
この記事では、Python(Selenium)を使ってYouTube上のデータをスクレイピングする方法を詳しく説明していきます。
このチュートリアルで学べること:
- YouTube APIとYouTubeのスクレイピングを比較する
- YouTubeから抽出できるデータ
- SeleniumでYouTubeをスクレイピングする
YouTube APIとYouTubeのスクレイピングを比較する
YouTubeにはYouTube Data APIという公式のAPIが用意されています。このAPIを使えば、YouTubeプラットフォームから動画情報や再生リストの情報、コンテンツ作成者の情報などのデータを取得できます。とはいえ少なくとも次の3つ理由から、公式のAPIに頼るよりも、スクレイピングでデータを取得するほうがアプローチとして優れていると言えます。
- 柔軟性とカスタマイズ性の高さ:YouTube用のスクレイピングプログラムを使用することで、必要なデータだけを取得するようにコードを調節できます。カスタマイズ性が高いので、その時々に必要な情報だけを収集できるのです。一方でAPIを使う場合は、YouTube側で用意されたデータにしかアクセスできません。
- 非公式データへのアクセス:公式APIからアクセスできるのは、YouTube側が用意した特定のデータセットのみです。つまり、YouTubeの仕様変更により、現在利用しているデータの一部を将来利用できなくなる可能性があります。スクレイピングを行うことで、APIでは公開されていないものを含むあらゆる情報をYouTubeから取得できるようになります。
- 制限なし:YouTube APIには通信頻度制限があり、一定期間の間に送信できるリクエストの頻度と回数が制限されていますが、スクレイピングでプラットフォームと直接やり取りすることで、この制限を回避できます。
YouTubeからスクレイピングできるデータ
YouTubeからスクレイピングできる主なデータ
- ビデオのメタデータ:
- タイトル
- 説明文
- 再生回数
- いいねの数
- 動画の長さ
- 公開日
- チャネル
- ユーザーのプロフィール:
- ユーザー名
- ユーザーの自己紹介
- 登録者
- 動画の数
- プレイリスト
- その他:
- コメント
- 関連動画
こういったデータを取得する1番の方法は、上述の通り自前のスクレイピングプログラムを作ることです。ここで、どのプログラミング言語を選ぶべきかということが問題となります。
この記事ではPythonの使用しています。Pythonはシンプルな構文と豊富なライブラリエコシステムが特徴であり、それ理由でスクレイピングに最もよく使われる言語の1つとなっています。Pythonは汎用があって読みやすく、また開発者コミュニティからのサポートも受けやすいため、スクレイピングにおすすめの言語となっています。Pythonでスクレイピングする方法を初めて学ぶ方は、こちらの詳細なガイドをご覧ください。
SeleniumでYouTubeデータをスクレイピングする
このチュートリアルに従い、YouTube上のデータをスクレイピングするためのPythonスクリプトの作成方法を学んでいきましょう。
ステップ1:開発環境を準備する
プログラムを書く前に、次のような環境を準備してください:
- Python 3+:インストーラーをダウンロードし、アイコンをダブルクリックした後、プロンプトの指示通りにインストールしてください。
- Python IDE:無料のものではPyCharm Community Editionか、Visual Studio CodeにPython拡張機能を入れたものがおすすめです。
以下のコマンドを使用することで、仮想環境を使ってPythonプロジェクトのイニシャライズができます。
mkdir youtube-scraper
cd youtube-scraper
python -m venv env
上記のコマンドで作成した youtube-scraper ディレクトリが、今回のPythonスクリプトのプロジェクトフォルダとなります。
このフォルダをIDEで開き、 scraper.py ファイルを作成してから、次のようにファイルをイニシャライズしてください:
print('Hello, World!')
このファイルは現在、「Hello, World!」と出力するだけのただのサンプルスクリプトです。これからスクレイピングのロジックを書いていきます。
IDEの実行(Run)ボタンを押すか、次のコマンドを実行して、スクリプトが機能することを確認してください:
python scraper.py
ターミナルには次のような出力結果が表示されるはずです:
Hello, World!
その調子です!これでYouTubeデータをスクレイピングするためのPythonプロジェクトができました。
ステップ2:スクレイピング用ライブラリを選択してインストールする
YouTubeを改めて使ってみると、非常にインタラクティブなサイトだということがわかると思います。YouTubeはユーザーのクリック操作やスクロール操作に応じて、データを動的にロードし、レンダリングしています。つまり、YouTubeにはJavaScriptが多用されているのです。
そのため、YouTube上のデータをスクレイピングするには、ブラウザでウェブページをレンダリングできるSeleniumのようなツールが必要になります。Seleniumを使用すると、Pythonを使ってブラウザ経由でウェブ操作を自動化し、動的なサイトからデータをスクレイピングできるようになります。
SeleniumとWebdriver Managerパッケージをプロジェクトの依存関係に追加します:
pip install selenium webdriver-manager
インストール作業には時間がかかる場合があるので、気長に待ちましょう。
webdriver-manager は厳密には必要ではありませんが、これがあるとSeleniumでウェブドライバーを管理しやすくなります。また、webdriver-managerをインストールすることで、ウェブドライバを手動でダウンロード、インストール、設定する必要がなくなります。
scraper.pyを開き、Seleniumを使い始めましょう:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
# initialize a web driver instance to control a Chrome window
# in headless mode
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# scraping logic...
# close the browser and free up the resources
driver.quit()
このスクリプトでは、Chromeウィンドウを操作するためのオブジェクトであるChrome WebDriverのインスタンスを作成しています。
SeleniumはデフォルトでGUIが付いたブラウザを起動します。GUIが付いたブラウザを使えば自動スクリプトがページ上で何をしているのかをそのまま確認できるため、デバッグ面では役立ちますが、その分多くのリソースが必要になります。そのため、ここではChromeをヘッドレスモードで実行するように設定しています。 このスクリプトには--headless=new オプションが加えられているので、バックグラウンドでUIなしのブラウザインスタンスを動かすことができます。
素晴らしい!では、これからスクレイピングのロジックの部分を作成していきます。
ステップ3:YouTubeに接続する
YouTubeでスクレイピングを実行するには、まずどの動画からデータを抽出するかを決めなければなりません。この記事では、Bright DataのYouTubeチャンネルの最新動画をスクレイピングしていきます。もちろん他の動画でも構いません。
今回は次のYouTubeページをターゲットにします。
https://www.youtube.com/watch?v=kuDuJWvho7Q
この動画は「Introduction to Bright Data | Scraping Browser.」というタイトルで、内容はスクレイピングに関するものです。
URLの文字列をPythonの変数に保存します:
url = 'https://www.youtube.com/watch?v=kuDuJWvho7Q'
これを次のようにドライバーに渡すと、Seleniumが目的のページにアクセスするようになります。
driver.get(url)
ここでは get() 関数にURLをパラメーターとして渡すことで、対象ブラウザにそのURLへアクセスするように指示を出しています。
この時点でのYouTubeスクレイピングプログラムの全文は以下の通りです:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
# initialize a web driver instance to control a Chrome window
# in headless mode
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# the URL of the target page
url = 'https://www.youtube.com/watch?v=kuDuJWvho7Q'
# visit the target page in the controlled browser
driver.get(url)
# close the browser and free up the resources
driver.quit()
スクリプトを実行するとブラウザウィンドウが一瞬開きますが、 quit () 文が実行されるのですぐに閉じます:
「Chrome は自動テストソフトウェアによって制御されています」というメッセージが表示されます。これはChromeがSelenium経由で正常に動作していることを示しています。
ステップ4:対象のページを検証する
前のスクリーンショットをご覧ください。YouTubeを初めて開くと、規約への同意を求めるダイアログが表示されます。ページ上のデータにアクセスするには、まず [全てに同意する] ボタンをクリックしてページを閉じなければなりません。その方法を学んでいきましょう。
YouTubeをシークレットモードで開き、新しいブラウザセッションを開始します。規約同意のダイアログを右クリックし、[検証] を選択します。Chromeのデベロッパーツールが開きます。
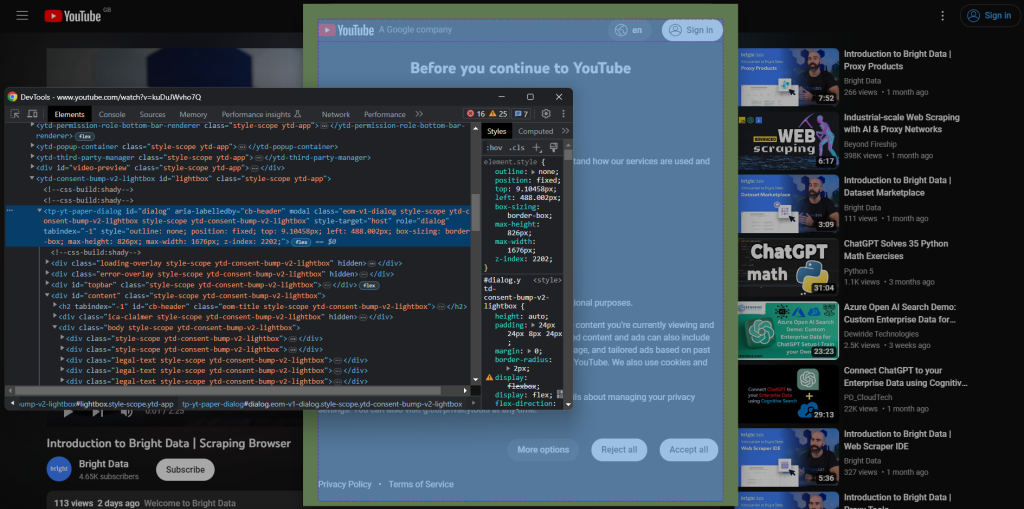
ダイアログに id 属性が付けられていることに注目してください。Seleniumでセレクターを選ぶ際に、このidが役立ちます。
次に、[全てに同意する] ボタンを検証します。
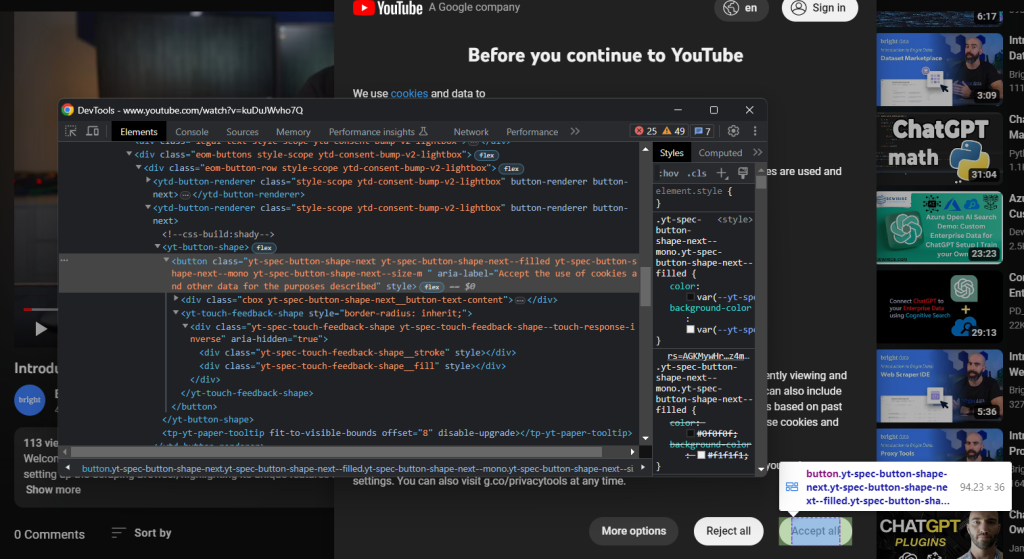
これは次のCSSセレクターが付けられた2番目のボタンのことです:
.eom-buttons button.yt-spec-button-shape-next
では、今見てきたこと全てをコードにまとめていきます。次のコードではSeleniumでYouTubeクッキーポリシーを処理しています:
try:
# wait up to 15 seconds for the consent dialog to show up
consent_overlay = WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.ID, 'dialog'))
)
# select the consent option buttons
consent_buttons = consent_overlay.find_elements(By.CSS_SELECTOR, '.eom-buttons button.yt-spec-button-shape-next')
if len(consent_buttons) > 1:
# retrieve and click the 'Accept all' button
accept_all_button = consent_buttons[1]
accept_all_button.click()
except TimeoutException:
print('Cookie modal missing')
規約同意ダイアログは動的に読み込まれるため、表示されるまでに時間がかかる場合があります。まずは WebDriverWait を使って、処理できる状態になるまでプログラムを待機させます。ここでは指定された時間内に何も起こらなかった場合、 TimeoutExceptionを発生させています。YouTubeはかなり遅いため、待機時間を10秒以上に設定するのがいいでしょう。
YouTubeの規約は頻繁に変更されるので、一部の国や特定の条件下ではダイアログが表示されないことがあります。したがって、ダイヤログが出てこない場合にもエラーが起こらないように、 try-catch でexceptionの処理をしています。
次のインポートを追加しなければ、スクリプトは動作しません:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException
[全てに同意する] ボタンを押した後、YouTubeがページを動的に再レンダリングするまでしばらく時間がかかります:
この間、Seleniumでページを操作することはできません。HTML要素を選択しようとすると、「stale element reference(古い要素を参照しています)」エラーが表示されます。これはレンダリングの途中でDOMが大きく変更されるためです。
ご覧のとおり、タイトル要素には灰色の線が含まれています。この要素を検証すると、次のコードが表示されます。
タイトル要素がきちんと表示されているかどうかが、ページが完全に読み込まれたかを知るための良い指標になります:
# wait for YouTube to load the page data
WebDriverWait(driver, 15).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, 'h1.ytd-watch-metadata'))
)
これで、PythonでYouTube上のデータをスクレイピングする準備が整いました。DevToolsで対象のサイトの分析を続け、そのDOMに慣れていくことが大切です。
ステップ5:YouTubeからデータを抽出する
まずは、スクレイピングした情報を保存するためのデータ構造を定義する必要があります。次のコードで、Pythonの辞書型オブジェクトをイニシャライズします:
video = {}
前のステップでお気づきの方もいるかもしれませんが、最も重要な情報の一部はビデオプレイヤーの下に入っています:

動画のタイトルは h1.ytd-watch-metadata というCSS セレクターから取得できます:
title = driver
.find_element(By.CSS_SELECTOR, 'h1.ytd-watch-metadata')
.text
チャンネル情報を含むHTML要素はタイトルのすぐ下にあります:
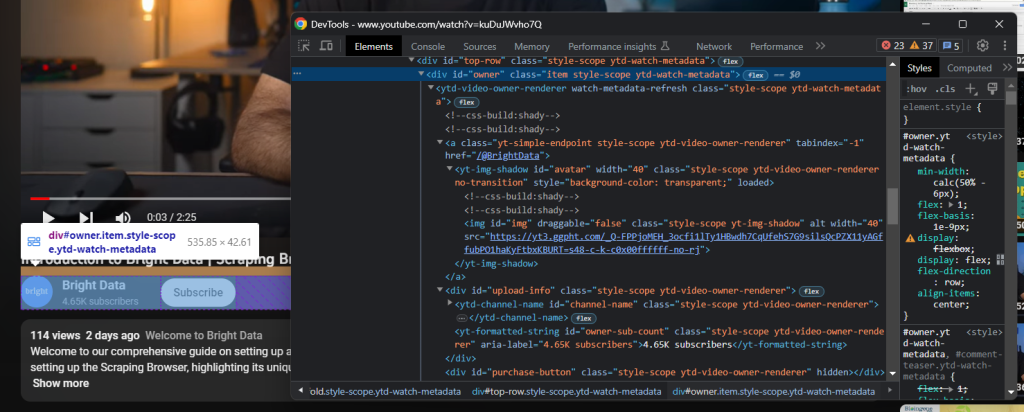
“owner”という id 属性に注目してください。次のコードを使えば、この属性の全データを取得できます:
# dictionary where to store the channel info
channel = {}
# scrape the channel info attributes
channel_element = driver
.find_element(By.ID, 'owner')
channel_url = channel_element
.find_element(By.CSS_SELECTOR, 'a.yt-simple-endpoint')
.get_attribute('href')
channel_name = channel_element
.find_element(By.ID, 'channel-name')
.text
channel_image = channel_element
.find_element(By.ID, 'img')
.get_attribute('src')
channel_subs = channel_element
.find_element(By.ID, 'owner-sub-count')
.text
.replace(' subscribers', '')
channel['url'] = channel_url
channel['name'] = channel_name
channel['image'] = channel_image
channel['subs'] = channel_subs
さらに下に進むと、動画の説明があります。この要素は閉じているか開いているかによって表示されるデータが変わるため、挙動が複雑です。

クリックして、データ全文を表示させてください:
driver.find_element(By.ID, 'description-inline-expander').click()
説明セクションの情報全文の要素にアクセスできるはずです:
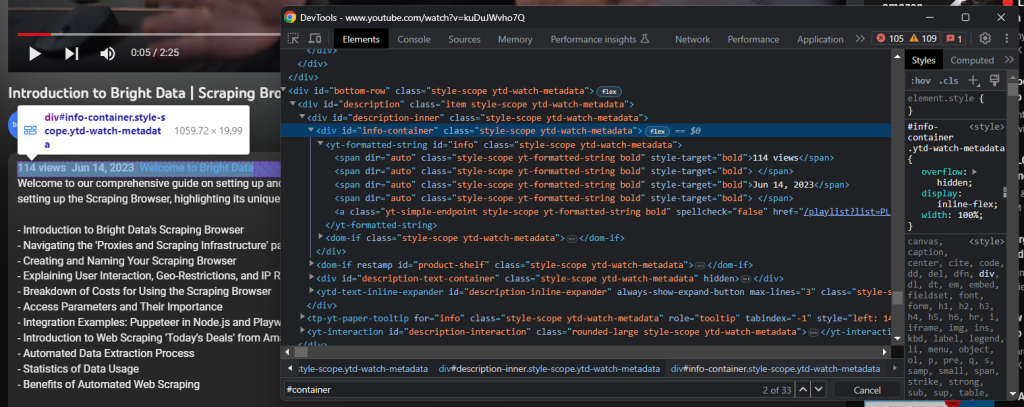
次のコードで動画の再生回数と公開日のデータを取得してください:
info_container_elements = driver
.find_elements(By.CSS_SELECTOR, '#info-container span')
views = info_container_elements[0]
.text
.replace(' views', '')
publication_date = info_container_elements[2]
.text
動画関連の説明文は次の子要素に含まれています:
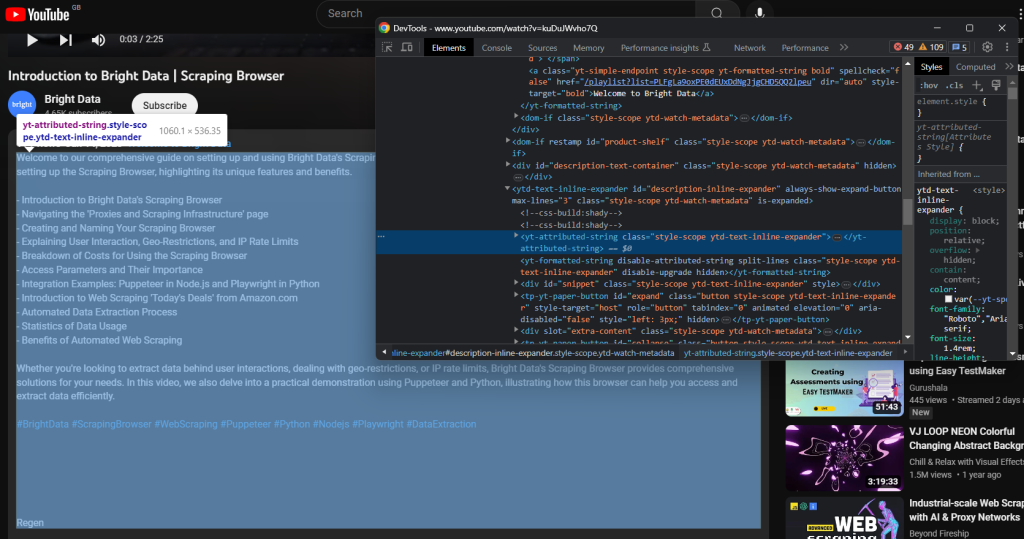
次のコードでデータを抽出しましょう:
description = driver
.find_element(By.CSS_SELECTOR, '#description-inline-expander .ytd-text-inline-expander span')
.text
次に、「いいね」ボタンを検証します:
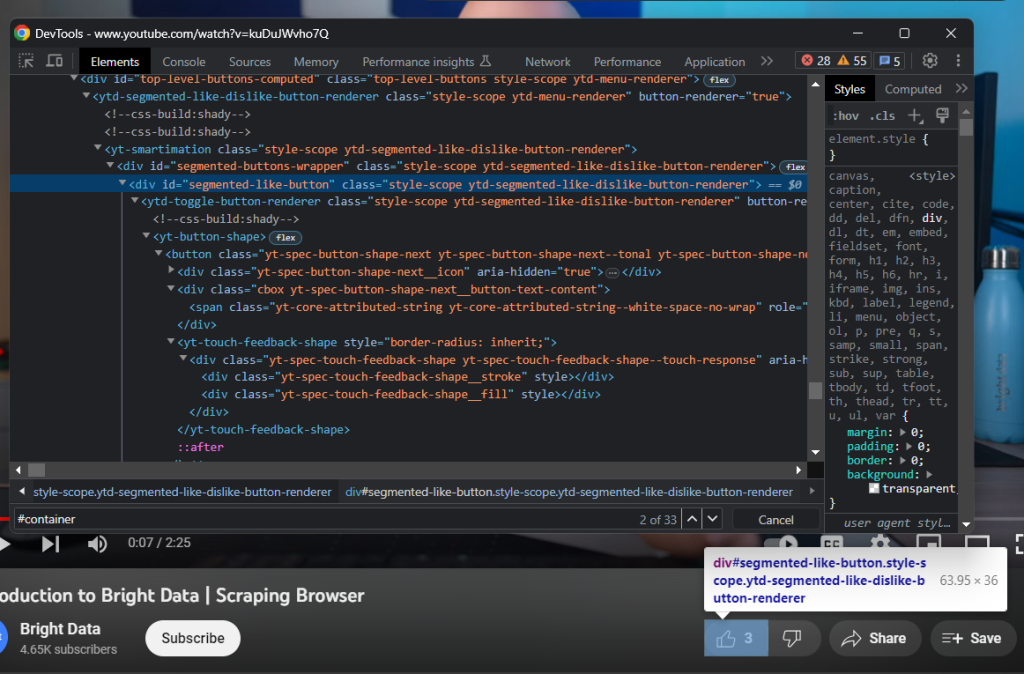
次の方法でいいねの数を取得してください:
likes = driver
.find_element(By.ID, 'segmented-like-button')
.text
最後に、スクレイピングしたデータを忘れずに video と名付けた辞書型オブジェクトに格納します:
video['url'] = url
video['title'] = title
video['channel'] = channel
video['views'] = views
video['publication_date'] = publication_date
video['description'] = description
video['likes'] = likes
素晴らしい!これで、Pythonでウェブスクレイピングができました!
ステップ6:スクレイピングしたデータをJSONにエクスポートする
今のところ、取得したデータはPythonの辞書型オブジェクトに保存されていますが、このままでは他の人と共有しにくいはずです。次の2行のコードで追加するだけで、取得した情報をJSONに変換し、ファイルにエクスポートできます:
with open('video.json', 'w') as file:
json.dump(video, file)
このサンプルコードでは、 video.json ファイルを open ()でイニシャライズしています。次に json.dump () を使い、辞書型オブジェクトの video をJSONファイルに書き込みます。PythonでJSONを解析する方法について詳しく学びたいという方は、こちらの記事をご覧ください。
この機能を実装するのに、新しい依存関係を追加する必要はありません。次のコードで、Pythonの標準ライブラリの json パッケージをインポートするだけです:
import json
お疲れ様です。動的なHTMLページに含まれる生データから始め、最終的におおよその構造が付いたJSONデータを作ることができました。では、最後にYouTubeスクレイピングプログラムの全文を確認してみましょう。
ステップ7:コードを確認する
これが scraper.py のスクリプト全文です:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException
import json
# enable the headless mode
options = Options()
# options.add_argument('--headless=new')
# initialize a web driver instance to control a Chrome window
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# the URL of the target page
url = 'https://www.youtube.com/watch?v=kuDuJWvho7Q'
# visit the target page in the controlled browser
driver.get(url)
try:
# wait up to 15 seconds for the consent dialog to show up
consent_overlay = WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.ID, 'dialog'))
)
# select the consent option buttons
consent_buttons = consent_overlay.find_elements(By.CSS_SELECTOR, '.eom-buttons button.yt-spec-button-shape-next')
if len(consent_buttons) > 1:
# retrieve and click the 'Accept all' button
accept_all_button = consent_buttons[1]
accept_all_button.click()
except TimeoutException:
print('Cookie modal missing')
# wait for YouTube to load the page data
WebDriverWait(driver, 15).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, 'h1.ytd-watch-metadata'))
)
# initialize the dictionary that will contain
# the data scraped from the YouTube page
video = {}
# scraping logic
title = driver
.find_element(By.CSS_SELECTOR, 'h1.ytd-watch-metadata')
.text
# dictionary where to store the channel info
channel = {}
# scrape the channel info attributes
channel_element = driver
.find_element(By.ID, 'owner')
channel_url = channel_element
.find_element(By.CSS_SELECTOR, 'a.yt-simple-endpoint')
.get_attribute('href')
channel_name = channel_element
.find_element(By.ID, 'channel-name')
.text
channel_image = channel_element
.find_element(By.ID, 'img')
.get_attribute('src')
channel_subs = channel_element
.find_element(By.ID, 'owner-sub-count')
.text
.replace(' subscribers', '')
channel['url'] = channel_url
channel['name'] = channel_name
channel['image'] = channel_image
channel['subs'] = channel_subs
# click the description section to expand it
driver.find_element(By.ID, 'description-inline-expander').click()
info_container_elements = driver
.find_elements(By.CSS_SELECTOR, '#info-container span')
views = info_container_elements[0]
.text
.replace(' views', '')
publication_date = info_container_elements[2]
.text
description = driver
.find_element(By.CSS_SELECTOR, '#description-inline-expander .ytd-text-inline-expander span')
.text
likes = driver
.find_element(By.ID, 'segmented-like-button')
.text
video['url'] = url
video['title'] = title
video['channel'] = channel
video['views'] = views
video['publication_date'] = publication_date
video['description'] = description
video['likes'] = likes
# close the browser and free up the resources
driver.quit()
# export the scraped data to a JSON file
with open('video.json', 'w') as file:
json.dump(video, file, indent=4)
わずか約100行のコードで、YouTubeの動画からデータを取得するスクレイピングプログラムを作成できました!
このプログラムを起動すると、次の video.json ファイルがプロジェクトのルートフォルダに表示されます:
{
"url": "https://www.youtube.com/watch?v=kuDuJWvho7Q",
"title": "Introduction to Bright Data | Scraping Browser",
"channel": {
"url": "https://www.youtube.com/@BrightData",
"name": "Bright Data",
"image": "https://yt3.ggpht.com/_Q-FPPjoMEH_3ocfi1lTy1HBwdh7CqUfehS7G9silsQcPZX11yAGffubPO1haKyFtbxKBURT=s48-c-k-c0x00ffffff-no-rj",
"subs": "4.65K"
},
"views": "116",
"publication_date": "Jun 14, 2023",
"description": "Welcome to our comprehensive guide on setting up and using Bright Data's Scraping Browser for efficient web data extraction. This video walks you through the process of setting up the Scraping Browser, highlighting its unique features and benefits.nn- Introduction to Bright Data's Scraping Browsern- Navigating the 'Proxies and Scraping Infrastructure' pagen- Creating and Naming Your Scraping Browsern- Explaining User Interaction, Geo-Restrictions, and IP Rate Limitsn- Breakdown of Costs for Using the Scraping Browsern- Access Parameters and Their Importancen- Integration Examples: Puppeteer in Node.js and Playwright in Pythonn- Introduction to Web Scraping 'Today's Deals' from Amazon.comn- Automated Data Extraction Processn- Statistics of Data Usagen- Benefits of Automated Web ScrapingnnWhether you're looking to extract data behind user interactions, dealing with geo-restrictions, or IP rate limits, Bright Data's Scraping Browser provides comprehensive solutions for your needs. In this video, we also delve into a practical demonstration using Puppeteer and Python, illustrating how this browser can help you access and extract data efficiently.nn#BrightData #ScrapingBrowser #WebScraping #Puppeteer #Python #Nodejs #Playwright #DataExtraction",
"likes": "3"
}
おめでとうございます!これで、Pythonを使ってYouTube上のデータをスクレイピングする方法を習得できました!
まとめ
この記事ではYouTubeのデータAPIを使用するよりも、YouTube上のデータを直接スクレイピングする方が良い理由を学びました。その後、YouTubeから動画データを取得するため、Pythonのスクレイピングプログラムの作成チュートリアルをステップバイステップで行いました。チュートリアルから分かるように、スクレイピングプログラムはさほど複雑でなく、必要なコードも数行のみです。
一方で、YouTubeは変化を続けるダイナミックなプラットフォームであるため、ここで作成したスクレイピングプログラムは将来的に機能しなくなる可能性があります。ターゲットとなるサイトの仕様変更に対応できるようにメンテナンスを行うのには、時間と手間がかかります。Bright DataがYouTube Scraperを開発した理由はここにあります。YouTube Scraperは信頼性が高く使いやすいツールで、これを使えば必要な全てなデータをお手軽に取得できます。
Googleのボット対策システムの存在も見過ごせません。Seleniumは素晴らしいツールですが、ボット対策システムに検出されては何の役にも立ちません。GoogleがYouTubeからボットを排除すると決めた場合、ほとんどの自動スクリプトが締め出されることになります。そうなれば、JavaScriptをレンダリングでき、フィンガープリント、Captcha、スクレイピング対策プログラムを自動的に処理して回避できるツールが必要になります。実はボット対策に対応したツールはすでに存在しており、それこそがScraping Browserなのです。
YouTubeデータのスクレイピング処理に手を煩わせたくないが、動画データには興味があるという方もいらっしゃるでしょう。その場合は、ぜひYouTubeデータセットをお求めください。





