

この実践チュートリアルでは、Playwright Python を使用してGlassdoorからデータをスクレイピングする方法を学びます。また、Glassdoorが採用している反スクレイピング対策と、Bright Dataがどのように役立つかについても理解します。さらに、Glassdoorのスクレイピングを大幅に高速化するBright Dataのソリューションについても学びます。
スクレイピングをスキップしてデータを取得
スクレイピングプロセスをスキップして直接データにアクセスしたいですか?当社のGlassdoorデータセットをご検討ください。
Glassdoorデータセットは、求人や企業に関する洞察を提供するレビューやFAQを含む、完全な企業概要を提供します。当社のGlassdoorデータセットを活用すれば、企業の市場動向やビジネス情報、現従業員・元従業員の評価や認識を把握できます。ご要件に応じて、データセット全体またはカスタマイズされたサブセットをご購入いただけます。
データセットはJSON、NDJSON、JSON Lines、CSV、Parquetなどの形式で提供され、オプションで.gzファイルに圧縮することも可能です。
Glassdoorのスクレイピングは合法ですか?
はい、Glassdoorからのデータスクレイピングは合法です。ただし、倫理的に行われ、Glassdoorの利用規約、robots.txtファイル、プライバシーポリシーに準拠している必要があります。最大の誤解の一つは、企業レビューや求人情報といった公開データのスクレイピングが違法であるというものです。しかし、これは事実ではありません。法的・倫理的な範囲内で実施されるべきです。
Glassdoorデータのスクレイピング方法
GlassdoorはコンテンツのレンダリングにJavaScriptを使用しているため、スクレイピングが複雑になる場合があります。これを処理するには、JavaScriptを実行しブラウザのようにウェブページとやり取りできるツールが必要です。代表的な選択肢としてPlaywright、Puppeteer、Seleniumがあります。このチュートリアルではPlaywright Pythonを使用します。
さあ、Glassdoorスクレイパーを一から構築しましょう!Playwrightが初めての方でも、既に使い慣れている方でも、このチュートリアルはPlaywright Pythonを使用したウェブスクレイパーの構築を支援します。
作業環境のセットアップ
始める前に、お使いのマシンに以下の環境が整っていることを確認してください:
- 公式ウェブサイト
- Visual Studio Code
次に、ターミナルを開き、Pythonプロジェクト用の新しいフォルダを作成し、そのフォルダに移動します:
mkdir glassdoor-scraper
cd glassdoor-scraper
仮想環境を作成して有効化します:
python -m venv glassdoorenv
glassdoorenvScriptsactivate
Playwrightをインストールします:
pip install playwright
次に、ブラウザバイナリをインストール:
playwright install
インストールには時間がかかる場合がありますので、しばらくお待ちください。
完全なセットアップ手順は以下の通りです:
これで準備が整い、Glassdoorスクレイパーコードの記述を開始できます!
Glassdoorウェブサイトの構造を理解する
Glassdoorのスクレイピングを始める前に、その構造を理解することが重要です。このチュートリアルでは、特定の地域にある企業で特定の職種をスクレイピングすることに焦点を当てます。
例えば、ニューヨーク市に所在し、機械学習関連の職種を募集しており、総合評価が3.5以上の企業を検索したい場合、適切なフィルターを適用する必要があります。
Glassdoorの企業ページをご覧ください:
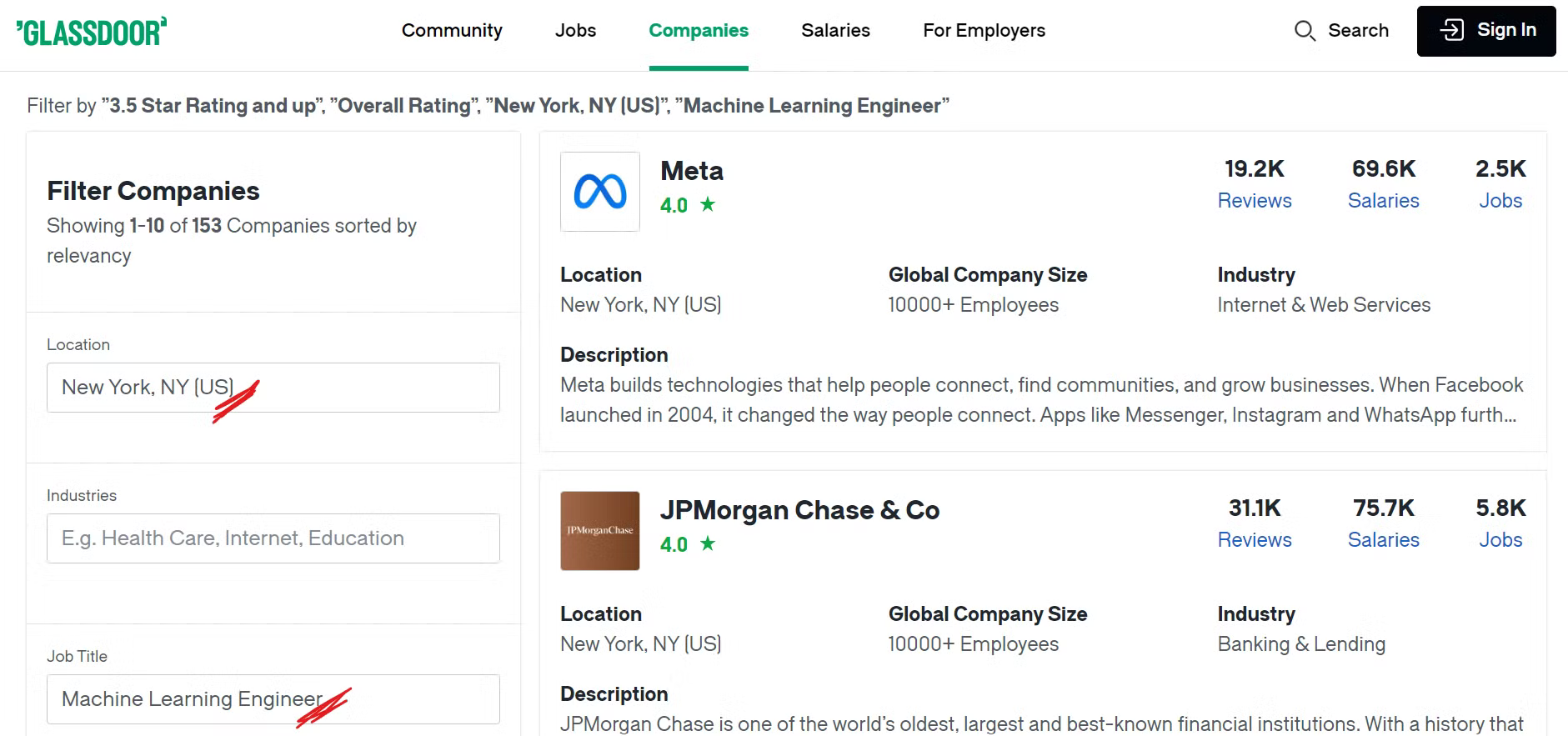
ここで、希望するフィルターを適用した結果、多くの企業がリストアップされているのがわかります。では、具体的にどのようなデータをスクレイピングするのか、次に見ていきましょう!
主要データポイントの特定
Glassdoorから効果的にデータを収集するには、スクレイピング対象となるコンテンツを特定する必要があります。
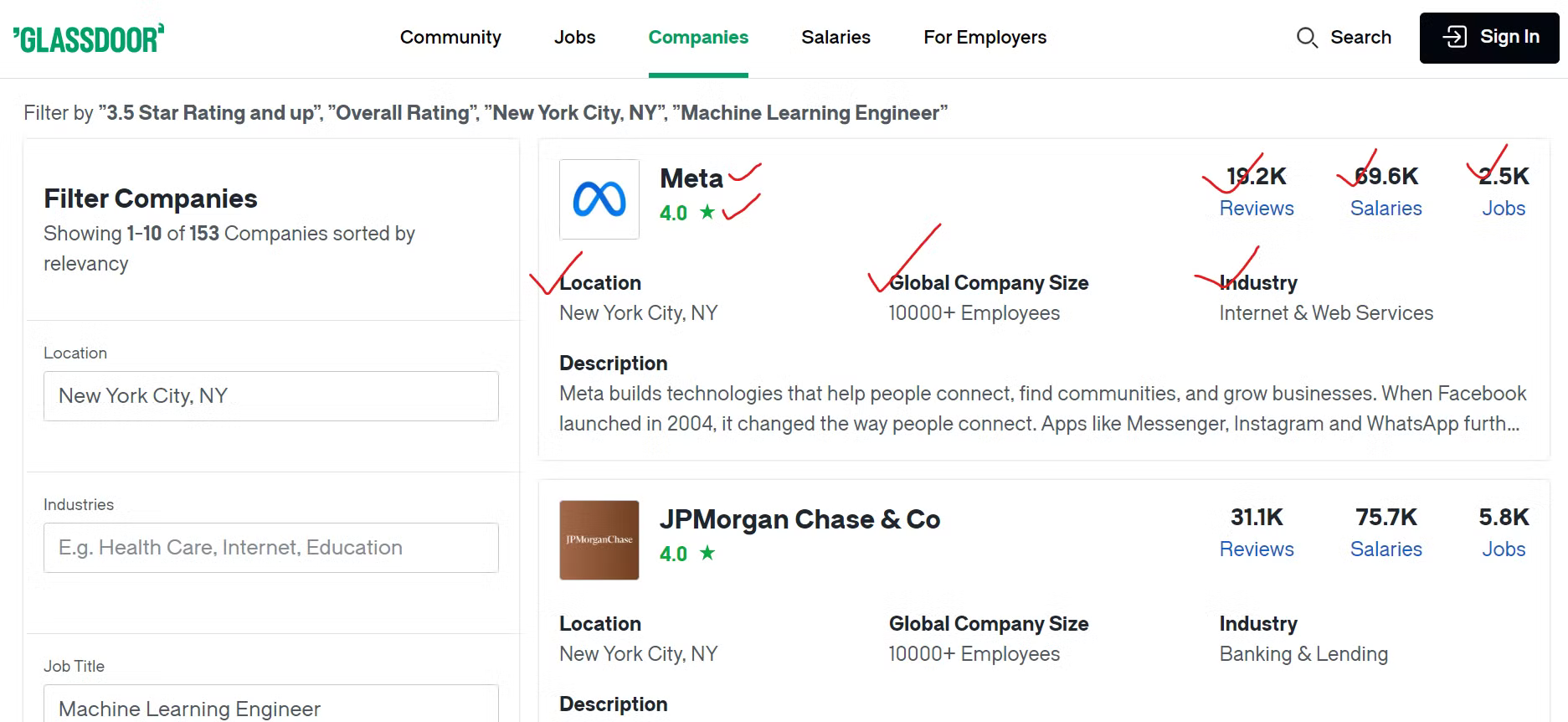
各企業について、会社名、求人情報へのリンク、求人総数などの詳細情報を抽出します。さらに、従業員レビュー数、報告された給与件数、企業の事業分野もスクレイピングします。また、企業の所在地と全世界の従業員総数も抽出します。
Glassdoorスクレイパーの構築
スクレイピング対象データを特定したところで、Playwright Pythonを使用したスクレイパーの構築に取り掛かりましょう。
まず、Glassdoorのウェブサイトを調査し、下図のように会社名と評価の要素を特定します:
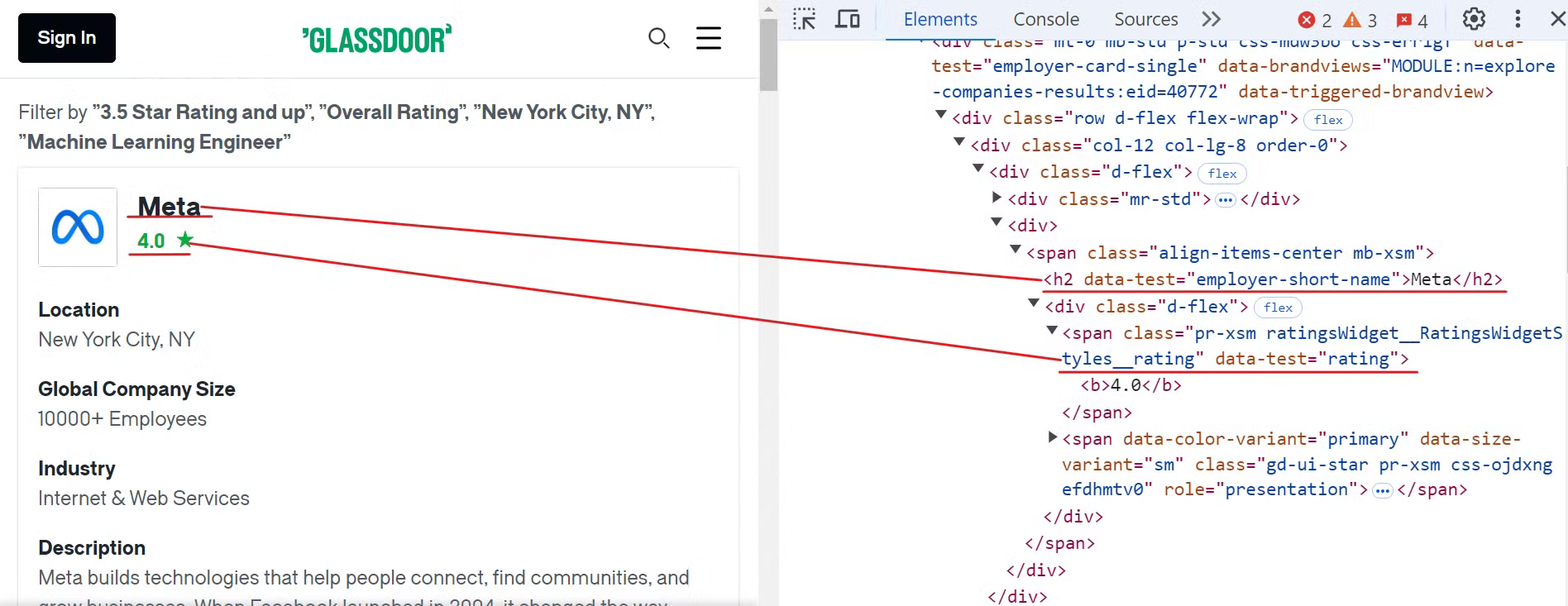
このデータを抽出するには、以下のCSSセレクタを使用できます:
[data-test="employer-short-name"]
[data-test="rating"]
同様に、以下の画像に示すように、シンプルなCSSセレクタを使用して他の関連データを抽出できます:
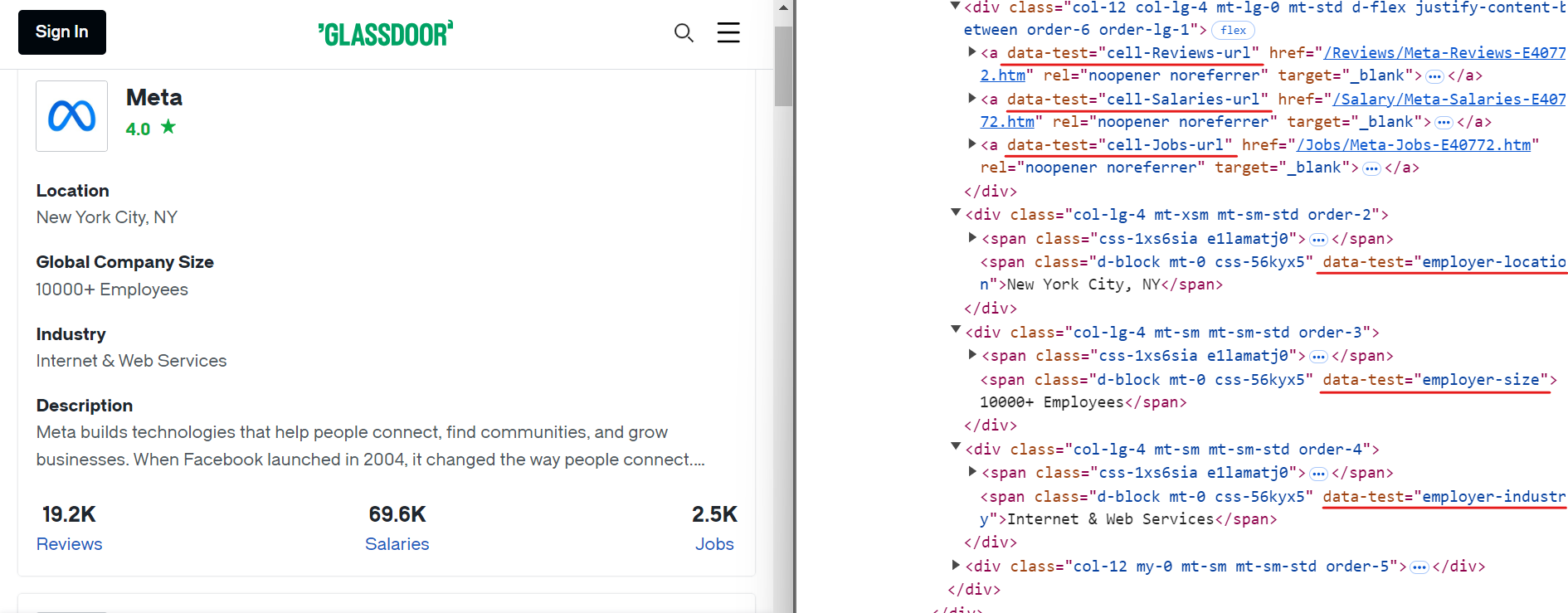
追加データを抽出するために使用できるCSSセレクタは以下の通りです:
[data-test="employer-location"] /* 企業の地理的位置 */
[data-test="employer-size"] /* 世界中の従業員数 */
[data-test="employer-industry"] /* 企業が事業を展開する業界 */
[data-test="cell-Jobs-url"] /* 企業の求人情報へのリンク */
[data-test="cell-Jobs"] h3 /* 求人情報総数 */
[data-test="cell-Reviews"] h3 /* 従業員レビュー数 */
[data-test="cell-Salaries"] h3 /* 報告された給与件数 */
次に、glassdoor.py という名前の新しいファイルを作成し、以下のコードを追加します:
import asyncio
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Chromiumブラウザインスタンスを起動
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Glassdoor検索のベースURLとクエリパラメータを定義
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "New York, NY (US)",
"occ": "Machine Learning Engineer",
"filterType": "RATING_OVERALL",
}
# クエリパラメータを含む完全なURLを構築し、そのURLにナビゲートする
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# 抽出されたレコードのカウンターを初期化する
record_count = 0
# ページ上の全企業カードを検索し、データを抽出するために反復処理
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# 各企業カードから関連データを抽出
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# 求人情報用URLの構築
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# 求人、レビュー、給与に関する追加データを抽出
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# 抽出したデータを表示
print({
"Company": company_name,
"Rating": rating,
"Jobs URL": jobs_url_path,
"求人数": jobs_count,
"レビュー数": reviews_count,
"給与データ数": salaries_count,
"業界": industry,
"所在地": location,
"グローバル企業規模": global_company_size,
})
record_count += 1
except Exception as e:
print(f"企業データ抽出エラー: {e}")
print(f"抽出総レコード数: {record_count}")
# ブラウザを閉じる
await browser.close()
# スクリプトのエントリポイント
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
このコードは、特定のフィルターを適用して企業データをスクレイピングするPlaywrightスクリプトを設定します。例えば、所在地(ニューヨーク州ニューヨーク)、評価(3.5以上)、職種(機械学習エンジニア)などのフィルターを適用します。
その後、Chromiumブラウザインスタンスを起動し、これらのフィルターを含むGlassdoorのURLにアクセスし、ページ上の各企業カードからデータを抽出します。データ収集後、抽出された情報をコンソールに出力します。
出力結果は以下の通りです:

よくできました!
まだ問題があります。現在、コードは10件のレコードしか抽出していませんが、ページには約150件のレコードが存在します。これはスクリプトが最初のページからのデータのみを取得していることを示しています。より多くのレコードを抽出するには、次のセクションで説明するページネーション処理を実装する必要があります。
ページネーションの処理
Glassdoorの各ページには約10社のデータが表示されます。全レコードを抽出するには、最終ページに到達するまで各ページをナビゲートするページネーション処理が必要です。具体的には「次へ」ボタンを特定し、有効状態を確認した上でクリックして次ページへ移動します。この処理を、ページが存在しなくなるまで繰り返します。
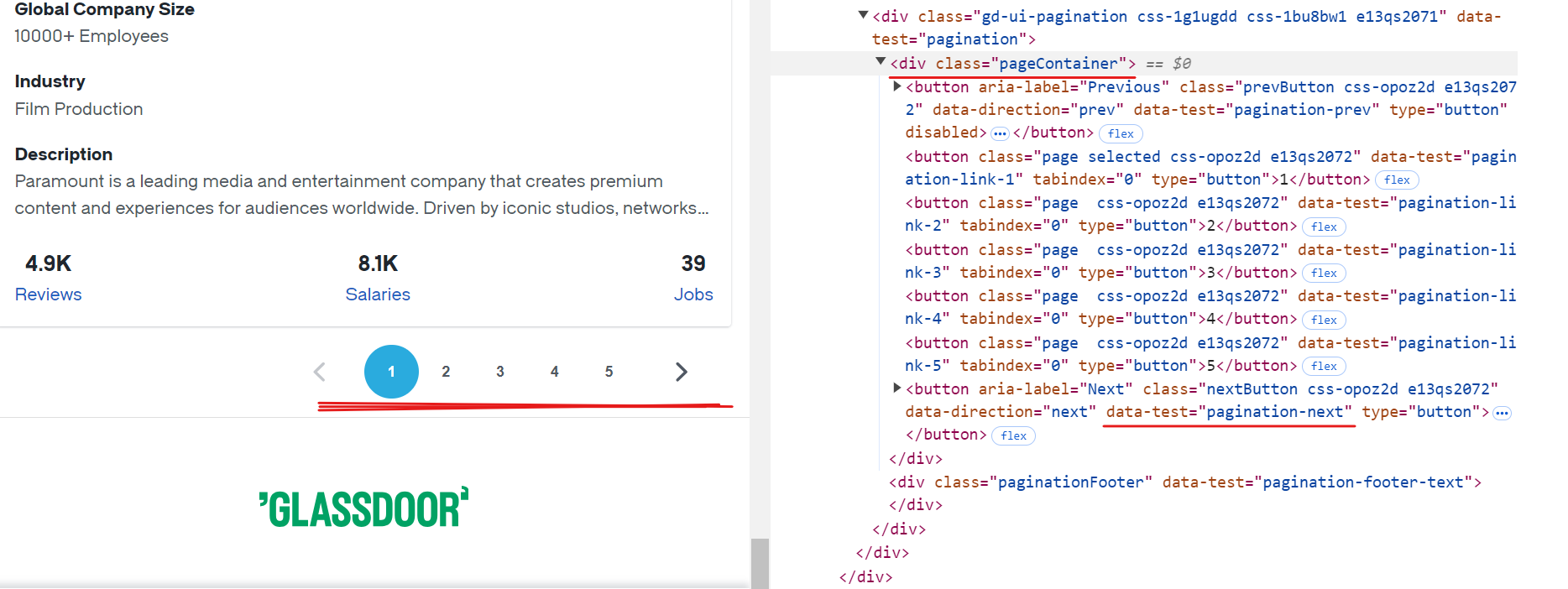
「次へ」ボタンのCSSセレクタは[data-test="pagination-next"]です。これは上記画像に示す通り、クラスpageContainerを持つ <div>タグ内に存在します。
以下はページネーション処理のコード例です:
while True:
# 処理を進める前にページネーションコンテナが表示されていることを確認
await page.wait_for_selector(".pageContainer", timeout=3000)
# ページ上の「次へ」ボタンを特定
next_button = page.locator('[data-test="pagination-next"]')
# 「次へ」ボタンが無効化され、これ以上ページがない状態か判定
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # 移動可能なページがなくなったら停止
# 次のページに移動
await next_button.click()
await asyncio.sleep(3) # ページが完全に読み込まれるまでの待機時間
以下が修正後のコードです:
import asyncio
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Chromiumブラウザインスタンスを起動
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Glassdoor検索のベースURLとクエリパラメータを定義
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "New York, NY (US)",
"occ": "Machine Learning Engineer",
"filterType": "RATING_OVERALL",
}
# クエリパラメータを含む完全なURLを構築し、そのURLにナビゲートする
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# 抽出されたレコードのカウンターを初期化
record_count = 0
while True:
# ページ上の全企業カードを検索し、データを抽出するために反復処理
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# 各企業カードから関連データを抽出
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# 求人情報用URLの構築
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# 求人、レビュー、給与に関する追加データを抽出
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# 抽出したデータを表示
print({
"会社名": company_name,
"評価": rating,
"求人URL": jobs_url_path,
"求人数": jobs_count,
"レビュー数": reviews_count,
"給与データ数": salaries_count,
"業界": industry,
"所在地": location,
"グローバル企業規模": global_company_size,
})
record_count += 1
except Exception as e:
print(f"企業データ抽出エラー: {e}")
try:
# ページネーションコンテナが表示されていることを確認
await page.wait_for_selector(".pageContainer", timeout=3000)
# ページ上の「次へ」ボタンを特定
next_button = page.locator('[data-test="pagination-next"]')
# 「次へ」ボタンが無効化され、これ以上ページが表示されない状態か判定
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # ナビゲート可能なページがなくなったら停止
# 次のページに移動
await next_button.click()
await asyncio.sleep(3) # ページ完全読み込みまでの待機時間
except Exception as e:
print(f"次のページ移動エラー: {e}")
break # 移動エラー時はループ終了
print(f"抽出総レコード数: {record_count}")
# ブラウザを閉じる
await browser.close()
# スクリプトのエントリポイント
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
結果は次の通りです:

素晴らしい!これで最初のページだけでなく、利用可能な全ページからデータを抽出できます。
データをCSVに保存
データを抽出できたので、さらに処理するためにCSVファイルに保存しましょう。これにはPythonのcsvモジュールを使用できます。以下はスクレイピングしたデータをCSVファイルに保存する更新されたコードです:
import asyncio
import csv
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Chromiumブラウザインスタンスを起動
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Glassdoor検索のベースURLとクエリパラメータを定義
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "New York, NY (US)",
"occ": "Machine Learning Engineer",
"filterType": "RATING_OVERALL",
}
# クエリパラメータを含む完全なURLを構築し、そのURLにアクセスする
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# 抽出データを書き込むCSVファイルを開く
with open("glassdoor_data.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow([
"会社名", "求人URL", "求人数", "レビュー数", "給与情報数",
"業界", "勤務地", "グローバル企業規模", "評価"
])
# 抽出されたレコード用のカウンターを初期化
record_count = 0
while True:
# ページ上の全企業カードを検索し、データを抽出するために反復処理
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# 各企業カードから関連データを抽出
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# 求人情報ページのURLを構築
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# 求人、レビュー、給与に関する追加データを抽出
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# 抽出したデータをCSVファイルに書き込む
writer.writerow([
company_name, jobs_url_path, jobs_count, reviews_count, salaries_count,
industry, location, global_company_size, rating
])
record_count += 1
except Exception as e:
print(f"企業データ抽出エラー: {e}")
try:
# ページネーションコンテナが表示されていることを確認
await page.wait_for_selector(".pageContainer", timeout=3000)
# ページ上の「次へ」ボタンを特定
next_button = page.locator('[data-test="pagination-next"]')
# 「次へ」ボタンが無効化され、これ以上ページがないか判定
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # ナビゲートするページがなければ停止
# 次のページに移動
await next_button.click()
await asyncio.sleep(3) # ページ完全読み込みまでの待機時間
except Exception as e:
print(f"次のページ移動エラー: {e}")
break # 移動エラー時はループ終了
print(f"抽出総レコード数: {record_count}")
# ブラウザを閉じる
await browser.close()
# スクリプトのエントリポイント
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
このコードは、スクレイピングしたデータをglassdoor_data.csvという名前のCSVファイルに保存します。
結果は次の通りです:
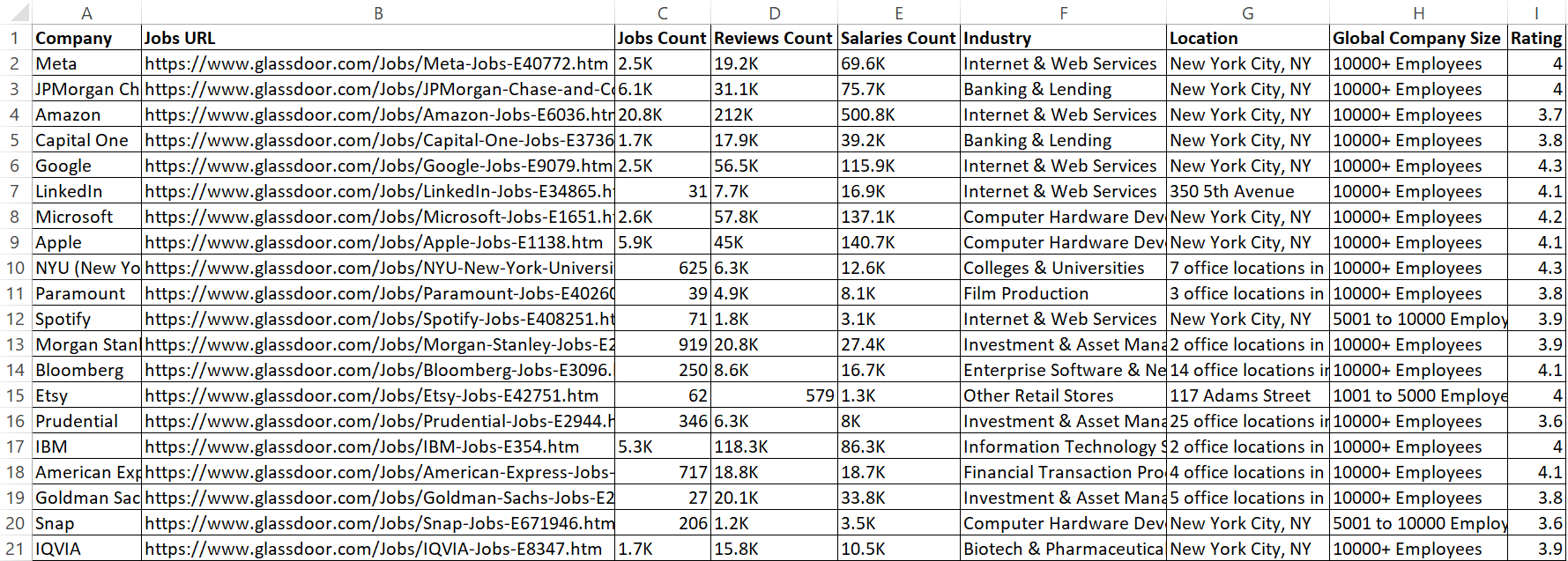
素晴らしい!これでデータがより整理され、読みやすくなりました。
Glassdoorが採用しているスクレイピング対策技術
Glassdoorは、一定期間内に同一IPアドレスから送信されるリクエスト数を監視しています。リクエストが設定された上限を超えた場合、GlassdoorはそのIPアドレスを一時的または恒久的にブロックする可能性があります。さらに、異常な活動が検出された場合、私が経験したように、GlassdoorはCAPTCHAによる認証を要求することがあります。
上記の方法は数百社のスクレイピングに適しています。しかし、数千社をスクレイピングする必要がある場合、大量のデータをスクレイピングした際に私が遭遇したように、Glassdoorのボット対策機構が自動スクレイピングスクリプトを検知するリスクが高まります。
Glassdoorからのデータスクレイピングは、その反スクレイピング対策のため困難を伴います。これらのボット対策機能を回避するのは煩わしく、リソースを大量に消費する可能性があります。しかし、スクレイパーが人間の行動を模倣し、ブロックされる可能性を低減させる戦略は存在します。 一般的な手法には、ローテーションプロキシ、実際のリクエストヘッダーの設定、リクエスト速度のランダム化などがあります。これらの手法はスクレイピング成功の可能性を高めるものの、100%の成功を保証するものではありません。
したがって、Glassdoorのボット対策にもかかわらず、最も効果的なスクレイピング手法はGlassdoor Scraper APIの利用です 🚀
より優れた代替手段:Glassdoor スクレイパー API
Bright Dataでは、ブログで先に説明したように、分析用に事前収集・構造化されたGlassdoorデータセットを提供しています。データセットの購入を避け、より効率的な解決策をお探しなら、Bright DataのGlassdoorスクレイパーAPIの利用をご検討ください。
この強力なAPIは、Glassdoorデータのシームレスなスクレイピングを目的に設計されており、動的コンテンツの処理やボット対策の回避を容易に行います。このツールを活用すれば、時間を節約し、データの正確性を確保しながら、データから実用的な知見を抽出することに集中できます。
Glassdoor APIの利用開始手順は以下の通りです:
まずアカウントを作成します。Bright Dataのウェブサイトにアクセスし、「無料トライアル」をクリックして登録手順に従ってください。ログイン後、ダッシュボードにリダイレクトされ、無料クレジットが付与されます。
次に、WebスクレイパーAPIセクションに移動し、B2BデータカテゴリからGlassdoorを選択します。URLから企業情報を収集する、URLから求人情報リストを収集するなど、様々なデータ収集オプションが用意されています。
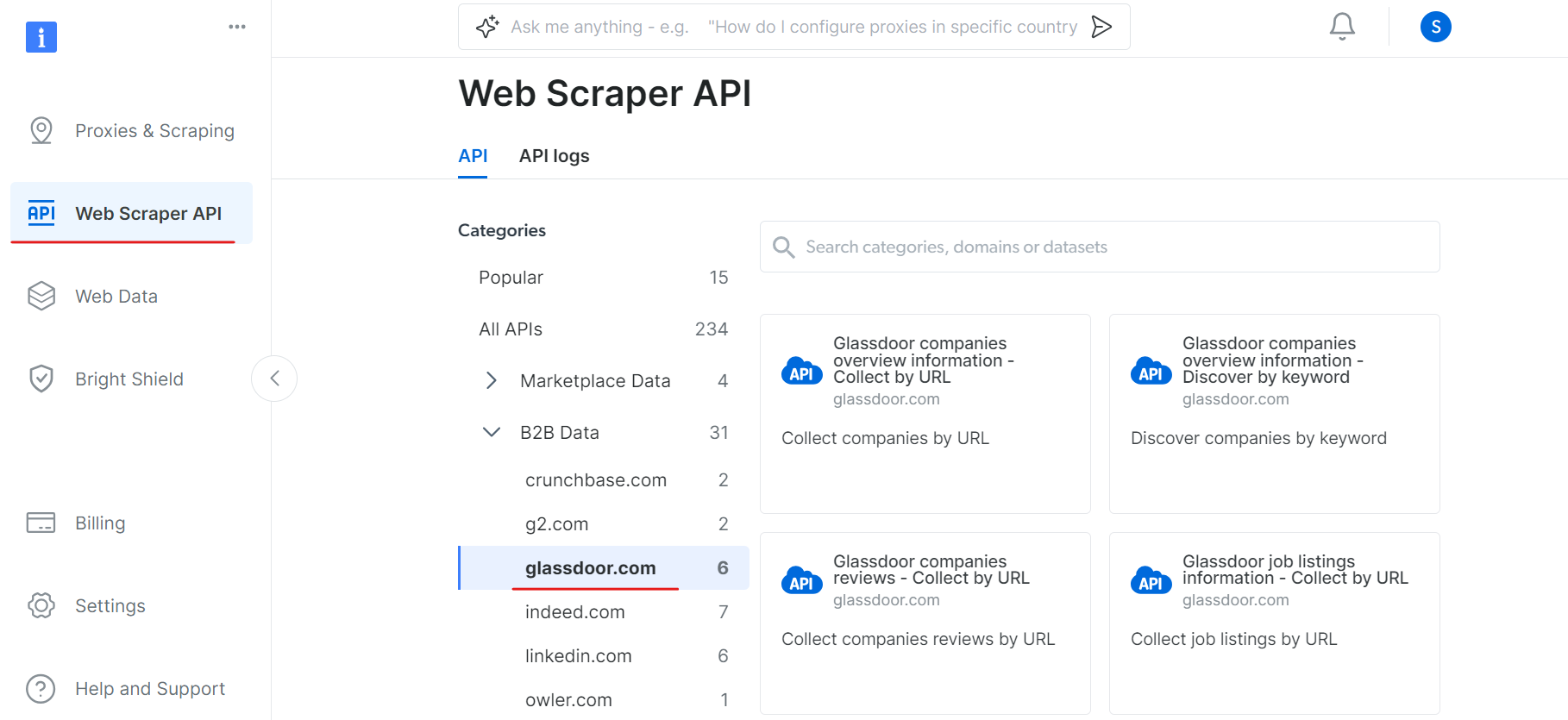
「Glassdoor企業概要情報」セクションでAPIトークンを取得し、データセットID(例:gd_l7j0bx501ockwldaqf)をコピーしてください。
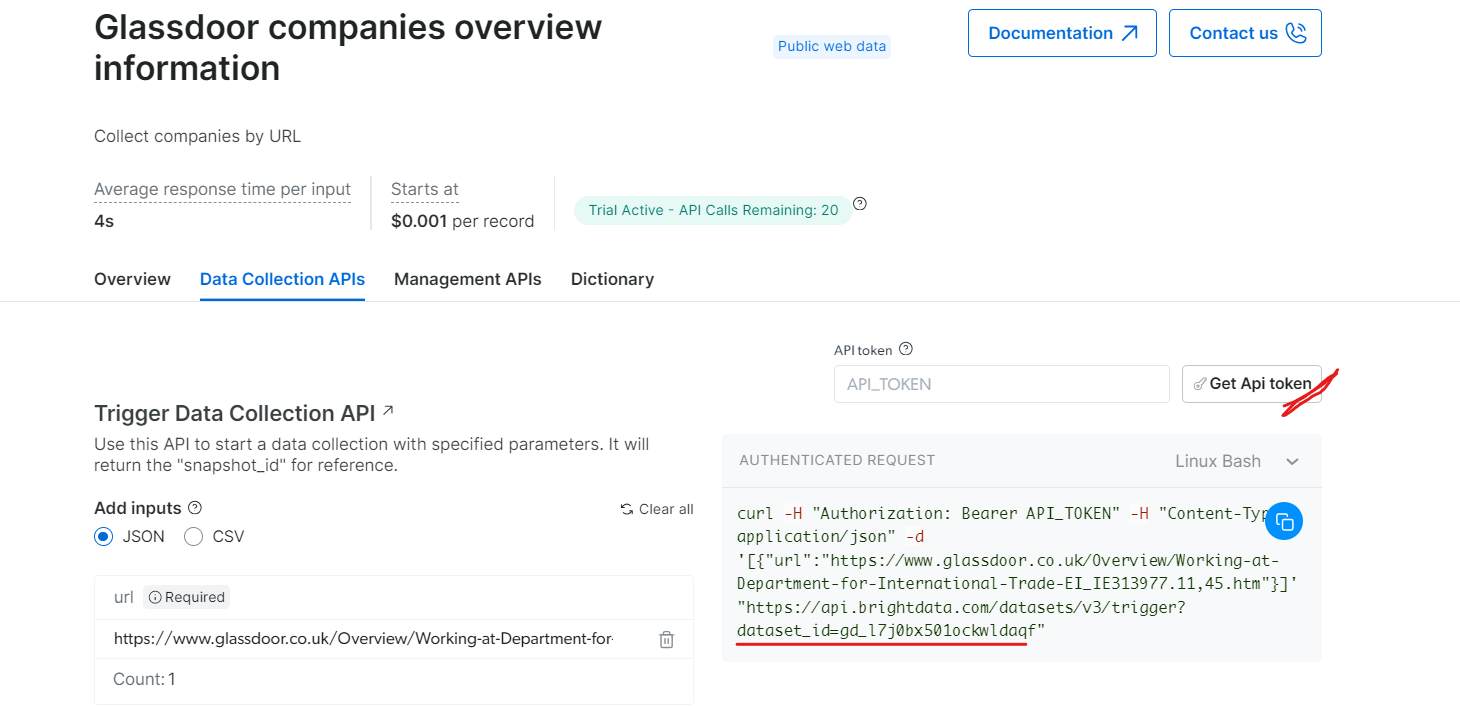
以下は、URL、APIトークン、データセットIDを指定して企業データを抽出する簡単なコードスニペットです。
import requests
import json
def trigger_dataset(api_token, dataset_id, company_url):
"""
BrightData APIを使用してデータセットをトリガーします。
引数:
api_token (str): 認証用のAPIトークン。
dataset_id (str): トリガーするデータセットID。
company_url (str): 分析対象の企業ページのURL。
Returns:
dict: APIからのJSONレスポンス。
"""
headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
payload = json.dumps([{"url": company_url}])
response = requests.post(
"https://api.brightdata.com/dataセット/v3/trigger",
headers=headers,
params={"dataset_id": dataset_id},
data=payload,
)
return response.json()
api_token = "API_Token"
dataset_id = "DATASET_ID"
company_url = "COMPANY_PAGE_URL"
response_data = trigger_dataset(api_token, dataset_id, company_url)
print(response_data)
コードを実行すると、以下のようにスナップショットIDが取得できます:

スナップショットIDを使用して、企業の実際のデータを取得します。ターミナルで以下のコマンドを実行してください。Windowsの場合は:
curl.exe -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/dataセット/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"
Linuxの場合:
curl -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/dataセット/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"
コマンドを実行すると、目的のデータが取得できます。
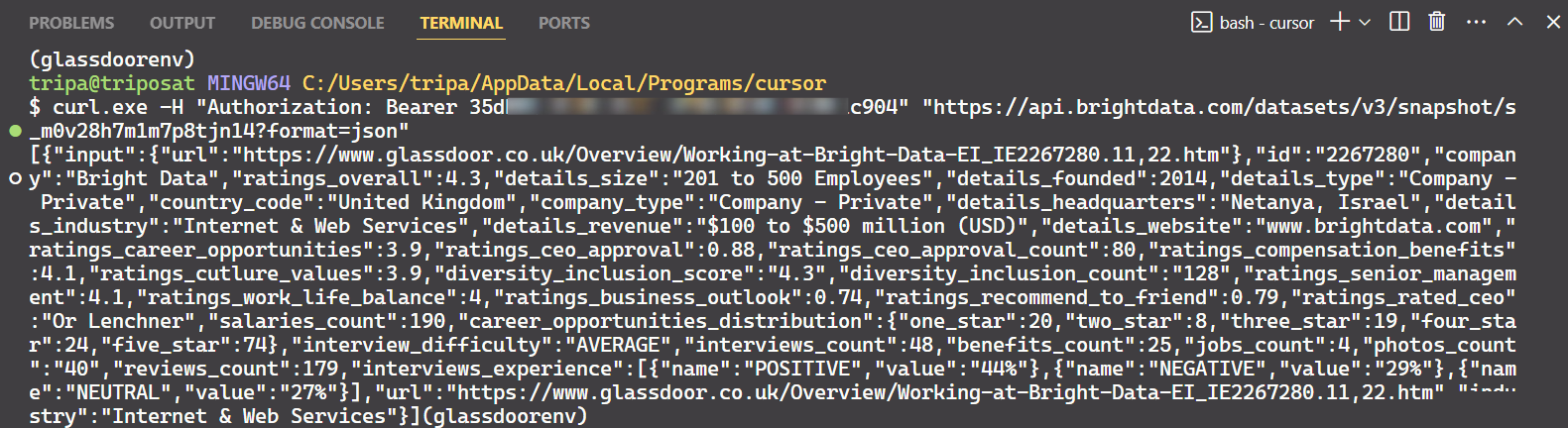
これで完了です!
同様に、コードを修正することでGlassdoorから様々な種類のデータを抽出できます。ここでは1つの方法を説明しましたが、他にも5つの方法があります。したがって、必要なデータをスクレイピングするには、これらのオプションを探ってみることをお勧めします。各方法は特定のデータニーズに合わせて設計されており、必要な正確なデータを取得するのに役立ちます。
結論
このチュートリアルでは、Playwright Pythonを使用したGlassdoorのスクレイピング方法を学びました。また、Glassdoorが採用する反スクレイピング対策とその回避方法についても理解しました。これらの課題を解決するため、Bright DataGlassdoor Scraper APIが紹介されました。このAPIはGlassdoorの反スクレイピング対策を克服し、必要なデータをシームレスに抽出するのに役立ちます。
次世代ブラウザ「スクレイピングブラウザ」も試すことができます。これは他のブラウザ自動化ツールと統合可能なブラウザです。スクレイピングブラウザは、ユーザーエージェントローテーション、IPローテーション、CAPTCHAの解決などの機能を活用し、ボット対策技術を容易に回避しつつブラウザフィンガープリントを回避します。
今すぐ登録して、Bright Dataの製品を無料で試してみてください。






