

このチュートリアルでは、次の内容を取り上げます。
- ウェブからEコマースデータをスクレイピングするのはなぜか?
- eBayスクレイピングライブラリとツール
- Beautiful SoupでeBayの商品データをスクレイピングする
ウェブからEコマースデータをスクレイピングするのはなぜか?
Eコマースのデータをスクレイピングすることで、さまざまなシナリオやアクティビティに役立つ情報を取得できます。これには以下が含まれます。
- 価格監視:Eコマースサイトを追跡することで、企業は商品価格をリアルタイムで監視できます。これにより、価格の変動を把握し、トレンドを見極め、それに応じて価格戦略を調整できます。消費者であれば、お得な情報を見つけてお金を節約するのに役立つでしょう。
- 競合分析:競合他社の商品提供、価格、割引、プロモーションに関する情報を収集することで、自社の価格戦略、品揃え、マーケティングキャンペーンについて、データに基づいた意思決定を行えます。
- 市場調査:電子商取引データは、市場動向、消費者の嗜好、需要パターンに関する貴重なインサイトを提供します。その情報は、新たなトレンドを研究し、顧客の行動を理解するためのデータ分析プロセスのソースとして活用できます。
- センチメント分析:Eコマースサイトからカスタマーレビューをスクレイピングすることで、顧客満足度、製品フィードバック、改善点に関するインサイトを得ることができます。
Eコマースのスクレイピングといえば、eBayが最も人気のある選択肢と言えますが、それには少なくとも3つの理由があります。
- 幅広い製品を取り揃えています。
- オークションと入札システムに基づいており、Amazonや同様のプラットフォームよりもはるかに多くのデータを取得できます。
- 同じ商品に複数の価格が設定されています(オークション + Buy It Now!)
eBayからデータを抽出することで豊富な情報にアクセスして、価格監視、比較、分析戦略に活用できます。
eBayスクレイピングライブラリとツール
Pythonは、その使いやすさ、シンプルな構文、膨大なライブラリのエコシステムのおかげで、スクレイピングに最適な言語の1つと考えられています。つまり、eBayのスクレイピングに最適なプログラミング言語というわけです。Pythonでウェブスクレイピングを行う方法については、詳細なガイドをご覧ください。
あとは、数多くあるスクレイピングライブラリの中から適切なものを選ぶ必要があります。正しい決定をするために、ブラウザでeBayを調査しましょう。ページで実行されるAJAXコールを調べると、サイト上のデータのほとんどが、サーバーから返されたHTMLドキュメントに埋め込まれていることに気が付くでしょう。
つまり、サーバーへのリクエストを複製する単純なHTTPクライアントとHTMLパーサーだけで十分ということになります。このような理由から、以下をお勧めします。
- Requests:最も一般的なPython用HTTPクライアントライブラリ。HTTPリクエストの送信とそのレスポンスの処理を簡略化し、ウェブサーバーからページコンテンツを簡単に取得できるようにします。
- Beautiful Soup:フル機能のHTMLおよびXML解析Pythonライブラリ。DOMを探索し、その要素からデータを抽出するための強力なメソッドを提供するため、主にウェブスクレイピングに使用されます。
RequestsとBeautiful Soupのおかげで、Pythonでターゲットサイトをスクレイピングできるようになります。では、その方法を見てみましょう!
Beautiful SoupでeBayの商品データをスクレイピングする
このステップバイステップのチュートリアルに従って、eBayウェブスクレイピングPythonスクリプトの作成方法を学びましょう。
ステップ1:はじめに
価格スクレイピングを実装するには、以下の前提条件を満たす必要があります。
- Python 3+がコンピュータにインストール済みであること:インストーラをダウンロードして起動し、インストールウィザードに従って操作を行います。
- お好みのPython IDE:Python拡張機能付きのVisual Studio CodeとPyCharm Community Editionは、どちらも素晴らしい選択肢です。
次に、以下のコマンドを実行して、ebay-scraperという仮想環境を持つPythonプロジェクトを初期化します。
mkdir ebay-scrapernncd ebay-scrapernnpython -m venv env
プロジェクトフォルダ内に入り、以下のスニペットを含むscraper.pyファイルを追加します。
print('Hello, World!')
これは「Hello, World!」を表示するだけのサンプルスクリプトですが、eBayをスクレイピングするロジックをすぐに追加していきます。
以下を実行して動作することを確認します。
python scraper.py
ターミナルには次のように表示されているはずです。
Hello, World!
これでPythonプロジェクトができました!
ステップ2:スクレイピングライブラリをインストールする
ウェブスクレイピングを実行するのに必要なライブラリをプロジェクトの依存関係に追加します。プロジェクトフォルダ内で以下のコマンドを実行し、Beautiful SoupとRequestsパッケージをインストールします。
pip install beautifulsoup4 requests
scraper.pyにあるライブラリをインポートして、eBayからデータを抽出する準備を行います。
import requestsnnfrom bs4 import BeautifulSoupnn# scraping logic...
Python IDEからエラーが出力されないことを確認できたら、スクレイピングによる価格監視を実装する準備が整いました!
ステップ3:ターゲットのウェブページをダウンロードする
eBayのユーザーであれば、商品ページのURLが以下のようなフォーマットになっていることにお気づきでしょう。
https://www.ebay.com/itm/u003cITM_IDu003e
ご覧のように、これはアイテムIDに基づいて変更される動的なURLです。
例えば、これはあるeBay商品のURLです。
https://www.ebay.com/itm/225605642071?epid=26057553242u0026hash=item348724e757:g:~ykAAOSw201kD1unu0026amdata=enc%3AAQAIAAAA4OMICjL%2BH6HBrWqJLiCPpCurGf8qKkO7CuQwOkJClqK%2BT2B5ioN3Z9pwm4r7tGSGG%2FI31uN6k0IJr0SEMEkSYRrz1de9XKIfQhatgKQJzIU6B9GnR6ZYbzcU8AGyKT6iUTEkJWkOicfCYI5N0qWL8gYV2RGT4zr6cCkJQnmuYIjhzFonqwFVdYKYukhWNWVrlcv5g%2BI9kitSz8k%2F8eqAz7IzcdGE44xsEaSU2yz%2BJxneYq0PHoJoVt%2FBujuSnmnO1AXqjGamS3tgNcK5Tqu36QhHRB0tiwUfAMrzLCOe9zTa%7Ctkp%3ABFBMmNDJgZJi
ここで、225605642071はアイテムの一意識別子です。なお、クエリパラメータは、ページにアクセスする上で必須ではありません。。それらを削除しても、eBayは商品ページを正しく読み込みます。
スクリプトにターゲットページをハードコードする代わりに、コマンドライン引数からアイテムIDを読み込ませることができます。こうすることで、どの商品ページからもデータをスクレイピングできます。
これは、scraper.pyを以下のように更新することで実現できます。
import requestsnnfrom bs4 import BeautifulSoupnnimport sysnn# if there are no CLI parametersnnif len(sys.argv) u003c= 1:nn print('Item ID argument missing!')nn sys.exit(2)nn# read the item ID from a CLI argumentnnitem_id = sys.argv[1]nn# build the URL of the target product pagennurl = f'https://www.ebay.com/itm/{item_id}'nn# scraping logic...nnAssume you want to scrape the product 225605642071. You can launch your scraper with:nnpython scraper.py 225605642071
sysのおかげで、コマンドライン引数にアクセスできます。sys.argvの最初の要素はスクリプトの名前、scraper.pyです。アイテムIDを取得するには、インデックス1の要素をターゲットにする必要があります。
CLIでアイテムIDを指定し忘れた場合、アプリケーションは以下のエラーを出力して失敗します。
Item ID argument missing!
そうでない場合は、CLIパラメータを読み込み、それをf文字列内で使用して、スクレイピングする商品のターゲットURLを生成します。この場合、URLには以下が含まれます。
nhttps://www.ebay.com/itm/225605642071
これで、requestsで、以下のコード行を使ってウェブページをダウンロードできます。
page = requests.get(url)
バックグラウンドで、request.get()はパラメータとして渡されたURLへのHTTP GETリクエストを実行します。pageにはeBayサーバーが生成したレスポンス(ターゲットページのHTMLコンテンツを含む)が格納されます。
素晴しいです!そこからデータを取り出す方法を学びましょう。
ステップ4:HTMLドキュメントを解析する
page.textには、サーバーから返されたHTMLドキュメントが含まれます。それをBeautifulSoup()コンストラクタに渡して解析します。
soup = BeautifulSoup(page.text, 'html.parser')
2番目のパラメータで、Beautiful Soupが使用するパーサーを指定します。html.parserはPythonの組み込みHTMLパーサーの名前です。
これで、soup変数には、DOMから要素を選択するための便利なメソッドを公開するツリー構造が格納されます。最も人気があるものを以下に示します。
- find():パラメータとして渡されたセレクタ条件に一致する最初のHTML要素を返します。
- find_all():入力セレクタの戦略に一致するHTML要素のリストを返します。
- select_one():入力されたCSSセクレタに一致するHTML要素を返します。
- select():パラメータとして渡されたCSSセレクタに一致するHTML要素のリストを返します。
これらを使って、タグ、ID、CSSクラスなどでHTML要素を選択します。次に、その属性とテキストの内容からデータを抽出できます。その様子を見てみましょう!
ステップ5:商品ページを検査する
効果的なデータスクレイピング戦略を構築したいのであれば、まずターゲットウェブページの構造に精通する必要があります。ブラウザを開き、eBayの商品をいくつか見てみましょう。
まず、商品カテゴリーごとに、ページに異なる情報が含まれることに気づくことでしょう。エレクトロニクス製品では、技術仕様にアクセスできます。

衣料品にアクセスすると、サイズや色を確認できます。

ウェブページの構造にこうした食い違いがあるため、スクレイピングは少々難しくなっています。ただし、商品価格や送料など、いくつかの情報フィールドは各ページにあります。
ブラウザのDevToolsにも慣れておきましょう。関心のあるデータを含むHTML要素を右クリックし、「検査」を選択します。以下のウィンドウが開きます。
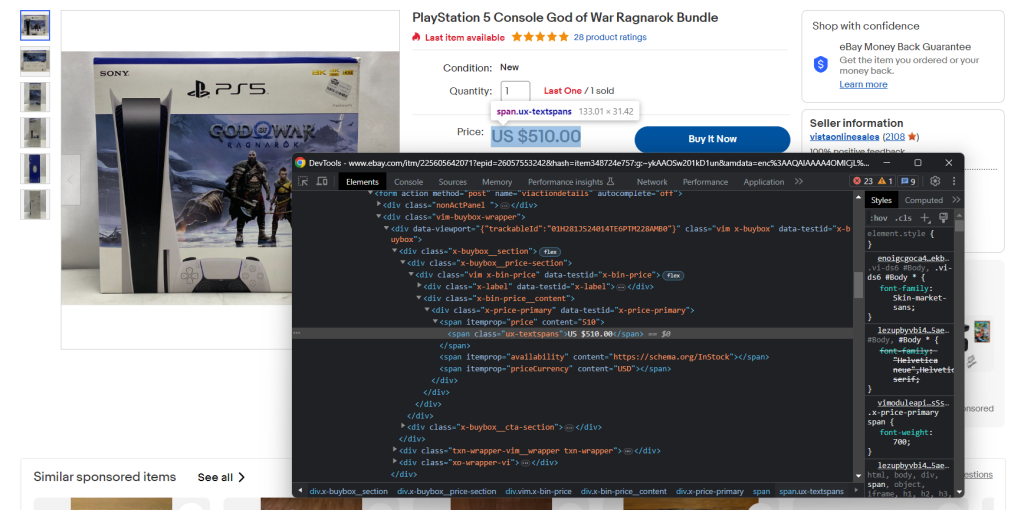
ここでページのDOM構造を調べることで、効果的なセレクタ戦略を定義する方法を理解できます。
DevToolsを使い、時間をかけて製品ページを検査してください。
ステップ6:価格データを抽出する
まず、スクレイピングするデータを格納するデータ構造が必要です。以下の方法で、Python辞書を初期化します。
item = {}
前のステップでお気づきのように、価格データはこのセクション内にあります。

HTML価格要素を検査します。
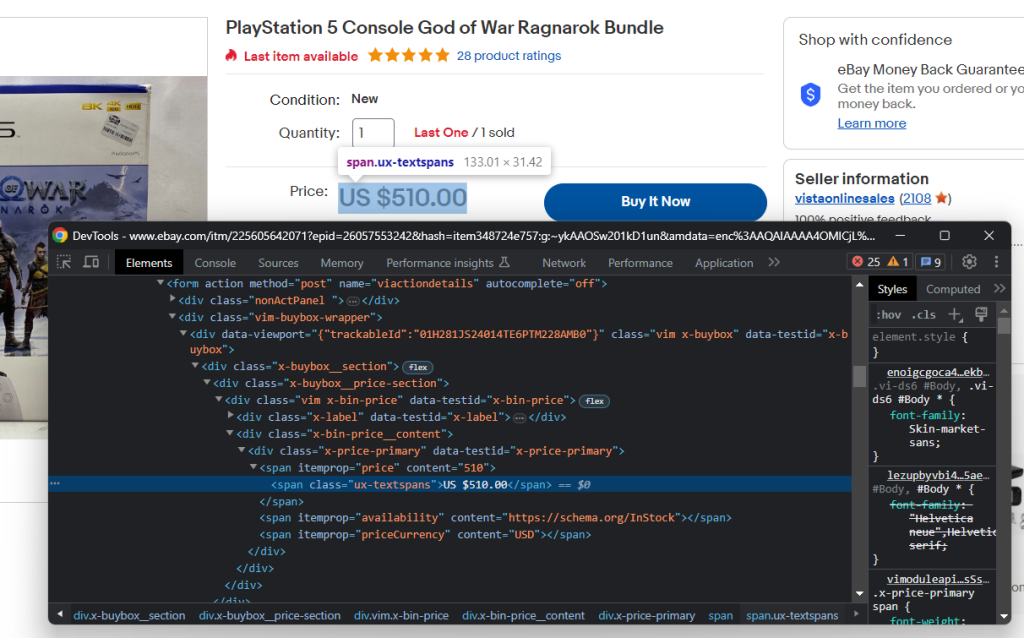
以下のCSSセレクタで商品価格を取得できます。
.x-price-primary span[itemprop=u0022priceu0022]nnAnd the currency with:nn.x-price-primary span[itemprop=u0022priceCurrencyu0022]nnApply those selectors in Beautiful Soup and retrieve the desired data with:nnprice_html_element = soup.select_one('.x-price-primary span[itemprop=u0022priceu0022]')nnprice = price_html_element['content']nncurrency_html_element = soup.select_one('.x-price-primary span[itemprop=u0022priceCurrencyu0022]')nncurrency = currency_html_element['content']
このスニペットは、価格と通貨のHTML要素を選択し、それらのコンテンツ属性に含まれる文字列を収集します。
上記でスクレイピングされる価格は、欲しいアイテムを入手するために支払わなければならない全額の一部に過ぎないことを心に留めておいてください。それには配送料も含まれます。
配送要素を検査します。
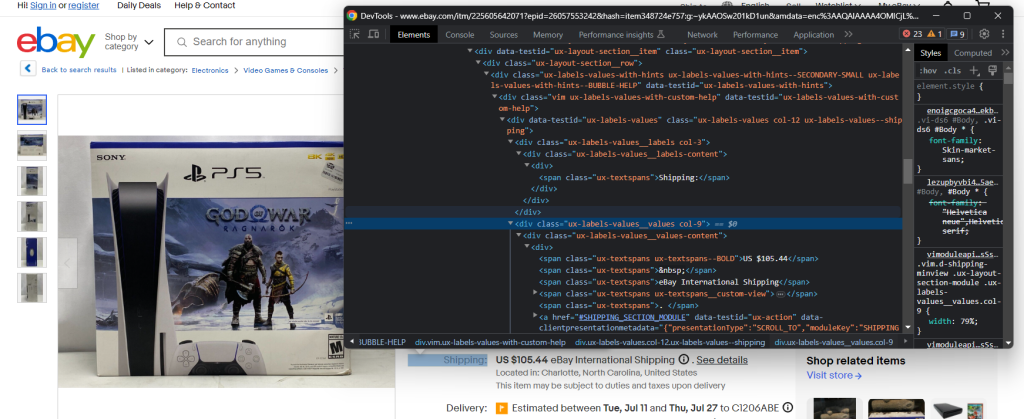
今回は、要素を取得するための簡単なCSSセレクタがないため、目的のデータを抽出するのが少し厄介です。できることは、それぞれの.ux-labels-values__labels divを繰り返し処理することです。現在の要素に「Shipping:」文字列が含まれている場合、DOM内の次の兄弟要素にアクセスし、.ux-textspans–BOLDから価格を抽出できます。
Your Code Here...
配送料要素には、以下の形式で求めるデータが含まれます。
US $105.44
価格を抽出するには、re.findall()メソッドで正規表現を使用します。スクリプトのimportセクションに以下の行を忘れずに追加してください。
import re nnAdd the collected data to the item dictionary:nnitem['price'] = pricennitem['shipping_price'] = shipping_pricennitem['currency'] = currencynnPrint it with:nnprint(item)nnAnd you will get:nn{'price': '499.99', 'shipping_price': '72.58', 'currency': 'USD'}
Pythonで価格追跡プロセスを実装するにはこれで十分でしょう。とはいえ、eBayの商品ページには他にも役立つ情報がたくさんあります。そのため、その抽出方法を学ぶことには価値があります!
ステップ7:アイテムの詳細を取得するה
「About this item」タブを見ると、興味深いデータがたくさん含まれていることに気付きます。
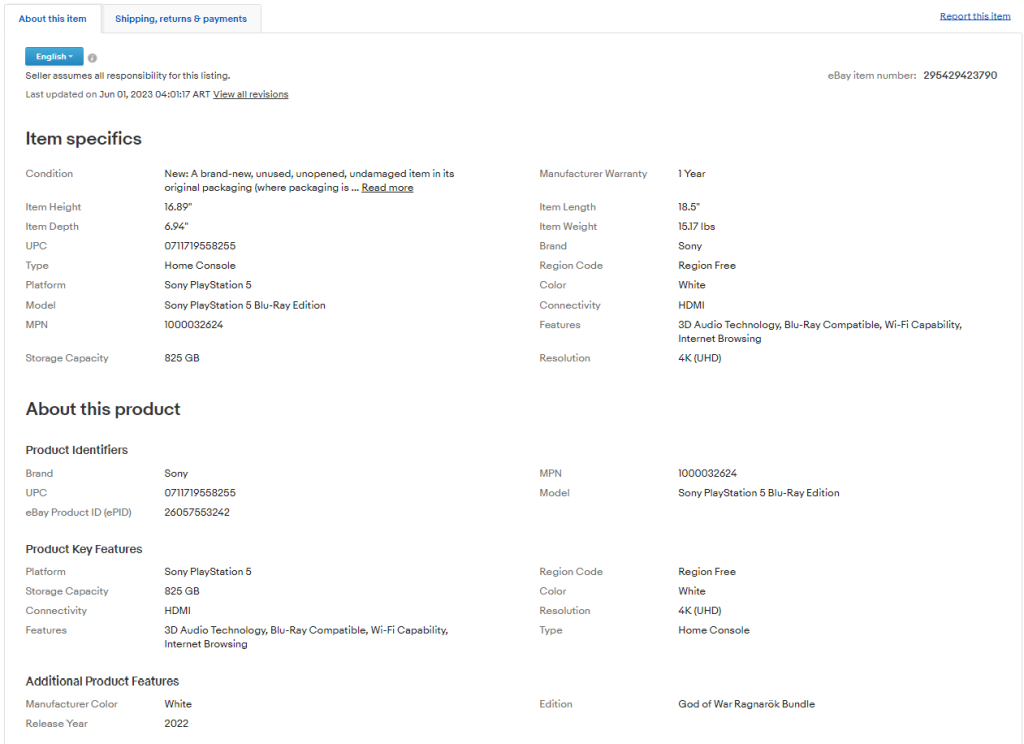
セクションやフィールドは商品によって異なるため、それらをすべてスマートにスクレイピングする方法を見つける必要があります。
具体的には、「Item specifics」と「About this product」が最も重要な項目です。この2つはほとんどの商品に備わっています。2つのうちの1つを点検すると、次の方法でそれらを選択できることに気付きます。
.section-title
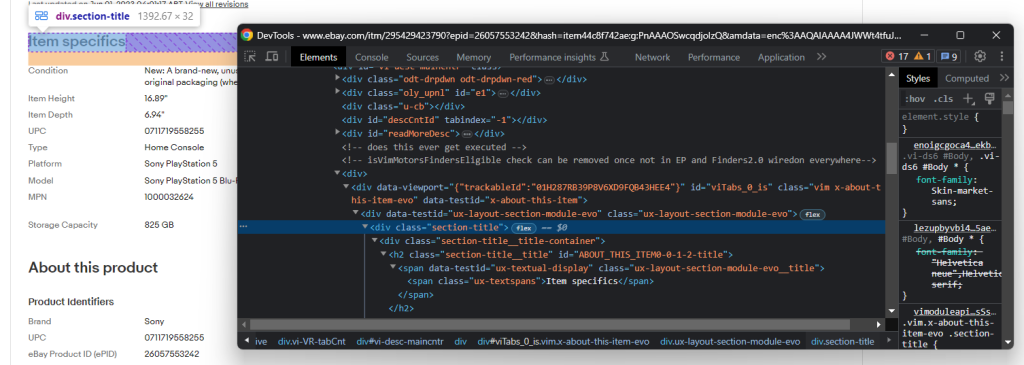
セクションを指定したら、そのDOM構造を調べます。
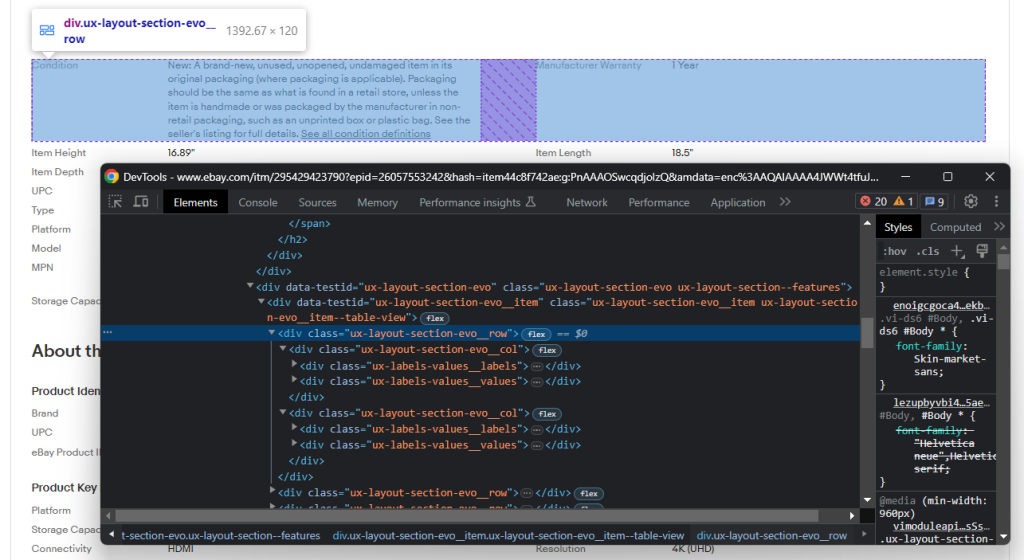
これは複数の行で構成されており、それぞれにいくつかの.ux-layout-section-evo__col要素が含まれることに留意してください。これらには、次の2つの要素が含まれます。
- .ux-labels-values__labels:属性名。
- .ux-labels-values__values:属性値。
これで、すべての詳細セクションの情報をプログラムでスクレイピングする準備が整いました。
section_title_elements = soup.select('.section-title')nnfor section_title_element in section_title_elements:nn if 'Item specifics' in section_title_element.text or 'About this product' in section_title_element.text:nn # get the parent element containing the entire sectionnn section_element = section_title_element.parentnn for section_col in section_element.select('.ux-layout-section-evo__col'):nn print(section_col.text)nn col_label = section_col.select_one('.ux-labels-values__labels')nn col_value = section_col.select_one('.ux-labels-values__values')nn # if both elements are presentnn if col_label is not None and col_value is not None:nn item[col_label.text] = col_value.text
このコードは、各HTML詳細フィールド要素を調べ、各商品属性に関連付けられたキーと値のペアをアイテム辞書に追加します。
forループの最後で、アイテムには以下が含まれます。
{'price': '499.99', 'shipping_price': '72.58', 'currency': 'USD', 'Condition': u0022New: A brand-new, unused, unopened, undamaged item in its original packaging (where packaging is applicable). Packaging should be the same as what is found in a retail store, unless the item is handmade or was packaged by the manufacturer in non-retail packaging, such as an unprinted box or plastic bag. See the seller's listing for full details. See all condition definitionsopens in a new window or tab u0022, 'Manufacturer Warranty': '1 Year', 'Item Height': '16.89u0022', 'Item Length': '18.5u0022', 'Item Depth': '6.94u0022', 'Item Weight': '15.17 lbs', 'UPC': '0711719558255', 'Brand': 'Sony', 'Type': 'Home Console', 'Region Code': 'Region Free', 'Platform': 'Sony PlayStation 5', 'Color': 'White', 'Model': 'Sony PlayStation 5 Blu-Ray Edition', 'Connectivity': 'HDMI', 'MPN': '1000032624', 'Features': '3D Audio Technology, Blu-Ray Compatible, Wi-Fi Capability, Internet Browsing', 'Storage Capacity': '825 GB', 'Resolution': '4K (UHD)', 'eBay Product ID (ePID)': '26057553242', 'Manufacturer Color': 'White', 'Edition': 'God of War Ragnarök Bundle', 'Release Year': '2022'}
素晴らしい!これでデータ取得目標を達成しました!
ステップ8:スクレイピングしたデータをJSONにエクスポートする
現在、スクレイピングされたデータはPython辞書に格納されています。より共有しやすく、読みやすくするために、以下の方法でJSONにエクスポートできます。
import jsonnn# scraping logic...nnwith open('product_info.json', 'w') as file:nn json.dump(item, file)
まず、product_info.jsonファイルをopen()で初期化する必要があります。次に、json.dump()を使用して、アイテム辞書のJSON表現を出力ファイルに書き出すことができます。Pythonでデータを解析してJSONにシリアライズする方法については、こちらの記事をご覧ください。
jsonパッケージはPython Standard Libraryから提供されているため、目的を達成するために追加の依存関係をインストールする必要はありません。
素晴らしい!ウェブページに含まれる生データから作業を始め、今では半構造化されたJSONデータが手元にあります。それでは、eBay Scraper全体を確認しましょう。
ステップ9:すべてを統合する
これが完全なscraper.pyスクリプトです。
Your Code Here...
70行未満のコードで、eBay商品のデータを監視するウェブスクレイパーを構築できます。
例として、ID 225605642071で識別されるアイテムに対して、次のように起動します。
python scraper.py 225605642071
スクレイピングプロセスの最後に、以下のproduct_info.jsonファイルがプロジェクトのルートフォルダに表示されます。
{nn u0022priceu0022: u0022499.99u0022,nn u0022shipping_priceu0022: u002272.58u0022,nn u0022currencyu0022: u0022USDu0022,nn u0022Conditionu0022: u0022New: A brand-new, unused, unopened, undamaged item in its original packaging (where packaging is applicable). Packaging should be the same as what is found in a retail store, unless the item is handmade or was packaged by the manufacturer in non-retail packaging, such as an unprinted box or plastic bag. See the seller's listing for full detailsu0022,nn u0022Manufacturer Warrantyu0022: u00221 Yearu0022,nn u0022Item Heightu0022: u002216.89"u0022,nn u0022Item Lengthu0022: u002218.5"u0022,nn u0022Item Depthu0022: u00226.94"u0022,nn u0022Item Weightu0022: u002215.17 lbsu0022,nn u0022UPCu0022: u00220711719558255u0022,nn u0022Brandu0022: u0022Sonyu0022,nn u0022Typeu0022: u0022Home Consoleu0022,nn u0022Region Codeu0022: u0022Region Freeu0022,nn u0022Platformu0022: u0022Sony PlayStation 5u0022,nn u0022Coloru0022: u0022Whiteu0022,nn u0022Modelu0022: u0022Sony PlayStation 5 Blu-Ray Editionu0022,nn u0022Connectivityu0022: u0022HDMIu0022,nn u0022MPNu0022: u00221000032624u0022,nn u0022Featuresu0022: u00223D Audio Technology, Blu-Ray Compatible, Wi-Fi Capability, Internet Browsingu0022,nn u0022Storage Capacityu0022: u0022825 GBu0022,nn u0022Resolutionu0022: u00224K (UHD)u0022,nn u0022eBay Product ID (ePID)u0022: u002226057553242u0022,nn u0022Manufacturer Coloru0022: u0022Whiteu0022,nn u0022Editionu0022: u0022God of War Ragnarok Bundleu0022,nn u0022Release Yearu0022: u00222022u0022nn}
おめでとうございます!PythonでeBayをスクレイピングする方法を学ぶことができました!
まとめ
このガイドでは、eBayが商品価格を追跡するのに最適なスクレイピングターゲットの1つである理由と、その実行方法について説明しました。ステップバイステップのチュートリアルで、アイテムデータを取得するPythonスクレイパーの作成方法を詳しく見ることができました。お見せしたように、これは複雑なものではなく、数行のコードで済みます。
同時に、eBayのページ構成がいかに一貫性に欠けるかも理解しました。そのため、ここで作成したスクレイパーは、ある製品には使えても、別の製品には使えないかもしれません。また、eBayのUIは頻繁に変更されるため、スクリプトを継続的にメンテナンスする必要があります。幸い、eBay Scraperを使えばこのような事態を避けることができます!
スクレイピングプロセスを拡張し、他のEコマースプラットフォームから価格を抽出したい場合、その多くはJavaScriptに大きく依存していることに留意してください。この種のサイトを扱う場合、HTMLパーサーに基づく従来のアプローチではうまくいきません。その代わりに、JavaScriptをレンダリングでき、フィンガープリンティング、CAPTCHA、自動再試行を自動的に処理できるツールが必要です。当社の新しいScraping Browserソリューションは、まさにそのためのツールです!
eBayのウェブスクレイピングを全く関心がないとしても、アイテムデータには興味がありますか?eBayデータセットをご購入いただけます。


