

ウェブスクレイピングとは、スクリプトや自動化ソフトウェアツールを用いてウェブサイトからコンテンツやデータを抽出するプロセスです。スクレイピングされた情報は通常、生のファイルやCSVなど、より有用な形式にエクスポートされ、利用しやすくなります。
ウェブスクレイピングのワークフローを簡素化したい場合、Google スプレッドシートが役立ちます。 構造化データや表形式データのスクレイピング、データ分析や可視化に最適なデータ管理ツールです。例えば、ECサイトから商品詳細や価格を取得したり、企業ディレクトリから連絡先情報を抽出したりできます。ソーシャルメディアのエンゲージメント追跡やキャンペーン効果測定のための世論分析にも有用です。
このチュートリアルでは、ウェブスクレイピング用にGoogleスプレッドシートを設定して使用する方法について学びます。
Google スプレッドシートの設定
Google スプレッドシートでウェブスクレイピングを始めるには、https://sheets.google.comにアクセスし、[+]ボタンをクリックして新しい Google スプレッドシートを作成します:
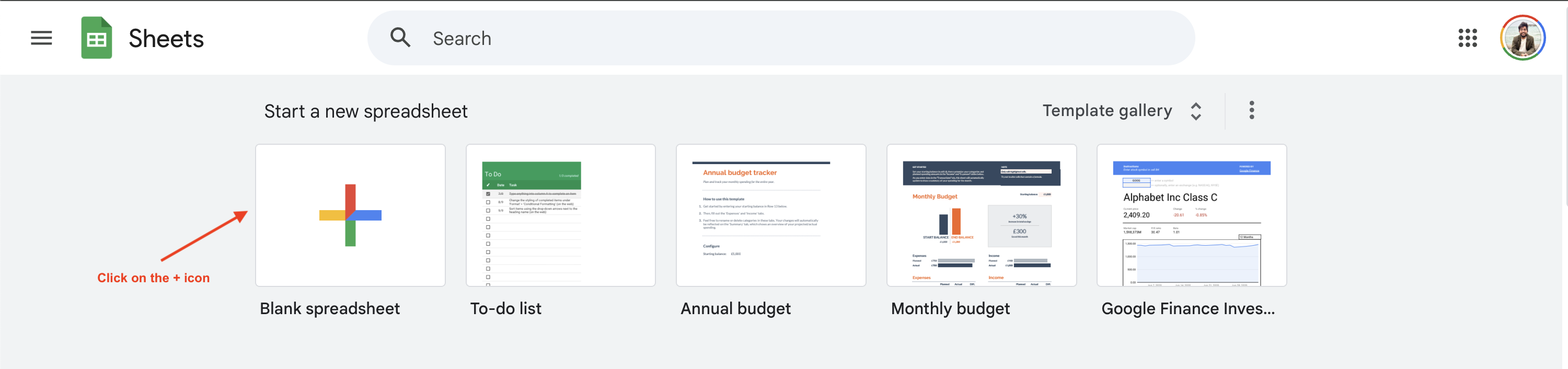
このチュートリアルではBooks to Scrapeサイトから書籍価格情報をスクレイピングする方法を紹介しますが、以下のURLとクエリを変更することで他のサイトにも応用可能です。
Google スプレッドシートの数式を理解する
Google スプレッドシートは、ウェブスクレイピングを含む様々な操作に使用できる多数のセル数式をサポートしています。これらの数式がどのように機能するか見てみましょう。
IMPORTXML
IMPORTXML関数を使用すると、構造化されたデータをクエリし、Googleスプレッドシートにインポートできます。XML、HTML、CSV、TSVファイル形式をサポートしています。関数の構文は次のとおりです:
=IMPORTXML(url, xpath_query)
この関数は指定されたウェブURLからデータをインポートし、XPathロケーターを使用してウェブページ上の関連要素を検索します。例えば、Googleスプレッドシートのセルに以下の数式を追加することで、Books to ScrapeウェブサイトからH1見出しを取得できます:
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//h1")
初回使用時、Google スプレッドシートはサードパーティのウェブサイトからデータを取得する前にアクセス許可を有効化するよう促します:
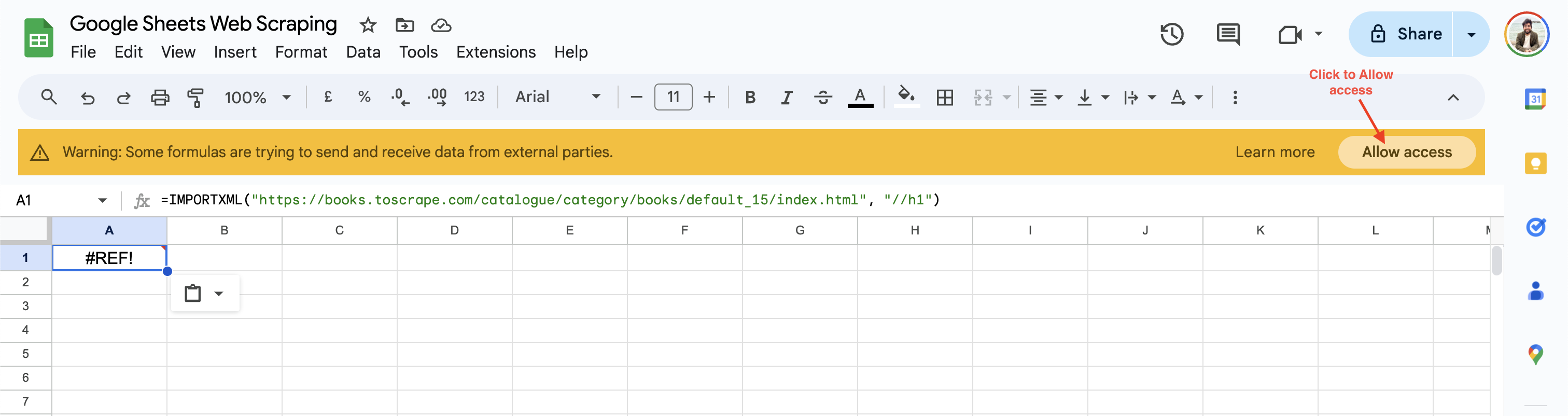
アクセスを許可をクリックすると、Google スプレッドシートはセルの値をウェブページのH1 見出しに解決し、デフォルト値を返します。
IMPORTHTML
IMPORTHTML関数を使用すると、HTMLページ上のテーブルやリストからデータをインポートできます。関数の構文は次のとおりです:
=IMPORTHTML(url, query, index)
この関数は、指定されたクエリに基づいて、URLからデータをシートにインポートします。クエリ属性は、インポートしたいデータのタイプに応じて、リストまたはテーブルのいずれかに設定できます。インデックスは 1から始まり、どのテーブルまたはリストをインポートするかを決定します。たとえば、次の数式を使用して、Books to Scrapeから書籍のリストを取得できます:
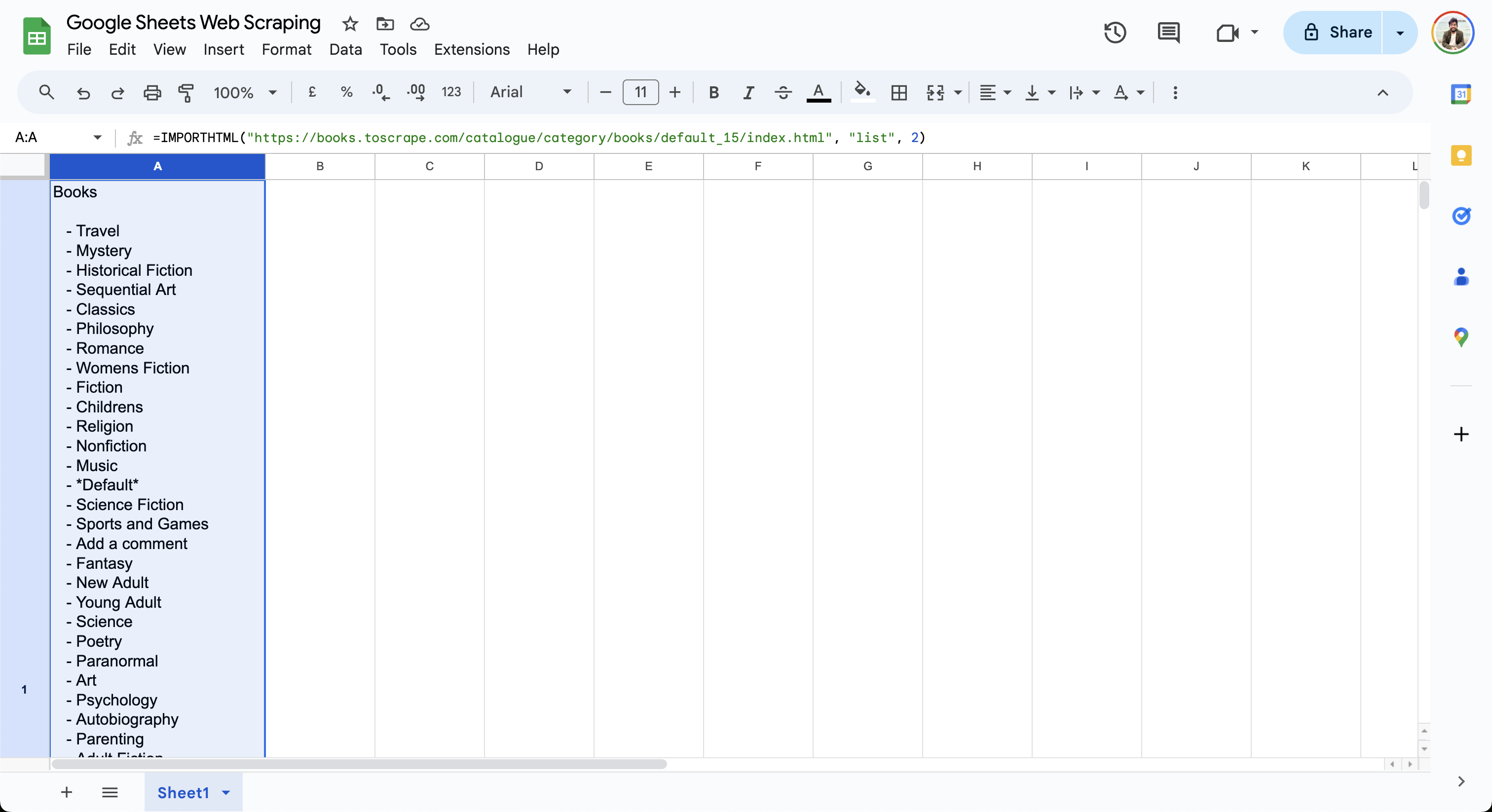
=IMPORTHTML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "list", 2)
この数式は現在のセルに書籍リストを出力します(以下参照):
ご覧の通り、IMPORTXMLとIMPORTHTML関数は簡単に使用でき、シンプルなクエリでウェブページからのデータスクレイピングを開始できます。より複雑なユースケースについては、ExcelでのウェブスクレイピングにVBAとSeleniumを使用する方法を説明するこのガイドを参照してください。
IMPORTXMLを使用したデータ抽出
前のセクションでは、関連するXPath属性を指定してページ見出しを取得するIMPORTXMLの基本的な使用方法を学びました。XPath属性は非常に強力で、階層に関係なくウェブページ内の任意の要素にアクセスできます。次のセクションでは、IMPORTXMLを使用して「Books to Scrape」ウェブページ上の全書籍のタイトル、価格、評価を取得します。
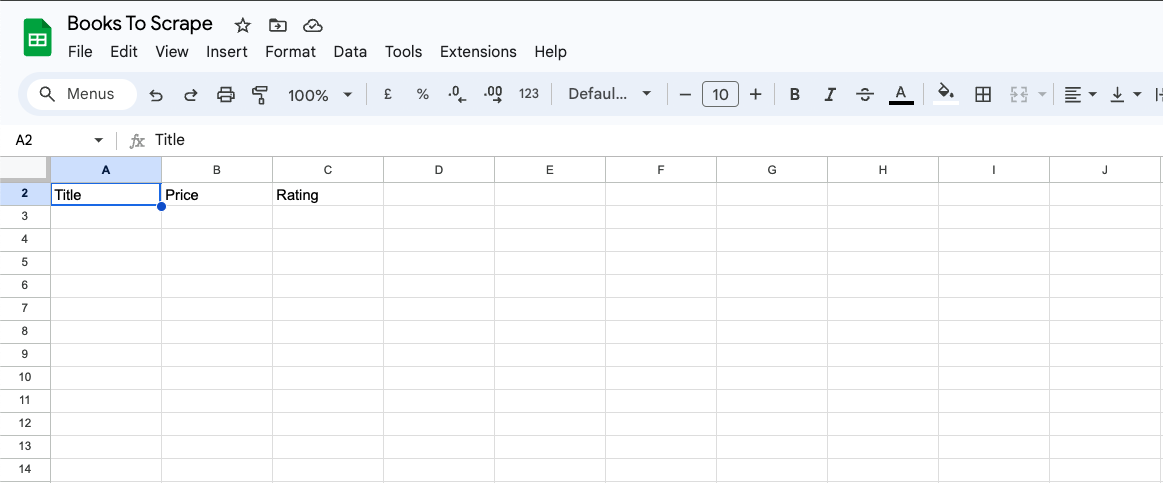
まず、Google スプレッドシートに「タイトル」「価格」「評価」の列を追加します:
Books to Scrapeから書籍タイトルを取得するには、そのXPath位置が必要です。これはブラウザの「要素を検査」ツールで確認できます。書籍タイトルのXPathを見つけるには、最初の書籍のタイトルを右クリックし、「要素を検査」を選択します。次に「コピー」>「XPath」をクリックしてXPathロケーターをコピーします:
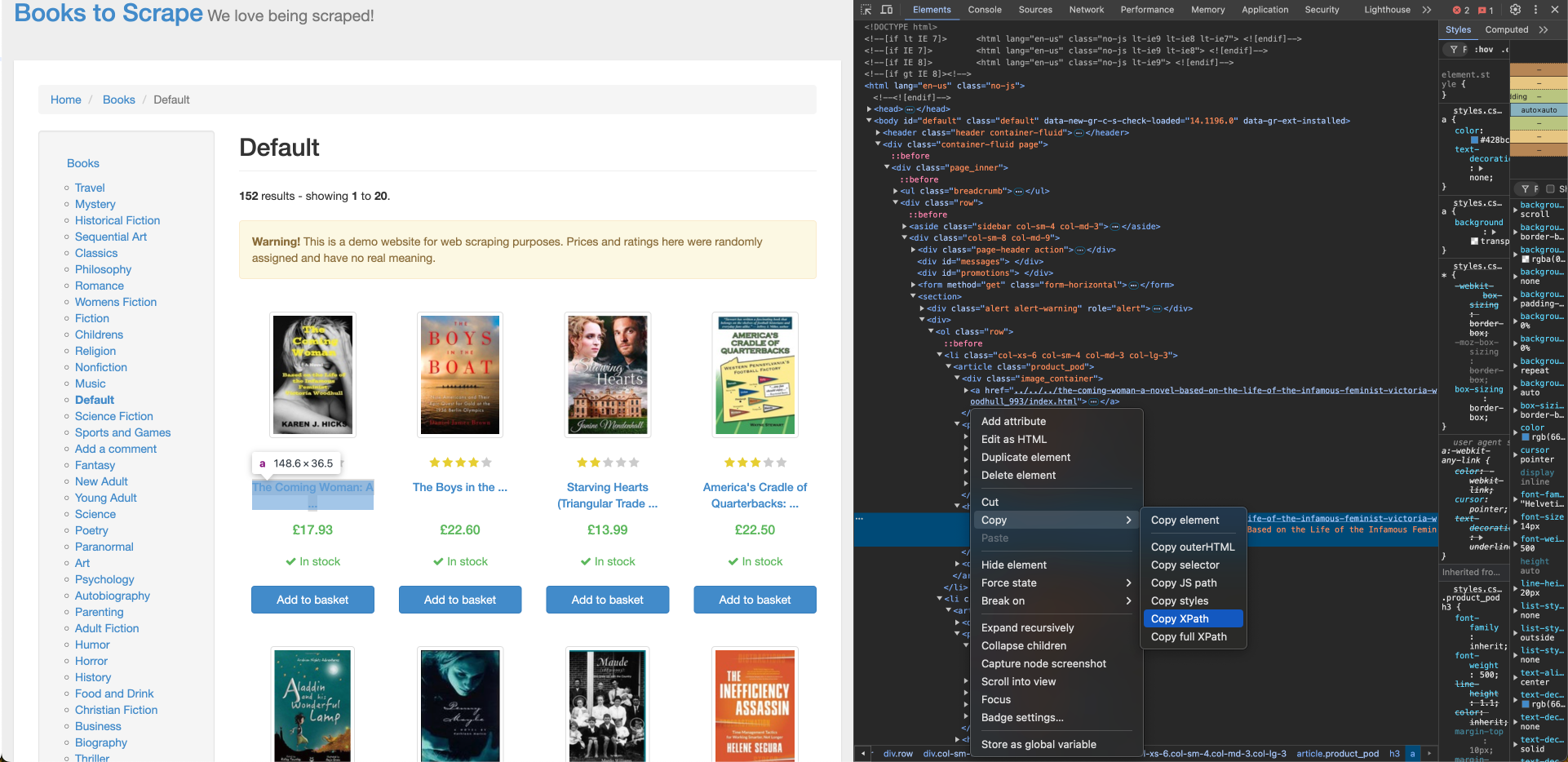
最初の書籍タイトルのXPathはアンカータグ(a)に対応し、以下のような形式になります:
//*[@id="default"]/div/div/div/div/section/div[2]/ol/li[1]/article/h3/a
リスト内の全書籍で書籍タイトルが正しくインポートされるよう、XPathを調整する必要があります:
- XPathのパス
にli[1]が含まれているのは、最初の書籍が選択されていることを示しています。これをliに置き換えてすべての要素を取得します。 aタグの内部コンテンツには書籍タイトルの一部が表示されますが、aタグには完全な書籍タイトルがtitle属性として含まれています。XPath内のaをa/@titleに変更し、title属性を使用するように修正します。- 数式内のエスケープ問題を回避するため、XPath内の二重引用符をすべて単一引用符に置き換えてください。
XPathを調整したら、更新したXPathを含む以下の数式をGoogleシートのA2セルに追加します:
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/h3/a/@title")
このシートはウェブページからデータをインポートし、行を次のように更新します:
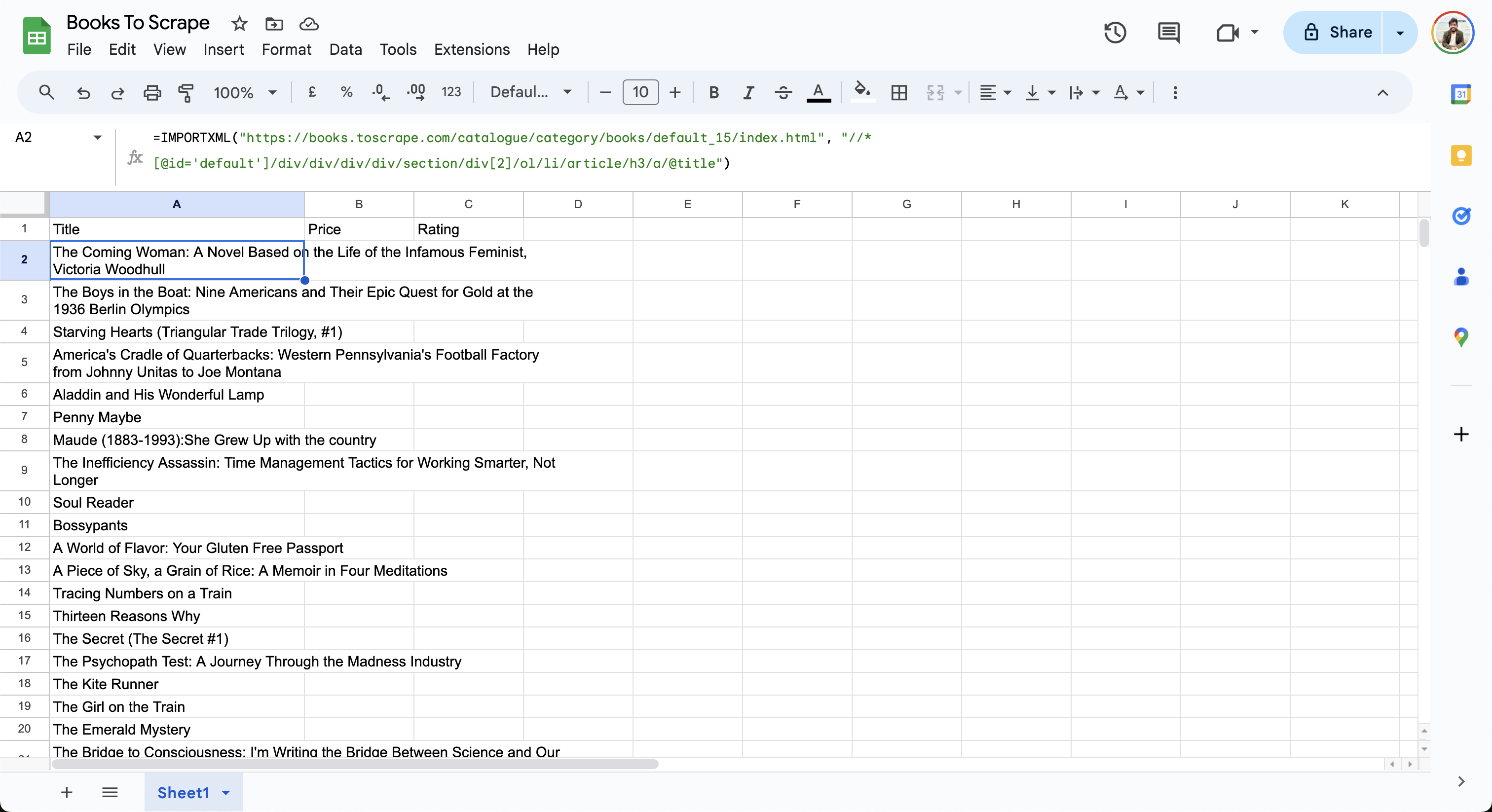
次に、価格用のXPathを構築し、GoogleスプレッドシートのB2セルに追加します:
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/div[2]/p[1]")
最後に、評価のXPathを検索し、GoogleシートのC2セルに追加します:
=IMPORTXML("https://books.toscrape.com/", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/p/@class")
シートの最終的なデータは以下のようになります:
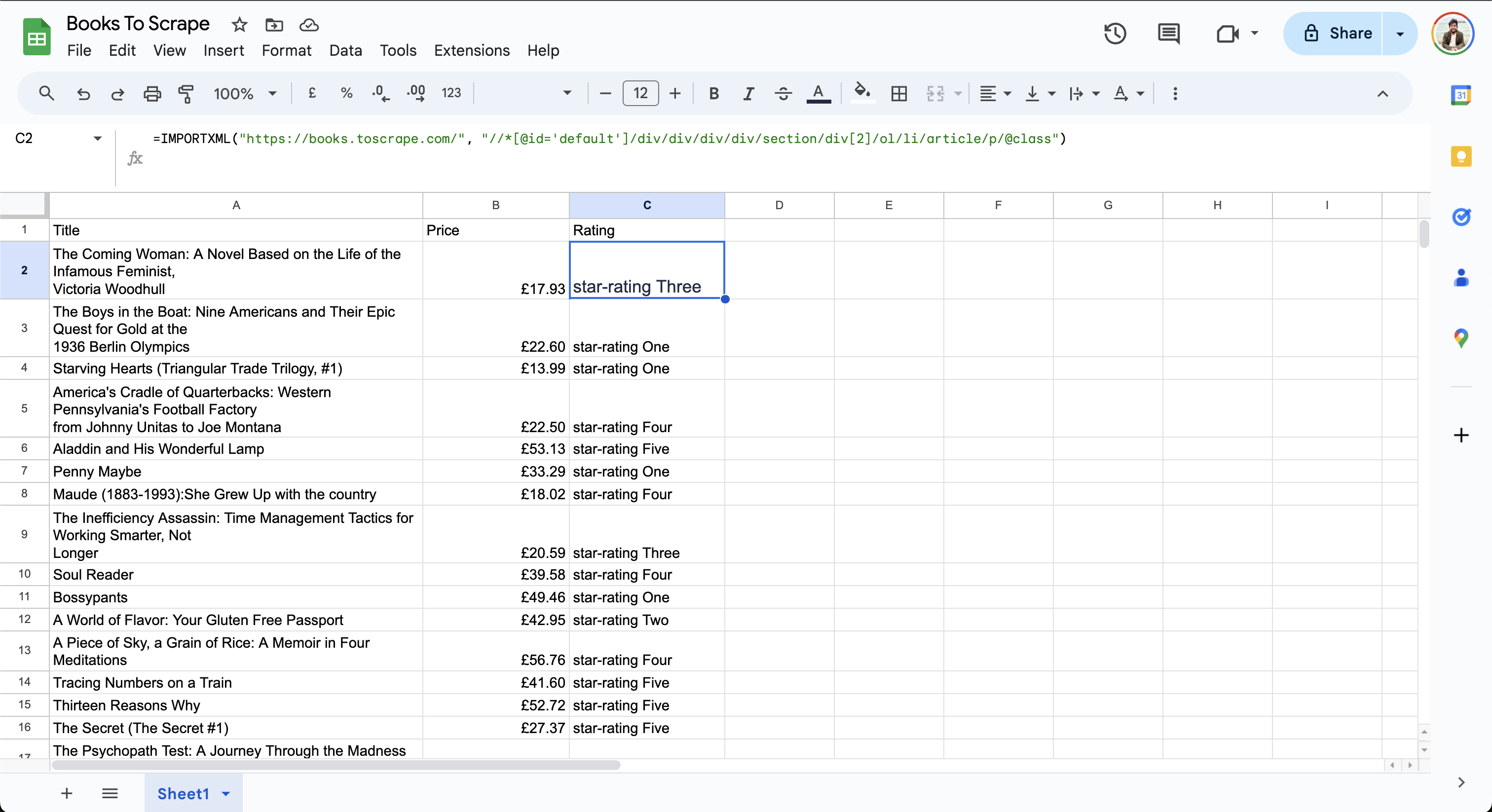
評価列には星3つまたは星4つの評価が表示されていることに注意してください。GoogleスプレッドシートではXPath 2.0がまだサポートされていないため、出力形式を簡素化するためのデータ操作はできません。
複雑なウェブページの処理
Google スプレッドシートは単純なスクレイピング作業に適していますが、対象ウェブサイトに動的コンテンツやページネーションが含まれている場合、あるいはクリック操作が必要な場合、ウェブスクレイピングは困難になる可能性があります。例えば、ウェブページが JavaScript を使用して非同期でコンテンツをロードする場合、Google スプレッドシートのIMPORTXMLおよびIMPORTHTML関数は静的ウェブページのみをサポートするため、そこからデータを抽出できません。 同様に、クリック・入力・スクロールなどのユーザー操作に依存するコンテンツも、これらの関数ではスクレイピングできません。動的コンテンツをスクレイピングするには、Seleniumなどのヘッドレスブラウザを利用するスクリプトを作成する必要があります。
Google スプレッドシートはページネーション処理も自動では対応できません。最終行の後に更新された URL を指定してIMPORTXML 関数を手動で追加することは可能ですが、ページごとにこの作業を繰り返す必要があるため、スケーラブルな方法とは言えません。
動的コンテンツや大量データの処理など、より高度なユースケースをお探しの場合は、効率的なデータ抽出のためにBright Dataの製品をご検討ください。Bright Dataはあらゆるデータ抽出タスクに対応する統合型ウェブスクレイピングAPIを提供し、プロキシ、CAPTCHA、ユーザーエージェントといった複雑な処理を内部で処理します。そのAPIは一括リクエスト、パース、検証を処理するため、より迅速なデプロイとスケーリングが可能です。 さらに、LinkedInやZillowなど人気サイトからの事前構築済みデータセットを豊富に提供しており、既存ワークフローに統合可能。これによりスクレイピングスクリプトの維持管理の手間を削減できます。
Google スプレッドシートでのデータ更新の自動化
価格やソーシャルメディアのエンゲージメント追跡など、一部のスクレイピングタスクでは、分析や意思決定に正確なデータを利用できるように、スクレイピングしたデータを定期的に自動更新する必要があります。
Google スプレッドシートで計算間隔を設定するには、[ファイル] > [設定] をクリックし、[計算] タブに移動します:
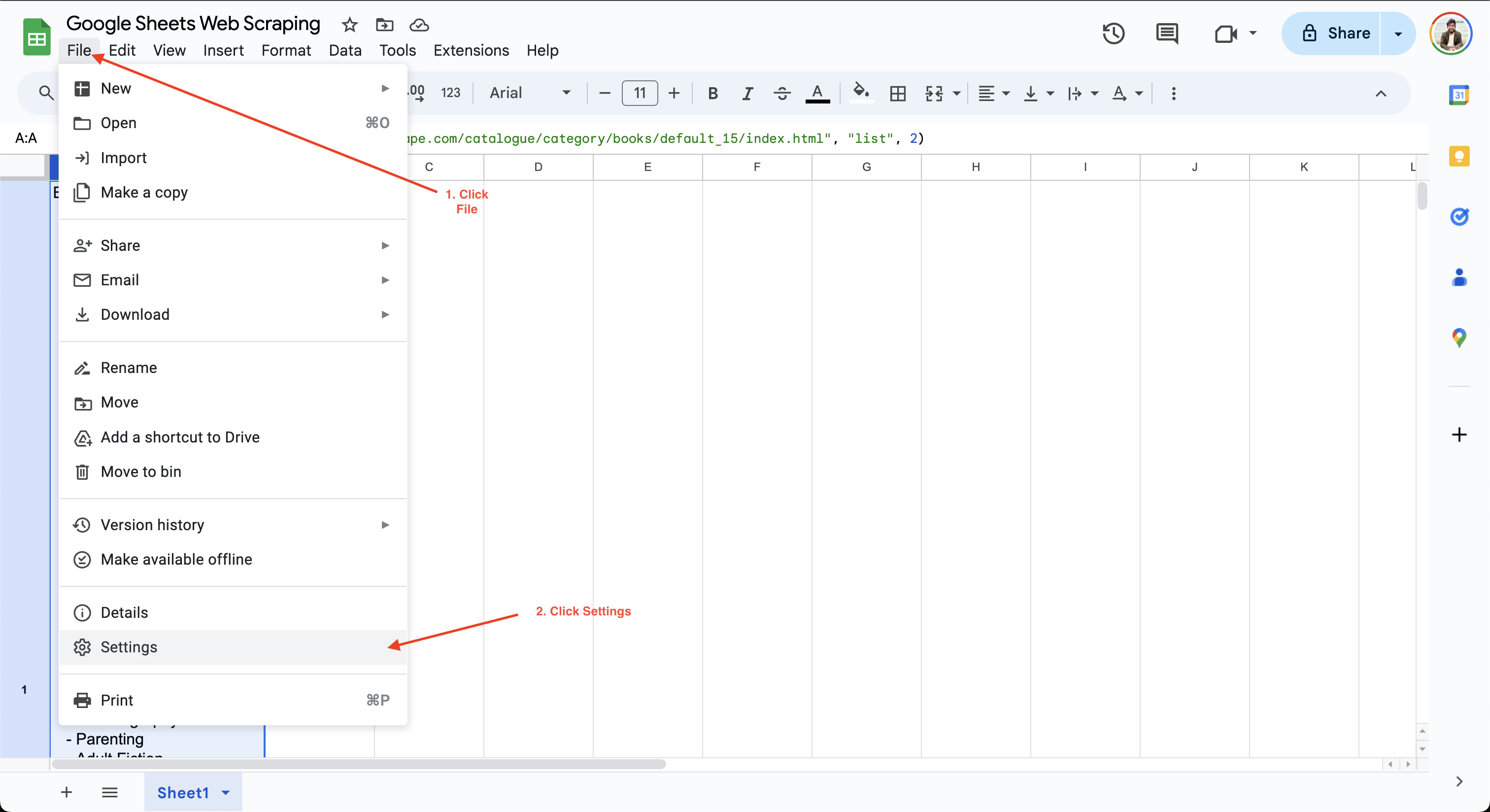
次に、計算間隔を1分または1時間に更新します。例えば、ここでは「変更時」と「毎分」に再計算設定を更新し、データが毎分自動更新されるようにしています:
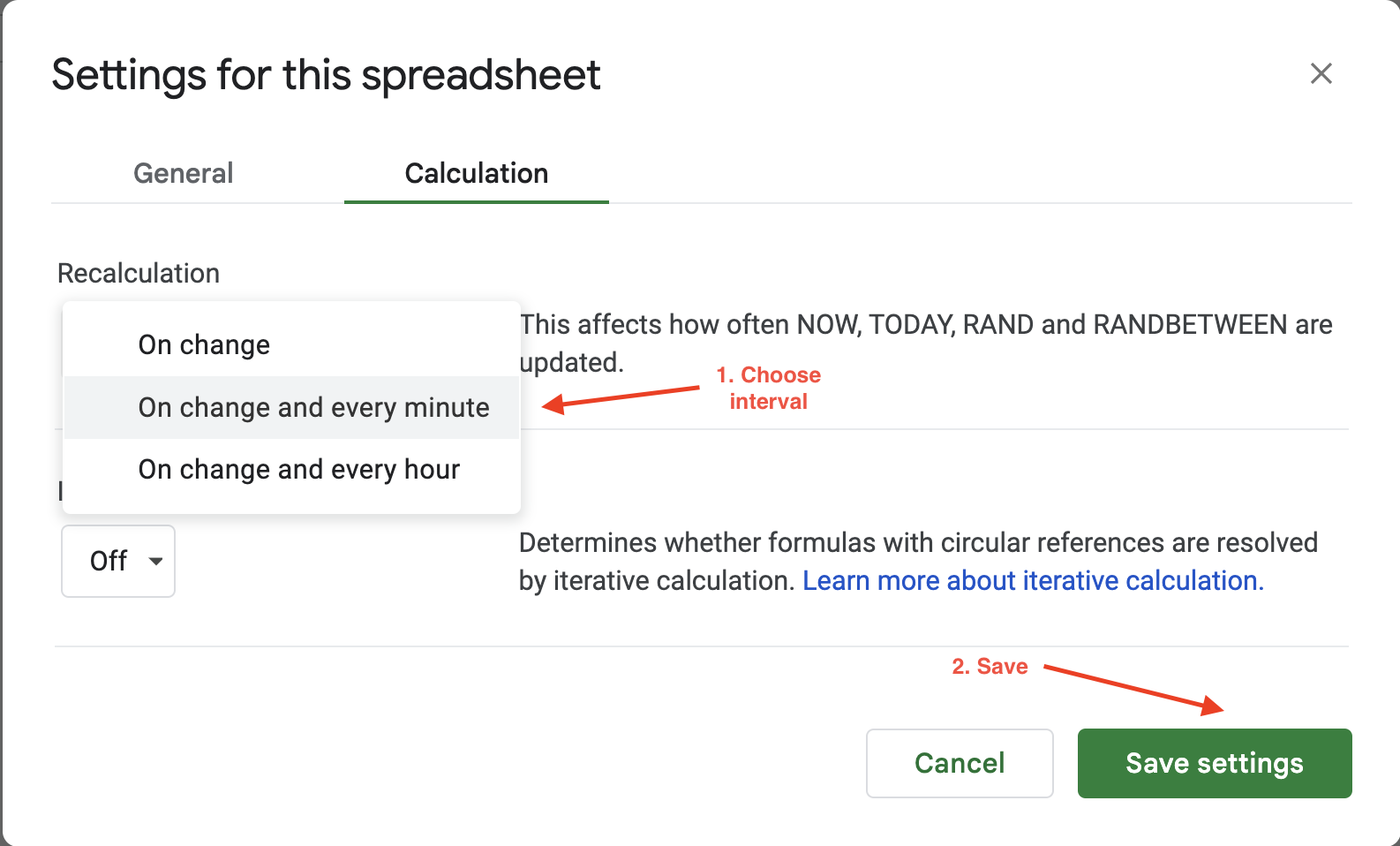
Google スプレッドシートの自動更新オプションでは、更新頻度やトリガーの設定に柔軟性が限られており、1時間ごとまたは1分ごとの2つの値から選択するのみです。より柔軟な設定をお求めの場合は、Bright Data が JSON、CSV、Parquet などの複数ファイル形式でクリーンかつ検証済み、最新のデータセットを提供します。そのため、大規模なスクレイピング作業に最適であり、膨大なスクレイピングインフラの維持が不要になります。
ベストプラクティスの実装とトラブルシューティング
スクレイピングの効率を向上させたい場合は、抽出するデータを選択的に行うようにしてください。不要なデータをスクレイピングしようとすると、プロセスが遅くなり、対象ウェブサイトの負荷が増加する可能性があります。
大量のデータをスクレイピングする場合は、リクエスト間に人工的な遅延を追加し、オフピーク時にタスクを実行することを検討してください。これにより、予期せぬトラフィックによるウェブサイトの過負荷を防げます。トラフィック量が多すぎると、IPブロックやレート制限が発生し、スクレイピングタスクを継続できなくなる可能性があります。ブロックされずにウェブサイトをスクレイピングする方法について詳しく学ぶ。
IPブロックに加え、ユーザーにCAPTCHAチャレンジを提示することも、ユーザーが人間であることを確認するまでコンテンツへのアクセスを制限する、ウェブサイトが採用する一般的なボット対策技術です。IPローテーションや自動CAPTCHAソルバーの恩恵を受ける高度なスクレイピングタスクには、Bright Dataのレジデンシャルプロキシの利用をご検討ください。
データスクレイピングを行う前には、必ずウェブサイトの利用規約を確認し、遵守していることを確認してください。スクリプトは、ウェブサイトとのやり取りにおいてrobot.txtの指示に従う必要があります。ウェブスクレイピングにおけるrobot.txtルールの使用方法の詳細については、こちらのガイドを参照してください。
結論
Google スプレッドシートは、動的コンテンツ、非表示要素、ページネーションを含まない静的ウェブサイトからのデータスクレイピングに最適です。本記事では、スクリプト作成の経験がなくても、IMPORTXML およびIMPORTHTML 関数を使用してデータ抽出タスクを簡単に自動化する方法を学びました。
動的コンテンツや大量データを含む複雑なウェブスクレイピング作業には、Bright Dataが提供する使いやすい柔軟でスケーラブルな高性能APIが最適です。JSON、CSV、NDJSONなど様々な形式でウェブデータをスクレイピング可能。内部ではIP/ユーザーエージェントローテーション、CAPTCHA、動的コンテンツ処理といった複雑なウェブスクレイピング作業を自動化します。 ウェブスクレイピングを次のレベルへ進化させる準備が整ったら、最高のウェブスクレイパーAPIの試用をご検討ください。
今すぐ無料トライアルに登録し、データワークフローの最適化を始めましょう!





