

ウェブスクレイピングでは、コンテンツが複数ページに分散するページネーションに頻繁に遭遇します。異なるウェブサイトが異なるページネーション手法を使用するため、この処理は困難を伴う場合があります。
本記事では、一般的なページネーション手法を解説し、実用的なコード例を用いてその処理方法を示します。
ページネーションとは?
ECプラットフォーム、求人サイト、ソーシャルメディアなどのウェブサイトは、大量のデータを管理するためにページネーションを利用しています。すべてのコンテンツを1ページに表示すると、読み込み時間が大幅に増加し、メモリを過剰に消費します。ページネーションはコンテンツを複数のページに分割し、「次へ」ボタン、ページ番号、スクロール時の自動読み込みなどのナビゲーションオプションを提供します。これにより、閲覧がより迅速かつ整理されたものになります。
ページネーションの種類
ページネーションの複雑さは、単純な番号付きページネーションから、無限スクロールや動的コンテンツ読み込みといった高度な技術まで様々です。私の経験上、ウェブサイトで最も一般的に使用されていると思われる3つの主要なページネーションの種類があります:
- 番号付きページネーション:番号付きリンクを使用して個別のページ間を移動します。
- クリック読み込み型ページネーション:ユーザーがボタン(「さらに読み込む」など)をクリックして追加コンテンツを読み込みます。
- 無限スクロール:ユーザーがページを下にスクロールすると、コンテンツが自動的に読み込まれます。
それでは、それぞれについて詳しく見ていきましょう!
番号付きページネーション
最も一般的なページネーション手法で、「次ページ/前ページ移動」「矢印ナビゲーション」「URLベースのページネーション」とも呼ばれます。名称は異なりますが、ページ番号付きリンクでページを連結するという基本原理は共通です。URL内のページ番号を変更することで移動できます。ページネーションの終了判断には、「次へ」ボタンが無効化されるか、新規データが存在しない状態を確認します。
通常は以下のような見た目になります:

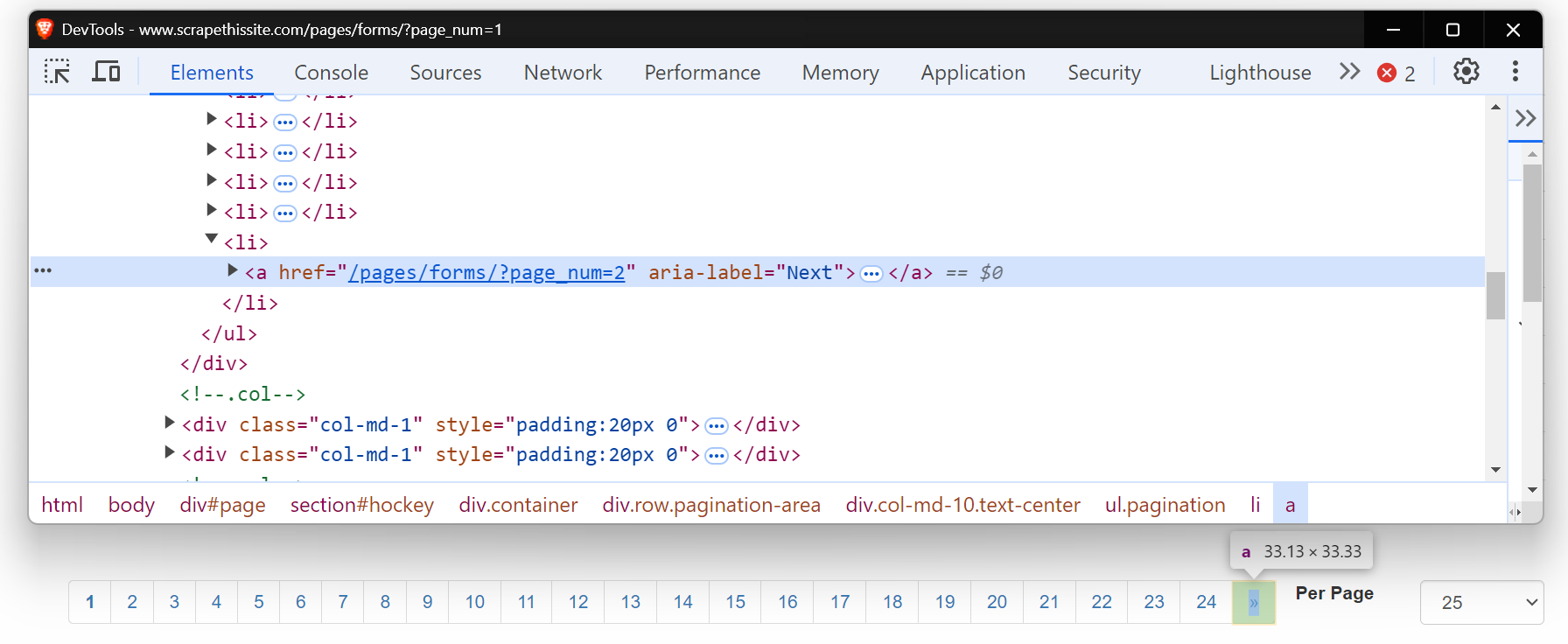
`例を見てみましょう!ウェブサイトScrapethesiteの全ページを閲覧します。このサイトのページネーションバーは全24ページで構成されています。

「>>」ボタンをクリックすると、URLが以下のように変化することに気づくでしょう:
- 1ページ目:https://www.scrapethissite.com/pages/forms/
- 2ページ目:https://www.scrapethissite.com/pages/forms/?page_num=2
- 3ページ目:https://www.scrapethissite.com/pages/forms/?page_num=3
次に、この「次へ」ボタンのHTMLを確認しましょう。これはアンカータグ(<a>)であり、href属性で次のページへリンクしています。aria-label属性は「次へ」ボタンがまだアクティブであることを示しています。
ページがこれ以上ない場合、aria-labelは存在せず、ページネーションの終了を示します。
まず、これらのページをナビゲートする基本的なウェブスクレイパーを作成しましょう。最初に、必要なパッケージをインストールして環境を整えます。Python を使ったウェブスクレイピングの詳細なガイドについては、こちらの詳細なブログ記事を参照してください。
pip install requests beautifulsoup4 lxml各ページをページネーションするコードは以下の通りです:
import requests
from bs4 import BeautifulSoup
base_url = "https://www.scrapethissite.com/pages/forms/?page_num="
# 1ページ目から開始
page_num = 1
while True:
url = f"{base_url}{page_num}"
response = requests.get(url)
soup = BeautifulSoup(response.content, "lxml")
print(f"現在のページ: {page_num}")
# 「次へ」ボタンが存在するかの確認
next_button = soup.find("a", {"aria-label": "Next"})
if next_button:
# 次のページへ移動
page_num += 1
else:
# ページ終了、ループ終了
print("最終ページに到達しました。")
breakこのコードは「次へ」ボタン(aria-label="Next")の存在を確認しながらページを移動します。ボタンが存在する場合、page_numをインクリメントし、更新されたURLで新たなリクエストを発行します。ループは「次へ」ボタンが見つからなくなる(最終ページを示す)まで継続します。
コードを実行すると、全ページを正常に巡回できたことが確認できます。

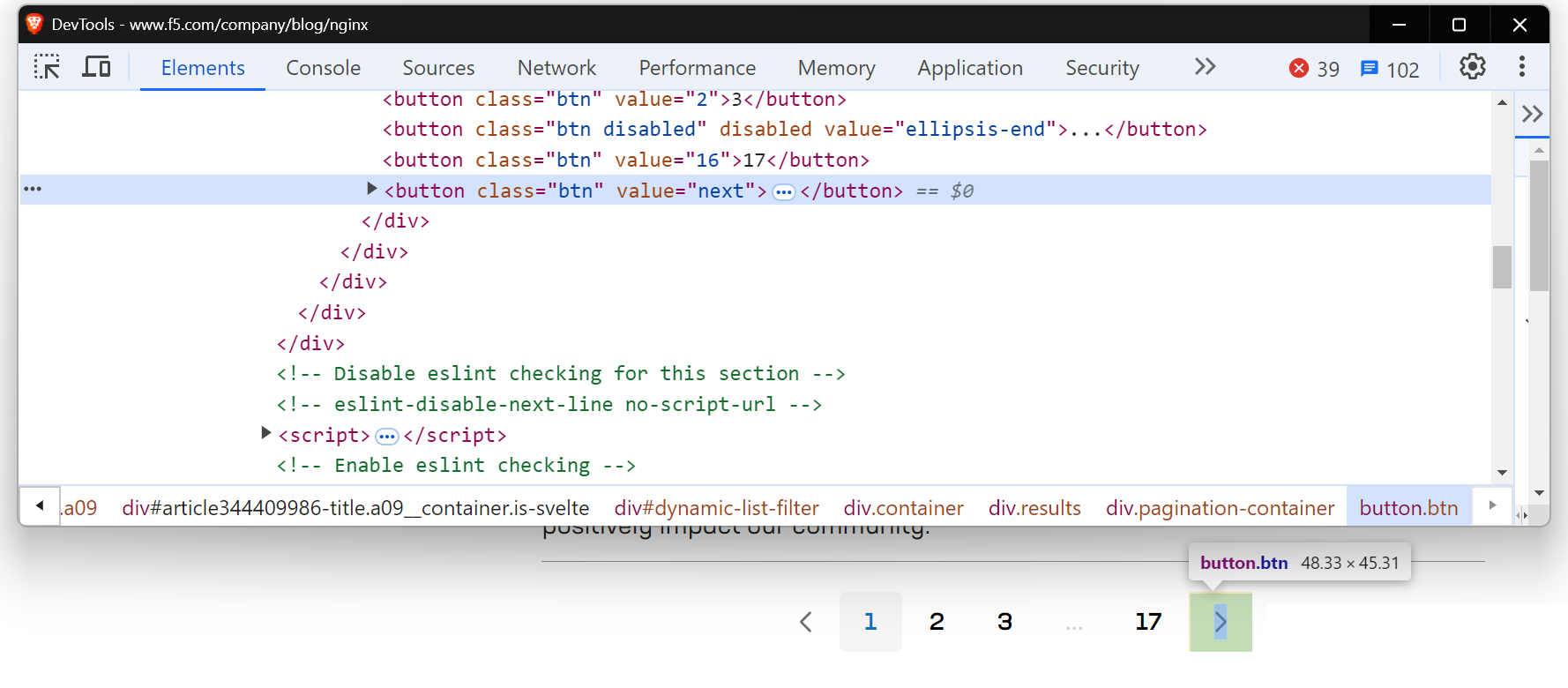
一部のウェブサイトでは、URLを変更せずに同じページ上で新しいコンテンツを読み込む「次へ」ボタンがあります。このような場合、従来のウェブスクレイピング手法ではうまく機能しない可能性があります。SeleniumやPlaywrightのようなツールは、ページと対話し、ボタンクリックなどの操作をシミュレートして動的に読み込まれたコンテンツを取得できるため、より適しています。このようなタスクにSeleniumを使用する方法の詳細については、こちらの詳細ガイドを参照してください。
NGINXのブログページをスクレイピングする際にも同様の状況に遭遇します。
動的に読み込まれるコンテンツの処理にはPlaywrightを使用しましょう。Playwrightが初めての方は、こちらの便利な入門ガイドを参照してください。
コードを書く前に、以下のコマンドを実行してマシンにPlaywrightをセットアップしてください:
pip install playwright
playwright installコードは以下の通りです:
import asyncio
from playwright.async_api import async_playwright
# 非同期関数を定義
async def scrape_nginx_blog():
async with async_playwright() as p:
# ヘッドレスモードでChromiumブラウザインスタンスを起動
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()()
# NGINXブログページへ移動
await page.goto("https://www.f5.com/company/blog/nginx")
page_num = 1
while True:
print(f"現在 {page_num} ページを表示中")
# 値 "next" を持つボタンロケーターで「次へ」ボタンを検索
next_button = page.locator('button[value="next"]')
# 「次へ」ボタンが有効かどうかを確認
if await next_button.is_enabled():
await next_button.click() # 「次へ」ボタンをクリックして次のページへ移動
await page.wait_for_timeout(
2000
) # 新しいコンテンツが読み込まれるまで2秒待機
page_num += 1
else:
print("ページがありません。スクレイピング終了しました。")
break # ページがこれ以上ない場合はループを終了
await browser.close() # ブラウザを閉じる
# 非同期スクレイピング関数を実行
asyncio.run(scrape_nginx_blog())このコードは非同期のPlaywrightを使用して全ページを巡回します。ループに入り「次へ」ボタンをチェックします。ボタンが有効ならクリックして次ページへ移動し、コンテンツの読み込みを待ちます。この処理はページがなくなるまで繰り返されます。最後にスクレイピング完了後、ブラウザを閉じます。
コードを実行すると、全ページへのナビゲーションが成功したことが確認できます。
クリックで読み込むページネーション
多くのウェブサイトで「さらに読み込む」「もっと見る」「続きを表示」といったボタンを目にしたことがあるでしょう。これらはクリックで読み込むページネーションの例であり、現代的なサイトで一般的に使用されています。これらのボタンはJavaScriptを通じて動的にコンテンツを読み込みます。ここでの主な課題は、ユーザー操作をシミュレートすること、つまりボタンをクリックしてコンテンツを読み込むプロセスを自動化することです。
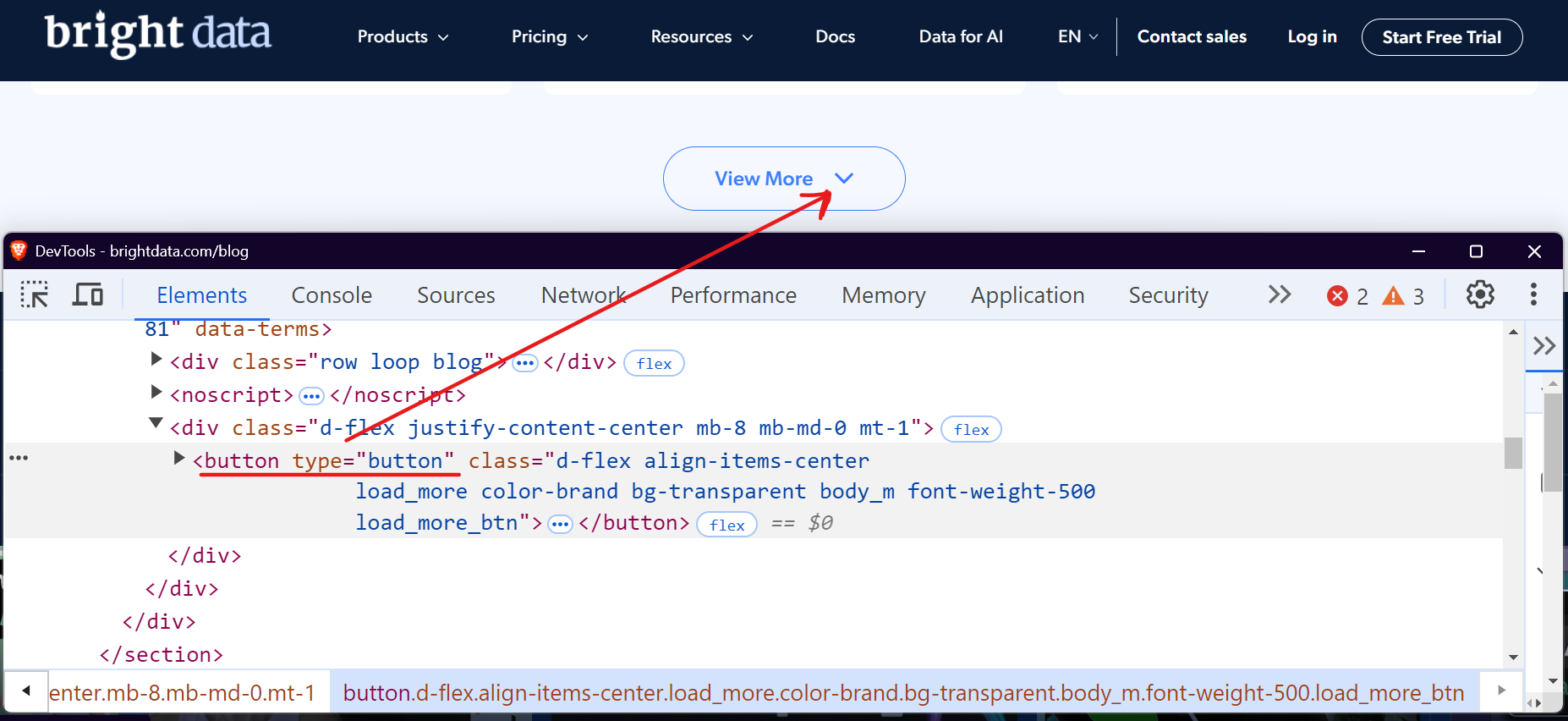
Bright Dataのブログセクションを例に挙げましょう。訪問してスクロールすると、「さらに表示」ボタンがあり、クリックするとブログ記事が読み込まれます。
SeleniumやPlaywrightなどのツールを使用すれば、コンテンツがなくなるまで「Load More」ボタンを繰り返しクリックするこのプロセスを自動化できます。Playwrightでこれを簡単に処理する方法を見てみましょう。
import asyncio
from playwright.async_api import async_playwright
async def scrape_brightdata_blog():
async with async_playwright() as p:
# ヘッドレスブラウザを起動
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Bright Dataブログへ移動
await page.goto("https://brightdata.com/blog")
page_num = 1
while True:
print(f"現在{page_num}ページを表示中")
# 「View More」ボタンを特定
view_more_button = page.locator("button.load_more_btn")
# ボタンが表示され有効か確認
if (
await view_more_button.count() > 0
and await view_more_button.is_visible()
):
await view_more_button.click()
await page.wait_for_timeout(2000)
page_num += 1
else:
print("読み込むページはありません。スクレイピング終了しました。")
break
# ブラウザを閉じる
await browser.close()
# スクレイピング関数を実行
asyncio.run(scrape_brightdata_blog())このコードはCSSセレクタ `button.load_more_btn`を使用して「View More」ボタンを特定します。その後、`count() > 0`と`is_visible()`を用いてボタンの存在と可視性を確認します。ボタンが可視の場合、`click()`メソッドで操作し、新規コンテンツの読み込みを待つため2秒間待機します。この処理はボタンが非表示になるまでループで繰り返されます。
コードを実行すると、全ページを正常に巡回できたことが確認できます。

Bright Dataブログセクションの全52ページをスクレイピングに成功しました。これによりサイトが合計52ページ存在することが判明しましたが、これはスクレイピング後に初めて明らかになった事実です。ただし、スクレイピング前に総ページ数を把握する方法は存在します。
これを行うには、開発者ツールを開き、「ネットワーク」タブに移動し、「フェッチ/XHR」を選択してリクエストをフィルタリングします。次に、「さらに表示」ボタンを再度クリックすると、AJAXリクエストがトリガーされることに気づくでしょう。
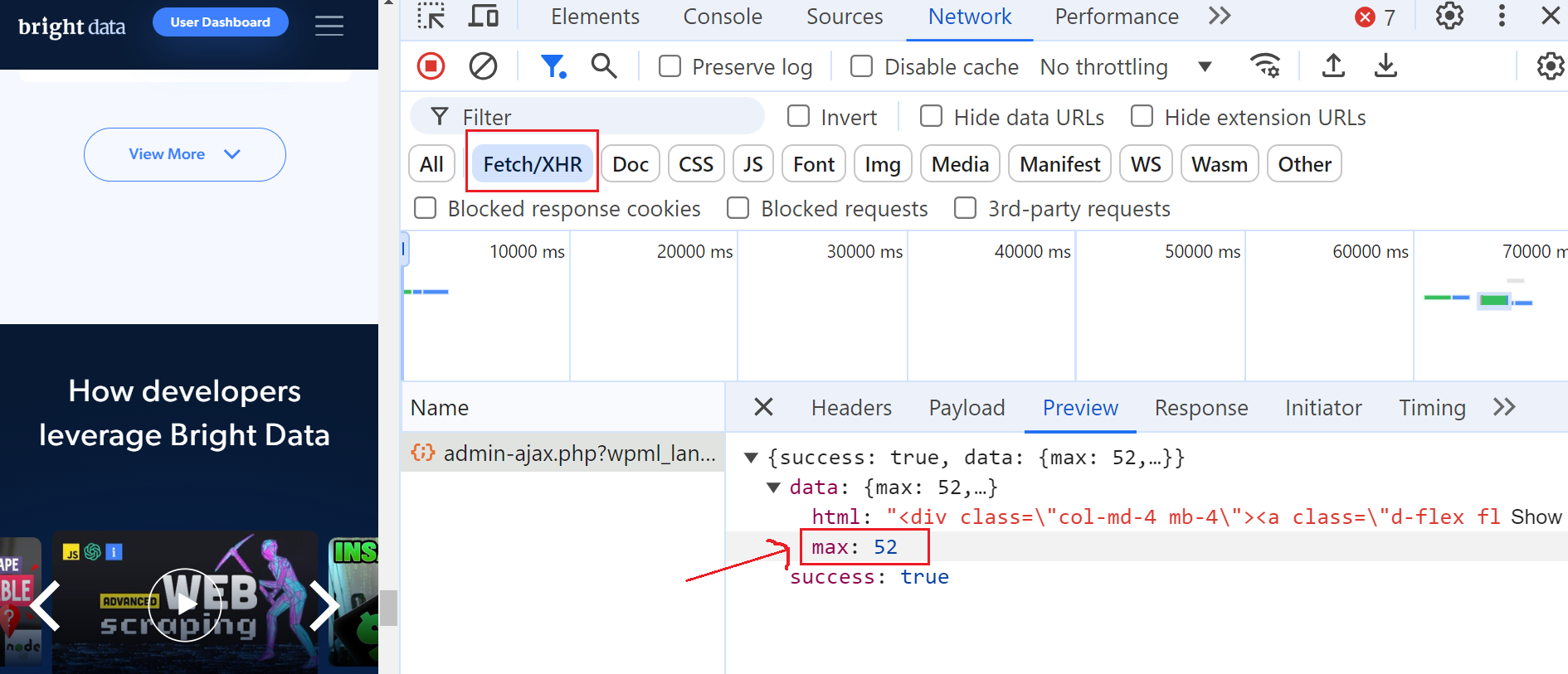
このリクエストをクリックし、「プレビュー」セクションに移動すると、最大ページ数が52であることが確認できます。次に「ペイロード」セクションを見ると、1ページあたり6件のブログ投稿があり、現在3ページ目にいることがわかります。
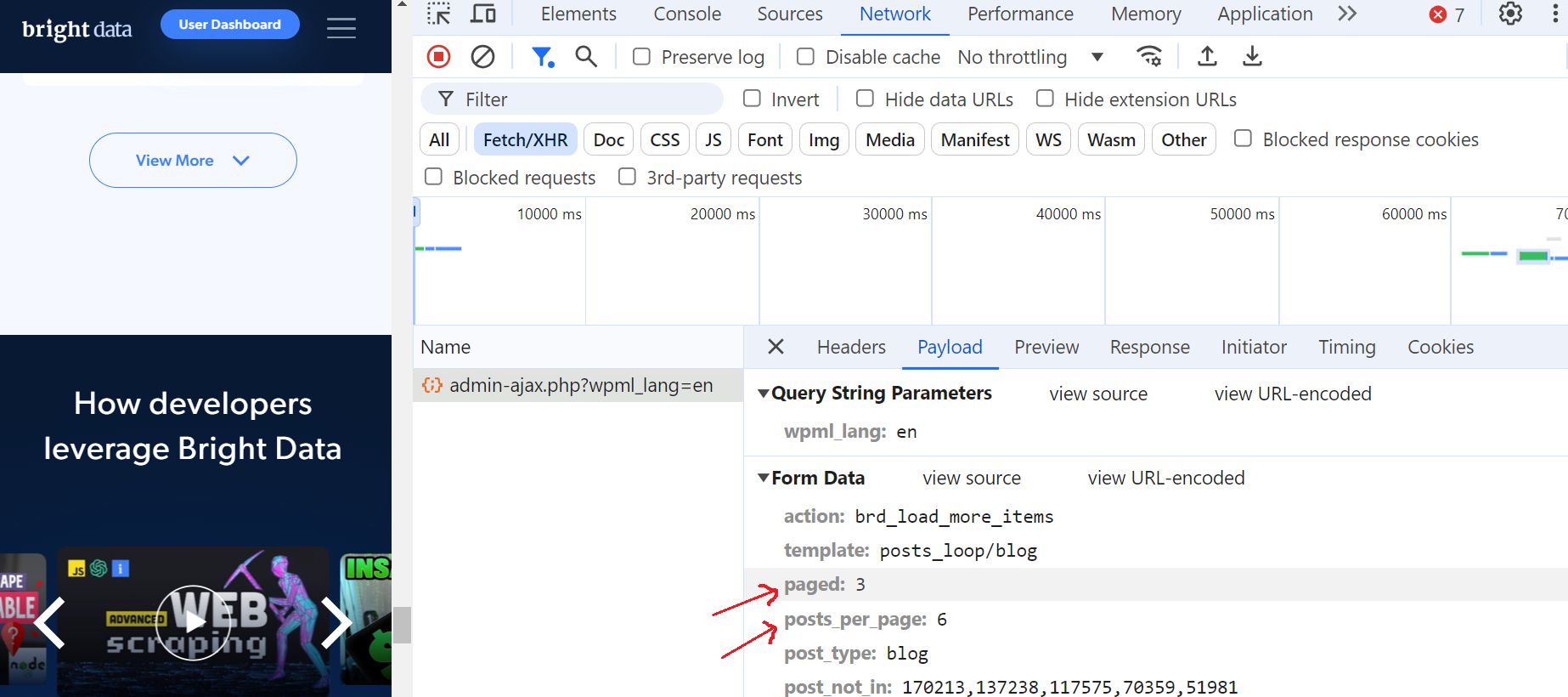
これは素晴らしい!
無限スクロールによるページネーション
多くのウェブサイトでは「前へ/次へ」ボタンに代わり、無限スクロールが採用されています。これによりユーザーは複数ページをクリックする必要がなくなり、ユーザー体験が向上します。この技術はユーザーがスクロールするたびに自動的に新しいコンテンツを読み込みます。しかし、DOMの変更を監視しAJAXリクエストを処理する必要があるため、ウェブスクレイパーにとっては特有の課題をもたらします。
実際の例を見てみましょう。ナイキのウェブサイトを訪れると、スクロールダウンするにつれて靴が自動的に読み込まれることに気づくでしょう。スクロールするたびにローディングアイコンが短時間表示され、瞬く間に以下の画像のようにさらに多くの靴が表示されます:
リクエスト(d9a5bc)をクリックすると、「応答」タブに現在のページの全データが表示されます。
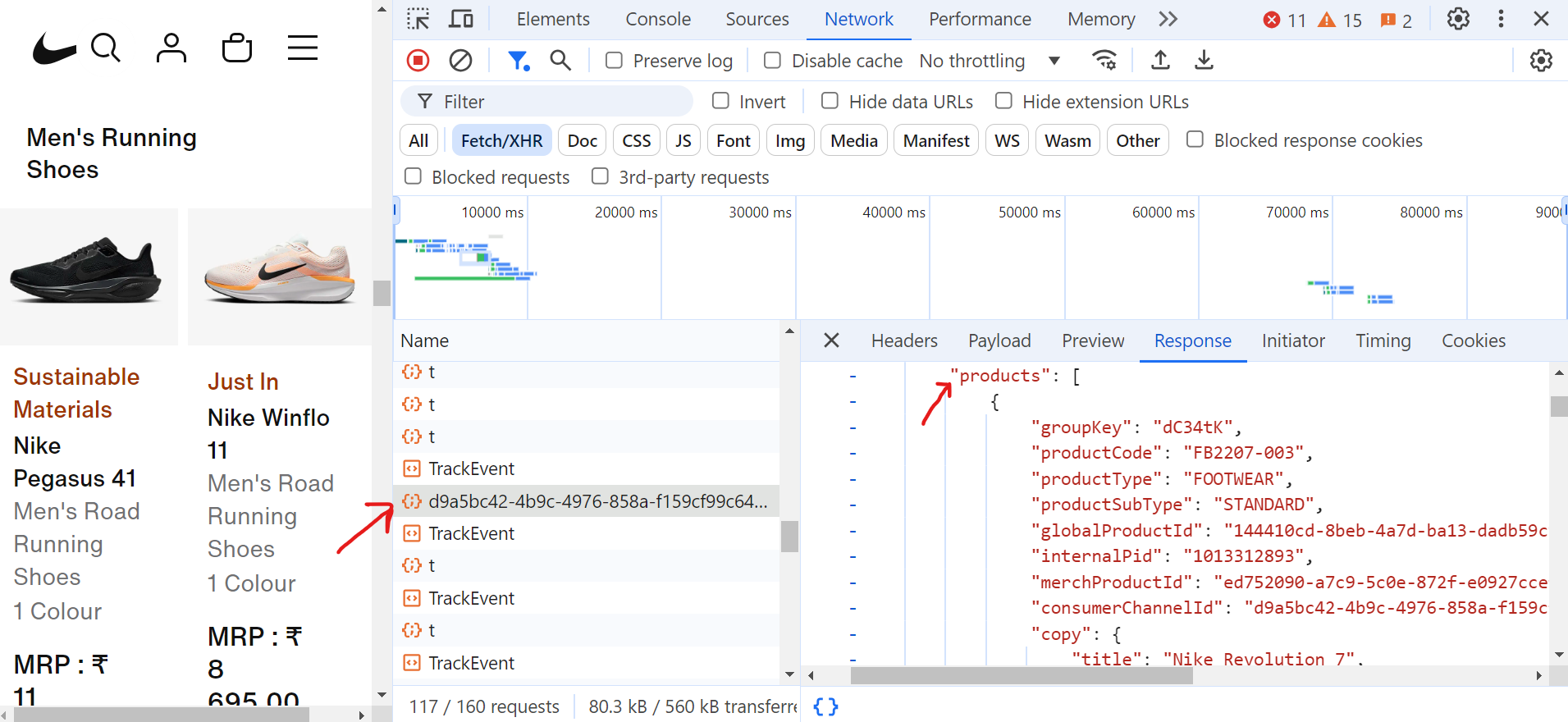
ページネーションを処理するには、ページ末尾までスクロールし続ける必要があります。スクロール中、ブラウザは多数のリクエストを送信しますが、必要な実際のデータを含むフェッチ/XHRリクエストは一部のみです。
以下はページネーションを処理し靴のタイトルを抽出するコードです:
import asyncio
from urllib.parse import parse_qs, urlparse
from playwright.async_api import async_playwright
async def scroll_to_bottom(page) -> None:
"""ページの下部までスクロールし、コンテンツの読み込みが終了するまで処理を続ける"""
last_height = await page.evaluate("document.body.scrollHeight")
scroll_count = 0
while True:
# スクロールダウン
await page.evaluate("window.scrollTo(0, document.body.scrollHeight);")
await asyncio.sleep(2) # 新しいコンテンツの読み込み待ち
scroll_count += 1
print(f"スクロール反復回数: {scroll_count}")
# スクロール高さが変化したか確認
new_height = await page.evaluate("document.body.scrollHeight")
if new_height == last_height:
print("ページ最下部まで到達しました。")
break # 新しいコンテンツが読み込まれなかった場合終了
last_height = new_height
async def extract_product_data(response, extracted_products) -> None:
"""レスポンスから製品データを抽出する"""
parsed_url = urlparse(response.url)
query_params = parse_qs(parsed_url.query)
if "queryType" in query_params and query_params["queryType"][0] == "PRODUCTS":
data = await response.json()
for grouping in data.get("productGroupings", []):
for product in grouping.get("products", []):
title = product.get("copy", {}).get("title")
extracted_products.append({"title": title})
async def scrape_shoes(target_url: str) -> None:
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=True)
page = await browser.new_page()
extracted_products = []
# 製品データ応答のリスナー設定
page.on(
"response",
lambda response: extract_product_data(
response, extracted_products),
)
# ページに移動し、最下部までスクロール
print("ページに移動中...")
await page.goto(target_url, wait_until="domcontentloaded")
await asyncio.sleep(2)
await scroll_to_bottom(page)
# 商品タイトルをテキストファイルに保存
with open("product_titles.txt", "w") as title_file:
for product in extracted_products:
title_file.write(product["title"] + "n")
print(f"スクレイピング完了!")
await browser.close()
if __name__ == "__main__":
asyncio.run(
scrape_shoes(
"https://www.nike.com/in/w/mens-running-shoes-37v7jznik1zy7ok")
)コード内の`scroll_to_bottom`関数は、ページ下部にコンテンツが追加されるよう継続的にスクロールします。まず現在のスクロール位置を記録し、その後繰り返し下方向にスクロールします。各スクロール後、新たなスクロール位置が前回記録した位置と異なるか確認します。位置が変化しない場合、コンテンツの追加読み込みが終了したと判断しループを終了します。この手法により、スクレイピング処理を継続する前に、利用可能な全商品が完全に読み込まれることが保証されます。
コードを実行すると以下の動作が発生します:

コードが正常に実行されると、ナイキのシューズ全商品のタイトルを収録した新しいテキストファイルが作成されます。
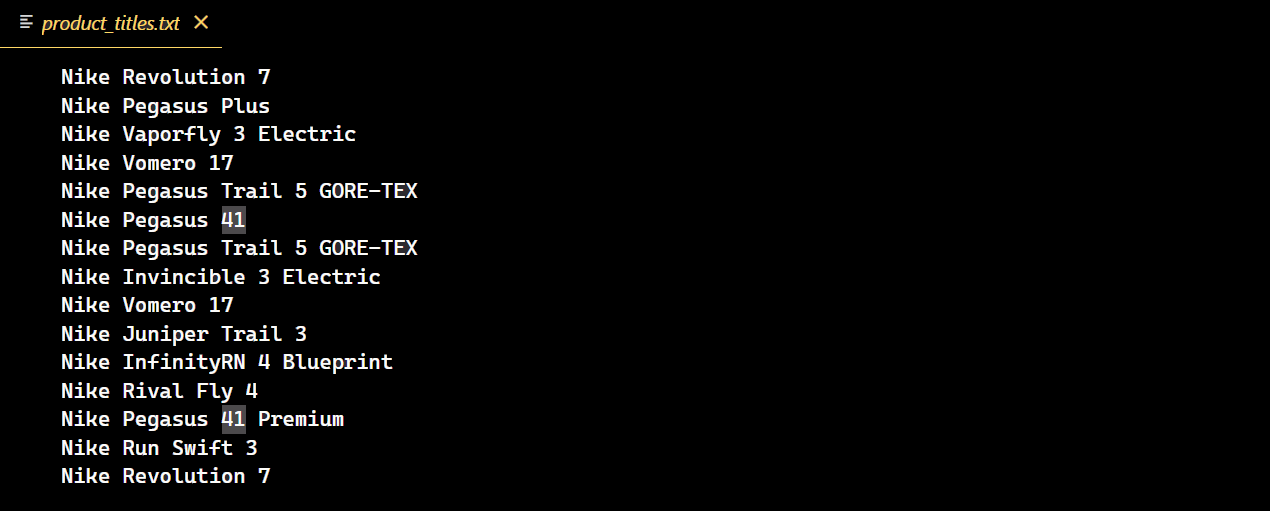
ページネーションにおける課題
ページネーションされたコンテンツを扱う場合、ブロックされるリスクが高まります。一部のウェブサイトでは、たった1ページスクロールしただけでブロックされる可能性があります。例えば、Glassdoorのスクレイピングを試みると、様々なウェブスクレイピングの課題に直面する可能性があります。私が経験したように、Cloudflare CAPTCHAチャレンジもその一つです。
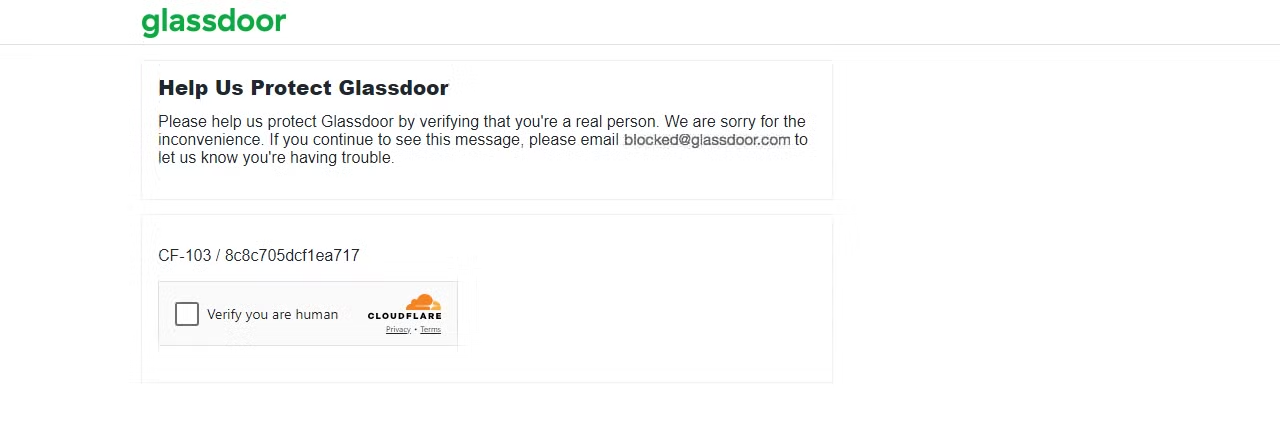
Glassdoorページにリクエストを送信して結果を確認しましょう。
import requests
url = "https://www.glassdoor.com/"
response = requests.get(url)
print(f"Status code: {response.status_code}")結果は403ステータスコードです。
これはGlassdoorがあなたのリクエストをボットやスクレイパーからのものと検知し、CAPTCHAチャレンジを発生させたことを示しています。複数のリクエストを送り続けると、IPが即座にブロックされる可能性があります。
これらのブロックを回避し、必要なデータを効果的に抽出するには、Python Requestsでプロキシを使用してIP禁止を回避するか、ユーザーエージェントをローテーションさせて実際のブラウザを模倣する方法があります。ただし、これらの方法のいずれも高度なボット検出を確実に回避できるわけではないことに注意が必要です。
では、究極の解決策とは? 次にその詳細を見ていきましょう!
Bright Dataソリューションの導入
Bright Dataは高度な反ボット対策を回避する優れたソリューションです。わずか数行のコードでプロジェクトにシームレスに統合でき、あらゆる高度な反ボットメカニズムに対応する多様なソリューションを提供します。
その一つがWebスクレイパーAPIです。IPローテーションとCAPTCHAの解決を自動処理することで、あらゆるウェブサイトからのデータ抽出を簡素化します。これにより、データ取得の複雑さではなく、データ分析に集中できます。
例えば、GlassdoorのCAPTCHA回避に課題が生じた場合、Bright DataのGlassdoorスクレイパーAPIを活用できます。このAPIは障害を回避し、サイトからシームレスにデータを抽出するよう特別に設計されています。
GlassdoorスクレイパーAPIの利用開始手順は以下の通りです:
まずアカウントを作成します。Bright Dataのウェブサイトにアクセスし、「無料トライアルを開始」をクリックして登録手順に従ってください。ログイン後、ダッシュボードにリダイレクトされ、無料クレジットが付与されます。
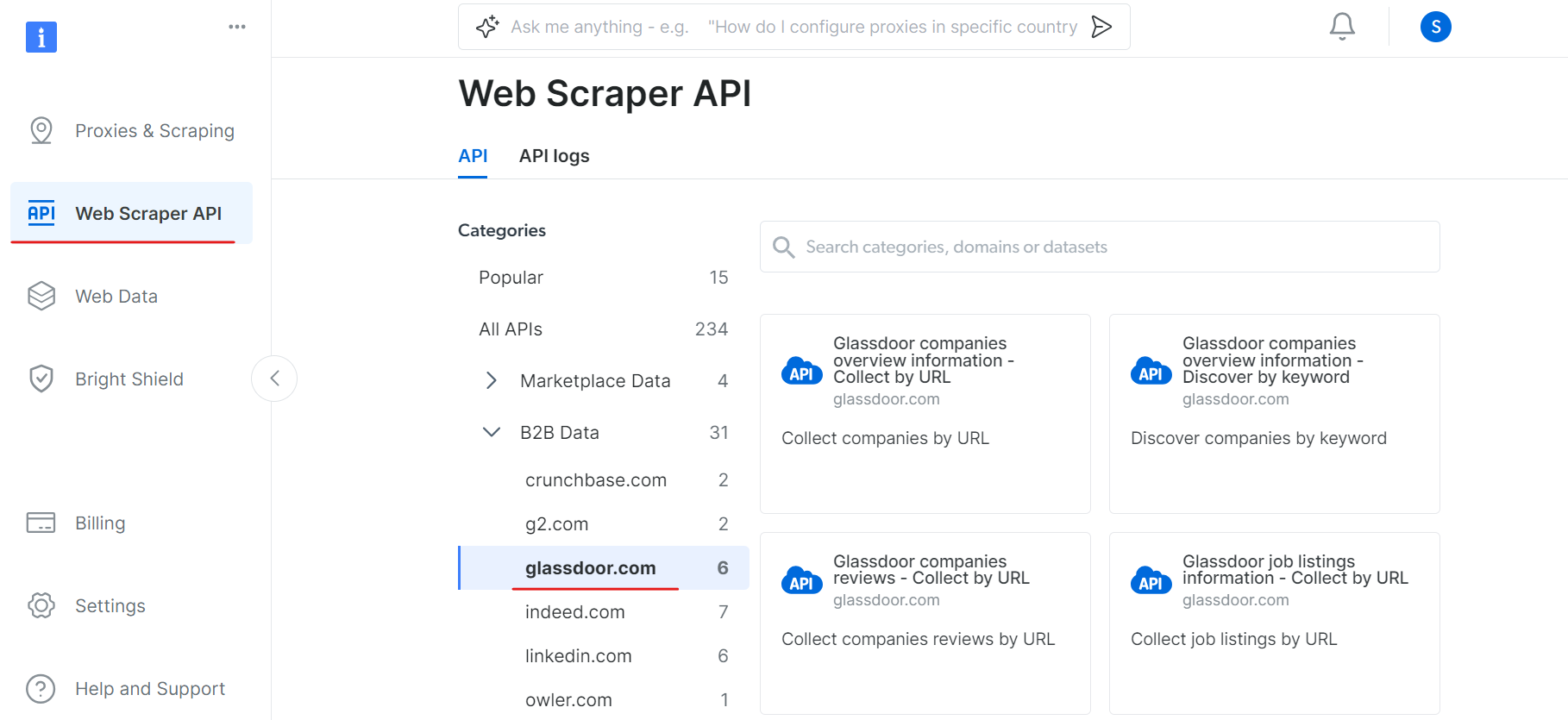
次に、WebスクレイパーAPIセクションに移動し、B2BデータカテゴリからGlassdoorを選択します。URLによる企業収集やURLによる求人情報収集など、様々なデータ収集オプションが用意されています。
「Glassdoor企業概要情報」セクションでAPIトークンを取得し、データセットID(例:gd_l7j0bx501ockwldaqf)をコピーします。
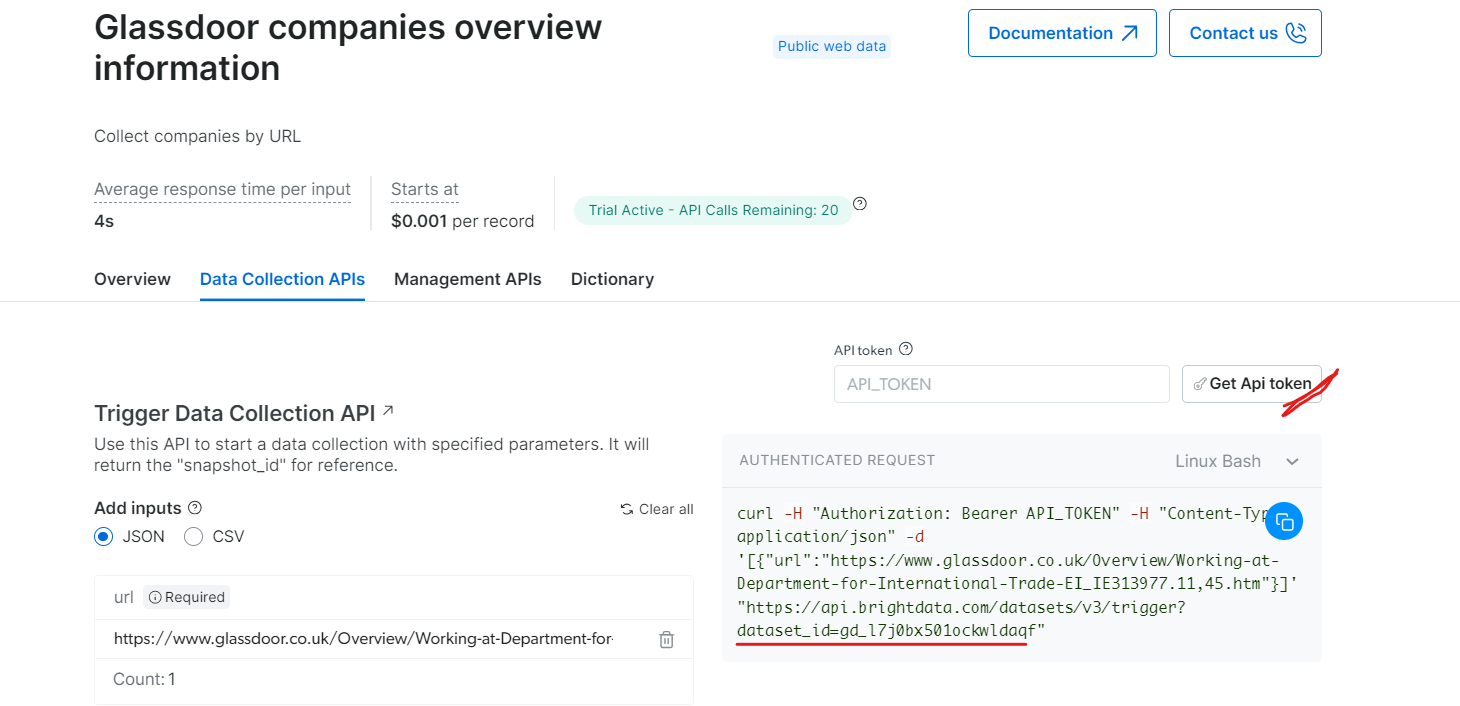
以下は、URL、APIトークン、データセットIDを指定して企業データを抽出するシンプルなコードスニペットです。
import requests
import json
def trigger_dataset(api_token, dataset_id, company_url):
"""
BrightData APIを使用してデータセットをトリガーします。
引数:
api_token (str): 認証用のAPIトークン。
dataset_id (str): トリガーするデータセットID。
company_url (str): 分析対象の企業ページのURL。
Returns:
dict: APIからのJSONレスポンス。
"""
headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
payload = json.dumps([{"url": company_url}])
response = requests.post(
"https://api.brightdata.com/データセット/v3/トリガー",
headers=headers,
params={"データセットID": dataset_id},
data=payload,
)
return response.json()
api_token = "API_Token"
dataset_id = "DATASET_ID"
company_url = "https://www.glassdoor.com/"
response_data = trigger_dataset(api_token, dataset_id, company_url)
print(response_data)コードを実行すると、以下のようにスナップショットIDが取得できます:

スナップショットIDを使用して、企業の実際のデータを取得します。ターミナルで以下のコマンドを実行してください。Windowsの場合は以下を使用します:
curl.exe -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/データセット/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"Linuxの場合:
curl -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/データセット/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"コマンドを実行すると、目的のデータが取得できます。
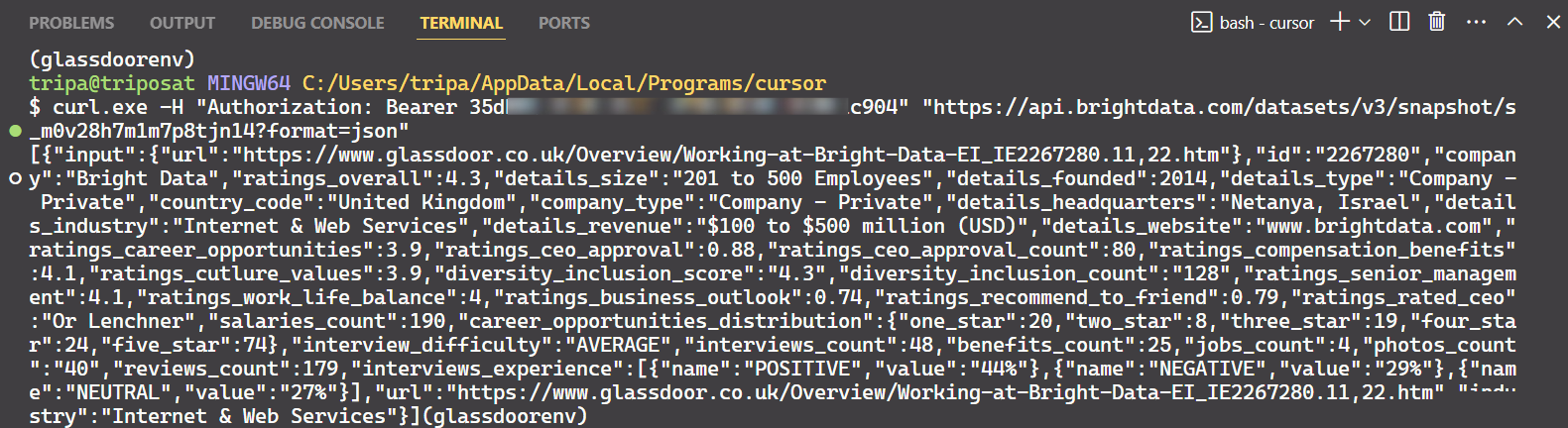
これで完了です!
同様に、コードを修正することでGlassdoorから様々な種類のデータを抽出できます。ここでは1つの方法を説明しましたが、他にも5つの方法があります。必要なデータをスクレイピングするには、これらのオプションを探ってみることをお勧めします。各方法は特定のデータニーズに合わせて設計されており、必要なデータを正確に取得するのに役立ちます。
まとめ
本記事では、番号付きページネーション、「さらに読み込む」ボタン、無限スクロールなど、現代のウェブサイトで一般的に使用される様々なページネーション手法について解説しました。また、これらのページネーション技術を効果的に実装するためのコード例も提供しました。ただし、ページネーションの処理はウェブスクレイピングの一部に過ぎず、ボット対策の回避が大きな課題となります。
高度なボット検知回避は極めて複雑で、成功率もまちまちです。Bright Dataのツール群(Web Unlocker、スクレイピングブラウザ、Web Scraper API)は、あらゆるウェブスクレイピングニーズに対応する効率的で費用対効果の高いソリューションを提供します。わずか数行のコードで、複雑なボット対策の管理に煩わされることなく、高い成功率を実現できます。
スクレイピングプロセス自体に関与したくない方へ:当社のデータセットマーケットプレイスをご覧ください!
今すぐ無料トライアルに登録しましょう。





