
このチュートリアルでは
- OpenAI Codex CLIとは何か、何ができるのか。
- Codexは、ウェブインタラクションとデータスクレイピング機能によって、どのようにさらに効果的になるのか。
- Codex CLIとBright Data MCPサーバーを接続し、次世代AIコーディングエージェントを構築する方法。
さあ、飛び込もう!
OpenAI Codex CLIとは?
OpenAI Codex CLI(単にCodexまたはCodex CLIとして知られている)は、OpenAIによって開発されたオープンソースのコマンドラインインターフェースツールです。その目的は、LLMのパワーを直接ターミナルにもたらすことです。
以下は、開発者を助けることができる主なタスクの一部である:
- コードの生成と変更:自然言語による指示を理解し、プロジェクト内で有効なコードを生成し、変更を適用します。
- コードの理解と説明:馴染みのないコードベースを理解したり、特定のコードセグメントを明確に説明したりするのに役立ちます。
- デバッグとテスト:バグの特定と修正、テストの作成、ローカルでのテストの実行を支援します。
- リポジトリ管理:Gitのようなバージョン管理システムと統合し、ファイルの管理、移行の設定、インポートの更新などを行う。
- シェルコマンドの実行:依存関係のインストールやテストの実行などのタスクのためにシェルコマンドを実行します。
お分かりのように、Codex CLIは軽量のローカル・コーディング・アシスタントとして機能する。このライブラリはRustで作られており、オープンソースのNode.jsパッケージとして提供されている。
2026年5月中旬にリリースされたばかりだが、GitHubではすでに34k以上のスターを獲得している。これは、ITコミュニティでの採用と人気を示す強力な指標だ。
なぜCodex CLIをWebインタラクションとデータ検索機能で拡張するのか?
Codex CLIに統合されたOpenAIのモデルがいかに先進的であっても、すべての大規模言語モデルに内在する共通の限界がある。
OpenAI LLMは、訓練された静的なデータセットに基づいて応答を生成する。開発技術が急速に進化していることを考えると、これは特に問題である。
あなたのCodex CLIコーディングアシスタントが、最新のチュートリアル、ドキュメントページ、ガイドにアクセスし、そこから学ぶことができるようになることを想像してみてください。さらに、ローカルのファイルシステムを探索するのと同じように、ダイナミックなウェブサイトを簡単にブラウズすることを想像してみてください。Bright Data MCPサーバーとの統合により、このような大幅な機能向上が実現します。
Bright Data MCPサーバーは、リアルタイムのウェブデータ抽出とインタラクションのために設計された60以上のAI対応ツールを提供します。これらのツールはすべて、ブライト・データの豊富なAIデータ・インフラストラクチャによって提供されています。
以下は、OpenAI CLIとBright Data MCPを組み合わせることで実現できることの例です:
- 検索エンジンの検索結果ページを自動的に取得し、テキスト文書に関連するコンテキストリンクを埋め込みます。
- 最新のチュートリアルやドキュメントを集め、情報を吸収し、動作するコードを生成するか、ゼロからプロジェクトを作成する。
- ウェブサイトからライブデータを抽出し、テスト、モッキング、分析に使用するためにローカルに保存します。
Bright Data MCPサーバーで利用可能なツールの完全なリストについては、ドキュメントをご覧ください。
Codex CLIでBright Data MCPサーバーが動作する様子をご覧ください!
OpenAI Codex CLIとBright Data Web MCPサーバーの接続方法
OpenAI Codex CLIをインストールし、Bright Data MCPサーバーと対話するように設定する方法を学びます。詳細には、その結果得られた強化されたコーディングCLIエージェントを使用して、以下のタスクを実行します:
- Amazonの商品ページから構造化データをスクレイピングする。
- データをローカルファイルに保存する。
- データをロードして処理するNode.jsスクリプトを定義します。
以下の手順に従ってください!
前提条件
このチュートリアルについて行くには、以下を確認してください:
- ローカルにインストールされたNode.js 20以上(最新のLTSバージョンをお勧めします)。
- OpenAI API キー。
- ブライトデータのアカウントとAPIキーをご用意ください。
OpenAIキーとBright Dataキーの両方が必要な場合は、以下の手順で設定します。
OpenAI Codex CLIのシステム要件は以下の通りです:
- macOS 12+ または
- Ubuntu 20.04+/Debian 10+ または
- WSL 2経由のWindows 11(Windows Subsystem for Linuxのバージョン2が必要です。)
次に、オプションではあるが、このガイドをよりよく理解するために役立つ背景知識である:
- MCPの仕組みについての一般的な理解。
- Bright Data MCPサーバーとその利用可能なツールに精通していること。
ステップ #1: OpenAI Codex CLIをインストールする
まず、公式ガイドに従ってOpenAIのAPIキーを取得します。すでに持っている場合は、このステップはスキップできます。
OpenAI API キーを取得したら、ターミナルを開き、環境変数として設定します:
export OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"APIキーを を実際の OpenAI API キーに置き換えてください。上記のコマンドは現在のターミナルセッションのキーしか設定しないことに注意してください。あるいは、ターミナルからログインして ChatGPT プラン経由で認証することもできます。
Thun、以下のコマンドを実行して、公式の@openai/codexパッケージ経由で OpenAI Codex CLI をグローバルにインストールしてください:
npm install -g @openai/codexOPENAI_API_KEYを設定したのと同じターミナルセッションで、作業したいフォルダに移動します。でCodex CLIを起動します:
codexカレントディレクトリの操作許可を求めるプロンプトが表示される:

これは単なるテストなので、オプション1を選択してください。より安全性を求める場合は、オプション2を選択してください。
Enterを押すと、こう表示される:
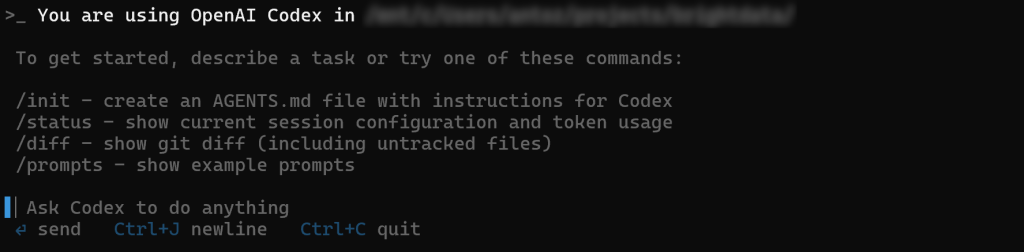
Ask Codex to do anything “セクションで、プロンプトを入力します。デフォルトでは、CodexはGPT-5モデルに依存します。基礎となるLLMを変更するには、公式ドキュメントを参照してください。
完了しました!これで OpenAI Codex CLI がインストールされ、すぐに使えるようになりました。
ステップ #2: Bright Data Web MCP サーバーのテスト
Bright Dataアカウントをまだお持ちでない場合は、Bright Dataにサインアップしてください。すでにお持ちの場合は、ログインするだけです。
次に、Bright Dataの公式ドキュメントに従ってAPIトークンを取得します。このガイドでは、Admin権限を持つトークンを使用することを想定しています。
Bright Data MCPサーバーを@brightdata/mcp公式パッケージからグローバルにインストールします:
npm install -g @brightdata/mcp以下のコマンドでインストールをテストする:
API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>" npx -y @brightdata/mcpプレースホルダを プレースホルダーを先ほど生成した実際のAPIトークンに置き換えます。上記のコマンドは、必要なAPI_TOKEN環境変数を設定し、Bright Data MCPサーバーをローカルで起動します。
すべてがうまくいっていれば、次のようなログが表示されるはずだ:

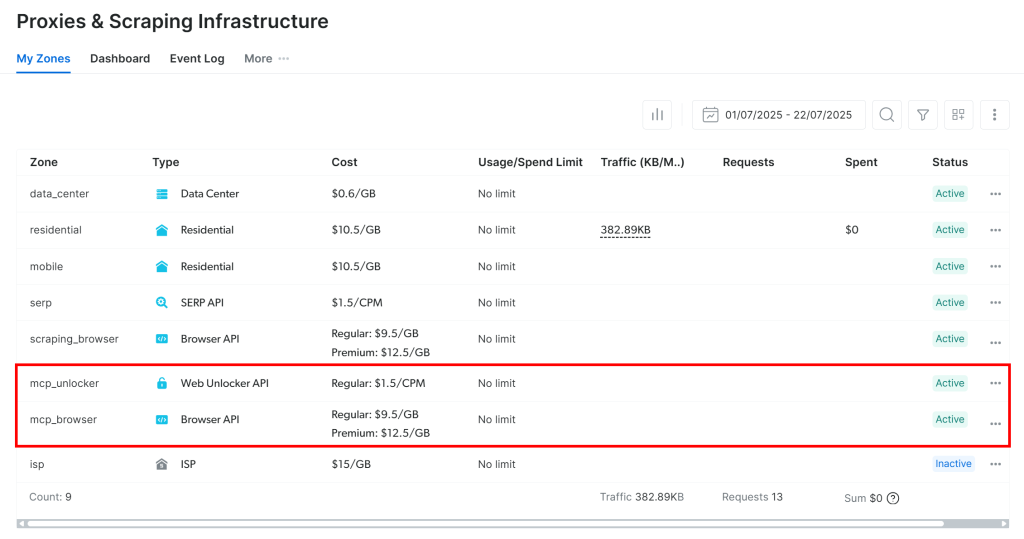
初回起動時に、MCPサーバーは自動的にBright Dataアカウントに2つのデフォルトプロキシゾーンを作成します:
mcp_unlocker:Web Unlockerのゾーン。mcp_browser:ブラウザAPIのゾーン。
これらのゾーンは、MCPサーバーがすべてのツールを動かすために必要です。
ゾーンが作成されたことを確認するには、Bright Dataのダッシュボードにログインします。Proxies & Scraping Infrastructure” ページにアクセスすると、両方のmcp_*ゾーンが表示されているはずです:
APIトークンに管理者権限がない場合、これらのゾーンは自動的に作成されません。公式ドキュメントに記載されているように、手動で作成し、環境変数で名前を設定する必要があります。
注: デフォルトでは、MCPサーバーはsearch_engineと scrape_as_markdownツールのみを公開します。ブラウザ自動化と構造化データ抽出のための他のすべてのツールにアクセスできるようにするには、MCPサーバをProモードで実行する必要があります。そのためには、サーバを起動する前にPRO_MODE=true環境変数を設定します:
API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>" PRO_MODE="true" npx -y @brightdata/mcp素晴らしい!Bright Data MCP サーバーがあなたのマシンで動作することが確認できました。次のステップで、OpenAI Codex CLI が自動的に起動するように設定します。
ステップ#3: CodexでBright Data Web MCPサーバー接続を設定する
Codexは、~/.codex/config.toml(~はあなたのホームディレクトリを意味します)にある設定ファイルを通してMCP統合をサポートしています。このファイルはインストール時には作成されないので、最初に作成する必要があります。
まず、.codexフォルダを追加します:
mkdir ~/.codex次にコンフィギュレーション・ファイルを作成し、編集する:
nano ~/.codex/config.tomlnanoエディターで、config.tomlファイルに以下のmcp_serversエントリーが含まれていることを確認する:
[mcp_servers.brightData]
command = "npx"
args = ["-y", "@brightdata/mcp"]
env = { "API_TOKEN" = "<YOUR_BRIGHT_DATA_API_KEY>", "PRO_MODE" = "true" }CTRL + Oと Enterキーを押してファイルを書き込み、CTRL + Xで保存して終了します(macOSではCTRLの代わりに⌘コマンドを使用)。
重要プレースホルダーの プレースホルダを実際の Bright Data API トークンに置き換えてください。
上記の設定スニペットの[mcp_servers]セクションは、Bright Data MCPサーバーの起動方法をCodexに伝えます。特に、先ほどテストしたのと同じnpxコマンドを生成するための引数と環境変数を指定します。PRO_MODEを有効にすることはオプションですが、推奨されることを覚えておいてください。
これで、OpenAI Codex CLIは、設定されたコマンドでバックグラウンドで自動的にMCPサーバーを起動し、接続できるようになります。
素晴らしい!統合をテストする時が来た。
ステップ#4: MCPサーバー接続の確認
OpenAI Codex CLI がまだ起動している場合は、/quitコマンドを使って終了させ、再度起動してください:
codexCodex CLIは自動的にBright Data MCPサーバーに接続します。
この記事を書いている時点では、CodexはMCPサーバーの統合を確認する専用のコマンドを提供していません(詳細なMCP接続情報を提供するGemini CLIとは異なります)。
しかし、Codexが設定されたMCPサーバーへの接続に失敗すると、次のようなエラーメッセージが表示されます:
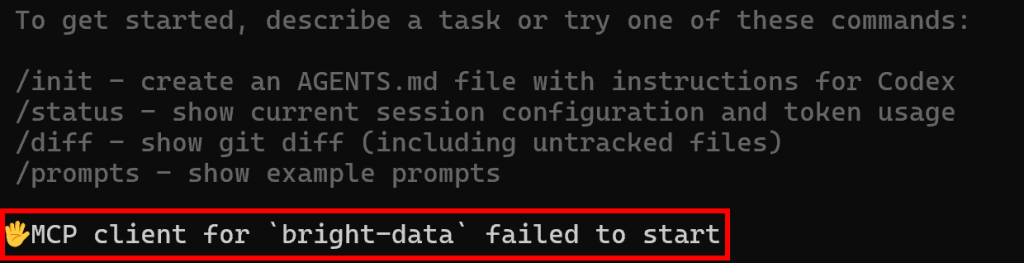
このエラーが表示されない場合は、MCPの統合が正しく機能していると考えてください。よくやった!
ステップ5:Codexでタスクを実行する
CodexがBright Data MCPサーバーに接続されたので、実際のタスクを使ってみましょう。例えば、OpenAI Codex CLIで以下のプロンプトを試してみてください:
Extract data from the following Amazon page: "https://www.amazon.com/crocs-Unisex-Classic-Black-Women/dp/B0014BYHJE/". Save the resulting JSON into a local "product.json" file. Next, build a Node.js "index.js" script to read and log its contents in the console.これは、分析のために実世界のデータを収集したり、APIをモックしたり、その他の開発作業を行ったりする実用的なユースケースを模倣している。
プロンプトをCLIに貼り付け、Enterを押す。実行フローは以下のようになるはずだ:
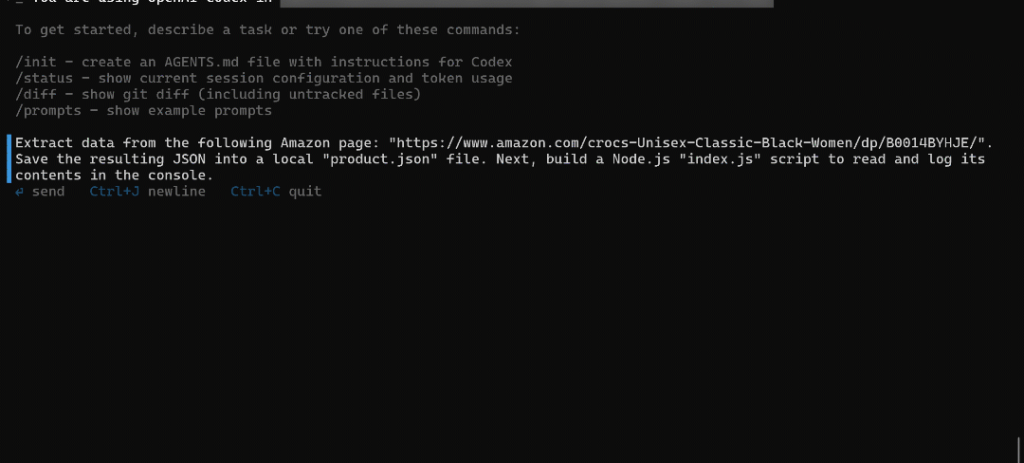
上のGIFはスピードアップされているが、こうなるはずだ:
- LLMは適切なMCPツール(この場合は
web_data_amazon_product)を選択し、MCPサーバーを通じてアマゾンのスクレイピングタスクを起動する。 - CLIは、スクレイピング・タスクが終了し、データが準備できたかどうかを定期的にチェックする。
- 完了すると、ツールからJSON形式で返された生の製品データが表示される。
- Codexは、JSONが適切に構造化されているかどうかを検証します。
- データは
product.jsonというローカルファイルに保存される。 - JSONにフィールドを追加するよう促されます。いいえ」と答えてください。
- Codexは、
product.jsonからJSONコンテンツをロードして表示するNode.jsスクリプト、index.jsを生成します。
実行中、次のようなログ・エントリーがあることに気づくだろう:

これは、CLIがプロンプトから読み取ったAmazon製品のURLを使用して、Bright Data MCPサーバーからweb_data_amazon_productツールを呼び出したことを確認します。表示されているJSONは、Bright DataのAmazon Scraperから返された構造化された結果であり、裏側でツールが呼び出したものです。
実行後、作業ディレクトリにはこれら2つのファイルがあるはずだ:
├── product.json
└── index.jsVSコードでproduct.jsonを開いてください:
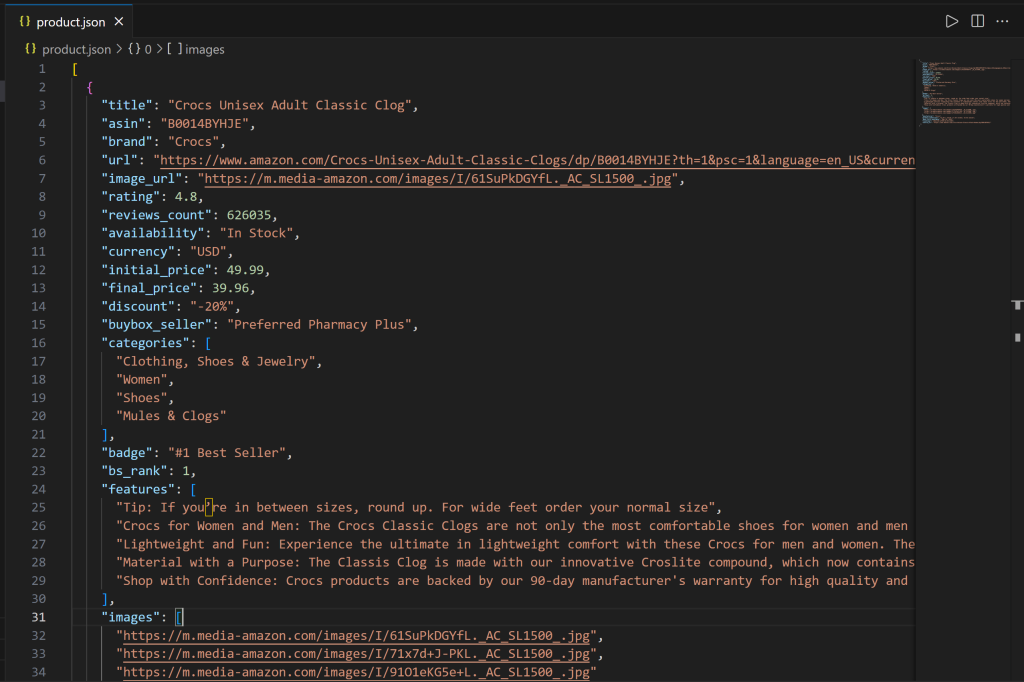
このファイルには、Bright Data MCP統合によってAmazonから抽出された実際の商品データが含まれています。
次に、index.jsを開く:
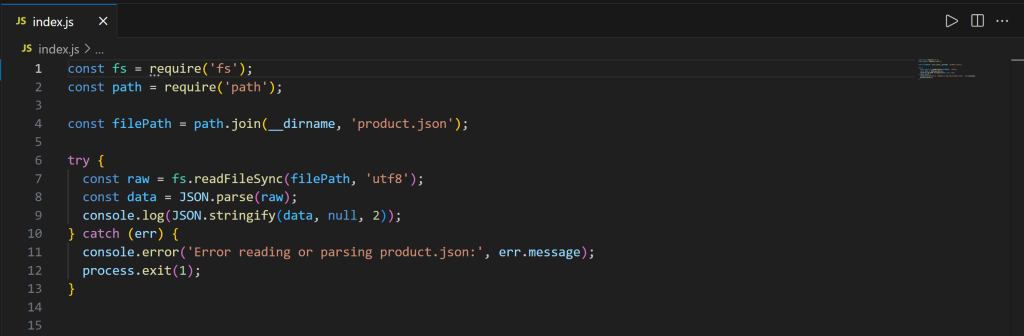
このスクリプトには、Node.jsでproduct.jsonの内容をロードして表示するJavaScriptロジックが含まれています。
でindex.jsスクリプトを実行する:
node index.js結果はこうなるはずだ:
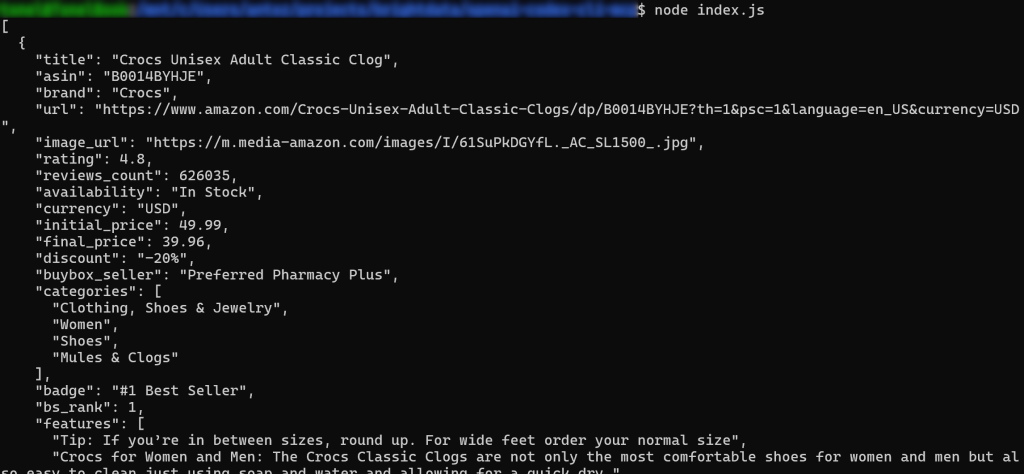
出来上がり!ワークフローは正常に完了した。
重要:あなたが見ているものは、実際にスクレイピングされたデータであり、AIによって作り上げられた情報や幻覚ではありません。具体的には、product.jsonの内容は、Amazonのオリジナルの商品ページで見ることができるデータと一致しています:
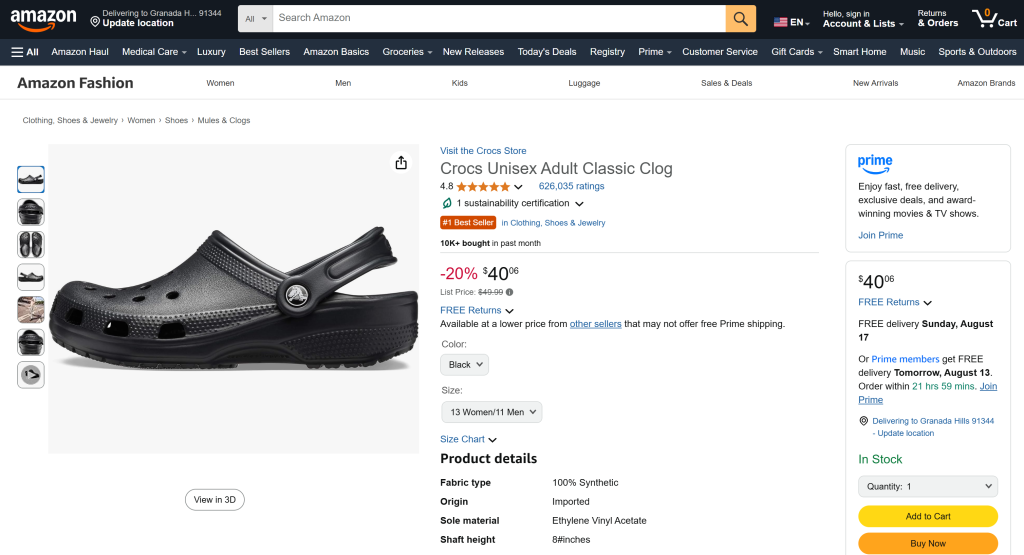
アマゾンのスクレイピングは、ボット対策(アマゾンのCAPTCHAなど)のために悪名高く困難であることを覚えておいてほしい。したがって、通常のLLMはAmazonのデータにアクセスすることはできない。それが可能になったのは、LLMがMCP経由でアクセスできるようになったブライト・データ機能のおかげだ。
この例では、OpenAI Codex CLIとBright DataのMCPサーバーの組み合わせの威力を紹介しました。さあ、もっと多くのプロンプトを試して、より高度なLLM駆動のデータワークフローを発見してください!
結論
この記事では、OpenAI Codex CLIとWeb MCPサーバを統合する方法を学びました。その結果、ウェブにアクセスして対話することができる強力なAIコーディングエージェントができました。
より複雑なAIエージェントを開発するには、ブライト・データのAIインフラストラクチャで利用可能なサービス、製品、機能のすべてを探求してください。これらのソリューションは、エージェントシナリオの長いリストをサポートすることができます。
ブライトデータのアカウントを作成し、毎月5,000件の無料リクエストでWeb MCPの実験を始めましょう!




