
ブラウザ自動化ツールは、Webスクレイパー、ボット、またはWebサイトと対話する必要があるAIエージェントを構築する開発者にとって不可欠なものになっています。PuppeteerやPlaywrightのようなオープンソースツールは広く使われていますが、Bright Dataのエージェントブラウザは、ステルス、スケール、AIネイティブワークフローのために構築された、異なるアプローチをもたらします。
このガイドで、あなたは学ぶだろう:
- Agent BrowserとPuppeteer、Playwrightのステルス性とフィンガープリンティングの違い。
- プロキシローテーションや自動セッション処理など、Bright Dataが提供する組み込み機能。
- 各ツールが得意とするシナリオ、あるいは不得意とするシナリオ。
- エージェントブラウザと従来のフレームワークの両方の限界と、どちらを選ぶべきか。
なぜエージェント・ブラウザ、人形遣い、劇作家を比較するのか?
ブラウザの自動化は、スクレイパー、ボット、AIエージェントを構築する開発者にとって、頼りになるソリューションとなっている。動的なウェブページからのデータ収集、自動ログインの実行、反復タスクの大規模実行など、ブラウザ・フレームワークは現代の開発ワークフローの重要な一部となっています。
この分野で最も人気のあるツールは、Puppeteerと Playwrightであり、どちらもオープンソースのNode.jsベースのライブラリで、ヘッドレスまたはフルブラウザを制御するための高レベルのAPIを提供している。Chromeチームによって保守されているPuppeteerは、Chromiumとの緊密な統合で知られており、Microsoftによって開発されたPlaywrightは、複数のブラウザ(Chromium、Firefox、WebKit)をサポートし、マルチページコンテキストやビルトインウェイトなどのより高度な機能を可能にすることで、その基盤を構築している。これらのツールは、特にカスタムワークフローのスクリプト化において、その柔軟性と制御性から広く採用されている。
しかし、ウェブサイトがますます攻撃的なボット検出メカニズムを導入するにつれ、多くの開発者はビジネスロジックを書くことよりも、フィンガープリンティング、CAPTCHA解決、プロキシローテーションのような課題に対処することに多くの時間を費やしていることに気づきます。そこでエージェントブラウザの登場です。
AIエージェントとオートメーションワークフローのために特別に構築されたエージェントブラウザは、PuppeteerとPlaywrightのユーザーが手動で管理しなければならない低レベルの作業の多くを抽象化します。ステルス、プロキシ管理、セッション永続化、CAPTCHA処理を組み込んだ、実際のユーザーを模倣するように設計されたフルブラウザ環境です。これは、スケールの大きなウェブデータを収集するためのBright Dataの広範なインフラの一部であり、開発者が検出されないようにするために必要な配管よりも、自動化の目標に集中できるように設計されています。
主な違いステルスとフィンガープリンティング
今日のブラウザ自動化における最大の課題のひとつは、検知を回避することです。ウェブサイトは、ブラウザのフィンガープリントの不一致からマウスの動きのパターンなど、あらゆるものを監視する洗練されたボット検知システムを使用するようになってきている。これは、PuppeteerやPlaywrightのようなツールが限界を見せ始めるところです。
PuppeteerとPlaywrightには、ステルス機能や検知防止機能はついていません。開発者は多くの場合、puppeteer-extra-plugin-stealthのようなツールに手動でパッチを当てたり、プロキシを回転させたり、ヘッダーやフィンガープリントを変更したりしなければなりません。それでも、特に高度なボット対策が施されたサイトでは、検出率が高いままであることがある。
一方Agent Browserは、ステルス性を第一機能として設計されている。人間のような指紋、自然なスクロールやインタラクションパターン、スマートなヘッダーコントロールなど、実際のユーザー行動を模倣したクラウドベースのヘッドフルブラウザセッションを実行します。すべてのセッションは、エミュレートされる場所、デバイスの種類、ブラウザのバージョンに合わせた現実的なブラウザ特性で起動します。
箱から出してすぐできることはこうだ:
- フィンガープリントの偽装Agent Browserは、(デフォルトのヘッドレス署名とは異なり)実際のユーザー環境に類似したブラウザフィンガープリントを作成します。
- CAPTCHAの解決:CAPTCHAが表示されたときに自動的に課題を処理し、自動化されたフローの中断を減らします。
- プロキシローテーション:IPアドレスをローテーションし、ブロックが検出された場合は自動的にリクエストを再試行する。
- クッキーとセッションのトラッキング:セッションの状態とクッキーを永続的に保持し、リクエストの繰り返しによる検出を減らします。
これらの機能は、動的なレイアウトやログインゲート、パーソナライズされたコンテンツを持つウェブサイトをスクレイピングする際に特に重要です。例えば、地域固有の価格や在庫を表示するeコマースストアなどです。このようなプラットフォームでは、ブラウザの動作に小さな矛盾があっても、ブロックや空のレスポンスを引き起こす可能性があります。Agent Browserでは、開発者はステルスプラグインを手動で設定したり、プロキシを回転させたりする必要はありません。
当社のプロキシインフラストラクチャとの緊密な統合は、開発者が特定の地理的位置からコンテンツにアクセスし、リファラーヘッダーを調整し、長期間のセッションを維持できることを意味し、マルチステップエージェントワークフローのための強力な選択肢となる。
セッション処理と認証
PuppeteerとPlaywrightでは、セッション処理はほとんど手作業です。開発者は、Cookieやローカルストレージを取得して再利用し、ログインの永続化や認証のためのロジックを記述し、トークンやCSRF保護を管理しなければなりません。このため、特に規模が大きくなると複雑さが増します。
Agent Browserは、セッションの永続化とローテーションを自動化します。クッキーとローカルストレージはクラウド上で自動的に管理されるため、カスタムロジックなしでページやタブをまたいでセッションの状態が維持されます。セッションがブロックされた場合、新しいIPとフィンガープリントで新しいセッションが開始されます。再試行や CAPTCHA 処理コードは必要ありません。
この自動化により、IPバンを減らし、セッションの失敗を最小限に抑え、開発者はセッション管理の代わりに自動化タスクに集中することができます。また、Bright Dataのプロキシネットワークと統合されているため、一貫したID管理が可能です。
使いやすさと開発者の経験
開発者がブラウザ自動化ツールを選択する際に重視する重要な要素の1つは、セットアップから最初の実行が成功するまでをいかに迅速に行えるかです。PuppeteerとPlaywrightを使えば、ヘッドレス・ブラウザを扱ったことがあれば、簡単に使い始めることができる。ライブラリをインストールし、ブラウザインスタンスを起動し、ページをナビゲートするには、ほんの数行のコードで済む。しかし、プロキシのサポート、CAPTCHAの処理、フィンガープリンティング、セッションの永続性などを追加する必要が出てくると、物事はより複雑になります。追加のプラグインをインストールし、プロキシライブラリを設定し、クッキーを手動で管理し、検出された問題のトラブルシューティングを行う必要があることが多いでしょう。
Agent Browserは、その複雑さを軽減するように設計されています。統合はAPIまたはMCPを通して行うことができ、サイトごとの設定は必要ありません。独自のブラウザインフラストラクチャを維持する必要はありません。ステルスプラグインのパッチやIPのローテーションを手動で行う必要はありません。
開発者は、最初から最後までセッションをプログラムでコントロールし、ヘッドフルまたはヘッドレスエクスペリエンスを選択できます。コードベースのワークフローを好む人のために、Agent Browserは、Playwright、Puppeteer、Seleniumと互換性があります。以下のコードサンプルは、最小限の摩擦で既存のスタックにプラグインするのに役立ちます。
JavaScriptだ:
const pw = require('playwright');
const SBR_CDP = 'wss://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9222';
async function main() {
console.log('Connecting to Scraping Browser...');
// Scraping browswer here...
const browser = await pw.chromium.connectOverCDP(SBR_CDP);
try {
const page = await browser.newPage();
console.log('Connected! Navigating to <https://example.com>...');
await page.goto('<https://example.com>');
console.log('Navigated! Scraping page content...');
const html = await page.content();
console.log(html);
} finally {
await browser.close();
}
}
main().catch(err => {
console.error(err.stack || err);
process.exit(1);
});
const puppeteer = require('puppeteer-core');
const SBR_WS_ENDPOINT = 'wss://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9222';
async function main() {
console.log('Connecting to Scraping Browser...');
const browser = await puppeteer.connect({
// Scraping browswer here...
browserWSEndpoint: SBR_WS_ENDPOINT,
});
try {
const page = await browser.newPage();
console.log('Connected! Navigating to <https://example.com>...');
await page.goto('<https://example.com>');
console.log('Navigated! Scraping page content...');
const html = await page.content();
console.log(html)
} finally {
await browser.close();
}
}
main().catch(err => {
console.error(err.stack || err);
process.exit(1);
});
const { Builder, Browser } = require('selenium-webdriver');
const SBR_WEBDRIVER = '<https://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9515>';
async function main() {
console.log('Connecting to Scraping Browser...');
const driver = await new Builder()
.forBrowser(Browser.CHROME)
// Scraping browswer here...
.usingServer(SBR_WEBDRIVER)
.build();
try {
console.log('Connected! Navigating to <https://example.com>...');
await driver.get('<https://example.com>');
console.log('Navigated! Scraping page content...');
const html = await driver.getPageSource();
console.log(html);
} finally {
driver.quit();
}
}
main().catch(err => {
console.error(err.stack || err);
process.exit(1);
});
パイソン
import asyncio
from playwright.async_api import async_playwright
SBR_WS_CDP = 'wss://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9222'
async def run(pw):
print('Connecting to Scraping Browser...')
# Scraping browswer here...
browser = await pw.chromium.connect_over_cdp(SBR_WS_CDP)
try:
page = await browser.new_page()
print('Connected! Navigating to <https://example.com>...')
await page.goto('<https://example.com>')
print('Navigated! Scraping page content...')
html = await page.content()
print(html)
finally:
await browser.close()
async def main():
async with async_playwright() as playwright:
await run(playwright)
if __name__ == '__main__':
asyncio.run(main())
const puppeteer = require('puppeteer-core');
const SBR_WS_ENDPOINT = 'wss://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9222';
async function main() {
console.log('Connecting to Scraping Browser...');
const browser = await puppeteer.connect({
# Scraping browswer here...
browserWSEndpoint: SBR_WS_ENDPOINT,
});
try {
const page = await browser.newPage();
console.log('Connected! Navigating to <https://example.com>...');
await page.goto('<https://example.com>');
console.log('Navigated! Scraping page content...');
const html = await page.content();
console.log(html)
} finally {
await browser.close();
}
}
main().catch(err => {
console.error(err.stack || err);
process.exit(1);
});
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
SBR_WEBDRIVER = '<https://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9515>'
def main():
print('Connecting to Scraping Browser...')
# Scraping browswer here...
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, 'goog', 'chrome')
with Remote(sbr_connection, options=ChromeOptions()) as driver:
print('Connected! Navigating to <https://example.com>...')
driver.get('<https://example.com>')
print('Navigated! Scraping page content...')
html = driver.page_source
print(html)
if __name__ == '__main__':
main()
目標は単純だ。定型的なセットアップを排除することで、開発者は自動化を確実に実行し続ける方法ではなく、自動化が必要とすることに集中できるようにすることだ。
ボンネットの下:明るいデータを備えた内蔵機能
Agent Browserが他と違うのは、セッション起動時にすでに含まれているものです。
- プロキシのローテーションは自動的に処理されます。各セッションは、195カ国にまたがる1億5,000万以上の居住用IPを含む、当社の広範なプロキシネットワークによって支えられています。
- ブラウザのフィンガープリンティングは設計上人間に近く、頭の悪い兆候を避け、実際の環境(デバイス、OS、ブラウザのバージョンに至るまで)をエミュレートする。
- CAPTCHAが組み込まれているため、外部サービスは必要なく、視覚的な問題によるセッションの失敗もありません。
- セッションの永続性は一貫している。タブ、クッキー、ローカルストレージは保存され、これは認証されたスクレイピングやステップベースのワークフローのようなタスクにとって重要です。
- HTTPヘッダーがページ配信に影響するような場合に便利です。
これらすべてが標準化されたクラウドベースの環境に包まれているため、セッションがいつどこで実行されても一貫したパフォーマンスを得ることができます。スケーラブルで、APIアクセス可能で、広範なデータ・パイプラインと緊密に統合されているため、出力は構造化されていても生でも、リアルタイムでもバッチでも、すぐにAIに対応できる。
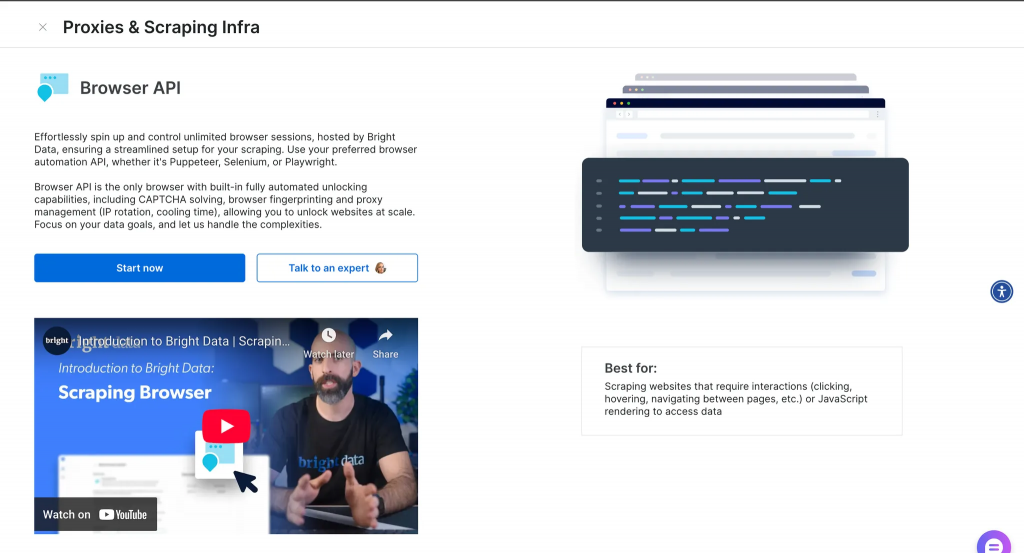
以下は、アカウント作成後にダッシュボードに表示される内容の概要です。

詳細を見るをクリックすると、以下のような詳細情報が表示される。
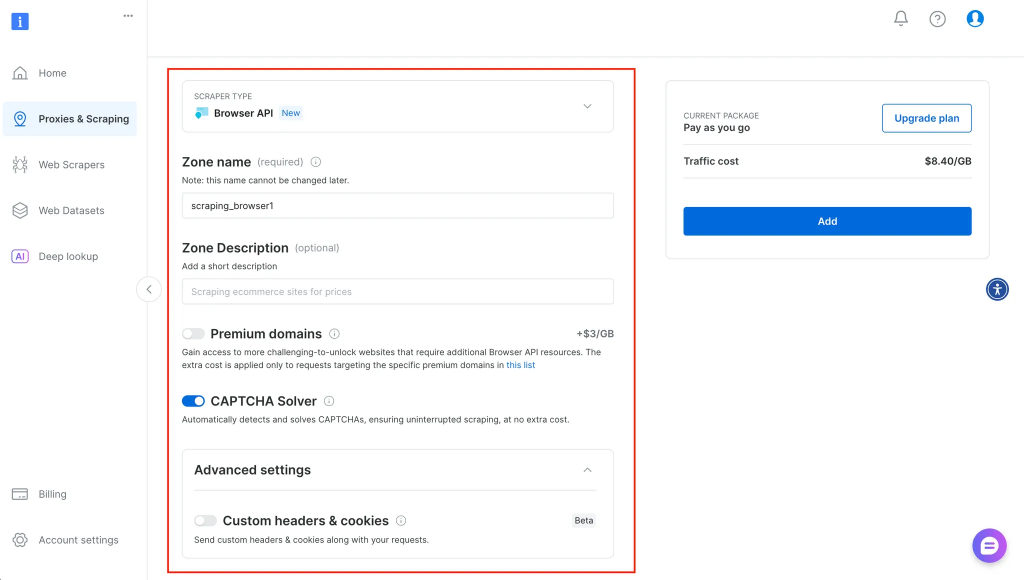
開始をクリックすると、以下のように、サービスに関する詳細情報を入力し、それに応じて設定できる場所にリダイレクトされる:
正しいツールの選択:それぞれに意味がある場合
各ツールにはそれぞれの役割があり、どちらを使うべきかを理解することで、時間とフラストレーションを節約することができる。
以下の場合は、エージェントブラウザを使用してください:
- カスタムステルスレイヤーを構築することなく、高度なアンチボット機構を扱う必要がある。
- ワークフローには、セッションの永続性を必要とするマルチステップタスクが含まれます(ログイン、フォーム送信など)。
- さまざまな地域にまたがる何百、何千ものブラウザセッションを立ち上げ、スケーリングしたい。
- あなたは、エージェントのインフラを管理する方法ではなく、エージェントが何をするかに集中したい。
人形遣いか脚本家にこだわるなら:
- あなたのタスクは、小規模で、高速で、ローカルなものだ。例えば、いくつかのヘッドラインを取得するスクリプトや、CIでテストを自動化するスクリプトのようなものだ。
- あなたは、ブラウザ環境を完全にコントロールしたいのであり、ビルトインのブロック解除は必要ない。
- オフラインまたはセキュアな環境で、リモートブラウザを使用できない場合。
場合によっては、ハイブリッドアプローチが最適です。例えば、ローカルでPlaywrightスクリプトを実行し、Bright Dataプロキシを使用してIPローテーションと ジオターゲティングを処理する。あるいは、リスクの高いターゲットにはWeb MCPを使用し、摩擦の少ないスクレイピングにはオープンソースのフレームワークを使用する。
制限と考慮事項
完璧なツールはなく、それぞれにトレードオフがある。
Agent Browserのクラウドベースの性質は、オフラインでの使用やデータのローカリティが重要な環境向けに設計されていないことを意味します。規制された業界や制限されたネットワークで働くチームにとっては、ローカルでブラウザを実行することが望ましいかもしれません。
PuppeteerとPlaywrightは柔軟ではありますが、ウェブサイトの進化に伴い、常にメンテナンスが必要です。特にステルス・プラグインが古くなると、新しいボット検知技術やレイアウトの変更によって既存のスクリプトが壊れてしまうことがよくある。また、規模が大きくなるにつれて、ブラウザのインフラを維持し、IPをローテーションし、ブロックを防ぐことが、フルタイムの関心事になることもある。
また、Agent Browserは、倫理的なスクレイピングに沿った公開ウェブサイトと自動化タスクのために構築されていることを考慮する価値があります。許可なくログインウォールを迂回したり、ペイウォールの背後にあるコンテンツをスクレイピングするためのものではありません。
結論と次のステップ
Agent Browser、Puppeteer、Playwrightのいずれを選択するかは、ワークフローが求めるものによります。ステルス性、スケール、シンプルさが必要であれば、Agent Browserは手間をかけずに自動化を実現します。高速でローカルなものをフルコントロールで構築するのであれば、PuppeteerとPlaywrightは堅実な選択肢です。どちらの場合でも、特にセッション管理、フィンガープリンティング、インフラストラクチャの違いを理解することで、無駄な時間や壊れたフローを避けることができます。
Agent Browser を検討したり、Playwright、Puppeteer、あるいは MCP を使って既存の自動化スタックに接続することができます。より詳細な背景については、ChatGPT を使ったウェブスクレイピングやMCP を使ったエージェント構築のガイドをご覧ください。





