

この記事では、以下の内容をご紹介します:
- CloakBrowserとは何か、何を提供し、どのように機能するか。
- Bright Data Browser APIとは何か、どのような機能を提供し、インフラのメリットは何か。
- 2つのソリューションがステルスブラウジングとフィンガープリント管理にどのようにアプローチするか。
- 2つのツールが依存する異なるインフラモデル。
- CloakBrowserとBrowser APIの両方で使用できる対応インテグレーションとツール。
- CloakBrowser vs Bright Data Browser APIの最終比較表。
さっそく見ていきましょう!
CloakBrowserの概要
CloakBrowser vs Bright Data Browser APIの比較に入る前に、CloakBrowserが提供するものを理解しておきましょう。
CloakBrowserとは?

CloakBrowserは、カスタムChromiumバイナリ上に構築されたオープンソースのステルスブラウザです。ブラウザ自動化およびウェブスクレイピングソリューションとして機能します。
JavaScriptインジェクション、ブラウザパッチ、または設定の調整に依存する従来のステルスプラグインとは異なり、CloakBrowserはChromium C++ソースレベルで直接ブラウザのフィンガープリントを変更します。このアプローチにより、より一貫性のある現実的なブラウザの動作を実現することを目指しています。
このツールはPlaywrightとPuppeteerのドロップイン代替として機能します。組み込みのフィンガープリント管理、人間に近いインタラクションシミュレーション、プロキシサポート、永続的なブラウザプロファイル、およびAIエージェントと自動化フレームワークとの統合が含まれています。
近週、このプロジェクトは大きな注目を集めています。数千のGitHubスターから執筆時点で21,200以上のスターに成長しました。
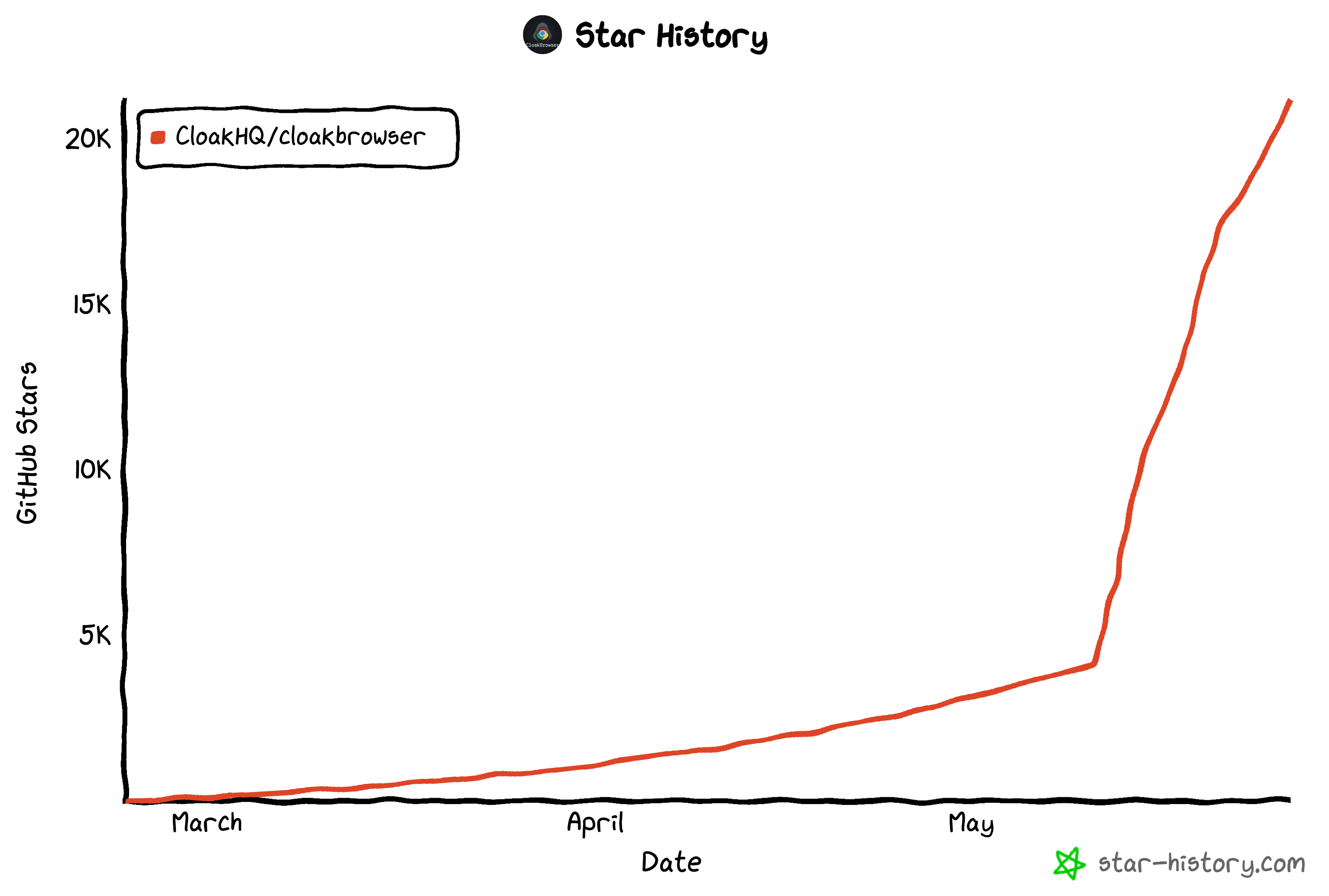
GitHubの週間トレンドリポジトリにも登場しました:
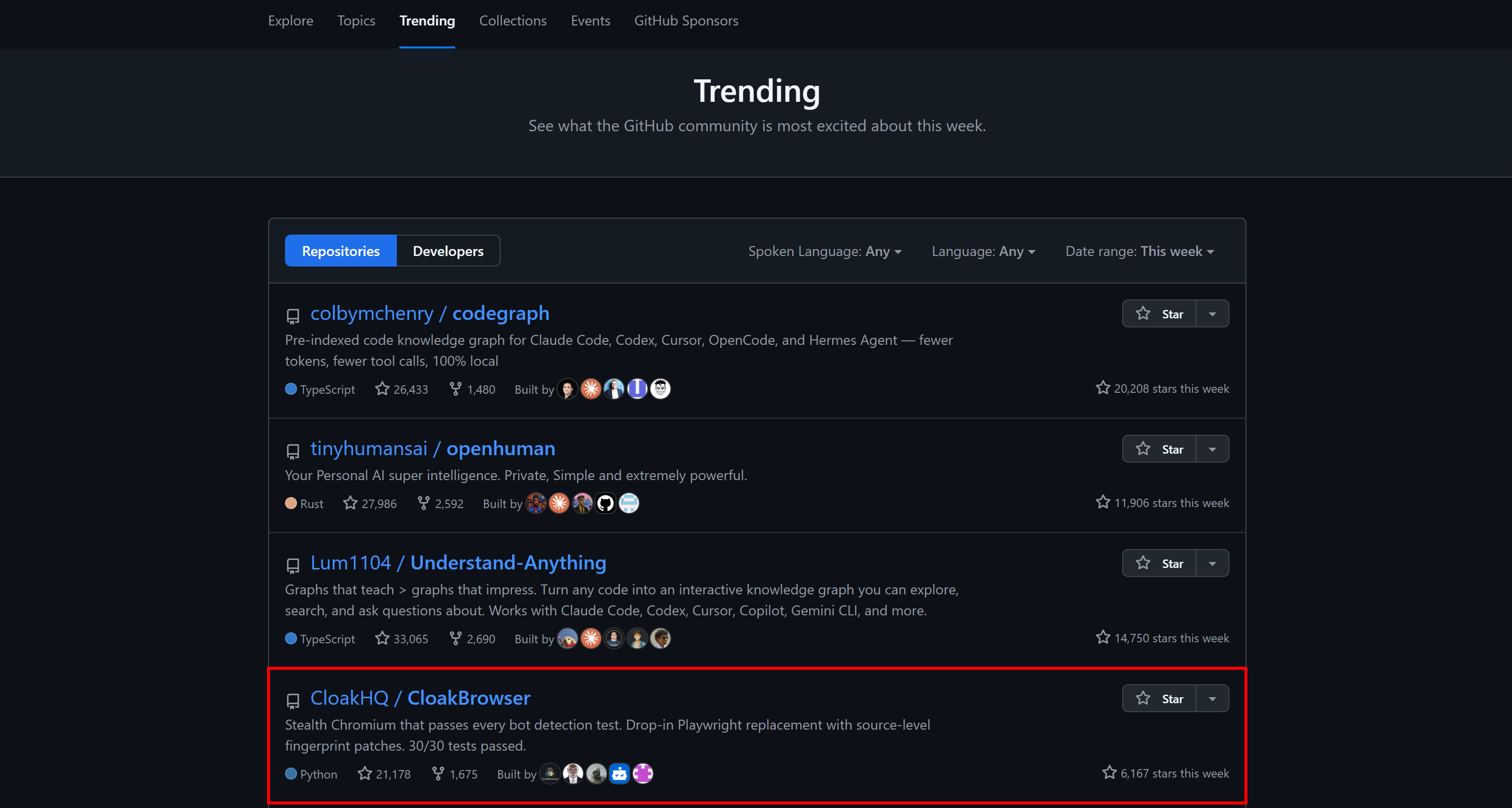
主な機能
以下はCloakBrowserプロジェクトが提供する主な機能です:
- ソースレベルのChromiumフィンガープリントパッチ:ブラウザエンジン内のGPU、キャンバス、WebGL、オーディオ、フォント、タイミング信号に対して58以上のC++変更を直接適用します。
- 自動バイナリ管理:手動セットアップ不要で、お使いのOSに合わせたカスタムChromiumビルドを自動的にダウンロードします。
- PlaywrightとPuppeteerのドロップイン代替:同じAPIを維持するため、数行のコード変更だけで既存の自動化コードが動作します。
- 人間に近いインタラクションエンジン:
humanize=Trueフラグ一つで、現実的なマウス動作、キーボードタイミング、スクロール動作、クリックダイナミクスをシミュレートします。 - 高度なプロキシサポート:認証付きHTTPおよびSOCKS5プロキシをサポートし、GeoIPベースのタイムゾーンとロケールの整合も任意で設定できます。
- 永続的なブラウザプロファイル:長期認証ワークフローを可能にするため、セッション間でCookie、
localStorage、キャッシュを維持できます。 - フィンガープリント制御システム:決定論的またはランダムなシードを使用して、セッション間で一貫したまたはローテーションするブラウザIDを生成します。
- 高いボット検出回避率:ベンチマークテストでreCAPTCHA v3、Cloudflare Turnstile、FingerprintJS、BrowserScanなどの主要システムを通過します。
CloakBrowserの仕組み
CloakBrowserはカスタムChromiumベースのブラウザ上の薄い自動化レイヤーとして動作します。以下がその仕組みです:
pipまたはnpmを使用してCloakBrowserをインストールします。- 初回実行時に、お使いのOSに合わせたプリビルドのChromiumバイナリを自動的にダウンロードします。
- 以降のセッションはすべてこのカスタムブラウザで起動します。
- 既存のコードはそのまま使用でき、標準のPlaywrightまたはPuppeteer APIを引き続き使用できます。
注意:CloakBrowserはDockerでもセットアップ可能で、Playwright、Puppeteer、Selenium、またはCDP互換フレームワークなどの標準ツールを通じて接続できます。
Chromiumバイナリには、ブラウザのフィンガープリント信号を調整またはマスクする多数の低レベルC++変更が含まれています。また、内部ブラウザおよびCDPレベルの信号を変更することで自動化検出を低減します。これらの変更はダウンロードされたChromiumバイナリに直接コンパイルされています。
この設計の重要な意味として、ラッパーレイヤーのみがオープンソースであり、ブラウザバイナリはプリコンパイル済みアーティファクトとして配布されます。これにより、フィンガープリントロジックの直接検査やリバースエンジニアリングが制限されます(WAFやその他のアンチボットソリューションの背後にある企業による)。重要な変更はコンパイル済みコードに埋め込まれているためです。
はじめ方
まずCloakBrowserをインストールします。Pythonの場合、次のコマンドを実行します:
pip install cloakbrowserまたはNode.jsプロジェクトの場合、次のコマンドでインストールします:
npm install cloakbrowserインストール後、標準のPlaywrightまたはPuppeteer APIを使用できます。たとえば、以下はPlaywrightスタイルのPythonの例です:
# pip install cloakbrowser
from cloakbrowser import launch
browser = launch()
page = browser.new_page()
page.goto("https://example.com")
print(page.title()) # Expected result: "Example Domain"
browser.close()またはJavaScriptで同等の処理を行う場合:
// npm install cloakbrowser
import { launch } from "cloakbrowser";
const browser = await launch();
const page = await browser.newPage();
await page.goto("https://example.com");
console.log(await page.title()); // Expected result: "Example Domain"
await browser.close();自動化ロジックは通常のPlaywrightまたはPuppeteerと同一であることに注意してください。CloakBrowserが変更するのはブラウザの起動方法のみで、自動化コードの書き方は変わりません。
唯一の違いはlaunch()関数で、これがCloakBrowserセッションを初期化します。デフォルトでは、デフォルトのステルス設定でヘッドレスブラウザセッションを開始します。より細かい制御については、launch()関数がサポートする引数を参照してください。
スクリプトを初めて実行すると、CloakBrowserは:
- お使いのOSを検出します。
- お使いのプラットフォーム向けのプリビルドChromiumベースバイナリをダウンロードします。
- 将来の使用のためにローカルにキャッシュします。
それ以降、すべてのlaunch()呼び出しはPlaywrightまたはPuppeteerを通じてカスタムChromiumバイナリを起動します。
料金
CloakBrowserにはサブスクリプション料金、使用制限、有料プランはありません。そのため、自由にインストールして使用できます。ただし、実際のコストは周辺インフラから発生します。
スケーラブルな使用のためには、信頼できるサードパーティプロキシプロバイダーとの統合が必要です。プロキシは分散自動化ワークロードに不可欠であり、トラフィック量と地理的カバレッジによっては主要な運用コストになる可能性があります。
また、CloakBrowserは本番環境でDockerを使用して複数のサーバーにデプロイされることが多いです。これにより水平スケーリングが可能になりますが、コンテナオーケストレーション、インスタンス管理、モニタリング、継続的なメンテナンスなどの追加オーバーヘッドも発生します。
その結果、CloakBrowser自体は無料ですが、スケールアップするにつれて運用の複雑さとインフラコストが増加します。
Bright Data Browser APIの紹介
CloakBrowser vs Bright Data Browser APIの比較を続け、Browser APIについて詳しく見ていきましょう。
Browser APIとは?
Bright DataのBrowser APIは、大規模な本番グレードのウェブインタラクションとデータ収集に最適化されたクラウド管理型ブラウザ自動化ソリューションです。
ローカルブラウザインフラを実行・維持する代わりに、既存のPlaywright、Puppeteer、またはSeleniumスクリプトを完全ホスト型のステルスブラウザに接続できます。これらのブラウザはクラウドで自動的にスケーリングおよび維持されます。
その核心は、信頼性、ブロック解除能力、スケールが重要なシナリオ向けに構築されています。一般的なユースケースには、動的なウェブスクレイピング、自動QA/テスト、リード生成などがあります。
Bright Dataの4億以上のIPを持つ大規模プロキシネットワークに支えられており、強力な地理的分散、IPローテーション、無制限の同時実行性とスケーラビリティを実現します。このソリューションはCAPTCHAの解決、フィンガープリント、セッション管理、JavaScriptレンダリングをすぐに処理します。これらの機能により、強固に保護されたウェブサイトに対して高い成功率を達成します。
Browser APIはすべてのCDP互換ツールをサポートするほか、Web MCPを介した最新のAIエージェントワークフローもサポートします。つまり、リアルタイムでブラウズ、クリック、情報抽出が必要な自律エージェントにも適しています。
主な機能
以下はBright Data Browser APIの主要機能です:
- クラウド管理型ブラウザインフラ:完全ホスト型ブラウザがクラウドで動作し、ローカルセットアップ、プロキシ管理、インフラメンテナンスが不要です。
- Playwright、Puppeteer、Selenium対応:主要なブラウザ自動化フレームワークとの直接統合により、最小限の変更で既存スクリプトを再利用でき、迅速な移行が可能です。
- 組み込みのCAPTCHAの解決:CAPTCHAとチャレンジレスポンスシステムを自動的に検出・解決し、スクレイピングの中断を減らし、外部サービスの必要性を排除します。
- 大規模プロキシネットワークへのアクセス:4億以上のアドレスのレジデンシャルIPプールを活用して、地理的に分散したリクエストを実現し、ブロックと検出を低減します。
- ブラウザフィンガープリントエミュレーション:実際のユーザーのブラウザ特性をシミュレートして検出リスクを低減し、高度なアンチボットシステムに対する信頼性を向上させます。
- 自動スケーリングインフラ:需要に応じてブラウザセッションを動的にプロビジョニングし、手動スケーリングなしで高い同時実行ワークロードをサポートします。
- Chrome DevToolsデバッグ:DevToolsを使用したセッション検査を提供し、スクレイピング実行中のログ、ネットワークリクエスト、ブラウザの動作を監視できます。
- ジオロケーションターゲティング:国、都市、またはASNレベルの精密なターゲティングを可能にし、ローカライズされたコンテンツへのアクセス、地域エクスペリエンスのテスト、地理的に制限されたデータの正確なスクレイピングを実現します。
- 自動リカバリー:セッションを復元して継続性を維持し、不安定またはブロックされた環境でのダウンタイムを削減し、堅牢性を向上させます。
- AIエージェント互換性(Web MCP経由):ナビゲーション、クリック、スクロール、ウェブデータ抽出が可能な自律ブラウザエージェントをサポートし、高度なAI駆動の自動化ワークフローを実現します。
- データ整合性検証:組み込みの検証メカニズムにより抽出データの一貫性と信頼性を確保し、ダウンストリーム分析および本番パイプラインの品質を向上させます。
詳細については、公式ドキュメントをご覧ください。
Browser APIの仕組み
Browser APIは、完全管理されたクラウドベースのブラウザ内でブラウザ自動化スクリプトを実行することで機能します。単一のCDPエンドポイントを使用して接続し、コードは実際のブラウザ環境でリモートに実行されます。基本的に、ブラウザがローカルにあるかのように操作しますが、実行、スケーリング、ブロック解除はすべてクラウドで完全に管理されます。
裏側では、プラットフォームがすべてのインフラの複雑さを処理します。プロキシローテーション、ブラウザフィンガープリント、セッション処理、CAPTCHAの解決などを自動的に管理します。各セッションは需要に応じてリソースを動的に割り当てるスケーラブルなクラウド環境で実行されます。つまり、手動セットアップなしで高い同時実行性を実現します。
はじめ方
まず、Bright DataアカウントでBrowser APIゾーンを設定する必要があります。まだお持ちでない場合は、Bright Dataアカウントを作成してください。すでにお持ちの場合は、ログインしてください。
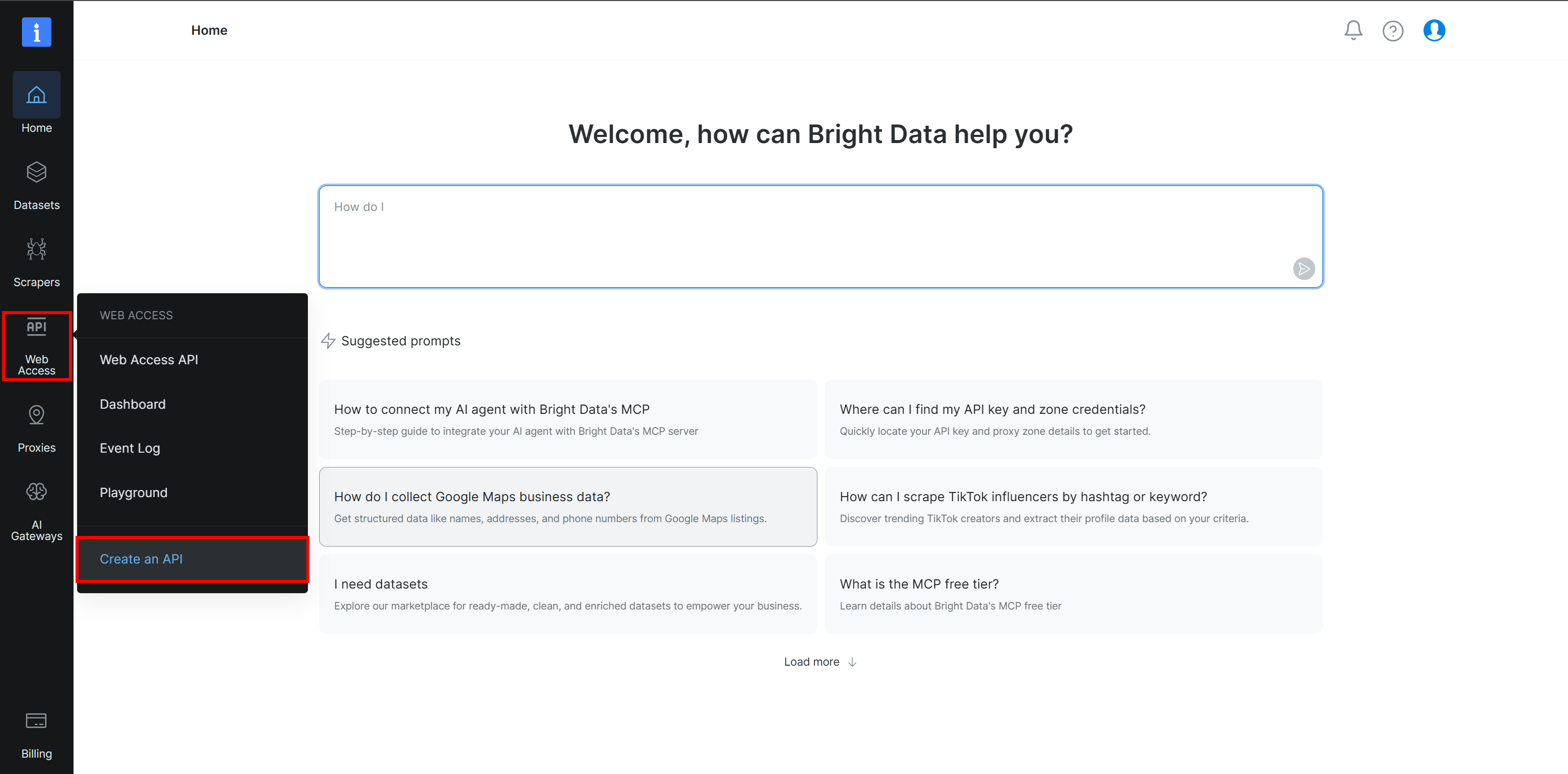
Bright Dataコントロールパネルで、「Web Access > Create an API」オプションを選択します:
「Web Access API > Add API」ページで、「Browser API」タイプを選択します:
ウィザードに従い、Browser APIゾーンに名前(例:browser_api)を付けて必要に応じて設定します。セットアップフローを完了すると、Puppeteer、Playwright、Selenium接続URLが提供されます:
次に、「Open API settings」ボタンを押してBrowser API Playgroundにアクセスします。ここでは、人気のブラウザ自動化フレームワークやプログラミング言語との統合のための使用可能なスニペットにアクセスできます:
リモート接続URLを使用して、PythonでPlaywrightのCDP経由で次のように接続します:
# pip install playwright
from playwright.sync_api import sync_playwright
# Replace with your Browser API connection URL
BROWSER_API_CDP = "wss://brd-customer-USER-zone-BROWSER_API_ZONE_NAME:[email protected]:9222"
with sync_playwright() as p:
browser = p.chromium.connect_over_cdp(BROWSER_API_CDP)
page = browser.new_page()
page.goto("https://example.com")
print(page.title()) # Expected result: "Example Domain"
browser.close()またはJavaScriptで同等の処理を行う場合:
// npm install playwright
const { chromium } = require("playwright");
# Replace with your Browser API connection URL
const BROWSER_API_CDP = "wss://brd-customer-USER-zone-BROWSER_API_ZONE_NAME:[email protected]:9222";
(async () => {
const browser = await chromium.connectOverCDP(BROWSER_API_CDP);
const page = await browser.newPage();
await page.goto("https://example.com");
console.log(await page.title()); // Expected result: "Example Domain"
await browser.close();
})();自動化ロジックは標準のPlaywrightまたはPuppeteerと同一です。唯一の変更点はブラウザへの接続方法です。connect_over_cdp()/connectOverCDP()を使用することで、実行を完全管理されたBrowser APIクラウドインスタンスにリダイレクトします(ローカルブラウザに依存する代わりに)。
料金
Browser APIはトラフィック従量課金モデルを採用しており、クラウドブラウザインフラを通じて転送されたデータのGBのみが課金されます。詳細は、Browser APIの料金は以下のプランに従います:
| プラン | 価格 |
|---|---|
| 従量課金制(コミットメントなし、使用量ベースの請求) | $8/GB |
| 71GB含む | $499/月($7/GB) |
| 166GB含む | $999/月($6/GB) |
| 399GB含む | $1,999/月($5/GB) |
ブラウザインスタンス、実行時間、同時実行性に対する追加料金はありません。すべての国が同じレートで課金されるため、地域を問わず料金が予測可能です。唯一の例外はプレミアムドメインで、追加のブロック解除の複雑さのためにGB単価が高くなります。
注意:Browser APIおよびその他のBright Data製品は、無料トライアルでテストすることもできます。
料金はトラフィックに直接依存するため、コスト効率とパフォーマンスのために帯域幅の最適化が重要です。帯域幅最適化に関する公式ガイドをお読みください。
ステルスブラウジングへのアプローチの違い
CloakBrowserとBrowser APIはどちらもボット検出の低減を目指しています。しかし、ステルスブラウジングとフィンガープリント管理に対して根本的に異なる2つのアプローチを採用しています。
CloakBrowserはローカルで動作する変更済みChromiumバイナリによってアンチボット回避を実現します。起動時に一貫したブラウザフィンガープリントを生成し、GPU、画面サイズ、フォント、キャンバス、WebGL、オーディオ、ハードウェア仕様などの検出可能なシグナルをスプーフィングします。
決定論的フィンガープリントシードを通じてIDの永続性を制御し、起動フラグで特定の属性を微調整することもできます。これにより、CloakBrowserはセッション間で精密なフィンガープリント制御と再現可能なブラウザIDが必要な場合に特に適しています。
一方、Browser APIは完全管理されたクラウドブラウザを通じてステルスを実現します。低レベルのフィンガープリントフラグを公開する代わりに、バックグラウンドでブラウザフィンガープリントを処理します。同時に、高度な動作を制御するための設定とカスタムCDPアクションを公開しています。これらにより、特定のデバイスのエミュレート、ジオロケーションの変更、広告のブロック、CAPTCHAの解決の設定などが可能です。
インフラのギャップ
CloakBrowserはステルス性の高いローカルChromiumバイナリを提供します。ただし、その周辺のすべてはあなたの責任です。つまり、大規模な自動化を実行したい場合は、マシンのプロビジョニング、ブラウザの同時実行管理、プロキシの設定とローテーション、障害の監視などが必要です。
確かに、CloakBrowser環境とCDP経由での接続用ブラウザサーバーを公開するDockerイメージが提供されています。しかし、Dockerイメージから真にスケーラブルなブラウザインフラに移行することは別の課題です。これには、すべてのチームが持っているわけではないエンジニアリングスキル、インフラの専門知識、予算が必要です。
Bright DataのBrowser APIはまったく異なるアプローチを取ります。管理するブラウザを提供する代わりに、クラウドで完全管理されたブラウザインフラを提供します。プロキシローテーション、ブラウザオーケストレーション、スケーリング、同時実行性、モニタリングはすべて管理されています。ブラウザ自動化スクリプトまたはAIエージェントをリモートエンドポイントに接続するだけで、Bright Dataがすべての運用の複雑さを処理します。
特に、Browser APIはBright DataのSLAに裏付けられたエンタープライズグレードのインフラに支えられています。99.99%のアップタイム、無制限の同時実行性、99.95%の成功率、無制限のスケーラビリティ、GDPR、CCPAおよびその他のプライバシーおよびセキュリティ規制への準拠を提供します。
この違いがCloakBrowser vs Browser API全体の比較における重要なポイントです。CloakBrowserは間違いなく優れたツールです。それでも、Browser APIこそが2つのうち真に完全なブラウザ自動化インフラと見なせる唯一のソリューションです。
これがCloakBrowserと比較したBrowser APIの最大のメリットでもあります。初日から運用負担を軽減することで、最も重要な自動化ロジックに集中できます。
対応インテグレーション
CloakBrowserはPlaywrightとPuppeteerスクリプトをネイティブにサポートします。ただし、標準のPlaywrightシステム依存関係に依存しながらも、追加の依存関係(cloakbrowser)が必要です。
ネイティブAPIを超えて、CloakBrowserはDockerベースのサーバーセットアップを通じてCDP互換ブラウザを公開します。これにより、CDP準拠のツールと統合できます。また、CrawAI、Browser Use、LangChainなどの一部のAIエージェントフレームワークをネイティブにサポートします。
Browser APIはPlaywright、Puppeteer、Seleniumをサポートしており、追加の依存関係は不要です。さらに、Browser Use、Stagehand、Agent Browser、および同様のAIベースの自動化フレームワークを含むすべてのCDPベースのツールと完全に互換性があります。
さらに、Bright DataのBrowser APIはWeb MCPツールを通じて公開されています。これらには以下が含まれます:
| ツール | 説明 |
|---|---|
scraping_browser_navigate |
セッションを開くまたは再利用してURLにナビゲートし、ネットワークトラッキングをリセット |
scraping_browser_go_back |
戻るナビゲーションを行い、更新されたURLとタイトルを返す |
scraping_browser_go_forward |
進むナビゲーションを行い、更新されたURLとタイトルを返す |
scraping_browser_snapshot |
インタラクティブ要素の参照付きARIAスナップショットをキャプチャ |
scraping_browser_click_ref |
ARIA参照を使用して要素をクリック |
scraping_browser_screenshot |
ページまたはフルページのスクリーンショットをキャプチャ |
scraping_browser_wait_for_ref |
ARIA参照による要素の表示を待機 |
scraping_browser_get_text |
ページ本文から表示テキストを抽出 |
scraping_browser_get_html |
ページのHTMLコンテンツを取得 |
scraping_browser_scroll |
ページの最下部までスクロール |
scraping_browser_scroll_to_ref |
特定の参照要素までスクロール |
MCPサポートによりBrowser APIはエージェントブラウザとなり、AIエージェントフレームワークの幅広いエコシステムとの互換性が拡張されます。対応ソリューションにはLangChain、Agno、OpenClaw、LlamaIndex、CrewAI、Dify、Mastra、Claude Code、Codex、Claude Desktop、および70以上のその他が含まれます。
Bright Data Browser API vs CloakBrowser:並列比較
以下の最終CloakBrowser vs Bright Data Browser API表で2つのソリューションを比較します:
| 比較項目 | CloakBrowser | Bright Data Browser API |
|---|---|---|
| コアコンセプト | ローカルステルスChromiumバイナリ | 完全管理型クラウドブラウザインフラ |
| 性質 | オープンソースラッパー + 独自パッチ済みブラウザバイナリ | プロプライエタリ |
| 依存関係 | cloakbrowser + システム依存関係が必要 |
追加依存関係なし |
| CDPサポート | ✔️(Dockerサーバー経由) | ✔️(ネイティブクラウドCDPエンドポイント) |
| ステルスアプローチ | ソースレベルのChromiumフィンガープリントパッチ | 管理型フィンガープリント |
| フィンガープリント制御 | シードと起動フラグによる高度な制御 | デバイスエミュレーションのCDPアクションで制御 |
| プロキシ管理 | 外部プロキシプロバイダーが必要 | 組み込みの4億以上のIPプロキシネットワーク |
| CAPTCHA処理 | ネイティブ非対応 | 組み込みのCAPTCHAの解決 |
| フレームワークサポート | Playwright、Puppeteer、CDP互換ツール | Playwright、Puppeteer、Selenium、CDP互換ツール |
| AIエージェント統合 | 一部のAIフレームワークをサポート(Browser Use、LangChain、CrawAI) | Web MCP経由で広範なエコシステム(LangChain、LlamaIndex、CrewAI、Agno、Claudeおよび70以上) |
| インフラ責任 | ユーザー管理 | Bright Dataが完全管理 |
| スケーリング | 手動の水平スケーリングが必要 | 無制限の同時実行性を持つ自動エラスティックスケーリング |
| アップタイム保証 | ユーザーインフラに依存 | SLA保証99.99%アップタイム |
| コストモデル | ソフトウェアは無料、インフラは別途コスト | GB単位のトラフィックベースの従量課金制 |
最終評価
CloakBrowserとBrowser APIはどちらも強力なステルス対応ブラウザ自動化ソリューションです。CloakBrowserはオープンソースの性質から、ブラウザフィンガープリントに対する最大限のローカル制御と完全な自己管理インフラが必要な場合に最適です。実験的または高度にカスタマイズされたセットアップに特に有用です。
本番規模のスクレイピング、信頼性の高い自動化、またはAIエージェントとの統合には、Bright DataのBrowser APIが最適な選択です。完全管理されたインフラ、組み込みのブロック解除機能、エラスティックスケーリングにより運用オーバーヘッドが排除されます。これにより、インフラ管理よりも自動化ロジックに集中したいチームにとって大幅に実用的です。
まとめ
このBright Data Browser API vs CloakBrowser比較記事では、両ツールが何であるか、どのような機能を提供し、どのように機能するか、そしてコストについて学びました。
CloakBrowserは低レベルの制御が必要な場合に優れたオープンソースのブラウザ自動化ソリューションです。一方、Browser APIはより信頼性が高く、エンタープライズレベルまたはエージェント型のブラウザ自動化統合に適しています。
今すぐBrowser APIを探索して、自動化スクリプトへの統合を始めましょう。
Bright Dataアカウントを作成して、AIに対応したウェブデータ自動化ソリューションをご覧ください!




