

この記事では以下を学びます:
- Microsoft TaskWeaver の概要とその独自性
- Bright DataサービスでTaskWeaverを拡張することでLLMの限界を克服できる理由。
- カスタムプラグインによるBright DataのTaskWeaverへの統合方法
それでは始めましょう!
Microsoft TaskWeaverとは?
Microsoft TaskWeaverは、自然言語リクエストを実行可能なPythonコードに変換するオープンソースのコードファースト型エージェントフレームワークです。その究極の目的は、複雑なタスクを自律的に計画・実行するAIエージェントを実現することにあります。
この技術は、プロンプトを受け取り実行可能なステップに分解します。その後、目標達成に適したプラグインを選択し、計画を実行するためのPythonコードを生成。安全な環境でコードを実行し、結果を返します。
TaskWeaverはオープンソースであり、GitHubで6,000以上のスターを獲得しています。その特徴的なコア機能には以下が含まれます:
- コードファーストアプローチ:ユーザーリクエストをPythonコードに変換し、エージェントが直接ソリューションを生成・実行する能力を提供。
- プラグインエコシステム:プラグインによる特殊タスクのサポートで、フレームワークの高い拡張性を実現。
- 豊富なデータ処理:DataFramesなどのPythonデータ構造をネイティブに扱い、高度なデータ分析の可能性を開きます。
- ドメイン適応:ドメイン固有の知識を統合し、より正確な結果を実現。
- ステートフルかつリフレクティブ実行:コンテキストを維持し、自身のコード実行を内省して自己修正が可能。
- 安全性と開放性: 安全な環境でコードを実行しつつ、オープンソースで即利用可能な体験を提供。
詳細は公式ドキュメントでご確認ください。
TaskWeaverにWebデータ取得機能を追加する理由
LLMは、訓練に使用されたデータに本質的に制限されます。テキスト、コード、マルチメディアを生成することは可能ですが、出力は常に古い知識に基づいています。さらに、人間のユーザーのようにライブウェブページと対話することもできません。これら2つが現在のAIモデルの主な制約です。
TaskWeaverはエージェントがカスタムプラグインと連携できるようにすることで、これらの制限を克服します。プラグインは、LLMが組み込み機能を超えたタスクを実行するために使用できる専用ツールと考えることができ、効果的にその範囲と実用性を拡張します。
これらのプラグインを呼び出すことで、TaskWeaverエージェントが生成するコードは外部環境と対話し、複雑な操作を実行できます。例えばBright Dataは以下のような強力なツール群を提供しています:
- Web Unlocker API: プロキシ、ブロック解除、ヘッダー、CAPTCHAの自動処理により、単一リクエストで任意のウェブサイトをスクレイピングし、クリーンなHTMLまたはMarkdownを取得。
- SERP API: Google、Bingなどの検索エンジン結果を大規模に収集。ブロックを気にせず。
- ウェブスクレイピングAPI:Amazon、Instagram、LinkedIn、Yahoo Financeなど既知サイトから構造化・パース済みデータを取得。
- その他Bright Dataソリューション…
これらのサービスに接続するプラグインを利用することで、TaskWeaverエージェントはウェブを検索し、コンテンツを抽出し、人気ドメインからリアルタイムで構造化データを取得できます。これにより、AIは標準的なLLMが単独で達成できる範囲をはるかに超えた、複雑でエンタープライズ対応のワークフローを処理できるようになります。
カスタムプラグインによるBright DataとTaskWeaverの統合方法
このチュートリアルセクションでは、ウェブデータ取得のためにTaskWeaverエージェントをBright Dataと統合する方法を学びます。
具体的には、Bright Data Web Unlocker APIに接続するカスタムツールでTaskWeaverアプリケーションを拡張する方法を解説します。これにより、コードファーストエージェントがインターネット上の任意のウェブページからデータを取得し、必要に応じて処理できるようになります。
注:類似のアプローチについては、別のコードファーストAI技術エージェントであるsmoleagentsとの統合ガイドを参照してください。
以下の手順を注意深く実行してください!
前提条件
このチュートリアルを実行するには、以下の環境が必要です:
- ローカルにインストールされたPython 3.10以上:TaskWeaverおよびそのプラグインの実行に必須。
- ローカルにGitがインストールされていること:GitHubからTaskWeaverリポジトリをクローンするために必要です。
- Dockerデーモンが実行中であること:コード検証機能(オプション)のエラー回避に必須です。
- OpenAI APIキー(またはその他のサポートされているLLMのAPIキー)。
Bright Dataを利用するには、以下のものも必要です:
- APIキー付きのBright Dataアカウント。
- アカウントに設定済みのWeb Unlockerゾーン。
Bright Dataの設定については、後ほど専用の手順で説明しますので、現時点では心配する必要はありません。
ステップ #1: Microsoft TaskWeaver プロジェクトの作成
まず、TaskWeaverプロジェクト用のプロジェクトフォルダを作成し、ターミナルでそのフォルダに移動します:
mkdir taskweaver-bright-data-example
cd taskweaver-bright-data-exampleプロジェクトフォルダ内で仮想環境を作成します:
python -m venv .venv次に、それをアクティブ化します。Linux/macOSでは、次のコマンドを実行します:
source .venv/bin/activateまたは、Windowsでは以下を実行:
.venvScriptsactivate次に、以下のコマンドでTaskWeaverをインストールします:
git clone https://github.com/microsoft/TaskWeaver.git
cd TaskWeaver
pip install -r requirements.txtこれにより、TaskWeaver/ がプロジェクトフォルダにクローンされ、pip を通じて作成した仮想環境にすべての依存関係がインストールされます。
TaskWeaverはプロセスとして実行され、プラグイン、設定ファイル、セッションデータを保存するためのプロジェクトディレクトリを必要とします。クローンしたリポジトリには、TaskWeaver/project/ディレクトリにサンプルプロジェクトが用意されています: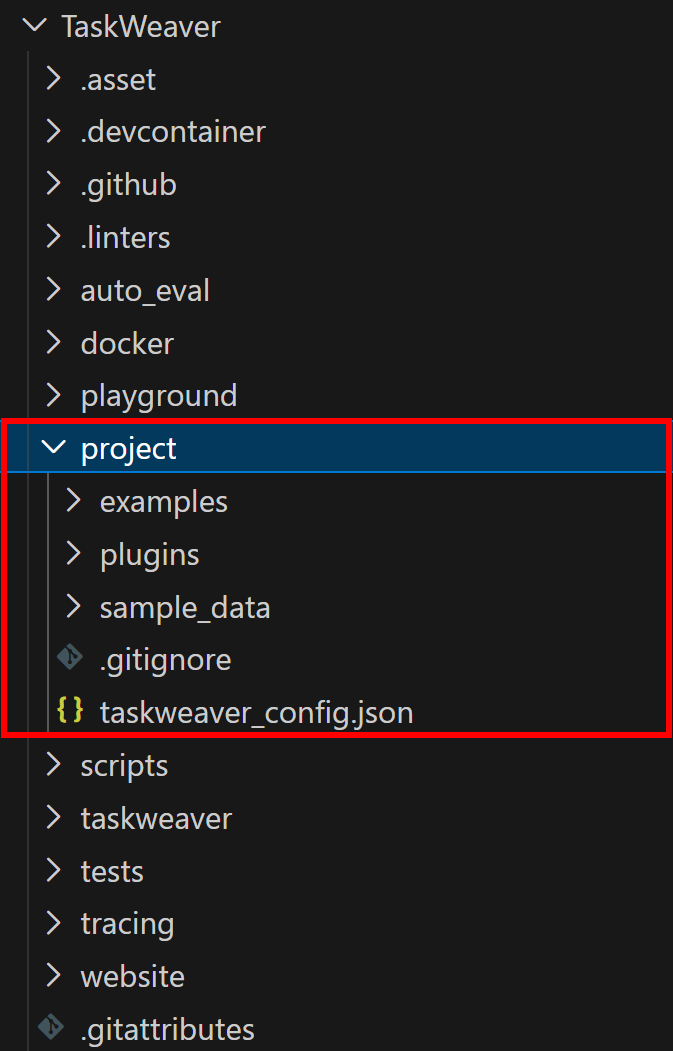
プロジェクトフォルダのコンテンツをワークスペースにコピーしてください。これにより、taskweaver-bright-data-example/フォルダは以下のように構成されます:
taskweaver-bright-data-example/
├─ .venv/
├─ TaskWeaver/
├─ plugins/ # プラグインを保存するフォルダ
├─ examples/
│ ├─ planner_examples/ # プランナースクリプトのサンプル
│ └─ code_generator_examples/ # コードジェネレータスクリプトのサンプル
├─ sample_data/ # オプションのサンプルデータセット
├─ .gitignore
└─ taskweaver_config.json # プロジェクト設定ファイル特に、典型的なMicrosoft TaskWeaverプロジェクトディレクトリには、公式ドキュメントに記載されている特定のフォルダとファイルが含まれます。
お気に入りのPython IDE(Visual Studio CodeやPyCharmなど)でtaskweaver-bright-data-example/を読み込みます。
仮想環境をアクティブにした状態で、/TaskWeaverフォルダ内にいる間にアプリケーションを起動します:
python -m taskweaverこれにより、/TaskWeaverフォルダから TaskWeaver プロセスが起動し、taskweaver-bright-data-example/フォルダ内のプロジェクトファイルとディレクトリが読み込まれます。
正常に動作している場合、ターミナルに以下が表示されます:
成功! Microsoft TaskWeaver が動作しています。アプリケーションを初回実行後、以下のフォルダが作成されます:
workspace/: プロジェクトのセッションデータを保存します。logs/: プログラムが生成するログファイルを保存します。
注意: 現時点でプロンプトを入力しようとすると失敗します。LLMへの接続設定がまだ必要だからです。これは次のステップで説明します。
ステップ #2: TaskWeaver で LLM を設定する
TaskWeaverは幅広いLLMをサポートしています。このチュートリアルではOpenAIモデルを統合しますが、他のサポート対象LLMプロバイダーにも手順を簡単に適用できます。
TaskWeaverでGPT-4.1 miniモデルを設定するには、taskweaver -bright-data-example/内のtaskweaver_config.jsonファイルに以下が含まれていることを確認してください:
{
"llm.api_key": "<YOUR_OPENAI_API_KEY>",
"llm.model": "gpt-4.1-mini"
}<YOUR_OPENAI_API_KEY>を実際のOpenAI API キーに置き換えてください。
注: 執筆時点では、TaskWeaverはGPT-5モデルをサポートしていません。GPT-5モデルを設定しようとすると、以下のエラーが発生します:
{'error': {'message': "Unsupported parameter: 'max_tokens' is not supported with this model. Use 'max_completion_tokens' instead.", 'type': 'invalid_request_error', 'param': 'max_tokens', 'code': 'unsupported_parameter'}}素晴らしい!TaskWeaverプロジェクトがOpenAI GPT-4.1 miniモデルで動作するようになりました。プロンプト処理の準備が整っています。
ステップ #3: Bright Data Web Unlocker API ゾーンの設定
TaskWeaverエージェントをBright Dataに接続し、ウェブスクレイピング機能を利用するには、まずいくつかの事前準備が必要です。具体的には、Bright DataアカウントでWeb Unlockerゾーンを設定する必要があります。
アカウントをお持ちでない場合は、Bright Dataアカウントを作成してください。既にアカウントをお持ちの場合は、ログインしてください。アカウントにログインしたら、「Proxies & Scraping」ページに移動します。「My Zones」セクションで、テーブル内に「Web Unlocker API」とラベル付けされた行があるか確認してください: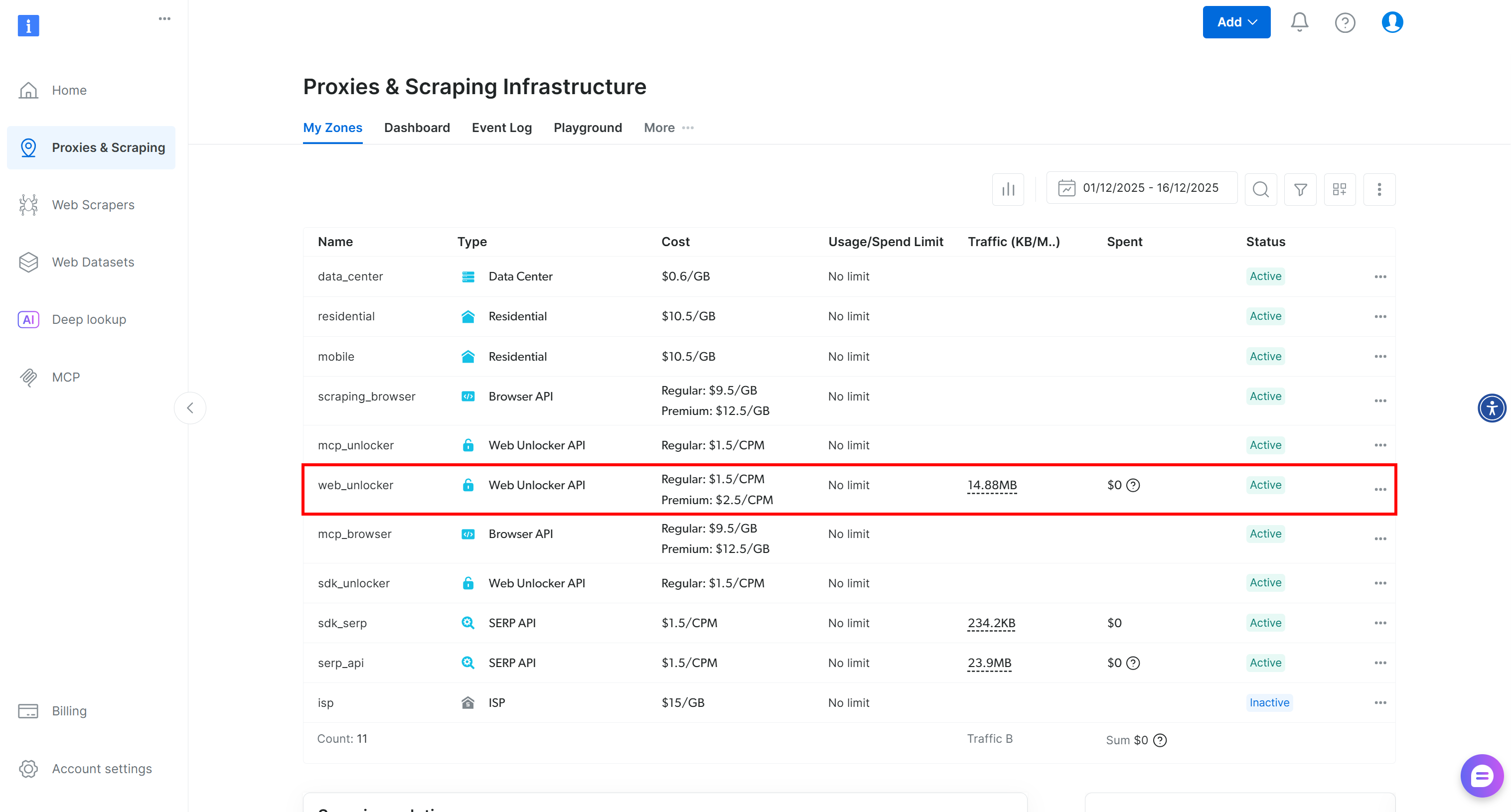
「Web Unlocker API」と表示された行がない場合、Bright Dataアカウントに該当ゾーンが未設定であることを意味します。作成するには、ページ下部の「Unlocker API」セクションまでスクロールし、「ゾーンを作成」をクリックして追加してください: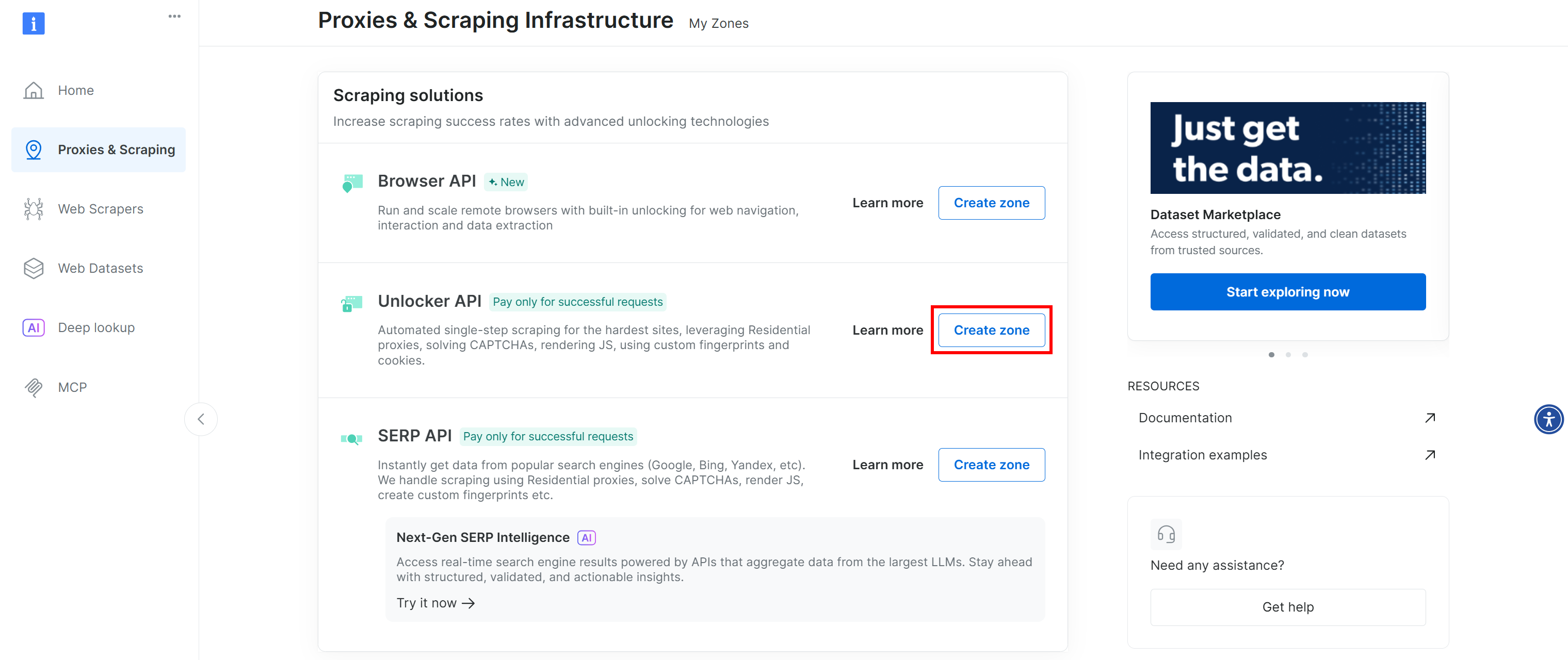
Web Unlocker APIゾーンを作成し、web_unlocker(または任意の名前)などの名前を付けます。カスタムプラグインでAPI経由にサービスにアクセスする際に必要となるため、ゾーン名を覚えておいてください。
Web Unlockerゾーンページで、トグルが「Active」に設定されていることを確認し、ゾーンが有効化されていることを確認してください。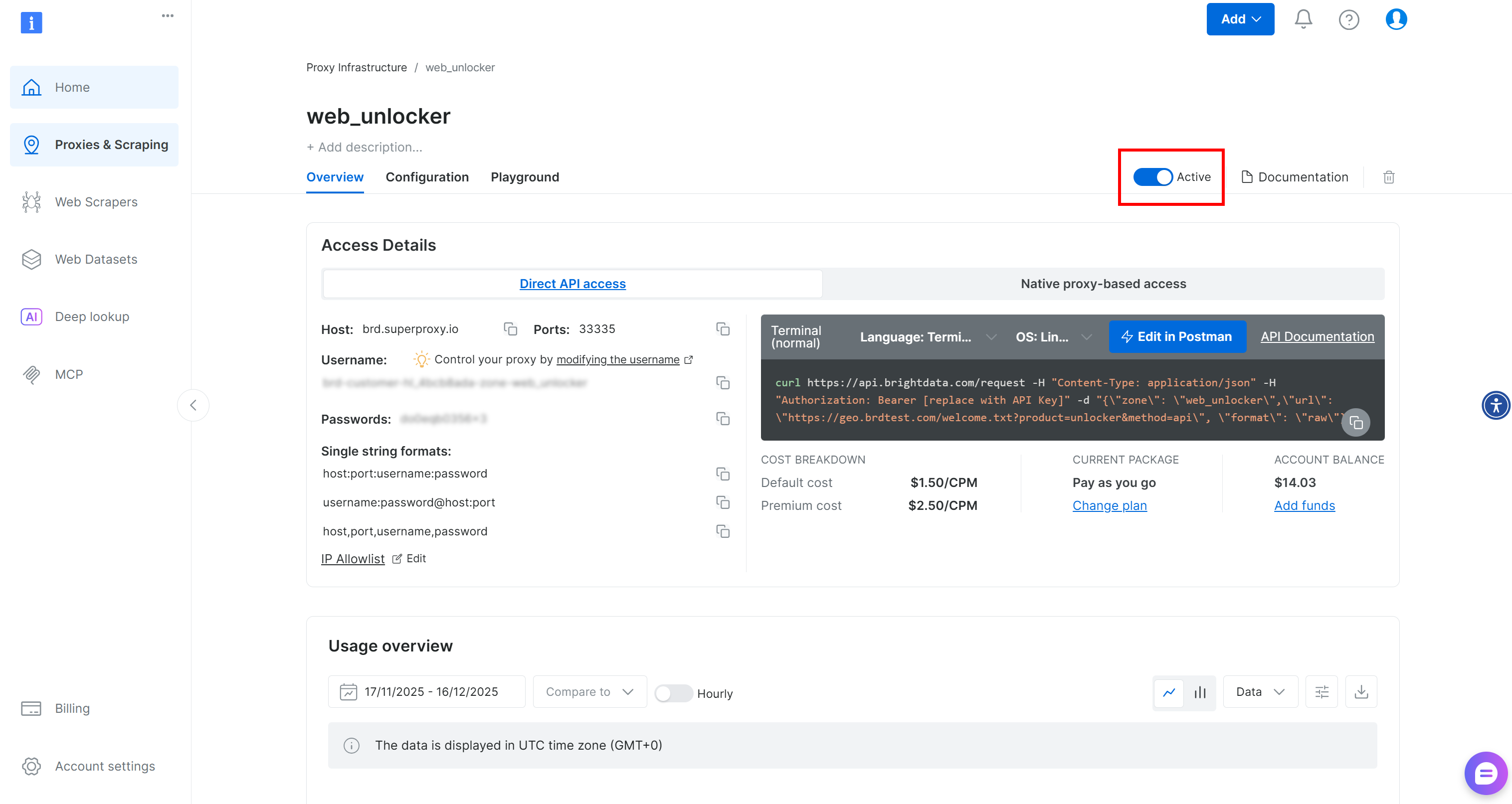
最後に、公式ガイドに従ってBright Data APIキーを生成してください。すぐに必要となるため、安全に保管してください。
これで、TaskWeaverアプリケーションでBright DataのWeb Unlocker APIプラグインを使用するための準備が整いました。
ステップ #4: Bright Data 統合用 TaskWeaver Web Unlocker プラグインの定義
プラグインは、TaskWeaverのコードインタープリタによって制御可能な単位です。具体的には、各プラグインは生成されたコード内で呼び出せるPython関数です。
TaskWeaverでは、プラグインは次の2つのファイルで構成されます:
- プラグイン実装:プラグインを定義するPythonファイル
- プラグインスキーマ:プラグインの入力、出力、メタデータを定義する YAML ファイル。
両ファイルはプロジェクト内のplugins/サブフォルダに配置する必要があります。
この場合、Bright Data Web Unlocker APIを呼び出すプラグインを追加する必要があります。そのAPIエンドポイントの呼び出し方法の詳細については、公式ドキュメントを参照してください。
アクティブな仮想環境で、まずRequestsなどのPython HTTPクライアントをインストールします:
pip install requests次に、plugins/フォルダ内にweb_unlocker.pyプラグインファイルを追加します。以下のように定義します:
# taskweaver-bright-data-example/plugins/web_unlocker.py
import requests
from taskweaver.plugin import Plugin, register_plugin
@register_plugin
class WebUnlockerPlugin(Plugin):
def __call__(
self,
url: str,
data_format: str = None
):
# API呼び出し用の設定値を読み込み
bright_data_api_key = self.config.get("api_key")
zone = self.config.get("zone", "web_unlocker")
default_format = self.config.get("data_format", "markdown")
# Bright Data API認証に必要なHTTPヘッダー
headers = {
"Authorization": f"Bearer {bright_data_api_key}",
"Content-Type": "application/json"
}
# Bright Data Web Unlockerに送信するリクエストペイロード
payload = {
"ゾーン": zone,
"url": url,
"format": "raw", # レスポンスを直接ボディで取得するため
"data_format": data_format or default_format
}
# Bright Data Web Unlocker APIへのリクエスト送信
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers,
)
# 2xx以外のHTTPレスポンスで例外を発生
response.raise_for_status()
# レスポンス内容とHTTPステータスコードを抽出
content = response.text
status = response.status_code
# LLMに返す自然言語要約
description = (
f"Bright Data Web Unlockerを使用してページを取得成功 "
f"(HTTP {status}, {len(content)}文字)。"
)
# 取得したページをセッションワークスペースにアーティファクトとして保存
self.ctx.add_artifact(
name="web_unlocker_page",
file_name="page_content.md",
type="txt",
val=content
)
# 生コンテンツと人間が読める説明の両方を返す
return content, descriptionこのプラグインはBright Data Web Unlocker APIを通じてウェブページを取得します。まず、self.config.get()を使用してプラグインのYAML設定セクション(後述)から設定値を読み込みます。
次にHTTPリクエストを送信し、エラーをチェックした後、取得したページをself.ctx.add_artifact()経由でワークスペースにアーティファクトとして保存します。これにより実行中および実行後に結果を確認できます。最後に、LLMが利用可能な生のページコンテンツと人間が読める要約の両方を返します。
注:デフォルトでは、Bright Data Web Unlocker API呼び出しはウェブページコンテンツをMarkdown形式で返すよう設定されています。これはLLMの取り込みに最適です。これはWeb Unlocker APIが提供する便利な機能であり、AI統合をサポートしコンテンツ処理を簡素化します。
素晴らしい!TaskWeaverエージェントがこのプラグインを使用するには、プラグインのYAMLスキーマファイルも指定する必要があります。
ステップ #5: プラグインスキーマ定義を続行
プラグインスキーマは、TaskWeaver内のLLMがプラグインを理解し呼び出す方法を定義します。これはYAML形式で記述する必要があるため、plugins/フォルダ内に以下のようにweb_unlocker.yamlというファイルを作成してください:
# taskweaver-bright-data-example/plugins/web_unlocker.yaml
name: web_unlocker
enabled: true
plugin_only: true
description: >-
Bright Data Web Unlocker APIを使用してウェブページを取得・アンロックし、
ボット対策機能を回避してクリーンなページコンテンツを返します。
parameters:
- name: url
type: str
required: true
description: 取得するウェブページの完全なURL。
- name: data_format
type: str
required: false
description: ページコンテンツの出力形式(「markdown」または省略時は生のHTML)。
returns:
- name: content
type: str
description: ロック解除されたページコンテンツ。
- name: description
type: str
description: フェッチ操作の自然言語による要約。
configurations:
api_key: <YOUR_BRIGHT_DATA_API_KEY> # Bright Data APIキーに置き換えてください
zone: web_unlocker # Web Unlockerゾーン名に置き換えてください
data_format: markdown上記のYAMLファイルは、先に定義したWebUnlockerPluginクラスの__call__ ()関数の入力と出力を記述しています。このスキーマにより、TaskWeaverのLLMはweb_unlocker.pyプラグインの動作方法と、生成されたPythonコード内での呼び出し方法を理解します。
設定セクションでは、Bright Data APIキー、Web Unlockerゾーン名、希望の出力形式を指定します。api_keyとzoneフィールドは、ステップ#3で設定した値に置き換えてください。
これで完了です!TaskWeaverとBright Dataの連携が完了しました。
注:この同じアプローチで、SERP APIやウェブスクレイピング APIなど、他のBright DataサービスをAPI経由で統合することも可能です。
ステップ #6: TaskWeaver エージェントのテスト
TaskWeaverのコードファーストエージェントがBright Dataプラグインを呼び出せることを確認します。生成されたコードがプラグイン関数を呼び出し、Web Unlocker APIのウェブアンロック機能を利用できることを検証します。
テストには、以下のようなプロンプトを試してください:
「https://modelcontextprotocol.io/specification/2025-11-25/changelog」から最新のMCP変更履歴を取得し、変更点を一覧表示してください。このタスクは通常、標準的なLLMでは不可能です。URLに移動して情報を抽出するにはカスタムツールが必要だからです。しかしTaskWeaverとBright Dataを組み合わせれば、エージェントが処理できます!
TaskWeaverアプリケーションを起動するには:
python -m taskweaverプロンプトを貼り付けてEnterキーを押します。以下のような出力が表示されるはずです: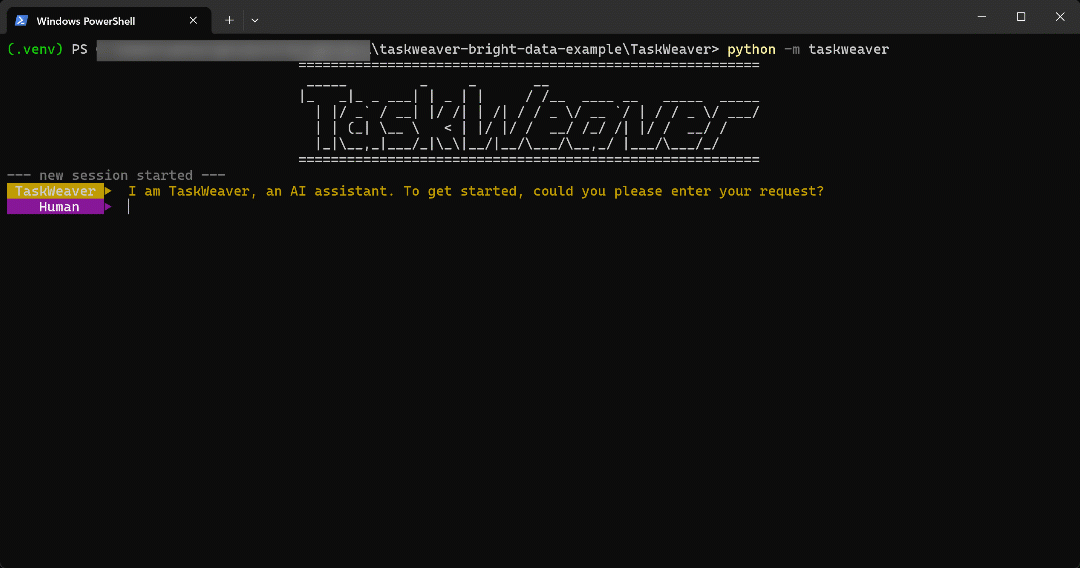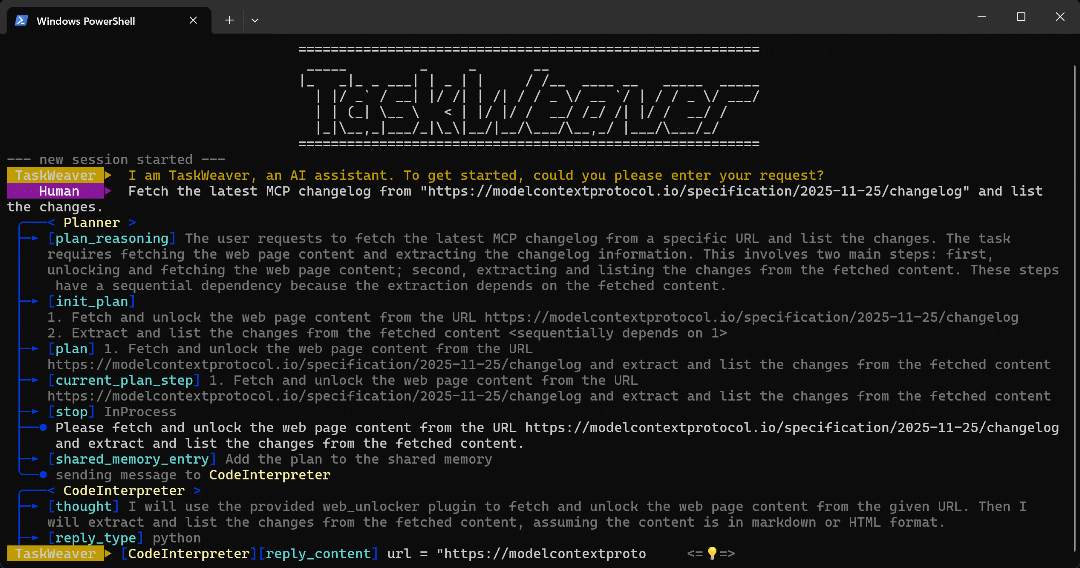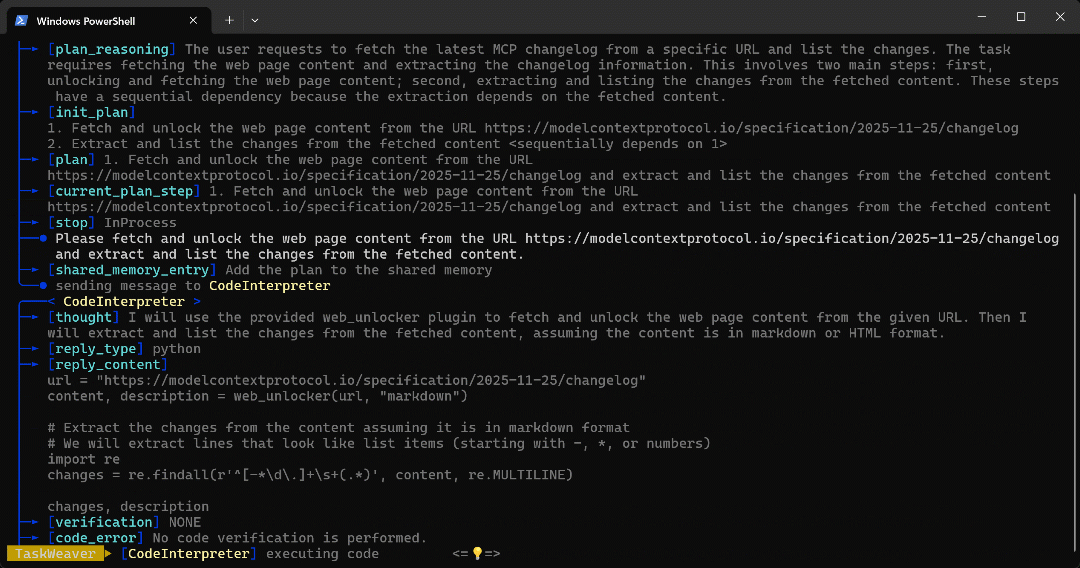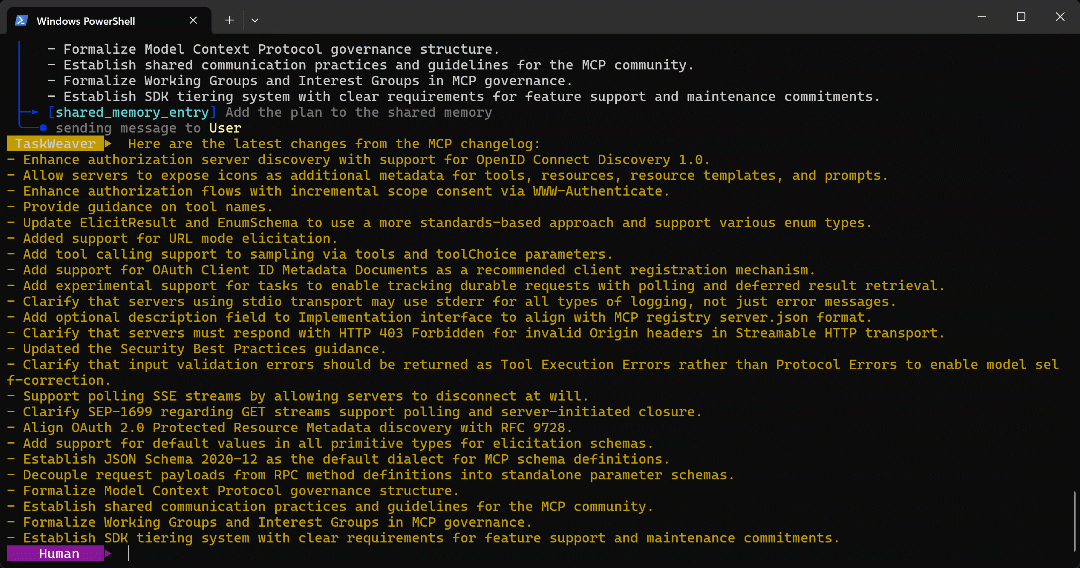
ご覧の通り、エージェントは:
TaskWeaver Plannerはまずタスク実行計画を生成します。- この計画は内部エージェント「
CodeInterpreter」に送信され、目標達成のためのPythonコードが生成されます。 - PythonコードはWeb Unlocker APIプラグインを呼び出し、正規表現を用いて記事内の箇条書きを全て抽出します。
- コードが実行され、Web Unlocker API経由で目的のデータが取得され、
self.ctx.add_artifact()で設定されたワークスペースフォルダに保存されます。 - URL で指定されたページの内容を含む返された Markdown データは、
プランナーに送り返され、プランナーは次のステップに進みます。 - 対象ページから抽出された箇条書きリストが意図通りユーザーに返されます。
素晴らしい!TaskWeaverエージェントは完璧に動作しています。生成された出力を確認する時間を取ってみましょう。
ステップ #7: 出力の確認
エージェント実行の最終出力は次の通りです:
対象ページで確認できるように、このリストはMCP変更履歴に記載された情報と完全に一致しています: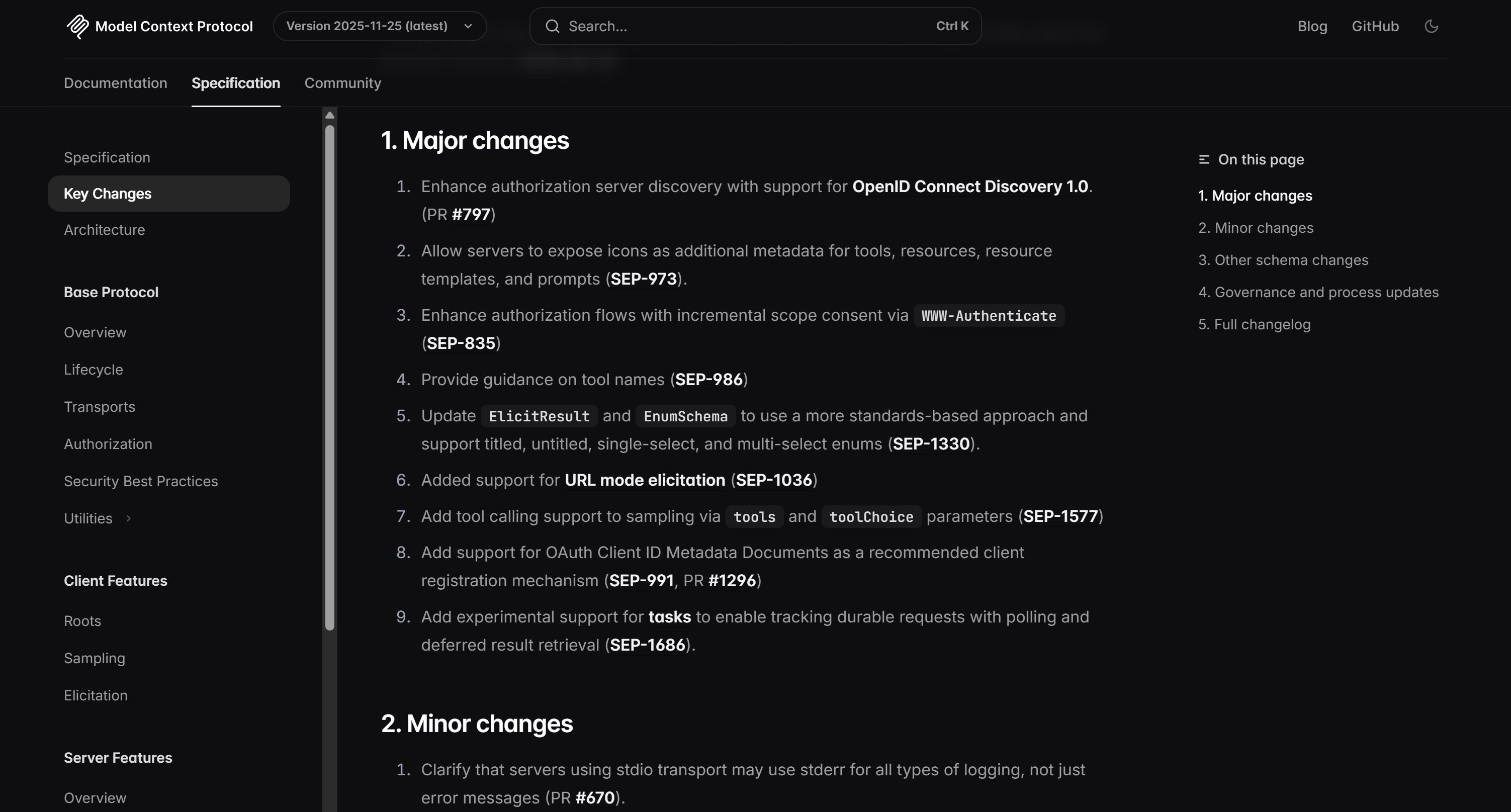
特に、エージェントは以下のPythonコードを通じて出力を生成しました:
url = "https://modelcontextprotocol.io/specification/2025-11-25/changelog"
content, description = web_unlocker(url, "markdown")
# コンテンツがマークダウン形式であると仮定し変更点を抽出
# リスト項目(-、*、または数字で始まる行)を抽出
import re
changes = re.findall(r'^[-*d.]+s+(.*)', content, re.MULTILINE)
changes, description生成されたスニペットが、入力ページをMarkdown形式で取得するためにweb_unlocker()関数プラグインを呼び出している点に注目してください。その後、単純な正規表現を使用して関連情報を抽出します。
Web Unlocker APIがページコンテンツをMarkdown形式で返したことを確認するには、workspace/フォルダ内のファイルを確認してください。各エージェント実行は、workspace/sessions/下にセッションサブフォルダを生成し、その特定の実行用のサブフォルダを含みます。
cwd/フォルダ内には、self.ctx.add_artifact()呼び出しによって作成された.mdファイルがあります。これを開くと、Web Unlocker APIから返されたコンテンツを確認できます: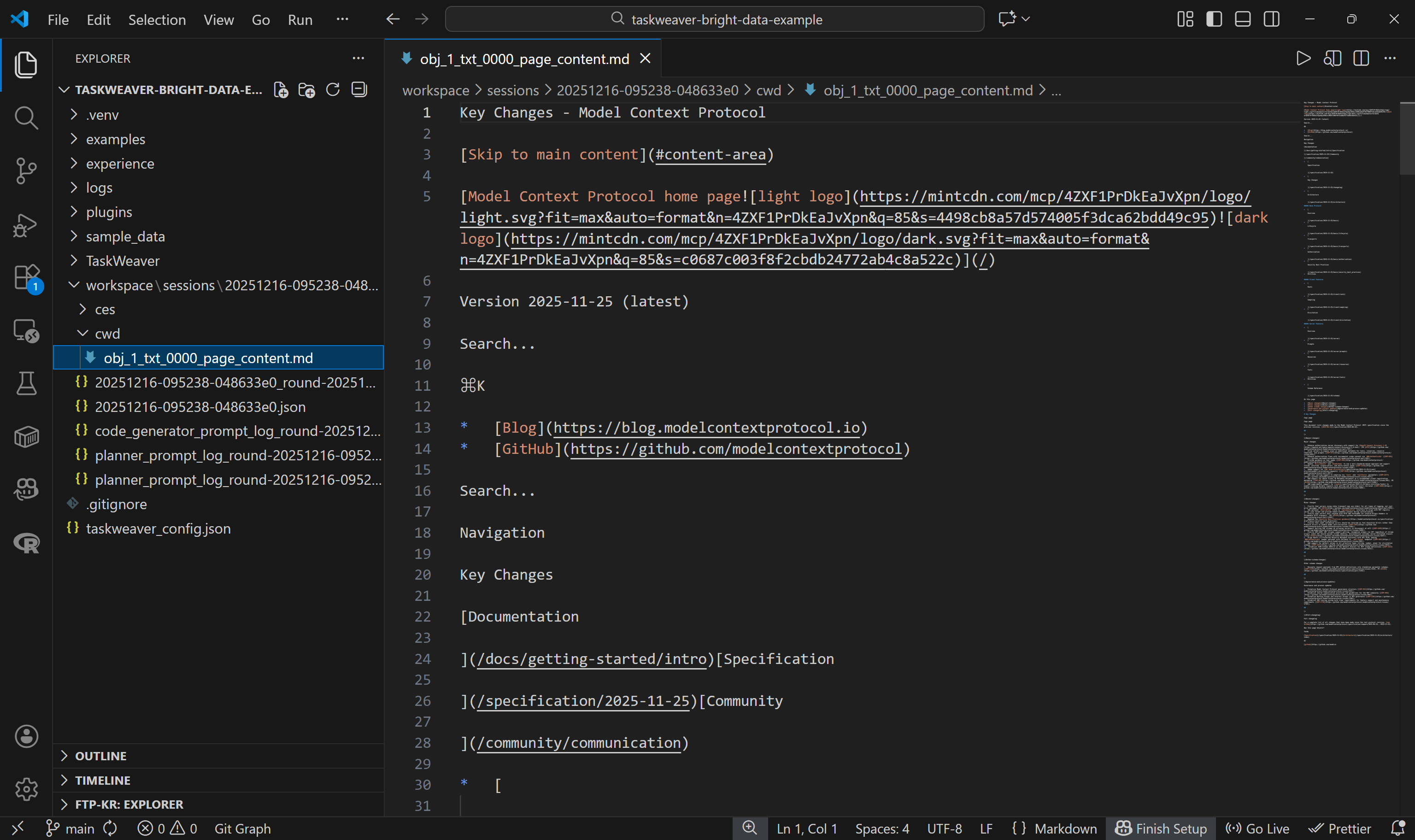
これは対象ページのMarkdown版と完全に一致しており、生成されたPythonコード内のWeb Unlocker API関数が完璧に機能したことを意味します。すごい!
さあ、エージェントをさらに進化させましょう。より現実的で企業対応可能なシナリオを扱うため、様々なプロンプトで実験してください。
これで完成です!TaskWeaverを使用してBright Dataと統合されたコードファーストAIエージェントを構築できました。このエージェントはあらゆるウェブページからAI対応データを確実に取得できます。
次のステップ
ここで示した統合は基本的な例です。TaskWeaverエージェントを次のレベルに引き上げ、本番環境対応にするには、以下の強化を検討してください:
- SERP APIなどの追加Bright Dataソリューションを統合し、エージェントにウェブ検索とライブデータ収集機能を持たせる。
- Web UIをエージェントの開発・テスト・監視を簡素化するプレイグラウンドとして設定する。
- プロンプト圧縮、自動プラグイン選択、テレメトリ/可観測性といった高度な機能を有効化し、パフォーマンス、スケーラビリティ、保守性を向上させる。
まとめ
このチュートリアルでは、外部APIに接続するカスタムプラグインを通じてBright DataをTaskWeaverに統合する方法を学びました。
この設定により、リアルタイムのウェブ検索、構造化データの抽出、ライブウェブフィードへのアクセス、自動化されたウェブインタラクションが可能になります。Bright DataのAIのためのデータサービススイートをフル活用することで、コードファーストAIエージェントの真の潜在能力を引き出せます!
今すぐBright Dataアカウントを無料で作成し、AIのためのWebデータソリューションを実際に体験してください。




