

このチュートリアルでは、次のことを学びます:
- AIを搭載したLinkedIn就活アシスタントがどのように機能するか。
- Bright DataからのLinkedInの求人データをOpenAIを搭載したワークフローと統合して構築する方法。
- このワークフローを改善し、堅牢な就活アシスタントに拡張する方法。
最終的なプロジェクトファイルはここで見ることができます。
さあ、飛び込もう!
LinkedIn就活AIアシスタントワークフローの説明
まず最初に、LinkedInの求人情報データにアクセスしなければ、LinkedIn就活AIアシスタントを構築することはできません。そこでBright Dataの出番です!
LinkedIn Jobs Scraperのおかげで、LinkedInの公開求人情報をウェブスクレイピングで取得することができます。LinkedInジョブズポータルで検索するのと同じような体験ができます。しかし、ウェブページの代わりに、構造化された求人データをJSONまたはCSV形式で直接受け取ることができます。
そのデータがあれば、AIにあなたのスキルと希望する職種に基づいて各求人に点数をつけてもらうことができる。これが、LinkedIn Job AI Assistantがあなたのためにしてくれることです。
技術的なステップ
LinkedInの求人AIワークフローを実装するために必要なステップは以下の通りです:
- CLIの引数をロードする:コマンドライン引数を解析し、実行時のパラメーターを取得する。これにより、コードを変更することなく、柔軟な実行と簡単なカスタマイズが可能になる。
- 環境変数をロードする:環境変数からOpenAIとBright Data APIキーをロードします。これらは、このAIワークフローを動かすサードパーティの統合に接続するために必要です。
- 設定ファイルを読み込む:求人検索パラメータ、候補者プロファイルの詳細、希望する求人情報を含むJSON設定ファイルを読み込みます。この設定情報は、求人の検索とAIのスコアリングの指針となる。
- LinkedInから求人をスクレイピングする:LinkedIn Jobs Scraper APIから、設定に従ってフィルタリングされた求人情報を取得します。
- AIによるスコアリング:求人情報の各バッチをOpenAIに送信します。AIは、あなたのプロフィールと希望する仕事に基づいて、
0点から100点まで採点します。また、各スコアを説明する短いコメントも追加され、マッチングの質を理解するのに役立ちます。 - AIのスコアとコメントで求人情報を拡大します:****AIが生成したスコアとコメントを元の求人情報にマージし、AIが生成した新しいフィールドで各求人記録を充実させます。
- スコアリングされた求人データをエクスポートします:エンリッチされた求人データをCSVファイルにエクスポートし、さらなる分析と処理を行います。
- 上位の求人情報を印刷コンソールにマッチした上位の求人案件を主な詳細とともに直接表示し、最も関連性の高い案件を即座に把握することができます。
PythonでこのAIワークフローを実装する方法をご覧ください!
OpenAIとBright Dataを使ってLinkedInの就活AIワークフローを構築する方法
このチュートリアルでは、LinkedInで求人を見つけるためのAIワークフローを構築する方法を学びます。LinkedInの求人データはBright Dataから、AI機能はOpenAIから提供されます。他のLLMを使うこともできる。
このセクションが終わる頃には、コマンドラインから実行できる完全なPython AIワークフローが完成しているはずだ。これは、LinkedInの最適な求人ポジションを特定し、求職活動という過酷でエネルギーを消耗する作業の時間と労力を節約してくれる。
LinkedInの求職AIアシスタントを作ってみよう!
前提条件
このチュートリアルに従うには、以下のものがあることを確認してください:
- Python 3.8以上がローカルにインストールされていること(最新バージョンの使用を推奨します)。
- Bright Data APIキー
- OpenAI API キー。
Bright Data APIキーをまだお持ちでない場合は、Bright Dataアカウントを作成し、公式のセットアップガイドに従ってください。同様に、OpenAIの公式手順に従ってOpenAI APIキーを取得してください。
ステップ #0: Pythonプロジェクトのセットアップ
ターミナルを開き、LinkedIn就活AIアシスタント用の新しいディレクトリを作成します:
mkdir linkedin-job-hunting-ai-assistant/linkedin-job-hunting-ai-assistantフォルダは、あなたのAIワークフローのためのすべてのPythonコードを保持します。
次に、プロジェクトディレクトリに移動し、その中で仮想環境を初期化する:
cd linkedin-job-hunting-ai-assistant/
python -m venv venv次に、お気に入りのPython IDEでプロジェクトを開きます。Python拡張機能付きのVisual Studio Codeか、PyCharm Community Editionをお勧めします。
プロジェクトフォルダの中に、assistant.pyという名前の新しいファイルを作成します。ディレクトリ構造はこのようになっているはずです:
linkedin-job-hunting-ai-assistant/」のようになります。
├─ venv/
└── assistant.pyターミナルで仮想環境を起動します。LinuxやmacOSの場合、以下のように実行します:
ソース venv/bin/activateWindowsの場合は、以下のコマンドを実行します:
venv/Scripts/activate次のステップでは、必要なPythonパッケージのインストールを案内します。アクティベートされた仮想環境で今すぐインストールしたい場合は、次のコマンドを実行してください:
pip install python-dotenv requests openai pydantic特に必要なライブラリは以下の通りです:
python-dotenv:.envファイルから環境変数をロードし、APIキーの安全な管理を容易にする。pydantic:設定ファイルを検証し、構造化されたPythonオブジェクトにパースする。requests:Bright DataのようなAPIを呼び出してデータを取得するためのHTTPリクエストを処理する。openaiAIジョブスコアリングのためのOpenAIの言語モデルと対話するためのOpenAIクライアントを提供します。
注:このチュートリアルでは言語モデルプロバイダとしてOpenAIに依存しているため、ここでopenaiライブラリをインストールしています。もし別のLLMプロバイダーを使うつもりなら、対応するSDKか依存関係をインストールしてください。
これで準備は完了です!これで、OpenAIとBright Dataを使ってAIワークフローを構築するためのPython開発環境が整いました。
ステップ #1: CLI引数をロードする
LinkedIn就活AIスクリプトにはいくつかの引数が必要です。コードを変更することなく、再利用性とカスタマイズ性を保つために、CLI経由でそれらを読み込む必要があります。
具体的には、以下のCLI引数が必要です:
-config_file:-config_file:求人検索のパラメータ、候補者のプロフィール詳細、希望する求人情報を含むJSON設定ファイルへのパス。デフォルトはconfig.jsonです。-batch_size:一度にAIにスコアリングのために送信する求人数。デフォルトは5。--jobs_number:Bright Data LinkedIn Jobs Scraperが返すジョブエントリーの最大数。デフォルトは20です。--output_csv: AIのスコアとコメントを含むエンリッチされた求人データを含む出力CSVファイルの名前。デフォルトはjobs_scored.csv。
これらの引数をコマンドラインインターフェイスから読み込むには、以下の関数を使用します:
def parse_cli_args():
# config と runtime オプションのコマンドライン引数を解析します。
parser = argparse.ArgumentParser(description="LinkedIn 就活アシスタント")
parser.add_argument("--config_file", type=str, default="config.json", help="設定JSONファイルへのパス")
parser.add_argument("--jobs_number", type=int, default=20, help="ブライトデータスクレイパーAPIが返すジョブ数を制限する")
parser.add_argument("---batch_size", type=int, default=5, help="各バッチで採点するジョブ数")
parser.add_argument("--output_csv", type=str, default="jobs_scored.csv", help="出力CSVファイル名")
return parser.parse_args()Python標準ライブラリからargparseをインポートすることを忘れないでください:
import argparse素晴らしい!これでCLIから引数にアクセスできるようになりました。
ステップ2: 環境変数の読み込み
環境変数から秘密を読み込むようにスクリプトを設定します。環境変数の読み込みを簡単にするために、python-dotenvパッケージを使います。仮想環境を起動した状態で、次のコマンドを実行してインストールします:
pip install python-dotenv次に、assistant.pyファイルでライブラリをインポートし、環境変数をロードするためにload_dotenv() を呼び出します:
from dotenv import load_dotenv
load_dotenv()これでアシスタントはローカルの.envファイルから変数を読み込めるようになりました。このように、プロジェクトディレクトリのルートに.envファイルを追加します:
linkedin-job-hunting-ai-assistant/に追加します。
├─ venv/
├── .env # <-----------
└── assistant.py.envファイルを開き、OPENAI_API_KEYと BRIGHT_DATA_API_KEYを追加します:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
bright_data_api_key="<your_bright_data_api_key>"<YOUR_OPENAI_API_KEY>プレースホルダーを実際のOpenAI APIキーに置き換えます。同様に、<YOUR_BRIGHT_DATA_API_KEY>プレースホルダをあなたのBright Data APIキーに置き換えてください。
そして、スクリプトに以下の関数を追加して、これら2つの環境変数をロードします:
def load_env_vars():
# 環境変数から必要なAPIキーを読み込み、存在を確認します。
openai_api_key = os.getenv("OPENAI_API_KEY")
brightdata_api_key = os.getenv("BRIGHT_DATA_API_KEY")
missing = [].
if not openai_api_key:
missing.append("OPENAI_API_KEY")
if not brightdata_api_key:
missing.append("BRIGHT_DATA_API_KEY")。
if missing:
raise EnvironmentError(
f "必要な環境変数がありません:{'、'.join(missing)}n"
"あなたの.envまたは環境で設定してください。"
)
return openai_api_key, brightdata_api_keyPython Standard Libraryから必要なimportを追加します:
import os素晴らしい!これで環境変数を使ったサードパーティ統合シークレットの安全なロードができました。
ステップ #3: 設定ファイルを読み込む
さて、どの求人に興味があるかをアシスタントに伝えるプログラム的な方法が必要です。正確な結果を得るためには、アシスタントはあなたの職歴とどのような仕事を探しているかも知っていなければなりません。
その情報をコードに直接ハードコーディングするのを避けるために、JSON設定ファイルから読み取るのが理にかなっています。具体的には、このファイルには
場所:求人を検索したい地理的な場所。求人情報が収集される主な地域を定義します。keyword: 「Python Developer」のように、探している職種や役割に関連する特定の単語やフレーズ。完全に一致させる場合は引用符を使用してください。国2文字の国コード(例:米国はUS、フランスはFR)で、求人情報を特定の国に絞り込むことができます。time_range:求人情報が掲載された時間枠。最近の求人や関連性のある求人を絞り込む(例:過去1週間、過去1ヶ月など)。job_type:フルタイム、パートタイムなどの雇用形態。経験レベル:エントリーレベル、アソシエイトなど、必要な職業経験レベル。リモート勤務地のモード(例:リモート、オンサイト、ハイブリッド)に基づいて求人情報をフィルタリングします。会社特定の企業や雇用主からの求人情報に焦点を絞って検索します。selective_search:有効にすると、指定したキーワードを含まない求人情報を除外し、より的を絞った検索結果を得ることができます。jobs_to_not_include:検索結果から除外する特定の求人IDのリスト。重複や不要な掲載を除外するのに便利です。location_radius:指定した場所の周辺を含む、検索範囲を定義します。profile_summary: プロフィールの概要。この情報はAIが各求人があなたにどの程度マッチするかを評価するために使用されます。desired_job_summary: 求めている職種についての簡単な説明で、AIが求人リストを適合性に基づいてスコアリングするのに役立ちます。
これらは、Bright DataのLinkedIn求人リスト「キーワードで検索」API(LinkedIn Jobs Scraperソリューションの一部)で必要とされる引数に正確に対応しています:
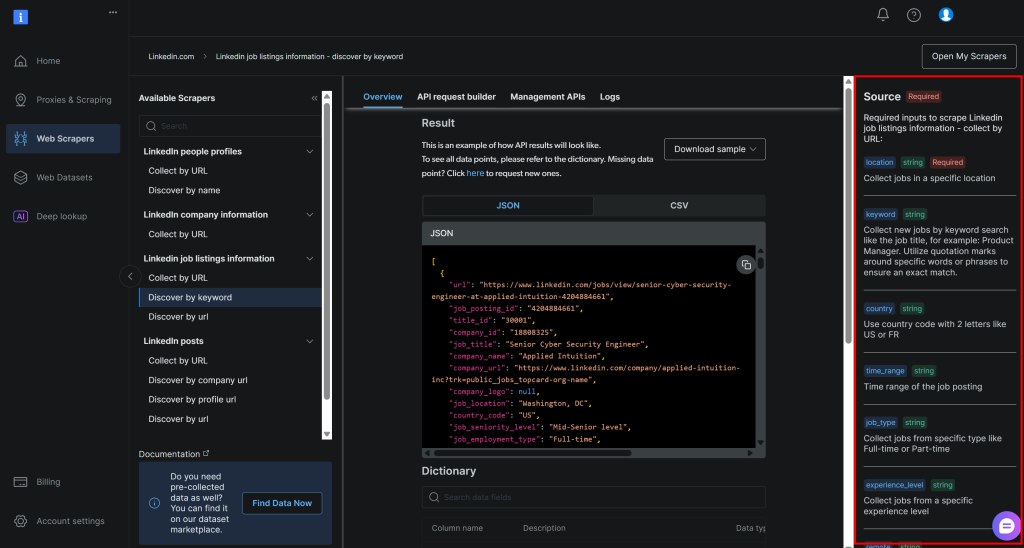
これらのフィールドの詳細と想定される値については、公式ドキュメントを参照してください。
最後の2つのフィールド(profile_summaryと difired_job_summary)は、あなたが職業上どのような人物で、何を探しているかを記述します。これらはAIに渡され、Bright Dataから返される各求人情報を採点します。
コード内で設定ファイルを扱いやすくするために、Pydanticモデルにマッピングすることをお勧めします。まず、Pydanticを仮想環境にインストールします:
pip install pydantic次に、JSON設定ファイルをマッピングするPydanticモデルを以下のように定義します:
class JobSearchConfig(BaseModel):
location: str
キーワードOptional[str] = None
country:オプション[str] = なし
時間範囲:任意[str] = なし
job_type:任意[str] = なし
経験レベルオプション[str] = なし
リモート任意[str] = なし
会社オプション[str] = なし
selective_search:オプション[bool] = Field(デフォルト=False)
jobs_to_not_include:オプション[リスト[str]] = フィールド(default_factory=list)
location_radius:オプション[str] = None
# 追加フィールド
profile_summary: str # AIスコアリングのための候補者のプロフィールサマリー
desired_job_summary: str # AIスコアリングのための希望職種の説明最初と最後の2つの設定フィールドだけが必須であることに注意してください。
次に、-config_fileファイルパスからJSONコンフィグを読み込む関数を作成します。それをJobSearchConfigインスタンスにデシリアライズします:
def load_and_validate_config(filename: str) -> JobSearchConfig:
# JSON コンフィグファイルを読み込む
try:
with open(filename, "r", encoding="utf-8") as f:
data = json.load(f)
except FileNotFoundError:
raise FileNotFoundError(f "Config file '{filename}'が見つかりません。")
try:
# 入力された JSON データを JobSearchConfig インスタンスにデシリアライズします。
config = JobSearchConfig(**data)
except ValidationError as e:
raise ValueError(f "Config deserialization error:˶n{e}")
return config今回はこれらのインポートが必要です:
from pydantic import BaseModel, Field, ValidationError
from typing import Optional, List
インポート jsonすごい!これで設定ファイルが正しく読み込まれ、意図したとおりにデシリアライズされました。
ステップ #4: LinkedInから求人をスクレイピングする
先ほど読み込んだ設定を使って、Bright Data LinkedIn Jobs Scraper APIを呼び出します。
Bright DataのWebスクレイパーAPIがどのように動作するのかよく知らない場合は、まずドキュメントをチェックする価値がある。
要するに、Web Scraper APIは、特定のドメインから公開データを取得できるAPIエンドポイントを提供する。舞台裏では、Bright Dataがサーバー上で既製のスクレイピング・タスクを初期化して実行する。これらのAPIは、IPローテーション、CAPTCHA、およびウェブページから公開データを効果的かつ倫理的に収集するためのその他の手段を処理します。タスクが完了すると、スクレイピングされたデータは構造化されたフォーマットに解析され、スナップショットとして利用できるようになります。
したがって、一般的なワークフローは次のようになる:
- APIコールをトリガーしてウェブスクレイピングタスクを開始する。
- スクレイピングされたデータを含むスナップショットの準備ができているか定期的にチェックする。
- スナップショットが利用可能になったら、スナップショットからデータを取得する。
上記のロジックは数行のコードで実装できる:
def trigger_and_poll_linkedin_jobs(config:jobSearchConfig, brightdata_api_key: str, jobs_number: int, polling_timeout=10):
# Bright Data LinkedInの求人検索をトリガーする
url = "https://api.brightdata.com/datasets/v3/trigger"
ヘッダー = {
"Authorization": f "ベアラ {brightdata_api_key}"、
"Content-Type":"application/json"、
}
params = {
"dataset_id":"gd_lpfll7v5hcqtkxl6l", # Bright Data "Linkedin job listings information - discover by keyword" dataset ID
"include_errors":"true"、
"type":"discover_new": "discover_new"、
"discover_by":「キーワード
「limit_per_input": str(jobs_number)、
}
# ユーザー設定に基づき、Bright Data API用のペイロードを準備する。
data = [{ {" location": config.location, } # Bright Data API用のペイロードを準備する
"location": config.location、
"keyword": config.keyword または ""、
"country": config.country または ""、
"time_range": config.time_range または ""、
「job_type": config.job_typeまたは""、
「経験レベル(experience_level)": config.experience_levelまたは""、
"remote": config.remoteまたは""、
"company": config.companyまたは""、
"selective_search": config.selective_search、
「jobs_to_not_include": config.jobs_to_not_includeまたは""、
「location_radius": config.location_radiusまたは""、
}]
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code != 200:
raise RuntimeError(f "Trigger request failed: {response.status_code} - {response.text}")
snapshot_id = response.json().get("snapshot_id")
if not snapshot_id:
raise RuntimeError("No snapshot_id returned from Bright Data trigger.")
print(f "LinkedIn job search triggered! Snapshot ID: {snapshot_id}")
# データが準備できるかタイムアウトするまでスナップショットエンドポイントをポーリングする
snapshot_url = f "https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization": f "ベアラ{brightdata_api_key}"}。
print(f "Polling snapshot for ID: {snapshot_id}")
while True:
snap_resp = requests.get(snapshot_url, headers=headers)
if snap_resp.status_code == 200:
# スナップショットの準備完了:求人情報のJSONデータを返す
print("Snapshot is ready")
return snap_resp.json()
elif snap_resp.status_code == 202:
# スナップショットの準備ができていない:待機して再試行する
print(f "スナップショットの準備ができていません。 {polling_timeout}秒後に再試行します...")
time.sleep(polling_timeout)
さもなければ
raise RuntimeError(f "Snapshot polling failed: {snap_resp.status_code} - {snap_resp.text}")この関数は設定ファイルの検索パラメーターを使用してBright DataのLinkedIn Jobs Scraperを起動します。そして、データスナップショットの準備ができるまでポーリングし、利用可能になるとJSON形式で求人情報を返します。認証は、先に環境変数から読み込んだBright Data API キーを使用して処理されることに注意してください。
LinkedIn Jobs Scraperで取得したスナップショットには、以下のようなJSON形式の求人情報が含まれます:
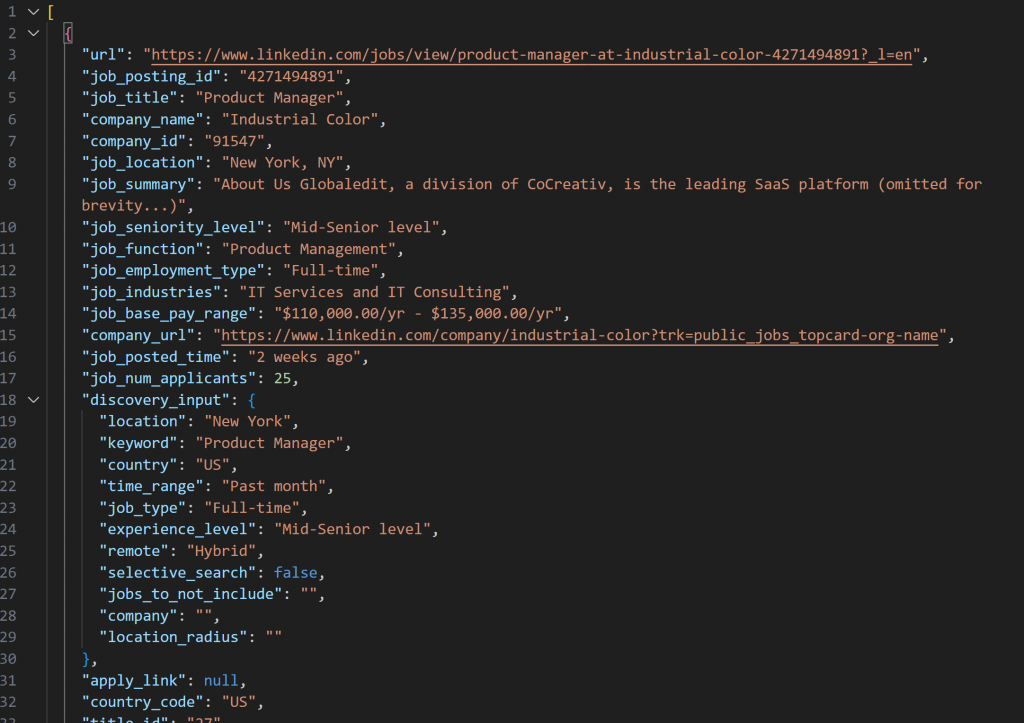
注意: 作成されたJSONスナップショットには、--jobs_numberまでの求人情報が含まれています。この場合、20件の求人情報が含まれています。
上記の機能を動作させるには、requestsをインストールする必要がある:
pip install requestsどのように動作するかの詳細については、Python HTTP Requestsのアドバンスガイドを参照してください。
次に、timeと一緒にPython標準ライブラリからインポートすることを忘れないでください:
import requests
import time素晴らしい!あなたはBright Dataと統合し、新鮮で具体的なLinkedInの求人データを収集しました。
ステップ #5: AIを使って求人情報をスコアリングする
今度は、LLM(OpenAIのモデルなど)にスクレイピングされた各求人情報を評価してもらう番だ。
ゴールは、求人がどれだけマッチしているかに基づいて、短いコメントとともに0から 100までのスコアを割り当てることだ:
- あなたの職務経験
(profile_summary) - 希望職種
(希望職種サマリー)
APIのラウンドトリップを減らしてスピードアップするために、求人をバッチで処理することは理にかなっています。特に、一度に--batch_size個のジョブを評価することになります。
openaiパッケージをインストールすることから始めよう:
pip install openaiそして、OpenAIをインポートし、クライアントを初期化します:
from openai import OpenAI
# ...
# OpenAIクライアントを初期化する
client = OpenAI()OpenAI のコンストラクタに API キーを手動で渡す必要はないことに注意してください。ライブラリは自動的にOPENAI_API_KEY環境変数からそれを読み込みます。
AIを使ったジョブスコアリング関数を作成します:
def score_jobs_batch(jobs_batch: List[dict], profile_summary: str, desired_job_summary: str) -> List[JobScore]:
# AIが候補者のプロファイルに基づいてマッチする仕事をスコアリングするためのプロンプトを構築する
prompt = f""
"あなたは採用のエキスパートです。次のような候補者プロフィールがあるとします。
"{profile_summary}nn"
"希望する職務内容:ⅳ{desired_job_summary}ⅳ"" "各求人広告を正確に採点してください。
"各求人情報に対して、プロフィールと希望職種との一致度を0から100まで正確に採点する。
"各求人に対して、スコアとマッチの質を説明する短いコメント(最大50文字)を追加します。"
"キー'job_posting_id'、'score'、'comment'を持つオブジェクトの配列を返す.˶"
"ジョブ:{json.dumps(jobs_batch)}}n".
"""
メッセージ = [
{"role":"system", "content":"you are a helpful job scoring assistant." }、
{"role":"user", "content": prompt}、
]
# OpenAI APIを使って、構造化されたレスポンスをJobScoresResponseモデルにパースする
response = client.responses.parse(
model="gpt-5-mini"、
input=messages、
text_format=JobScoresResponse、
)
# スコアされたジョブのリストを返す
return response.output_parsed.scoresこれは新しいgpt-5-miniモデルを使って、OpenAIにスクレイピングされた各求人投稿を0から 100の間でスコアリングさせ、短い説明コメントとともに返します。
レスポンスが常に必要なフォーマットで返されることを確認するために、parse()メソッドが呼び出されます。このメソッドは構造化された出力モデルを強制し、ここでは以下のPydanticモデルで定義されています:
class JobScore(BaseModel):
job_posting_id: str
score: int = Field(..., ge=0, le=100)
comment: str
class JobScoresResponse(BaseModel):
score: intリスト[JobScore]基本的に、AI は以下のような構造化された JSON データを返します:
{
"scores": [
{
"job_posting_id":"4271494891",
"score":80,
"comment":"エンドツーエンドのオーナーシップ、API、クロスファンクショナルワークを持つ強力なSaaSプロダクトフィットは、あなたのスタートアップPMと顧客第一の経験と一致します。このポジションは2-4年目をターゲットとしており、7年目としてはやや若手です。"
},
// 簡略化のため省略...
{
"job_posting_id":"4273328527",
"score":65,
"comment":"データ/技術に重きを置いたプロダクトの役割。アジャイルでクロスファンクショナルな責任は一致するが、定量的/技術的なドメイン経験(金融/統計モデリング)を好む。" "フィットしないかもしれない。
}
]
}parse()メソッドは、JSONレスポンスをJobScoresResponseインスタンスに変換します。そして、あなたのコードでスコアとコメントの両方にプログラムでアクセスできるようになります。
注意: もし別の LLM プロバイダを使いたい場合は、上記のコードを調整してください。
さあ、始めましょう!これでAIによるジョブ評価は完了です。
ステップ #6: AIアコアとコメントでジョブを拡張する
先ほどのAIが返した生のJSON出力を見てみましょう。各求人スコアにjob_posting_idフィールドが含まれていることがわかります。これはLinkedInが求人リストを識別するために使用するIDに対応しています。
これらのIDは、Bright Data LinkedIn Jobs Scraperによって生成されたスナップショットデータにも表示されるので、それを使って次のことができます:
- スクレイピングされた求人情報の配列から元の求人情報オブジェクトを見つける。
- AIが生成したスコアとコメントを追加することで、求人情報オブジェクトを充実させます。
以下の関数で実現できます:
def extend_jobs_with_scores(jobs: List[dict], all_scores: List[JobScore]) -> List[dict]:
# エンリッチされたデータを格納する場所
extended_jobs = [].
# 元のジョブにAIスコアとコメントを組み合わせる
for score_obj in all_scores:
matched_job = None
for job in jobs:
if job.get("job_posting_id") == score_obj.job_posting_id:
matched_job = job
ブレーク
if matched_job:
job_with_score = dict(matched_job)
job_with_score["ai_score"] = score_obj.score
job_with_score["ai_comment"] = score_obj.comment
extended_jobs.append(job_with_score)
# AIスコアで拡張ジョブをソートする(最も高いものからソートする)
extended_jobs.sort(key=lambda j: j["ai_score"], reverse=True)
return extended_jobsお分かりのように、タスクに取り組むには2つのforループで十分だ。エンリッチされたデータを返す前に、リストをai_scoreの降順でソートする。そうすることで、ベストマッチの求人が一番上に表示され、素早く簡単に見つけることができます。
素晴らしい!これでLinkedIn就活AIアシスタントの準備はほぼ整いました!
ステップ #7: スコアされた求人データをエクスポートする
Pythonの組み込みcsvパッケージを使って、スクレイピングされエンリッチされた求人データをCSVファイルにエクスポートします。
def export_extended_jobs(extended_jobs: List[dict], output_csv: str):
# 配列の最初の要素からフィールド名を動的に取得する
fieldnames = list(extended_jobs[0].keys())
with open(output_csv, mode="w", newline="", encoding="utf-8") as csvfile:
# AIスコアを含む拡張ジョブデータをCSVに書き込む
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for job in extended_jobs:
writer.writerow(job)
print(f"{len(extended_jobs)}ジョブを{output_csv}にエクスポート") 上記の関数は、output_csvを --output_csvCLI引数に置き換えて呼び出されます。
csvのインポートを忘れないでください:
インポートcsv完璧だ!LinkedIn就活AIアシスタントは、AIで強化されたデータを出力CSVファイルにエクスポートします。
ステップ #8: トップマッチを印刷する
出力されたCSVファイルを開かずにターミナルですぐにフィードバックを得るには、上位3つの求人から主要な詳細を印刷する関数を書きます:
def print_top_jobs(extended_jobs: List[dict], top: int = 3):
print(f"n*** Top {top} job matches ***")
for job in extended_jobs[:3]:
print(f "URL:{job.get('url', 'N/A')}")
print(f "Title:print(f "タイトル: {job.get('job_title', 'N/A')}")
print(f "AIスコア:{job.get('ai_score')}")
print(f "AIコメント:print(f "AIコメント:{job.get('ai_comment', 'N/A')}")
print("-" * 40)ステップ#9:すべてをまとめる
前のステップのすべての関数をLinkedIn就活アシスタントのメインロジックにまとめます:
# CLIから実行時のパラメーターを取得する
args = parse_cli_args()
tryする:
# 環境からAPIキーを読み込む
_, brightdata_api_key = load_env_vars()
# ジョブ検索の設定ファイルをロードする
config = load_and_validate_config(args.config_file)
# ジョブの取得
jobs_data = trigger_and_poll_linkedin_jobs(config, brightdata_api_key, args.jobs_number)
print(f"{len(jobs_data)} jobs found!")
except Exception as e:
print(f"[Error] {e}")
リターン
all_scores = [].
# APIへの過負荷を避け、大きなデータセットを扱うためにジョブをバッチ処理する
for i in range(0, len(jobs_data), args.batch_size):
バッチ = jobs_data[i : i + args.batch_size].
print(f "Scoring batch {i // args.batch_size + 1} with {len(batch)} jobs...")
scores = score_jobs_batch(batch, config.profile_summary, config.desired_job_summary)
all_scores.extend(scores)
time.sleep(1) # APIレート制限のトリガーを回避するため
# スコアをスクレイピングされたジョブにマージする
extended_jobs = extend_jobs_with_scores(jobs_data, all_scores)
# 結果をCSVに保存
export_extended_jobs(extended_jobs, args.output_csv)
# クイックレビューのために、キー情報とマッチしたトップジョブを印刷する
print_top_jobs(extended_jobs)信じられない!あとはアシスタントの完全なコードを確認し、期待通りに動作することを確認するだけです。
ステップ#10: 完全なコードと最初の実行
最終的なassistant.pyファイルには
# pip install python-dotenv requests openai pydantic
import argparse
from dotenv import load_dotenv
import os
from pydantic import BaseModel, Field, ValidationError
from typing import Optional, List
json をインポート
import requests
import time
from openai import OpenAI
インポート csv
# .env ファイルから環境変数をロードする
load_dotenv()
# プロジェクトをサポートする Pydantic モデル
class JobSearchConfig(BaseModel):
ソース: https://docs.brightdata.com/api-reference/web-scraper-api/social-media-apis/linkedin#discover-by-keyword
location: str
キーワードオプション[str] = なし
country:オプション[str] = なし
時間範囲:任意[str] = なし
job_type:任意[str] = なし
経験レベルオプション[str] = なし
リモート任意[str] = なし
会社オプション[str] = なし
selective_search:オプション[bool] = Field(デフォルト=False)
jobs_to_not_include:オプション[リスト[str]] = フィールド(default_factory=list)
location_radius:オプション[str] = None
# 追加フィールド
profile_summary: str # AIスコアリングのための候補者のプロフィールサマリー
desired_job_summary: str # AIスコアリングのための希望職種の説明
class JobScore(BaseModel):
job_posting_id: str
score: int = Field(..., ge=0, le=100)
コメント: str
class JobScoresResponse(BaseModel):
score: intリスト[JobScore]
def parse_cli_args():
# config と runtime オプションのコマンドライン引数を解析する
parser = argparse.ArgumentParser(description="LinkedIn 就活アシスタント")
parser.add_argument("--config_file", type=str, default="config.json", help="設定JSONファイルへのパス")
parser.add_argument("--jobs_number", type=int, default=20, help="ブライトデータスクレイパーAPIが返すジョブ数を制限する")
parser.add_argument("---batch_size", type=int, default=5, help="各バッチで採点するジョブ数")
parser.add_argument("--output_csv", type=str, default="jobs_scored.csv", help="出力CSVファイル名")
return parser.parse_args()
def load_env_vars():
# 環境から必要なAPIキーを読み込み、存在を確認する
openai_api_key = os.getenv("OPENAI_API_KEY")
brightdata_api_key = os.getenv("BRIGHT_DATA_API_KEY")
missing = [].
if not openai_api_key:
missing.append("OPENAI_API_KEY")
if not brightdata_api_key:
missing.append("BRIGHT_DATA_API_KEY")。
if missing:
raise EnvironmentError(
f "必要な環境変数がありません:{'、'.join(missing)}n"
"あなたの.envまたは環境で設定してください。"
)
return openai_api_key, brightdata_api_key
def load_and_validate_config(filename: str) -> JobSearchConfig:
# JSON コンフィグファイルをロードする
try:
with open(filename, "r", encoding="utf-8") as f:
data = json.load(f)
except FileNotFoundError:
raise FileNotFoundError(f "Config file '{filename}'が見つかりません。")
try:
# 入力されたJSONデータをJobSearchConfigインスタンスにデシリアライズします。
config = JobSearchConfig(**data)
except ValidationError as e:
raise ValueError(f "Config deserialization error:˶n{e}")
return config
def trigger_and_poll_linkedin_jobs(config:JobSearchConfig, brightdata_api_key: str, jobs_number: int, polling_timeout=10):
# Bright Data LinkedInの求人検索をトリガーする
url = "https://api.brightdata.com/datasets/v3/trigger"
ヘッダー = {
"Authorization": f "ベアラ {brightdata_api_key}"、
"Content-Type":"application/json"、
}
params = {
"dataset_id":"gd_lpfll7v5hcqtkxl6l", # Bright Data "Linkedin job listings information - discover by keyword" dataset ID
"include_errors":"true"、
"type":"discover_new": "discover_by"、
"discover_by":「キーワード
「limit_per_input": str(jobs_number)、
}
# ユーザー設定に基づき、Bright Data API用のペイロードを準備する。
data = [{ {" location": config.location, } # Bright Data API用のペイロードを準備する
"location": config.location、
"keyword": config.keyword または ""、
"country": config.country または ""、
"time_range": config.time_range または ""、
「job_type": config.job_typeまたは""、
「経験レベル(experience_level)": config.experience_levelまたは""、
"remote": config.remoteまたは""、
"company": config.companyまたは""、
"selective_search": config.selective_search、
「jobs_to_not_include": config.jobs_to_not_includeまたは""、
「location_radius": config.location_radiusまたは""、
}]
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code != 200:
raise RuntimeError(f "Trigger request failed: {response.status_code} - {response.text}")
snapshot_id = response.json().get("snapshot_id")
if not snapshot_id:
raise RuntimeError("No snapshot_id returned from Bright Data trigger.")
print(f "LinkedIn job search triggered! Snapshot ID: {snapshot_id}")
# データが準備できるかタイムアウトするまでスナップショットエンドポイントをポーリングする
snapshot_url = f "https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization": f "ベアラ{brightdata_api_key}"}。
print(f "Polling snapshot for ID: {snapshot_id}")
while True:
snap_resp = requests.get(snapshot_url, headers=headers)
if snap_resp.status_code == 200:
# スナップショットの準備完了:求人情報のJSONデータを返す
print("Snapshot is ready")
return snap_resp.json()
elif snap_resp.status_code == 202:
# スナップショットの準備ができていない:待機して再試行する
print(f "スナップショットの準備ができていません。 {polling_timeout}秒後に再試行します...")
time.sleep(polling_timeout)
さもなければ
raise RuntimeError(f "Snapshot polling failed: {snap_resp.status_code} - {snap_resp.text}")
# OpenAIクライアントを初期化する
client = OpenAI()
def score_jobs_batch(jobs_batch: List[dict], profile_summary: str, desired_job_summary: str) -> List[JobScore]:
# AIが候補者のプロファイルに基づいてマッチした仕事をスコアリングするためのプロンプトを構築する
prompt = f""
"あなたは採用のエキスパートです。次のような候補者プロフィールがあるとします。
"{profile_summary}nn"
"希望する職務内容:ⅳ{desired_job_summary}ⅳ"" "各求人広告を正確に採点してください。
"各求人情報に対して、プロフィールと希望職種との一致度を0から100まで正確に採点する。
"各求人に対して、スコアとマッチの質を説明する短いコメント(最大50文字)を追加します。"
"キー'job_posting_id'、'score'、'comment'を持つオブジェクトの配列を返す.˶"
"ジョブ:{json.dumps(jobs_batch)}}n".
"""
メッセージ = [
{"role":"system", "content":"you are a helpful job scoring assistant." }、
{"role":"user", "content": prompt}、
]
# OpenAI APIを使って、構造化されたレスポンスをJobScoresResponseモデルにパースする
response = client.responses.parse(
model="gpt-5-mini"、
input=messages、
text_format=JobScoresResponse、
)
# スコアされたジョブのリストを返す
return response.output_parsed.scores
def extend_jobs_with_scores(jobs: List[dict], all_scores: List[JobScore]) -> List[dict]:
# エンリッチされたデータを格納する場所
extended_jobs = [].
# 元のジョブにAIスコアとコメントを組み合わせる
for score_obj in all_scores:
matched_job = None
for job in jobs:
if job.get("job_posting_id") == score_obj.job_posting_id:
matched_job = job
ブレーク
if matched_job:
job_with_score = dict(matched_job)
job_with_score["ai_score"] = score_obj.score
job_with_score["ai_comment"] = score_obj.comment
extended_jobs.append(job_with_score)
# AIスコアで拡張ジョブをソートする(最も高いものからソートする)
extended_jobs.sort(key=lambda j: j["ai_score"], reverse=True)
return extended_jobs
def export_extended_jobs(extended_jobs: List[dict], output_csv: str):
# 配列の最初の要素からフィールド名を動的に取得する
fieldnames = list(extended_jobs[0].keys())
with open(output_csv, mode="w", newline="", encoding="utf-8") as csvfile:
# AIスコアを含む拡張ジョブデータをCSVに書き込む
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for job in extended_jobs:
writer.writerow(job)
print(f"{len(extended_jobs)}ジョブを{output_csv}にエクスポート")
def print_top_jobs(extended_jobs: List[dict], top: int = 3):
print(f"n*** Top {top} job matches ***")
for job in extended_jobs[:3]:
print(f "URL:{job.get('url', 'N/A')}")
print(f "Title:print(f "タイトル: {job.get('job_title', 'N/A')}")
print(f "AIスコア:{job.get('ai_score')}")
print(f "AIコメント:print(f "AIコメント:{job.get('ai_comment', 'N/A')}")
print("-" * 40)
def main():
# CLIからランタイムパラメータを取得
args = parse_cli_args()
try:
# 環境からAPIキーをロードする
_, brightdata_api_key = load_env_vars()
# ジョブ検索の設定ファイルをロードする
config = load_and_validate_config(args.config_file)
# ジョブの取得
jobs_data = trigger_and_poll_linkedin_jobs(config, brightdata_api_key, args.jobs_number)
print(f"{len(jobs_data)} jobs found!")
except Exception as e:
print(f"[Error] {e}")
リターン
all_scores = [].
# APIへの過負荷を避け、大きなデータセットを扱うためにジョブをバッチ処理する
for i in range(0, len(jobs_data), args.batch_size):
バッチ = jobs_data[i : i + args.batch_size].
print(f "Scoring batch {i // args.batch_size + 1} with {len(batch)} jobs...")
scores = score_jobs_batch(batch, config.profile_summary, config.desired_job_summary)
all_scores.extend(scores)
time.sleep(1) # APIレート制限のトリガーを回避するため
# スコアをスクレイピングされたジョブにマージする
extended_jobs = extend_jobs_with_scores(jobs_data, all_scores)
# 結果をCSVに保存
export_extended_jobs(extended_jobs, args.output_csv)
# クイックレビューのために、キー情報とマッチしたトップジョブを印刷する
print_top_jobs(extended_jobs)
if __name__ == "__main__":
main()あなたがニューヨークでハイブリッドジョブのポジションを探している7年の経験を持つプロダクトマネージャーだとします。config.jsonファイルを以下のように設定する:
{
"location":"New York"、
「キーワード":"Product Manager": "プロダクトマネージャー"、
"country":「アメリカ
"time_range":「過去1カ月
"job_type": "フルタイム":full-time": "フルタイム"、
"experience_level": "ミッドシニアレベル":"Mid-Senior level": "ミッドシニアレベル"、
"remote":「ハイブリッド
"profile_summary":"アジャイル方法論とクロスファンクショナルチームリーダーシップに特化した、技術系スタートアップで7年の経験を持つ経験豊富なプロダクトマネージャー"、
"desired_job_summary":"SaaS製品や顧客中心の開発を中心としたフルタイムのプロダクトマネージャー職を探している。", "Hope_job_summary": "アジャイル手法や部門横断的なチームリーダーを専門とする。
}次に、LinkedInの就活アシスタントを実行します:
python assistant.pyオプションです:カスタマイズして実行する場合は、次のように記述します:
python assistant.py --config_file=config.json --batch_size=10 --jobs_number=40 --output_csv=results.csvこのコマンドは指定したconfig.jsonファイルを使用してアシスタントを実行します。このコマンドは10バッチでジョブを処理し、Bright Dataから最大40のジョブリストを取得し、AIスコアとコメントでエンリッチされた結果をresults.csvに保存します。
さて、デフォルトのCLI引数でアシスタントを実行すると、ターミナルにこのようなものが表示されるはずです:
LinkedInの仕事検索がトリガーされました!スナップショットID: s_me6x0s3qldm9zz0wv
ID:s_me6x0s3qldm9zz0wvのスナップショットをポーリングしています。
スナップショットの準備ができていません。10秒後に再試行します。
# 簡潔にするため省略...
スナップショットの準備ができていません。10秒後に再試行...
スナップショットの準備ができました。
20のジョブが見つかりました!
バッチ1を5ジョブで採点...
バッチ2を5ジョブで採点...
バッチ3を5ジョブで採点...
バッチ 4 を 5 件で採点...
20のジョブをjobs.csvにエクスポートすると、上位3つのジョブのインサイトが以下のように出力されます:
*** トップ3ジョブマッチ
URL: https://www.linkedin.com/jobs/view/product-manager-growth-at-yext-4267903356?_l=en
タイトルプロダクトマネージャー、グロース
AIスコア: 92
AIコメント素晴らしいフィット感:SaaSに特化したグロースPMで、顧客中心の目標、製品主導のグロース、実験、部門横断的なコラボレーションがあり、候補者の経験と希望する役割に直接マッチする。
----------------------------------------
URL: https://www.linkedin.com/jobs/view/product-manager-at-industrial-color-4271494891?_l=en
タイトルプロダクトマネージャー
AIスコア: 90
AIコメント強力なマッチング:SaaS製品、API/インテグレーション、アジャイル、クロスファンクショナルリーダーシップを重視。唯一の小さなミスマッチは、2-4年のターゲット(あなたは7を持っている)と記載されていることです。
----------------------------------------
URL: https://www.linkedin.com/jobs/view/product-manager-at-resourceful-talent-group-4277945862?_l=en
タイトルプロダクトマネージャー
AIスコア: 88
AIコメントアジャイルプラクティスと顧客主導のイテレーションを伴う非常に類似したSaaS/統合の役割。採用担当者のリストでは2-4年をターゲットにしているが、あなたの7年間のスタートアップPM経験とクロスファンクショナルリーダーシップはうまくマッピングされる。
----------------------------------------生成されたjobs_scored.csvファイルを開く。主な列が表示されます:
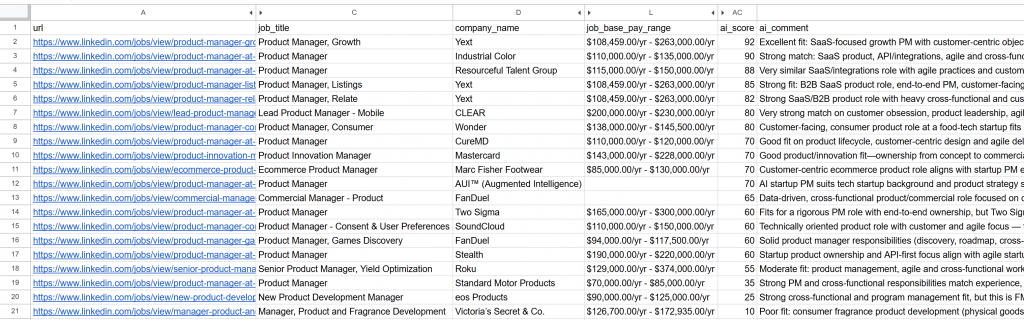
各ジョブがAIによってどのように採点され、コメントされているかに注目してください。これで、成功する可能性のある仕事だけに集中することができます!
ほら!このAIを活用したLinkedInの就活ワークフローのおかげで、次の仕事を見つけるのがかつてないほど簡単になりました。
次のステップ
LinkedInの就活アシスタントは、チャットのように機能しますが、いくつかの改良点があります:
- 同じ求人を繰り返し評価しないスクリプトを実行するたびに異なる求人を評価するには、
config.jsonファイルにjobs_to_not_include配列を設定します。この配列には、アシスタントがすでに分析したジョブのjob_posting_idが含まれます。例えば、現在のスクレイピングされたジョブを除外するために、設定は次のようになります:
{
"location":"New York"、
"keyword":「プロダクトマネージャー
"country":"US"、
"time_range":「過去1カ月
"job_type": "フルタイム":full-time": "フルタイム"、
"experience_level": "ミッドシニアレベル":"Mid-Senior level": "ミッドシニアレベル"、
"remote":"Hybrid": "ハイブリッド"、
"jobs_to_not_include": ["4267903356", "4271494891", "4277945862", "4267906118", "4255405781", "4267537560", "4245709356", "4265355147", "4277751182", "4256914967", "4281336197", "4232207277", "4273328527", "4277435772", "4253823512", "4279286518", "4224506933", "4250788498", "4256023955", "4252894407"], // <--- NOTE: The IDs of the jobs to exclude
"profile_summary":"アジャイル方法論とクロスファンクショナルチームリーダーシップを専門とする、技術系スタートアップで7年の経験を持つ経験豊富なプロダクトマネージャー。"、
"desired_job_summary":"SaaS製品や顧客中心の開発に焦点を当てたフルタイムのプロダクトマネージャーの役割を探しています。"
}- 定期的なスクリプト実行の自動化:Cronのようなツールを使って、スクリプトを定期的(毎日など)に実行するようにスケジュールする。この場合、適切な
time_range引数(「過去24時間」など)を設定し、jobs_to_not_includeリストを更新して、すでに評価したジョブを除外することを忘れないようにします。こうすることで、新鮮な求人情報に集中することができます。 - 専用のAIジャッジモデルを使用する:一般的なGPT-5モデルの代わりに、求人情報のマッチングとスコアリングのために微調整された専用のAIモデルを使用することを検討してください。この単純な変更により、求人評価の精度と関連性を大幅に向上させることができます。
まとめ
この記事では、Bright DataのLinkedIn求人スクレイピング機能を活用して、AIを活用した求人検索アシスタントを構築する方法を学びました。
ここで構築されたAIワークフローは、新しい仕事を探していて、最高の機会だけに集中することでチャンスを最大化したい人に最適です。自分のキャリア目標に本当にマッチし、採用の可能性が高い求人に応募することで、時間と労力を節約することができます。
より高度なワークフローを構築するには、Bright DataのAIインフラストラクチャでライブウェブデータを取得、検証、変換するためのあらゆるソリューションをお試しください。
無料のBright Dataアカウントを作成し、AI対応データツールの実験を開始してください!
よくある質問
上記の例ではLinkedInをデータソースとして使用していますが、スクリプトを簡単に拡張してIndeedやBright Dataで利用可能なその他の求人情報ソースと連携させることができます。Indeedとの統合の詳細については、Indeed Jobs Scraperを参照してください。
このAIワークフローは、広く採用され人気があるOpenAIに依存しています。しかし、Gemini、Anthropic、Cohereなどの他のLLMプロバイダーや、APIが利用可能な大規模言語モデルでも簡単にワークフローを適応させることができます。
LinkedIn Jobs Scraperから返されるデータは非常に高品質で構造化されているため、LLMを直接使用してスコアリングのために処理することができます。そのため、推論や意思決定機能を持つ自律型エージェントのような複雑さは必ずしも必要ではありません。
それでも、より高度なLinkedIn就活AIエージェントを構築したい場合は、次のようなマルチエージェントアーキテクチャを検討することができます。
Job fetcher agent:(ツールまたはMCPを介して)Bright Dataインフラストラクチャと統合されたAIエージェントで、LinkedIn Jobs Scraper APIを呼び出して求人情報を継続的にフェッチして更新する。
Job scorerエージェント:
オーケストレーターエージェント:他の2つのエージェントを調整するトップレベルのエージェントで、高得点で関連性の高い求人情報が希望する数得られるまで、データ検索とスコアリングのサイクルを繰り返しトリガーします。
エージェントにプログラムして、自動的に求人情報に応募してもらうことも可能です。このようなLinkedIn就活システムの構築を考えているのであれば、CrewAIのようなマルチエージェントプラットフォームを使うことをお勧めします。




