
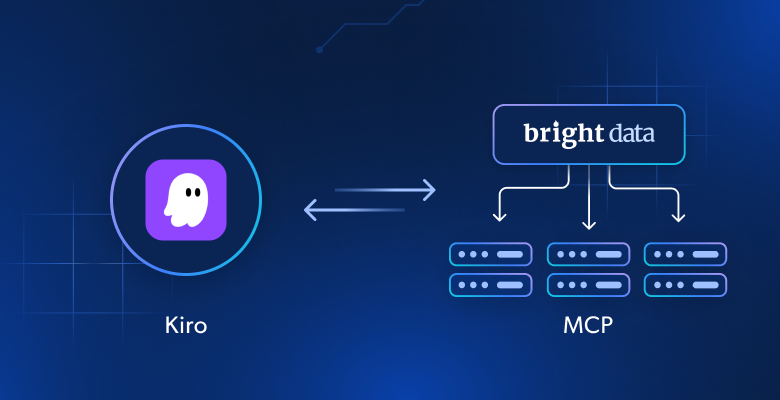
このチュートリアルでは、次のことを学びます:
- Kiroとは何か、その技術的能力。
- KiroをBright DataのWeb MCPサーバーに接続することで、静的なコードジェネレーターから、リアルタイムのデータを取得し、ボット対策を回避し、構造化された出力を生成できる動的なエージェントに変換する方法。
- Kiroを使用して、生の求人市場データをスクレイピングし、CSVファイルに整理し、分析スクリプトを生成し、洞察に満ちたレポートを作成するプロセス全体を自動化する方法。
GitHubのプロジェクトをご覧ください。
さあ、始めましょう!
Kiroとは?
KiroはAIを搭載したIDEであり、仕様主導の開発と自動化されたプロセスを使用することで、開発者の作業方法を変えます。コードを生成するだけの通常のAIコーディングツールとは異なり、Kiroは独自に動作し、コードベースをチェックし、複数のファイルを変更し、最初から最後まで完全な機能を構築します。
主な技術的能力
- 仕様主導のワークフロー:Kiroはプロンプトを明確な要件、技術設計、タスクに変換し、「バイブ・コーディング」を排除します。
- エージェントフック:ドキュメントの更新、テスト、コードの品質チェックを管理するバックグラウンドの自動タスク。
- MCPの統合:モデルコンテキストプロトコルのビルトインサポートにより、外部ツール、データベース、APIへの直接リンクが可能です。
- エージェントの自律性:ゴールにフォーカスした推論を使用して、マルチステップの開発タスクを実行します。
Anthropicのクロードモデルと共にVS Codeの基盤上に構築されたKiroは、使い慣れたワークフローを維持しながら、すぐに使える開発のための強力な構造を追加します。
Bright Data MCPサーバーでKiroを拡張する理由
Kiroのエージェント推論は強力ですが、そのLLMは古いトレーニングデータに依存しています。KiroをBright DataのWeb MCPサーバーに接続すると、これらの「凍結された」モデルはライブデータのエージェントに変わります。リアルタイムのウェブコンテンツにアクセスし、ボット対策防御を回避し、構造化された結果をKiroのワークフローに直接提供することができます。
| MCPツール | 使用方法 |
|---|---|
検索エンジン |
Google/Bing/Yandexの新鮮なSERP結果を取得し、即座に競合やトレンドの調査を行います。 |
スクレイプ_アズ_マークダウン |
読みやすいMarkdownを返す1ページのスクレイプ。 |
スクレイプ_バッチ |
複数URLの並列スクレイピング; 価格監視や一括チェックに最適 (タイムアウト時に単一ページツールにフォールバック) |
web_data_amazon_product |
アマゾンASINのタイトル、価格、評価、画像を含むクリーンなJSON。 |
どのように役立つのか
- リアルタイムの入力(価格、ドキュメント、ソーシャルトレンド)は、Kiroの生成された仕様とコードに直接流れ込みます。
- 自動的なアンチボット処理により、エージェントはスクレイピングの頭痛の種ではなく、開発ロジックに集中できます。
- 構造化された JSON レスポンスは、正規表現に煩わされることなく TypeScript/Python に直接取り込まれます。
Bright Data MCPが接続されていれば、Kiroのすべてのプロンプトは「ライブデータ」を重要な部分として使用することができ、静的なコード生成を完全ですぐに使用できるオートメーションに変えることができます。
KiroをBright DataのMCPに接続する方法
このガイドセクションでは、KiroをBright DataのWeb MCPサーバーにインストールして設定する方法を学びます。最終的な結果は、コーディングワークフロー内でリアルタイムのウェブデータに直接アクセスして処理できるAI開発環境となります。
具体的には、ウェブデータ機能を備えた拡張Kiroセットアップを構築し、それを使用して以下を行います:
- 複数のサイトからライブデータをスクレイピングする。
- 現在の市場情報に基づいて構造化された仕様を生成する。
- 開発環境内で収集したデータを処理し、分析します。
以下のステップに従って始めてください!
前提条件
このチュートリアルに従うには、以下が必要です:
- ローカルにインストールされたNode.js 18+(最新のLTSバージョンをお勧めします)
- Kiroへのアクセス(ウェイティングリストに参加して確認を受ける必要があります。)
- Bright Dataアカウント
Bright Dataアカウントをまだお持ちでない方もご安心ください。次のステップで設定方法を説明します。
ステップ#1: Kiroのインストールと設定
Kiroをインストールする前に、kiro.devのウェイティングリストに参加し、アクセスの確認を受ける必要があります。アクセスできたら、公式のインストールガイドに従ってください。
初回起動時には、ようこそ画面が表示されます。セットアップウィザードに従ってIDEを設定します。
ステップ2: Bright Data MCPサーバーのセットアップ
Bright Dataにアクセスし、Bright Dataアカウントを作成するか、既存のアカウントにログインします。
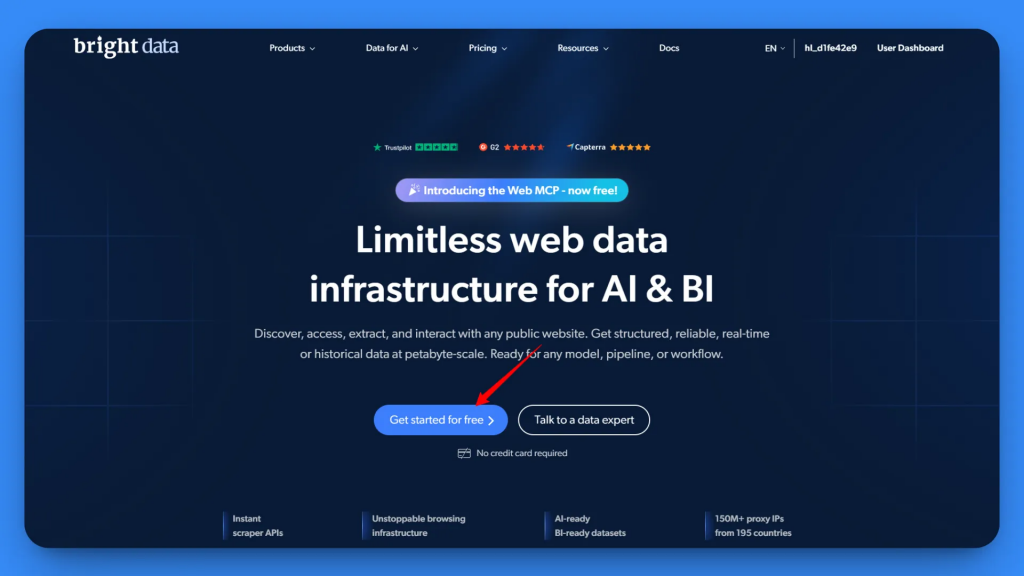
ログイン後、スタートページに移動します。左サイドバーからMCPセクションに移動します。
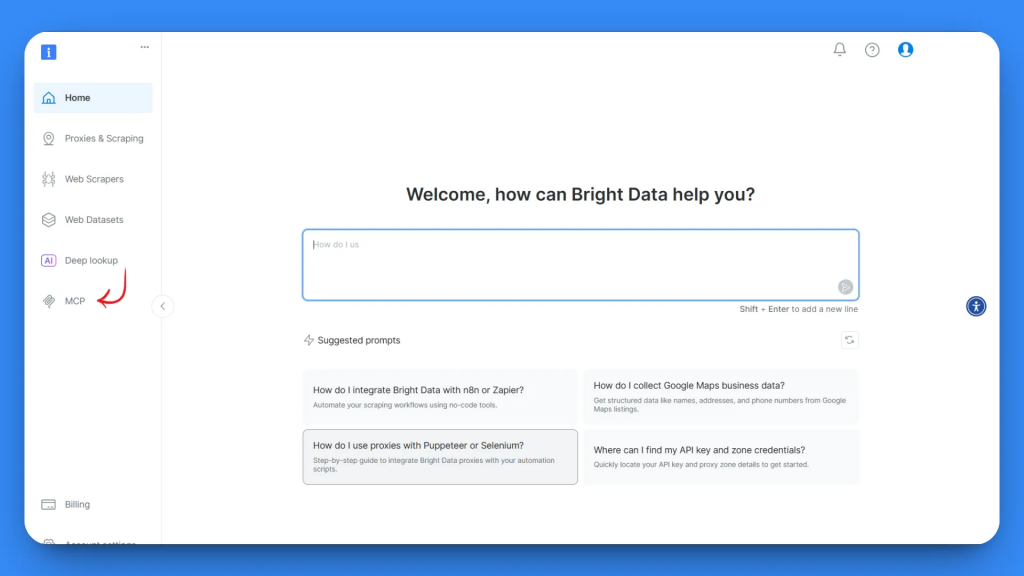
MCPの設定ページには、2つのオプションがあります:セルフホストとホスト型です。このチュートリアルでは、最大限のコントロールが可能なSelf-hostedオプションを使用します。
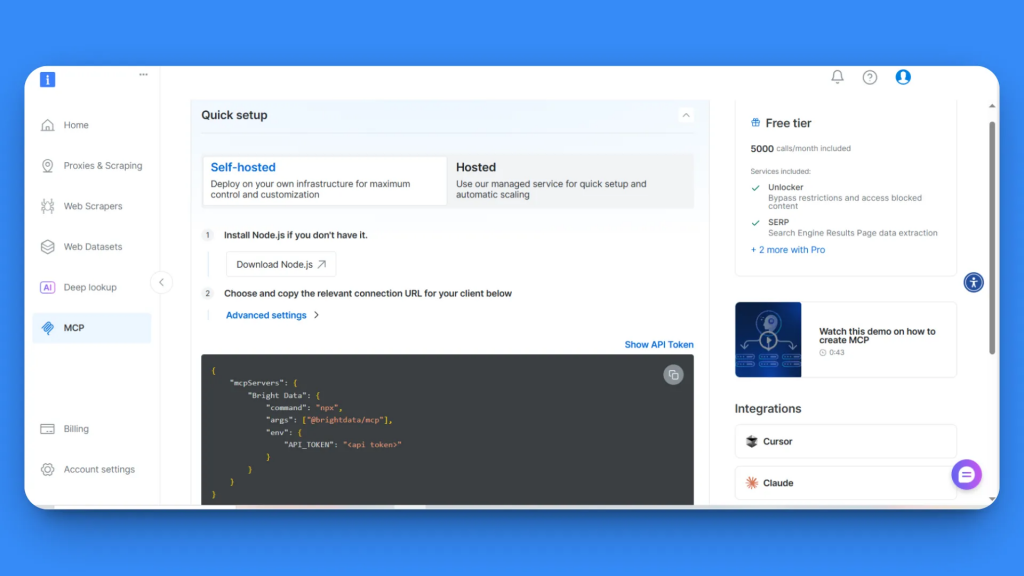
ステップ2で、APIキーとMCP設定コードブロックが表示されます。MCP設定コード全体をコピーしてください:
{
"mcpServers":{
"Bright Data":{
"command":"npx"、
"args": ["@brightdata/mcp"]、
"env":{
"API_TOKEN":"<APIトークン>"
}
}
}
}これには、必要なすべての接続の詳細とAPIトークンが含まれています。
ステップ #3: KiroでMCPを設定する
Kiroを開き、新しいプロジェクトを作成するか、既存のフォルダを開きます。
左側のサイドバーでKiroタブに移動します。4つのセクションが表示されます:
- SPECS
- エージェント・フック
- エージェント・ステアリング
- MCPサーバー
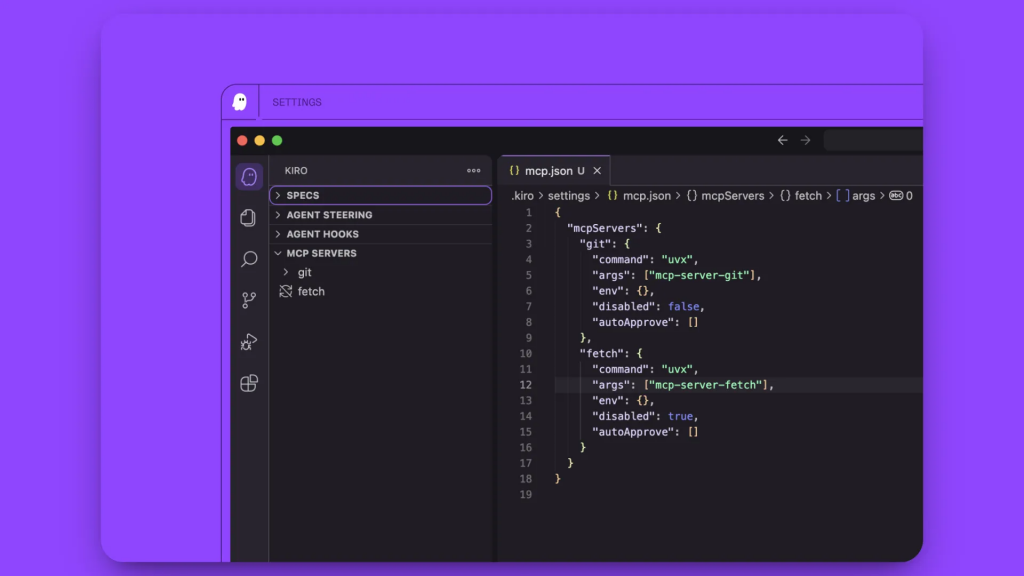
MCP SERVERSセクションをクリックしてください。設定済みのサーバーが1つ表示されますので、このデフォルトのサーバー設定を削除します。
Bright DataからコピーしたMCP設定コードを設定エリアに貼り付けて追加します。
Kiroが設定の処理を開始します。最初は、接続を確立する間、”Connecting… “または “Not Connected “ステータスが表示されるかもしれません。
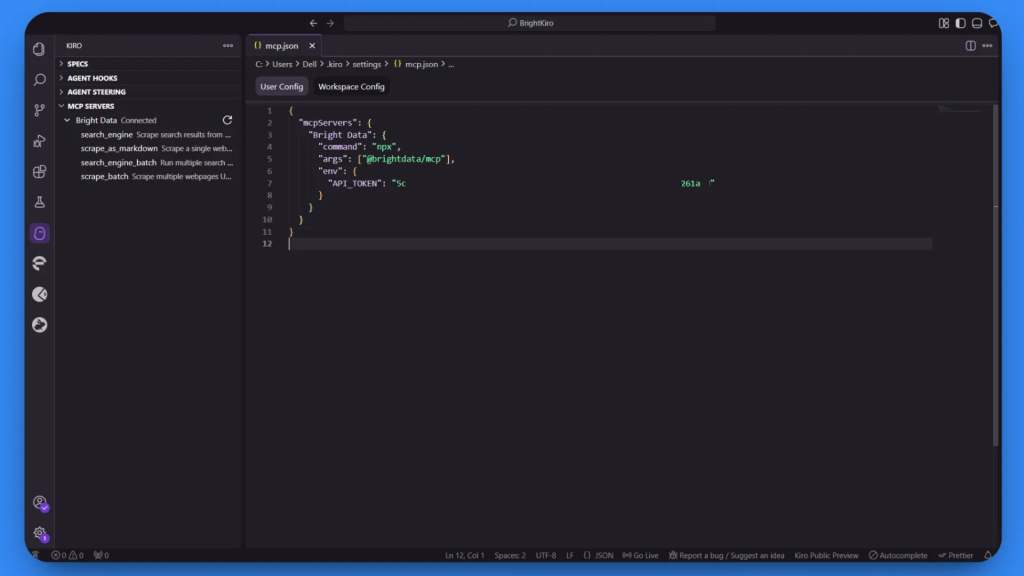
処理が正常に完了すると、ステータスが “Connected “に変わり、4つのMCPツールが使用可能になります:
search_engineスクレイプ_アス_マークダウンsearch_engine_batchスクレイプ_バッチ
ステップ#4: MCP接続の確認
統合をテストするには、サイドバーの利用可能なMCPツールのいずれかをクリックしてください。これにより、Kiroのチャット・インターフェースにツールが自動的に追加されます。
Enterキーを押してテストを実行します。Kiro は Bright Data MCP サーバーを通してリクエストを処理し、適切にフォーマットされた結果を返し、統合が正しく機能していることを確認します。
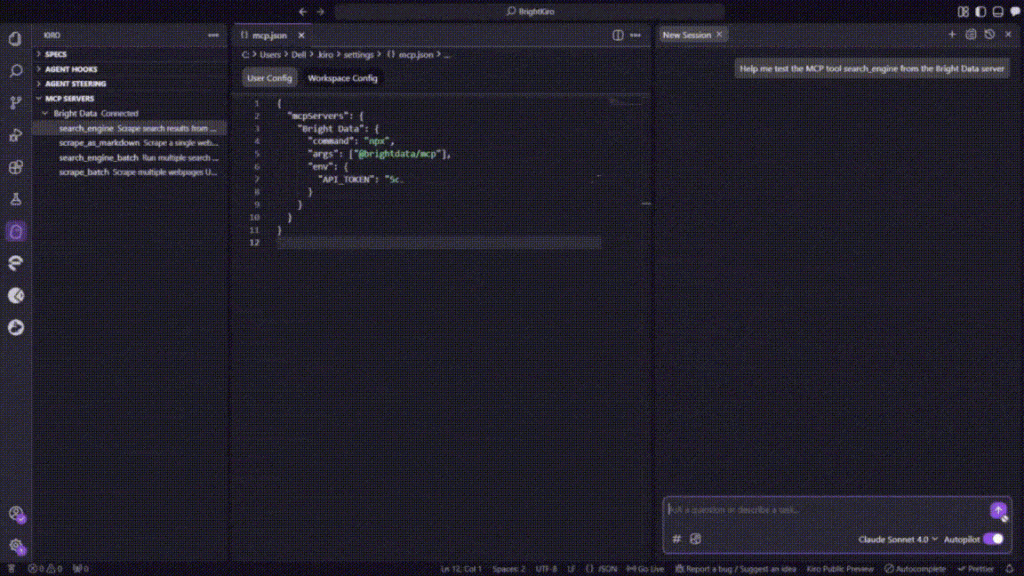
完璧です!Kiroのインストールは、MCP統合を通じてBright Dataのウェブスクレイピング機能にアクセスできるようになりました。自然言語プロンプトを使用して、開発内で直接あらゆる公開ウェブサイトからデータを抽出できるようになりました。
ステップ #5: Kiroで最初のMCPタスクを実行する
それでは、Kiro + Bright Data MCP統合を実用的なデータ収集タスクでテストしてみましょう。この例では、現在の求人市場データを収集し、それを自動的に処理する方法を示します。
テストプロンプト:
Googleで "remote React developer jobs "を検索し、上位5つの求人情報サイトをスクレイピングし、職種、企業、給与範囲、必要なスキルを抽出する。このデータでCSVファイルを作成し、平均給与と最も一般的な要件を分析するPythonスクリプトを生成する。これは、以下のような実際のユースケースをシミュレートします:
- 市場調査と給与ベンチマーク
- キャリアプランニングのためのスキルトレンド分析
- 採用チームの競争情報
このプロンプトをKiroのチャットインターフェースに貼り付け、Enterキーを押します。
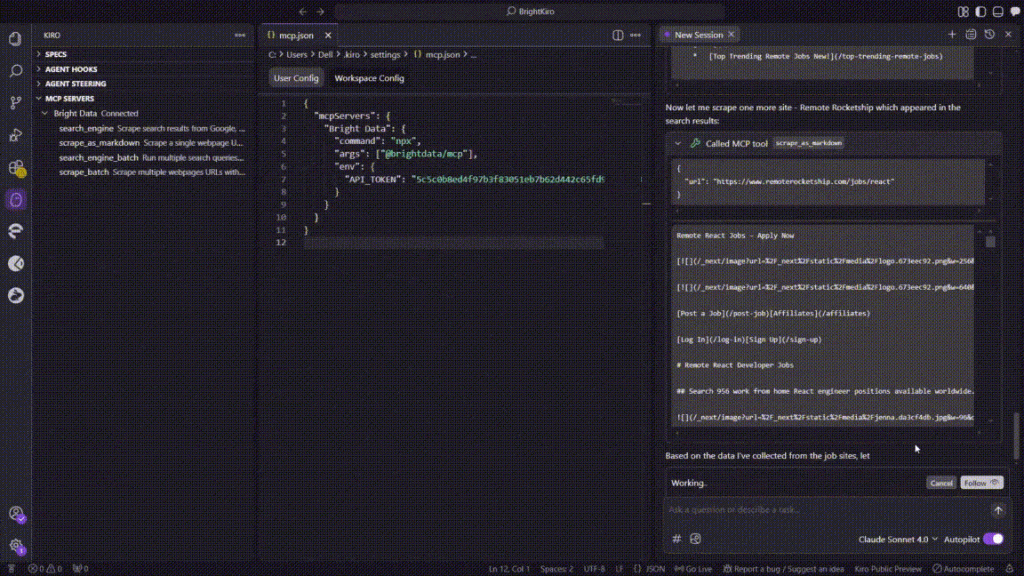
以下は、Kiroがこのタスクの実行中にたどった正確なシーケンスです:
- 検索段階
- Kiroは
search_engineMCPツールを呼び出し、Googleで「remote React developer jobs」をクエリしました。 - この呼び出しは、~3秒で求人掲示板のトップURLのリストを返しました。
- Kiroは
- バッチスクレイプの試み
- Kiroは一度に5つ全てのURLをプルするために
scrape_batchを呼び出した。 - バッチリクエストは60秒後にタイムアウトしたので、KiroはMCPエラー
(32001 Request timed out)を記録しました。
- Kiroは一度に5つ全てのURLをプルするために
- 単一ページスクレイピングへのフォールバック
- Kiroは
scrape_as_markdownに切り替え、各サイトを順次スクレイピングした:
- Indeed
- ZipRecruiter
- ウェルファウンド
- リモートワーク
- 各スクレイプは4-10秒で終了し、読みやすいMarkdownを返しました。
- Kiroは
- データの構造化
- 解析ルーチンは、職種、会社、給与、スキル、ソースフィールドを抽出した。
- Kiroはクリーニングされた行をメモリ内のテーブルに集約した。
- CSVファイルの作成
- Kiroはテーブルを
remote_react_jobs.csvとしてワークスペース内に保存しました。
- Kiroはテーブルを
- セッションのハンドオフ(コンテキストの継続)
- 元のチャットがKiroのコンテキストウィンドウを超えました。
- Kiroは新しいチャットセッションを開き、データの損失を避けるために以前のコンテキストを自動的にインポートしました。
- Python分析スクリプト生成
- 新しいセッションで、Kiroは
analyze_react_jobs.pyを作成しました:- CSVロードとクリーニング
- 給与/スキルサマリーロジック
- Matplotlib + Seabornのチャートコード
- スクリプトは
print("分析完了")で終わる。
- 新しいセッションで、Kiroは
BrightDataのMCPツールは、Kiroの自動処理に役立っています:
- 求人サイトのCAPTCHA解決とボット検出
- 異なるウェブサイトレイアウトからのデータ抽出
- 給与フォーマットとスキルリストの標準化
- ヘッダー付きの適切なCSV構造の作成
- バッチ処理でタイムアウトが発生した場合の適応的なスクレイピング戦略
ステップ #6: アウトプットの探索と使用
Kiroがタスクを完了すると、プロジェクトディレクトリに2つのメインファイルができます:
remote_react_jobs.csv:構造化された求人市場データを含むanalyze_react_jobs.py:データ分析と洞察のためのPythonスクリプト
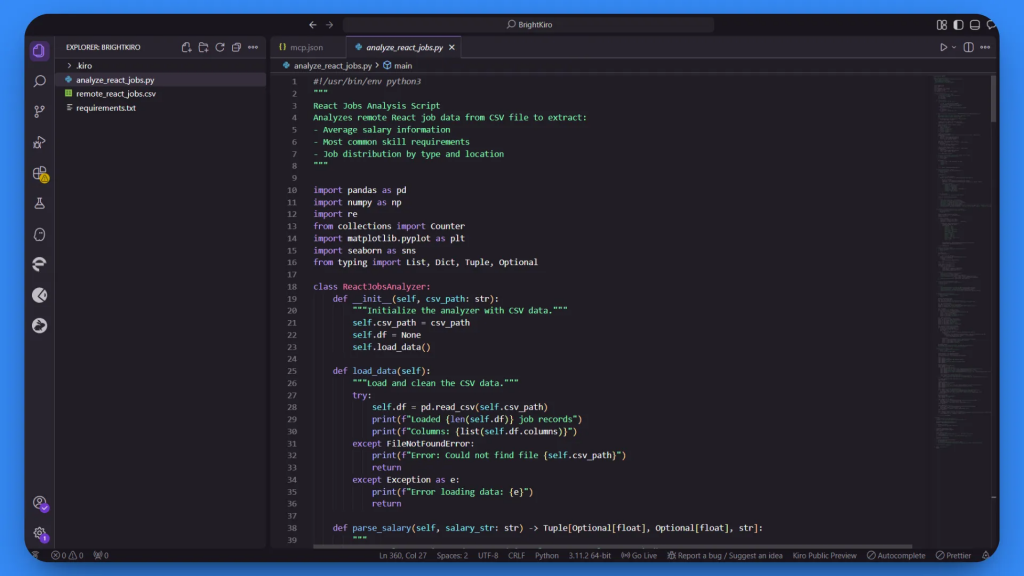
remote_react_jobs.csvファイルを開き、収集したデータを確認する:
CSVには以下のようなカラムがあり、実際の求人情報が含まれている:
- 職種名
- 会社名
- 給与範囲
- 必要なスキル
- ジョブボードのソース
このデータは、プレースホルダーのコンテンツではなく、実際の求人情報からのものです。Bright DataのMCPサーバーは、レイアウトやフォーマットの異なる複数の求人サイトから構造化された情報を抽出するという複雑なタスクを処理しました。
次に、生成されたanalyze_react_jobs.pyスクリプトを確認します。
このスクリプトには以下の関数が含まれています:
- CSVデータのロードとクリーニング
- 平均給与範囲を計算する
- 最も一般的な必須スキルを特定する
- 要約統計の作成
- ビジュアライゼーションと詳細レポートの作成
分析スクリプトを実行する前に、必要な依存関係をインストールします:
pip install -r requirements.txt次に分析スクリプトを実行して、詳細な洞察を得ます:
python analyze_react_jobs.pyスクリプトを実行すると、2つの追加ファイルが自動的に生成されます:
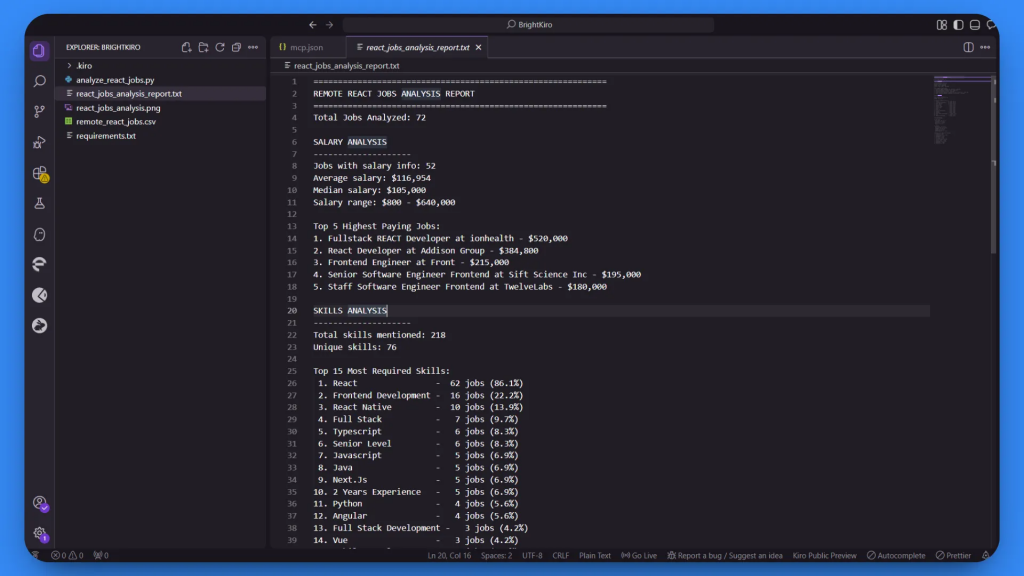
1.詳細テキストレポート (react_jobs_analysis_report.txt):
2.ビジュアル分析チャート(react_jobs_analysis.png):
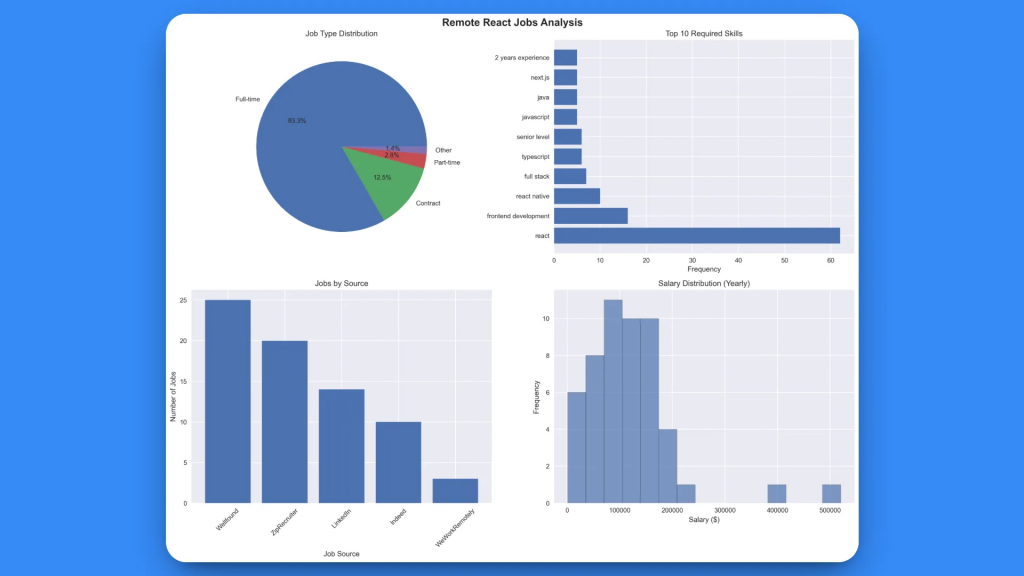
包括的な分析は、収集に成功した72のジョブに基づいています。
生成された視覚化によって、4つの重要な洞察が得られます:
- 職種分布:フルタイム、契約社員、パートタイムの明確な内訳
- 必要スキルトップ10:スキル需要の頻度を視覚的に表現
- ソース別の求人情報:プラットフォーム別の求人掲載量
- 給与分布:全職種の給与範囲を示すヒストグラム
これは、Kiroが自然言語による単純なリクエストを、完全なデータ収集と分析プロセスにどのように変えるかを示している。この統合は、バッチ操作がタイムアウトした場合の調整など、ウェブスクレイピングの問題を自動的に処理し、すぐに使えるコード、詳細なレポート、継続的な市場調査のためのプロフェッショナルなビジュアルを作成します。
まとめ
今回のチュートリアルは以上です。このブログでは、KiroをBright DataのWeb MCPサーバーと接続することで、Kiroをより良くする方法を学びました。これにより、ライブのウェブデータをスクレイピングし、AI開発のセットアップでリアルタイムの情報を処理することができます。
異なるソースからのリモートReactデベロッパージョブのスクレイピング、クリーニング、分析、可視化の実践的な例でこれを示しました。この完全な自動化は、KiroのAIとBright Dataの一流のスクレイピング・ツールを組み合わせることの強さを示している。
この統合を利用することで、開発者は静的なコード生成にとどまらず、製品開発をスピードアップし、精度を向上させる完全自動化されたデータ主導のワークフローを実現することができます。
今すぐBright Dataのアカウントを作成し、リアルタイムのウェブインテリジェンスを使用してAIエージェントをパワーアップさせましょう。





