

{
“@context”: “https://schema.org”,
“@type”: “HowTo”,
“name”: “2026年にAirbnbをスクレイピングする方法”,
“description”: “2026年にAirbnbのリストデータを収集する4つの方法。手動のPythonスクレイパーから管理されたスクレイパーAPIと既製データセットまで。”,
“step”: [
{
“@type”: “HowToStep”,
“position”: 1,
“name”: “手動Pythonスクレイピング”,
“text”: “Pythonでリクエストを送信しHTMLをパースします。学習には適していますが、大規模なAirbnbのアンチボット層では機能しません。”
},
{
“@type”: “HowToStep”,
“position”: 2,
“name”: “カスタムページ向けWeb Unlocker”,
“text”: “Bright DataのWeb Unlockerを使用してボット検出を回避しレンダリングされたページを取得し、独自のコードで必要なフィールドをパースします。”
},
{
“@type”: “HowToStep”,
“position”: 3,
“name”: “Airbnb スクレイパーAPI”,
“text”: “AirbnbスクレイパーAPIを呼び出して、パースやメンテナンスなしで任意のボリュームのクリーンな構造化JSONリストレコードを取得します。”
},
{
“@type”: “HowToStep”,
“position”: 4,
“name”: “既製Airbnbデータセット”,
“text”: “コードやスクレイピング不要で、一括または過去データ向けの既製Airbnbデータセットをダウンロードします。”
}
]
}
Airbnbは旅行・不動産分野で最も需要の高いデータソースの一つであり、同時に最も収集が難しいものの一つでもあります。ページはアンチボット層の背後にあり頻繁に変更されます。また2026年には、そのデータがダイナミックプライシングモデルやAIエージェントにますます活用されるようになり、新鮮で構造化されたデータが必要とされています。このガイドでは、シンプルなPythonリクエストから完全に管理されたデータセットまで、実際にテストされたコードと各アプローチのライブ出力を含む4つの取得方法を紹介します。
このガイドの内容
- 2026年にAirbnbデータを取得する4つの方法と、それぞれの使い時
- 手動Pythonスクレイパーと、正確にどこで機能しなくなるか
- カスタムページ向けWeb Unlockerと、自分でコントロールできるパースコード
- 任意のボリュームでクリーンな構造化JSONを取得するAirbnbスクレイパーAPI
- 一括・過去データ向けの既製Airbnbデータセット
- Web MCP経由でAIエージェントにAirbnbデータを提供する方法
構築をスキップしたい方へ:AirbnbスクレイパーAPIでライブリストを今すぐ取得するか、既製のAirbnbデータセットをダウンロードするか、クレジットカード不要で月5,000レコードから無料で始めることができます。
収集する価値のあるAirbnbデータ
Airbnbの1件のリストには、1泊あたりの料金をはるかに超えるデータが含まれています。ほとんどのプロジェクトで重要なフィールドは以下の通りです:
- 料金:1泊あたりの料金、税前合計、割引、清掃料
- 空き状況:予約カレンダーと最低宿泊日数
- レビューと評価:総合スコア、レビュー数、カテゴリ別内訳
- ホストのシグナル:スーパーホストのステータス、応答率、履歴
- 物件詳細:収容人数、アメニティ、座標、画像
これらはそれぞれ、ライブリストページの特定の要素に対応しています。以下の赤いボックスは、構造化フィールドがどこから来るかを示しています:
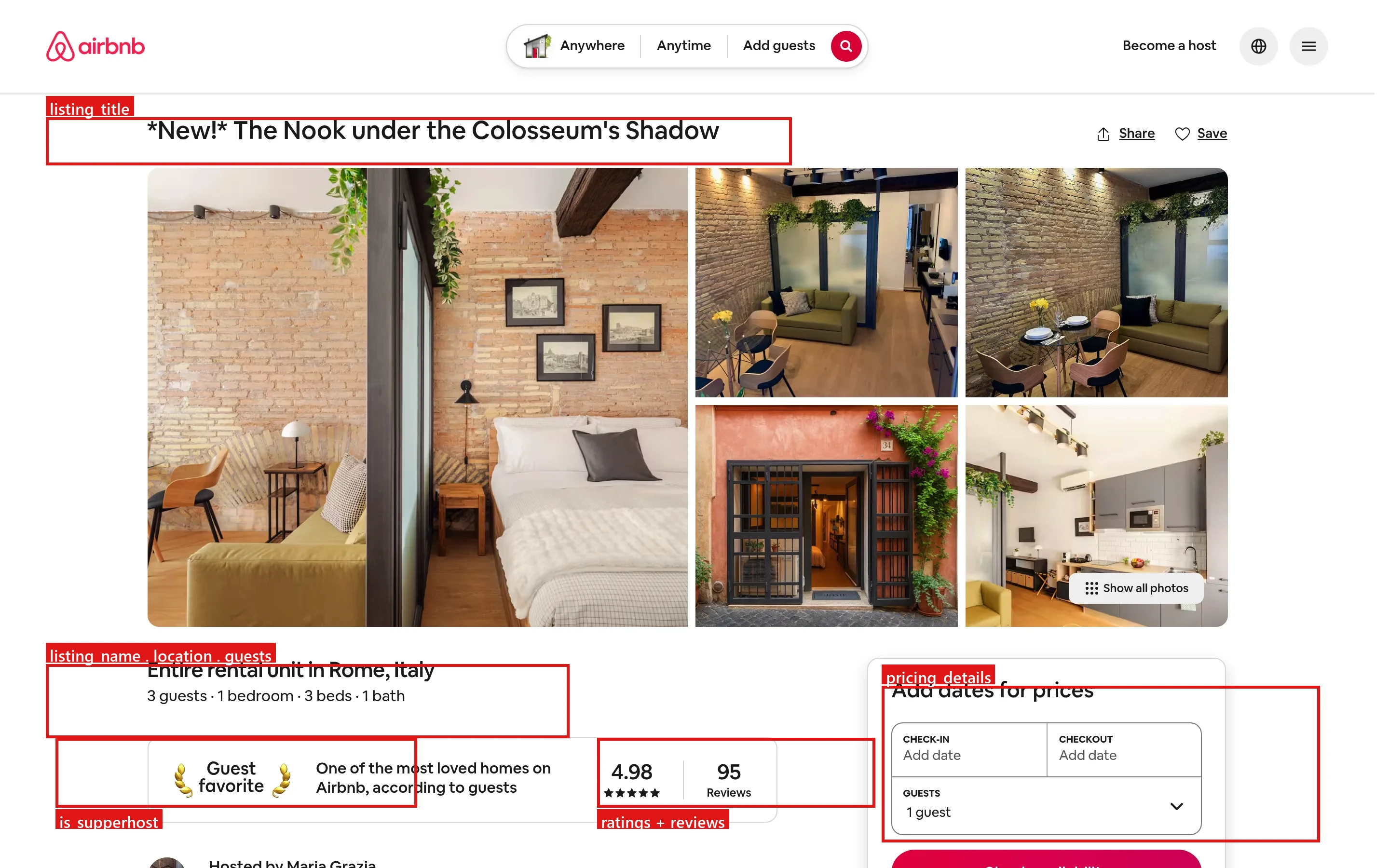
主なユースケース:民泊投資のスクリーニング、地域競合に対するダイナミックプライシング、稼働率と市場トレンド分析、AIと分析パイプラインへのクリーンな位置データの提供。
4つのアプローチの概要
| アプローチ | 手間 | スケール | メンテナンス | 最適な用途 |
|---|---|---|---|---|
| 手動Python | 高 | 低 | 高 | 学習、小規模な単発の取得 |
| Web Unlocker | 中 | 中 | 中 | カスタムパース、既製スクレイパーのないページ |
| Airbnbスクレイパーapi | 低 | 高 | なし | 任意のボリュームでの構造化リストデータ |
| Airbnbデータセット | なし | 大量 | なし | 過去または市場全体のデータ、コード不要 |
率直なまとめ:手動スクレイピングは学習コストが最も低く、運用コストが最も高い方法です。他の3つのアプローチは、ブロック解除、パース、メンテナンスという難しい部分を管理されたインフラストラクチャに移行します。
アプローチ1:手動スクレイピングと機能しなくなる箇所
まず明白な方法から始めましょう:requestsで検索ページを取得してパースします。以下がその試みの全体です。
import requests
url = "https://www.airbnb.com/s/Rome, Italy/homes"
resp = requests.get(url, headers={"User-Agent": "Mozilla/5.0"}, timeout=30)
print("status:", resp.status_code)
print("DataDome anti-bot active:", "datadome" in resp.text.lower())実行すると、実際に直面する問題が明らかになります:
status: 200
DataDome anti-bot active: Trueリクエストは200を返しますが、すべてのレスポンスはDataDomeのボット検出層でラップされています。場合によってはリストのないチャレンジページが返され、別の場合には1回のリクエストが通過することもあります。この不安定さが本当の問題です:ページネーション、複数都市、または実際のリクエスト量を追加した途端、DataDomeがトラフィックにフラグを立て、CAPTCHA、レート制限、IPバンに直面します。安定して機能させるには、レジデンシャルプロキシのローテーション、実際のブラウザフィンガープリント、自動CAPTCHAの解決、そしてAirbnbの頻繁なマークアップ変更に対応できるパーサーが必要です。これはスクリプトではなくメンテナンスプロジェクトです。DIYルートを希望する場合は、Pythonウェブスクレイピングガイドで基本を説明しています。次の3つのアプローチはその負担を取り除きます。
アプローチ2:カスタムページ向けWeb Unlocker
生のページが必要な場合(例えば、既製スクレイパーがないページタイプ)、Web Unlockerがブロック解除を処理し、完全にレンダリングされたHTMLを返します。抽出を完全にコントロールしたい場合に適切なトレードオフとなり、データのパースは自分で行います。
AirbnbはリストデータをページのJSON内に埋め込んでいるため、HTMLを取得したら壊れやすいCSSセレクターを使わずに直接フィールドを取得できます。
import os
import re
import requests
API = "https://api.brightdata.com/request"
payload = {
"zone": os.environ["BRIGHTDATA_UNLOCKER_ZONE"],
"url": "https://www.airbnb.com/s/Rome, Italy/homes",
"format": "raw",
"country": "us", # geo-target for consistent currency and language
}
headers = {"Authorization": f"Bearer {os.environ['BRIGHTDATA_API_KEY']}"}
html = requests.post(API, json=payload, headers=headers, timeout=120).text
names = re.findall(r'"localizedStringWithTranslationPreference":"([^"]+)"', html)
prices = re.findall(r'"accessibilityLabel":"([^"]*?$[d,]+[^"]*?)"', html)
print(len(set(names)), "listings parsed")
for name, price in list(zip(names[::2], prices))[:4]:
print("-", name, "|", price)これにより実際にパースされたリストが返されます:
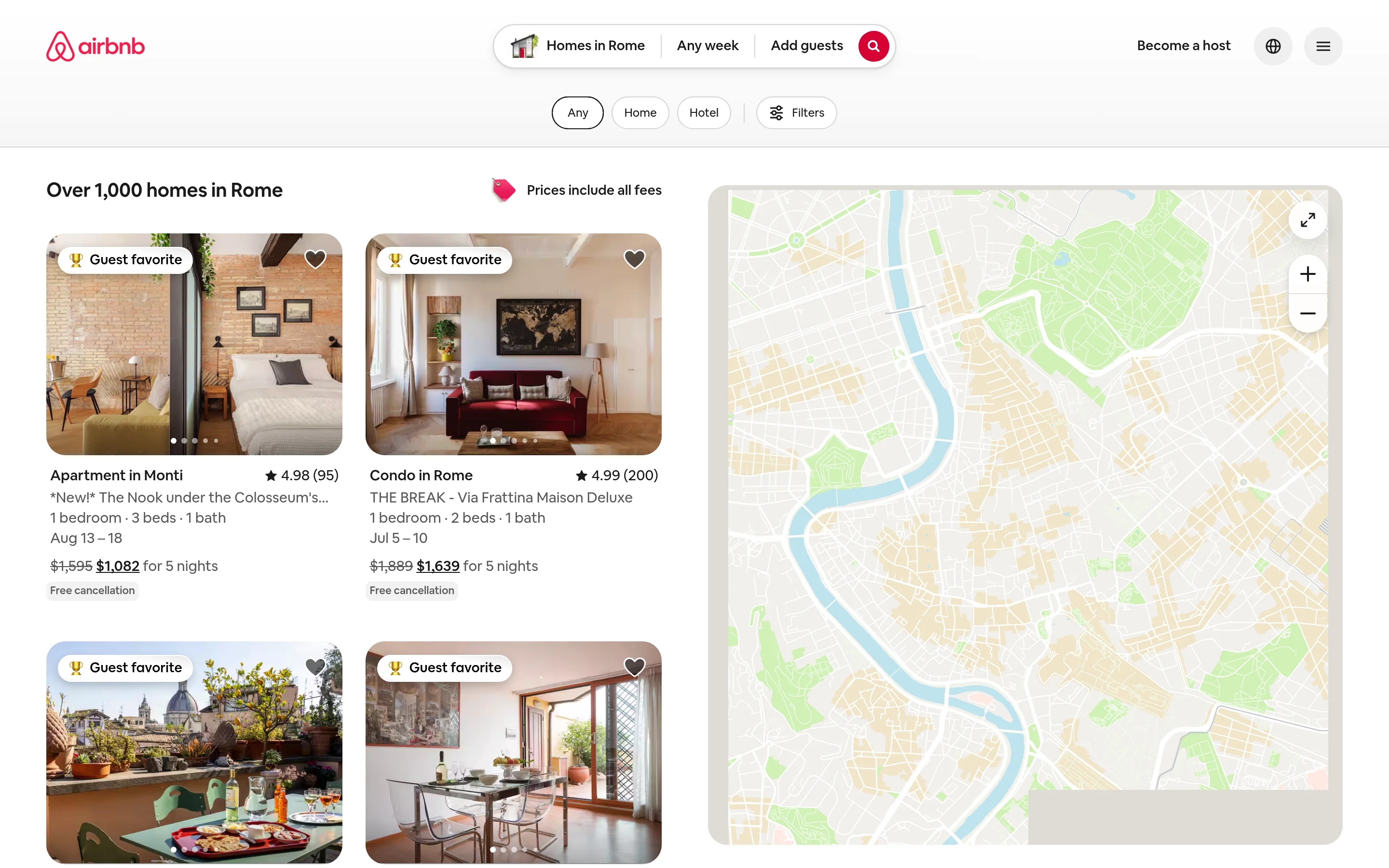
30 listings parsed
- *New!* The Nook under the Colosseum's Shadow | $1,082 for 5 nights, originally $1,595
- THE BREAK - Via Frattina Maison Deluxe | $1,639 for 5 nights, originally $1,889
- The Unique Home Pantheon | $1,064 for 5 nights, originally $1,481
- 360 penthouse overlooking central Rome | $3,010 for 5 nightsWeb Unlockerは壁を突破し、パースの完全なコントロールを維持できます。コストは、抽出ロジックを自分で所有し、AirbnbがページStructureを変更した際に更新する必要があることです。必要なのがクリーンなリストデータだけであれば、スクレイパーAPIはそのステップを完全に排除します。
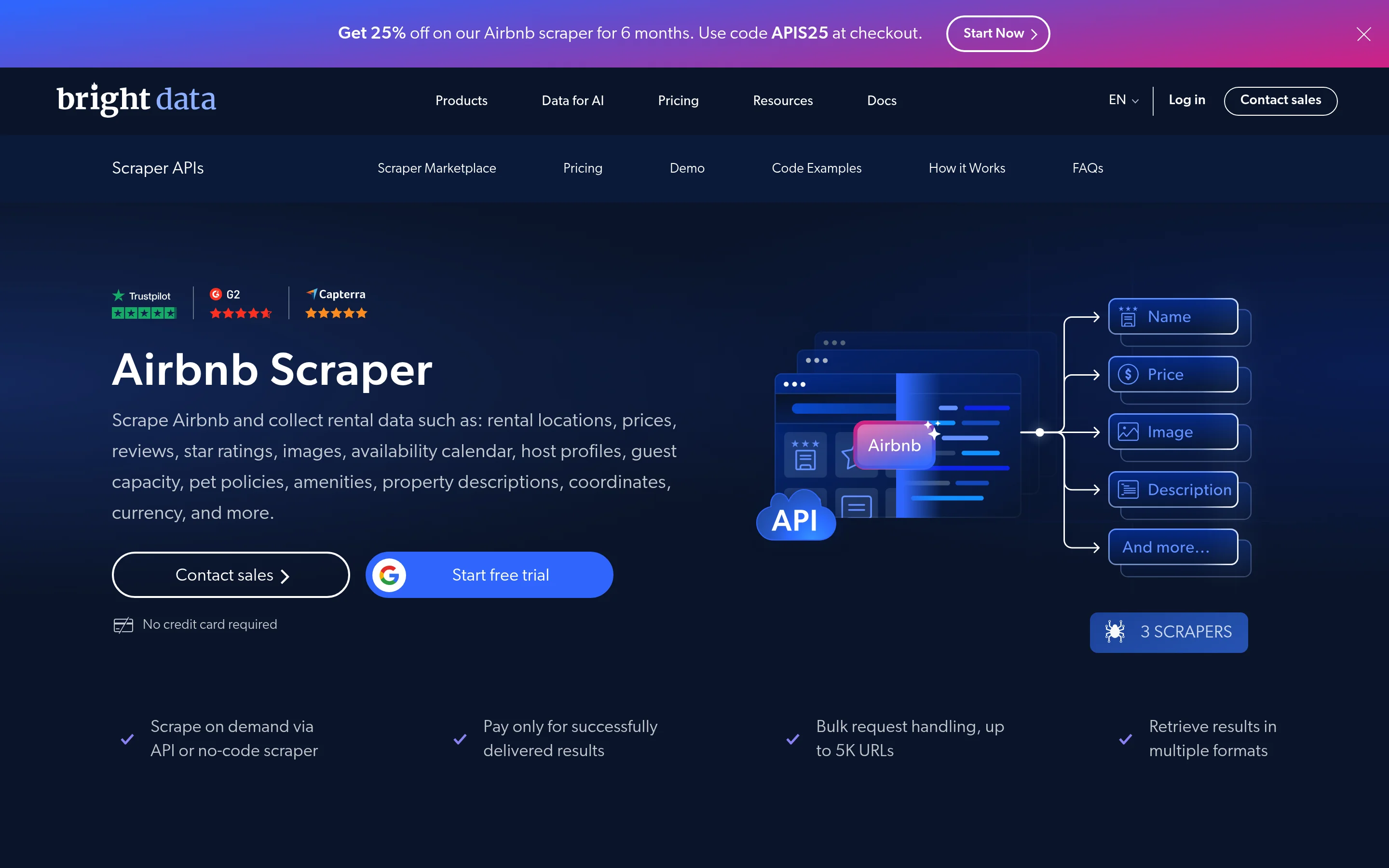
アプローチ3:AirbnbスクレイパーAPI
AirbnbスクレイパーAPIは既製のスクレイパーです。リストまたは検索URLを送信すると、構造化されたJSONが返されます。プロキシ、パース、マークアップのメンテナンスは不要です。700以上のサイトをカバーするBright DataのWeb Scraper APIの一部です。
以下の例では、Airbnbでライブに見られるこの特定のリストを収集します。
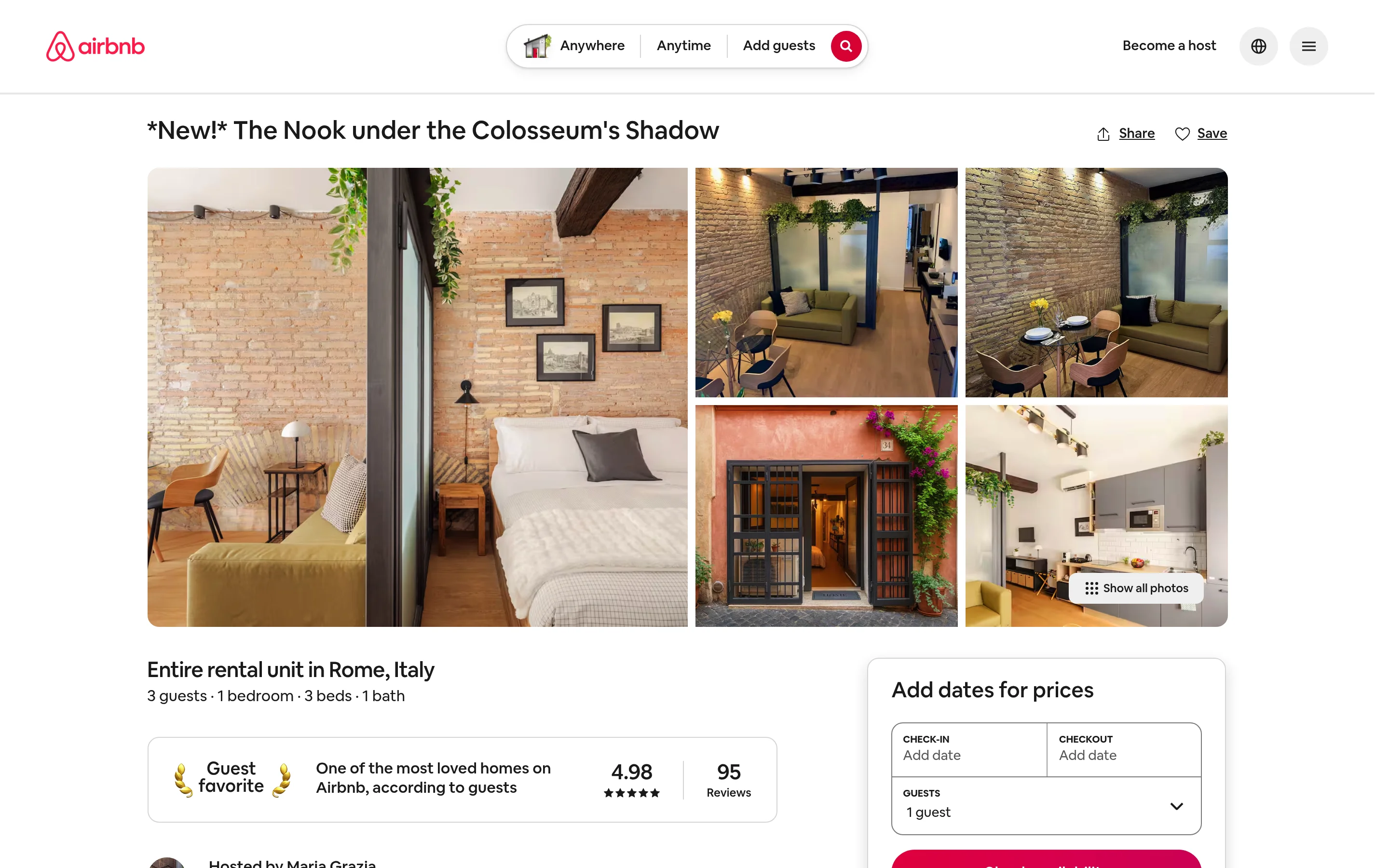
最大20件のURLには同期エンドポイントを使用し、1回の呼び出しで結果を取得できます。
import os
import requests
DATASET_ID = "gd_ld7ll037kqy322v05" # Airbnb Properties Information
TOKEN = os.environ["BRIGHTDATA_API_KEY"]
resp = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={"dataset_id": DATASET_ID, "format": "json"},
headers={"Authorization": f"Bearer {TOKEN}", "Content-Type": "application/json"},
json={"input": [{"url": "https://www.airbnb.com/rooms/1409274854260723534"}]},
timeout=180,
)
listing = resp.json()[0]
for field in ("listing_title", "ratings", "property_number_of_reviews",
"is_supperhost", "guests", "location", "lat", "long"):
print(f"{field}: {listing[field]}")
print("amenities:", len(listing["amenities"]), "| images:", len(listing["images"]),
"| available_dates:", len(listing["available_dates"]))レスポンスは51フィールドを含む1件のクリーンなレコードです。そのリストの実際の出力:
listing_title: *New!* The Nook under the Colosseum's Shadow
ratings: 4.98
property_number_of_reviews: 95
is_supperhost: True
guests: 3
location: Rome, Lazio, Italy
lat: 41.8949
long: 12.4895
amenities: 12 | images: 66 | available_dates: 185パースロジックなし、プロキシ管理なし、AirbnbがHTMLを変更してもスキーマは安定しています。これがページをスクレイピングすることと、管理されたデータ製品を消費することの違いです。
大規模なジョブには非同期エンドポイントに切り替えます。収集をトリガーし、完了をポーリングしてからダウンロードします。これにより1つのジョブで数千のURLにスケールできます。
import os
import time
import requests
DATASET_ID = "gd_ld7ll037kqy322v05"
TOKEN = os.environ["BRIGHTDATA_API_KEY"]
HEADERS = {"Authorization": f"Bearer {TOKEN}", "Content-Type": "application/json"}
# 1. Trigger
urls = [
"https://www.airbnb.com/rooms/1409274854260723534",
"https://www.airbnb.com/rooms/667303913003951222",
# ... hundreds more
]
trigger = requests.post(
"https://api.brightdata.com/datasets/v3/trigger",
params={"dataset_id": DATASET_ID, "format": "json"},
headers=HEADERS,
json={"input": [{"url": u} for u in urls]},
)
snapshot_id = trigger.json()["snapshot_id"]
# 2. Poll until ready
while True:
status = requests.get(
f"https://api.brightdata.com/datasets/v3/progress/{snapshot_id}",
headers=HEADERS,
).json()["status"]
if status == "ready":
break
if status == "failed":
raise RuntimeError("collection failed")
time.sleep(10)
# 3. Download
data = requests.get(
f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}",
params={"format": "json"},
headers=HEADERS,
).json()
print(len(data), "listings collected")配信されたレコードに対してのみ支払い、Web Scraper APIは1,000レコードあたり$0.70から始まり、すべての新規アカウントはクレジットカード不要で月5,000レコードの無料テストが可能です。コントロールパネルにはコードなしのバージョンもあります。
アプローチ4:既製Airbnbデータセット
特定のURLリストではなく過去データや市場全体のカバレッジが必要な場合は、収集を完全にスキップしてAirbnbデータセットを購入します。事前収集・更新済みの同じ構造化スキーマです。
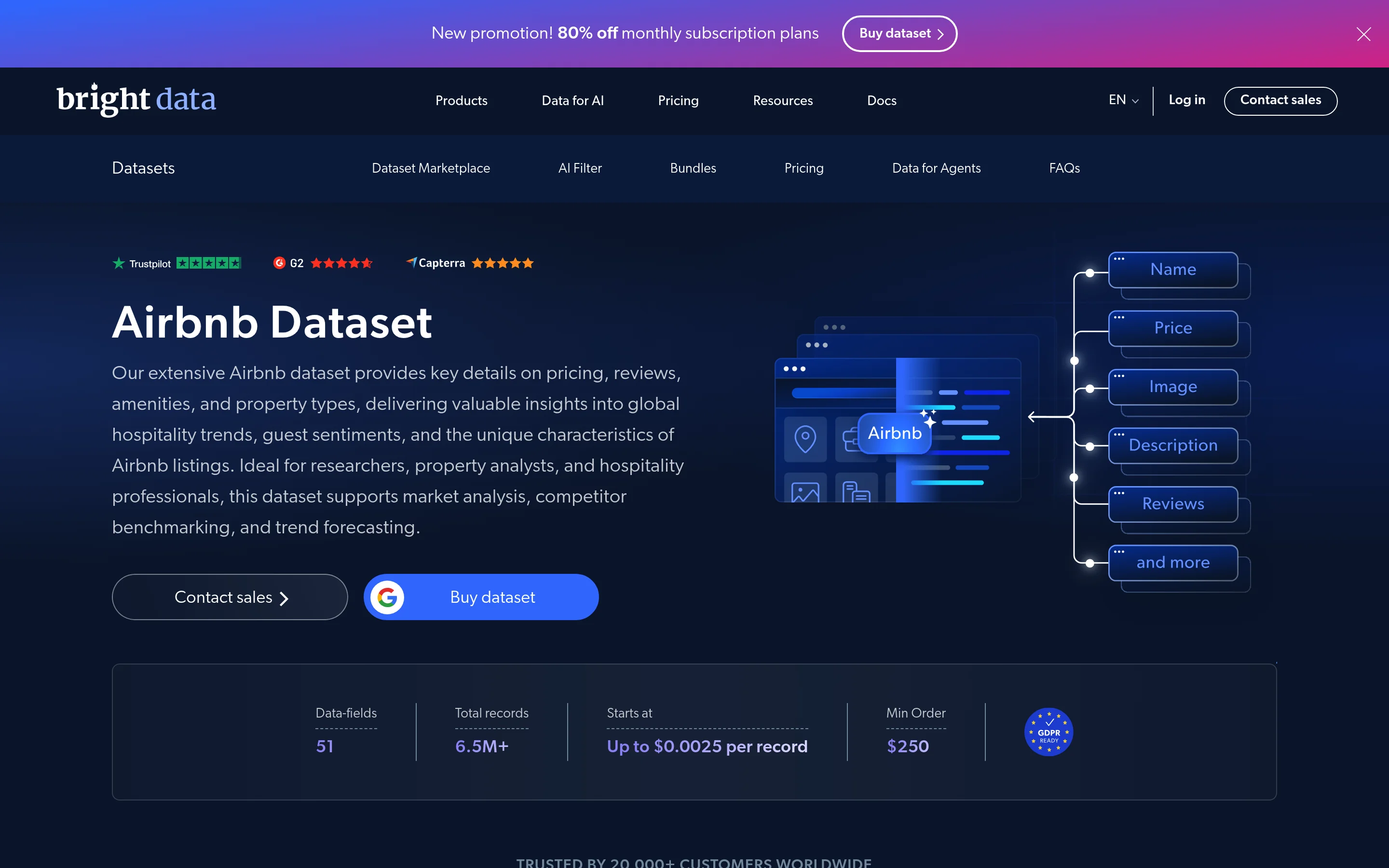
マーケットプレイスのデータセットには51フィールドにわたる650万件以上のレコードが含まれ、最低注文額250ドルで1レコードあたり0.0025ドルから、ワンタイムダウンロードまたは更新サブスクリプションとして提供されます。場所、日付、その他の属性でフィルタリングし、JSON、CSV、またはParquet形式でダウンロードできます。これは購入対構築の選択肢です:エンジニアリングゼロ、即座のアクセス、価格モデルのバックテストや都市全体の一括分析に最適です。Bright Dataは他のマーケットプレイスでも同様の既製データを提供しており、最良のAmazonデータプロバイダーや最良のeコマースデータプロバイダーも含まれます。
ボーナス:AirbnbデータをAIエージェントに直接提供する(MCP)
2026年の最大の変化は、このデータの消費者がダッシュボードではなくAIエージェントであることが多いことです。エージェントはオンデマンドでライブウェブデータを必要とし、Model Context Protocol(MCP)は外部ツールを呼び出す方法です。Bright DataのWeb MCPサーバーは、Claude、GPT、GeminiなどあらゆるLLMに、同じブロック解除インフラを通じてライブ検索(SERP API)とスクレイピングを提供するため、エージェントはアプローチ1のDataDomeの壁に当たりません。
インストール不要で、1行でMCPクライアントをホストサーバーに向けます:
https://mcp.brightdata.com/mcp?token=YOUR_API_TOKENまたはnpxでローカル実行:
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": { "API_TOKEN": "your-token-here" }
}
}
}さらに速く、Bright Data CLIは1つのコマンドでMCPをエージェントに組み込みます:
brightdata add mcp, agent claude-code,cursor,codex無料のRapidモードは、リクエストごとに1クレジットでsearch_engine、scrape_as_markdown、discoverを公開し、同じ月5,000の無料クレジットから引き出します。エージェントは「ローマで1泊200ドル以下のAirbnbリストを見つけて最安値5件をまとめて」というプロンプトに、アプリケーションにスクレイピングコードなしで、ライブで検索・スクレイピングして答えられます。Proモードは本番エージェント向けに、既製ウェブデータ抽出ツールやスクレイピングブラウザ自動化を含む60以上の構造化ツールを追加します。詳細なウォークスルーはWeb MCPスクレイピングチュートリアルをご覧ください。
エージェントに組み込む前に、同じ無料クレジットを使用してBright Data CLIからターミナルで同じツールを試すことができます。Airbnbに対するクイックなsearchとscrape:
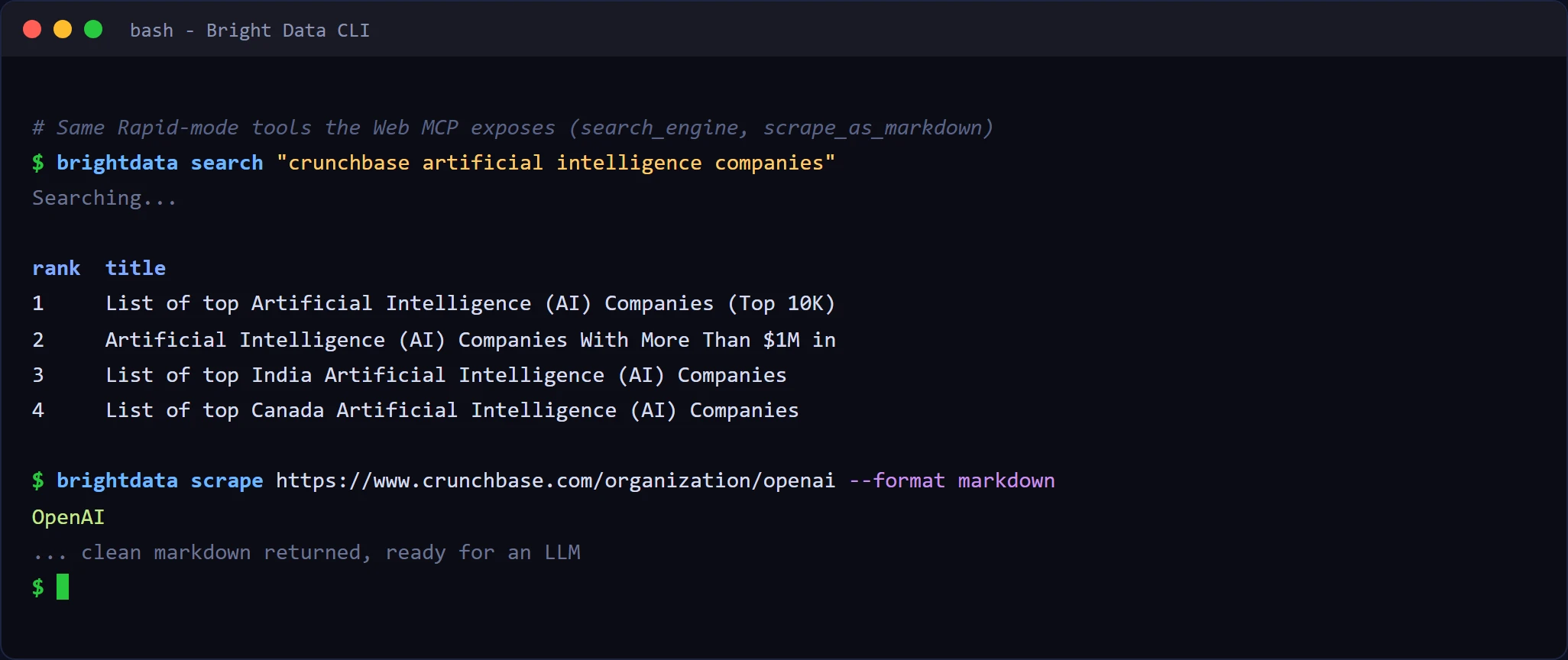
CLIのsearchとscrapeはMCPのsearch_engineとscrape_as_markdownツールに1対1でマッピングされるため、ターミナルで返される内容は接続後にエージェントが受け取るものと全く同じです。
エージェント内での動作を確認する
接続後は、自然言語で質問するとエージェントがどのMCPツールを呼び出すかを決定します。すぐに使えるプロンプト:
- 「AirbnbでローマのアパートメントレンタルをAIで調べて、評価付きのおすすめをいくつか教えて。」
- 「airbnb.com/rooms/IDの主要な詳細を取得して:評価、スーパーホストのステータス、収容人数。」
- 「ローマとフィレンツェの2ベッドルームAirbnbの1泊料金を比較して。」
- 「このリストのレビューの感情を3つの箇条書きでまとめて。」
以下はClaude Codeで最初のプロンプトを実行した例です。エージェントは自動的にsearch_engineとscrape_as_markdownを呼び出し、プロジェクトにスクレイピングコードなしでライブデータで回答します。
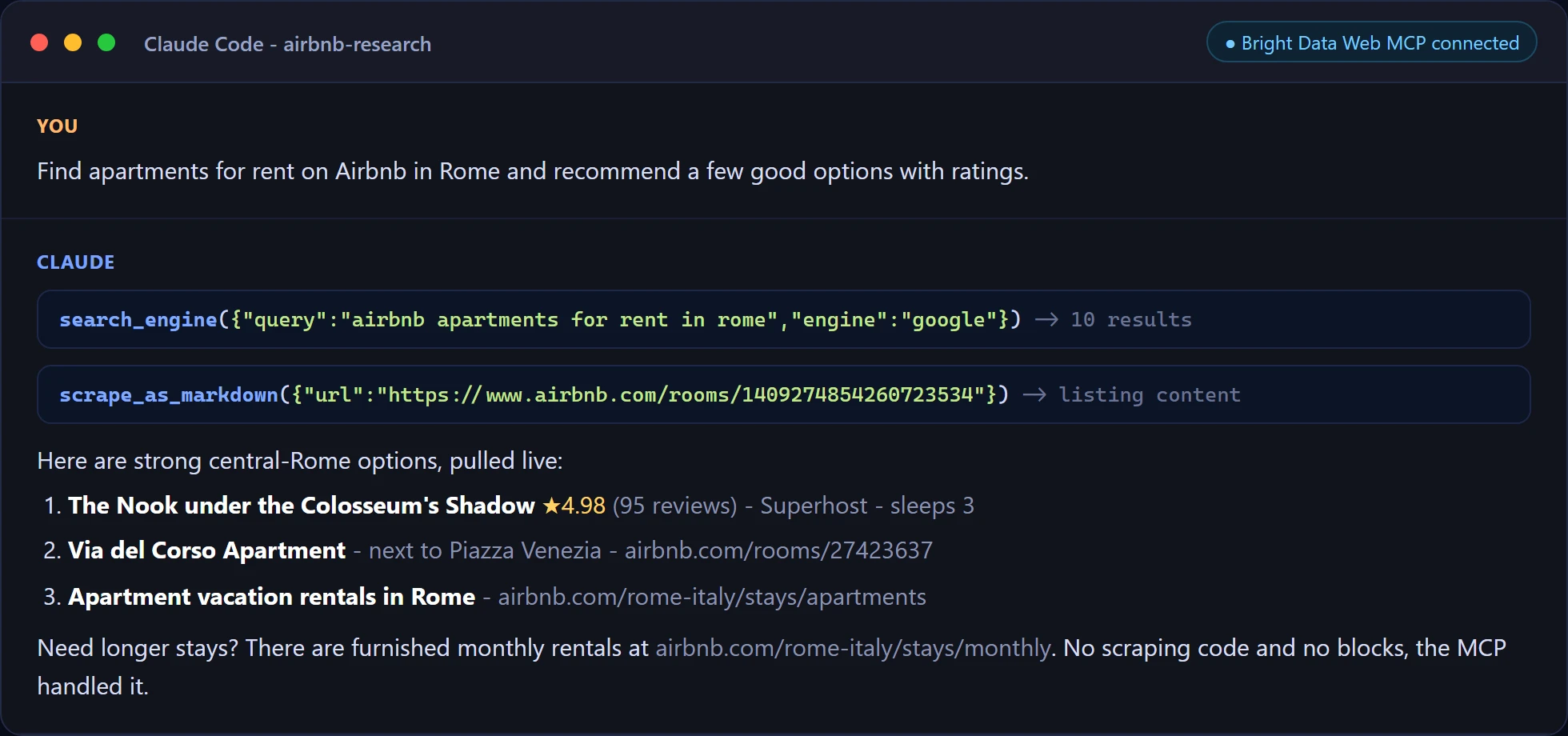
そしてCursorでのターゲット抽出、ライブページから1つのリストのフィールドを直接取得します。
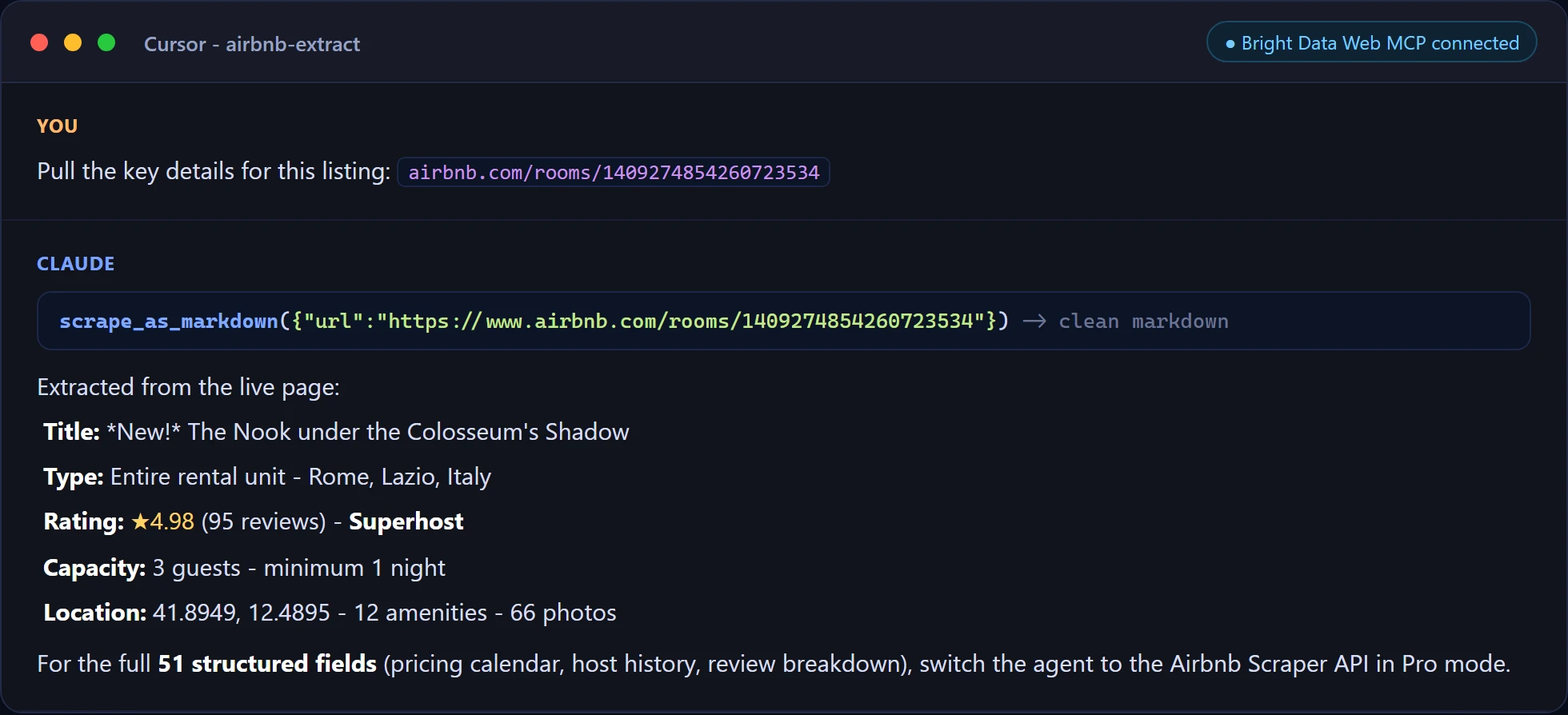
すべてのフィールドを必要とする本番エージェントには、Proモードを有効にすると、アプローチ3のAirbnbスクレイパーAPIと並んで60以上の構造化ウェブデータツールが利用できます。
データをインサイトに変換する
リストを取得したら、分析は素早く行えます。アプローチ2でパースした価格を使用して、短いスニペットでローカル市場をまとめます。
import statistics
prices = [1082, 1639, 1064, 3010, 904, 1115, 2008, 1398] # USD, 5-night totals
print("listings:", len(prices))
print("median:", statistics.median(prices))
print("range:", min(prices), "to", max(prices))完全なサンプルをプロットすると、ローマ中心部全体の価格分布が一目でわかります。
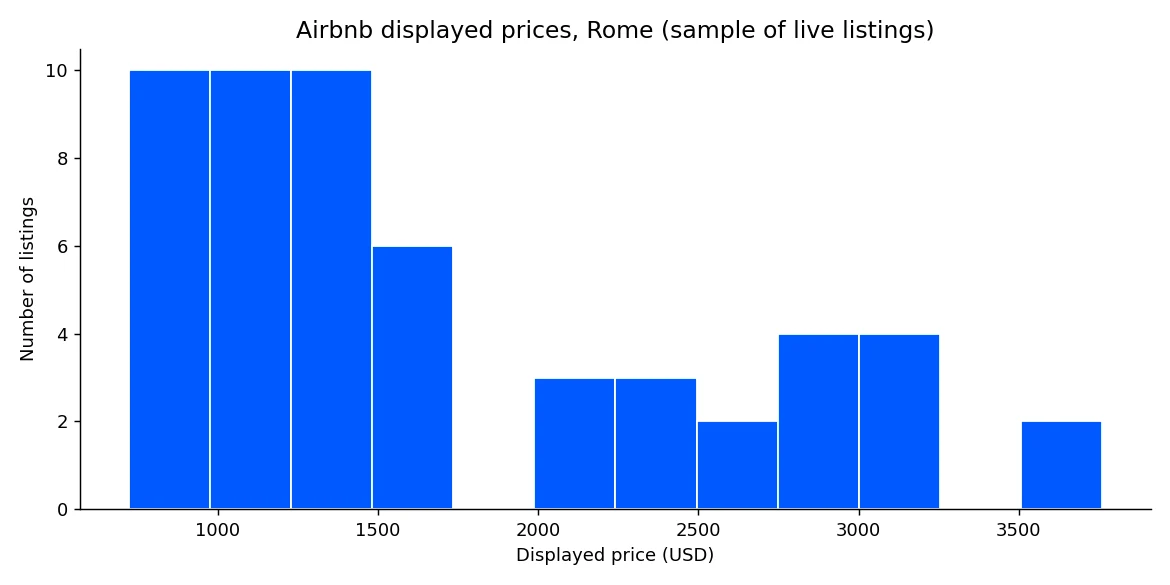
この分布は競合価格設定、外れ値検出、稼働率モデリングの基盤となります。
選択方法
- 探索中または学習中? 手動スクレイピングはページの構造を理解するのに役立ちます。本番環境では使用しないでください。
- 既製スクレイパーがないページでパースを自分でコントロールしたい? Web Unlockerを使用してください。
- 任意のボリュームでクリーンな構造化リストデータが必要? AirbnbスクレイパーAPIを使用してください。これがほとんどのプロジェクトのデフォルトです。
- コードなしで過去または市場全体のデータが必要? Airbnbデータセットを使用してください。
専用ツールの直接比較については、最良のAirbnbスクレイパーと最良のAirbnbデータプロバイダーのまとめをご覧ください。
すべてに共通するパターン:管理されたインフラストラクチャにブロック解除と構造化を任せることで、チームがスクレイパーの管理ではなく分析に時間を費やせます。Bright Dataのネットワークはまさにこのために構築されており、GDPRおよびCCPAに準拠し、ISO 27001認定、倫理的に調達されたインフラストラクチャがすべてのリクエストを支えています。
まとめ
2026年のAirbnbスクレイピングは、巧妙なパースよりも適切な抽象化レベルを選ぶことが重要です。手動コードは学習には適していますが、Airbnbのアンチボット層では機能しません。Web Unlockerはカスタムコントロールが必要な場合にページを提供します。AirbnbスクレイパーAPIはメンテナンスゼロで構造化レコードを提供します。データセットはコードゼロで市場全体を提供します。スクレイパーAPIの5,000リクエストから始め、対象のリストに向けて、そこから構築していきましょう。
{
“@context”: “https://schema.org”,
“@type”: “FAQPage”,
“mainEntity”: [
{
“@type”: “Question”,
“name”: “PythonのrequestsだけでアAirbnbをスクレイピングできますか?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “信頼性高くはできません。AirbnbはDataDomeボット検出でページを保護しています。デフォルトのリクエストはチャレンジページを返すことが多く、たまに通過しても大規模ではCAPTCHA、レート制限、IPバンで機能しなくなります。管理されたブロック解除、実際のブラウザフィンガープリント、プロキシが必要なため、ほとんどのチームはWeb UnlockerまたはAirbnbスクレイパーAPIを使用します。”
}
},
{
“@type”: “Question”,
“name”: “AirbnbスクレイパーAPIはどのようなデータを返しますか?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “1件のレコードには51フィールドが含まれます:リストのタイトルとタイプ、1泊および合計料金、空き状況カレンダー、評価とレビュー数、ホストとスーパーホストのシグナル、アメニティ、座標、画像など。パース不要のクリーンなJSONとして受け取れます。”
}
},
{
“@type”: “Question”,
“name”: “スクレイパーAPIと既製データセットのどちらを使うべきですか?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “特定のリストまたは検索URLがあり、オンデマンドで新鮮なデータが必要な場合はスクレイパーAPIを使用します。URLを提供せずに過去または市場全体のカバレッジが必要な場合はデータセットを使用します。データセットには650万件以上のレコードが含まれ、1レコードあたり0.0025ドルから始まります。”
}
},
{
“@type”: “Question”,
“name”: “開始コストはどれくらいですか?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “すべての新規Bright Dataアカウントには、Web Scraper API、Web Unlocker、SERP APIで月5,000件の無料レコードが含まれ、クレジットカード不要です。それ以降はWeb Scraper APIが1,000レコードあたり0.70ドルから始まり、配信されたデータに対してのみ支払います。”
}
},
{
“@type”: “Question”,
“name”: “AIエージェントはMCPを通じてAirbnbデータを収集できますか?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “はい。Bright DataのWeb MCPサーバーは、MCP対応のLLM(Claude、GPT、Gemini)をライブウェブデータに接続します。無料のRapidモードでは、エージェントはリクエストごとに1クレジットでsearch_engineとscrape_as_markdownを取得し、アプリにスクレイピングコードなしでオンデマンドで現在のAirbnbリストを取得できます。Proモードは本番エージェント向けに60以上の構造化データツールを追加します。”
}
},
{
“@type”: “Question”,
“name”: “大規模なAirbnbスクレイピングジョブはどのように処理しますか?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “非同期エンドポイントを使用します:URLリストで収集をトリガーし、スナップショットが準備できるまで進捗エンドポイントをポーリングし、JSON、CSV、またはNDJSON形式でダウンロードします。1つのジョブで数千のURLを処理でき、スナップショットは30日間利用可能です。”
}
}
]
}
よくある質問
PythonのrequestsだけでAirbnbをスクレイピングできますか?
信頼性高くはできません。AirbnbはDataDomeボット検出でページを保護しています。デフォルトのリクエストはチャレンジページを返すことが多く、たまに通過しても大規模ではCAPTCHA、レート制限、IPバンで機能しなくなります。管理されたブロック解除、実際のブラウザフィンガープリント、プロキシが必要なため、ほとんどのチームはWeb UnlockerまたはAirbnbスクレイパーAPIを使用します。
AirbnbスクレイパーAPIはどのようなデータを返しますか?
1件のレコードには51フィールドが含まれます:リストのタイトルとタイプ、1泊および合計料金、空き状況カレンダー、評価とレビュー数、ホストとスーパーホストのシグナル、アメニティ、座標、画像など。パース不要のクリーンなJSONとして受け取れます。
スクレイパーAPIと既製データセットのどちらを使うべきですか?
特定のリストまたは検索URLがあり、オンデマンドで新鮮なデータが必要な場合はスクレイパーAPIを使用します。URLを提供せずに過去または市場全体のカバレッジが必要な場合はデータセットを使用します。データセットには650万件以上のレコードが含まれ、1レコードあたり0.0025ドルから始まります。
開始コストはどれくらいですか?
すべての新規Bright Dataアカウントには、Web Scraper API、Web Unlocker、SERP APIで月5,000件の無料レコードが含まれ、クレジットカード不要です。それ以降はWeb Scraper APIが1,000レコードあたり0.70ドルから始まり、配信されたデータに対してのみ支払います。
AIエージェントはMCPを通じてAirbnbデータを収集できますか?
はい。Bright DataのWeb MCPサーバーは、MCP対応のLLM(Claude、GPT、Gemini)をライブウェブデータに接続します。無料のRapidモードでは、エージェントはリクエストごとに1クレジットでsearch_engineとscrape_as_markdownを取得し、アプリにスクレイピングコードなしでオンデマンドで現在のAirbnbリストを取得できます。Proモードは本番エージェント向けに60以上の構造化データツールを追加します。
大規模なAirbnbスクレイピングジョブはどのように処理しますか?
非同期エンドポイントを使用します:URLリストで収集をトリガーし、スナップショットが準備できるまで進捗エンドポイントをポーリングし、JSON、CSV、またはNDJSON形式でダウンロードします。1つのジョブで数千のURLを処理でき、スナップショットは30日間利用可能です。






