

データチームの多くは、データを収集できないから失敗するのではありません。生データが乱雑で重複し、一貫性がない状態で届くにもかかわらず、アナリストやモデルが信頼できる形に変換する規律ある方法がないために失敗するのです。メダリオンアーキテクチャは、まさにその問題を解決するために現代のデータプラットフォームの多くが採用するパターンであり、データをブロンズ、シルバー、ゴールドという3つの段階的にクリーンなレイヤーに移行させます。
このガイドでは、データエンジニアが理解すべき方法でこのパターンを解説します。各レイヤーの動作、レイヤー間でのデータの物理的な移動方法、そして外部から取得したウェブデータがブロンズの生入力としてどこに組み込まれるかについて説明します。
この記事の内容:
- メダリオンアーキテクチャとは何か、そしてなぜDatabricksが普及させたのか
- ブロンズ、シルバー、ゴールドの各レイヤーの役割と消費者
- テーブルフォーマット、ACIDトランザクション、変更データキャプチャを使ったレイヤー間のデータ移動方法
- 外部データおよびウェブデータがブロンズソースとしてパターンに組み込まれる場所
- ベストプラクティス、よくある落とし穴、およびこのパターンが効果を発揮するユースケース
メダリオンアーキテクチャとは何か?
メダリオンアーキテクチャは、レイクハウス内のデータを整理するための設計パターンであり、ブロンズからシルバー、ゴールドへと流れるにつれて、各段階でデータの構造と品質が向上します。この名前はメダルの比喩を借用しており、データは価値の低い生のブロンズとして入り、より価値の高いシルバーへ、そしてゴールドへと精製されます。すべてのレコードが消費に適した状態になるまでいくつかのホップを経るため、マルチホップアーキテクチャとも呼ばれます。
このパターンは、Databricksがレイクハウスパラダイムおよび2019年にオープンソース化されたDelta Lakeテーブルフォーマットとともに普及させました。レイクハウスは、データレイクの低ストレージコストと、ACIDトランザクションやスキーマ強制などのデータウェアハウスの信頼性機能を組み合わせたものです。メダリオンアーキテクチャは、そのレイクハウスに明確な信頼のフローを与える組織原則です。現在はクロスプラットフォームの慣例となっており、同じブロンズ、シルバー、ゴールドの用語がDatabricks、Microsoft Fabric、Snowflakeのドキュメントに登場します。
核心的なアイデアはシンプルです。1つの不透明なステップでデータをクリーニングする代わりに、永続的な生のコピーを保持し、各段階に明確な契約がある形で段階的に精製します。この分離こそがパターンを永続的なものにしており、以下のすべての基盤となっています。
データチームが採用する理由
メダリオンアーキテクチャは、複数の問題を同時に解決するため、その価値が認められています。
段階的で検査可能なデータ品質。品質は、推論が難しい単一の変換ではなく、段階的に改善されます。各ホップには明確な役割があるため、何かがおかしいと気づいたときにどのレイヤーを調べればよいかがわかります。
生データからの再処理。ブロンズレイヤーは永続的な履歴アーカイブであるため、ソースシステムに戻ることなく、いつでもシルバーテーブルとゴールドテーブルを再構築できます。変換にバグがある場合や、ビジネスロジックが変更された場合は、もはや利用できなくなったデータを再収集するのではなく、ブロンズから再生します。
系譜と監査可能性。ブロンズは元のペイロードを保存するため、フォレンジックレコードが得られます。コンプライアンスおよび監査チームは、ダッシュボード上の任意の数値をその元となった正確な生レコードまで遡ることができます。
消費者間での関心の分離。異なるレイヤーは異なるオーディエンスにサービスを提供します。データエンジニアと運用チームはブロンズとシルバーで作業します。アナリストとデータサイエンティストはシルバーで作業します。ビジネスアナリスト、経営幹部、アプリケーションはゴールドを消費します。
マルチコンシューマーサービング。1つのクリーンなシルバーエンティティが多くのゴールドテーブルに供給できるため、財務、運用、マーケティングは、それぞれ同じ信頼できるソースから独自の消費対応ビューを構築できます。
これはまた、このパターンがELTの考え方と自然にペアを組む理由でもあります。すべてをランディング前に変換するのではなく、まず生データをロードし、次にプラットフォーム内で変換します。より広いインジェストフローについての復習が必要な場合は、ETLパイプラインの解説とデータパイプラインアーキテクチャの概要がメダリオンモデルにきれいにマッピングされています。
3つのレイヤーの詳細
フローは概念的には線形です。生データはブロンズに着地し、シルバーで精製され、ゴールドで消費用に形成されます。
flowchart LR
S["外部およびウェブソース"] --> B["ブロンズ:生、そのまま、追記のみ"]
B --> SI["シルバー:クリーニング済み、適合済み、重複排除済み"]
SI --> G["ゴールド:集計済み、ビジネスレベル"]
G --> C["BI、ダッシュボード、ML、アプリケーション"]データはブロンズからシルバー、ゴールドへと移動するにつれて段階的に精製されます。
ブロンズレイヤー:生データと不変性
ブロンズは、外部ソースシステムから到着するすべてのデータのランディングゾーンです。そのテーブルはソースの形状をそのままミラーリングし、ロードタイムスタンプや行を書き込んだプロセスなどの詳細を記録するいくつかの追加メタデータ列があります。ここでの優先事項は、キャプチャの速度、ソースの耐久性のある履歴アーカイブ、クリーンな系譜、そして元のシステムを再度読み取ることなく後で再処理するオプションです。
ブロンズにはいくつかの定義的な特性があります。元の形式でのデータの生の状態を含みます。増分的に追記され、時間とともに成長します。データが到着したときの忠実度を正確に保持する、唯一の信頼できる情報源として機能します。直接のアナリストアクセスではなく、ダウンストリーム処理を目的としています。
重要な実装の詳細:ブロンズでは一般的に型を強制しません。Databricksは、上流からの予期しないスキーマ変更から保護するために、ほとんどのフィールドをstring、VARIANT、またはbinaryとして保存することを推奨しています。実質的に、ブロンズはスキーマオンリードです。まずキャプチャして、後で解釈します。これはソーススキーマがコントロール外にある場合に正確に必要なことです。ブロンズソースは、Amazon S3、Google Cloud Storage、Azure Data Lake StorageなどのクラウドオブジェクトストレージやKafka、Kinesisなどのメッセージバスおよびフェデレーテッドシステムを含むストリーミングとバッチ入力の任意の組み合わせが可能です。
シルバーレイヤー:クリーニングと適合
シルバーは、ブロンズレコードがマッチング、マージ、適合、クリーニングされる場所であり、ビジネスがコアエンティティ、概念、トランザクションの単一の一貫したビューを得るのに十分です。マスター顧客レコード、重複排除されたトランザクション、クロスリファレンステーブルを想像してください。多くのソースからのデータを1つの一貫した形状に照合することで、シルバーはセルフサービス分析、アドホックレポート、高度な分析、機械学習を支えるレイヤーになります。
ここで通常行われる操作は具体的です:スキーマ強制、nullおよび欠損値の処理、重複排除、順序外れおよび遅延到着レコードの解決、データ品質チェック、スキーマ進化、型キャスト、ジョインです。ここでは、より正規化された書き込みパフォーマンスの高い構造を使用して、本格的なデータモデリングも開始します。この段階でデータ品質メトリクスを追跡することが、信頼できるシルバーレイヤーとブロンズの単なるコピーを区別するものです。
1つの確固たるベストプラクティス:インジェストからシルバーに直接書き込まないこと。ブロンズをスキップしてシルバーに直接書き込むと、スキーマ変更や破損したソースレコードによる障害が発生し、再生する能力を失います。シルバーには常に各レコードの検証済みの非集計表現を少なくとも1つ含める必要があり、生のブロンズに降りることなく詳細な分析が可能です。
ゴールドレイヤー:ビジネス対応
ゴールドは消費対応のプロジェクト固有のデータを保持します。ここのモデルはより非正規化されており、ジョインが少ない高速読み取りに最適化されており、最終的な変換とビジネスルールが配置されます。プレゼンテーションレイヤーの作業の本拠地です:顧客と在庫の分析、セグメンテーション、販売レポートなど。実際には、このレイヤーにKimballスタイルのスタースキーマまたはInmonスタイルのデータマートが存在することが多いです。
ゴールドは、ダッシュボード、機械学習、アプリケーションを駆動する高度に精製されたビューを表します。データは特定の期間や地域に対して大幅に集計およびフィルタリングされることが多いです。単一のビジネスドメインが1つの形状に収まることはほとんどないため、多くのチームは複数のゴールドテーブルを構築します。例えば、同じシルバー基盤から派生した財務、運用、HRの個別ビューなどです。
以下の表は、3つのレイヤーの違いをまとめたものです。
| レイヤー | データの状態 | 典型的な操作 | 主な消費者 |
|---|---|---|---|
| ブロンズ | 生、そのまま、追記のみ | インジェスト、メタデータのキャプチャ、履歴の保存 | データエンジニア、監査・コンプライアンスチーム |
| シルバー | クリーニング済み、適合済み、重複排除済み | 検証、重複排除、スキーマ強制、ジョイン | データエンジニア、アナリスト、データサイエンティスト |
| ゴールド | 集計済み、ビジネスレベル | 最終集計、ビジネスルール、スタースキーマ | BIデベロッパー、経営幹部、アプリケーション、ML |
レイヤー間のデータ移動方法
メダリオンアーキテクチャは論理的なパターンですが、特定の物理的なメカニクスの上に成り立っています。全体像は次のようになります:多くのソースがブロンズに供給し、データはレイクハウス内でシルバーとゴールドを通じて精製され、多くの消費者がゴールドから読み取ります。
flowchart LR
subgraph SRC["ソース"]
WEB["Bright Dataを介したウェブデータ"]
DB["データベースとアプリ"]
MB["メッセージバス:Kafka、Kinesis"]
end
subgraph LH["レイクハウス:Parquet上のDelta、Iceberg、またはHudi"]
BRONZE["ブロンズ:生、追記のみ"] --> SILVER["シルバー:クリーニング済み、適合済み"] --> GOLD["ゴールド:ビジネス集計"]
end
subgraph CON["消費者"]
BI["BIとダッシュボード"]
ML["MLとAI"]
APP["アプリケーション"]
end
WEB --> BRONZE
DB --> BRONZE
MB --> BRONZE
GOLD --> BI
GOLD --> ML
GOLD --> APP参照メダリオンスタック:多くのソースがブロンズに着地し、シルバーとゴールドを通じて精製され、多くの消費者にサービスを提供します。
テーブルおよびファイルフォーマット。レイヤーは通常、クラウドオブジェクトストレージのParquetファイルの上に置かれたオープンテーブルフォーマットで構築されます。Delta LakeはDatabricksとMicrosoft Fabricのネイティブフォーマットです:内部的にはデータをParquetとして保存しますが、トランザクションログと統計を追加し、プレーンParquetを超えた信頼性とパフォーマンスを提供します。Apache Icebergはマルチエンジンの相互運用性が重要な場合の同等に有能な代替手段であり、Apache Hudiはアップサート重視の変更データキャプチャインジェストに適しています。3つすべてが、このパターンが依存するACID保証を提供します。
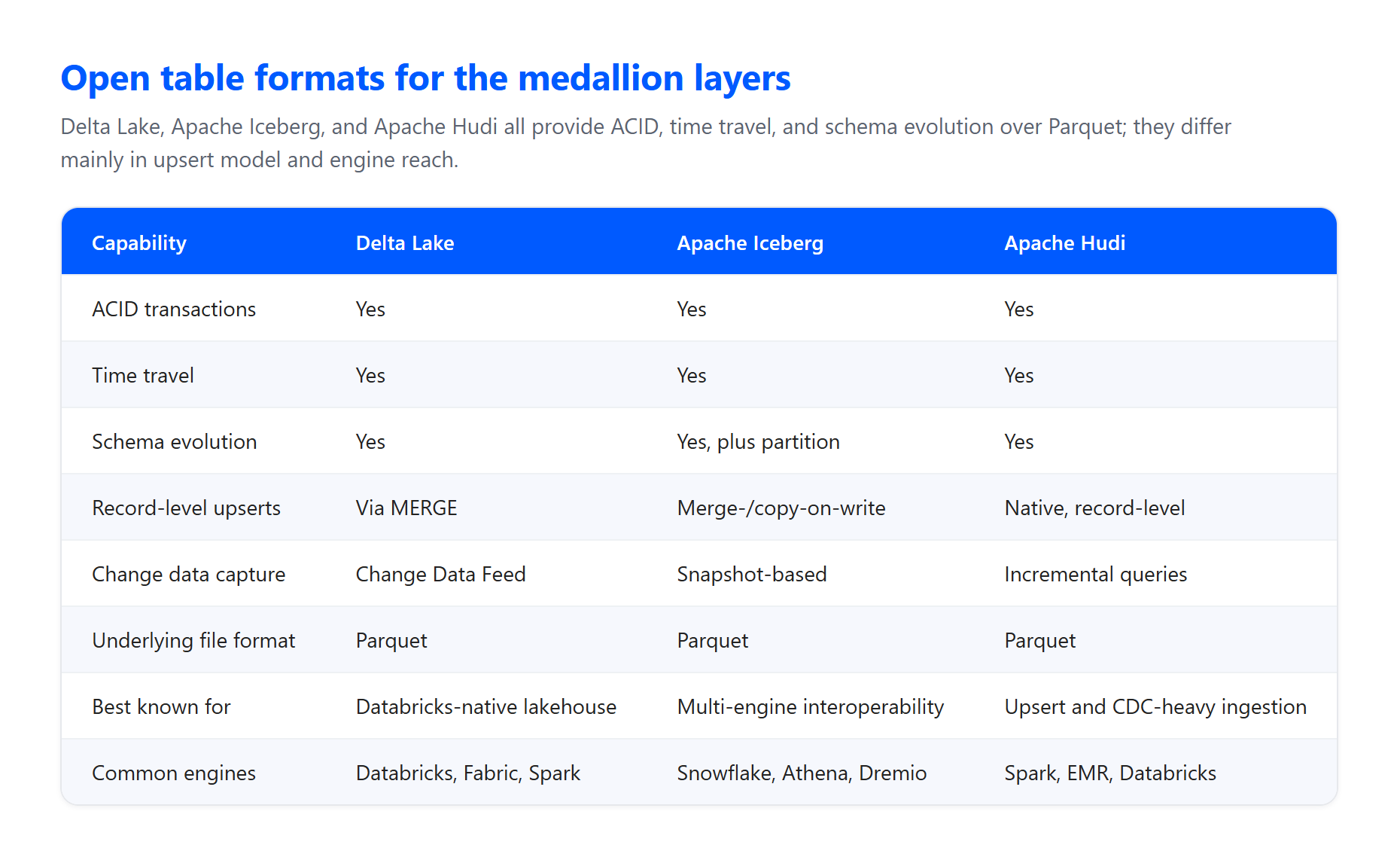
ACIDトランザクション。アーキテクチャは、データが検証と変換を通過する際に、原子性、一貫性、分離性、耐久性を保証します。これにより、失敗したジョブがテーブルを半書き込み状態で破損させることを防ぎます。多くのパイプラインが同時に読み書きする場合、これは非常に重要です。
増分ロードと変更データキャプチャ。実行のたびにすべてを再処理することはほとんどありません。Delta LakeのChange Data Feedにより、ダウンストリームレイヤーは変更されたものだけを消費できます。例えば、シルバーテーブルでフィードを有効にして、各実行で完全なリフレッシュなしにゴールド集計を増分更新するために使用できます。ブロンズでの増分インジェストはコストとレイテンシのトレードオフです:継続的なストリーミングは最低レイテンシと最高コスト、トリガーされた増分ロードはコストが低くレイテンシが追加され、フルバッチロードは最高レイテンシです。
冪等性。ブロンズのインジェストは冪等性を持つべきであり、ロードを再実行しても重複が作成されたりデータが失われたりしないようにします。追記のみの設計とシルバーでの重複排除が、安全な再生を可能にします。
オーケストレーション、バッチ、ストリーミング。Apache Sparkなどのツールが、バッチモードと構造化ストリーミングモードの両方でブロンズからシルバー、シルバーからゴールドへの変換を処理します。Spark Declarative Pipelines、Microsoft Fabricのマテリアライズドレイクビュー、Snowflakeのタスクなどの宣言型フレームワークは、レイヤー間のデータ移動のボイラープレートを削減します。Apache Airflowなどのオーケストレーターが実行を調整します。スケジューリングにAirflow、変換にSparkを使用したこのオーケストレーションパターンの実例は、このAirflowとSparkパイプラインのウォークスルーに示されており、ストリーミングバリアントはこのSpark Structured Streamingガイドにあります。
メダリオンの用語は普遍的ではないことに注意する価値があります。人気のある変換フレームワークdbtは、プロジェクトをステージング、中間、マートのレイヤーに構造化します。懸念事項はブロンズ、シルバー、ゴールドに密接にマッピングされますが、名前は異なるため、ドキュメントを読むときに2つの用語が互換性があると仮定しないでください。
ウェブデータがブロンズレイヤーに入る場所
ほとんどのアーキテクチャ図が見落としている部分があります:外部データは実際にどこから来るのか、そしてどのようにして使用可能な状態でブロンズに着地するのか?
ブロンズレイヤーはすべての外部ソースシステムのランディングゾーンとして定義されており、DatabricksはS3、GCS、ADLSなどのクラウドオブジェクトストレージを有効なブロンズソースとして明示的にリストしています。これが外部から収集されたウェブデータが適合する継ぎ目です。競合他社の価格設定、製品カタログ、公開企業記録、検索結果、レビューデータはすべて、シルバーレイヤーが解決するための独自の問題や不一致を保持した元の形式でブロンズに属する生の入力です。
これはまさにBright Dataが機能する場所です。Bright Dataはウェブデータプラットフォームであり、大規模に公開ウェブデータを収集し、生の構造化ファイルとして配信します。これにより、自然なブロンズレイヤーのソースとなります。整合性は直接的です:Bright Dataが配信する宛先は、レイクハウスプラットフォームがブロンズ入力として扱う同じクラウドオブジェクトストアです。
flowchart LR
W["公開ウェブ:サイト、SERP、マーケットプレイス"] --> BD["Bright Dataインジェスト:Web Scraper API、データセット、Data Firehose"]
BD -->|"JSON、NDJSON、CSV、Parquet"| L["クラウドストレージ:S3、GCS、Azure、またはSnowflake"]
L --> BR["ブロンズレイヤー:生、信頼できる情報源として保存"]
BR --> SV["シルバー:クリーニングと適合"]
SV --> GD["ゴールド:分析とMLにサービス提供"]Bright Dataが配信する外部ウェブデータはクラウドストレージにブロンズレイヤーとして着地し、シルバーとゴールドを通じて流れます。
バッチ、オンデマンド、継続的なデータストリームのいずれが必要かに応じて、ブロンズに供給する方法はいくつかあります:
- Web Scraper APIは、437以上のプリビルドスクレイパーを使用して任意のサイトを構造化データエンドポイントに変換し、JSON、NDJSON、またはCSVとしてデータを返します。これは新鮮なブロンズレコードのオンデマンドトリガーです。
- すぐに使えるデータセットは、何百もの人気ドメインから事前収集されたデータを提供し、即時ダウンロードまたはスケジュールに基づいて更新されます。これはブロンズへのバッチパスです。
- Data Firehoseは、ウェブレコードの継続的なリアルタイムストリームをAmazon S3、Webhook、またはストリームに直接配信し、ストリーミングブロンズインジェストパターンに適しています。
- SERP APIは、競合情報や生成エンジン監視パイプラインの一般的なブロンズ入力である構造化検索エンジン結果を提供します。
- スクレイピングブラウザはJavaScript重視のサイトを処理し、静的収集では見逃すレンダリングされたページデータを供給します。
- 目的に特化したフィードのために、Company Data APIとキュレーションされたAIおよびLLMデータセットはパイプラインにドロップする準備ができた垂直データを提供し、Web Archive APIは時系列ブロンズテーブルの歴史的スナップショットを供給します。
配信の仕組みがこれをクリーンにします。Bright Dataのデータセットは、JSON、NDJSON、CSV、XLSX、そして重要なことにParquetとしてエクスポートされます。Parquetはレイクハウステーブルがネイティブに使用する列指向フォーマットです。配信先にはAmazon S3、Google Cloud Storage、Microsoft Azure Blob Storage、Snowflake、Google Cloud Pub/Sub、SFTP、Webhook、直接APIダウンロードが含まれます。実際には、スケジュールされたデータセットが定期的なケイデンスでParquetとしてS3ブロンズバケットに着地でき、グルーコードを書く必要がありません。ノーコードのScraper Studioはこれをさらに拡張し、スクレイパーを視覚的に構築して出力をS3、GCS、Azure、BigQuery、またはSnowflakeに直接ロードできます。
2つの原則がこれをメダリオンパターンに忠実に保ちます。まず、生のペイロードを保存します。まだ使用していないフィールドを含め、プロバイダーの出力をブロンズに正確に着地させ、完全なフォレンジックレコードを保持します。次に、ブロンズではなくシルバーで正規化します。外部プロバイダーがデータをどのように構造化したかに関わらず、日付フォーマット、通貨、フィールドマッピング、クロスソース重複排除はすべてシルバーホップに属します。バッチとオンデマンドパスのどちらを選ぶかを決める場合は、データセットとウェブスクレイピングAPIの比較が有用な出発点であり、構造化データと非構造化データの入門書も役立ちます。
信頼性はどこよりもここで重要です。なぜなら、静かに失敗するブロンズソースはその上のすべてのレイヤーを汚染するからです。Bright Dataは11のプロバイダーの独立したベンチマークで平均98.44%の成功率を報告しており、倫理的に調達された4億以上のIPのレジデンシャルプロキシネットワークと99.99%のアップタイム目標に支えられています。ガバナンス要件を持つチームのために、Bright DataはGDPR、CCPA、SOC 2 Type II、ISO 27001コンプライアンスを維持し、公開されているデータのみを収集します。これはブロンズレイヤーの監査証跡が捕捉することを意図した出所の種類です。
実例:生スクレイプからゴールドテーブルへ
理論は実行できるときに信頼しやすくなります。以下は、ウェブ製品データの小さな実際のサンプルに関する最小限のメダリオンパイプラインです:3つのカテゴリにわたるAmazon USとUKのライブ検索結果から収集された12件のリスティングです。コードは意図的にシンプルにしてあり、ツールではなくパターンが際立つようにしています。
ブロンズ。収集されたとおりに行を着地させます。価格はまだ文字列で、通貨は混在しており、何もクリーニングまたは削除されていません。
import pandas as pd
# ブロンズ:インジェストメタデータとともにそのまま着地した生のスクレイプ行
bronze = pd.DataFrame(scraped_rows)
bronze["_ingested_at"] = "2026-06-23T00:00:00Z"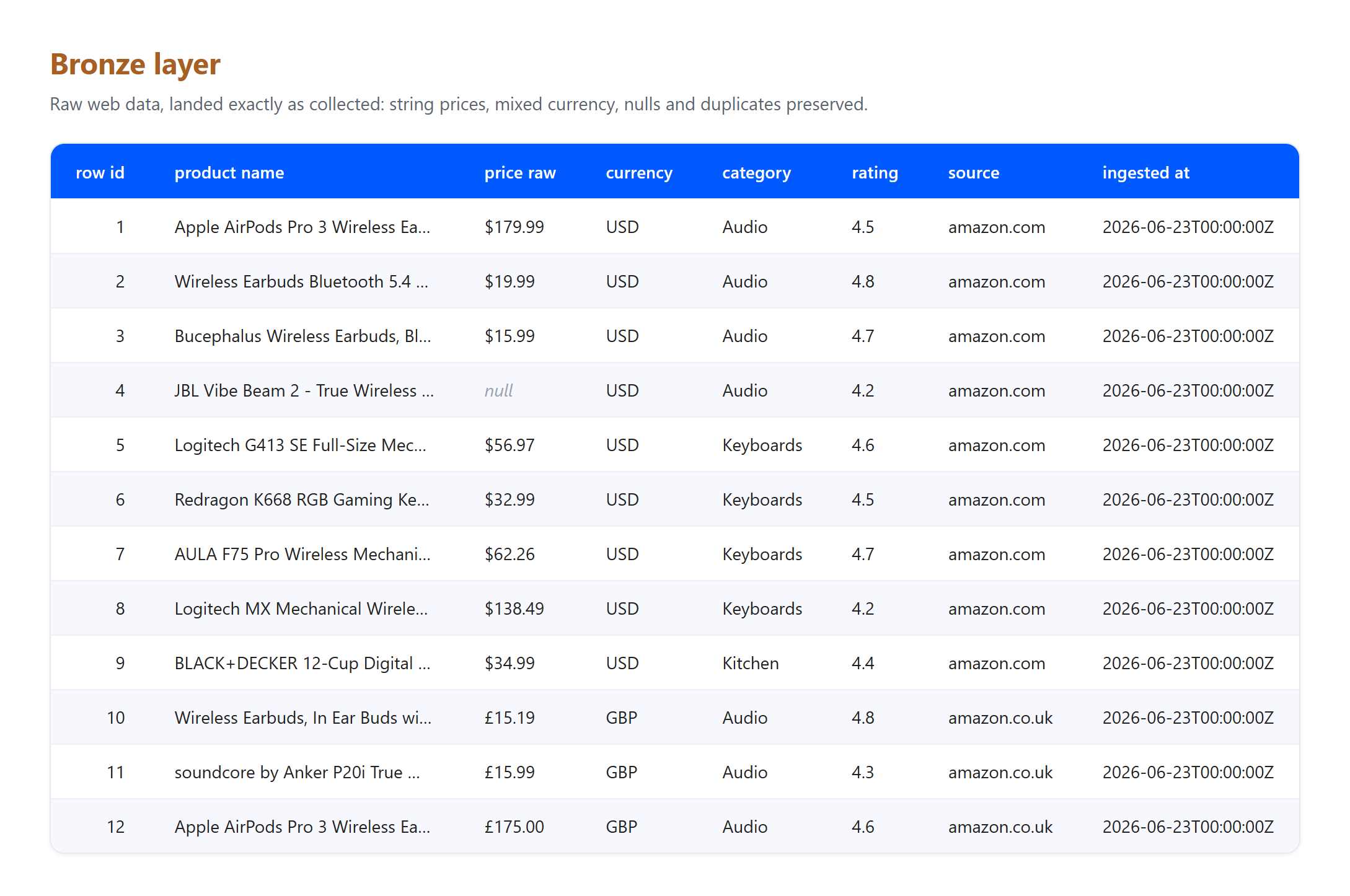
シルバー。価格を数値にパースし、すべてをUSDに正規化し、タイトルのHTMLエンティティをデコードし、使用可能な価格がない行を削除し、同じ製品が複数回キャプチャされた場合の重複を排除します。
import html, re
def to_usd(price_raw, gbp_rate=1.27): # 1.27は説明のための固定レート
if not price_raw:
return None # 価格なし、行は信頼できない
is_gbp = "£" in price_raw
value = float(re.sub(r"[^0-9.]", "", price_raw.replace(",", "")))
return round(value * gbp_rate, 2) if is_gbp else round(value, 2)
silver = bronze.copy()
silver["price_usd"] = silver["price_raw"].map(to_usd)
silver["rating"] = silver["rating"].astype(float) # テキストの評価を数値に
silver["product_name"] = silver["product_name"].map(html.unescape) # & が & になる
silver = silver[silver["price_usd"].notna()] # 価格なしの行を削除
silver = silver.sort_values("price_usd").drop_duplicates("product_name") # 重複排除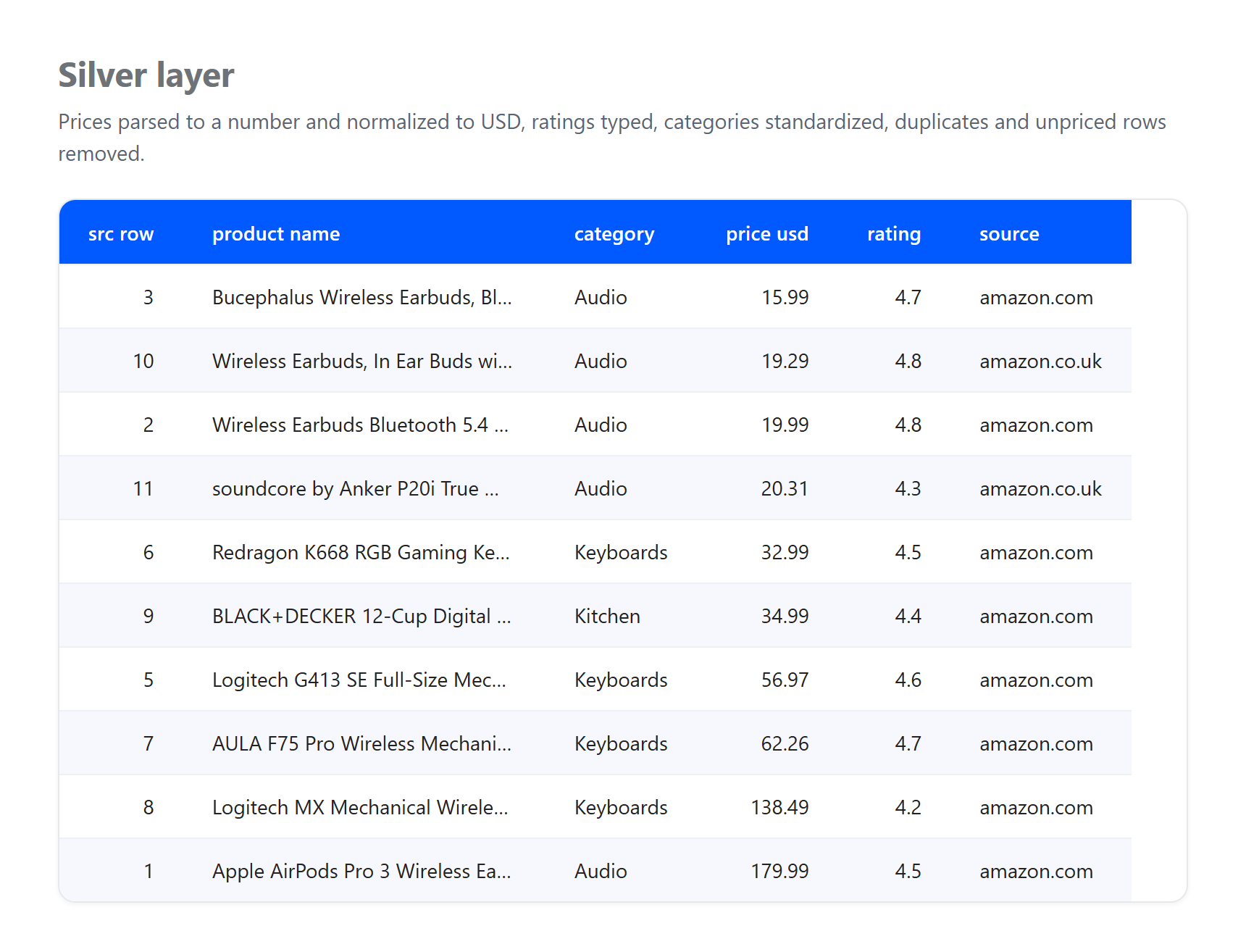
ゴールド。クリーンなレコードをダッシュボードまたはモデルが実際にクエリするビジネスビューに集計します。
gold = (
silver.groupby("category")
.agg(
products=("product_name", "count"),
avg_price_usd=("price_usd", "mean"),
min_price_usd=("price_usd", "min"),
max_price_usd=("price_usd", "max"),
avg_rating=("rating", "mean"),
)
.round(2)
.reset_index()
)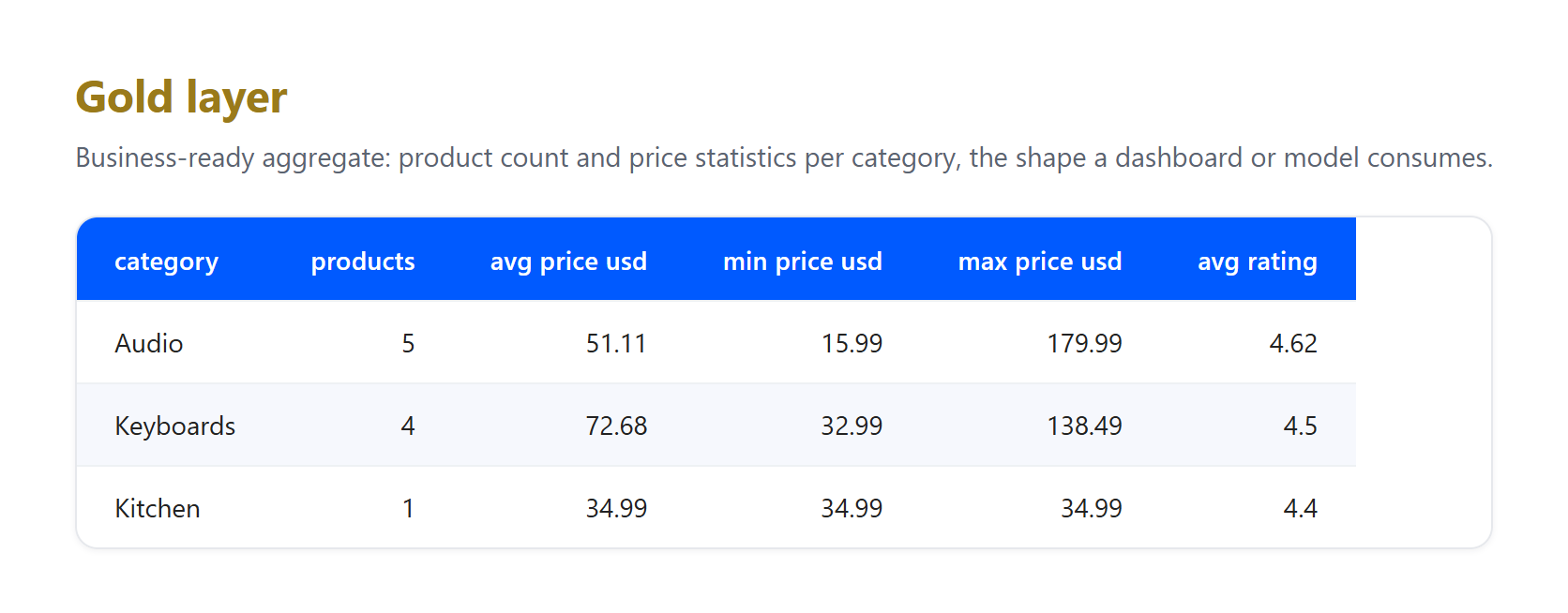
レイヤーが何を吸収したかに注目してください。これはまさに実際のパイプラインが直面しなければならないことです。これは2026年6月23日に収集された小さな実際のサンプルであり、GBPからUSDの数値は説明のための固定レートであり、ライブ変換ではありません。ブロンズに3つの本物のアーティファクトが到着し、シルバーで解決されました:1つのリスティングが価格なしで到着して削除され、同じApple AirPods Pro 3製品がUSとUKの両方のページからキャプチャされて1つのレコードに重複排除され、&などの生のHTMLエンティティを含むタイトルがプレーンテキストにデコードされました。そのクリーンアップはどれもブロンズに属しません。ブロンズの唯一の仕事は到着したものを保存することです。この職務の分離こそがパターンの要点です。
レイクハウスツールエコシステム
メダリオンパターンは、使い慣れたツールセット全体で実装されています。これらのどれも互換性があるわけではありませんが、動作するアーキテクチャは通常いくつかを組み合わせます。
- Databricksは、レイクハウスパラダイムとメダリオンアーキテクチャの両方を生み出した商業レイクハウスプラットフォームであり、ネイティブのDelta Lakeサポートと宣言型パイプラインツールを備えています。
- Delta Lakeは、Parquetの上にACIDトランザクション、スキーマ強制、タイムトラベル、変更データキャプチャを追加するオープンソースのテーブルフォーマットです。
- Apache Sparkは、バッチまたはストリーミングでブロンズからシルバー、シルバーからゴールドへの変換を実行する分散コンピューティングエンジンです。
- Apache Icebergは、複数のエンジンが同じテーブルを読む必要がある場合に好まれるオープンテーブルフォーマットです。
- Apache Hudiは、強力なレコードレベルのアップサートと増分プルサポートを持つオープンテーブルフォーマットであり、変更が多いブロンズレイヤーで一般的です。
- Snowflakeは、ゴールドレイヤーのマネージドIcebergテーブルを含め、このパターンをネイティブにサポートしています。
- dbtは、多くのチームがシルバーとゴールドレイヤーを構築するために使用するSQLファーストの変換フレームワークです。
- Microsoft Fabricは、Delta Lakeを標準化してOneLake上でメダリオンアーキテクチャをネイティブに実装しています。
プラットフォームがSnowflakeまたはGoogle Cloudの場合、Bright DataとSnowflake Cortexの統合ガイドとVertex AIとSERP APIのワークフローでブロンズのハンドオフをコンテキストで示しています。
ベストプラクティス
いくつかの慣例が、クリーンな実装と脆弱な実装を区別します。
- インジェストからシルバーに直接書き込まない。スキーマ変更や破損したレコードが精製されたテーブルを壊さないよう、常に生データをまずブロンズに着地させます。
- ブロンズは緩やかな型付けにする。上流のスキーマドリフトがデータを削除しないよう、ほとんどのフィールドをstring、VARIANT、またはbinaryとして保存します。
- 可能な場合はブロンズをストリームとして読む。追記のみのソースでは、ストリーミング読み取りがレイテンシを低く保ちます。小さなデータセットにはバッチ読み取りを予約します。
- 常にシルバーに非集計レコードを保持する。集計はゴールドに属するため、シルバーは多くの消費者にわたって再利用可能なままです。
- ゴールドをリアルタイムにしようとしない。ゴールドは頻繁にクエリされるバッチ更新集計に最適化されています。低レイテンシのワークロードに後付けすると、脆弱で高価なパイプラインが生まれる傾向があります。
- レイヤー別にテーブルに名前を付ける。catalog.bronze.table、catalog.silver.table、catalog.gold.tableのような名前空間は、任意のテーブルの信頼レベルを一目で伝えます。
よくある落とし穴と批判
このパターンは堅牢ですが、誤用されることが多いため、失敗パターンは十分に文書化されています。
ブロンズのスキップ。外部データがすでにきれいに見える場合は魅力的ですが、ブロンズをスキップすると監査証跡と再処理する能力が失われます。シルバーレイヤーのセマンティクスは、その背後に生のレコードがない場合、静かに変化します。
シルバーをゴールドとして扱う。チームがビジネスKPIと重い集計をシルバーに直接構築すると、チームによってメトリクスの定義が異なり、権威ある単一のバージョンがなくなります。集計はゴールドに保持します。
生のブロンズを本番データとして読む。ブロンズは未検証で、しばしば乱雑です。ダッシュボードをブロンズに向けると、重複カウントと不一致な結果が生じます。ブロンズは履歴レコードであり、分析の信頼できる情報源ではありません。
クロスレイヤーの絡み合い。パイプラインがレイヤー間で責任を漏らす場合、例えば生のイベントをゴールドに直接インジェストすると、単一のスキーマ変更がスタック全体にカスケードする可能性があります。
パターンを厳格に適用することへの正当な批判もあります。ある分析が指摘したように、すべてのソースに厳格な3レイヤー構造を適用すると、特定のデータセットが広範なクリーニングを必要としない場合に非効率が生じ、順次レイヤリングはリアルタイムのユースケースが許容できないレイテンシを追加します。実践者コミュニティは、一部の設計に追加レイヤーを提案することで対応しています。例えば、ブロンズの前のランディングゾーンや、運用と機械学習サービングのためのゴールドの上のプラチナレイヤーなどです。
これらすべてを健全に読む方法は、メダリオンアーキテクチャは義務ではなく柔軟なフレームワークであるということです。Databricks自体は、メダリオンアーキテクチャに従うことは推奨されるベストプラクティスであるが要件ではないと述べており、Delta Lakeプロジェクトはオプションの柔軟なフレームワークとして説明しています。クエリパターンと消費者に合ったレイヤー数と命名を使用してください。
一般的なユースケース
このパターンは、生の入力が乱雑で多くの消費者が信頼できる出力を必要とする場合に最も明確に効果を発揮します。
- 競合価格設定とeコマースインテリジェンス。多くの小売業者から収集された製品と価格データがそのままブロンズに着地し、シルバーで正規化・重複排除され、ゴールドの価格追跡と品揃えダッシュボードに供給されます。
- AIおよび機械学習トレーニングデータ。ウェブスケールのテキストと構造化データが生のままブロンズに着地し、シルバーでクリーニング・重複排除され、ゴールドでモデル対応の特徴に形成されます。実際のステップはこの機械学習のためのウェブスクレイピングガイドに記載されており、より広い戦略はAIデータフライホイールの記事にあります。
- 市場調査および代替データリサーチ。多くのソースからの外部シグナルがシルバーで単一のリサーチビューに適合され、ゴールドの指標に集計されます。
- 検索とSERP監視。継続的な検索結果のストリームがブロンズに流れ込み、シルバーで構造化され、ゴールドの可視性とシェアオブボイスメトリクスにまとめられます。
- ファーモグラフィックおよび顧客エンリッチメント。企業データフィードがシルバーレイヤーで内部レコードをエンリッチし、販売とマーケティングのゴールドテーブルを生成します。
これらのエンジニアリング配管については、AWS Glue ETL、AWS Step Functions、Kubeflowパイプライン、Mage AIパイプライン、およびライブウェブデータをTableauに接続するのウォークスルーがそれぞれ実際のブロンズからサービングへのパスを示しています。抽出ステップ自体の基本は、このデータ抽出の入門書に記載されています。
まとめ
メダリオンアーキテクチャが持続するのは、チームが生データを信頼できるデータに変換するための共通言語を提供するからです。一度に一つの規律あるホップで。ブロンズは真実を保存し、シルバーはそれを一貫させ、ゴールドはそれを有用にします。このパターンは、供給する生データと同じくらいうまく機能します。これが、信頼性の高い、よく構造化されたブロンズソースが詳細ではなく基盤である理由です。
外部データとウェブデータのために、その基盤はBright Dataが適合する場所です:プロダクショングレードのコレクションがJSON、CSV、またはParquetとしてレイクハウスがすでにブロンズとして扱うクラウドストレージに直接配信されます。信頼性の高いウェブデータでブロンズレイヤーを供給する準備ができていますか?無料トライアルを開始して、生のウェブデータがどれだけ迅速にパイプラインに流れるかを確認してください。
よくある質問
Q: メダリオンアーキテクチャを簡単に説明すると?
レイクハウス内のデータを3つのレイヤーを通じて移動させながら、よりクリーンで有用にする方法です。生データはブロンズレイヤーに着地し、シルバーレイヤーでクリーニング・標準化され、ゴールドレイヤーでビジネス対応テーブルに集計されます。各レイヤーには明確な役割があり、データ品質の管理と監査が容易になります。
Q: ブロンズ、シルバー、ゴールドレイヤーの違いは何ですか?
ブロンズは到着したままの生データを追記のみ・未変換の永続的な信頼できる情報源として保持します。シルバーは重複排除、スキーマ強制、ジョインが適用されたクリーニング済み・適合済みのデータを保持し、信頼性と一貫性があります。ゴールドは特定のレポート、ダッシュボード、機械学習、アプリケーション向けにモデル化された集計済みのビジネスレベルデータを保持します。
Q: メダリオンアーキテクチャはETLと同じですか?
いいえ、ただし関連しています。ETLはデータの抽出、変換、ロードを説明します。メダリオンアーキテクチャは、それらの変換がどこで行われるかを整理するレイヤリングパターンです。レイクハウスでは通常ELTスタイルに従い、生データをまずブロンズにロードし、プラットフォーム内でシルバーとゴールドへと段階的に変換します。
Q: 常に3つのレイヤーすべてが必要ですか?
いいえ。Databricksはメダリオンアーキテクチャを推奨されるベストプラクティスとして説明しており、要件ではありません。クリーンな状態で到着する一部のデータセットは広範なシルバーステップを必要としない場合があり、一部のリアルタイムユースケースはフローの一部を意図的にバイパスします。レイヤーの数と命名はクエリパターンと消費者に合わせるべきです。主な注意点は、ブロンズをスキップすると生の監査証跡と再処理する能力が失われることです。
Q: メダリオンテーブルにはどのファイルフォーマットを使用すべきですか?
ほとんどの実装では、Delta Lake、Apache Iceberg、Apache Hudiなどのオープンテーブルフォーマットを使用し、いずれもクラウドオブジェクトストレージのParquetファイルの上に置かれます。これらのフォーマットはACIDトランザクション、スキーマ強制、タイムトラベルを追加し、パターンが依存するものです。Delta LakeはDatabricksとMicrosoft Fabricのネイティブフォーマットであり、Icebergは複数のエンジンが同じテーブルを読む場合に一般的です。
Q: 外部またはウェブデータはメダリオンアーキテクチャにどのように適合しますか?
外部データとウェブデータはブロンズレイヤーの入力です。収集した生データ(例:製品、価格、検索、企業データ)をブロンズの元の形式で着地させ、シルバーで正規化・重複排除します。レイクハウスプラットフォームがS3、GCS、Azureなどのクラウドオブジェクトストレージを有効なブロンズソースとして扱うため、Bright DataなどのプロバイダーがウェブデータをJSON、CSV、またはParquetとしてそれらのストアに直接配信でき、ブロンズレイヤーになります。
Q: メダリオンアーキテクチャはDatabricksに縛られていますか?
DatabricksはレイクハウスパラダイムとDelta Lakeとともにこの用語を普及させましたが、パターンはDatabricksに限定されません。同じブロンズ、シルバー、ゴールドの言語はMicrosoft FabricとSnowflakeのドキュメント全体で使用されており、基礎となるオープンテーブルフォーマットは多くのエンジンで動作します。このパターンは一般的な慣例であり、単一ベンダーの製品ではありません。





