

出品者や市場調査を行う場合、商品のASINを知っていると、正確な商品の一致を素早く見つけ、競合他社の出品を分析し、市場で優位に立つのに役立ちます。この記事では、AmazonのASINを大規模にスクレイピングするシンプルで効果的な方法をご紹介します。また、このプロセスを大幅にスピードアップできるBright Dataのソリューションについても学びます。
AmazonにおけるASINとは?
ASINとは、英数字を組み合わせた10文字のコード(例:B07PZF3QK9)です。Amazonは書籍から電子機器、衣類に至るまで、カタログ内の全商品にこの固有コードを割り当てています。
商品のASINを調べるには、以下の2つの簡単な方法があります:
1.商品URLを確認する – アドレスバーの「/dp/」の直後にASINが表示されます。
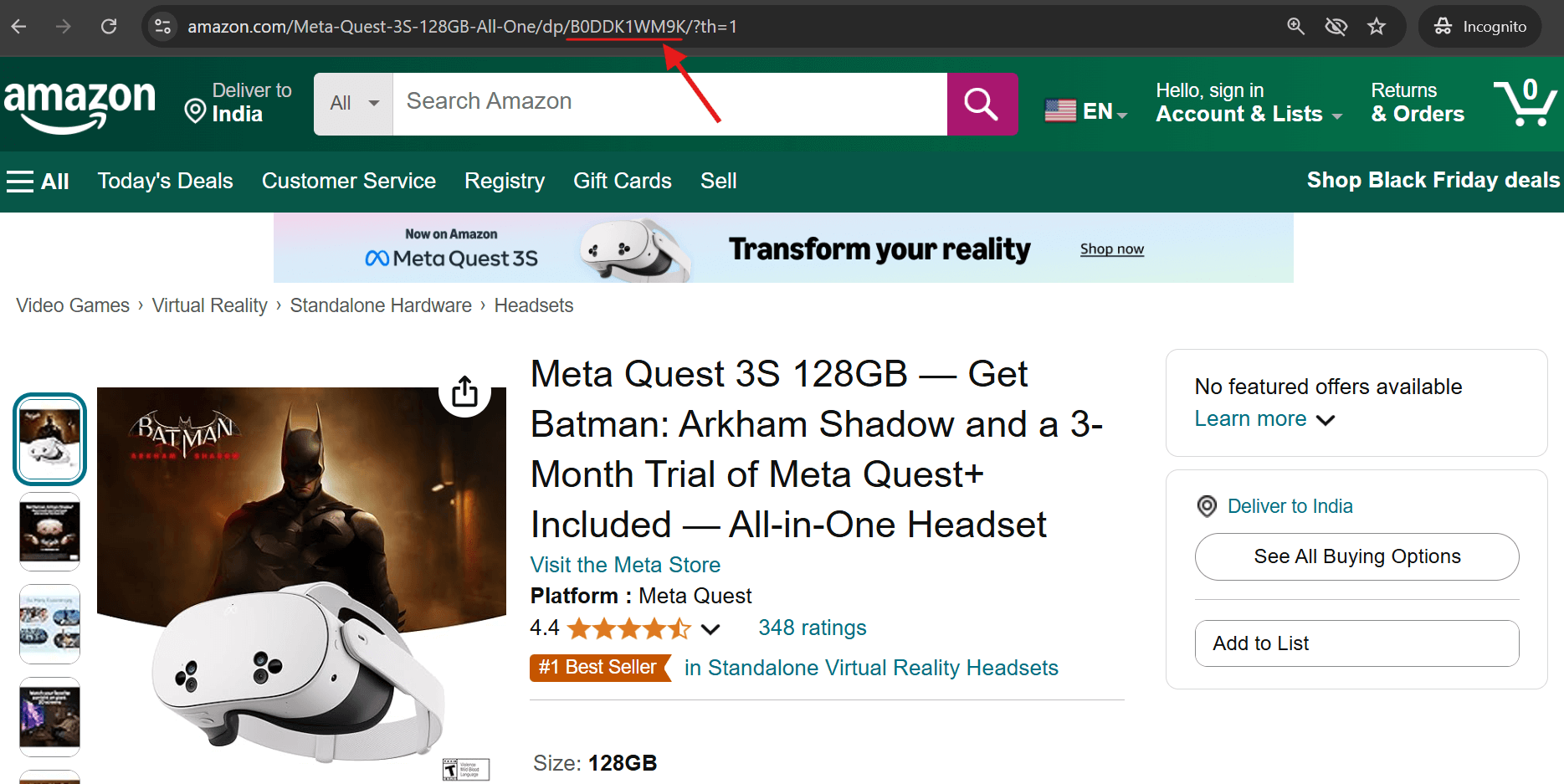
2.Amazon商品ページの「商品情報」セクションまでスクロールダウンすると、ASINが記載されています。
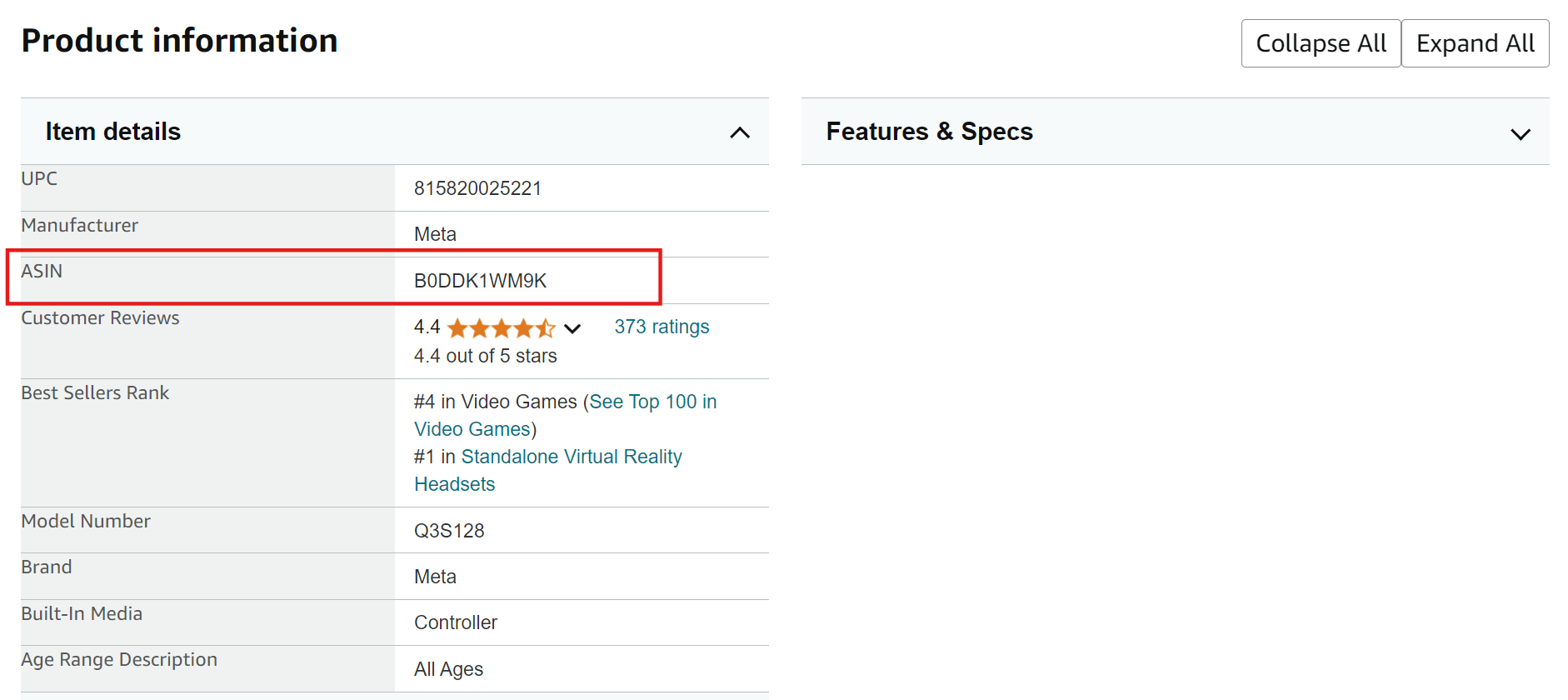
AmazonからASINを抽出する方法
Amazonからのデータスクレイピングは一見単純に見えますが、強力な反スクレイピング対策により非常に困難です。Amazonは以下のような高度な手法で自動データ収集を積極的に防止しています:
- CAPTCHAによる認証
- 要求されたページへのアクセスをブロックするHTTP503エラー
- パースロジックを無効化する頻繁なサイトレイアウト変更
Amazonによって引き起こされる典型的なHTTP 503エラーのスクリーンショット:

AmazonのASINをスクレイピングする簡単なスクリプト例:
import asyncio import os from curl_cffi import requests from bs4 import BeautifulSoup from tenacity import retry, stop_after_attempt, wait_random class AsinScraper: def __init__(self): self.session = requests.Session() self.asins = set() def create_url(self, keyword: str, page: int) -> str: return f"https://www.amazon.com/s?k={keyword.replace(' ', '+')}&page={page}" @retry(stop=stop_after_attempt(3), wait=wait_random(min=2, max=5)) async def fetch_page(self, url: str) -> str | None: try: print(f"Fetching URL: {url}") response = self.session.get( url, impersonate="chrome120", timeout=30) print(f"HTTP Status Code: {response.status_code}") if response.status_code == 200: # レスポンス内にブロックを示す文字列がないか確認 if "Sorry" not in response.text: return response.text else: print("Sorry, request blocked!") else: print(f"Unexpected HTTP status code: {response.status_code}") except Exception as e: print(f"フェッチ中に例外が発生しました: {e}") return None def extract_asins(self, html: str) -> set[str]: soup = BeautifulSoup(html, "lxml") containers = soup.find_all( "div", {"data-component-type": "s-search-result"}) new_asins = set() for container in containers: asin = container.get("data-asin") if asin and asin.strip(): new_asins.add(asin) return new_asins def save_to_csv(self, keyword: str): if not self.asins: print("保存するASINがありません") return # 結果ディレクトリが存在しない場合作成 os.makedirs("results", exist_ok=True) # ファイル名生成 csv_path = f"results/amazon_asins_{keyword.replace(' ', '_')}.csv" # CSVとして保存 with open(csv_path, 'w') as f: f.write("asinn") for asin in sorted(self.asins): f.write(f"{asin}n") print(f"ASINを保存しました: {csv_path}") async def main(): scraper = AsinScraper() keyword = "laptop" max_pages = 5 for page in range(1, max_pages + 1): print(f"ページ {page} をスクレイピング中...") html = await scraper.fetch_page(scraper.create_url(keyword, page)) if not html: print(f"ページ {page} の取得に失敗しました") break new_asins = scraper.extract_asins(html) if new_asins: scraper.asins.update(new_asins) print(f"ページ {page} で {len(new_asins)} 個のASINを発見しました。 合計ASIN数: {len(new_asins)}") 合計ASIN数: {len(scraper.asins)}") else: print("ASINが見つかりませんでした。スクレイピングを終了します。") break # 結果をCSVに保存 scraper.save_to_csv(keyword) if __name__ == "__main__": asyncio.run(main())
では、Amazon ASINをスクレイピングする解決策は何でしょうか?最も信頼性の高いアプローチは、優れたプロキシプロバイダーのレジデンシャルプロキシと適切なHTTPヘッダーを併用することです。
Bright Dataプロキシを使用したAmazon ASINスクレイピング
Bright Dataは、グローバルなプロキシネットワークを有する主要プロキシプロバイダーです。共有サーバーと専用サーバーの両方で様々なタイプのプロキシを提供し、幅広いユースケースに対応しています。これらのサーバーはHTTP、HTTPS、SOCKSプロトコルを使用してトラフィックをルーティングできます。
AmazonスクレイピングにBright Dataを選ぶ理由
- 広大なIPネットワーク:195カ国にまたがる400M+ monthly個のIPアドレスにアクセス可能
- 精密な地理的ターゲティング:特定の都市、郵便番号、通信事業者まで指定可能
- 高信頼性:99.9%の成功率、オプションで100%稼働率
- 柔軟なスケーリング:あらゆる規模の企業向けに従量課金制オプションを提供
AmazonスクレイピングのためのBright Data設定
Amazon ASINスクレイピングにBright Dataプロキシを利用するには、以下の簡単な手順に従ってください:
ステップ1: Bright Dataへの登録
Bright Dataのウェブサイトにアクセスし、アカウントを作成してください。既にアカウントをお持ちの場合は、次のステップに進んでください。
ステップ2: 新しいプロキシゾーンを作成
ログイン後、「プロキシ&スクレイピングインフラ」セクションに移動し、「追加」をクリックして新しいプロキシゾーンを作成します。実際のデバイスのIPを使用するため、スクレイピング対策回避に最適な「レジデンシャルプロキシ」を選択してください。
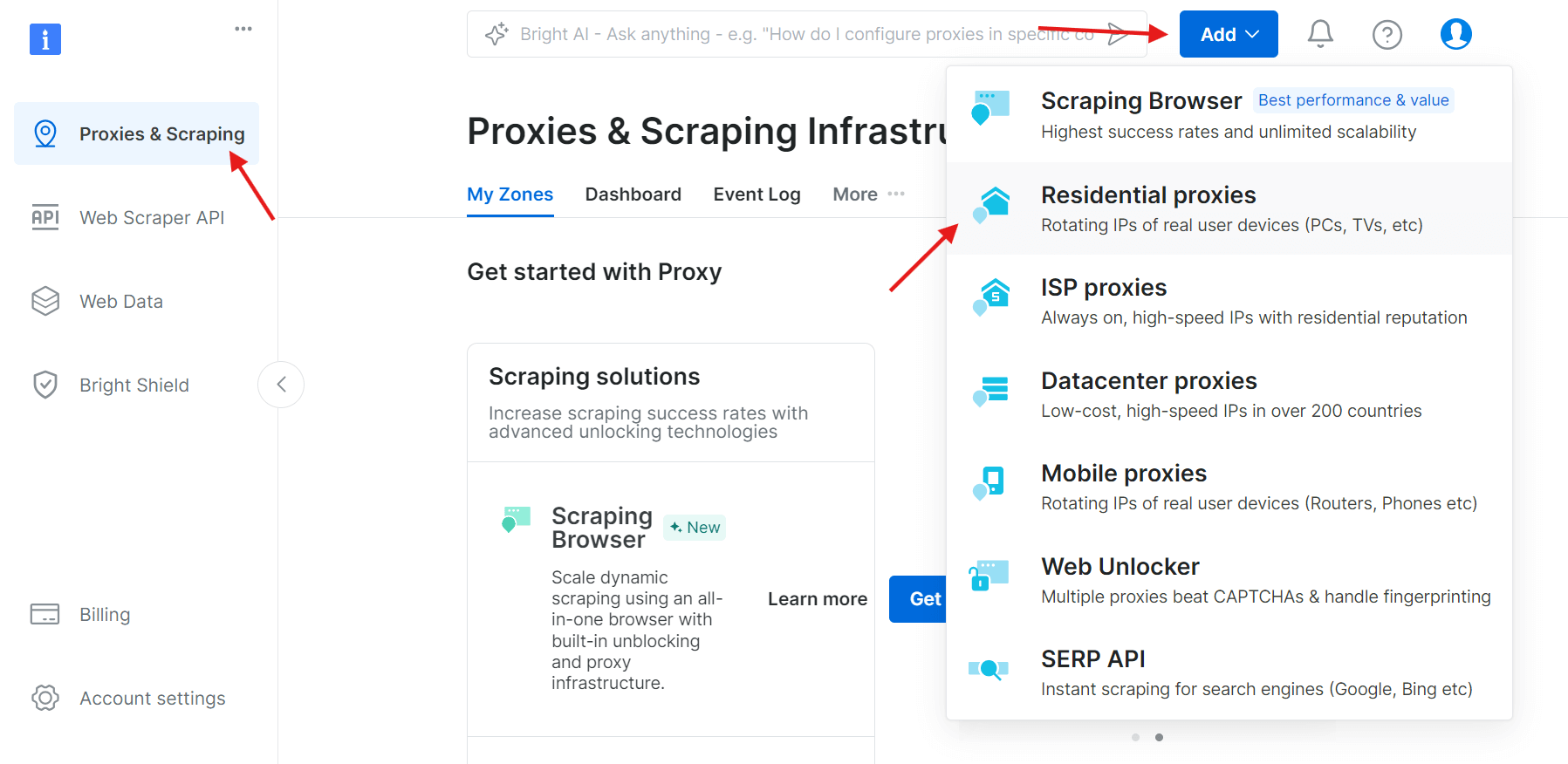
ステップ3:プロキシ設定を構成
ブラウジング対象の地域または国を選択します。ゾーンに適切な名前を付けます(例:「asin_scraping」)。
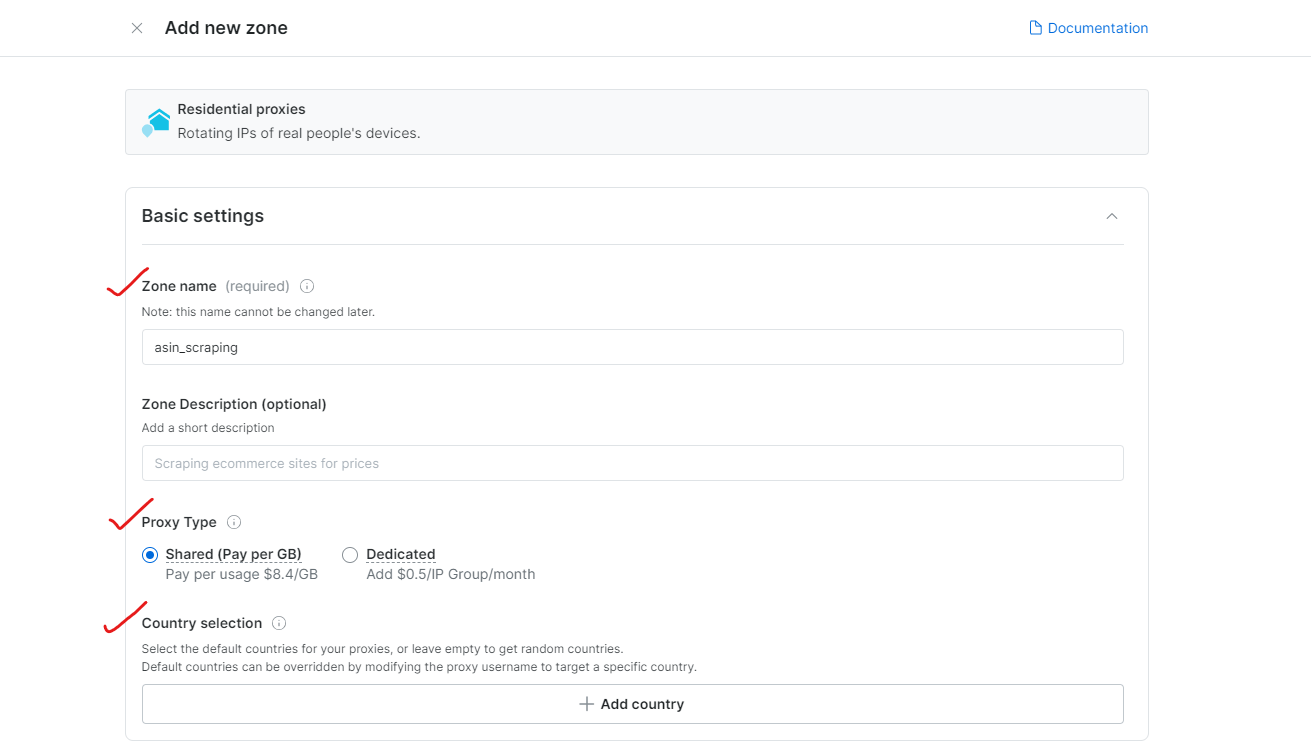
Bright Dataでは、都市や郵便番号単位の精密な地理的ターゲティングが可能です。
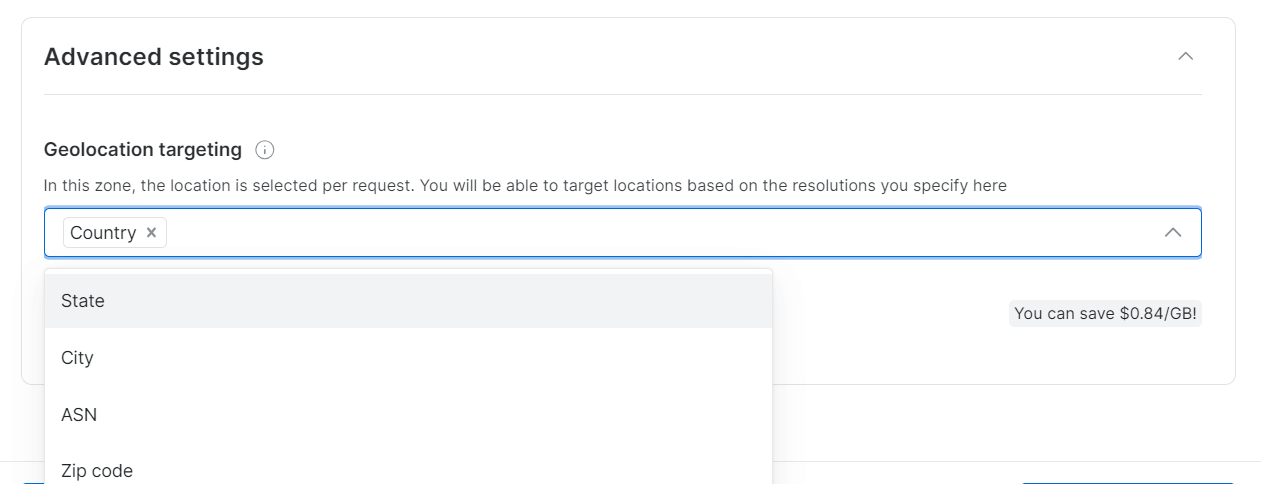
ステップ4: KYC確認を完了する
Bright Dataのレジデンシャルプロキシをフルアクセスするには、KYC確認プロセスを完了してください。
ステップ5: プロキシの使用開始
プロキシゾーンが作成されると、スクレイピングを開始するための認証情報(ホスト、ポート、ユーザー名、パスワード)が表示されます。
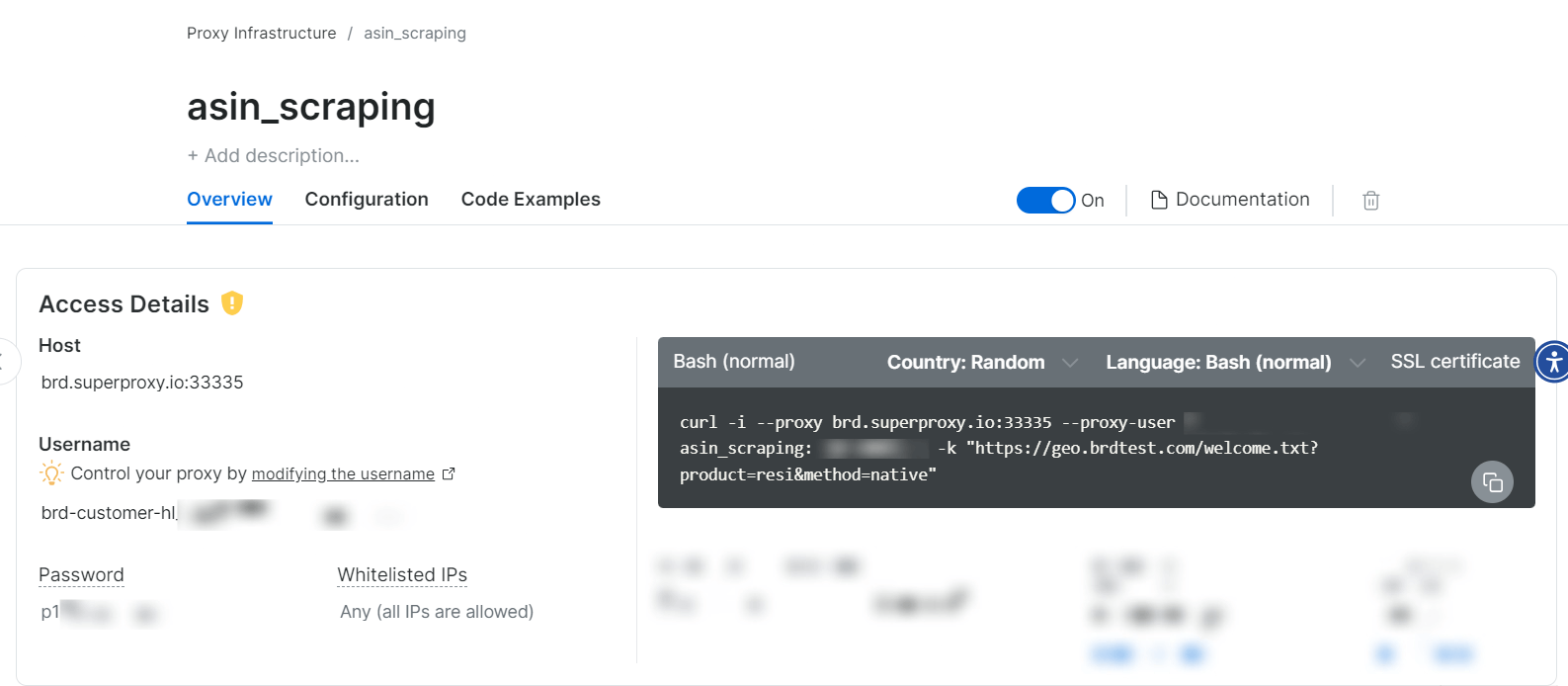
はい、それだけの簡単さです!
スクレイパーの実装
ステップ1: ブラウザヘッダーの設定
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US,en;q=0.9",
"sec-ch-ua": '"Chromium";v="119", "Not?A_Brand";v="24"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}
ステップ2: プロキシ設定の構成
proxy_config = {
"username": "YOUR_USERNAME",
"password": "YOUR_PASSWORD",
"server": "brd.superproxy.io:33335",
}
proxy_url = f"http://{proxy_config['username']}:{proxy_config['password']}@{proxy_config['server']}"
ステップ3: リクエストの実行
curl_cffiライブラリを使用してヘッダーとプロキシでリクエストを送信します:
response = session.get(
url,
headers=headers,
impersonate="chrome120",
proxies={"http": proxy_url, "https": proxy_url},
timeout=30,
verify=False,
)
注: curl_cffiライブラリはウェブスクレイピングに最適で、標準のrequestsライブラリを上回る高度なブラウザ偽装機能を提供します。
ステップ4: スクレイパーの実行
スクレイパーを実行するには、対象キーワードを設定する必要があります。例:
keywords = [
"coffee maker",
"office desk",
"cctv camera"
]
max_pages = None # 全ページ取得の場合はNoneを設定
完全なコードはこちらで確認できます。
スクレイパーは結果をCSVファイルに出力します。内容は以下の通りです:
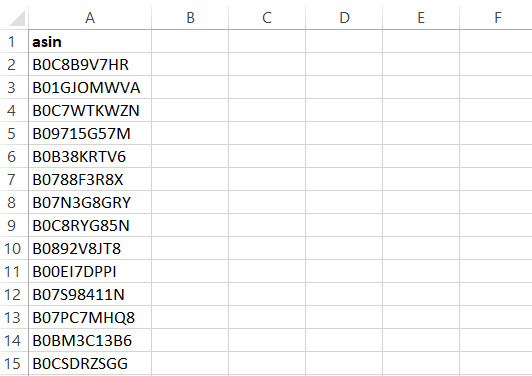
Bright Data AmazonスクレイパーAPIを使用したASIN抽出
プロキシベースのスクラッピングも有効ですが、Bright Data AmazonスクレイパーAPIを利用すると以下の大きな利点があります:
- インフラ管理不要:プロキシ、IPローテーション、キャプチャを気にする必要がありません
- 地理的位置情報に基づくスクレイピング:あらゆる地域からスクレイピング可能
- 簡単な統合:あらゆるプログラミング言語で数分で実装可能
- 複数のデータ配信オプション:
- Amazon S3、Google Cloud、Azure、Snowflake、SFTPへのエクスポート
- JSON、NDJSON、CSV、.gz形式でデータ取得
- GDPRおよびCCPA準拠:倫理的なウェブスクレイピングにおけるプライバシーコンプライアンスを保証
- 20回の無料APIコール:サービス導入前にテスト可能
- 24時間365日サポート:API関連の質問や問題に対応する専任サポート
AmazonスクレイパーAPIの設定
APIの設定は簡単で、数ステップで完了します。
ステップ1: APIにアクセス
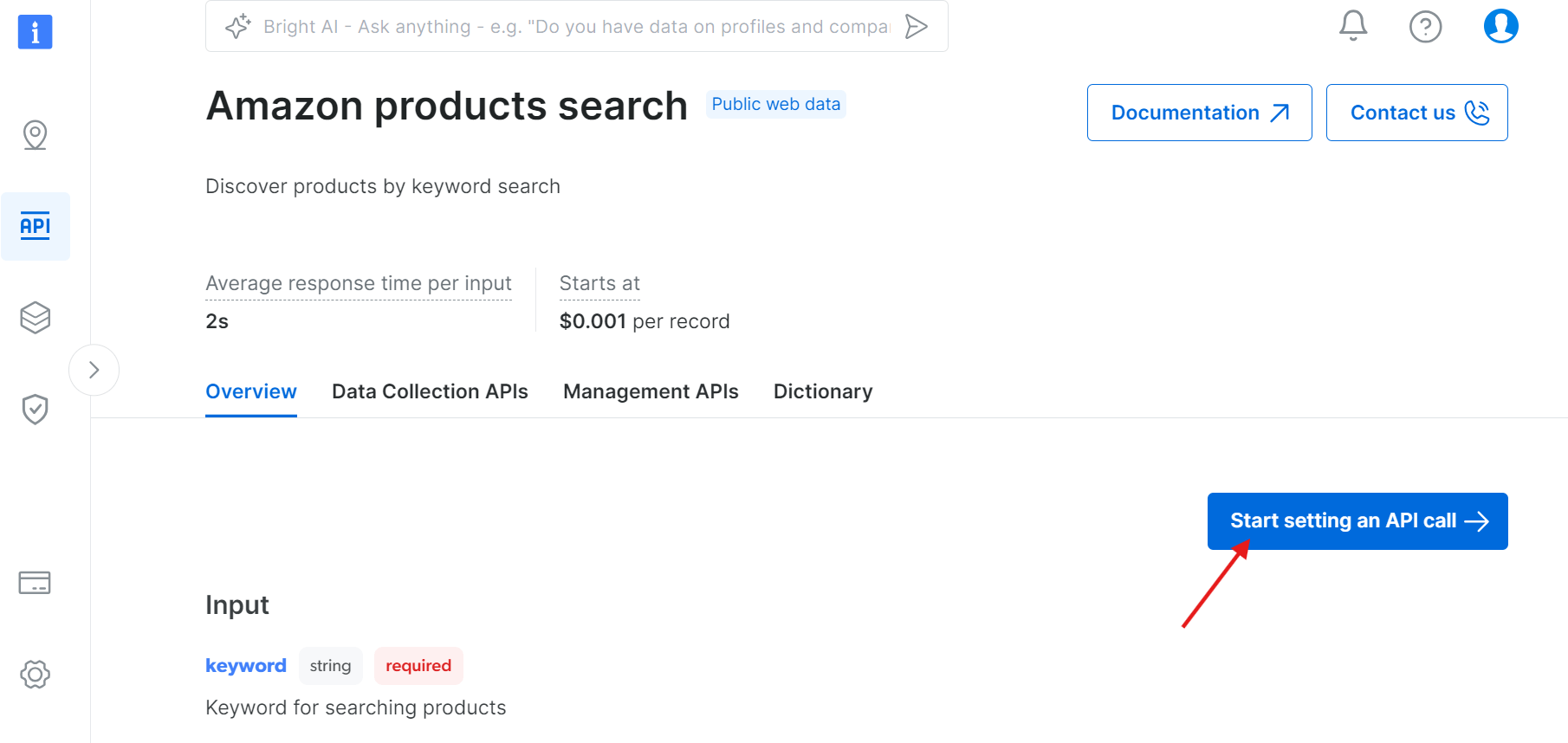
WebスクレイパーAPI に移動し、利用可能なAPIの中から「amazon products search」を検索してください:
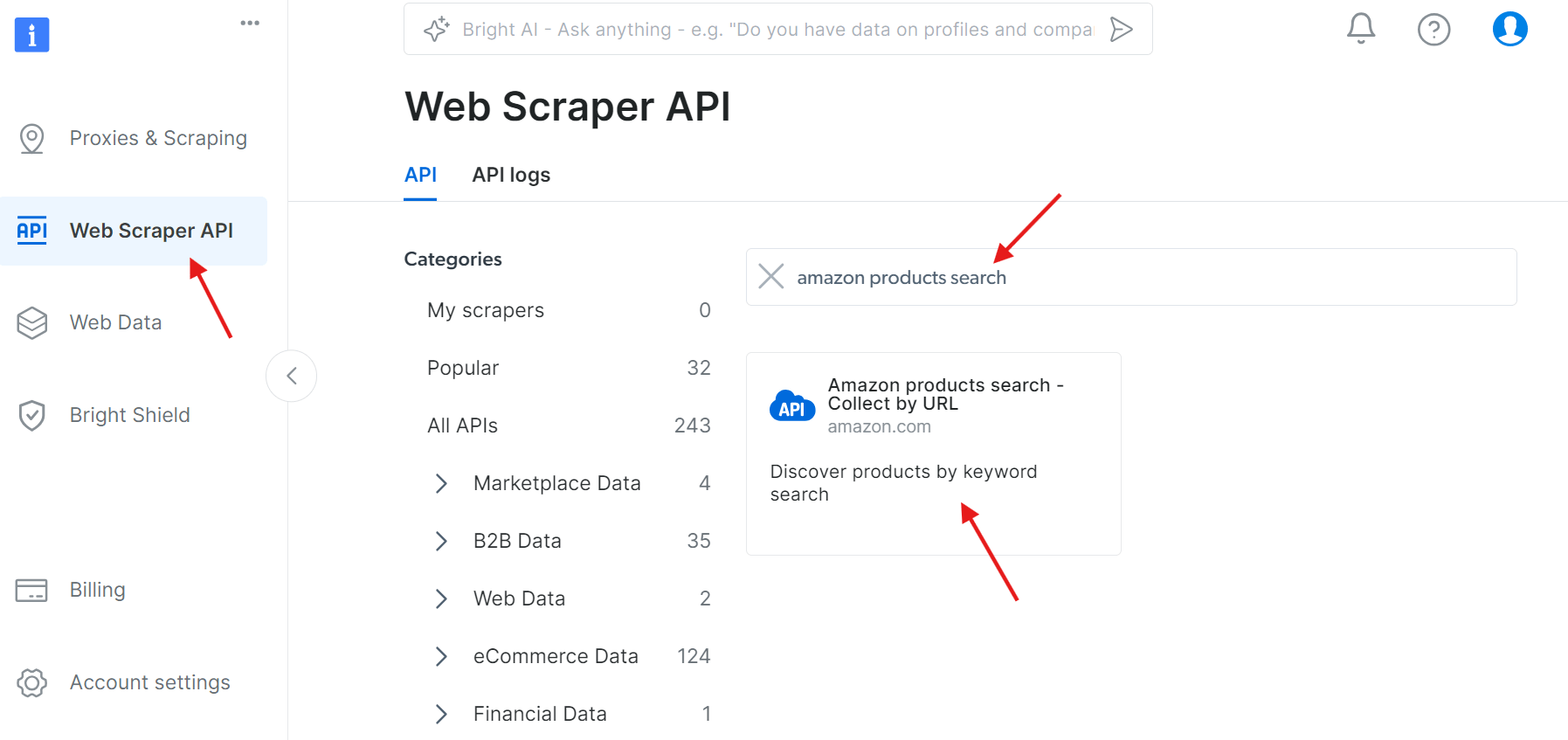
「API呼び出しの設定を開始」をクリック:
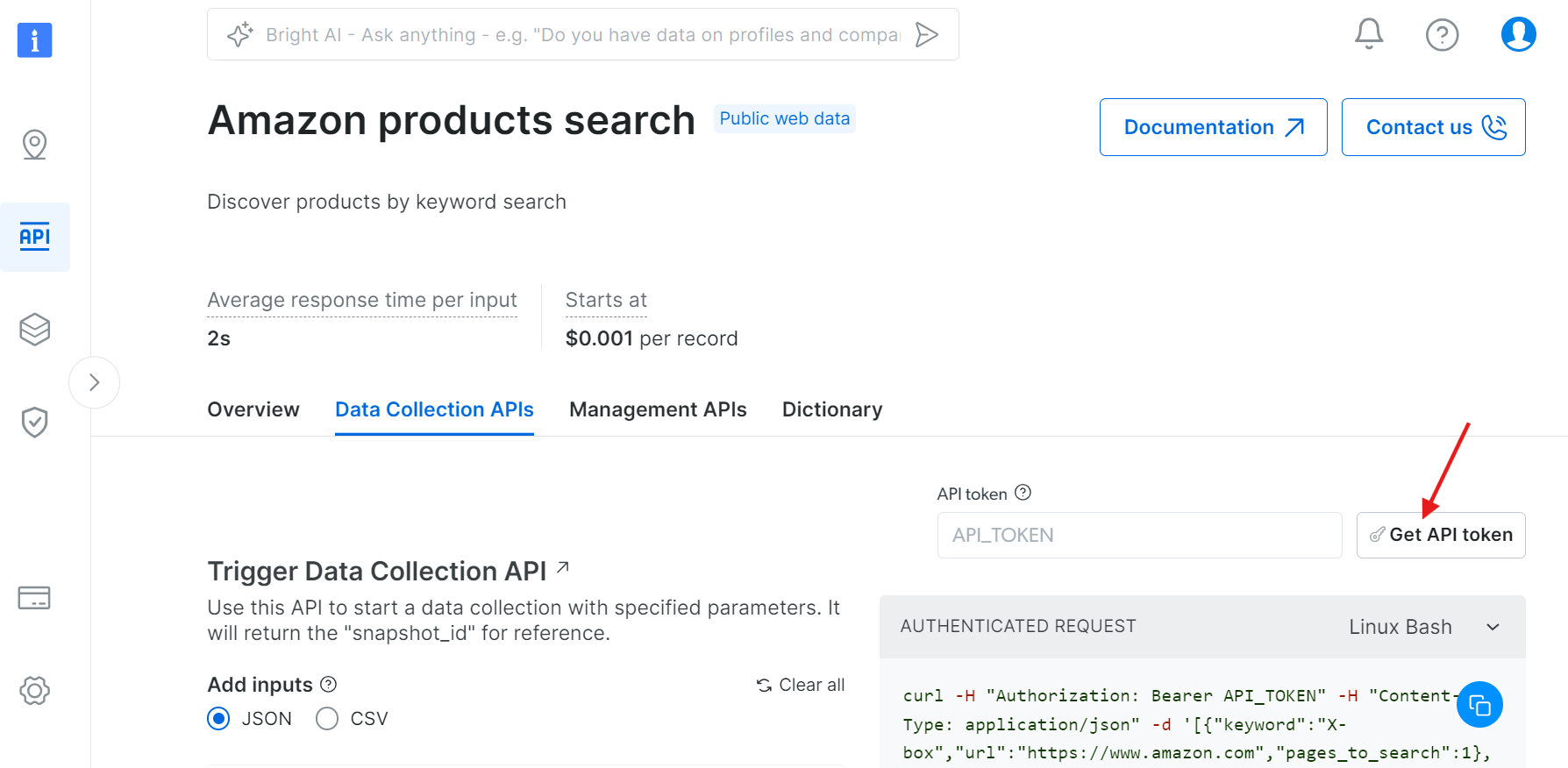
ステップ2: APIトークンを取得
「APIトークンを取得」をクリック:
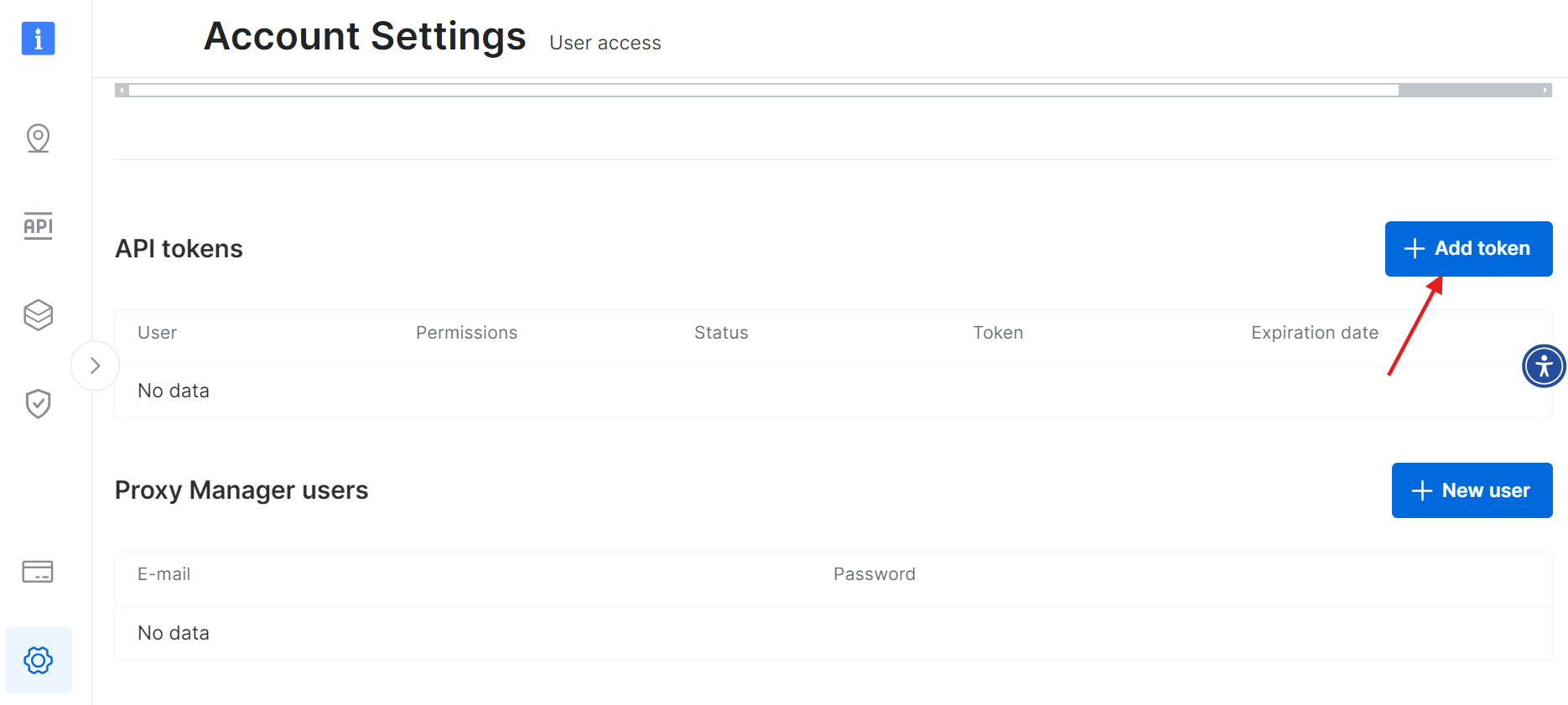
「トークンを追加」を選択:
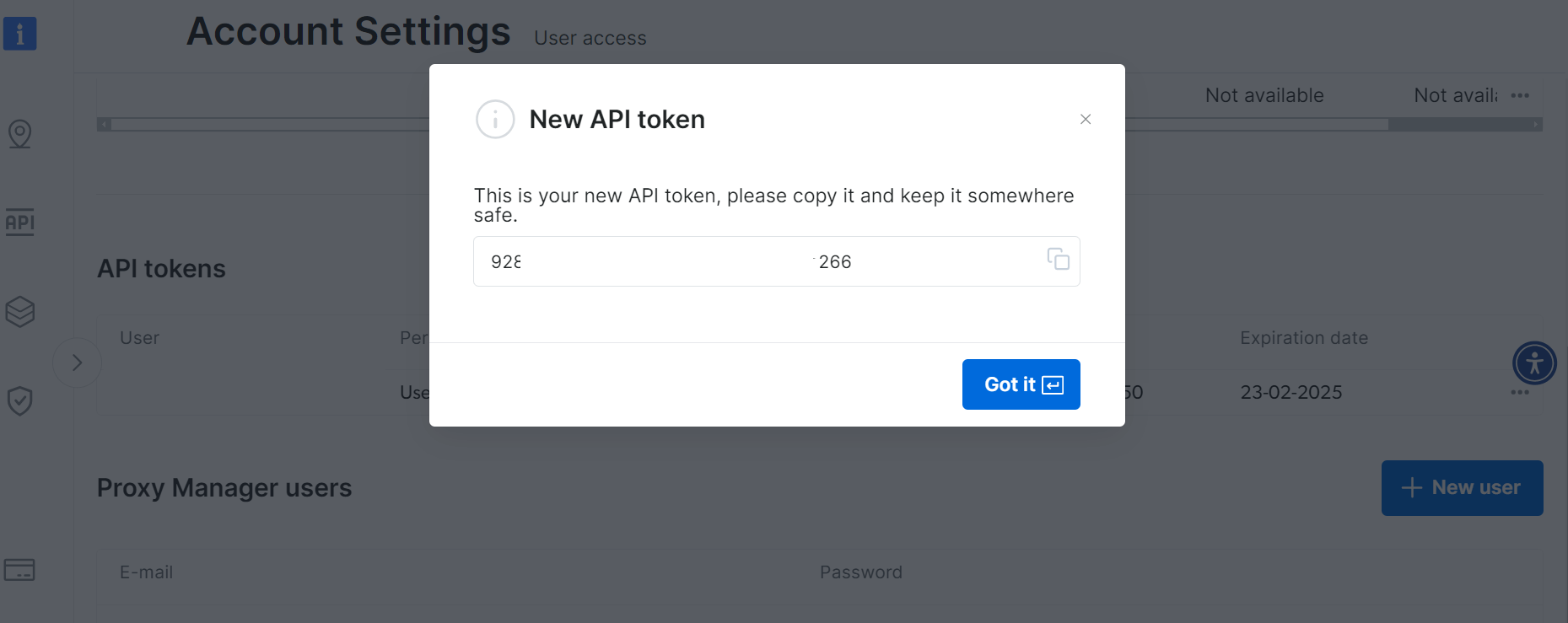
新しいAPIトークンを安全に保存してください:
ステップ3: データ収集の設定
データ収集APIタブで:
- 商品検索のキーワードを指定
- 対象のAmazonドメインを設定
- スクレイピングするページ数を定義
- 追加フィルター(任意)
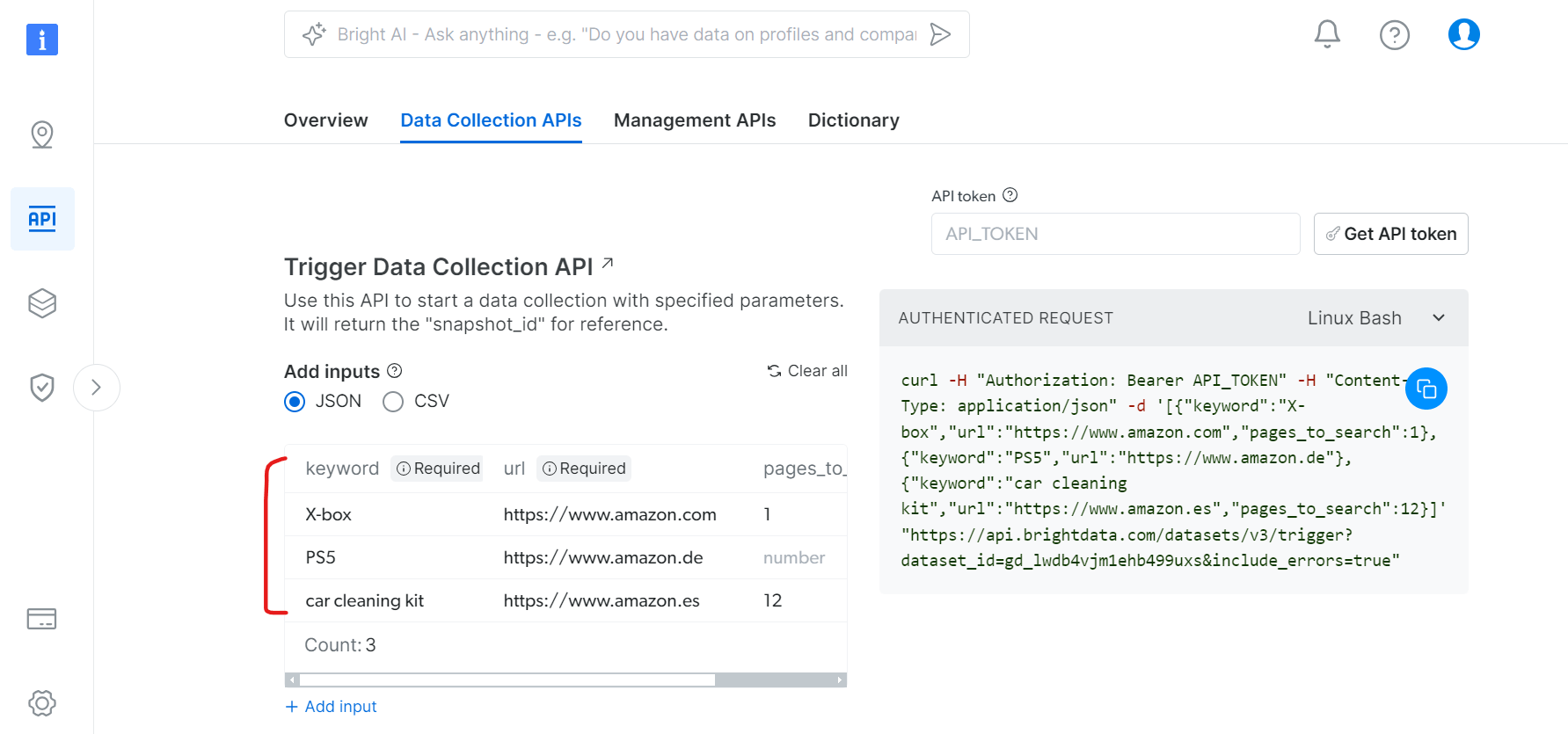
PythonでのAPI使用
データ収集をトリガーし結果を取得するPythonスクリプトの例:
import json
import requests
import time
from typing import Dict, List, Optional, Union, Tuple
from datetime import datetime, timedelta
import logging
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
from enum import Enum
class SnapshotStatus(Enum):
SUCCESS = "success"
PROCESSING = "processing"
FAILED = "failed"
TIMEOUT = "timeout"
class BrightDataAmazonScraper:
def __init__(self, api_token: str, dataset_id: str):
self.api_token = api_token
self.dataset_id = dataset_id
self.base_url = "https://api.brightdata.com/データセット/v3"
self.headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
# カスタムフォーマットでロギングを設定
logging.basicConfig(
level=logging.INFO,
format='%(message)s' # メッセージのみを表示する簡略化されたフォーマット
)
self.logger = logging.getLogger(__name__)
# リトライ戦略付きセッションの設定
self.session = self._create_session()
# 進捗の追跡
self.last_progress_update = 0
def _create_session(self) -> requests.Session:
"""リトライ戦略付きセッションを作成"""
session = requests.Session()
retry_strategy = Retry(
total=3,
backoff_factor=0.5,
status_forcelist=[500, 502, 503, 504]
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("https://", adapter)
session.mount("http://", adapter)
return session
def trigger_collection(self, datasets: List[Dict]) -> Optional[str]:
"""指定されたデータセットの収集をトリガーする"""
trigger_url = f"{self.base_url}/trigger?dataset_id={self.dataset_id}"
try:
response = self.session.post(
trigger_url,
headers=self.headers,
json=データセット
)
response.raise_for_status()
snapshot_id = response.json().get("snapshot_id")
if snapshot_id:
self.logger.info("Amazonデータ収集の初期化中...")
return snapshot_id
else:
self.logger.error("データ収集の初期化に失敗しました。")
return None
except requests.exceptions.RequestException as e:
self.logger.error(f"コレクション初期化失敗: {str(e)}")
return None
def check_snapshot_status(self, snapshot_id: str) -> Tuple[SnapshotStatus, Optional[Dict]]:
"""スナップショットの現在のステータスを確認する"""
snapshot_url = f"{self.base_url}/snapshot/{snapshot_id}?format=json"
try:
response = self.session.get(snapshot_url, headers=self.headers)
if response.status_code == 200:
return SnapshotStatus.SUCCESS, response.json()
elif response.status_code == 202:
return SnapshotStatus.PROCESSING, None
else:
return SnapshotStatus.FAILED, None
except requests.exceptions.RequestException:
return SnapshotStatus.FAILED, None
def wait_for_snapshot_data(
self,
snapshot_id: str,
timeout: Optional[int] = None,
check_interval: int = 10,
max_interval: int = 300,
callback=None
) -> Optional[Dict]:
"""最小限のコンソール出力でスナップショットデータを待機"""
start_time = datetime.now()
current_interval = check_interval
attempts = 0
progress_shown = False
while True:
attempts += 1
if timeout is not None:
elapsed_time = (datetime.now() - start_time).total_seconds()
if elapsed_time >= timeout:
self.logger.error("データ収集が時間制限を超えました。")
return None
status, data = self.check_snapshot_status(snapshot_id)
if status == SnapshotStatus.SUCCESS:
self.logger.info(
"Amazonデータ収集が正常に完了しました!")
return data
elif status == SnapshotStatus.FAILED:
self.logger.error("データ収集中にエラーが発生しました。")
return None
elif status == SnapshotStatus.PROCESSING:
# 進行状況インジケーターは30秒ごとにのみ表示
current_time = time.time()
if not progress_shown:
self.logger.info("Amazonからデータを収集中...")
progress_shown = True
elif current_time - self.last_progress_update >= 30:
self.logger.info("データ収集中...")
self.last_progress_update = current_time
if callback:
callback(attempts, (datetime.now() -
start_time).total_seconds())
time.sleep(current_interval)
current_interval = min(current_interval * 1.5, max_interval)
def store_data(self, data: Dict, filename: str = "amazon_data.json") -> None:
"""収集したデータをJSONファイルに保存"""
if data:
try:
with open(filename, "w", encoding='utf-8') as file:
json.dump(data, file, indent=4, ensure_ascii=False)
self.logger.info(f"Data saved successfully to {filename}")
except IOError as e:
self.logger.error(f"データ保存エラー: {str(e)}")
else:
self.logger.warning("保存可能なデータがありません。")
def progress_callback(attempts: int, elapsed_time: float):
"""最小限のコールバック関数 - 必要に応じてカスタマイズ可能"""
pass # デフォルトでは無音
def main():
# 設定
API_TOKEN = "YOUR_API_TOKEN"
DATASET_ID = "gd_lwdb4vjm1ehb499uxs"
# スクレイパーの初期化
scraper = BrightDataAmazonScraper(API_TOKEN, DATASET_ID)
# 検索パラメータの定義
datasets = [
{"keyword": "X-box", "url": "https://www.amazon.com", "pages_to_search": 1},
{"keyword": "PS5", "url": "https://www.amazon.de"},
{"keyword": "car cleaning kit",
"url": "https://www.amazon.es", "pages_to_search": 4},
]
# スクラッピング処理の実行
snapshot_id = scraper.trigger_collection(データセット)
if snapshot_id:
data = scraper.wait_for_snapshot_data(
snapshot_id,
timeout=None,
check_interval=10,
max_interval=300,
callback=progress_callback
)
if data:
スクレイパー.store_data(data)
print("nスクレイピング処理が正常に完了しました!n")
if __name__ == "__main__":
main()
このコードを実行するには、以下の値を必ず置き換えてください:
API_TOKENを実際のAPIトークンに置き換えてください。- 検索対象の製品やキーワードを含めるよう、
データセットリストを修正してください。
取得されるデータのサンプルJSON構造は以下の通りです:
{
"asin": "B0CJ3XWXP8",
"url": "https://www.amazon.com/Xbox-X-Console-Renewed/dp/B0CJ3XWXP8/ref=sr_1_1",
"name": "Xbox Series X コンソール (再生品) Xbox Series X コンソール (再生品)2023年9月15日",
"sponsored": "false",
"initial_price": 449.99,
"final_price": 449.99,
"currency": "USD",
"sold": 2000,
"rating": 4.1,
"num_ratings": 1529,
"variations": null,
"badge": null,
"business_type": null,
"brand": null,
"delivery": ["無料配送 12月1日(日)", "または最速配送 11月29日(金)"],
"keyword": "X-box",
"image": "https://m.media-amazon.com/images/I/51ojzJk77qL._AC_UY218_.jpg",
"domain": "https://www.amazon.com/",
"bought_past_month": 2000,
"page_number": 1,
"rank_on_page": 1,
"timestamp": "2024-11-26T05:15:24.590Z",
"input": {
"keyword": "X-box",
"url": "https://www.amazon.com",
"pages_to_search": 1,
},
}
このサンプルJSONファイルをダウンロードすると、出力結果全体を確認できます。
結論
Pythonを使用したAmazon ASIN収集プロセスについて議論しましたが、その過程でいくつかの課題にも直面しました。 CAPTCHAやレート制限などの問題は、データ収集作業を大きく妨げる可能性があります。解決策として、Bright DataのプロキシやAmazonスクレイパーAPIなどのツールを利用できます。これらの選択肢はプロセスの高速化や一般的な障害の回避に役立ちます。スクレイピングツールの設定の手間を完全に避けたい場合は、Bright Dataが提供するすぐに使える既製のAmazonデータセットも利用可能です。
今すぐ登録して無料トライアルを開始しましょう!





