

Walmartは、売上高と従業員数の両面で世界最大の企業です。一般的な意見とは異なり、Walmartは単なる小売企業ではありません。実際のところ、世界最大級のeコマースウェブサイトであり、商品に関する優れた情報源となっています。しかし、膨大な商品ポートフォリオのため、人が手作業でこのデータを収集することは不可能であり、だからこそウェブスクレイピングに理想的なユースケースなのです。
ウェブスクレイピングを使用すると、Walmartの何千もの商品に関するデータ(商品名、価格、説明、画像、評価など)をすばやく取得し、都合の良い任意の形式で保存できます。Walmartのデータをスクレイピングすることで、さまざまな商品の価格や在庫レベルを監視したり、市場の動きや顧客の行動を分析したり、さまざまなアプリケーションを作成したりできます。
この記事では、Walmart.comをスクレイピングする全く異なる2つの方法を紹介します。最初に、PythonとSelenium(主にテスト目的でウェブアプリケーションを自動化するために使用されるツール)を使って、Walmartをスクレイピングする方法を手順を追って学びます。次に、Bright Data Walmart Scraperを使って同じことをより簡単に行う方法を学びます。
Walmartをスクレイピングする
ご存知かもしれませんが、Walmartを含め、ウェブサイトをスクレイピングする方法にはさまざまなものがあります。その1つが、PythonとSeleniumを利用する方法です。
PythonとSeleniumを使用してWalmartをスクレイピングする方法
Pythonは、ウェブスクレイピングに関して最も人気のあるプログラミング言語の1つです。一方、Seleniumは主にテストの自動化に使用されます。ただし、ウェブブラウザを自動化できるため、ウェブスクレイピングにも使用できます。
要するに、Seleniumはウェブブラウザでの手動操作をシミュレートするものです。PythonとSeleniumを使えば、ウェブブラウザと任意のウェブページを開いて、その特定のページから情報をスクレイピングするシミュレーションを行えます。これは、ウェブブラウザの制御に使われるWebDriverを利用することで実現できます。
Seleniumをまだインストールしていない場合は、Seleniumライブラリとブラウザドライバーの両方をインストールする必要があります。手順については、Seleniumのドキュメントを参照してください。
人気があるため、この記事ではChromeDriverも使用しますが、ドライバーに関係なく手順は同じです。
では、PythonとSeleniumを使って一般的なウェブスクレイピングタスクを実行する方法を見てみましょう。
商品を検索する
Seleniumを使ってWalmartの商品を検索するシミュレーションを始めるには、Seleniumをインポートする必要があります。これは、次のコードで実行できます。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import ServiceSeleniumをインポートしたら、次のステップは、それを使ってウェブブラウザ(この場合はChrome)を開くことです。ただし、ブラウザは好みのものでかまいません。ブラウザを開いたら、後の手順はどのブラウザでも同じです。ブラウザを開くのはとても簡単です。次のコードをPythonスクリプトとして、またはJupyter Notebookから実行するだけです。
s=Service('/path/to/chromedriver')
driver = webdriver.Chrome(service=s)このシンプルなコードは、Chromeを開く以外は何も行いません。出力は次のとおりです。
Chromeを開いたら、Walmartのホームページにアクセスする必要があります。これは次のコードで実行できます。
driver.get("https://www.walmart.com")
スクリーンショットからわかるように、これは単にWalmart.comを開くだけです。
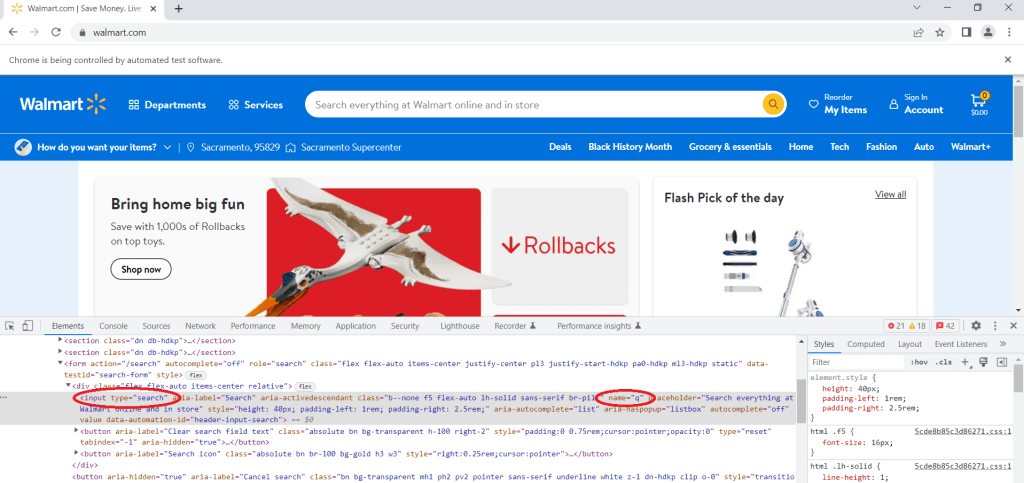
次のステップは、検査ツールでページのソースコードを手動で確認することです。このツールを使用すると、ウェブページ上の特定の要素を検査できます。これを使えば、任意のウェブページのHTMLとCSSを表示(さらには編集も)できます。
製品を検索したいので、検索バーに移動し、その上で右クリックして、検査をクリックする必要があります。type属性がsearchに等しい入力タグを見つけます。これは検索バーで、検索語をここに入力する必要があります。次に、name属性を見つけ、その値を確認する必要があります。この場合、name属性の値がqであることがわかります。
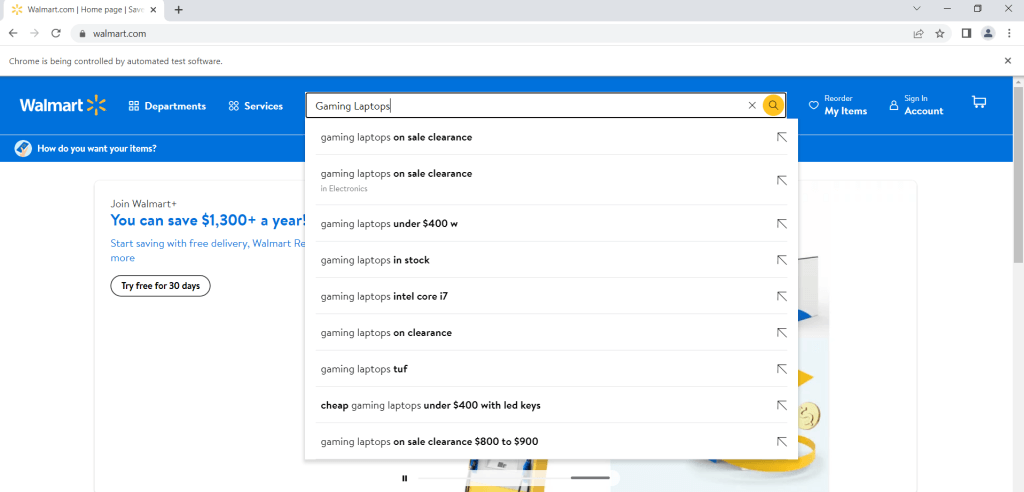
検索バーにクエリーを入力するには、次のコードを使用します。
search = driver.find_element("name", "q")
search.send_keys("Gaming Laptops")このコードはGaming Laptopsというクエリーを入力しますが、「Gaming Laptops」という語を他の語に置き換えることで、好きなフレーズを入力できます。
なお、前のコードは検索バーに検索語を入力しただけで、実際には検索を実行していません。実際に用語を検索するには、次のコード行が必要です。
search.send_keys(Keys.ENTER)そして出力は次のようになります。
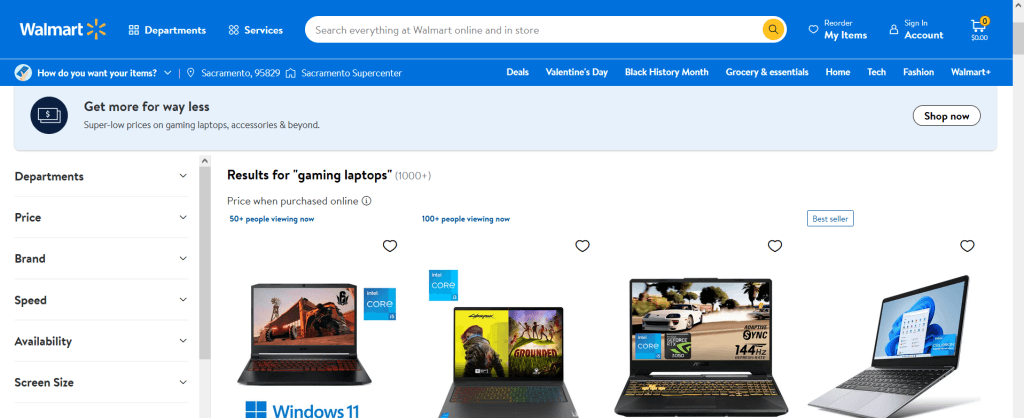
これで、入力した検索語の結果がすべて表示されるはずです。また、別の用語を検索したい場合は、新しい検索語を使用して最後の2行のコードを実行するだけです。
商品ページに移動し、商品情報をスクレイピングする
Seleniumで実行できるもう1つの一般的なタスクは、特定の商品ページを開き、その商品に関する情報をスクレイピングすることです。例えば、商品名、説明、価格、評価、レビューをスクレイピングできます。
例えば、情報をスクレイピングしたい商品を選択したとします。まず、商品のページを開きます。これは次のコードでできます(最初の例では、すでにSeleniumをインストールしてインポートしていると仮定します):
url = "https://www.walmart.com/ip/Acer-Nitro-5-15-6-Full-HD-IPS-144Hz-Display-11th-Gen-Intel-Core-i5-11400H-NVIDIA-GeForce-RTX-3050Ti-Laptop-GPU-16GB-DDR4-512GB-NVMe-SSD-Windows-11-Ho/607988022?athbdg=L1101"
driver.get(url)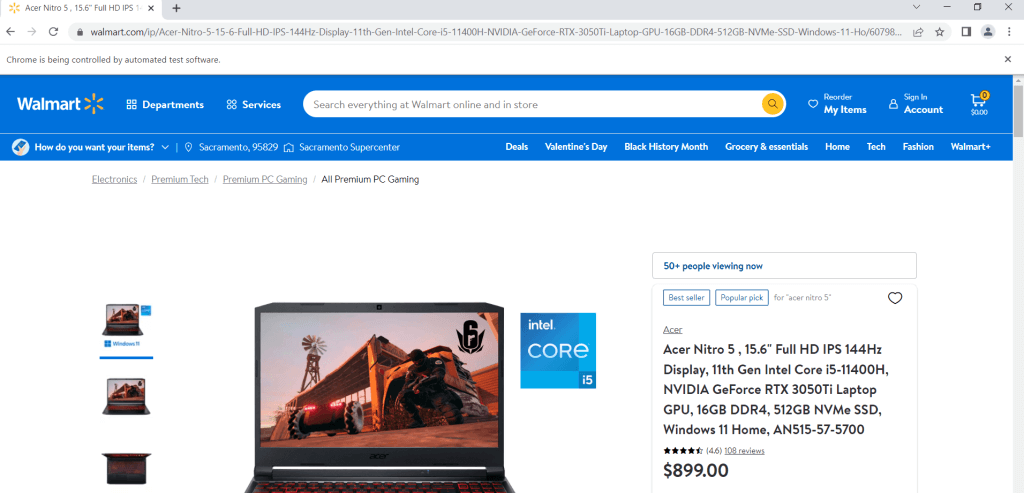
ページを開いたら、検査ツールを利用する必要があります。要するに、情報をスクレイピングしたい要素に移動し、その要素を右クリックして、検査をクリックする必要があります。例えば、商品のタイトルを見てみると、タイトルがH1タグに含まれていることがわかります。これはページ上の唯一のH1タグなので、次のコードで取得できます。
title = driver.find_element(By.TAG_NAME, "h1")
print(title.text)
>>>'Acer Nitro 5 , 15.6" Full HD IPS 144Hz Display, 11th Gen Intel Core i5-11400H, NVIDIA GeForce RTX 3050Ti Laptop GPU, 16GB DDR4, 512GB NVMe SSD, Windows 11 Home, AN515-57-5700'同様の方法で、商品の価格、評価、レビューの数を特定して、スクレイピングできます。
price = driver.find_element(By.CSS_SELECTOR, '[itemprop="price"]')
print(price.text)
>>> '$899.00'
rating = driver.find_element(By.CLASS_NAME,"rating-number")
print(rating.text)
>>> '(4.6)'
number_of_reviews = driver.find_element(By.CSS_SELECTOR, '[itemprop="ratingCount"]')
print(number_of_reviews.text)
>>> '108 reviews'覚えておくべき重要なことの1つは、ここに示す方法でデータをスクレイピングすることは、Walmartにより非常に困難になっているということです。Walmartには、ウェブスクレイパーを積極的にブロックしようとするスパム対策システムがあるためです。ですから、ウェブスクレイピングの取り組みが一貫してブロックされていることに気づいた場合、それはおそらくあなたのせいではなく、できることはそれほどないことを知っておいてください。しかし、次のセクションで示す解決策を使えば、はるかに効果的であることがわかります。
Bright DataでWalmartをスクレイピングするステップバイステップの手順
お分かりのように、PythonとSeleniumを使ったWalmartのスクレイピングはそれほど簡単ではありません。Walmartのウェブサイトをスクレイピングするには、Bright Data Web Scraper IDEを使用する、もっと簡単な方法があります。このツールを使えば、前回示したのと同じタスクをより簡単かつ効率的に行うことができます。Web Scraper IDEを使うもう一つの利点は、Walmartはあなたの努力を即座にブロックできないことです。
Web Scraper IDEを使用するには、まずBright Dataアカウントにサインアップする必要があります。登録が完了してログインすると、次の画面が表示されます。左側のデータセット&Web Scraper IDEボタンをクリックします。
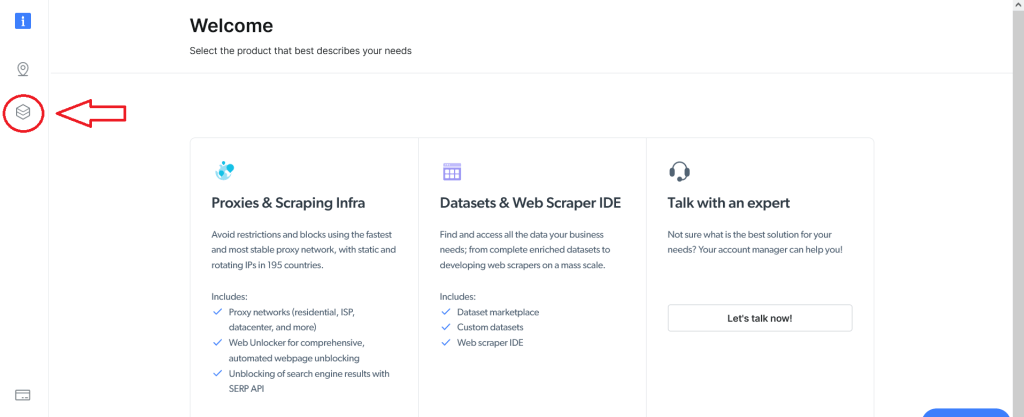
すると、次の画面に移動します。そこからマイスクレイパーフィールドに移動します。
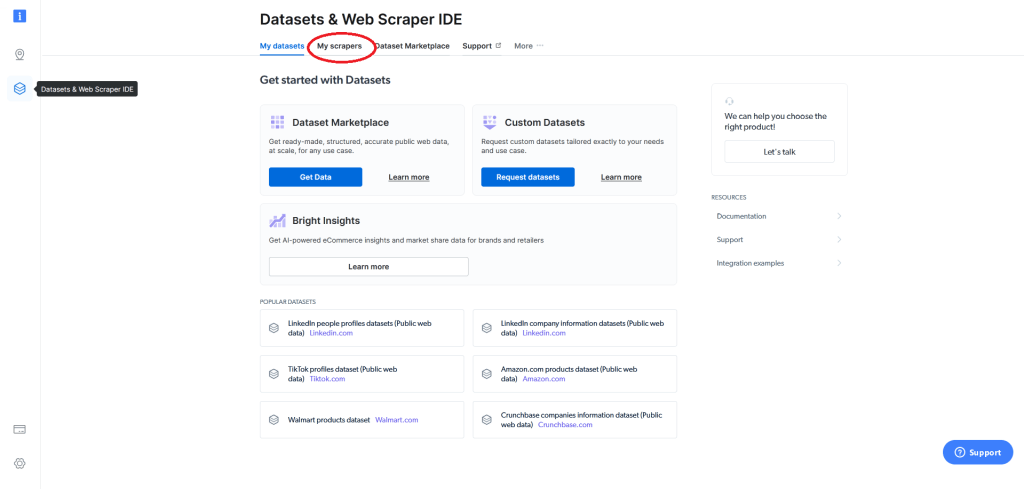
これにより、既存のウェブスクレイパー(存在する場合)が表示され、ウェブスクレイパー(IDE)を開発するオプションが提供されます。Bright Dataを使うのが初めてであれば、ウェブスクレイパーはありません。ウェブスクレイパー(IDE)を開発するをクリックします。
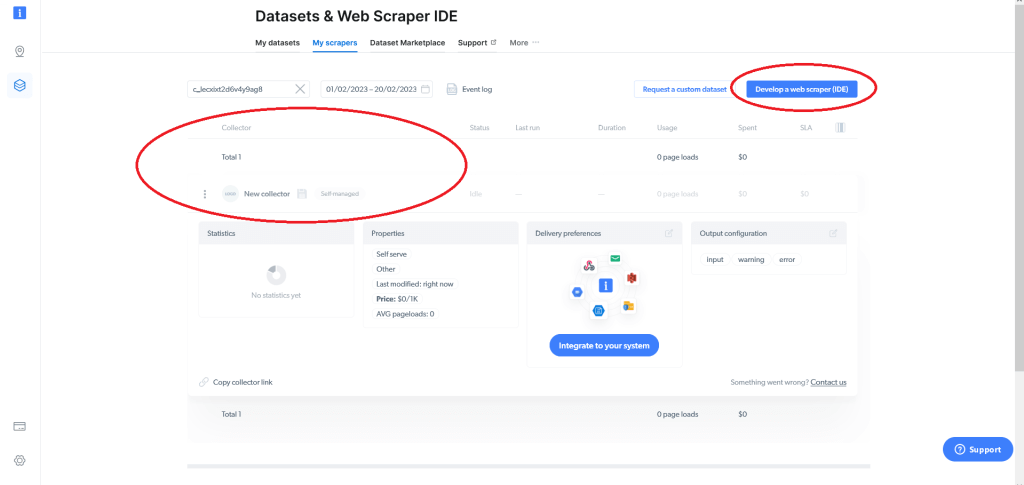
既存のテンプレートのいずれかを使用するか、コードをゼロから始めるかを選択できます。Walmart.comを具体的にスクレイピングするには、ゼロから始めるをクリックします。これで、Bright Data Web Scraper IDEが開きます。
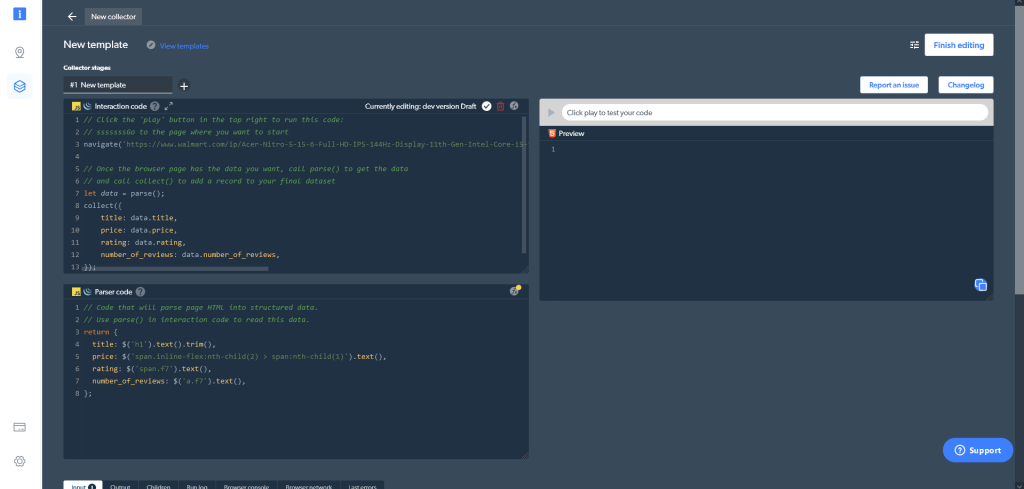
Web Scraper IDEは、いくつかの異なるウィンドウで構成されています。左上に、インタラクションコードウィンドウがあります。名前が示すように、このウィンドウを使用して、ウェブサイトをナビゲートしたり、スクロールしたり、ボタンをクリックしたり、その他さまざまなアクションを実行したりして、ウェブサイトを操作できます。その下にはパーサーコードウィンドウがあり、ウェブサイトとのやり取りから得られたHTMLの結果を解析できます。右側では、コードのプレビューとテストができます。
さらに、右上にあるコード設定では、さまざまなワーカータイプを選択できます。コード(デフォルトのオプション)とブラウザワーカーを切り替えて、データのナビゲートとクローリングができます
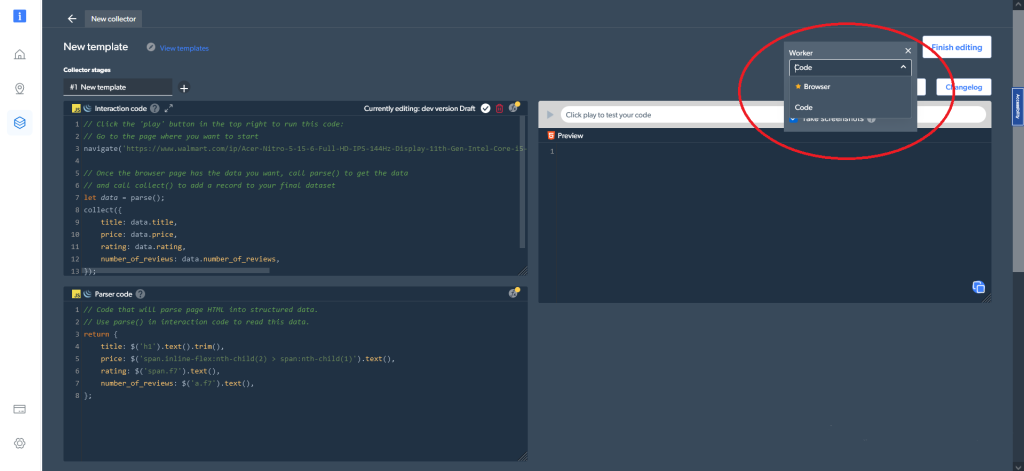
次に、PythonとSeleniumを使用して行ったのと同じ製品、同じデータをどのようにスクレイピングできるか見てみましょう。最初に商品ページに移動します。これには、インタラクションコードウィンドウ内の次のコード行を使用します。
navigate('https://www.walmart.com/ip/Acer-Nitro-5-15-6-Full-HD-IPS-144Hz-Display-11th-Gen-Intel-Core-i5-11400H-NVIDIA-GeForce-RTX-3050Ti-Laptop-GPU-16GB-DDR4-512GB-NVMe-SSD-Windows-11-Ho/607988022?athbdg=L1101');あるいは、navigate(input.url)で変更可能な入力パラメータを使うこともできます。その場合は、次に示すように、スクレイピングしたいURLを入力として追加します。
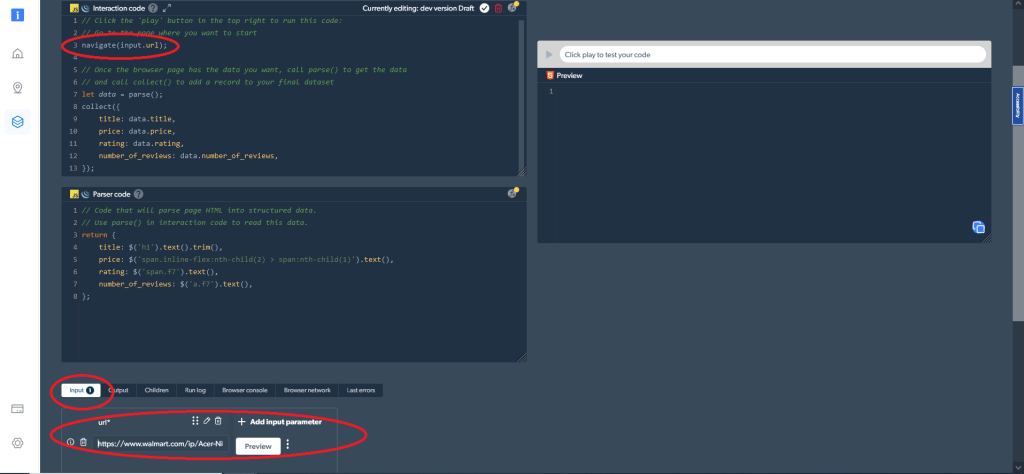
これに続いて、必要なデータを収集する必要があります。次のコードで実行できます。
let data = parse();
collect({
title: data.title,
price: data.price,
rating: data.rating,
number_of_reviews: data.number_of_reviews,
});最後にすべきことは、HTMLを構造化データに解析することです。これは、パーサーコードウィンドウにある次のコードで行うことができます。
return {
title: $('h1').text().trim(),
price: $('span.inline-flex:nth-child(2) > span:nth-child(1)').text(),
rating: $('span.f7').text(),
number_of_reviews: $('a.f7').text(),
};そうすれば、Web Scraper IDEで欲しいデータをすぐに入手できます。右側の再生ボタンをクリックする(またはCtrl+Enterキーを押す)だけで、必要な結果が出力されます。また、Web Scraper IDEからデータを直接ダウンロードすることもできます。
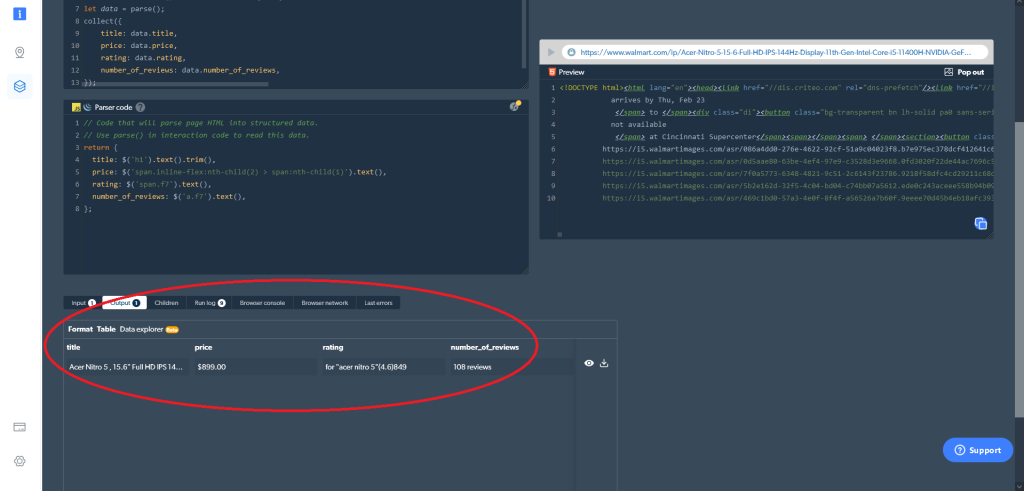
ワーカータイプとしてコードではなくブラウザを選択した場合、出力は次のようになります。
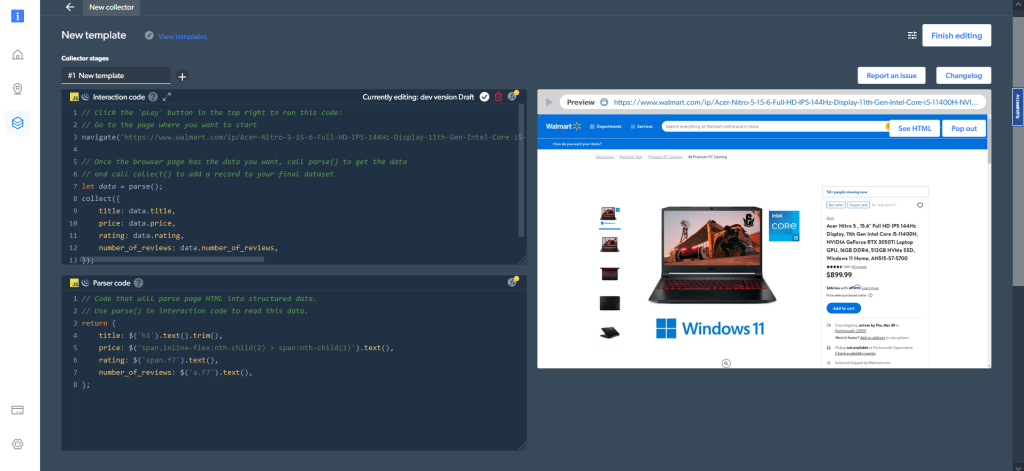
Web Scraper IDEから直接結果を取得することは、データを取得するためのオプションの1つに過ぎません。マイスクレイパーダッシュボードで配信設定を行うこともできます。
最後に、Web Scraper IDEを使ってもウェブスクレイピングが難しい場合、Bright Dataは利用可能なWalmart商品データセットをデータセットマーケットプレイスで提供しています。そこでは、ボタンをクリックするだけで多数のデータセットを利用できます。
ここに示すように、Bright Data Web Scraper IDEを使用することは、PythonとSeleniumを使用して独自のウェブスクレイパーを作成するよりも簡単で使い勝手に優れています。さらに、Bright Data Web Scraper IDEを使えば、初心者でもWalmartからデータ収集を始めることができます。対照的に、PythonとSeleniumを使ってWalmart.comをスクレイピングするには、確かなコーディングの知識が必要です。
使いやすさに加え、Bright Data Walmart Scraperのもう1つの印象的な点は、その拡張性です。必要な数の商品データを、問題を抱えることなくスクレイピングできます。
ウェブスクレイピングに関して指摘すべき重要なことの1つに、プライバシー法があります。多くの企業が、ウェブサイトからスクレイピングできる情報を禁止または制限しています。このため、PythonとSeleniumを使って独自のウェブスクレイパーを作成する場合、ルールに違反していないことを確認する必要があります。ただし、Bright Data Web Scraper IDEを使用する場合は、Bright Dataがこの責任を負い、業界のベストプラクティスとすべてのプライバシー規制を遵守していることを確認します。
まとめ
この記事では、Walmartのデータをスクレイピングする理由について説明しましたが、さらに重要なのは、Walmartの何千もの商品の価格、商品名、レビュー数、評価をスクレイピングする方法を実際に学べたことです。
ここで学んだように、PythonとSeleniumを使えばこのデータをスクレイピングできます。しかし、その方法は難しく、初心者を脅かすような課題もあります。Web Scraper IDEのように、Walmartのデータをはるかに簡単にスクレイピングできるソリューションもあります。これは、多くの人気ウェブサイトをスクレイピングする機能とコードテンプレートを提供し、CAPTCHAを回避することができ、データ保護法に準拠しています。






