

この記事を読み終える頃には、以下の方法が理解できるようになります:
- Bright Data Google AIモードスクレイパーAPIサービスの活用方法
- Skyvernを活用したタスク自動化
- – Bright Data APIサービスをSkyvernと組み合わせてウェブタスクを自動化する
- 自動化とデータフィードを組み合わせてeコマースアシスタントを構築する方法
- カート商品の詳細を自動取得する方法
さあ始めましょう!
Bright DataのAPIサービスを活用する
ブラウザ自動化の基盤は、CAPTCHA、IP禁止、動的ウェブ読み込みなどの課題を回避する能力です。ここでBright Dataが不可欠となります。
120以上のウェブドメインをサポートするBright Dataのウェブスクレイパーにより、ブラウザ自動化はより効率的かつ信頼性の高いものになります。IP禁止、CAPTCHA、クッキー、その他のボット検出など、一般的なウェブスクレイピングの課題を管理します。
まずは無料トライアルに登録し、スクレイピング対象ドメインのAPI キーとdataset_idを取得しましょう。これらが揃えば準備完了です。
以下はBBCニュースなど、任意のドメインから最新データを取得する手順です:
- Bright Dataアカウントをお持ちでない場合は作成してください。無料トライアルが利用可能です。
- Web Scrapersページに移動します。Web Scrapersライブラリで、利用可能なスクレイパーテンプレートを探します。
- 対象ドメイン(例:BBC News)を検索して選択します。
- BBC News用スクレイパー一覧から「BBC News — collect by URL」を選択します。このスクレイパーはドメインへのログインなしでデータを取得できます。
- 「Scraper API」オプションを選択します。「No-Code Scraper」はコードなしでデータセットを取得するのに役立ちます。
- APIリクエストビルダーをクリックし、
APIキー、BBCデータセットURL、dataset_idをコピーします。 APIキーとdataset_idは、ワークフローで自動化機能を有効にするために必要です。これらはプログラミング中にBright Dataの機能を直接利用することを可能にします。
Skyvernとは
Skyvernは、人工知能を活用してウェブブラウザ内のタスクを自動化するAIブラウザ自動化ツールです。機械学習、自然言語処理、コンピュータビジョンを組み合わせて複雑なブラウザ操作を処理します。
SkyvernはSeleniumやPlaywrightなどの従来型自動化ツールと以下の点で異なります:
- UI変更への適応性:自己修復機能により、Skyvernはスクリプトを壊すことなく動的にUI変更に適応します。
- ワークフローの複雑性:単一のプロンプトを通じてAI推論による多段階ワークフローを処理可能。
- 視覚認識:コンピュータビジョンを活用し、UI要素を視覚的に理解・操作します。
これらの機能により、Skyvernは予約サイトへのログイン、フォーム入力、ショッピングカートへの商品追加などに活用できます。Bright Dataのウェブスクレイピング機能と統合することで、Skyvernは多様なウェブ自動化ニーズに対応する強力なフレームワークを提供します。
自動化ワークフロー
例:オンラインストアで自動車部品を購入する場合、利用可能なオプションを比較し、自動的にカートに追加したいとします。ワークフローは以下のようになります:
- Bright Data AIモードスクレイパーAPIが指定メーカーから部品番号などの製品詳細・説明を取得。
- 出力内容を確認し選択します。Bright Dataは高速かつ信頼性の高いウェブデータ取得を提供します。
- SkyvernはBright Dataから取得した詳細情報を使用してfinditparts.comにアクセスします。その後、サイト内をナビゲートし、選択した製品をカートに追加し、カート詳細とカートURLを出力します。
- そのままチェックアウトと支払いに進みます。
前提条件
- Pythonプログラミングの基礎知識。Pythonはこちらからダウンロード
- 有効なBright Dataアカウント。こちらから登録し、ウェルカムメールからAPIキーを取得してください
- JSONおよびREST APIに関する基礎知識
プロジェクトの設定
ステップ1: Bright Dataの設定
BrightDataのAPIキー、データセットID、Google AIモードURLを取得するには、「Bright Dataの堅牢なAPIサービスをユースケースに活用する」で説明されている手順に従ってください。
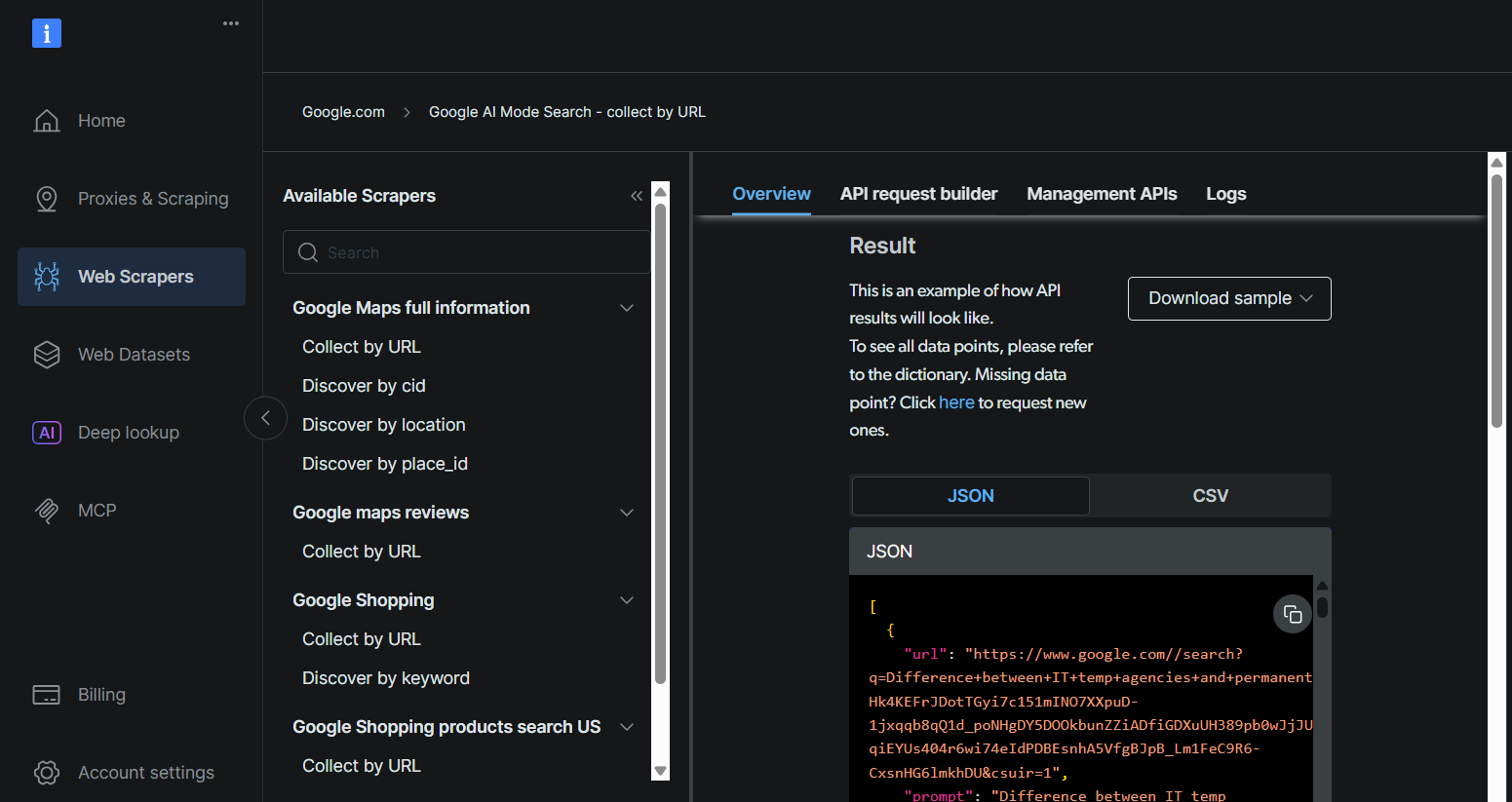
ステップ2: Skyvern Cloudへの登録
- https://app.skyvern.com/ にアクセスし、5米ドル分の無料クレジットを受け取るためにサインアップしてください。
- Skyvernエージェントにタスクの実行を依頼し、動作を確認します。例:Hacker Newsのホームページに移動し、上位3つの投稿を取得する。
- タスクの進捗状況を追跡するには履歴を確認してください。ステータスが「完了」と表示されたら、タスクは正常に終了したことを示します。
- 完了後、履歴から該当タスクをクリックすると、出力結果・パラメータ・詳細情報を確認できます。
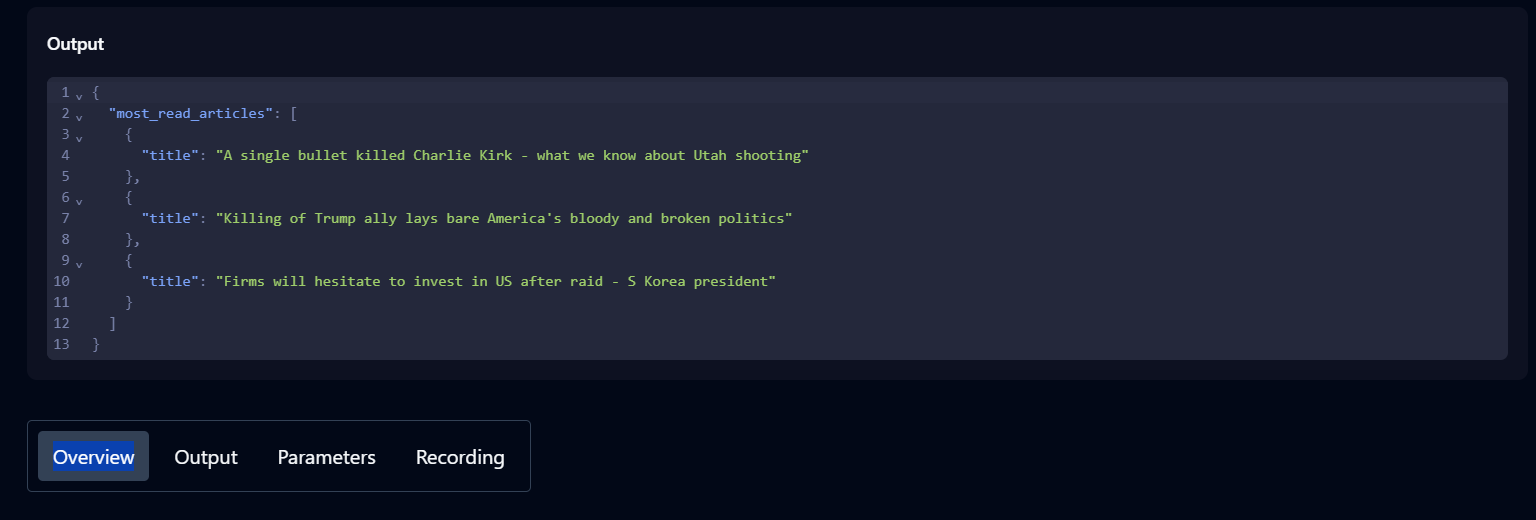
Skyvernの設定が完了したので、コードスクリプトの記述を開始できます。
ステップ3: ローカルマシンへのSkyvernインストール
3.1 仮想環境の作成
対象プロジェクトフォルダ内で、Python を使用して仮想環境を作成します:
python -m venv .venv
環境を有効化します。
.venvScriptsactivate
3.2 Skyvern を任意のデバイスにインストール
pip install skyvern
インストールで問題が発生した場合は、Windows上のUbuntuターミナルを使用できます。Ubuntuターミナルの設定方法についてはこちらの投稿を参照してください。
ターミナルが起動したら、目的のディレクトリに移動し、以下を実行します:
pip install uv仮想環境を作成するには:
uv venv venv次にSkyvernをインストールします:
uv pip install skyvern3.3 Skyvern クイックスタート
インストール完了後、以下を実行:
skyvern quickstart- 「Skyvernをローカルで実行しますか、それともクラウドで実行しますか?」とプロンプトが表示されたら、「cloud」と入力してください。
- 「Skyvern baseURLを入力してください」と表示されたら、Enterキーを押します。
- MCPプロンプト(ここで「y」と入力)を除くすべてのインストールプロンプトでは「n」と入力してください。
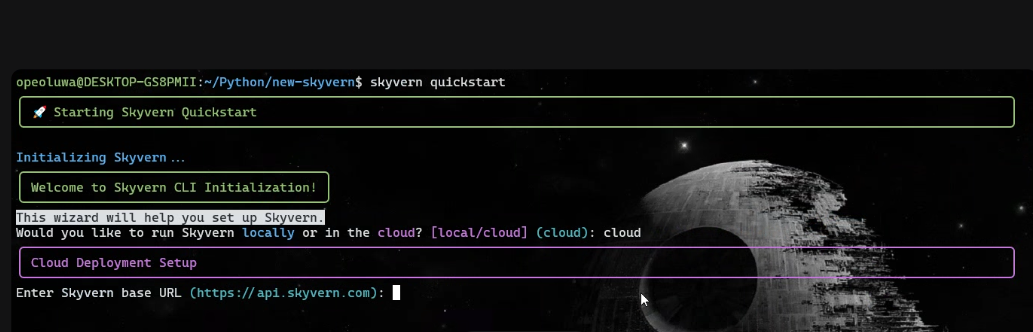
セットアップ後、以下を実行してください:
skyvern initapp.py という名前の Python スクリプトを作成します。
ステップ4: Bright Dataで製品詳細を取得
4.1 app.pyに以下のコードを追加し、Bright Dataで部品番号を取得:
import asyncio
import requests
import time
import json
def trigger_scraping_job(api_key, data):
"""
URL、プロンプト、国を含む辞書のリストでBright Dataデータセットジョブをトリガーします。
成功した場合、snapshot_idを返します。
"""
endpoint = "https://api.brightdata.com/datasets/v3/trigger"
params = {
"dataセットID": "gd_mcswdt6z2elth3zqr2", # あなたのデータセットID
"include_errors": "true",
}
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(endpoint, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json().get("snapshot_id")
print(f"リクエスト成功!スナップショットID: {snapshot_id}")
return snapshot_id
else:
print(f"リクエスト失敗! ステータス: {response.status_code}")
print(response.text)
return None
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
"""
データが準備できるまでBright Dataのスナップショットエンドポイントをポーリングする。
JSONレスポンスを出力ファイルに保存する。
"""
snapshot_url = f"https://api.brightdata.com/データセット/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"スナップショットID: {snapshot_id} のポーリング中...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("スナップショットの準備が整いました。ダウンロード中...")
snapshot_data = response.json()
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"スナップショットを {output_file} に保存しました")
return
elif response.status_code == 202:
print(f"スナップショットはまだ準備できていません。{polling_timeout} 秒後に再試行します...")
time.sleep(polling_timeout)
else:
print(f"リクエスト失敗!ステータス: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "YOUR_BRIGHT_DATA_API_KEY" # あなたのAPIキー
# curlのJSONデータ構造と完全に一致させる
data = [
{
"url": "https://google.com/aimode",
"prompt": "finditparts.comからSKF製ホイールシールの部品番号を検索",
"country": ""
}
]
snapshot_id = trigger_scraping_job(BRIGHT_DATA_API_KEY, data)
if snapshot_id:
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "product.json")プロンプトは次の通りです: ‘finditparts.com から、メーカーが SKF のホイールシールの部品番号を検索してください。’
これにより、SKFメーカーの製品説明と部品番号を含むproduct.jsonファイルが作成されます。
{
"url": "https://www.finditparts.com/products/16775486/skf-45093xt?srcid=CHL01SCL010-Npla-Dmdt-Gusa-Svbr-Mmuu-K16775486-L22",
"title": "www.finditparts.com",
"description": "SKF 45093XT ホイールシール | FinditParts",
"icon": "https://encrypted-tbn0.gstatic.com/faviconV2?url=https://www.finditparts.com&client=AIM&size=128&type=FAVICON&fallback_opts=TYPE,SIZE,URL",
"domain": "https://www.finditparts.com",
"cited": true
},
{
"url": "https://www.finditparts.com/products/193780/cr-slash-skf-14115?srcid=CHL01SCL010-Npla-Dmdt-Gusa-Svbr-Mmuu-K193780-L1464",
"title": "www.finditparts.com",
"description": "SKF 14115 ホイールシール | FinditParts",
"icon": "https://encrypted-tbn0.gstatic.com/faviconV2?url=https://www.finditparts.com&client=AIM&size=128&type=FAVICON&fallback_opts=TYPE,SIZE,URL",
"domain": "https://www.finditparts.com",
"cited": true
},
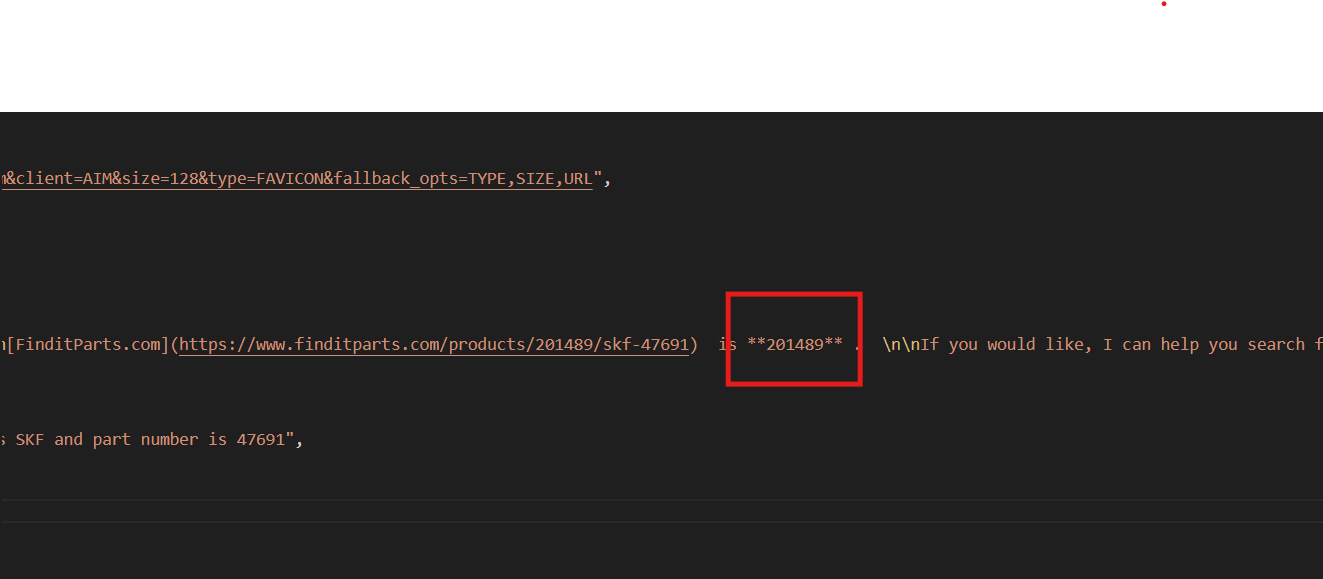
{次に、お好みの部品番号(説明欄に記載)を選択し、以下のプロンプトでBright Dataコードを再実行してください:’部品番号47691のSKFホイールシールの製品IDを検索’
# curlのJSONデータ構造を厳密に一致させる
data = [
{
"url": "https://google.com/aimode",
"prompt": "SKFホイールシール(部品番号47691)の製品IDを検索",
"country": ""
}
]Skyvernは、finditparts.com(自動車部品のECサイト)でカートに詳細を追加するために製品IDを必要とします。
このプロセスにより、目的の製品IDを含むproduct.jsonファイルが生成されます。
ステップ5: Skyvernにタスクを指示する
まず、https://app.skyvern.com/tasks/create/finditparts にアクセスします。このURLはSkyvernでタスクを作成するためのショートカットです。
「基本コンテンツ」セクションの「詳細設定」をクリックし、ご自身のユースケースに合わせて製品IDとプロンプトを更新してください。
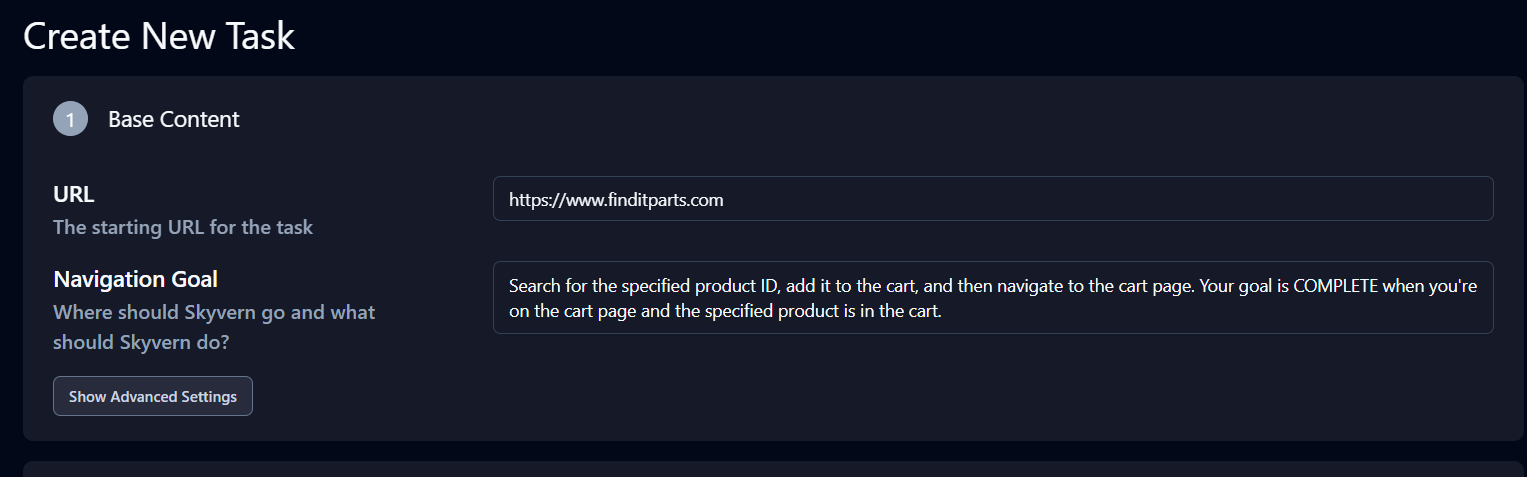
プロンプト例: ‘指定された商品IDを検索し、カートに追加した後、カートページに移動してください。カートページに到達し、指定商品がカート内にある状態で目標は完了となります。’
詳細設定の下にある「抽出」セクションも重要です。「データ抽出目標」を以下のように変更してください:’カートページのURLと、カートページ上の全商品の数量情報を抽出する。’
ページ下部の「APIコマンドをコピー」をクリックし、ターミナルに貼り付けてEnterキーを押します。
これにより、ターミナルにtask_idが生成され、Skyvern Cloud上にタスクのインスタンスが作成されます。履歴でステータスを確認し、キュー待ち、実行中、完了のいずれかを確認できます。
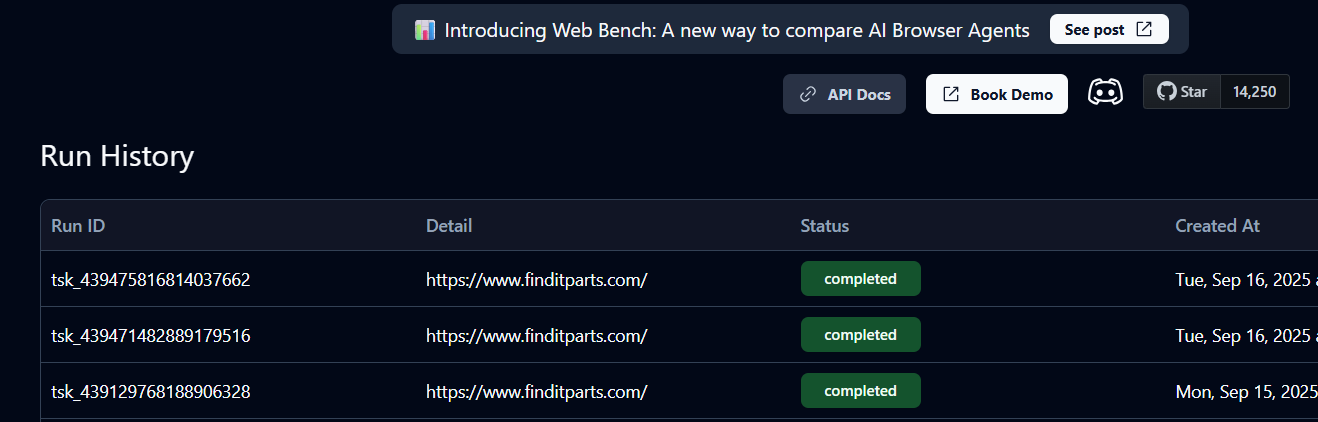
ステータスが「完了」の場合、タスクは終了しています。これでSkyvernから返されたカート詳細と商品URLを確認できます。
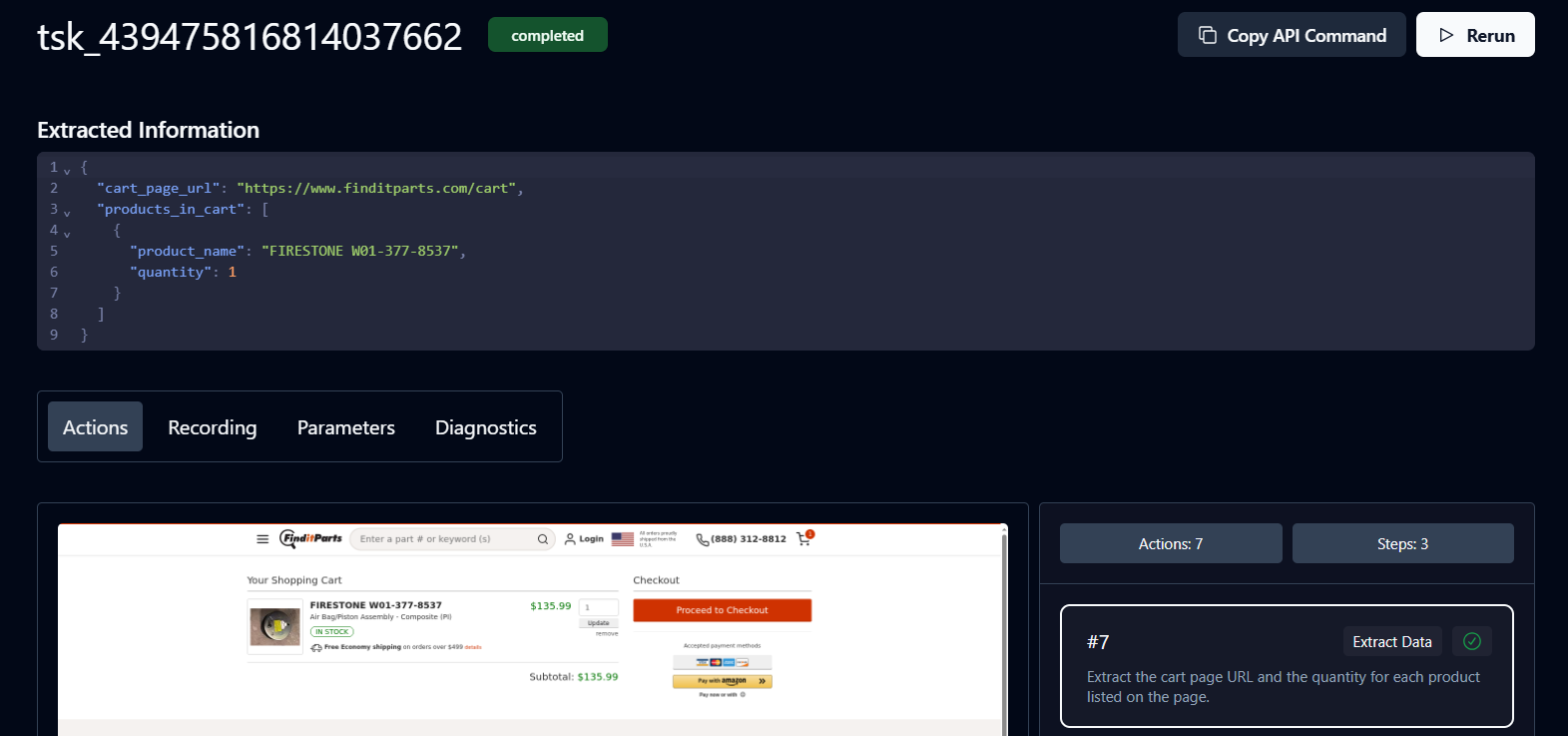
おめでとうございます。ワークフローが完了しました。URLをクリックして支払いを進めてください。
Bright Dataはオンライン商品を手動で検索する手間を省き、選択肢を直接端末に提供します。これにより最適な商品を選択し、Skyvernで購買プロセスを自動化できます。
次のステップ
ワークフローを拡張して、複数の商品をカートに追加してチェックアウトしたり、全商品の自然言語処理(NLP)サマリーを生成したりできます。また、ワークフローをクラウドにデプロイして継続的な監視を実現することも可能です。最後に、Googleカレンダーと統合して割引情報を追跡できます。
まとめ
本チュートリアルでは、Bright DataのスクレイパーAPIとSkyvernを組み合わせて、オンラインでの商品検索・購入プロセスを自動化する方法を学びました。 Scraper API以外にも、Bright DataはAIエージェントを強化するツールを提供しています。例えば、eコマース やソーシャルメディア向けにカスタマイズされた即利用可能なデータセット、高度な多段階自動化を実現するWeb MCPサーバー、40以上の専門ツールへのアクセスなどです。これらの製品を組み合わせることで、ウェブデータを効率的に収集・分析・活用するAI駆動型ワークフローを容易に構築できます。
Bright Dataのフルスイートを今すぐ探索し、AI自動化プロジェクトを強化しましょう。





