

Amazon商品データパイプラインをノートPCで動作させるのは一つの課題です。プロキシ、CAPTCHA、レイアウト変更、IPブロックを伴う本番環境での継続的な稼働は別の課題です。スクレイピング自体を解決しても、スケジューリング、再試行、エラー処理、収集したデータの可視化手段が必要です。
ここではそれら全てを構築します。Bright DataのウェブスクレイピングAPIと Mage AIを活用し、Amazon商品とレビューを収集→Gemini感情分析を実行→PostgreSQLとStreamlitダッシュボードへ全データをプッシュするパイプラインを構築します。フルパイプラインはDockerと単一APIキー(AI分析用Geminiキーはオプション)で動作します
要約:スクレイピングインフラを構築せずに実現するAmazon商品インテリジェンス。
- 得られるもの:キーワードで商品を発見し、Gemini AIでレビューを分析し、ライブStreamlitダッシュボードを提供するパイプライン
- 費用:従量課金制(レコード単位課金・価格ページ参照)、エンドツーエンド処理時間5~8分
- 仕組み:Bright Dataがプロキシ・CAPTCHA・パース処理を担当、Mage AIがスケジューリング・再試行・分岐処理を担当
- 開始方法:
docker compose up– 全コードはGitHubリポジトリに公開
構築内容:Bright DataとMage AIの連携パイプライン
Bright DataのウェブスクレイピングAPIがスクレイピング層を処理。キーワードまたは商品URLを送信すると、構造化されたJSON(タイトル、価格、評価、レビュー、販売者情報)が解析済みで返却されます。プロキシインフラの管理やHTMLのパースは不要。Amazonがサイトを変更しても、Bright Dataが通常はパーサーを更新。コードは変更不要。
Mage AIを初めて利用する場合:Airflowのような無料のオープンソースデータパイプラインツールですが、定型コードが不要です。ノートブック形式のエディターでPythonを記述し、各ブロックは独自のテストと出力プレビューを備えた再利用可能な単位となります。 重要な点:Mage AIは分岐パイプライン(並列パスを持つ有向非循環グラフ)をサポート。ブロック単位の再試行ロジックと、UIから変更可能なパイプライン変数を内蔵しており、コード編集は不要です。
このパイプラインは2つの並列分岐に6つのブロックを配置:
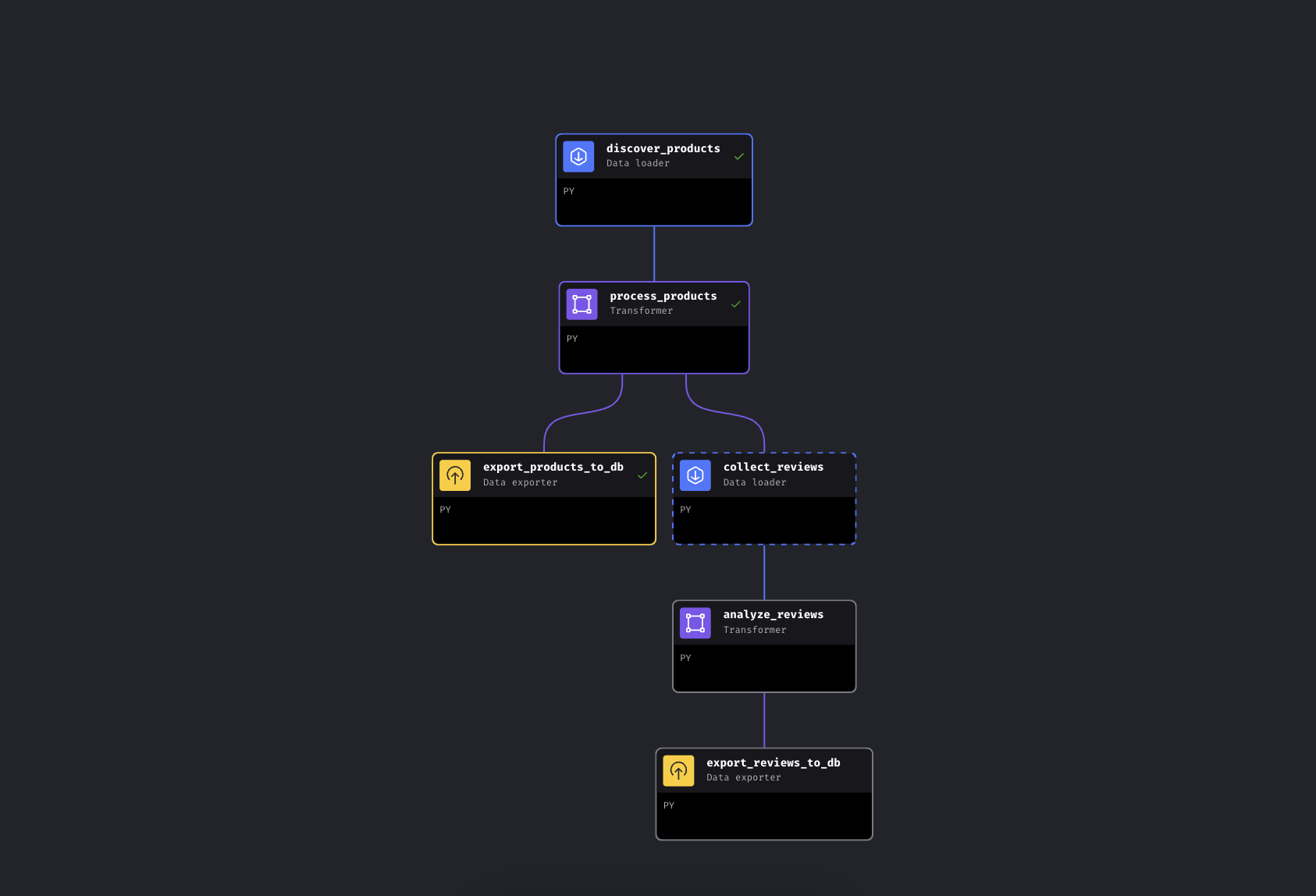
Mage AIの分岐パイプライン。左分岐は製品を即時エクスポート、右分岐はレビューを収集・分析
パイプラインはBright Data経由でキーワードから商品を発見し、価格帯と評価で情報を補完した後、分岐します。一方の経路は商品をPostgreSQLへ即時エクスポートし、もう一方の経路は上位商品のレビューを収集、Geminiで感情分析を実行し、それらもエクスポートします。
ここでMage AIを使用しているのは、パイプラインが分岐する(線形スクリプトではなくDAGであるため、レビュー収集に失敗しても製品データは既に安全)ためです。ただしBright Data API呼び出しは単なるHTTPリクエストであり、Airflow、Prefect、Dagster、あるいは単純なPythonスクリプトでも同様に動作します。
クイックスタート
リポジトリをクローンし、APIキーを追加して実行してください。すべてDocker内で動作するため、ローカルにPythonをインストールする必要はありません。
前提条件
以下のものが必要です:
- Docker および Docker Compose(Docker を入手)
- APIトークン付きのBright Dataアカウント
- Google GeminiAPIキー(無料利用枠あり、制限あり。詳細は後述のGeminiセクションを参照)
- PythonとDockerの基本的な知識。スクレイピング経験は不要です。それがポイントです
ステップ1: クローンと設定
リポジトリをクローンし設定ファイルを作成:
git clone https://github.com/triposat/mage-brightdata-demo.git
cd mage-brightdata-demo
cp .env.example .env次に、.envにAPIキーを追加します:
BRIGHT_DATA_API_TOKEN=your_api_token_here
GEMINI_API_KEY=your_gemini_api_key_hereBright Data APIトークンの取得方法:[Bright Data](https://brightdata.com) でサインアップ(無料トライアル、クレジットカード不要)後、アカウント設定からAPIキーを作成します。本パイプラインでは2つのウェブスクレイピング APIスクレイパー(商品発見用とレビュー用)を使用し、レコード単位で課金される従量課金制です。最新料金は価格ページをご確認ください。
Gemini APIキーの取得方法:Google AI Studioにアクセスし、ログイン後「APIキーを作成」をクリック。無料プランでクレジットカード不要。本パイプラインはキーなしでも動作し、評価ベースの感情分析にフォールバックします。
ステップ2: サービスの起動
docker compose up -dキーの読み込み状態を確認したい場合:
docker compose exec mage python -c "import os; t=os.getenv('BRIGHT_DATA_API_TOKEN',''); assert t and t!='your_api_token_here', 'Token not set'; print('OK')"これにより3つのコンテナが起動します:
| サービス | URL | 目的 |
|---|---|---|
| Mage AI | http://localhost:6789 |
パイプラインエディターおよびスケジューラー |
| Streamlit ダッシュボード | http://localhost:8501 |
ライブデータ可視化 + チャット |
| PostgreSQL | localhost:5432 |
データストレージ |
初回実行時はイメージの取得と依存関係のインストールが行われ、接続環境により約3~5分かかります。docker compose stop/startによる再起動は数秒で完了します。docker compose down/upはpipパッケージの再インストールを伴い、約1分かかります。
3つのサービスすべてが稼働中
ステップ3: パイプラインの実行
http://localhost:6789 を開き、[Pipelines] に移動してamazon_product_intelligence をクリックし、左サイドバーの[Triggers]をクリックして[Run@once] を押します。
Mage AIダッシュボード
パイプラインの全体所要時間は約5~8分です。大半の時間はBright Data APIがAmazonからデータを収集する工程に費やされます。エンリッチメントとデータベースエクスポートは数秒で完了し、Gemini分析はバッチサイズとレート制限に依存します。6つのブロック全てが緑色に変わったら、http://localhost:8501でダッシュボードを確認してください。
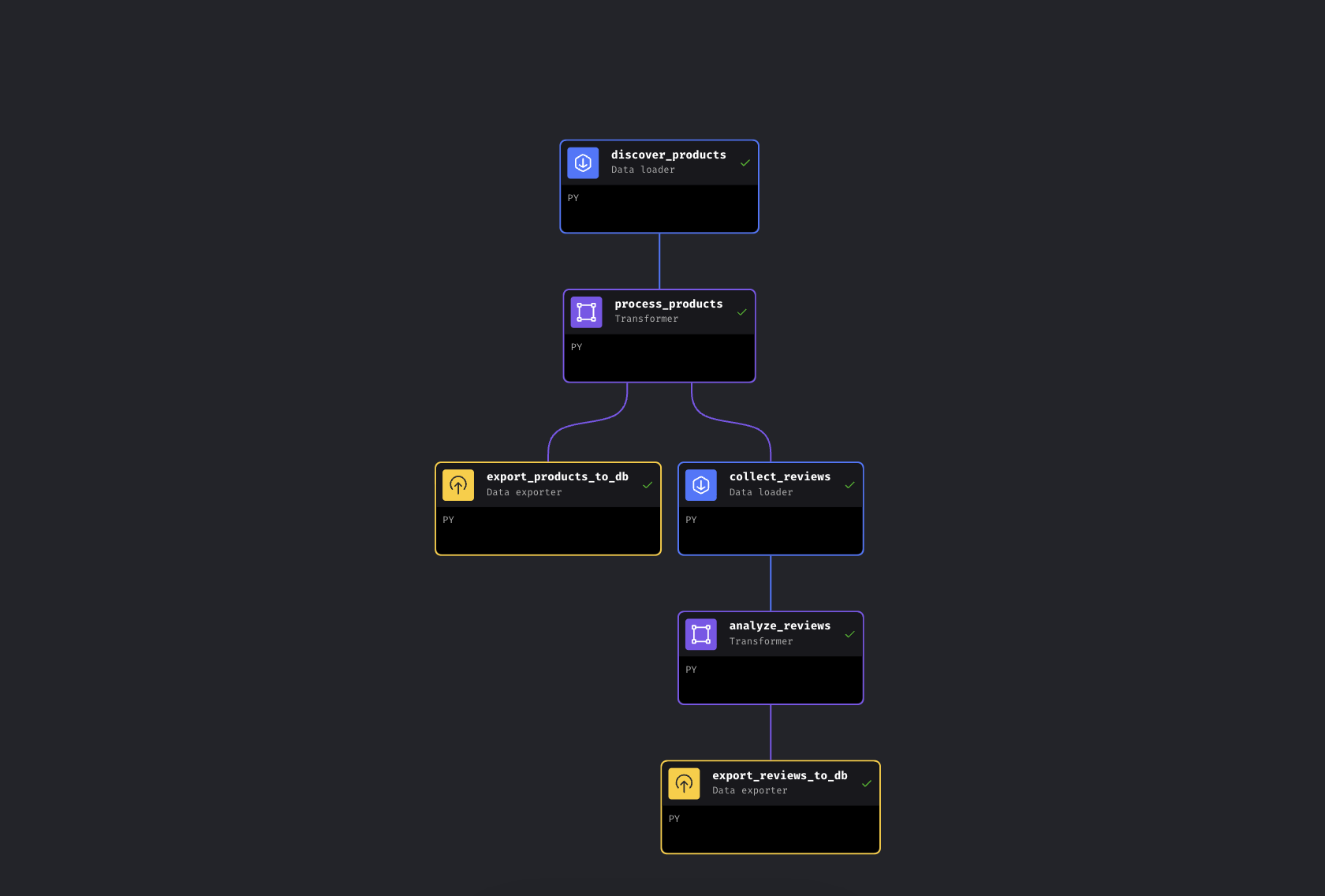
全6ブロックが緑色に。パイプライン完了
Mage AIデータパイプラインの仕組み
コードの流れを解説します。Bright Dataの統合とGemini分析に焦点を当てます。
Bright DataのウェブスクレイピングAPIをMage AIに接続
Amazon Products APIにキーワードを送信し、構造化データを取得します。Bright Dataはこれを「ディスカバリー」スクレイパーと呼び、キーワードやカテゴリで製品を検索します。レビューブロックでは別途「レビュー」スクレイパーを使用し、製品URLを入力として受け取ります。APIは非同期パターンを採用:収集をトリガー→スナップショットID取得→結果準備完了までポーリング。
DATASET_ID = "gd_l7q7dkf244hwjntr0" # Amazon Products(最新IDはリポジトリで確認)
API_BASE = "https://api.brightdata.com/data sets/v3"
# 収集をトリガー(/scrapeを使用 – 1分超で自動非同期化;本番環境では/triggerを検討)
response = requests.post(
f"{API_BASE}/scrape",
headers={"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json"},
params={"dataset_id": DATASET_ID,
"type": "discover_new",
"discover_by": "keyword",
"limit_per_input": kwargs.get('limit_per_keyword', 5)},
json={"input": [{"keyword": kw} for kw in keywords]})
snapshot_id = response.json()["snapshot_id"]
# 結果が準備できるまでポーリング
data = requests.get(
f"{API_BASE}/snapshot/{snapshot_id}",
headers={"Authorization": f"Bearer {api_token}"},
params={"format": "json"}
).json()Bright Dataから返される内容は以下の通りです:
{
"title": "BESIGN LS03 Aluminum Laptop Stand",
"asin": "B07YFY5MM8", // Amazonの固有商品ID
"url": "https://www.amazon.com/dp/B07YFY5MM8",
"initial_price": 19.99,
"final_price": 16.99,
"currency": "USD",
"rating": 4.8,
"reviews_count": 22776,
"seller_name": "BESIGN",
"categories": ["Office Products", "Office & School Supplies"],
"image_url": "https://m.media-amazon.com/images/I/..."
}kwargs.get('limit_per_keyword', 5)は Mage AI パイプライン変数から取得するため、UI から調整可能です。
2つ目のAPI呼び出しの追加:Amazonレビュー収集
レビュー収集ツールは上流ブロックから処理済み製品を受け取り、レビュー数でソートします。上位 N 件を選択し、それらのAmazon URLを2つ目のBright Data APIに渡します:
REVIEWS_DATASET_ID = "gd_le8e811kzy4ggddlq" # Amazonレビュー
# 上流からの上位商品(Mage AIから自動渡される)
top_products = data.sort_values('reviews_count', ascending=False).head(top_n)
product_urls = top_products['url'].dropna().tolist()
# レビューAPIにURLを送信(/scrapeパターンと同様)
response = requests.post(
f"{API_BASE}/scrape",
headers={"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json"},
params={"dataset_id": REVIEWS_DATASET_ID},
json={"input": [{"url": url} for url in product_urls]})
# 製品APIと同様の非同期ポーリングパターン...両方のAPIブロックには、デモのmetadata.yamlにリトライ設定があります:呼び出しが失敗した場合、パイプラインは30秒間隔で3回リトライします。このデモの各ブロックには、実行後に実行される@test関数もあります。これが失敗すると、下流のブロックは実行されず、不良データがデータベースに保存されることはありません。
AI分析の追加: Gemini感情分析パイプラインブロック
キーワードマッチング(例:「not cheap, great quality!」を「cheap」という単語のためネガティブと判定)の代わりに、Geminiで文脈を理解します。ブロックは無料利用枠の制限内に収めるため、3モデルローテーションでレビューをバッチ処理します:
GEMINI_MODELS = ["gemini-2.5-flash-lite", "gemini-2.5-flash", "gemini-2.5-pro"] # 最新モデルはリポジトリで確認
prompt = f"""これらのレビューを分析してください。各レビューに対して、以下のJSONを返します:
- "sentiment": "Positive", "Neutral", or "Negative"
- "issues": 言及された具体的な製品の問題点
- "themes": 1~3つのトピックタグ
- "summary": 一文の要約
JSON形式でのみ返すこと。nn{reviews_text}"""
for model in models:
try:
response = client.models.generate_content(model=model, contents=prompt)
return json.loads(response.text.strip())
except Exception as e:
if '429' in str(e):
continue # レート制限 -- 次のモデルへローテーションローテーションはflash-lite(最安・最速)から開始し、flash→proの順でフォールバック。3モデル全てが枯渇した場合、レビューは評価ベースの感情分析に切り替わる。 無料プランのクォータは定期的に変更されますが、3モデルローテーションにより大半のレート制限は自動で処理されます。Geminiは各レビューに対し、感情分析結果、具体的な問題点(「凹凸のある路面で揺れる」「ヒンジが経年劣化で緩む」など)、1~3つのテーマタグを返します。各レビューには1文の要約も付随します。
残りのブロック(価格帯と割引計算用のトランスフォーマー、およびアップサートロジックを備えた2つのデータベースエクスポーター)は単純明快です。詳細を確認したい場合はGitHubリポジトリにあります。
パイプライン出力:結果とStreamlitダッシュボード
デフォルトキーワード「laptop stand」と「wireless earbuds」でパイプラインを1回実行した結果です。Amazonの現在の商品リストによって結果は異なります。
今回の実行結果:10商品検出、Geminiによる20件のレビュー分析。イヤホンのレビューからは、4.3点という平均評価には表れない不満が浮上しました。「音質」「バッテリー持続時間」「接続性」といったテーマと具体的な問題点が指摘されています。
パイプラインが生成データに付加する価値:
| フィールド | 例 | 追加元 |
|---|---|---|
best_price |
$16.99 | 変換率(計算値) |
discount_percent |
15.0% | トランスフォーマー(計算済み) |
価格帯 |
予算(25ドル未満) | トランスフォーマー(強化版) |
評価カテゴリ |
優秀 (4.5-5) | トランスフォーマー(強化版) |
感情 |
ネガティブ | ジェミニAI |
問題 |
[“Bluetoothが頻繁に接続を落とす”] | ジェミニAI |
テーマ |
[“接続性”, “バッテリー寿命”] | Gemini AI |
ai_summary |
「8時間持続と謳っているのに、バッテリーはわずか2時間しか持たない」 | Gemini AI |
実際の表示例 – 拡張フィールドが表示された全10商品:
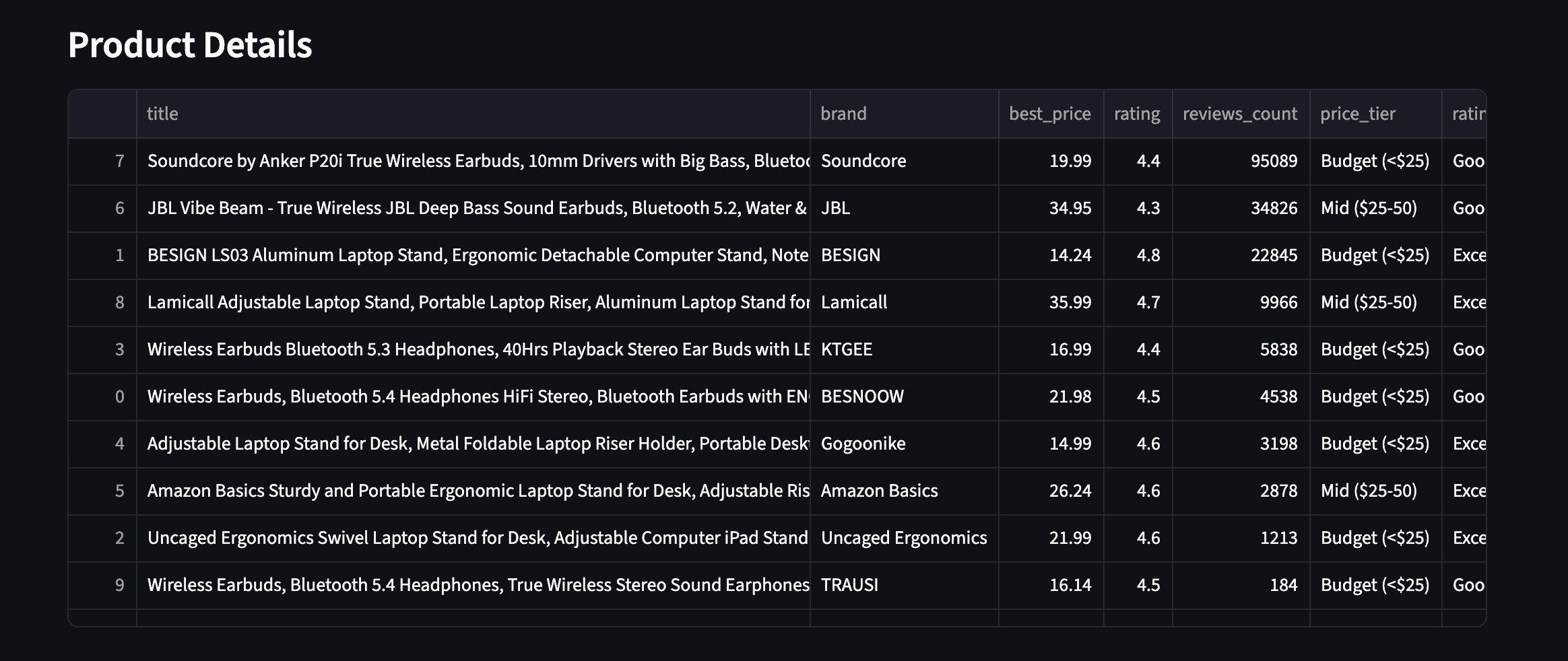
強化フィールド付き全10商品。2つの異なる商品カテゴリからの価格帯、評価、レビュー数
ダッシュボード
Streamlitダッシュボードはhttp://localhost:8501で表示。サイドバーの「Refresh Data」をクリックするとPostgreSQLから最新データを取得します。
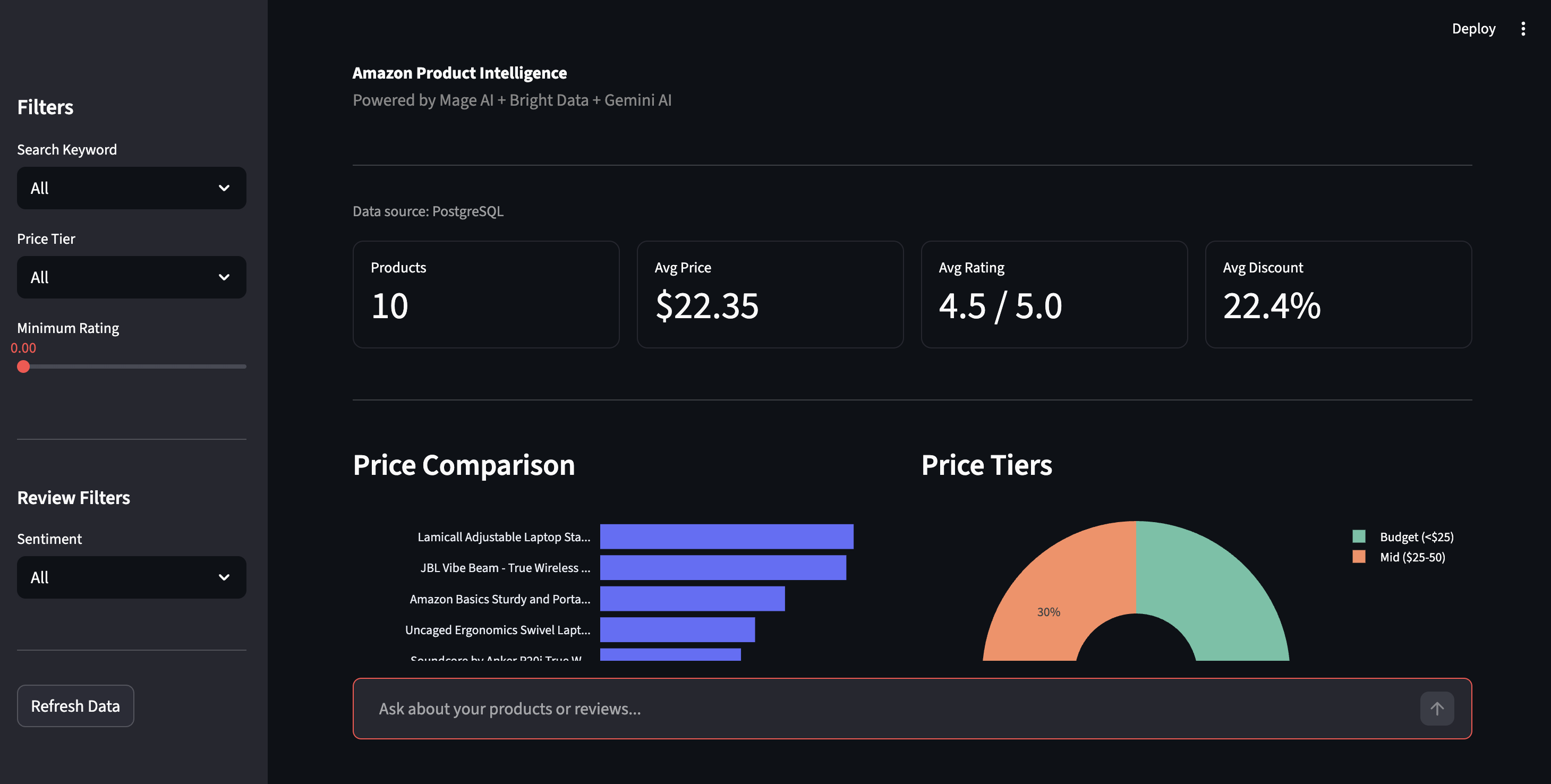
製品インテリジェンスダッシュボード ― 価格比較、価格帯、フィルタリング機能
サイドバーでは価格帯・評価・感情でフィルタリング可能。感情ビューでは全レビューの肯定/否定内訳と、Geminiが抽出した具体的な問題点(「Bluetooth接続が切れる」「ヒンジが経年劣化で緩む」など)を表示。星評価では埋もれる詳細情報を可視化。

感情分析の内訳とAI検出の製品問題点。Geminiが抽出した実際の苦情(キーワードマッチングではない)
ダッシュボードには「データと対話」機能も搭載。平易な英語で質問すると、Geminiが実際のスクレイピングデータを文脈として用いて回答します。別の実行例(より多くの製品を含む)を以下に示します:
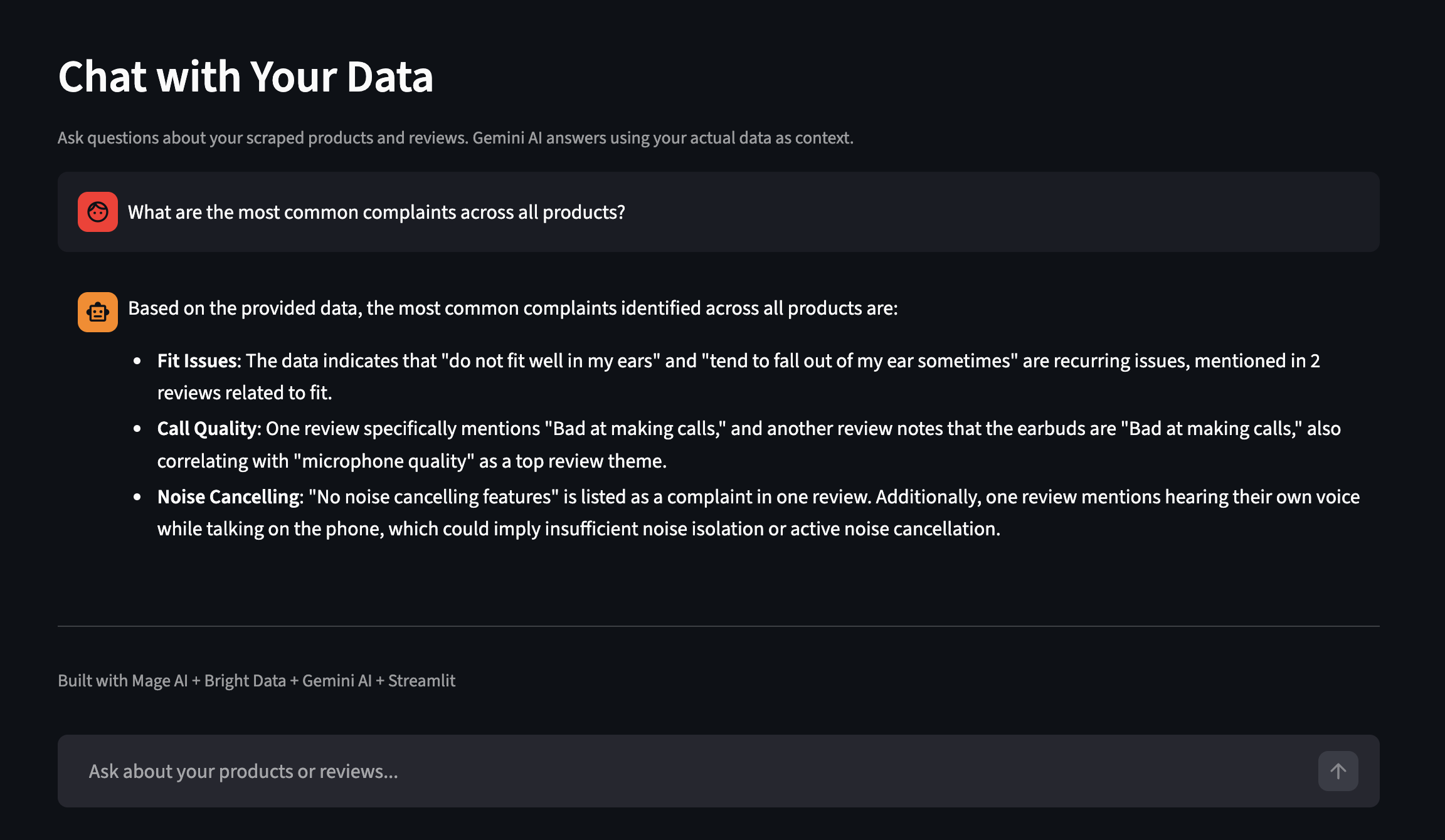
スクレイピングしたデータについて平易な英語で質問
パイプラインのスケーリング
デモは2つのキーワードと10商品で実行されます。
パイプライン変数
Mage AI UIまたはmetadata.yamlからすべて設定可能:
| 変数 | 制御対象 | デフォルト |
|---|---|---|
キーワード |
Amazon検索用語 | ["ノートパソコンスタンド", "ワイヤレスイヤホン"] |
キーワードごとの制限 |
Bright Dataからのキーワードごとの製品数 | 5 |
上位n商品 |
上位製品のレビュー収集数 | 2 |
reviews_per_product |
商品ごとの最大レビュー数 | 10 |
sort_by |
レビュー選択のための商品ランク付け方法 | レビュー数 |
キーワードを ["phone case", "USB-C hub"]に変更するだけで、全く異なるデータセットが得られます。コードの変更は不要です。
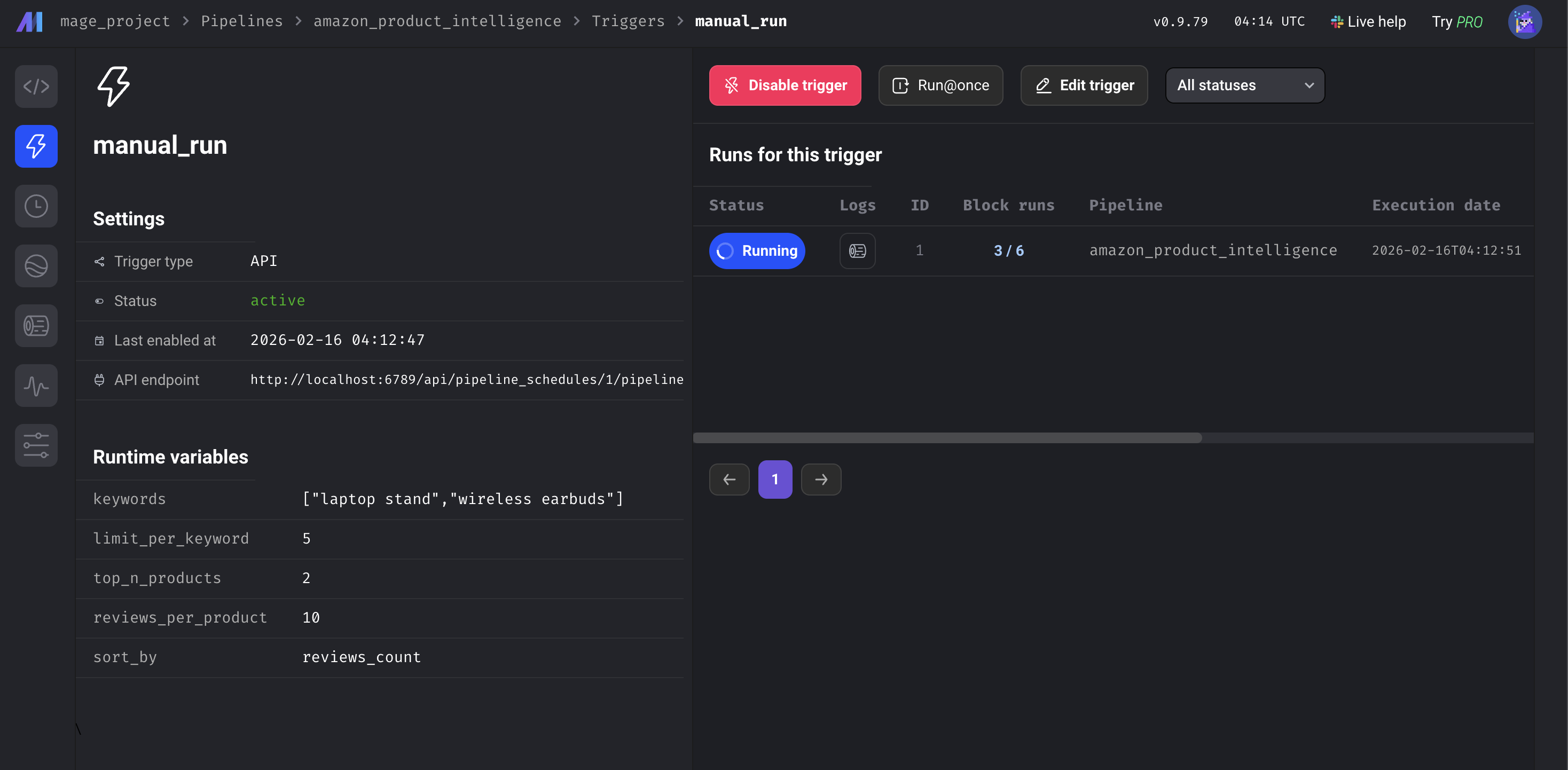
Mage AI UI内のパイプライン変数
スケジュール設定
スケジュールで実行するには、Mage AI サイドバーの「トリガー」に移動し、「+ 新規トリガー」をクリック、「スケジュール」を選択し、頻度(1 回、毎時、毎日、毎週、毎月、またはカスタム cron)を選択します。
各実行はASIN単位でアップサート(上書き更新)します。つまり、同一商品のデータは上書きされますが、他のキーワードの結果は保持されます。タイムスタンプ付きのCSVバックアップも保存され、履歴比較が可能です。
数回の実行データが蓄積されたら、星評価では捕捉できない苦情を抽出するため、PostgreSQLを直接クエリできます:
-- ネガティブな感情が強い商品を探す
SELECT asin, product_name,
AVG(CASE WHEN sentiment = 'Negative' THEN 1 ELSE 0 END) as negative_rate
FROM amazon_reviews
GROUP BY asin, product_name
HAVING AVG(CASE WHEN sentiment = 'Negative' THEN 1 ELSE 0 END) > 0.2;検索キーワードではなく自社製品を監視するには、type、discover_by、limit_per_inputパラメータを削除し、製品URLを直接[{"url": "https://www.amazon.com/dp/YOUR_ASIN"} ]として渡します。
ダッシュボードやアラートを自作せずに利用したい場合、Bright Insightsは小売データ向けに追加設定なしでこれを実現します。
スケーリングについて。このデモは単一マシン上のDockerで実行されますが、Mage AIは本番環境向けにKubernetesエグゼキュータをサポートし、Bright DataのAPIはバッチリクエストのレート制限により並行処理を処理します。スケーリングとは、データ収集コードを変更するのではなく、Mage AIの容量を追加することです。
他のBright Dataスクレイパーとの統合
同じパイプラインパターンは、100以上のウェブサイトに対応するBrightDataの既製スクレイパーすべてで機能します。例として、Google Maps Scraper、LinkedIn Scraper、Crunchbase Scraperのリポジトリを参照してください。Amazonから別のプラットフォームに切り替えるには、データローダーブロック内のDATASET_IDを交換し、新しいスクレイパーのスキーマに合わせて入力パラメータを調整します。
適切なIDと入力フィールドを見つけるには、ダッシュボードのスクレイパーライブラリを参照するか、/dataセット/listエンドポイントを呼び出してください。ダッシュボードのAPIリクエストビルダーでは、各スクレイパーが要求する内容を正確に確認できます。Geminiの分析とパイプライン構造はそのまま引き継がれます。エンリッチメントブロックとエクスポートブロックは、新しいスクレイパーのレスポンスフィールドがAmazonと異なる場合、列名の調整が必要になる可能性があります。
トラブルシューティング
設定または実行中に問題が発生した場合、最も一般的な解決策は以下の通りです:
- ポート6789または8501が既に使用中。他のサービスがポートを占有しています。該当サービスを停止するか、
docker-compose.ymlを編集してポートを再マッピングしてください(例:6789:6789→6790:6789に変更)。 - Bright Data APIが401 Unauthorizedを返す。APIトークンが欠落または不正な形式です。アカウント設定で完全なトークンをコピーし、
.envファイルに末尾の空白がないことを確認してください。トークンは長い16進数文字列(64文字)です。コピーした文字列が短い、またはUUIDのようなダッシュを含む場合は、誤ったフィールドをコピーした可能性があります。 - Geminiが全モデルで429(レート制限)を返す。無料プランには分単位の制限があり、定期的に変更される。パイプラインは3モデルをローテーションすることで対応するが、全てが上限に達した場合、レビューは評価ベースの感情分析にフォールバックする。回避策:
パイプライン変数のreviews_per_productを減少させる、Geminiブロック内のバッチ間にtime.sleep(60)を追加する、またはGoogle AIプロジェクトで課金機能を有効化しクォータを増やす。 現在のクォータはGoogleのレート制限ページで確認してください。 - パイプラインブロックが赤色(失敗)で表示される場合、パイプラインのログページ(左サイドバーからアクセス可能)でエラーを確認してください。ブロック名やログレベルでフィルタリングできます。主な原因:APIトークンの期限切れ、Bright Data APIのネットワークタイムアウト(
ブロック内のmax_wait_secondsを増やす)、Geminiの応答が有効なJSONでない場合(ブロックの@test関数がこれを捕捉します)。 - Apple Silicon環境でDocker Composeの動作が遅い/失敗する場合。Mage AIイメージはマルチアーキテクチャ対応でARMでも動作しますが、初回プルに時間がかかることがあります。メモリエラーでビルドが失敗する場合は、Docker Desktopの設定→リソースでメモリ割り当てを4GB以上に増やしてください。
次のステップ
Amazon商品データを収集し、AIによるレビュー分析を実行し、すべてをPostgreSQLに保存する動作するパイプラインが完成しました。プロキシもパーサーも、触るのが怖いcronジョブも不要です。
手順に沿って進めた方は、これを自分用にカスタマイズしてください。メタデータ.yaml内のキーワードリストを別の商品カテゴリに置き換えるだけで、コード変更は不要です。さらに詳細なカスタマイズには、特定のASINを指定するか、別のBright Dataスクレイパーに完全に切り替えてください。
初めての方?[Bright Dataの無料トライアルから始める]()(クレジットカード不要) →デモリポジトリをクローン → `docker compose up`を実行。
よくある質問
この設定に関するよくある質問:
PythonでAmazon商品データをスクレイピングするには?
requestsとBeautifulSoupで独自スクレイパーを構築する方法(Amazonのレイアウト変更で動作しなくなる)か、単一API呼び出しで構造化JSONを返すBrightDataのAmazonスクレイパーを利用する方法があります。スタンドアロンのPython例はAmazon Scraperリポジトリを参照。詳細な解説はBright Dataの完全なAmazonスクレイピングガイドをご覧ください
Bright DataでAmazonをスクレイピングする費用は?
ウェブスクレイピングAPIは従量課金制で、収集したレコード1,000件ごとに課金されます。Geminiの無料プランではAI分析が対象です。新規アカウントは無料トライアルを利用できます。現在の料金は価格ページをご確認ください。
このパイプラインでウォルマート、eBay、その他のeコマースサイトもスクレイピングできますか?
データローダーブロック内のDATASET_IDを交換し、入力パラメータを新しいスクレイパーのスキーマに合わせて調整してください。Geminiの分析とパイプライン構造は引き継がれますが、エンリッチメントブロックとエクスポートブロックでは列名の調整が必要になる場合があります。
Amazonがページレイアウトを変更した場合、どうなりますか?
ユーザー側での対応は不要です。Bright Dataがパーサーを管理するため、AmazonがHTMLを更新しても、API呼び出しと応答形式は通常変更されません。
Geminiが必要ですか?他のLLMは使えますか?
Geminiなしでもパイプラインは動作します(評価ベースの感情分析にフォールバック)。別のLLM(OpenAI、Claude、Llama)に切り替えるには、Geminiブロック内のanalyze_reviews関数を修正してください。プロンプト形式は変更不要で、API呼び出しのみ変更します。






