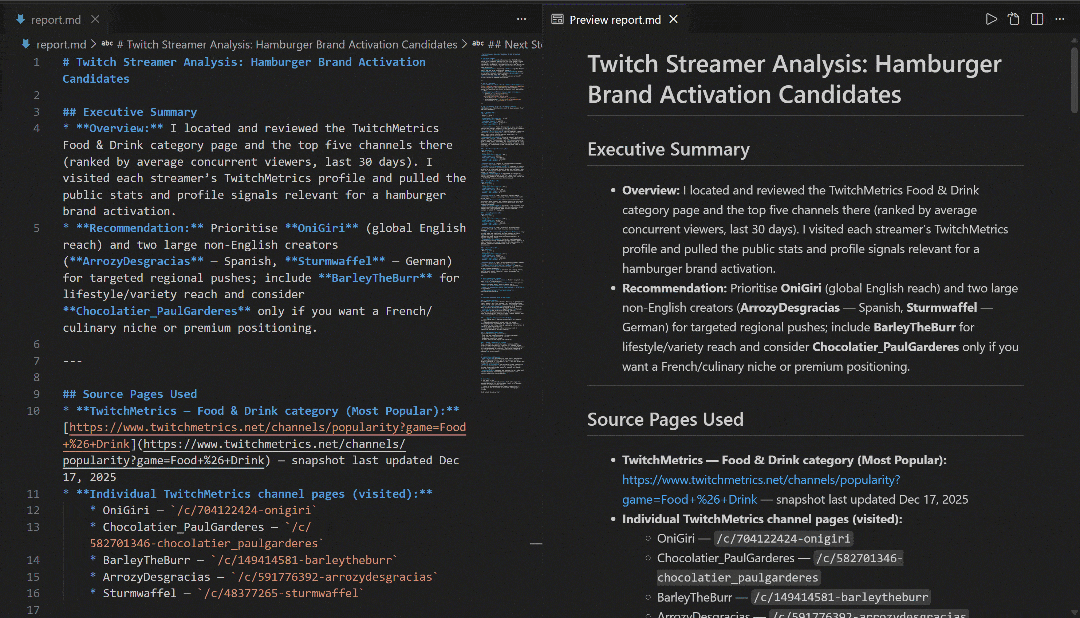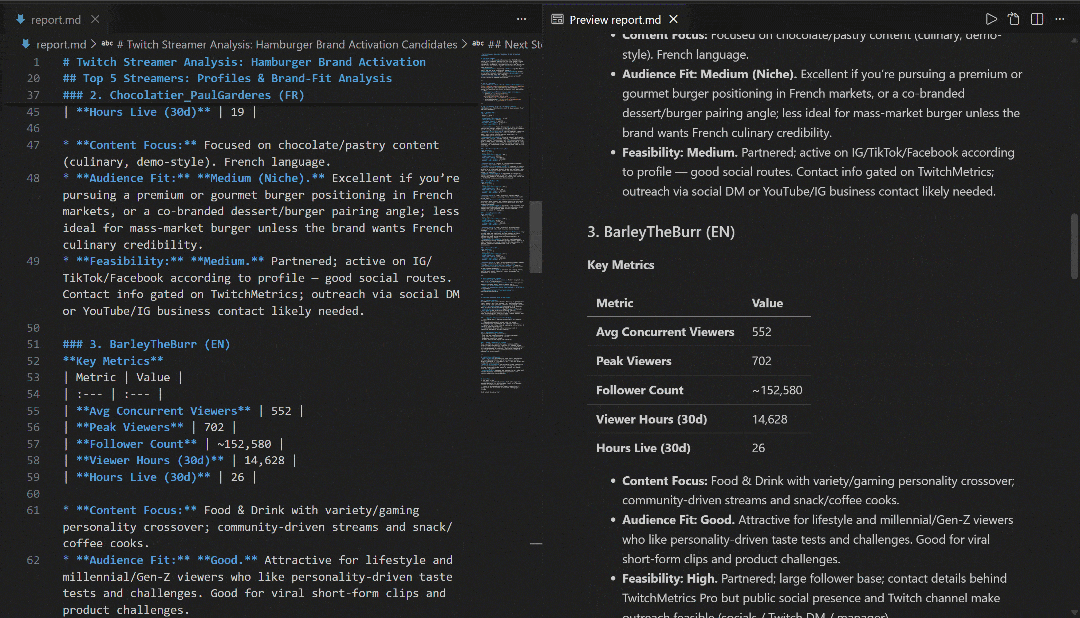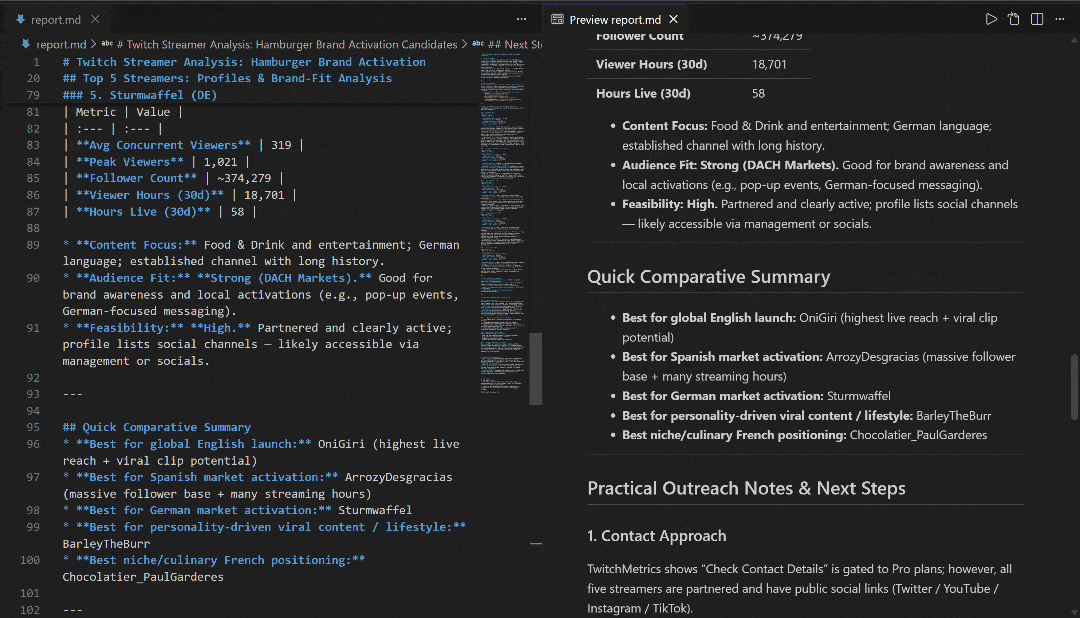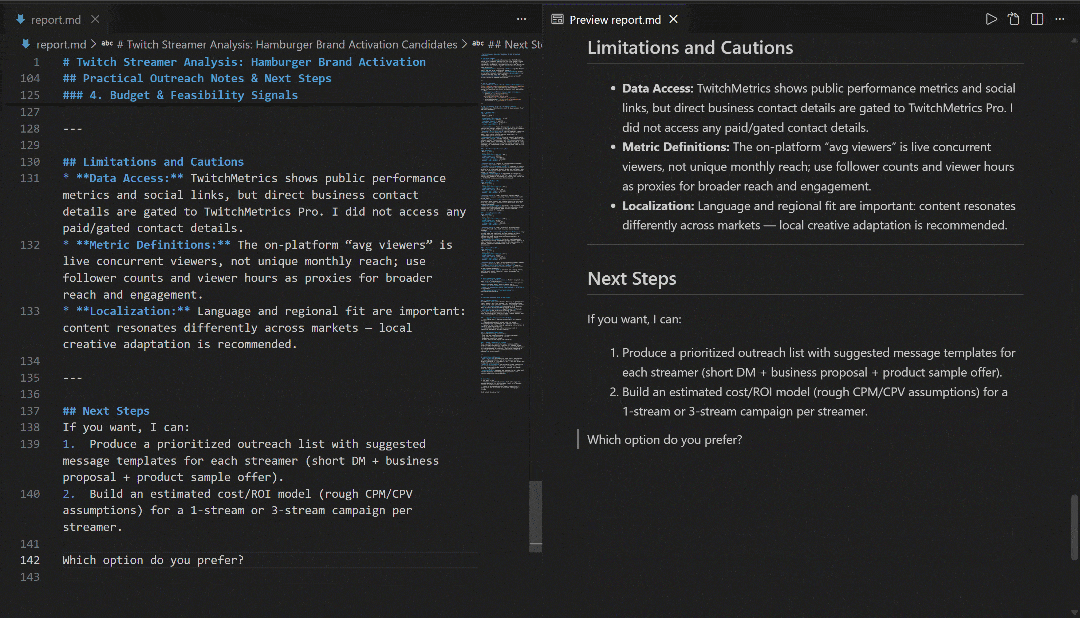
ソースデータの出所が気になる場合は、TwitchMetricsの「Food & Drink」Twitchストリームカテゴリページを確認してください: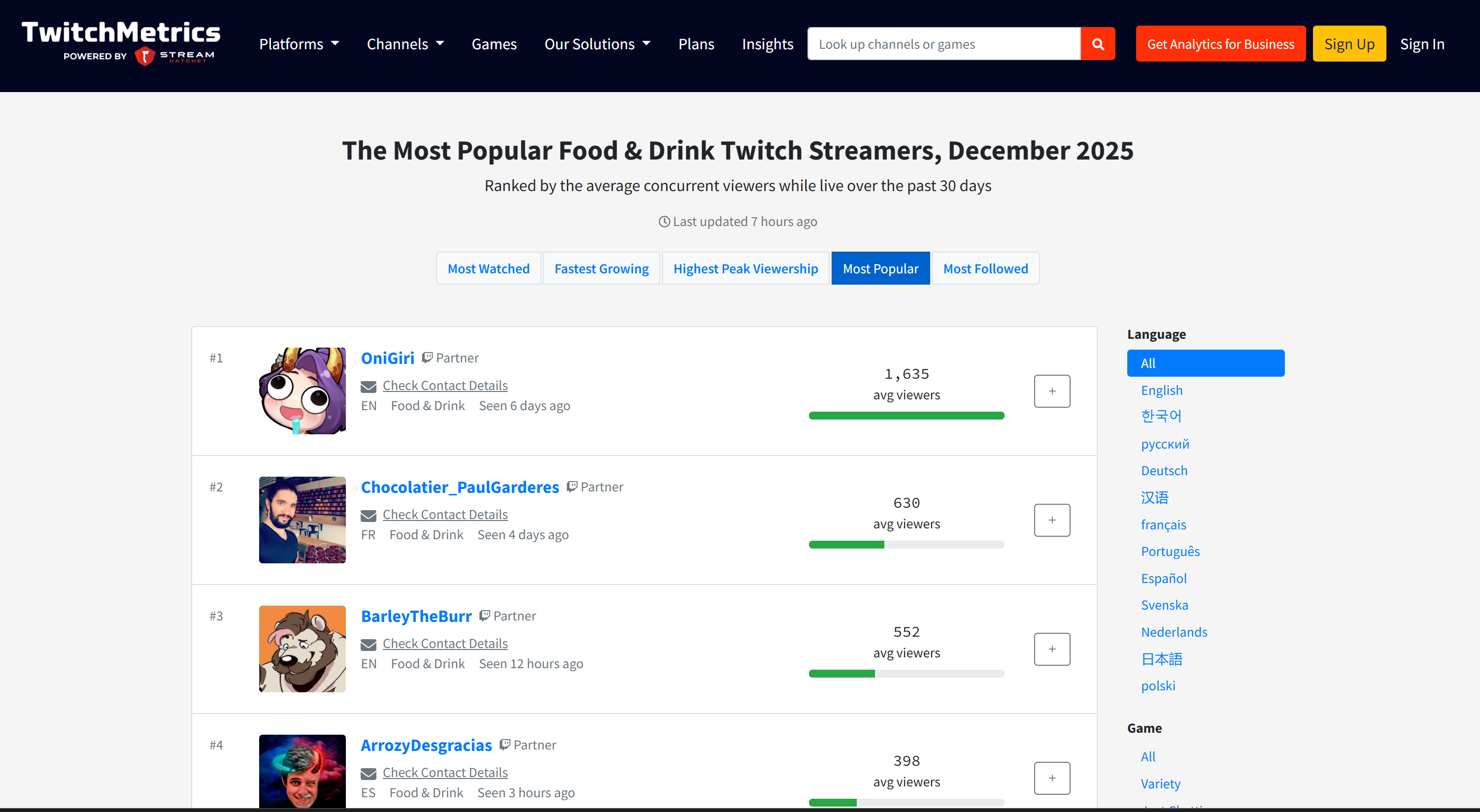
レポート内のTwitchストリーマー情報は、上位5プロファイルそれぞれの専用TwitchMetricsプロフィールページと一致している点に注意してください: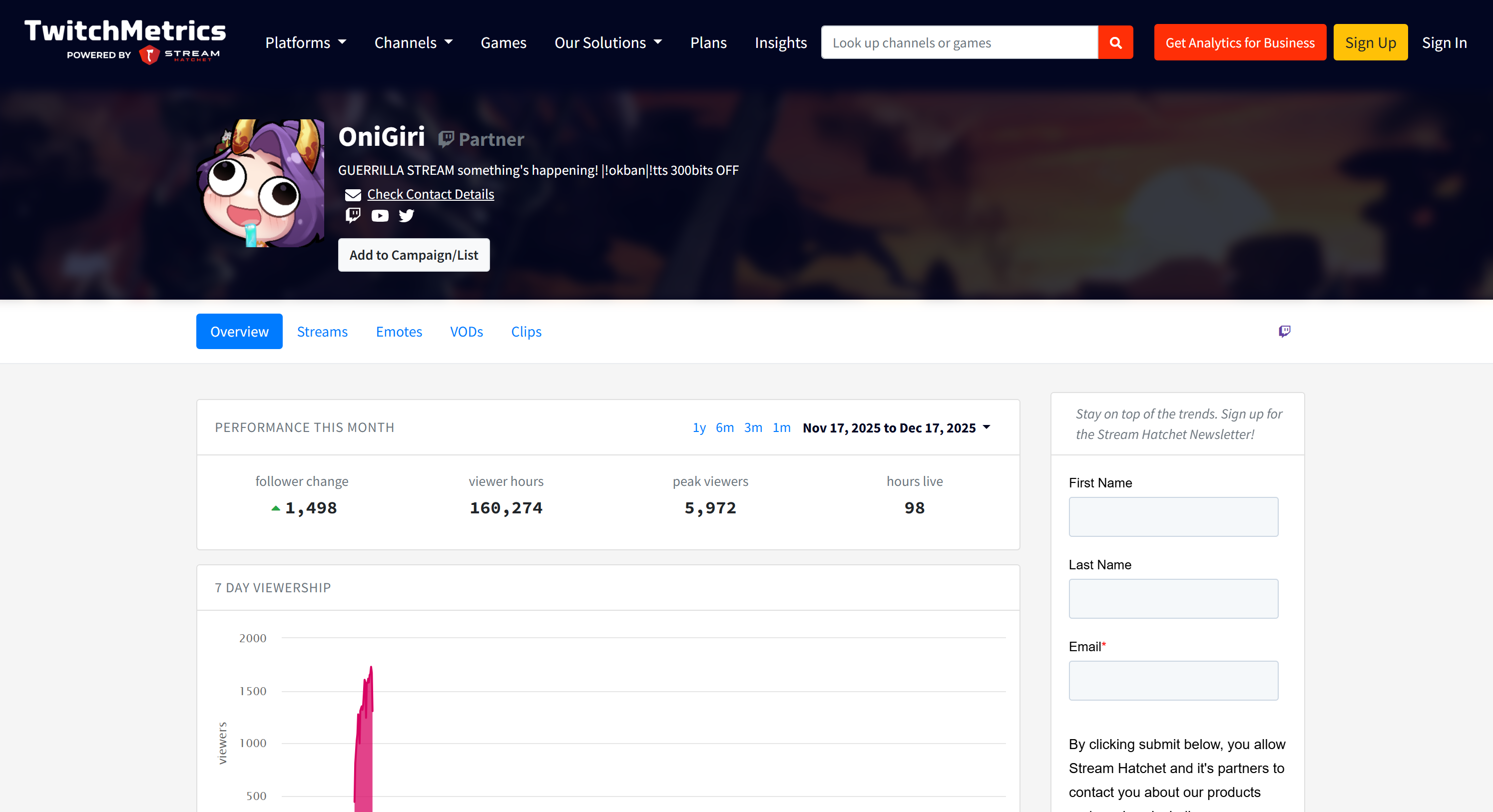
これらの情報はすべてマルチエージェントシステムによって自動的に取得されており、AG2の能力とBright Dataとの連携の威力を示しています。
さあ、様々な入力プロンプトで自由に試してみてください。Bright Dataのおかげで、AG2マルチエージェントワークフローは多様な実世界のタスクを処理できます。
さあ、どうぞ! Bright Dataで強化されたAG2ワークフローの能力を目の当たりにしました
AG2とBright Data Web MCPの接続:ステップバイステップガイド
Bright DataをAG2に統合する別の方法は、Bright DataWeb MCPサーバーを経由することです。
Web MCPでは、Bright DataのWeb自動化・データ収集プラットフォーム上に構築された60以上のツールを利用できます。無料プランでも、以下の2つの強力なツールが利用可能です:
| ツール | 説明 |
|---|---|
search_engine |
Google、Bing、Yandexの検索結果をJSONまたはMarkdown形式で取得します。 |
scrape_as_markdown |
あらゆるウェブページを、ボット対策機能を回避しながらクリーンなMarkdown形式にスクレイピングします。 |
WebMCPのProモードでは機能がさらに拡張されます。このプレミアムオプションでは、Amazon、LinkedIn、Instagram、Reddit、YouTube、TikTok、Google Mapsなどの主要プラットフォーム向け構造化データ抽出が可能になります。また、高度なブラウザ自動化ツールも追加されます。
注:プロジェクト設定については、前章のステップ#1を参照してください。
次に、AG2内でBright DataのWeb MCPを使用する方法を見ていきましょう!
前提条件
このチュートリアルのセクションを実行するには、ローカルにNode.jsがインストールされている必要があります。Web MCPをマシン上で実行するために必須です。
また、AG2用のMCPパッケージを以下のようにインストールする必要があります:
pip install ag2[mcp]これによりAG2がMCPクライアントとして動作します。
ステップ #1: Bright Data の Web MCP を始める
AG2をBright DataのWeb MCPに接続する前に、ローカルマシンでMCPサーバーを実行できることを確認してください。これは、ローカルでWeb MCPサーバーに接続する方法を示すため重要です。
注: Web MCPは、無制限のスケーラビリティによりエンタープライズグレードのユースケースに適した、ストリーム可能なHTTP経由のリモートサーバーとしても利用可能です。
まず、Bright Dataアカウントをお持ちであることを確認してください。既にアカウントをお持ちの場合は、ログインしてください。迅速なセットアップには、ダッシュボードの「MCP」セクションの手順に従ってください:
追加のガイダンスが必要な場合は、以下の手順を参照してください。
Bright Data APIキーの生成から始めます。ローカルWeb MCPインスタンスの認証にすぐに使用するため、安全な場所に保管してください。
次に、@brightdata/mcpパッケージを使用してWeb MCPをマシンにグローバルインストールします:
npm install -g @brightdata/mcpMCPサーバーを起動するには以下を実行:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpまたは、PowerShellでは同等の方法で実行できます:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp<YOUR_BRIGHT_DATA_API>を Bright Data API トークンに置き換えてください。これらのコマンドは必要なAPI_TOKEN環境変数を設定し、Web MCP サーバーをローカルで起動します。
正常に実行されると、以下のような出力が表示されます:
デフォルトでは、Web MCP は初回起動時に Bright Data アカウント内に 2 つのゾーンを作成します:
mcp_unlocker:Web Unlocker 用のゾーン。mcp_browser:ブラウザAPI用のゾーン。
これらのゾーンは、Web MCPで利用可能な60以上のツールを支えています。
ゾーンが作成されたかどうかは、Bright Dataダッシュボードの「プロキシとスクレイピングインフラストラクチャ」で確認できます: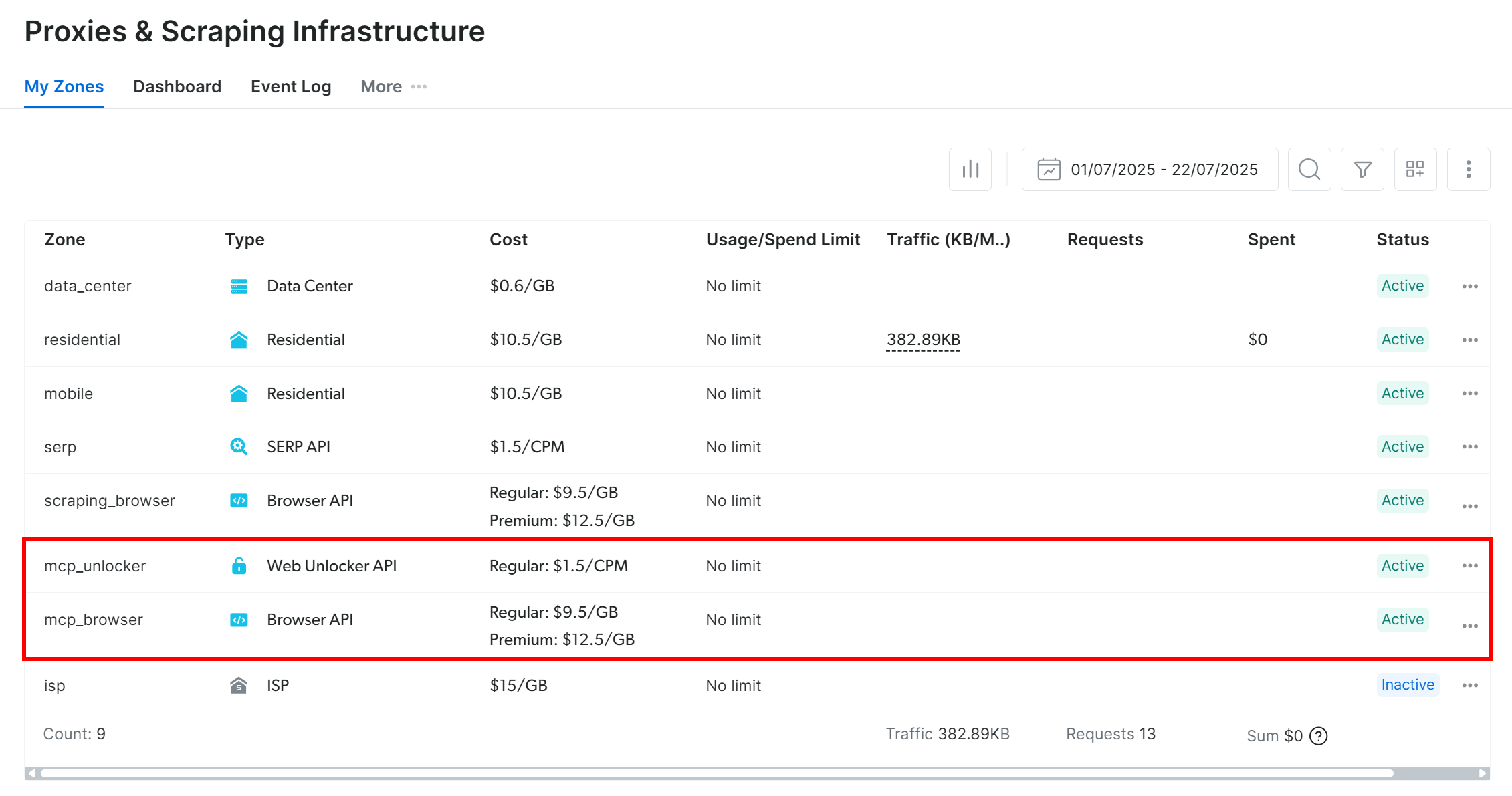
Web MCPの無料プランでは、search_engineおよびscrape_as_markdownツール(およびそれらのバッチ版)のみが利用可能です。
全ツールをアンロックするには、環境変数PRO_MODE="true"を設定して Pro モードを有効化してください:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpまたは、Windowsの場合:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpプロモードでは60以上のツールがすべて利用可能になりますが、無料プランには含まれず追加料金が発生する可能性があります。
完了!これでWeb MCPサーバーがローカルで動作することを確認しました。次のステップはAG2を設定してサーバーをローカルで起動し接続するため、現時点ではMCPプロセスを停止してください。
ステップ #2: AG2 での Web MCP 統合
AG2 MCPクライアントを使用して、STDIO経由でローカルWeb MCPインスタンスに接続し、利用可能なツールを取得します:
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from autogen.mcp import create_toolkit
# ローカルWeb MCPインスタンスへの接続手順
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # オプション
},)
async with stdio_client(server_params) as (read, write), ClientSession(read, write) as session:
# MCP接続セッションを作成し、ツールを取得
await session.initialize()
web_mcp_toolkit = await create_toolkit(session, use_mcp_resources=False)StdioServerParametersオブジェクトは、以前実行したnpxコマンドを反映し、認証情報や設定用の環境変数を含みます:
API_TOKEN: 必須。Bright Data APIキーを設定してください。PRO_MODE: オプション。無料プランのまま利用したい場合は削除してください(search_engine、scrape_as_markdown、およびそれらのバッチ版のみ)。
セッションは Web MCP への接続に使用され、create_toolkit を使用して AG2 MCP ツールキットを作成します。
注:専用のGitHubイシューで強調されている通り、mcp.shared.exceptions.McpError: Method not foundエラーを回避するには、use_mcp_resources=Falseオプションが必須です。
作成後、web_mcp_toolkitオブジェクトには全てのWeb MCPツールが含まれます。以下で確認してください:
for tool in web_mcp_toolkit.tools:
print(tool.name)
print(tool.description)
print("---n")出力例: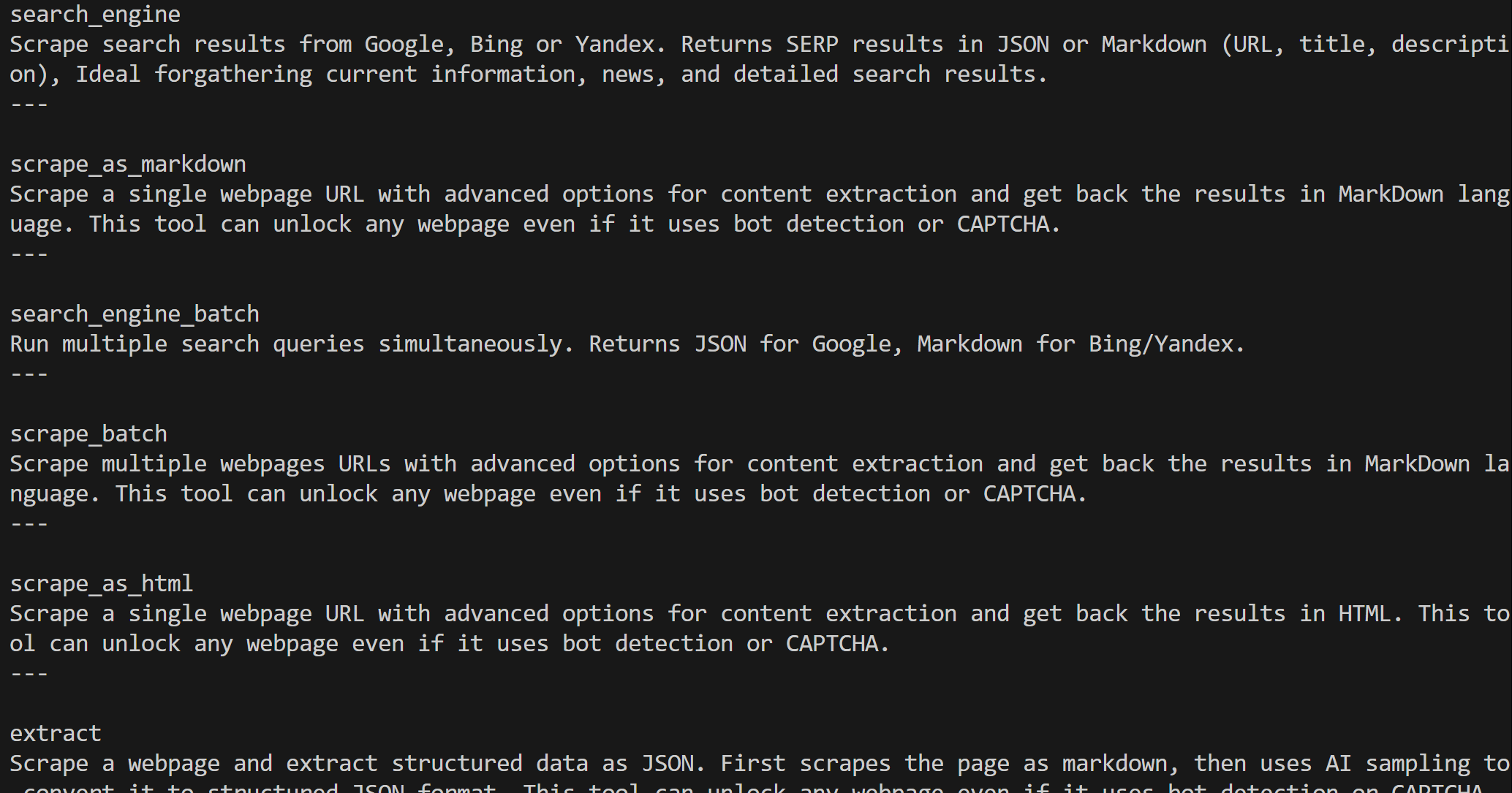
設定されたティアに応じて、60以上のWeb MCPツール全て(Proモード)または無料ティアのツールのみが利用可能です。
これでWeb MCP接続がAG2で完全に機能するようになりました。
ステップ #3: Web MCP ツールをエージェントに接続する
AG2でWeb MCP統合をテストする最も簡単な方法は、LLMを使用してタスクを迅速に解決するように設計されたConversableAgentの サブクラスであるAssistantAgentを利用することです。まず、エージェントを定義し、Web MCPツールキットを登録します:
from autogen import AssistantAgent
# Webデータの検索・取得が可能なエージェントを定義
assistant_agent = AssistantAgent(
name="assistant",
code_execution_config=False,
llm_config=llm_config,
system_message="""
Web MCPが公開する全ツール(以下を含む)を利用可能です:
- Web検索
- ウェブスクレイピングとページフェッチング
- Webデータフィード
- ブラウザベースのユーザーシミュレーション
必要な時にこれらのツールを使用してください。
""")
# Web MCPツールキットをエージェントに登録
web_mcp_toolkit.register_for_llm(assistant_agent)登録後、a_run()関数でエージェントを起動し、使用するツールを直接指定できます。例えば、Amazonウェブスクレイピングタスクでエージェントをテストする方法は以下の通りです:
prompt = """
以下のAmazon商品からデータを取得し、主要情報を含む簡易要約を生成してください:
"""
# Web MCP拡張エージェントを非同期実行
result = await assistant_agent.a_run(
message=prompt,
tools=web_mcp_toolkit.tools,
user_input=False,)
await result.process()重要: これは統合を実演するためのデモに過ぎない点にご留意ください。Web MCPツール群のおかげで、エージェントは異なるWebプラットフォームやデータソースを跨いだ、より複雑な多段階タスクを処理できます。
ステップ #4: 最終コード + 実行
以下は、AG2 + Bright Data Web MCP 統合の最終コードです:
import asyncio
from autogen import (
LLMConfig,
AssistantAgent,)
from dotenv import load_dotenv
import os
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from autogen.mcp import create_toolkit
# .envファイルから環境変数をロード
load_dotenv()
# 環境変数からBright Data APIキーを取得
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# すべてのWeb MCPツールを含むMCPツールキットを定義
async def launch_mcp_agent():
# OpenAI設定リストファイルからLLM設定を読み込み
llm_config = LLMConfig.from_json(path="OAI_CONFIG_LIST")
# ローカルWeb MCPインスタンスへの接続指示
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # オプション
},
)
async with stdio_client(server_params) as (read, write), ClientSession(read, write) as session:
# MCP接続セッションを作成し、ツールを取得
await session.initialize()
web_mcp_toolkit = await create_toolkit(session, use_mcp_resources=False)
# Webデータの検索・取得が可能なエージェントを定義
assistant_agent = AssistantAgent(
name="assistant",
code_execution_config=False,
llm_config=llm_config,
system_message="""
Web MCPが公開する全ツールを利用可能です:
- Web検索
- ウェブスクレイピングとページ取得
- ウェブデータフィード
- ブラウザベースのユーザーシミュレーション
必要な時にこれらのツールを使用してください。
"""
)
# Web MCPツールをエージェントに登録
web_mcp_toolkit.register_for_llm(assistant_agent)
# エージェントに渡すプロンプト
prompt = """
以下のAmazon商品からデータを取得し、主要情報を含む簡易要約を作成してください:
"""
# Web MCP拡張エージェントを非同期で実行
result = await assistant_agent.a_run(
message=prompt,
tools=web_mcp_toolkit.tools,
user_input=False,
)
await result.process()
asyncio.run(launch_mcp_agent())実行すると、結果は次のようになります: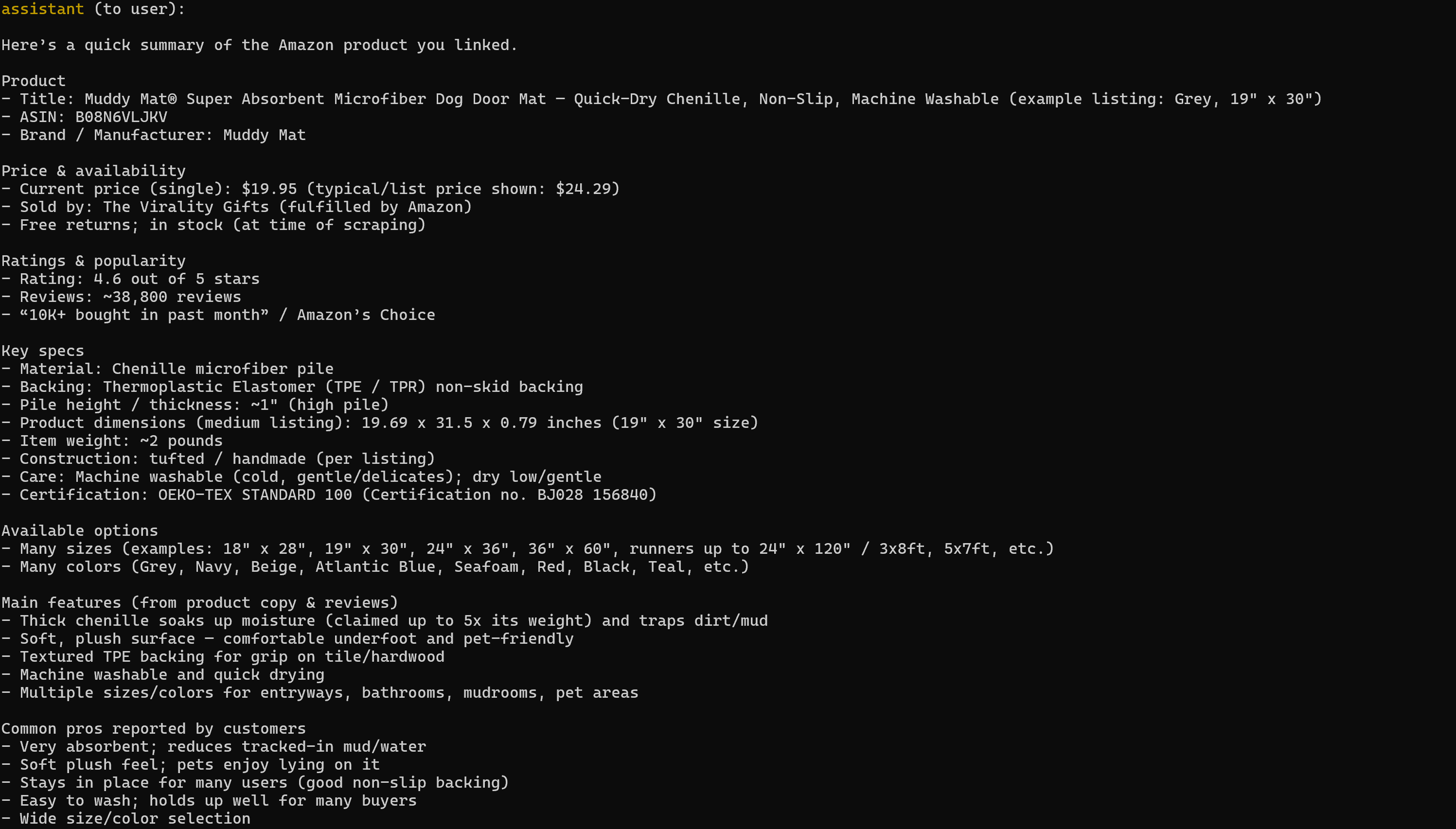
生成されたレポートには、対象のAmazon商品ページから関連する全データが含まれている点に注意してください:
PythonでAmazon商品データをスクレイピングしたことがある方なら、その難しさをよくご存知でしょう。Amazonは悪名高いAmazon CAPTCHAをはじめ、様々なボット対策を採用しています。さらに商品ページは絶えず変更され、構造も多様です。
Bright DataのWeb MCPがこれら全てを処理します。無料プランでは、Web Unlockerを介してページ構造をクリーンなMarkdown形式で取得するため、バックグラウンドでscrape_as_markdownツールを呼び出します。Proモードでは、Bright DataのAmazonスクレイパーを呼び出して完全に構造化された商品データを収集する「web_data_amazon_product」製品を活用します。
以上です!これでBright Data Web MCPを用いてAG2を拡張する方法が理解できました。
まとめ
本チュートリアルでは、カスタム関数またはWeb MCPを介したBright DataとAG2の連携方法を学びました。
この統合により、AG2エージェントはウェブ検索の実行、構造化データの抽出、ライブウェブフィードへのアクセス、ウェブインタラクションの自動化が可能になります。これらすべてはBright DataのAIのためのデータスイートによって実現されています。
Bright Dataアカウントを無料で作成し、AI対応のウェブデータツールを今すぐお試しください!




