
このブログ記事では、以下の内容を学びます:
- Stagehandとは何か、そしてブラウザ自動化において何を提供するか。
- Bright DataのBrowser APIが提供するクラウドベースのステルスブラウザセッションとStagehandを組み合わせるメリット。
- StagehandにBrowser APIを設定するためのステップバイステップガイド。
早速始めましょう!
Stagehandとは?
Stagehandは、Browserbaseが開発したオープンソースのブラウザ自動化フレームワークです。自然言語AIと決定論的コードを組み合わせており、脆弱なセレクターベースのツール(Playwrightなど)と予測不能なAIエージェントのトレードオフを、各アプローチをいつ使用するかを選択できるようにすることで解決します。
基盤となるLLMと制御された実行レイヤーを使用して、命令をブラウザアクションや構造化出力に変換することで動作します。StagehandはブラウザベースのAIエージェントの開発もサポートしています。
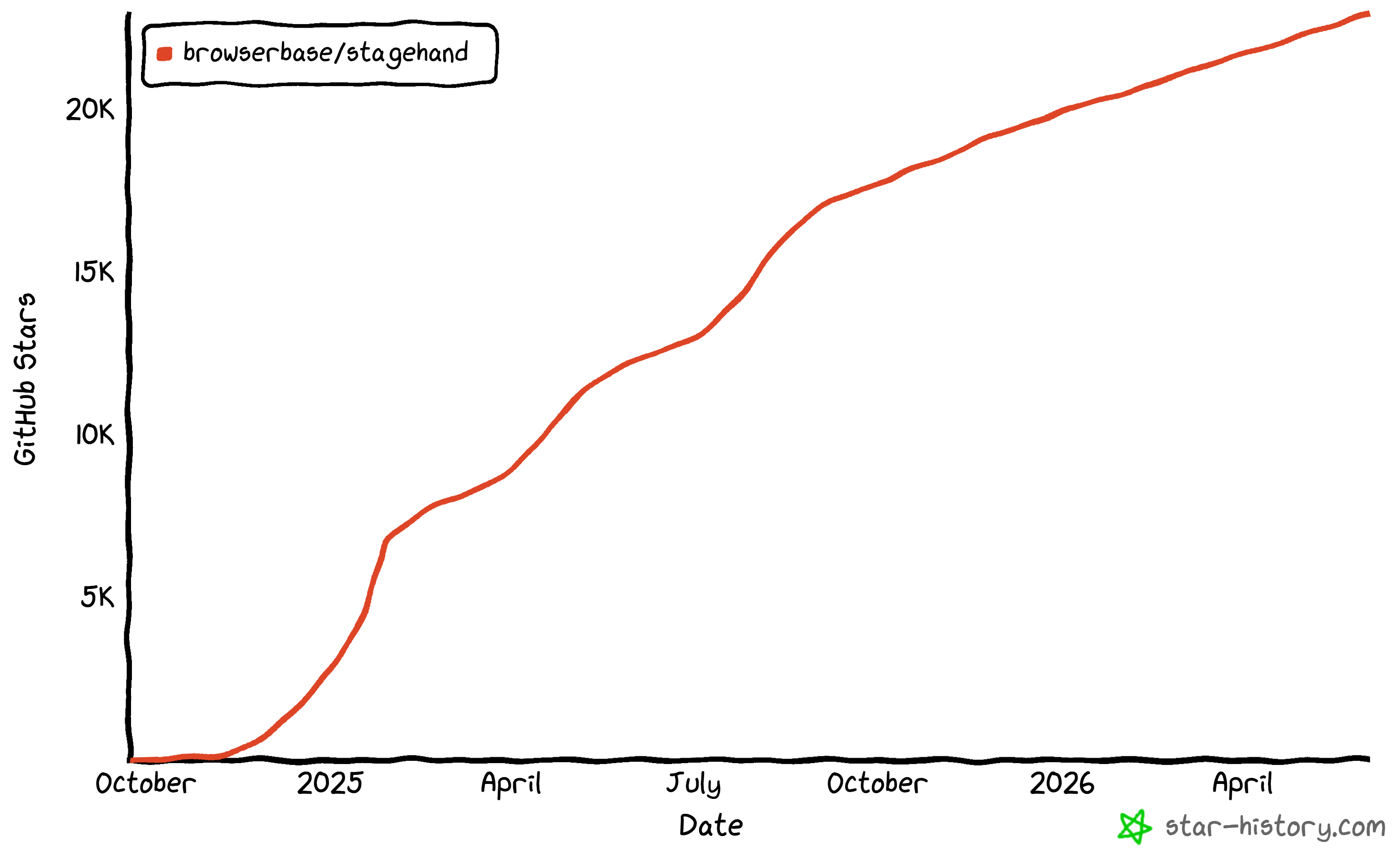
AIウェブスクレイピングツールとして機能させる機能も備えています。Stagehandは大規模な開発者コミュニティに支えられており、GitHubで22,900以上のスターとnpmで週100万以上のダウンロードを誇ります。
Stagehandの機能
Stagehandが提供する主な機能は次のとおりです:
act()実行:平易な英語のプロンプトを使用して、クリック、スクロール、フォーム入力などのブラウザアクションを実行します。extract()構造化データ:信頼性の高い下流利用のために、ページコンテンツを厳格なZod検証済みスキーマに抽出します。observe()ページ認識:操作を実行する前にページ上のアクション可能な要素を検出し、安全性と精度を向上させます。agent()自律ワークフロー:最小限の監視でマルチステップのブラウザタスクをエンドツーエンドで実行します。- 自己修復型自動化:UIの変更に適応し、脆弱なセレクターベースの障害を軽減します。
- アクションキャッシング:アクションをキャッシュすることで冗長なLLM呼び出しを回避し、複数回の実行にわたって高度に予測可能でコスト効率の高い実行を保証します。
- LLMの柔軟性:実行を決定論的かつデバッグ可能に保ちながら、複数のプロバイダーと連携します。
- コンポーザブルプリミティブ:act、extract、observe、agentを組み合わせてカスタム自動化パイプラインを構築します。
- 開発者向けツール:保守性、再現性、最新のAIシステムへの統合を重視して設計されています。
詳細は公式ドキュメントをご覧ください。
StagehandとBright DataのBrowser APIを組み合わせる理由
Stagehandのようなブラウザ自動化ツールは、同じ根本的な問題に直面します:
- ウェブサイトはボット検出システム、CAPTCHA、フィンガープリンティング、IPレピュテーションチェックを使用して自動化されたトラフィックを積極的にブロックします。これにより自動化が脆弱になり、テストでは機能するスクリプトが本番環境で予期せず失敗する場合があります。
- 多くのブラウザインスタンスをローカルまたは自己管理インフラで実行することはリソース集約的です。ブラウザは大量のCPUとメモリを必要とし、多くのインスタンスを同時に実行することはコストが高く、確実にスケールすることが困難です。
- プロキシと地理的分散の管理は運用上のオーバーヘッドを増加させます。時間の経過とともに、この複雑さは本番グレードのスクレイピングやAIエージェントのワークロードにとって維持が困難になります。
Bright DataのBrowser APIは、ローカルのブラウザ実行をスケールとステルスのために設計された完全マネージドのクラウドベースインフラにシフトすることで、これらの問題に対処します。
ブラウザをローカルで処理する代わりに、単一のCDPエンドポイントを介して接続できます。組み込みのプロキシローテーション、CAPTCHAの解決、高度なフィンガープリント回避を備えたリモートの事前設定済みブラウザにアクセスできます。
Bright Dataが際立っているのは、4億以上のレジデンシャルIPのプロキシネットワークに裏打ちされたエンタープライズグレードのアーキテクチャです。これにより、99.95%の成功率とSLAに裏付けられた99.99%の稼働時間を実現しながら、高い匿名性、グローバルな地理的ターゲティング、無限の同時実行が可能になります。
StagehandとBrowser APIの統合方法
この章では、Stagehandを使用してリモートブラウザインスタンスを自動化する方法を説明します。具体的には、Bright DataのBrowser APIを介してステルス性の高いアンチ検出の無限にスケーラブルなクラウドブラウザセッションに接続します。
以下の手順に従ってください。
前提条件
このチュートリアルセクションに沿って進めるために、以下が必要です:
- Node.js 20以上がローカルにインストールされていること(Node.js 22以上を推奨)。
- サポートされているStagehand AIプロバイダーのAPIキー(ここではOpenAI APIキーを使用します)。
- Bright Dataアカウント。
- Stagehand APIとそのAI駆動ブラウザ自動化機能の基本知識。
ステップ#1:Stagehandプロジェクトを初期化する
クイックスタートガイドに従って新しいStagehandプロジェクトを設定します。または、以下のコマンドを実行します:
npx create-browser-app bright-data-stagehand-examplenpx create-browser-appコマンドは、bright-data-stagehand-exampleディレクトリに新しいStagehandプロジェクトを作成します。
実行後、次のような結果が得られるはずです:
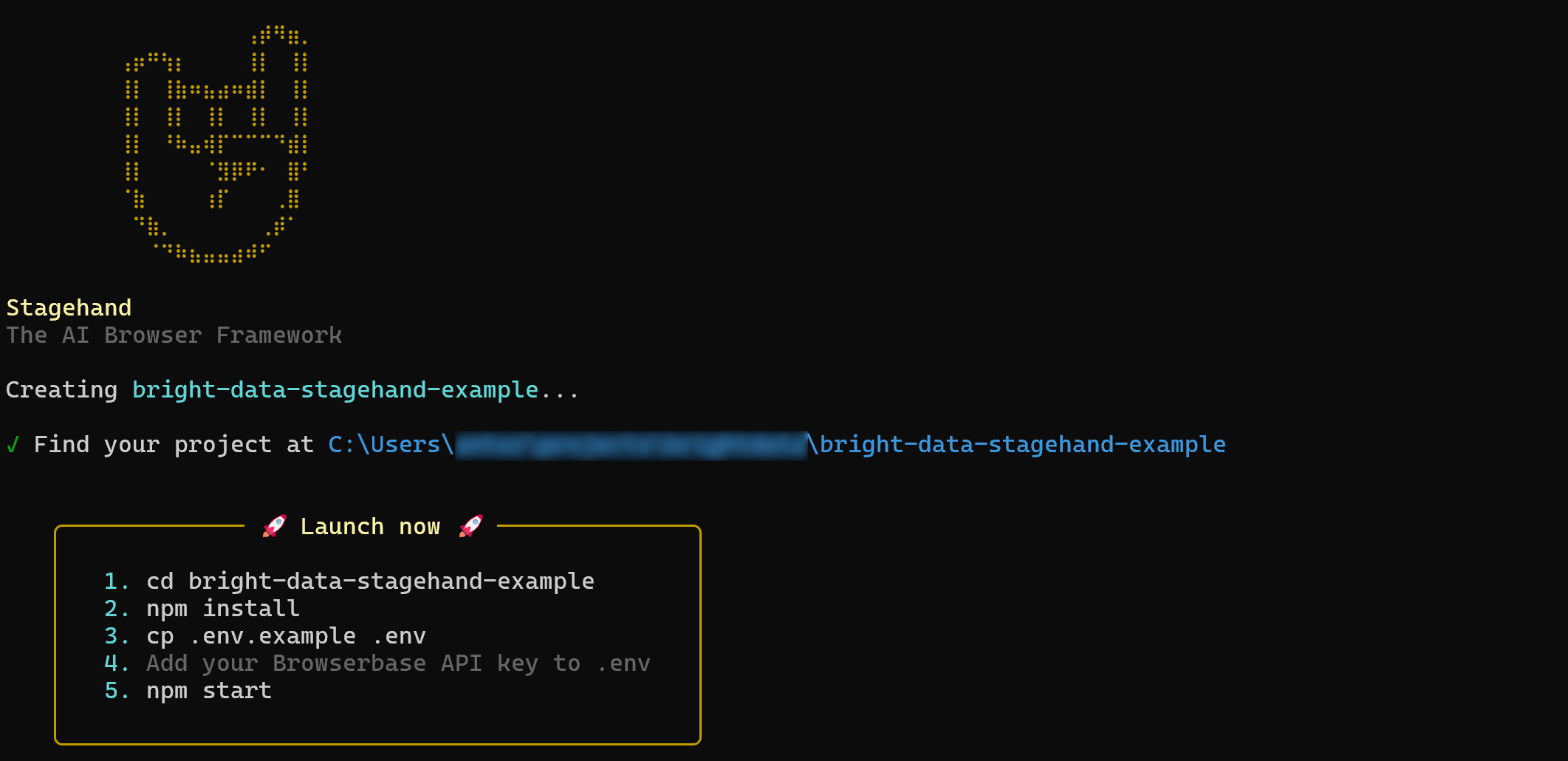
次に、プロジェクトディレクトリに入ります:
cd bright-data-stagehand-exampleプロジェクト構造は次のようになります:
bright-data-stagehand-example/
├── .cursorrules
├── .env.example
├── claude.md
├── index.ts
├── package.json
├── README.md
└── tsconfig.json数分かけて生成されたファイルを探索し、プロジェクト構造に慣れてください。Stagehandのメインファイルを表すindex.tsに注目してください。
次に、index.tsファイルを以下のみを残してクリーンにします:
import { Stagehand } from "@browserbasehq/stagehand";まもなく、StagehandをBright DataのBrowser APIに接続する方法を確認します。お疲れ様でした!
ステップ#2:環境変数の読み込みを設定する
Stagehandクラウド自動化プロジェクトは、いくつかのシークレット(AIプロバイダーのAPIキー、Bright Data Browser APIの認証情報など)に依存します。コードにハードコードする代わりに、環境変数から読み込むのがベストプラクティスです。
デフォルトでは、Stagehandは.envファイルを自動的に読み込みません。これを有効にするために、まずdotenvパッケージをインストールします:
npm install dotenv次に、index.tsに以下を追加します:
import dotenv from "dotenv";
dotenv.config({
path: ".env",
});次に、.envファイルを定義する必要があります。npx create-browser-appを実行したときに生成された.env.exampleファイルをコピーして作成できます。または、Stagehandプロジェクトに手動で.envファイルを追加します:
bright-data-stagehand-example/
├── .cursorrules
├── .env # <---------
├── .env.example
├── claude.md
├── index.ts
├── package.json
├── README.md
└── tsconfig.jsonAIプロバイダーのAPIキー(この場合はOpenAI)で.envファイルを設定します:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"<YOUR_OPENAI_API_KEY>プレースホルダーを実際のOpenAI APIキーに置き換えてください。
Stagehandは実行時にOPENAI_API_KEY環境変数を自動的に読み込むため、追加の設定は必要ありません。完璧です!
ステップ#3:Bright Data Browser APIを始める
Bright Data Browser APIのCDPベースのリモート接続URLを取得する時が来ました。
まだの場合は、Bright Dataアカウントを作成してください。既にお持ちの場合は、ログインしてコントロールパネルにアクセスします:
次に、左メニューから「Web Access > Web Access API」オプションに移動します:
「My APIs」テーブルに既にBrowser APIエントリが表示されている場合(以下のように、browser_api APIを介して)、準備完了です:
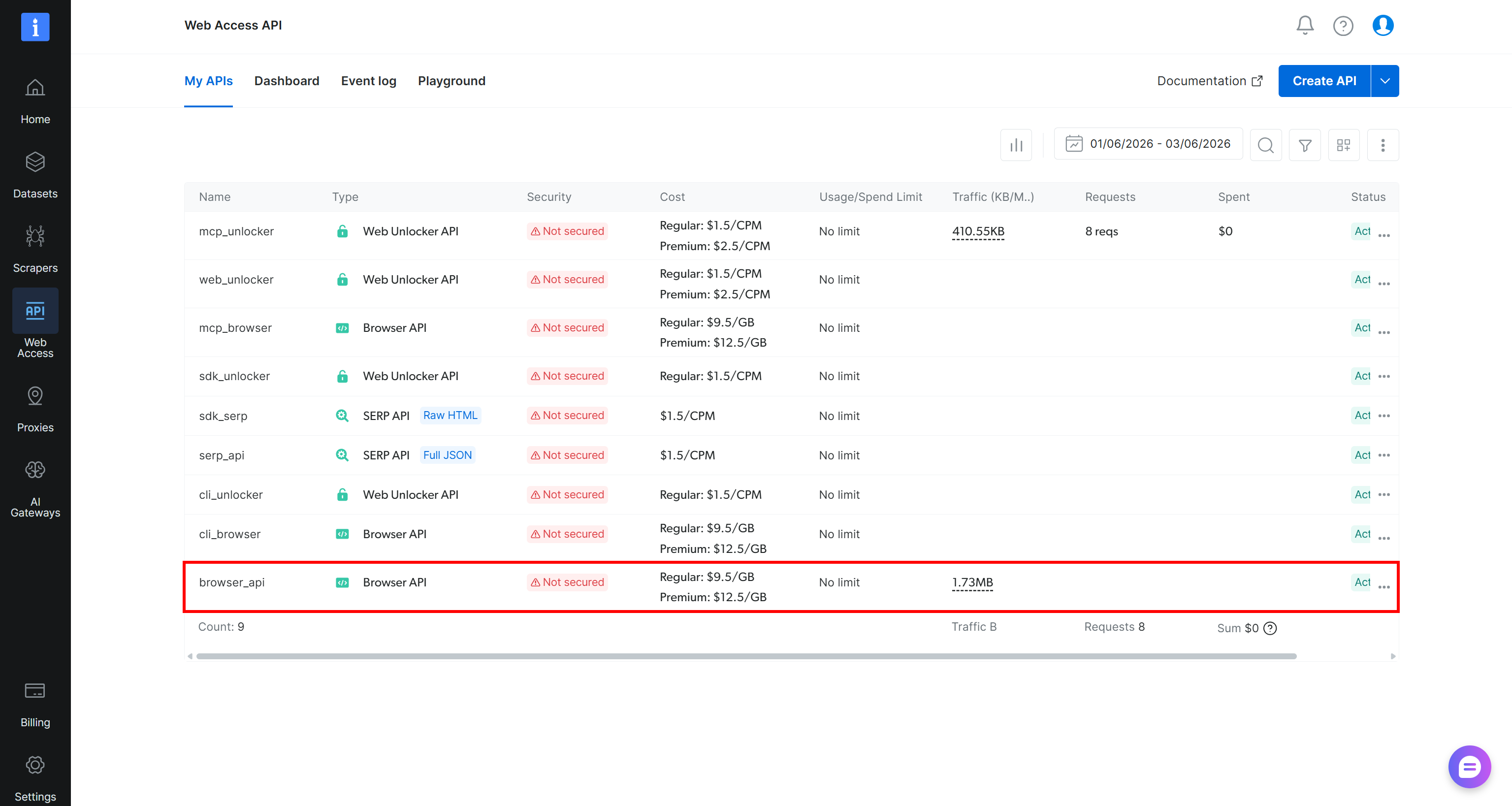
そうでない場合は、「Create API」ボタンのドロップダウンをクリックして「Browser API」を選択します:
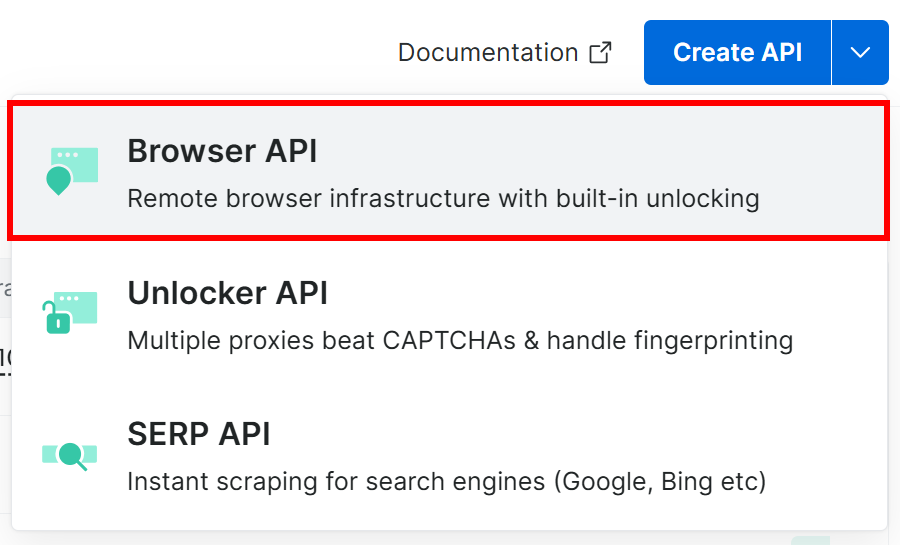
これでBrowser APIのセットアップウィザードが起動します。Browser APIに名前(例:browser_api)を付け、ニーズに合わせてAPIを設定します:
完了したら、「Add API」ボタンをクリックします。Browser APIの詳細ページに移動します:
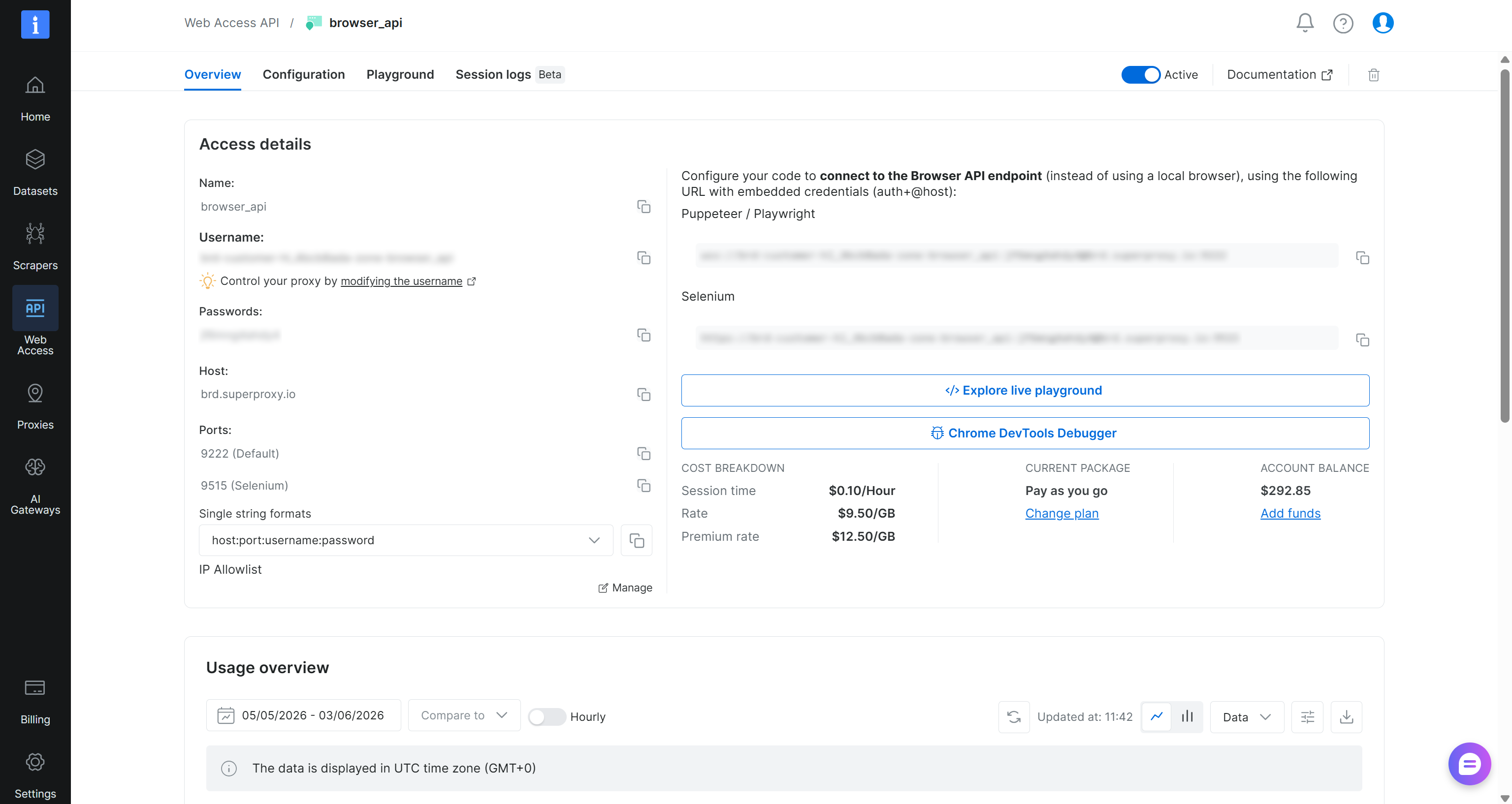
ここでは、CDPベースの統合の接続詳細(「Puppeteer / Playwright」の下のURL)が見つかります。Browser API WebSocket URLは次の形式に従います:
wss://<BROWSER_API_USERNAME>:<BROWSER_API_USERNAME>@brd.superproxy.io:9222Browser APIページからBrowser APIのユーザー名とパスワードをコピーして、.envファイルに追加します:
BRIGHT_DATA_BROWSER_API_USERNAME="<BROWSER_API_USERNAME>"
BRIGHT_DATA_BROWSER_API_PASSWORD="<BROWSER_API_PASSWORD>"後でこれらの変数をindex.tsでリモートCDP接続URLを構築するために使用します。
これで、Bright Data Browser APIを介したStagehandによるクラウドブラウザ自動化に必要なすべての構成要素が揃いました。素晴らしい!
ステップ#4:StagehandでBright Data Browser APIに接続する
index.tsで、環境変数からBrowser APIの認証情報を読み込むことから始めます:
const BRIGHT_DATA_BROWSER_API_USERNAME = process.env.BRIGHT_DATA_BROWSER_API_USERNAME || "";
const BRIGHT_DATA_BROWSER_API_PASSWORD = process.env.BRIGHT_DATA_BROWSER_API_PASSWORD || "";次に、CDP WebSocket URLを介してBright Data Browser APIに接続するために、main()関数内でStagehandを初期化します:
async function main() {
// Bright DataのBrowser APIにリモートで接続し、
// OpenAIモデルを使用するようにStagehandを設定する
const stagehand = new Stagehand({
env: "LOCAL",
localBrowserLaunchOptions: {
cdpUrl: `wss://${BRIGHT_DATA_BROWSER_API_USERNAME}:${BRIGHT_DATA_BROWSER_API_PASSWORD}@brd.superproxy.io:9222`,
},
model: "openai/gpt-5.4-mini",
});
// Stagehandを起動してブラウザページを取得する
await stagehand.init();
const page = stagehand.context.pages()[0];
// ブラウザ自動化ロジック...
// Stagehandインスタンスを閉じてブラウザリソースを解放する
await stagehand.close();
}
main().catch(console.error); 上記のスニペットは、環境変数から読み込んだ認証情報を使用して構築された認証済みBrowser API WSSのURLでStagehandを設定します。次に、リモートブラウザセッションを起動し、自動化のためのページオブジェクトを公開します。自動化ロジックを実行した後、セッションをシャットダウンしてすべてのリモートブラウザリソースを解放します。
上記の例では、OpenAI GPT-5.4 Miniを設定しました。他のOpenAIモデル(またはサポートされているAIプロバイダーの設定)も機能することに注意してください。
重要な部分はStagehandコンストラクタにあります。リモートブラウザに接続するためにenvを"LOCAL"に設定する必要があるため、設定が最初は少し紛らわしく見えるかもしれません。次に、localBrowserLaunchOptions内で、cdpUrlフィールドを介してBright Data Browser API WSSのURLを提供する必要があります。
したがって、envが"LOCAL"に設定されていても、Stagehandは実際にはBright Dataのリモートなアンチ検出クラウドブラウザインスタンスに接続しています。
これで、すべてが正しく機能していることを確認するために、簡単な例で統合をテストできます。
ステップ#5:Bright Data Browser API統合を確認する
Browser APIとの統合が機能することを確認するために、次の自動化ロジックを試してください:
// example.comページに接続する
await page.goto("https://example.com");
// ページのスクリーンショットを撮る
await page.screenshot({
path: "screenshot.png",
type: "png",
fullPage: false,
});これは、リモートブラウザ(Bright Data Browser APIを介して公開される)にexample.comを開いてスクリーンショットを撮るよう指示します。
すべてをまとめます:
// index.ts
import { Stagehand } from "@browserbasehq/stagehand";
import dotenv from "dotenv";
// .envファイルから環境変数を読み込む
dotenv.config({
path: ".env",
});
// Bright Data Browser APIの認証情報を読み込む
const BRIGHT_DATA_BROWSER_API_USERNAME = process.env.BRIGHT_DATA_BROWSER_API_USERNAME || "";
const BRIGHT_DATA_BROWSER_API_PASSWORD = process.env.BRIGHT_DATA_BROWSER_API_PASSWORD || "";
async function main() {
// Bright DataのBrowser APIにリモートで接続し、
// OpenAIモデルを使用するようにStagehandを設定する
const stagehand = new Stagehand({
env: "LOCAL",
localBrowserLaunchOptions: {
cdpUrl: `wss://${BRIGHT_DATA_BROWSER_API_USERNAME}:${BRIGHT_DATA_BROWSER_API_PASSWORD}@brd.superproxy.io:9222`,
},
model: "openai/gpt-5.4-mini",
});
// Stagehandを起動してブラウザページを取得する
await stagehand.init();
const page = stagehand.context.pages()[0];
// example.comページに接続する
await page.goto("https://example.com");
// ページのスクリーンショットを撮る
await page.screenshot({
path: "screenshot.png",
type: "png",
fullPage: false,
});
// Stagehandインスタンスを閉じてブラウザリソースを解放する
await stagehand.close();
}
main().catch(console.error);スクリプトを実行します:
npm run startターミナルには、次のようなログが表示されるはずです:

重要:ログに「connecting to local browser」と表示される場合があります。これは必須のenv: "LOCAL"設定によるものです。ただし、実際の接続はBright Dataのリモートなbrowser APIに対して行われています。
実行が完了すると、プロジェクトディレクトリにscreenshot.pngファイルが表示されます:
bright-data-stagehand-example/
├── .cursorrules
├── .env
├── .env.example
├── claude.md
├── index.ts
├── package.json
├── README.md
├── screenshot.png # <---------
└── tsconfig.jsonscreenshot.pngを開くと、レンダリングされたexample.comページが表示されるはずです:
これにより、Stagehandがターゲットサイトに正常に接続し、期待どおりにブラウザ自動化を実行したことが確認されます。
Bright Data Browser APIが使用されたことを確認するには、Bright Dataダッシュボードを確認してください:
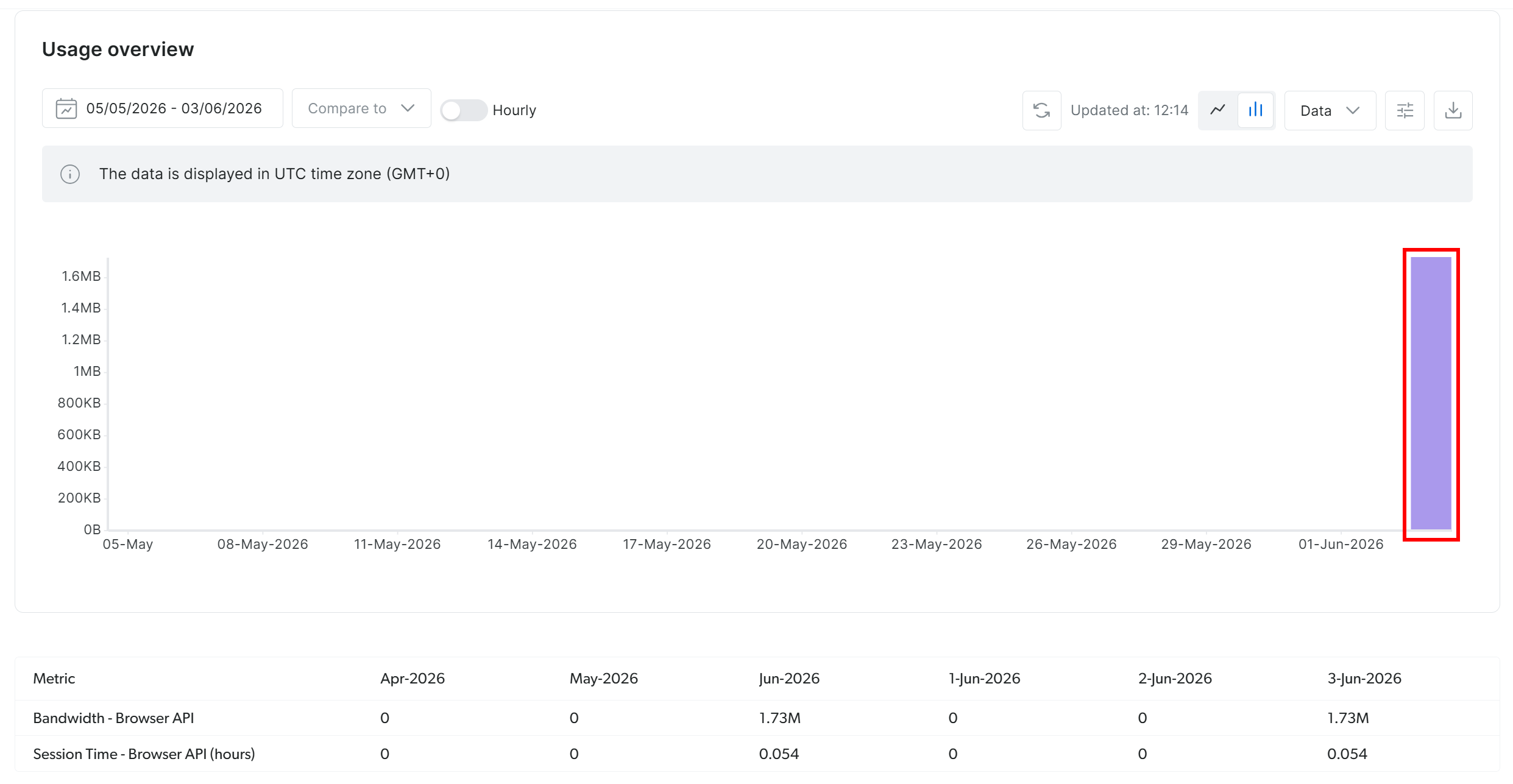
リモートCDP接続を介して設定されたBrowser APIセッションからのアクティブな使用を示すトラフィックのスパイクが表示されるはずです。これにより、すべてのStagehand自動化がBright DataのBrowser APIを通じて正しくルーティングされていることが確認されます。素晴らしい!
ステップ#6:実世界のAI駆動リモートブラウザ自動化を実装する
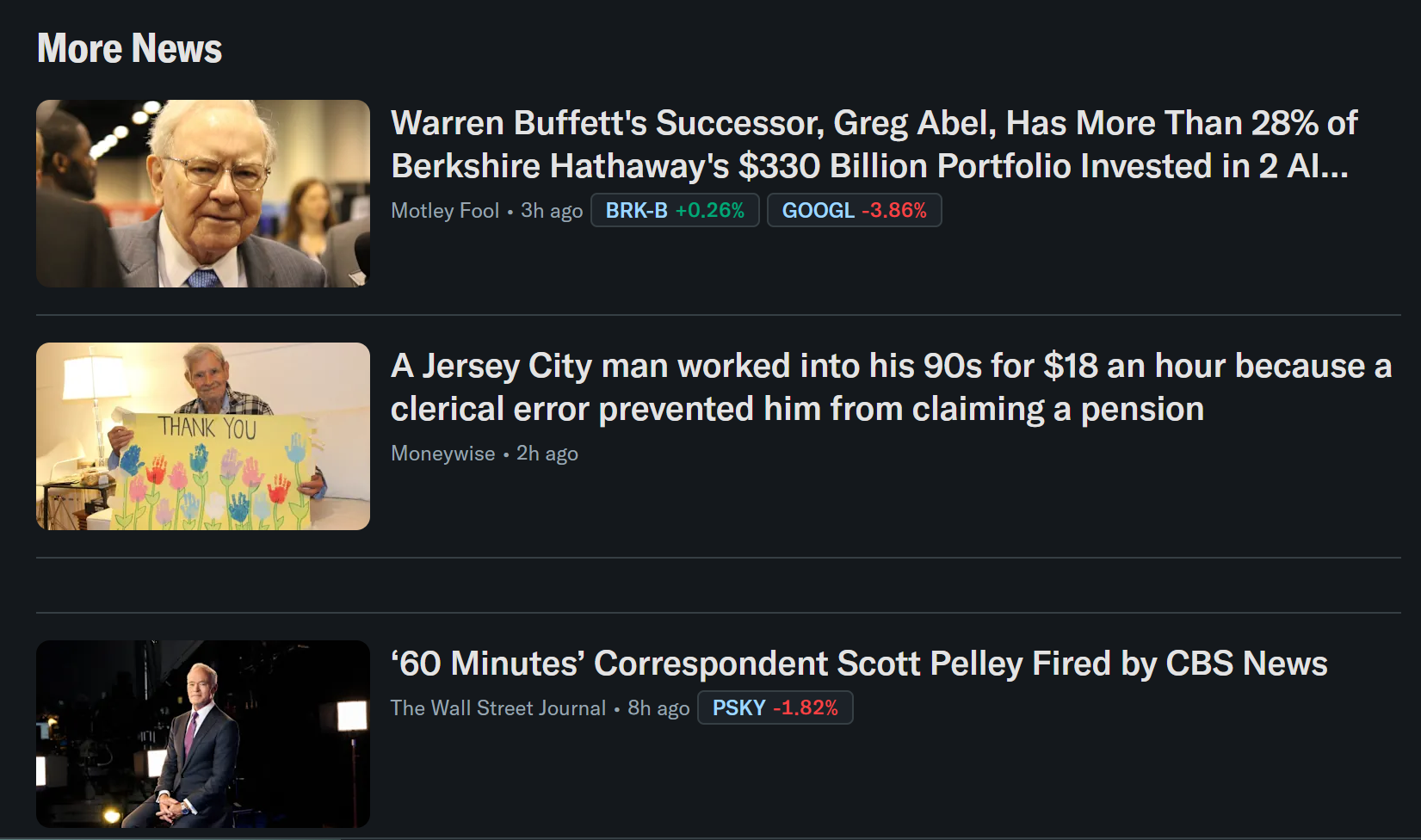
次に、Yahoo Financeからニュース記事データを収集するブラウザロジックを自動化したいとします。
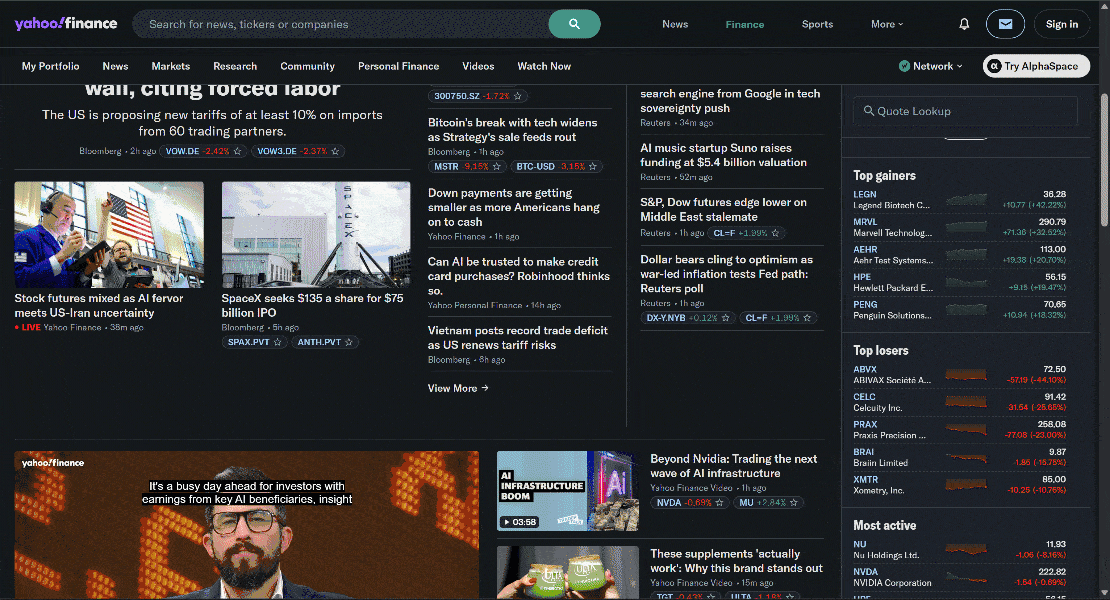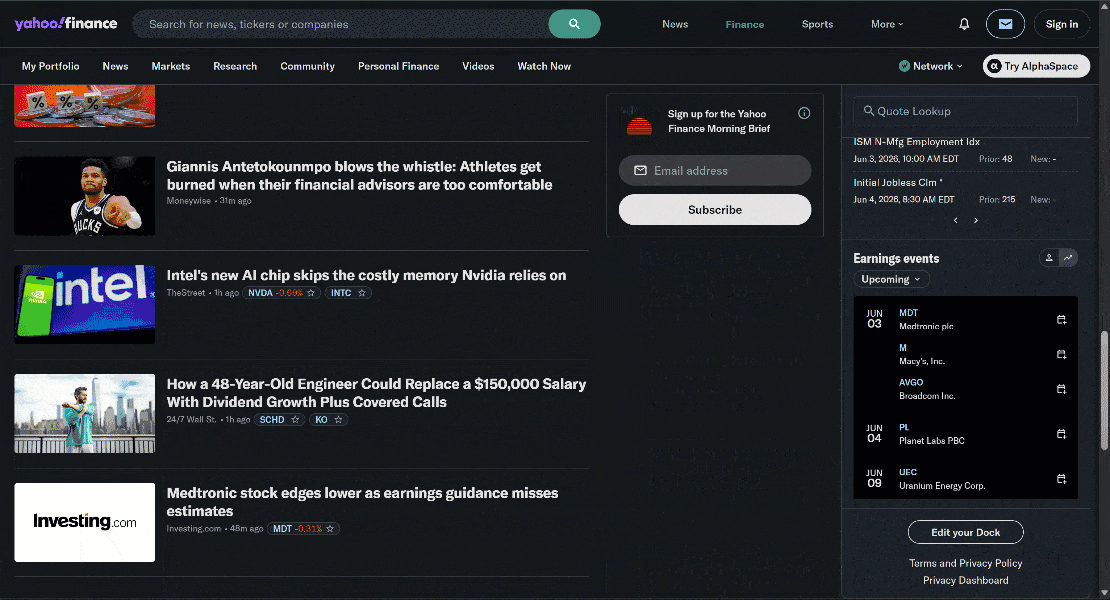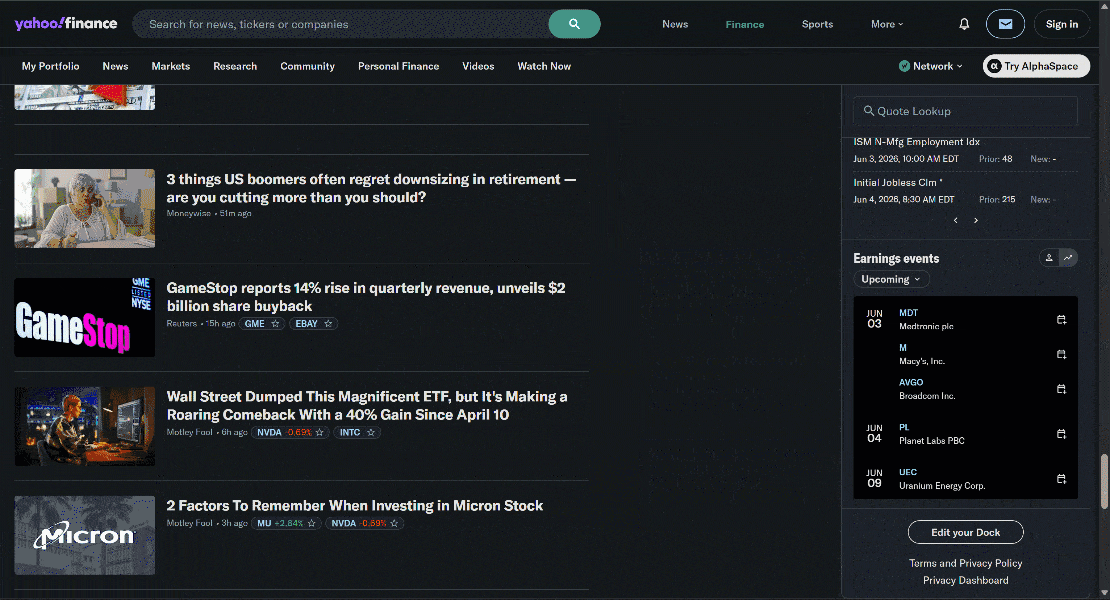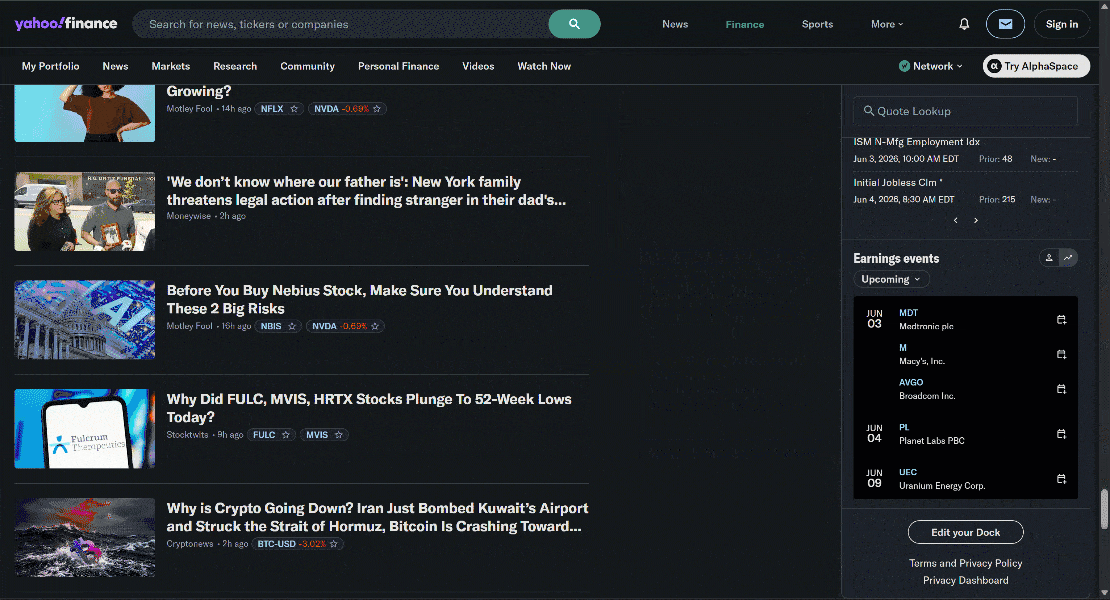
これは良い例です。なぜなら、Yahoo Financeホームページは無限スクロールを使用して新しい記事を動的に読み込み、厳格なアンチボットおよびアンチスクレイピング保護で知られているサイトだからです。
Browser APIが提供するステルスおよびアンチボットバイパス機能のおかげで、ブロックされることなくStagehandを介してYahoo Financeにアクセスできます。
スクレイピングされたデータが特定の構造に従うようにしたいので、まずZodで出力データ型を定義します:
import { z } from "zod";
// ...
// 構造化出力スキーマ
const YahooFinanceNewsSchema = z.object({
news: z.array(
z.object({
title: z
.string()
.describe("ニュース記事の見出しテキスト"),
articleUrl: z
.string()
.describe("完全な記事URL"),
imageUrl: z
.string()
.describe("完全な画像URL"),
source: z
.string()
.optional()
.describe("ReutersやYahoo Financeなどの発行元名"),
timestamp: z
.string()
.optional()
.describe("「4h ago」などの表示される公開時刻"),
marketMoves: z
.array(
z.object({
ticker: z
.string()
.describe("NVDAや^GSPCなどの株式ティッカーシンボル"),
changePercent: z
.string()
.optional()
.describe(
"「+2.4%」や「-0.69%」などの表示される市場の変化率"
),
})
)
.optional()
.describe(
"記事フッターに記載された株式ティッカーとその変化率のリスト"
),
})
),
});これはスクレイピングされたデータの期待される出力構造を定義します。特に、Yahoo Financeのニュースカードで利用可能な情報に一致します:
npx create-browser-appでStagehandアプリを初期化した場合、zodを手動でインストールする必要はありません。プロジェクトの依存関係に既に含まれています。そうでない場合は、次のコマンドでインストールします:
npm install zod これで、ブラウジングと抽出フローを自動化できます:
// ニュース記事の読み込みを自動化する
await stagehand.act(
`「More News」セクションで記事が読み込まれるまで複数回スクロールダウンして待機します。少なくとも20のニュース記事が読み込まれるまで繰り返します。`,
{
timeout: 90000, // 90秒タイムアウト
}
);
// ニュース情報をスクレイピングする
const data = await stagehand.extract(
`すべての表示されているニュース記事をスクレイピングする`,
YahooFinanceNewsSchema,
{
"timeout": 120000, // 120秒タイムアウト
}
);これは、AI命令によって駆動されながら、より多くの記事を読み込むためにページをスクロールする実際のユーザーの動作を再現します。次に、AI駆動の構造化抽出を使用して、ページコンテンツを定義されたスキーマに変換します。
自動化スクリプトが2つのStagehand AI駆動APIに依存していることに注目してください:
.act():ブラウザセッションでアクションを実行します(例:スクロール、クリック、ナビゲーション).extract():スキーマを使用してページから構造化データを抽出します
素晴らしい!次のステップはスクレイピングされたデータをエクスポートすることです。
ステップ#7:スクレイピングされたデータを抽出する
この時点で、スクレイピングされたデータは既にstagehand.extract()によって返されたdataオブジェクトに格納されています。最終ステップは、後で再利用または処理できるようにnews.jsonファイルにエクスポートすることです。
Node.jsのネイティブfs/promises APIを使用してそれを実現します:
import fs from "fs/promises";
// ...
// 抽出したニュースをJSONファイルに保存する
await fs.writeFile(
"news.json",
JSON.stringify(data.news, null, 2),
"utf-8"
);これにより、クリーンで読みやすい形式の構造化ニュースデータを含むnews.jsonファイルが書き込まれます。
ミッション完了!Browser APIをブラウザAIエージェントとして使用するStagehandスクレイピングワークフローが完全に実装されました。
ステップ#8:すべてをまとめる
StagehandでYahoo Financeスクレイピングを自動化するための最終的なindex.tsスクリプトは次のようになります:
import { Stagehand } from "@browserbasehq/stagehand";
import dotenv from "dotenv";
import { z } from "zod";
import fs from "fs/promises";
// .envファイルから環境変数を読み込む
dotenv.config({
path: ".env",
});
// Bright Data Browser APIの認証情報を読み込む
const BRIGHT_DATA_BROWSER_API_USERNAME = process.env.BRIGHT_DATA_BROWSER_API_USERNAME || "";
const BRIGHT_DATA_BROWSER_API_PASSWORD = process.env.BRIGHT_DATA_BROWSER_API_PASSWORD || "";
// 構造化出力スキーマ
const YahooFinanceNewsSchema = z.object({
news: z.array(
z.object({
title: z
.string()
.describe("ニュース記事の見出しテキスト"),
articleUrl: z
.string()
.describe(
"完全な記事URL"
),
imageUrl: z
.string()
.describe(
"完全な画像URL"
),
source: z
.string()
.optional()
.describe("ReutersやYahoo Financeなどの発行元名"),
timestamp: z
.string()
.optional()
.describe("「4h ago」などの表示される公開時刻"),
marketMoves: z
.array(
z.object({
ticker: z
.string()
.describe("NVDAや^GSPCなどの株式ティッカーシンボル"),
changePercent: z
.string()
.optional()
.describe(
"「+2.4%」や「-0.69%」などの表示される市場の変化率"
),
})
)
.optional()
.describe(
"記事フッターに記載された株式ティッカーとその市場変化率のリスト"
),
})
),
});
async function main() {
// Bright DataのBrowser APIにリモートで接続し、
// OpenAIモデルを使用するようにStagehandを設定する
const stagehand = new Stagehand({
env: "LOCAL",
localBrowserLaunchOptions: {
cdpUrl: `wss://${BRIGHT_DATA_BROWSER_API_USERNAME}:${BRIGHT_DATA_BROWSER_API_PASSWORD}@brd.superproxy.io:9222`,
},
model: "openai/gpt-5.4-mini",
keepAlive: true,
verbose: 1,
});
// Stagehandを起動してブラウザページを取得する
await stagehand.init();
const page = stagehand.context.pages()[0];
// Yahoo Financeに移動する
await page.goto("https://finance.yahoo.com/");
// ニュース記事の読み込みを自動化する
await stagehand.act(
`「More News」セクションで記事が読み込まれるまで複数回スクロールダウンして待機します。少なくとも20のニュース記事が読み込まれるまで繰り返します。`,
{
timeout: 90000, // 90秒タイムアウト
}
);
// ニュース情報をスクレイピングする
const data = await stagehand.extract(
`すべての表示されているニュース記事をスクレイピングする`,
YahooFinanceNewsSchema,
{
"timeout": 120000, // 120秒タイムアウト
}
);
// 抽出したニュースをJSONファイルに保存する
await fs.writeFile(
"news.json",
JSON.stringify(data.news, null, 2),
"utf-8"
);
console.log("ニュースをnews.jsonにエクスポートしました");
// Stagehandインスタンスを閉じてブラウザリソースを解放する
await stagehand.close();
}
main().catch(console.error);次に、.envファイルには以下を格納します:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
BRIGHT_DATA_BROWSER_API_USERNAME="<BROWSER_API_USERNAME>"
BRIGHT_DATA_BROWSER_API_PASSWORD="<BROWSER_API_PASSWORD>"スクリプトを起動します:
npm run startスクリプトの実行が完了すると、プロジェクトフォルダにnews.jsonファイルが表示されます。開くと、次のような構造化データが表示されるはずです:
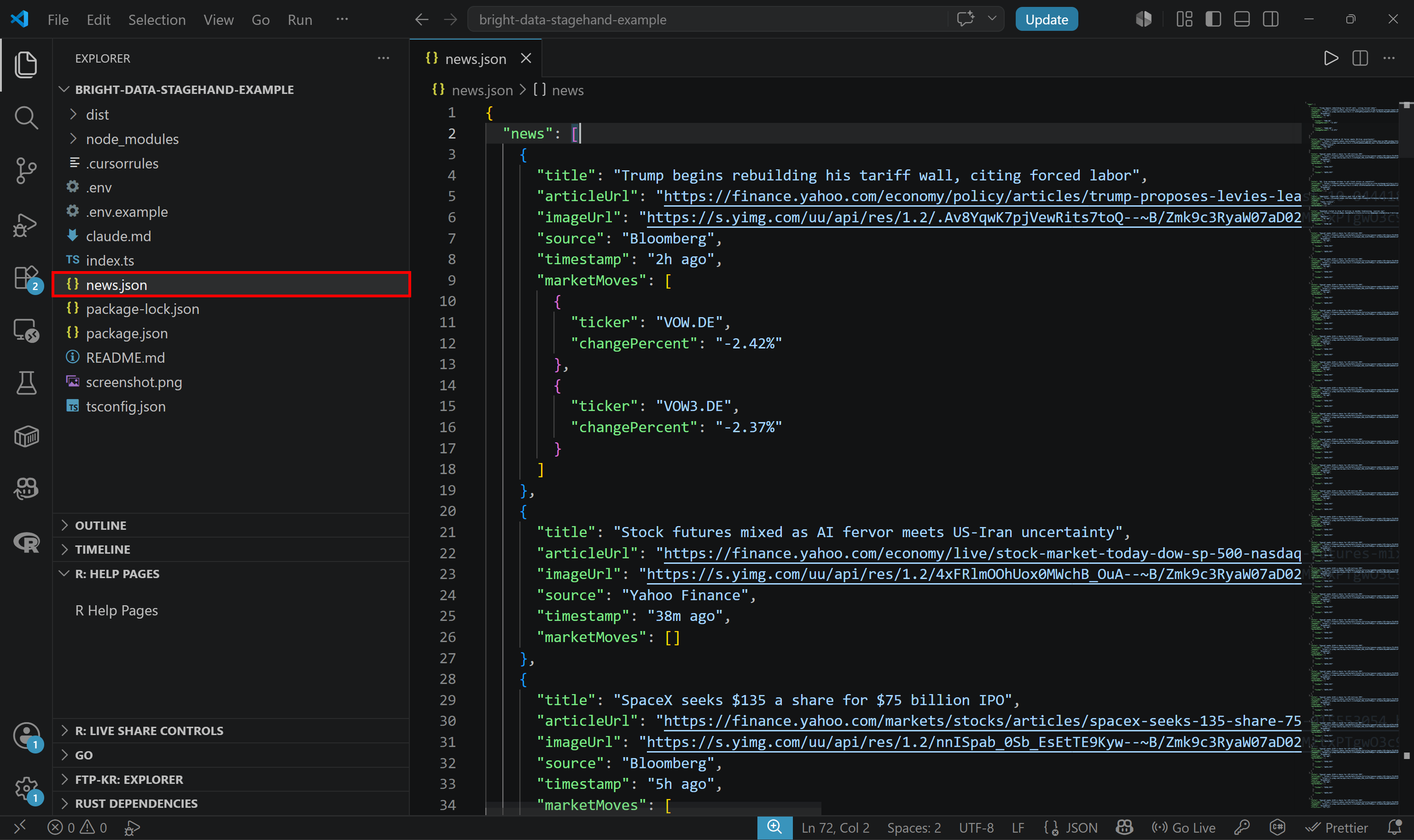
ファイルには、複数回スクロールした後のYahoo Financeホームページに表示されるのと同じ記事が、クリーンで構造化された形式で含まれていることに注目してください。
これにより、Browser APIがアンチボット保護のあるサイトからでも、動的コンテンツにアクセスしてデータを大規模に抽出できることが証明されます。
Et voilà!これは一例に過ぎませんが、Stagehandを使用してBright Data Browser APIのワークフローを多くの他のシナリオやユースケースで自動化できます。
まとめ
この記事では、Stagehandとは何か、そしてブラウザ自動化をどのようにサポートするかを学びました。特に、Bright DataのBrowser APIと組み合わせて、高度にスケーラブルな検出されないクラウドブラウザセッションを実行する方法を確認しました。
その結果、エンタープライズレベルのワークロードにスケールできるブラウザ自動化セットアップが実現します。同じ統合で、大規模なクラウドインフラに裏付けられたエージェント型ブラウザAI操作も実装できます。
新しいBright Dataアカウントを作成して、AI対応のウェブデータスクレイピングとブラウザ自動化ソリューションをご覧ください!






