

このガイドで、あなたは学ぶだろう:
- Agnoとは何か、なぜエージェント型ワークフローの構築に最適なのか。
- ウェブスクレイピングがAIエージェントにとって貴重な役割を果たす理由。
- Webスクレイピングエージェントを作成するために、Agnoと内蔵のBright Dataツールを統合する方法。
さあ、飛び込もう!
アグノとは?
Agnoは、記憶、知識、高度な推論を活用したマルチエージェントシステムを構築するためのフルスタックのPythonフレームワークです。Agnoは、幅広いユースケースのための洗練されたAIエージェントの作成を可能にします。これらは、単純なツールを使用するエージェントから、状態と決定論を持つ協調的なエージェントチームに及びます。
Agnoはモデルにとらわれず、高いパフォーマンスを発揮し、推論を設計の中心に据えています。マルチモーダルな入力と出力、複雑なマルチエージェントオーケストレーション、ベクトルデータベースによるビルトインエージェント検索、完全なメモリ/セッションハンドリングをサポートします。
この記事を書いている時点で、AgnoはAIエージェントを構築するための最も人気のあるオープンソースライブラリの1つで、GitHubで29k以上のスターを誇っている:
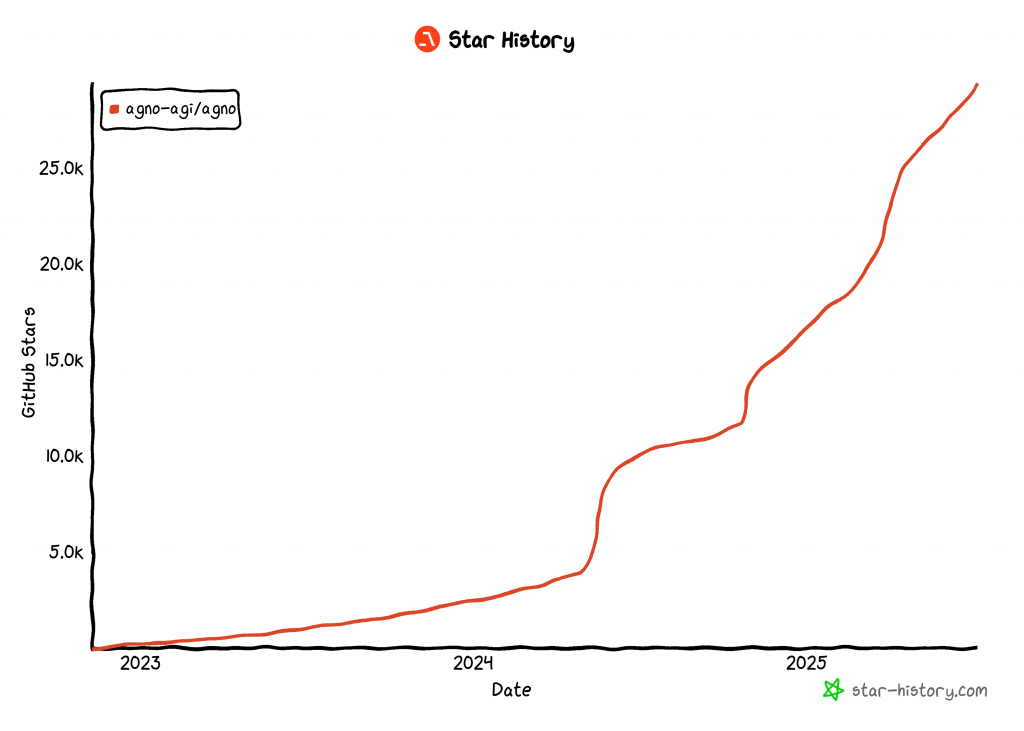
その急成長は、Agnoが開発者やAIコミュニティでいかに急速に支持を集めているかを浮き彫りにしている。
エージェント・ウェブ・スクレイピングが便利な理由
従来のウェブスクレイピングは、特定のウェブページからデータを抽出するために、厳密なデータ解析ルールを書くことに依存していた。問題はサイトの構造が頻繁に変わるため、スクレイピングのロジックを常に更新しなければならない。これは、高いメンテナンスコストと脆弱なパイプラインにつながります。
だからこそ、AIによるウェブスクレイピングが支持を集めているのだ。カスタムの解析スクリプトを作成する代わりに、AIモデルを使ってウェブページのHTMLから直接データを抽出することができる。このアプローチは非常に人気があるため、最近では多くのAIスクレイピング・ツールが登場している。
それでも、AIによるウェブスクレイピングは、エージェント型AIアーキテクチャに組み込むことで、さらに強力になる。特に、他のAIエージェントが接続できる専用のウェブスクレイピングエージェントを構築することができる。これは、マルチエージェントワークフローやGoogleのA2AのようなAIプロトコルで可能だ。
Agnoは、上記の全てを可能にします。スタンドアローンのAIスクレイピングエージェントや複雑なマルチエージェントエコシステムを構築することができます。しかし、通常のLLMは、ウェブスクレイピングに精通するようには設計されていません。強力なボット防御を持つサイトへの接続に失敗したり、もっと悪いことに、”幻覚 “を見て偽のデータを返したりすることがよくあります。
これらの制限に対処するため、Agnoは専用のスクレイピングツールを介してBright Dataとネイティブに統合しています。これらのツールを使用することで、AIエージェントはあらゆるウェブサイトから新鮮で構造化されたデータをスクレイピングすることができます。
ブロックや中断を避けるため、Bright DataはTLSフィンガープリンティング、ブラウザやデバイスのフィンガープリンティング、CAPTCHA、Cloudflareプロテクションなどの課題を克服しています。データが取得されると、解釈と分析のためにLLMに供給されます。
Bright DataツールをAgnoエージェントに統合し、次のレベルのウェブスクレイピングを実現する方法をご紹介します!
WebスクレイピングのためのブライトデータツールをAgnoに統合する方法
このステップバイステップでは、WebスクレイピングAIエージェントを構築するためにAgnoを使用する方法を説明します。Bright Data ツールを統合することで、Agno エージェントにあらゆるウェブページからデータをスクレイピングする能力を与えることができます。
以下の手順に従って、AgnoにBright Dataを利用したスクレイピングエージェントを作成してください!
前提条件
このチュートリアルに従うには、以下のものを用意してください:
- Python 3.7以上をローカルにインストール(最新版の使用を推奨)。
- Bright Data APIキー。
- サポートされているLLMプロバイダーのAPIキー(ここでは、API経由で無料で使用できるGeminiを使用しますが、サポートされているLLMプロバイダーであれば何でもかまいません)。
Bright Data APIキーまたはGemini APIキーをまだお持ちでない方もご安心ください。次のステップで作成方法を説明します。
ステップ1:プロジェクトのセットアップ
ターミナルを開き、WebスクレイピングにBright Dataを使用するAgno AIエージェントプロジェクト用の新しいディレクトリを作成します:
mkdir agno-web-scraperagno-web-scraperフォルダには、Agno エージェントをスクレイピングするための Python コードが格納されます。
次に、プロジェクト・ディレクトリに移動し、その中に仮想環境をセットアップする:
cd agno-web-scraper
python -m venv venv次に、お気に入りのPython IDEでプロジェクトをロードします。Pythonエクステンション付きのVisual Studio Codeか、PyCharm Community Editionをお勧めします。
プロジェクトフォルダ内に、scraper.py という名前の新しいファイルを作成します。ディレクトリ構造は以下のようになります:
agno-web-scraper/
├── venv/
└── scraper.pyターミナルで仮想環境をアクティブにする。LinuxまたはmacOSでは、以下を実行する:
source venv/bin/activateWindowsでは、このコマンドを実行する:
venv/Scripts/activate次のステップでは、必要なPythonパッケージのインストールを案内します。今すぐすべてをインストールしたい場合は、起動した仮想環境で以下を実行してください:
pip install agno python-dotenv google-genai requests注:このチュートリアルでは、LLMプロバイダーとしてGeminiを使用しているため、google-genaiをインストールしています。他のLLMを使用する場合は、そのプロバイダーに適したライブラリをインストールしてください。
これで準備完了です!これでAgnoとBright Dataを使ってスクレイピングエージェントワークフローを構築するためのPython開発環境が整いました。
ステップ2:環境変数の設定 読み方
Agnoのスクレイピングエージェントは、APIインテグレーションを通してBright DataやGeminiのようなサードパーティのサービスに接続します。物事を安全に保つために、APIキーを直接Pythonコードにハードコードすることは避けてください。代わりに、環境変数として保存してください。
環境変数のロードを簡単にするために、python-dotenvライブラリを採用します。仮想環境をアクティブにした状態で、python-dotenv ライブラリをインストールします:
pip install python-dotenv次に、scraper.pyファイルでライブラリをインポートし、load_dotenv()を呼び出して環境変数をロードします:
from dotenv import load_dotenv
load_dotenv()この関数を使うと、スクリプトはローカルの.envファイルから変数を読み込むことができます。プロジェクトディレクトリのルートに.envファイルを作成してください:
agno-web-scraper/
├── venv/
├── .env # <-----------
└── scraper.pyすばらしい!これで、環境変数を使って統合の秘密を安全に扱うための準備が整った。
ステップ3:ブライト・データの設定
Agnoに統合されたBright Dataツールは、いくつかのデータ収集ソリューションへのアクセスを提供します。このチュートリアルでは、これら2つのスクレイピングに特化した製品の統合に焦点を当てます:
- Web Unlocker API:ボット保護を克服する高度なスクレイピングAPIで、Markdown形式のあらゆるウェブページへのアクセスを提供します。
- ウェブスクレーパーAPI:LinkedIn、Amazonなど、人気のあるウェブサイトから新鮮で構造化されたデータを倫理的に抽出するための特別なエンドポイントです。
これらのツールを使うには
- Bright DataアカウントでWeb Unlockerソリューションを設定します。
- Web Unlocker および Web Scraper API へのリクエストを認証するための Bright Data API トークンを取得します。
以下の手順に従ってください!
まず、Bright Dataアカウントをまだお持ちでない場合は、無料でサインアップしてください。すでにお持ちの場合は、ログインしてダッシュボードを開きます。ここで、”Get proxy products “ボタンをクリックします:
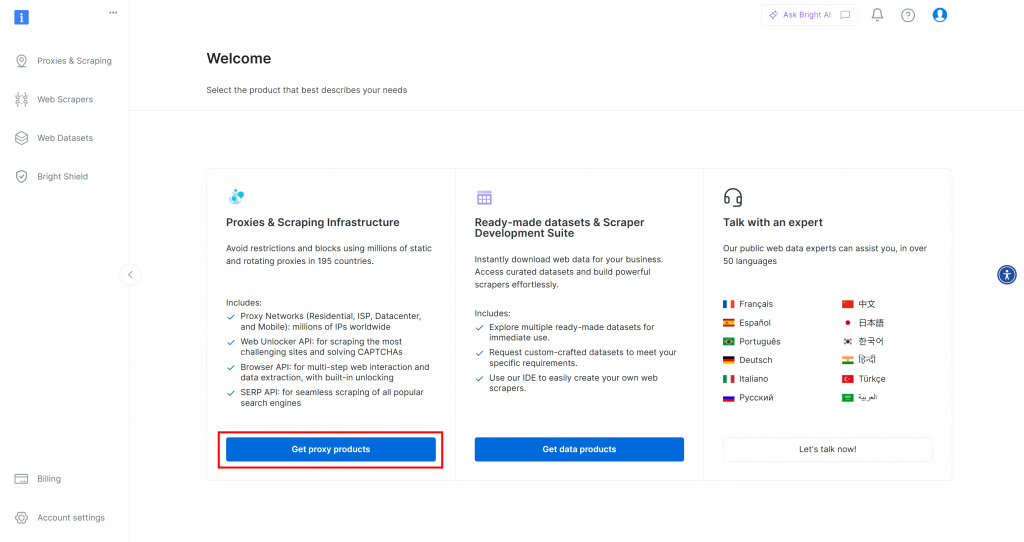
プロキシとスクレイピング・インフラストラクチャ」ページにリダイレクトされます:
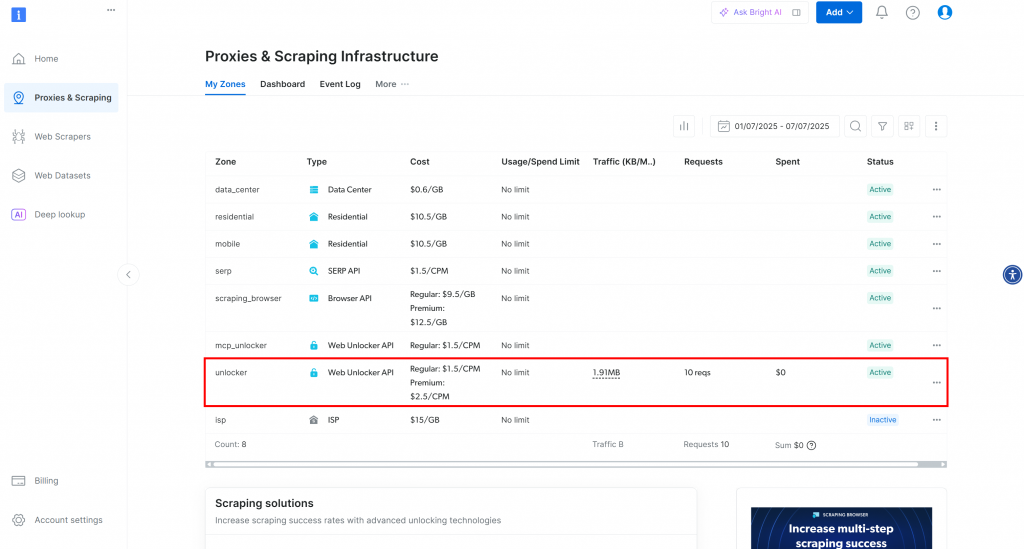
このページでは、すでに設定されたBright Dataソリューションを見ることができます。この例では、Web Unlokerゾーンが有効化されています。ゾーンの名前は「unblocker」です(後でスクリプトに統合する際に必要になります)。
Web Unlockerゾーンがまだない場合は、「Web Unlocker API」カードまでスクロールダウンし、「Create zone」をクリックします:
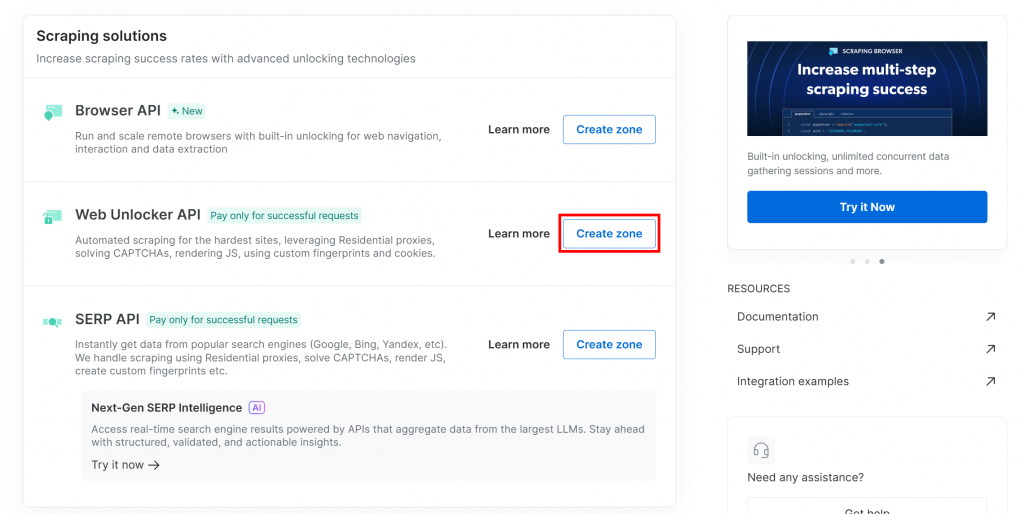
ゾーンに名前(”unlocker “など)をつけ、最高のパフォーマンスを発揮するために高度な機能を有効にし、”Add “ボタンを押す:
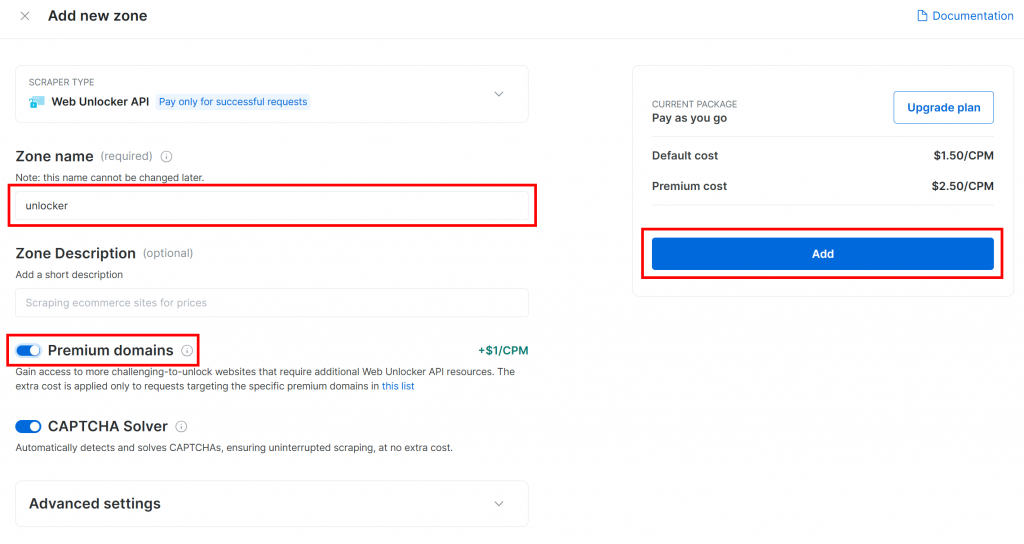
新しいゾーンのページが表示されます。トグルが “Active “になっていることを確認してください:
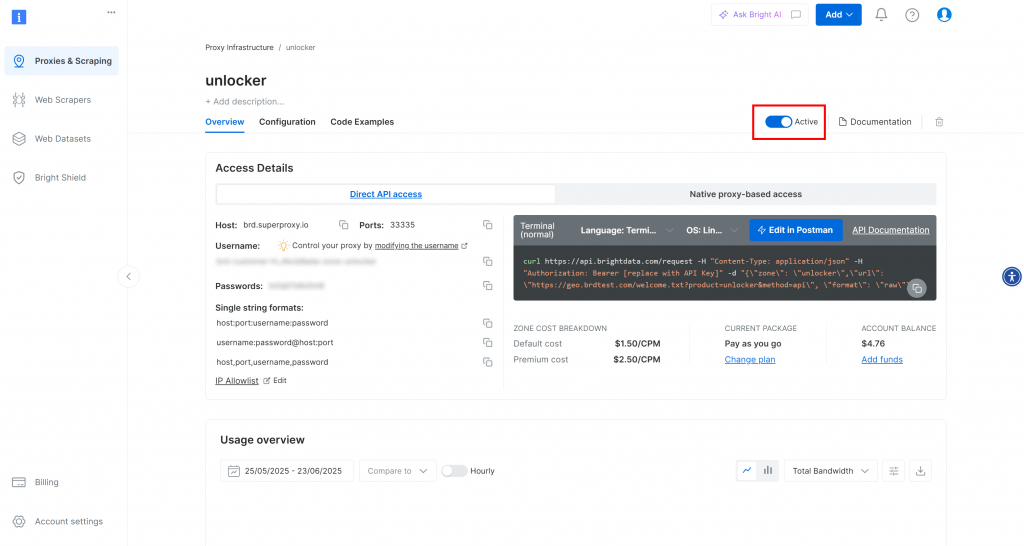
Bright Dataの公式ドキュメントに従ってAPIキーを生成してください。APIキーを取得したら、.envファイルに以下のように追加します:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"プレースホルダを プレースホルダを実際のAPIキー値に置き換える。
完璧です!Agno エージェントスクリプトに Bright Data ツールを統合して、エージェントのウェブスクレイピングを行う時が来ました。
ステップ #4: Agno Bright データツールのウェブスクレイピングへの統合
プロジェクトフォルダで、仮想環境をアクティブにした状態で、Agnoをインストールしてください:
pip install agnoagnoパッケージには、Bright Dataツールのビルトインサポートが含まれています。そのため、特別な統合パッケージは必要ありません。
追加で必要なパッケージはPython Requests ライブラリのみで、Bright Data ツールが先に設定した製品を API 経由で呼び出すのに使用します。Requestsをインストールします:
pip install requestsscraper.pyファイルにagnoのBright Dataスクレイピングツールをインポートします:
from agno.tools.brightdata import BrightDataToolsそして、次のようにツールを初期化する:
bright_data_tools = BrightDataTools(
web_unlocker_zone="unlocker", # Replace with your Web Unlocker API zone name
search_engine=False,
)unlocker"は、Bright Data Web Unlocker ゾーンの実際の名前に置き換えてください。
また、この例ではSERP API ツールを使用していないため、search_engineがFalse に設定されていることに注意してください。
ヒント:ゾーン名をハードコーディングする代わりに、.envファイルから読み込むことができます。そのためには、次の行を.envファイルに追加してください:
BRIGHT_DATA_WEB_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE>"プレースホルダを実際の Web Unlocker ゾーン名に置き換えます。次に、BrightDataTools からweb_unlocker_zone引数を削除します。このクラスは、あなたの環境からゾーン名を自動的にピックアップします。
注意: Bright Dataに接続するために、BrightDataToolsは環境変数BRIGHT_DATA_API_KEYでAPIキーを探します。これが、前のステップで.envファイルに追加した理由です。
すごい!Geminiを統合して、Agnoウェブスクレイピングエージェントワークフローをパワーアップさせましょう。
ステップ#5: ジェミニからLLMモデルを設定する
このチュートリアルで選んだLLMプロバイダーであるGeminiに接続する時間だ。google-genaiパッケージをインストールすることから始めましょう:
pip install google-genai次に、AgnoからGemini統合クラスをインポートする:
from agno.models.google import GeminiLLMモデルを次のように初期化する:
llm_model = Gemini(id="gemini-2.5-flash")上記のスニペットでは、gemini-2.5-flashはエージェントに利用させたいGeminiモデルの名前です。他のサポートされているGeminiモデルで置き換えてもかまいません(API経由で自由に使えないものもあることを覚えておいてください)。
google-genaiライブラリは、あなたのGemini APIキーがGOOGLE_API_KEYという環境変数に格納されていることを期待します。これを設定するには、.envファイルに以下の行を追加します:
GOOGLE_API_KEY="<YOUR_GOOGLE_API_KEY>"プレースホルダを プレースホルダを実際のAPIキーに置き換えてください。まだお持ちでない場合は、公式ガイドに従ってGemini APIキーを生成してください。
注:別のLLMプロバイダーに接続したい場合は、公式ドキュメントでセットアップ手順を確認してください。
素晴らしい!これでAgnoスクレイピングエージェントを構築するのに必要なコアコンポーネントは全て揃いました。
ステップ6:スクレイピング・エージェントの定義
scraper.pyファイルで、Agnoスクレイピングエージェントを次のように設定します:
agent = Agent(
tools=[bright_data_tools],
model=llm_model,
)これは、設定された LLM を使用してプロンプトを処理し、Bright Data ツールを使用してウェブスクレイピングを行う Agno Agent オブジェクトを作成します。
このインポートをファイルの先頭に追加することを忘れないでください:
from agno.agent import Agent素晴らしい!あとはエージェントにクエリーを送り、スクレイピングされたデータをエクスポートするだけだ。
ステップ #7: Agnoスクレイピングエージェントに問い合わせる
CLIからプロンプトを読み、実行するためにAgnoスクレイピングエージェントに渡します:
# Read the agent request from the CLI
request = input("Request -> ")
# Run a task in the AI agent
response = agent.run(request)最初の行は、Pythonの組み込みのinput()関数を使用して、ユーザーが入力したプロンプトを読み取ります。プロンプトには、エージェントに処理させたいスクレイピングタスクや質問を記述します。2行目は、プロンプトを処理してタスクを実行するためにエージェント上で[run()を呼び出します](https://docs.agno.com/agents/run#running-your-agent)。
レスポンスをターミナルにきれいに表示するには、次のようにする:
pprint_run_response(response)このヘルパー関数をAgnoからインポートする:
from agno.utils.pprint import pprint_run_responsepprint_run_responseはAIエージェントの応答をプリントする。しかし、おそらくBright Dataツールによって返された生のスクレイピングデータを抽出して保存したいでしょう。次のステップでそれを処理しよう!
ステップ#8:スクレイピングしたデータをエクスポートする
スクレイピングタスクを実行する際、Agno ウェブスクレイピングエージェントは、設定された Bright Data ツールを裏で呼び出します。スクリプトがこれらのツールによって返された生データもエクスポートするようにすることで、ワークフローに多くの価値が加わります。なぜなら、そのデータを他のシナリオ(例えば、データ分析)や追加のエージェントのユースケースに再利用することができるからです。
現在、スクレイピングエージェントはBrightDataToolsのこれら2つのツールメソッドにアクセスできます:
scrape_as_markdown():任意のウェブページをスクレイピングし、その内容をMarkdown形式で返します。web_data_feed():LinkedIn、Amazon、Instagramなどの人気サイトから構造化されたJSONデータを取得する。
したがって、タスクに応じて、スクレイピングされたデータ出力は、MarkdownまたはJSON形式のいずれかになります。両方のケースを扱うには、response.tools[0].resultでツールの結果から生の出力を読むことができる。その後、JSONとしてパースを試みる。それが失敗した場合は、スクレイピングされたデータをMarkdownとして扱います。
上記のロジックを以下のコードで実装する:
if (len(response.tools) > 0):
# Access the scraped data from the Bright Data tool
scraping_data = response.tools[0].result
try:
# Check if the scraped data is in JSON format
parsed_json = json.loads(scraping_data)
output_extension = "json"
except json.JSONDecodeError:
output_extension = "md"
# Write the scraped data to an output file
with open(f"output.{output_extension}", "w", encoding="utf-8") as file:
file.write(scraping_data) Python Standard Libraryからjsonをインポートすることを忘れないでください:
import json素晴らしい!これでAgnoウェブスクレイピングエージェントのワークフローは完了です。
ステップ9:すべてをまとめる
これがscraper.pyファイルの最終コードです:
from dotenv import load_dotenv
from agno.tools.brightdata import BrightDataTools
from agno.models.google import Gemini
from agno.agent import Agent
from agno.utils.pprint import pprint_run_response
import json
# Load the environment variables from the .env file
load_dotenv()
# Configure the Bright Data tools for Agno integration
bright_data_tools = BrightDataTools(
web_unlocker_zone="web_unlocker", # Replace with your Web Unlocker API zone name
search_engine=False, # As the SERP API tool is not required in this use case
)
# The LLM that will be used by the AI scraping agent
llm_model = Gemini(id="gemini-2.5-flash")
# Define your Agno agent with Bright Data tools
agent = Agent(
tools=[bright_data_tools],
model=llm_model,
)
# Read the agent request from the CLI
request = input("Request -> ")
# Run a task in the AI agent
response = agent.run(request)
# Print the agent response in the terminal
pprint_run_response(response)
# Export the scraped data
if (len(response.tools) > 0):
# Access the scraped data from the Bright Data tool
scraping_data = response.tools[0].result
try:
# Check if the scraped data is in JSON format
parsed_json = json.loads(scraping_data)
output_extension = "json"
except json.JSONDecodeError:
output_extension = "md"
# Write the scraped data to an output file
with open(f"output.{output_extension}", "w", encoding="utf-8") as file:
file.write(scraping_data)50行以下のコードで、あらゆるウェブページからデータを引き出せるAI主導のスクレイピングワークフローを構築しました。これが、Bright DataとAgnoを組み合わせたエージェント開発の力です!
ステップ #10: Agnoスクレイピングエージェントの実行
ターミナルで、Agnoウェブスクレイピングエージェントを起動してください:
python scraper.pyリクエストを入力するプロンプトが表示されます。次のように入力してください:
Give me a short summary from "https://www.reuters.com/sports/formula1/hulkenberg-rids-himself-unwanted-record-239th-attempt-2025-07-06/"このような出力が表示されるはずだ:
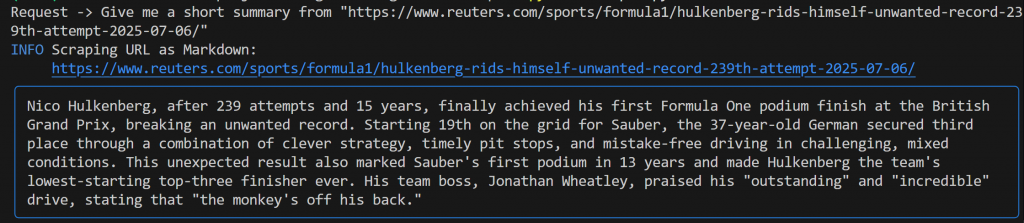
この出力には以下が含まれる:
- 提出したオリジナルのプロンプト。
- どのBright Dataツールがスクレイピングに使用されたかを示すログ。この場合、
scrape_as_markdown() が起動されたことが確認できます。 - Geminiによって生成されたMarkdown形式の要約。青い四角形で強調されている。
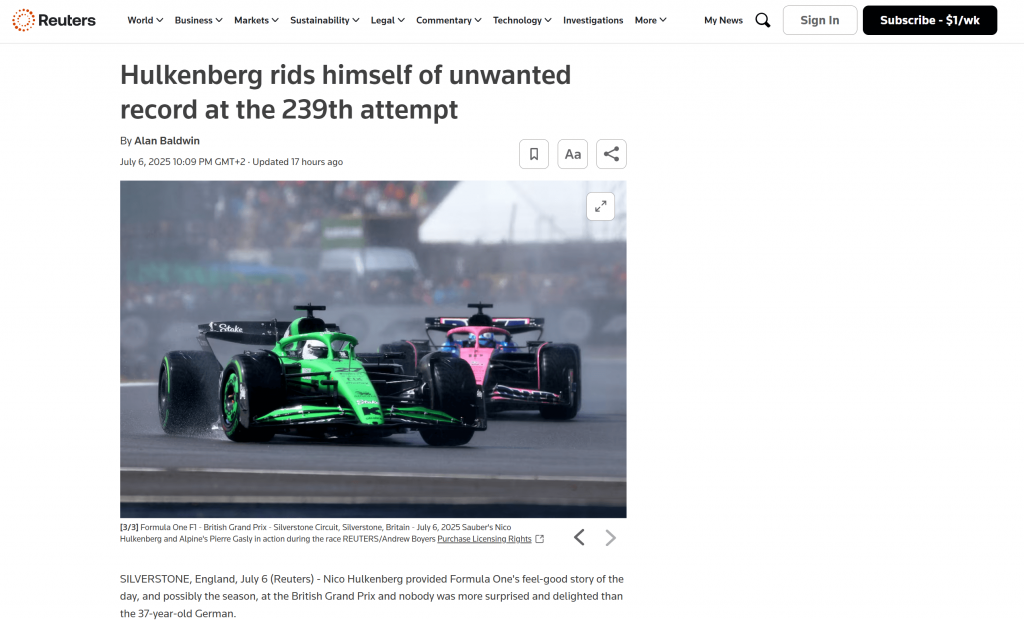
プロジェクトのルート・フォルダー内を見ると、output.mdという新しいファイルがあります。このファイルをMarkdownビューアで開くと、スクレイピングされたページのコンテンツのMarkdownバージョンが得られます:

お分かりのように、Bright DataのMarkdown出力は、元のウェブページの内容を正確にとらえている:
次に、異なる、より具体的なリクエストでスクレイピング・エージェントを再度起動してみる:
Summarize the main features of the product on this Amazon page: "https://www.amazon.com/PlayStation%C2%AE5-console-slim-PlayStation-5/dp/B0CL61F39H/" 今回の出力は次のようになる:
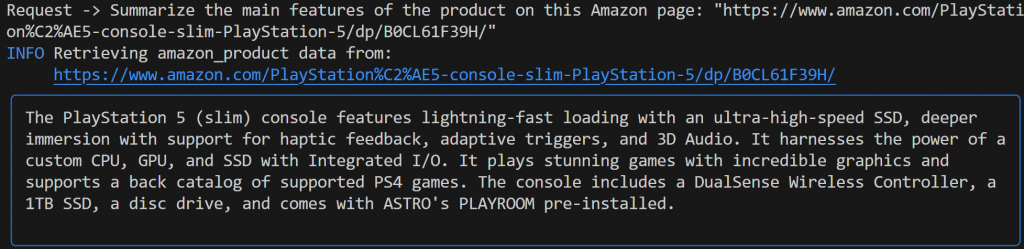
Geminiを搭載したAgnoエージェントが自動的にweb_data_feedツールを選択したことに注目してください。web_data_feedツールは、Amazon商品ページの構造化スクレイピング用に正しく設定されています。
その結果、プロジェクトフォルダにoutput.jsonファイルができます。このファイルを開き、その内容を任意のJSONビューアーに貼り付けてください:
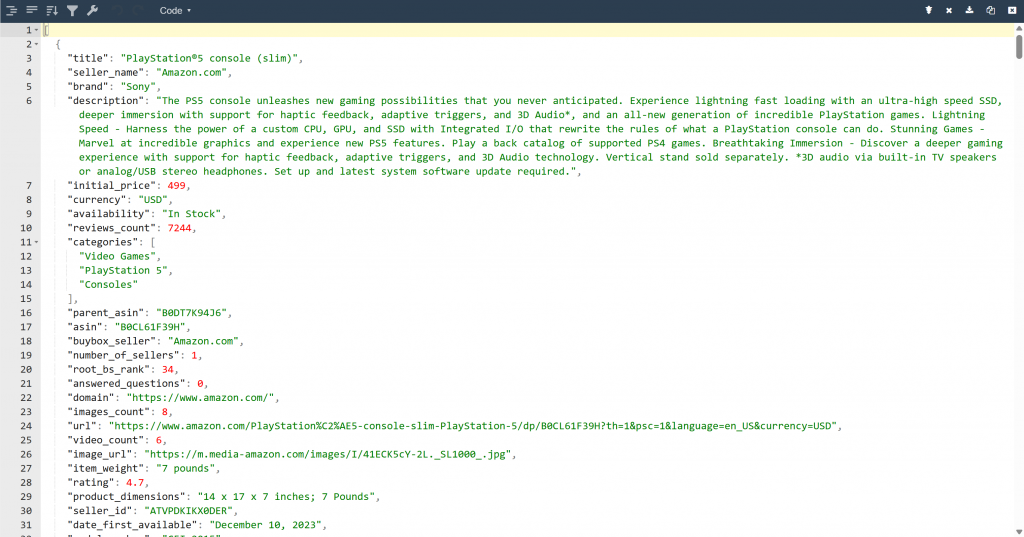
ブライト・データ・ツールが、このアマゾンのページから構造化されたJSONデータをいかにきれいに抽出したかを見てほしい:
これらの例は、エージェントが事実上どのようなウェブページからでもデータを取得できることを示しています。これは、Amazonのような複雑なサイトであっても同様です。Amazonのような複雑なサイトは、スクレイピング対策が厳しいことで有名です(悪名高いAmazon CAPTCHAのような)。
出来上がりです!BrightデータツールとAgnoを利用したAIエージェントで、シームレスなウェブスクレイピングを体験できます。
次のステップ
Agnoで構築したウェブスクレイピングエージェントは、ほんの始まりに過ぎません。ここから、あなたのプロジェクトを拡張し、強化するいくつかの方法を探ることができます:
- メモリレイヤーを組み込む:Agno のネイティブベクターデータベースを使用して、Bright Dataを通じてエージェントが収集したデータを保存します。これにより、エージェントに長期的な記憶を与え、エージェントRAGのような高度なユースケースへの道を開きます。
- ユーザーフレンドリーなインターフェースの作成ユーザが自然な会話形式でエージェントとチャットできるように、シンプルなウェブまたはデスクトップUIを構築します(ChatGPTやGeminiとの対話に似ています)。これにより、あなたのスクレイピングツールは、はるかにアクセスしやすくなります。
- より豊かな統合を探る:Agno は、エージェントのスキルをスクレイピング以上に拡張できる様々なツールや機能を提供しています。より多くのデータソースを接続したり、異なる LLM を使用したり、マルチステップエージェントのワークフローをオーケストレーションする方法については、Agno のドキュメントをご覧ください。
結論
この記事では、WebスクレイピングのためのAIエージェントを構築するためにAgnoを使用する方法を学びました。これは、Agnoに組み込まれたBright Dataツールとの統合によって可能になりました。これらのツールは、選ばれたLLMにあらゆるウェブサイトからデータを抽出する力を与えます。
これは簡単な例であることに注意してください。より高度なエージェントを開発したい場合は、ライブのウェブデータを取得、検証、変換するソリューションが必要になります。これこそが、Bright Data AIインフラストラクチャにあるものです。
無料のBright Dataアカウントを作成し、AI対応スクレイピングツールの実験を開始しましょう!




