

このチュートリアルでは、次の内容を取り上げます。
Yelpをスクレイピングする理由
Yelpをスクレイピングする理由はいくつかあります。これには以下が含まれます。
- 包括的なビジネスデータにアクセスできる:レビュー、評価、連絡先など、ローカルビジネスに関する豊富な情報を入手できます。
- 顧客からのフィードバックに関するインサイトを得られる:ユーザーレビューでよく知られており、顧客の意見や体験に関するインサイトの宝庫です。
- 競合分析とベンチマーキングを実行できる:競合他社の業績、強み、弱み、顧客センチメントに関する貴重なインサイトが提供されます。
同様のプラットフォームはありますが、データスクレイピングにはYelpが適しています。その理由は以下の通りです。
- 幅広いユーザーベース
- 多様なビジネスカテゴリー
- 確立された評価
Yelpからスクレイピングされたデータは、市場調査、競合分析、センチメント分析、意思決定に役立ちます。この種の情報は、改善すべき分野を特定し、提供するサービスを微調整し、競合他社の一歩先を行くのに役立ちます。
Yelpスクレイピングライブラリとツール
Pythonは、そのユーザーフレンドリーな性質、わかりやすい構文、豊富なライブラリにより、ウェブスクレイピングに最適な言語として広く知られています。そのため、Yelpをスクレイピングするための推奨プログラミング言語です。詳しくは、Pythonでウェブスクレイピングを行う方法についての詳細なガイドをご覧ください。
次のステップでは、膨大な選択肢の中から適切なスクレイピングライブラリを選択します。十分な情報を得た上で決断を下すには、まずウェブブラウザでプラットフォームを探索する必要があります。ウェブページによって実行されるAJAXコールを検査すると、データの大部分がサーバーから取得されたHTMLドキュメント内に埋め込まれていることがわかります。
これは、サーバーにリクエストを出すためのシンプルなHTTPクライアントと、HTMLパーサーを組み合わせればタスクを実行可能であることを意味します。その理由は以下の通りです。
- Requests:最も一般的なPython用HTTPクライアントライブラリ。HTTPリクエストを送信し、対応するレスポンスを処理するプロセスを効率化します。
- Beautiful Soup:ウェブスクレイピングに広く使用されている包括的なHTMLおよびXML解析ライブラリ。DOMをナビゲートし、そこからデータを抽出するための堅牢なメソッドを提供します。
RequestsとBeautiful Soupのおかげで、Pythonを使ってYelpを効果的にスクレイピングできます。では、このタスクを達成する方法を詳しく見てみましょう!
Beautiful SoupでYelpのビジネスデータをスクレイピングする
このステップバイステップのチュートリアルに従って、Yelpスクレイパーの作成方法を学びましょう。
ステップ1:Pythonプロジェクトのセットアップ
始める前に、まず次のことを確認する必要があります。
- Python 3+がコンピュータにインストール済みであること:インストーラーをダウンロードして実行し、表示される指示に従います。
- お好みのPython IDE:Python拡張機能を含むVisual Studio Code、またはPyCharm Community Edition(どちらでも構いません)。
まず、以下のコマンドを実行してyelp-scraperフォルダを作成し、仮想環境でPythonプロジェクトとして初期化します。
mkdir yelp-scrapernncd yelp-scrapernnpython -m venv env
Windowsでは、以下のコマンドを実行してこの環境をアクティブにします。
Your Code Here...
次に、以下の行を含むscraper.pyファイルをプロジェクトフォルダに追加します。
print('Hello, World!')
これは最も簡単なPythonスクリプトです。今は「Hello, World!」を出力するだけですが、すぐにYelpをスクレイピングするロジックを組み込みます。
次の方法でスクレイパーを起動できます。
python scraper.py
ターミナルに次のように出力されるはずです。
Hello, World!
まさに予想通りでした。すべてが機能することがわかったので、Python IDEでプロジェクトフォルダを開きます。
素晴らしい、ではPythonのコードを書く準備をしましょう!
ステップ2:スクレイピングライブラリをインストールする
次に、ウェブスクレイピングの実行に必要なライブラリをプロジェクトの依存関係に追加する必要があります。アクティブな仮想環境で、以下のコマンドを実行してBeautiful SoupとRequestsをインストールします。
pip install beautifulsoup4 requests
scraper.pyファイルの内容を消去し、以下の行を追加してパッケージをインポートします。
import requestsnnfrom bs4 import BeautifulSoupnn# scraping logic...
Python IDEからエラーが報告されないことを確認してください。未使用のインポートがあるために警告が出るかもしれませんが、それらは無視して構いません。これから、これらのスクレイピングライブラリを使ってYelpからデータを抽出します。
ステップ3:ターゲットページを特定し、ダウンロードする
Yelpを閲覧し、スクレイピングしたいページを特定します。このガイドでは、New Yorkで高評価のイタリアンレストランのリストからデータを取得する方法を見ていきます。
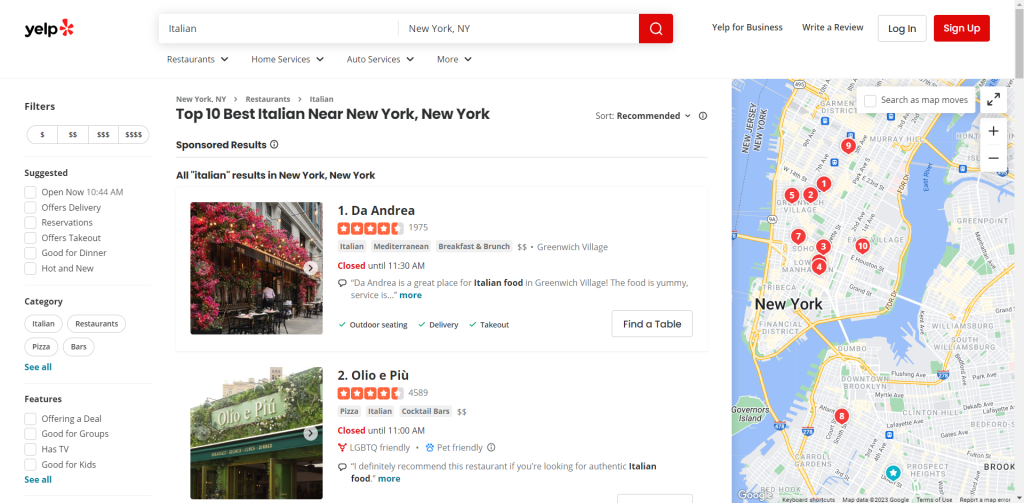
ターゲットページのURLを変数に代入します。
url = 'https://www.yelp.com/search?find_desc=Italianu0026find_loc=New+York%2C+NY'nnNext, use requests.get() to make an HTTP GET request to that URL:nnpage = requests.get(url)
これで、変数pageにはサーバーが生成したレスポンスが含まれるようになります。
具体的には、page.textにターゲットウェブページに関連するHTMLドキュメントが格納されます。ログに記録することで確認できます。
print(page.text)
これで以下の出力が得られるはずです。
u003c!DOCTYPE htmlu003eu003chtml lang=u0022en-USu0022 prefix=u0022og: http://ogp.me/ns#u0022 style=u0022margin: 0;padding: 0; border: 0; font-size: 100%; font: inherit; vertical-align: baseline;u0022u003eu003cheadu003eu003cscriptu003edocument.documentElement.className=document.documentElement.className.replace(no-j/,u0022jsu0022);u003c/scriptu003eu003cmeta http-equiv=u0022Content-Typeu0022 content=u0022text/html; charset=UTF-8u0022 /u003eu003cmeta http-equiv=u0022Content-Languageu0022 content=u0022en-USu0022 /u003eu003cmeta name=u0022viewportu0022 content=u0022width=device-width, initial-scale=1, shrink-to-fit=nou0022u003eu003clink rel=u0022mask-iconu0022 sizes=u0022anyu0022 href=u0022https://s3-media0.fl.yelpcdn.com/assets/srv0/yelp_large_assets/b2bb2fb0ec9c/assets/img/logos/yelp_burst.svgu0022 content=u0022#FF1A1Au0022u003eu003clink rel=u0022shortcut iconu0022 href=u0022https://s3-media0.fl.yelpcdn.com/assets/srv0/yelp_large_assets/dcfe403147fc/assets/img/logos/favicon.icou0022u003eu003cscriptu003e window.ga=window.ga||function(){(ga.q=ga.q||[]).push(arguments)};ga.l=+new Date;window.ygaPageStartTime=new Date().getTime();u003c/scriptu003eu003cscriptu003ennu003c!u002du002d Omitted for brevity... u002du002du003e
完璧です!それでは、これを解析してデータを取得する方法を学びましょう。
ステップ4:HTMLコンテンツを解析する
サーバーから取得したHTMLコンテンツをBeautifulSoup()コンストラクタに送って解析します。
soup = BeautifulSoup(page.text, 'html.parser')
この関数は次の2つの引数を取ります。
- HTMLを含む文字列。
- Beautiful Soupがコンテンツを処理するために使用するパーサー。
「html.parser」はPython組み込みのHTMLパーサーの名前です。
BeautifulSoup()は、解析されたコンテンツを探索可能なツリー構造として返します。特に、soup変数はDOMツリーから要素を選択するのに便利なメソッドを公開しています。最も人気のあるものを以下に示します。
- find():パラメータとして渡されたセレクタ戦略にマッチする最初のHTML要素を返します。
- find_all():入力セレクタ戦略にマッチするHTML要素のリストを返します。
- select_one():パラメータとして渡されたCSSセレクタにマッチする最初のHTML要素を返します。
- select():入力されたCSSセレクタにマッチするHTML要素のリストを返します。
素晴しいです!まもなく、これらを使用してYelpから目的のデータを抽出します。
ステップ5:ページをよく理解する
効果的な選択戦略を考案するには、まずターゲットのウェブページの構造をよく理解する必要があります。ブラウザで開いて、探索を始めます。
ページ上のHTML要素を右クリックし、「検査」を選択してDevToolsを開きます。
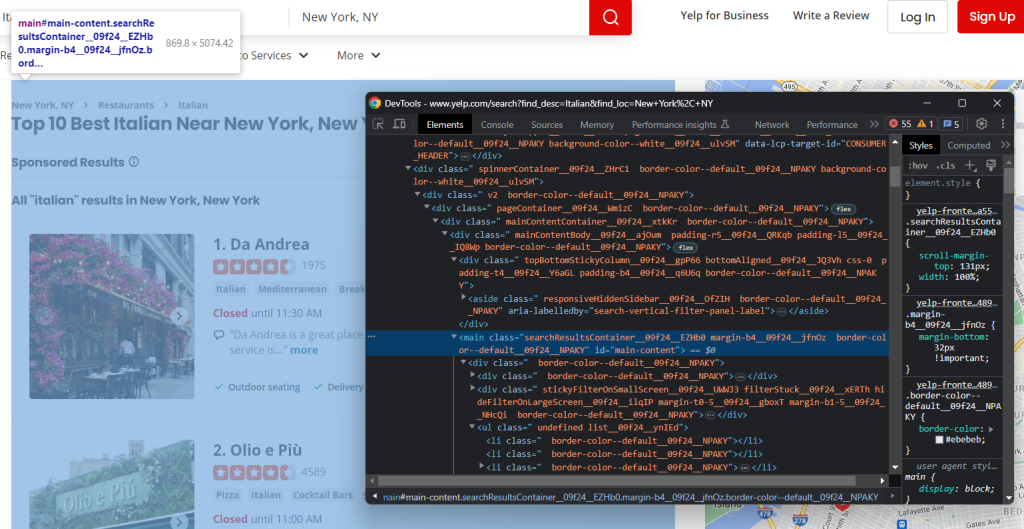
すぐに気づくと思いますが、このサイトが依存しているCSSクラスは、構築時にランダムに生成されるようです。デプロイごとに変更される可能性があるため、それらに基づいてCSSセレクターを作成すべきではありません。これは、効果的なスクレイパーを作成するために知っておくべき重要な情報です。
DOMを詳しく調べると、最も重要な要素には特徴的なHTML属性があることもわかります。従って、セレクタ戦略はそれらに依存すべきです。
Pythonでスクレイピングする準備ができるまで、DevToolsでページを検査し続けてください!
ステップ6:ビジネスデータを抽出する
ここでの目標は、ページ上の各カードからビジネス情報を抽出することです。このデータを追跡するためには、データを格納するデータ構造が必要になります。
items = []
まず、カードのHTML要素を検査します。
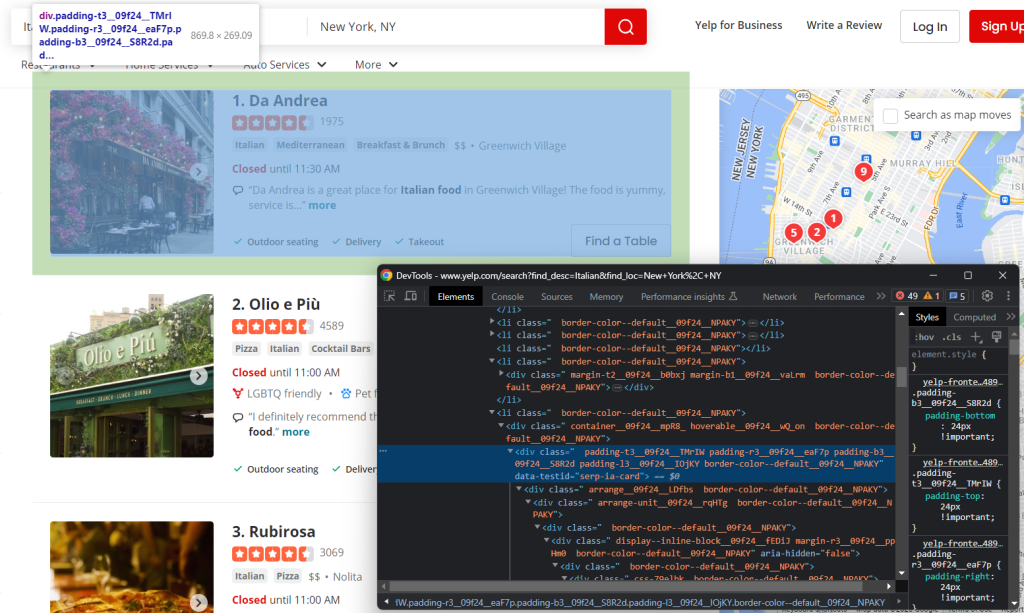
なお、次の方法ですべてを選択できます。
html_item_cards = soup.select('[data-testid=u0022serp-ia-cardu0022]')
それらを反復処理して、以下を実行するスクリプトを準備します。
- それぞれからデータを抽出する。
- データをPython辞書項目に保存する。
- これを項目に追加する。
for html_item_card in html_item_cards:nn item = {}nn # scraping logic...nn items.append(item)
さあ、スクレイピングロジックを実装しましょう!
画像要素を検査します。
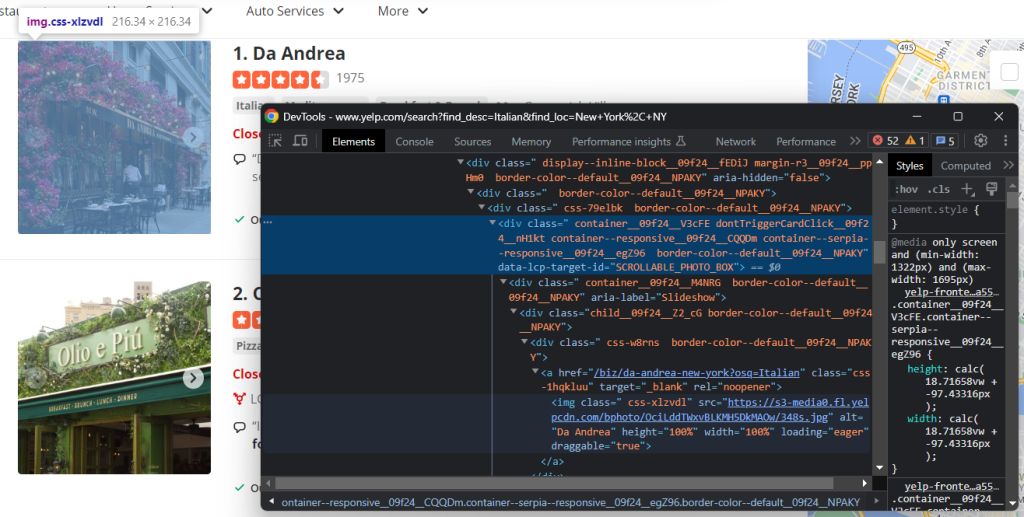
次の方法で、ビジネスの画像の URL を取得します。
image = html_item_card.select_one('[data-lcp-target-id=u0022SCROLLABLE_PHOTO_BOXu0022] img').attrs['src']
select_one()で要素を取得したら、attrsメンバーを介してそのHTML属性にアクセスできます。
取得するその他の有用な情報は、ビジネス詳細ページのタイトルとURLです。
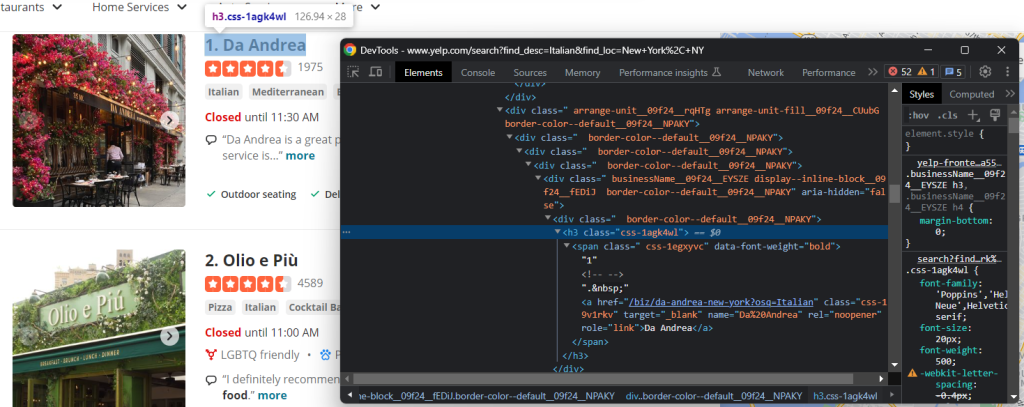
ご覧のとおり、h3 aノードから両方のデータフィールドを取得できます。
name = html_item_card.select_one('h3 a').textnnurl = 'https://www.yelp.com' + html_item_card.select_one('h3 a').attrs['href']
text属性は、現在の要素とそのすべての子要素内のテキスト内容を返します。一部のリンクは相対リンクであるため、ベースURLを追加して完成させる必要があるかもしれません。
Yelpで最も重要なデータの1つは、ユーザーレビュー率です。
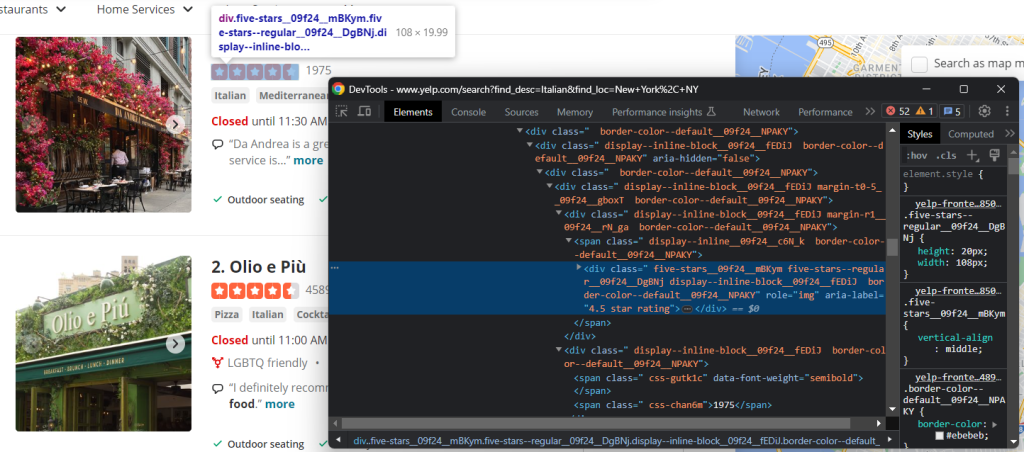
この場合、簡単に手に入れる方法はありませんが、それでも次の方法で目標を達成できます。
html_stars_element = html_item_card.select_one('[class^=u0022five-starsu0022]')nnstars = html_stars_element.attrs['aria-label'].replace(' star rating', '')nnreviews = html_stars_element.parent.parent.next_sibling.text
replace() Python関数を使用して文字列をクリーンアップし、関連するデータのみを取得することに留意してください。
タグと価格帯の要素も検査します。
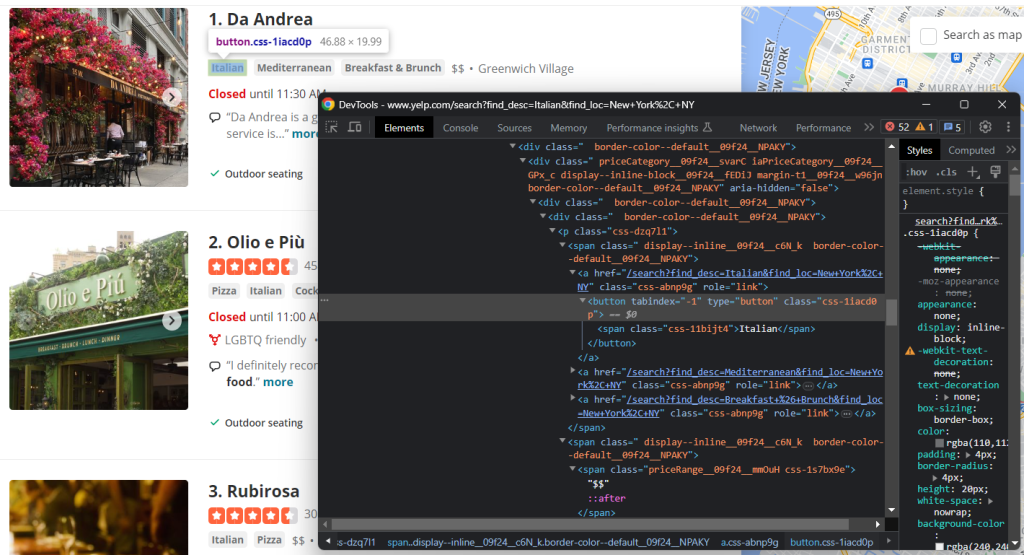
すべてのタグ文字列を収集するには、それらをすべて選択し、反復処理する必要があります。
tags = []nnhtml_tag_elements = html_item_card.select('[class^=u0022priceCategoryu0022] button')nnfor html_tag_element in html_tag_elements:nn tag = html_tag_element.textnn tags.append(tag)
代わりに、オプションの価格帯表示を取得する方がはるかに簡単です。
price_range_html = html_item_card.select_one('[class^=u0022priceRangeu0022]')nn# since the price range info is optionalnnif price_range_html is not None:nn price_range = price_range_html.text
最後に、レストランが提供するサービスもスクレイピングします。
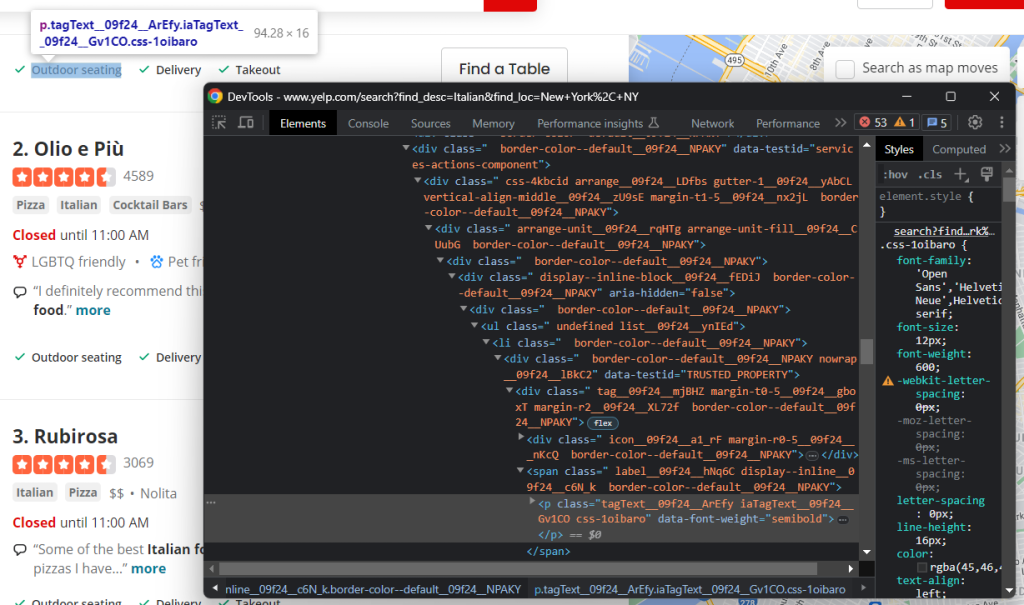
この場合も、すべての単一ノードを反復処理する必要があります。
services = []nnhtml_service_elements = html_item_card.select('[data-testid=u0022services-actions-componentu0022] p[class^=u0022tagTextu0022]')nnfor html_service_element in html_service_elements:nn service = html_service_element.textnn services.append(service)
よくできました!これでスクレイピングロジックを実装できました。
スクレイピングしたデータ変数を辞書に追加します。
item['name'] = namennitem['image'] = imagennitem['url'] = urlnnitem['stars'] = starsnnitem['reviews'] = reviewsnnitem['tags'] = tagsnnitem['price_range'] = price_rangennitem['services'] = services
print(item)を使って、データ抽出プロセスが期待通りに動作することを確認します。最初のカードでは、次のものが得られます。
{'name': 'Olio e Più', 'image': 'https://s3-media0.fl.yelpcdn.com/bphoto/CUpPgz_Q4QBHxxxxDJJTTA/348s.jpg', 'url': 'https://www.yelp.com/biz/olio-e-pi%C3%B9-new-york-7?osq=Italian', 'stars': '4.5', 'reviews': '4588', 'tags': ['Pizza', 'Italian', 'Cocktail Bars'], 'price_range': '$$', 'services': ['Outdoor seating', 'Delivery', 'Takeout']}
おめでとう!ゴールは間近です!
ステップ7:クローリングロジックを実装する
ビジネスはページ分割されたリストでユーザーに表示されることを忘れないでください。これで、単一ページをスクレイピングする方法を見てみましたが、すべてのデータを取得したい場合はどうすればよいでしょうか?そのためには、ウェブクローリングをYelpデータスクレイパーに統合する必要があります。
まず、スクリプトの上にいくつかのサポートデータ構造を定義します。
visited_pages = []nnpages_to_scrape = ['https://www.yelp.com/search?find_desc=Italianu0026find_loc=New+York%2C+NY']n
visited_pages will contain the URLs of the pages scraped, while pages_to_scrape the next ones to visit.nnCreate a while loop that terminates when there are no longer pages to scrape or after a specific number of iterations:nnnlimit = 5 # in production, you can remove itnni = 0nnwhile len(pages_to_scrape) != 0 and i u003c limit:nn # extract the first page from the arraynn url = pages_to_scrape.pop(0)nn # mark it as u0022visitedu0022nn visited_pages.append(url)nn # download and parse the pagenn page = requests.get(url)nn soup = BeautifulSoup(page.text, 'html.parser')nn # scraping logic...nn # crawling logic...nn # increment the page counternn i += 1
各反復では、リストから1つのページを削除し、スクレイピングし、新しいページを検出してキューに追加します。limitは単にスクレイパーが永久に実行されるのを防ぐだけです。
あとはクローリングロジックを実装するだけです。HTMLのページネーション要素を検査します。

これはいくつかのリンクで構成されています。それらをすべて収集し、新しく発見したものを次の方法でpages_to_visitに追加します。
pagination_link_elements = soup.select('[class^=u0022pagination-linksu0022] a')nnfor pagination_link_element in pagination_link_elements:nn pagination_url = pagination_link_element.attrs['href']nn # if the discovered URL is newnn if pagination_url not in visited_pages and pagination_url not in pages_to_scrape:nn pages_to_scrape.append(pagination_url)
素晴らしい!これで、スクレイパーはすべてのページネーションページを自動的に処理します。
ステップ8:スクレイピングしたデータをCSVにエクスポートする
最後のステップは、収集したデータの共有しやすく、読みやすくすることです。そのための最善の方法は、CSVのような人間が読める形式にエクスポートすることです。
import csvnn# ...nn# initialize the .csv output filennwith open('restaurants.csv', 'w', newline='', encoding='utf-8') as csv_file:nn writer = csv.DictWriter(csv_file, fieldnames=headers, quoting=csv.QUOTE_ALL)nn writer.writeheader()nn # populate the CSV filenn for item in items:nn # transform array fields from u0022['element1', 'element2', ...]u0022nn # to u0022element1; element2; ...u0022nn csv_item = {}nn for key, value in item.items():nn if isinstance(value, list):nn csv_item[key] = '; '.join(str(e) for e in value)nn else:nn csv_item[key] = valuenn # add a new recordnn writer.writerow(csv_item)
open()でrestaurants.csvファイルを作成します。次に、DictWriterといくつかのカスタムロジックを使用してデータを入力します。csvパッケージはPython標準ライブラリから提供されるため、追加の依存関係をインストールする必要はありません。
素晴らしい!ウェブページに含まれる生データから作業を始め、今では半構造化されたCSVデータが手元にあります。それでは、Yelp Pythonスクレイパー全体を見てみましょう。
ステップ9:すべてを統合する
完全なscraper.pyスクリプトは次のようになります。
import requestsnnfrom bs4 import BeautifulSoupnnimport csvnn# support data structures to implement thenn# crawling logicnnvisited_pages = []nnpages_to_scrape = ['https://www.yelp.com/search?find_desc=Italianu0026find_loc=New+York%2C+NY']nn# to store the scraped datannitems = []nn# to avoid overwhelming Yelp's servers with requestsnnlimit = 5nni = 0nn# until all pagination pages have been visitednn# or the page limit is hitnnwhile len(pages_to_scrape) != 0 and i u003c limit:nn # extract the first page from the arraynn url = pages_to_scrape.pop(0)nn # mark it as u0022visitedu0022nn visited_pages.append(url)nn # download and parse the pagenn page = requests.get(url)nn soup = BeautifulSoup(page.text, 'html.parser')nn # select all item cardnn html_item_cards = soup.select('[data-testid=u0022serp-ia-cardu0022]')nn for html_item_card in html_item_cards:nn # scraping logicnn item = {}nn image = html_item_card.select_one('[data-lcp-target-id=u0022SCROLLABLE_PHOTO_BOXu0022] img').attrs['src']nn name = html_item_card.select_one('h3 a').textnn url = 'https://www.yelp.com' + html_item_card.select_one('h3 a').attrs['href']nn html_stars_element = html_item_card.select_one('[class^=u0022five-starsu0022]')nn stars = html_stars_element.attrs['aria-label'].replace(' star rating', '')nn reviews = html_stars_element.parent.parent.next_sibling.textnn tags = []nn html_tag_elements = html_item_card.select('[class^=u0022priceCategoryu0022] button')nn for html_tag_element in html_tag_elements:nn tag = html_tag_element.textnn tags.append(tag)nn price_range_html = html_item_card.select_one('[class^=u0022priceRangeu0022]')nn # this HTML element is optionalnn if price_range_html is not None:nn price_range = price_range_html.textnn services = []nn html_service_elements = html_item_card.select('[data-testid=u0022services-actions-componentu0022] p[class^=u0022tagTextu0022]')nn for html_service_element in html_service_elements:nn service = html_service_element.textnn services.append(service)nn # add the scraped data to the objectnn # and then the object to the arraynn item['name'] = namenn item['image'] = imagenn item['url'] = urlnn item['stars'] = starsnn item['reviews'] = reviewsnn item['tags'] = tagsnn item['price_range'] = price_rangenn item['services'] = servicesnn items.append(item)nn # discover new pagination pages and add them to the queuenn pagination_link_elements = soup.select('[class^=u0022pagination-linksu0022] a')nn for pagination_link_element in pagination_link_elements:nn pagination_url = pagination_link_element.attrs['href']nn # if the discovered URL is newnn if pagination_url not in visited_pages and pagination_url not in pages_to_scrape:nn pages_to_scrape.append(pagination_url)nn # increment the page counternn i += 1nn# extract the keys from the first object in the arraynn# to use them as headers of the CSVnnheaders = items[0].keys()nn# initialize the .csv output filennwith open('restaurants.csv', 'w', newline='', encoding='utf-8') as csv_file:nn writer = csv.DictWriter(csv_file, fieldnames=headers, quoting=csv.QUOTE_ALL)nn writer.writeheader()nn # populate the CSV filenn for item in items:
# transform array fields from u0022['element1', 'element2', ...]u0022nn # to u0022element1; element2; ...u0022nn csv_item = {}nn for key, value in item.items():nn if isinstance(value, list):nn csv_item[key] = '; '.join(str(e) for e in value)nn else:nn csv_item[key] = valuenn # add a new recordnn writer.writerow(csv_item)
約100行のコードで、Yelpからビジネスデータを抽出するウェブスパイダーを構築できます。
次のコマンドでスクレイパーを実行します。
python scraper.pypython scraper.py
実行が完了するまで待つと、プロジェクトのルートフォルダに以下のrestaurants.csvファイルが見つかります。
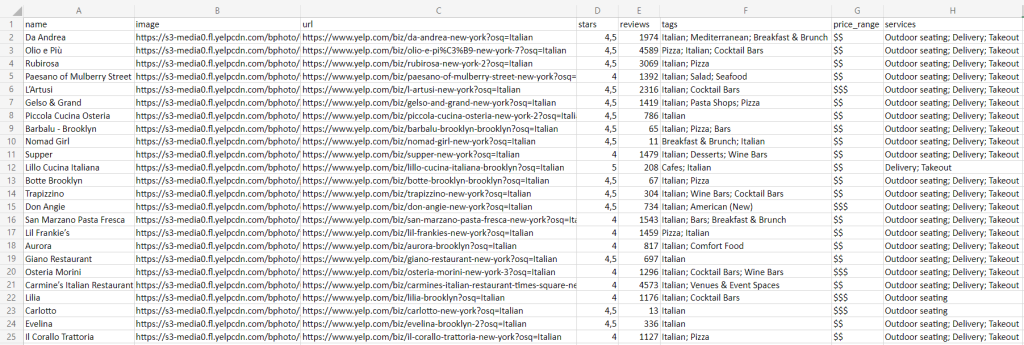
おめでとうございます!PythonでYelpをスクレイピングする方法を学ぶことができました!
まとめ
このステップガイドを通じて、Yelpがローカルビジネスに関するユーザーデータを取得するのに最適なスクレイピングターゲットの1つである理由を理解しました。特に、Yelpデータを取得可能なPythonスクレイパーの構築方法を詳しく学びました。ここで示したように、必要なコードは数行だけです。
同時に、サイトは進化を続け、ユーザーの絶え間なく変化する期待に合わせてUIと構造を適応させています。ここで作成したスクレイパーは、今日は機能しても、明日は機能しない可能性があります。メンテナンスに時間とお金を費やさなくても済む、当社のYelp Scraperをお試しください!
また、ほとんどのサイトはJavaScriptに大きく依存していることにも留意してください。このようなシナリオでは、HTMLパーサーに基づく従来のアプローチは機能しません。代わりに、JavaScriptをレンダリングし、フィンガープリンティング、CAPTCHA、自動再試行を処理できるツールを使用する必要があります。当社の新しいScraping Browserソリューションは、まさにそのためのツールです!
Yelpのウェブスクレイピングには取り組まず、データだけを入手することをご希望ですか?Yelpデータセットをご購入ください






