

ウェブサイト全体をクローリングし、ウェブスクレイピングによってすべての重要な方法を抽出するため、Pythonによるウェブスクレイパーの構築方法を学びます。
ウェブスクレイピングとは、ウェブからデータを抽出することを意味します。具体的には、ウェブスクレイパーは、ウェブスクレイピングを実行するツールであり、一般にスクリプトによって表されます。Pythonは、利用可能な最も簡単で信頼できるスクリプト言語の1つです。また、さまざまなウェブスクレイピングライブラリが付属しています。これにより、Pythonはウェブスクレイピングのための完全なプログラミング言語になります。具体的には、ウェブスクレイピングを実行するため、Pythonでは数行のコードしか使用しません。
このチュートリアルでは、シンプルなPythonスクレイパーを作成するために必要なすべてのことを学べます。このアプリケーションは、ウェブサイト全体を巡回し、各ページからデータを抽出します。次に、PythonでスクレイピングしたすべてのデータをCSVファイルに保存します。このチュートリアルは、Pythonのデータスクレイピングライブラリーとして最適なものはどれか、採用すべきものはどれか、どのように使用すべきかを理解するのに役立ちます。このステップバイステップのチュートリアルに従って、ウェブスクレイピングを実行するPythonスクリプトの作成方法を学習します。
目次:
- 前提条件
- 最高のPythonウェブスクレイピングライブラリ
- ウェブスクレイパーをPythonで作成する
- まとめ
- FAQ
前提条件
Pythonウェブスクレイパーを構築するには、次の前提条件を満たす必要があります。
お使いのコンピューターにPythonがインストールされていない場合は、上記の最初のリンクに従ってダウンロードできます。Windowsユーザーの場合は、Pythonをインストールする際に、以下のように「Add python.exe to PATH」チェックボックスにチェックを入れてください。
この方法で、Windowsはpythonおよびpipコマンドをターミナル内で自動的に認識するようになります。具体的には、pipはPythonパッケージ用のパッケージマネージャーです。なお、Pythonバージョン3.4以降には、デフォルトでpipが含まれています。そのため、手動でインストールする必要はありません。
これで、最初のPythonウェブスクレイパーを作成する準備ができました。その前に、Pythonのウェブスクレイピングライブラリが必要です。
最高のPythonウェブスクレイピングライブラリ
Python vanillaを使用して、ウェブスクレイピングスクリプトをゼロから作成することもできますが、これは理想的なソリューションではありません。何といっても、Pythonは豊富なライブラリーを利用できることでよく知られています。つまり、いくつものウェブスクレイピングライブラリの中から選択できるのです。では、その中でも特に重要なものを見てみましょう。
Requests
requestsライブラリを使うと、PythonでHTTPリクエストを実行できます。具体的には、requestsは、Pythonの標準的なHTTPライブラリと比較して、HTTPリクエストを簡単に送信できます。requestsは、Pythonのウェブスクレイピングプロジェクトで重要な役割を果たします。なぜなら、ウェブページに含まれるデータをスクレイピングするには、まずHTTP GETリクエストでデータを取得する必要があるからです。また、ターゲットウェブサイトのサーバーに対して、他のHTTPリクエストを実行することが必要な場合もあります。
requestsは、以下のpipコマンドでインストールできます。
pip install requestsBeautiful Soup
Beautiful Soup Pythonライブラリを使用すると、ウェブページからの情報のスクレイピングが容易になります。特に、Beautiful SoupはあらゆるHTMLやXMLパーサーに対応し、パースツリーの反復、検索、修正に必要なすべてを提供します。なお、Beautiful Soupは、html.parser(Python標準ライブラリに付属のHTMLテキストファイル解析用パーサー)と一緒に使用できます。具体的には、Beautiful Soupを使ってDOMをトラバースし、そこから必要なデータを抽出できます。
Beautiful Soupは、以下のようにpipでインストールできます。
pip install beautifulsoup4Selenium
Seleniumは、オープンソースの高機能自動テストフレームワークで、ブラウザ上でウェブページに対する操作を実行できます。つまり、Seleniumを使えば、ブラウザーに特定のタスクを実行するように指示することができます。なお、Seleniumはヘッドレスブラウザ機能を備えているため、ウェブスクレイピングライブラリとして使用することもできます。この概念に馴染みがない場合は、ヘッドレスブラウザは、GUI(グラフィカルユーザーインターフェイス)なしで実行されるウェブブラウザーであると理解してください。ヘッドレスモードで構成されている場合、Seleniumはブラウザをバックグラウンドで実行します。
したがって、Seleniumで閲覧したウェブページは、JavaScriptを実行できる実際のブラウザでレンダリングされます。その結果、Seleniumはスクレイピング可能なウェブサイトにはJavaScriptを必要とするものも含まれますリクエストや他のHTTPクライアントでは、これは実現できないことに留意してください。これは、JavaScriptを実行するにはブラウザが必要なのに対して、リクエストは単にHTTPリクエストを実行できるようにするだけだからです。
Seleniumは、他のライブラリを必要とせず、ウェブスクレイパーを作成するために必要なものをすべて備えています。次のpipコマンドでインストールできます。
pip install seleniumウェブスクレイパーをPythonで作成する
では、Pythonでウェブスクレイパーを作成する方法を学びましょう。このチュートリアルでは、Quotes to Scrapeウェブサイトに含まれるすべての引用データを抽出する方法を学習します。それぞれの引用について、本文、著者、タグのリストをスクレイピングする方法を学びます。
まず、対象となるウェブサイトを見てみましょう。Quote to Scrapeのウェブページは次のように表示されます。

ご覧のように、Quotes to Scrapeはウェブスクレイピングのためのサンドボックスにすぎません。具体的には、引用のページ番号付きリストが含まれています。これから作成するPythonウェブスクレイパーは、各ページに含まれるすべての引用を取得し、それらをCSVデータとして返します。
ここで、目標を達成するために最適なPythonウェブスクレイピングライブラリは何かを理解する必要があります。下記のChrome DevToolsウィンドウの「ネットワーク」タブにあるように、ターゲットウェブサイトはFetch/XHRリクエストを一切実行しません。

つまり、Quotes to Scrapeは、ウェブページにレンダリングされたデータを取得するためにJavaScriptに依存しないのです。これは、ほとんどのサーバーレンダリングされたウェブサイトに共通する状況です。ターゲットウェブサイトはページのレンダリングやデータの取得をJavaScriptに依存しないため、Seleniumを使用してページをスクレイピングする必要はありません。使用することはできますが、必須ではありません。
以前に学習したように、Seleniumはブラウザでウェブページを開きます。これには時間とリソースがかかるため、Seleniumではパフォーマンスオーバーヘッドが発生します。Requestsと一緒にBeautiful Soupを使うことで、これを回避できます。それでは、Beautiful Soupを使用してウェブサイトからデータを取得する、単純なPythonのウェブスクレイピングスクリプトの作成方法を説明します。
はじめに
最初のコード行を書き始める前に、Pythonウェブスクレイピングプロジェクトをセットアップする必要があります。技術的には、必要な.pyファイルは1つだけです。しかし、高度なIDE(統合開発環境)を使用することで、より簡単にコーディングできるようになります。ここでは、PyCharm 2022.2.3でPythonプロジェクトをセットアップする方法を学びますが、他のIDEでもかまいません。
まず、PyCharmを起動して、「ファイル > 新規プロジェクト…」を選択します。「新規プロジェクト」ポップアップウィンドウで「Pure Python」を選択し、プロジェクトを初期化します。

たとえば、プロジェクトの名前をpython-web-scraperとすることができます。「作成」をクリックすると、空のPythonプロジェクトにアクセスできるようになります。デフォルトでは、PyCharmはmain.pyファイルを初期化します。わかりやすくするために、名前をscraper.pyに変更します。これで、プロジェクトは次のようになります。
このように、PyCharmは自動的にPythonファイルを初期化します。このファイルの内容を無視して、コードの各行を削除します。そうすることで、ゼロから作業を開始します。
さて、いよいよプロジェクトの依存関係をインストールします。ターミナルで以下のコマンドを実行して、RequestsとBeautiful Soupをインストールします。
pip install requests beautifulsoup4このコマンドにより、両方のライブラリが一度にインストールされます。インストールプロセスが完了するまで待ちます。これで、Beautiful SoupとRequestsを使用して、Pythonでウェブクローラーとスクレイパーを作成する準備ができました。scraper.pyスクリプトファイルの先頭に以下の行を追加して、2つのライブラリがインポートされていることを確認します。
import requests
from bs4 import BeautifulSoupPyCharmでは、これらの2行はグレーで表示されます。これはコード内でライブラリが使用されていないためです。赤い下線が付いている場合は、インストールプロセス中に問題が発生したことを示します。この場合は、再度一度インストールを試みてください。
現在、scraper.pyファイルはこのようになっているはずです。これで、ウェブスクレイピングのロジックを定義する準備ができました。
スクレイピングターゲットのURLに接続する
ウェブスクレイパーで最初に行うことは、ターゲットのウェブサイトに接続することです。まず、ウェブブラウザーからページの完全なURLを取得します。http://やhttps://も必ずコピーしてください。HTTPプロトコルセクション。この場合、ターゲットウェブサイトのURL全体は次のようになります。
https://quotes.toscrape.comここで、requestsで、以下のコード行を使ってウェブページをダウンロードできます。
page = requests.get('https://quotes.toscrape.com')この行はrequest.get()メソッドの結果を変数pageに代入しているだけです。その裏側で、request.get()はパラメータとして渡されたURLを使ってGETリクエストを実行します。次に、HTTPリクエストに対するサーバーの応答を含むResponseオブジェクトを返します。
HTTPリクエストが正常に実行された場合、page.status_codeには200が格納されます。これは、HTTPリクエストの実行が成功したことをHTTP 200 OKステータスレスポンスコードで示すためです。4xxまたは5xx HTTPステータスコードは、エラーを表します。これはいくつかの理由が考えられますが、ほとんどのウェブサイトでは有効なUser-Agentヘッダーを含まないリクエストはブロックされることを覚えておいてください。具体的には、User-Agentリクエストヘッダーは、リクエスト元のアプリケーションとオペレーティングシステムのバージョンを示す文字列です。ウェブスクレイピングのためのUser-Agentについては、こちらをご覧ください。
requests内で有効なUser-Agentヘッダーを設定するには、次のようにします。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
page = requests.get('https://quotes.toscrape.com', headers=headers)これで、requestsは、パラメータとして渡されたヘッダーを含むHTTPリクエストを実行するようになります。
ここで注目すべきなのは、page.textプロパティです。これは、サーバーから返されたHTMLドキュメントを文字列形式で格納します。textプロパティをBeautiful Soupに与えて、ウェブページからデータを抽出します。その方法を学びましょう。
Pythonウェブスクレイパーでデータを抽出する
ウェブページからデータを抽出するには、まず対象となるデータを含むHTML要素を特定する必要があります。具体的には、DOMからこれらの要素を抽出するために必要なCSSセレクタを見つける必要があります。これを実現するには、ブラウザーが提供する開発ツールを使用します。Chromeで、対象のHTML要素を右クリックして「検査」を選択します。
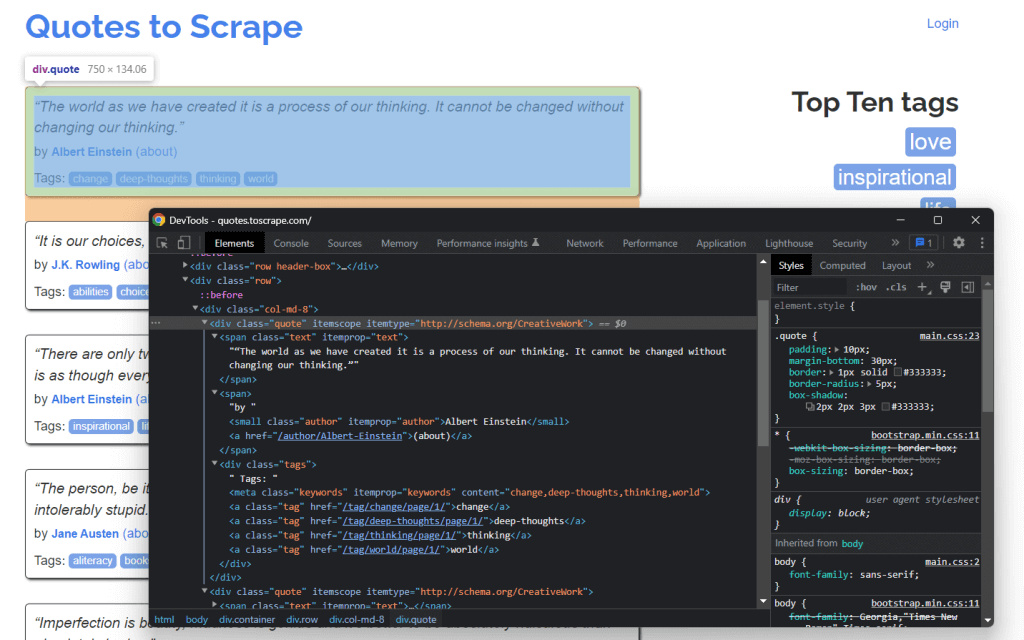
ここでわかるように、引用<div> HTML要素は、quoteクラスで識別されます。内容は次のとおりです。
- <span> HTML要素内の引用テキスト
- <small> HTML要素内の引用の作者
- <a> HTML要素に含まれる各<div>要素内のタグのリスト
具体的には、.quote上で以下のCSSセレクタを使用して抽出できます。
.text.author.tags .tag
では、これを実現する方法をPythonのBeautiful Soupを使って学びましょう。まず、page.text HTMLドキュメントをBeautifulSoup()コンストラクタに渡します。
soup = BeautifulSoup(page.text, 'html.parser')2番目のパラメータは、Beautiful SoupがHTMLドキュメントの構文解析に使用するパーサーを指定します。これで、soup変数にBeautifulSoupオブジェクトが格納されました。これpage.textに含まれるHTMLドキュメントをPython組み込みのhtml.parserで構文解析して生成されたパースツリーです。
次に、スクレイピングされた全データのリストを格納する数を初期化します。
quotes = []さて、いよいよsoupを使って、以下のようにDOMから要素を抽出します。
quote_elements = soup.find_all('div', class_='quote')find_all()メソッドは、quoteクラスで識別されるすべての<div> HTML要素のリストを返します。言い換えれば、このコード行は、ページ上の引用 HTML 要素のリストを取得するために.quote CSSセレクタを適用することに相当します。そして、以下のように.quoteリストに対して反復処理を行い、引用データを取得できます。
for quote_element in quote_elements:
# extracting the text of the quote
text = quote_element.find('span', class_='text').text
# extracting the author of the quote
author = quote_element.find('small', class_='author').text
# extracting the tag <a> HTML elements related to the quote
tag_elements = quote_element.find('div', class_='tags').find_all('a', class_='tag')
# storing the list of tag strings in a list
tags = []
for tag_element in tag_elements:
tags.append(tag_element.text)Beautiful Soup find()メソッドのおかげで、対象のHTML要素を1つだけ抽出できます。引用に関連するタグは複数あるため、リストに格納する必要があります。
そして、このデータを以下のように辞書化して、quotesリストに追記できます。
quotes.append(
{
'text': text,
'author': author,
'tags': ', '.join(tags) # merging the tags into a "A, B, ..., Z" string
}
)抽出したデータをこのような辞書形式で保存しておくと、データへのアクセスと理解が容易になります。
ここでは、1つのページからすべての引用データを抽出する方法について説明しました。ただし、ターゲットウェブサイトは複数のウェブページで構成されていることに留意してください。それでは、ウェブサイト全体をクローリングする方法を学びましょう。
クローリングロジックを実装する
トップページの下部には、対象サイトの次のページにリダイレクトする「次へ →」 <a>というHTML要素があります。このHTML要素は、最後のページを除くすべてのページに含まれています。このようなシナリオは、ページ付けされたウェブサイトでは一般的です。
「次へ →」<a> HTML要素に含まれるリンクをたどると、ウェブサイト全体を簡単に移動できます。では、ホームページから始めて、ターゲットウェブサイトが構成する各ページに進む方法を見てみましょう。必要なのは、.next <li> HTML要素を探し、次のページへの相対リンクを抽出するだけです。
クローリングロジックは次のように実装できます。
# the url of the home page of the target website
base_url = 'https://quotes.toscrape.com'
# retrieving the page and initializing soup...
# getting the "Next →" HTML element
next_li_element = soup.find('li', class_='next')
# if there is a next page to scrape
while next_li_element is not None:
next_page_relative_url = next_li_element.find('a', href=True)['href']
# getting the new page
page = requests.get(base_url + next_page_relative_url, headers=headers)
# parsing the new page
soup = BeautifulSoup(page.text, 'html.parser')
# scraping logic...
# looking for the "Next →" HTML element in the new page
next_li_element = soup.find('li', class_='next')このwhereサイクルは、次のページがなくなるまで各ページごとに繰り返されます。具体的には、次のページの相対URLを抽出し、それを使用して次のページのURLを作成してスクレイピングを行います。その後、次のページをダウンロードします。次に、それをスクレイピングして、このロジックを繰り返します。
ここでは、ウェブサイト全体をスクレイピングするためのクローリングロジックの実装方法について説明しました。次に、抽出したデータをより有用な形式に変換する方法を見てみましょう。
データをCSV形式に変換する
スクレイピングした引用データを含む辞書のリストをCSVファイルに変換する方法を見てみましょう。これを実現するには、以下の行を使用します。
import csv
# scraping logic...
# reading the "quotes.csv" file and creating it
# if not present
csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='')
# initializing the writer object to insert data
# in the CSV file
writer = csv.writer(csv_file)
# writing the header of the CSV file
writer.writerow(['Text', 'Author', 'Tags'])
# writing each row of the CSV
for quote in quotes:
writer.writerow(quote.values())
# terminating the operation and releasing the resources
csv_file.close()このスニペットが行うのは、辞書のリストに含まれる引用データをquotes.csvファイルに書き出すことです。csvはPython標準ライブラリの一部であることに留意してください。そのため、追加の依存関係をインストールしなくても、インポートして使用できます。具体的には、open().でファイルを作成するだけです。その後、csvライブラリのWriterオブジェクトからwriterow()関数を使用して入力することができます。これにより、各引用辞書がCSV形式の行としてCSVファイルに書き込まれます。
ウェブサイトに含まれる生データを、CSVファイルに格納された構造化データに移行できます。これで、データ抽出プロセスが完了し、Pythonウェブスクレイパーの全体像を見ることができます。
すべてを統合する
Pythonウェブスクレイピングスクリプトの完成形は、次のようになります。
import requests
from bs4 import BeautifulSoup
import csv
def scrape_page(soup, quotes):
# retrieving all the quote <div> HTML element on the page
quote_elements = soup.find_all('div', class_='quote')
# iterating over the list of quote elements
# to extract the data of interest and store it
# in quotes
for quote_element in quote_elements:
# extracting the text of the quote
text = quote_element.find('span', class_='text').text
# extracting the author of the quote
author = quote_element.find('small', class_='author').text
# extracting the tag <a> HTML elements related to the quote
tag_elements = quote_element.find('div', class_='tags').find_all('a', class_='tag')
# storing the list of tag strings in a list
tags = []
for tag_element in tag_elements:
tags.append(tag_element.text)
# appending a dictionary containing the quote data
# in a new format in the quote list
quotes.append(
{
'text': text,
'author': author,
'tags': ', '.join(tags) # merging the tags into a "A, B, ..., Z" string
}
)
# the url of the home page of the target website
base_url = 'https://quotes.toscrape.com'
# defining the User-Agent header to use in the GET request below
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
# retrieving the target web page
page = requests.get(base_url, headers=headers)
# parsing the target web page with Beautiful Soup
soup = BeautifulSoup(page.text, 'html.parser')
# initializing the variable that will contain
# the list of all quote data
quotes = []
# scraping the home page
scrape_page(soup, quotes)
# getting the "Next →" HTML element
next_li_element = soup.find('li', class_='next')
# if there is a next page to scrape
while next_li_element is not None:
next_page_relative_url = next_li_element.find('a', href=True)['href']
# getting the new page
page = requests.get(base_url + next_page_relative_url, headers=headers)
# parsing the new page
soup = BeautifulSoup(page.text, 'html.parser')
# scraping the new page
scrape_page(soup, quotes)
# looking for the "Next →" HTML element in the new page
next_li_element = soup.find('li', class_='next')
# reading the "quotes.csv" file and creating it
# if not present
csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='')
# initializing the writer object to insert data
# in the CSV file
writer = csv.writer(csv_file)
# writing the header of the CSV file
writer.writerow(['Text', 'Author', 'Tags'])
# writing each row of the CSV
for quote in quotes:
writer.writerow(quote.values())
# terminating the operation and releasing the resources
csv_file.close()ここで学んだように、100行未満のコードでウェブスクレイパーを作成できます。このPythonスクリプトは、ウェブサイト全体をクローリングして、その全データを自動的に抽出してCSVファイルに変換できます。
おめでとうございます!RequestsとBeautiful Soupライブラリーを使ってPythonウェブスクレイパーを作成する方法を学ぶことができました。
ウェブスクレイピングPythonスクリプトを実行する
PyCharmを使用している場合は、下のボタンをクリックしてスクリプトを実行します。

それ以外の場合は、プロジェクトディレクトリ内のターミナルで、以下のPythonコマンドを起動します。
python scraper.pyプロセスが終了するのを待つと、quotes.csvファイルにアクセスできるようになります。これを開くと、次のデータが含まれているはずです。
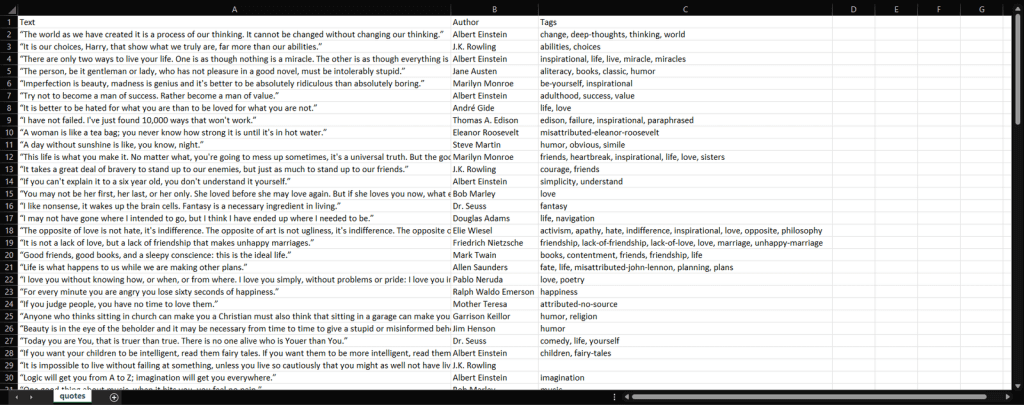
はい、できました!これで、ターゲットウェブサイトに含まれる100件の引用が、1つのCSVファイルに収まりました。
まとめ
このチュートリアルでは、ウェブスクレイピングとは何か、Pythonで始めるために必要なものは何か、そしてウェブスクレイピングに最適なPythonライブラリは何かについて学びました。次に、Beautiful SoupとRequestsを使ってウェブスクレイピングアプリケーションを作成する方法を、実例を通して学ぶことができました。Pythonでウェブスクレイピングを行うには、数行のコードで済むことがおわかりいただけたと思います。
ただし、ウェブスクレイピングにはいくつかの課題があります。具体的には、ボット対策やスクレイピング対策の技術がますます一般的になってきました。そのため、Bright Dataが提供する高度で完全な自動ウェブスクレイピングツールが必要なのです。
また、ブロックを回避するために、Bright Dataが提供するさまざまなプロキシサービスから、用途に応じてプロキシを選択することをお勧めします。
FAQ
ウェブスクレイピングやクローリングは、データサイエンスの一部ですか?
はい。ウェブスクレイピングやクローリングは、データサイエンスの大きな分野の一部です。スクレイピングやクローリングは、構造化および非構造化データから得られる他のすべての副産物の基礎となるものです。これには、アナリティクス、アルゴリズムモデル/アウトプット、インサイト、「応用可能な知識」などが含まれます。
Pythonでウェブサイトから特定のデータをスクレイピングする方法は?
Pythonでウェブサイトからデータをスクレイピングするには、ターゲットURLのページを調査し、抽出したいデータを特定し、データ抽出コードを記述して実行し、最後にデータを希望の形式で保存する必要があります。
Pythonでウェブスクレイパーを作成する方法は?
Pythonデータスクレイパーを作成する最初のステップは、文字列メソッドを使ってウェブサイトのデータを解析し、次にHTMLパーサーを使ってウェブサイトのデータを解析し、最後に必要なフォームおよびウェブサイトコンポーネントと対話することです。





