

このガイドで、あなたは学ぶだろう:
- 開発AIエージェントのための
ブラウザ用ライブラリとは何か - なぜブラウザによって機能が制限されるのか?
- スクレイピング・ブラウザーを使ってこれらの制限を克服する方法
- ブラウザ上で動作し、スクレイピング・ブラウザとの統合によりブロックを回避するAIエージェントを構築する方法
さあ、飛び込もう!
ブラウザの使用とは?
Browser Useは、AIエージェントがウェブサイトにアクセスできるようにするオープンソースのPythonプロジェクトである。ウェブページ上のすべてのインタラクティブ要素を識別し、エージェントがそれらと意味のあるインタラクションを行うことを可能にする。つまり、ブラウザユースライブラリによって、AIはプログラムでブラウザを制御し、対話することができる。
主な特徴は以下の通り:
- 強力なブラウザ自動化:高度なAIと堅牢なブラウザ自動化を組み合わせ、AIエージェントのウェブインタラクションを簡素化します。
- 視覚+HTML抽出:視覚的理解とHTML構造抽出を統合し、より効果的なナビゲーションと意思決定を実現。
- マルチタブ管理:複数のブラウザ・タブに対応し、複雑なワークフローや並行タスクへの扉を開く。
- 要素のトラッキング:XPathを使用してクリックされた要素を追跡し、LLMによって実行されたアクションを正確に繰り返すことができるため、一貫性が保証されます。
- カスタムアクション:ファイルへの保存、データベースへの書き込み、通知の送信、人間の入力処理などのカスタムアクションの定義をサポートします。
- 自己修正メカニズム:より信頼性の高い自動化パイプラインのためのエラー処理と自動回復システムが組み込まれています。
- あらゆるLLMをサポート:GPT-4、Claude 3、Llama 2を含むLangChain経由の主要なLLMと互換性があります。
AIエージェント開発におけるブラウザ利用の限界
Browser Useは、ITコミュニティにかつてないインパクトを与えた画期的なテクノロジーだ。このプロジェクトがわずか数ヶ月で6万以上のGitHubスターを獲得したのも驚きではない:

その上、このプロジェクトを支えるチームは1700万ドル以上のシード資金を確保しており、このプロジェクトの可能性と将来性を物語っている。
しかし、Browser Useが提供するブラウザ制御機能は、魔法に基づくものではないことを認識することが重要です。その代わり、このライブラリは視覚的入力とAI制御を組み合わせ、Playwright(機能豊富なブラウザ自動化フレームワーク)を介してブラウザを自動化します。
Playwrightのウェブ・スクレイピングに関する以前の記事で指摘したように、制限は自動化フレームワーク自体に起因するものではない。全く逆で、Playwrightがコントロールするブラウザに起因している。具体的には、Playwrightのようなツールは、自動化を可能にする特別な設定とインスツルメンテーションを持つブラウザを起動する。問題は、これらの設定がボット対策検知システムにさらされる可能性があることだ。
これは、特に厳重に保護されたサイトとやりとりする必要があるAIエージェントを構築する場合に、大きな問題となる。例えば、ブラウザー利用を利用して、アマゾンのショッピングカートに特定の商品を追加するAIエージェントを構築したいとする。このような結果になる可能性が高い:

ご覧のように、Amazonのアンチボットシステムは、あなたのAI自動化を検出し、停止することができます。特に、eコマース・プラットフォームは、難易度の高いAmazon CAPTCHAを表示したり、”Sorry, something went wrong on our end “というエラー・ページで応答したりします:

このような場合、AIエージェントにとっては「ゲームオーバー」である。つまり、ブラウザーの使用は素晴らしく強力なツールですが、その可能性をフルに発揮するには、思慮深い調整が必要なのです。最終的なゴールは、アンチボット・システムをトリガーしないようにすることであり、それによってAIオートメーションが望むように動作できるようにすることである。
スクレイピング・ブラウザが解決策となる理由
さて、あなたはこう考えているかもしれない:”Playwrightでブラウザを制御するブラウザに手を加えて、特別なフラグを使って検出される可能性を下げればいいじゃないか “と思うかもしれない。それは確かに可能であり、Playwright Stealthのようなライブラリによって使われる戦略の一部である。
しかし、アンチボット検知を回避するのは、いくつかのフラグをめくるよりもはるかに複雑だ……。
IPレピュテーション、レート制限、ブラウザフィンガープリント、その他の高度な側面などの要素が含まれます。洗練されたアンチボットシステムを、いくつかの手動トリックで単に出し抜くことはできません。本当に必要なのは、アンチボットやアンチスクレイピングの防御に検出されないようにゼロから構築されたソリューションです。そして、スクレイピング・ブラウザの出番です!
スクレイピング・ブラウザ・ソリューションは、信じられないほど効果的な検知防止機能を提供している。では、市場で最高のアンチ・ディテクト・ブラウザは何でしょうか?Bright Dataのスクレイピング・ブラウザです!
特に、Scraping Browserは、次世代のクラウドベースのウェブブラウザであり、以下のような特長がある:
- 実際のユーザーに紛れ込む信頼性の高いTLSフィンガープリント
- 大量スクレイピングのための無制限のスケーラビリティ
- 150M以上のIPプロキシネットワークに支えられた自動IPローテーション
- 失敗したリクエストを潔く処理するための組み込みリトライロジック
- すぐに使えるCAPTCHA解決機能
- 包括的なアンチボット・バイパス・ツールキット
Scraping Browserは、Playwright、Puppeteer、Seleniumを含むすべての主要なブラウザ自動化ライブラリと統合している。このライブラリはPlaywrightの上に構築されているため、ブラウザでの使用に完全に対応している。
Scraping BrowserをBrowser Useに統合することで、先ほど遭遇したAmazonのブロックを回避することができる。
スクレイピング・ブラウザとブラウザ利用を統合する方法
このチュートリアルでは、Bright DataのScraping BrowserとBrowser Useを統合する方法を学びます。Amazonのカートに商品を追加できるOpenAIを搭載したAIエージェントを構築します。
これは、AIによるブラウザ自動化のパワーを示す一例に過ぎません。AIエージェントは、あなたのニーズや目標に応じて、他のサイトと相互作用することができることに注意してください。重要なのは、面倒な操作を代行することで、時間と労力を大幅に節約できることです。
具体的には、私たちがこれから作ろうとしているアマゾンAIエージェントは、以下のことができるようになる:
- 検出やブロックを避けるため、リモートのスクレイピング・ブラウザ・インスタンスを使ってAmazonに接続する。
- プロンプトから項目のリストを読む。
- 検索し、正しい商品を選び、自動的にカートに入れる。
- カートにアクセスし、注文全体の概要を提供する。
スクレイピング・ブラウザでブラウザを使用する方法については、以下の手順に従ってください!
前提条件
このチュートリアルに従うには、以下のものを用意してください:
- ブライトデータのアカウント。
- OpenAI、Anthropic、Gemini、DeepSeek、Grok、Novitaなど、サポートされているAIプロバイダーのAPIキー。
- Pythonの非同期プログラミングと ブラウザの自動化に関する基本的な知識。
Bright DataまたはAIプロバイダーのアカウントをまだお持ちでない方もご安心ください。以下のステップで作成方法を説明します。
ステップ1:プロジェクトのセットアップ
始める前に、システムにPython 3がインストールされていることを確認してください。そうでなければ、公式サイトからダウンロードし、インストールの指示に従ってください。
ターミナルを開き、AIエージェントプロジェクト用の新しいフォルダを作成します:
mkdir browser-use-amazon-agentbrowser-use-amazon-agentフォルダには、PythonベースのAIエージェントのすべてのコードが格納されます。
プロジェクトフォルダーに移動し、その中に仮想環境をセットアップする:
cd browser-use-amazon-agent
python -m venv venvお気に入りのPython IDEでプロジェクトフォルダを開いてください。Python拡張機能付きのVisual Studio Codeか PyCharm Community Editionが有効です。
browser-use-amazon-agentフォルダに、agent.py という Python ファイルを新規作成します。プロジェクトの構造は以下のようになります:
この時点では、agent.pyはただの空のスクリプトですが、すぐに完全なAIブラウザ自動化ロジックが含まれるようになります。
IDEのターミナルで、仮想環境を有効にします。Linux/macOSでは、以下を実行する:
source venv/bin/activate同様に、Windowsでは、実行する:
venv/Scripts/activateこれで準備完了です!これでPython環境は、Browser UseとScraping Browserを使ってAIエージェントを構築する準備が整いました。
ステップ2:環境変数の設定 読み込み
プロジェクトは、Bright Dataや選択したAIプロバイダーのようなサードパーティ・サービスと統合することになります。APIキーや接続シークレットをPythonコードに直接ハードコーディングするのではなく、環境変数から読み込むのがベストプラクティスです。
この作業を簡単にするために、python-dotenvライブラリを使います。アクティベートされた仮想環境に、次のようにインストールします:
pip install python-dotenvagent.pyファイルで、ライブラリをインポートし、load_dotenv() で環境変数をロードします:
from dotenv import load_dotenv
load_dotenv()これでローカルの.envファイルから変数を読み込めるようになります。プロジェクトに追加してください:

これで、あなたのコードでこれらの環境変数にアクセスできるようになる:
env_value = os.getenv("<ENV_NAME>")Python標準ライブラリからosをインポートするのを忘れないこと:
import os素晴らしい!これで、envsからサードパーティのサービスと統合するための秘密を安全に読み取る準備ができました。
ステップ3: ブラウザ使用開始
仮想環境をアクティブにした状態で、ブラウザユースをインストールする:
pip install browser-useライブラリーはいくつかの依存関係に依存しているので、数分かかるかもしれない。だから、気長に待とう。
browser-useはPlaywrightを使用しているので、Playwrightのブラウザ依存ファイルもインストールする必要があるかもしれない。そのためには、以下のコマンドを実行してください:
python -m playwright installこれにより、必要なブラウザ・バイナリがダウンロードされ、Playwrightが正しく機能するために必要なすべてのものがセットアップされる。
次に、必要なクラスをbrowser-useからインポートする:
from browser_use import Agent, Browser, BrowserConfigこれらのクラスを使用して、AIエージェントのブラウザ自動化ロジックを構築する。
browser-useは非同期APIを提供するので、agent.pyを非同期エントリポイントで初期化する必要があります:
# other imports..
import asyncio
async def main():
# AI agent logic...
if __name__ == "__main__":
asyncio.run(main())上記のスニペットは、Pythonのasyncioライブラリを使って非同期タスクを実行している。
よくできた!次のステップは、スクレイピング・ブラウザを設定し、スクリプトに統合することです。
ステップ #4: スクレイピング・ブラウザを使い始める
一般的な統合手順については、スクレイピング・ブラウザの公式ドキュメントを参照してください。それ以外の場合は、以下の手順に従ってください。
まずは、Bright Dataのアカウントを作成してください。ログインして、ユーザーダッシュボードに行き、”Get proxy products “ボタンをクリックしてください:
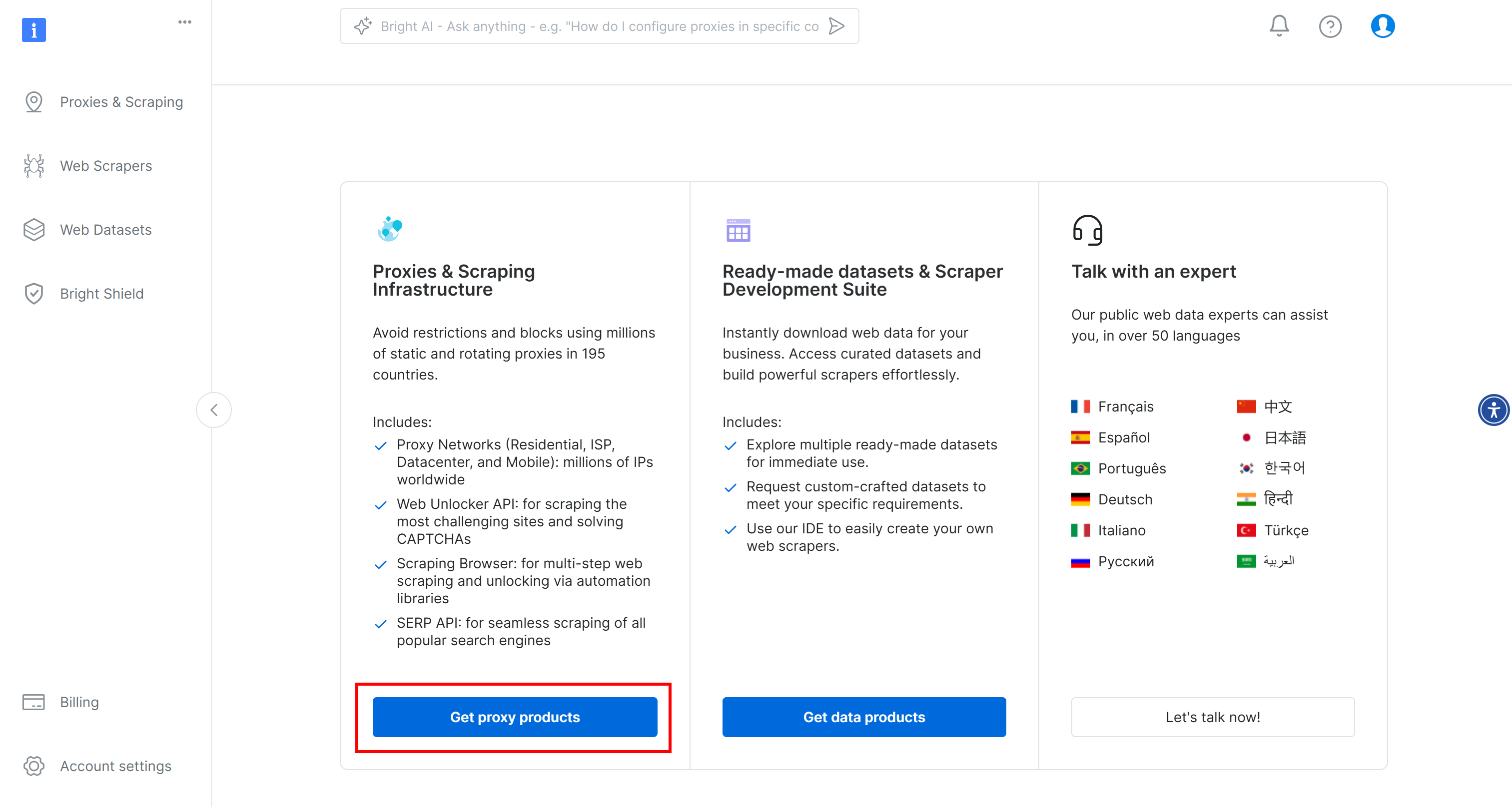
プロキシ&スクレイピング・インフラストラクチャ “ページで、”マイ・ゾーン “テーブルを探し、”スクレイピング・ブラウザ “タイプを参照する行を選択する:

そのような行が表示されない場合は、まだスクレイピング・ブラウザ・ゾーンを設定していないことを意味します。その場合、”Browser API “カードを見つけるまで下にスクロールし、”Get Started “ボタンを押してください:

次に、ガイドされたセットアップに従って、スクレイピング・ブラウザを初めて設定する。
製品ページに到達したら、オン/オフスイッチを切り替えて有効にする:

次に、”Configuration “タブに行き、最大の効果を得るために “Premium domains “と “CAPTCHA Solver “の両方が有効になっていることを確認する:

概要」タブに切り替え、Playwrightスクレイピングブラウザの接続文字列をコピーする:

この接続文字列を.envファイルに追加する:
SBR_CDP_URL="<YOUR_PLAYWRIGHT_SCRAPING_BROWSER_CONNECTION_STRING>"置き換える をコピーした値で置き換える。
次に、agent.pyファイルで環境変数をロードします:
SBR_CDP_URL = os.getenv("SBR_CDP_URL")驚き!これで、Scraping Browserをブラウザーの中で使うことができる。その前に、OpenAIをスクリプトに追加して、サードパーティとの統合を完了させましょう。
ステップ5:OpenAIを使い始める
免責事項:以下の手順はOpenAIの統合に焦点を当てていますが、Browser Useでサポートされている他のAIプロバイダーにも簡単に適用できます。
ブラウザでAI機能を有効にするには、外部のAIプロバイダーからの有効なAPIキーが必要です。ここではOpenAIを使用する。まだAPIキーを作成していない場合は、OpenAIの公式ガイドに従って作成してください。
キーが手に入ったら、それを.envファイルに追加する:
OPENAI_API_KEY="<YOUR_OPENAI_KEY>"必ず を実際のAPIキーに置き換えてください。
次に、ChatOpenAIクラスをagent.pyの langchain_openaiからインポートします:
from langchain_openai import ChatOpenAIBrowser UseはAIの統合をLangChainに依存していることに注意してください。そのため、プロジェクトに明示的にlangchain_openaiをインストールしていなくても、すでに利用可能です。より詳しいガイダンスについては、LangChainワークフローにBright Dataを統合する方法についてのチュートリアルをお読みください。
gpt-4oモデルを使ってOpenAIの統合をセットアップする:
llm = ChatOpenAI(model="gpt-4o")追加の設定は必要ありません。なぜなら、langchain_openaiは自動的にOPENAI_API_KEY環境変数からAPIキーを読み込むからだ。
他のAIモデルやプロバイダーとの統合については、公式のBrowser Useドキュメントを参照してください。
ステップ6:スクレイピング・ブラウザをブラウザに組み込む
ブラウザ使用でリモート・ブラウザに接続するには、次のようにBrowserConfigオブジェクトを使用する必要がある:
config = BrowserConfig(
cdp_url=SBR_CDP_URL
)
browser = Browser(config=config)この設定は、リモート Bright Data Scraping Browser インスタンスに接続するよう Playwright に指示します。
ステップ #7: 自動化するタスクを定義する
次に、AIエージェントにブラウザ上で自然言語を使って実行させたいタスクを定義する。
その前に、ゴールが明確に定義されていることを確認してください。この場合、AIエージェントに次のことをさせたいとします:
- Amazon.co.jpに接続する。
- PlayStation 5本体とAstro Bot PS5ゲームをカートに入れる。
- カートページに到達し、現在の注文の概要を生成します。
ブラウザー・ユースへの基本的な指示だけを出しても、期待通りにはいかないかもしれない。なぜなら、商品によっては複数のバージョンがあったり、ページによっては追加保険への加入を促されたり、商品によっては入手できなかったりするからです。
したがって、このような状況でAIエージェントの決定を導くために、特別なメモを追加することは理にかなっている。
また、パフォーマンスを向上させるためには、最も重要なステップの概要を言葉で明確に示すことが有効である。
それを念頭に置くと、AIエージェントがブラウザで実行すべきタスクは次のように記述できる:
task="""
# Prompt for Your Amazon Agent
**Objective:**
Visit [Amazon](https://www.amazon.com/), search for the required items, add them to the cart, and show a summary of the current order.
**Important:**
- Click on a product's title to access its page. There, you can find the "Add to cart" button.
- If you are asked for extended warranty or similar after adding a product to the cart, decline the option.
- You can find the search bar to search for products at the top section of each Amazon page. If you cannot use it, go back to the Amazon home page before a search.
- If the product is unavailable, add the cheapest used option to the cart instead. If no used options are available, skip the product.
- If any modal/section occupying a part of the page appears, remember that you can close it by clicking the "X" button.
- Avoid refurbished items.
---
## Step 1: Navigate to the Target Website
- Open [Amazon](https://www.amazon.com/)
---
## Step 2: Add Items to the Cart
- Add the items you can find in the shopping list below to the Amazon cart:
- PlayStation 5 (Slim) console
- Astro Bot PS5 game
---
## Step 3: Output Summary
- Reach the cart page and use the info you can find on that page to generate a summary of the current order. For each item in the cart, include:
- **Name**
- **Quantity**
- **Cost**
- **Expected delivery time**
- At the end of the report, mention the total cost and any other useful additional info.
"""このバージョンは、AIエージェントを一般的なシナリオに誘導し、行き詰まるのを防ぐのに十分なほど詳細であることに注目してほしい。
美しい!このタスクの開始方法をご覧ください。
ステップ#8: AIタスクの起動
AIエージェントのタスク定義を使って、ブラウザ用の Agentオブジェクトを初期化します:
agent = Agent(
task=task,
llm=llm,
browser=browser,
)これでエージェントを実行できる:
await agent.run()また、タスクが完了したら、Playwrightがコントロールするブラウザを閉じて、リソースを解放することもお忘れなく:
await browser.close()完璧です!ブラウザの使用+ブライトデータスクレイピングブラウザの統合はこれで完全にセットアップされました。あとはすべてをまとめて、完全なコードを実行するだけです。
ステップ9:すべてをまとめる
agent.pyファイルには
from dotenv import load_dotenv
import os
from browser_use import Agent, Browser, BrowserConfig
from browser_use.browser.context import BrowserContextConfig, BrowserContext
import asyncio
from langchain_openai import ChatOpenAI
# Load the environment variables from the .env file
load_dotenv()
async def main():
# Read the remote URL of Scraping Browser from the envs
SBR_CDP_URL = os.getenv("SBR_CDP_URL")
# Set up the AI engine
llm = ChatOpenAI(model="gpt-4o")
# Configure the browser automation to connect to a remote Scraping Browser instance
config = BrowserConfig(
cdp_url=SBR_CDP_URL
)
browser = Browser(config=config)
# The task you want to automate in the browser
task="""
# Prompt for Your Amazon Agent
**Objective:**
Visit [Amazon](https://www.amazon.com/), search for the required items, add them to the cart, and show a summary of the current order.
**Important:**
- Click on a product's title to access its page. There, you can find the "Add to cart" button.
- If you are asked for extended warranty or similar after adding a product to the cart, decline the option.
- You can find the search bar to search for products at the top section of each Amazon page. If you cannot use it, go back to the Amazon home page before a search.
- If the product is unavailable, add the cheapest used option to the cart instead. If no used options are available, skip the product.
- If any modal/section occupying a part of the page appears, remember that you can close it by clicking the "X" button.
- Avoid refurbished items.
---
## Step 1: Navigate to the Target Website
- Open [Amazon](https://www.amazon.com/)
---
## Step 2: Add Items to the Cart
- Add the items you can find in the shopping list below to the Amazon cart:
- PlayStation 5 (Slim) console
- Astro Bot PS5 game
---
## Step 3: Output Summary
- Reach the cart page and use the info you can find on that page to generate a summary of the current order. For each item in the cart, include:
- **Name**
- **Quantity**
- **Cost**
- **Expected delivery time**
- At the end of the report, mention the total cost and any other useful additional info.
"""
# Initialize a new AI browser agent with the configured browser
agent = Agent(
task=task,
llm=llm,
browser=browser,
)
# Start the AI agent
await agent.run()
# Close the browser when the task is complete
await browser.close()
if __name__ == "__main__":
asyncio.run(main())出来上がり!100行以下のコードで、Bright Dataのスクレイピング・ブラウザとブラウザを組み合わせた強力なAIエージェントを構築しました。
AIエージェントを実行するには、以下を実行する:
python agent.py一度起動すると、ブラウザーユーズは全ての動作をログに記録する。スクレイピングブラウザはクラウド上で実行され、視覚的なインターフェイスがないため、これらのログはエージェントが何をしているかを理解するために不可欠です。
以下は、ログがどのように見えるかの短い抜粋である:
INFO [agent] 📍 Step 1
INFO [browser] 🔌 Connecting to remote browser via CDP wss://brd-customer-hl_4bcb8ada-zone-scraping_browser:[email protected]:9222
INFO [agent] 🤷 Eval: Unknown - Task has just started, beginning with navigating to Amazon.
INFO [agent] 🧠 Memory: Step 1: Navigate to Amazon's website. Open tab to Amazon's main page.
INFO [agent] 🎯 Next goal: Navigate to Amazon's website by opening the following URL: https://www.amazon.com/.
INFO [agent] 🛠️ Action 1/1: {"go_to_url":{"url":"https://www.amazon.com/"}}
INFO [controller] 🔗 Navigated to https://www.amazon.com/
INFO [agent] 📍 Step 2
INFO [agent] 👍 Eval: Success - Navigated to Amazon homepage. The search bar is available for input.
INFO [agent] 🧠 Memory: On the Amazon homepage, ready to search for items. 0 out of 2 items added to cart.
INFO [agent] 🎯 Next goal: Search for the 'PlayStation 5 (Slim) console' in the search bar.
INFO [agent] 🛠️ Action 1/2: {"input_text":{"index":2,"text":"PlayStation 5 (Slim) console"}}
INFO [agent] 🛠️ Action 2/2: {"click_element_by_index":{"index":4}}
INFO [controller] ⌨️ Input PlayStation 5 (Slim) console into index 2
INFO [agent] Something new appeared after action 1 / 2
# Omitted for brevity...
INFO [agent] 📍 Step 14
INFO [agent] 👍 Eval: Success - Extracted the order summary from the cart page.
INFO [agent] 🧠 Memory: Amazon cart page shows both items: PlayStation 5 Slim and Astro Bot PS5 game added successfully. Extracted item names, quantities, costs, subtotal, and delivery details.
INFO [agent] 🎯 Next goal: Finalize the task by summarizing the order details.
INFO [agent] 🛠️ Action 1/1: {"done":{"text":"Order Summary:nnItems in Cart:n1. Name: Astro Bot PS5n Quantity: 11n Cost: $58.95nn2. Name: PlayStation®5 console (slim)n Quantity: 1n Cost: $499.00nnSubtotal: $557.95nDelivery Details: Your order qualifies for FREE Shipping. Choose this option at checkout.nnTotal Cost: $557.95","success":true}}
INFO [agent] 📄 Result: Order Summary:
Items in Cart:
1. Name: Astro Bot PS5
Quantity: 1
Cost: $58.95
2. Name: PlayStation®5 console (slim)
Quantity: 1
Cost: $499.00
Subtotal: $557.95
Delivery Details: Your order qualifies for FREE Shipping. Choose this option at checkout.ご覧の通り、AIエージェントは目的の商品を見つけ、カートに追加し、きれいなサマリーを作成することに成功した。スクレイピング・ブラウザのおかげで、Amazonからブロックされたり、禁止されたりすることなく、これらすべてを行うことができた!
browser-useには、デバッグ用にブラウザセッションを録画する機能もある。これはまだリモート・ブラウザでは動作しないが、もし動作すれば、AIエージェントの動作の魅惑的なプレイバックを見ることができるだろう:
まさに催眠術のようであり、AIによるブラウジングがどこまで進化したかを垣間見ることができる。
ステップ#10:次のステップ
私たちがここで作ったアマゾンAIエージェントは、何が可能かを示す概念実証の出発点に過ぎません。本番で使えるようにするために、以下にいくつかの改善案を示します:
- Amazonアカウントに接続します:エージェントにログインを許可し、注文履歴やおすすめ商品などのパーソナライズされた機能にアクセスできるようにします。
- 購入ワークフローを実装する:実際に購入を完了するためのエージェントを拡張します。これには、配送オプションの選択、プロモーションコードやギフトカードの適用、支払いの確認などが含まれます。
- 電子メールによる確認またはレポートの送信決済を確定する前に、エージェントがカートの詳細な概要と意図したアクションをEメールで送信し、ユーザーの承認を得ることができます。これにより、ユーザは管理しやすくなり、説明責任を果たすことができます。
- ウィッシュリストまたは入力リストからアイテムを読み込む:エージェントに、保存されたAmazonウィッシュリスト、ローカルファイル(JSONやCSVなど)、またはリモートAPIエンドポイントから動的にアイテムを読み込ませます。
結論
このブログポストでは、Pythonで非常に効果的なAIエージェントを構築するために、人気のブラウズ使用ライブラリとスクレイピングブラウザAPIを組み合わせて使用する方法を学びました。
実証されているように、Browse UseとBright DataのScraping Browserを組み合わせることで、事実上あらゆるウェブサイトと確実に対話できるAIエージェントを作成することができます。これは、Bright Dataのツールとサービスが、高度なAI主導の自動化をどのように支援できるかの一例に過ぎません。
AIエージェント開発のためのソリューションをご覧ください:
- 自律型AIエージェント:強力なAPIセットを使って、あらゆるウェブサイトをリアルタイムで検索、アクセス、対話。
- 業種別AIアプリ:信頼性の高いカスタムデータパイプラインを構築し、業種固有のソースからウェブデータを抽出します。
- 基礎モデル:ウェブスケールのデータセットにアクセスし、事前学習、評価、微調整を行うことができます。
- マルチモーダルAI:AIに最適化された世界最大の画像、動画、音声のリポジトリを利用できます。
- データプロバイダー:信頼できるプロバイダーと接続し、高品質でAIに対応したデータセットを大規模に調達。
- データパッケージ:キュレーションされた、すぐに使える、構造化された、エンリッチされた、注釈付きのデータセットを入手。
詳しくはAIハブをご覧ください。
ブライトデータのアカウントを作成し、AIエージェント開発のためのすべての製品とサービスをお試しください!




