

Googleは2025年9月、事前 通知なくnumパラメータを廃止した。JavaScriptレンダリングが必須となり、AI概要表示が200の国と地域に展開された。Googleをスクレイピングする場合、生のHTTPリクエストは空または劣化レスポンスを返し、numベースのページネーションは機能せず、AI生成コンテンツが自然検索結果をスクロールせずに見える領域(above the fold)より下に押し下げる。
すべてのGoogle検索URLは「?」以降のパラメータを含みます(クエリ用q、国別gl、言語別hl、時間フィルター用tbsなど数十種類)。これらを誤ると、スクレイパーが誤った国のデータやデバッグ困難な空結果を返すことになります。
以下に重要な全パラメータを、テスト済みコードと実践例と共に示します。全コードはBright Data SERP APIの実稼働環境で実行済みです。
要約:2026年に知っておくべきこと
- 順位追跡:
q=...&gl=us&hl=en&pws=0&udm=14&brd_json=1(非パーソナライズ、AI概要なし)- ページネーション:
start=10,start=20など(1ページあたり10件)。num は機能しなくなりました- 時間フィルター:
tbs=qdr:d(過去1日)、tbs=sbd:1(日付順)、tbs=li:1(完全一致)- 新規:
udm はtbm を拡張し、udm=14(ウェブ専用、AI非対応) などのモードを追加。現在両方が動作。両方サポート。- 必須:JavaScriptレンダリング。
生のrequests.get()呼び出しは2025年1月以降空結果を返す
最小動作例:
curl -X POST "https://api.brightdata.com/request"
-H "Content-Type: application/json"
-H "Authorization: Bearer <API_TOKEN>"
-d '{"ゾーン":"<ゾーン名>","url":"https://www.google.com/search?q=ウェブスクレイピング+ツール&gl=us&hl=en&brd_json=1","format":"raw"}'(URL内のbrd_json=1は、Bright DataにGoogleのHTMLを構造化されたJSONにパースするよう指示します。リクエストボディのformat: rawは、Bright Dataのインフラから返されるレスポンスをそのまま返します。この場合、brd_json=1によって生成されたパース済みJSONが返されます。)
クイックリファレンス: Google検索パラメータ一覧
| パラメータ | 機能 | ステータス |
|---|---|---|
q |
検索クエリ | アクティブ |
hl |
インターフェース言語 (en,fr,de) |
Active |
gl |
位置情報 / 国 (us,gb,in) |
有効 |
lr |
結果を特定の言語に制限 | 有効 |
cr |
特定の国でホストされているページに結果を制限する | 有効 |
num |
1ページあたりの結果数 | 廃止予定 (2025年9月) |
開始 |
ページネーションオフセット | アクティブ |
tbm |
検索タイプ (isch,nws,shop,vid) |
アクティブ |
udm |
コンテンツモードフィルター (14,2,39,50) |
アクティブ (新規) |
tbs |
時間および高度なフィルター (qdr:d、qdr:w) |
有効 |
安全 |
セーフサーチフィルタリング | 有効 |
フィルタ |
重複結果のフィルタリング | 有効 |
nfpr |
自動修正を無効化 | 有効 |
pws |
パーソナライズされた結果を無効にする (pws=0) |
有効 |
uule |
エンコードされた場所(都市レベルのターゲティング) | 有効 |
sclient |
検索クライアント識別子 | アクティブ(内部) |
kgmid |
ナレッジグラフエンティティID | 有効 |
si |
ナレッジグラフタブ(不透明なエンコード文字列。ユーザーが作成できない) | アクティブ(内部) |
ibp |
レンダリング制御(ジョブ、ビジネスリスト) | アクティブ |
ei、ved、sxsrf |
内部トラッキング/セッショントークン | アクティブ(内部) |
Google検索演算子(site:、filetype:、intitle:など)については、後述の演算子セクションで説明しています。
SERP API Playgroundで基本的な検索をお試しください – ログインは不要です。完全なパラメータセットについては、API を直接ご利用ください。
Google検索パラメータとは?
Google検索パラメータは、クエリ、場所、言語、結果のフィルタリングを制御します。SEOランク追跡、競合分析、広告モニタリング、LLMアプリケーションへの検索結果のフィードに重要です。
2025年に変更された点:Googleは2025年4月、ccTLD(google.co.uk、google.de、google.caなどの国別コードトップレベルドメイン)がgoogle.comにリダイレクトされることを発表しました。展開は段階的であり、一部のccTLDでは依然として直接結果を提供しています。いずれの場合も、ローカライズにはドメインではなくglとhlを使用してください。
コア検索パラメータ
ほぼ全てのリクエストで設定するパラメータ:クエリ、言語、国、ページネーション。
q – 検索クエリ
検索クエリはqに指定します。
https://www.google.com/search?q=bright+data+ウェブスクレイピングクエリ内のスペースは+または%20 でエンコードされます。qパラメータは Google の検索演算子もサポートします。例:
https://www.google.com/search?q=filetype:pdf+ウェブスクレイピング+ガイド
https://www.google.com/search?q=site:github.com+SERP API
https://www.google.com/search?q=intitle:プロキシ・ローテーション・チュートリアルクエリ文字列は適切にURLエンコードしてください。特に非ラテン文字(中国語、アラビア語、日本語、韓国語など)は必ずエンコードしてください。エンコードを怠ると、予期しない結果や空の結果が返される原因となります。Bright DataのSERP APIを使用する場合、URLでは常にqパラメータを最初に配置してください。BrightDataのドキュメントで必須とされています。qの前に他のパラメータを配置すると、応答速度の低下や成功率の低下の原因となる可能性があります。
Bright DataのSERP APIプロキシメソッド経由:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-ゾーン-<ゾーン名>:<パスワード> -k
"https://www.google.com/search?q=ウェブスクレイピングツール&brd_json=1"JSON内に生のHTMLを保持する必要がある場合は、`brd_json=1`の代わりに`brd_json=html`を使用してください。Direct APIはMarkdown、スクリーンショット、軽量パース出力など追加の出力形式をサポートしています。
JSONレスポンスは次のようになります(一部省略):
{
"general": {
"search_engine": "google",
"results_cnt": 33500000,
"search_time": 0.21,
"language": "en",
"mobile": false,
"search_type": "text"
},
"input": {
"original_url": "https://www.google.com/search?q=ウェブスクレイピング+ツール&brd_json=1"
},
"organic": [
{
"link": "https://www.reddit.com/r/automation/comments/1ncuv8k/best_web_scraping_tools_ive_tried_and_what_i/",
"title": "私が試した最高のウェブスクレイピングツール(そしてそこから学んだこと)",
"description": "Playwright: 構造化された自動化とテストに最適ですが、軽量なスクレイピングにはコード量が多めです。",
"rank": 1,
"global_rank": 5
}
]
}JSONはSERPセクションごとにすべてをグループ化しています。オーガニック検索結果はtop_adsやbottom_adsとは別扱い、ナレッジパネルはpeople_also_askとは別扱い、ローカル検索結果はsnack_packにまとめられ、ai_overviewのような新機能はそれぞれ独自のフィールドに格納されます。クエリによって異なりますが、合計で十数以上のセクションが存在します。
hl – ホスト言語
「ホスト言語」の略称。hlはGoogleインターフェースの言語と、Googleがクエリを解釈する方法を制御します。
https://www.google.com/search?q=coffee&hl=en
https://www.google.com/search?q=coffee&hl=es
https://www.google.com/search?q=coffee&hl=ja値はISO 639-1コード(例:hl=en(英語)、hl=fr(フランス語)、hl=de(ドイツ語))またはBCP 47言語タグ(例:hl=en-gb(イギリス英語)、hl=pt-br(ブラジルポルトガル語)、hl=es-419(ラテンアメリカスペイン語))です。
SERP APIを介すると、同じ検索は次のようになります:
curl --proxy brd.superproxy.io:33335
--プロキシ-ユーザー brd-customer-<CUSTOMER_ID>-ゾーン-<ゾーン名>:<パスワード> -k
"https://www.google.com/search?q=meilleurs+outils+de+scraping&hl=fr&gl=fr&brd_json=1"このコマンドはフランス語のクエリに対してフランス語の結果を取得します。あたかもフランス国内から検索しているかのように動作します。
gl – 地理的位置情報
検索場所によって結果が変わります。glパラメータは地理的位置(検索が発信されたと見なされる国)をシミュレートします。ISO 3166-1 alpha-22文字の国コードを使用します。
https://www.google.com/search?q=pizza+delivery&gl=us
https://www.google.com/search?q=pizza+delivery&gl=gb
https://www.google.com/search?q=pizza+delivery&gl=in同じクエリを2カ国で比較:
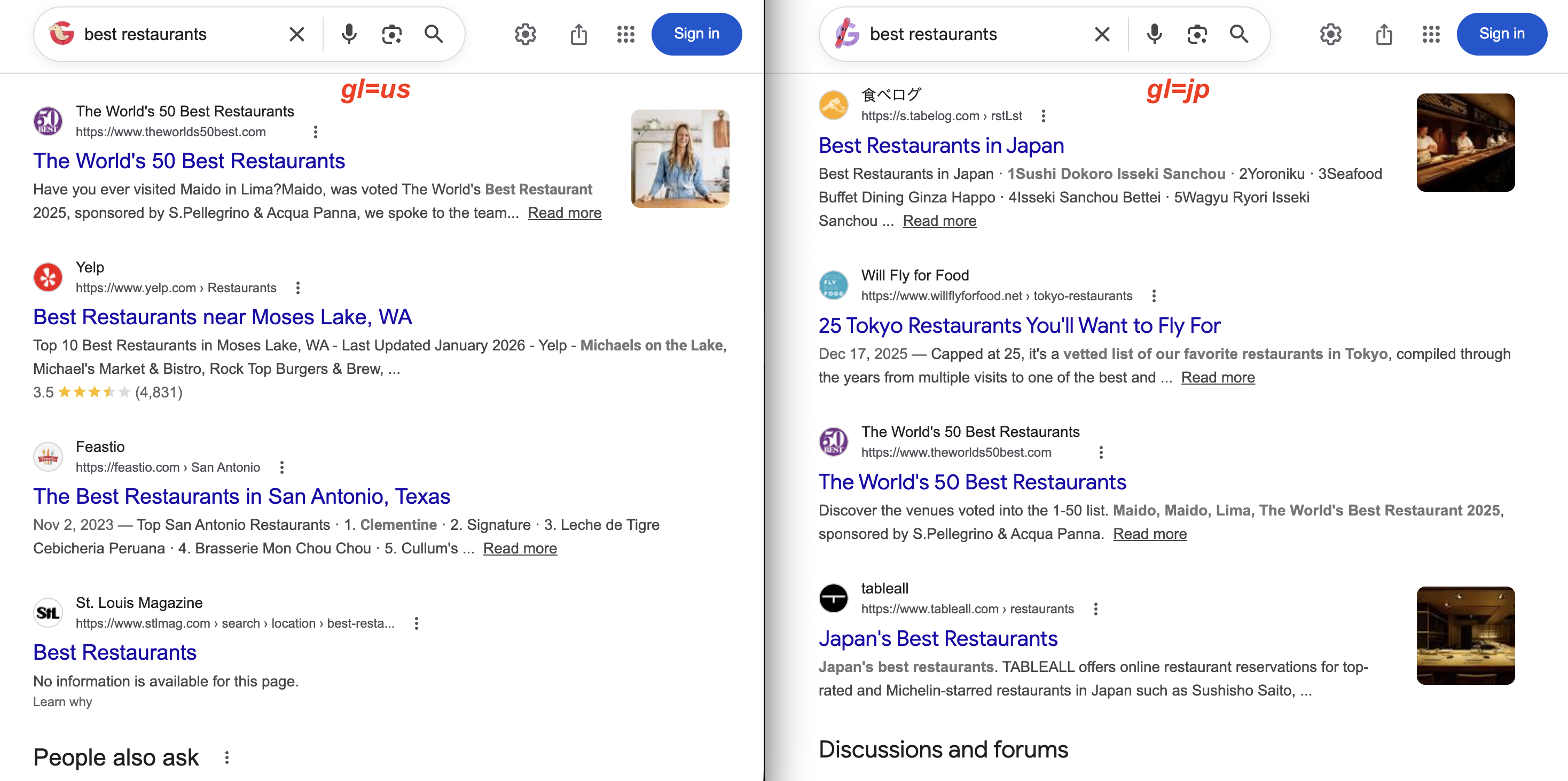
gl=usでは Yelp と米国のローカル雑誌が表示されます。gl=jp では代わりに食べログと東京のレストランガイドが表示されます。同じクエリでも結果は大きく異なります。
lr – 言語制限
機械学習を 検索する際にhl=enを指定しても、Googleが関連性があると判断すれば中国語・日本語・ドイツ語の論文が返される。lrパラメータはこの問題を解決する。インターフェース言語だけでなく、実際に特定の言語で書かれたページに結果を限定する。
https://www.google.com/search?q=machine+learning&lr=lang_en
https://www.google.com/search?q=machine+learning&lr=lang_en|lang_fr言語コードの前にlang_を付加します(例:英語はlang_en、フランス語はlang_fr)。複数の言語を組み合わせるにはパイプ記号|を使用します。
cr – 国別制限
lrと同様ですが、コンテンツ言語ではなくホスティング国でフィルタリングします。単一国にはcr=countryUS、複数国にはcr=countryUS|countryGBを使用します。glとの主な違い:glは検索をその国にいるかのように地理的に特定しますが、crは実際にその国でホスティングされているページにフィルタリングします。正確なフィルタリングが必要な場合は両方を組み合わせて使用してください。
num – 検索結果数
numパラメータは、1ページに表示される検索結果の数を制御するために使用されていました(例:num=20、num=50、num=100)。
2025年9月以降にスクレイパーが10件の結果しか返さなくなった場合、このパラメータ変更が原因です。2025年9月時点でGoogleはnumパラメータを非表示で無効化しました。現在は完全に無視されます。Googleはnumの値に関わらず1ページあたり10件の結果を返し、エラーやリダイレクトも発生しません。これにより、numに依存していたSEOツールやSERPスクレイピングワークフローが機能しなくなりました。 Google広報担当者は「このURLパラメータの使用は正式にサポートするものではありません」と確認しています。2025~2026年の変更点セクションでは、Bright Dataの「Top 100 Results」エンドポイントを用いた回避策を解説しています。
この動作は確認可能です。URLにnum=100が含まれていても、返される結果は10件のみです:
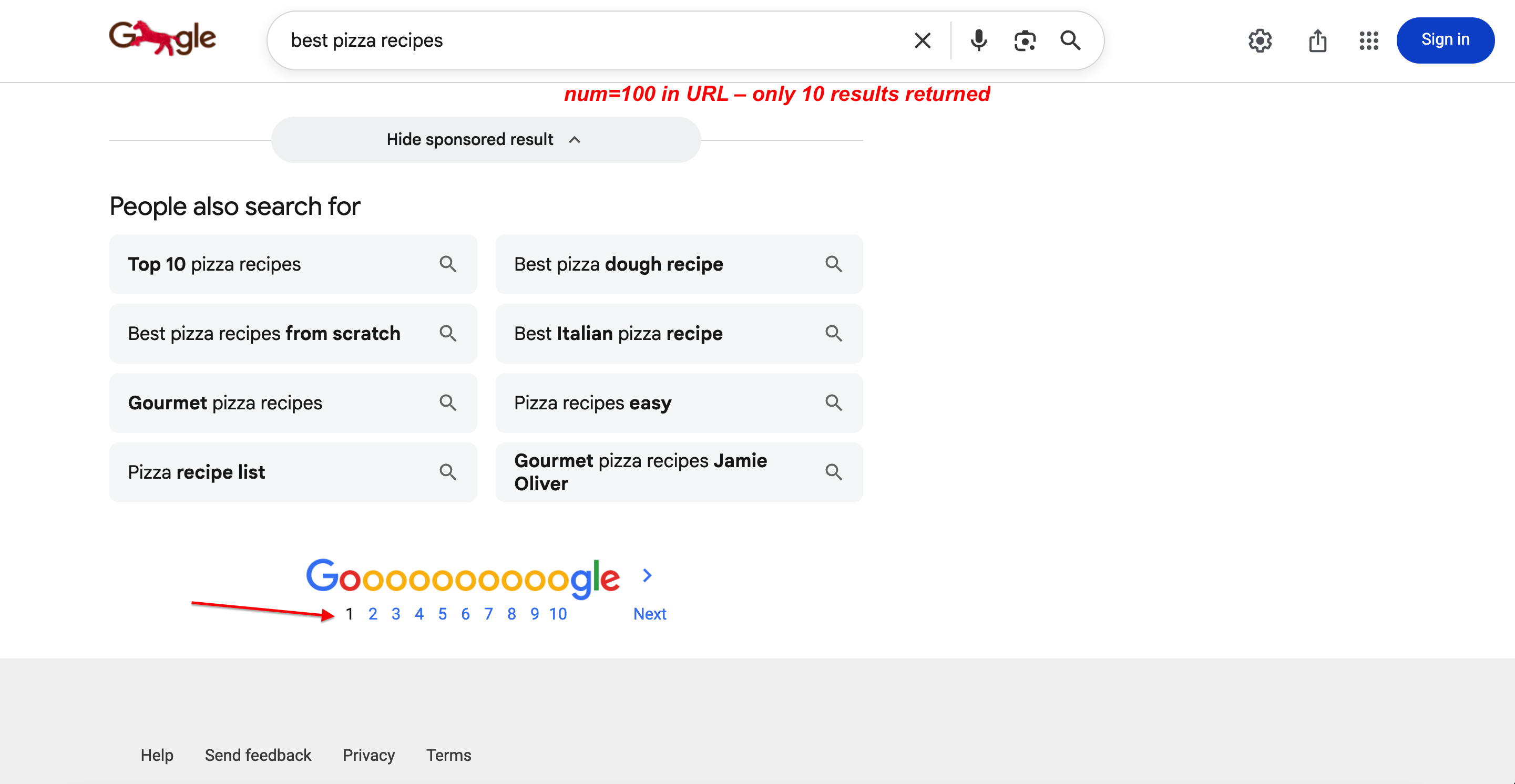
URLにnum=100を含めて検索。Googleは依然として完全なページネーションで1ページあたり10件のみを返す。パラメータは完全に無視される。
start – 結果オフセット(ページネーション)
Googleがnumを廃止したため、startが唯一のネイティブページネーションオプションとなります。これは結果オフセットを設定し、開始する結果位置を制御します。
https://www.google.com/search?q=ウェブスクレイピング&start=0
https://www.google.com/search?q=ウェブスクレイピング&start=10
https://www.google.com/search?q=ウェブスクレイピング&start=20start=0はページ 1(デフォルト)、start=10はページ 2、start=20はページ 3 です。
Googleは1ページあたり10件の結果を返すため、start=20で21~30件目、start=30で31~40件目…となります。複数ページにまたがるページネーションでは、Googleがページ間で重複する結果や順序がわずかに異なる結果を返す場合があります。処理前にURLで重複を除去してください。
SERP APIによるページネーション:
# 検索結果の3ページ目を取得
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=serp+scraping&start=20&brd_json=1"検索タイプのパラメータ
Googleには検索分野(画像、ニュース、ショッピング、動画)を切り替えるための2つのパラメータがあります:tbmと udm。
tbm – 検索コンテンツタイプ
tbmパラメータ(一般的に「to be matched」と解釈されますが、Google はこの頭字語を公式に確認したことはありません)は、Googleにどのタイプの検索結果を望むかを伝えます。指定しない場合、Google は通常のウェブ検索をデフォルトとします。
| 値 | 検索タイプ | 例 |
|---|---|---|
| (空) | ウェブ検索 | q=コーヒー |
isch |
画像検索 | tbm=isch&q=コーヒー |
vid |
ビデオ検索 | tbm=vid&q=coffee |
nws |
ニュース検索 | tbm=nws&q=coffee |
shop |
ショッピング検索 | tbm=shop&q=coffee |
bks |
書籍検索 | tbm=bks&q=coffee |
3種類の検索タイプで同じクエリを実行:
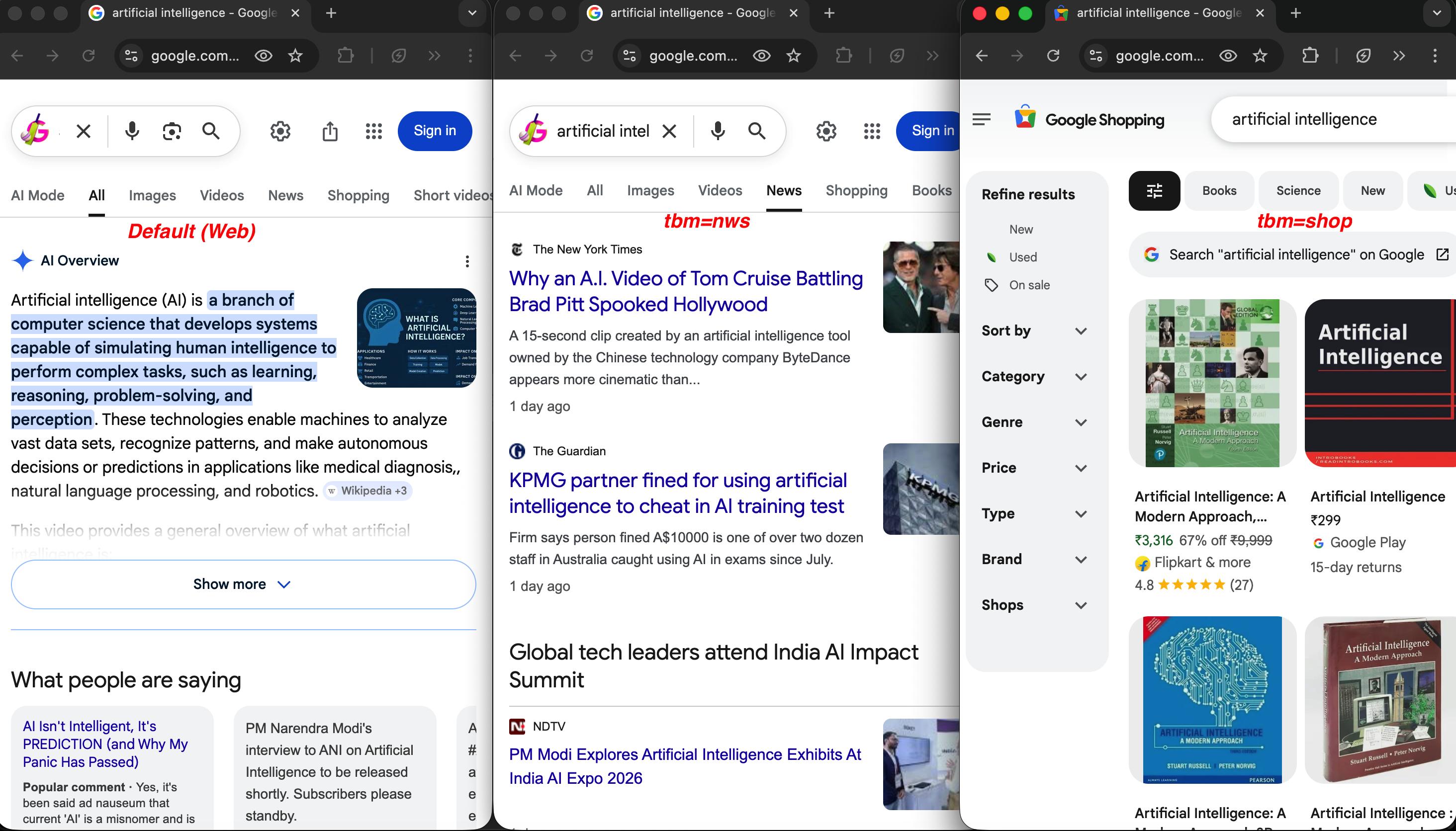
同じクエリ、異なるtbm値:デフォルトのウェブ検索(左)はAI概要を表示、tbm=nws(中央)はNYTとガーディアンのニュース記事を返す、tbm=shop(右)は価格と評価付きの商品リストを表示。
人工知能に関するニュース検索:
https://www.google.com/search?q=artificial+intelligence&tbm=nws&hl=en&gl=usメカニカルキーボードのショッピング検索:
https://www.google.com/search?q=mechanical+keyboard&tbm=shop&gl=usこれらの検索タイプはすべてネイティブで動作します。JSONレスポンスをパースする際、広告はtop_adsと bottom_adsフィールドに分離され、商品リストはpopular_products下に表示され、いずれもオーガニック検索結果とは区別されます。 広告専用のモニタリングについては、Google Adsスクレイパーを参照してください。旅行・ホテル関連パラメータ(hotel_occupancy、hotel_dates、brd_dates、brd_occupancy、brd_currencyなど)はBright Data固有のもので、SERP APIパラメータリファレンスに記載されています。
udm – ユーザー表示モード
Googleの新しい コンテンツモードフィルターであるudmは、tbmに追加の結果タイプを拡張したものです。これは検索結果の「モード」を制御します。udmの値はいずれもGoogleの公式ドキュメントに記載されていません。これらはすべて開発者コミュニティによるテストを通じてリバースエンジニアリングされたものです。以下の値は安定して広く使用されていますが、Googleは予告なく変更する可能性があります。
| 値 | 結果モード | 説明 |
|---|---|---|
udm=2 |
画像 | 画像検索結果 |
udm=7 |
ビデオ | ビデオ検索結果;tbm=vidの新しい同等物 |
udm=12 |
ニュース | ニュース検索結果;tbm=nwsの新しい同等物 |
udm=14 |
Web | AI機能なしのクラシックWeb検索結果 |
udm=18 |
フォーラム | ディスカッションおよびフォーラム検索結果 |
udm=28 |
ショッピング | ショッピング/商品検索結果 |
udm=36 |
書籍 | 書籍検索結果;tbm=bksの新しい同等物 |
udm=39 |
ショート動画 | ショートフォーム動画コンテンツ |
udm=50 |
AIモード | GoogleのAI搭載会話型検索 |
最も注目すべき値はudm=14です。これによりGoogleはAI概要やその他のAI生成コンテンツなしで従来のウェブ検索結果を表示します:
https://www.google.com/search?q=ウェブスクレイピング+ツール&udm=14デフォルトとudm=14の違いは一目瞭然です:
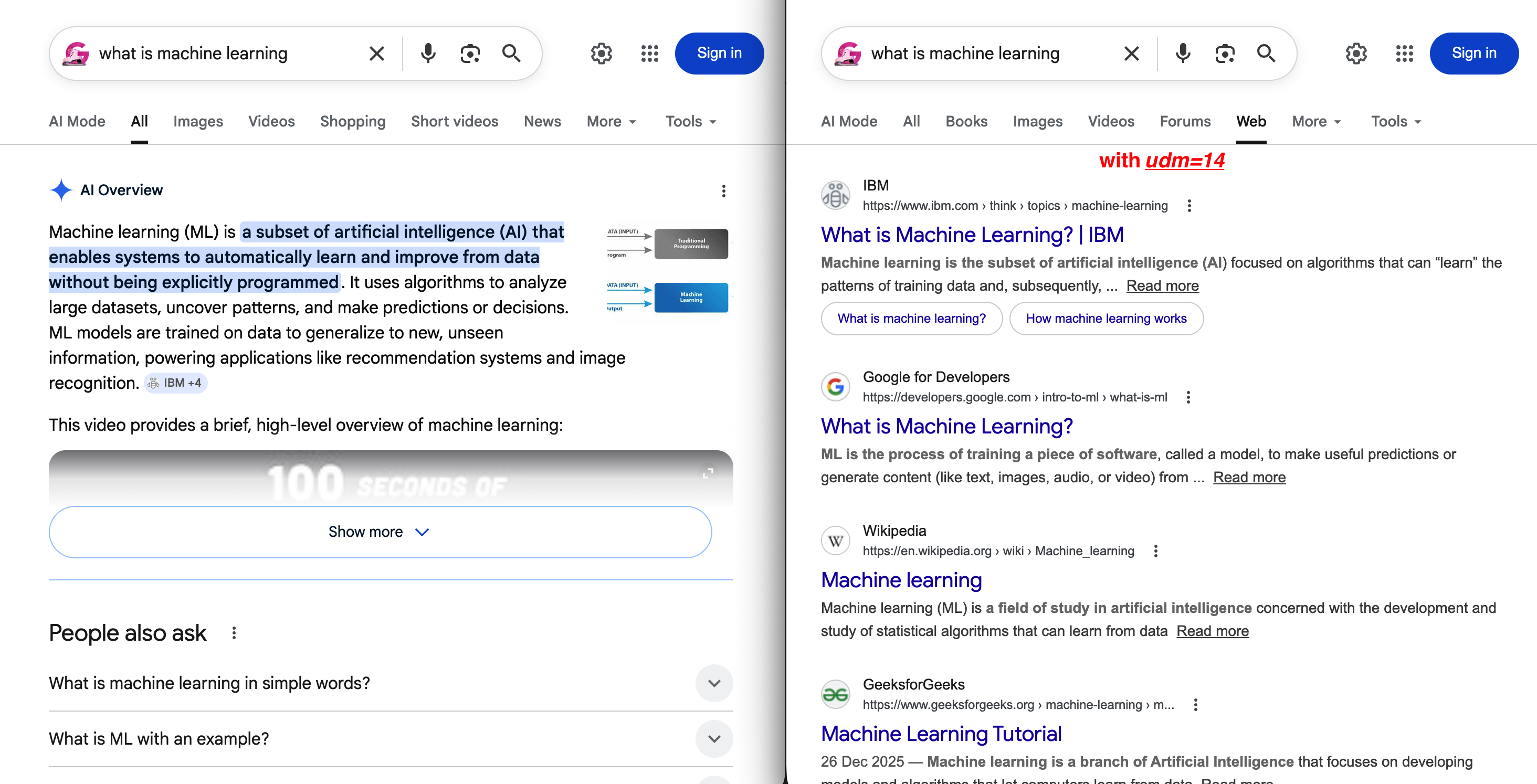
左:AI概要が表示され、オーガニック検索結果がスクロールしないと見えない位置に押し下げられたデフォルトのSERP。右:udm=14を適用するとこれら全てが除去され、従来の青いリンクのみが表示されたクリーンな「Web」タブが表示される。
短い動画結果にはudm=39を使用(Google非公式、地域により動作が異なる可能性あり):
https://www.google.com/search?q=coffee+recipes&udm=39AIモード(udm=50)は全く異なる検索形態です:
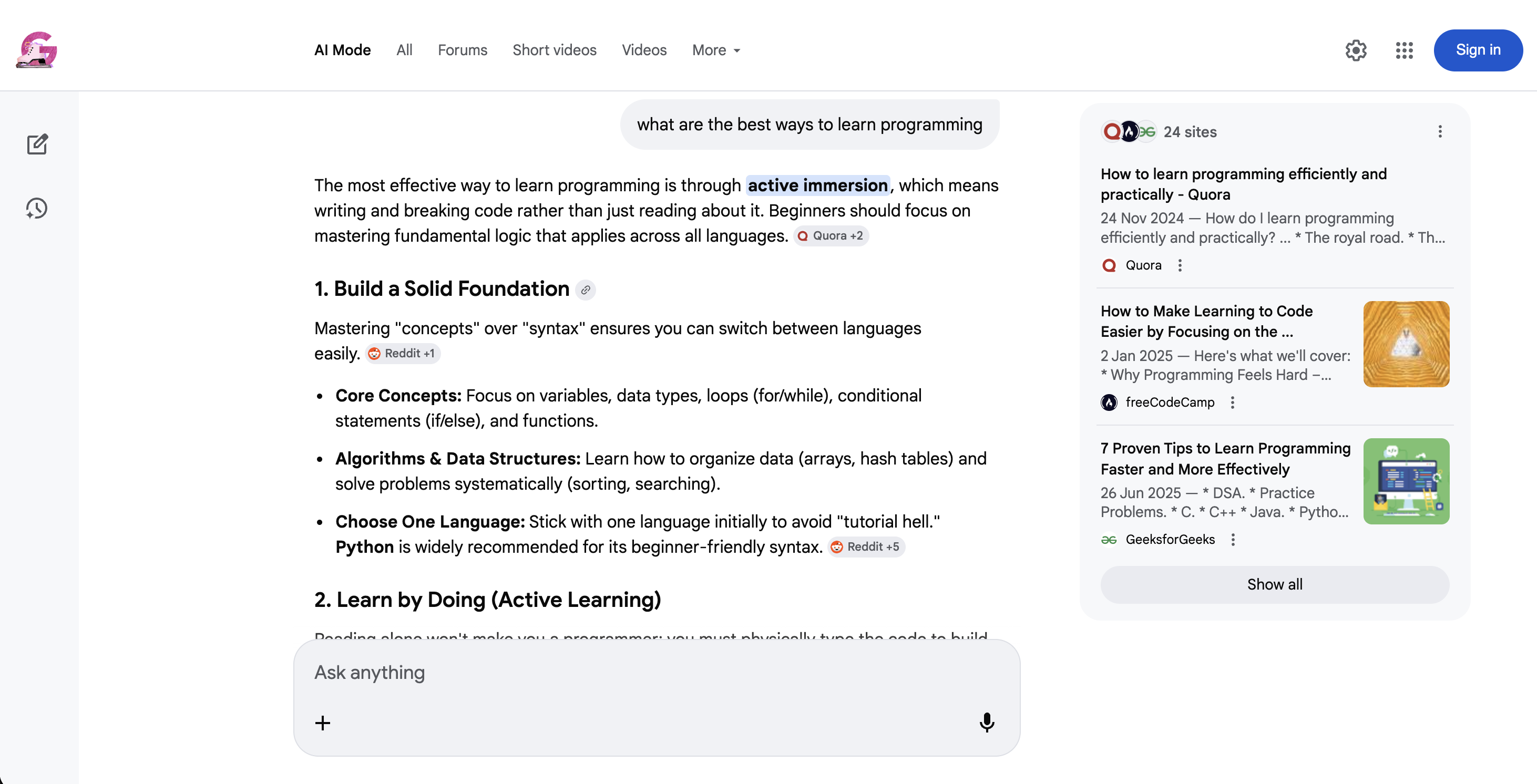
Google AIモード(udm=50):従来の検索結果の代わりに、Googleは対話型AI応答を返します。これにはソースの引用がインラインで表示され、推奨されるフォローアップ質問が含まれます。
tbmとudmは画像・ニュース・ショッピングでは重複するが、udm はtbmがカバーしないモード(フォーラム・ショート動画・AIモード・ウェブ限定)も対象とする。現在両方が機能する。新規スクレイピングワークフローを構築する場合は、最大限の互換性のため両パラメータをサポートすること。
フィルタリングとソートパラメータ
tbs – 時間ベースおよび高度なフィルター
tbsパラメータ(公式情報では確認されていないが、一般的に「検索対象」と解釈される)は、時間フィルタリング、日付ソート、完全一致検索を制御します。
最も一般的な用途は、qdr(クエリ日付範囲)による時間フィルタリングです:
| 値 | 時間範囲 |
|---|---|
tbs=qdr:h |
過去1時間 |
tbs=qdr:d |
過去24時間 |
tbs=qdr:w |
過去1週間 |
tbs=qdr:m |
過去1か月 |
過去1年 |
過去1年 |
tbs=cdr:1,cd_min:01/01/2025,cd_max:12/31/2025 でカスタム日付範囲を設定することも可能です。特定の期間における検索結果の変化を追跡するのに便利です。
時間フィルタリング以外にも、tbsには2つの便利なモードがあります。tbs=sbd:1は検索結果を関連性順ではなく日付順(新しい順)に並べ替え、最近の言及を監視するのに有用です。またtbs=li:1は完全一致検索を有効化します。Googleは自動修正・類義語・関連語なしで、入力した文字列を正確に検索します。
トピックに関する最新ニュースを監視するには:
curl --proxy brd.superproxy.io:33335
--プロキシユーザ brd-customer-<CUSTOMER_ID>-ゾーン-<ゾーン名>:<パスワード> -k
"https://www.google.com/search?q=ウェブスクレイピング規制&tbs=qdr:w&brd_json=1"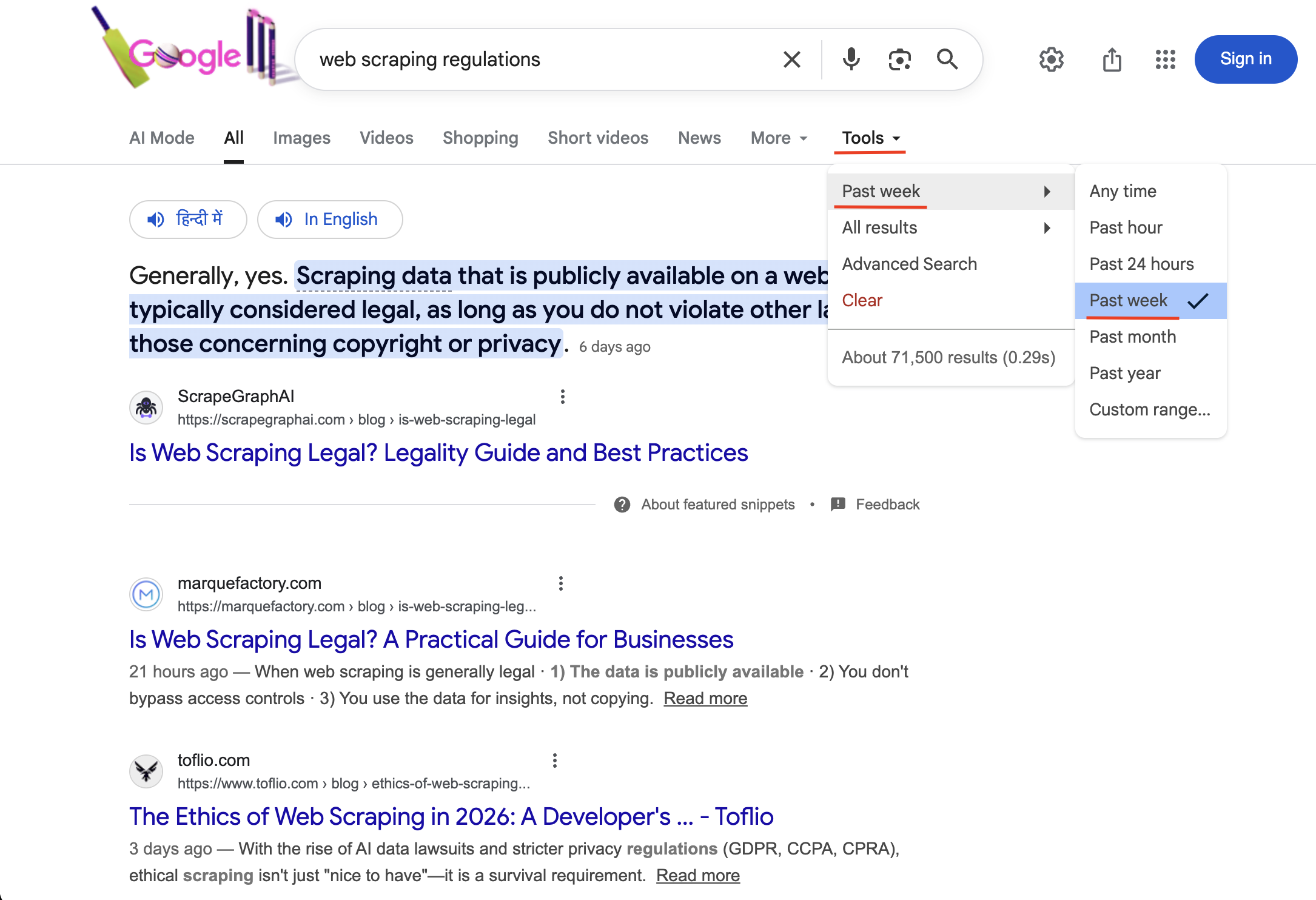
tbs=qdr:wで検索すると「過去1週間」の時間フィルターが有効になります(ツール内のチェックマークで確認可能)。過去7日以内に公開された結果のみが返されます。
ヒント: すべての結果を取得するには、filter=0 を任意のtbs時間フィルターと組み合わせてください。これを指定しない場合、Google は類似ページをグループ化するため、関連する報道を見逃す可能性があります。
safe – セーフサーチフィルタリング
safe=activeで露骨なコンテンツをフィルタリング、safe=offでフィルタリングを無効化。
https://www.google.com/search?q=photography&safe=active
https://www.google.com/search?q=photography&safe=offfilter – 重複結果のフィルタリング
filterパラメータは、Googleが類似または重複する結果をどのようにグループ化するかを制御します。
https://www.google.com/search?q=ウェブスクレイピング&filter=0
https://www.google.com/search?q=ウェブスクレイピング&filter=1filter=0 は重複を含む全結果を表示します。filter=1(デフォルト)は類似ページをグループ化します。時間フィルターと組み合わせると最も効果的です(上記のtbsヒント参照)。
nfpr – 自動修正を無効化
nfpr=1を設定すると、Googleによるクエリの自動修正を停止します。
https://www.google.com/search?q=scraping+brwser&nfpr=11に設定すると、Googleは「スクレイピングブラウザ」の候補を表示せず、入力した文字列を正確に検索します。意図的にスペルミスした用語、Googleが誤記と判断するブランド名、Googleが修正を試みる可能性のある専門用語を検索する際に有用です。 注:nfpr=1 は自動修正のみを抑制します。tbs=li:1(文字通りモード) はさらに同義語、語幹処理、関連語も無効化します。最も厳密な一致を求める場合は両方を併用してください。
pws – パーソナライズドウェブ検索
Googleはデフォルトで検索結果をパーソナライズします。pwsは パーソナライゼーションの有効/無効を制御します。
https://www.google.com/search?q=ウェブスクレイピング+ツール&pws=0パーソナライゼーションを無効化(pws=0)することが重要なのは、パーソナライズされた結果はユーザーごとに異なるため、大量データの整合性が損なわれるからです。本格的なSERPデータ収集では、常にpws=0を含めて、ベースラインとなる非パーソナライズされたランキングを取得してください。
ロケーションパラメータ
ほとんどの順位追跡ではglによる国レベルターゲティングで十分です。ただしローカルSEOではより精密なターゲティングが必要です。
uule – エンコードされた位置情報
glでは粒度が不十分な場合に、uuleで 都市レベルの精度を実現します。
uuleの値はGoogle Ads APIの地域ターゲティングに基づくエンコード文字列です。Googleの地域ターゲティングデータベースからの正規名エンコーディング、またはGPS座標エンコーディング(緯度/経度)のいずれかを使用します。
https://www.google.com/search?q=best+restaurants&uule=w+CAIQICIGUGFyaXMuule値の手動生成は複雑です。GoogleのGeo Targetsドキュメントで場所の正規名を検索し、Googleが要求する特定の形式でエンコードする必要があります。
Bright DataのSERP APIを使えば、エンコーディングを完全に省略し、場所の名前を読みやすい文字列としてそのまま渡すことができます:
https://www.google.com/search?q=best+restaurants&uule=New+York,New+York,United+StatesAPIが自動的に検索とエンコードを処理します。
国レベルでのターゲティングにはglを、都市レベルの精度が必要な場合はuuleを使用します。ほとんどの順位追跡ではglで十分です。uuleは、同じ国内で都市ごとに結果が異なるローカルSEO監査に留めておいてください。
デバイスとクライアントのパラメータ
Googleはモバイルとデスクトップで異なる結果を返します。これらのパラメータはデバイスエミュレーションとブラウザ識別を制御します。
sclient – 検索クライアント
sclient はほぼ全ての Google 検索 URL に含まれます。検索を開始したクライアントを識別します。主な値:gws-wiz(ウェブ検索)、gws-wiz-serp(SERP 経由)、img(画像検索)、psy-ab(Google インスタント/予測検索関連)。Google 内部分析用であり、検索結果には影響しません。
brd_mobile / brd_browser – デバイスとブラウザのエミュレーション
SERP APIは特定のデバイスからの検索をシミュレートするためbrd_mobileを提供します:
| 値 | デバイス | ユーザーエージェントタイプ |
|---|---|---|
0または省略 |
デスクトップ | デスクトップ |
1 |
モバイル | モバイル |
iosまたはiphone |
iPhone | iOS |
iPadまたはiOS_tablet |
iPad | iOSタブレット |
Android |
Android | Android |
android_tablet |
Android Tablet | Android Tablet |
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=best+apps&brd_mobile=ios&brd_json=1"プロキシ方式
でbrd_mobileを使用中にexpect_bodyエラーが発生した場合は、代わりにDirect API方式を試してください。デバイスエミュレーションにおいてより信頼性が高い傾向があります。LangChain統合もここで有効です。Direct API経由でdevice_typeが自動的に渡されるためです。
また、brd_browser でブラウザの種類を制御することも可能です:
brd_browser=chrome(Google Chrome)brd_browser=safari(Safari)brd_browser=firefox(Mozilla Firefox、brd_mobile=1とは互換性なし)
指定しない場合、APIはランダムなブラウザを選択します。両パラメータを組み合わせて正確なデバイス+ブラウザの組み合わせを設定できます:
curl --proxy brd.superproxy.io:33335
--プロキシ-ユーザー brd-customer-<CUSTOMER_ID>-ゾーン-<ゾーン名>:<パスワード> -k
"https://www.google.com/search?q=best+smartphones&brd_browser=safari&brd_mobile=ios&brd_json=1"高度な内部パラメータ
これらの設定は不要です。これらはGoogleの内部パラメータです。ただし、GoogleのURLでei、ved、sxsrfを見かけた際にその意味を知りたい場合は、このセクションで説明します。
kgmid – ナレッジグラフマシンID
kgmidパラメータは Googleのナレッジグラフから結果を提供し、qパラメータを完全に上書きすることがあります。
https://www.google.com/search?kgmid=/m/07gyp7これはマクドナルドのナレッジグラフパネルを直接読み込みます。各エンティティには固有のマシンIDがあり、kgmid経由で渡すことでそのエンティティのパネルを取得します。
Googleが当該IDに対して返すパネル:
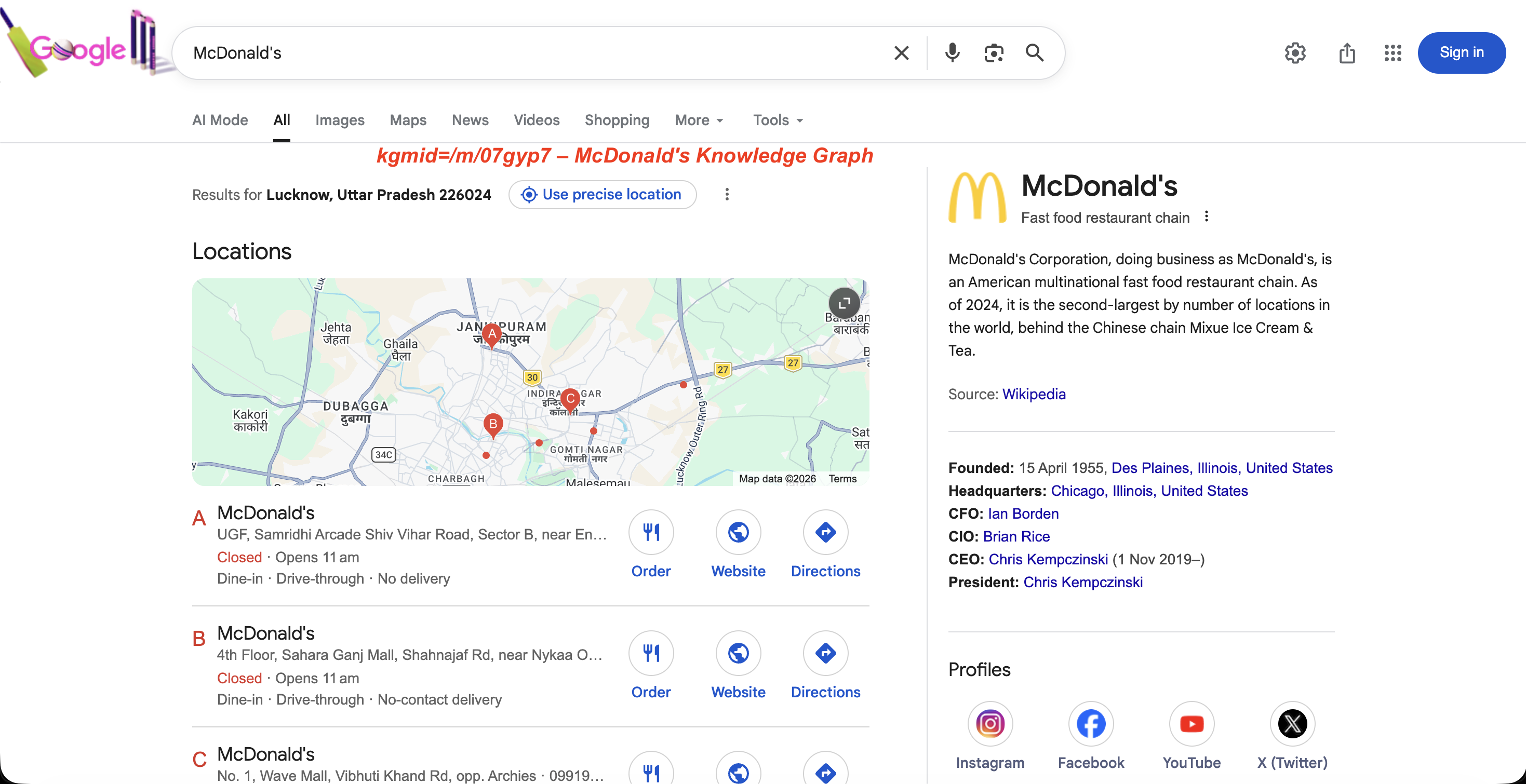
kgmid=/m/07gyp7 のナレッジグラフパネル:エンティティの説明、設立日、経営陣、ソーシャルプロフィール。
ブランド監視チームは、自社や競合他社のGoogleナレッジグラフパネルが時間とともにどのように変化するかを追跡するためにこれを利用します。
ibp – レンダリング制御
Googleは通常の検索結果でibpを使用しません。SERP上の特定の要素(特にGoogleビジネスリスティングと Googleジョブ)の表示方法を制御します。
https://www.google.com/search?ibp=gwp%3B0,7&ludocid=1663467585083384531ludocidパラメータ(Googleビジネスリスティングの固有ID)と併用すると、ibpはビジネスリスティングのフルページ表示をトリガーします。
求人検索では、ibp=htl;jobs(URLエンコードはibp=htl%3Bjobs)により、完全な求人リストを含むGoogleジョブパネルが表示されます:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=technical+copywriter&ibp=htl%3Bjobs&brd_json=1"ibp=htl%3Bjobsでトリガーされる求人パネル:
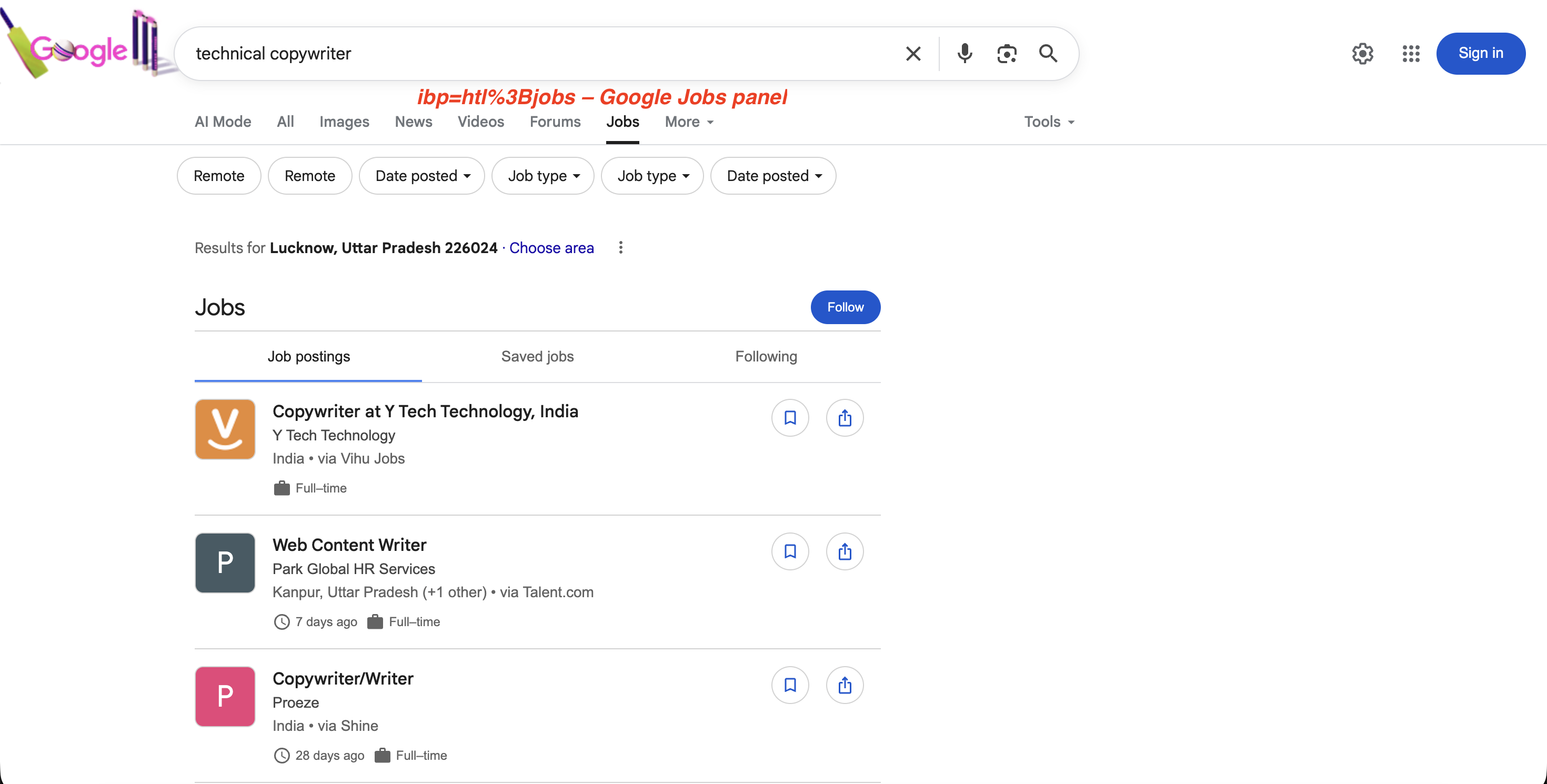
ibp=htl%3Bjobsパラメータは、求人投稿、フィルター、および「フォロー」オプションを備えた Google の専用求人パネルをトリガーします。これらはすべて SERP API 経由で抽出可能です。
htl;jobs内のセミコロンは、curlやHTTPクライアントで使用する際、URLエンコード(%3B)する必要があります(例:ibp=htl%3Bjobs)。適切なエンコードがない場合、リクエストが空の結果を返す可能性があります。
ei, ved, sxsrf, oq, gs_lp – 内部トラッキングパラメータ
これらは検索結果に影響を与えません。URLから削除しても問題ありません。各パラメータの機能は以下の通りです:
| パラメータ | 目的 |
|---|---|
ei |
Unixタイムスタンプと不透明な値を含むセッション識別子 |
ved |
クリック追跡:どの SERP 要素がクリックされたか、そのインデックスとタイプをエンコード |
sxsrf |
エンコードされたUnixタイムスタンプを持つCSRFトークン |
oq |
オートコンプリートによって変更される前の、入力された元のクエリ(例:q=web+ウェブスクレイピング+API の場合、oq=web+scrap) |
gs_lp |
検索クライアントの状態に関連する内部セッションデータ |
ie/oe |
入力/出力文字エンコーディング(ほとんどの場合UTF-8。無視しても問題なし) |
client |
検索クライアントの種類(例:firefox-b-d、safari)。ブラウザまたはアプリを識別します |
ソース |
検索ソース識別子(例:ホームページはhp、モード切り替えはlnms) |
biw/bih |
ブラウザの内部幅/高さ(ピクセル単位)。Googleが提供するSERPレイアウトのバリエーションに影響する可能性がある |
Google検索演算子
検索演算子はqパラメータ内の特殊コマンドで、ドメイン・ファイルタイプ・タイトル・URL・完全一致フレーズで結果をフィルタリングします。Googleは検索絞り込みヘルプページで一部を説明しています。
これらはURLパラメータとは異なります:演算 子はq値 内に記述され、パラメータはURL内の独立したキーと値のペアです。スクレイピングやデータ収集に最も有用なものは以下の通りです:
| 演算子 | 機能 | 例 |
|---|---|---|
site: |
特定のドメインに制限する | site:github.com python スクレイパー |
filetype: |
ファイルタイプを指定 | filetype:pdf ウェブスクレイピングガイド |
intitle: |
ページタイトル内を検索 | intitle:SERP API比較 |
inurl: |
URL内検索 | inurl:API documentation |
intext: |
ページ本文内を検索 | intext:ローテーションプロキシ |
allintitle: |
タイトル内の全単語 | allintitle:ウェブスクレイピング Python |
URL内の全単語 |
URL内の全単語 | allinurl:API ドキュメント スクラッピング |
関連: |
類似サイトを検索 | related:brightdata.com |
OR |
いずれかの用語に一致 | ウェブスクレイピング または ウェブクローリング |
"完全一致フレーズ" |
完全一致 | "SERP API for python" |
- |
除外語句 | ウェブスクレイピング -selenium |
開始:/終了: |
日付範囲 | AI概要後:2025-01-01 |
AROUND(n) |
近接検索 | scraping AROUND(3) python |
定義: |
辞書定義 | 定義:ウェブスクレイピング |
* |
ワイルドカード | "best * forウェブスクレイピング" |
これらすべてはAPIリクエストでも機能します。例:
curl --proxy brd.superproxy.io:33335
--プロキシユーザー brd-customer-<CUSTOMER_ID>-ゾーン-<ゾーン名>:<パスワード> -k
"https://www.google.com/search?q=site:reddit.com+ウェブスクレイピング+ツール+2026&brd_json=1"2026年のウェブスクレイピングツールに関する議論をRedditで特定し、構造化されたJSON形式で出力します。
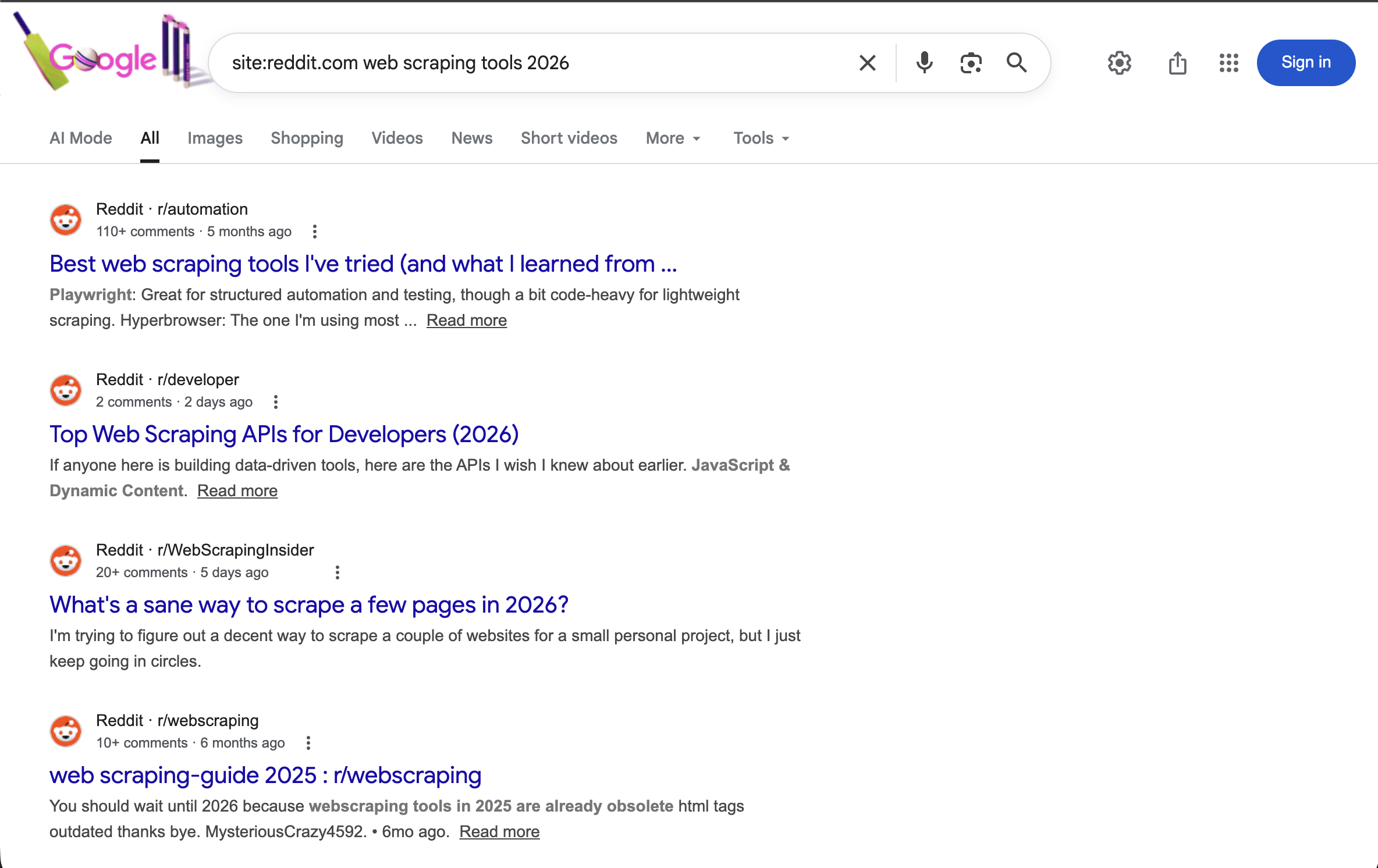
site:reddit.comオペレーターは結果をRedditに限定します。年指定と組み合わせることで、ウェブスクレイピングツールに関する最近のコミュニティ議論を表示します。
演算子は組み合わせ可能:
site:github.com filetype:pdf machine learning は、GitHub上にホストされ「machine learning」に一致するPDFファイルのみを返す。
as_* – 高度な検索パラメータ
Googleの高度な検索フォームは、上記の演算子に対応するas_接頭辞付きパラメータ(as_q、as_epq、as_sitesearch、as_filetypeなど)を生成します。多くのエンジニアは代わりにクエリに直接演算子を使用します。これらは主に、検索フォームUIを構築し、演算子文字列を連結せずにフォームフィールドをURLパラメータにマッピングしたい場合に有用です。
2025-2026年に知っておくべき変更点
Googleは2025年から2026年にかけて、既存のスクラッピング設定を破綻させる3つの変更を実施しました:JavaScriptレンダリングの必須化(2025年1月)、numパラメータの削除(2025年9月)、AI概要の200カ国以上への拡大です。
GoogleがJavaScriptレンダリングを必須化
2025年1月より、GoogleはJavaScriptレンダリングなしでは検索結果を提供しません。requests+BeautifulSoupスクレイパーを運用していた場合、この変更が原因です。requests.get('https://google.com/search?q=...')はすべて空または劣化レスポンスを返すようになりました。完全なブラウザレンダリング、または代わりに処理するSERP APIが必要です。
SERP APIではJavaScriptレンダリングが自動化されているため、API呼び出しは変更不要です。
numパラメータは機能しなくなりました
2025年9月12日~14日にかけて、Googleはnumを無断で無効化しました。影響は広範囲に及び、319のプロパティを対象とした調査によると、追跡対象サイトの87.7%でGoogle Search Consoleのインプレッションが減少しました。
10件以上の結果を取得する場合、BrightDataのSERP APIには「Top 100 Results」エンドポイントがあり、1回のリクエストで1~100位の順位を返します。これは別のAPIインターフェース(/datasets/v3/trigger、データセットIDgd_mfz5x93lmsjjjylob)を使用し、start_page とend_pageパラメータでページネーションの深さを制御できます:
curl -X POST "https://api.brightdata.com/データセット/v3/トリガー?データセット_id=gd_mfz5x93lmsjjjylob&include_errors=true"
-H "Authorization: Bearer <API_TOKEN>"
-H "Content-Type: application/json"
-d '[{
"url": "https://www.google.com/",
"keyword": "ウェブスクレイピング tools",
"language": "en",
"country": "US",
"start_page": 1,
"end_page": 10
}]'ページ範囲:1..2= トップ20、1..5= トップ50、1..10= トップ100(1ページあたり10件)。GoogleがAI概要テキスト(aio_textフィールド)を表示する場合、レスポンスに含みます。また、解析データと共に生のHTMLを取得するには"include_paginated_html": true を追加できます。バッチ処理もサポートされています。 単一リクエストで複数のキーワードを検索するには、クエリオブジェクトの配列を渡します。
検索結果のAI概要
GoogleのAI概要(検索結果上部に表示されるAI生成の要約)は現在、200以上の国と言語で利用可能です。2026年1月、GoogleはAI概要をGemini 3にアップグレードしました。また、AI概要からAIモード(udm=50)会話への移行機能を追加しています。このコンテンツの取得にはJavaScriptレンダリングと特定の抽出ロジックが必要です。実際のSERP上のAI概要例:
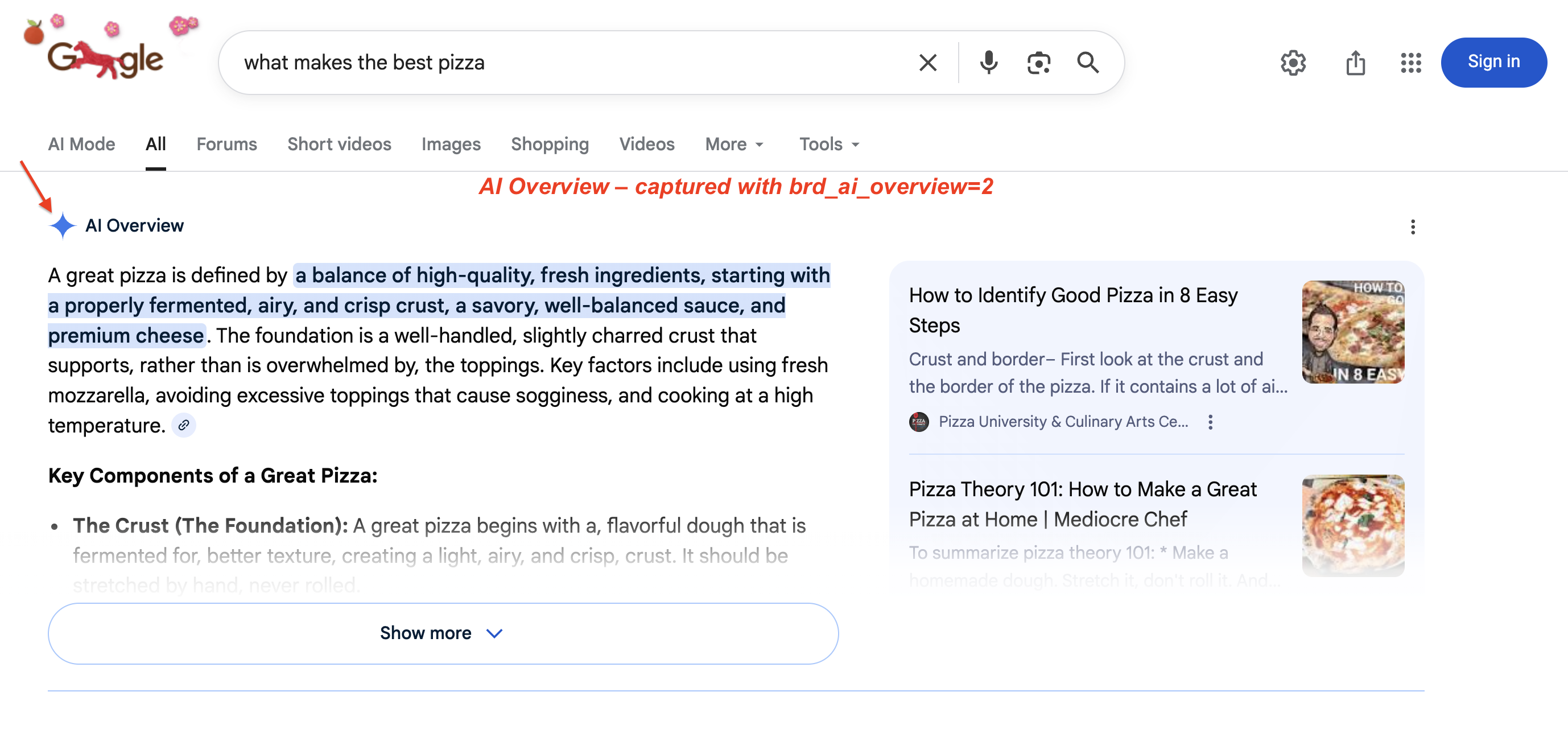
典型的なAI概要: Googleは複数の段落からなる要約を生成し、右側に強調表示されたキーフレーズとソースカードを表示します。このブロックにより、オーガニック検索結果は画面下部に押し下げられます。SERP API経由で取得するにはbrd_ai_overview=2を使用してください。
AI概要スクレイパーはbrd_ai_overviewパラメータで動作します。結果にAI生成概要が表示される確率を高めるにはbrd_ai_overview=2を設定:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=what+makes+the+best+pizza&brd_ai_overview=2&brd_json=1"当社のテスト(米国クエリ)では、AI概要の取得を有効化すると応答時間に5~10秒の遅延が生じました。この追加遅延は、Googleの動的に読み込まれるAIコンテンツがヘッドレスブラウザでレンダリング完了するまでの待機時間に起因します。
SERP APIでGoogle検索パラメータを使用する方法
大規模なスクレイピングを行う場合、CAPTCHA、IPブロック、必須のJavaScriptレンダリング、そしてパーサーを黙って壊すGoogleのインフラ変更に遭遇します。下記の手法はすべて、実際のAPIに対してテストし、文書通り動作することを確認済みです。
Bright DataのSERP APIでこれらのパラメータを使用する4つの方法(最も単純なものから高度なものへ)。探索段階なら方法1(ダイレクトAPI)から開始。カスタムヘッダーで既存コードベースに統合する場合は方法2(プロキシ)を選択。AIエージェントワークフローには方法4(LangChain)へスキップ。セットアップ手順は入門ガイドを参照。
| 方法 | 最適な用途 | レスポンス | 複雑さ |
|---|---|---|---|
| ダイレクトAPI | 導入時、単一クエリ | 同期 | 低 |
| プロキシルーティング | 既存のHTTPワークフロー、カスタムリクエストヘッダー | 同期 | 低 |
| 非同期バッチ | 高ボリューム(1,000以上のクエリ)、ページネーションスイープ | キューイング | 中 |
| LangChain | AIエージェント、RAGパイプライン、マルチツールワークフロー | 同期 | 低 |
方法1: 直接APIリクエスト
最もシンプルな方法。検索URLをPOSTリクエストで送信し、構造化データを取得します:
import requests
import json
from urllib.parse import urlencode
# 適切なエンコーディングでGoogle検索URLを構築(非ラテン文字や特殊文字に対応)
params = urlencode({"q": "ウェブスクレイピング API", "gl": "us", "hl": "en", "brd_json": "1"})
search_url = f"https://www.google.com/search?{params}"
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer <API_TOKEN>"
}
payload = {
"ゾーン": "<ゾーン名>",
"url": search_url,
"format": "raw"
}
response = requests.post(url, headers=headers, json=payload, timeout=30)
response.raise_for_status()
data = response.json()
# 処理前にレスポンスを検証
if "organic" not in data or len(data.get("organic", [])) == 0:
print("警告: オーガニック検索結果が返されませんでした (ソフトブロックまたは空のSERPの可能性あり)")
print(json.dumps(data, indent=2))デフォルトのゾーン名は通常「serp」です。パースされたレスポンスは以下のように返されます:
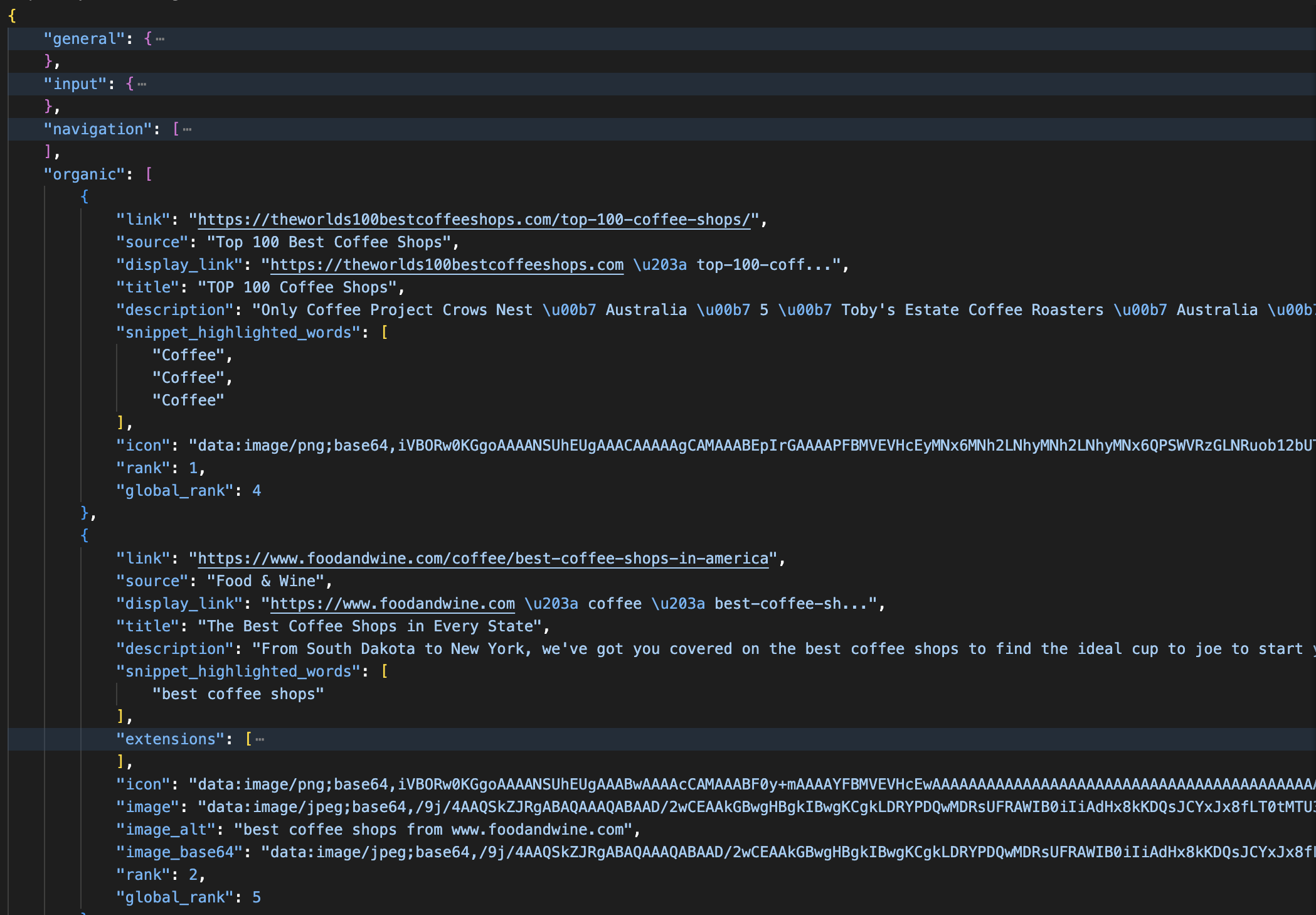
SERP APIからの解析済みJSONレスポンス: 各オーガニック結果にはtitle、link、description、rank、global_rankフィールドが含まれます。また広告、ナレッジパネル、AI概要は別セクションに分類されます。
Direct APIは「data_format」ボディフィールド(「format」とは別)も受け付けます:LLM/RAG(検索強化生成)パイプライン用「markdown」、PNGキャプチャ用「screenshot」、上位10件の自然検索結果のみ用「parsed_light」。JSON内に生のHTMLを保持したい場合はURLで`brd_json=html`を使用してください。
ボディ
内のcountryとURLのglは異なります。「country」:「us」はプロキシ出口ノード(リクエストのIP位置)を制御します。gl=usはGoogleに表示する国を指示します。正確な地域ターゲティング結果を得るには、両方を設定してください。
方法2: プロキシルーティング
リクエストをBright Dataのプロキシインフラ経由でルーティングします。 プロキシ側でJavaScriptレンダリングを処理するため、標準的なHTTPリクエストを送信しても完全にレンダリングされた結果が返されます。あらゆるHTTPクライアントで動作し、Direct APIでは利用できないカスタムヘッダー、クッキー、リクエストレベルの設定が可能です。プロキシアプローチではURLパラメータで出力形式を制御します:生のHTMLではなくパース済みJSONを取得するにはbrd_json=1を追加:
import requests
# セッションで接続プール化(リクエスト間でTCP接続を再利用)
session = requests.Session()
session.proxies = {
"http": "http://brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD>@brd.superproxy.io:33335",
"https": "http://brd-customer-<CUSTOMER_ID>-ゾーン-<ゾーン名>:<パスワード>@brd.superproxy.io:33335"
}
session.verify = False # テスト用。本番環境ではBright DataのTLS/SSL証明書を読み込む
url = "https://www.google.com/search?q=SERP API+comparison&gl=us&hl=en&tbs=qdr:m&brd_json=1"
response = session.get(url, timeout=30)
response.raise_for_status()
print(response.json())認証情報はダッシュボードのSERP APIゾーン「アクセス詳細」タブに記載されています。処理前に必ずレスポンスを検証してください。Googleのソフトブロックは、空または結果が減少した有効なJSONを返す場合があります。general.results_cntが数百万件の推定結果を示すにもかかわらず、organic配列が空または1~2件しか含まれていない場合、通常は真の空SERPではなくソフトブロックを示しています。
verify=Falseフラグ(またはcurlの-kオプション)はTLS/SSL検証をスキップします。テスト環境では問題ありませんが、本番環境ではBright DataのSSL証明書を読み込んでください。
方法3 非同期バッチ処理
高ボリューム操作(1,000件以上のクエリ)には非同期モードを使用してください。非同期モードは、start/gl/hlパラメータを使用して数百のキーワード+ロケーションの組み合わせをページングする場合(例:10カ国で500キーワードを追跡)に有効です。課金対象はリクエスト送信時のみで、レスポンス収集は無料です。コールバック時間はボリュームとピーク負荷により変動します。
まず、ゾーンの「詳細設定」で「非同期リクエスト」トグルを有効化します。その後、/unblocker/reqエンドポイントを使用します:
import requests
import json
import time
url = "https://api.brightdata.com/unblocker/req"
params = {"customer": "<CUSTOMER_ID>", "ゾーン": "<ゾーン_名>"}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer <API_TOKEN>"
}
payload = {
"url": "https://www.google.com/search?q=ウェブスクレイピング+ツール&gl=us&hl=en&brd_json=1",
"country": "us"
}
response = requests.post(url, params=params, headers=headers, json=payload, timeout=30)
response.raise_for_status()
response_id = response.headers.get("x-response-id")
print(f"キュー登録済み。レスポンスID: {response_id}")
# 結果をポーリング(本番環境では代わりにゾーン設定でWebhook URLを設定)
# 総ポーリング時間: 30回 × 10秒 = 300秒。大量バッチの場合はrange()を拡大。
for attempt in range(30):
time.sleep(10) # チェック前の待機 - 結果は即時準備されない
result = requests.get(
"https://api.brightdata.com/unblocker/get_result",
params={"customer": "<CUSTOMER_ID>", "ゾーン": "<ゾーン_名>", "response_id": response_id},
headers={"Authorization": "Bearer <API_TOKEN>"},
timeout=30
)
if result.status_code == 200:
data = result.json()
if "organic" in data and len(data["organic"]) > 0:
print(json.dumps(data, indent=2))
else:
print("警告: レスポンスは返されたが、オーガニック検索結果を含んでいない")
break
elif result.status_code == 202:
continue # 結果はまだ準備できていない
else:
print(f"response_id={response_id} の待機中に 300 秒でタイムアウトしました")ポーリングの代わりに、Webhook URLを設定できます(ゾーンの設定のデフォルトとして、またはリクエストごとにwebhook_urlパラメータを使用して)。Bright Dataは結果が準備できた際に通知をエンドポイントに送信します(response_idとステータス付き)。これにより/get_resultエンドポイントを手動でポーリングする必要はありません。応答は最大48時間保存されます。
マネージドAPIを利用する場合でも、ゾーンのレート制限を遵守してください。デフォルト設定では高スループットに対応していますが、ペース調整なしに数千の同時同期リクエストを送信するとHTTP 429応答が発生する可能性があります。非同期モードではAPIが内部でリクエストをキューイングしペース調整するため、この問題を回避できます。
方法4: AIワークフロー向けLangChain統合
ライブ検索データを必要とするAIエージェントを構築する場合、公式のLangChain統合(langchain-brightdata)を利用できます。これによりエージェントワークフロー内でライブ検索をツールとして活用可能です:
pip install langchain-brightdatafrom langchain_brightdata import BrightDataSERP
serp_tool = BrightDataSERP(
bright_data_api_key="<API_TOKEN>",
zone="<ZONE_NAME>", # Bright Dataダッシュボードのゾーン名と一致させる必要あり
search_engine="google",
country="us",
language="en",
results_count=10,
parse_results=True)
# この特定のリクエスト用にコンストラクタのデフォルト値を上書き:
results = serp_tool.invoke({
"query": "best web scraping tools 2026",
"country": "de",
"language": "de",
"search_type": "shop",
"device_type": "mobile",
})この統合で注意すべき点:
results_count は内部的に Google のnumにマッピングされます。num は機能しなくなったため(num のセクションを参照)、10 を超える値は効果がありません。countryとlanguageはそれぞれglとhlにマッピングされます(どの国の結果を、どの言語で取得するか)。Direct API では「country」がプロキシ出口ノードを制御しますが、LangChain はプロキシルーティングを自動的に処理します。ゾーンはデフォルトで"serp"になります。ゾーン名が異なる場合(例:"serp_api1")、明示的に設定しないと “zone not found” エラーが発生します。
LangChain以外の統合ガイドについては、CrewAI、AWS Bedrock、Google Vertex AIを参照してください。検索以外のデータ収集については、BrightDataのAIウェブアクセスツールを参照してください。
全パラメータ一覧:SERP API ドキュメント
管理型 SERP API を利用する理由
SERP APIはJavaScriptレンダリング、プロキシローテーション、CAPTCHAの解決、地域ターゲティングを処理します:
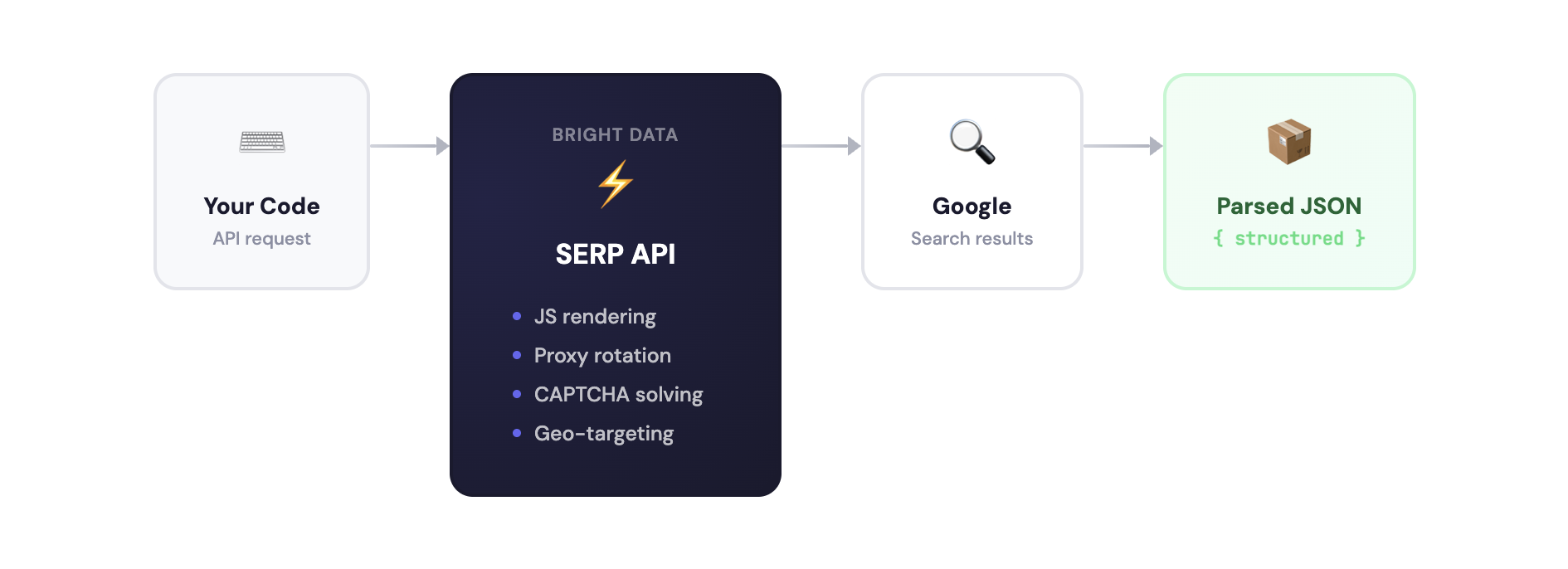
Playwright、Selenium、またはBrightDataのBrowser APIで独自に構築することも可能です。ただしGoogleスクレイパーの維持には、CAPTCHA処理、IPブロック回避、レジデンシャルプロキシ、JavaScriptレンダリング、そしてGoogleがマークアップを更新するたびに破綻するHTMLパースが必要です。両アプローチの比較については「マネージド vs APIベースのスクレイピング」を参照してください。
SERP APIでは、検索URLを送信すると構造化されたJSONが返されます。Google、Bing、DuckDuckGo、Yandexなどに対応しています。現在の料金は価格ページをご覧ください。
SERP API Playgroundではコードなしで基本検索を実行でき、Postmanワークスペースには事前構築済みリクエストが用意されています。Playgroundはこちら:
プレイグラウンドのUI:検索エンジン・国・言語を選択し、クエリを入力すると、右側にパース済みJSONレスポンスが表示されます。
上記例を実行するにはアカウント作成が必要です(新規アカウントにはテスト用無料クレジットが付与されます)。
実世界のユースケース
これらのパラメータの組み合わせは、本番環境のスクラッピングワークフローで繰り返し登場します。
SEO順位追跡
q,gl,hl,pws=0,udm=14,start を組み合わせて地域別キーワード順位を追跡:
# 米国、英国、ドイツにおける「ウェブスクレイピングツール」の順位を確認
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=ウェブスクレイピング+ツール&gl=us&hl=en&pws=0&udm=14&brd_json=1"
# 次にgl=gbとgl=deで繰り返す
# start=10, start=20で1ページ目以降の順位を確認v0とSERP APIを使ったSEOランクトラッカーの構築方法については、完全な手順解説を参照してください。
競合他社の広告モニタリング
競合他社の広告掲載位置は日々変化します。ブランド用語とtbs=qdr:d を組み合わせて最近の変更を確認しましょう:
https://www.google.com/search?q=competitor+brand+name&gl=us&hl=en&tbs=qdr:d&brd_json=1JSONレスポンスでは、top_ads、bottom_ads、popular_products(商品リスト広告)が自然検索結果から分離されます。
価格比較とeコマースインテリジェンス
市場横断的な価格比較には、tbm=shopを維持したままgl値を変更してください:
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=us&brd_json=1
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=gb&brd_json=1
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=de&brd_json=1ニュース監視と感情分析
https://www.google.com/search?q=openai&tbm=nws&tbs=qdr:h&filter=0&brd_json=1。ニュース監視にはtbm=nws、過去1時間分にはtbs=qdr:h、類似記事のクラスタリング防止にはfilter=0 を指定。毎時監視のためcronジョブで実行。
AIを活用した検索とRAGアプリケーション
SERP APIを検索層として活用し、LLMアプリケーションをライブ検索データに基盤化。LangChain統合(上記方法4)、MCPサーバー、直接API呼び出しのいずれも有効。動作例については「SERP APIを用いたRAGチャットボット構築方法」を参照。
ローカルSEOと複数拠点モニタリング
都市間でローカルランキングが大きく異なる場合があります。比較にはglオプションとpws=0を指定したuuleを使用:
# 3都市における「近くの配管工」の順位確認
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=plumber+near+me&uule=Chicago,Illinois,United+States&gl=us&pws=0&brd_json=1"
# uule=Miami,Florida,United+States および uule=Seattle,Washington,United+States で繰り返し各地域でスナックパック(ローカル3パック)とオーガニック検索結果を比較し、改善が必要なリスティングを特定します。
学術研究および市場調査
https://www.google.com/search?q=site:arxiv.org+large+language+models&lr=lang_en&tbs=cdr:1,cd_min:01/01/2025,cd_max:12/31/2025&brd_json=1site:とlrおよび日付範囲tbsフィルターを組み合わせて、焦点を絞った調査データセットを構築します。arxiv.orgをscholar.google.com、pubmed.ncbi.nlm.nih.gov、または任意のドメインに置き換えてください。
結論
上記すべてから実際に重要な点:
- 市場を跨いだ一貫性のある非パーソナライズドなランク追跡には
gl+hl+pws=0+udm=14を採用 numは廃止。ページネーションにはstartを使用、またはBright DataのTop 100エンドポイントで一括取得udm=14 はAI 概要を除外し、従来のオーガニック検索結果を返します。udm はtbmに追加モードを拡張しますtbsは時間フィルタリング、日付ソート(sbd:1)、完全一致検索(li:1)を処理する- 特殊文字はURLエンコードが必要です。
ibp=htl%3Bjobsのセミコロンは、非ラテン文字クエリと並んで最も一般的なエンコードミスです
Googleはこれらのパラメータを頻繁に変更します。numは予告なく削除され、startも同様の変更や、udm優先でtbmが廃止される可能性があります。意味のある規模でスクレイピングを行う場合、Bright DataのSERP APIがレンダリング、ローテーション、パースを処理します。上記の例で試してみてください。
次のステップ
ユースケースに基づく推奨文献:
今すぐGoogleのスクレイピングを始めたい場合:
- PythonでGoogle検索結果をスクレイピングする方法:動作するコード付き完全チュートリアル
- Google AI概要のスクレイピング方法:AI生成サマリーの抽出
- Google AIモードのスクレイピング方法:対話型AI検索のスクレイピング
AIアプリケーションを構築する場合:
- SERP APIでRAGチャットボットを構築:LLM応答をリアルタイム検索データで強化
- v0とSERP APIでSEOランクトラッカーを構築:ステップバイステップ解説
- GEO & SEO AIエージェント:AI搭載検索エンジン向けにコンテンツを最適化
- CrewAIとSERP API:マルチエージェントAIワークフロー
SERP APIプロバイダーを評価する場合:
- 2026年最高のSERPおよびWeb検索API:主要プロバイダーの比較
- マネージド vs APIベースのスクレイピング:マネージドサービスとAPIベース手法の比較
その他のGoogleデータソース:
- Googleトレンドデータのスクレイピング方法
- 最高のホテルデータプロバイダー:ホテルデータ収集サービスの比較
- 最良のフライトデータプロバイダー:フライトデータ収集サービスの比較
外部参照:
- Google検索の絞り込み: 検索クエリを絞り込むGoogle公式ガイド
参考文献:
よくある質問
Google検索パラメータとは何ですか?
Google検索パラメータとは、https://www.google.com/search?URLに追加されるキーと値のペアであり、検索結果の生成および表示方法を制御します。例えば、q=pizza は検索クエリを設定し、gl=usは米国をターゲットとし、hl=enはインターフェース言語を英語に設定します。これらはURL内の? の後に&で区切られて続きます。
Google検索におけるglとhlの違いは何ですか?
glパラメータは地理的位置(検索の発信元と見なされる国)を制御し、表示される結果に影響を与えます。hlパラメータはホスト言語(Google インターフェースの言語)を制御します。例えば、gl=de&hl=enとすると、ドイツに関連する結果が表示されますが、インターフェースは英語で表示されます。
Googleのnumパラメータは廃止されましたか?
廃止されただけでなく、まったく機能しません。Googleは2025年9月12日から14日の間にこれを無音で無効化しました。num=100を指定しても何も起こらず、Googleは常に10件の結果を返します。ページネーションにはstartを使用するか、BrightDataのWebスクレイパーAPI Top 100エンドポイントを使用して1回のリクエストで1~100位を取得してください。
Googleのudmパラメータとは何ですか?
udmはおそらくUserDisplay Mode(ユーザー表示モード)の略称です(コミュニティによるリバースエンジニアリングに基づく推測。Googleは正式な略称を認めていません)。主にudm=14を使用します。これはAI概要を非表示にし、従来の自然検索結果を返します。その他の値にはudm=2(画像)、udm=39(ショート動画)、udm=50(AIモード)があります。ud m はtbmに追加モードを拡張するもので、両方が依然として機能します。全値はudmセクションに記載されています。
tbmとudm の違いは?
tbmは古いパラメータ、udmは新しい拡張機能です。画像・ニュース・ショッピングでは機能がかぶります(tbm=isch≈udm=2)。ただしudm にはtbmがサポートしない機能(AIモード:udm=50、フォーラム:udm=18、ショート動画:udm=39)が含まれます。現在両方が動作します。 新規コードはudm向けに構築し、tbmはフォールバックとして維持してください。
numパラメータが廃止された現在、Google検索結果のページネーションはどうすればよいですか?
startパラメータを使用します。start=0(または省略)で1~10件目、start=10で11~20件目…と表示されます。各ページは10件の結果を返します。単一リクエストで1~100件目を取得するには、Bright DataのTop 100エンドポイントにstart_pageと end_pageパラメータを指定します。
Google検索結果を日付でフィルタリングするには?
tbsパラメータを使用します。tbs=qdr:h= 過去1時間、tbs=qdr:d= 過去1日、tbs=qdr:w= 過去1週間、tbs=qdr:m= 過去1ヶ月、tbs=qdr:y= 過去1年。 カスタム日付範囲の場合:tbs=cdr:1,cd_min:MM/DD/YYYY,cd_max:MM/DD/YYYY。関連性ではなく日付順に並べ替えるにはtbs=sbd:1を追加してください。
Google検索結果をブロックされずにスクレイピングするには?
大規模なGoogleスクレイパーを維持するには、Googleがマークアップを変更するたびにHTMLパーサーを更新し、CAPTCHAの解決を行い、IPをローテーションし、2025年1月以降のリクエストごとにJavaScriptをレンダリングする必要があります。マネージドSERP APIはこのインフラストラクチャを処理します。URLを送信すると構造化されたJSONが返され、パーサーの維持は不要です。





