
この記事では、以下の内容を学びます:
- Akamaiとは何か、そのアンチボットシステムがどのように機能するか。
- サイトがAkamaiを使用しているかどうかを確認する方法。
- Akamaiボット検出バイパスの高レベルなアプローチ。
- Akamaiのチャレンジを通過するためのオープンソースツールの使用方法。
- 静的リクエストとブラウザ自動化シナリオの両方で、Bright DataによるAkamaiバイパスをより確実に処理する方法。
さっそく始めましょう!
Akamaiのアンチボットメカニズムの仕組み
Akamaiは、ユーザーとオリジンサーバーの間に位置するCDNおよびボット管理レイヤーとして機能します。すべてのリクエストはエッジネットワークを通過し、そこで検査されて許可、チャレンジ、またはブロックされます。
アンチボットの観点から、Akamaiは多層的な検出システムに依存しています:
- レイヤー#1 – ネットワークおよびリクエスト分析:IPレピュテーションとプロトコルレベルのパターン(TLSフィンガープリンティングなど)を評価します。
- レイヤー#2 – フィンガープリンティングとクライアントサイド分析:Akamaiはブラウザで実行されるJavaScriptチャレンジを注入し、デバイス特性、ブラウザ設定、実行環境の動作などのシグナルを収集します。これらのフィンガープリントは、HTTPリクエストが有効に見える場合でも、実際のブラウザとヘッドレスまたは自動化されたブラウザを区別するのに役立ちます。
- レイヤー#3:行動分析:マウスの動き、キーストロークパターン、ナビゲーションフロー、アクション間のタイミングが含まれます。これは、より高度なボットが検出を回避するために人間を模倣しようとし、不確実性の「グレーゾーン」に陥る場所です。
これらのシグナルに基づいて、Akamaiはリスクスコア(ボットスコア)を割り当て、トラフィックを正規ユーザー、既知のボット、疑わしいトラフィックなどのカテゴリに分類します。応答はそれに応じて異なります:トラフィックは許可、レート制限、CAPTCHAなどのメカニズムでチャレンジ、または完全にブロックされる場合があります。
WebサイトがAkamaiで保護されているかどうかを確認する方法
WebサイトがAkamaiに依存しているかどうかを判断するには、ネットワークレベルとブラウザレベルのインジケーターの組み合わせを探す必要があります。
例えば、Zalandoの商品ページを考えてみましょう。これはAkamaiのCDNおよびアンチボットレイヤーの背後にあることで広く知られています。ブラウザのDevToolsを開き、「ネットワーク」タブに移動してページをリロードします。ブラウザが行ったリクエストを検査し、レスポンスヘッダーに注目します: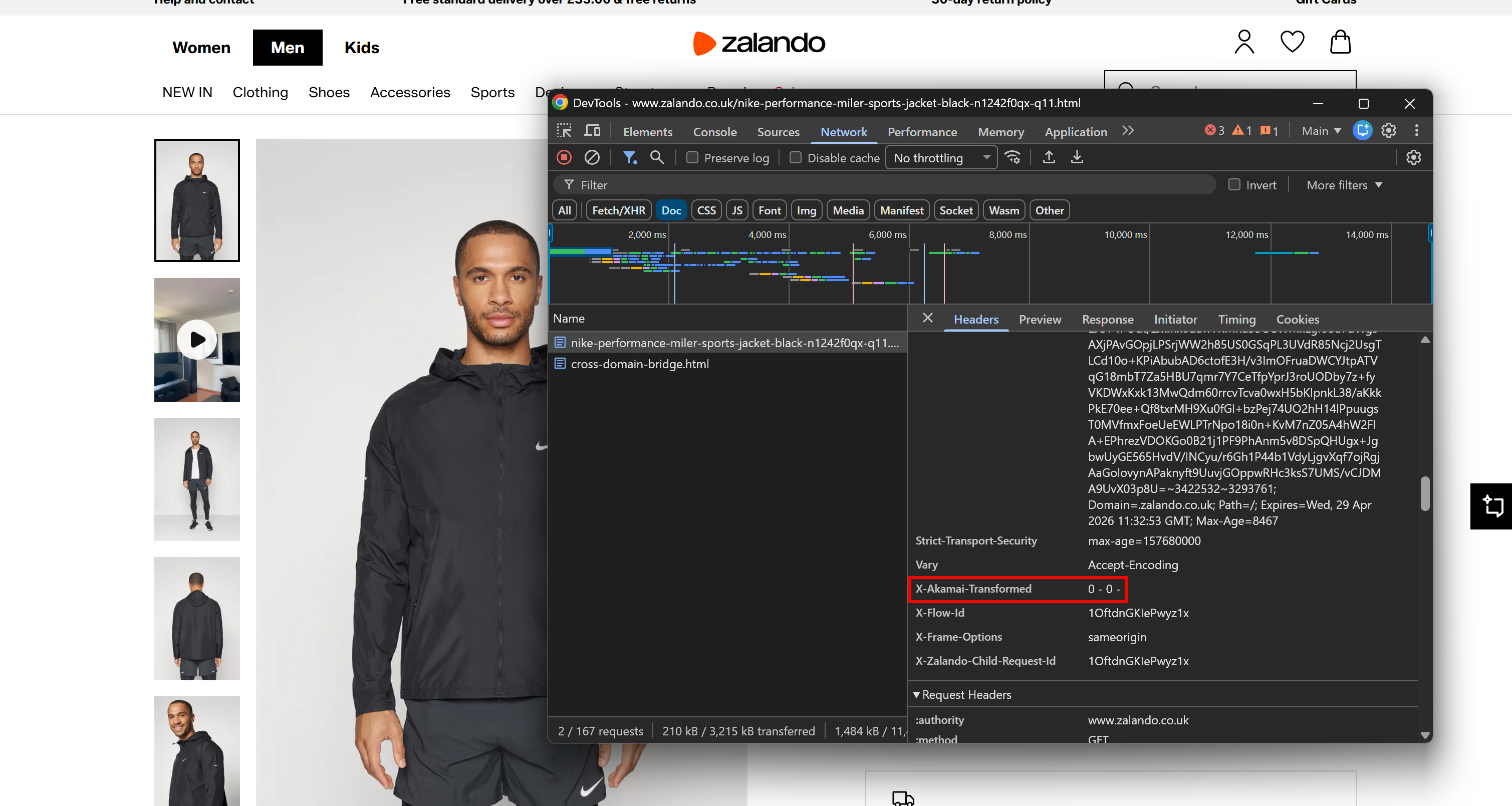
X-Akamai-Transformedヘッダーが見られるかもしれません。X-Akamai-*ヘッダーの存在は、トラフィックがAkamaiのCDNレイヤーを通じて処理されていることを示します。
別の強力なシグナルは、サーバーによって設定されたCookieから来ます。「アプリケーション」タブの「Cookie」セクションで確認できます。Akamaiに支えられたページでは、_abckとak_bmscが見られます。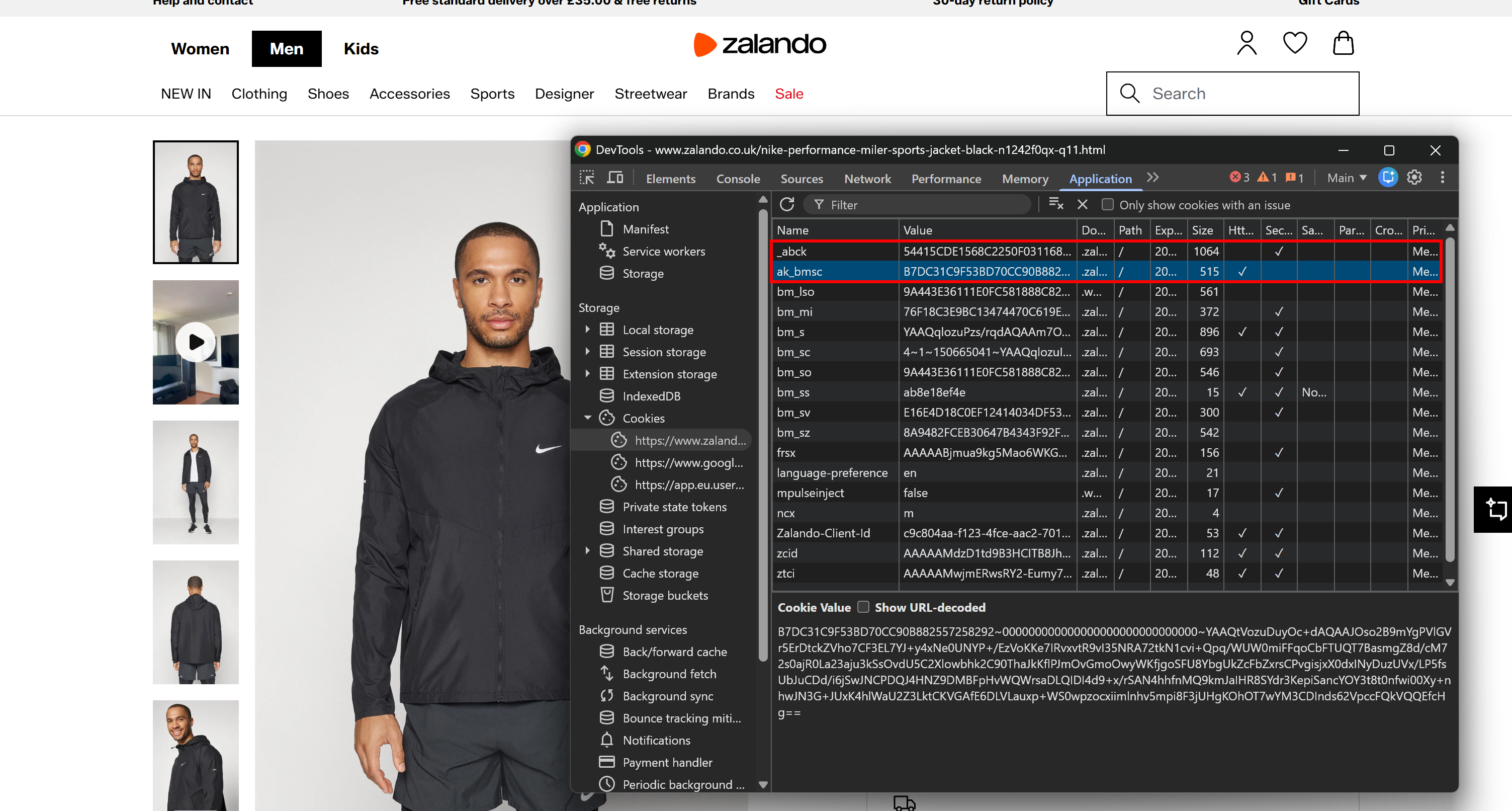
これらはAkamaiのボット検出システムによって設定される重要なCookieです:
_abck:行動追跡とリスクスコアリングに使用される長期的なCookie(数ヶ月間持続する場合があります)。ak_bmsc:閲覧行動の異常を検出するために使用される短期的なセッションCookie(数時間以内に期限切れになります)。
追加のシグナルがある場合もありますが、これらはほとんどのAkamai支援Webサイトを識別するのに十分です。
Akamaiボット検出の実際の動作
自動化シナリオでAkamaiのアンチボットメカニズムがどのように動作するかを理解するために、2つの一般的なアプローチを考えてみましょう:
- RequestsなどのHTTPクライアントを使用してターゲットサーバーに直接リクエストを送信します。
- Playwrightなどのブラウザ自動化ツールを使用してヘッドレスモードでページをレンダリングします。
注意:ターゲットページは前述の同じZalandoの商品ページです。
Akamai対Requests
requestsライブラリを使用してAkamai管理ページを取得してみましょう:
# pip install requests
import requests
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
response = requests.get(url)
print("Status code:", response.status_code)
print("\nPage HTML:\n")
print(response.text[:2500])スクリプトは以下を出力します:
Status code: 403これは、サーバーが403 Forbiddenレスポンスでリクエストを拒否したことを示しています。返されたHTMLは、期待される商品コンテンツの代わりにエラーページを返します。
したがって、基本的なrequests呼び出しはAkamai管理ページにアクセスするには不十分です。ほとんどの標準HTTPクライアントでも同じ結果になります。
Akamai対Playwright
Playwrightをヘッドレスモードで使用してターゲットページにアクセスします。次に、HTTPステータスコードを出力してスクリーンショットを撮ります:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
with sync_playwright() as p:
# Visit the target page in headless mode
browser = p.chromium.launch(headless=True)
context = browser.new_context()
page = context.new_page()
response = page.goto(url)
# Print the response's HTTP status code
if response:
print("Status code:", response.status)
else:
print("No response received")
# Take a screenshot of the page
page.screenshot(path="zalando.png")
browser.close()再び、リクエストはブロックされ、出力は次のようになります:
Status code: 403結果のスクリーンショットには、期待される商品コンテンツの代わりにアクセス拒否ページが含まれます: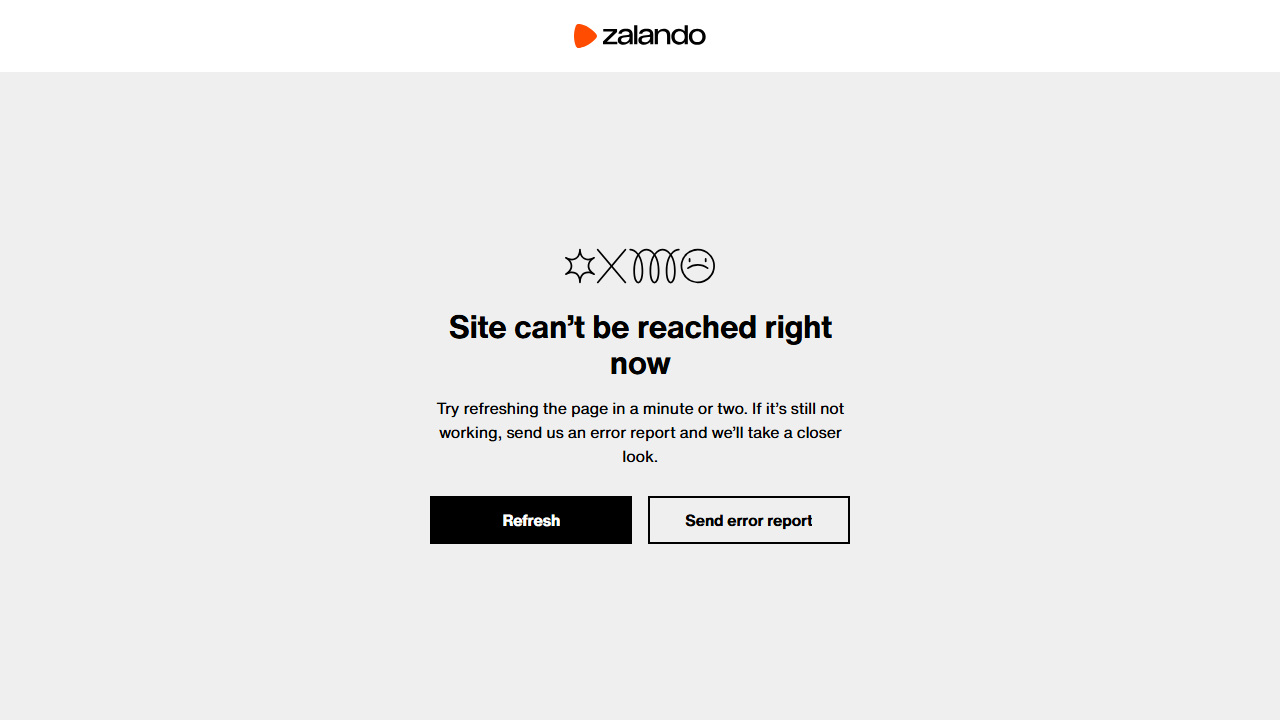
エラーページは、詳細情報を提供せずにアクセスが許可されていないことを示しています。
注意:他のアンチボットシステム(例:Cloudflare)とは異なり、Akamaiのエラーレスポンスは通常、Webサイトによって異なります。
Akamaiボット検出バイパスの高レベルなアプローチ
この章では、Akamaiボット検出をバイパスするための主なアプローチを探ります。急いでいる場合は、以下のサマリーテーブルを参照してください。
| アプローチ | 簡単な説明 | メリット | デメリット |
|---|---|---|---|
| オリジンへの直接アクセス | オリジンサーバーのIPが公開されている場合、CDNをバイパスしてオリジンサーバーに直接リクエストを送信しようとします | 追加ツール不要 | 実際にはほとんど機能しない |
| オープンソースブラウザ自動化バイパスツール | 特定の自動化フレームワークを使用して実際のユーザーブラウザセッションをシミュレートします | 無料 | リバースエンジニアリングとIPベースのブロックにより検出可能 |
| プレミアムアンチボットスクレイピングツール | すべてを処理するマネージドクラウドベースサービスを使用します | 高い信頼性、スケーラブル、最小限のセットアップ、完全なアンチボットスタックを処理 | 有料 |
アプローチ#1:オリジンへの直接アクセス
結局のところ、AkamaiはCDNです。つまり、ターゲットオリジンサーバーとユーザーの間に位置し、分散エッジネットワークを通じてトラフィックをルーティングしながらコンテンツをキャッシュして保護します。
理論的には、オリジンサーバーのIPアドレスが公開されている場合(例:過去のDNSレコードや設定ミスを通じて)、直接リクエストを送信しようとすることができます。これは、トラフィックがCDNレイヤーの外側にルーティングされるため、Akamaiネットワークを直接バイパスすることを意味します。
実際には、このアプローチはいくつかの理由から信頼性がありません:
- オリジンアクセス制限:適切に設定されたオリジンサーバーは、CDNのIP範囲からのトラフィックのみを受け入れるか、認証済みリクエスト(例:署名付きヘッダーやトークン)を要求します。
- ネットワークレベルの制御:ファイアウォールとセキュリティグループは通常、直接パブリックアクセスをブロックします。
- 限られた公開:CDNの背後にあるオリジンIPを発見することは珍しく、現代のセットアップはこの種の漏洩を防ぐように設計されています。
これらの制限により、オリジンへの直接アクセスは適切に設定された環境では一般的に実行不可能です。これは実用的なアプローチというよりも理論的な概念です。
アプローチ#2:オープンソースブラウザ自動化バイパスツールに依存する
様々なオープンソースのブラウザ自動化ライブラリは、実際のユーザー行動に似た自動化セッションを生成します。これには、Camoufox、SeleniumBase、NODRIVER、およびその他のアンチボット指向の自動化フレームワークなどのツールが含まれます。また、Scraplingのようなオールインワンスクレイピングフレームワークも同様の機能を提供します。
これらのツールは、SeleniumライクまたはPlaywrightライクのブラウザ自動化APIを提供しながら、リアルなフィンガープリントを実現するために基礎となるブラウザを調整します。これはブラウザ自動化をヘッドレスモードで実行する場合にも適用されます。
ただし、このAkamaiボット検出バイパスアプローチには2つの主な制限があります:
- オープンソースの可視性:これらのツールはオープンソースであるため、実装の詳細が公開されています。その結果、Akamaiなどのアンチボットプロバイダーはそれらをリバースエンジニアリングし、一時的にブロックするか効果を低下させることができます(更新がリリースされるまで)。これにより、検出システムと自動化ツールの間で継続的なイタチごっこが生まれます。
- IPベースの実施:このアプローチはフィンガープリントベースのチェックをバイパスするのに優れています。ただし、スクレイピングリクエストは依然としてあなたのIPアドレスから発信されます。そのため、Akamaiはレート制限またはIPレピュテーションベースのメカニズムを通じてブロックすることができます。これを軽減するには、サードパーティのプレミアムプロキシローテーションサービスを統合する必要があります。
アプローチ#3:プレミアムAkamaiバイパススクレイピングツールを統合する
Akamaiボット保護をバイパスする最も信頼性が高くスケーラブルな方法は、プレミアムウェブスクレイピングツールを使用することです。これらのサービスは、ブラウザフィンガープリンティング、自動化検出、IP管理、CAPTCHAの解決、インフラスケーリングなど、チャレンジの完全なスタックを処理します。
リクエストを直接管理する代わりに、ターゲットURLを提供するとアンロックされたコンテンツが返されます。これは標準的なHTTPレスポンスを通じて、または場合によってはブラウザ自動化セッションを通じて提供される場合があります。
これらのソリューションはクラウドに展開されているため、オープンソースライブラリとは異なり、リバースエンジニアリングのリスクがありません。さらに、通常は大規模なプロキシネットワーク上に構築されており、エンタープライズレベルのスケーラビリティを実現します。
主なデメリットはコストです。これらのサービスは商業製品です。ただし、成功したリクエストあたりのコストは非常に低い場合があります(場合によっては1セントの端数)。
オープンソースソリューションでAkamaiをバイパスする方法
オリジンへの直接アクセスは実用的なアプローチというよりも理論的なものです。そのため、アンチボット専用のブラウザ自動化ツールを使用してAkamai保護をバイパスする方法のデモから始めましょう。
このセクションでは、CamoufoxとSeleniumBaseをテストしますが、他のツールも信頼できます。テストの目標は、前述の保護されたZalandoの商品ページにアクセスし、スクリーンショットを撮ることです。
注意:以下の結果は、レジデンシャルIPを使用した単一のスクリプト実行を参照しています。同じスクリプトをサーバーから実行するか大規模に実行すると、レート制限やIPレピュテーションの問題により失敗する可能性があります。
Akamai保護コンテンツに対するCamoufoxとSeleniumBaseの動作をご覧ください!
CamoufoxによるAkamaiバイパステスト
まず、PythonプロジェクトにCamoufoxをインストールします:
pip install camoufox次に、ブラウザバイナリを取得します:
python -m camoufox fetchCamoufoxはPlaywrightの上に構築されているため、APIは非常に似ています。ターゲットページにアクセスし、HTTPステータスコードを出力して、以下でスクリーンショットを撮ります:
# pip install camoufox
# python -m camoufox fetch
from camoufox.sync_api import Camoufox
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
with Camoufox(headless=True) as browser:
# Visit the target page
page = browser.new_page()
response = page.goto(url)
# Print the response's HTTP status code
if response:
print("Status code:", response.status)
else:
print("No response received")
# Take a screenshot of the page
page.screenshot(path="camoufox_zalando.png")このライブラリの詳細については、Camoufoxを使ったウェブスクレイピングガイドをお読みください。
ヘッドレスモードでも、期待される結果は次のとおりです:
Status code: 200生成されたcamoufox_zalando.pngファイルには、レンダリングされたページが含まれているはずです: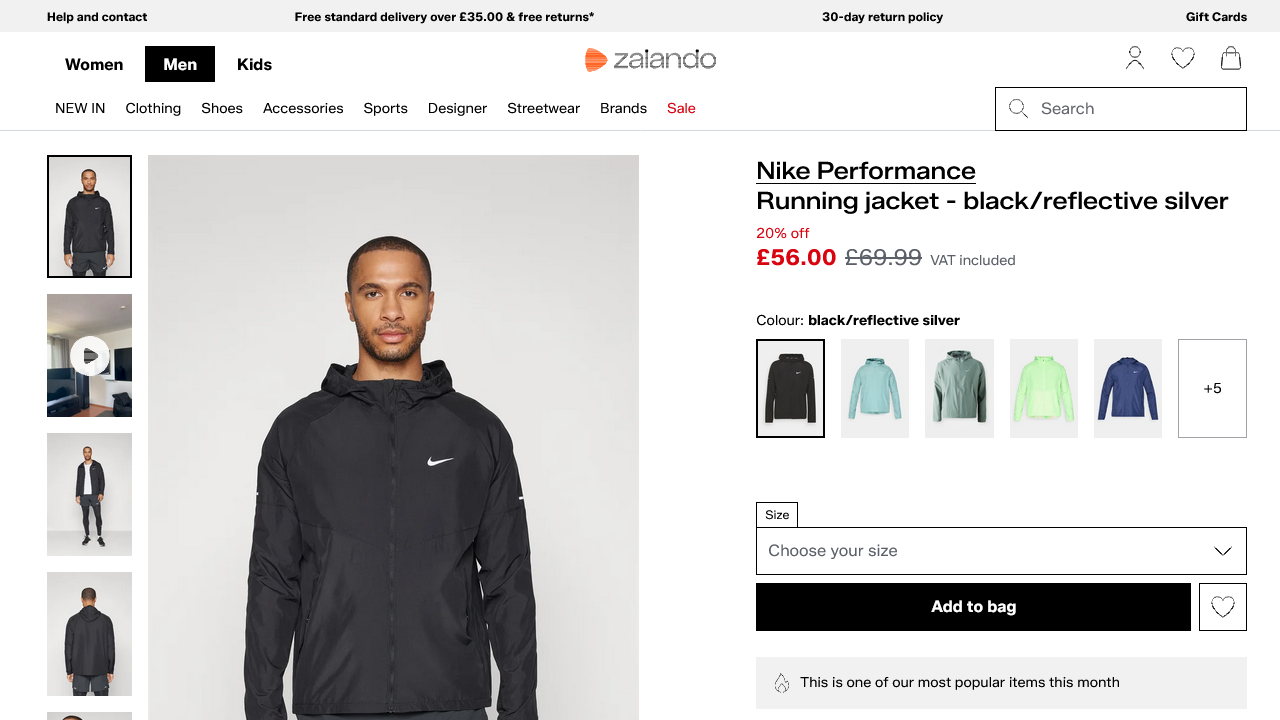
素晴らしい!CamoufoxはAkamaiをバイパスすることに成功しました。
SeleniumBaseによるAkamaiバイパステスト
SeleniumBaseをインストールします:
pip install seleniumbase次に、UCモードでターゲットページにアクセスしてスクリーンショットを撮ります:
# pip install seleniumbase
from seleniumbase import SB
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
with SB(uc=True, headless=True) as sb:
# Open the page
sb.open(url)
# Get status code via JS (as Selenium does not expose it directly)
status = sb.execute_script(
"return window.performance.getEntries()[0]?.responseStatus || 'unknown';"
)
print("Status code:", status)
# Wait for page load
sb.sleep(3)
# Take a screenshot
sb.save_screenshot("seleniumbase_zalando.png")UCモードの動作と設定方法の詳細については、SeleniumBaseスクレイピングガイドを参照してください。
期待される結果は次のとおりです:
Status code: 200生成されたseleniumbase_zalando.pngファイルは以下を示すはずです: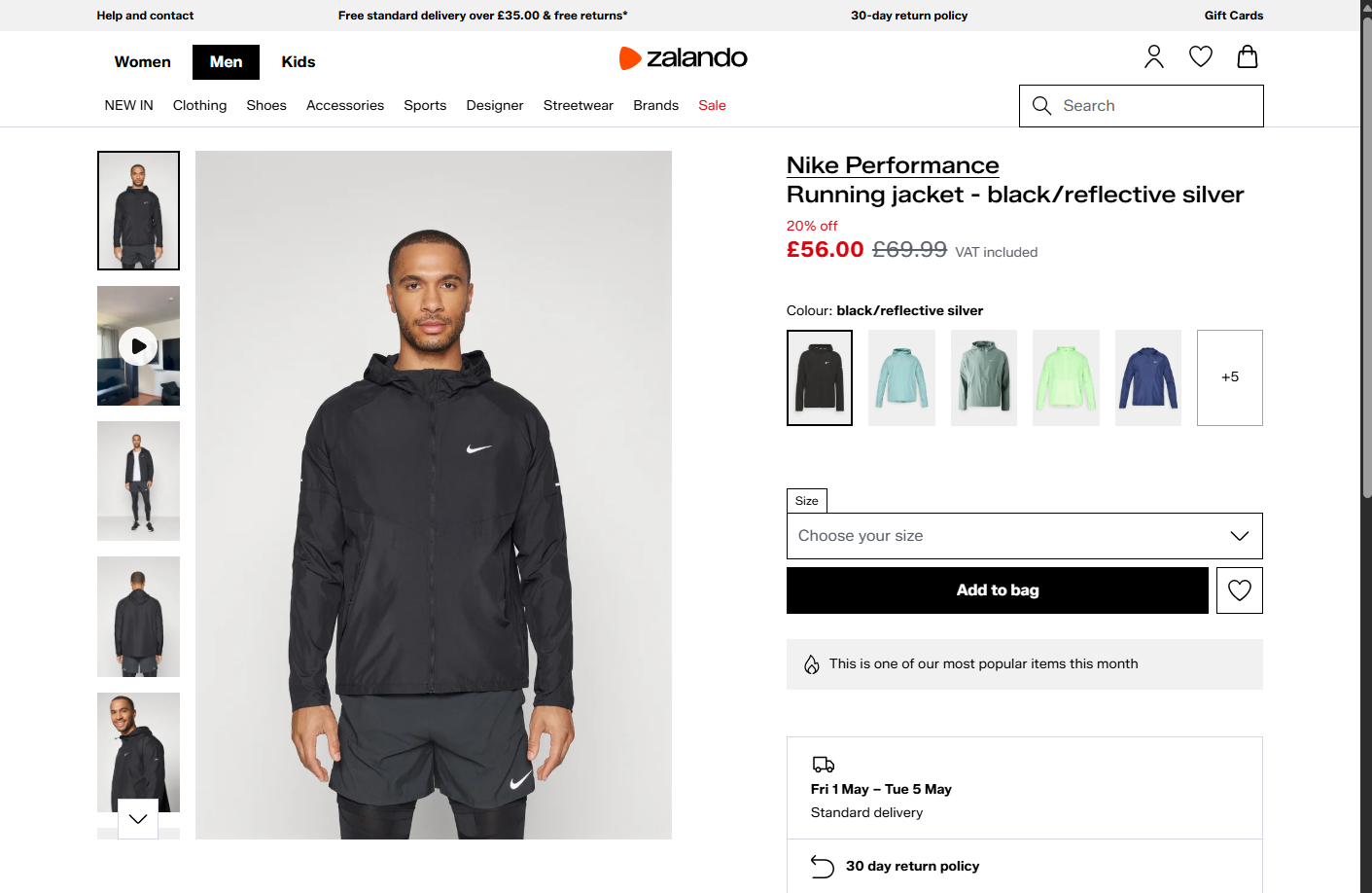
素晴らしい!SeleniumBaseもAkamaiのアンチボット保護をバイパスしました。
Bright DataでAkamaiを大規模にバイパスする方法
Bright Dataを使用すると、AkamaiやCloudflare、その他のアンチボットシステムで保護されているかどうかに関わらず、実質的にあらゆるWebページにアクセスできます。
特に、すべてのBright Dataスクレイピングサービスは、専用のAkamaiボットバイパスシステムに支えられています。これにより、Akamaiのアンチボットチャレンジが自動的に処理されます。
Bright Dataの主な利点は、世界最大のプロキシネットワークの1つに支えられており、4億以上のIPを持ち、99.99%のアップタイムと99.95%のリクエスト成功率で無制限の同時実行が可能なことです。また、これにより、オープンソースのブラウザ自動化ツールとは異なり、IPに関連するブロックやレート制限の影響を受けません。
以下では、以下を使用してAkamai保護をバイパスする方法を示します:
- Web Unlocker API:プロキシローテーション、アンチボットチャレンジ(Akamaiを含む)、CAPTCHAの解決を単一のリクエストで処理するスクレイピングAPIです。
- Browser API:Playwright、Selenium、Puppeteer、またはCDP互換の自動化ツールで制御できるクラウドベースのアンチボット最適化ブラウザセッションです。
次の章の手順に従ってください!
Bright DataのWeb Unlocker APIでAkamaiをバイパスする
静的スクレイピングシナリオでBright Data Web Unlocker APIを使用したAkamaiボット検出バイパスを体験してください。
前提条件
このセクションに従うには、以下を確認してください:
- APIキーが設定されたBright Dataアカウント。
- アカウントに設定されたWeb Unlocker APIゾーン。
- HTTPクライアントアプローチに基づいたスクレイピングスクリプト。
Web Unlocker API使用のためのBright Dataアカウントの設定については、公式の「最初のUnlocker APIを作成する」ガイドに従ってください。
例
ページのAkamai解除済みHTMLを取得したい場合は、次のようにWeb Unlocker APIを使用します:
import requests
# Replace with your Bright Data API key and Web Unlocker API zone name
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>"
BRIGHT_DATA_WEB_UNLOCKER_API_ZONE = "<YOUR_WEB_UNLOCKER_API_ZONE_NAME>"
target_url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
payload = {
"zone": BRIGHT_DATA_WEB_UNLOCKER_API_ZONE,
"url": target_url,
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Perform a request to the Bright Data Web Unlocker API
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers
)
print("Status code:", response.status_code)
html = response.text
print("\nPage HTML:\n")
print(html)
# Perform web scraping on the returned HTML...結果は次のようになります:
Status code: 200その後、html変数には完全なページソースが含まれます。HTMLパーサーで簡単に解析し、ウェブスクレイピングワークフローで必要なデータを抽出できます。大規模なスクレイピングについては、Zalandoスクレイパーをご確認ください。
Bright DataのBrowser APIでAkamaiをバイパスする
ここでは、ブラウザ自動化シナリオでBright Data Browser APIを使用してAkamaiのアンチボットチェックを通過する方法を示します。
前提条件
このセクションを進めるには、以下を確認してください:
- Bright DataアカウントにBrowser APIゾーンが設定されていること。
- ブラウザ自動化スクレイピングスクリプト。
Browser API接続URLを取得するには、公式の「最初のBrowser APIを作成する」ガイドをお読みください。
ここではPlaywrightの例を示しますので、Browser API接続URLは次のようになります:
wss://<BRIGHT_DATA_BROWSER_API_USERNAME>:<BRIGHT_DATA_BROWSER_API_PASSWORD>@brd.superproxy.io:9222例
PlaywrightスクリプトをBright DataのBrowser APIに接続し、先ほど示したスクリーンショットロジックを繰り返します:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
BRIGHT_DATA_BROWSER_API_CDP_URL = "wss://<BRIGHT_DATA_BROWSER_API_USERNAME>:<BRIGHT_DATA_BROWSER_API_PASSWORD>@brd.superproxy.io:9222"
with sync_playwright() as p:
# Connect to Bright Data CDP endpoint
browser = p.chromium.connect_over_cdp(BRIGHT_DATA_BROWSER_API_CDP_URL)
# Create a new context and page
context = browser.new_context()
page = context.new_page()
# Visit the target page in headless mode
response = page.goto(url)
# Print the response's HTTP status code
if response:
print("Status code:", response.status)
else:
print("No response received")
# Take a screenshot of the page
page.screenshot(path="zalando.png")
browser.close()実行すると、スクリプトは次を返します:
Status code: 200結果のスクリーンショットにはレンダリングされたページコンテンツが含まれます: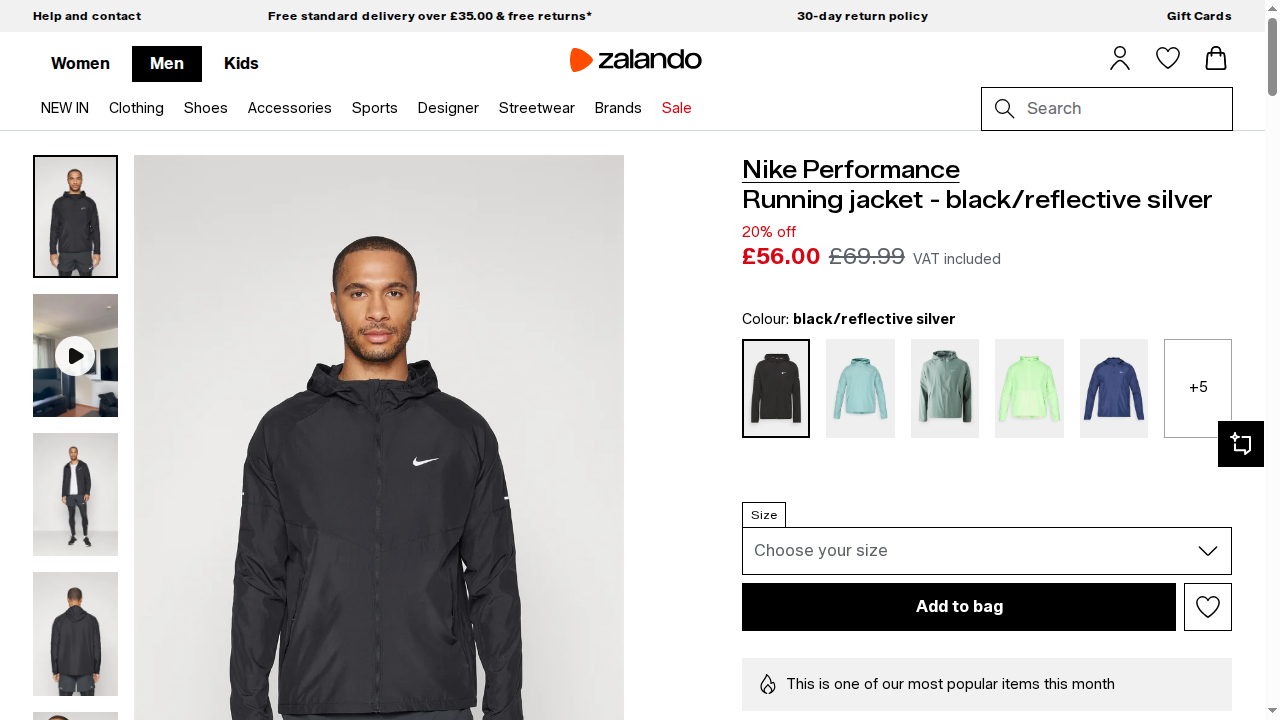
素晴らしい!今回は、Browser APIの統合のおかげで、Playwrightスクリプトが正常に動作しました。Browser APIは、Bright Dataクラウドインフラで管理される実際のブラウザセッションで自動化を処理します。
これで、制限なくページと対話する自動化ワークフローを構築できます!
結論
この記事では、Akamaiのアンチボットシステムがどのように機能するかを学び、自動化およびスクレイピングワークフローでそれを処理するための実践的なアプローチを探りました。
どの方法を選択しても、以下のようなプロフェッショナルで高速かつ信頼性の高いエンタープライズソリューションを使用することでプロセスが容易になります:
- Web Unlocker API:レート制限、フィンガープリンティングチャレンジ、その他のアンチボットメカニズムを自動的に処理するAPIエンドポイント。
- Browser API:あらゆるWebサイトとの大規模な自動化インタラクションを可能にするマネージドクラウドアンチ検出ブラウザ。
他のBright Dataスクレイピング製品と同様に、これらのサービスはAkamaiボットソルバーに支えられています。
今日、新しいBright Dataアカウントを無料で作成し、スクレイピングソリューションをご覧ください!




