
デジタル経済の急激な成長が続き、 API、Webサイト、データベースなどのさまざまなソースからデータを収集することがこれまで以上に重要になっています。
データを抽出する一般的な方法の1つは、 ウェブスクレイピングを使用することです。ウェブスクレイピングでは、自動ツールを使用してWebページを取得し、そのコンテンツを解析して特定の情報を抽出し、さらに分析して使用します。一般的なユースケースには、市場調査、価格監視、データ集計などがあります。
ウェブスクレイピングの実装には、動的コンテンツの処理、セッションとクッキーの管理、スクレイピング対策への対処、および法令順守の確保が必要です。これらの課題には、効果的なデータ抽出のための高度なツールと技術が必要です。 ChatGPT は、自然言語処理機能を活用してコードを生成し、エラーのトラブルシューティングを行うことで、このような複雑な問題の解決につなげます。
この記事では、主に静的HTMLコンテンツに依存するWebサイトや、より複雑なページ生成技術を採用する複雑なWebサイト向けに、ChatGPTを使用してスクレイピングコードを生成する方法をご紹介します。
前提条件
このチュートリアルを始める前に、以下をご確認ください。
- Pythonに精通
- Python環境がVisual Studio Codeを使用して マシンにインストールおよび構成されています
- ChatGPT アカウント
ChatGPTを使用してウェブスクレイピングスクリプトを生成する場合、主に2つのステップがあります。
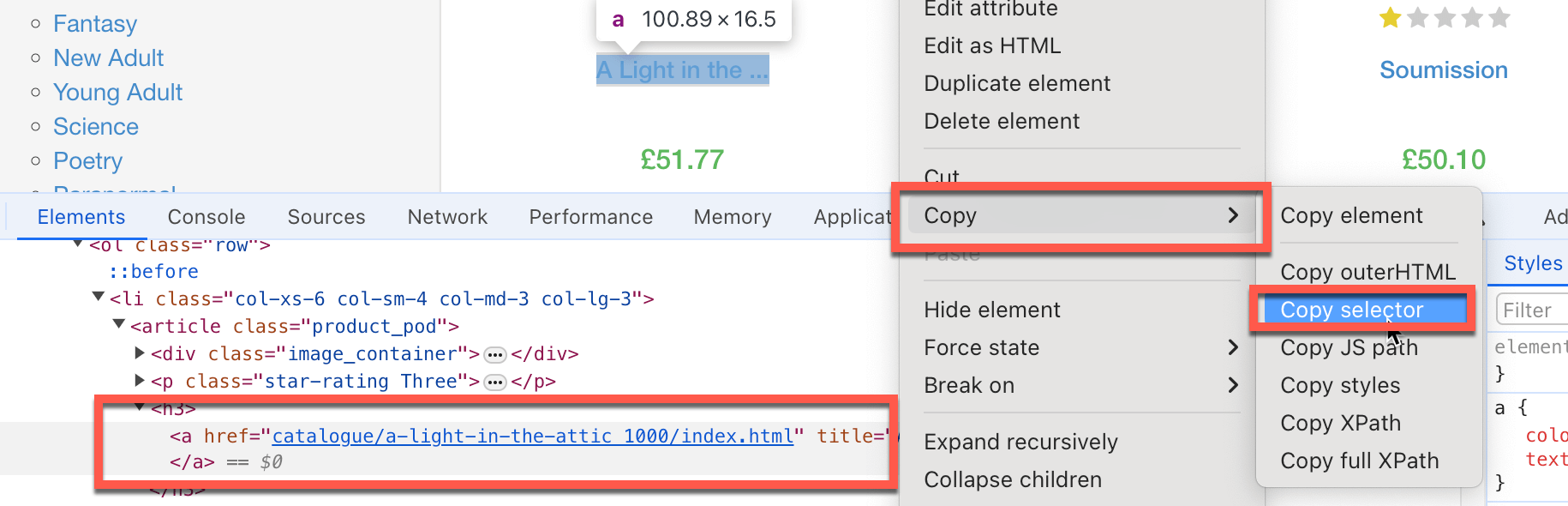
- ターゲットにするHTML要素、入力するテキストボックス、クリックするボタンなど、スクレイピングすべき情報を見つけるためにコードが従うべき各ステップを文書化します。多くの場合、特定のHTML要素セレクタをコピーする必要があります。これを行うには、スクレイピングしたい特定のページ要素を右クリックして、 Inspectをクリックします。Chromeは特定の DOM 要素を強調表示します。右クリックして コピー > セレクタをコピー を選択すると、HTMLセレクタパスがクリップボードにコピーされます。
- 具体的で詳細なChatGPTプロンプトを作成して、スクレイピングコードを生成します。
- 生成されたコードを実行してテストします。
ChatGPTを使った、静的HTMLを含むWebサイトのスクレイピング
一般的なワークフローに慣れてきたので、ChatGPTを使用して 静的HTML 要素を含むWeb サイトをスクレイピングしてみましょう。まず、 https://books.toscrape.comから本のタイトルと価格を取得します。
最初に、必要なデータを含むHTML要素を特定する必要があります。
- 本のタイトル の セレクタは
#default > div.container-fluid.page > div > div > div > section > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > aです。 - 本の価格 の セレクタは *
#default > div.container-fluid.page > div > div > div > section > div > div: nth-child(2)> ol > li:nth-child(1) > article > div.product_price > p.price_colorです。
次に、スクレイピングコードを生成するための具体的で詳細なChatGPTプロンプトを作成する必要があります。そのためには、必要な PythonパッケージをすべてインストールするようにChatGPTに指示し、(前に特定した) HTMLセレクタを抽出し、データをExcelファイルとして保存するように指示する必要があります。
ChatGPTバージョンをGPT-4oに必ず設定してください。
ChatGPTには次のような内容を入力できます。
あなたはPython の Beautiful Soup ライブラリと必要な自動化ツールを利用しているウェブスクレイピングのエキスパートです。
https://books.toscrape.comをスクレイピングするための詳細なステップバイステップスクリプトを生成するには、以下を実行してください。
- 必要なPythonパッケージをすべてインストールします。
- HTMLセレクタ
#default > div.container-fluid.page > div > div > div > section > div: nth-child(2) > ol > li:nth-child(1) > article > h3 > aを含む本のタイトルと、セレクタ#default > div.contain.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.product_price > p.price_colorを含む本の価格を抽出します。- すべての本のタイトルと価格のリストを抽出し、Excelファイルに保存します。
- 最初のページのみスクレイピングしてください。
注意: 返答が若干異なる場合があります。
返答では、ChatGPTは次のコマンドを実行してウェブスクレイピングを行うBeautiful Soupライブラリと、データをExcelとして保存する包括的なデータ分析ライブラリである pandasライブラリをインストールするように指示しています。
pip3 install requests beautifulsoup4 pandas openpyxl
ChatGPTは openpyxlのインストールも推奨していますが、ここでは必要ありません。
ChatGPTは以下のウェブスクレイピングコードも提供しています。
import requests
from bs4 import BeautifulSoup
import pandas as pd
# URL of the website
url = 'https://books.toscrape.com'
# Send a GET request to the website
response = requests.get(url)
if response.status_code == 200:
# Parse the HTML content of the page
soup = BeautifulSoup(response.content, 'html.parser')
# Initialize lists to store the titles and prices
book_titles = []
book_prices = []
# Extract the first book title and price using the provided selectors
book_title_selector = "#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > a"
book_price_selector = "#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.product_price > p.price_color"
title_element = soup.select_one(book_title_selector)
price_element = soup.select_one(book_price_selector)
if title_element and price_element:
book_titles.append(title_element.get('title'))
book_prices.append(price_element.text.strip()[1:])
# Extract all book titles and prices on the first page
books = soup.select('section > div:nth-child(2) > ol > li')
for book in books:
title = book.select_one('h3 > a')
price = book.select_one('div.product_price > p.price_color')
if title and price:
book_titles.append(title.get('title'))
book_prices.append(price.text.strip()[1:])
# Create a DataFrame from the lists
df = pd.DataFrame({
'Title': book_titles,
'Price': book_prices
})
# Save the DataFrame to an Excel file
df.to_excel('books_scraped.xlsx', index=False)
print('Data has been successfully scraped and saved to books_scraped.xlsx')
else:
print('Failed to retrieve the webpage')
このコードは requests モジュールをインポートし、スクレイピングしたWebサイトへのHTTP呼び出しを実行します。また、スクレイピングされたデータをExcelファイルに保存するpandasパッケージもインポートします。このコードは、WebサイトのベースURL と、要求されたデータを取得するためにターゲットとする特定のHTMLセレクタを定義します。
次に、コードはWebサイトを呼び出し、Webサイトのコンテンツを soupという名前の BeautifulSoup オブジェクトとして配置します。このコードは、HTMLセレクタを使用して soup オブジェクトから本のタイトルと価格の値をリストとして選択します。最後に、コードは本のタイトルと価格リストからPandas DataFrameを作成し、それをExcel ファイルとして保存します。
次に、コードを books_scraping.py という名前のファイルに保存し、コマンドラインから python3 books_scraping.py コマンドを実行する必要があります。このコードは books_scraped.xlsx という名前のExcelファイルを books_scraping.pyと同じディレクトリに生成します。
1つの例を確認したので、このチュートリアルをさらに一歩進めて、引用集を含む、もう1つの簡単なWebサイト https://quotes.toscrape.comをスクレイピングしてみましょう。
繰り返しますが、ステップの順序を確認することから始めましょう。
Chromeを使用している場合は、次のHTMLセレクタを見つけてください。
body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.textで 引用をスクレイピング- body > div.container > div: nth-child (2) > div.col-md-8 > div: nth-child (1) > span:nth-child (2) > small
で 著者を特定
スクレイピングしたいHTMLセレクタを特定したら、次のような詳細なプロンプトを書いてスクレイピングコードを生成できます。
あなたはPythonのBeautiful Soupライブラリと必要な自動化ツールを利用するウェブスクレイピングのエキスパートです。
https://quotes.toscrape.comをスクレイピングするための詳細なステップバイステップスクリプトを生成してください。次の操作を行ってください。
- 必要なPythonパッケージをすべてインストールします。
- HTMLセレクタ
body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.textを含む引用と、セレクタbody > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > smallを含む筆者名を抽出します。- すべての引用と著者のリストを抽出し、Excelファイルに保存します。
- 最初のページのみスクレイピングしてください。
この情報を入力すると、ChatGPTから次のコマンドが表示され、Beautiful Soup、pandas、およびopenpyxlライブラリがインストールされます。
pip3 install requests beautifulsoup4 pandas openpyxl
ChatGPTは次のウェブスクレイピングコードも提供する必要があります。
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Step 1: Fetch the web page content
url = "https://quotes.toscrape.com"
response = requests.get(url)
html_content = response.text
# Step 2: Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
# Step 3: Extract the specific quote and author
quote_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.text"
author_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > small"
specific_quote = soup.select_one(quote_selector).get_text()
specific_author = soup.select_one(author_selector).get_text()
print(f"Specific Quote: {specific_quote}")
print(f"Specific Author: {specific_author}")
# Step 4: Extract all quotes and authors
quotes = soup.find_all('div', class_='quote')
all_quotes = []
for quote in quotes:
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
all_quotes.append({"quote": text, "author": author})
# Step 5: Save the quotes to an Excel file
df = pd.DataFrame(all_quotes)
df.to_excel('quotes.xlsx', index=False)
print("Quotes have been saved to quotes.xlsx")
soup = BeautifulSoup(html_content, 'html.parser')
# Step 3: Extract the specific quote and author
quote_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.text"
author_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > small"
specific_quote = soup.select_one(quote_selector).get_text()
specific_author = soup.select_one(author_selector).get_text()
print(f"Specific Quote: {specific_quote}")
print(f"Specific Author: {specific_author}")
# Step 4: Extract all quotes and authors
quotes = soup.find_all('div', class_='quote')
all_quotes = []
for quote in quotes:
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
all_quotes.append({"quote": text, "author": author})
# Step 5: Save the quotes to an Excel file
df = pd.DataFrame(all_quotes)
df.to_excel('quotes.xlsx', index=False)
print("Quotes have been saved to quotes.xlsx")
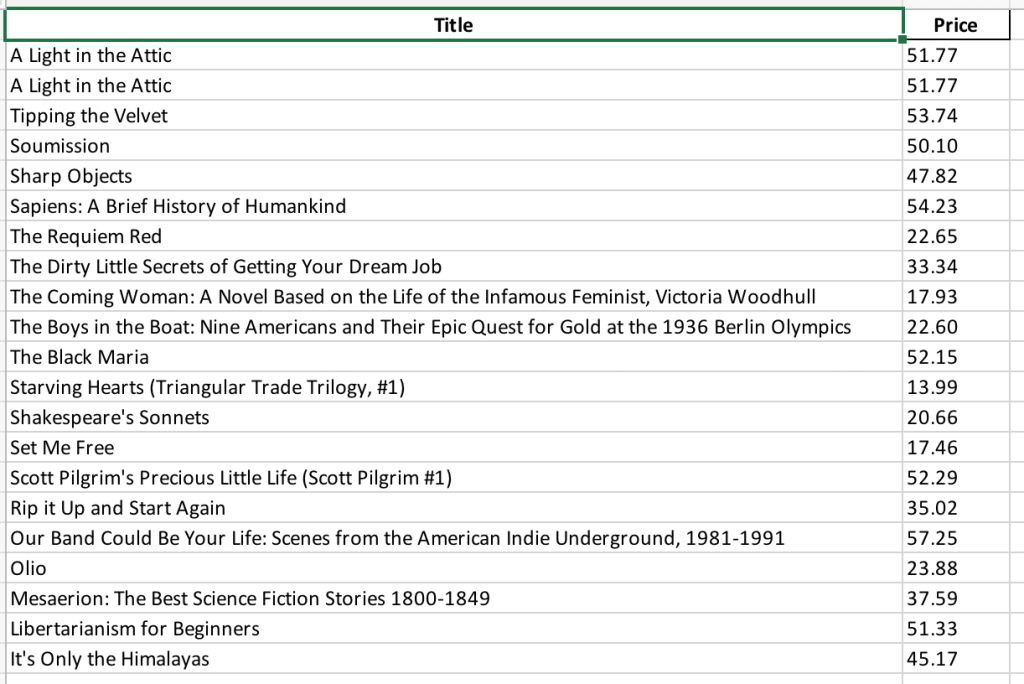
このコードを quotes_scraping.py という名前のファイルに保存し、コマンドラインから python3 books_scraping.py コマンドを実行します。このコードは quotes_scraped.xlsx という名前のExcelファイルを quotes_scraping.pyと同じディレクトリに生成します。生成されたExcelファイルを開くと、次のようになります。

複雑なWebサイトのスクレイピング
動的コンテンツはJavaScript経由で読み込まれることが多く、 リクエスト や BeautifulSoup などのツールで処理できないため、複雑なWebサイトのスクレイピングは難しい場合があります。これらのサイトでは、すべてのデータにアクセスするために、ボタンのクリックやスクロールなどの操作が必要になる場合があります。この課題に対処するには、 WebDriverを使用できます。これにより、ページをブラウザのようにレンダリングし、ユーザーとの対話のシミュレートして、一般的なユーザーと同じようにすべてのコンテンツにアクセスできるようにします。
たとえば、 Yelp は企業向けのクラウドソーシングのレビューサイトです。Yelpは動的なページ生成に依存しているため、複数のユーザーインタラクションをシミュレートする必要があります。ここでは、ChatGPTを使用して、ストックホルムの企業のリストとその評価を取得するスクレイピングコードを生成します。
Yelpをスクレイピングするには、まず手順を文書化することから始めます。
- スクリプトが使用するロケーションテキストボックスのセレクタを見つけます。この場合は
#search_locationです。ロケーション検索ボックスに「ストックホルム」と入力し、検索ボタンセレクタを見つけます。この場合は#header_find_form > div.y-css-1iy1dwt > buttonです。検索ボタンをクリックすると、検索結果が表示されます。これには数秒かかる場合があります。企業名を含むセレクタ (ie#main-content > ul > li:nth-child(3) > div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(1) > div > div > h3 > a)を見つけます。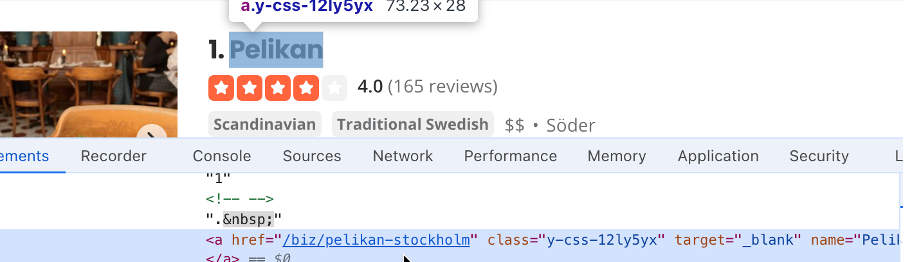
- 企業の評価を含むセレクタ (ie
#main-content > ul > li:nth-child(3) > div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(2) > div > div > div > div.y-css-ohs7lg > span.y-css-jf9frv)を見つけます。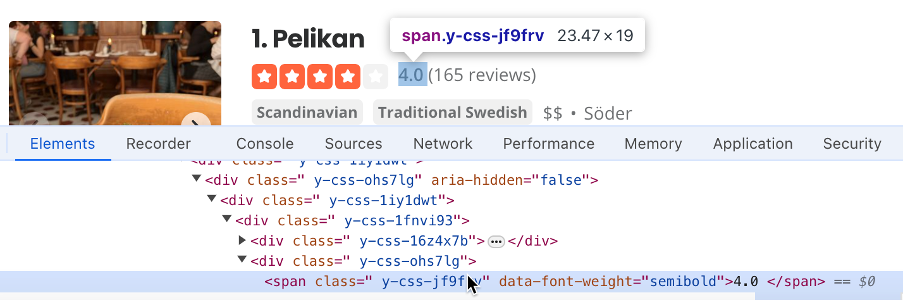
- 今すぐ開く ボタンのセレクタを見つけます。ここでは
#main-content > div.stickyFilterOnSmallScreen__09f24__UWWJ3.hideFilterOnLargeScreen__09f24__ilqIP.y-css-9ze9ku > div > div > div > div > div > span > button:nth-child(3) > spanです。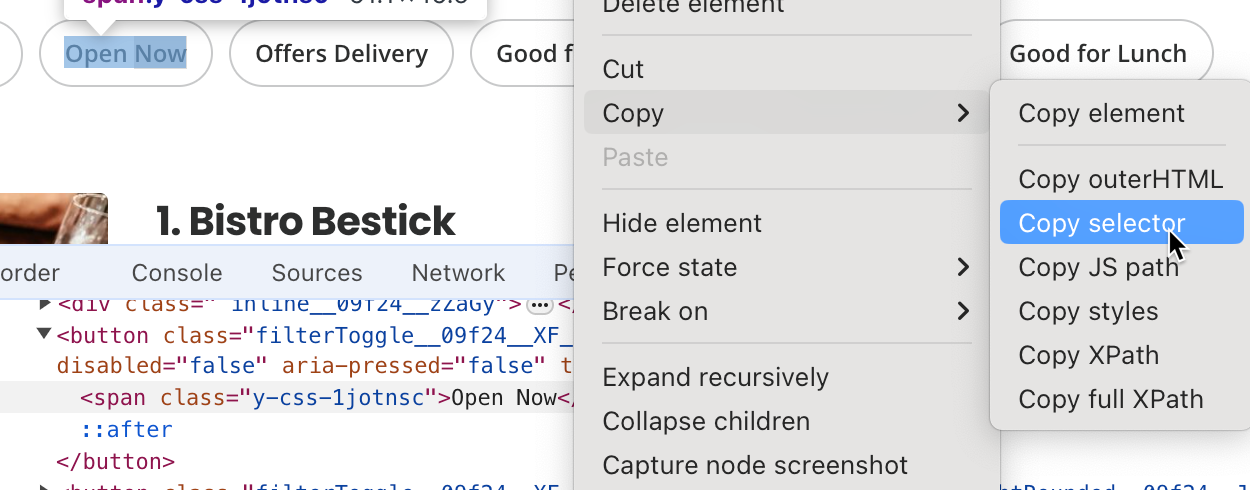
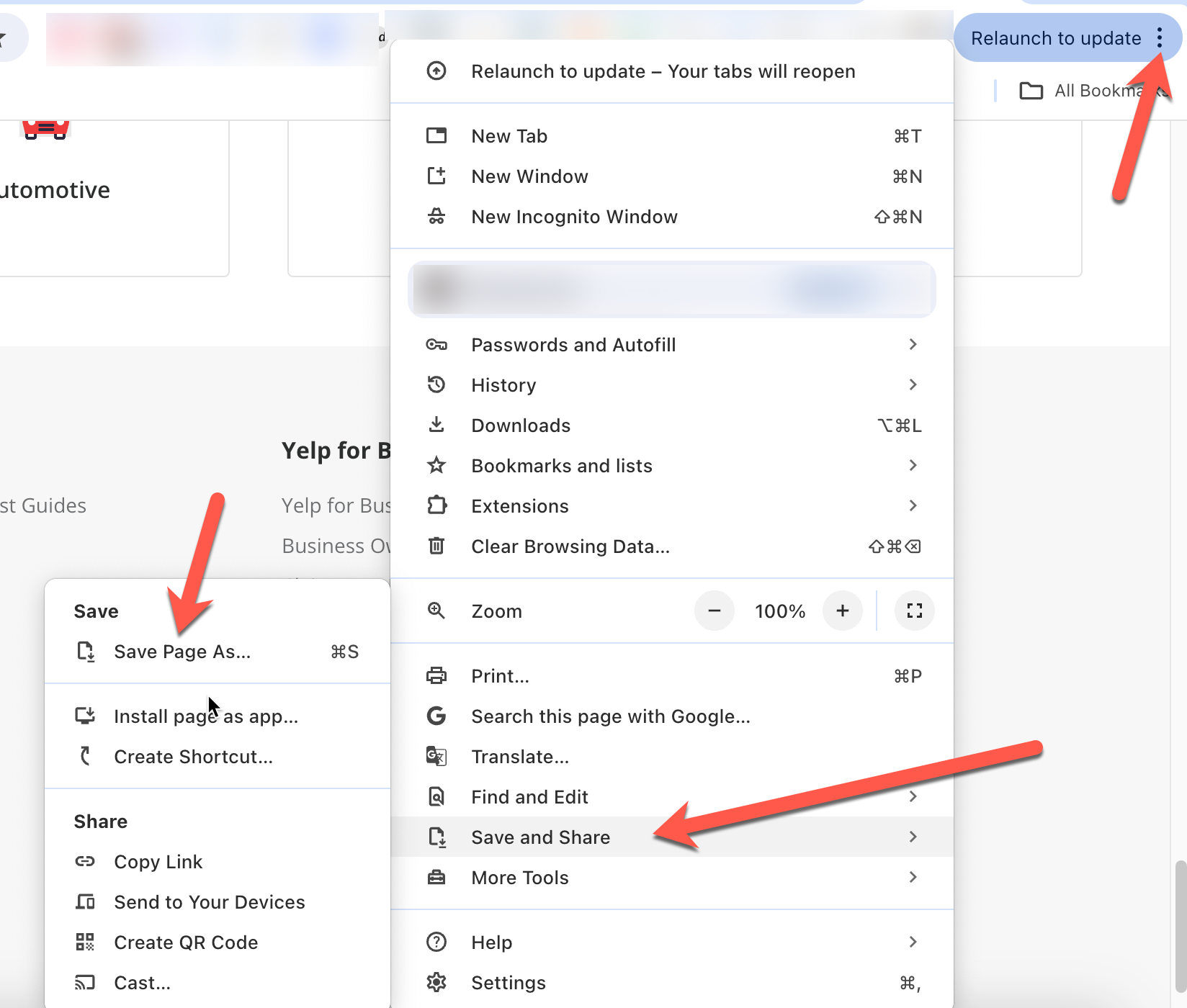
- ChatGPTがプロンプトのコンテキストを理解できるように、ChatGPTプロンプトとともに、後でアップロードできるようにWebページのコピーを保存してください。Chromeでは、右上の3つの点をクリックし、 保存して共有 > 名前を付けてページを保存 > 名前を付けてページを保存をクリックすることでこれを行うことができます。
 ]
]
次に、前に抽出したセレクタ値を使用して、ChatGPTがスクレイピングスクリプトを生成する際のガイドとなる詳細なプロンプトを作成する必要があります。
あなたはウェブスクレイピングのエキスパートです。 https://www.yelp.com/ をスクレイピングして特定の情報を抽出してください。スクレイピングする前に次の手順に従ってください。
- セレクタ
#search_locationでボックスをクリアします。- セレクタ
#search_locationで検索ボックスに「ストックホルム」と入力します。- セレクタ
#header_find_form > div.y-css-1iy1dwt > ボタンをクリックします。- ページが検索結果を読み込むまで数秒かかります。
- セレクタ
#main-content > div.stickyFilterOnSmallScreen__09f24__UWWJ3.hideFilterOnLargeScreen__09f24__ilqIP.y-css-9ze9ku > div > div > div > div > div > span > button:nth-child(3) > spanを含む今すぐ開くボタン をクリックし、現在営業している企業をフィルタリングします。- 企業名のリストを作成します。企業名にはセレクタ
#main-content > ul > li:nth-child(3) > div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(1) > div > div > h3 > aが含まれます。- 企業レビューのリストを作成します。レビューにはセレクタ
#main-content > ul > li:nth-child(3) > div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(2) > div > div > div > div.y-css-ohs7lg > span.y-css-jf9frvがあります。- 会社名とそのレビューを集めたExcelファイルを作成します。
- 関連するPythonパッケージをすべてインストールします。
- Selenium のWebDriverを使用してプロセスを自動化します。
- 添付されたHTMLページのコピーを参照して、HTML形式に関するコンテキストを確認します。
この情報を入力すると、ChatGPTから、WebDriverをサポートするWeb自動化のフレームワークであるSeleniumとpandasをインストールするように指示されます。
pip3 install selenium pandas
ChatGPTは、説明とともにスクレイピングコードも提供しています。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pandas as pd
import time
# Initialize the WebDriver
driver = webdriver.Chrome()
try:
# Open Yelp
driver.get('https://www.yelp.com/')
# Clear the location search box
location_box = driver.find_element(By.CSS_SELECTOR, '#search_location')
location_box.clear()
# Enter "Stockholm" in the location search box
location_box.send_keys('Stockholm')
# Click the search button
search_button = driver.find_element(By.CSS_SELECTOR, '#header_find_form > div.y-css-1iy1dwt > button')
search_button.click()
# Wait for search results to load
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#main-content'))
)
# Click on "Open Now" filter
open_now_button = driver.find_element(By.CSS_SELECTOR, '#main-content > div.stickyFilterOnSmallScreen__09f24__UWWJ3.hideFilterOnLargeScreen__09f24__ilqIP.y-css-9ze9ku > div > div > div > div > div > span > button:nth-child(3) > span')
open_now_button.click()
# Wait for the filter results to load
time.sleep(5)
# Extract business names and reviews
business_names = []
business_reviews = []
businesses = driver.find_elements(By.CSS_SELECTOR, '#main-content > ul > li')
for business in businesses:
try:
name = business.find_element(By.CSS_SELECTOR, 'div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(1) > div > div > h3 > a').text
review = business.find_element(By.CSS_SELECTOR, 'div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(2) > div > div > div > div.y-css-ohs7lg > span.y-css-jf9frv').text
business_names.append(name)
business_reviews.append(review)
except Exception as e:
print(f"Error extracting data for a business: {e}")
# Create a DataFrame and save to Excel
df = pd.DataFrame({'Business Name': business_names, 'Reviews': business_reviews})
df.to_excel('stockholm_businesses.xlsx', index=False)
print("Data saved to stockholm_businesses.xlsx")
finally:
# Close the WebDriver
driver.quit()
このスクリプトを保存して、Visual Studio CodeのPythonを使用して実行します。コードがChromeを起動し、Yelpに移動し、位置情報のテキストボックスをクリアして「ストックホルム」と入力し、検索ボタンをクリックして、現在営業している企業をフィルタリングして、ページを閉じるのがわかります。その後、スクレイピングの結果はExcelファイル stockholm_bussinsess.xlsxに保存されます。

このチュートリアルで使用されたソースコードは GitHubで利用可能です。
まとめ
このチュートリアルでは、ChatGPTを使用して、静的HTMLレンダリングを使用するWebサイトや、動的ページ生成、外部JavaScriptリンク、ユーザーインタラクションを備えたより複雑なWebサイトから、特定の情報を抽出する方法を学びました。
YelpのようなWebサイトのスクレイピングは簡単でしたが、実際には複雑なHTML構造のWebスクレイピングは困難な場合があり、IP禁止や CAPTCHAが発生する可能性があります。
Bright Data はそれらを簡単にするため、IP禁止を回避するのに役立つ高度なプロキシサービス、CAPTCHAを回避して解決する Web Unlocker、自動データ抽出のためのWeb Scraping API 、効率的なデータ抽出のための Scraping Browser など、さまざまなデータ収集サービスを提供しています。
今すぐ登録して、Bright Dataが提供するすべての製品をご覧ください。今すぐ無料トライアルを始めましょう!



