
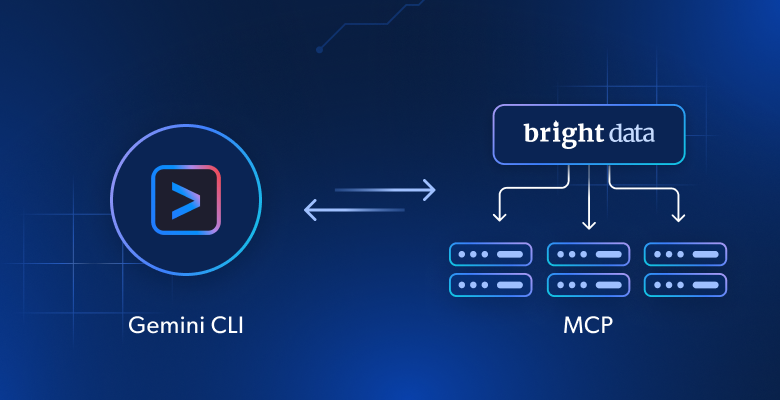
このチュートリアルでは、次のことを学びます:
- Gemini CLIとは何か、なぜコーディングコミュニティでこれほど人気があるのか。
- ウェブ・インタラクションやデータ抽出機能を追加することで、どのように次のレベルに引き上げることができるのか。
- Gemini CLIとBright Data Web MCPサーバーを接続し、強化されたAIコーディングエージェントを構築する方法。
さあ、飛び込もう!
Gemini CLIとは?
Gemini CLIは、Googleによって開発されたAIエージェントであり、Geminiの大規模言語モデルのパワーをあなたの端末に直接もたらす。開発者の生産性を向上させ、特にコーディングに関連する様々なタスクを簡素化するように設計されている。
このライブラリーはオープンソースで、Node.jsパッケージで利用できる。この記事を書いている時点で、GitHubではすでに67k以上のスターを集めている。わずか数ヶ月前にリリースされたばかりにもかかわらず、コミュニティの熱意とその急速な普及には目を見張るものがある。
特に、ジェミニCLIを特別なものにしている主な点は以下の通りである:
- ターミナルからの直接対話:コマンドラインから直接Geminiモデルを操作できます。
- コーディングにフォーカス:デバッグ、新機能の生成、テストカバレッジの向上、さらにはプロンプトやスケッチから新しいアプリケーションを作成することを支援します。
- ツールの統合と拡張性:ReAct(「理由と行動」)ループを活用し、組み込みツール(
grep、ターミナル、ファイル読み書きなど)や外部のMCPサーバーと統合できる。 - 無料で使える:グーグルはまた、このツールに広くアクセスできるよう、寛大な無料利用層を提供している。
- マルチモーダル機能:画像やスケッチからコードを生成するようなタスクをサポートします。
なぜGemini CLIをWebインタラクションとデータ抽出機能で拡張するのですか?
Gemini CLIに統合されたGeminiモデルがいかに強力であっても、すべてのLLMに共通する制限に直面する。
ジェミニ・モデルは、トレーニングされた静的なデータセットに基づいてのみ反応することができる。しかし、それは過去のスナップショットである!さらに、LLMは、人間のユーザーのように生きたウェブページをレンダリングしたり、対話したりすることはできません。その結果、LLMの精度と行動範囲は本質的に制限されます。
さて、Gemini CLIコーディングアシスタントに、リアルタイムのチュートリアル、ドキュメントページ、ガイドを取得し、そこから学習する機能を持たせることを想像してみてください。ちょうどファイルシステムをナビゲートするように、生きているウェブサイトと対話することを想像してみてください。これは、Bright Data Web MCPサーバーとの統合によって可能となる、機能性の大きな飛躍を意味します。
Bright Data Web MCPサーバーは、リアルタイムのWebデータ収集とWebインタラクションのための60以上のAI対応ツールへのアクセスを提供します。これらはすべて、Bright Dataの豊富なAIデータ・インフラストラクチャによって提供されています。
Bright Data Web MCP サーバが公開するツールの完全なリストについては、ドキュメントを参照してください。
以下は、Gemini CLIとWeb MCPを組み合わせることで実現できることのほんの一部です:
- SERPを取得し、レポートや記事に文脈リンクを自動的に挿入。
- Geminiに最新のチュートリアルやドキュメントを取得し、それらから学び、それに従ってコードやプロジェクトテンプレートを生成するよう依頼する。
- 実際のウェブサイトからデータをスクレイピングし、モック、テスト、分析のためにローカルに保存します。
この統合の実際の例を探ってみよう!
Gemini CLIでWeb MCPサーバーを統合する方法
Gemini CLIをローカルにインストールして設定し、Bright Data Web MCPサーバーと統合する方法を学びます。セットアップの結果、以下のことが可能になります:
- アマゾンの商品ページをスクレイピングする。
- データをローカルに保存する。
- データをロードして処理するNode.jsスクリプトを作成する。
以下の手順に従ってください!
前提条件
このチュートリアル・セクションの手順を再現するには、以下のものを用意してください:
- ローカルにインストールされたNode.js 20以上(最新のLTSバージョンを使用することをお勧めします)。
- Gemini APIキーまたはVertex AI APIキー(ここではGemini APIキーを使用する)。
- ブライトデータのアカウント。
まだAPIキーを設定する必要はありません。以下の手順で、GeminiとBright Dataの両方のAPIキーを設定することができます。
厳密には必須ではないが、以下の予備知識は役に立つだろう:
- MCPの仕組みについての一般的な理解。
- Bright Data Web MCPサーバーとその利用可能なツールにある程度精通している。
ステップ1: Gemini CLIのインストール
Gemini CLIの使用を開始するには、まずGoogle AI StudioからAPIキーを生成する必要があります。公式の手順に従って、Gemini APIキーを取得してください。
注:すでにVertex AI APIキーをお持ちの方、または使用したい方は、代わりに公式ドキュメントをご覧ください。
Gemini APIキーを入手したら、ターミナルを開き、次のBashコマンドで環境変数として設定する:
export GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"あるいは、WindowsではこのPowerShellコマンドを使う:
$env:GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"APIキーを APIキーを実際に生成したキーに置き換えてください。
次に、公式の@google/gemini-cliパッケージ経由でGemini CLIをグローバルにインストールする:
npm install -g @google/gemini-cliGEMINI_API_KEY(またはVERTEX_API_KEY)を設定したのと同じターミナルセッションで、Gemini CLIを次のように起動します:
geminiこれが見るべきものだ:
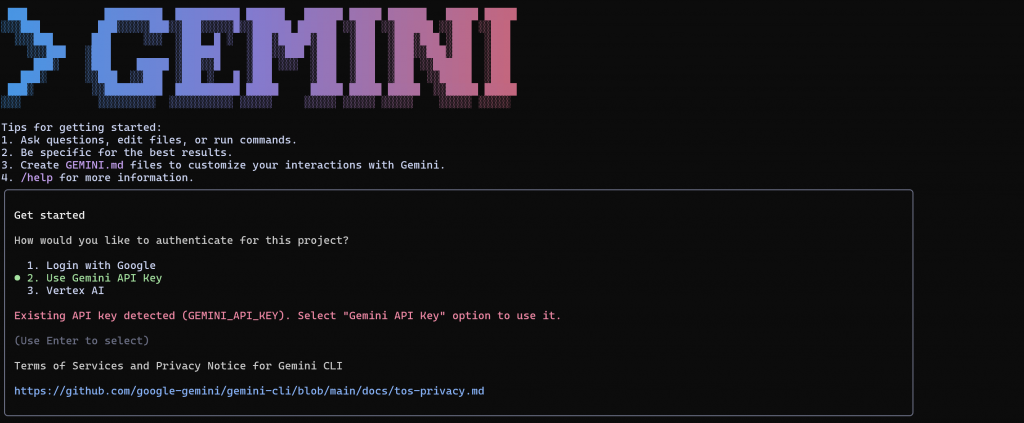
Enterを押して、オプション2(「Use Gemini API key」)を選択します。CLIが自動的にAPIキーを検出し、プロンプト表示に進むはずです:
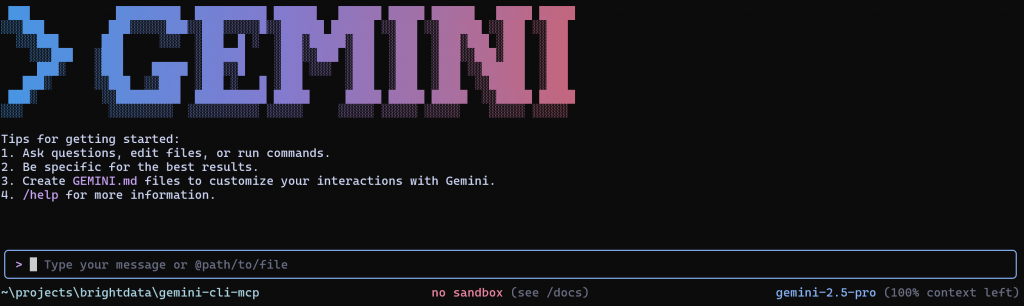
Type your message or @path/to/file “セクションでは、プロンプトを直接記述するか、ファイルを参照してGemini CLIに送信して実行させることができます。
右下隅で、Gemini CLIがgemini-2.5-proモデルを使用していることがわかります。これは、箱から出した状態で設定されているモデルです。幸いなことに、Gemini APIは、gemini-2.5-proモデルを使用した1日あたり100リクエストまでの無料階層を提供しているので、有料プランがなくてもテストすることができます。
gemini-2.5-flashなど、より高いレート制限を持つモデルを好む場合は、GEMINI_MODEL環境変数を定義することで、CLIを起動する前に設定することができます。LinuxまたはmacOSでは、以下を実行する:
export GEMINI_MODEL="gemini-2.5-flash"あるいは、ウィンドウズでも同様だ:
$env:GEMINI_MODEL="gemini-2.5-flash"その後、通常通りgeminiコマンドでGemini CLIを起動する。
素晴らしい!これでGemini CLIがセットアップされ、使用できるようになった。
ステップ#2: Bright Data Web MCPサーバーを使い始める
まだの方は、Bright Dataにご登録ください。すでにアカウントをお持ちの場合は、ログインするだけです。
次に、公式の指示に従ってBright Data APIキーを生成してください。簡単のため、このステップでは管理者権限を持つトークンを使用することを想定しています。
このコマンドでBright Data Web MCP サーバーをグローバルにインストールします:
npm install -g @brightdata/mcp次に、以下のBashコマンドですべてが動作することをテストする:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpあるいは、Windowsの場合、同等のPowerShellコマンドは次のようになる:
$env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpプレースホルダーを プレースホルダーを先ほど取得した実際のAPIトークンに置き換えてください。どちらのコマンドも、必要なAPI_TOKEN環境変数を設定し、@brightdata/mcpnpmパッケージ経由でMCPサーバーを起動します。
すべてが正常に機能していれば、以下のようなログが表示されるはずだ:

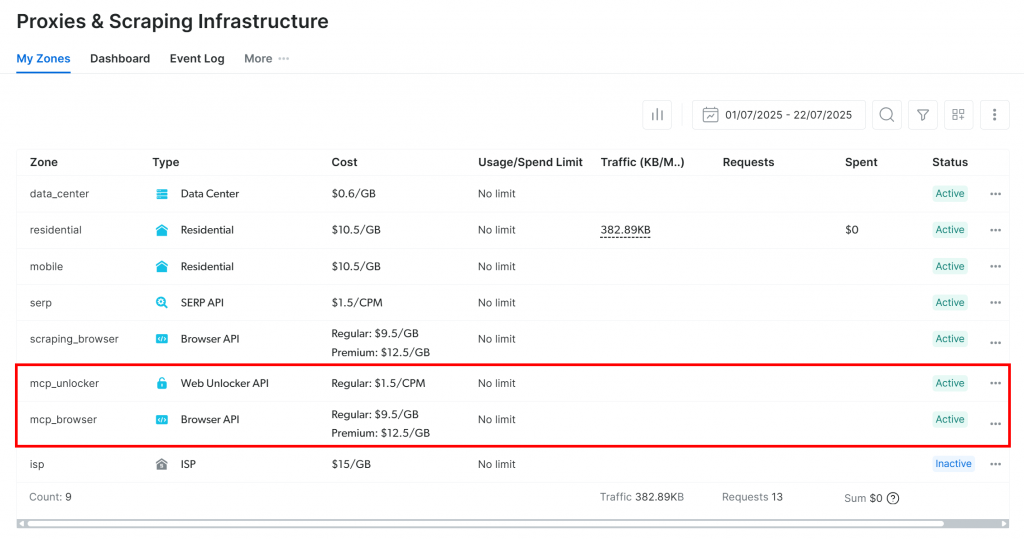
最初の起動時に、MCPサーバーは自動的にBright Dataアカウントに2つのデフォルトプロキシゾーンを作成します:
mcp_unlocker:Web Unlockerのゾーン。mcp_browser:ブラウザAPIのゾーン。
これら2つのゾーンは、MCPサーバーの全ツールを有効にするために必要です。
ゾーンが作成されたことを確認するには、Bright Dataのダッシュボードにログインし、「Proxies & Scraping Infrastructure」ページに移動します。両方のゾーンが表示されているはずです:
注:管理者権限を持つAPIトークンを使用していない場合、これらのゾーンは自動的に作成されません。その場合は、公式ドキュメントで説明されているように、手動で作成し、環境変数を使って名前を指定する必要があります。
デフォルトでは、MCPサーバーはsearch_engineと scrape_as_markdownツールのみを公開します。ブラウザの自動化や構造化データ抽出のような高度な機能をアンロックするには、MCPサーバーを起動する前にPRO_MODE=true環境変数を設定してProモードを有効にしてください:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpそして、ウィンドウズの場合:
$env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $env:PRO_MODE="true"; npx -y @brightdata/mcp素晴らしい!Bright Data Web MCPサーバーがあなたのマシン上で正しく動作していることが確認できました。これからGemini CLIを設定してサーバーを起動させるので、サーバープロセスを終了させることができます。
ステップ#3: Gemini CLIでWeb MCPサーバーを設定する
Gemini CLIは、 ~/.gemini/settings.jsonにある設定ファイルを介してMCP統合をサポートします。Windowsの場合は、$HOME/.gemini/settings.jsonです。
このファイルは、Visual Studio Codeで開くことができます:
code "~/.gemini/settings.json"あるいはウィンドウズの場合:
code "$HOME/.gemini/settings.json"注意:settings.jsonファイルがまだ存在しない場合は、手動で作成する必要があります。
settings.jsonで、Bright Data Web MCPサーバーをサブプロセスとして自動的に起動し、接続するようにGemini CLIを構成します。settings.jsonに以下の内容が含まれていることを確認してください:
{
"mcpServers": {
"brightData": {
"command": "npx",
"args": [
"-y",
"@brightdata/mcp"
],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
}
}
}上記のコンフィグでは
mcpServersオブジェクトは、Gemini CLIに外部MCPサーバの起動方法を指示します。brightDataエントリは、Bright Data Web MCPサーバを実行するために必要なコマンドと環境変数を定義します(PRO_MODEを有効にすることはオプションですが、推奨します)。先ほどテストしたものとまったく同じコマンドが実行されますが、Gemini CLIが裏で自動的に実行してくれることに注意してください。
重要認証を有効にするには プレースホルダを実際の Bright Data API トークンに置き換えてください。
MCPサーバ設定を追加したら、ファイルを保存します。これで、Gemini CLI内でMCP統合をテストする準備ができました!
ステップ4:MCP接続の確認
Gemini CLIがまだ実行されている場合は、/quitコマンドを使用して終了し、再度起動します。これで、Bright Data Web MCPサーバーに自動的に接続されるはずです。
接続を確認するには、Gemini CLIで/mcpコマンドを入力します:
次に、リスト・オプションを選択して、構成済みのMCPサーバーと使用可能なツールを表示します。Enterキーを押すと、次のように表示されます:
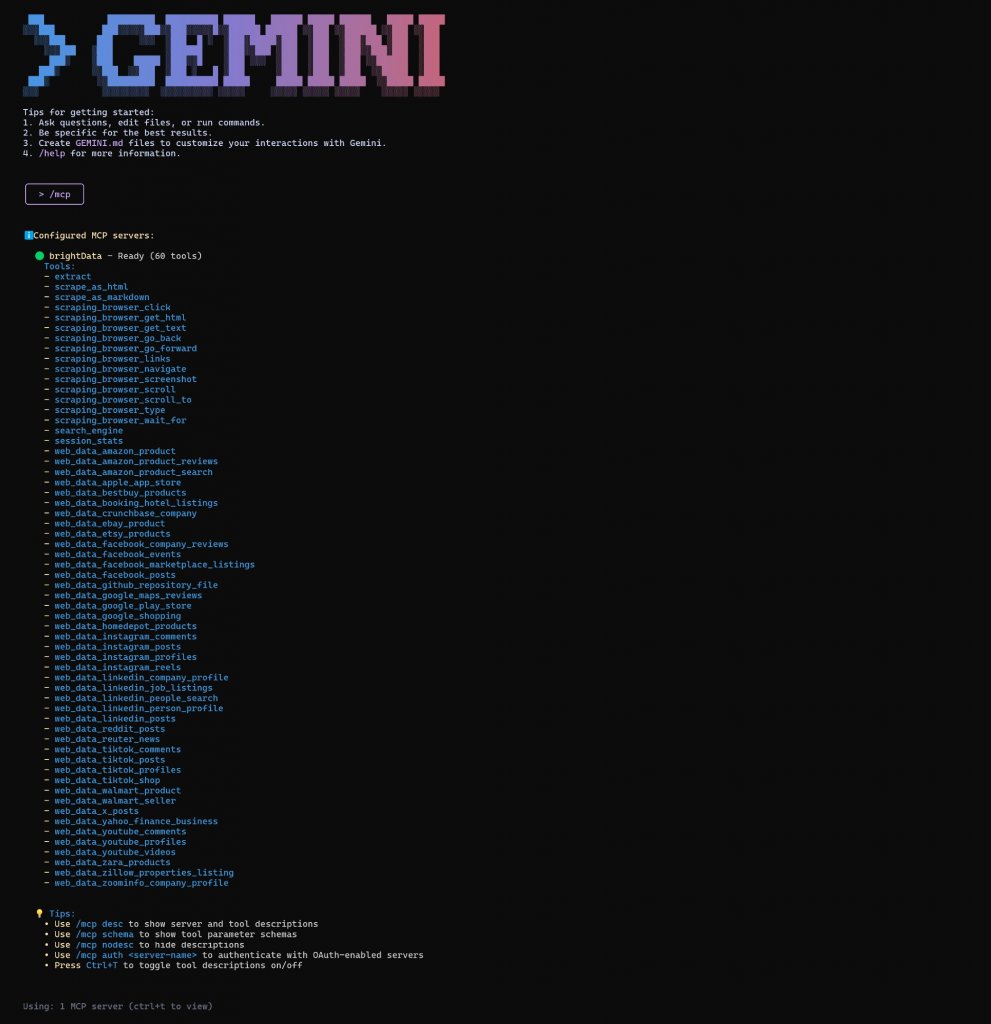
ご覧のように、Gemini CLIはBright Data Web MCPサーバーに接続し、60以上のツールにアクセスできるようになりました。よくやった!
ヒント: 他のすべてのGemini CLIコマンドについては、ドキュメントを参照してください。
ステップ #5: Gemini CLIでタスクを実行する
Gemini CLIセットアップのWeb機能をテストするには、以下のようなプロンプトを使用できます:
Scrape data from "https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/" and store the resulting JSON data in a local data.json file. Then, create a Node.js index.js script to load and print its contents.これは実際のユースケースを表しており、分析、APIのモック、テストのためにライブデータを収集するのに役立つ。
プロンプトをGemini CLIに貼り付けます:

そして、Enterを押して実行する。これがエージェントがあなたのタスクに対処する方法です:
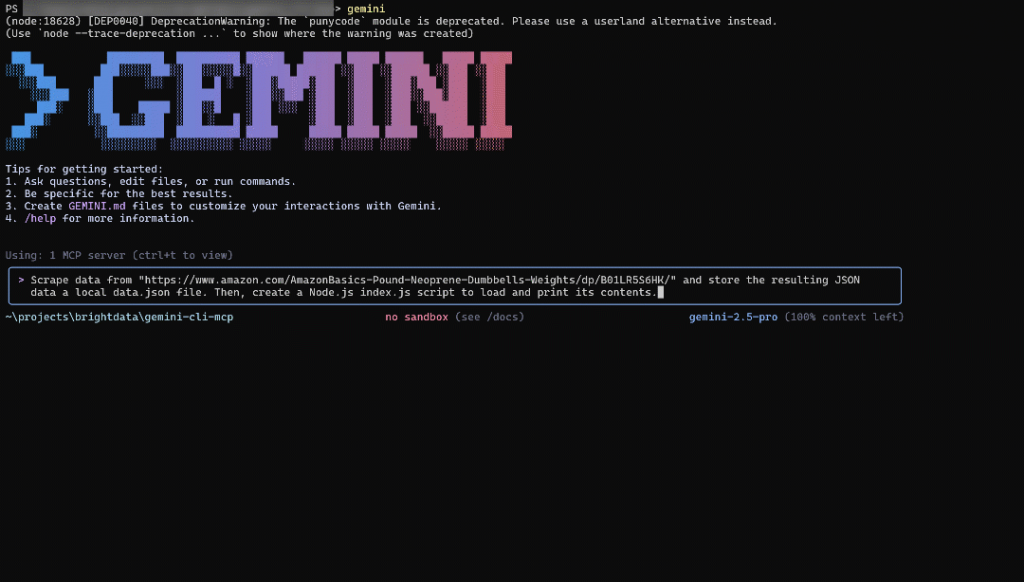
上のGIFはスピードアップされているが、こうなるはずだ:
- Gemini CLIは、設定されたLLM(すなわち、
gemini-2.5-pro)にプロンプトを送信します。 - LLMは適切なMCPツール
(ここではweb_data_amazon_product)を選択する。 - 提供されたAmazon製品URLを使用して、Web MCP経由でツールを実行できることを確認するよう求められます。
- 承認されると、MCPの統合によってスクレイピング・タスクが開始される。
- 出来上がった商品データは、生のフォーマット(つまりJSON)で表示される。
- Gemini CLIは、このデータを
data.jsonという名前のローカルファイルに保存できるかどうかを尋ねます。 - 承認後、ファイルが作成され、入力されます。
- 次に、Gemini CLIは、JSONデータをロードして表示する
index.jsのJavaScriptロジックを表示します。 - 承認されると、
index.jsファイルが作成されます。 - Node.jsスクリプトの実行許可を求められます。
- 許可されると、
index.jsが実行され、data.jsonのデータがタスクの説明通りにターミナルに出力される。 - Gemini CLIは、生成されたファイルを削除するかどうかを尋ねます。
- 処刑を終わらせるために、彼らをキープする。
Gemini CLIは、タスクで明示的にスクリプトの実行を要求していないにもかかわらず、スクリプトの実行を要求したことに注意してください。それでも、これはテストに役立つので、意味があり、実際にあなたのタスクに追加されたのは良いことでした。
インタラクションの最後には、作業ディレクトリにこれら2つのファイルが保存される:
├── data.json
└── index.jsVSコードでdata.jsonを開くと、こう表示される:
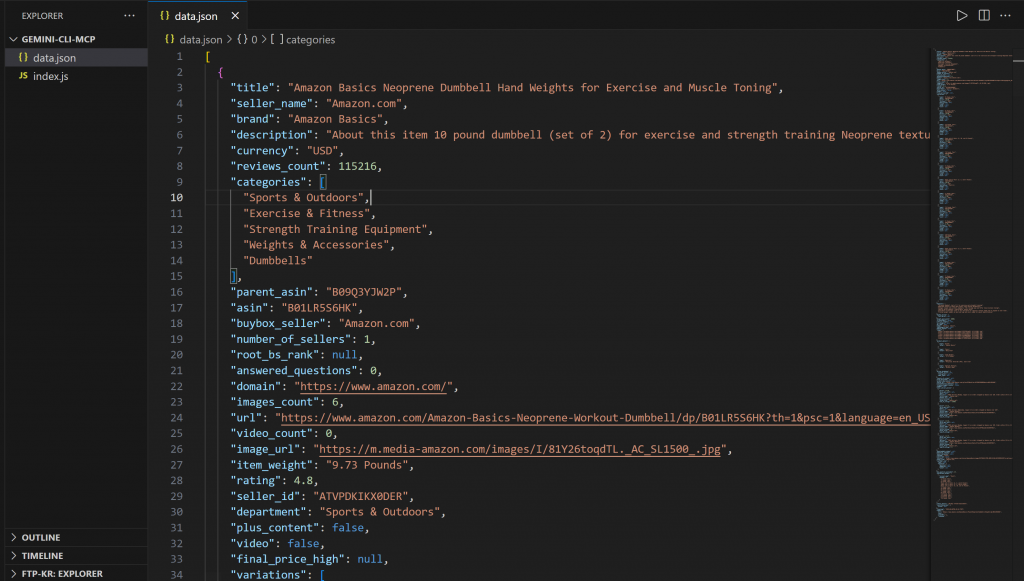
このファイルには、Bright Data Web MCP統合を使用してAmazonからスクレイピングされた実際の商品データが含まれています。
同様に、index.jsを開くとこうなる:
このスクリプトには、data.jsonの内容をロードして表示するNode.jsロジックが含まれています。
でNode.jsのindex.jsスクリプトを実行する:
node index.js結果はこうなる:

出来上がり!ワークフローは正常に完了した。
具体的には、data.jsonからロードされターミナルに表示される内容は、オリジナルのアマゾンの商品ページの実際のデータと一致する:

data.jsonには、AIによって生成された幻覚や作り物のコンテンツではなく、実際にスクレイピングされたデータが含まれていることを覚えておいてほしい。また、Amazonのスクレイピングは、その強固なボット対策(Amazon CAPTCHAなど)のために、悪名高く困難であることを覚えておいてほしい。普通のLLMにはできないことだ!
この例は、Gemini CLIとBright DataのWeb MCPサーバを組み合わせることの威力を示しています。では、さらに多くのプロンプトを試し、CLIで直接LLM駆動の高度なデータワークフローを探求してください!
結論
この記事では、Gemini CLIとBright Data Web MCPサーバーを接続して、WebにアクセスできるAIコーディングエージェントを構築する方法を学びました。この統合は、Gemini CLIに組み込まれたMCPのサポートによって可能になりました。
より複雑なエージェントを構築するには、ブライトデータのAIインフラストラクチャで利用可能なあらゆるサービスをご利用ください。これらのソリューションは、様々なエージェントのシナリオをサポートします。
Bright Dataのアカウントを無料で作成し、AIに対応したウェブデータツールの実験を開始しましょう!






