

このガイドでは以下を学びます:
- データセットの定義
- データセット作成の最適な方法
- Pythonでのデータセット作成方法
- Rでデータセットを作成する方法
さっそく見ていきましょう!
データセットとは?
データセットとは、特定のテーマ、トピック、または業界に関連するデータの集合体です。データセットは、数値、テキスト、画像、動画、音声など様々な種類の情報を包含し、CSV、JSON、XLS、XLSX、SQLなどの形式で保存されます。
基本的に、データセットは特定の目的に向けた構造化データで構成されています。
データセット作成のためのトップ5戦略
データセット作成のための5つの最良の戦略を探り、その仕組みと長所・短所を分析します。
戦略 #1: 業務の外部委託
データセット作成のための事業部門を設立・管理することは、実現不可能または非現実的である場合があります。特に、社内にリソースや時間が不足している場合にはそうです。そのような状況では、データセット作成の効果的な戦略として、タスクを外部委託することが挙げられます。
外部委託とは、データセット作成プロセスを社内で処理するのではなく、外部の専門家や専門機関に委任することを意味します。このアプローチにより、データ収集、クリーニング、フォーマットに精通した専門家や組織のスキルを活用できます。
データセット作成を誰に委託すべきか?多くの企業が既製データセットやカスタムデータ収集サービスを提供しています。詳細は「優れたデータセットサイトガイド」をご参照ください。
これらのプロバイダーは高度な技術を用いて、取得したデータの正確性と仕様に基づくフォーマットを保証します。外部委託によりビジネスの他の重要事項に集中できる一方、品質要件を満たす信頼できるパートナーの選定が不可欠です。
メリット:
- 一切の心配が不要
- あらゆるサイトからのあらゆる形式のデータセット
- 過去データまたは最新データ
デメリット:
- データ取得プロセスを完全に制御できない
- GDPRやCCPAなどのデータコンプライアンス上の問題が発生する可能性がある
- 最も費用対効果の高い解決策ではない可能性がある
戦略 #2: 公開APIからのデータ取得
ソーシャルメディアネットワークからECサイトまで、多くのプラットフォームが豊富なデータを公開する公開APIを提供しています。例えば、XのAPIでは公開アカウント、投稿、返信に関する情報にアクセスできます。
公開APIからのデータ取得は、データセット作成に効果的な手法です。その理由は、これらのエンドポイントが構造化された形式でデータを返すため、応答からデータセットを生成しやすくなるからです。当然ながら、APIはデータ収集における最良の戦略の一つです。
これらのAPIを活用することで、確立されたプラットフォームから直接、信頼性の高いデータを大量に迅速に収集できます。主な欠点は、APIの利用制限と利用規約を遵守する必要があることです。
長所:
- 公式データへのアクセス
- あらゆるプログラミング言語での簡易な統合
- ソースから直接構造化データを取得
デメリット:
- すべてのプラットフォームが公開APIを備えているわけではない
- APIプロバイダーが課す制限に従う必要がある
- これらのAPIが返すデータは時間の経過とともに変更される可能性がある
戦略 #3: オープンデータを探す
オープンデータとは、無料で一般に公開されているデータセットを指します。このデータは主に研究や学術論文で利用されますが、市場分析などのビジネスニーズにも活用できます。
オープンデータは政府、非営利団体、学術機関などの信頼できる情報源から提供されるため信頼性が高いです。これらの組織は社会動向、健康統計、経済指標、環境データなど幅広い分野を網羅するオープンデータリポジトリを提供しています。
オープンデータを取得できる代表的なサイトには以下があります:
- Data.gov: 米国連邦政府データの包括的なリポジトリ。
- European Union Open Data Portal:欧州全域のデータセットを提供。
- World Bank Open Data:世界経済・開発データを提供。
- 国連データ:世界の社会・経済指標に関する多様なデータセットを掲載。
- AWS上のオープンデータ登録簿:AWSリソース経由で利用可能なデータセットを発見・共有するプラットフォーム。
オープンデータは、自由に利用可能なデータを提供することでデータ収集の必要性を排除するため、データセット作成の一般的な方法です。ただし、プロジェクトの要件を満たすためには、データの品質、完全性、ライセンス条件を確認する必要があります。
長所:
- 無料のデータ
- すぐに利用可能な大規模で完全なデータセット
- 政府機関などの信頼できるソースによるデータセット
デメリット:
- 通常は過去のデータのみにアクセス可能
- ビジネスに役立つ洞察を得るには一定の作業が必要
- 関心のあるデータが見つからない可能性がある
戦略 #4: GitHubからデータセットをダウンロードする
GitHubには、機械学習やデータサイエンスからソフトウェア開発や研究まで、様々な目的のデータセットを含む数多くのリポジトリがホストされています。これらのデータセットは、フィードバックを得てコミュニティに貢献するために、個人や組織によって共有されています。
場合によっては、これらのGitHubリポジトリにはデータの処理、分析、探索のためのコードも含まれています。
主なリポジトリの例:
- Awesome Public Datasets: 金融、気候、スポーツなど様々な分野の高品質なデータセットを厳選してまとめたコレクション。特定のトピックや業界に関連するデータセットを見つけるためのハブとして機能します。
- Kaggleデータセット:データサイエンスコンテストの主要プラットフォームであるKaggleは、一部のデータセットをGitHubで公開しています。ユーザーはGitHubリポジトリからわずか数クリックでKaggleデータセットを作成できます。
- その他のオープンデータリポジトリ: 多くの組織や研究グループがGitHubを利用してオープンデータセットを公開しています。
これらのリポジトリでは、既存のデータセットをそのまま利用したり、必要に応じて適応させたりできます。アクセスにはgit cloneコマンド1行、または「ダウンロード」ボタンをクリックするだけです。
長所:
- すぐに使える既成データセット
- データ分析・操作用コード
- 多様なデータカテゴリから選択可能
デメリット:
- ライセンスに関する潜在的な問題
- これらのリポジトリの大半は最新ではない
- 汎用データであり、ニーズに最適化されていない
戦略 #5: ウェブスクレイピングで独自のデータセットを作成する
ウェブスクレイピングとは、ウェブページからデータを抽出し、利用可能な形式に変換するプロセスです。
ウェブスクレイピングによるデータセット作成が広く採用される理由は以下の通りです:
- 膨大なデータへのアクセス:ウェブは世界最大のデータ源です。ウェブスクレイピングによりこの広範なリソースを活用でき、他の手段では入手困難な情報を収集できます。
- 柔軟性:取得するデータ、データセットの生成形式、更新頻度を自由に選択・制御できます。
- カスタマイズ性:特定のニーズに合わせてデータ抽出を調整できます。例えば、公開データセットではカバーされていないニッチ市場や専門分野からのデータ抽出が可能です。
ウェブスクレイピングの一般的な流れは以下の通りです:
- 対象サイトを特定する
- ウェブページを調査し、データ抽出戦略を立案
- 対象ページに接続するスクリプトを作成する
- ページのHTMLコンテンツをパース
- 関心のあるデータを含むDOM要素を選択する
- これらの要素からデータを抽出する
- 収集したデータをJSON、CSV、XLSXなどの希望の形式でエクスポートする
ウェブスクレイピング用のスクリプトは、Python、JavaScript、Rubyなど、ほぼあらゆるプログラミング言語で記述可能です。詳細は「ウェブスクレイピングに最適な言語」の記事をご覧ください。また「ウェブスクレイピングに最適なツール」も参照してください。
ほとんどの企業は自社サイトのデータが公的にアクセス可能であってもその価値を認識しているため、ボット対策技術で保護しています。これらのソリューションはスクリプトによる自動リクエストをブロックする可能性があります。ブロックされずにウェブスクレイピングを行う方法については、当社のチュートリアルをご覧ください。
さらに、ウェブスクレイピングと公開APIからのデータ取得の違いについて知りたい場合は、ウェブスクレイピングとAPIの比較記事をご覧ください。
長所:
- あらゆるサイトの公開データ
- データ抽出プロセスを制御可能
- ほとんどのプログラミング言語で動作する費用対効果の高いソリューション
デメリット:
- ボット対策やスクレイピング対策によりブロックされる可能性あり
- 一定のメンテナンスが必要
- カスタムデータ集計ロジックが必要になる場合がある
Pythonでデータセットを作成する方法
Pythonはデータサイエンス分野で主要な言語であり、データセット作成に広く採用されています。これからご覧いただくように、Pythonでのデータセット作成はわずか数行のコードで実現可能です。
ここでは、Bright Data Dataset Marketplaceで入手可能な全データセットに関する情報をスクレイピングすることに焦点を当てます:
ガイド付きチュートリアルに従って目標を達成しましょう!
より詳細な手順については、Pythonウェブスクレイピングガイドをご覧ください。
ステップ1: インストールと設定
お使いのマシンにPython 3以上がインストール済みで、Pythonプロジェクトが設定済みであることを前提とします。
まず、このプロジェクトに必要なライブラリをインストールします:
- requests: HTTPリクエストの送信と、ウェブページに関連するHTMLドキュメントの取得に使用します。
- Beautiful Soup: HTMLおよびXMLドキュメントのパースと、ウェブページからのデータ抽出。
- pandas: データの操作とCSVデータセットへのエクスポートに使用します。
プロジェクトフォルダ内のアクティブな仮想環境でターミナルを開き、以下を実行します:
pip install requests beautifulsoup4 pandasインストール後、Pythonスクリプトでこれらのライブラリをインポートできます:
import requests
from bs4 import BeautifulSoup
import pandas as pdステップ2: 対象サイトへの接続
データを抽出したいページのHTMLを取得します。requestsライブラリを使用してターゲットサイトにHTTPリクエストを送信し、HTMLコンテンツを取得します:
url = 'https://brightdata.com/products/データセット'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36' }
response = requests.get(url=url, headers=headers)詳細については、Python requests でユーザーエージェントを設定する方法に関するガイドを参照してください。
ステップ3: スクラッピングロジックの実装
HTMLコンテンツを取得したら、BeautifulSoupを使用してパースし、必要なデータを抽出します。対象となるデータを含むHTML要素を選択し、そこからデータを取得します:
# 取得したHTMLをパース
soup = BeautifulSoup(response.text, 'html.parser')
# スクレイピングしたデータの保存先
data = []
# スクレイピングロジック
dataset_elements = soup.select('.datasets__loop .datasets__item--wrapper')
for dataset_element in dataset_elements:
dataset_item = dataset_element.select_one('.datasets__item')
title = dataset_item.select_one('.datasets__item--title').text.strip()
url_item = dataset_item.select_one('.datasets__item--title a')
if (url_item is not None):
url = url_item['href']
else:
url = None
type = dataset_item.get('aria-label', 'regular').lower()
data.append({
'title': title,
'url': url,
'type': type
})ステップ4: CSVへのエクスポート
pandasを使用してスクレイピングしたデータをDataFrame に変換し、CSVファイルにエクスポートします。
df = pd.DataFrame(data, columns=data[0].keys())
df.to_csv('dataset.csv', index=False)ステップ5: スクリプトの実行
最終的なPythonスクリプトには以下のコードが含まれます:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# カスタムユーザーエージェントでターゲットサイトにGETリクエストを送信
url = 'https://brightdata.com/products/データセット'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36' }
response = requests.get(url=url, headers=headers)
# 取得したHTMLをパース
soup = BeautifulSoup(response.text, 'html.parser')
# スクレイピングしたデータの保存先
data = []
# スクラッピングロジック
dataset_elements = soup.select('.datasets__loop .datasets__item--wrapper')
for dataset_element in dataset_elements:
dataset_item = dataset_element.select_one('.datasets__item')
title = dataset_item.select_one('.datasets__item--title').text.strip()
url_item = dataset_item.select_one('.datasets__item--title a')
if (url_item is not None):
url = url_item['href']
else:
url = None
type = dataset_item.get('aria-label', 'regular').lower()
data.append({
'title': title,
'url': url,
'type': type
})
# CSVへのエクスポート
df = pd.DataFrame(data, columns=data[0].keys())
df.to_csv('dataset.csv', index=False)実行すると、プロジェクトフォルダに以下のdataset.csvファイルが生成されます:
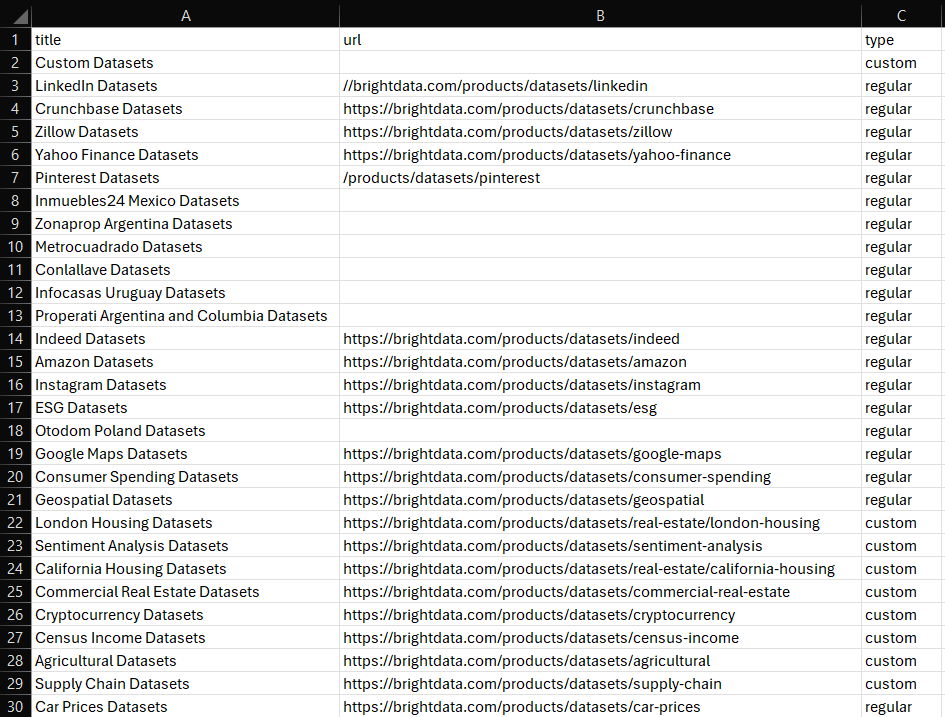
これで完了です!Pythonでデータセットを作成する方法がわかりました。
Rでデータセットを作成する方法
Rも研究者やデータサイエンティストに広く採用されている言語です。以下は、Pythonで見た内容に相当するRでのデータセット作成スクリプトです:
library(httr)
library(rvest)
library(dplyr)
library(readr)
# カスタムユーザーエージェントでターゲットサイトにGETリクエストを送信
url <- "https://brightdata.com/products/データセット"
headers <- add_headers(`User-Agent` = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
response <- GET(url, headers)
# 取得したHTMLをパース
page <- read_html(response)
# スクレイピングしたデータの保存先
data <- tibble()
# スクレイピングロジック
dataset_elements <- page %>%
html_nodes(".datasets__loop .datasets__item--wrapper")
for (dataset_element in dataset_elements) {
title <- dataset_element %>%
html_node(".datasets__item .datasets__item--title") %>%
html_text(trim = TRUE)
url_item <- dataset_element %>%
html_node(".datasets__item .datasets__item--title a")
url <- if (!is.null(url_item)) {
html_attr(url_item, "href")
} else {
""
}
type <- dataset_element %>%
html_attr("aria-label", "regular") %>%
tolower()
data <- bind_rows(data, tibble(
title = title,
url = url,
type = type
))
}
# CSVへのエクスポート
write_csv(data, "dataset.csv")詳細なガイダンスについては、R を使用したウェブスクレイピングのチュートリアルをご覧ください。
まとめ
本ブログ記事では、データセットの作成方法について学びました。データセットの定義を理解し、作成のための様々な戦略を探求しました。また、PythonとRにおけるウェブスクレイピング戦略の適用方法も確認しました。
Bright Dataは、大規模で高速かつ信頼性の高いプロキシネットワークを運用しており、フォーチュン500企業の多くや20,000以上の顧客にサービスを提供しています。このネットワークは、倫理的にウェブからデータを取得し、以下を含む広範なデータセットマーケットプレイスで提供するために使用されます:
- ビジネスデータセット:LinkedIn、CrunchBase、Owler、Indeedなどの主要ソースからのデータ。
- Eコマースデータセット:Amazon、Walmart、Target、Zara、Zalando、Asosなどからのデータ。
- 不動産データセット:Zillow、MLSなどのウェブサイトからのデータ。
- ソーシャルメディアデータセット:Facebook、Instagram、YouTube、Redditからのデータ。
- 金融データセット:Yahoo Finance、Market Watch、Investopediaなどからのデータ。
これらの既製オプションがニーズに合わない場合は、カスタムデータ収集サービスをご検討ください。
さらに、Bright DataではWeb Scraper APIや スクレイピングブラウザなど、強力なスクレイピングツールを幅広く提供しています。
今すぐ登録して、Bright Dataの製品・サービスの中からご自身のニーズに最適なものを見つけてください。




