

このガイドでは以下を確認できます:
- NVIDIA NeMo Frameworkが提供する機能、特にNVIDIA NeMo Agent Toolkitを用いたAIエージェント構築に関する内容。
- LangChainを介したカスタムツールでBright DataをNAT AIエージェントに統合する方法
- NVIDIA NeMo Agent ToolkitワークフローをBright Data Web MCPに接続する方法
それでは始めましょう!
NVIDIA NeMoフレームワークの概要
NVIDIA NeMo フレームワークは、LLM やマルチモーダルモデルを含む生成型 AI モデルの構築、カスタマイズ、デプロイのために設計された、包括的なクラウドネイティブの AI 開発プラットフォームです。
トレーニングや微調整から評価、デプロイに至るまで、AIライフサイクル全体をカバーするエンドツーエンドのツールを提供します。NeMoはまた、大規模分散トレーニングを活用し、データキュレーション、モデル評価、安全対策の実装などのタスクのためのコンポーネントを含んでいます。
16,000以上のGitHubスターを獲得したオープンソースPythonライブラリと専用のDockerイメージによってサポートされています。
NVIDIA NeMo Agent Toolkit
NVIDIA NeMo フレームワークの一部であるNVIDIA NeMo Agent Toolkit(略称「NAT」)は、複雑な AI エージェントシステムの構築、最適化、管理のためのオープンソースフレームワークです。
多様なエージェントやツールを、深い可観測性、プロファイリング、コスト分析を備えた統一ワークフローに接続し、マルチエージェント操作の「指揮者」として機能し、AI アプリケーションの拡張を支援します。
NAT は構成可能性を重視し、エージェントやツールをモジュール化された関数呼び出しとして扱います。また、ボトルネックの特定、評価の自動化、エンタープライズグレードのエージェント型 AI システムの管理機能も提供します。
詳細は以下を参照:
Bright DataツールによるLLMとライブデータの連携
NVIDIA NeMo Agent Toolkitは、エンタープライズグレードのAIプロジェクトを構築・管理するために必要な柔軟性、カスタマイズ性、可観測性、スケーラビリティを提供します。これにより組織は、複雑なAIワークフローのオーケストレーション、複数エージェントの連携、パフォーマンスとコストの監視が可能になります。
しかし、最も洗練されたNATアプリケーションでさえ、LLMに内在する限界に直面します。これには、静的なトレーニングデータによる知識の陳腐化や、ライブWeb情報へのアクセス不足が含まれます。
解決策は、NVIDIA NeMo Agent ToolkitのワークフローをBright DataのようなAIのためのウェブデータプロバイダーと統合することです。
Bright Dataは、ウェブスクレイピング、検索、ブラウザ自動化などのツールを提供しています。これらのソリューションにより、AIシステムはリアルタイムで実用的なデータを取得し、エンタープライズアプリケーションにおけるその潜在能力を最大限に引き出すことが可能になります。
Bright DataをNVIDIA NeMo AIエージェントに接続する方法
NVIDIA NeMo AI AgentでBright Dataの機能を活用する一つの方法は、NeMo Agent Toolkitを通じてカスタムツールを作成することです。
これらのツールは、LangChain(またはAIエージェント構築ライブラリでサポートされているその他の統合手段)を活用したカスタム関数を通じてBright Data製品に接続します。
以下の手順に従ってください!
前提条件
このチュートリアルを実行するには、以下の環境が必要です:
- ローカルにインストールされたPython 3.11、3.12、または3.13
- 公式LangChainツールとの連携用に設定済みのBright Dataアカウント。
- APIキーが設定済みのNVIDIA NIMアカウント。
Bright DataとNVIDIA NIMアカウントの設定については、後ほど専用の章で手順を説明しますので、現時点では心配する必要はありません。
注意: インストール時またはツールキット実行中に問題が発生した場合は、サポート対象プラットフォームのいずれかを使用していることを確認してください。
ステップ #1: NVIDIA NIM API キーの取得
ほとんどのNVIDIA NeMo Agentワークフローでは、NVIDIA_API_KEY環境変数が必要です。これはワークフローの背後にあるNVIDIA NIM LLMへの接続を認証するために必要です。
APIキーを取得するには、まずNVIDIA NIMアカウントを作成します(未作成の場合)。ログイン後、右上のアカウント画像をクリックし、「API Keys」オプションを選択します:
API Keysページが表示されます。「APIキーを生成」ボタンをクリックして新しいキーを作成します: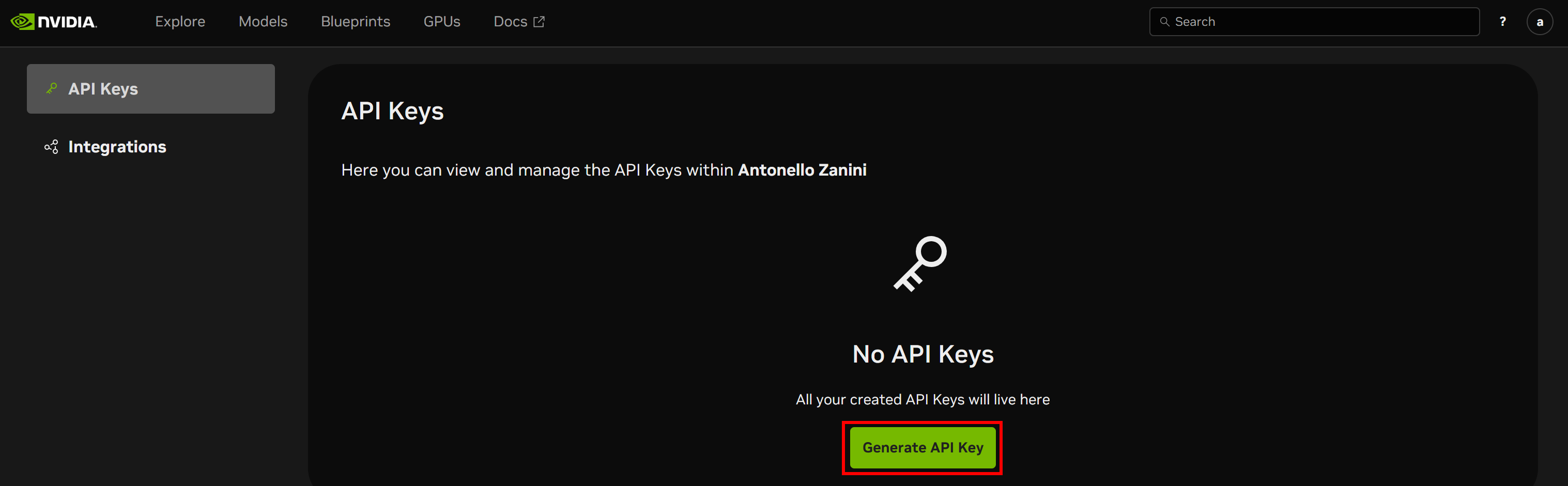
APIキーに名前を付け、「キーを生成」をクリックします: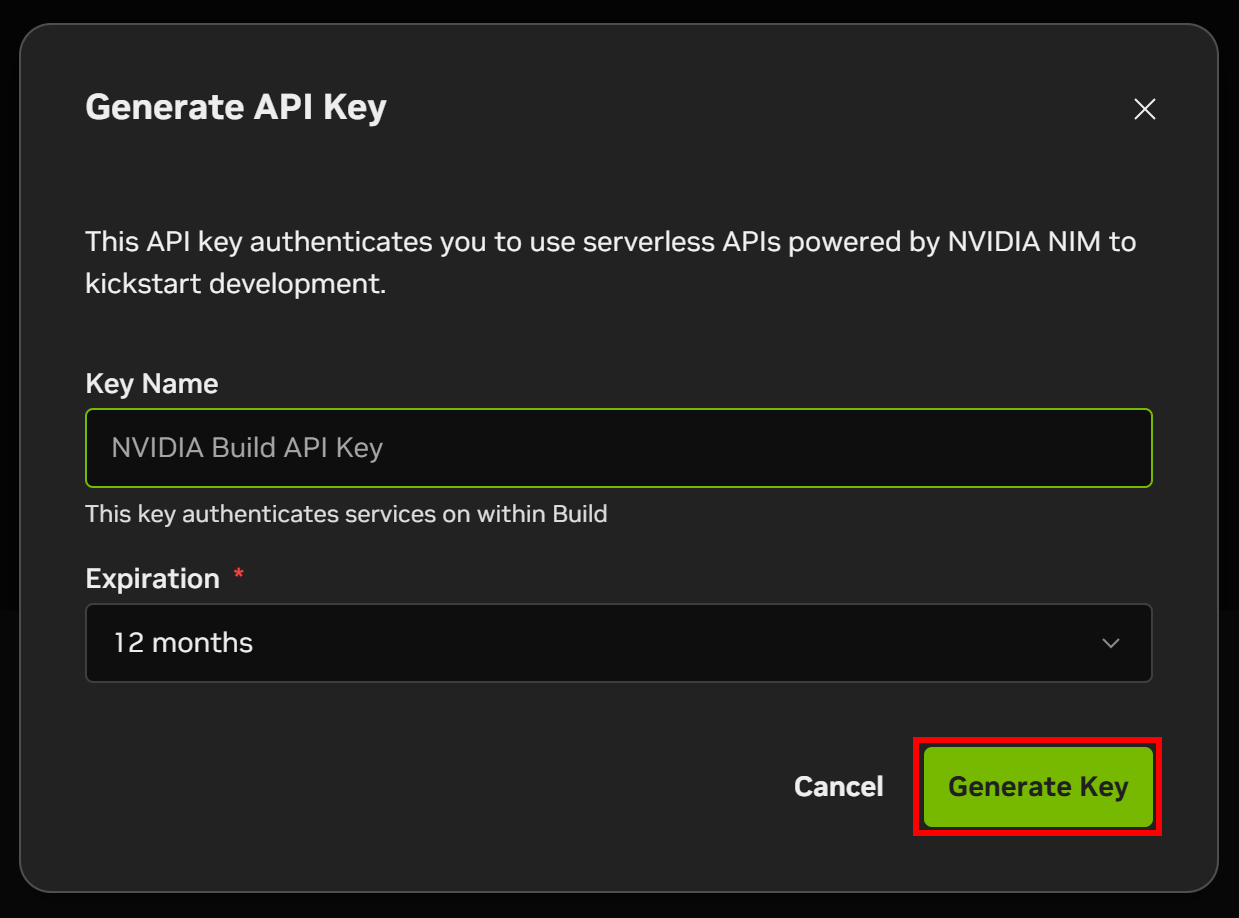
モーダルにAPIキーが表示されます。「APIキーをコピー」ボタンをクリックし、すぐに必要となるため安全な場所に保管してください。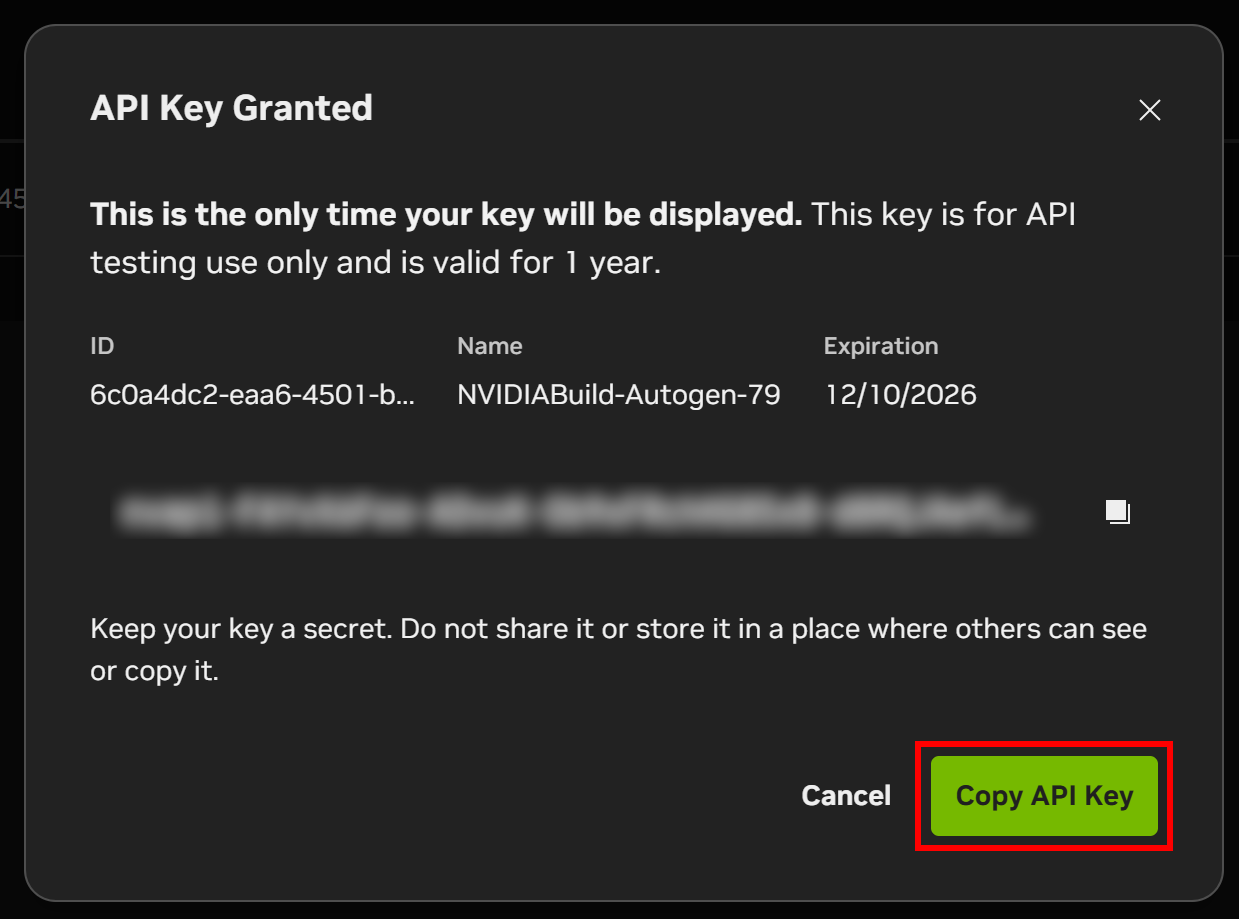
完了です!これでNVIDIA NeMo Agent Toolkitのインストールと使用準備が整いました。
ステップ #2: NVIDIA NeMoプロジェクトの設定
NeMo Agent Toolkit の最新安定版をインストールするには、以下を実行してください:
pip install nvidia-natNeMo Agent Toolkitには、コアパッケージと共にインストール可能な多数のオプション依存関係があります。これらのオプション依存関係はフレームワークごとにグループ化されています。
インストールが完了すると、natコマンドが使用可能になります。動作確認のため、以下を実行してください:
nat --version以下のような出力が表示されるはずです:
nat, version 1.3.1次に、NVIDIA NeMoアプリケーションのルートフォルダを作成します。例えば「bright_data_nvidia_nemo」という名前で作成します:
mkdir bright_data_nvidia_nemoこのフォルダ内で、以下のコマンドを使用して「web_data_workflow」という名前の NeMo Agent ワークフローを作成します:
nat workflow create --workflow-dir bright_data_nvidia_nemo web_data_workflow 注: 「A required privilege is not held by the client」というエラーが発生した場合は、管理者としてコマンドを実行してください。
正常に実行されると、以下のようなログが表示されます:
ワークフロー 'web_data_workflow' をインストール中...
ワークフロー 'web_data_workflow' のインストールに成功しました。
ワークフロー 'web_data_workflow' が <your_path> に正常に作成されましたプロジェクトフォルダbright_data_nvidia_nemo/web_data_workflowには以下の構造が作成されます:
bright_data_nvidia_nemo/web_data_workflow/
├── configs -> src/web_data_workflow/configs
├── data -> src/text_file_ingest/data
├── pyproject.toml
└── src/
├── web_data_workflow.egg-info/
└── web_data_workflow/
├── __init__.py
├── configs/
│ └── config.yml
├── data/
├── __init__.py
├── register.py
└── web_data_workflow.py各ファイルとフォルダの役割は以下の通りです:
configs/→src/web_data_workflow/configs: ワークフロー設定へのアクセスを容易にするシンボリックリンク。data/→src/text_file_ingest/data: サンプルデータや入力ファイルを格納するためのシンボリックリンク。pyproject.toml: プロジェクトのメタデータと依存関係ファイル。src/: ソースコードディレクトリ。web_data_workflow.egg-info/: Pythonパッケージングツールによって作成されるメタデータフォルダ。web_data_workflow/: メインのワークフローモジュール。__init__.py: モジュールを初期化します。configs/config.yml: 実行時の動作(LLM設定、関数/ツール定義、エージェントタイプと設定、ワークフローオーケストレーションなど)を定義するワークフロー設定ファイル。
data/: ワークフロー固有のデータ、サンプル入力、テストファイルを保存するディレクトリ。register.py: カスタム関数をNATに接続するための登録モジュール。web_data_workflow.py: カスタムツールを定義するサンプルファイル。
お好みのPython IDEでプロジェクトを開き、生成されたファイルに慣れる時間を取ってください。
ワークフロー定義は以下のファイルに配置されています:
bright_data_nvidia_nemo/web_data_workflow/web_data_workflow/configs/config.ymlこのファイルを開くと、以下のYAML設定が確認できます:
functions:
current_datetime:
_type: current_datetime
web_data_workflow:
_type: web_data_workflow
prefix: "Hello:"
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.1-70b-instruct
temperature: 0.0
workflow:
_type: react_agent
llm_name: nim_llm
tool_names: [current_datetime, web_data_workflow]これは、NVIDIA NIMのmeta/llama-3.1-70b-instructモデルを利用したReActエージェントワークフローを定義し、以下のアクセス権限を持ちます:
- 組み込みの
current_datetimeツール。 - カスタムの
web_data_workflowツール。
特に、web_data_workflowツール自体は以下で定義されています:
bright_data_nvidia_nemo/web_data_workflow/web_data_workflow/web_data_workflow.pyこのサンプルツールはテキスト入力を受け取り、事前に定義された文字列(例:「Hello:」)を接頭辞として付加して返します。
素晴らしい!これでNAT付きのワークフローが準備できました。
ステップ #3: 現在のワークフローをテストする
生成されたワークフローをカスタマイズする前に、その仕組みを理解し、操作に慣れる時間を取ることをお勧めします。これにより、Bright Dataとの統合に向けたワークフローの調整が容易になります。
まず、ターミナルでワークフローフォルダに移動します:
cd ./bright_data_nvidia_nemo/web_data_workflowワークフローを実行する前に、NVIDIA_API_KEY環境変数を設定する必要があります。Linux/macOSでは以下を実行してください:
export NVIDIA_API_KEY="<YOUR_NVIDIA_API_KEY>"同様に、Windows PowerShellでは以下を実行します:
$Env:NVIDIA_API_KEY="<YOUR_NVIDIA_API_KEY>"<YOUR_NVIDIA_API_KEY>プレースホルダーを、事前に取得した NVIDIA NIM API キーに置き換えてください。
次に、nat runコマンドでワークフローをテストします:
nat run --config_file configs/config.yml --input "Hey! How's it going?"これにより、configs/シンボリックリンク経由でconfig.ymlファイルが読み込まれ、「Hey! How's it going?」というプロンプトが送信されます。
以下のような出力が表示されるはずです: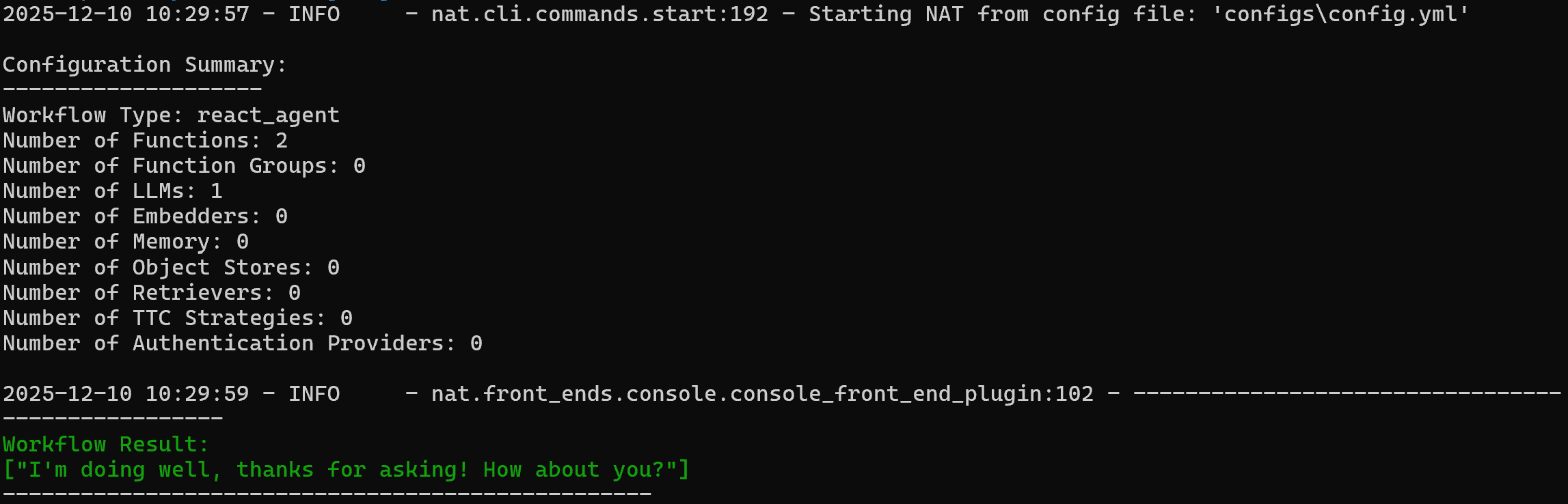
エージェントの応答例:
お元気ですか?お尋ねいただきありがとうございます!あなたはどうですか?カスタムweb_data_workflowツールが動作することを確認するには、次のようなプロンプトを試してください:
nat run --config_file configs/config.yml --input "Use the web_data_workflow tool on 'World!'"web_data_workflowツールは「Hello:」プレフィックスで設定されているため、期待される出力は以下の通りです:
ワークフロー結果:
['Hello: World!']結果が期待通りの動作と一致している点にご注目ください: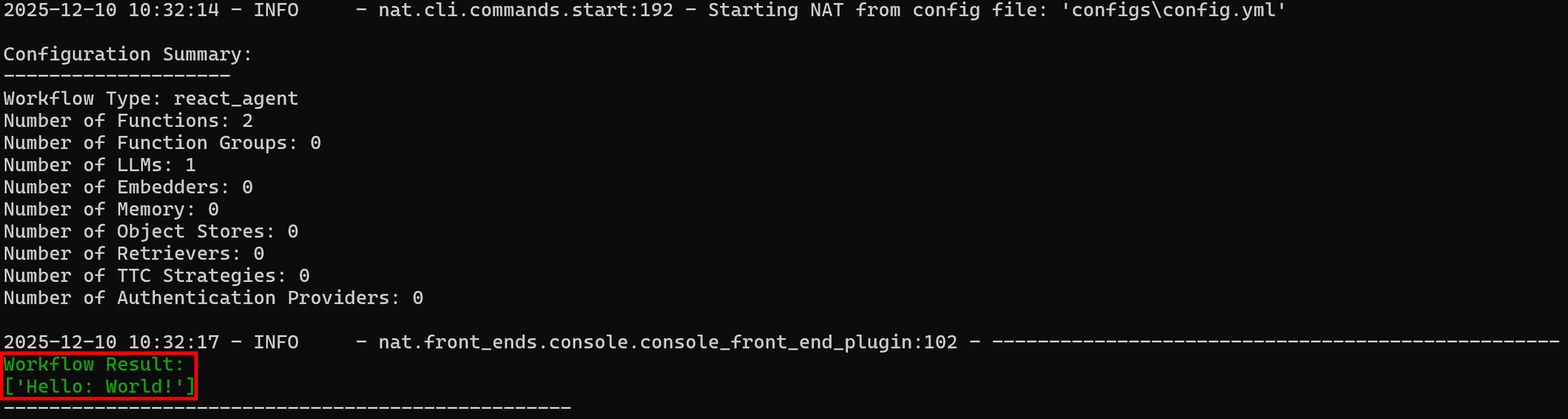
素晴らしい!NATワークフローは完璧に動作しています。これでBright Dataとの統合準備が整いました。
ステップ #4: LangChain Bright Data ツールのインストール
NVIDIA NeMo Agent Toolkitの特異な点の一つは、LangChain、LlamaIndex、CrewAI、Agno、Microsoft Semantic Kernel、GoogleADKなど、他のAIライブラリと連携できることです。
Bright Dataとの統合を簡素化するため、既存の仕組みを活用し、LangChain用の公式Bright Dataツールを使用します。
これらのツールの詳細なガイダンスについては、公式ドキュメントまたは以下のブログ記事を参照してください:
NVIDIA NeMo Agent Toolkit内でLangChainを使用する準備として、以下のライブラリをインストールします:
pip install "nvidia-nat[langchain]" langchain-brightdata必要なパッケージは以下の通りです:
"nvidia-nat[langchain]": LangChain(またはLangGraph)をNeMo Agent Toolkitに統合するためのサブパッケージ。langchain-brightdata: Bright DataのWebデータ収集ツール群をLangChainに統合します。AIエージェントが検索エンジン結果を収集し、地域制限やボット対策のあるWebサイトにアクセスし、Amazon、LinkedInなど主要プラットフォームから構造化データを抽出することを可能にします。
デプロイ時の問題を回避するため、プロジェクトのpyproject.tomlファイルに以下を含めることを確認してください:
dependencies = [
"nvidia-nat[langchain]~=1.3",
"langchain-brightdata~=0.1.3",
]注:プロジェクトの要件に応じて、これらのパッケージのバージョンを適宜調整してください。
これで、NVIDIA NeMo AgentワークフローがLangChainツールと連携し、Bright Dataへの接続が簡素化されました。
ステップ #5: Bright Data 統合の準備
LangChain Bright Dataツールは、アカウントで設定されたBright Dataサービスに接続して動作します。本記事で紹介する2つのツールは以下の通りです:
BrightDataSERP: 検索エンジン結果を取得し、関連する規制関連ウェブページを特定します。BrightDataのSERP APIに接続します。BrightDataUnblocker: 地理的制限やボット対策で保護された公開ウェブサイトにもアクセス可能。エージェントが個々のウェブページからコンテンツをスクレイピングし学習するのに役立ちます。BrightDataのWeb Unblocker APIに接続します。
これらのツールを利用するには、SERP APIゾーンとWeb Unblocker APIゾーンの両方が設定されたBright Dataアカウントが必要です。設定方法をご説明します。
Bright Dataアカウントをお持ちでない場合は新規作成してください。お持ちの場合はログインし、ダッシュボードにアクセスします。次に「プロキシ&スクレイピング」ページに移動し、「マイゾーン」テーブルを確認してください: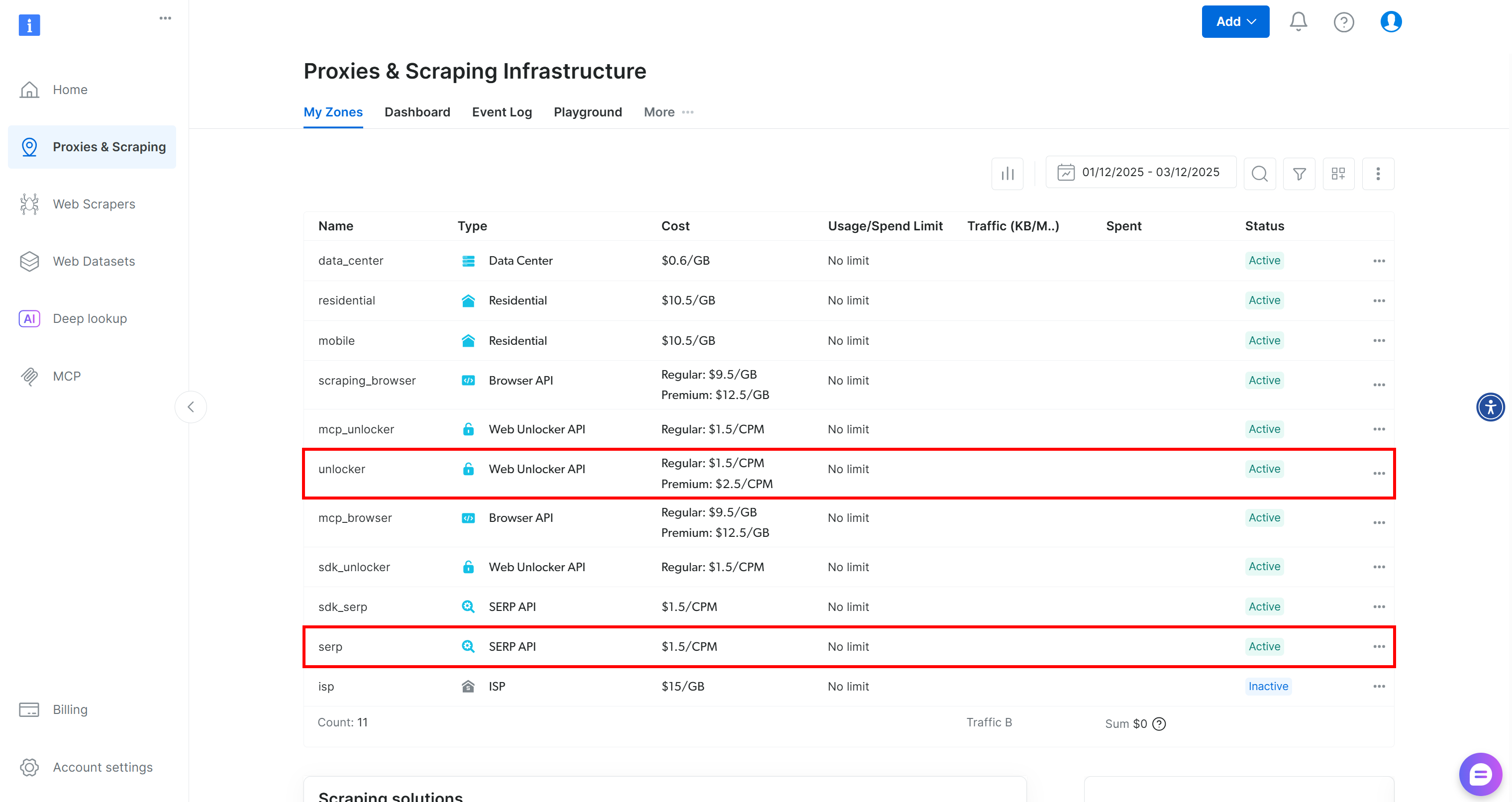
このテーブルに既に「unlocker」というWeb Unlocker APIゾーンと「serp」というSERP APIゾーンが存在する場合、準備は完了です。その理由は:
BrightDataSERPLangChainツールは自動的に「serp」という名前のSERP APIゾーンに接続します。BrightDataUnblockerLangChainツールは、自動的に「web_unlocker」というWeb Unblocker APIゾーンに接続します。
これらの2つのゾーンが存在しない場合は、作成する必要があります。「アンブロッカーAPI」および「SERP API」カードを下にスクロールし、「ゾーンを作成」ボタンをクリックしてください。ウィザードに従い、必要な名前で2つのゾーンを追加します: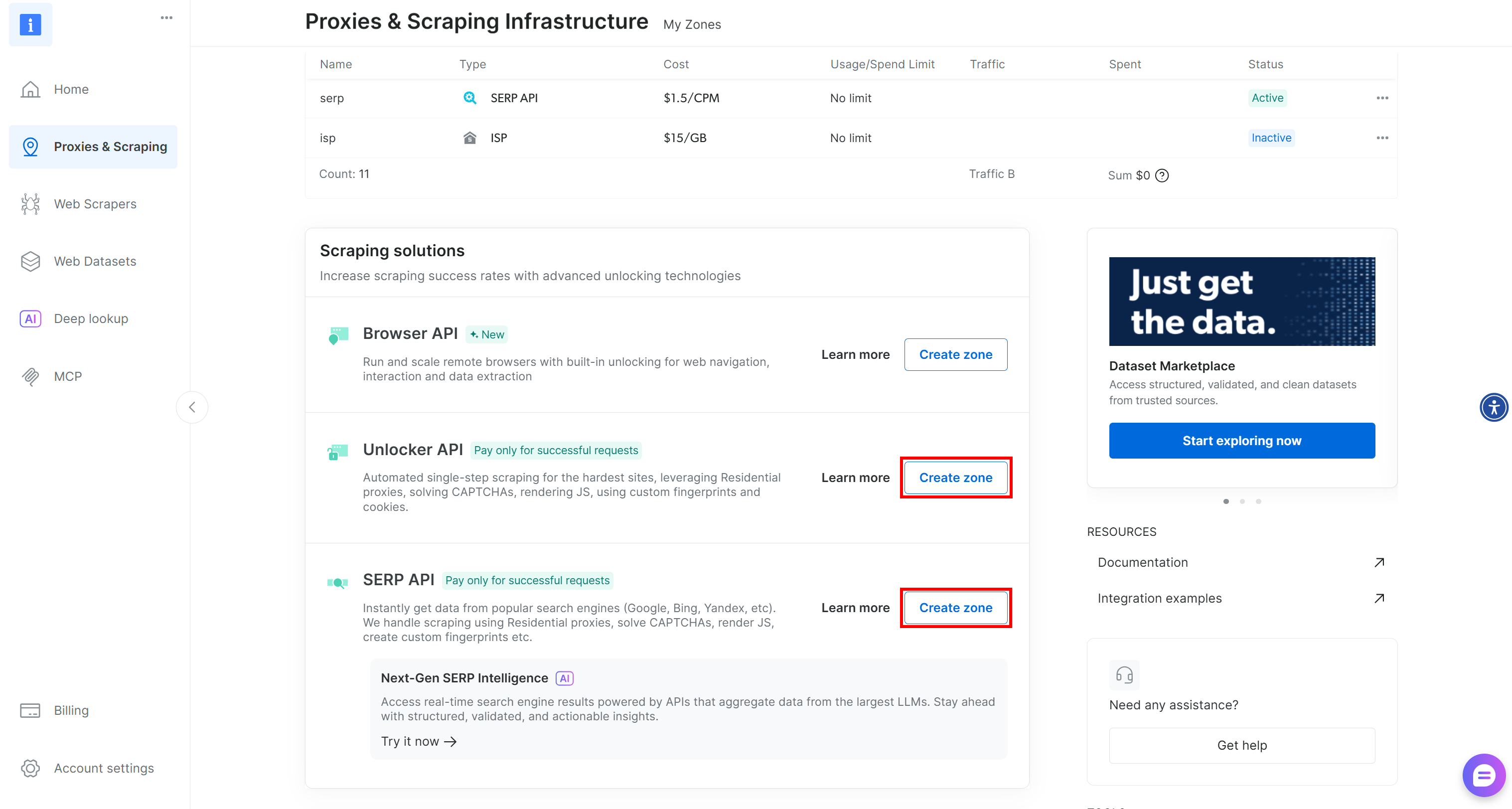
詳細な手順については、以下のドキュメントページを参照してください:
最後に、LangChain Bright Dataツールにアカウント認証方法を指示する必要があります。Bright Data APIキーを生成し、環境変数として保存してください:
export BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"または、PowerShellでは:
$Env:BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"素晴らしい!これで LangChain ツールを介して NVIDIA NeMo エージェントを Bright Data に接続するためのすべての前提条件が整いました。
ステップ #6: カスタム Bright Data ツールの定義
これで、NVIDIA NeMo Agent Toolkitワークフロー内で新しいツールを作成するための基盤が整いました。これらのツールにより、エージェントはBright DataのSERP APIおよびWeb Unblocker APIと連携し、ウェブ検索や公開ウェブページからのデータスクレイピングが可能になります。
まず、プロジェクトのsrc/フォルダにbright_data.pyファイルを追加します:
SERP APIとのやり取りを行うカスタムツールを以下のように定義します:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/bright_data.py
from pydantic import Field
from typing import Optional
from nat.builder.builder import Builder
from nat.builder.function_info import FunctionInfo
from nat.cli.register_workflow import register_function
from nat.data_models.function import FunctionBaseConfig
import json
class BrightDataSERPAPIToolConfig(FunctionBaseConfig, name="bright_data_serp_api"):
"""
Bright Data SERP API ツールの設定。
BRIGHT_DATA_API_KEY が必要です。
"""
api_key: str = Field(
default="",
description="SERPリクエストに使用するBright Data APIキー。"
)
# デフォルトのSERPパラメータ(オプションで上書き可能)
search_engine: str = Field(
default="google",
description="クエリ対象の検索エンジン(デフォルト: google)"
)
country: str = Field(
default="us",
description="地域別検索結果用の2文字の国コード(デフォルト: us)"
)
language: str = Field(
default="en",
description="2文字の言語コード(デフォルト: en)"
)
search_type: Optional[str] = Field(
default=None,
description="検索タイプ: None, 'shop', 'isch', 'nws', 'jobs'."
)
device_type: Optional[str] = Field(
default=None,
description="デバイス種別: None, 'mobile', 'ios', 'android'."
)
parse_results: Optional[bool] = Field(
default=None,
description="生のHTMLではなく構造化されたJSONを返すかどうか。"
)
@register_function(config_type=BrightDataSERPAPIToolConfig)
async def bright_data_serp_api_function(tool_config: BrightDataSERPAPIToolConfig, builder: Builder):
import os
from langchain_brightdata import BrightDataSERP
# APIキーが設定されていない場合の設定
if not os.environ.get("BRIGHT_DATA_API_KEY"):
if tool_config.api_key:
os.environ["BRIGHT_DATA_API_KEY"] = tool_config.api_key
async def _bright_data_serp_api(
query: str,
search_engine: Optional[str] = None,
country: Optional[str] = None,
language: Optional[str] = None,
search_type: Optional[str] = None,
device_type: Optional[str] = None,
parse_results: Optional[bool] = None,
) -> str:
"""
Bright Data SERP API を使用してリアルタイム検索クエリを実行します。
引数:
query (str): 検索クエリテキスト。
search_engine (str, optional): 使用する検索エンジン(デフォルト: google)。
country (str, optional): ローカライズされた結果のための国コード。
language (str, optional): ローカライズされた結果の言語コード。
search_type (str, optional): 検索タイプ(例: None, 'isch', 'shop', 'nws')。
device_type (str, optional): デバイスタイプ(例: None, 'mobile', 'ios')。
parse_results (bool, optional): 構造化JSONを返すかどうか。
戻り値:
str: JSON形式の検索結果。
"""
serp_client = BrightDataSERP(
bright_data_api_key=os.environ["BRIGHT_DATA_API_KEY"]
)
payload = {
"query": query,
"search_engine": search_engine or tool_config.search_engine,
"country": country or tool_config.country,
"language": language or tool_config.language,
"search_type": search_type or tool_config.search_type,
"device_type": device_type or tool_config.device_type,
"parse_results": (
parse_results
if parse_results is not None
else tool_config.parse_results
),
}
# 明示的にNoneに設定されたパラメータを除去
payload = {k: v for k, v in payload.items() if v is not None}
results = serp_client.invoke(payload)
return json.dumps(results)
yield FunctionInfo.from_fn(
_bright_data_serp_api,
description=_bright_data_serp_api.__doc__,
)
このスニペットは、bright_data_serp_api というカスタム NVIDIA NeMo Agent ツールを定義します。まず、SERP API for Google でサポートされる必須引数と設定可能なパラメータ(API キー、検索エンジン、国、言語、デバイスタイプ、検索タイプ、結果を JSON にパースするかどうかなど)を指定するBrightDataSERPAPIToolConfigクラスを定義する必要があります。
次に、カスタム関数 `bright_data_serp_api_function()` を NeMo ワークフロー関数として登録します。この関数は環境変数に Bright Data API キーが設定されていることを確認し、非同期関数`_bright_data_serp_api()` を定義します。
_bright_data_serp_api()は LangChain のBrightDataSERPクライアントを使用して検索リクエストを構築し、それを呼び出し、結果を JSON 形式で返します。最後に、エージェントが関数を呼び出すために必要なすべてのメタデータを含むFunctionInfo を通じて、この関数を NeMo Agent フレームワークに公開します。
注: 結果をJSON形式で返すことで標準化された文字列出力が得られます。SERP APIの応答は設定引数によって異なる形式(解析済みJSON、生のHTMLなど)で返される可能性があるため、これは有用な手法です。
同様に、同じファイル内でbright_data_web_unlocker_apiツールを以下のように定義できます:
class BrightDataWebUnlockerAPIToolConfig(FunctionBaseConfig, name="bright_data_web_unlocker_api"):
"""
Bright Data Web Unlockerツールの設定。
Bright Data Web Unlockerを使用して、地理的制限やボット対策が施されたページにアクセス可能にします。
BRIGHT_DATA_API_KEYが必要です。
"""
api_key: str = Field(
default="",
description="Web Unlocker用のBright Data APIキー。"
)
country: str = Field(
default="us",
description="リクエスト用にシミュレートする2文字の国コード(デフォルト: us)"
)
data_format: str = Field(
default="html",
description="出力コンテンツ形式: 'html'、'markdown'、または 'screenshot'。"
)
zone: str = Field(
default="unblocker",
description='使用するBright Dataゾーン(デフォルト: "unblocker")。'
)
@register_function(config_type=BrightDataWebUnlockerAPIToolConfig)
async def bright_data_web_unlocker_api_function(tool_config: BrightDataWebUnlockerAPIToolConfig, builder: Builder):
import os
import json
from typing import Optional
from langchain_brightdata import BrightDataUnlocker
# 必要に応じて環境変数を設定
if not os.environ.get("BRIGHT_DATA_API_KEY") and tool_config.api_key:
os.environ["BRIGHT_DATA_API_KEY"] = tool_config.api_key
async def _bright_data_web_unlocker_api(
url: str,
country: Optional[str] = None,
data_format: Optional[str] = None,
) -> str:
"""
Bright Data Web Unlockerを使用して、地理的制限またはボット対策が施されたURLにアクセスします。
引数:
url (str): 取得対象のURL。
country (str, optional): シミュレートする国を上書きします。
data_format (str, optional): 出力コンテンツ形式 ('html', 'markdown', 'screenshot')。
戻り値:
str: 対象ウェブサイトから取得したコンテンツ。
"""
unlocker = BrightDataUnlocker()
result = unlocker.invoke({
"url": url,
"country": country or tool_config.country,
"data_format": data_format or tool_config.data_format,
"ゾーン": tool_config.ゾーン,
})
return json.dumps(result)
yield FunctionInfo.from_fn(
_bright_data_web_unlocker_api,
description=_bright_data_web_unlocker_api.__doc__,
)
両ツールのデフォルト引数値は必要に応じて調整してください。
BrightDataSERPとBrightDataUnlockerは、環境変数BRIGHT_DATA_API_KEYから API キーを読み取ろうとします(これは以前に設定済みですので、準備は完了しています)。
次に、register.py に以下の行を追加して、これら 2 つのツールをインポートします。
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/register.py
# ...
from .bright_data import bright_data_serp_api_function, bright_data_web_unlocker_api_functionこれらの2つのツールはconfig.ymlファイルでは使用できません。その理由は、自動生成されたpyproject.tomlファイルに以下が含まれているためです:
[project.entry-points.'nat.components']
web_data_workflow = "web_data_workflow.register"これはnatコマンドに対して「web_data_workflowワークフローをロードする際、web_data_workflow.registerモジュール内のコンポーネントを検索せよ」と指示しています。
注:同様の手法で、BrightDataWebScraperAPIツールを作成し、Bright Data のウェブスクレイピング API と統合できます。これにより、エージェントは Amazon、Instagram、LinkedIn、Yahoo Finance などの人気ウェブサイトから構造化データフィードを取得する機能が追加されます。
さあ始めましょう!あとはconfig.ymlファイルを適切に更新し、エージェントがこれら2つの新ツールに接続できるようにするだけです。
ステップ #7: Bright Data ツールの設定
config.ymlでBright Dataツールをインポートし、以下のようにエージェントに渡します:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/configs/config.yml
functions:
# カスタムBright Dataツールの定義とカスタマイズ
bright_data_serp_api:
_type: bright_data_serp_api
bright_data_web_unlocker_api:
_type: bright_data_web_unlocker_api
data_format: markdown
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.1-70b-instruct # エンタープライズ対応AIモデルに置き換えてください
temperature: 0.0
workflow:
_type: react_agent
llm_name: nim_llm
tool_names: [bright_data_serp_api, bright_data_web_unlocker_api] # Bright Dataツールを設定
先に定義したツールを使用するには:
config.ymlファイルのfunctionsセクションに追加します。FunctionBaseConfigクラスが公開する引数を通じてカスタマイズ可能です。例えばbright_data_web_unlocker_apiツールはMarkdown形式でデータを返すよう設定されており、AIエージェントが処理するのに 最適な形式です。- エージェントがツールを呼び出せるよう、
ワークフローブロック内のtool_namesフィールドにツールを列挙してください。
素晴らしい!meta/llama-3.1-70b-instructで駆動されるReactエージェントが、LangChainベースのカスタムツール両方にアクセス可能になりました:
bright_data_serp_apibright_data_web_unlocker_api
注:この例ではLLMはNVIDIA NIMモデルとして設定されています。導入要件に応じて、よりエンタープライズ向けのモデルへの切り替えをご検討ください。
ステップ #8: NVIDIA NeMo Agent Toolkit ワークフローのテスト
NVIDIA NeMo Agent ToolkitワークフローがBright Dataツールと連携できることを確認するには、ウェブ検索とウェブデータ抽出の両方をトリガーするタスクが必要です。
例として、ビジネスインテリジェンスを支援するため、競合他社の新製品と価格を監視したいと仮定します。競合相手が Nike の場合、以下のようなプロンプトを作成できます:
ウェブを検索し、最新のナイキシューズを発見してください。取得した検索結果から、ナイキ公式ウェブサイトページを優先し、関連性の高いウェブページを最大3つ選択してください。これらのページにアクセスし、内容をMarkdown形式で取得してください。発見したシューズモデルについて、名称、発売状況、価格、主要情報、および公式ナイキページへのリンク(利用可能な場合)を提供してください。NVIDIA_API_KEYおよびBRIGHT_DATA_API_KEY環境変数が定義されていることを確認し、エージェントを以下のように実行してください:
nat run --config_file configs/config.yml --input "ウェブを検索し、最新のナイキシューズを発見する。取得した検索結果から、公式ナイキウェブサイトページを優先し、最も関連性の高いウェブページを最大3つ選択する。 これらのページにアクセスし、内容をMarkdown形式で取得する。発見したシューズモデルについて、名称、発売状況、価格、主要情報、および公式Nikeページへのリンク(利用可能な場合)を提供する。」初期出力は以下のような内容になります: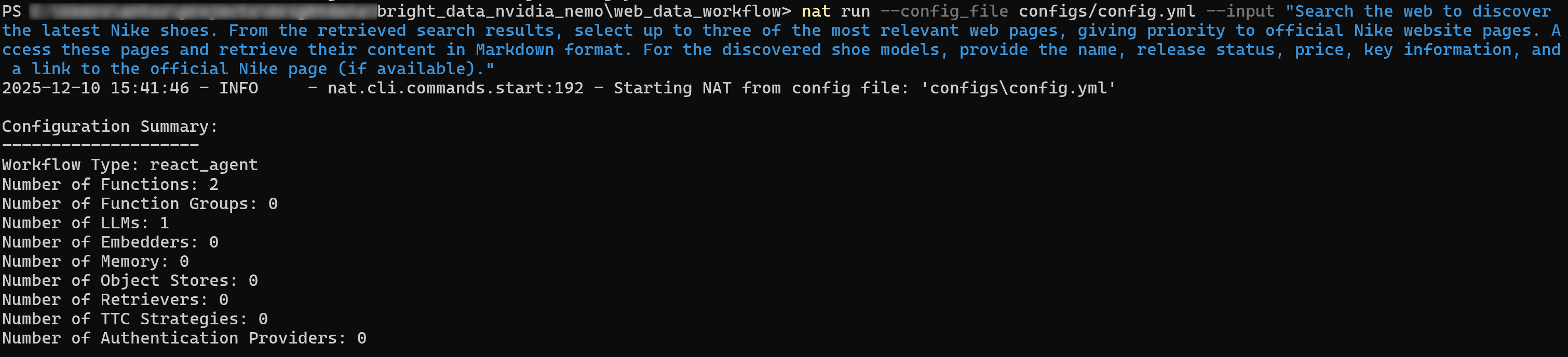
詳細モードを有効化(ワークフローブロックでverbose: trueを設定)すると、エージェントが以下の手順を実行する様子を確認できます:
- 「最新のナイキシューズ」や「新発売のナイキシューズ」などのクエリでSERP APIを呼び出す。
- 公式Nike「新着シューズ」ページを優先し、最も関連性の高いページを選択。
- Web Unlocker APIツールを使用して選択したページにアクセスし、内容をMarkdown形式でスクレイピングする。
- スクレイピングしたデータを処理し、構造化された結果リストを生成します:
[エアジョーダン11 レトロ "ガンマ" - メンズシューズ](https://www.nike.com/t/air-jordan-11-retro-gamma-mens-shoes-DYkD1oXL/CT8012-047)
発売状況: 近日発売予定
カラー: 1
価格: $235
[エアジョーダン11レトロ「ガンマ」 - ビッグキッズシューズ](https://www.nike.com/t/air-jordan-11-retro-gamma-big-kids-shoes-LJyljnZt/378038-047)
発売状況: 近日発売予定
カラー: 1
価格: $190
# 簡略化のため省略...これらの結果は、ナイキの「新着シューズ」ページで確認できる内容と完全に一致しています: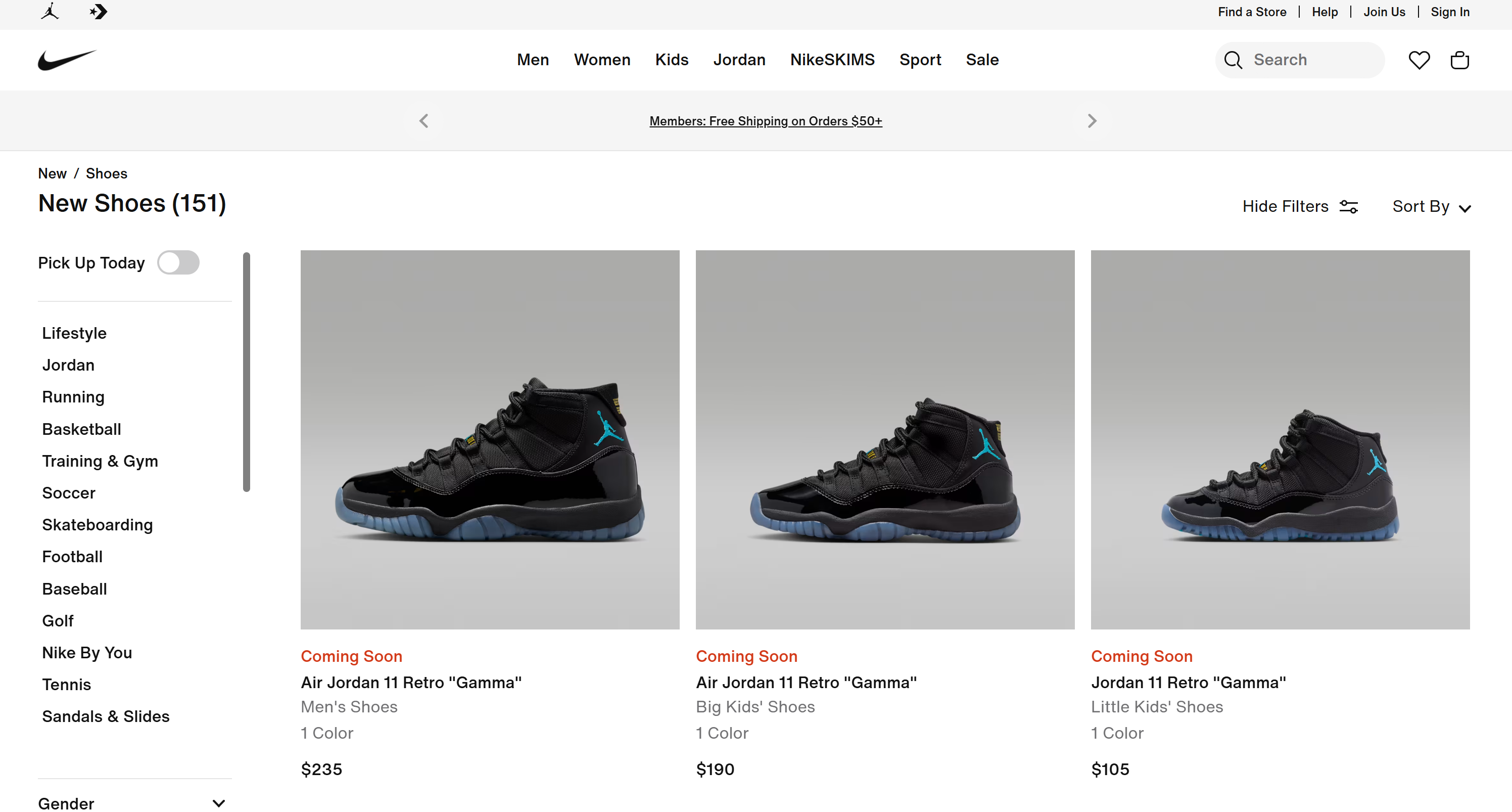
ミッション完了!AIエージェントが自律的にウェブを検索し、適切なページを選択、ウェブスクレイピングを行い、構造化された製品情報を抽出しました。NATワークフローへのBright Dataツールの統合がなければ、これは実現不可能でした!
エージェント型ビジネスインテリジェンスは、NVIDIA NeMo Agent Toolkitと組み合わせたBright Dataソリューションが実現する数多くのユースケースの一つに過ぎません。ツール設定の調整、追加ツールの統合、入力プロンプトの変更を試みて、さらなるシナリオを探索してください!
Web MCP経由でNVIDIA NeMo Agent ToolkitとBright Dataを連携
NVIDIA NeMo Agent ToolkitとBright Data製品を統合する別の方法は、Web MCPへの接続です。詳細は公式ドキュメントを参照してください。
Web MCPは、Bright DataのWeb自動化およびデータ収集プラットフォーム上に構築された60以上のツールへのアクセスを提供します。無料プランでも、以下の2つの強力なツールを利用可能です:
| ツール | 説明 |
|---|---|
search_engine |
Google、Bing、Yandexの検索結果をJSONまたはMarkdown形式で取得します。 |
scrape_as_markdown |
あらゆるウェブページを、ボット対策機能を回避しながらクリーンなMarkdown形式にスクレイピングします。 |
しかし Web MCP の真価はPro モードで発揮されます。このプレミアムプランは有料ですが、Amazon、Zillow、LinkedIn、YouTube、TikTok、Google Maps などの主要プラットフォームからの構造化データ抽出が可能になり、さらに自動化されたブラウザ操作のための追加ツールも利用できます。
注:プロジェクト設定と前提条件については、前の章を参照してください。
それでは、NVIDIA NeMo Agent Toolkit内でBright DataのWeb MCPを使用する方法を見ていきましょう!
ステップ #1: NVIDIA NAT MCPパッケージのインストール
前述の通り、NVIDIA NeMo Agent Toolkitはモジュール式です。コアパッケージが基盤を提供し、追加機能はオプションの拡張機能を通じて追加されます。
MCPサポートに必要なパッケージはnvidia-nat[mcp]です。以下のコマンドでインストールしてください:
pip install nvidia-nat[mcp]これでNVIDIA NeMo Agent ToolkitエージェントがMCPサーバーに接続可能になります。特に、エンタープライズレベルのパフォーマンスと信頼性を確保するため、マネージドリモートサーバー経由のリモートStreamable HTTP通信を用いてBright DataのWeb MCPに接続します。
ステップ #2: リモート Web MCP 接続の設定
config.yml ファイルで、Streamable HTTP プロトコルを使用した Bright Data のリモート Web MCP サーバーへの接続を設定します:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/configs/config.yml
function_groups:
bright_data_web_mcp:
_type: mcp_client
server:
transport: streamable-http
url: "https://mcp.brightdata.com/mcp?token=<YOUR_BRIGHT_DATA_API_KEY>&pro=1" tool_call_timeout: 600
auth_flow_timeout: 300
reconnect_enabled: true
reconnect_max_attempts: 3
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.1-70b-instruct # エンタープライズ対応AIモデルに置き換えてください
temperature: 0.0
workflow:
_type: react_agent
llm_name: nim_llm
tool_names: [bright_data_web_mcp]
今回は、functionsブロックでツールを定義する代わりにfunction_groupsを使用します。これによりWeb MCP接続が設定され、リモートサーバーからMCPツール一式全体が取得されます。このグループは、個々のツールと同様にtool_namesフィールドを通じてエージェントに渡されます。
Web MCP URLには&pro=1クエリパラメータが含まれます。これによりProモードが有効化されます。これはオプションですが、基本的なツールだけでなく構造化データ抽出ツールの全機能を利用できるため、企業利用には強く推奨されます。
ステップ #3: Web MCP接続の確認
新しいプロンプトで NVIDIA NeMo Agent を実行します。初期ログには、Web MCP が公開する全ツールの読み込み状況が表示されるはずです: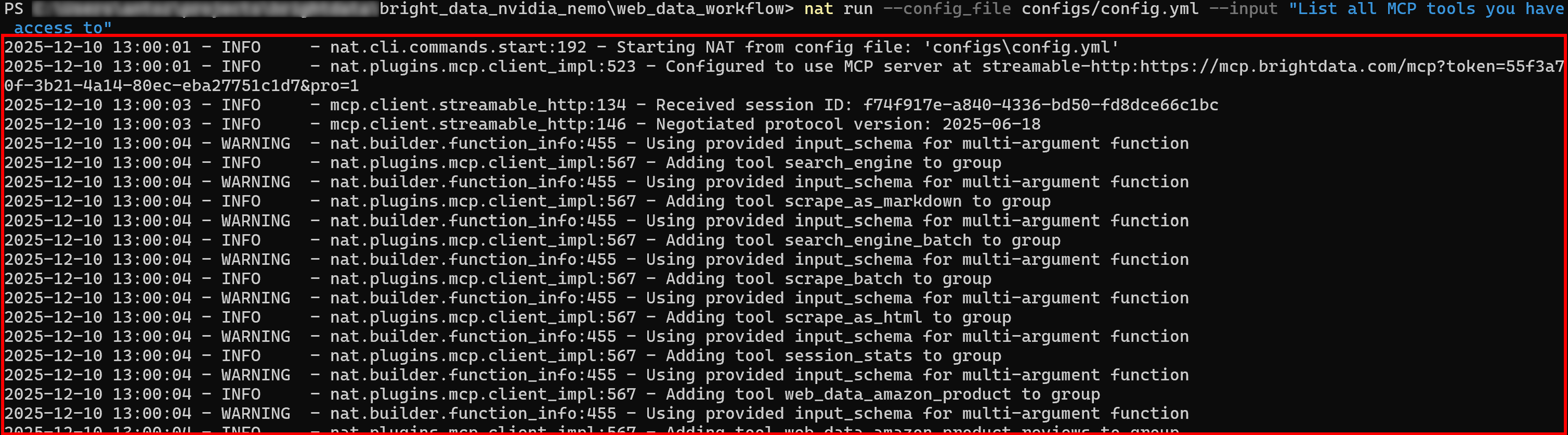
Proモードが有効な場合、60以上の全ツールが初期状態でロードされます。
その後、設定サマリーログには期待通り単一の機能グループが表示されます: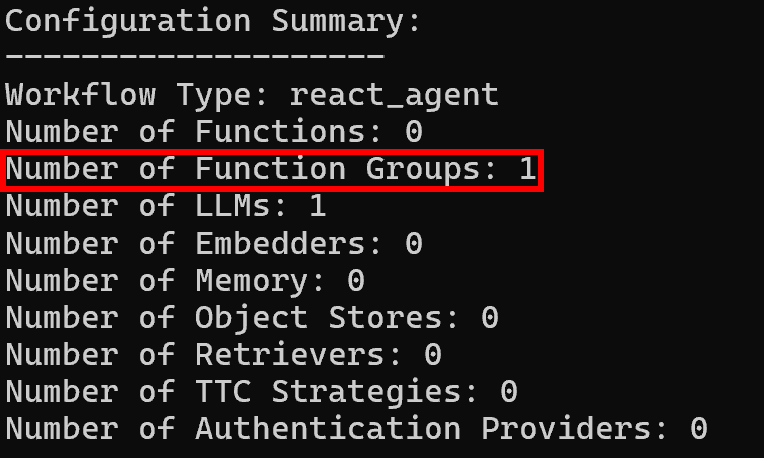
これで完了です! NVIDIA NeMo Agent Toolkitワークフローが、Bright Data Web MCPが提供する全機能に完全にアクセス可能になりました。
結論
本ブログ記事では、LangChainで駆動されるカスタムツールまたはWeb MCPを介して、Bright DataをNVIDIA NeMo Agent Toolkitに統合する方法を学びました。
これらの設定により、NATワークフロー内でリアルタイムのウェブ検索、構造化データ抽出、ライブウェブフィードへのアクセス、自動化されたウェブインタラクションが可能になります。AIのためのBright Dataサービス一式を活用し、AIエージェントの潜在能力を最大限に引き出します!
今すぐBright Dataに登録し、AI対応のウェブデータツールの統合を始めましょう!




