

Google AIモードは、検索結果の表示方法の根本的な転換を意味し、複数のソースからの情報を合成する会話型のAIを搭載した応答を提供します。デジタルプレゼンスを追跡する企業、競合情報チーム、SEOの専門家にとって、この新しい検索形式はデータ抽出の機会と課題の両方を生み出します。
この包括的なガイドでは、Google AIモードとは何か、このデータのスクレイピングが戦略的なビジネス価値をもたらす理由、直面する技術的課題、そしてこの情報を効率的に抽出するための手動と自動の両方のアプローチについて説明します。
Google AIモードとは?
Google AIモードは、Googleの新しい検索エクスペリエンスであり、合成された会話形式の回答を検索結果の上部に表示し、ユーザーがフォローアップの質問を自然に行えるようにします。各回答には目立つソースリンクが含まれており、基本的なコンテンツに簡単にジャンプすることができる。
AIモードは、「クエリファンアウト」アプローチを使用して、Googleの検索システムとともにGeminiを活用している。このテクニックは、質問をサブトピックに分割し、関連する複数の検索を並行して実行することで、従来の単一のクエリよりも関連性の高い情報を表示する。
以下は、Google AIモードが検索クエリに回答した例で、引用元(右側)が表示されているため、ユーザーはクリックしてさらに詳細を確認することができます:
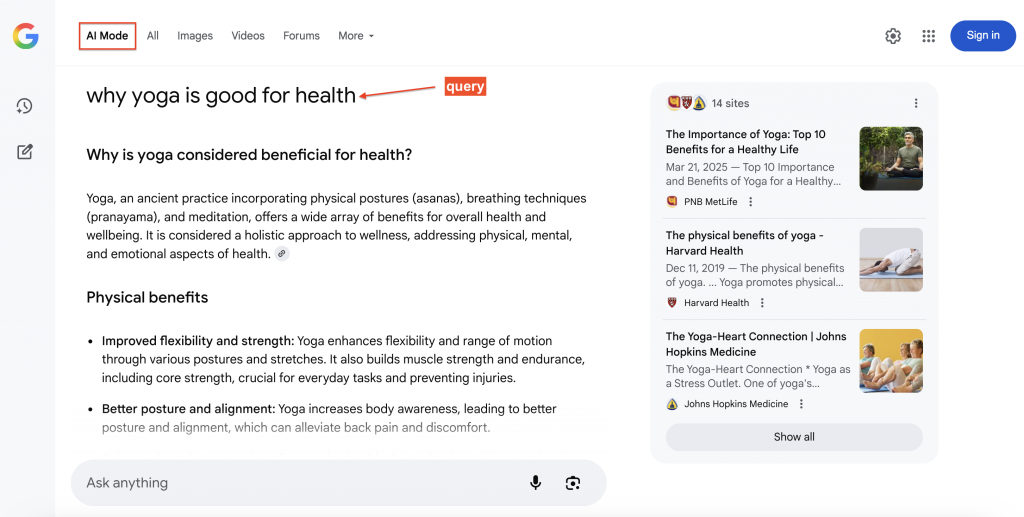
なぜGoogle AI Modeデータをスクレイピングするのか?
Google AI Modeのデータは、SEO、製品開発、競合調査に大きな影響を与える測定可能なインサイトを提供します。
- 引用シェア追跡。ターゲットクエリに対してGoogle AIがどのドメインを参照しているかを、ランキング順位や時系列での頻度も含めて監視します。これは、トピックのオーソリティを示し、コンテンツの改善がAIレスポンスのインクルージョンの増加につながるかどうかを測定するのに役立ちます。
- 競合情報。レコメンデーションや比較クエリに表示されるブランド、製品、場所を把握します。これにより、市場のポジショニング、競争力、AI回答が強調する属性が明らかになります。
- コンテンツギャップ分析。AIモードの回答における重要な事実を既存のコンテンツと比較し、引用を獲得するFAQ、ガイド、データ表などの構造化コンテンツを作成する機会を特定します。
- ブランドモニタリング。AIが生成したブランドや業界に関する回答をレビューして、古い情報を特定し、それに応じてコンテンツを更新します。
- 研究開発。AIモードの応答をメタデータ(タイムスタンプ、場所、エンティティ)と一緒に保存し、社内のAIシステムに燃料を供給し、研究チームをサポートし、RAGアプリケーションを強化します。
方法 1 – ブラウザ自動化による手動スクレイピング
GoogleのAIモードをスクレイピングするには、AIが生成するコンテンツが動的でJavaScriptを多用するため、高度なブラウザ自動化が必要です。Playwright、Selenium、またはPuppeteerのようなブラウザ自動化フレームワークは、JavaScriptを実行し、コンテンツがロードされるのを待ち、人間のブラウジング体験を再現するために実際のブラウザエンジンを使用します。
GoogleのAIモードが検索結果にどのように表示されるかを示します:
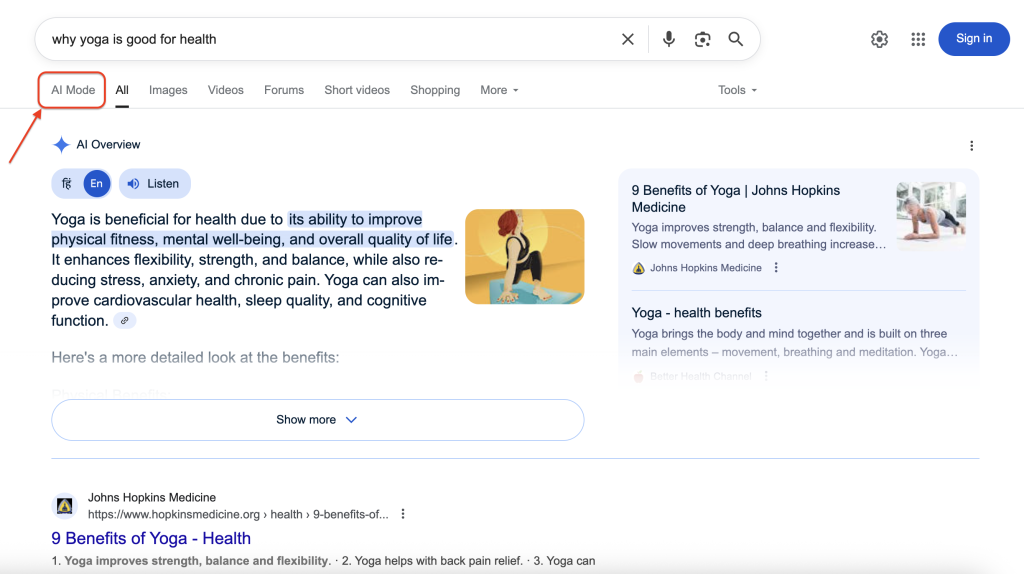
AIモードをクリックすると、詳細な回答とソースの引用を含む完全な会話インターフェースが表示されます。私たちの目標は、このリッチで構造化された情報にプログラムでアクセスし、抽出することです。
ステップ1 – 環境のセットアップと前提条件
最新バージョンのPythonをインストールし、必要な依存関係をインストールする。このチュートリアルでは、ターミナルで以下のコマンドを実行してPlaywrightをインストールする:
pip install playwright
playwright インストールこのコマンドはPlaywrightをインストールし、必要なブラウザバイナリ(自動化に必要なブラウザ実行ファイル)をダウンロードします。
ステップ2 – 依存関係のインポートとセットアップ
スクレイピングタスクに不可欠なライブラリをインポートする:
インポート asyncio
import urllib.parse
from playwright.async_api import async_playwrightライブラリの内訳
- asyncio– パフォーマンスの向上と並行処理のための非同期プログラミングを可能にする。
- urllib.parse– URL エンコーディングを処理し、クエリが Web リクエスト用に適切にフォーマットされるようにします。
- playwright– 人間のユーザーのようにGoogleと対話するためのブラウザ自動化機能を提供。
ステップ3 – 関数のアーキテクチャとパラメータ
メインのスクレイピング関数を明確なパラメータと戻り値で定義する:
async def scrape_google_ai_mode(query: str, output_path: str = "ai_response.txt") -> bool:関数のパラメータ
- query– Google AI Mode に送信する検索語。
- output_path– レスポンスの保存先ファイル (デフォルトは “ai_response.txt”).
- コンテンツ抽出の成功(True)または失敗(False)を示すブール値を返します。
ステップ4 – URLの作成とAIモードの有効化
GoogleのAIモード・インターフェースを起動する検索URLを構築する:
url = f "https://www.google.com/search?q={urllib.parse.quote_plus(query)}&udm=50"主要なコンポーネント
- urllib.parse.quote_plus(query)– 検索クエリを安全にエンコードし、スペースを’+’に変換し、特殊文字をエスケープする。
- udm=50– GoogleのAIモード・インターフェースを有効にする重要なパラメーター。
ステップ5 – ブラウザの設定と検知防止
現実的な動作を維持しながら、検出を回避するように設定されたブラウザ・インスタンスを起動する:
async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False, args=["--disable-blink-features=AutomationControlled"])
)
page = await browser.new_page(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36(KHTML、Geckoのような) "
"Chrome/120.0.0.0 Safari/537.36"
)設定の詳細
- headless=False– デバッグ用にブラウザウィンドウを表示します(本番環境ではTrueに設定)。
- -disable-blink-features=AutomationControlled– 自動検出インジケータを削除します。
- ユーザーエージェント– macOS上の正規のChromeブラウザを模倣し、ボット検出の可能性を低減します。
これらの検知防止策により、スクレイパーは自動化されたスクリプトではなく、Googleをブラウズしている通常のユーザーのように見える。
ステップ6 – ナビゲーションと動的コンテンツの読み込み
構築されたURLに移動し、動的コンテンツが完全にロードされるのを待つ:
await page.goto(url, wait_until="networkidle")
await page.wait_for_timeout(2000)ロード戦略の説明:
- wait_until=”networkidle“(ネットワークアイドル) – ネットワークの動きが止まるまで待ちます。
- wait_for_timeout– AIコンテンツ生成のための追加バッファ。
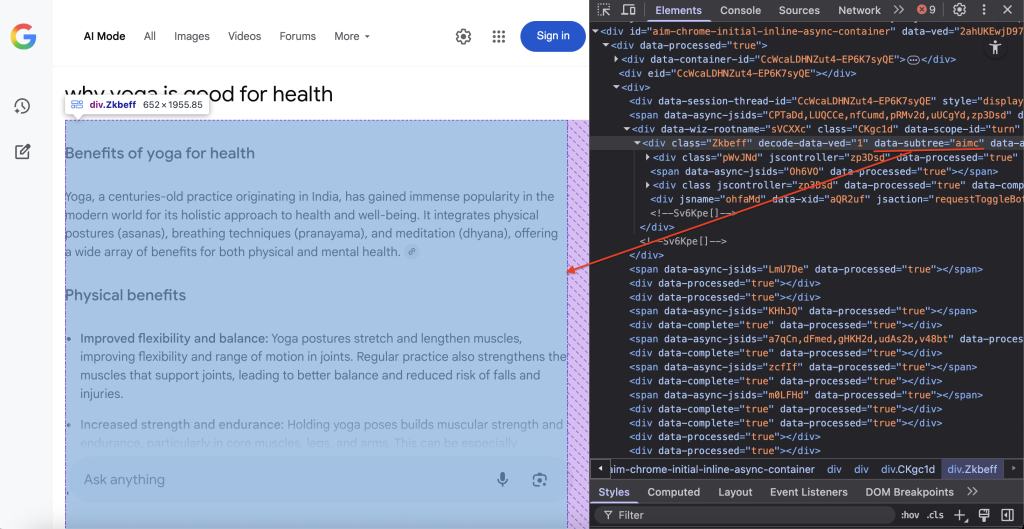
ステップ7 – コンテンツの位置とDOM抽出
グーグルのAIモード・コンテンツを格納する特定のDOMコンテナを見つける:
container = await page.query_selector('div[data-subtree="aimc"]')CSSセレクタdiv[data-subtree=”aimc”]は、グーグルのAIMC(AIモードコンテナ)をターゲットにしている。
ステップ8 – データの抽出と保存
テキストコンテンツを抽出し、指定されたファイルに保存します:
if container:
text = (await container.inner_text()).strip()
if text:
with open(output_path, "w", encoding="utf-8") as f:
f.write(text)
print(f "Saved AI response to '{output_path}' ({len(text):,}文字)")
await browser.close()
真を返す
else:
print("AIモードコンテナが見つかりましたが、内容が含まれていません。")
else:
print("ページ上でAIモードのコンテンツが検出されませんでした。")
await browser.close()
False を返す処理の流れ
- DOMクエリを使用して、ページ上にAIコンテナが存在することを確認する。
- inner_text()を使用して、HTMLマークアップなしのプレーン・テキスト・コンテンツを抽出する。
- コンテンツをUTF-8エンコーディングで指定されたファイルに保存する。
- メモリ・リークを防ぐために、ブラウザ・リソースを適切に閉じる。
ステップ9 – スクレイピング関数を実行する
希望するクエリーで関数を呼び出して、完全なスクレイピング処理を実行します:
if __name__ == "__main__":
asyncio.run(scrape_google_ai_mode("Why yoga is good for health"))完全なコード
以下は全てのステップを組み合わせた完全なコードです:
インポート asyncio
import urllib.parse
from playwright.async_api import async_playwright
async def scrape_google_ai_mode(
query: str, output_path: str = "ai_response.txt".
) -> bool:
url = f "https://www.google.com/search?q={urllib.parse.quote_plus(query)}&udm=50"
async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False, args=["--disable-blink-features=AutomationControlled"])
)
page = await browser.new_page(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36(KHTML、Geckoのような) "
"Chrome/139.0.0.0 Safari/537.36"
)
await page.goto(url, wait_until="networkidle")
await page.wait_for_timeout(1000)
コンテナ = await page.query_selector('div[data-subtree="aimc"]')
if container:
text = (await container.inner_text()).strip()
if text:
with open(output_path, "w", encoding="utf-8") as f:
f.write(text)
print(
f "Saved AI response to '{output_path}' ({len(text):,}文字)"
)
await browser.close()
真を返す
else:
print("AIモードコンテナが見つかりましたが、空です。")
else:
print("AIモードのコンテンツが見つかりません。")
await browser.close()
偽を返す
if __name__ == "__main__":
asyncio.run(scrape_google_ai_mode("Why yoga is good for health"))正常に実行されると、このスクリプトは抽出されたAIレスポンスを含むテキストファイルを作成します:

よくやった!グーグルAIモードのコンテンツのスクレイピングに成功した。
手動スクレイピングの課題と限界
手作業によるスクレイピングには、運用上の大きな課題がつきまとうが、それは規模が大きくなるほど顕著になる。
- アンチボット検出とCAPTCHA検証。Googleは、自動化されたトラフィックパターンを識別する高度な検出メカニズムを実装しています。限られた数のリクエストの後、システムはCAPTCHA検証をトリガーし、それ以上のデータ収集を効果的にブロックする。
- インフラとメンテナンスの複雑さ。大規模な運用を成功させるには、ブロックされないようにするためのさまざまなテクニックが必要です。たとえば、高品質な家庭用プロキシネットワーク、ユーザーエージェントのローテーション、ブラウザのフィンガープリント回避、洗練されたリクエスト配信戦略などです。これにより、多大な技術的オーバーヘッドと継続的なメンテナンスコストが発生します。
- 動的なコンテンツとレイアウトの変更。Googleは頻繁にインターフェース構造を更新するため、既存のパーサーが一晩で壊れてしまう可能性があり、機能を維持するために早急な対応とコードの更新が求められます。
- 解析の複雑さ。AIモードのレスポンスには、高度な解析ロジックを必要とする入れ子構造、動的引用、可変フォーマットが含まれています。さまざまなタイプの応答で精度を維持するには、広範なテストとエラー処理が必要です。
- スケーラビリティの制限。手作業によるアプローチでは、一括処理、同時リクエスト管理、地理的地域や検索バーティカルにまたがる一貫したパフォーマンスに苦労する。
これらの限界は、多くの組織が複雑さを専門的に処理する特別なソリューションを好む理由を浮き彫りにしています。そこで、Bright DataのGoogle AI Mode Scraper APIをご紹介します。
方法2 – Google AIモードスクレーパーAPI
Bright DataのGoogle AI Mode Scraper APIは、エンタープライズグレードの信頼性とパフォーマンスを提供しながら、スクレイピングインフラストラクチャを維持する複雑さを排除するプロダクションレディのソリューションを提供します。このAPIは、回答HTML、回答テキスト、添付リンク、引用、および12の追加フィールドを含む包括的なデータポイントを抽出します。
主な機能
- 自動化されたアンチボットとプロキシ管理。APIは、高度なアンチボット回避技術と組み合わせた、1億5000万以上のIPアドレスからなるBright Dataの広範なレジデンシャルプロキシネットワークを活用しています。このインフラストラクチャーにより、CAPTCHAの遭遇やIPブロックの心配がなくなります。
- 構造化されたデータ出力。APIは、柔軟な統合オプションのために、JSON、NDJSON、CSVを含む複数のエクスポート形式で一貫してフォーマットされたデータを提供します。
- エンタープライズグレードのスケーラビリティ。APIは大量のクエリーを効率的に処理し、成功報酬型の価格設定モデルにより、予測可能なコスト削減を実現します。
- 地理的なカスタマイズ。地域固有の結果を得るために対象国を指定することで、異なる市場やユーザー層でAIの回答がどのように異なるかを理解できます。
- メンテナンス不要の運用。当社のチームが継続的に監視し、Googleの変更にスクレーパーを適応させます。GoogleがAIモードのインターフェイスを変更したり、新しいアンチボット対策を実装した場合、開発チームが何もしなくても、アップデートが自動的に展開されます。
その結果、包括的なGoogle AIモードのデータ抽出が、企業の信頼性とインフラストラクチャーのオーバーヘッドなしに実現します。
Google AI Mode Scraper APIを使い始める
導入プロセスでは、新規Bright DataユーザーのアカウントセットアップとAPIキー生成を行い、次にご希望の統合方法を選択します。無料のBright Dataアカウントを作成し、4つの簡単なステップでAPI認証トークンを生成します。
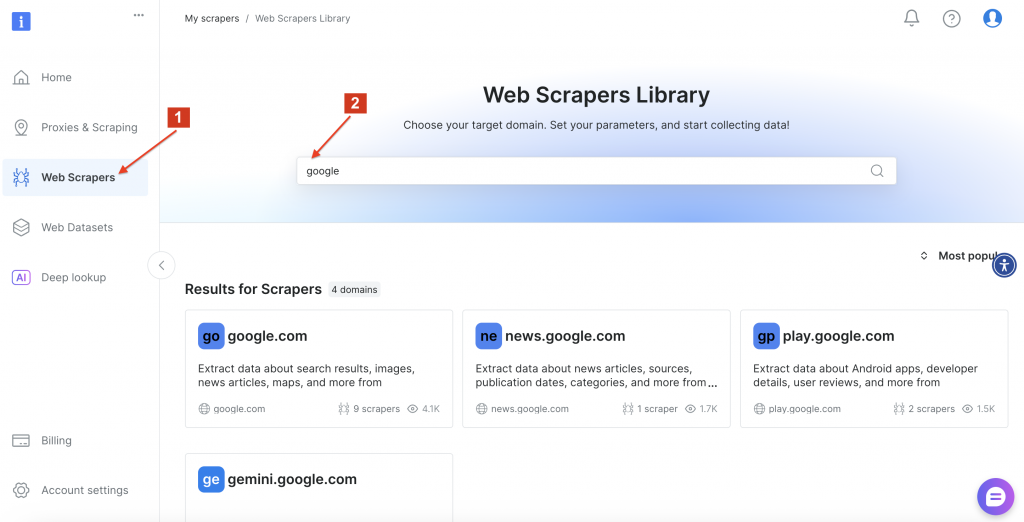
その後、Bright DataWeb Scrapers Libraryに移動し、”google “を検索して利用可能なスクレーパーオプションを探します。google.com” をクリックします。
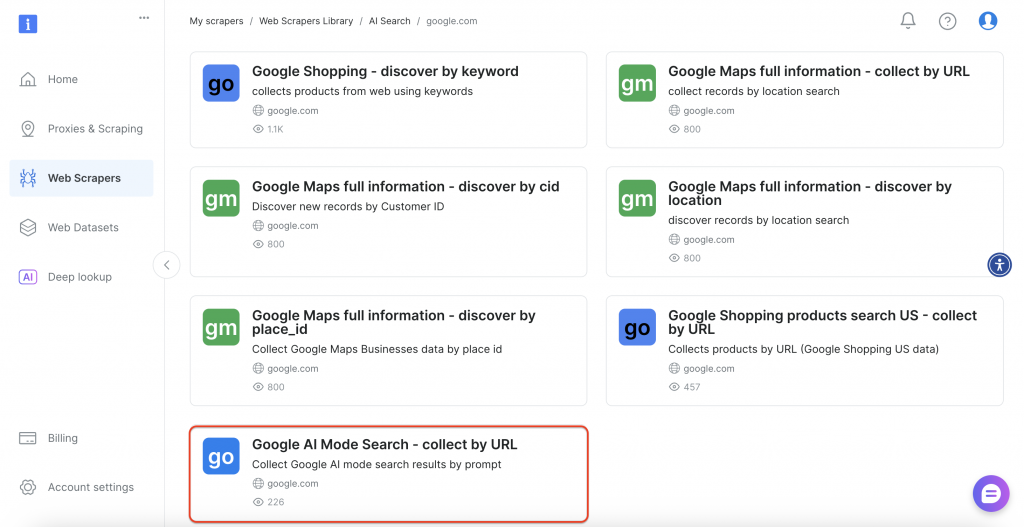
次に、インターフェースから「Google AI Mode Search」オプションを選択します。
このスクレイパーは、異なる技術要件やチームの能力に対応するために、コードなしとAPIベースの両方の実装方法を提供している。
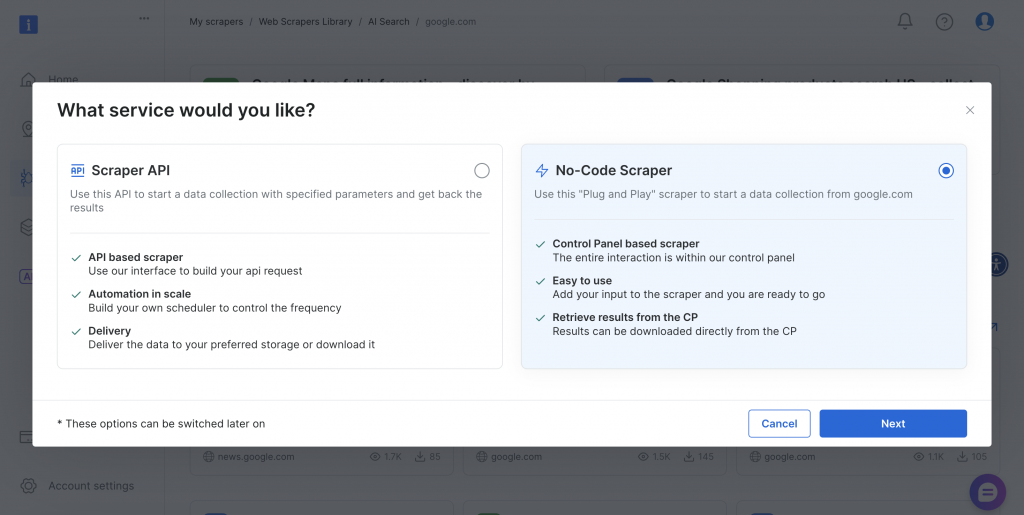
両方のアプローチを試してみよう。
インタラクティブスクレイピング(ノーコードスクレイパー)
ウェブベースのインターフェイスは、コードで作業したくない人にユーザーフレンドリーなアプローチを提供する。ダッシュボードから直接検索クエリを入力することも、バッチ処理のために複数のクエリを含むCSVファイルをアップロードすることもできる。プラットフォームがすべてを自動的に処理し、結果をダウンロード可能なファイルとして提供します。
必須パラメーター
- URL– デフォルトは https://google.com/aimode に設定されています。
- プロンプト– GoogleのAI分析のための検索クエリまたは質問。
- 国– 地域固有の結果を得るための地理的位置(オプション)。
その他の設定
- 配信設定– お好みの出力形式と配信方法を選択します。
- カスタムスキーマ– エクスポートに含めるデータフィールドを選択します。
- バッチ処理– CSVアップロードにより複数のクエリを同時に処理します。
瞑想がメンタルヘルスにどのように役立つか」というプロンプトを使用して、「インド」を対象国として簡単な検索を行ってみましょう。Start collecting “ボタンをクリックして処理を開始します。
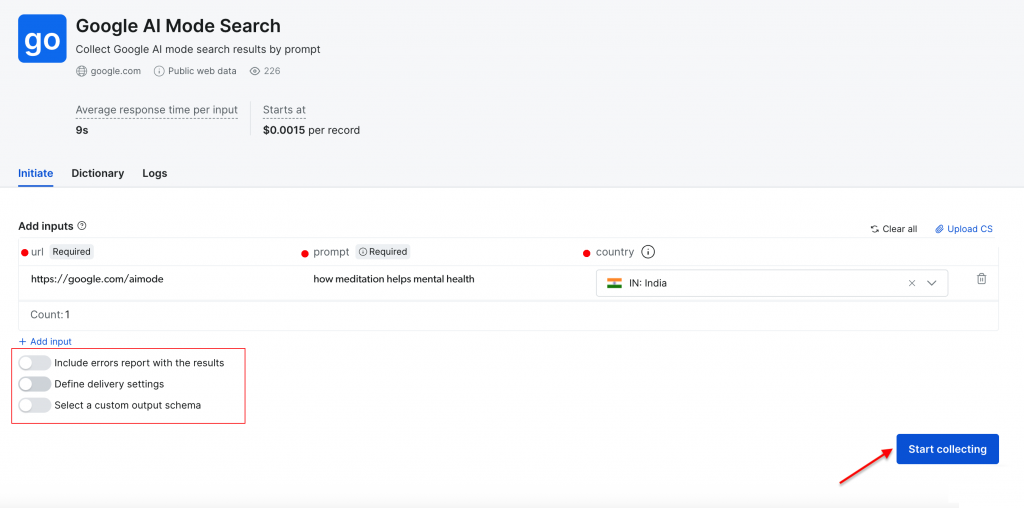
ダッシュボードはリアルタイムの進捗追跡(Ready,Running)を提供し、完了すると結果を好きなフォーマットでダウンロードできる。
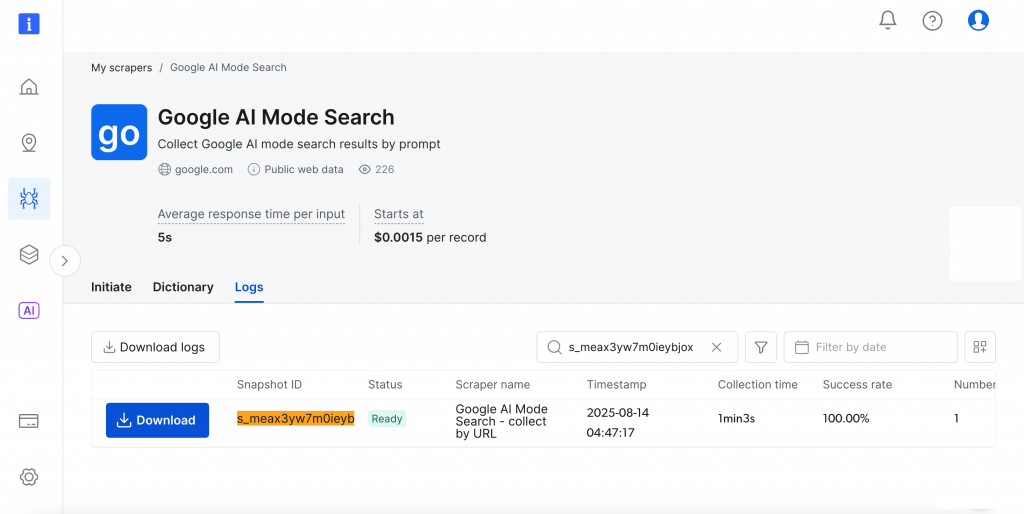
かなり素晴らしいでしょう?
APIベースのスクレイピング(Scraper API)
プログラム的アプローチは、RESTful APIエンドポイントを通して、より大きな柔軟性と自動化機能を提供します。包括的なAPIリクエストビルダーと管理インターフェイスは、スクレイピング操作の完全なコントロールを提供します:
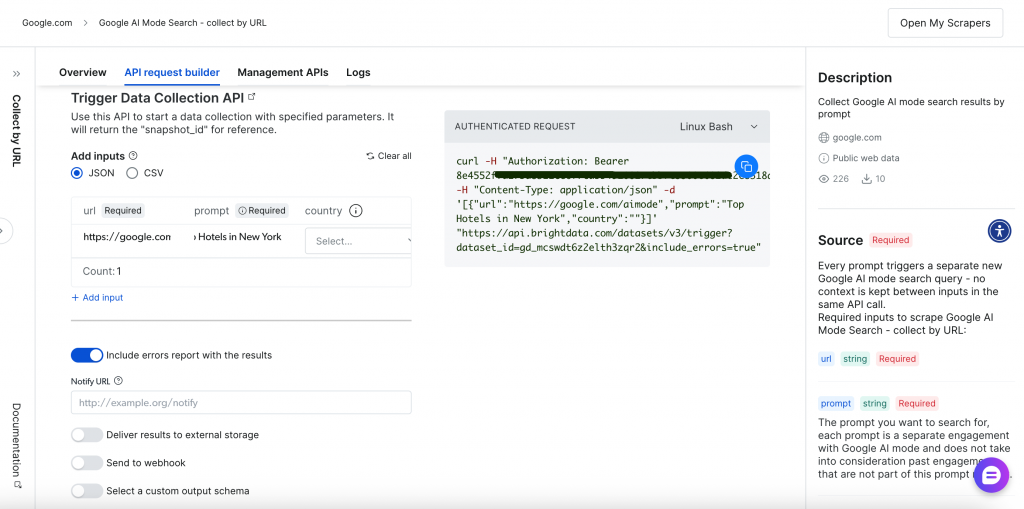
APIベースのスクレイピング・プロセスを説明しよう。
ステップ1 – データ収集のトリガー
まず、以下のいずれかの方法でデータ収集をトリガーする:
単一のクエリー実行:
curl -H "Authorization:curl -H "Authorization: Bearer <YOUR_API_TOKEN>
-H "Content-Type: application/json" ୧-͈ᴗ-͈
-d '[
{
"url":"https://google.com/aimode"、
"prompt":"コンピュータユーザーのための健康のヒント"、
"country":"US"
}
]'
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_mcswdt6z2elth3zqr2&include_errors=true"CSVアップロードで一括処理:
curl -H "Authorization:CSV アップロードの一括処理: curl -H "Authorization: Bearer <YOUR_API_TOKEN>" ¦ -F ''
-F 'data=@/path/to/your/queries.csv'
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_mcswdt6z2elth3zqr2&include_errors=true"リクエストの構成要素:
- Authentication– 安全なアクセスのためのヘッダー内のベアラートークン。
- Dataset ID– Google AI Modeスクレイパー専用の識別子。
- 入力形式– クエリパラメータを含むJSON配列またはCSVファイル。
- エラー処理– 包括的なフィードバックのためにエラーパラメータを含める。
また、自動結果処理のためにウェブフックを介して配信方法を選択することもできます。
ステップ2 – ジョブの進捗を監視する
返されたスナップショットIDを使用して、コレクションの進行状況を追跡します:
curl -H "Authorization:curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
"https://api.brightdata.com/datasets/v3/progress/<snapshot_id>"レスポンスは、データ収集中は “running “を示し、結果がダウンロード可能になると “ready “を示す。
ステップ3 – 結果のダウンロード
スナップショットの内容をダウンロードするか、指定されたストレージに配信します。完了した結果をお好みのフォーマットで取得します:
curl -H "Authorization:curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
"https://api.brightdata.com/datasets/v3/snapshot/<snapshot_id>?format=json"APIは各クエリに対して包括的な構造化データを返す:
{
"url":"https://www.google.co.in/search?q=health+tips+for+computer+users&hl=ja&udm=50&aep=11&..."、
"prompt":プロンプト": "コンピュータユーザーのための健康のヒント"、
「answer_html":"<html>...完全なHTML回答...</html>"、
「answer_text":"Health tips for computer users": "コンピューターの前で長時間過ごすと、眼精疲労、筋骨格系の痛み、運動量の低下など、さまざまな健康上の懸念が生じる可能性があります、
「links_attached": [
{
"url":"https://www.aao.org/eye-health/tips-prevention/computer-usage"、
"text": null、
"position": null:1
},
{
"url":"https://uhs.princeton.edu/health-resources/ergonomics-computer-use"、
"text": null、
"position":2
}
],
"引用": [
{
"url":"https://www.ramsayhealth.co.uk/blog/lifestyle/five-healthy-tips-for-working-at-a-computer"、
"title": null、
"description":「ラムジー・ヘルスケア
"アイコン":"https://...icon-url..."、
"ドメイン":"https://www.ramsayhealth.co.uk"、
「引用": false
},
{
"url":"https://my.clevelandclinic.org/health/diseases/24802-computer-vision-syndrome"、
"title": null、
"description":「クリーブランド・クリニック
"アイコン":"https://...icon-url..."、
"ドメイン":"https://my.clevelandclinic.org"、
「引用": false
}
],
「country":「IN"、
「answer_text_markdown":"コンピュータユーザーのための健康のヒント..."、
"timestamp":"2026-08-07T05:02:56.887Z",
"input":{
"url":"https://google.com/aimode"、
"prompt":"コンピュータユーザーのための健康のヒント"、
"country":"IN"
}
}とてもシンプルで効果的です!
このわかりやすいAPIワークフローは、どのようなアプリケーションやプロジェクトにもシームレスに統合できます。Bright Data APIリクエストビルダーは、簡単に実装できるように、複数のプログラミング言語によるコード例も提供しています。
結論
PythonとPlaywrightを使用したDIYソリューションと、Bright DataのターンキーGoogle AI Mode Scraper APIです。
アルゴリズムやインターフェースが頻繁に変更され、急速に進化する検索ランドスケープにおいて、堅牢でメンテナンスの行き届いたスクレイピングインフラを持つことは非常に貴重です。このAPIを使用することで、常に解析ロジックを更新したり、IP制限を管理したりする必要がなくなり、Googleの検索結果からAIが生成した豊富なインサイトを分析し、データから最大の価値を引き出すことに集中することができます。
次に行うこと
- Googleのデータ収集を拡大する。すでにGoogle AIモードで作業しているのですから、さらにGoogleのデータソースを探索することを検討してください。より広い範囲をカバーするために、Google AI概要のスクレイピングに関する包括的なガイドも用意しています。Google News、Maps、Search、Trends、Reviews、Hotels、Videos、Flightsに特化した機能にアクセスできます。
- リスクなしでテスト すべての主要製品には無料トライアルオプションが含まれています。また、初回入金額に応じて500ドルまでのマッチングを行っています。
- 統合ソリューションで拡張。ニーズの拡大に合わせて、Web MCPサーバーをご検討ください。このサーバーは、サイトごとにカスタム開発することなく、AIアプリケーションをWebデータに直接接続します。月間5,000リクエストの無料プランで今すぐ始めましょう!
- 準備ができたら、エンタープライズ・インフラストラクチャを。多くのチームは、あなたのような個々のプロジェクトから始め、後に大規模な運用のための堅牢なインフラストラクチャを必要とします。完全なプラットフォームは、拡張の準備が整ったときに基盤となるインフラを提供します。
次のステップがわからない?私たちのチームにご相談ください。






