





- APIベースのスクレイパー
APIリクエスト構築用インターフェース - 大規模な自動化
頻度を制御する独自のスケジューラーを構築 - 配信
データを指定のストレージに配信、またはダウンロード
- リアルタイムデータをスクレイピング API経由で
- 成果物の納品が成功した場合のみ支払いを行う
- 一括リクエスト処理(最大5,000URLまで対応)
- 結果を取得する 複数の形式で取得
世界中の20,000+人のお客様から信頼されています。

ウェブスクレイパー API
ウェブスクレイパー API ライブラリ
インフラの開発・保守の必要性を排除します。当社のWeb Scraper APIを活用し、大量のウェブデータを抽出するだけで、スケーラビリティと信頼性を確保できます。
LinkedIn people profiles
ID, Name, City, Country code, Position, About, Posts, Current company, and more.
 11K+
11K+Amazon products
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by best sellers category URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by specific category URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by specific keywords
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - find products by using upc numbers
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
LinkedIn company information
ID, Name, Country code, Locations, Followers, Employees in linkedin, About, Specialties, and more.
Instagram - Profiles
Account, Fbid, ID, Followers, Posts count, Is business account, Is professional account, Is verified, and more.
Instagram - Profiles - Collect profile information by user name
Account, Fbid, ID, Followers, Posts count, Is business account, Is professional account, Is verified, and more.
Crunchbase companies information
Name, URL, ID, Cb rank, Region, About, Industries, Operating status, and more.
Crunchbase companies information - Searching data by keyword
Name, URL, ID, Cb rank, Region, About, Industries, Operating status, and more.
Linkedin job listings information
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Linkedin job listings information - Discover new jobs by keyword
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Linkedin job listings information - Discover jobs by company URL
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Instagram - Posts
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Photos, and more.
Instagram - Posts - Collects posts from a specific URLs by using profile URL
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Photos, and more.
Google Maps full information
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - discover records by location search
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - Collect Google Maps Businesses data by place id
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - Discover new records by Customer ID
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Zillow properties listing information
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
Zillow properties listing information - Discover by custom filters - location, home type and status
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
Zillow properties listing information - Search by parameters on zillow and use the direct link as input
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
LinkedIn posts
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover user's articles by URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover posts by Profile URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover new posts company URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
X (formerly Twitter) - Posts
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - Collecting Twitter posts URLs
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - Getting x posts by array of profiles
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
TikTok - Profiles
Account id, Nickname, Biography, Awg engagement rate, Comment engagement rate, Like engagement rate, Bio link, Predicted lang, and more.
TikTok - Profiles - Discover by search URL and country
Account id, Nickname, Biography, Awg engagement rate, Comment engagement rate, Like engagement rate, Bio link, Predicted lang, and more.
Youtube - Videos posts
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Search new youtube videos by keyword
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discover videos by channel URL
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Search videos by keyword and then apply relevant video filters
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Collect YouTube posts by hashtags
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discovery records by Explore page URL
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discovery videos by podcast url
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Amazon Reviews
URL, Product name, Product rating, Product rating object, Product rating max, Rating, Author name, Asin, and more.
TikTok - Posts
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - Input specific profile URL to get posts published by it
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - Search posts by specific keyword or hashtag
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - discover new records by TikTok discover URL
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
Facebook - Pages Posts by Profile URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Indeed job listings information
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Indeed job listings information - Collect new jobs by keyword search in specific location
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Indeed job listings information - Discover jobs by company URL
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Walmart - products
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Find new products by using specific category URL
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Collects products by specific keywords
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Discover products by using sku numbers
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
TikTok Shop
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - category
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - Collect TikTok shop products by keywords search
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - discover records by shop url
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
YouTube - Channels
URL, Handle, Handle md5, Banner img, Profile image, Name, Subscribers, Description, and more.
YouTube - Channels - Collects channel by keyword related to the channel or video's of the channel
URL, Handle, Handle md5, Banner img, Profile image, Name, Subscribers, Description, and more.
Reddit- Posts
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discover Reddit posts by Subreddit URL
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discovery by keyword of Reddit posts
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discover posts by author
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Glassdoor companies overview information
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - Search for companies by keyword
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - discover new companies by input filters
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - discover by search url
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Google maps reviews
URL, Place id, Place name, Country, Address, Review id, Reviewer name, Reviews by reviewer, and more.
Instagram - Reels
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Instagram - Reels - Discover reels video from Instagram profile or direct search url
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Instagram - Reels - Collect all Reels from Instagram profiles (without the post timestamp)
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Airbnb Properties Information
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
Airbnb Properties Information - Search Airbnb by location
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
Airbnb Properties Information - Discover by search url
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
X (formerly Twitter) - Profiles
X id, URL, ID, Profile name, Biography, Is verified, Profile image link, External link, and more.
X (formerly Twitter) - Profiles - Collect profile information by user name
X id, URL, ID, Profile name, Biography, Is verified, Profile image link, External link, and more.
Glassdoor companies reviews
Overview id, Review id, Review url, Rating date, Count helpful, Count unhelpful, Employee job end year, Employee length, and more.
Booking Hotel Listings
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Booking Hotel Listings -
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Yahoo Finance business information
Name, Company id, Entity type, Summary, Stock ticker, Currency, Earnings date, Exchange, and more.
Yahoo Finance business information - Discover records by keyword
Name, Company id, Entity type, Summary, Stock ticker, Currency, Earnings date, Exchange, and more.
Instagram - Comments
URL, Comment user, Comment user url, Comment date, Comment, Likes number, Replies number, Replies, and more.
Yelp businesses overview
Business id, Yelp biz id, Name, Updates from business, Overall rating, Reviews count, Is claimed, Categories, and more.
Yelp businesses overview - Collect Yelp businesses by url
Business id, Yelp biz id, Name, Updates from business, Overall rating, Reviews count, Is claimed, Categories, and more.
Yelp businesses overview - Discover Yelp businesses by location and category, using a bounding box with recursive quad-tree splitting to bypass Yelp’s 240-result limit.
Business id, Yelp biz id, Name, Updates from business, Overall rating, Reviews count, Is claimed, Categories, and more.
pitchbook companies information
URL, ID, Company name, Company socials, Year founded, Status, Employees, Latest deal type, and more.
Facebook - Comments
URL, Post id, Post url, Comment id, User name, User id, User url, Date created, and more.
Zoominfo companies information
URL, ID, Name, Description, Revenue, Revenue currency, Revenue text, Stock symbol, and more.
Zoominfo companies information - discover records by search url
URL, ID, Name, Description, Revenue, Revenue currency, Revenue text, Stock symbol, and more.
Amazon sellers info
Seller id, URL, Seller name, Description, Detailed info, Stars, Feedbacks, Return policy, and more.
Glassdoor job listings information
URL, Company url overview, Company name, Company rating, Job title, Job location, Job overview, Company headquarters, and more.
Glassdoor job listings information - Collect new jobs by keyword search like the job title
URL, Company url overview, Company name, Company rating, Job title, Job location, Job overview, Company headquarters, and more.
Glassdoor job listings information - Discover jobs by company URL
URL, Company url overview, Company name, Company rating, Job title, Job location, Job overview, Company headquarters, and more.
eBay
URL, Product id, Title, Seller name, Seller rating, Seller reviews, Breadcrumbs, Root category, and more.
eBay - Gather data on products using specified keywords
URL, Product id, Title, Seller name, Seller rating, Seller reviews, Breadcrumbs, Root category, and more.
eBay - Collect products from shops on eBay
URL, Product id, Title, Seller name, Seller rating, Seller reviews, Breadcrumbs, Root category, and more.
eBay - Collect records by category
URL, Product id, Title, Seller name, Seller rating, Seller reviews, Breadcrumbs, Root category, and more.
Google Shopping
URL, Product id, Title, Product description, Rating, Reviews count, Images, Variations, and more.
Google Shopping - collects products from web using keywords
URL, Product id, Title, Product description, Rating, Reviews count, Images, Variations, and more.
Github repository
URL, ID, Code language, Code, Num lines, User name, User url, Size, and more.
Github repository - Discover github code by repository URL
URL, ID, Code language, Code, Num lines, User name, User url, Size, and more.
Github repository - discover new records by search url
URL, ID, Code language, Code, Num lines, User name, User url, Size, and more.
Facebook - Posts by group URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Amazon products global dataset
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products global dataset - Collects products by specific category URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products global dataset - Collecting products by keyword search
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products global dataset - Collect Amazon products by seller URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products global dataset - Collect products from Brands URLs
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Home Depot US
URL, Domain, Country code, Model number, Sku, Product id, Product name, Manufacturer, and more.
Home Depot US - Gather data on products using specified keywords
URL, Domain, Country code, Model number, Sku, Product id, Product name, Manufacturer, and more.
Home Depot US - Discover products by specified URL
URL, Domain, Country code, Model number, Sku, Product id, Product name, Manufacturer, and more.
Home Depot US - Discover products by specified UPC
URL, Domain, Country code, Model number, Sku, Product id, Product name, Manufacturer, and more.
Home Depot US - Discovery products by specific category URL
URL, Domain, Country code, Model number, Sku, Product id, Product name, Manufacturer, and more.
Facebook Marketplace
URL, Title, Initial price, Final price, Currency, Product id, Breadcrumbs, Condition, and more.
Facebook Marketplace - Collect Facebook marketplace listings by keyword
URL, Title, Initial price, Final price, Currency, Product id, Breadcrumbs, Condition, and more.
Facebook Marketplace - discover by url
URL, Title, Initial price, Final price, Currency, Product id, Breadcrumbs, Condition, and more.
Facebook - Posts by post URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Etsy
URL, Product id, Listing inventory id, Title, Rating, Reviews count shop, Reviews count item, Initial price, and more.
Etsy - Collect data on products using specified keywords
URL, Product id, Listing inventory id, Title, Rating, Reviews count shop, Reviews count item, Initial price, and more.
Etsy - Collects data from shop's URL
URL, Product id, Listing inventory id, Title, Rating, Reviews count shop, Reviews count item, Initial price, and more.
TikTok - Comments
URL, Post url, Post id, Post date created, Date created, Comment text, Num likes, Num replies, and more.
Trustpilot business reviews
Company name, Review id, Review date, Review rating, Review title, Review content, Is verified review, Review date of experience, and more.
Google Play Store
URL, Title, Developer, Monetization features, Images, About, Data safety, Rating, and more.
Australia real estate properties
Rea property id, Property type, State, Postcode, Year built, Last sold date, Last sold agency, Bedrooms, and more.
Australia real estate properties - discover records by search url
Rea property id, Property type, State, Postcode, Year built, Last sold date, Last sold agency, Bedrooms, and more.
Australia real estate properties - Discover records by Listing type
Rea property id, Property type, State, Postcode, Year built, Last sold date, Last sold agency, Bedrooms, and more.
Reddit - Comments
URL, Comment id, User posted, Comment, Date posted, Post url, Post id, Community name, and more.
Amazon products search
Asin, URL, Name, Sponsored, Initial price, Final price, Currency, Sold, and more.
G2 software - product reviews
Review id, Author id, Author, Position, Company size, Stars, Date, Title, and more.
Booking Listings Search
URL, Location, Check in, Check out, Adults, Children, Rooms, ID, and more.
Facebook - Profiles
URL, Name, ID, Profile photo, Cover photo, Work, College, High school, and more.
Yelp businesses reviews
Business id, Review auther, Rating, Date, Content, Review image, Reactions, Replies, and more.
Yelp businesses reviews - Search for Yelp businesses by country, category and location
Business id, Review auther, Rating, Date, Content, Review image, Reactions, Replies, and more.
Youtube - Comments
Comment id, Comment text, Likes, Replies, Username, Username md5, User channel, Date, and more.
Facebook - Pages and Profiles
ID, URL, Page name, Username, Entity type, Summary text, Primary category, Work, and more.
Target
URL, Product id, Title, Product description, Rating, Reviews count, Initial price, Discount, and more.
Target - Gather data on products using specified keywords
URL, Product id, Title, Product description, Rating, Reviews count, Initial price, Discount, and more.
Target - Discover products by category url
URL, Product id, Title, Product description, Rating, Reviews count, Initial price, Discount, and more.
Target - Discover products by specified UPC
URL, Product id, Title, Product description, Rating, Reviews count, Initial price, Discount, and more.
Zillow price history
URL, Zpid, Date, Event, Posting is rental, Price, Price change rate, Price per squarefoot, and more.
Zara - Products
Category id, Product id, Product name, Price, Currency, Colour code, Colour, Description, and more.
Zara - Products - discovery by category url
Category id, Product id, Product name, Price, Currency, Colour code, Colour, Description, and more.
Wikipedia articles
URL, Title, Table of contents, Raw text, Cataloged text, Images, See also, References, and more.
Wikipedia articles - Discover new articles by searching keywords in Wikipedia
URL, Title, Table of contents, Raw text, Cataloged text, Images, See also, References, and more.
Pinterest - Posts
URL, Post id, Title, Content, Date posted, User name, User url, User id, and more.
Pinterest - Posts - Collects posts by specific keywords
URL, Post id, Title, Content, Date posted, User name, User url, User id, and more.
Pinterest - Posts - Discover posts by using specific profile url
URL, Post id, Title, Content, Date posted, User name, User url, User id, and more.
Indeed companies info
Name, Description, URL, Work happiness, Jobs categories, Website, Industry, Company size, and more.
Indeed companies info - By company list
Name, Description, URL, Work happiness, Jobs categories, Website, Industry, Company size, and more.
Indeed companies info - Discover companies by Industries and location (State) in US
Name, Description, URL, Work happiness, Jobs categories, Website, Industry, Company size, and more.
Indeed companies info - Search company by company name
Name, Description, URL, Work happiness, Jobs categories, Website, Industry, Company size, and more.
Best Buy products
URL, Product id, Title, Images, Final price, Currency, Discount, Initial price, and more.
Best Buy products - Collect data on products using specified keywords
URL, Product id, Title, Images, Final price, Currency, Discount, Initial price, and more.
Zoopla properties listing information
URL, Property type, Property title, Address, Google map location, Virtual tour, Street view, URL property, and more.
Zoopla properties listing information - Discover by custom filters - location and property type
URL, Property type, Property title, Address, Google map location, Virtual tour, Street view, URL property, and more.
Lowes.com
URL, Domain, Marketplace pn, Sku, Other pn, Model number, Gtin ean pn, Product name, and more.
Lowes.com - Gather data on products using specified keywords
URL, Domain, Marketplace pn, Sku, Other pn, Model number, Gtin ean pn, Product name, and more.
Lowes.com - Collect records by category
URL, Domain, Marketplace pn, Sku, Other pn, Model number, Gtin ean pn, Product name, and more.
Lazada - Products
URL, Title, Rating, Reviews, Initial price, Final price, Currency, Stock, and more.
Lazada - Products - Discover products by keyword
URL, Title, Rating, Reviews, Initial price, Final price, Currency, Stock, and more.
Lazada - Products - Discover products by category URL or brand URL
URL, Title, Rating, Reviews, Initial price, Final price, Currency, Stock, and more.
Lazada - Products - Discover products by seller URL
URL, Title, Rating, Reviews, Initial price, Final price, Currency, Stock, and more.
Lazada - Products - Discover products by brand URL
URL, Title, Rating, Reviews, Initial price, Final price, Currency, Stock, and more.
Facebook Events
Event id, URL, Main image, Event date, Title, People responded, Event by, Location, and more.
Facebook Events - discover Facebook events search URL
Event id, URL, Main image, Event date, Title, People responded, Event by, Location, and more.
Facebook Events - Discover events by venue URL
Event id, URL, Main image, Event date, Title, People responded, Event by, Location, and more.
Ikea - Products
Description, In stock, Color, Size, Reviews count, Main image, Category url, Category, and more.
Ikea - Products - Discovery new products by category URL
Description, In stock, Color, Size, Reviews count, Main image, Category url, Category, and more.
Walmart sellers info
Seller id, URL, Catalog seller id, Seller name, Seller display name, Seller email, Seller phone, Seller about us, and more.
Ozon.ru products
URL, Sku, Breadcrumbs, Name, Rating, Review count, Description, Image, and more.
OLX Brazil - marketplace ads
Body, Subject, Currency, PriceValue, ProfessionalAnnouncement, Category, ParentCategoryName, CategoryName, and more.
Sephora products
URL, ID, Name, Sku, In stock, Regular price, Actual price, Unit price, and more.
Xing social network
Account id, FamilyName, Gender, Membership, Country code, Experience, Education, Languages, and more.
Google Shopping products search US
URL, Product id, Title, Final price, Initial price, Currency, Rating, Reviews count, and more.
Facebook - Reels by profile URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Wayfair products
URL, Product id, Title, Rating, Reviews count, Initial price, Discount, Final price, and more.
Wayfair products - Gather data on products using specified keywords
URL, Product id, Title, Rating, Reviews count, Initial price, Discount, Final price, and more.
Wayfair products - discover records by category url
URL, Product id, Title, Rating, Reviews count, Initial price, Discount, Final price, and more.
Naver products
URL, Product id, Title, Original price, Final price, Discount rate, Currency, Description, and more.
Naver products - Discover products by category
URL, Product id, Title, Original price, Final price, Discount rate, Currency, Description, and more.
Digikey - Products
Product url, Category url, Part number, Description, Manufacturer, Manufacturer url, Datasheet url, Rohs compliant, and more.
Digikey - Products - Discover by category url
Product url, Category url, Part number, Description, Manufacturer, Manufacturer url, Datasheet url, Rohs compliant, and more.
Facebook Company Reviews
Company name, Company id, Company url, URL, Review time, Recommends, Review content, Review attachments, and more.
Google Play Store reviews
URL, Review id, Reviewer name, Review date, Review rating, Review, Found helpful, App url, and more.
US lawyers directory
URL, Address, Admission, Areas of practice, Isln, Law school attended, Location, Name, and more.
US lawyers directory - Search on the website by attorney name, practice area, school, articles, or location
URL, Address, Admission, Areas of practice, Isln, Law school attended, Location, Name, and more.
Owler companies information
CompanyID, Ownership, IndustrySectors, Revenue, Founded, CompanyName, Country, EmployeeCount, and more.
Mouser - Products
Product url, Category url, Mouser part num, Mfr part number, Manufacturer, Image, Image high, Manufacturer url, and more.
Mouser - Products - Discovery new products by category URL
Product url, Category url, Mouser part num, Mfr part number, Manufacturer, Image, Image high, Manufacturer url, and more.
mercadolivre.com.br products
URL, Product id, Title, Breadcrumbs, Category, Tags, Final price, Original price, and more.
Myntra products
URL, Product id, Title, Product description, Rating, Ratings count, Initial price, Discount, and more.
Myntra products - Collect products by category URL
URL, Product id, Title, Product description, Rating, Ratings count, Initial price, Discount, and more.
Myntra products - Collect products by keyword
URL, Product id, Title, Product description, Rating, Ratings count, Initial price, Discount, and more.
Myntra products - Collect products by brand URL
URL, Product id, Title, Product description, Rating, Ratings count, Initial price, Discount, and more.
Webmotors Brasil - Cars Listings
ID SELLER, ID, URL, Tipo, Marca, Modelo, Ano, Variante, and more.
Webmotors Brasil - Cars Listings - Discover new records by category URL
ID SELLER, ID, URL, Tipo, Marca, Modelo, Ano, Variante, and more.
Agoda Properties Listings
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Agoda Properties Listings - collect properties by country
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Agoda Properties Listings - collect properties by filter url
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
H&M - Products
Category tree, Color, Country code, County of origin, Currency, Delivery, Description, Domain, and more.
H&M - Products - Discovery new products by category URL
Category tree, Color, Country code, County of origin, Currency, Delivery, Description, Domain, and more.
Apple App Store reviews
URL, Review id, Review title, Review rating, Reviewer name, Review date, Review, Developer response, and more.
Tokopedia Products
Product id, Title, URL, Currency, Delivery, Final price, Initial price, Seller name, and more.
Tokopedia Products - Search products by keyword
Product id, Title, URL, Currency, Delivery, Final price, Initial price, Seller name, and more.
Tokopedia Products - Collect URLs of products by category URLs
Product id, Title, URL, Currency, Delivery, Final price, Initial price, Seller name, and more.
Tokopedia Products - Collect Tokopedia's products by seller URL
Product id, Title, URL, Currency, Delivery, Final price, Initial price, Seller name, and more.
Zonaprop Argentina - Properties Listing
URL, Title, GeneratedTitle, Imagenes, Numero de imagenes, Description, Precio, Currency, and more.
Zonaprop Argentina - Properties Listing - Discover products by domain
URL, Title, GeneratedTitle, Imagenes, Numero de imagenes, Description, Precio, Currency, and more.
Wildberries.ru products
URL, Sku, Breadcrumbs, Name, Rating, Review count, Image, Brand, and more.
VentureRadar company information
URL, Location, Name, Country code, Ownership, Score, Auto analyst score, Website popularity, and more.
Quora posts
URL, Post id, Author name, Title, Post date, Originally answered, Over all answers, Post text, and more.
Quora posts - Search url of a question on Quora to discover answers given
URL, Post id, Author name, Title, Post date, Originally answered, Over all answers, Post text, and more.
Pinterest - Profiles
URL, Profile picture, Name, Nickname, Website, Bio, Following count, Follower count, and more.
Pinterest - Profiles - Discover profiles by Keyword in profile name and profile posts
URL, Profile picture, Name, Nickname, Website, Bio, Following count, Follower count, and more.
Chileautos Chile - Cars Listings
URL, Marca, Modelo, Ano, Variante, Kilometraje, Condicion, Combustible, and more.
Zalando products
Domain, Country code, URL, Sku, Condition, Gender, Product name, Brand, and more.
Zalando products - Discover products by domain
Domain, Country code, URL, Sku, Condition, Gender, Product name, Brand, and more.
Zalando products - Discover records by search keyword
Domain, Country code, URL, Sku, Condition, Gender, Product name, Brand, and more.
Zalando products - Discover products by category URL
Domain, Country code, URL, Sku, Condition, Gender, Product name, Brand, and more.
Zalando products - Collect products by brand URL
Domain, Country code, URL, Sku, Condition, Gender, Product name, Brand, and more.
Inmuebles24 Mexico - Properties Listings
URL, Title, GeneratedTitle, Description, Seller, Precio, Publicado hace, CreatedDate, and more.
Aliexpress products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Aliexpress products - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Yapo Chile - marketplace ads
Title, Description, Seller name, Root category id, Root category name, Parent category id, Parent category name, Active, and more.
Trustradius product reviews
URL, Product id, Product name, Review id, Review url, Review title, Review rating, Review date, and more.
Trustradius product reviews - discover all reviews by product url
URL, Product id, Product name, Review id, Review url, Review title, Review rating, Review date, and more.
Asos - Products
URL, Name, Brand, Description, About me, Availability, Buy the look, Category, and more.
Asos - Products - Collect products by category URL
URL, Name, Brand, Description, About me, Availability, Buy the look, Category, and more.
Asos - Products - Collect products by keyword
URL, Name, Brand, Description, About me, Availability, Buy the look, Category, and more.
Asos - Products - Collect products by brand URL
URL, Name, Brand, Description, About me, Availability, Buy the look, Category, and more.
Hermes- Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Hermes- Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Costco products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Vimeo - Videos posts
Video id, Title, URL, Uploader, Video url, Video length, Views, Likes, and more.
Vimeo - Videos posts - focus on licensed videos with "common creative" license
Video id, Title, URL, Uploader, Video url, Video length, Views, Likes, and more.
Vimeo - Videos posts - scrape videos by URL
Video id, Title, URL, Uploader, Video url, Video length, Views, Likes, and more.
Lazada - Reviews
URL, Title, Rating, Reviews, Seller name, Sku, Mpn, Is super seller, and more.
Alibaba
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Alibaba - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Bluesky - Posts
URL, Post id, Post date, Posted by, Post text, Comments, Reposts, Likes, and more.
Bluesky - Posts - Collect posts from profile URL
URL, Post id, Post date, Posted by, Post text, Comments, Reposts, Likes, and more.
carsales.com.au - Cars Listings
Car id, URL, Manufacturer, Model, Badge, Colour, Year, Price, and more.
carsales.com.au - Cars Listings - Collect car listings by keyword
Car id, URL, Manufacturer, Model, Badge, Colour, Year, Price, and more.
Kroger.com
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Kroger.com - Discovery by category
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Kroger.com - Discovery by keyword
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Lego - Products
Product name, Category, Description, Initial price, Final price, Currency, In stock, Availability, and more.
Lego - Products - Discovery new products by category URL
Product name, Category, Description, Initial price, Final price, Currency, In stock, Availability, and more.
Home Depot CA
Domain, Country code, URL, Model number, Sku, Product name, Manufacturer, Description, and more.
Home Depot CA - Gather data on products using specified keywords
Domain, Country code, URL, Model number, Sku, Product name, Manufacturer, Description, and more.
Home Depot CA - discover records by category url
Domain, Country code, URL, Model number, Sku, Product name, Manufacturer, Description, and more.
Metrocuadrado - Properties Listings
URL, ID, Precio, Habitaciones, Banos, Dimension propiedad, Dimension terreno, Comuna Ciudad, and more.
Snapchat posts
URL, Post id, Profile name, Profile handle, Profile link, Num comments, Num shares, Num views, and more.
Snapchat posts - Discover posts by profile url
URL, Post id, Profile name, Profile handle, Profile link, Num comments, Num shares, Num views, and more.
Snapchat posts - Discover new posts by search url
URL, Post id, Profile name, Profile handle, Profile link, Num comments, Num shares, Num views, and more.
Chanel Products
Product name, Product description, Country, Currency, Color, Variations, Free sample, Image slider, and more.
Chanel Products - Discover new products in Chanel by category URL
Product name, Product description, Country, Currency, Color, Variations, Free sample, Image slider, and more.
Lazada products search (GMV)
URL, Name, Price, Currency, Number sold, Sku, Image url, Rating, and more.
Coupang products
URL, ID, Title, Rating, Reviews, Initial price, Final price, Discount, and more.
Coupang products - Collect products by category
URL, ID, Title, Rating, Reviews, Initial price, Final price, Discount, and more.
Coupang products - Collect product by brand URL
URL, ID, Title, Rating, Reviews, Initial price, Final price, Discount, and more.
Coupang products - Collect products by seller URL
URL, ID, Title, Rating, Reviews, Initial price, Final price, Discount, and more.
Dior - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Dior - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Sephora Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Sephora Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Toctoc - Properties Listings
Imagen, No de imagenes, Descripcion, Precio, Currency, Ubicacion, Habitaciones, Banos, and more.
Properati Argentina and Colombia - Properties Listings
Type, Name, Estrato, Habitaciones, Banos, M2, Descripcion, Precio, and more.
Infocasas Uruguay - Properties Listings
URL, ID, Imagen, Descripcion, Precio, Ubicacion, Habitaciones, Banos, and more.
Macys.com
URL, Star rating distribution, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, and more.
Macys.com - By category url
URL, Star rating distribution, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, and more.
Macys.com - Search by keyword
URL, Star rating distribution, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, and more.
Fanatics.com - Products
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Color, and more.
Fanatics.com - Products - Discovery new products by category URL
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Color, and more.
Ashleyfurniture - Products
Product name, Brand, Initial price, Final price, Currency, In stock, Availability, Color, and more.
Ashleyfurniture - Products - sitemap
Product name, Brand, Initial price, Final price, Currency, In stock, Availability, Color, and more.
Ashleyfurniture - Products - Discovery new products by category URL
Product name, Brand, Initial price, Final price, Currency, In stock, Availability, Color, and more.
Mango Products
Product name, Price, Image, Size, Product article, Availability, Description, Colour code, and more.
Crateandbarrel - Products
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Availability, and more.
Crateandbarrel - Products - Discovery new products by category URL
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Availability, and more.
Mediamarkt.de products
Brand, Description, Manufacturer, Ean, Sku, Initial price, Final price, In stock, and more.
apple shop products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
AE.com - Complete Products
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Availability, and more.
AE.com - Complete Products - Discovery new products by category URL
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Availability, and more.
chewy products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Grainger
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Grainger - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Autozone - products
URL, Item id, Mpn, Title, Description, Product category, Category tree, Brand, and more.
Apple App Store
URL, Title, Sub title, Developer, Top charts, Monetization features, Image, Screenshots, and more.
Westelm products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Westelm products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Balenciaga.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Balenciaga.com - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
ChatGPT Search
URL, Prompt, Answer html, Answer text, Links attached, Citations, Recommendations, Country, and more.
Instacart Products unified schema
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Instacart Products unified schema - Collect products by category URL
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Toysrus - Products
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Reviews count, and more.
Toysrus - Products - Discovery new products by category URL
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Reviews count, and more.
Threads - Profiles
URL, Profile name, Profile id, About formatted, Number of followers, Website, Instagram profile url, Threads, and more.
Loewe.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Loewe.com - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Sally Beauty Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Sally Beauty Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Carters.com - Products
Product name, Description, In stock, Availability, Color, Size, Reviews count, Category url, and more.
Carters.com - Products - Discovery new products by category URL
Product name, Description, In stock, Availability, Color, Size, Reviews count, Category url, and more.
adidas products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Flipkart Products unified schema
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Flipkart Products unified schema - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Zara Home Products
Category id, Category key, Category name, Product id, Product name, Price, Price discount, Price with fillings, and more.
llbean.com - Products
IDentity, Product name, URL, Description, Category tree, Color, Country code, County of origin, and more.
llbean.com - Products - Discovery new products by category URL
IDentity, Product name, URL, Description, Category tree, Color, Country code, County of origin, and more.
Nike products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Nike products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Fendi Products
Product id, URL, Product name, Product description, Short description, Image, Price, Currency, and more.
Fendi Products - Discover products by category URL
Product id, URL, Product name, Product description, Short description, Image, Price, Currency, and more.
Prada.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Prada.com - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Google Maps Images
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Micro Center Products
URL, Item id, Gtin, Mpn, Title, Description, Product category, Category tree, and more.
Hoka products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Hoka products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Ulta
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Ulta - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Dick’s Sporting Goods
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Nordstrom
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Nordstrom - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Rei
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Rei - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Twitch - streams dataset
URL, Stream id, Streamer name, Verified partner, Stream title, Tags, Viewers number, Stream time, and more.
Twitch - streams dataset - Discover stream by a search term
URL, Stream id, Streamer name, Verified partner, Stream title, Tags, Viewers number, Stream time, and more.
Twitch - streams dataset - Discover stream by category url
URL, Stream id, Streamer name, Verified partner, Stream title, Tags, Viewers number, Stream time, and more.
Lululemon products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Lululemon products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Free people
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Free people - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
LLBean
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
LLBean - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Massimo Dutti - Products
URL, Title, Price, Product type, Family name, Subfamily name, Images, Size, and more.
Massimo Dutti - Products - Discovery new products by category URL
URL, Title, Price, Product type, Family name, Subfamily name, Images, Size, and more.
Bottegaveneta.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Bottegaveneta.com - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Ysl.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Delvaux - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Delvaux - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Google SERP - 100 Results
URL, Keyword, General, Related, Pagination, Organic, People also ask, Navigation, and more.
Advance Auto Parts
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Advance Auto Parts - Collect products by category URL
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Dell Products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Overstock Products unified schema
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Overstock Products unified schema - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Harbor Freight Products
URL, Item id, Mpn, Title, Description, Product category, Category tree, Brand, and more.
Harbor Freight Products - Collect products by category URL
URL, Item id, Mpn, Title, Description, Product category, Category tree, Brand, and more.
Google AI Mode Search
URL, Prompt, Answer html, Answer text, Links attached, Citations, Index, Country, and more.
Vinted - Global
URL, Seller id, Sku, Rootdomain, Name, Brand, Currency, Price, and more.
Vinted - Global - Discovery by category URL
URL, Seller id, Sku, Rootdomain, Name, Brand, Currency, Price, and more.
Vinted - Global - Discovery by search
URL, Seller id, Sku, Rootdomain, Name, Brand, Currency, Price, and more.
Mattressfirm - Products
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Color, and more.
Mattressfirm - Products - Discovery new products by category URL
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Color, and more.
Mybobs.com - Products
Product name, Initial price, Final price, Currency, In stock, Main image, Category tree, Country code, and more.
Mybobs.com - Products - Discovery new products by category URL
Product name, Initial price, Final price, Currency, In stock, Main image, Category tree, Country code, and more.
Barnes & Noble Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Mercari Products
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Samsclub products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Samsclub products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
OLD NAVY Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
OLD NAVY Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Sleepnumber.com - Products
Description, Initial price, Final price, Currency, In stock, Color, Size, Reviews count, and more.
Sleepnumber.com - Products - Discovery new products by category URL
Description, Initial price, Final price, Currency, In stock, Color, Size, Reviews count, and more.
B&H Products
URL, Item id, Gtin, Mpn, Title, Description, Product category, Category tree, and more.
Neiman Marcus
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Neiman Marcus - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Samsung
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Samsung - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Montblanc - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Montblanc - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Quince Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Quince Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Berluti.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Berluti.com - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
American Eagle
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
American Eagle - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Zoro Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Zoro Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Celine.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Celine.com - Products - Discover new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Williams sonoma products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
HP products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
La-z-boy.com - Products
Product name, Description, Initial price, Final price, Currency, In stock, Size, Reviews count, and more.
La-z-boy.com - Products - Discovery new products by category URL
Product name, Description, Initial price, Final price, Currency, In stock, Size, Reviews count, and more.
Kohl's Products unified schema
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Kohl's Products unified schema - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Poshmark Products unified schema
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Walmart - products zipcodes
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products zipcodes - Collect data by category URL
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products zipcodes - Collect data by Keyword
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
OUAI Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
OUAI Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Bass Pro Shops
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Ferguson Home Products
URL, Item id, Variant id, Mpn, Title, Description, Product category, Category tree, and more.
Ferguson Home Products - Collect products by category URL
URL, Item id, Variant id, Mpn, Title, Description, Product category, Category tree, and more.
Bath & Body Works
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Sweetwater
URL, Item id, Mpn, Title, Description, Product category, Category tree, Brand, and more.
Garmin Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Garmin Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Moynat.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Anthropologie Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Anthropologie Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
iherb products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Threads - Posts
Post id, URL, Post time, Profile name, Profile url, Post content, Number of likes, Number of comments, and more.
Threads - Posts - Discover posts by profile URL
Post id, URL, Post time, Profile name, Profile url, Post content, Number of likes, Number of comments, and more.
Sears Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
ACE products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
ACE products - Sitemap
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Tatcha Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Vevor Products
URL, Item id, Variant id, Mpn, Title, Description, Product category, Category tree, and more.
Vevor Products - Collect products by category URL
URL, Item id, Variant id, Mpn, Title, Description, Product category, Category tree, and more.
Poshmark.com
URL, Is promo, Seller id, Other price options, Sku, Rootdomain, Name, Brand, and more.
Poshmark.com - Discovery by category
URL, Is promo, Seller id, Other price options, Sku, Rootdomain, Name, Brand, and more.
Poshmark.com - Discovery by keyword
URL, Is promo, Seller id, Other price options, Sku, Rootdomain, Name, Brand, and more.
Newegg Products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Bed Bath & Beyond
URL, Item id, Variant id, Mpn, Title, Description, Product category, Category tree, and more.
Gemini Search
URL, Prompt, Answer html, Answer text, Links attached, Citations, Country, Index, and more.
Suumo.jp
URL, Property name, Type, Rent fee, Management Fees common Expenses, Shikikin, Key money, Security deposit, and more.
Suumo.jp - Discovery records by category
URL, Property name, Type, Rent fee, Management Fees common Expenses, Shikikin, Key money, Security deposit, and more.
Guitar Center Products
URL, Item id, Variant id, Gtin, Title, Description, Product category, Category tree, and more.
Staples
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
GNC Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
 238+
238+Crateandbarrel - Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
237+Crateandbarrel - Products - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
237+Victoria's Secret products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Macys Products unified schema
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Fragrance Net Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Fragrance Net Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
H&M products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
236+Patagonia Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Perplexity Search
URL, Prompt, Answer html, Answer text, Answer text markdown, Sources, Source html, Is shopping data, and more.
Abercrombie & Fitch
URL, Item id, Variant id, Mpn, Title, Description, Product category, Category tree, and more.
Ikea products unified schema
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Ikea products unified schema - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Summit Racing Products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Saks Fifth Avenue products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Saks Fifth Avenue products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Office Depot Products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Office Depot Products - Collect products by category URL
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
academy products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Lenovo Products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Dior Products Unified Schema
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Clothing Shop Online Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
234+Clothing Shop Online Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
234+Zillow Full Properties Information
URL, Photos, Responsive photos, Has vr model, Description, Home status, Contingent listing type, What i love, and more.
Zillow Full Properties Information - Discover zillow records by zillow search url
URL, Photos, Responsive photos, Has vr model, Description, Home status, Contingent listing type, What i love, and more.
Flipkart.com
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Flipkart.com - Discovery by category
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Flipkart.com - Discovery by keyword
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
GameStop Products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
ON Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
ON Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Pottery barn products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Pottery barn products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Parts Geek
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Parts Geek - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Overstock.com
URL, Star rating distribution, Is promo, Other price options, Sku, Rootdomain, Name, Brand, and more.
Overstock.com - Discovery by category
URL, Star rating distribution, Is promo, Other price options, Sku, Rootdomain, Name, Brand, and more.
Overstock.com - keyword
URL, Star rating distribution, Is promo, Other price options, Sku, Rootdomain, Name, Brand, and more.
vitamin shoppe products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Walgreens
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Walgreens - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
tractor supply products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
J.Crew Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
J.Crew Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Newbalance products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Newbalance products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Napa Online
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Napa Online - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Zales
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Zales - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Underarmour Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Flooranddecor Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Ferguson Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Ferguson Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Urban Outfitters
URL, Item id, Variant id, Mpn, Title, Description, Product category, Category tree, and more.
229+Stradivarius Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Stradivarius Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Zara.com products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
229+Sony Electronics Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Sony Electronics Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Flipkart - Reviews
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Purchased date, and more.
Flipkart - Reviews - Collect reviews by SKU
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Purchased date, and more.
Pet Smart Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Pet Smart Products - Collect by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Theordinary products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Theordinary products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
AT&T Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
AT&T Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Massimodutti
URL, Item id, Variant id, Title, Description, Brand, Image url, Price, and more.
Massimodutti - Collect products by category URL
URL, Item id, Variant id, Title, Description, Brand, Image url, Price, and more.
Paula's Choice Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Paula's Choice Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Bjs Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Bjs Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
World Market products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
World Market products - Collect products URLs by sitemap
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Athome products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Athome products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Backcountry products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Backcountry products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Editorialist products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Dollar General Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Dollar General Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Farfetch Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
227+Farfetch Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
227+Discount Tire Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
227+Discount Tire Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
227+Lakeland Toyota Parts Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
227+Lakeland Toyota Parts Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
227+Trip Hotel Listings
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Trip Hotel Listings - Collect hotels listings by location
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
thorne products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Markandgraham products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Markandgraham products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Lyst
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Lyst - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Pottery Barn Teen
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
226+Pottery Barn Teen - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
226+Bloomingdale's
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Bloomingdale's - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Bershka Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Bershka Products - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Zara Home products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
226+Zara Home products - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
226+Oxo Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Soma Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
226+Soma Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
226+Sprouts Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Sprouts Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Vitacost products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Vitacost products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Cabelas products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Cabelas products - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Terrain Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Terrain Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Midway USA Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
225+Midway USA Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
225+Cuisinart Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
225+Cuisinart Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
225+Nectar Sleep Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
225+Nectar Sleep Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
225+WeatherTech Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
225+WeatherTech Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
225+Elfcosmetics Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Bing Copilot Search
URL, Prompt, Answer text, Answer text markdown, Sources, Index, Answer section html, Answer html, and more.
Falabella.com - Reviews
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Purchased date, and more.
Falabella.com - Reviews - Collect reviews data by SKU
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Purchased date, and more.
Instacart products
URL, Product id, Product name, Brand, Description, Category path, Size unit, Price, and more.
Instacart products - Collect products by category URL
URL, Product id, Product name, Brand, Description, Category path, Size unit, Price, and more.
L'oreal Paris Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
L'oreal Paris Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Belk products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Belk products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Hobbylobby
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Hobbylobby - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Adorama
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Adorama - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Sharkninja
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Sharkninja - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Michaels Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Michaels Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
LA Roche Posay Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
LA Roche Posay Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Kiehl's Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Kiehl's Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
American Trucks Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
224+Uniqlo Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
224+CARiD Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
224+CARiD Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
224+Eriks Bike Shop Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
224+Eriks Bike Shop Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
224+Restaurant Supply Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
224+Restaurant Supply Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
224+Sigma Aldrich Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
224+Sigma Aldrich Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
224+Skims Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
LinkedIn people search
URL, Name, Subtitle, Location, Experience, Education, Avatar, and more.
Falabella.com
URL, Star rating distribution, Is promo, Seller id, Store id, Other price options, Sku, Rootdomain, and more.
Falabella.com - Discovery by category
URL, Star rating distribution, Is promo, Seller id, Store id, Other price options, Sku, Rootdomain, and more.
Falabella.com - Discovery by keyword
URL, Star rating distribution, Is promo, Seller id, Store id, Other price options, Sku, Rootdomain, and more.
Oscaro products - Global
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
Oscaro products - Global - Discovery by category
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
Oscaro products - Global - Discovery by keyword
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
scheels products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Pull & Bear Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Pull & Bear Products - Collect by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Containerstore products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Containerstore products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Greenrow
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Greenrow - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Rocksbox
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Rocksbox - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Peoples Jewellers products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Peoples Jewellers products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Yesstyle Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Goat Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Goat Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+StockX Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+StockX Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Ring Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Ring Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Adafruit Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Adafruit Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Boohoo Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Boohoo Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Tennis Warehouse Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Walmart Reviews
URL, Product name, Product id, Rating, Author name, Review header, Review id, Review text, and more.
Walmart products search
ID, URL, Typename, Buy box suppression, Similar items, Us item id, Is bad split, Name, and more.
Agoda Listings Search
URL, Location, Check in, Check out, Adults, Children, Rooms, ID, and more.
222+Snapchat profile
URL, Profile id, Profile name, Profile username, Profile alternate name, Profile description, Profile address, Profile image url, and more.
Trip Listings Search
URL, Location, Check in, Check out, Adults, Children, Rooms, ID, and more.
Idealo Global
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Idealo Global - Discovery by category URL
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Idealo Global - Discovery by keyword
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Idealo Global - Discovery by category URL and keyword
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Oysho
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Oysho - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Pottery Barn Kids products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Pottery Barn Kids products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Ashley Furniture
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Ashley Furniture - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
WebstaurantStore
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
WebstaurantStore - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Diamonds Direct
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Diamonds Direct - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+LG Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
LG Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Car Parts Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Car Parts Products - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Clinique Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Clinique Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Nature Made Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Nature Made Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Blick Art Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Blick Art Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Asics Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Microsoft Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Microsoft Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Trek Bikes Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Trek Bikes Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Light In The Box Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Light In The Box Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Gap Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Gap Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Supply House Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Supply House Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Ford OEM Parts Online Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Ford OEM Parts Online Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Birkenstock Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Birkenstock Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Micro Ingredients Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Google Flights - Collect flights by input filters
URL, Itinerary id, Search, Pricing, Providers, Legs, and more.
Kroger.com - Search
Rank, Page, Sku, URL, Rootdomain, Name, Brand, Currency, and more.
Kroger.com - Search - Discovery by category
Rank, Page, Sku, URL, Rootdomain, Name, Brand, Currency, and more.
Kroger.com - Search - Discovery by keyword
Rank, Page, Sku, URL, Rootdomain, Name, Brand, Currency, and more.
Flipkart.com - Search
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
Flipkart.com - Search - Discovery by category
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
Flipkart.com - Search - Discovery by keyword
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
Myfood4less.com
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
Myfood4less.com - Discovery by category
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
Myfood4less.com - Discovery by keyword
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
Motointegrator.de
URL, Sku, Rootdomain, Name, Brand, Currency, Price, Image urls, and more.
Motointegrator.de - Discovery by category
URL, Sku, Rootdomain, Name, Brand, Currency, Price, Image urls, and more.
Motointegrator.de - Discovery by keyword
URL, Sku, Rootdomain, Name, Brand, Currency, Price, Image urls, and more.
PetCo products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
PetCo products - Collect products by sitemap
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Dillard's
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Nintendo products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Converse Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Converse Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Sur La Table Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Sur La Table Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Backmarket Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Dermalogica Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Famousfootwear Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Naturium Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Naver hotels
URL, Hotel id, Hotel name, Rating, Review count, Star classification, Address, District, and more.
221+Naver hotels - Discover records by filter URL
URL, Hotel id, Hotel name, Rating, Review count, Star classification, Address, District, and more.
221+Naver hotels - Discovery records by search
URL, Hotel id, Hotel name, Rating, Review count, Star classification, Address, District, and more.
221+Naver hotels - Discover all hotel listings on Naver Hotels by country
URL, Hotel id, Hotel name, Rating, Review count, Star classification, Address, District, and more.
221+The North Face Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Banana Republic Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Banana Republic Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Revolve Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Revolve Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Saatva Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Saatva Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Coach Outlet Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Coach Outlet Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Global Industrial Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Global Industrial Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Louis Vuitton Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Louis Vuitton Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Merrell Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Merrell Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Hollister Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Hollister Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+TCGplayer Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+TCGplayer Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Pandora Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Pandora Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Nespresso Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Nespresso Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Salomon Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Microsoft Store Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Google Hotel
URL, Hotel id, Hotel name, Rating, Review count, Star classification, Address, Phone number, and more.
Google Hotel - Discovery records by search
URL, Hotel id, Hotel name, Rating, Review count, Star classification, Address, Phone number, and more.
Google Hotel - Discover records by filter URL
URL, Hotel id, Hotel name, Rating, Review count, Star classification, Address, Phone number, and more.
Macys.com - Reviews
URL, Rootdomain, Sku, Review id, Author, Rating, Date, Location, and more.
Macys.com - Reviews - In/out collector
URL, Rootdomain, Sku, Review id, Author, Rating, Date, Location, and more.
Rejuvenation
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Rejuvenation - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Banana Republic Factory Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Grocerye Shop Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Coach Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Coach Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Rev Zilla Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Rev Zilla Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Robot Shop Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Robot Shop Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Fisher Scientific Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Fisher Scientific Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Mens Wear House Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Mens Wear House Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Crutchfield Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Crutchfield Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Evo Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Evo Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+JEGS Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+JEGS Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+TradeInn Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+TradeInn Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Farm and Fleet Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Farm and Fleet Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Chrono24 Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Chrono24 Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Moen Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Moen Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Eddie Bauer Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Eddie Bauer Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+PGA Tour Superstore Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+PGA Tour Superstore Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+PacSun Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+PacSun Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Chicco Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Logitech G Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+BrandsMart USA Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Crocs Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Burrow Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Nutricost Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
SmallRig Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Zillow properties search page
URL, Zpid, Zipcode, Description, City, Country, State, Address, and more.
Falabella.com - Search
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
219+Falabella.com - Search - Discovery by category
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
219+Falabella.com - Search - Discovery by keyword
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
219+Sayweee.com
URL, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, Currency, and more.
219+Sayweee.com - Discovery by category
URL, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, Currency, and more.
219+Sayweee.com - Discovery by keyword
URL, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, Currency, and more.
219+Canon USA products
URL, Item id, Variant id, Gtin, Mpn, Title, Description, Product category, and more.
Ecstuning Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Acme Tools Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Acme Tools Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Journeys Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Journeys Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Gear 4 Music Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Gear 4 Music Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Kitchen Aid Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Kitchen Aid Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Tire Rack Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Tire Rack Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+JCPenney Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+JCPenney Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Sierra Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Sierra Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Corsair Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Corsair Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+AllModern Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+AllModern Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Newegg Business Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Newegg Business Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+PRFO Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+PRFO Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+The Company Store Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+The Company Store Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Menards Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Menards Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
FCP Euro Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+FCP Euro Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+West Marine Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+West Marine Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Bambu Lab Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Bambu Lab Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Provantage Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Provantage Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+AJ Madison Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+AJ Madison Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+1A Auto Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+1A Auto Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Casio Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Casio Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Breville Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Breville Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Parts Express Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Rocky Mountain ATV MC Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Rocky Mountain ATV MC Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+HD Supply Solutions Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+HD Supply Solutions Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+StarTech Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+StarTech Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+PetSafe Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+PetSafe Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Home Depot Appliance Repair Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Home Depot Appliance Repair Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Maxpeedingrods Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Throtl Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+LG Parts Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Blindsgalore Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Casper Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Vuoriclothing Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+TikTok - Posts by Profile Fast API
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok Shop Category Products
URL, Product id, Category url, Category name, Sub categories, Title, Initial price, Final price, and more.
Kohls.com - Reviews
URL, Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, and more.
Kohls.com - Reviews - Discovery by SKU
URL, Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, and more.
Therealreal.com
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
218+Therealreal.com - Discovery by category
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
218+Therealreal.com - Discovery by keyword
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
218+Supergoop Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Supergoop Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Abe Books Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Columbia Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Living Spaces Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Sun And Ski Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Sun And Ski Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Musicians Friend Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Musicians Friend Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Boot Barn Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Boot Barn Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Aritzia Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Aritzia Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Helly Hansen Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Helly Hansen Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Gap Factory Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Gap Factory Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Skechers Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Skechers Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Reverb Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Reverb Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+SanDisk Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+SanDisk Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Life Extension Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Life Extension Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+DJI Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+DJI Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Dyson Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Dyson Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Article Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Article Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+DreamCloud Sleep Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+DreamCloud Sleep Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Logitech Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Logitech Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Levi Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Levi Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Rogue Fitness Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Rogue Fitness Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Rough Country Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Rough Country Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Cycle Gear Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Cycle Gear Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Athleta Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Athleta Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Costway Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Costway Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+AFW Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+AFW Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Monoprice Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Monoprice Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Arcteryx Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Arcteryx Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+MSI Store Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+MSI Store Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Delta Children Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Delta Children Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Tires Easy Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Tires Easy Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Kate Spade Outlet Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Kate Spade Outlet Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Whirlpool Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Whirlpool Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+SkinCeuticals Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+SkinCeuticals Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Kirklands Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Kirklands Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Camping World Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Camping World Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Lowes Appliance Parts Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Lowes Appliance Parts Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Custom Ink Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Custom Ink Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Honda Factory Parts Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Honda Factory Parts Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+K&N Filters Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+K&N Filters Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Shades of Light Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Shades of Light Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Motocard Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Motocard Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Shop Jimmy Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Discount Today Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Discount Today Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+GM Parts Online Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+GM Parts Online Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Vans Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Vans Products - collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Pioneer Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Pioneer Products - collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+AptDeco Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Excel Disc Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Five Below Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+KaTom Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Shure Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+1-800 Contacts Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Estée Lauder Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Trueclassictees Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Marinelayer Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Ergobaby Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Outdoor Research Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Flaconi Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Agoda Properties Listings with Pricing
URL, Listing id, Title, Location, Country, City, Metro railway access, Images, and more.
Agoda Properties Listings with Pricing - Collect properties listings by search inputs
URL, Listing id, Title, Location, Country, City, Metro railway access, Images, and more.
Reddit - Profiles
URL, Profile id, Name, Followers, Social links, Karma, Contributions, Reddit age, and more.
Kohls.com
URL, Star rating distribution, Quantity sold, Views, Is promo, Seller id, Store id, Other price options, and more.
Kohls.com - Discovery PDPs by category URL
URL, Star rating distribution, Quantity sold, Views, Is promo, Seller id, Store id, Other price options, and more.
Kohls.com - Discovery by keyword
URL, Star rating distribution, Quantity sold, Views, Is promo, Seller id, Store id, Other price options, and more.
Overstock.com - Reviews
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Title, and more.
217+Overstock.com - Reviews - Collect reviews data by SKU
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Title, and more.
217+NFM Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Mountain Warehouse Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Mountain Warehouse Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+JBL Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+JBL Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Zumiez Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Zumiez Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Rockler Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Rockler Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Ann Taylor Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Ann Taylor Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Lamps Plus Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Lamps Plus Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Eye Buy Direct Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Eye Buy Direct Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Vistaprint Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Vistaprint Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Flexispot Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Flexispot Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Megelin Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Megelin Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Christianbook Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Christianbook Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+American Muscle Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+American Muscle Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Brother USA Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Brother USA Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Lights Daddy Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Lights Daddy Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Joss and Main Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Joss and Main Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Kohler Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Kohler Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Pretty Little Thing Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Pretty Little Thing Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Graco Baby Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Graco Baby Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Nordic Store Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Nordic Store Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+iFixit Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+iFixit Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+World of Books Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+World of Books Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Speedway Motors Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Speedway Motors Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Abt Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Abt Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+J.Crew Factory Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+J.Crew Factory Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Sportsmans Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Sportsmans Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Tempur-Pedic Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Tempur-Pedic Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Electronic Express Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Electronic Express Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+GE Appliance Parts Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Woodcraft Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Woodcraft Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Finish Line Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Finish Line Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Greatmats Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Greatmats Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+VitalSource Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+VitalSource Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Sorel Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Sorel Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Oura Ring Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Oura Ring Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+GlassesUSA Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+GlassesUSA Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Dermstore Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Dermstore Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Timberland Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Timberland Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+MotoSport Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+MotoSport Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Everything Promo Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Everything Promo Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Hanes Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Hanes Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Reebok Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Reebok Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Simon Shop Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Simon Shop Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Decathlon Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Decathlon Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Brooks Brothers Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Brooks Brothers Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Frigidaire Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Frigidaire Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Arc'teryx Outlet Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Arc'teryx Outlet Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Uncommon Goods Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Uncommon Goods Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+2nd Swing Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Uniform Advantage Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Bare Necessities Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Express Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Express Products - Discover urls by sitmap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+BKSTR Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+SelectBlinds Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Moroccanoil Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Ottocast Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Ritual Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+GE Appliances Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+ThriftBooks Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Brooklinen Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+GreenPan Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Bedsure Home Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Ruggable Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Fentybeauty Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Kyliecosmetics Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Kith Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Glowrecipe Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Tower28beauty Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Tataharperskincare Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+OutdoorMaster Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Primally Pure Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Stylevana Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+Action Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+TikTok - Posts by URL Fast API
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
Booking Hotel Listings with Pricing
URL, Listing id, Title, Location, Country, City, Metro railway access, Images, and more.
Booking Hotel Listings with Pricing - Collect listings by search input
URL, Listing id, Title, Location, Country, City, Metro railway access, Images, and more.
PC Richard Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Foot Locker Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Foot Locker Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+A Main Hobbies Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+A Main Hobbies Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Books A Million Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Books A Million Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Quadratec Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Quadratec Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Jomashop Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Jomashop Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Brooks Running Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Brooks Running Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Loft Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Loft Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+CDW Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+CDW Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Levoit Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Levoit Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Extreme Terrain Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Extreme Terrain Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Vivid Racing Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Vivid Racing Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Bissell Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Bissell Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Safeway Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Safeway Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+eTrailer Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+eTrailer Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Verizon Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Verizon Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Banggood Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Banggood Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Bambu Lab Asia Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Bambu Lab Asia Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Belkin Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Evenflo Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Evenflo Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Fossil Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Fossil Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Cotton On Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Cotton On Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Signature Hardware Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Signature Hardware Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Blindster Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Blindster Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Helzberg Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Helzberg Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Michael Kors Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Michael Kors Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Azure Standard Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Zalesoutlet Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Zalesoutlet Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Total Wine Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Total Wine Products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Acer Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Acer Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Ssense Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Boscov's Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Grizzly Industrial Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+The Tile Shop Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Marriott Shop Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+FurniturePick Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Mountain Rose Herbs Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Nuna Baby Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Omnilux LED Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+UpTrade Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Lucky Brand Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Specialized Bikes Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Swappa Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+AlpinStore Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+US Water Systems Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Gymshark Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Hims Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Avocadomattress Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Chubbiesshorts Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Milkmakeup Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Sundayriley Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Buckmason Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Universalstandard Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Vegamour Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Jonesroadbeauty Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Publicgoods Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Yeti Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Shock Surplus Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Solos Smart Glasses Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Thursday Boots Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Vionic Shoes Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Walker Edison Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Manscaped Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Vitamix Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Peloton Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+Therabody Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
216+TikTok - Posts by Search URL Fast API
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
SparkFun Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
SparkFun Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Harrys Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Drsquatch Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Allbirds Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Glossier Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Thereformation Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Nativecos Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Rothys Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Beekman1802 Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Taylorstitch Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Mackweldon Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Italic Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Cuyana Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Mgemi Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Rhodeskin Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Ministryofsupply Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Alexmill Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Kosas Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Summerfridays Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Scotch and Soda Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
True Classic Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Helix Sleep Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Albertsons Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Traeger Product
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Web スクレイパー API 料金
正常に配信されたデータ分のみお支払いください。隠れた費用はなく、配信失敗に対する請求もありません。
これらの支払い方法を受け付けています:
すべてのプランで完全アクセス可能 - スケールに応じて1レコードあたりのコストを削減
データ収集
- 自動プロキシ管理
- 完全なブラウザレンダリング
- CAPTCHA解決
大規模なパフォーマンス
- 無制限の同時実行性
- バッチ&スケジュール収集
- ジョブ管理API
データ配信
- データ検証&発見
- データ解析(JSONまたはCSV)
- WebhookまたはAPI配信
Web スクレイパー API デモ
CODE EXAMPLES
100以上のドメイン専用エンドポイント。
入力
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.linkedin.com/in/elad-moshe-05a90413/"},{"url":"https://www.linkedin.com/in/jonathan-myrvik-3baa01109"},{"url":"https://www.linkedin.com/in/aviv-tal-75b81/"},{"url":"https://www.linkedin.com/in/bulentakar/"},{"url":"https://www.linkedin.com/in/nnikolaev/"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_l1viktl72bvl7bjuj0&format=json&uncompressed_webhook=true"
出力
JSON
[
{
"db_source": "1781626137968",
"timestamp": "2026-06-16",
"id": "m-p***een***ar-*********0a9******",
"name": "M p**********r P*****n",
"city": "Kolar, Karnataka, India",
"country_code": "IN",
"position": "Business Analyst at Ha",
"about": null
},
{
"db_source": "1781626137968",
"timestamp": "2026-06-16",
"id": "did***-pe***ta-*********",
"name": "Didier P*****a",
"city": "Colombia",
"country_code": "CO",
"position": "Operario en Cb ingenieria",
"about": null
},
{
"db_source": "1781626137968",
"timestamp": "2026-06-16",
"id": "ais***kha***481******",
"name": "Aisha K**n",
"city": "United Arab Emirates",
"country_code": "AE",
"position": "Audit Associate at Baker Tilly Meralis",
"about": null
},
{
"db_source": "1781626137968",
"timestamp": "2026-06-16",
"id": "ben***tif***sma*********",
"name": "ben l****a a**a",
"city": "Mahdia, Tunisia",
"country_code": "TN",
"position": "Gérante Call Center",
"about": null
},
{
"db_source": "1781626137968",
"timestamp": "2026-06-16",
"id": "yog***-ku***-b3*********",
"name": "yogesh K***r",
"city": "Jaipur, Rajasthan, India",
"country_code": "IN",
"position": "Ca at Self",
"about": null
}
]
入力
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.amazon.com/Quencher-FlowState-Stainless-Insulated-Smoothie/dp/B0CRMZHDG8","asin":"B0CRMZHDG8","origin_url":"https://www.amazon.com/Quencher-FlowState-Stainless-Insulated-Smoothie/dp/B0CRMZHDG8","zipcode":"94107","language":""},{"url":"https://www.amazon.com/KitchenAid-Protective-Dishwasher-Stainless-8-72-Inch/dp/B07PZF3QS3","asin":"B07PZF3QS3","zipcode":"","language":""},{"url":"https://www.amazon.com/TruSkin-Naturals-Vitamin-Topical-Hyaluronic/dp/B01M4MCUAF","asin":"","origin_url":"https://www.amazon.com/TruSkin-Naturals-Vitamin-Topical-Hyaluronic/dp/B01M4MCUAF","zipcode":"94124","language":""}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_l7q7dkf244hwjntr0&format=json&uncompressed_webhook=true"
出力
JSON
[
{
"db_source": "1781629939943",
"timestamp": "2026-06-16",
"title": "MelonArt Garden Tool Set,10 Pcs Heavy Duty Gardening Hand Tool Kit for Women Aluminum with Non Slip Ergonomic Handle, St...",
"seller_name": "Mel***rt",
"brand": "MelonArt",
"description": "About this item Garden Tool Sets: The garden tools for gardening comes with folding saw, serrated trower, small trowel, ...",
"initial_price": 31.99,
"currency": "USD"
},
{
"db_source": "1781629939943",
"timestamp": "2026-06-16",
"title": "Smart Watches for Men Android \u0026 iPhone, 1.8\u0022 HD Alexa Built-in Smartwatches Fitness Tracker Watch with Bluetooth Calls, ...",
"seller_name": "Fit***n-U***",
"brand": "Fitpolo",
"description": "About this item 【Alexa Built-in \u0026 Bluetooth Calls】Built-in Amazon Alexa, you can ask questions, check the weather, set a...",
"initial_price": 44.98,
"currency": "USD"
},
{
"db_source": "1781629939943",
"timestamp": "2026-06-16",
"title": "Ortho BugClear Lawn Insect Killer1 - Lawn Bug Killer Granules, Kills Ants, Spiders, Ticks, Fleas, \u0026 Grubs, Treats up to ...",
"seller_name": "Ama***.co***",
"brand": "Ortho",
"description": "Protect your lawn from ants, spiders, ticks, fleas, armyworms, and grubs with Ortho BugClear Lawn Insect Killer1. These ...",
"initial_price": 13.99,
"currency": "USD"
},
{
"db_source": "1781629939943",
"timestamp": "2026-06-16",
"title": "Healthy Gut HistaHarmony | Delayed Release DAO Enzyme Supplement | 30,000 HDU Diamine Oxidase Histamine Blocker | 60 Ser...",
"seller_name": "Healthy G**, ***",
"brand": "Healthy Gut, LLC",
"description": "About this item Supports Histamine Balance: Helps your body break down histamine from food, promoting a more comfortable...",
"initial_price": 38.89,
"currency": "USD"
},
{
"db_source": "1781629939943",
"timestamp": "2026-06-16",
"title": "Ortho WeedClear Lawn Weed Killer Ready-To-Spray - Weed Killer for Lawns, Kills Crabgrass, Dandelion and Clover, Hose-End...",
"seller_name": null,
"brand": "Ortho",
"description": "Get rid of listed weeds in your lawn. Ortho WeedClear Lawn Weed Killer Ready-to-Spray kills all listed weeds without har...",
"initial_price": null,
"currency": "USD"
}
]
入力
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.zillow.com/homedetails/2506-Gordon-Cir-South-Bend-IN-46635/77050198_zpid/?t=for_sale"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lfqkr8wm13ixtbd8f5&format=json&uncompressed_webhook=true"
出力
JSON
[
{
"db_source": "1781625006788",
"timestamp": "2026-06-16",
"zpid": 98005132,
"city": "Lawrenceville",
"state": "GA",
"homeStatus": "SOLD",
"address:city": "Lawrenceville",
"address:streetAddress": "1525 Tapestry Rdg"
},
{
"db_source": "1781625006788",
"timestamp": "2026-06-16",
"zpid": 244599628,
"city": "Douglas",
"state": "GA",
"homeStatus": "RECENTLY_SOLD",
"address:city": "Douglas",
"address:streetAddress": "56 Glenridge Dr"
},
{
"db_source": "1781625006788",
"timestamp": "2026-06-16",
"zpid": 63762902,
"city": "McDonough",
"state": "GA",
"homeStatus": "OTHER",
"address:city": "McDonough",
"address:streetAddress": "1108 Cameron Rd"
},
{
"db_source": "1781625006788",
"timestamp": "2026-06-16",
"zpid": 243422085,
"city": "Richmond Hill",
"state": "GA",
"homeStatus": "FOR_SALE",
"address:city": "Richmond Hill",
"address:streetAddress": "130 Timberland Cir"
},
{
"db_source": "1781625006788",
"timestamp": "2026-06-16",
"zpid": 89751550,
"city": "Pooler",
"state": "GA",
"homeStatus": "FOR_SALE",
"address:city": "Pooler",
"address:streetAddress": "45 Olde Gate Court"
}
]
入力
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.instagram.com/p/Cuf4s0MNqNr"},{"url":"https://www.instagram.com/p/DP861NijuwE"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lk5ns7kz21pck8jpis&format=json&uncompressed_webhook=true"
出力
JSON
[
{
"db_source": "1781615940707",
"timestamp": "2026-06-16",
"url": "https:\/\/www.instagram.com\/p\/C8jobkPPvc4",
"user_posted": "mamabon.gourmet",
"description": ".\n.\n\nアガパンサス(紫君子蘭)\n沢山咲いていました。\n\n.\n\n.\n\n.今日は雨です。\n\n.\n\n☆♡☆☆♡☆\n#アガパンサス \n#花 \n#花が好き \n#写真 \n#flower \n#fleur \n#fleurs \n#flowers \n#ag...",
"hashtags": [
"#flower",
"#fleur",
"#fleurs",
"#flowers",
"#agapanthus"
],
"num_comments": 0,
"date_posted": "2024-06-23T11:35:50.000Z"
},
{
"db_source": "1781615940707",
"timestamp": "2026-06-16",
"url": "https:\/\/www.instagram.com\/p\/DYBq9ObE7Oe\/",
"user_posted": "ro07mio14",
"description": "綺麗な場所がすき #03 #青森 #自然界隈",
"hashtags": [
"#03"
],
"num_comments": 0,
"date_posted": "2026-05-07T05:42:45.000Z"
},
{
"db_source": "1781615940707",
"timestamp": "2026-06-16",
"url": "https:\/\/www.instagram.com\/p\/DYrqXZ7kv4S\/",
"user_posted": "kitayama_akira2024",
"description": "🚀\n\n\\\\ お店価格なら出前でゆっくりと!! \/\/\n\n今日はロケットナウ🚀で出前にしました!\n\n日頃から様々なデリバリーアプリを\n使っておりますが、配送料にサービス料…\n更には〇〇パスに入らないと配送料ありなど\n”誰でも配送料無料...",
"hashtags": [
"#RocketNow"
],
"num_comments": 0,
"date_posted": "2026-05-23T13:16:15.000Z"
},
{
"db_source": "1781615940707",
"timestamp": "2026-06-16",
"url": "https:\/\/www.instagram.com\/p\/DYmOvUUGow3\/",
"user_posted": "newlife__1998",
"description": "#PR\n♥ユイクルーとしての投稿です♥\n 《UIQ》\n\n美容液じゃないの⁇いいえ、これクレンザーなんです♡\nお肌に負担はかけたくないけどメイクはしっかり落としたい!\nって人に本当にオススメのアンプルクレンザーだよ★\n\nQoo10・楽天公式シ...",
"hashtags": [
"#PR",
"#UIQ"
],
"num_comments": 0,
"date_posted": "2026-05-21T10:28:05.000Z"
},
{
"db_source": "1781615940707",
"timestamp": "2026-06-16",
"url": "https:\/\/www.instagram.com\/p\/DZdpM7COhHT\/",
"user_posted": "corhuilaoficial",
"description": "📢 ¡Atención estudiantes!\n\nYa se encuentra publicado el LISTADO DE INSCRITOS de la Décima Tercera Convocatoria Donatón P...",
"hashtags": [
"#Donat",
"#Convocatoria13",
"#CORHUILA",
"#ApoyoEstudiantil"
],
"num_comments": 0,
"date_posted": "2026-06-11T22:58:02.000Z"
}
]
最高峰の DX
簡単に開始可能。容易にスケーリング可能。
比類のない安定性
世界をリードするプロキシインフラストラクチャを利用することで、一貫したパフォーマンスを確保し、障害を最小限に抑えることができます。
Web スクレイピングをシンプルに
本番環境に対応した API でスクレイピングを自動化することで、リソースを節約し、メンテナンスの手間を減らせます。
無限のスケーラビリティ
最適なパフォーマンスを維持しつつ、データ需要に合わせてスクレイピングプロジェクトを簡単にスケーリングできます。
より迅速な導入
1回の API 呼び出し。大量のデータ。
データディスカバリー
データの構造とパターンを検出し、効率的で的を絞ったデータ抽出を行います。
一括要求処理
サーバーの負荷を軽減し、大規模なスクレイピングタスクのデータ収集を最適化します。
データ解析
未加工のHTMLを構造化データに効率的に変換し、データの統合と分析を容易にします。
データ検証
データの信頼性を確保し、手作業での確認と前処理にかかる時間を節約できます。
仕組み
プロキシとCAPTCHAの心配はもう不要
- 自動IP ローテーション
- CAPTCHAソルバー
- ユーザーエージェントのローテーション
- カスタムヘッダー
- JavaScriptレンダリング
- レジデンシャルプロキシ
15分ごとに、当社の顧客はChatGPTを一から訓練するのに十分なデータを収集します。
シームレスなWebデータアクセスのためのAPI
包括的でスケーラブル、かつ準拠したウェブデータ抽出
シームレスなWebデータアクセスのためのAPI
包括的でスケーラブル、かつ準拠したウェブデータ抽出
ワークフローに合わせたカスタマイズ
WebhookまたはAPI配信を通じて、JSON、NDJSON、またはCSVファイルで構造化データを取得。
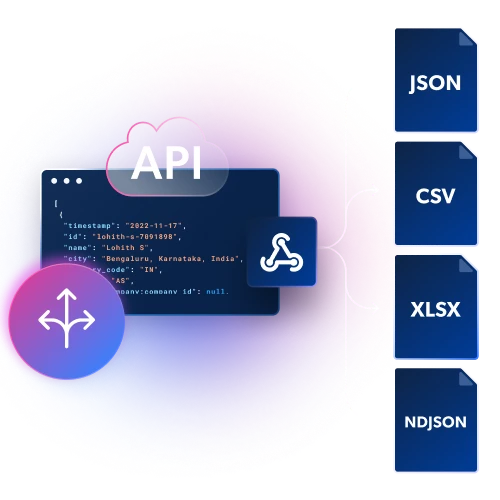
組み込みのインフラとブロック解除
プロキシとブロック解除インフラを維持することなく、最大限のコントロールと柔軟性を実現。CAPTCHAやブロックを回避しながら、あらゆる地域からデータを簡単にスクレイピング。

実績あるインフラ
Bright Dataのプラットフォームは世界中の20,000社以上を支え、99.99%の稼働率と195カ国をカバーする1億5,000万以上の実ユーザーIPへのアクセスで安心を提供。

業界をリードするコンプライアンス
当社のプライバシー慣行は、EUデータ保護規制フレームワーク、GDPR、CCPAを含むデータ保護法に準拠しています。

シームレスなWebデータアクセスのためのAPI
包括的でスケーラブル、かつ準拠したウェブデータ抽出
フレキシブル
ワークフローに合わせたカスタマイズ
WebhookまたはAPI配信を通じて、JSON、NDJSON、またはCSVファイルで構造化データを取得。スケーラブル
組み込みのインフラとブロック解除
プロキシとブロック解除インフラを維持することなく、最大限のコントロールと柔軟性を実現。CAPTCHAやブロックを回避しながら、あらゆる地域からデータを簡単にスクレイピング。安定
実績あるインフラ
Bright Dataのプラットフォームは世界中の20,000社以上を支え、99.99%の稼働率と195カ国をカバーする1億5,000万以上の実ユーザーIPへのアクセスで安心を提供。準拠
業界をリードするコンプライアンス
当社のプライバシー慣行は、EUデータ保護規制フレームワーク、GDPR、CCPAを含むデータ保護法に準拠しています。ユースケース
あらゆるユースケースに対応するスクレイパーAPI





Web API スクレイパー よくある質問
WebスクレイパーAPIとは何ですか?
Web Scraper APIは、ウェブデータ抽出を簡素化するクラウドベースのサービスです。IPローテーション、CAPTCHAの解決、構造化フォーマットへのデータパースを自動処理します。貴重なウェブデータにシームレスにアクセスする必要がある企業向けに設計され、効率的でスケーラブルなデータ収集を実現します。
WebスクレイパーAPIの利用でメリットを得られるのは誰ですか?
AIのためのデータ、機械学習、ビッグデータアプリケーションなどに向けたウェブデータの収集・分析効率化を求めるデータアナリスト、科学者、エンジニア、開発者にとって、Web Scraper APIは特に有益です。
手動スクレイピング手法ではなくウェブスクレイパーAPIを選ぶ理由とは?
Web Scraper APIは、手動によるウェブスクレイピングの限界(ウェブサイト構造の変更への対応、ブロックやキャプチャの発生、インフラ維持に伴う高コストなど)を克服します。データ抽出のための自動化され、拡張性があり、信頼性の高いソリューションを提供し、運用コストと時間を大幅に削減します。
Bright DataのWebスクレイパーAPIが市場でユニークな理由は何か?
Webスクレイパー APIの独自性は、レジデンシャルプロキシやJavaScriptレンダリングといった先進技術を基盤とした、一括リクエスト処理、データ発見、自動検証といった専門機能にあります。これらの機能により広範なアクセスが保証され、高いデータ完全性が維持され、全体的な効率性が向上するため、競争環境においてスクレイパー APIは際立った存在となっています。
Webスクレイパー API の利用を開始するにはどうすればよいですか?
Webスクレイパー APIの利用開始はBright Dataのコントロールパネル経由で簡単に行えます。同パネルは包括的なドキュメントと、APIキー管理・設定用のユーザーフレンドリーなダッシュボードを提供します。このアプローチにより設定要件が最小限に抑えられ、ウェブデータ抽出ニーズに対応する高拡張性・高信頼性のプラットフォームへ即時アクセスが可能となります。
WebスクレイパーAPIは具体的にどのようなユースケースに最適化されていますか?
WebスクレイパーAPIは、競合ベンチマーク、市場トレンド分析、動的価格設定アルゴリズム、感情分析、機械学習パイプラインへのデータ供給など、多様な開発ニーズをサポートします。Eコマース、フィンテック、ソーシャルメディア分析に不可欠なこれらのAPIは、開発者がデータ駆動型戦略を効果的に実装することを可能にします。
WebスクレイパーAPIは、大規模なデータ抽出タスクをどのように管理しますか?
Web Scraper APIは高同時接続性とバッチ処理機能を備え、大規模データ抽出シナリオにおいて優れた性能を発揮します。これにより開発者はスクレイピング操作を効率的に拡張でき、高スループットで膨大なリクエスト量を処理可能です。
WebスクレイパーAPIは、抽出された情報をどのデータ形式で提供できますか?
Webスクレイパー APIは、NDJSONやCSVを含む多様な形式で抽出データを配信し、幅広い分析ツールやデータ処理ワークフローとのシームレスな統合を保証します。これにより、開発者環境での容易な導入が促進されます。