
このブログ記事では、以下の内容を学びます:
- Zencoderとは何か、またAIを活用したソフトウェア開発を改善するためにどのような製品を提供しているか。
- ウェブアクセスを拡張することで、出力の信頼性と精度が向上する理由。
- Bright DataがZencoderとの統合においてウェブスクレイピング、検索、ディスカバリー、ブラウザ自動化をどのようにサポートするか。
- MCPを使用してBright DataをZencoder Zenflow(およびそのIDEプラグイン)に接続する方法。
- 公式のAgent Skillsを使用してZencoder製品にBright Dataの知識を付与する方法。
- Bright Data+Zencoder統合が可能にすること(完全な例を用いて説明)。
さっそく始めましょう!
Zencoderとは?
Zencoderは、自律的なペアプログラマーとして機能するAI搭載コーディングエージェントのソリューションを提供する企業です。
主力製品はZenflowで、IDE、CI/CDパイプライン、デスクトップ環境全体でマルチエージェントワークフローを実行するAIオーケストレーションプラットフォームです。エージェントがコードを計画・構築・テスト・検証できるようにし、完全なコードベースコンテキスト、構造化されたワークフロー、組み込みの品質ゲートを活用します。最終目標は、ソフトウェア開発と運用タスクを大規模に自動化することです。
Zenflowは2つのモードをサポートしています:
- Zenflow Code:ソフトウェア開発用AIエージェント(構築、テスト、リファクタリング)。
- Zenflow Work:Jira、Slackなどのツール全体にわたるエンタープライズワークフロー用AIエージェント。
注意:ZencoderはVisual Studio CodeおよびJetBrainsのIDEエージェントからも利用できます。
Zencoder製品がサポートする主な機能は次のとおりです:
- マルチエージェントオーケストレーション:複数のAIエージェントが計画、コーディング、レビュー、監査タスクで協力します。
- 完全なコードベースコンテキスト:エージェントは行動する前にマルチリポジトリアーキテクチャと依存関係を理解します。
- 構造化されたワークフロー:「仕様→計画→構築→テスト→検証」パイプラインがアドホックなプロンプトに取って代わります。
- 組み込み検証:自動テスト、リンティング、コードレビューにより、出力が受け入れられる前に品質を確保します。
- 並列実行:複数のエージェントが隔離された環境で同時に実行されます。
- クロスツール統合:GitHub、Jira、Slack、CI/CDシステムなどと連携します。
- エンタープライズコントロール:ロールベースのアクセス、承認ゲート、監査ログ、コンプライアンスサポート(SOC 2、ISO)。
- 自律スケジューリング:エージェントが依存関係の更新やPRレビューなどの定期タスクを自動的に実行します。
詳細は公式ドキュメントをご覧ください。
ZencoderのAIエージェントにウェブの探索とデータ収集能力を付与すべき理由
他のLLM搭載ソリューションと同様に、Zencoderエージェントには根本的な制限があります:情報の陳腐化です。大規模言語モデルはトレーニングデータセットから導き出された応答を生成するため、過去の固定されたウィンドウ内で動作します。
急速に進化する技術エコシステムにおいて、このレイテンシは大きな障害となります。コーディングエージェントが廃止されたライブラリメソッドを提案したり、重要な新しいセキュリティアップデートを見落としたりする可能性があります。これらの制限を回避するには、AIモデルにライブウェブ接続が必要です。まさにここでBright Dataが役立ちます!
Bright DataのAI対応インフラにより、Zencoderエージェントは初期トレーニングを超えることができます。これにより、以下の能力が得られます:
- リアルタイム検索の実行:最新のドキュメントや情報をGoogleなどの検索エンジンで検索し、ハルシネーションや古い提案を削減します。
- 精度の検証:Stack OverflowのディスカッションやGitHubのイシューに対してコードスニペットをクロスチェックし、デバッグ精度を向上させます。
- 構造化データの抽出:ライブウェブページからデータを収集し、ローカルリポジトリに格納したり、開発とテスト用のリアルなモックデータを生成したりします。
- ドキュメントの強化:READMEファイルや内部プロジェクトウィキ向けに、信頼性の高い評判の良いURLを推薦します。
- その他多数…
Bright Dataの決定的な優位性は、195カ国にわたる4億以上のレジデンシャルIPという巨大なグローバルプロキシネットワークです。このインフラは無制限の同時実行性、99.99%の稼働時間、99.95%の成功率を提供します。
Bright DataをZencoder製品に統合することで、構造化された最新のコンテキストウェブデータに基づいたスケーラブルなAIエージェントが実現します。
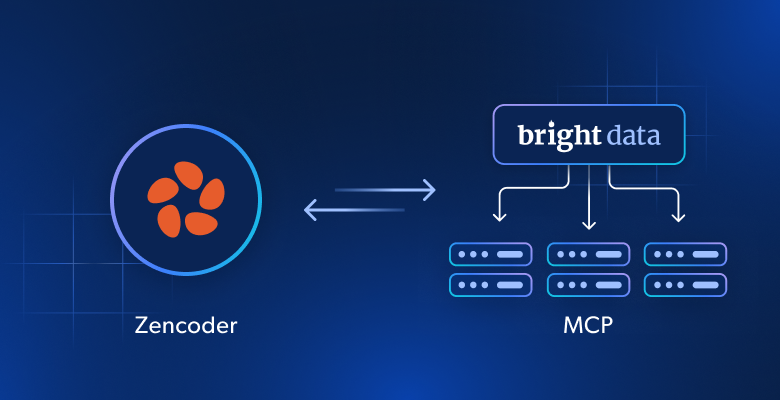
ZencoderのAIエージェントをBright Dataのウェブデータインフラに接続する方法
Bright DataはZencoderを2つの統合でサポートしています:
- Bright Data Web MCP:ウェブデータアクセス、抽出、ブラウザ自動化のための70以上のツールを公開するMCPサーバー。
- Bright Dataスキル:ZencoderエージェントがBright Dataソリューションを効果的に使用するためのガイドとなるAgent Skills。
これらのアプローチは代替手段ではなく、相乗効果をもたらすものであることに注意してください。具体的には、特定のスキルがWeb MCPツールの最適な使用方法についてのガイダンスを提供します。
重要:以下の章では、MCPとAgent Skillsを介してBright DataをZenflowに統合することについて説明します。ZencoderのIDEプラグインも同じ設定ファイルに依存しています。そのため、セットアップは変わりません(UIのスクリーンショットといくつかの細かい手順のみが異なります)。
Bright Data Web MCP
Bright Data Web MCPは、Bright DataのAPIベースの製品とサービスと連携するための70以上のツールを提供します。
Rapidモード(無料プラン)でも、主要なツールには以下が含まれます:
| ツール | 説明 |
|---|---|
search_engine+並列使用のバッチ版 |
Google、Bing、またはYandexの結果を構造化されたJSONまたはMarkdownで取得 |
scrape_as_markdown+並列使用のバッチ版 |
アンチボット保護をバイパスしながら、任意のウェブページをクリーンなMarkdownに変換 |
discover |
ランク付けされた関連ウェブ結果を返すAI搭載検索 |
次に、Proモードでは、GitHub、NPM、PyPI、Amazon、LinkedIn、Yahoo Finance、YouTube、Zillow、Google Maps、その他40以上のプラットフォームからの構造化データ抽出のための高度な機能が解放されます。また、完全なブラウザ自動化のためのツールも公開されます。
Bright Dataスキル
Bright Dataスキルには以下が含まれます:
| スキル | 説明 |
|---|---|
search |
ウェブ検索を実行し、構造化された結果を返す |
scrape |
ボット保護を処理しながらページをクリーンなMarkdownにスクレイピングする |
data-feeds |
スケジュールされたポーリングで40以上のサイトから構造化データを抽出する |
bright-data-mcp |
検索、スクレイピング、自動化を改善するためにWeb MCPツールをオーケストレーションする |
brightdata-cli |
スクレイピング、プロキシ、データセット管理のためのBright Data CLIの使用ガイド |
bright-data-best-practices |
Bright Data APIを正確かつ効率的に使用するためのリファレンス |
scraper-builder |
ガイド付きサイト分析と抽出ステップを通じて本番スクレイパーを構築する |
competitive-intel |
市場と競合他社全体のウェブデータを使用したライブ競合情報分析 |
seo-audit |
ライブウェブシグナル、構造、ランキング指標を使用したSEO監査 |
design-mirror |
UIデザインパターン、トークン、コンポーネント構造を再現する |
共通ステップ
次の2つの章では、MCPとAgent Skillsをそれぞれ使用してBright DataをZenflowに統合する方法を説明します。まず、始める前に必要な共通のセットアップ手順に焦点を当てましょう。
前提条件
このチュートリアルに従うには、以下を準備してください:
- Node.js 22以上をローカルにインストール。
- Zencoderアカウント(無料プランまたはトライアルで十分)。
- APIキーが設定されたBright Dataアカウント(APIキーの生成方法の公式ガイドを参照)。
Zenflowのインストールと設定
Zenflowインストーラーをダウンロードし、実行してからアプリケーションを起動します。表示されるウェルカム画面はこちらです:
ログイン(まだの場合はサインアップ)して、ZencoderアカウントをZenflowに接続します。
いくつかのセットアップ質問が表示されます。回答してから、デフォルトのAIエージェントを選択します:
最後に「次へ」をクリックしてセットアップを完了します:
完了です!Zenflowのインストールに成功しました。次はBright Data統合のための設定を行います。
Web MCPを通じてBright DataをZencoderに接続する
このセクションでは、ZenflowにBright Data Web MCPをセットアップする手順を説明します。
前提条件
よりスムーズに進めるために、以下を準備することをお勧めします:
- MCPの仕組みに関する基本的な理解。
- Bright Data Web MCPが提供するツールへの精通。
注意:「共通ステップ」の章に記載されている前提条件もここに適用されます。
ステップ#1:Bright DataのWeb MCPを使い始める
Bright DataのWeb MCPをZenflowに接続する前に、MCPサーバーがマシン上で正しく動作することを確認してください。
まずBright Dataアカウントにログインします。クイックセットアップには、Bright Dataコントロールパネルの「MCP」セクションの指示に従ってください: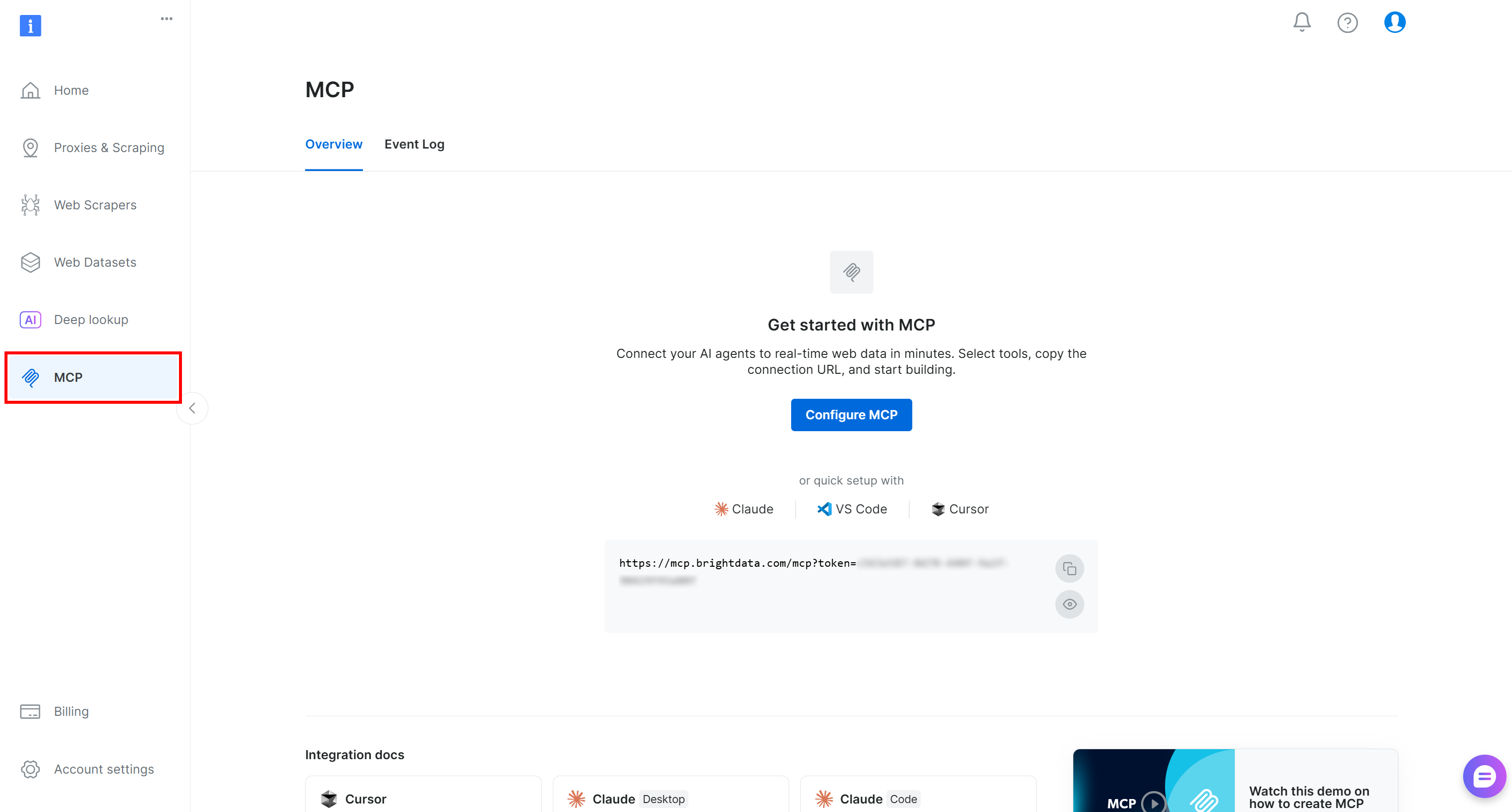
または、より詳細なガイダンスが必要な場合は、以下の手動セットアップ手順に従ってください。
まず、Web MCPをグローバルにインストールします:
npm install -g @brightdata/mcpMCPサーバーが起動することを確認します:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpまたは、PowerShellで同等のコマンド:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp<YOUR_BRIGHT_DATA_API>プレースホルダーを実際のBright Data APIキーに置き換えてください。このコマンドは必要なAPI_TOKEN環境変数を設定し、@brightdata/mcpパッケージを介してローカルでWeb MCPサーバーを起動します。
すべてが正常に動作する場合、以下のログが表示されます:
初回実行時、@brightdata/mcpパッケージはBright Dataアカウントに2つのゾーンを作成します:
mcp_unlocker:Web Unlocker用のゾーン。mcp_browser:Browser API用のゾーン。
これらのゾーンがWeb MCPで利用可能な70以上のツールを動かします。必要に応じて、公式リポジトリで説明されているようにカスタムゾーンを設定することもできます。
ゾーンが作成されたことを確認するには、Bright Dataコントロールパネルの「プロキシ&スクレイピングインフラ」セクションに移動します: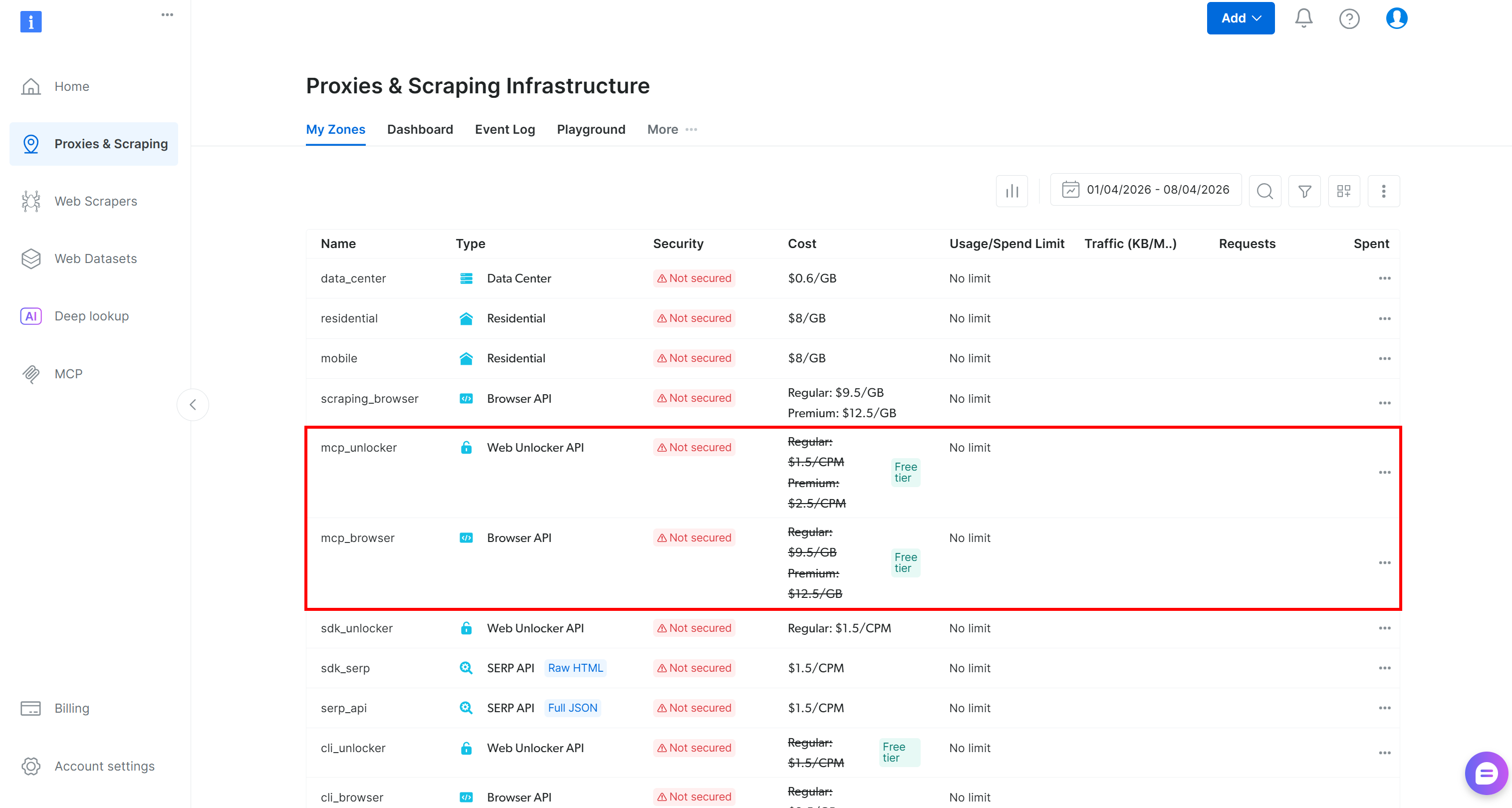
Web MCPの無料プラン(Rapidモード)では、限られたツールセットにのみアクセスできることを覚えておいてください。
70以上のツールすべてを解放するには、Proモードを有効にする必要があります。そのためには、PRO_MODE="true"環境変数を設定します:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpまたは、Windowsの場合:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcp注意:Proモードは無料プランには含まれておらず、追加料金が発生します。
完璧です!Bright Data Web MCPがマシン上で動作することを確認しました。次に、Zencoder ZenflowをこれのWeb MCPに接続するよう設定します。
ステップ#2:ZenflowでWeb MCPを設定する
すべてのZencoder製品はMCP統合をサポートしており、~/.zencoder/settings.jsonにある設定ファイルを通じて行います。このファイルを手動で編集するか、Zenflow UIからアクセスすることができます。
UIワークフローの場合、左下隅の「設定」アイコンをクリックして開始します:
次に「MCP Servers」セクションに移動します。ここでUIから直接設定ファイルを編集できます: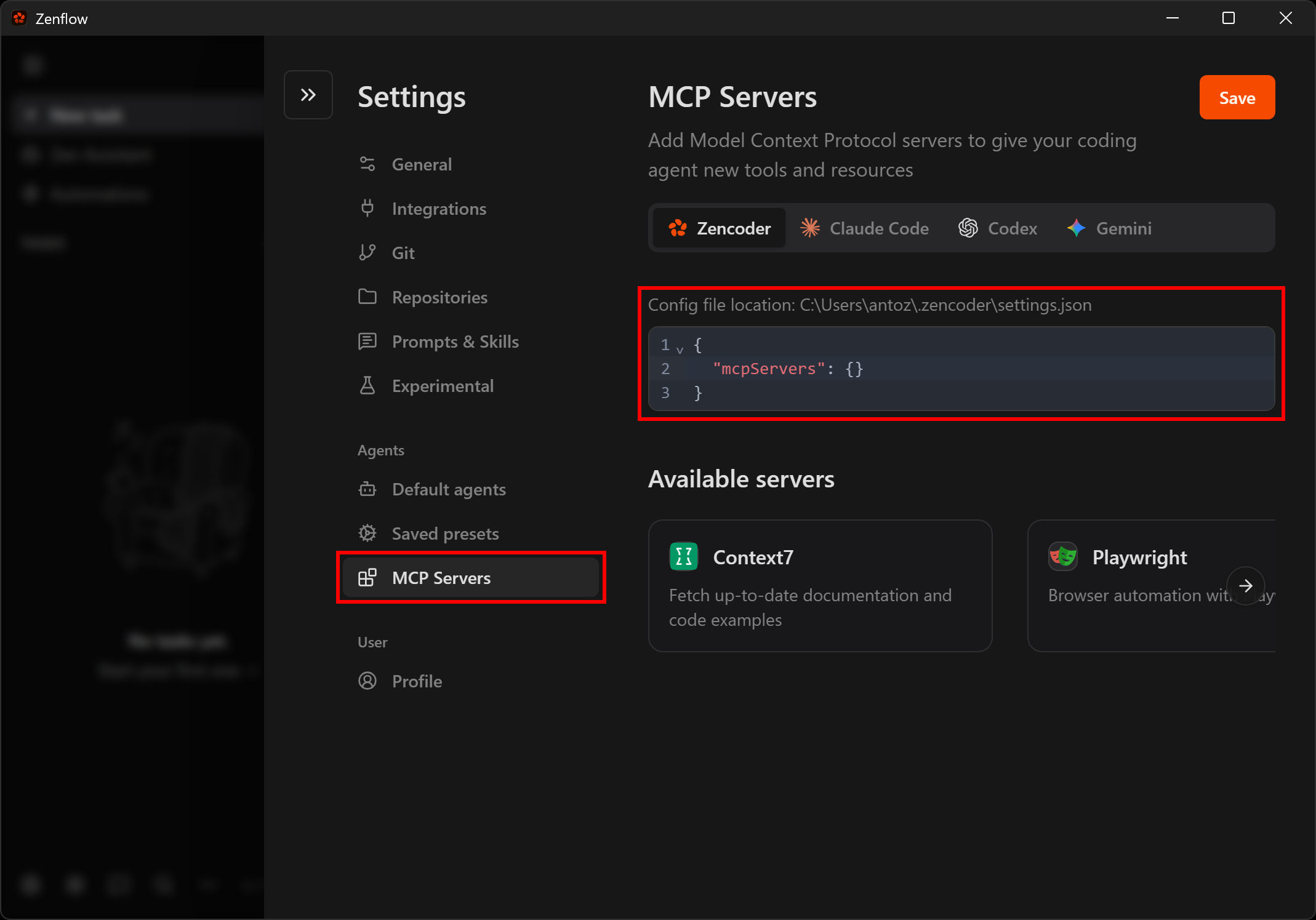
~/.zencoder/settings.jsonファイルに以下が含まれていることを確認します:
{
"mcpServers": {
"bright-data-web-mcp": {
"type": "stdio",
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
}
}
}UIから編集する場合は、同じ設定を入力して「保存」をクリックします: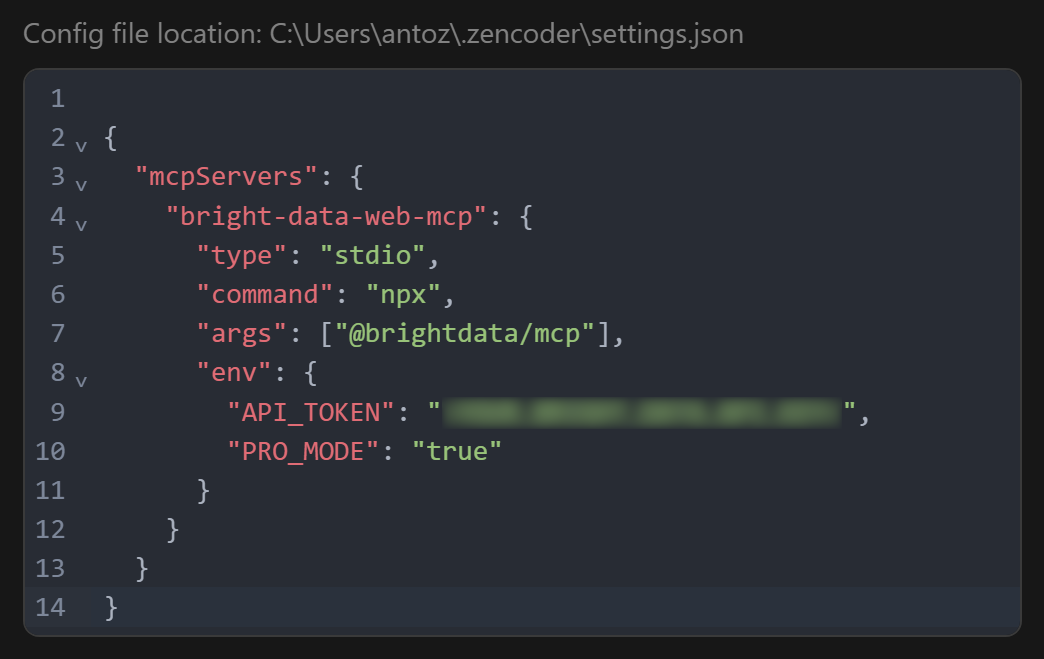
このセットアップは先ほどテストしたnpxコマンドを反映しており、認証と設定に環境変数を使用します:
API_TOKEN(必須):Bright Data APIキー。PRO_MODE(オプション):Pro機能を有効にするには"true"に設定するか、無料プランを使用する場合は削除します。
設定が完了すると、Zencoderは指定されたnpxコマンドを使用してローカルのWeb MCPサーバーを起動し、接続します。素晴らしい!
ステップ#3:Web MCP接続を確認する
執筆時点では、ZenflowはMCPツールを検査するための直接UIを提供していません。接続を確認するには、Workモードに切り替えて、次のようなプロンプトを送信します:
Which MCP tools do you have access to?以下のような結果が表示されるはずです: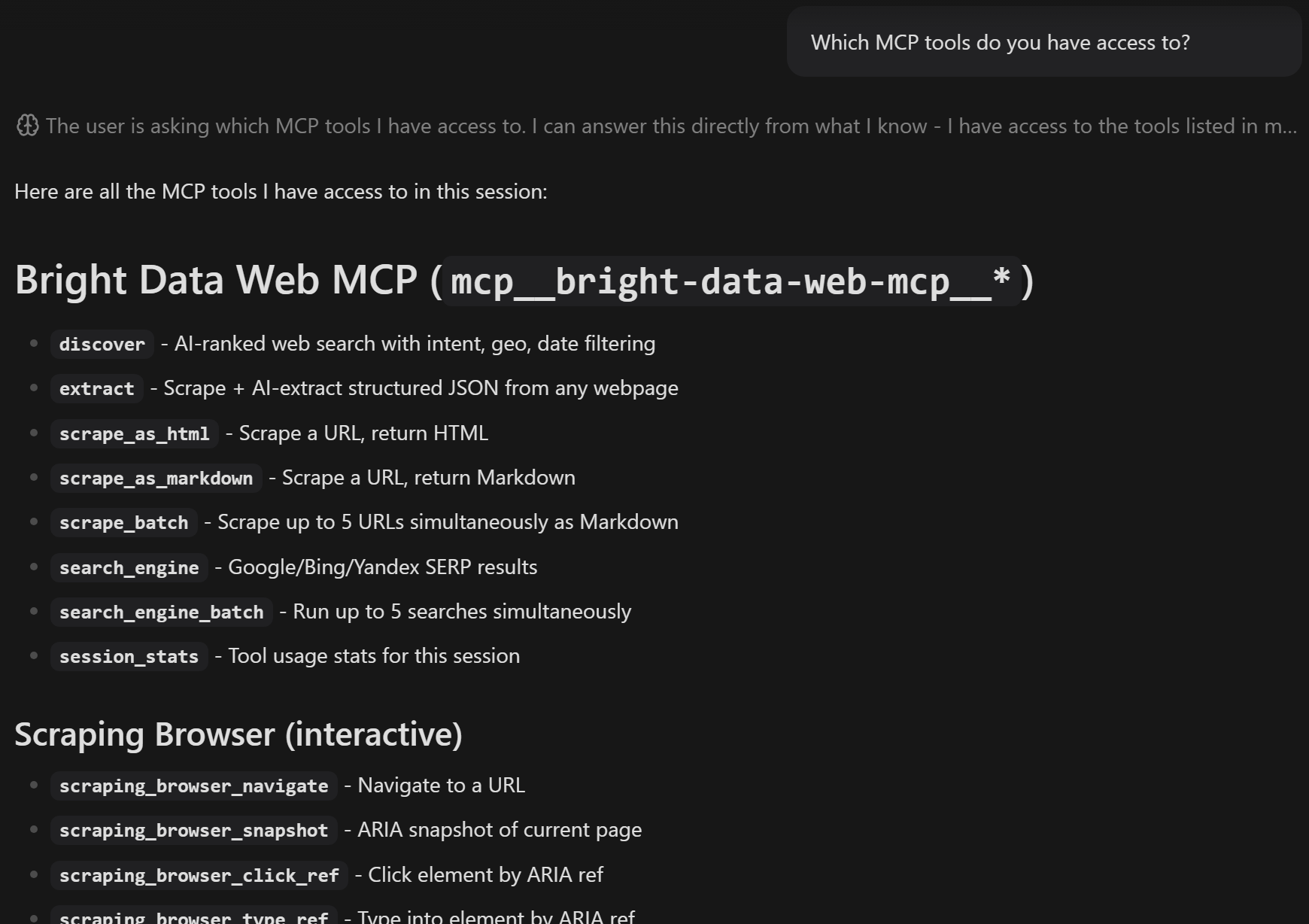
応答には利用可能なすべてのMCPツールが一覧表示されます。Proモードでは、70以上のWeb MCPツールが含まれます。それ以外の場合は、Rapid(無料)モードで利用可能なツールのみが表示されます。
これで、Bright Data Web MCPが正しく接続され、Zencoder製品にツールを公開していることが確認できました。このブログ記事の後半では、実際のワークフローでWeb MCPをBright Data Skillsと組み合わせて使用する方法を紹介します。
ZencoderにBright Data Skillsを追加する
ここでは、Vercelのskillsツールが提供するガイド付きワークフローを通じて、ZencoderセットアップにBright Data Skillsを追加する方法を学びます。
クイック手動セットアップ:手動でのアプローチを好む場合は、まずBright Dataスキルリポジトリをクローンします。次に、スキルを~/.zencoder/skillsディレクトリにコピーします:
git clone https://github.com/brightdata/skills
cp -r skills/skills/* ~/.zencoder/skills/それ以外の場合は、以下のより詳細なガイド付きアプローチに従ってください!
前提条件
以下を準備してください:
- Bright Data CLIがローカルにインストールされ設定されていること(Bright Dataスキルの主な前提条件)。
- Bright Dataスキルの基本的な知識。
注意:Bright Data CLIのクイックセットアップについては、「Bright Data CLI:インストール&セットアップ」ガイドを参照してください。または、専用のブログ記事をお読みください。
Agent Skillsスタンダードの基本的な理解とVercelのCLIツールskillsへのある程度の精通も役立ちます。
ステップ#1:Bright Data Skillsをインストールする
Zencoder環境にBright Data Skillsをインストールするには、以下を実行します:
npx skills add brightdata/skills -a zencoder上記のコマンドはskillsパッケージをインストールし、セットアッププロセスを起動します。これにより以下が行われます:
- 公式Agent SkillsディレクトリからBright Dataスキルをダウンロードします。
- ZenflowやIDEプラグインを含む、すべてのZencoder製品での使用に向けて設定します。
最初に、インストールするスキルを選択できる画面が表示されます: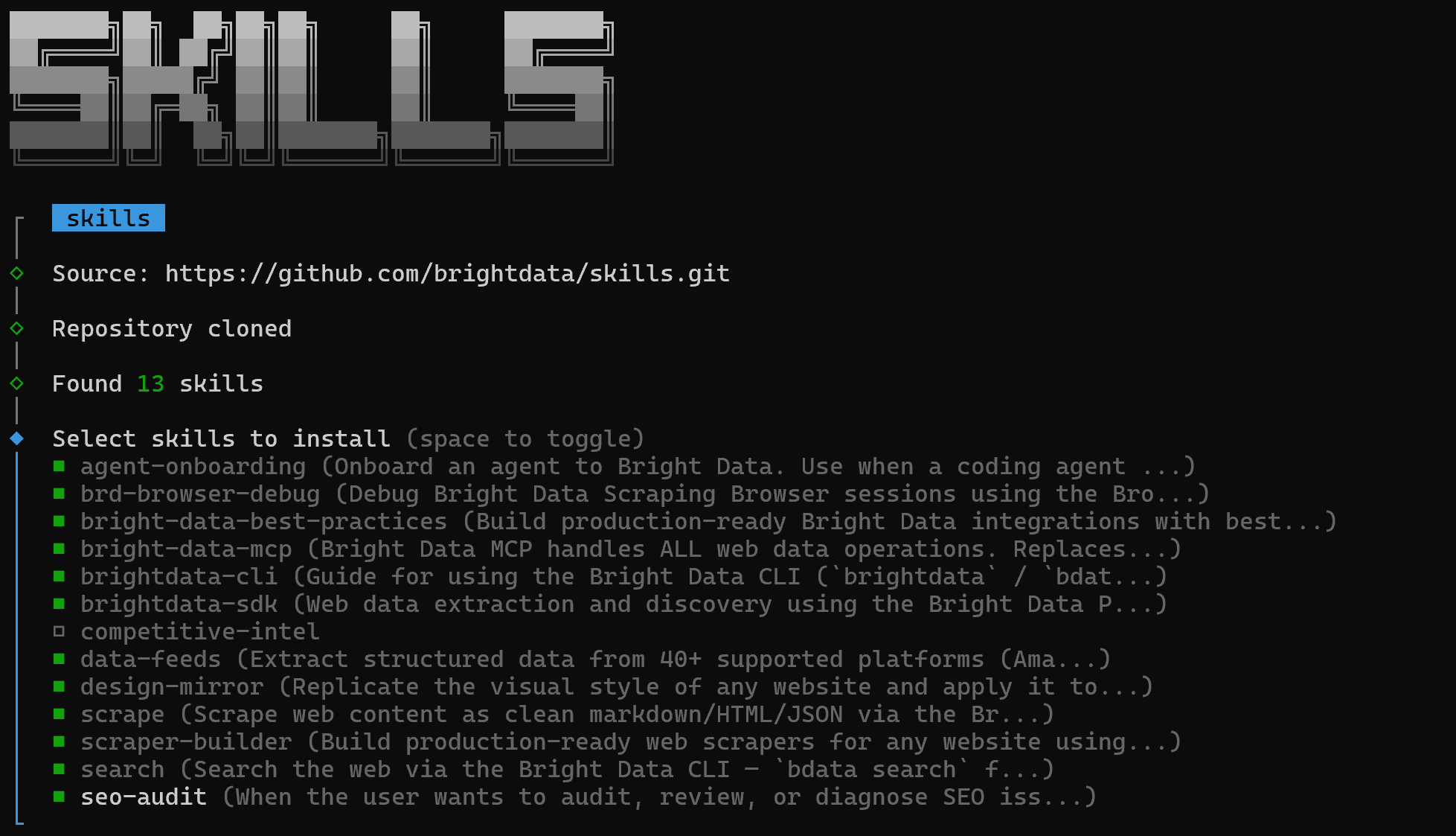
すべてをインストールするには、スペースバーで各スキルを選択し、Enterを押します。
次に、インストールスコープを選択するよう求められます。Web MCP統合はグローバルに設定されているため、Bright Dataスキルもグローバルにインストールする必要があります。そのため、「Global」オプションを選択します:
次に、「インストール概要」と「セキュリティリスク評価」セクションが表示されます。両方を注意深く確認し、Enterを押して確認します。最後に確認メッセージが表示されます: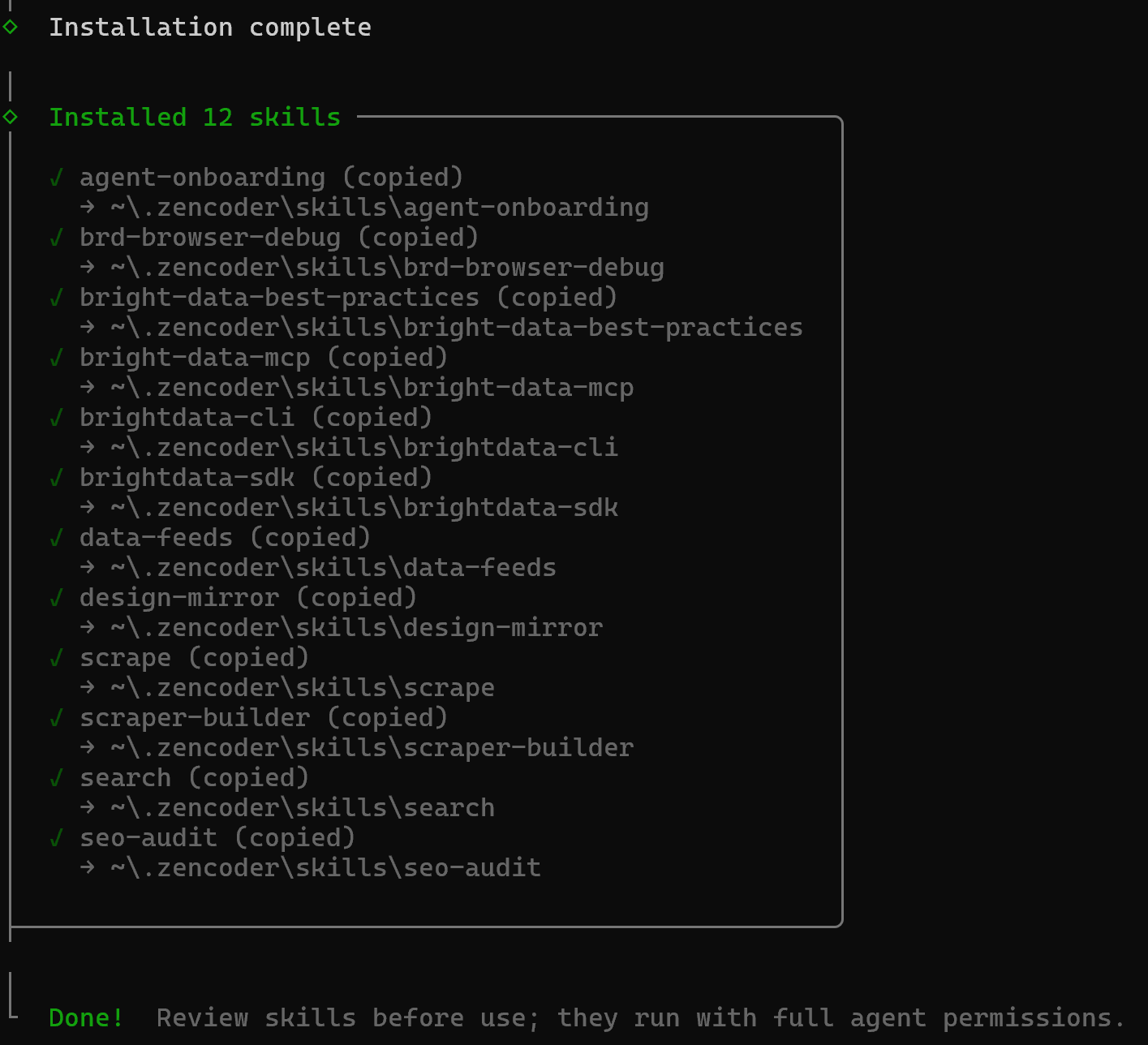
Bright Dataスキルは~/.zencoder/skillsディレクトリにインストールされます。変更が読み込まれるよう、Zencoder製品を再起動してください。素晴らしい!
ステップ#2:スキルが利用可能であることを確認する
インストールされたスキルに特別なコマンドとしてアクセスできるようになるはずです。確認するには、Zencoderで/を押し、Bright Dataスキルがリストに表示されることを確認します(デフォルトのZencoderスキルとともに):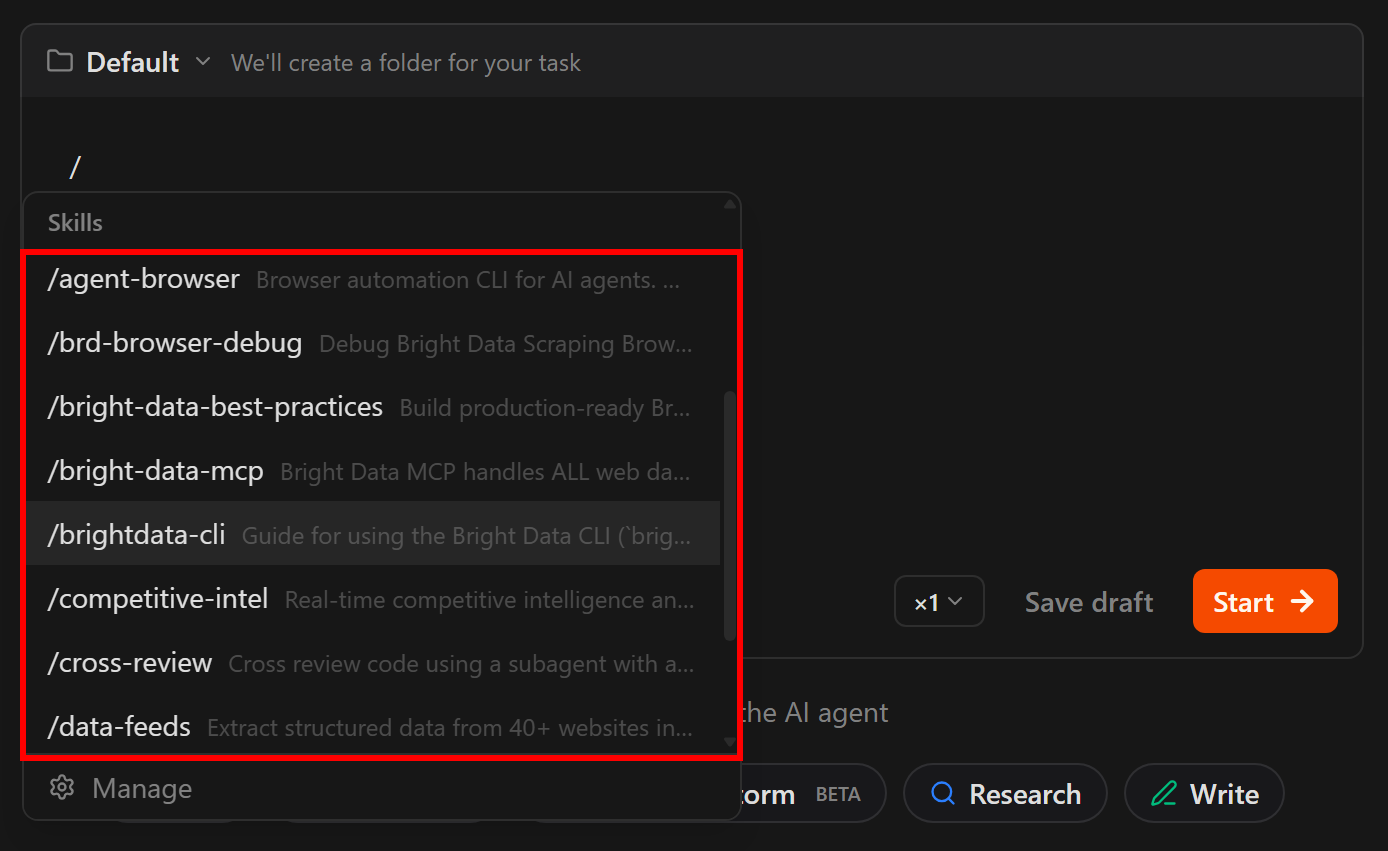
リストされたコマンドがBright Dataスキルと一致していれば、インストールが成功したことが確認できます。
重要:スキルが表示されない場合は、Zencoder製品を再起動してください。Zenflowでは、スキルが~/.agents/skillsにもコピーされていることを確認してください(npx skills add brightdata/skills -a clineでそのフォルダにインストールすることもできます)。その後、Zenflowを再起動します。
オプション:Bright Data CLIをまだ設定していない場合は、オンボーディングスキルを実行して指示に従ってください:
/agent-onboarding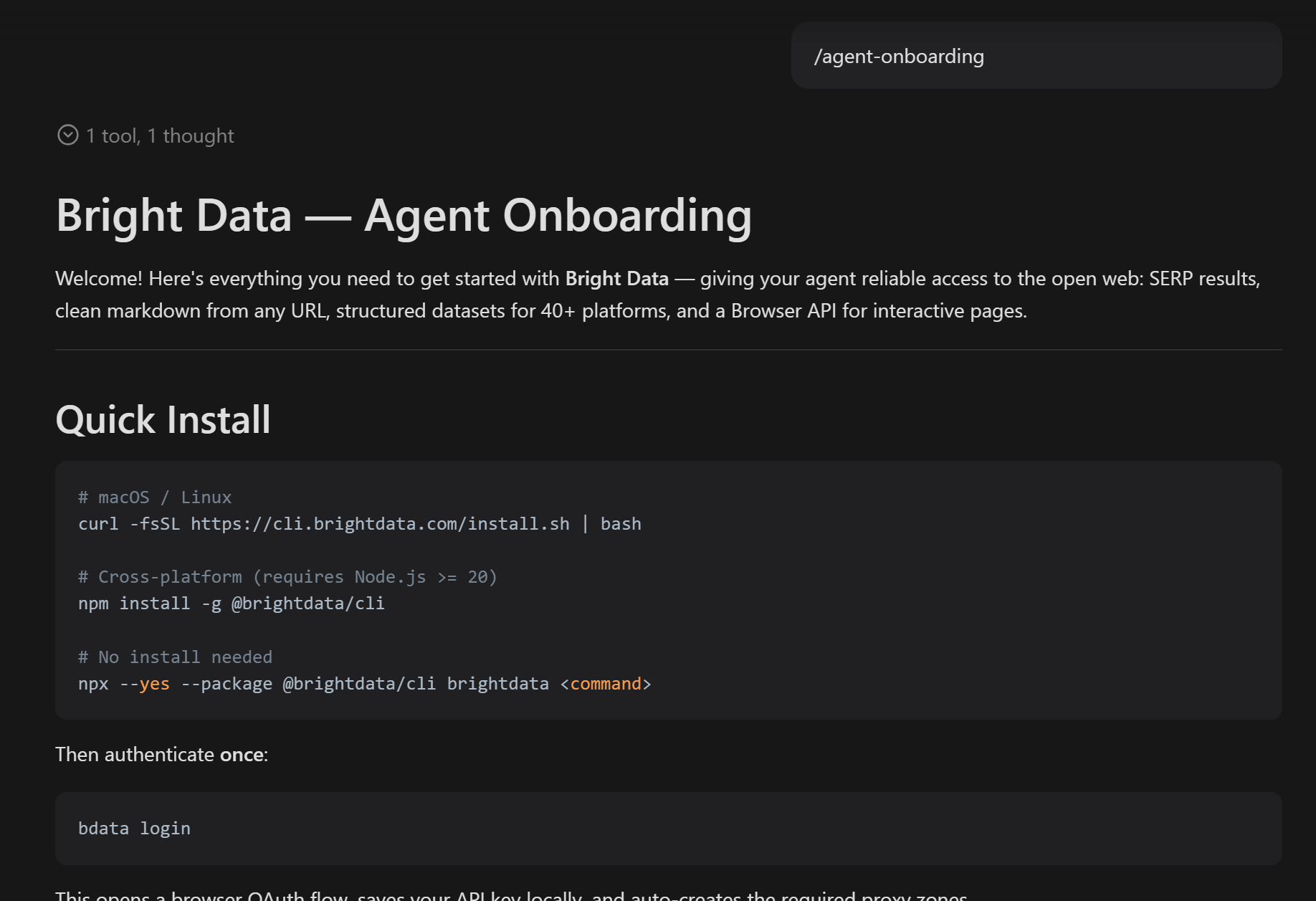
ミッション完了!次の章では、Zencoder AIエージェント内でBright Data Web MCPとスキルを最大限に活用する方法を紹介します。
Zencoder+Bright Data:次世代のAIアシスタンス体験
Zencoder+Bright Dataセットアップの強力さを確認するために、実際のウェブデータを必要とする具体的なタスクを考えてみましょう。
作業中のプロジェクトに最適なPythonハッシュライブラリを探しているとします。
このようなシナリオでLLMだけに頼るのはリスクがあります。AIモデルは最近のアップデート、セキュリティ問題、特定のライブラリに影響するCVE、または基盤となるアルゴリズムの変更を把握していない可能性があります。このため、エージェントをライブウェブデータに基づかせることが重要です。
PyPIやGitHubなどのソースから情報をスクレイピングすることも考えられます。これにより、AIエージェントは依存関係、インストールコマンド、メンテナンス状況などについての詳細情報を得られます。
次のようなプロンプトで目標を達成します:
Discover online the best Python libraries for hashing. Start by performing a contextual search on Google, access the most relevant 2-3 pages, and then select a list of the top 5-7 Python libraries. For each library, scrape structured data from its PyPI page.
With the scraped data, produce a final structured report with a ranking, including for each library: a description, main capabilities, installation instructions, and (if available) requirements, GitHub links, and other relevant details.Workモードで起動すると、以下のことが起こります: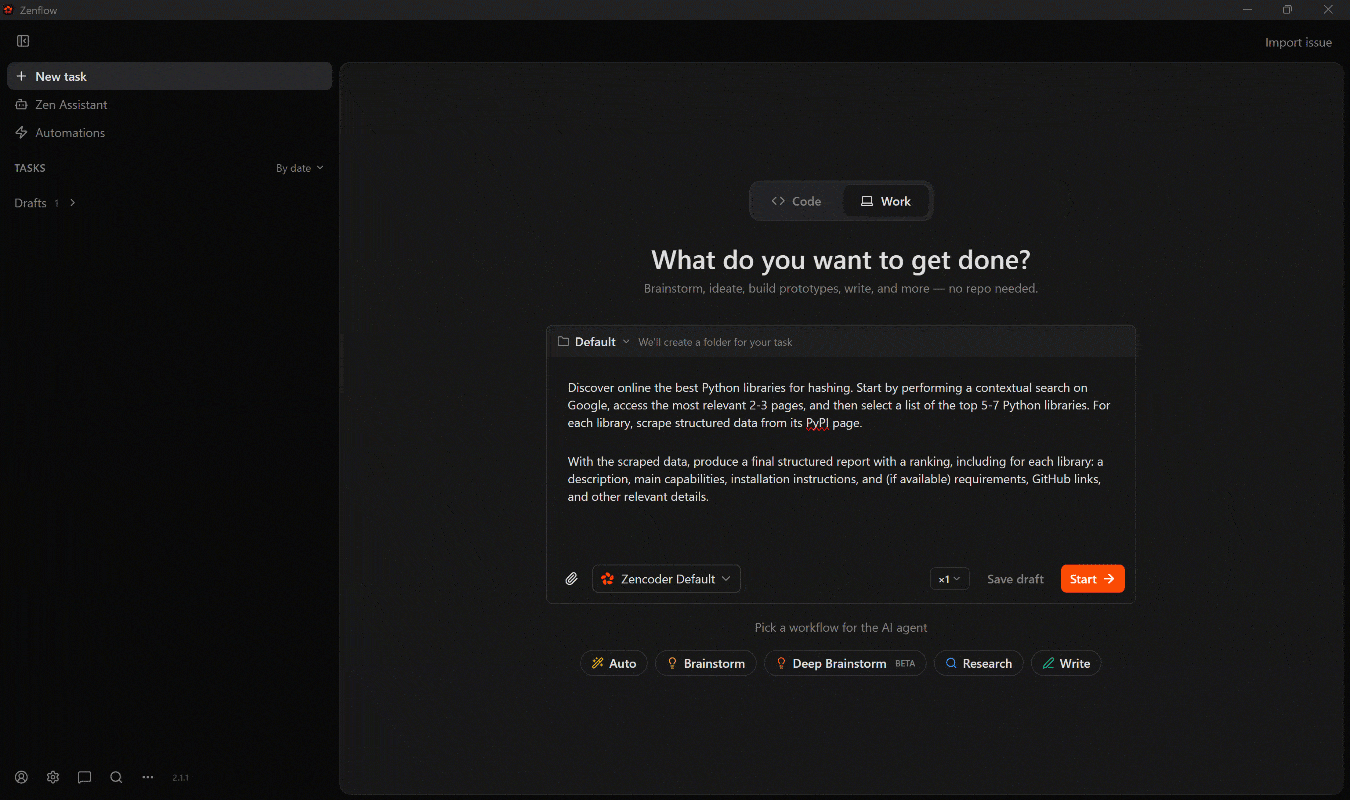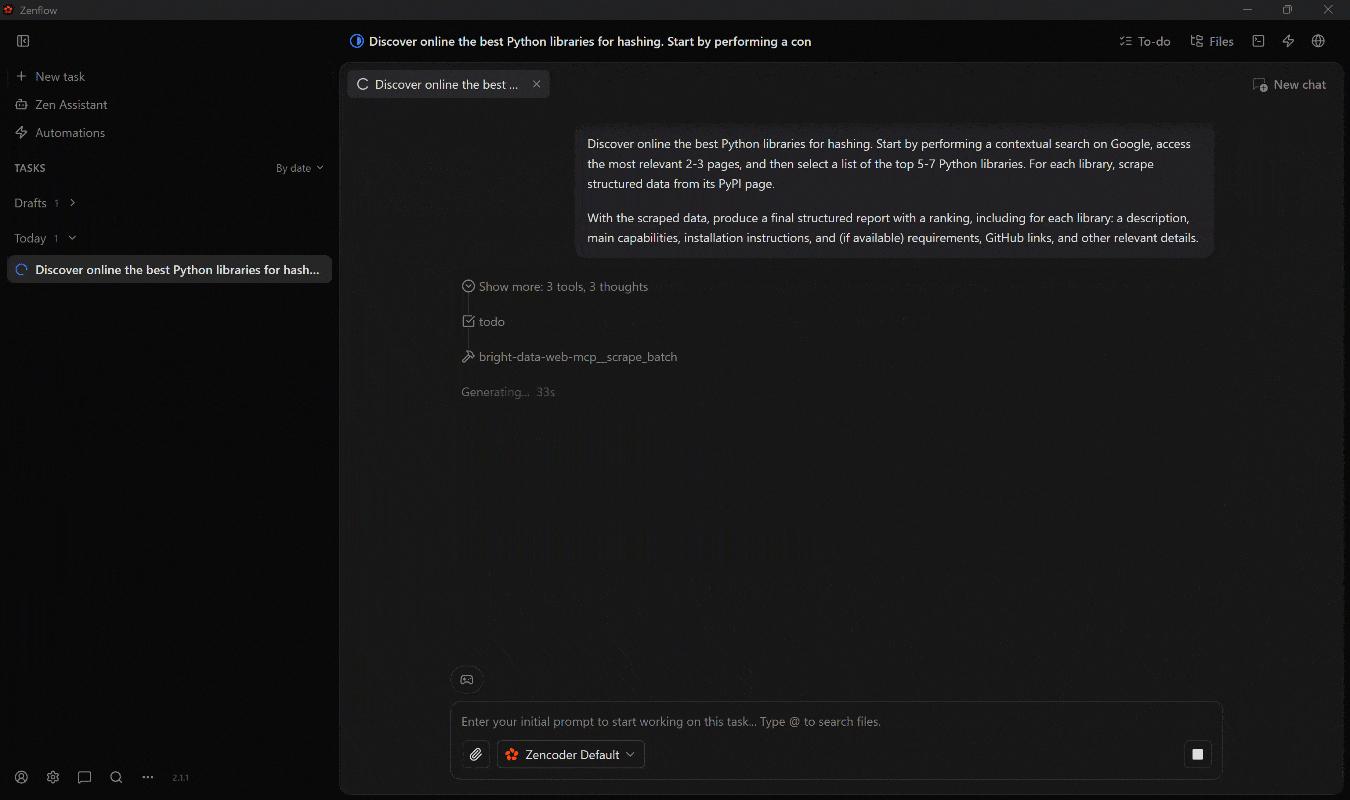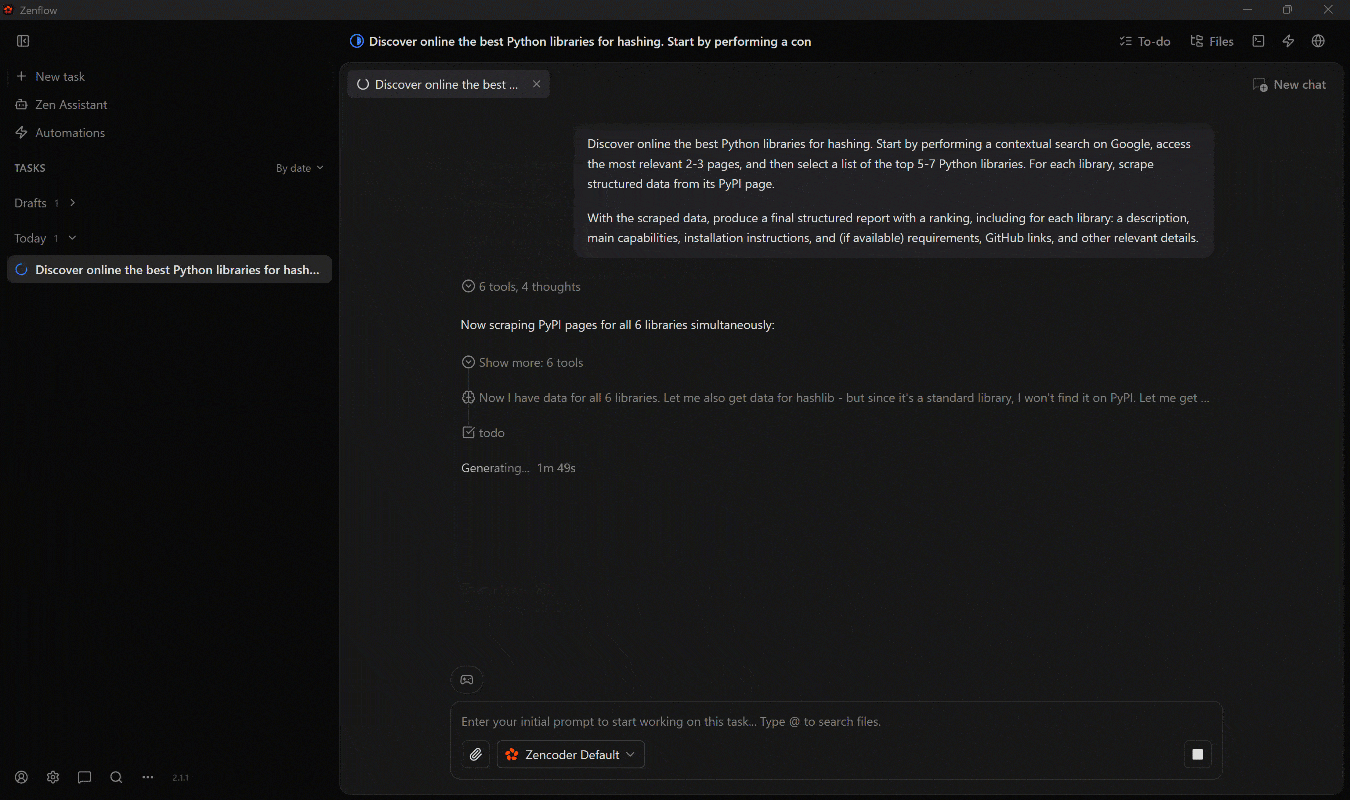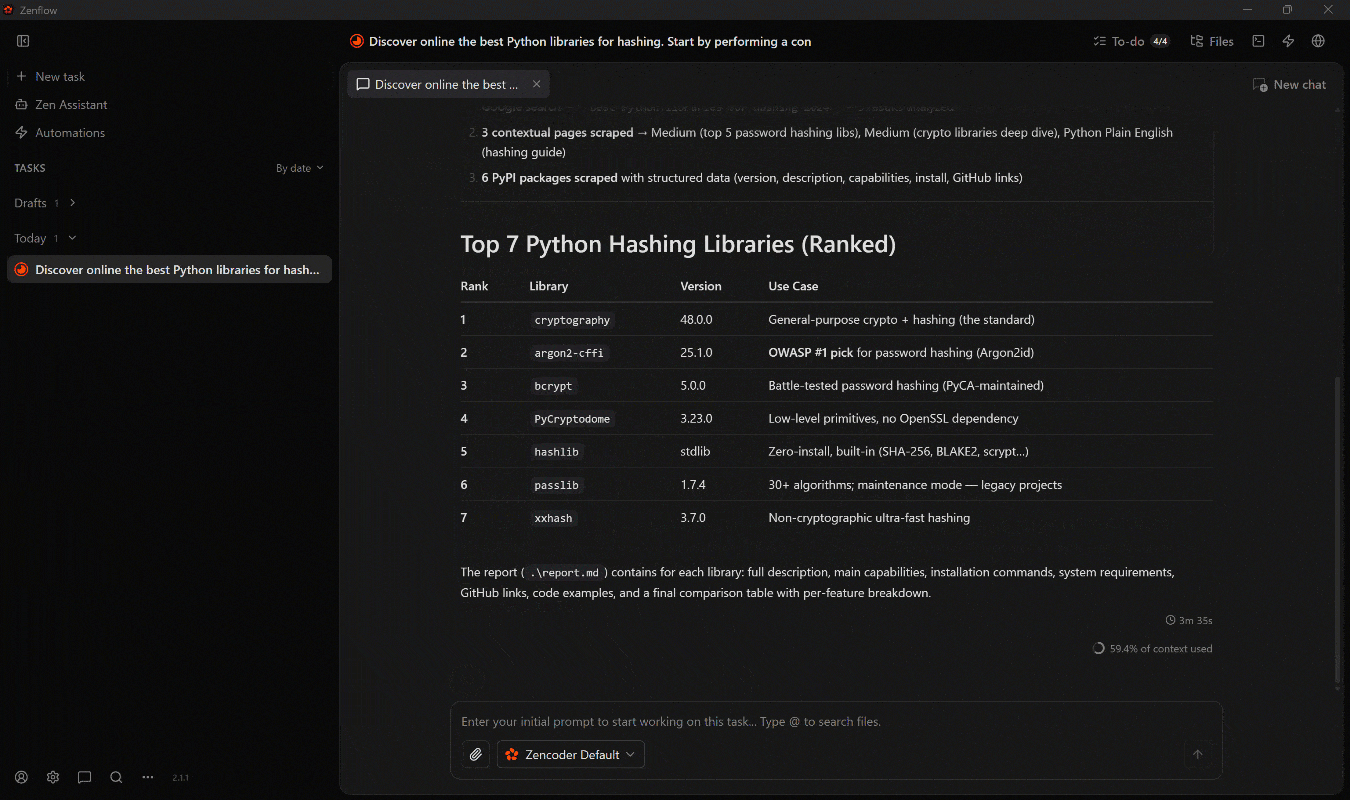
何が起きたかを説明します:
- エージェントがまず計画を定義します。
- Web MCPの
search_engineツール(Bright Data SERP APIによって支援)を使用して、コンテキストのあるGoogle SERP結果を取得します。 - 最も関連性の高いページを選択し、
scrape_batch(Web Unlocker API経由)を使用してスクレイピングします。 - 最も関連性の高い上位7つのライブラリを特定し、
web_data_pypi_packageWeb MCP Proツールを並行して呼び出し、構造化されたPyPIデータで情報を補強します。 - 収集したすべての情報を最終的な
report.mdファイルに集約します。
最終出力はプロジェクトディレクトリのreport.mdファイルです: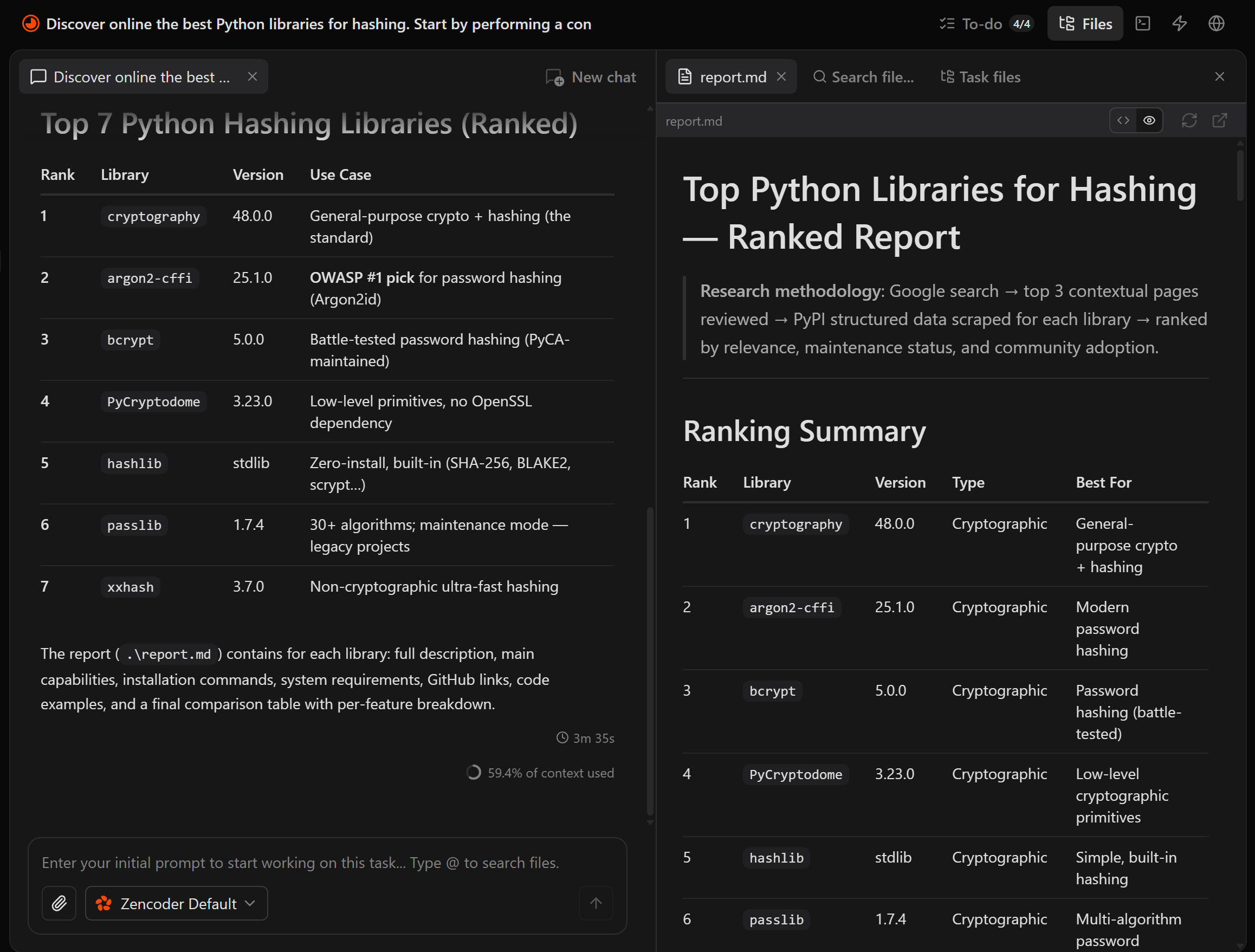
ファイルを開くと、詳細で検証可能な情報を含む構造化されたMarkdownレポートが確認できます。Pythonハッシュライブラリに注目してみましょう: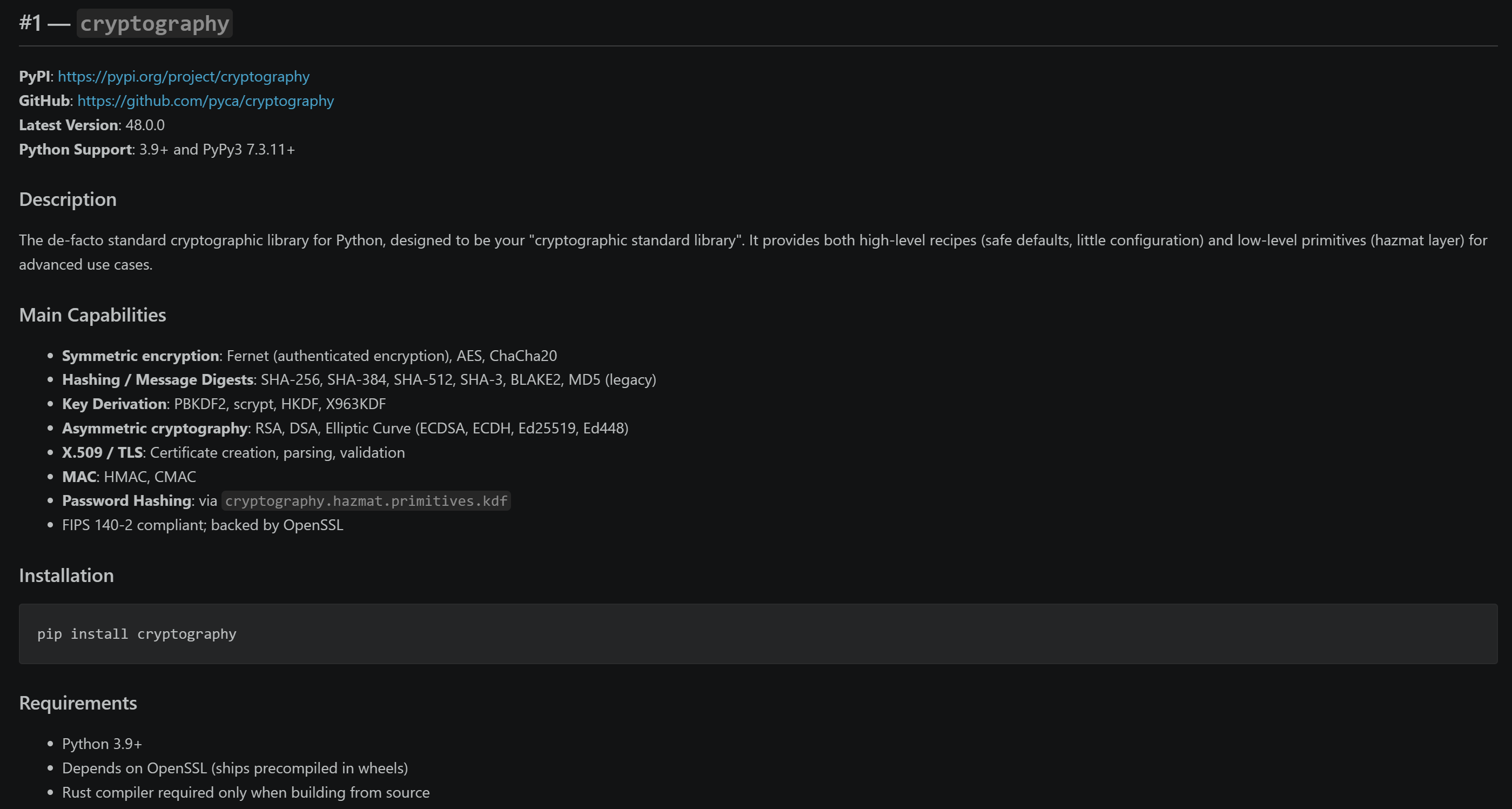
各ライブラリのセクションが、モデルのみのトレーニング知識ではなく、ライブPyPIデータに基づいていることに注目してください。
レポートには意思決定をサポートする比較表も含まれています: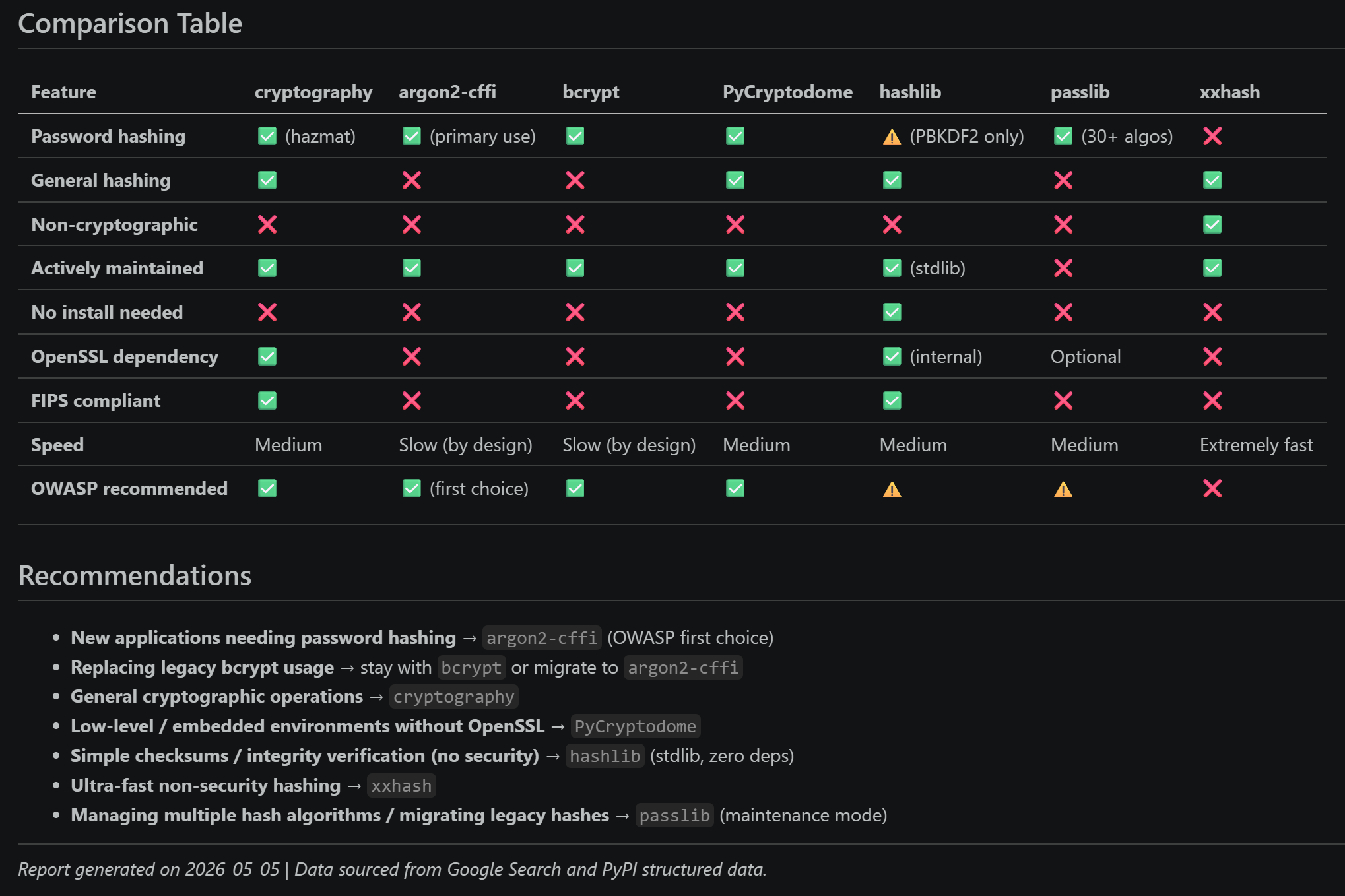
これで完了です!この簡単な例は、Bright DataをZenflow Work(または他のZencoder製品)に統合する価値を示しています。Zencoderエージェントは、ウェブからAI対応の最新情報を取得し、幅広いユースケースでより信頼性の高い出力を生成できるようになりました。
まとめ
このチュートリアルでは、Zencoderとは何か、ZenflowとそのIDEプラグインを通じてどのような機能を提供するかを学びました。特に、Web MCPと公式スキルを通じてZencoder製品をBright Dataに接続することで拡張する理由と方法を確認しました。
この統合により、ZencoderのAIコーディングアシスタンス体験が大幅に向上します。これにより、基盤となるAIエージェントはグラウンディング、リサーチ、自動化されたブラウザ操作のためにウェブと連携できるようになります。
さらに高度なワークフローのために、Bright DataのエコシステムにおけるAI対応サービスの全範囲を探索してください。
今すぐBright Dataの無料アカウントを作成し、AI対応のウェブデータインフラツールの統合を始めましょう!




