
この記事では
- Google Gen AI SDKとは何か?
- なぜMCPを介した拡張が有効なのか。
- Bright Data Web MCPでGoogle Gen AI SDKを使用し、センチメント分析AIワークフローの例を構築する方法。
さっそく見ていきましょう!
Google Gen AI SDKとは?
Google Gen AI SDKは、GeminiなどのGoogleのジェネレーティブAIモデルをAIアプリケーションに統合するためのソフトウェア開発キットのセットです。これらのオープンソースSDKは、複数のプログラミング言語で利用可能です。
簡単に言えば、Gemini Developer APIと Vertex AI上のGemini APIの両方を通じて、これらのモデルと対話するための統一インターフェースを提供する。特に、Google Gen AI SDKの主な特徴は以下の通りである:
- 多言語サポート:SDKは、Python、Node.js、Java、Goで利用可能であり、AIを利用した機能を構築する際に好みの言語を選択することができる。
- Geminiモデルへのアクセス:Gemini 2.5 LLMなど、Googleの高度な生成AIモデルへのアクセスを提供します。
- 統一されたAPIアクセス:ラピッドプロトタイピングのためのGemini Developer APIと、量産可能なアプリケーションのためのVertex AI上のGemini APIの両方に一貫したインターフェースを提供します。
- 関数呼び出し機能:MCP経由など、外部ツールやサービスとの相互作用をサポートします。
Google Gen AI SDKをウェブアクセス用のMCPサーバーと統合する理由
Google Gen AI SDKでどのGoogle Generative AIモデルを設定しても、その知識は静的であるという点で共通しています!
LLMは、時間のスナップショットを表すデータで学習されるため、すぐに古くなってしまいます。これはLLMの主な限界の一つであり、生きたウェブサイトと直接対話する能力の欠如でもある。
ほとんどの場合、AIのワークフローやアプリケーションは、新鮮で高品質なデータにアクセスできることが望ましい。理想的には、AIは自動化がすべてであるため、ワークフローはあなたに代わってこのデータを取得できなければならない。Google Gen AI SDKとBright DataのWeb MCPを統合すると、まさにこのようなことが可能になります。
Web MCPは、60以上のAI対応ツールへのアクセスを提供し、これらはすべて、Webインタラクションとデータ収集のためのBright DataのAIインフラストラクチャによって支えられています。無料でも、AIにこれらのツールのうち2つにアクセスさせることができます:
| ツール | ツール |
|---|---|
スクレイプ_アス_マークダウン |
高度な抽出オプションを使用して、1つのウェブページからコンテンツをスクレイピングし、データをMarkdownで返します。ボット検知やCAPTCHAを回避できる。 |
サーチエンジン |
Google、Bing、Yandexから検索結果を抽出する。SERPデータをJSONまたはMarkdown形式で返す。 |
これら以外にも、Amazon、LinkedIn、Yahoo Finance、TikTokなどのドメインにわたって、ウェブインタラクションや構造化データ収集のための約60の専門ツールがある。
要するに、Google Gen AI SDKをWeb MCPと統合することで、AIワークフローは効果的にウェブにアクセスできるようになる。これにより、Googleの生成モデルのパワーを活用しながら、最も新鮮なデータから洞察を生成することができます。
Google Gen AI SDKとBright DataのWeb MCPを使用したセンチメント分析AIワークフローの作成方法
このガイドセクションでは、Pythonで書かれたGoogle Gen AI SDKワークフローにBright DataのWeb MCPを接続する方法を学びます。具体的には、この統合を使用して、以下のようなセンチメント分析AIワークフローを構築します:
- Bright DataのWeb MCPツールを利用して、CNNのニュース記事をスクレイピングします。
- Geminiモデルに、要約と感情分析のためにコンテンツを処理させる。
- 結果をお客様に返します。
注:これは単なる例です。プロンプトを変更することで、他の多くのシナリオをカバーすることができます。また、以下のPythonスクリプトは、サポートされている他のプログラミング言語にも簡単に適応させることができます。
さあ、始めよう!
前提条件
このチュートリアルを始める前に、以下を確認してください:
- Python 3.9+がローカルにインストールされていること。
- Node.jsがローカルにインストールされていること(最新のLTSバージョンを推奨します)。
- Gemini APIキー。
- APIキーが設定されたBright Dataアカウント。
Bright Dataアカウントの設定については、後のステップで説明しますので、心配しないでください。
ステップ #1: Pythonプロジェクトの作成
ターミナルを開き、Google Gen AIプロジェクト用の新しいディレクトリを作成します:
mkdir google-genai-mcp-workflowgoogle-genai-mcp-workflow/フォルダには、Google Gen AIワークフローのPythonコードが格納されます。これは、WebデータスクレイピングのためにBright Data Web MCPに接続します。
次に、プロジェクトディレクトリに移動し、その中に仮想環境を作成します:
cd google-genai-mcp-agent
python -m venv .venv次に、お好きなPython IDEでプロジェクトをロードします。Python拡張機能付きのVisual Studio CodeまたはPyCharm Community Editionを推奨します。
プロジェクトフォルダに、workflow.py という名前の新しいファイルを作成します。ディレクトリ構造は以下のようになります:
google-genai-mcp-workflow/
├─ .venv/
└──.workflow.pyターミナルで仮想環境を起動します。LinuxやmacOSの場合は、以下のように実行します:
source .venv/bin/activate を実行します。Windowsの場合は、以下のコマンドを実行します:
.venv/Scripts/activate環境がアクティブになったら、必要な依存関係をインストールします:
pip install google-genai mcp python-dotenvこれでインストールされます:
google-genai:Googleの生成モデルをPythonアプリケーションに統合するためのGoogle Gen AI Python SDK。mcp:MCP(Model Context Protocol)のPython実装。python-dotenv:.envファイルから環境変数の値をロードします。
これで準備完了です!これで、Bright Data Web MCP統合によるAIワークフローを構築するためのPython開発環境が整いました。
ステップ #2: 環境変数の読み込みのセットアップ
AIワークフローは、Gemini AIモデルやBright Data Web MCPサーバーなどのサードパーティコンポーネントに接続します。これらの統合を安全に保つために、APIキーをPythonコードに直接ハードコードすることは避けるべきです。代わりに、環境変数として保存します。
環境変数の読み込みを簡単にするには、python-dotenvライブラリを使用します。これをインポートし、workflow.pyファイルの先頭でload_dotenv() を呼び出します:
import os
from dotenv import load_dotenv
load_dotenv()load_dotenv()関数により、スクリプトはローカルの.envファイルから変数を読み込むことができます。このため、プロジェクトディレクトリのルートに.envファイルを作成します:
google-genai-mcp-workflow/
├─ venv/
├── .env # <-----------
└── workflow.py素晴らしい!これで、APIキーやその他のシークレットを環境変数を使って安全に管理する準備が整いました。
ステップ #3: Bright Data Web MCP のテスト
スクリプトでBright Data Web MCPへの接続を設定する前に、まずマシンがMCPサーバーを実行できることを確認してください。
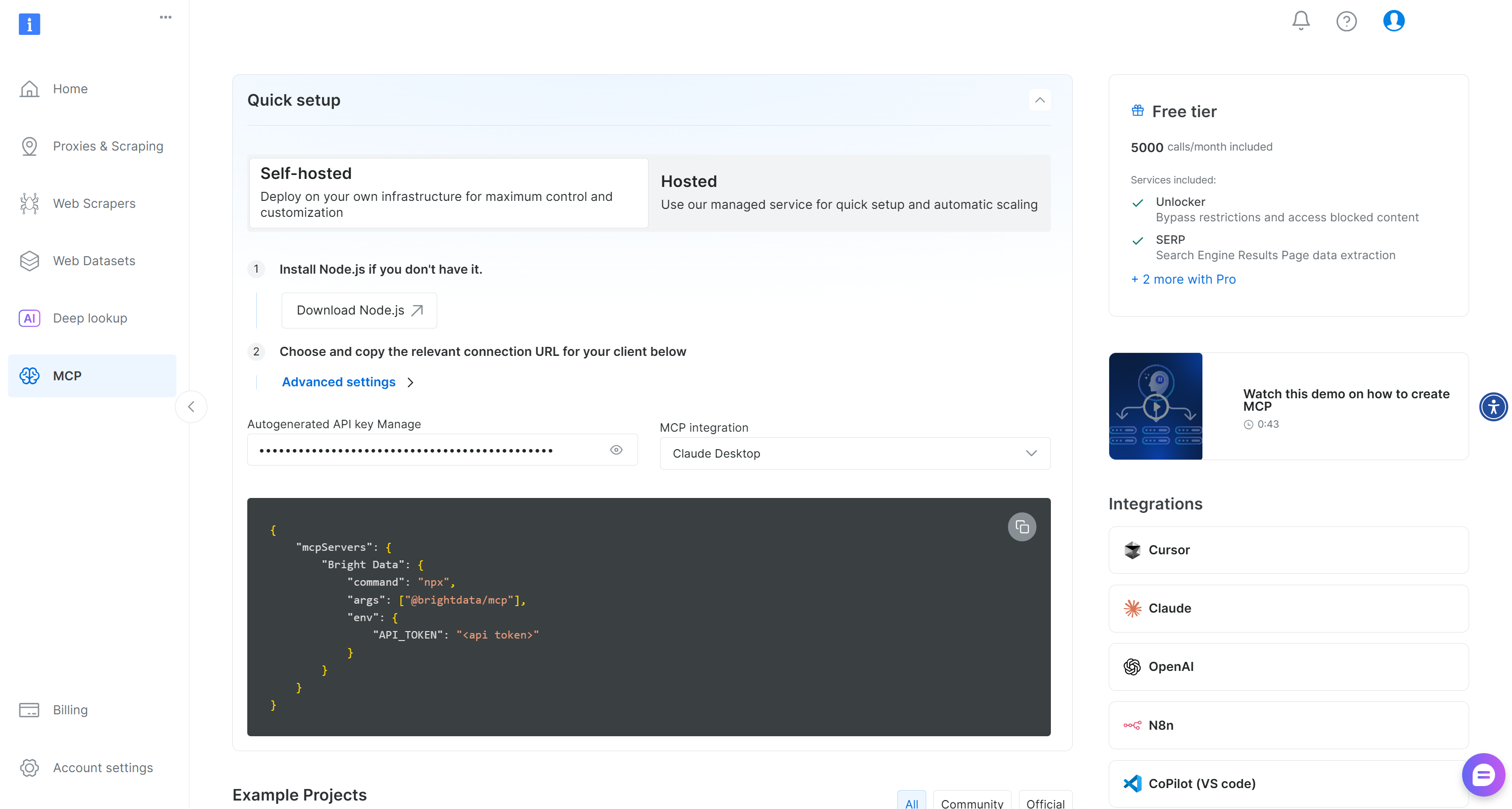
Bright Dataアカウントをまだお持ちでない場合は、アカウントを作成してください。お持ちの場合は、ログインしてください。クイックセットアップの場合は、ダッシュボードの「MCP」セクションに到達し、指示に従ってください:
そうでない場合は、以下の手順に従ってください。
まず、Bright Data API キーを生成し、安全な場所に保管してください。このガイドでは、API キーに管理者権限があると仮定しています。
以下のコマンドを実行して、Web MCP をグローバルにインストールします:
npm install -g @brightdata/mcp次に、以下のコマンドを実行して、ローカルのMCPサーバーが動作することを確認します:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpまたは、Windowsの場合
Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp<YOUR_BRIGHT_DATA_API>を実際のBright Data APIトークンに置き換えてください。このコマンドは必要なAPI_TOKEN環境変数を設定し、@brightdata/mcpパッケージを使用してWeb MCPを起動します。
成功すると、以下のようなログが表示されます:

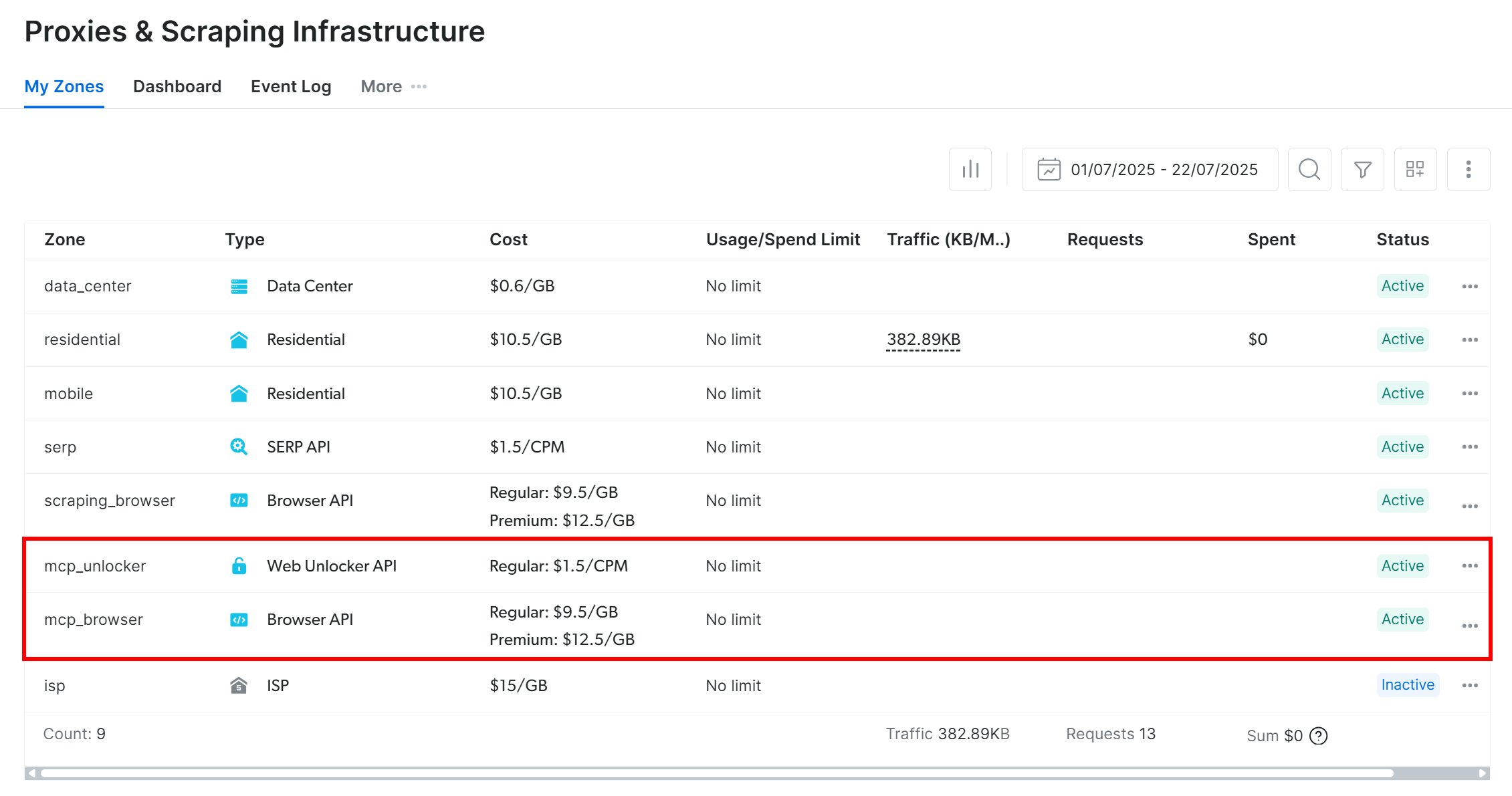
最初の起動で、パッケージは Bright Data アカウントに2つのデフォルトゾーンを作成します:
mcp_unlocker:mcp_unlocker: Web Unlocker 用のゾーンです。mcp_browser:mcp_unlocker: Web Unlocker用のゾーン。
これらのゾーンは、Web MCPの60以上のツールすべてに必要です。
ゾーンが作成されたことを確認するには、Bright Dataダッシュボードにログインします。Proxies & Scraping Infrastructure” ページに移動し、2つのゾーンがテーブルに表示されていることを確認します:
注意: API トークンにAdmin権限がない場合、これらのゾーンは自動的に作成されません。その場合は、ダッシュボードで手動で追加し、環境変数で名前を設定する必要があります(詳細はGitHubページを参照)。
デフォルトでは、MCPサーバーはsearch_engineと scrape_as_markdownツール(とそのバッチ版)のみを公開しています。これらは、Web MCPフリー・ティアのおかげで無料で使うことができます。
おまけ:MCPサーバーを起動する前に、PRO_MODE="true "環境変数を設定することで、Proモードを有効にすることができます:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpまたは、Windowsの場合
Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpプロ・モードは60以上のツールをアンロックしますが、無料版には含まれておらず、追加料金が発生する場合があります。
完璧です!これでWeb MCPサーバーがあなたのマシンで動作することが確認できました。Google Gen AIスクリプトを起動し、自動的にサーバーに接続するように設定します。
ステップ #4: MCP接続設定の定義
workflow.pyで、以下の設定を使ってWeb MCP接続ロジックを表現します:
from mcp import StdioServerParameters
# Bright Data APIキーをenvから読み込む
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# stdio 接続で Bright Data Web MCP に接続するための設定
server_params = StdioServerParameters(
command="npx"、
args=["-y", "@brightdata/mcp"]、
env={
"API_TOKEN":bright_data_api_key、
# "PRO_MODE":"true"(オプション。)
},
)この設定により、先ほどと同じnpxコマンドが、正しい環境変数とともに、Web MCPサーバーをローカルに起動し、stdio経由で接続するようになります。
注:PRO_MODE環境変数はオプションです。60以上のツールすべてにアクセスしたい場合のみ有効にしてください。そうでなければ、無料版で利用可能なsearch_engineと scrape_as_markdownツール(とそのバッチ版)に限定することができます。
次に、.envファイルに Bright Data API キーを追加します:
bright_data_api_key="<your_bright_data_api_key>"<YOUR_BRIGHT_DATA_API_KEY>プレースホルダーを、前のステップで生成しテストした実際のAPIキーに置き換えてください。
素晴らしい!AIワークフローはこの設定を使用して、mcpパッケージを経由してローカルのBright Data Web MCPサーバーに接続することができます。
ステップ #5: Google Gen AI SDK クライアント + MCP セッションの作成
.envファイルにGemini APIキーを追加することから始めます:
gemini_api_key="<your_gemini_api_key>"<YOUR_GEMINI_API_KEY>プレースホルダを実際のGemini APIキーに置き換えてください。
次に、Google Gen AI SDKクライアントを初期化し、MCP統合のセッションをセットアップします:
インポート asyncio
from mcp import ClientSession
from google import genai
from mcp.client.stdio import stdio_client
# Google Gen AI SDK クライアントの初期化
クライアント = genai.Client()
async def run():
# MCPクライアントコンテキストを初期化
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# AISDKクライアント・セッションを初期化します。
await session.initialize()
# MCP を統合した Google Gen AI SDK...
# asyncioのイベントループを開始し、メイン関数を実行する
asyncio.run(run())stdio_client()を介してセッションが開始される。その結果、 読み書きオブジェクトがClientSessionに渡され、MCP接続が確立される。このセッションは、すぐにGeminiのMCP統合のためにGoogle Gen AI SDKインスタンスに渡されます。
注意: このセットアップには非同期操作が含まれるため、asyncioが必要です。
よくできました!これで、クライアント経由でGeminiモデルにリクエストを送信し、必要に応じてMCPツールを呼び出すことができるようになりました。
ステップ#6: MCPツールとの統合を確認する
Bright Data Web MCPローカルサーバが公開しているツールが正しく利用可能であることを確認します。利用可能なツールをすべてリストアップします:
tools = await session.list_tools()次に、それらを表示します:
print(tools)スクリプトを実行すると(Proモードではありません)、次のようになります:
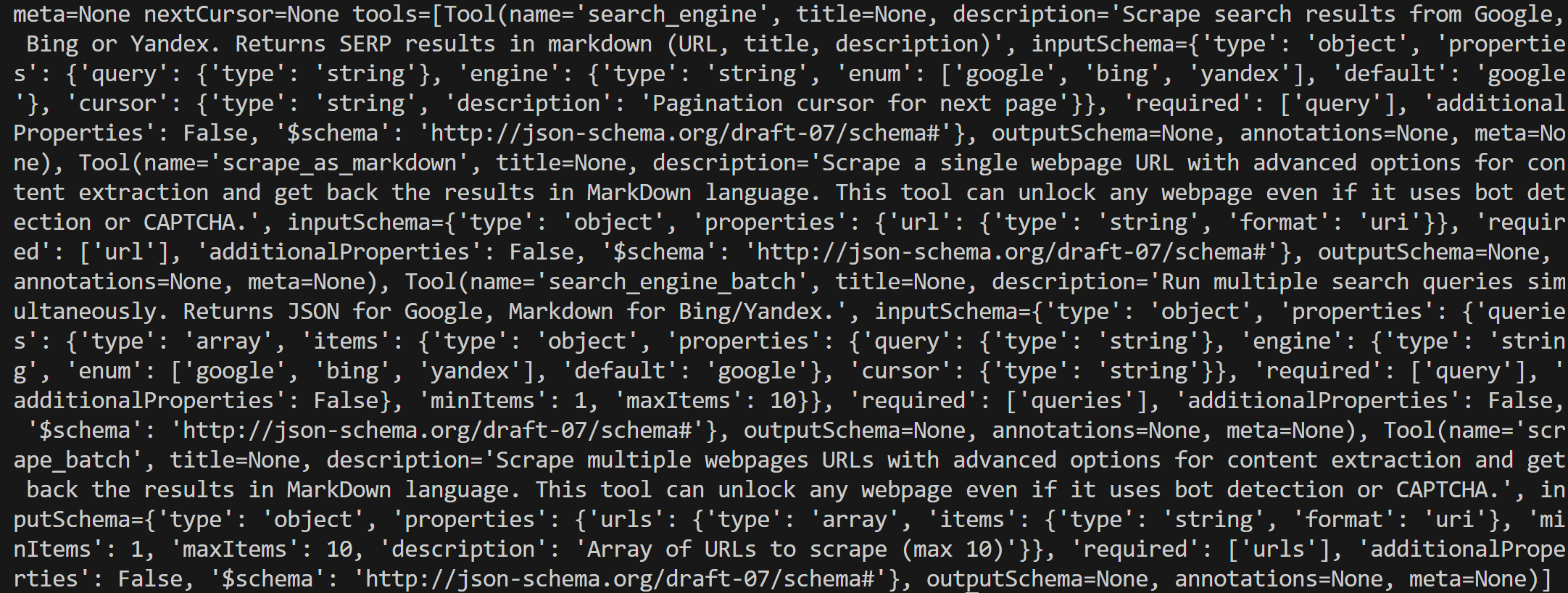
上記の出力は少し乱雑ですが、注意深く見てみると、以下のようにリストされていることがわかります:
search_engine: Google、Bing、Yandexの検索結果をスクレイピング。SERPの結果をMarkdown形式で返す(URL、タイトル、説明)。scrape_as_markdown:1つのウェブページを高度なオプションでスクレイピングし、コンテンツをMarkdownで返す。ボット検知やCAPTCHAがあっても機能する。search_engine_batch:複数の検索クエリを同時に実行する。GoogleにはJSON、Bing/YandexにはMarkdownを返す。scrape_batch:一度に複数のウェブページをスクレイピングし、高度なオプションを使って、結果をMarkdownで返します。バッチあたり10URLまでサポート。
これらはまさにWeb MCPの無料版で公開されているツールであり、統合が完璧に機能していることが確認できる!
ステップ #7: タスクの実行
これで、Bright DataのWeb MCPに接続可能なGoogle Gen AI SDKワークフローでタスクを実行するためのすべてのピースが揃いました。
特定のニュース記事(この例ではCNN)を参照するプロンプトを作成します。Geminiモデル(例:gemini-2.5-flash)に記事の内容をスクレイピングするよう依頼し、要約とセンチメント分析のコメントを返します:
prompt = """
以下のニュース記事の内容をMarkdownとしてスクレイピングする:
https://www.cnn.com/2026/09/15/tech/meta-future-ai-smart-glasses
そして、それを分析し、提供する:
1.50ワード程度の短い要約。
2.その記事がポジティブ、ネガティブ、ニュートラルのいずれであるかを示すセンチメント分析コメント。
"""プロンプトをclient.aio.models.generate_content()メソッドに渡し、Google Gen AI SDKを介して設定されたGeminiモデルに質問します:
# プロンプトをGeminiモデルに送る
response = await client.aio.models.generate_content(
model="gemini-2.5-flash"、
contents=prompt、
config=genai.types.GenerateContentConfig(
temperature=0, # より再現性の高い結果を得るために
tools=[session], # 設定されたMCPツールを自動的に呼び出せるようにする。
),
)
# AIからの応答を表示する
print(response.text)先ほど初期化したMCPセッションをtoolsパラメータに渡すことで、GeminiモデルはWeb MCPツールを自動的に呼び出すことができるようになります。詳細には、記事の内容をスクレイピングするには、scrape_as_markdownを使用します。
重要:gemini-2.5-flashモデルには寛大な制限があり、Bright Data Web MCPは無料ティアの下で動作するように設定されています。これは、ワークフローが完全に無料で動作するため、料金が発生しないことを意味します。
素晴らしい!あとは、センチメント分析AIワークフローをテストするだけです。
ステップ #8: 全てをまとめる
workflow.pyの最終的なコードは以下の通りです:
import asyncio
import os
from dotenv import load_dotenv
from mcp.client.stdio import stdio_client
from mcp import ClientSession, StdioServerParameters
from google import genai
# 環境変数を.envファイルから読み込む
load_dotenv()
# Bright Data APIキーをenvから読み込む
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# stdio 接続で Bright Data Web MCP に接続するための設定
server_params = StdioServerParameters(
command="npx"、
args=["-y", "@brightdata/mcp"]、
env={
"API_TOKEN":bright_data_api_key、
# "PRO_MODE":"true"(オプション。)
},
)
# Google Gen AI SDK クライアントの初期化
クライアント = genai.Client()
非同期 def run():
# MCPクライアントコンテキストを初期化
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# AISDKクライアント・セッションを初期化します。
await session.initialize()
# ニュース記事からセンチメント分析を取得するプロンプト
prompt = """
以下のニュース記事からコンテンツをMarkdownとしてスクレイピングする:
https://www.cnn.com/2026/09/15/tech/meta-future-ai-smart-glasses
そして、それを分析して提供する:
1.50ワード程度の短い要約。
2.その記事がポジティブ、ネガティブ、ニュートラルのいずれであるかを示すセンチメント分析コメント。
"""
# プロンプトをGeminiモデルに送る
response = await client.aio.models.generate_content(
model="gemini-2.5-flash"、
contents=prompt、
config=genai.types.GenerateContentConfig(
temperature=0, # より再現性の高い結果を得るために
tools=[session], # 設定されたMCPツールを自動的に呼び出せるようにする。
),
)
# AIからの応答を表示する
print(response.text)
# asyncioイベントループを開始し、メイン関数を実行する
asyncio.run(run())すごい!約50行のコードで、センチメント分析のためのAIワークフローを構築したことになる。これは、Bright Data Web MCPとGoogle Gen AI SDKなしには不可能だったでしょう。
スクリプトが動作することを
python workflow.pyスクリプトの実行には時間がかかるかもしれません。オンデマンドでサイトをスクレイピングし、AIで分析するには時間がかかるからです。
出力は以下のようになるはずです:
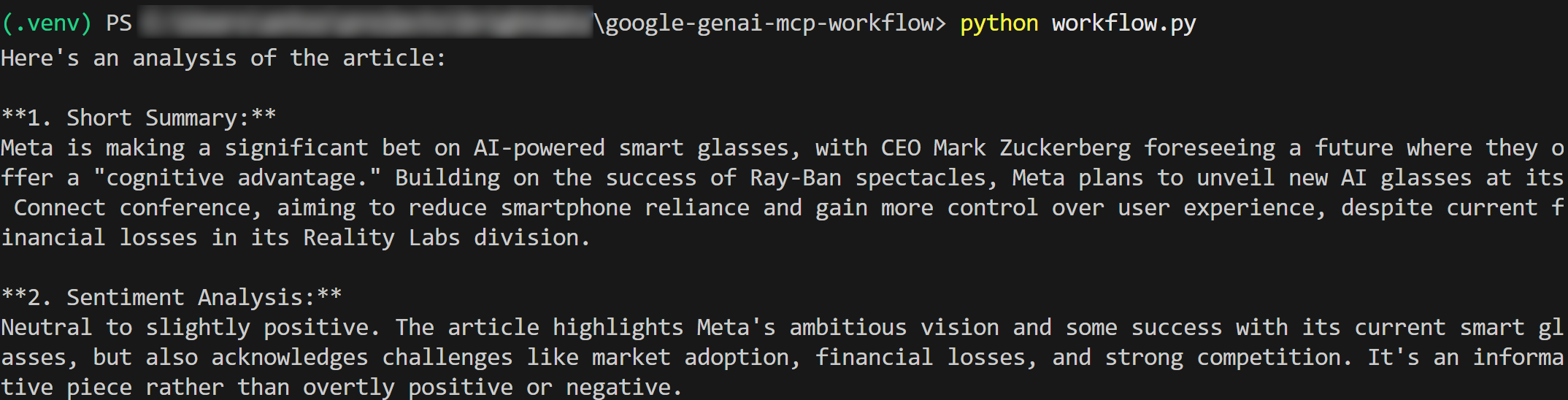
元のCNNのニュース記事で確認できるように、要約と感情分析の結果は正確です。
ニュースのスクレイピングは、特にCNNのような人気のあるサイトでは簡単ではないことに注意してください。そこでBright Data Web MCPサーバーが活躍し、ウェブデータ検索、インタラクション、検索のためのAI対応ソリューションの完全なツールキットを提供する。
これはほんの一例ですが、Gen AI SDKで利用可能な幅広いBright Dataツールを使えば、プロンプトを調整するだけで、実際のユースケースをカバーするワークフローを構築することができます。
出来上がり!GoogleのGen AIワークフローの中でBright Data Web MCPの統合のパワーを体験したことになります。
まとめ
このブログポストでは、Google Gen AI SDKをBright DataのWeb MCP(現在は無料版もあります!)に接続する方法をご紹介しました。その結果、ウェブデータの抽出とインタラクションのための複数のツールにアクセスできるAIワークフローが強化されました。
より複雑なAIエージェントを構築するには、Bright DataのAIインフラストラクチャで利用可能なすべての製品とサービスをご覧ください。これらのソリューションは、多様なAIワークフローとエージェントシナリオをサポートします。
今すぐ無料のBright Dataアカウントを作成し、当社のAI対応ウェブデータツールの実験を開始してください!






