このガイドでは以下の内容を確認できます:
- DuckDuckGoスクレイピングの第一歩を踏み出すために必要なすべて。
- DuckDuckGoでウェブスクレイピングを行う最も人気で効果的な手法。
- カスタムDuckDuckGoスクレイパーの構築方法。
- DDGSライブラリを用いたDuckDuckGoスクレイピングの方法
- Bright Data SERP APIを介した検索エンジン結果データの取得方法。
- MCPを介してAIエージェントにDuckDuckGo検索データを提供する方法。
さあ、始めましょう!
DuckDuckGoスクレイピング入門
DuckDuckGoは、オンライントラッカーに対する組み込み保護機能を提供する検索エンジンです。検索履歴や閲覧履歴を追跡しないというプライバシー重視のポリシーがユーザーから高く評価されており、主流の検索プラットフォームとは一線を画す存在として、ここ数年で着実に利用者を増やしています。
DuckDuckGo検索エンジンには2つのバリエーションがあります:
- 動的バージョン:デフォルトのバージョン。JavaScriptが必要で、「検索アシスト」などの機能が含まれます。これはGoogleのAI概要に代わるものです。
- 静的バージョン:JavaScriptがなくても動作する簡略化されたバージョン。
選択するバージョンに応じて、異なるスクレイピング手法が必要となります。概要表にまとめました:
| 機能 | 動的 SERP バージョン | 静的SERPバージョン |
|---|---|---|
| JavaScriptが必要 | はい | いいえ |
| URL 形式 | https://duckduckgo.com/?q=<検索クエリ> |
https://html.duckduckgo.com/html/?q=<検索クエリ> |
| 動的コンテンツ | はい、AIサマリーやインタラクティブ要素など | いいえ |
| ページネーション | 複雑(”More Results”ボタンに基づく) | シンプル、従来の「次へ」ボタンによるページ再読み込み |
| スクレイピング手法 | ブラウザ自動化ツール | HTTPクライアント+HTMLパーサー |
2つのDuckDuckGo SERP(検索エンジン結果ページ)バージョンにおけるスクレイピングの影響を探る時が来ました!
DuckDuckGo: ダイナミックSERPバージョン
デフォルトでは、DuckDuckGoはJavaScriptレンダリングを必要とする動的ウェブページを読み込みます。URLは以下のような形式です:
https://duckduckgo.com/?q=<検索クエリ>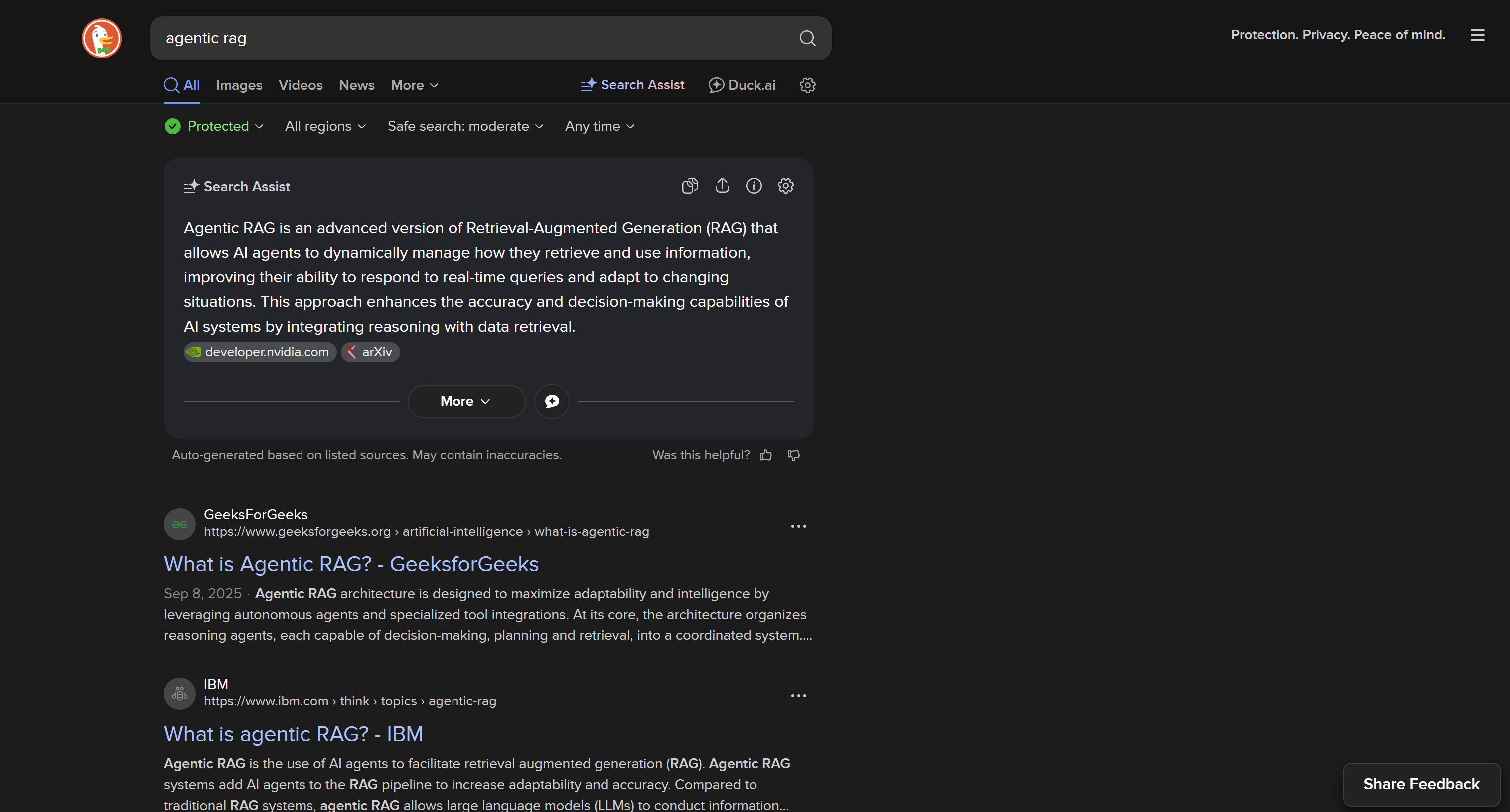
このバージョンには「More Results」ボタンによる動的検索結果追加など、複雑なページ内ユーザー操作が含まれます:
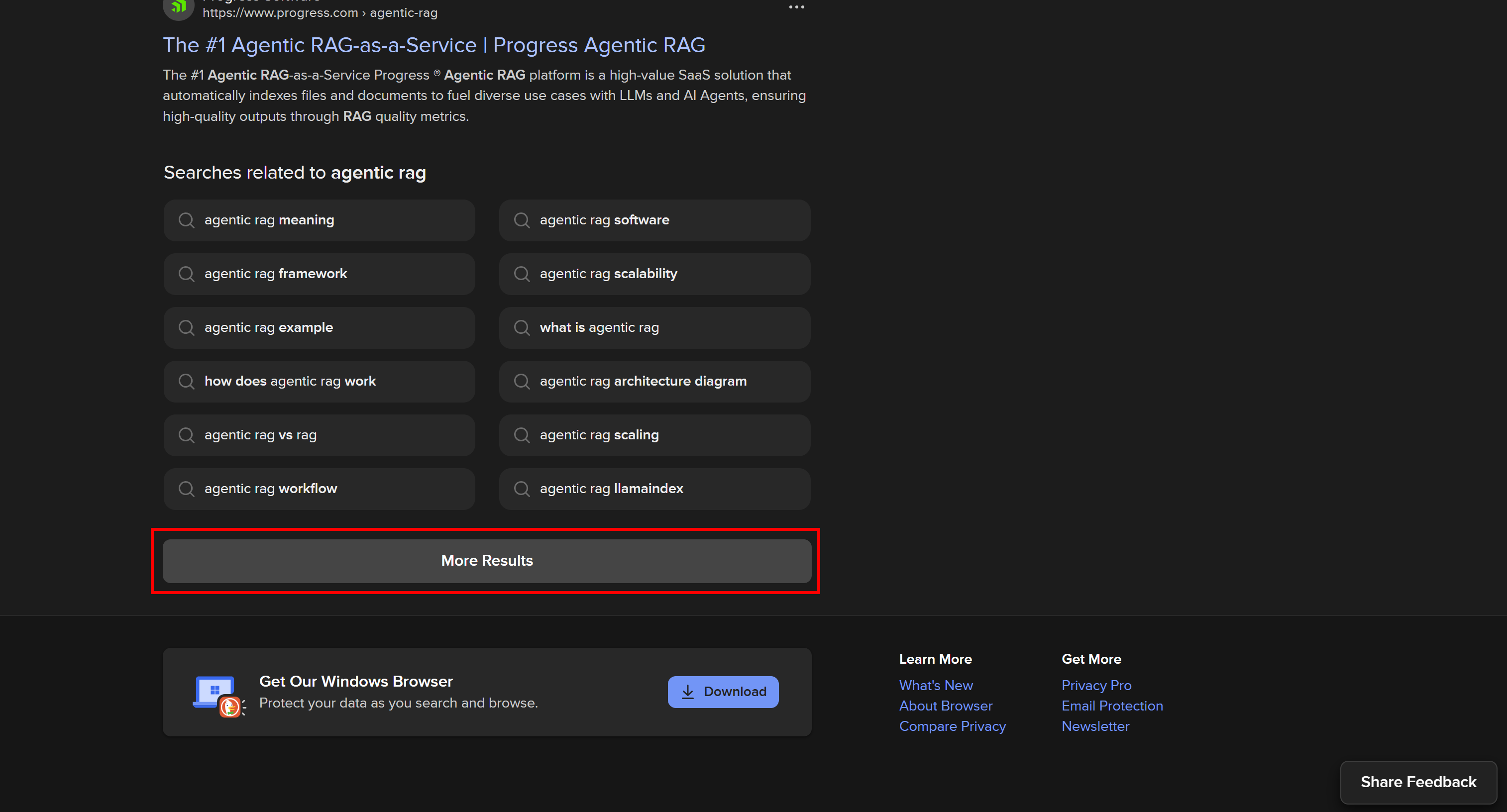
動的DuckDuckGo SERPはより多くの機能と豊富な情報を提供しますが、スクレイピングにはブラウザ自動化ツールが必要です。その理由は、JavaScriptに依存するページをレンダリングできるのはブラウザだけだからです。
問題は、ブラウザ制御が追加の複雑さとリソース使用をもたらすことです。そのため、ほとんどのスクレイパーはサイトの静的バージョンに依存しています!
DuckDuckGo: 静的SERPバージョン
JavaScriptをサポートしないデバイス向けに、DuckDuckGoはSERPの静的バージョンも提供しています。これらのページは以下のようなURL形式に従います:
https://html.duckduckgo.com/html/?q=<検索クエリ>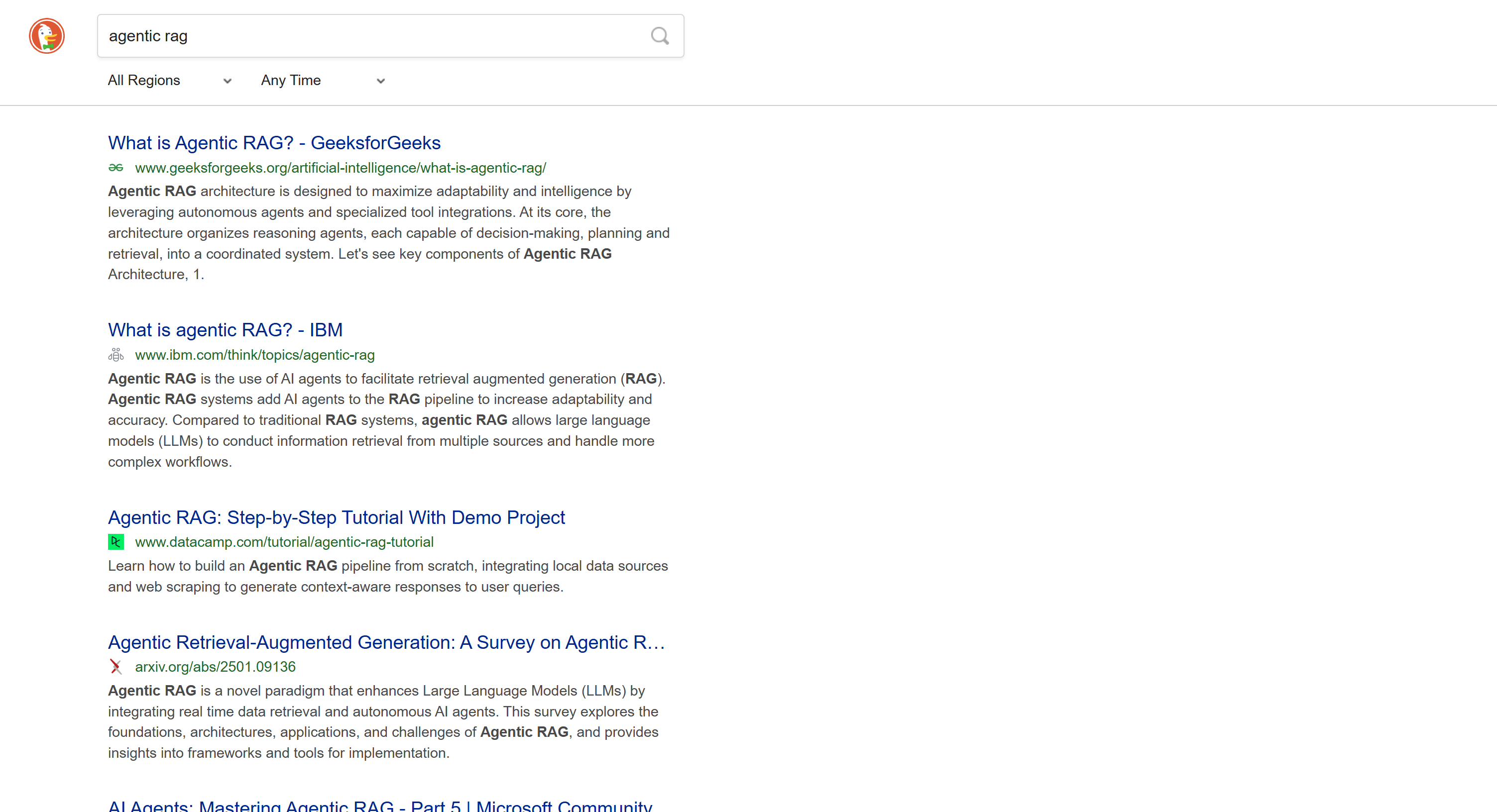
このバージョンにはAI生成サマリーなどの動的コンテンツは含まれません。またページネーションは「次へ」ボタンで次のページへ移動する従来型のアプローチを採用しています:
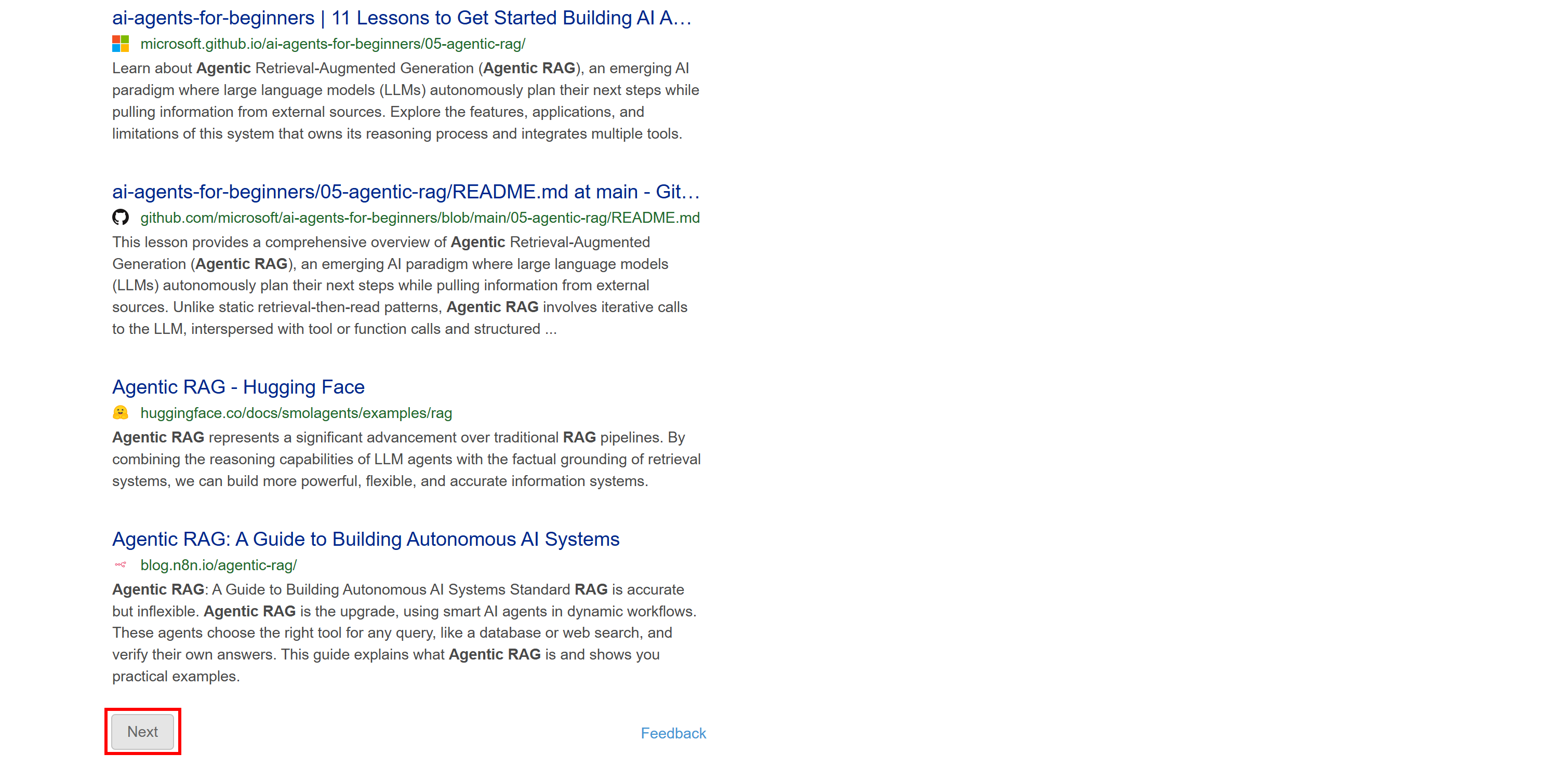
このSERPは静的であるため、従来のHTTPクライアント+HTMLパーサー方式でスクレイピングが可能です。この方法は高速で実装が容易、かつリソース消費が少ないという利点があります。
DuckDuckGoスクレイピングの可能なアプローチ
本記事で紹介する4つのDuckDuckGoウェブスクレイピング手法をご覧ください:
| 手法 | 統合の複雑さ | 必要条件 | 価格 | ブロックリスク | スケーラビリティ |
|---|---|---|---|---|---|
| カスタムスクレイパーの構築 | 中~高 | Pythonプログラミングスキル | 無料(ブロック回避には有料プロキシが必要な場合あり) | 可能 | 限定的 |
| DuckDuckGoスクレイピングライブラリに依存 | 低 | Pythonスキル/CLI使用 | 無料(ブロック回避のため有料プロキシが必要な場合あり) | 可能 | 限定的 |
| Bright DataのSERP APIを使用 | 低 | 任意のHTTPクライアント | 有料 | なし | 無制限 |
| Web MCPサーバーを統合 | 低 | AIエージェントフレームワーク/ソリューション | 無料プランあり、その後は有料 | なし | 無制限 |
このチュートリアルを進めていくうちに、それぞれの詳細について学んでいきます。
どのアプローチを採用する場合でも、このブログ記事のターゲット検索クエリは「agentic rag」となります。つまり、そのクエリに対するDuckDuckGoの検索結果を取得する方法を確認します。
Pythonがローカルにインストール済みで、その使用に慣れていることを前提とします。
アプローチ #1: カスタムスクレイパーの構築
ブラウザ自動化ツールまたはHTTPクライアントとHTMLパーサーを組み合わせて、DuckDuckGoウェブスクレイピングボットをゼロから構築します。
👍 長所:
- スクレイピングロジックを完全に制御可能。
- 必要な情報を正確に抽出できるようカスタマイズ可能。
👎 デメリット:
- 設定とコーディングが必要。
- 大規模スクレイピングではIPブロックに遭遇する可能性がある。
アプローチ #2: DuckDuckGo用スクレイピングライブラリの利用
DDGS(Duck Distributed Global Search)のような既存のDuckDuckGo用スクレイピングライブラリを利用すれば、コードを1行も書かずに必要な機能をすべて提供できます。
👍 長所:
- 最小限の設定で済む。
- PythonコードまたはシンプルなCLIコマンドで、検索エンジンのスクレイピングタスクを自動的に処理。
👎 デメリット:
- カスタムスクレイパーに比べて柔軟性が低く、高度なユースケースへの制御が制限される。
- IPブロックに遭遇する可能性がある。
アプローチ #3: Bright DataのSERP APIを利用する
プレミアムなBright DataSERP APIエンドポイントを活用します。これは任意のHTTPクライアントから呼び出せます。DuckDuckGoを含む複数の検索エンジンをサポートし、複雑な処理をすべて代行しながら、スケーラブルで高ボリュームのスクラッピングを実現します。
👍 長所:
- 無制限のスケーラビリティ。
- IP禁止やボット対策の回避。
- あらゆるプログラミング言語のHTTPクライアントや、Postmanなどのビジュアルツールとも統合可能。
👎 デメリット:
- 有料サービス。
アプローチ #4: Web MCP サーバーの統合
Bright Data Web MCP経由でBright Data SERP APIに無料でアクセスし、AIエージェントにDuckDuckGoスクレイピング機能を提供します。
👍 長所:
- AIとの統合が容易。
- 無料プランあり。
- AIエージェントやワークフロー内での使用が容易。
👎 デメリット:
- LLMを完全に制御できない。
アプローチ #1: PythonでカスタムDuckDuckGoスクレイパーを構築する
以下の手順に従って、PythonでカスタムDuckDuckGoスクレイピングスクリプトを作成する方法を学びましょう。
注:データパースを簡略化・高速化するため、DuckDuckGoの静的バージョンを使用します。AI生成の「検索アシスト」収集に興味がある場合は、 GoogleのAI概要結果をスクレイピングするガイドを参照してください。これをDuckDuckGoに簡単に適応できます。
ステップ #1: プロジェクト環境のセットアップ
まずターミナルを開き、DuckDuckGoスクレイパープロジェクト用の新規フォルダを作成します:
mkdir duckduckgo-スクレイパーduckduckgo-scraper/フォルダにスクレイピングプロジェクトを格納します。
次に、プロジェクトディレクトリに移動し、その中にPython仮想環境を作成します:
cd duckduckgo-スクレイパー
python -m venv .venvお好みのPython IDEでプロジェクトフォルダを開きます。Python拡張機能付きのVisual Studio CodeまたはPyCharm Community Editionを推奨します。
プロジェクトディレクトリのルートにscraper.pyという名前の新規ファイルを作成します。プロジェクト構造は次のようになります:
duckduckgo-スクレイパー/
├── .venv/
└── agent.pyターミナルで仮想環境を有効化します。LinuxまたはmacOSの場合は以下を実行:
source venv/bin/activateWindowsでは同等の操作として以下を実行します:
venv/Scripts/activate仮想環境をアクティブ化した状態で、プロジェクトの依存関係をインストールします:
pip install requests beautifulsoup4必要なライブラリは次の2つです:
requests:人気のPython HTTPクライアント。DuckDuckGoのSERP(検索結果ページ)の静的バージョンを取得するために使用されます。beautifulsoup4:HTMLパース用のPythonライブラリ。DuckDuckGo検索結果ページからデータを抽出するために使用します。
これでPython開発環境の準備が整い、DuckDuckGoスクレイピングスクリプトを作成できます。
ステップ #2: 対象ページへの接続
まず、スクレイパー.pyでrequestsをインポートします:
import requests次に、requests.get()メソッドを使用して、DuckDuckGoの静的バージョンに対してブラウザのようなGETリクエストを実行します:
# DuckDuckGo静的バージョンのベースURL
base_url = "https://html.duckduckgo.com/html/"
# 検索クエリの例
search_query = "agentic rag"
# ブラウザリクエストをシミュレートし403エラーを回避
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
}
# 対象のSERPページに接続
params = {
"q": search_query
}
response = requests.get(base_url, params=params, headers=headers)この構文に慣れていない場合は、Python HTTPリクエストに関するガイドを参照してください。
上記のスニペットは、https://html.duckduckgo.com/html/?q=agentic+rag(このチュートリアルの対象SERP)に対して、以下のUser-Agentヘッダーを含むGET HTTPリクエストを送信します:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36DuckDuckGoから403 Forbiddenエラーを受け取らないためには、上記のような実在するUser-Agentを設定する必要があります。ウェブスクレイピングにおけるUser-Agentヘッダーの重要性について詳しくはこちら。
サーバーは GET リクエストに対して DuckDuckGo の静的ページの HTML で応答します。以下でアクセスしてください:
html = response.textページの内容を印刷して確認します:
print(html)以下のようなHTMLが表示されるはずです:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="content-type" content="text/html; charset=UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=3.0, user-scalable=1" />
<meta name="referrer" content="origin" />
<meta name="HandheldFriendly" content="true" />
<meta name="robots" content="noindex, nofollow" />
<title>agentic rag at DuckDuckGo</title>
<!-- 簡略化のため省略... -->
</head>
<!-- 簡略化のため省略... -->
<body>
<div>
<div class="serp__results">
<div id="links" class="results">
<div class="result results_links results_links_deep web-result">
<div class="links_main links_deep result__body">
<h2 class="result__title">
<a rel="nofollow" class="result__a"
href="//duckduckgo.com/l/?uddg=https%3A%2F%2Fwww.geeksforgeeks.org%2Fartificial%2Dintelligence%2Fwhat%2Dis%2Dagentic%2Drag%2F&rut=db125a181b0852a6be3a488cb8060da7f7359f97d50cdc2b70fd9cd4dd3d1df9">
エージェント型RAGとは? - GeeksforGeeks
</a>
</h2>
<!-- 簡略化のため省略... -->
</div>
</div>
<!-- その他の結果 ... -->
</div>
</div>
</div>
</body>
</html>素晴らしい!このHTMLには、スクレイピングしたいすべてのSERPリンクが含まれています。
ステップ #3: HTMLをパースする
scraper.pyでBeautiful Soupをインポート:
from bs4 import BeautifulSoup次に、これを使用して、先に取得した HTML 文字列をナビゲーション可能なツリー構造にパースします:
soup = BeautifulSoup(html, "html.parser")これはPython組み込みの"html.parser"でHTMLをパースします。BeautifulSoupウェブスクレイピングガイドで説明しているように、lxmlやhtml5libなどの他のパーサーを設定することも可能です。
よくできました!これでBeautifulSoup APIを使用してページ上のHTML要素を選択し、必要なデータを抽出できます。
ステップ #4: すべてのSERP結果をスクレイピングする準備
スクレイピングロジックに入る前に、DuckDuckGo SERPの構造を理解しておきましょう。ブラウザのシークレットモード(クリーンなセッションを確保するため)で以下のウェブページを開いてください:
https://html.duckduckgo.com/html/?q=agentic+rag次に、SERP結果要素を右クリックし、「要素を検査」を選択してブラウザのDevToolsを開きます:
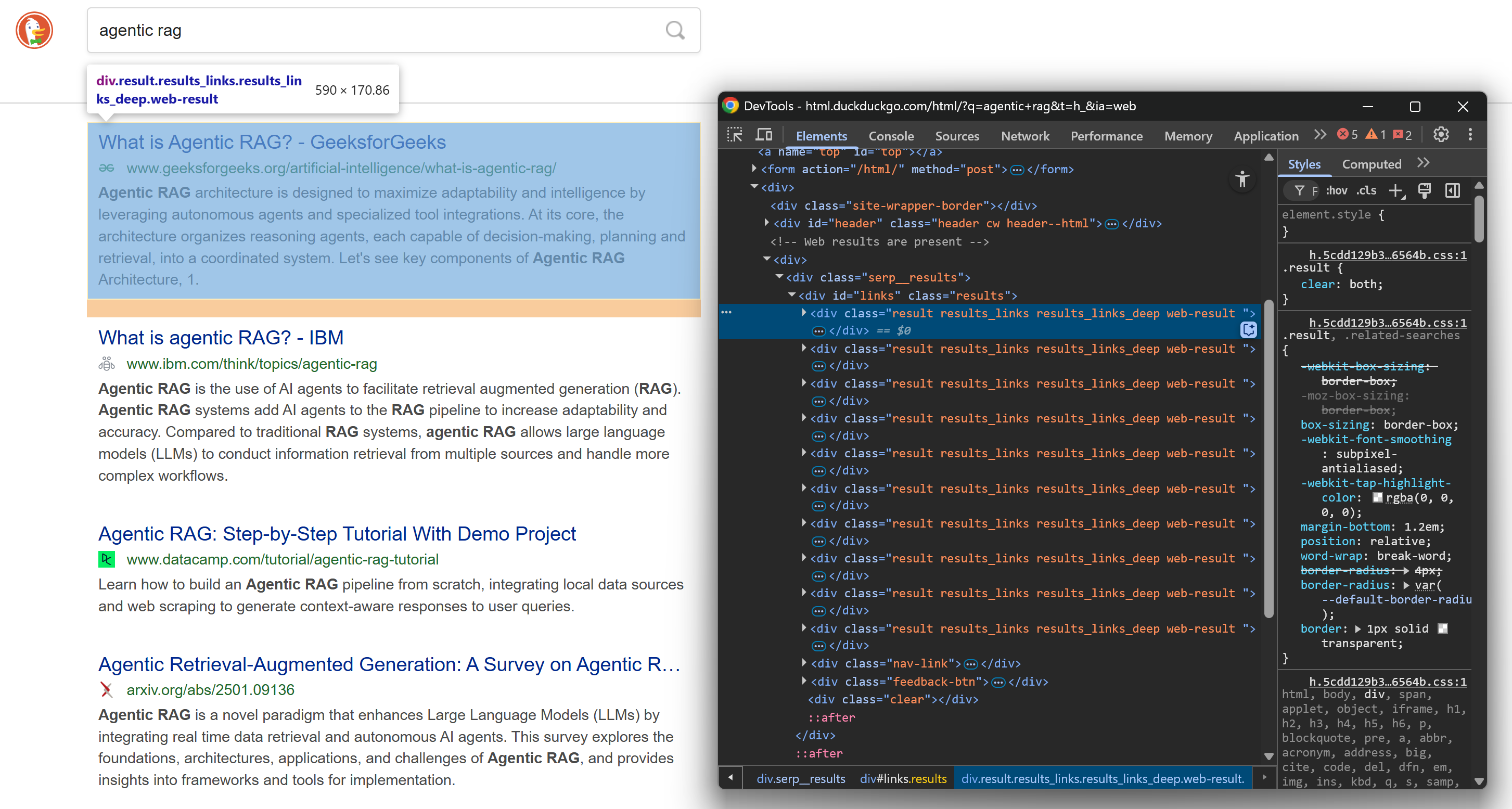
HTML構造を確認してください。各SERP要素にはresultクラスが設定され、linksIDで識別される<div>内に格納されていることに注目してください。これは、以下のCSSセレクタを使用してすべての検索結果要素を選択できることを意味します:
#links .resultBeautifulSoupのselect()メソッドでパース済みページにこのセレクタを適用します:
result_elements = soup.select("#links .result") ページには複数のSERP要素が含まれるため、スクレイピングしたデータを格納するリストが必要です。以下のように初期化します:
serp_results = []最後に、選択した各HTML要素を反復処理します。DuckDuckGo検索結果を抽出するスクレイピングロジックを適用し、serp_resultsリストに格納する準備をします:
for result_element in result_elements:
# データパースロジック...素晴らしい!これでDuckDuckGoスクレイピングの目標達成に近づきました。
ステップ #5: 結果データのスクレイピング
再度、検索結果ページのSERP要素のHTML構造を確認します:
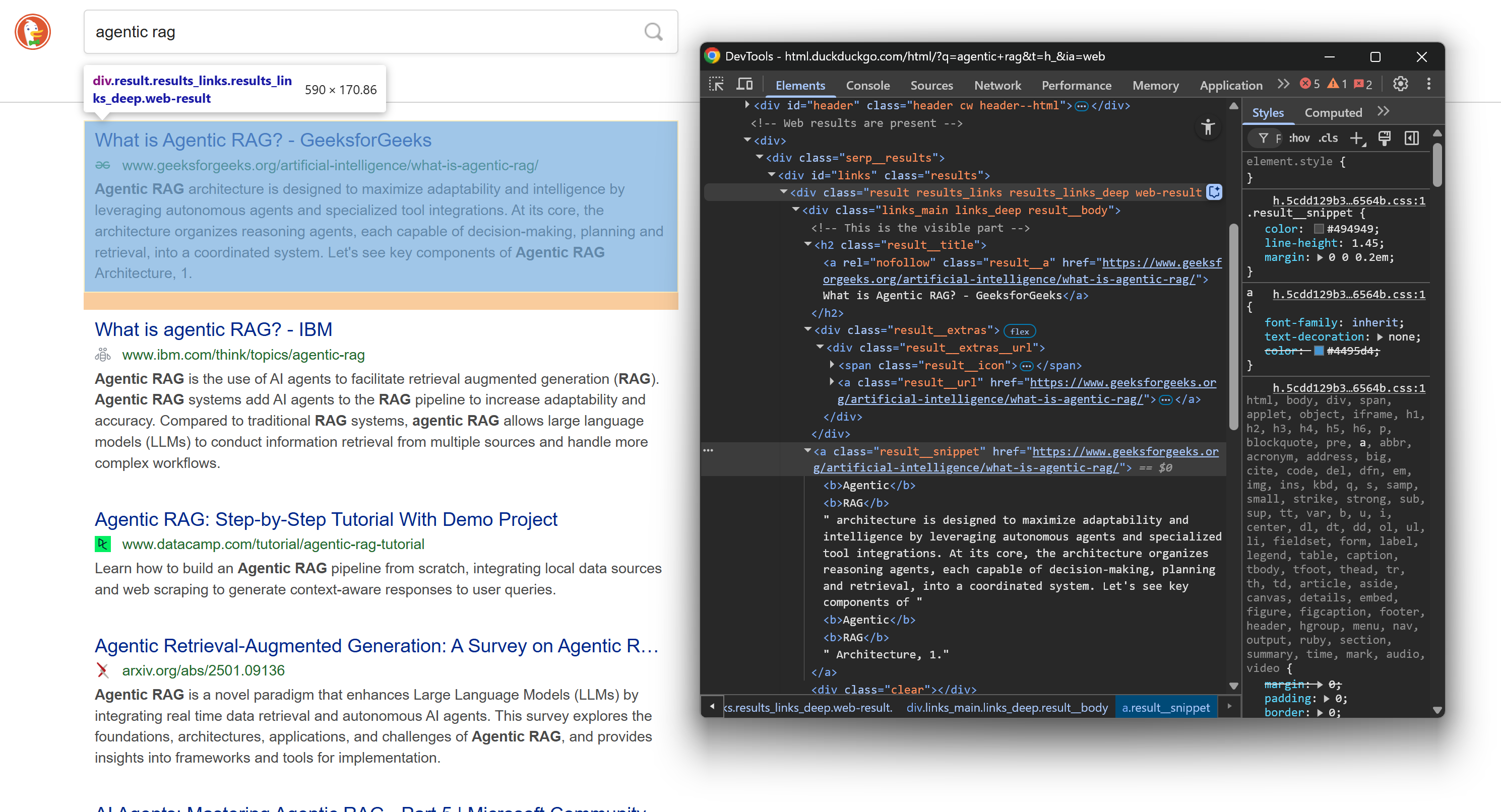
今回は、そのネストされたHTMLノードに注目してください。ご覧の通り、これらの要素から以下のデータをスクレイピングできます:
.result__aテキストから結果タイトルを取得.result__aのhref属性から結果URL- 表示URL:
.result__urlのテキスト .result__snippetのテキストから結果スニペット/説明文を取得
特定のノードを選択するにはBeautifulSoupのselect_one()メソッドを適用し、テキスト抽出には.get_text()を、HTML属性へのアクセスには[<attribute_name>]を使用します。
スクレイピングロジックを実装する:
title_element = result_element.select_one(".result__a")
url = "https:" + title_element["href"]
title = title_element.get_text(strip=True)
url_element = result_element.select_one(".result__url")
display_url = url_element.get_text(strip=True)
snippet_element = result_element.select_one(".result__snippet")
snippet = snippet_element.get_text(strip=True)注:strip=True は、抽出されたテキストから先頭と末尾の空白を削除するため有用です。
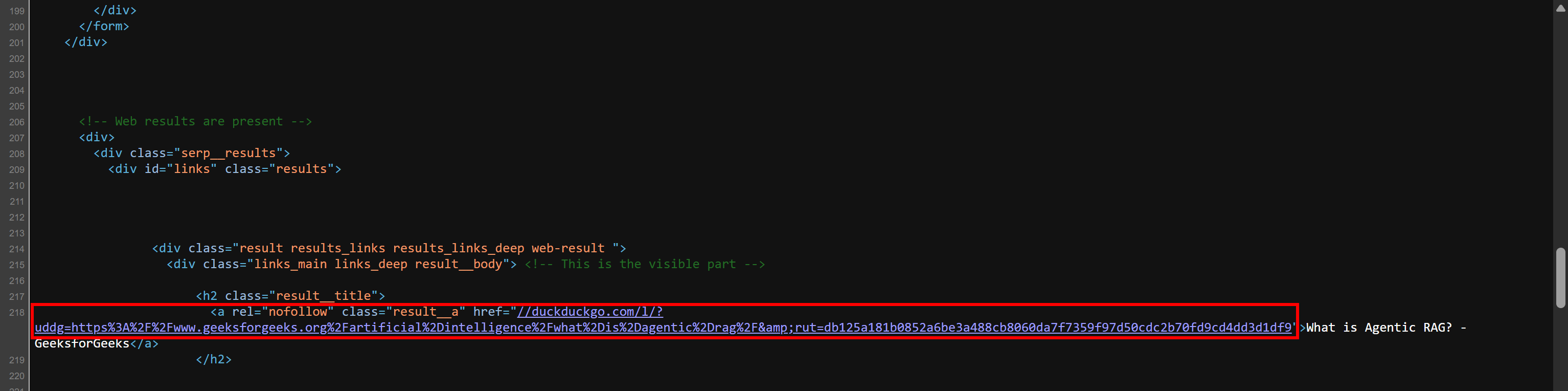
title_element["href"]に「https:」を連結する必要がある理由について疑問に思うかもしれませんが、それはサーバーから返されるHTMLがブラウザでレンダリングされるものとは若干異なるためです。スクレイパーが実際にパースする生のHTMLには、URLが次のような形式で含まれています:
//duckduckgo.com/l/?uddg=https%3A%2F%2Fwww.geeksforgeeks.org%2Fartificial%2Dintelligence%2Fwhat%2Dis%2Dagentic%2Drag%2F&rut=db125a181b0852a6be3a488cb8060da7f7359f97d50cdc2b70fd9cd4dd3d1df9ご覧の通り、URLはスキーム(https://)を含まず、//で始まります。「https:」を先頭に付けることで、URLがより使いやすくなります(この形式をサポートするブラウザ以外でも)。
この動作を自身で確認してください。ページを右クリックし、「ページのソースを表示」を選択します。これにより、サーバーから返された生のHTMLドキュメント(ブラウザのレンダリングが適用されていない状態)が表示されます。SERPリンクが以下の形式で表示されるはずです:
次に、スクレイピングしたデータフィールドを用いて、各検索結果に対応する辞書を作成し、serp_resultsリストに追加します:
serp_result = {
"url": url,
"title": title,
"display_url": display_url,
"snippet": snippet
}
serp_results.append(serp_result) 完璧です! DuckDuckGoのウェブスクレイピングロジックが完成しました。あとはスクレイピングしたデータをエクスポートするだけです。
ステップ #6: スクレイピングしたデータを CSV にエクスポート
ここまでで、DuckDuckGoの検索結果がPythonリストに格納されました。他のチームやツールでこのデータを利用できるようにするため、Pythonの組み込みcsvライブラリを使用してCSVファイルにエクスポートします:
with open("duckduckgo_results.csv", "w", newline="", encoding="utf-8") as f:
headers = serp_results[0].keys()
writer = csv.DictWriter(f, fieldnames=headers)
# ヘッダーを書き込む
writer.writeheader()
# 全データ行を書き込む
writer.writerows(serp_results)csvのインポートを忘れないでください:
import csvこれで、DuckDuckGoスクレイパーは、スクレイピングしたすべての結果をCSV形式で含む「duckduckgo_results.csv」という出力ファイルを生成します。ミッション完了!
ステップ #7: すべてを統合する
scraper.pyに含まれる最終コードは以下の通りです:
import requests
from bs4 import BeautifulSoup
import csv
# DuckDuckGo静的バージョンのベースURL
base_url = "https://html.duckduckgo.com/html/"
# 検索クエリ例
search_query = "agentic rag"
# ブラウザリクエストをシミュレートし403エラーを回避
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
}
# 対象のSERPページに接続
params = {
"q": search_query
}
response = requests.get(base_url, params=params, headers=headers)
# レスポンスからHTMLコンテンツを取得
html = response.text
# HTMLをパース
soup = BeautifulSoup(html, "html.parser")
# 検索結果コンテナを全て取得
result_elements = soup.select("#links .result")
# スクレイピングしたデータの保存先
serp_results = []
# 各SERP結果を反復処理しデータをスクレイピング
for result_element in result_elements:
# データパースロジック
title_element = result_element.select_one(".result__a")
url = "https:" + title_element["href"]
title = title_element.get_text(strip=True)
url_element = result_element.select_one(".result__url")
display_url = url_element.get_text(strip=True)
snippet_element = result_element.select_one(".result__snippet")
snippet = snippet_element.get_text(strip=True)
# 新しいSERP結果オブジェクトを作成し、リストに追加
serp_result = {
"url": url,
"title": title,
"display_url": display_url,
"snippet": snippet
}
serp_results.append(serp_result)
# スクレイピングしたデータをCSVにエクスポート
with open("duckduckgo_results.csv", "w", newline="", encoding="utf-8") as f:
headers = serp_results[0].keys()
writer = csv.DictWriter(f, fieldnames=headers)
# ヘッダーを書き込む
writer.writeheader()
# 全データの行を書き込む
writer.writerows(serp_results)すごい!65行未満のコードでDuckDuckGoデータスクレイピングスクリプトを作成しました。
以下のコマンドで実行:
python スクレイパー.py出力結果はduckduckgo_results.csvファイルとなり、プロジェクトフォルダ内に生成されます。開くと、以下のようなスクレイピングされたデータが表示されるはずです:

これで完了!DuckDuckGoウェブページの非構造化検索結果を構造化されたCSVファイルに変換できました。
[追加] ブロック回避のためのローテーションプロキシ統合
上記のスクレイパーは少量の処理には有効ですが、拡張性に乏しいです。DuckDuckGoは同一IPからの過剰なトラフィックを検知するとリクエストをブロックするためです。その場合、サーバーは以下のようなメッセージを含む403 Forbiddenエラーページを返します:
この状態が続く場合は、<a href="mailto:[email protected]?subject=Error getting results">メールでお問い合わせください</a>。<br />
サポート用メールアドレスには匿名化されたエラーコードが含まれており、検索の状況を把握するのに役立ちます。これはサーバーがリクエストを自動化と識別し、通常はレート制限の問題によりブロックしたことを意味します。ブロックを回避するには、IPアドレスをローテーションさせる必要があります。
解決策はローテーションプロキシ経由でリクエストを送信することです。この仕組みの詳細については、IPアドレスローテーション方法のガイドをご覧ください。
Bright Dataは1億5000万以上のIPアドレスネットワークを基盤としたローテーションプロキシを提供しています。DuckDuckGoスクレイパーに統合してブロック回避する方法をご覧ください!
公式プロキシ設定ガイドに従うと、最終的に以下のようなプロキシ接続文字列が得られます:
<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335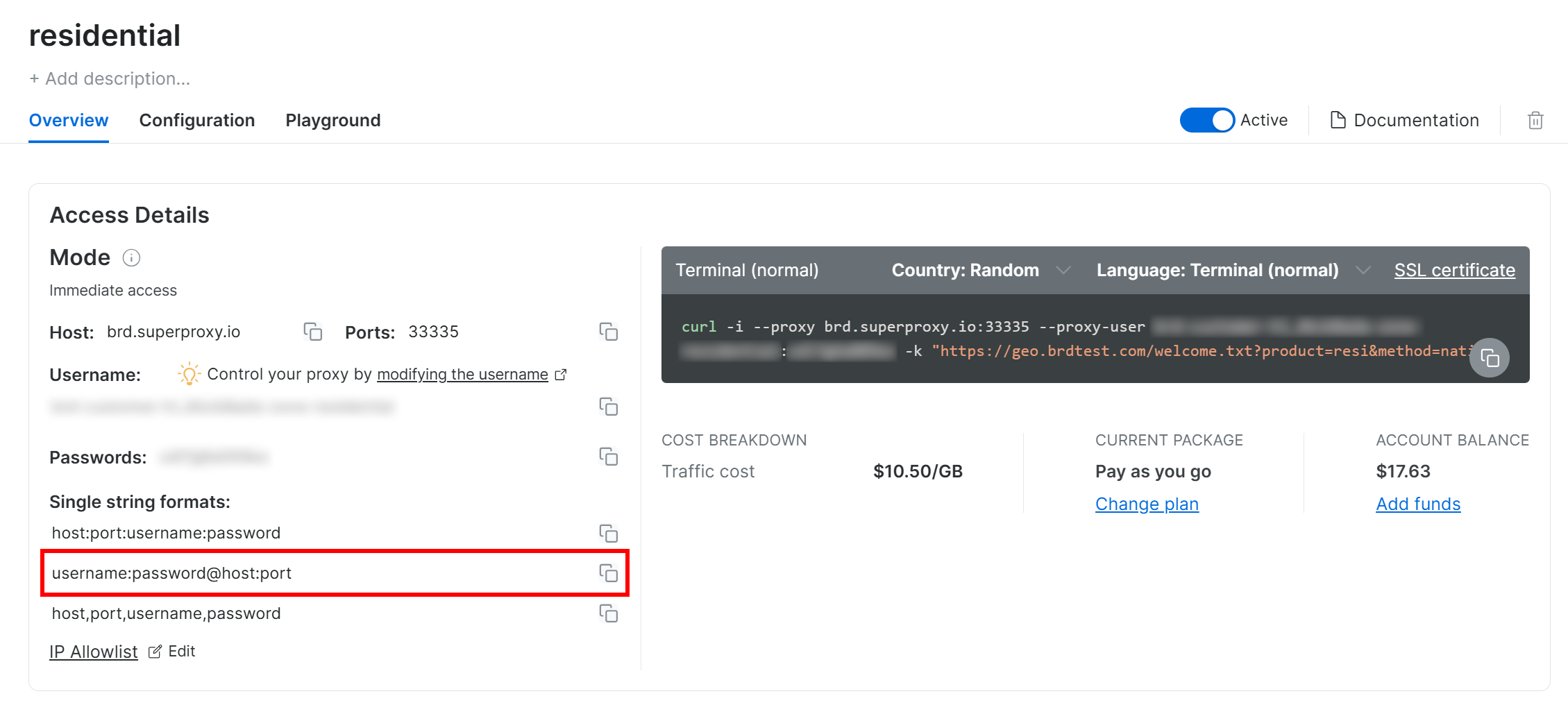
Requestsでプロキシを以下のように設定します:
proxy_url = "http://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335"
proxies = {
"http": proxy_url,
"https": proxy_url,
}
# パラメータとヘッダーの定義...
response = requests.get(
base_url,
params=params,
headers=headers,
proxies=proxies, # ローテーションプロキシ経由でリクエストをルーティング
verify=False,
)注:verify=False はSSL 証明書検証を無効化します。これによりプロキシ証明書検証関連のエラーは回避できますが、セキュリティ上危険です。本番環境向けの実装については、SSL 証明書検証に関するドキュメントページを参照してください。
これでDuckDuckGoへのGETリクエストは、Bright Dataの1億5000万レジデンシャルプロキシIPからなるネットワークを経由してルーティングされます。これにより毎回新しいIPが確保され、IP関連のブロック回避に役立ちます。
アプローチ #2: DDGSのようなDuckDuckGoスクレイピングライブラリの利用
このセクションでは、DDGSライブラリの使用方法を学びます。GitHubで1.8k以上のスターを獲得しているこのオープンソースプロジェクトは、以前はDuckDuckGoに特化していたため「duckduckgo-search」として知られていました。最近では他の検索エンジンもサポートするようになったため、DDGS(Dux Distributed Global Search)にリブランドされました。
ここでは、コマンドラインからDuckDuckGoの検索結果をスクレイピングする方法を解説します!
ステップ #1: DDGS のインストール
PyPIパッケージddgsを使用して、グローバルまたは仮想環境内にDDGSをインストールします:
pip install -U ddgsインストール後、ddgsコマンドラインツールでアクセス可能になります。以下のコマンドでインストールを確認してください:
ddgs --help出力は以下のような内容になります:
ご覧の通り、このライブラリは様々なデータ(テキスト、画像、ニュースなど)をスクレイピングするための複数のコマンドをサポートしています。今回はSERPからの検索結果を対象とするtextコマンドを使用します。
注:ドキュメントに記載されている通り、Pythonコード内のDDGS API経由でもこれらのコマンドを呼び出せます。
ステップ #2: CLI経由でDDGSを使用しDuckDuckGoウェブスクレイピングを実施
まず、textコマンドを実行して操作に慣れましょう:
ddgs text --helpこれにより、サポートされているすべてのフラグとオプションが表示されます:
「agentic rag」のDuckDuckGo検索結果をスクレイピングしCSVファイルにエクスポートするには、以下を実行します:
ddgs text -q "agentic rag" -b duckduckgo -o duckduckgo_results.csv出力結果はduckduckgo_results.csvファイルになります。開くと以下のような内容が表示されるはずです:

素晴らしい!カスタムPython DuckDuckGoスクレイパーと同じ検索結果を、単一のCLIコマンドで取得できました。
[追加] ローテーションプロキシの統合
ご覧の通り、DDGSは非常に強力なSERP検索・ウェブスクレイピングツールです。とはいえ魔法ではありません。大規模なスクレイピングプロジェクトでは、前述のIP禁止やブロックに遭遇します。
こうした問題を回避するには、以前と同様にローテーションプロキシが必要です。当然ながら、DDGSは-pr(または--proxy)フラグによるプロキシ統合をネイティブでサポートしています。
Bright DataのローテーションプロキシURLを取得し、ddgsCLIコマンドで以下のように設定します:
ddgs text -q "agentic rag" -b duckduckgo -o duckduckgo_results.csv -pr <BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335完了!ライブラリが行う基盤となるウェブリクエストは、Bright Dataローテーションプロキシネットワーク経由でルーティングされます。これにより、IP関連のブロックを気にせず安全にウェブスクレイピングできます。
アプローチ #3: Bright DataのSERP APIを使用する
この章では、Bright DataのオールインワンSERP APIを使用して、DuckDuckGoの動的バージョンからプログラム的に検索結果を取得する方法を学びます。以下の手順に従って始めましょう!
注:設定を簡略化・迅速化するため、Pythonプロジェクトが既に存在し、requestsライブラリがインストールされていることを前提とします。
ステップ #1: Bright Data SERP API ゾーンの設定
まず、Bright Dataアカウントを作成するか、既存アカウントでログインします。以下では、DuckDuckGoスクレイピング用のSERP API製品を設定する手順を案内します。
より迅速な設定には、公式SERP API「クイックスタート」ガイドも参照可能です。そうでない場合は、以下の手順を続行してください。
ログイン後、Bright Dataアカウントに移動し、「Proxy & Scraping」オプションをクリックして以下のページにアクセスします:
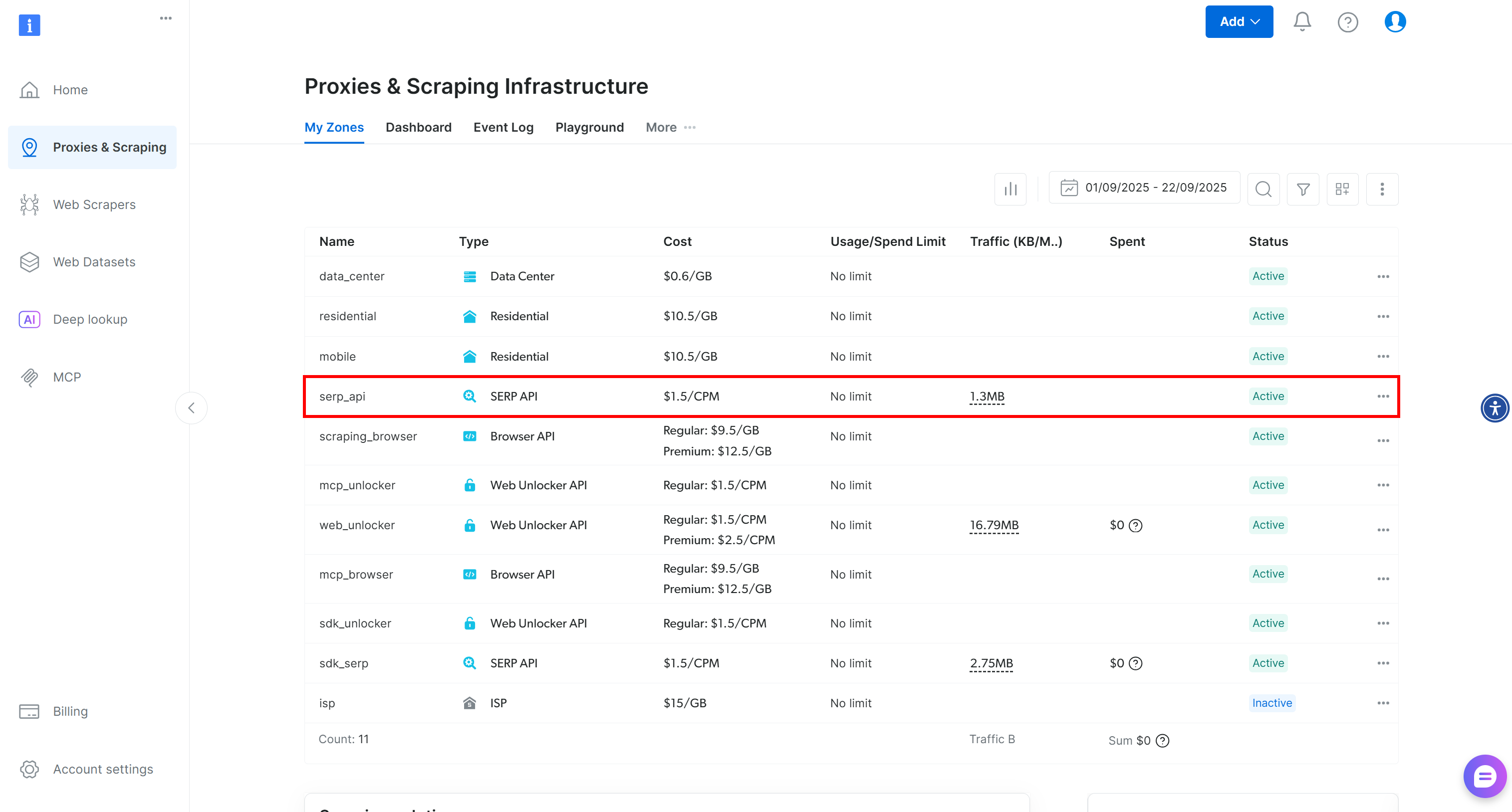
設定済みのBright Data製品が一覧表示される「My Zones」テーブルを確認してください。アクティブなSERP APIゾーンが既に存在する場合、準備は完了です。後で必要になるため、ゾーン名(この例ではserp_api)をコピーしてください。
ゾーンが存在しない場合は、ページを下にスクロールして「Scraping Solutions」セクションに移動し、「SERP API」カードの「Create Zone」ボタンをクリックしてください:
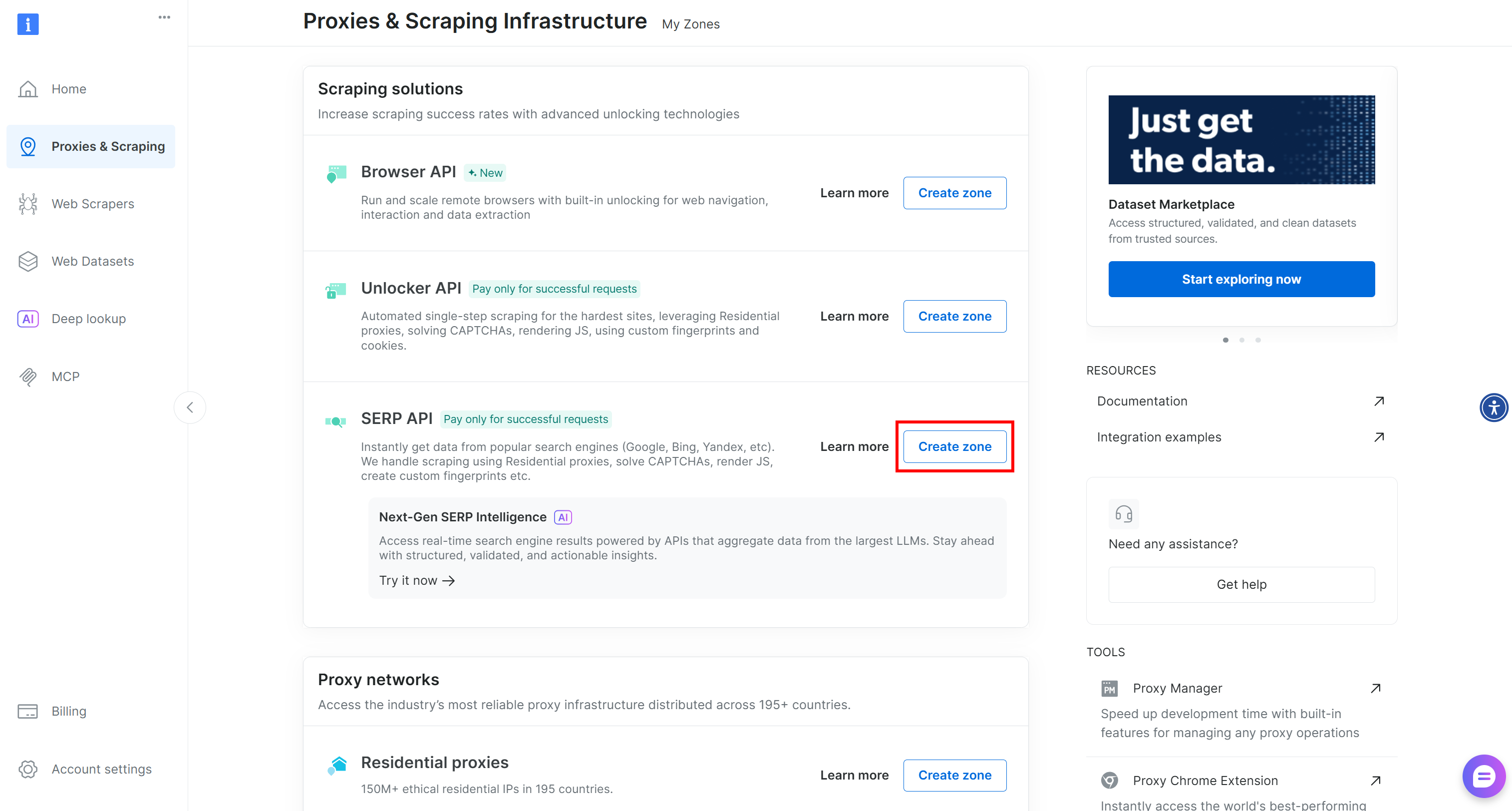
ゾーンに名前を付け(例:SERP API)、「追加」を押します:
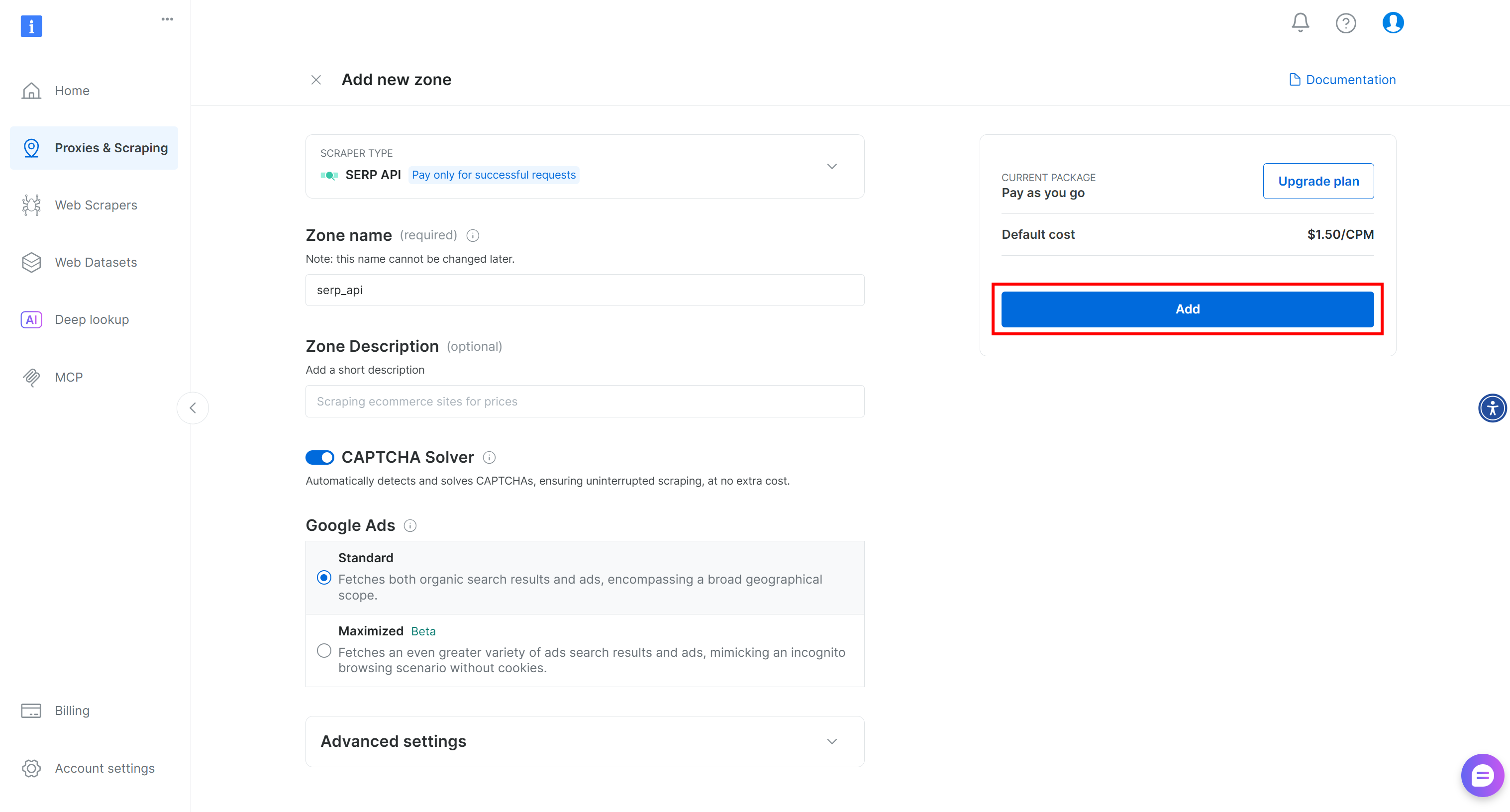
次に、ゾーンのプロダクトページに移動し、スイッチを「Active」に切り替えて有効化を確認してください:
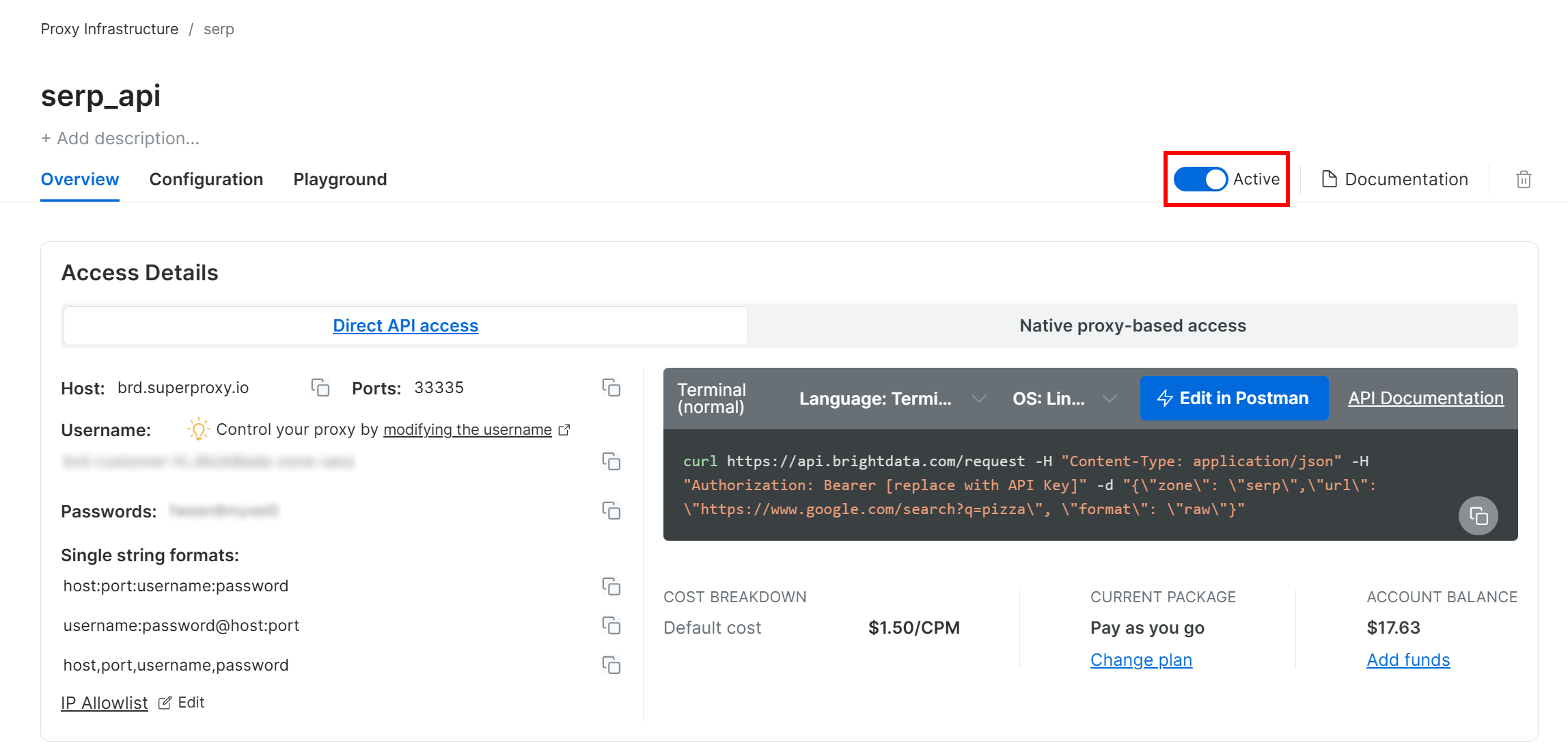
これでBright DataのSERP API設定が完了しました。
ステップ #2: Bright Data API キーの取得
SERP APIリクエストの認証には、Bright Data APIキーの使用が推奨されます。まだ生成していない場合は、公式ガイドに従って取得してください。
SERP APIへのPOSTリクエスト送信時には、認証のためAPIキーをAuthorizationヘッダーに以下のように含めてください:
"Authorization: Bearer <BRIGHT_DATA_API_KEY>"これで、Pythonスクリプト(またはその他のHTTPクライアント)からBright DataのSERP APIを呼び出すために必要なすべての要素が揃いました。
ステップ #3: SERP API を呼び出す
以下のPythonスニペットで、DuckDuckGoの「agentic rag」検索ページに対してBright Data SERP APIを呼び出します:
# pip install requests
import requests
# Bright Data認証情報(TODO: 自身の値に置き換えてください)
bright_data_api_key = "<YOUR_BRIGHT_DATA_API_KEY>"
bright_data_serp_api_zone_name = "<YOUR_SERP_API_ZONE_NAME>"
# 対象のDuckDuckGo検索ページ
duckduckgo_page_url = "https://duckduckgo.com/?q=agentic+rag"
# Bright DataのSERP APIへのリクエスト実行
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Authorization": f"Bearer {bright_data_api_key}",
"Content-Type": "application/json"
},
json={
"ゾーン": bright_data_serp_api_ゾーン_名,
"url": duckduckgo_page_url,
"format": "raw"
})
# 動的バージョンのDuckDuckGoからレンダリングされたHTMLを取得
html = response.text
# パースロジック...より完全な例については、GitHubの「Bright Data SERP API Pythonプロジェクト」を参照してください。
今回は、ターゲットURLが動的なDuckDuckGoバージョン(例:https://duckduckgo.com/?q=agentic+rag)でも構わないことに注意してください。 SERP APIはJavaScriptレンダリングを処理し、Bright Dataプロキシネットワークと連携してIPローテーションを実現し、ブラウザフィンガープリントやCAPTCHAなどのその他のスクレイピング対策も管理します。したがって、動的SERPのスクレイピング時に問題は発生しません。
html変数にはDuckDuckGoページの完全レンダリング済みHTMLが含まれます。以下の方法でHTMLを出力して確認してください:
print(html)以下のような結果が得られます:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Agentic RAG at DuckDuckGo</title>
<!-- 簡略化のため省略 ... -->
</head>
<body>
<div class="site-wrapper" style="min-height: 825px;">
<div id="content">
<div id="duckassist-answer" class="answer-container">
<DIV class="answer-content-block">
<P class="answer-text">
<SPAN class="highlight">エージェント型RAG</SPAN>は、検索拡張生成(RAG)の高度な形態であり、AIエージェントが情報の検索・利用方法を動的に管理できるようにします。これにより、リアルタイムのクエリへの応答能力や変化する状況への適応力が向上します。 このアプローチは、推論とデータ検索を統合することで、AIシステムの精度と意思決定能力を向上させます。
</P>
<!-- 簡略化のため省略 ... -->
</DIV>
<!-- 簡略化のため省略 ... -->
</DIV>
<ul class="results-list">
<li class="result-item">
<article class="result-card">
<div <!-- 省略 ... -->
<div class="result-body">
<h2 class="result-title">
<a href="https://www.geeksforgeeks.org/artificial-intelligence/what-is-agentic-rag/" rel="noopener" target="_blank" class="result-link">
<span class="title-text">エージェント型RAGとは? - GeeksforGeeks</span>
</a>
</h2>
<div class="result-snippet-container">
<div class="result-snippet">
<div>
<span class="snippet-text">
<span class="snippet-date">2026年9月8日</span>
<span>
<b>Agentic RAG</b> アーキテクチャは、自律エージェントと専用ツールの統合を活用することで、適応性と知能を最大化するように設計されています。その中核では、推論エージェント(それぞれ意思決定、計画、検索が可能なもの)を協調システムとして組織化しています。 <b>Agentic RAG</b>アーキテクチャの主要コンポーネントを見てみましょう。1.
</span>
</span>
</div>
</div>
</div>
</div>
</article>
</li>
<!-- その他の検索結果 ... -->
</ul>
<!-- 簡略化のため省略 ... -->
</div>
<!-- 簡略化のため省略 ... -->
</div>
</body>
</html>注:出力HTMLには、ページの動的バージョンを扱っているため、「Search Assist」AI生成の要約が含まれる場合があります。
では、最初のアプローチで示したようにこのHTMLをパースし、必要なDuckDuckGoデータにアクセスしましょう!
アプローチ #4: MCP経由でDuckDuckGoスクレイピングツールをAIエージェントに統合
SERP API製品は、Bright Data Web MCPで利用可能なsearch_engineツール経由でも公開されていることを覚えておいてください。
このオープンソースのMCPサーバーは、DuckDuckGoスクレイピング機能を含むBright Dataのウェブデータ取得ソリューションへのAIアクセスを提供します。具体的には、search_engineツールはWeb MCPの無料プランで利用可能なため、AIエージェントやワークフローに無償で統合できます。
Web MCPをAIソリューションに統合するには、通常、ローカルにNode.jsがインストールされていることと、以下のような設定ファイルが必要です:
{
"mcpServers": {
"Bright Data Web MCP": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>"
}
}
}
}例えば、この設定はClaude Codeで動作します。その他の連携機能についてはドキュメントでご確認ください。
この連携により、自然言語でSERPデータを取得し、AI駆動のワークフローやエージェントで利用できるようになります。
まとめ
このチュートリアルでは、DuckDuckGoをスクレイピングするための4つの推奨手法を紹介しました:
- カスタムスクレイパー経由
- DDGSの使用
- DuckDuckGo検索APIの利用
- WebMCPに感謝
実証された通り、ブロックを回避しつつ大規模にDuckDuckGoをスクレイピングする唯一の信頼できる方法は、Bright Dataのような堅牢なボット回避技術と大規模プロキシネットワークを備えた構造化されたスクレイピングソリューションを利用することです。
無料のBright Dataアカウントを作成し、当社のスクレイピングソリューションを探索しましょう!