

このガイドで、あなたは発見するだろう:
- PerplexityがAIによるウェブスクレイピングに適している理由
- Pythonでウェブサイトをスクレイピングする方法とステップバイステップのチュートリアル
- このウェブスクレイピング手法の主な限界と、それを回避する方法
始めよう!
なぜWebスクレイピングにPerplexityを使うのか?
PerplexityはAIを搭載した検索エンジンで、大規模な言語モデルを利用して、ユーザーのクエリに対する詳細な回答を生成する。リアルタイムで情報を検索し、要約し、引用元を回答することができる。
ウェブスクレイピングにPerplexityを利用することで、構造化されていないHTMLコンテンツからのデータ抽出プロセスをシンプルなプロンプトに減らすことができます。これにより、手作業によるデータ解析が不要になり、関連情報の抽出が大幅に容易になります。
その上、Perplexityはウェブページを発見し探索する機能により、高度なウェブクローリングシナリオのために構築されている。
詳細については、ウェブスクレイピングにAIを使用するガイドを参照してください。
使用例
Perplexityを利用したスクレイピングの使用例としては、以下のようなものがある:
- 頻繁に構造が変わるページ Amazonのようなeコマースサイトのように、レイアウトやデータ要素が頻繁に変更される動的なページにも適応できる。
- 大規模なウェブサイトのクローリング:ページの発見とナビゲーションを支援したり、スクレイピング・プロセスをガイドするAI主導の検索を実行することができる。
- 複雑なページからデータを抽出パースしにくい構造を持つサイトの場合、Perplexityは大規模なカスタムパースロジックを必要とせずにデータ抽出を自動化することができます。
シナリオ
Perplexityを使ったスクレイピングが便利な例をいくつか挙げよう:
- RAG(Retrieval-Augmented Generation):リアルタイムのデータスクレイピングを統合することで、AIの洞察を強化する。同様のAIモデルを使用した実用的な例については、SERPデータを使用したRAGチャットボットの作成に関するガイドをお読みください。
- コンテンツの集約:ニュース、ブログ記事、記事を複数のソースから収集し、要約や分析を作成すること。
- ソーシャルメディアスクレイピング:動的または頻繁に更新されるコンテンツを持つプラットフォームから構造化データを抽出すること。
PythonでPerplexityを使ってWebスクレイピングを行う方法
このセクションでは、”ウェブスクレイピングを学ぶためのEコマーステストサイト“のサンドボックスから特定の商品ページを使用します:

Eコマースの商品ページは、しばしば異なる構造を持ち、様々なタイプのデータを表示するため、このページはその好例となる。これがeコマースのウェブスクレイピングを難しくしている点であり、AIが役立つ点でもある。
特に、Perplexityを搭載したスクレーパーは、AIを活用して、手作業による解析ロジックを必要とせずに、ページからこれらの製品詳細を抽出する:
- SKU
- 名称
- 画像
- 価格
- 説明
- サイズ
- カラー
- カテゴリー
注:以下の例では、簡単のため、またSDKの人気のため、Pythonを使用します。それでも、JavaScriptや他のプログラミング言語でも同じ結果を得ることができます。
Perplexityでウェブデータをスクレイピングする方法は、以下の手順に従ってください!
ステップ1:プロジェクトの設定
始める前に、Python 3があなたのマシンにインストールされていることを確認してください。インストールされていない場合は、ダウンロードしてインストール手順に従ってください。
次に、以下のコマンドを実行して、スクレイピング・プロジェクト用のフォルダを初期化する:
mkdir perplexity-scraperperplexity-scraperディレクトリは、Perplexityを使ったウェブスクレイピングのプロジェクトフォルダとなります。
ターミナルでそのフォルダに移動し、その中にPython仮想環境を作成する:
cd perplexity-scraper
python -m venv venvお好みのPython IDEでプロジェクトフォルダを開きます。Python拡張機能付きのVisual Studio Codeや PyCharm Community Editionはどちらも優れた選択肢です。
プロジェクトのフォルダにscraper.pyファイルを作成します:

現時点では、scraper.pyはただの空のPythonスクリプトですが、すぐにLLMウェブスクレイピングのロジックを含むようになります。
次に、IDEのターミナルで仮想環境を有効にする。LinuxまたはmacOSでは、以下を実行する:
source venv/bin/activate同様に、Windowsでは
venv/Scripts/activate素晴らしい!これであなたのPython環境はPerplexityを使ったウェブスクレイピングのためのセットアップが完了しました。
ステップ #2: Perplexity API キーの取得
多くのAIプロバイダーと同様、PerplexityはAPIを通じてモデルを公開している。プログラムでモデルにアクセスするには、まずPerplexityのAPIキーを入手する必要がある。公式の “Initial Setup“を参照するか、以下のガイドステップに従ってください。
Perplexityアカウントをまだお持ちでない場合は、アカウントを作成してログインしてください。API “ページに移動し、”Setup “をクリックして支払い方法を追加してください:

注:このステップでは課金されません。Perplexityは将来のAPI使用のためにのみ、あなたの支払い詳細を保存します。クレジットカードやデビットカード、Google Pay、その他サポートされているお支払い方法をご利用いただけます。
支払い方法が設定されると、以下のセクションが表示されます:

クレジットを購入する “をクリックしてクレジットを購入し、アカウントに追加されるのを待ちます。クレジットが利用可能になると、APIキーセクションの下にある “+ Generate “ボタンがアクティブになります。このボタンを押すと、Perplexity APIキーが生成されます:

APIキーが表示されます:

キーをコピーして安全な場所に保管してください。簡単にするために、scraper.pyでは定数として定義します:
PERPLEXITY_API_KEY="<YOUR_PERPLEXITY_API_KEY>"重要: Perplexityのスクレイピングスクリプトでは、APIキーをプレーンテキストで保存することは避けてください。その代わりに、環境変数やpython-dotenvのようなライブラリで管理される.envファイルにそのような秘密を保存してください。
素晴らしい!これでOpenAI SDKを使って、PythonでPerplexityのモデルにAPIリクエストをする準備ができました。
ステップ3:PythonでPerplexityを設定する
前のステップの最後の文は、OpenAI SDKについて言及しているにもかかわらず、タイプミスを含んでいない。なぜなら、Perplexity APIは完全にOpenAIと互換性があるからです。実際、Pythonを使ってPerplexity APIに接続するには、OpenAI SDKを使うことが推奨されています。
最初のステップとして、OpenAI Python SDKをインストールします。アクティベートされた仮想環境で、実行します:
pip install openai次に、scraper.pyスクリプトにインポートします:
from openai import OpenAIOpenAIの代わりにPerplexityに接続するには、以下のようにクライアントを設定します:
client = OpenAI(api_key=PERPLEXITY_API_KEY, base_url="https://api.perplexity.ai")素晴らしい!これでPerplexity Pythonのセットアップは完了し、モデルへのAPIリクエストを行う準備ができました。
ステップ#4: ターゲットページのHTMLを取得する
次に、ターゲットページのHTMLを取得する必要があります。これはRequestsのような強力なPython HTTPクライアントで実現できます。
有効化された仮想環境で、Requestsをインストールします:
pip install requests次に、scraper.pyでライブラリをインポートします:
import requestsget()メソッドを使用して、ページURLにGETリクエストを送信します:
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)ターゲット・サーバーはページの生のHTMLで応答する。
response.contentを表示すると、完全なHTMLドキュメントが表示されます:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="profile" href="https://gmpg.org/xfn/11">
<link rel="pingback" href="https://www.scrapingcourse.com/ecommerce/xmlrpc.php">
<!-- omitted for brevity... -->
<title>Ajax Full-Zip Sweatshirt – Ecommerce Test Site to Learn Web Scraping</title>
<!-- omitted for brevity... -->
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>これでターゲットページの正確なHTMLをPythonで取得できました。これをパースして必要なデータを取り出してみましょう!
ステップ #5: ページのHTMLをMarkdownに変換する(オプション)
警告このステップは技術的には必須ではないが、時間と費用を大幅に節約できる。ですから、検討する価値はあります。
Crawl4AIや ScrapeGraphAIのような他のAIを搭載したウェブスクレイピングテクノロジーが生のHTMLをどのように扱うかを少し調べてみよう。設定されたLLMにコンテンツを渡す前にHTMLをMarkdownに変換するオプションを提供していることに気づくだろう。
なぜそんなことをするのか?主な理由は2つある:
- コスト効率:Markdownに変換することで、AIに送信されるトークンの数が減り、コスト削減につながります。
- 処理の高速化:入力データが少ないため、計算コストが低く、応答が速い。
詳しくは、新しいAIエージェントがHTMLではなくMarkdownを選ぶ理由についてのガイドをお読みください。
トークンの使用量を減らすために、HTMLからマークダウンへの変換ロジックを複製する時が来た!
まず、対象のウェブページをシークレットモードで開きます(新しいセッションで操作していることを確認するため)。次に、ページ上の任意の場所で右クリックし、”Inspect “を選択して開発者ツールを開きます。
ページの構造を見てください。関連するデータはすべて、CSSセレクタ#mainで特定されるHTML要素に含まれていることがわかります:

技術的には、生のHTML全体をPerplexityに送ってデータを解析することもできます。しかし、その場合、ヘッダーやフッターなどの不要な情報がたくさん含まれてしまいます。その代わり、#main内のコンテンツを入力生データとして使用することで、最も関連性の高いデータのみを扱うことが保証される。これによってノイズを減らし、AIの幻覚を抑えることができる。
main要素だけを抽出するには、Beautiful SoupのようなPythonのHTML解析ライブラリが必要です。起動したPython仮想環境に、以下のコマンドでインストールします:
pip install beautifulsoup4そのAPIについてよく知らない場合は、Beautiful Soupのウェブスクレイピングに関するガイドを読んでほしい。
これをscraper.pyにインポートします:
from bs4 import BeautifulSoupビューティフル・スープを使って
- Requestsで取得した生のHTMLを解析する。
メイン要素を選択する- HTMLコンテンツを取得する
このスニペットでそれを達成しよう:
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)main_htmlを表示すると、次のようになる:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<div class="woocommerce-notices-wrapper"
id="notices-wrapper"
data-testid="notices-wrapper"
data-sorting="notices">
</div>
<div id="product-309"
class="product type-product post-309 status-publish first outofstock
product_cat-hoodies-sweatshirts has-post-thumbnail
shipping-taxable purchasable product-type-variable">
<!-- omitted for brevity... -->
</div>
</main>OpenAIのTokenizerツールを使って、選択したHTMLがいくつのトークンに対応しているかをチェックします:

次に、LLM API Pricing Calculatorを使用して、これらのトークンをPerplexityのAPIに送信するコストを見積もる:

ご覧のように、このアプローチでは20,000トークン以上になる。つまり、1リクエストあたり0.21ドルから約0.63ドルです。何千ものページがある大規模なプロジェクトでは、これは大変なことです!
トークンの消費を抑えるために、markdownifyのようなライブラリを使って抽出したHTMLをMarkdownに変換します。これをPerplexityを使ったスクレイピングプロジェクトにインストールしてください:
pip install markdownifyscraper.pyに markdownifyをインポートします:
from markdownify import markdownifyそして、それを使って#mainのHTMLをMarkdownに変換する:
main_markdown = markdownify(main_html)データ変換処理は以下のような出力を生成する:

2つのテキストエリアの最後にある “size “要素から、入力データのMarkdownバージョンは、オリジナルの#mainHTMLよりもはるかに小さいことがわかります。さらに、見てみると、スクレイピングするための重要なデータがすべて含まれていることに気づくだろう!
OpenAIのTokenizerをもう一度使って、新しいMarkdown入力が消費するトークンの数をチェックします:

この簡単なトリックで、20,658トークンを950トークンに減らすことができました。これは、リクエストあたりのPerplexity APIコストの大幅な削減にもつながります:
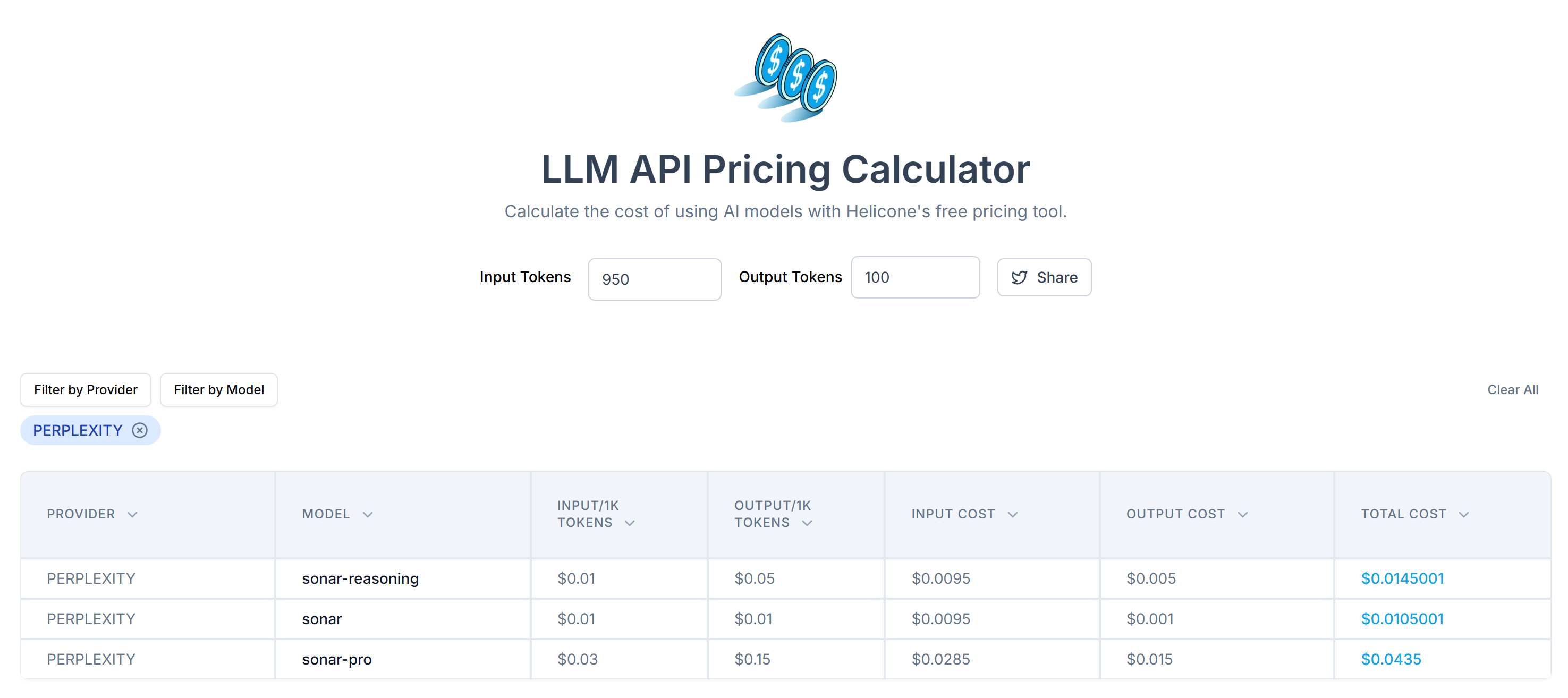
1リクエストあたり約$0.21〜$0.63だったコストは、わずか$0.014〜$0.04に下がる!
ステップ#6:データ解析にパープレキシティを使う
Perplexityを使用してデータをスクレイピングするには、以下の手順に従ってください:
- Markdown入力から希望する形式のJSONデータを抽出するための、構造化されたプロンプトを書く。
- OpenAI Python SDKを使ってPerplexityのLLMモデルにリクエストを送る
- 返されたJSONを解析する
最初の2つのステップを以下のコードで実行する:
# Prepare the Perplexity scraping API request body
prompt = f"""
Extract data from the content below and return JSON string with the specified attributes:nn
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
messages = [
{
"role": "system",
"content": (
"""
You are a scraping agent that returns scraped data in raw JSON format with no other content.
You only return a JSON string with the scraped data, as instructed.
Do not explain what you did whatsoever and only return the JSON string in raw format.
"""
),
},
{
"role": "user",
"content": (
prompt
),
},
]
# Perform the request to Perplexity
completion = client.chat.completions.create(
model="sonar",
messages=messages,
)
# Get the returned raw JSON data
product_raw_string = completion.choices[0].message.contentprompt変数は、main_markdownコンテンツから構造化データを抽出するようPerplexityに指示します。結果を改善するために、システムに明確なプロンプトを定義し、どのように振る舞い、何をすべきかを認識させることを推奨します。
注意: Perplexityは、APIコールを行うための古いOpenAIのレガシー構文にまだ依存しています。新しいrespons.create()構文を使おうとすると、以下のエラーが発生します:
httpx.HTTPStatusError: Client error '404 Not Found' for url 'https://api.perplexity.ai/responses'さて、product_raw_stringには、以下の形式のJSONデータが含まれていなければならない:
"```json
{
"sku": "MH12",
"name": "Ajax Full-Zip Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_back.jpg"
],
"price": "$69.00",
"description": "The Ajax Full-Zip Sweatshirt makes the optimal layering or outer piece for archers, golfers, hikers and virtually any other sportsmen. Not only does it have top-notch moisture-wicking abilities, but the tight-weave fabric also prevents pilling from repeated wash-and-wear cycles.nnMint striped full zip hoodie.n• 100% bonded polyester fleece.n• Pouch pocket.n• Rib cuffs and hem.n• Machine washable.",
"sizes": ["XS", "S", "M", "L", "XL"],
"colors": ["Blue", "Green", "Red"],
"category": "Hoodies & Sweatshirts"
}
```"ご覧のように、PerplexityはデータをMarkdown形式で返します。
冒頭のアルゴリズムのステップ3を実装するには、正規表現を使用して生のJSONコンテンツを抽出する必要があります。次に、結果のJSONデータをPython辞書json.loads()にパースします:
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
Try to parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)Python Standard Libraryからjsonとreをインポートするのを忘れないでください:
import json
import re注:Perplexity Tier-3ユーザの場合、構造化されたJSONフォーマットで直接データを返すようにAPIを設定することで、正規表現解析ステップをスキップすることができます。詳しくはPerplexity “Structured Outputs” ガイドをご覧ください。
product_dataディクショナリを解析したら、フィールドにアクセスしてさらにデータを処理できます。例えば
price = product_data["price"]
price_eur = price * USD_EUR
# ...素晴らしい!Perplexityをウェブスクレイピングに活用することができました。あとは必要に応じてスクレイピングしたデータをエクスポートするだけです。
ステップ#7:スクレイピングしたデータをエクスポートする
現在、スクレイピングされたデータはPython辞書に保存されています。JSONファイルとして保存するには、以下のコードを使用します:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)これにより、スクレイピングされたデータをJSON形式で含むproduct.jsonファイルが生成されます。
よくやった!これであなたのPerplexity搭載ウェブスクレーパーの準備は完了です。
ステップ8:すべてをまとめる
データ解析にPerplexityを使用したスクレイピングスクリプトの完全なコードです:
from openai import OpenAI
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import re
import json
# Your Perplexity API key
PERPLEXITY_API_KEY = "<YOUR_PERPLEXITY_API_KEY>" # replace with your API key
# Conffigure the OpenAI SDK to connect to Perplexity
client = OpenAI(api_key=PERPLEXITY_API_KEY, base_url="https://api.perplexity.ai")
# Retrieve the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)
# Convert the #main HTML to Markdown
main_markdown = markdownify(main_html)
# Prepare the Perplexity scraping API request body
prompt = f"""
Extract data from the content below and return JSON string with the specified attributes:nn
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
messages = [
{
"role": "system",
"content": (
"""
You are a scraping agent that returns scraped data in raw JSON format with no other content.
You only return a JSON string with the scraped data, as instructed.
Do not explain what you did whatsoever and only return the JSON string in raw format.
"""
),
},
{
"role": "user",
"content": (
prompt
),
},
]
# Perform the request to Perplexity
completion = client.chat.completions.create(
model="sonar",
messages=messages,
)
# Get the returned raw JSON data
product_raw_string = completion.choices[0].message.content
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Try to parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)
# Futher data processing... (optional)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)でスクレイピング・スクリプトを実行する:
python scraper.py実行の最後に、product.jsonファイルがプロジェクトフォルダに生成されます。それを開くと、次のような構造化データが見つかります:
{
"sku": "MH12",
"name": "Ajax Full-Zip Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_back.jpg"
],
"price": "69.00",
"description": "The Ajax Full-Zip Sweatshirt makes the optimal layering or outer piece for archers, golfers, hikers and virtually any other sportsmen. Not only does it have top-notch moisture-wicking abilities, but the tight-weave fabric also prevents pilling from repeated wash-and-wear cycles.n• Mint striped full zip hoodie.n• 100% bonded polyester fleece.n• Pouch pocket.n• Rib cuffs and hem.n• Machine washable.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Blue",
"Green",
"Red"
],
"category": "Hoodies & Sweatshirts"
}ほらね!このスクリプトは、HTMLページの非構造化データをきれいに整理されたJSONファイルに変換した。
次のステップ
Perplexityを搭載したスクレーパーを次のレベルに引き上げるために、以下の改善を検討してください:
- 再利用可能にする:プロンプトとターゲットURLをコマンドライン引数として受け付けるようにスクリプトを修正する。こうすることで、スクレーパーはより柔軟になり、さまざまなユースケースやプロジェクトに適応できるようになる。
- 安全なAPI認証PerplexityのAPIキーを.envファイルに保存し、python-dotenvを使って安全にロードします。このアプローチでは、スクリプトに機密性の高い認証情報をハードコードすることを避け、コードベースから分離して秘密を保持することでセキュリティを向上させます。
- ウェブクローリングの実装 PerplexityのAIを搭載した検索とクローリング機能を活用し、インテリジェントで最適化されたクローリングを実現。リンクされたページをナビゲートし、様々なソースから構造化データを抽出するようにスクレーパーを設定します。
このウェブスクレイピング手法の最大の限界を突破する
このAIを駆使したウェブスクレイピングの最大の限界は何か?リクエストによるHTTPリクエスト!
上記の例は完璧に機能したが、それは対象サイトが本質的にウェブスクレイピングの遊び場だからである。現実には、企業やウェブサイトの所有者は、たとえそれが一般にアクセス可能であっても、データの価値を理解している。それを保護するために、自動化されたHTTPリクエストを簡単にブロックできるスクレイピング対策を導入しているのです。
このような場合、スクリプトは403 Forbiddenエラーで失敗する:
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: <YOUR_TARGET_URL>
さらに、このアプローチは、レンダリングにJavaScriptを使用したり、非同期にデータをフェッチするダイナミックなウェブページでは機能しない。したがって、ウェブサイトは、LLMを搭載したスクレーパーをブロックするための高度なボット対策も必要としません。
では、これらの問題を解決する方法は?Web Unlocking APIだ!
Bright Data の Web Unlocker API は、任意の HTTP クライアントから呼び出すことができるスクレイピングエンドポイントです。この API は、スクレイピング防止ブロックをバイパスして、任意の URL の完全なロック解除された HTML を返します。ターゲットサイトのプロテクションの数に関係なく、Web Unlocker へのシンプルなリクエストでページの HTML を取得できます。
まずは、Web Unlockerの公式ドキュメントに従ってAPIキーを取得してください。次に、「ステップ#4」の既存のリクエストコードを以下の行に置き換えてください:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers for Web Unlocker
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the request payload
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/", # Replace with your target URL
"format": "raw"
}
# Fetch the unlocked HTML of the target page
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)
もうブロックも制限もありません!これで、Perplexityを使ってウェブをスクレイピングしても、ブロックされる心配はありません。
結論
このチュートリアルでは、PerplexityをRequestsや他のツールと組み合わせて、AIを搭載したスクレイパーを作成する方法を学びました。ウェブスクレイピングの最大の課題の1つはブロックされるリスクですが、Bright DataのWeb Unlocker APIを使用してこれに対処しました。
説明したように、PerplexityとWeb Unlocker APIを統合することで、カスタム解析ロジックを必要とせずに、あらゆるサイトからデータを抽出することができます。これは、ブライト・データの製品やサービスがサポートする多くのユースケースの1つに過ぎず、効率的なAI主導のウェブスクレイピングを実装することができます。
他のウェブスクレイピングツールもご覧ください:
- プロキシ・サービス:400M+ monthly以上の家庭用IPへのアクセスを含む、ロケーション制限を回避する4種類のプロキシ。
- ウェブスクレーパーAPI:100以上の人気ドメインから新鮮で構造化されたウェブデータを抽出するための専用エンドポイント。
- SERP API:SERPの継続的なロック解除を管理し、個々のページを抽出するためのAPI。
- スクレイピング・ブラウザ:Puppeteer、Selenium、Playwrightと互換性のあるクラウドブラウザで、組み込みのロック解除機能を備えています。
今すぐBright Dataに登録し、プロキシサービスやスクレイピング製品を無料でお試しください!






