

営業チームが「検証済み」コンタクト先に何時間も電話をかけたにもかかわらず、不通回線、メール不達、数ヶ月前に離脱した見込み客ばかりだった。これがB2Bデータ劣化の実態だ。あらゆるデータベースに影響するコンタクト情報の正確性が徐々に低下する現象である。
本ガイドでは、B2Bデータとは何か、なぜ劣化するのか、その発生源、そして組織に適したデータ取得手法の選び方を学びます。
B2Bデータとは?
B2Bデータとは、企業とその従業員に関するビジネス情報を指し、営業・マーケティングチームが適切な見込み客を特定・接触・関与させることを可能にします。
現代のB2Bデータには5つの主要タイプが含まれます:企業属性データ(企業規模、業種、収益)、技術属性データ(使用ソフトウェア・技術)、行動意図シグナル(ソリューション調査の兆候)、時系列データ(資金調達ラウンドなどの重要イベント)、連絡先情報(メールアドレス、電話番号、役職)。
課題:連絡先データは年間22.5%(月間約2.1%)の割合で劣化します。専門家の転職、メールのバウンス、電話番号の切断により、静的な連絡先リストは数か月で陳腐化します。
このため、現代のGTM(市場投入)チームは、リストの一括購入からリアルタイムデータフィードへ移行しています。自動化されたエンリッチメントにより、見込み客の役職や所属企業の変更に応じてレコードが更新され、CRMが常に最新の状態を保ちます。これにより、アウトリーチが正確に維持され、送信者の評判が保護されます。
B2Bデータの5種類
B2Bデータの異なる種類を理解することで、特定のビジネス目標にとって最も重要な情報を特定できます。
1. 識別データ(連絡先情報)
アイデンティティデータには、見込み客に連絡するために必要な基本連絡先が含まれます:
- 氏名と役職
- メールアドレス(業務用および個人用)
- 電話番号(直通と携帯)
- LinkedInプロフィールURL
- 所属企業と報告ライン
重要な知見:連絡先情報は頻繁に変更される(テクノロジー、ヘルスケア、専門サービスなどの高成長分野では年間30~40%)。しかしLinkedInプロフィールURLは、転職を経ても持続する安定した識別子を提供する。データチームはプロフィールURLをプライマリキーとして活用し、個々の見込み顧客のキャリア全体を追跡。これにより、メールアドレスや電話番号が変更されても継続性を維持できる。
2. ファームグラフィックデータ(企業特性)
企業属性データは組織の中核的属性を記述します:
- 企業規模(従業員数、年間収益)
- 業界およびサブ業界分類
- 地理的所在地と本社
- 設立年月日と企業年齢
- 所有構造(上場企業、非上場企業、子会社)
- 成長指標(採用ペース、最近の資金調達状況)
実用的な応用例:企業属性データを活用すれば、市場をセグメント化し、理想的な顧客プロファイル(ICP)に合致する企業を特定できます。例えば、エンタープライズソフトウェアを販売する場合、従業員数百名規模で、テクノロジーまたは金融サービス分野において多額の年間収益を上げる企業をフィルタリングできます。
遅行指標である収益予測(1年以上古い場合が多い)に依存する代わりに、先進的なチームは資金調達発表や採用急増といったリアルタイムのシグナルを優先します。これらの指標は、予算を確保した成長段階にある企業を特定します。
3. テクノグラフィックデータ(技術スタック)
テクノグラフィックデータは、企業が使用するソフトウェアとインフラを明らかにします:
- CRMシステム(Salesforce、HubSpot、Microsoft Dynamics)
- マーケティングオートメーションプラットフォーム(Marketo、Pardot、ActiveCampaign)
- eコマースプラットフォーム(Shopify、Magento、WooCommerce)
- クラウドインフラストラクチャ(AWS、Azure、Google Cloud)
- 推定技術予算と契約更新時期
戦略的価値:テクノグラフィックスは、テクノロジーのギャップや更新機会を明らかにすることで、精密なターゲティングを可能にします。
例えば、営業支援ソフトウェアを販売している場合、企業がSalesforceを利用しているがメールシーケンスツールを欠いていることを把握すれば、明確な参入ポイントが得られます。同様に、更新時期を予測することで、契約の見直し時期に合わせたアプローチのタイミングを計ることができます。
4. 意図データ(行動シグナル)
意図データは、積極的なソリューション調査を示すシグナルを捕捉します。自社データ(自社ウェブサイトとの直接的なインタラクション)とサードパーティデータ(広範なウェブ上での調査活動)の両方を含みます:
- ・ウェブサイト訪問とコンテンツ消費パターン
- 製品レビューサイトでの活動(G2、Capterra、TrustRadius)
- 検索行動とキーワード調査
- ソーシャルシグナル(競合他社や業界議論への関与)
- 御社のようなソリューションを通常使用する役職の求人情報
実用的な応用例:意図データは、積極的な購買意欲を示す高シグナルアカウントを優先します。
例えば、ある企業が1週間で3回価格ページを訪問し、競合比較記事を読み、「営業オペレーションマネージャー」の求人を掲載した場合、強い購買意図を示しています。こうしたマルチタッチのシグナルは積極的な評価を示しており、高購買意図アカウントへのレスポンス率はコールドアウトリーチよりも大幅に高くなる可能性があります。
5. クロノグラフィックデータ(時間ベースのイベント)
クロノグラフィックデータは購買機会を生み出す重要なイベントを追跡します:
- 資金調達ラウンドと買収(新規予算配分)
- 経営陣の交代(技術スタックの見直し)
- 製品ローンチや主要発表
- オフィスの開設または移転
- 合併・再編
タイミングの優位性:これらのイベントは、企業が積極的にソリューションを評価する狭い機会を生み出します。
例えば、シリーズB資金調達を終えたばかりの企業は、成長イニシアチブに充てる新たな資金を確保している可能性が高い。同様に、新たに就任した営業担当副社長は、通常、就任後数ヶ月以内に技術スタックの見直しを行う。調査によると、こうしたトリガーを起点にタイミングを計ってアプローチすることで、応答率を大幅に改善できることが分かっている。
B2Bデータの劣化を理解する
B2Bコンタクトデータベースは急速に劣化します。AI駆動の自動化が標準化する中、古いデータは単に時間を浪費するだけでなく、大規模な財務損失や評判の毀損を引き起こします。
データ劣化の実態
調査によると、コンタクトレコードの約22.5%が年間で完全に無効化されます(月間劣化率2.1%)。しかし部分的な変更まで含めると、影響範囲はさらに広範です:
12ヶ月以内に変更される項目:
- 役職と職務内容。65.8%のコンタクトが変更(昇進や社内異動を含む)。
- 電話番号: 42.9%が変更または使用不能に
- メールアドレス:職務変更により37.3%が劣化。
10,000件のコンタクトデータベースの場合、これは1年以内に2,250件の無効レコードと6,580件の古い情報を含むレコードに相当します。
データが劣化するのはなぜか
この継続的な劣化には複数の要因が作用している:
- 職業上の流動性。成長著しい分野(テクノロジー、医療、専門サービス)では、専門職の30~40%が毎年転職する。安定した業界でも25~30%の流動率により、約4人に1人の連絡先が毎年雇用主を変える。
- 企業変革。合併、買収、再編により報告構造が一夜で変化します。企業合併時には、通常12ヶ月以内に管理職ポジションの30~50%が統合されます。
- 購買委員会の流動性。現代のB2B営業では、1件の取引あたり平均11名の関係者が関与する。現在の流動率を考慮すると、主要委員の少なくとも1名が営業サイクルの途中で離脱し、取引が停滞するケースが頻発している。
- AIの増幅効果。 AI搭載営業エージェントは機能するために最新データが必要だ。6~12ヶ月前の情報を与えると、単に誤ったメールを送るだけでなく、恥ずかしいパーソナライゼーションエラーを引き起こす。エージェントが相手の古い役職を引用したり、数ヶ月前に退職した会社を言及したりすると、そのアプローチは明らかに自動化されたものと感じられ、信頼性を損なう。
陳腐化したデータの代償
調査によれば、データ品質の問題は、無駄なマーケティング支出、機会損失、業務効率の低下を通じて、中堅企業1社あたり年間数百万ドルの損失につながると推定されている。
直接的な影響:
- 営業生産性の低下。営業担当者は時間の4分の1以上を誤った情報に基づくリード追跡に費やし、1人当たり年間数万ドルの給与が無駄になっている。
- メール配信率の低下。バウンス率が2%を超えるとGmailやOutlookからペナルティが発生し、受信トレイ到達率が半減以上となる。5%を超えるとブラックリスト登録のリスクがあり、配信が完全に失敗し回復に数ヶ月を要する。
- 無駄なマーケティング費用。データベースの大部分が不正確な場合、各キャンペーンは同等の予算を浪費します。アウトバウンドマーケティングに多額の費用を投じる企業では、これは純粋な無駄として数十万ドルに相当します。
B2Bデータはどこから来るのか?
B2Bデータは公開情報源とベンダー管理データベースに由来し、収集方法・更新頻度・価格モデルがそれぞれ異なります。
主な情報源
大半のB2Bデータは公開情報源から収集されます:
- LinkedIn:職業上の身元情報と職歴の主要情報源(会員数11億人以上、企業ページ数6,700万以上)。
- Crunchbase:ベンチャー企業および資金調達ラウンドの標準情報源(200万社以上)。
- Indeed/Glassdoor:採用動向追跡の主要ソース。ベンダーは700万件以上の有効求人情報を監視し、成長企業を特定します。
- Google Maps:地域ビジネス情報の主要ソース(全世界で2億以上の企業・施設)。
- 公的記録。SEC報告書や営業許可証を含む政府提出書類が検証済みの法的情報を提供する。
重要なポイント:主要なB2Bデータベンダーは全て、これらの同じ公開情報源から収集しています。差別化要因は更新頻度と検証方法です。
従来型データベース vs. 直接取得データセット
核心的な差異はデータソースではなく、更新サイクルの速度と頻度にある。
従来型ベンダーモデル:
ZoomInfoやApolloなどのベンダーは、公開情報源からデータを収集し、「コミュニティ」データ(CRM連携によるメール署名情報)と統合します。しかし、中央データベースの更新は通常、四半期ごとのシステムサイクル(90~120日)で行われます。B2Bデータは月間2.1%の割合で劣化するため、購入したコンタクトの約3~6%は、記録の古さにより納品時点で無効になっている可能性が高いです。
ダイレクトデータセットの代替案:
ダイレクトデータセット(Bright DataのB2Bデータセットなど)は自動化されたインフラを活用し、高頻度スケジュールで構造化データを取得します:
- 毎日更新:求人投稿、資金調達アラート、経営陣変更など変動の激しいデータ向け。
- 週次/月次更新:企業属性データや本社所在地など安定したデータ向け。
この手法では、公開更新から24~48時間以内にデータを提供するため、四半期ごとの更新と比較してデータの劣化を最大80%削減します。
価格比較(2026年価格)
| 機能 | 従来型ベンダー | ダイレクトデータセット(Bright Data) |
|---|---|---|
| 基本費用 | 15,000~30,000ドル以上(年間契約) | 10万レコードあたり250ドル |
| 価格モデル | ユーザー単位 / クレジット制 | レコード単位課金 / ユーザー数制限なし |
| データの鮮度 | 90~120日ごとの更新 | 毎日/毎週更新 |
| 所有権 | データ「リース」(多くの場合期限あり) | 永続的所有権 |
トレードオフ:ダイレクトデータセットは60~80%低コストでより新鮮なデータを提供しますが、組み込みの営業エンゲージメントプラットフォームではなく、生のファイル(JSON、CSV、Parquet)を配信します。これにより、Salesforce、HubSpot、Outreachなどの既存ツールを使用しているチームや、カスタムAI SDRエージェントを構築しているチームに最適です。
カスタムスクレイピングとAI統合
競合他社の価格追跡やニッチな求人掲示板の監視など、特定のニーズにはカスタムウェブスクレイピングインフラが必要です。
- WebスクレイパーAPI。 B2B特化型スクレイパーはCAPTCHAの解決とプロキシローテーションを自動処理し、成功したレコード1,000件あたり0.75ドルから利用可能。
- AIエージェント効率化。AI向け生のウェブページ処理はコストがかかります。MCP(Model Context Protocol)サーバーは、クリーンで構造化されたデータをLLMに直接配信することでこの課題を解決し、AIエージェントの高速化と低コスト化を実現します。
- ディープルックアップ。特定のデータ不足に対して、自然言語クエリでレコードを照合。成功した照合結果のみ課金されます。
B2Bデータ調達における3つの戦略
戦略的な課題は、単にB2Bデータの入手先を見つけることではありません。壊れたスクレイパーの維持、古いレコードの管理、未使用機能への過剰な支払いを伴わずに、確実にアクセスする方法です。
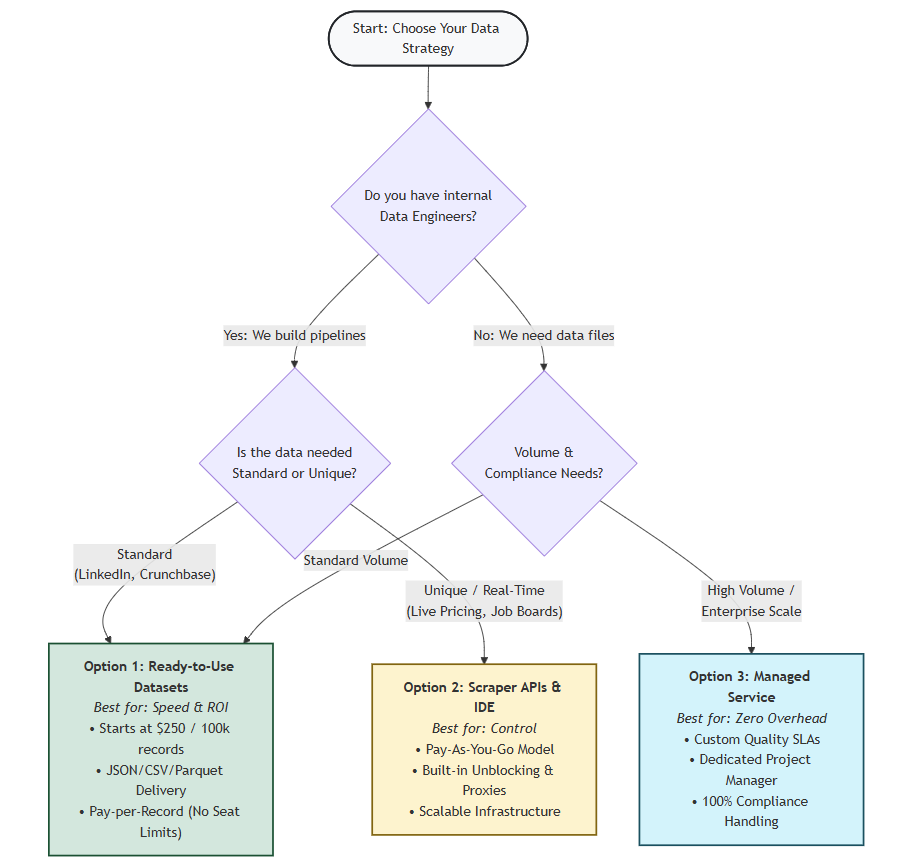
選択肢1:即利用可能なデータセットの購入
最適:構造化された連絡先・企業データへの即時かつ大量アクセスが必要な組織向け。
事前構築済みデータセットは、LinkedIn、Crunchbase、G2などの主要プラットフォームから定期的に更新されるデータのスナップショットを提供します。自らデータをスクレイピングする代わりに、業界、所在地、企業規模でフィルタリングされた、必要なフィールドを正確に含む構造化ファイルをダウンロードできます。
- 主な利点:120以上のドメインにまたがる数十億件のレコードにアクセス可能。Snowflake、S3、Google Cloudに直接配信。事前クリーニング済みのフォーマット(JSON、CSV、Parquet)により前処理時間を80~90%削減。
- 選択すべきタイミング。24~48時間以内にデータが必要な場合、年間予算が5,000~25,000ドルの場合、チームがソフトウェアインターフェースよりも生データパイプラインを好む場合。
- 価格。 10万レコードあたり250ドルから。
オプション2:カスタム収集を構築
最適なケース:独自ツールを構築するエンジニア中心のチーム、または独自のデータ組み合わせが必要な場合。
CAPTCHAの解決、プロキシローテーション、レート制限といった技術的な複雑さは最新のインフラが処理するため、エンジニアはスクレイピングの仕組みではなくデータロジックに集中できます。
- 利用可能なツール: Web Scraper IDE(スクレイパーをサーバーレス関数として実行)、スクレイピングブラウザ(動的サイトの自動ブロック解除)、世界最大級のレジデンシャルプロキシネットワーク(1億5000万以上の倫理的に調達されたIPアドレス)へのアクセス。
- 選択すべきタイミング:独自AI製品の開発中、リアルタイム更新が必要、データエンジニアが1~2名在籍する場合。
- コスト見積もり:初年度TCO(インフラ・エンジニアリング時間含む)30,000~60,000ドル。
オプション3:マネージドデータサービス
最適な対象:技術的負担なく大規模なAI対応データパイプラインを必要とする企業組織。
データとフォーマットを指定するだけで、Bright Dataのマネージドデータ取得サービスが収集・クリーニング・配信を処理します。
- 主な利点:技術的オーバーヘッドゼロ、95~99%の精度を保証するSLA、99.99%のネットワーク稼働率、専任アカウントマネージャー。
- 選択すべきタイミング:1,000万件以上の継続的データ取得が必要/社内データエンジニアリングチームが存在しない/市場投入までの時間を最優先とする場合。
- 価格設定。 標準スクレイパー1台あたり500ドルからの初期設定費(複雑なエンタープライズパイプライン向けにスケーリング);月額サービスは1,500ドル/月から。
現代のチームがB2Bデータを活用する方法
B2Bデータは営業部門の枠を超え、組織全体の基幹インフラへと進化しました。
営業チームはB2Bデータを活用し、ICP(理想顧客像)に完全に合致する高精度ターゲットリストを構築。検証済みダイレクトダイヤル、企業属性フィルター、技術属性データ、購買意図シグナルを組み合わせ、購買タイミングにあるアカウントを特定します。これによりコンタクト成功率は3~5倍向上(1~2%→5~10%)、営業サイクルは20~30%短縮されます。
マーケティングチームはテクノグラフィックデータと購買意図シグナルを組み合わせ、見込み客のニーズに直接訴求するキャンペーンを構築します。レガシーシステムの制限といった具体的な課題に対処することで、CACは通常30~50%低下し、CTRは汎用ターゲティングと比較して2~4倍向上します。
オペレーションチームは 自動データ補完を活用し、手動入力作業を排除。見込み客がCRMに登録されると、職務タイトル・企業規模・技術スタックが完全なデータ系譜と共に即時入力されます。調査時間はリード1件あたり数分からほぼ瞬時に短縮されます。
戦略チームはB2Bデータシグナルを活用し、競合他社の採用急増・技術シフト・地理的拡大を追跡。遅れた市場調査ではなく観察されたトレンドに基づき、未開拓のニッチ市場を特定し新興競合を早期に発見します。
データ品質管理の実践
正確なB2Bデータを維持するには、定期的なクリーンアップから継続的な検証への移行が必要です。自動化されたシステムにより、データの劣化がCRMに影響を与えるのを防ぎます。
3つの主要な実践方法:
- ソースでのフィルタリング。全てのリードを収集しない。収集時に厳格なフィルターを適用(例:「過去6ヶ月以内にシリーズB資金調達済み」「Salesforce Enterprise利用必須」)。CRMに50,000件のコンタクトがあっても、ICPに合致するのは10,000件のみなら、40,000件の無関係なレコード維持にコストを払っていることになる。
- 定期的な更新をスケジュールする。アカウント価値に基づいて更新スケジュールを設定する。高価値アカウント(潜在価値10万ドル以上)は週次~月次更新が必要。標準的な見込み客開拓には月次~四半期ごとの更新(30~90日)が求められる。月次劣化率2.1%の場合、90日経過したリストには約6%の無効コンタクトが蓄積する。
- 階層的アプローチを採用。まず既存CRMデータを確認(コストゼロ)。低コスト(1フィールドあたり0.01ドル未満)でデータセットをバッチエンリッチメント。リアルタイムエンリッチメント(1コンタクトあたり0.05~0.25ドル)は高価値アカウントのみに限定。全コンタクトをリアルタイムでエンリッチする場合と比べ、総コストを80~90%削減。
品質目標:メールバウンス率を1%未満に維持(2%でGmail/Outlookのペナルティ発生)、携帯電話の通話接続率を20%以上、重複率を2%未満に保つ。
適切なB2Bデータプロバイダーの選定
適切なB2Bデータプロバイダーの選択は、営業生産性、データ品質、予算に数年にわたり影響します。レコード数だけでなく、運用上の要素に焦点を当ててください:
1. データの正確性と鮮度
検証基準。プロバイダーはリアルタイム検証を採用しているか?目標:メールバウンス率1%未満、電話接続率15%以上。
具体的に確認すべき事項:
- 全顧客における測定済みバウンス率は?
- 電話番号の検証方法は?
- 連絡先はどのくらいの頻度で再検証されますか?
更新頻度。 データベースは30~90日ごとに更新されていますか?120日を超える更新サイクルは重大な品質リスクを生じます。劣化率の計算例:120日ごとに更新されるデータベースでは、配信時点で約8%の無効連絡先が存在します(4ヶ月×月2.1%)。月次更新により劣化率を2%未満に抑えられます。
インフラの信頼性。カスタムスクレイピングの場合、文書化された稼働率保証(99.9%以上のSLA)と公表された成功率(スクレイピング成功率95%以上、CAPTCHAの解決率、プロキシ稼働率)を確認してください。
2. 法的コンプライアンスとデータ出所
プロバイダーはデータの出所を文書化できますか?コンプライアンス文書(GDPR、CCPA)を要求し、Do Not Callフィルタリングなどのプライバシー制御を提供していることを確認してください。ほとんどの確立されたベンダーはこれを扱っています。契約交渉中に法務チームが詳細を確認できます。
要求事項:データ系譜の文書化、収集タイムスタンプ、ソース参照情報。
3. AI統合と技術的機能
データはAIツール、CRM、データウェアハウスで即時利用可能な状態であること:
CRM互換性: CRM(Salesforce、HubSpot、Pipedrive)と同期し、レコードを充実させ重複を防止できるか?ネイティブ統合、APIアクセス、Webhookサポート、一括インポート/エクスポートを確認。
標準フォーマット。データは標準フォーマット(JSON、CSV、Parquet)で提供され、一貫したスキーマと文書化されたデータディクショナリを備えていますか?
リアルタイム更新。プロバイダーは必要時にリアルタイムでレコードを更新できますか?リアルタイムAPIにより、フォーム送信時の連絡先強化、キャンペーン前のメール検証、発信前の電話番号確認が可能になります。
4. 明確な価格と契約条件
成果に応じた課金: 品質基準を満たしたレコードのみに課金されますか?一部プロバイダーは検索、プレビュー、不一致の照会にも課金します。ベストプラクティス:正常に配信され、品質検証済みのレコードのみに課金されること。
隠れた費用なし。ユーザー数ベースのライセンス料、APIリクエスト料、エクスポート料、超過ペナルティ、設定費、トレーニング費用に注意。
データ所有権。解約後もエクスポート済みレコードへのアクセス権は保持できますか?データを購入した時点で、永続的な所有権を得るべきです。
契約の柔軟性。 月単位で解約可能か、それとも年間契約に縛られるか?季節的な需要に応じてスケールアップ/ダウンできるか?
重要なポイント
本ガイドから5点だけ覚えておくべきこと:
- 連絡先データは数ヶ月で信頼性を失います。専門職の転職率は年間25~40%です。継続性を保つため、定期的に(30~90日ごと)検証し、LinkedInプロフィールURLなどの安定した識別子を活用してください。
- 従来型ベンダーは四半期ごとの更新(90~120日ごと)のため、納品時点でデータは30~90日経過しており、既に3~6%が劣化している。日次/週次/月次更新の直接データセットは劣化を60~80%低減する。
- 価格モデルは劇的に異なる(2026年時点の料金)— 従来型契約は年間数万ドルでユーザー数制限がある一方、直接データセットは大幅に低コストでユーザー制限なし。同等のカバレッジでは、直接データセットが通常はるかに安価。
- 階層的アプローチを採用:まず既存CRMデータを確認(無コスト)、バッチエンリッチメントにデータセットを活用(フィールド毎最小コスト)、リアルタイムエンリッチメントは高価値アカウントのみに限定。
- 契約前に検証を– 貴社のICPに合致するサンプルデータを要求し、小規模キャンペーンで実際のバウンス率をテストし、契約前に電話接続率を測定してください。
高品質データがもたらす効果を実感
現在のプロバイダーと比較するため、B2Bデータセットの無料サンプルをダウンロード。理想的な顧客プロファイルでフィルタリングし、データ品質をテスト、実際のバウンス率を測定。クレジットカード不要。
よくあるご質問
B2Bデータベースの更新頻度は?
アカウントの重要度に応じて、30~90日ごとに連絡先データを更新してください。優先度の高いアカウントは週次更新、標準的な見込み客開拓には月次更新が必要です。データは月2.1%の割合で劣化するため、90日経過したリストには6%の無効な連絡先が蓄積されます。これはGmailやOutlookで2%を超えるとバウンスペナルティが発生する水準です。
B2BデータをAIエージェントにどう供給しますか?
AIエージェントにはリアルタイムデータアクセスが必要です。現代的な手法には、オンデマンドクエリ用のDeep Lookup(コンタクトあたり0.05~0.25ドル)などの自然言語ツール、SQL経由の定期更新データベース(週次/月次更新)、または直接ウェブ抽出用のMCPサーバーが含まれます。エージェントの自律レベルと予算制約に基づいて選択してください。
B2Bデータソリューションは自社開発と購入のどちらが適切ですか?
70/20/10フレームワークを活用:広範なカバレッジには既成データセット(レコードあたり0.01ドル未満)を70%、アクティブなリードにはリアルタイムエンリッチメント(コンタクトあたり0.05~0.25ドル)を20%、独自シグナルにはカスタムスクレイピングを10%割り当てます。これにより低コストのバルクデータと新鮮なエンリッチメント、競争優位性のバランスが取れます。
データ品質改善のROIをどう測定するか?
3つの指標を追跡:エージェント成功率(データ不良時20-30%に対し60%以上のタスク完了率、SDR1人あたり3万ドル以上節約)、ドメイン評価(バウンス率1%未満維持、2%超はペナルティ発生)、時間削減効果(リード1件あたり15-20分から2秒へ、月間500件以上処理チームで年間7万5千ドル以上節約)。





