

30年にわたり、Craigslistはあらゆる取引の定番マーケットプレイスでした。1990年代風の非常にシンプルなデザインにもかかわらず、Craigslistは「個人直売」の取引を探すのに世界最高の場所と言えるでしょう。
本日はPythonスクレイパーを用いてCraigslistから自動車データを抽出します。手順を追えば、すぐにプロ並みのスクレイピングが可能になります。大規模処理をお探しですか?最高のスクレイピングツール比較記事をご覧ください。
クレイグリストから抽出する情報
HTMLを掘り下げる:困難な方法
ウェブスクレイピングで最も重要なスキルは、どこを探すべきかを知ることです。HTMLコードから個々のアイテムを抽出する複雑すぎるパーサーを書くこともできます。
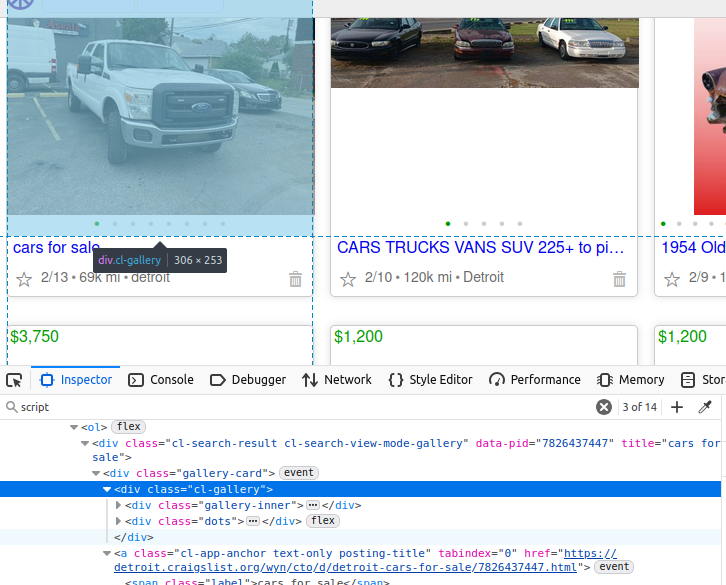
下の画像のトラックを見ると、そのデータはクラス「cl-gallery」のdiv要素内にネストされています。手間のかかる方法を選ぶなら、このタグを見つけ、そこからさらに要素をパースすることができます。
JSONを見つける:貴重な時間を節約
しかし、より良い方法があります。Craigslistを含む多くのサイトは、ページ全体を構築するために埋め込みJSONデータを使用しています。このJSONを見つけられれば、パース作業をほぼゼロに削減できます。
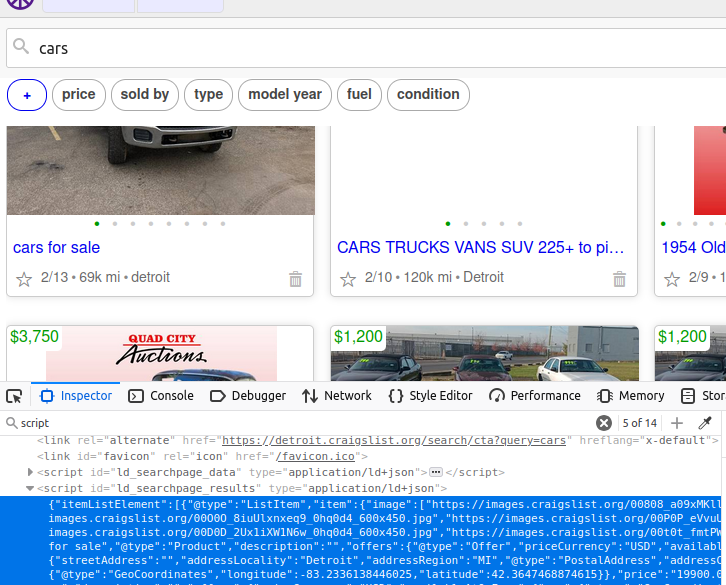
Craigslistのページには、必要な全データを保持するscriptオブジェクトが存在します。この1つの要素を取得すれば、ページ全体のデータを取得できます。そのid はld_searchpage_resultsです。CSSセレクタ script[id='ld_searchpage_results']でこの要素を特定できます。
Pythonによるクレイグリストのスクレイピング
目的の要素が特定できたことで、Craigslistのスクレイピングは格段に容易になります。次の数セクションでは、個々のコードを解説し、最終的に機能するスクレイパーとして統合します。
ページのパース
def scrape_listings(location, keyword):
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
scraped_data = []
success = False
while not success:
try:
response = requests.get(url)
# 異常なステータスコードを受信した場合、エラーを発生させる
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']")
json_data = json.loads(embedded_json_string.text).get("itemListElement")
for dirty_item in json_data:
item = dirty_item.get("item")
offers = item.get("offers")
location_info = item.get("offers").get("availableAtOrFrom")
images = item.get("image")
image = None
if len(images) > 0:
image = images[0]
clean_item = {
"name": item.get("name"),
"image": image,
"price": item.get("offers").get("price"),
"currency": item.get("offers").get("priceCurrency"),
"city": location_info.get("address").get("addressLocality"),
"region": location_info.get("address").get("addressRegion"),
"country": location_info.get("address").get("addressCountry")
}
scraped_data.append(clean_item)
#全リストの処理が完了したので、success = True を設定しループを終了
success = True
except Exception as e:
print(f"リストのスクレイピングに失敗しました: {e} at {url}")
return scraped_data
- まず、
url、scraped_data、success変数を作成します。url: 検索を実行する正確なURL。scraped_data: 検索結果を格納する場所。success: このスクレイパーを永続的に動作させたい。whileループと組み合わせることで、ジョブが完了しsuccessをTrueに設定するまでスクレイパーは終了しない。
- 次に、ページを取得し、不正なレスポンスの場合はエラーを発生させます。
soup = BeautifulSoup(response.text, "html.parser")は、ページをパースするために使用できるBeautifulSoupオブジェクトを作成します。- 埋め込まれたJSONを以下のように検索します:
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']")。 - 次に、
json.loads()でこれを辞書に変換します。 - 次に、すべての項目を反復処理し、データをクリーンアップします。
clean_itemはscraped_dataに追加されます。 - 最後に
successをTrueに設定し、スクレイピングしたリストの配列を返します。
データの保存
ウェブスクレイピングで最も一般的な保存方法はCSVとJSONです。両形式でのリスト保存方法を順を追って説明します。
JSONファイルへの保存
この基本的なスニペットは、JSON保存ロジックを含んでいます。ファイルを開き、データとともにjson.dump()に渡します。JSONファイルを読みやすくするために、indent=4を使用しています。
with open(f"{QUERY}-{LOCATION}.json", "w") as file:
try:
json.dump(listings, file, indent=4)
except Exception as e:
print(f"結果の保存に失敗しました: {e}")
CSVファイルへの保存
CSVへの保存には少し手間がかかります。CSVは配列の扱いが得意ではありません。これが、データクリーニング時に画像を1枚しか抽出しなかった理由です。
リストが存在しない場合、関数は終了します。リストが存在する場合、配列の最初の要素からkeys() を使用して CSV ヘッダーを書き込みます。その後、csv.DictWriter() を使用してヘッダーとリストを書き込みます。
def write_listings_to_csv(listings, filename):
if not listings:
print("リストが見つかりません。CSV書き込みをスキップします。")
return
# CSV列ヘッダーを定義
fieldnames = listings[0].keys()
# CSVへのデータ書き込み
with open(filename, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(listings)
すべてを統合する
では、これらのパーツをすべて組み合わせてみましょう。このコードは完全に機能するスクレイパーです。
import requests
from bs4 import BeautifulSoup
import json
import csv
def write_listings_to_csv(listings, filename):
if not listings:
print("リストが見つかりませんでした。CSV書き込みをスキップします。")
return
# CSV列ヘッダーを定義
fieldnames = listings[0].keys()
# CSVへのデータ書き込み
with open(filename, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(listings)
def scrape_listings(location, keyword):
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
scraped_data = []
success = False
while not success:
try:
response = requests.get(url)
# 異常なステータスコードを受信した場合、エラーを発生させる
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']")
json_data = json.loads(embedded_json_string.text).get("itemListElement")
for dirty_item in json_data:
item = dirty_item.get("item")
offers = item.get("offers")
location_info = item.get("offers").get("availableAtOrFrom")
images = item.get("image")
image = None
if len(images) > 0:
image = images[0]
clean_item = {
"name": item.get("name"),
"image": image,
"price": item.get("offers").get("price"),
"currency": item.get("offers").get("priceCurrency"),
"city": location_info.get("address").get("addressLocality"),
"region": location_info.get("address").get("addressRegion"),
"country": location_info.get("address").get("addressCountry")
}
scraped_data.append(clean_item)
#全リストの処理完了、success = True を設定しループを終了
success = True
except Exception as e:
print(f"リストのスクレイピングに失敗しました: {e} at {url}")
return scraped_data
if __name__ == "__main__":
LOCATION = "detroit"
QUERY = "cars"
OUTPUT = "csv"
listings = scrape_listings(LOCATION, QUERY)
if OUTPUT == "json":
with open(f"{QUERY}-{LOCATION}.json", "w") as file:
try:
json.dump(listings, file, indent=4)
except Exception as e:
print(f"結果の保存に失敗しました: {e}")
elif OUTPUT == "csv":
try:
write_listings_to_csv(listings, f"{QUERY}-{LOCATION}.csv")
print(f"{len(listings)}件のリストを{QUERY}-{LOCATION}.csvに保存しました")
except Exception as e:
print(f"CSV出力の書き込みに失敗しました: {e}")
else:
print("出力方法がサポートされていません")
メインブロック内では、OUTPUT変数で保存方法を指定できます。JSONファイルに保存する場合はjsonに設定し、CSVの場合はcsvに設定します。データ収集では、これらの保存方法を常に両方使用することになります。
JSON出力
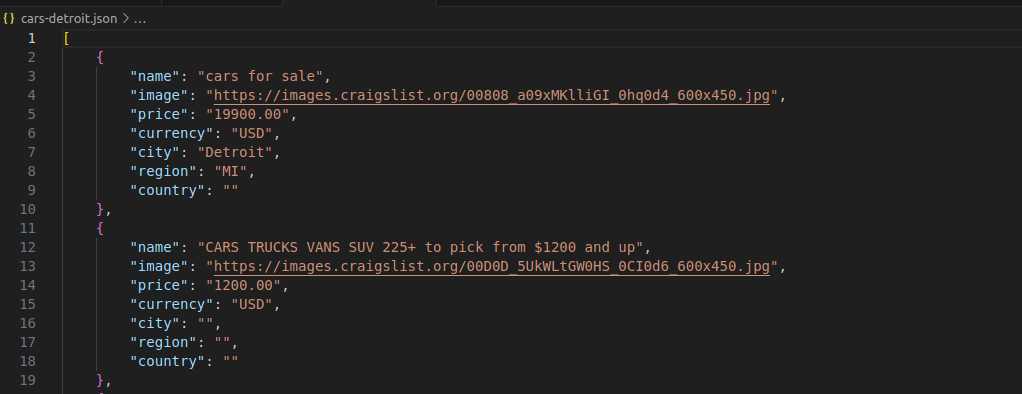
下の画像でわかるように、各車両は読みやすいJSONオブジェクトで表現され、明確で整った構造を持っています。
CSV出力
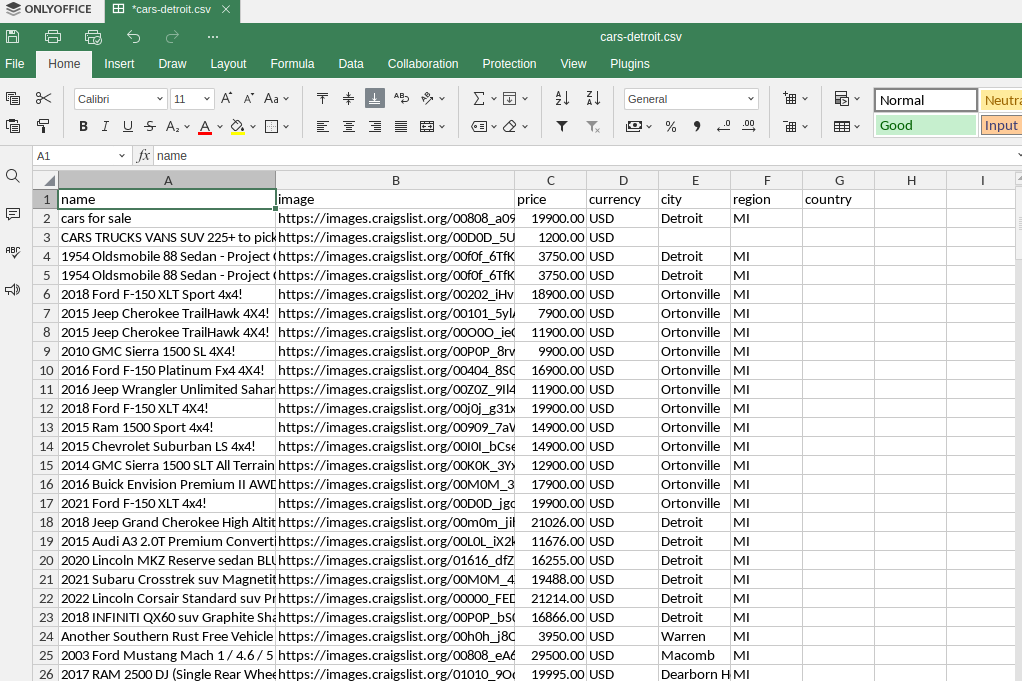
CSV出力もほぼ同様です。すべてのリストを保持した整然としたスプレッドシートが得られます。
Web UnlockerでCraigslistの保護機能を回避
Craigslistのスクレイピング作業を拡大するにつれ、CAPTCHA、IP禁止、ボット検知システムといった障害に直面し、スクレイパーが完全に停止する可能性があります。
Bright DataのWeb Unlockerは、大規模データ収集のために特別に設計されたエンタープライズグレードのインフラストラクチャで、これらの課題を自動的に解決します。
自動CAPTCHAの解決
手動でCAPTCHAを解いたり、リクエストブロックで貴重なデータを失う代わりに、Web Unlockerが処理します:
- ✅ reCAPTCHA、hCaptchaなどへの自動CAPTCHA解決
- ✅ 検出回避のためのリアルタイムフィンガープリントランダム化
- ✅ 各サイトの保護メカニズムに適応するスマートな再試行ロジック
- ✅ 厳重に保護されたページでも99.9%の成功率
CAPTCHAソルバーの機能について詳しくはこちら。
簡単な統合
import requests
# Web Unlocker エンドポイント
WEB_UNLOCKER_URL = 'https://brd.superproxy.io:33335'
AUTH = 'brd-customer-<CUSTOMER_ID>-zone-web_unlocker:<ZONE_PASSWORD>'
def scrape_with_unlocker(location, keyword):
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
response = requests.get(
url,
プロキシ={
'http': f'http://{AUTH}@{WEB_UNLOCKER_URL}',
'https': f'http://{AUTH}@{WEB_UNLOCKER_URL}'
},
verify=False
)
return response.text
# ブロックやCAPTCHAを気にせずスクレイピング
listings = scrape_with_unlocker("detroit", "cars")Web Unlockerを使用すると、以下が得られます:
- 手動でのCAPTCHAの解決不要
- プロキシ管理の煩わしさなし
- IPローテーション設定不要
- 大規模なクリーンで信頼性の高いデータ収集を実現
スクレイピングブラウザの利用
スクレイピングブラウザを使用すると、プロキシ統合機能を備えたPlaywrightインスタンスを実行できます。Pythonスクリプトからフルブラウザを操作することで、スクレイピングを次のレベルへ引き上げます。Playwrightへのプロキシ統合にご興味がある場合
以下のコードでは、パース処理の大部分は従来通りですが、asyncioと async_playwrightを使用してヘッドレスブラウザを開き、実際にこのブラウザでページを取得します。BeautifulSoupの代わりに、CSSセレクタをPlaywrightのquery_selector()メソッドに渡します。
import asyncio
from playwright.async_api import async_playwright
import json
AUTH = 'brd-customer-<YOUR-USERNAME>-zone-<YOUR-ZONE-NAME>:<YOUR-PASSWORD>'
SBR_WS_CDP = f'wss://{AUTH}@brd.superproxy.io:9222'
async def scrape_listings(keyword, location):
print('Connecting to スクレイピングブラウザ...')
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
scraped_data = []
async with async_playwright() as p:
browser = await p.chromium.connect_over_cdp(SBR_WS_CDP)
context = await browser.new_context()
page = await context.new_page()
try:
print('接続完了! Navigating to webpage...')
await page.goto(url)
embedded_json_string = await page.query_selector("script[id='ld_searchpage_results']")
json_data = json.loads(await embedded_json_string.text_content())["itemListElement"]
for dirty_item in json_data:
item = dirty_item.get("item")
offers = item.get("offers")
location_info = item.get("offers").get("availableAtOrFrom")
images = item.get("image")
image = None
if len(images) > 0:
image = images[0]
clean_item = {
"name": item.get("name"),
"image": image,
"price": item.get("offers").get("price"),
"currency": item.get("offers").get("priceCurrency"),
"city": location_info.get("address").get("addressLocality"),
"region": location_info.get("address").get("addressRegion"),
"country": location_info.get("address").get("addressCountry")
}
scraped_data.append(clean_item)
except Exception as e:
print(f"データスクレイピングに失敗しました: {e}")
finally:
await browser.close()
return scraped_data
async def main():
QUERY = "cars"
LOCATION = "detroit"
listings = await scrape_listings(QUERY, LOCATION)
try:
with open(f"{QUERY}-スクレイピングブラウザ.json", "w") as file:
json.dump(listings, file, indent=4)
except Exception as e:
print(f"結果の保存に失敗しました {e}")
if __name__ == '__main__':
asyncio.run(main())
カスタム構築のノーコードスクレイパーの使用
Bright Dataでは、ノーコードのCraigslistスクレイパーも提供しています。ノーコードスクレイパーでは、スクレイピングしたいデータとページを指定するだけで、当社がスクレイパーを作成・デプロイします!
「マイスクレイパー」セクションで「新規」をクリックし、「カスタム構築スクレイパーをリクエスト」を選択してください。
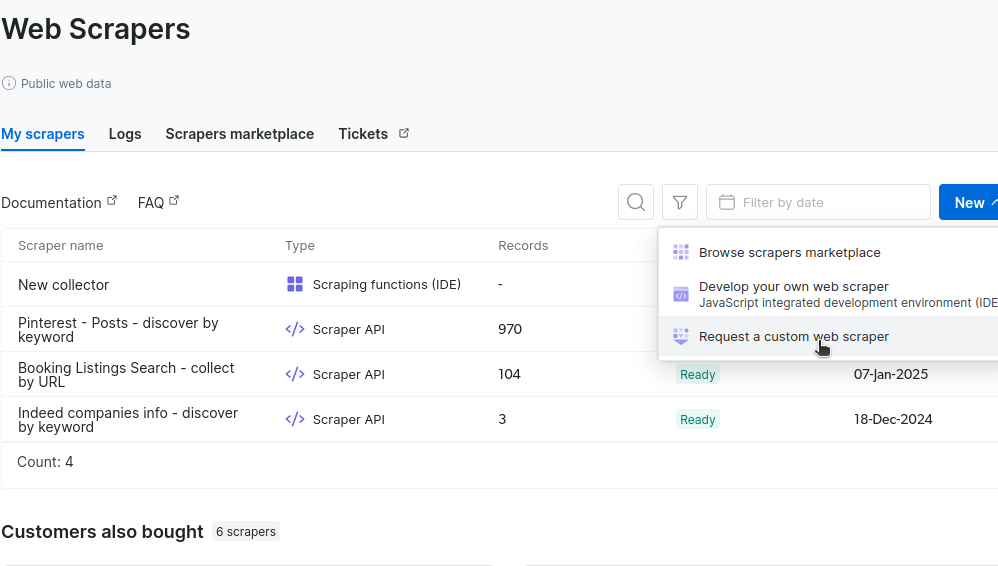
次に、サイトのレイアウトを含むURLの入力が求められます。下の画像では、デトロイトでの自動車検索用URLを送信しています。別の都市用のURLを追加することも可能です。
自動化されたプロセスにより、当社がサイトをスクレイピングし、確認用のスキーマを作成します。
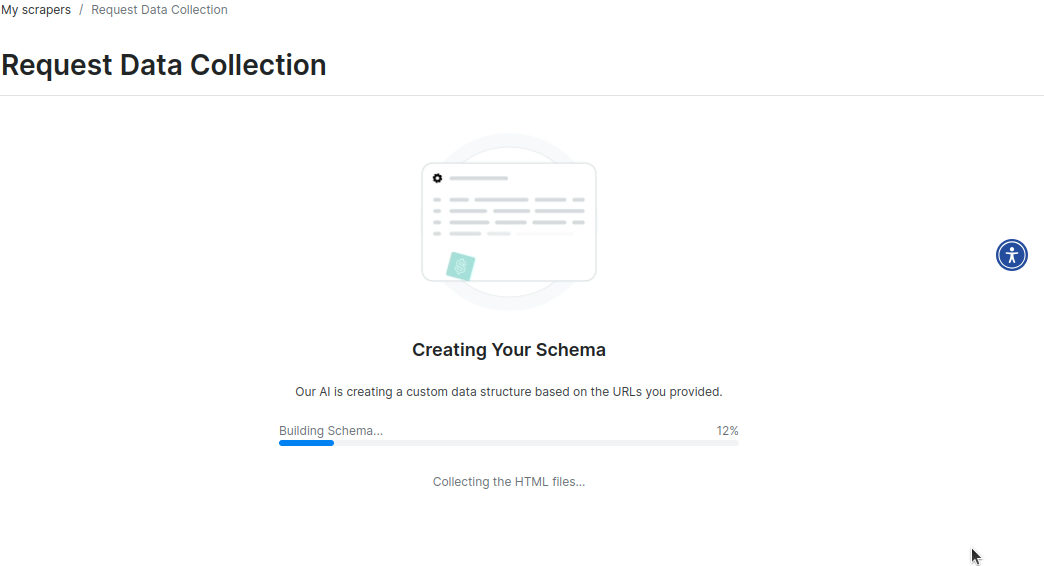
スキーマ作成後、必ず内容をご確認ください。
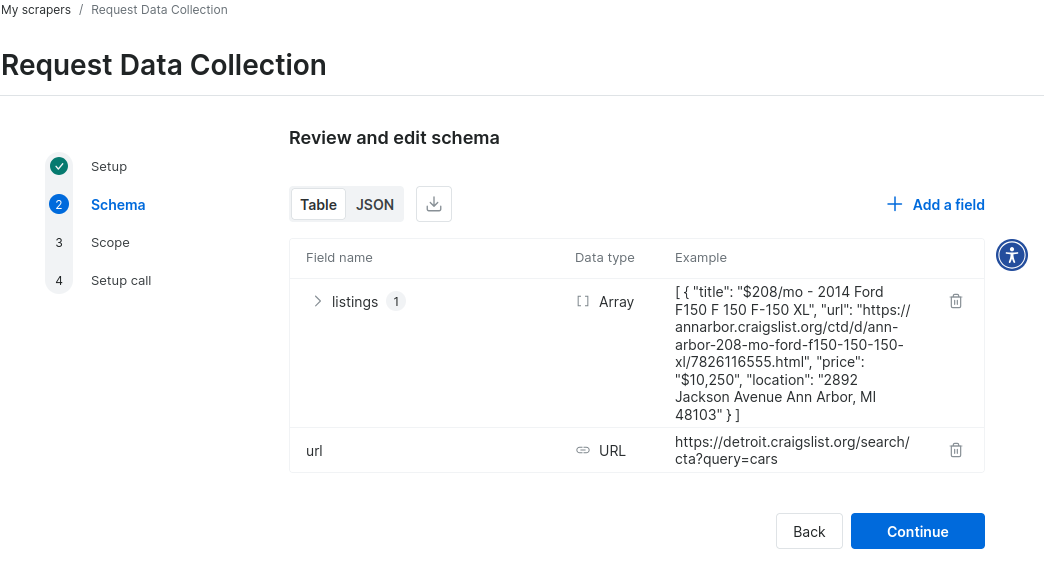
カスタムCraigslistスクレイパーのスキーマから生成されたサンプルJSONデータです。数分以内に機能するプロトタイプが完成します。
{
"type": "object",
"fields": {
"listings": {
"type": "array",
"active": true,
"items": {
"type": "object",
"fields": {
"title": {
"type": "text",
"active": true,
"sample_value": "$208/mo - 2014 Ford F150 F 150 F-150 XL"
},
"url": {
"type": "url",
"active": true,
"sample_value": "https://annarbor.craigslist.org/ctd/d/ann-arbor-208-mo-ford-f150-150-150-xl/7826116555.html"
},
"price": {
"type": "price",
"active": true,
"sample_value": "$10,250"
},
"location": {
"type": "text",
"active": true,
"sample_value": "2892 Jackson Avenue Ann Arbor, MI 48103"
}
}
}
},
"url": {
"type": "url",
"required": true,
"active": true,
"sample_value": "https://detroit.craigslist.org/search/cta?query=cars"
}
}
}
次に、収集範囲を設定します。Craigslist全体や特定のセクションだけをスクレイピングする必要はないため、収集を開始するURLを指定します。
最後に、デプロイメントに関する専門家との電話相談をスケジュールするよう促されます。月額300ドルで保守・メンテナンスを利用するか、1,000ドルの一括デプロイメント料金を選択できます。
結論
Craigslistをスクレイピングする際、Pythonを活用して迅速かつ効率的なデータ処理が可能になりました。データのパースとクリーニング方法、CSVやJSONを用いた保存方法も習得しました。完全なブラウザ機能が必要な場合は、プロキシ完全統合機能を備えたスクレイピングブラウザを活用できます。スクレイピングプロセスを完全に自動化したい場合は、当社のノーコードスクレイパーの扱い方も理解できました。
さらに、スクレイピングプロセス自体を省略したい場合、Bright Dataではすぐに使えるクレイグリストデータセットを提供しています。今すぐ登録して無料トライアルを始めましょう!





