

このチュートリアルでは
- Qwen3とは何か、そしてLLMとして何が際立っているのか
- ウェブスクレイピング作業に適している理由
- Hugging Faceを使ったウェブスクレイピングのためにQwen3をローカルで使う方法
- 主な制限とその回避方法
- AIによるスクレイピングのためのQwen3に代わるいくつかの方法
さあ、飛び込もう!
Qwen3とは?
Qwen3は Alibaba CloudのQwenチームによって開発された最新世代のLLMだ。このモデルはオープンソースで、Apache 2.0ライセンスの下、GitHubで自由に探索することができる。研究開発には最適だ。
Qwen3の主な特徴は以下の通り:
- ハイブリッド推論:複雑な論理的推論(数学やコーディングなど)のための「思考モード」と、より高速で汎用的な応答のための「非思考モード」を切り替えることができます。これにより、最適なパフォーマンスとコスト効率を実現するために、推論の深さをコントロールすることができます。
- 多様なモデル:Qwen3 は、密なモデル(0.6B から 32B のパラメータ)や、MoE(Mixture-of-Experts)モデル(30B や 235B など)を含む、包括的なモデル群を提供しています。
- 強化された能力:推論、指示フォロー、エージェント機能、多言語サポート(100以上の言語と方言をカバー)において大きな進歩を示している。
- トレーニングデータ:Qwen3 は約 36 兆トークンという、前作Qwen2.5 の約 2 倍に相当する膨大なデータセットで学習された。
ウェブスクレイピングにQwen3を使う理由
Qwen3は、HTMLページ内の非構造化コンテンツの解釈と構造化を自動化することで、ウェブスクレイピングを容易にします。これにより、手作業によるデータ解析が不要になります。データを抽出するために複雑なロジックを書く代わりに、モデルがあなたに代わってページの構造を理解します。
ウェブデータの解析にQwen3を利用することは、次のようなウェブスクレイピングの一般的な課題に対処する際に特に役立ちます:
- 頻繁に変わるページレイアウト:よくあるシナリオはAmazonで、商品ページごとに異なるデータを表示することができる。
- 非構造化データ:Qwen3は、ハードコードされたセレクタや正規表現ロジックを必要とせず、乱雑で自由形式のテキストから価値ある情報を抽出できます。
- 解析が困難なコンテンツ:一貫性のないページや複雑な構造のページでは、Qwen3のようなLLMを使用することで、独自の解析ロジックが不要になります。
より深く掘り下げるには、ウェブスクレイピングにAIを使用するガイドをお読みください。
もうひとつの大きな利点は、Qwen3がオープンソースであることだ。つまり、サードパーティのAPIに頼ったり、OpenAIのようなプレミアムLLMにお金を払ったりすることなく、自分のマシンでローカルに無料で実行できる。これにより、スクレイピング・アーキテクチャを完全にコントロールすることができる。
PythonでQwen3を使ってWebスクレイピングを行う方法
このセクションでは、”Webスクレイピングを学ぶためのEコマーステストサイト“のサンドボックスにある “Affirm Water Bottle “の商品ページを対象とする:
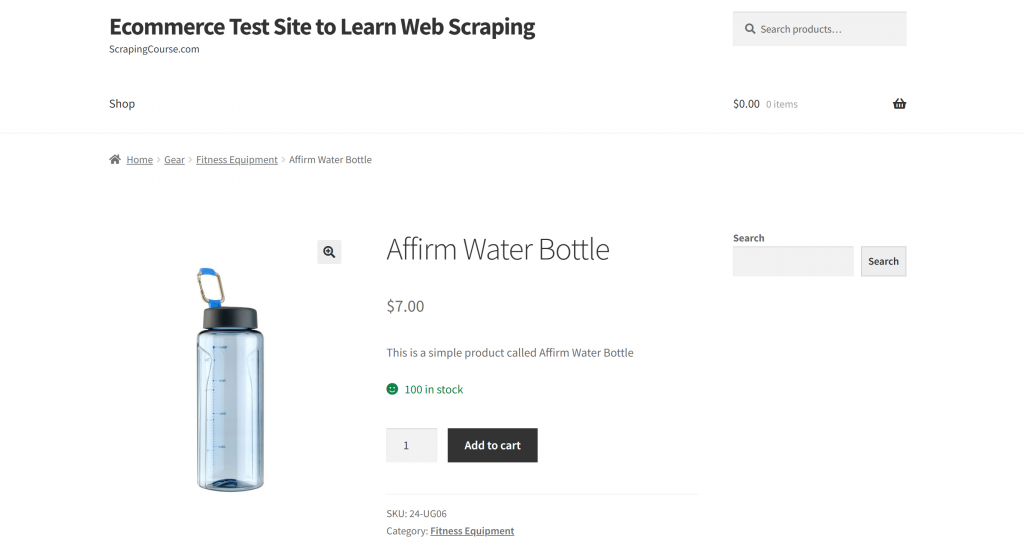
Eコマースの商品ページには通常、一貫性のない構造があり、さまざまなタイプのデータが表示されるため、このページは確かな例となる。このばらつきが、eコマースのウェブスクレイピングを特に困難なものにしており、またAIが大きな違いを生み出すところでもある。
ここでは、Qwen3を搭載したスクレーパーを使用し、手動で解析ルールを記述することなく、インテリジェントに商品情報を抽出します。
注:このチュートリアルでは、Hugging Faceを使ってQwen3モデルをローカルで、しかも無料で動かす方法を紹介します。さて、他にも実行可能なオプションがあります。Qwen3モデルをホスティングしているLLMプロバイダーに接続したり、Ollamaのようなソリューションを利用することです。
Qwen3を使用してウェブデータのスクレイピングを開始するには、以下の手順に従ってください!
ステップ1:プロジェクトの設定
始める前に、あなたのマシンにPython 3.10+がインストールされていることを確認してください。そうでなければ、ダウンロードしてインストール手順に従ってください。
次に、以下のコマンドを実行して、スクレイピング・プロジェクト用のフォルダを作成する:
mkdir qwen3-scraperqwen3-scraperディレクトリは、Qwen3を使用したウェブスクレイピングのプロジェクトフォルダとして機能します。
ターミナルでそのフォルダに移動し、その中でPython仮想環境を初期化する:
cd qwen3-scraper
python -m venv venvお好みのPython IDEでプロジェクトフォルダをロードします。Python拡張機能付きのVisual Studio Codeや PyCharm Community Editionはどちらも優れた選択肢です。
プロジェクトのフォルダにscraper.pyファイルを作成します:

今のところ、scraper.pyはただの空のPythonスクリプトですが、すぐにLLMウェブスクレイピングのロジックを含むようになります。
次に、仮想環境をアクティベートする。LinuxまたはmacOSで、実行する:
source venv/bin/activate同様に、Windowsでは
venv/Scripts/activate注:以下のステップでは、必要なライブラリーをすべてインストールします。一度にすべてをインストールしたい場合は、以下のコマンドを使用してください:
pip install transformers torch accelerate requests beautifulsoup4 markdownify素晴らしい!あなたのPython環境はQwen3によるWebスクレイピングのために完全にセットアップされています。
ステップ2:ハギング・フェイスでQwen3を設定する
このセクションの冒頭で述べたように、ハギング・フェイスを使ってQwen3モデルをローカルで走らせる。これは、ハギング・フェイスが最近Qwen3モデルをサポートするようになったからです。
まず、有効化された仮想環境にいることを確認してください。次に、必要なハギング・フェイスの依存関係をインストールしてください:
pip install transformers torch accelerate次に、scraper.pyファイルで、Hugging Face のtransformersライブラリから必要なクラスをインポートします:
from transformers import AutoModelForCausalLM, AutoTokenizer次に、これらのクラスを使って、トークナイザーとQwen3モデルをロードします:
model_name = "Qwen/Qwen3-0.6B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)今回はQwen/Qwen3-0.6Bモデルを使用していますが、Hugging Faceでは他にも40種類以上のQwen3モデルからお選びいただけます。
素晴らしい!これでPythonスクリプトでQwen3を利用するための準備が全て整いました。
ステップ #3: ターゲットページのHTMLを取得する
さて、次はターゲットページのHTMLコンテンツを取得する番だ。これはRequestsのような強力なPython HTTPクライアントを使うことで実現できます。
起動した仮想環境に、Requestsライブラリをインストールします:
pip install requestsそして、scraper.pyファイルでライブラリをインポートします:
import requestsget()メソッドを使用して、ページURLにHTTP GETリクエストを送信します:
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)サーバーはページの生のHTMLで応答する。完全なHTMLコンテンツを見るには、response.contentを表示すればよい:
print(response.content)結果はこのHTML文字列になるはずだ:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="profile" href="https://gmpg.org/xfn/11">
<link rel="pingback" href="https://www.scrapingcourse.com/ecommerce/xmlrpc.php">
<!-- omitted for brevity... -->
<title>Affirm Water Bottle – Ecommerce Test Site to Learn Web Scraping</title>
<!-- omitted for brevity... -->
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>これでPythonでターゲットページの完全なHTMLが利用できるようになりました。Qwen3を使ってHTMLを解析し、必要なデータを抽出しましょう!
ステップ#4:ページのHTMLをMarkdownに変換する(オプションだが推奨)
注:このステップは厳密には必須ではありません。しかし、ローカルでの時間を大幅に節約することができます(有料のQwen3プロバイダーを使っている場合はお金も節約できます)。ですから、検討する価値はあります。
Crawl4AIや ScrapeGraphAIのような他のAIを搭載したウェブスクレイピングツールが生のHTMLをどのように扱うか少し調べてみよう。設定されたLLMにコンテンツを渡す前にHTMLをMarkdownに変換するオプションを提供していることに気づくだろう。
なぜそんなことをするのか?主な理由は2つある:
- コスト効率:マークダウン変換により、AIに送信されるトークンの数を減らし、コスト削減に貢献します。
- 処理の高速化:入力データが少ないため、計算コストが低く、応答が速い。
詳しくは、新しいAIエージェントがHTMLではなくMarkdownを選ぶ理由についてのガイドをお読みください。
この場合、Qwen3はローカルで実行されるため、サードパーティのLLMプロバイダーに接続するわけではないので、コスト効率は重要ではない。ここで本当に重要なのは、処理の高速化だ。なぜか?というのも、選択されたQwen3モデル(これは利用可能なモデルの中でも小さい部類に入る)にHTMLページ全体の処理を依頼すると、i7のCPUを数分間100%の使用率に簡単に押し上げることができるからだ。
ノートパソコンやPCをオーバーヒートさせたり、フリーズさせたりしたくないのだから。だから、Markdownに変換することで入力サイズを小さくすることは理にかなっている。
HTMLからMarkdownへの変換ロジックを複製し、トークンの使用量を減らす時が来た!
まず、対象のウェブページをシークレット・モードで開き、新しいセッションを確保する。次に、ページ上の任意の場所で右クリックし、”Inspect “を選択してDevToolsを開く。次に、ページの構造を調べてください。すべての関連データが、CSSセレクタ#mainで識別されるHTML要素内に含まれていることがわかります:
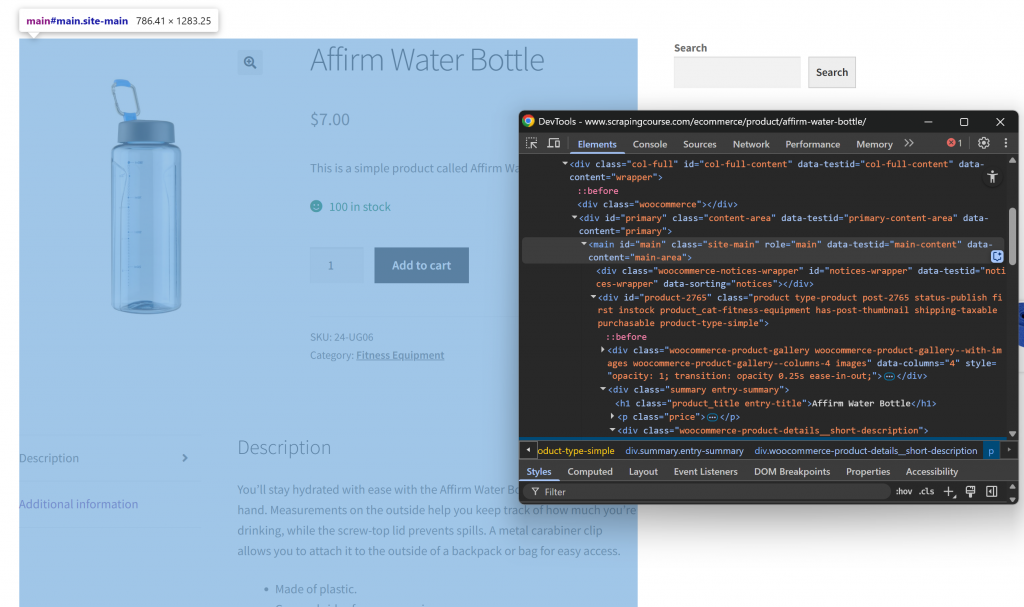
HTMLからMarkdownへの変換プロセスで#mainの中のコンテンツに焦点を当てることで、ページ内の関連データのある部分のみを抽出することができます。これにより、ヘッダーやフッター、その他興味のないセクションを含めずに済みます。そうすれば、最終的なMarkdownの出力はずっと短くなります。
main要素内のHTMLだけを選択するには、Beautiful SoupのようなPythonのHTML解析ライブラリが必要です。アクティベートした仮想環境に、次のコマンドでインストールしてください:
pip install beautifulsoup4そのAPIについてよく知らない場合は、Beautiful Soupのウェブスクレイピングに関するガイドに従ってほしい。
そして、scraper.py でインポートします:
from bs4 import BeautifulSoupでは、ビューティフル・スープを使ってみよう:
- Requestsで取得した生のHTMLを解析する。
メイン要素を選択する- HTMLコンテンツを抽出する
このスニペットで上記の3つのマイクロステップを実行する:
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get the outer HTML of the selected element
main_html = str(main_element)main_htmlを表示すると、次のようになる:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<!-- omitted for brevity... -->
<div id="product-2765" class="product type-product post-2765 status-publish first instock product_cat-fitness-equipment has-post-thumbnail shipping-taxable purchasable product-type-simple">
<!-- omitted for brevity... -->
</div>
</main>この文字列はHTMLページ全体よりはずっと小さいが、それでも約13,402文字を含んでいる。
重要なデータを失うことなくサイズをさらに小さくするには、抽出したHTMLをMarkdownに変換する。まず、markdownifyライブラリをインストールする:
pip install markdownifyscraper.pyに markdownifyをインポートします:
from markdownify import markdownifyそして、#mainのHTMLをMarkdownに変換する:
main_markdown = markdownify(main_html)データ変換処理により、以下のような出力が得られるはずである:
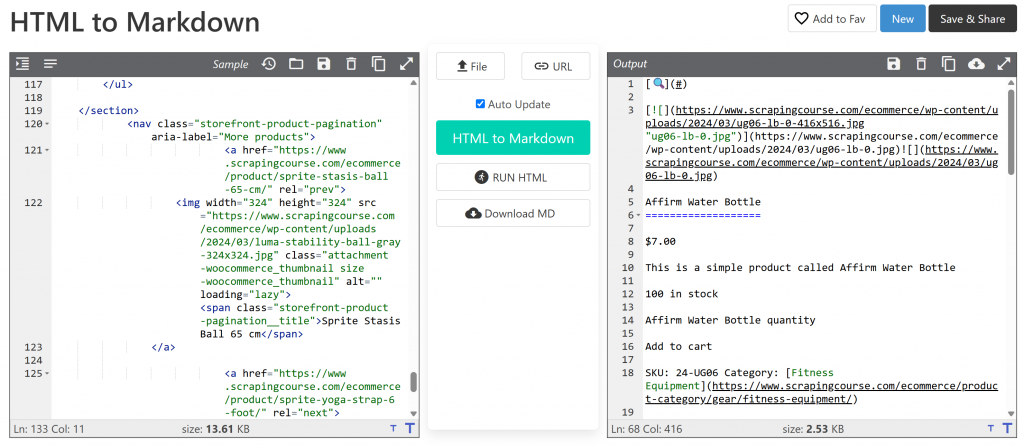
元の#mainHTMLが13.61KBであるのに対し、Markdownバージョンは約2.53KBである。これは81%のサイズ削減だ!その上、重要なのは、Markdownバージョンはスクレイピングに必要な主要データをすべて保持しているということだ。
この簡単なトリックで、かさばるHTMLスニペットをコンパクトなMarkdown文字列に減らすことができます。これで、Qwen3経由のローカルLLMデータ解析が大幅にスピードアップする!
ステップ #5: Qwen3を使ってデータを解析する
Qwen3に正しくデータをスクレイピングさせるには、効果的なプロンプトを書く必要があります。ターゲットページの構造を分析することから始めましょう:
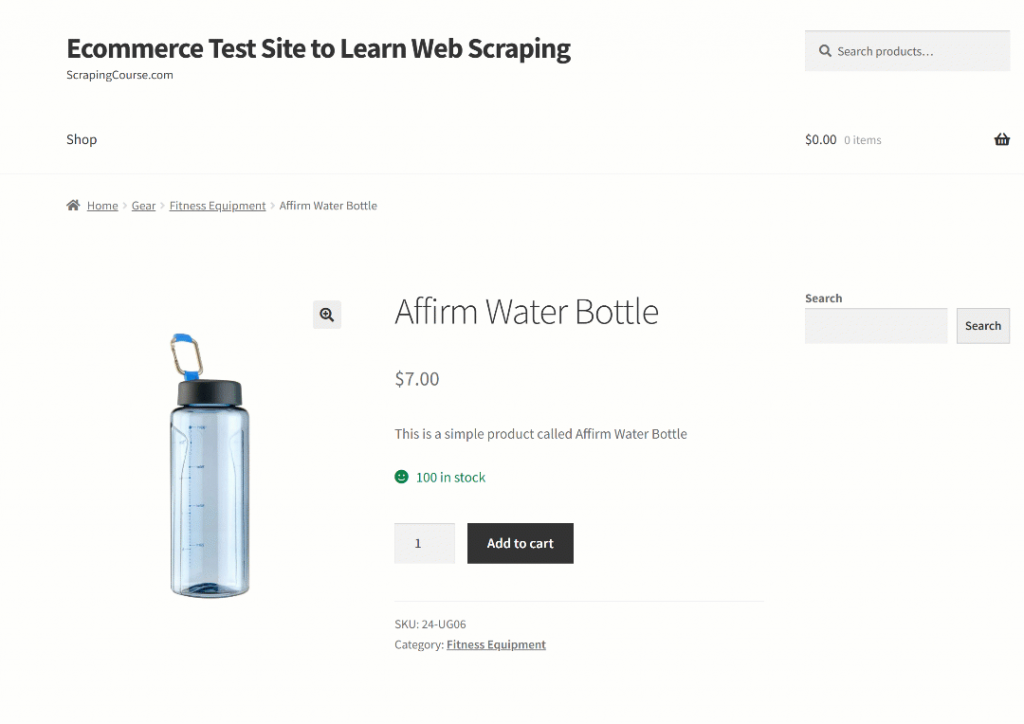
ページ上部のセクションはすべての商品で一貫している。一方、「追加情報」の表は商品によって変わります。あなたのプロンプトがプラットフォーム上のすべての商品ページで機能することを望むかもしれないので、あなたのタスクを一般的な用語で次のように記述することができます:
Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
<MARKDOWN_PRODUCT_CONTENT>このプロンプトは、main_markdownコンテンツから構造化データを抽出するようQwen3に指示します。信頼できる結果を得るためには、プロンプトをできるだけ明確かつ具体的にすることをお勧めします。そうすることで、モデルがあなたが期待していることを正確に理解できるようになります。
さて、公式ドキュメントで説明されているように、Hugging Faceを使ってプロンプトを実行する:
# Define tge data extraction prompt
prompt = prompt = f"""Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
{main_markdown}
"""
# Execute the prompt
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# Retrieve the output in text format
product_raw_string = tokenizer.decode(output_ids, skip_special_tokens=True).strip("n")上記のコードでは、apply_chat_template()を使って入力メッセージをフォーマットし、設定されたQwen3モデルからレスポンスを生成しています。
注:重要な詳細は、apply_chat_template() でenable_thinking=False を設定することである。デフォルトでは、このオプションはTrueに設定されており、モデル内部の “推論 “モードを有効にします。このタスクは複雑な問題解決には便利ですが、ウェブスクレイピングのような単純なタスクには不要で、逆効果になる可能性があります。これを無効にすると、モデルは説明や仮定を追加することなく、純粋に抽出に集中するようになります。
素晴らしい!Qwen3にターゲットページのWebスクレイピングを実行するよう指示しました。
あとは出力を微調整してJSONにエクスポートするだけです。
ステップ6:Qwen3の出力を変換する
Qwen3-0.6Bモデルの出力は、実行ごとにわずかに異なることがある。これはLLMの典型的な挙動であり、特に今回使用したような小規模なモデルでは顕著である。
したがって、product_raw_string変数には、プレーンなJSON文字列として必要なデータが格納されることもある。また、次のようにJSONをMarkdownコードブロックの中にラップすることもある:
```jsonn{n "sku": "24-UG06",n "name": "Affirm Water Bottle",n "images": ["https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/ug06-lb-0.jpg"],n "price": "$7.00",n "description": "You’ll stay hydrated with ease with the Affirm Water Bottle by your side or in hand. Measurements on the outside help you keep track of how much you’re drinking, while the screw-top lid prevents spills. A metal carabiner clip allows you to attach it to the outside of a backpack or bag for easy access.",n "category": "Fitness Equipment",n "additional_information": {n "Activity": "Yoga, Recreation, Sports, Gym",n "Gender": "Men, Women, Boys, Girls, Unisex",n "Material": "Plastic"n }n}n```両方のケースに対応するには、JSONコンテンツがMarkdownブロックの中に現れた場合、正規表現を使ってJSONコンテンツを抽出することができます。そうでない場合は、文字列を生のJSONとして扱います。そして、結果のJSONデータをPython辞書json.loads()にパースします:
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)さあ、始めるぞ!この時点で、あなたはスクレイピングされたデータを使用可能なPythonオブジェクトにパースしました。最後のステップは、スクレイピングしたデータをより使いやすい形式にエクスポートすることです。
ステップ#7:スクレイピングしたデータをエクスポートする
これでPython辞書に商品データが入ったので、次のようにJSONファイルに保存できます:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)これにより、構造化された商品データを含むproduct.jsonという名前のファイルが作成されます。
よくやった!これであなたのQwen3ウェブスクレーパーは完成です。
ステップ8:すべてをまとめる
スクレイピングスクリプトscraper.pyの最終コードです:
from transformers import AutoModelForCausalLM, AutoTokenizer
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import json
import re
# The Qwen3 model to use for web scraping
model_name = "Qwen/Qwen3-0.6B"
# Load the tokenizer and the Qwen3 model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# Fetch the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/affirm-water-bottle/"
response = requests.get(url)
# Parse the HTML of the target page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get the outer HTML of the selected element and convert it to Markdown
main_html = str(main_element)
main_markdown = markdownify(main_html)
# Define tge data extraction prompt
prompt = prompt = f"""Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
{main_markdown}
"""
# Execute the prompt
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# Retrieve the output in text format
product_raw_string = tokenizer.decode(output_ids, skip_special_tokens=True).strip("n")
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)でスクリプトを実行する:
python scraper.pyスクリプトを初めて実行すると、Hugging Faceは選択したQwen3モデルを自動的にダウンロードします。このモデルは約1.5GBあるので、インターネットの速度によってはダウンロードに時間がかかるかもしれません。ターミナルでは、次のような出力が表示されます:
model.safetensors: 100%|██████████████████████████████████████████████████████████| 1.50G/1.50G [00:49<00:00, 30.2MB/s]
generation_config.json: 100%|█████████████████████████████████████████████████████████████████| 239/239 [00:00<?, ?B/s]PyTorchはモデルをロードして実行するためにCPUに負荷をかけるので、スクリプトが完了するまで少し時間がかかるかもしれません。
スクリプトが終了すると、projectフォルダにproduct.jsonというファイルが作成されます。このファイルを開くと、次のような構造化された商品データが表示されるはずです:
{
"sku": "24-UG06",
"name": "Affirm Water Bottle",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/ug06-lb-0.jpg"
],
"price": "$7.00",
"description": "You’ll stay hydrated with ease with the Affirm Water Bottle by your side or in hand. Measurements on the outside help you keep track of how much youu2019re drinking, while the screw-top lid prevents spills. A metal carabiner clip allows you to attach it to the outside of a backpack or bag for easy access.",
"category": "Fitness Equipment",
"additional_information": {
"Activity": "Yoga, Recreation, Sports, Gym",
"Gender": "Men, Women, Boys, Girls, Unisex",
"Material": "Plastic"
}
}注:LLMの性質上、スクレイピングされたコンテンツは様々な方法で構造化されるため、正確な出力は若干異なる場合があります。
出来上がり!あなたのスクリプトは、生のHTMLコンテンツをクリーンで構造化されたJSONに変換しました。すべてQwen3のウェブスクレイピングのおかげです。
ウェブスクレイピングの主な限界の克服
確かに、私たちの例ではすべてがスムーズに動いた。しかしそれは、その目的のために特別に作られたデモサイトをスクレイピングしていたからに他ならない。
現実の世界では、ほとんどのウェブサイトが公開データの価値を十分に認識している。そのため、requestsのようなツールを使って自動化されたHTTPリクエストを素早くブロックできるアンチスクレイピング技術を実装していることが多い。
さらに、このアプローチはJavaScriptを多用するサイトでは機能しない。リクエストとBeautifulSoupの組み合わせは静的なページには有効だが、動的なコンテンツを扱うことができないからだ。この違いについてよくわからない場合は、静的コンテンツと動的コンテンツについての記事をご覧ください。
その他の潜在的なブロッカーには、IPバン、レートリミッター、TLSフィンガープリンティング、CAPTCHAなどがある。要するに、ウェブスクレイピングは容易ではないのだ-特に、ほとんどのウェブサイトがAIクローラーやボットを検知し、ブロックする機能を備えている現在においては。
解決策は、リクエストによる最新のウェブスクレイピングのために構築されたWeb Unlocker APIを利用することだ。このようなサービスは、IPのローテーション、CAPTCHAの解決、JavaScriptのレンダリング、ボットプロテクションのバイパスなど、難しいことをすべて代行してくれます。
Web Unlocker API のエンドポイントにターゲットページの URL を渡すだけです。API は、そのページが JavaScript に依存していたり、高度なボット対策システムで保護されていたりしても、完全にロック解除された HTML を返します。
スクリプトに組み込むには、ステップ#3のrequests.get()の行を以下のコードに置き換えるだけです:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the payload with the target URL
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/affirm-water-bottle/", # Replace this with your target URL on a different scraping scenario
"format": "raw"
}
# Send the request
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)
# Get the unlocked HTML
html_content = response.text詳細については、Web Unlockerの公式ドキュメントを参照してください。
Web Unlocker があれば、Qwen3 を使用して、ブロックやレンダリングの問題、コンテンツの欠落がない、あらゆる Web サイトから構造化データを自信を持って抽出できます。
ウェブスクレイピングのためのQwen3の代替品
ウェブデータの自動解析に使えるLLMはQwen3だけではありません。以下のガイドで、いくつかの代替アプローチを試してみてください:
- GeminiによるWebスクレイピング:完全チュートリアル
- Perplexityを使ったウェブスクレイピング:ステップバイステップガイド
- ScrapeGraphAIによるLLMウェブスクレイピング
- Crawl4AIとDeepSeekを使ったAIスクレイパーの作り方
- LLaMAによるウェブスクレイピング3:あらゆるウェブサイトを構造化JSONに変換する
結論
このチュートリアルでは、AIを搭載したウェブスクレーパーを構築するために、Hugging Faceを使用してQwen3をローカルで実行する方法を学びました。ウェブスクレイピングの最大のハードルの1つはブロックされることですが、Bright DataのWeb Unlocker APIを使って対処しました。
前述したように、Qwen3 と Web Unlocker API を組み合わせることで、事実上あらゆる Web サイトからデータを抽出できます。カスタム解析ロジックは必要ありません。このセットアップは、Bright Dataのインフラストラクチャが可能にする数多くの強力な使用例のほんの一例であり、スケーラブルでAI主導のウェブデータパイプラインの構築を支援します。
では、なぜここで止めるのか?ウェブスクレーパーAPI-120以上の人気のあるウェブサイトから、新鮮で、構造化され、完全に準拠したウェブデータを抽出するための専用エンドポイントを探索することを検討してください。
今すぐBright Dataの無料アカウントにサインアップして、AI対応のスクレイピング・ソリューションでビルドを始めましょう!




