

このブログ記事では、以下の内容を学びます:
- Amazon SageMakerとは何か、そして機械学習にもたらす価値。
- 特徴量エンジニアリングを成功させるためにウェブデータが不可欠な理由。
- 特徴量エンジニアリングや他の機械学習シナリオに向けた高品質なウェブデータの取得先。
- ウェブデータを格納したデータセットを使用してAmazon SageMakerで特徴量エンジニアリングを実行する方法。
さっそく始めましょう!
Amazon SageMakerとは?
Amazon SageMakerは、機械学習モデルとAIアプリケーションを大規模に構築・トレーニング・デプロイするためのフルマネージドサービスです。分析とAIのための統合されたエンドツーエンド環境を提供します。
Amazon S3データレイク、Redshiftデータウェアハウス、サードパーティやフェデレーテッドシステムなど、複数のソースからデータにアクセスできます。これらすべてにおいて、エンタープライズグレードのセキュリティとガバナンスが保証されています。
つまり、SageMakerはMLワークフローを簡素化し、特徴量エンジニアリングからモデルデプロイまでのモデル開発を加速します。以下が主な機能と特徴です:
- SageMaker Unified Studio:フルマネージドインフラと統合ツールを使用して、MLおよび生成AIモデルの構築・トレーニング・デプロイを行うための単一開発環境。
- モデル開発とMLOps:迅速なプロトタイピング、トレーニング、モデルの運用化のための事前構築済みテンプレート、HyperPod、JumpStartを含む。
- 生成AIサポート:Amazon Bedrockでアプリケーションを構築・スケールし、Amazon Q Developerなどの組み込みAIアシスタントを活用。
- データ処理とSQL分析:Amazon Athena、EMR、Glue、Redshift上のオープンソースフレームワークを使用してデータを準備・分析・統合。
- レイクハウスアーキテクチャ:包括的な分析とAIをサポートするために、ストレージシステム全体にわたるサイロ化されたデータへのアクセスを統合。
ウェブデータを使った特徴量エンジニアリング入門
特徴量エンジニアリングとは、生データを「特徴量」と呼ばれる意味のある変数に変換し、機械学習モデルがより効果的に活用できるようにするプロセスです。未処理のデータをモデルに与える代わりに、ソースデータセットのパターンをより適切に捉えた派生メトリクスを作成するという考え方です。
例としては、値の集約、スコアの正規化、関連変数の組み合わせ、異なるフィールド間の関係を強調する比率の作成などがあります。優れた特徴量エンジニアリングは、アルゴリズムの選択よりもモデルのパフォーマンスに大きな影響を与えることがあります。これは、適切に設計された特徴量が、そうでなければ隠れたままになるシグナルをモデルが識別するのに役立つためです。
ウェブデータは、現実世界の活動を大規模に反映しているため、特徴量エンジニアリングに特に価値があります。公開ウェブサイトには、企業、製品、求人、レビュー、価格、ユーザー行動に関する大量の情報が含まれています。これらのシグナルは、人気指標、市場需要指標、感情スコア、採用トレンドなどの特徴量に変換できます。このような特徴量は、機械学習パイプラインのパフォーマンスを大幅に向上させることができます。
ただし、ウェブデータの扱いにはいくつかの課題があります。データにノイズが多かったり、不完全だったり、一貫性がない場合があります。これは入力データの品質に大きく影響する可能性があります。さらに、多くのウェブサイトはアンチボット対策を採用しています。
そのため、ウェブスクレイピングで機械学習を強化するのは難しいです。収集したデータをMLパイプラインで使用する前に、クリーニング、検証、準備が必要です。
大量の高品質ウェブデータの取得先
お気づきのように、ウェブデータは特徴量エンジニアリングにおいて重要な役割を果たします。同時に、エンタープライズ用途で信頼性高く取得するのは困難です。ウェブスクレイピングのロードマップに従えば、数ページからデータを収集することは簡単に見えるかもしれませんが、多くのドメインや大規模なサイト全体で一貫して行うのははるかに複雑です。
ウェブサイトは頻繁に構造を変更し、レート制限を適用し、自動リクエストをブロックするアンチボット保護を展開します。さらに、データを収集できた場合でも、高品質で完全かつ最新の状態を維持することは難しい場合があります。
そのため、多くの組織はBright Dataのようなウェブデータセット会社やウェブデータプロバイダーに依存しています。これらのプラットフォームは、スクレイピングインフラを構築・維持することなく、大量のウェブデータにアクセスできるようにします。
Bright Dataは、215以上の人気ウェブドメインから数百のデータセットを提供しており、総レコード数は170億件以上です。これらのデータセットには、継続的に更新されるウェブデータが含まれており、構造化されていてすぐに使用でき、MLおよびAIアプリケーション向けに最適化されています。データセットマーケットプレイスをぜひご覧ください!
事前収集されたデータセットがニーズを満たさない場合、Bright DataはWeb Scraping APIやその他のデータ収集ツールも提供しています。これらは、スクレイピングの課題を自分で処理することなく、オンデマンドでウェブサイトから新鮮なデータを取得するのに役立ちます。
Bright Dataの強みはそのデータ収集インフラにあります。195カ国以上にわたる1億5,000万以上のIPを持つグローバルプロキシネットワーク上に構築されており、99.99%の稼働率と99.95%の成功率を達成しています。この基盤により、信頼性の高いウェブデータを活用したデータドリブンなアプリケーションやMLパイプラインの構築が容易になります。
Amazon SageMakerでウェブデータの特徴量エンジニアリングを実行する方法
このステップバイステップのセクションでは、Amazon SageMakerで特徴量エンジニアリングを実行するプロセスを順を追って説明します。
Bright DataのGlassdoorデータセットから始め、Amazon S3にアップロードし、SageMakerノートブックに読み込み、特徴量エンジニアリングを適用して意味のあるメトリクスを作成します。特徴量が準備できたら、それらを使用して従業員満足度が高いかどうかを予測する機械学習モデルをトレーニングします。
これはあくまで一例であり、他にも多くのユースケースが可能です。
手順に従ってください!
前提条件
このガイドに従うには、以下が必要です:
- AWSアカウント(無料トライアルでも可)。
- Bright Dataアカウント。
- AWSアカウントで定義されたS3バケット。
- 基本的なPythonの知識、特に機械学習開発とデータサイエンスに関するもの。
以降では、S3バケット名がbright-data-sagemakerであると仮定します:
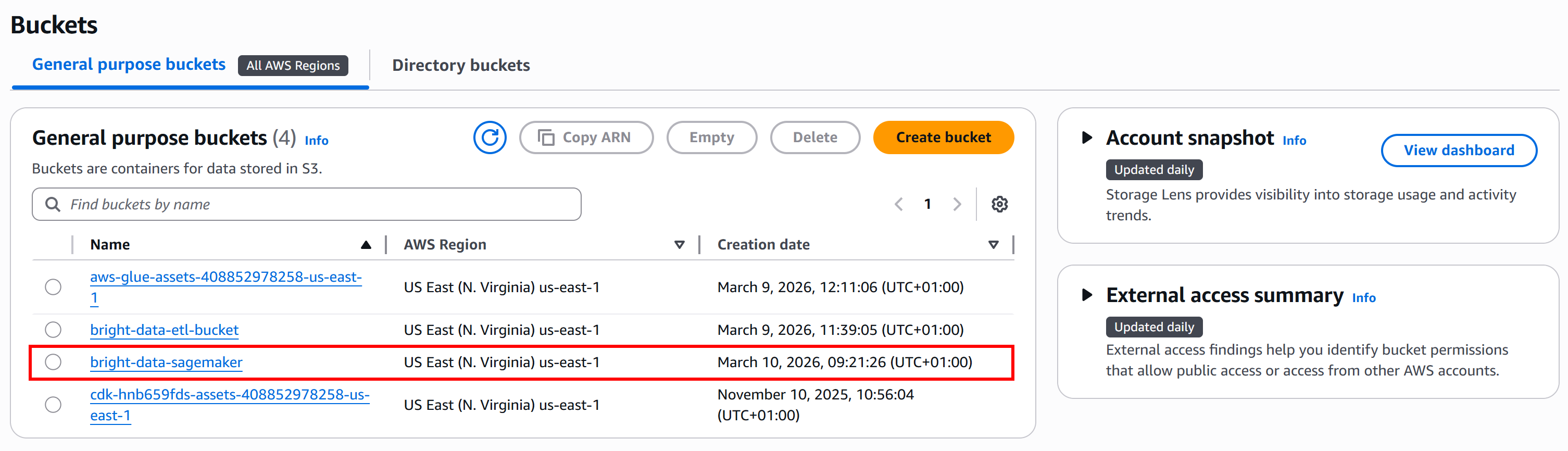
ステップ1:Bright Dataから入力データセットを取得する
最初のステップは、入力ウェブデータを取得することです。特徴量エンジニアリングには、大規模で高品質なデータセットから始めるのが最善です。この例では、Bright Dataの豊富なデータセットコレクションを活用し、先ほど計画したGlassdoorデータセットに焦点を当てます。
代替手段:新しいデータを収集したい場合は、Bright DataのWeb Scraping APIのいずれかを使用して、新鮮で構造化されたML対応データセットを収集できます。これらのAPIは、Amazon S3アカウントに直接データを送信できるデリバリーオプションを提供しており、SageMakerとのシームレスな統合が可能です。
Bright Dataアカウントをお持ちでない場合は、まずアカウントを作成してください。すでにお持ちの場合は、ログインするだけです。
Bright Dataのコントロールパネルで「Web Datasets」メニューオプションを選択します。「データセットマーケットプレイス」タブに移動して、利用可能なデータセットを閲覧します:
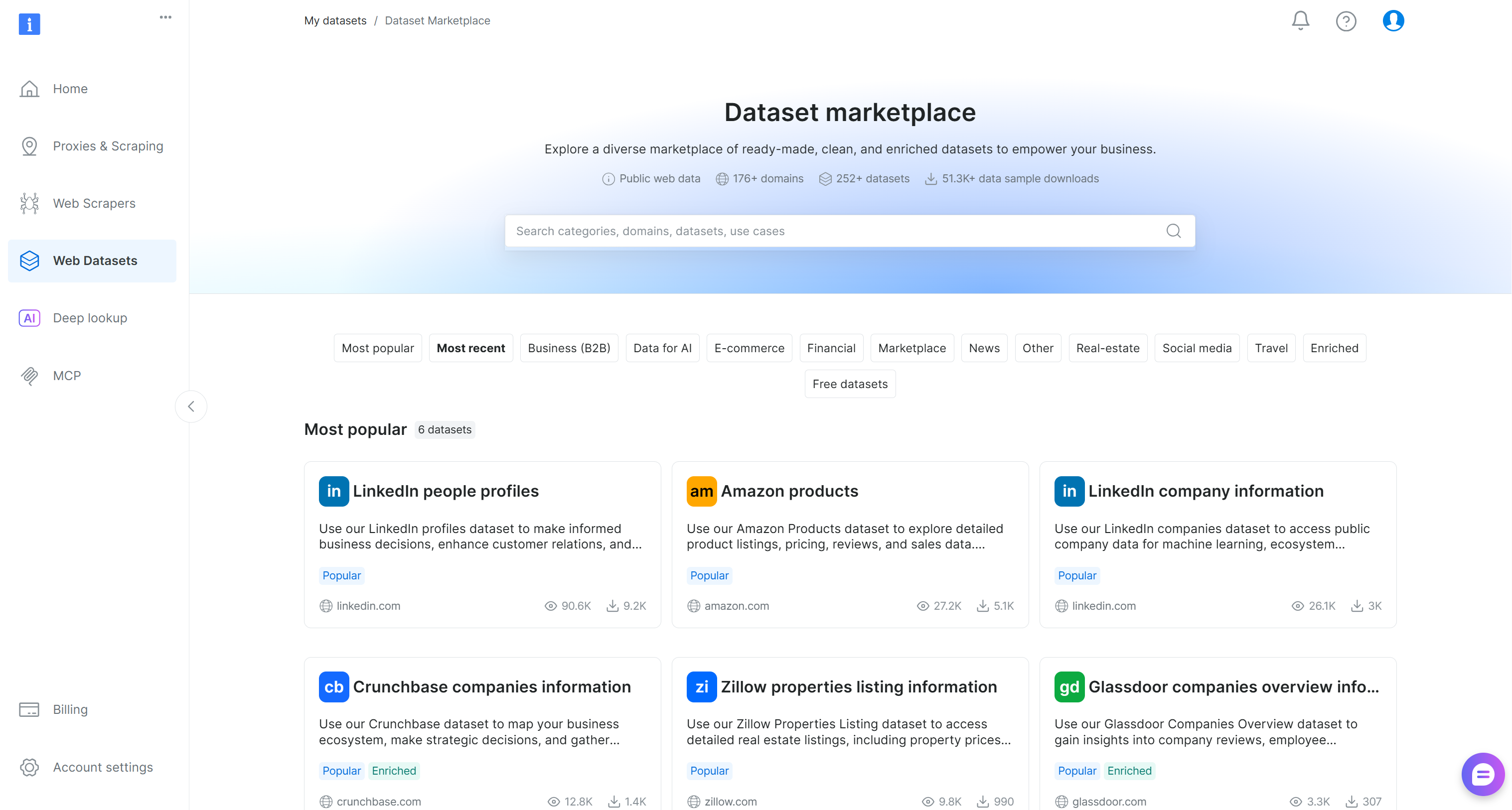
ここでは、155以上のドメインからの200以上のスクレイピング済みデータセットを探索でき、数十億件のレコードが含まれています。
次に、「Glassdoor companies overview information」データセットを探してそのページを開きます:
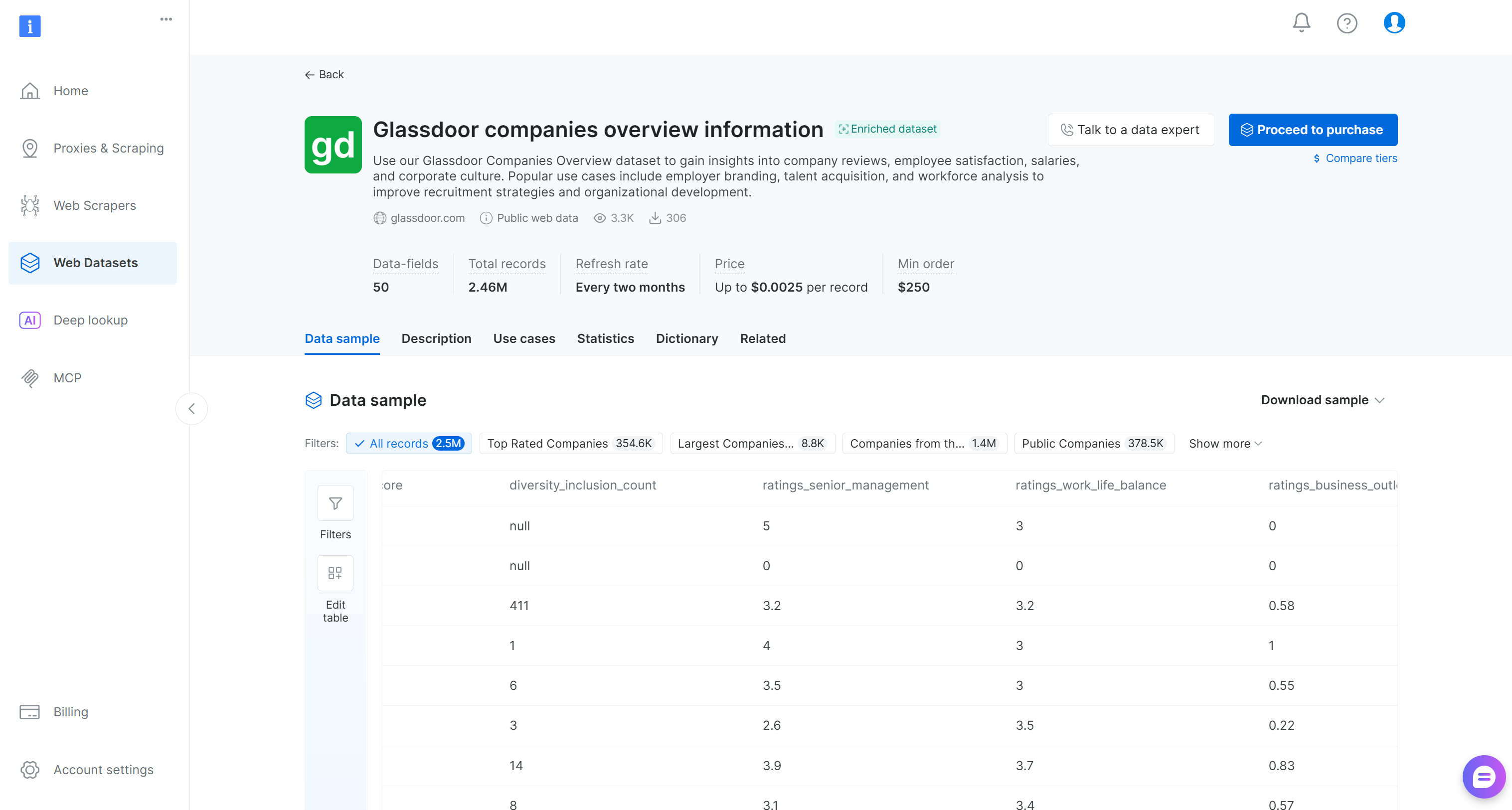
このデータセットには、企業レビュー、従業員満足度スコア、給与、企業文化情報が含まれています。主なユースケースには、雇用主ブランディング、人材獲得、労働力分析などがあります。50のデータフィールドを持つ246万件以上のエントリが含まれています。
フィルタリングされたサブセットを購入するか、無料サンプルをダウンロードするかを選択できます。本番シナリオでは、入力データセットが大きいほど、特徴量エンジニアリングの結果がより信頼性の高いものになります。
このチュートリアルはあくまで例示なので、無料サンプルを使用します。取得するには、「Download sample」ドロップダウンをクリックして「Download as JSON」オプションを選択します:
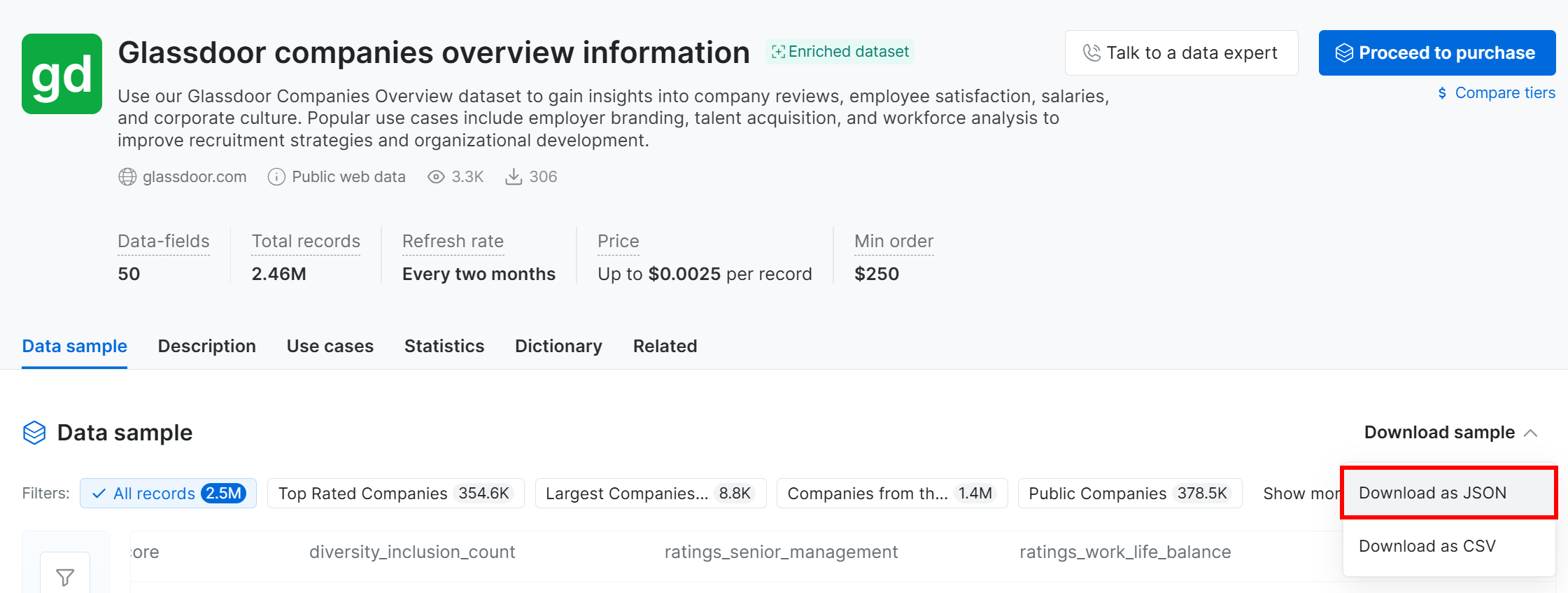
Glassdoor companies overview information.jsonという名前のサンプルファイルを受け取ります。このファイルには、それぞれ50フィールドを持つ1,000件の企業レコードが含まれています。
ファイルをglassdoor-companies.jsonにリネームし、S3バケットにアップロードする準備をしましょう。これがSageMakerの特徴量エンジニアリングノートブックの入力として使用されます。よくできました!
ステップ2:ウェブデータをS3バケットにアップロードする
Amazon S3バケットのページに移動し、「Upload」ボタンをクリックしてglassdoor-companies.jsonファイルを追加します。アップロードが完了すると、バケットに次のように表示されます:
または、多くあるAmazon S3クライアントのいずれかを使用してファイルをアップロードすることもできます。
注意:Bright DataのWeb Scraping APIを使用すると、スクレイピングしたデータをAmazon S3に直接送信できます。
素晴らしい!これでAmazon SageMakerでの特徴量エンジニアリング用の入力ウェブデータが準備できました。
ステップ3:Amazon SageMakerを始める
AWSコンソールにログインして「SageMaker」を検索します。サービスを選択してメインページを開きます:
「Get started」ボタンをクリックして、Amazon SageMakerの使用を開始します。
セットアップページで、自動IAMセットアップのために「Auto-create a new role with admin permissions」が選択されていることを確認します。「Set up」ボタンを押して続行します:
初期化プロセスには数分かかる場合があるので、しばらくお待ちください。実行中は「Setting up Amazon SageMaker Unified Studio…」というメッセージが表示されます。
セットアップが完了すると、次のページに到達します:
「Open」をクリックしてAmazon SageMaker Unified Studioを起動します:
ここから、ノートブックの開発・実行を含め、SageMaker環境を探索・管理できます。素晴らしい!
ステップ4:新しいノートブックを作成する
Amazon SageMaker Unified Studioで、「Build in the notebook」ボタンをクリックして新しいノートブックを作成します:

新しいSageMakerノートブックはこのような外観になります:
「Company Data Feature Engineering」などの説明的な名前をノートブックに付けることを検討してください。
Amazon SageMakerノートブックは、Jupyter Notebookを実行するマネージド機械学習コンピューティングインスタンスです。データの準備・処理、トレーニングコードの記述・テスト、SageMakerホスティングへのモデルのデプロイ、モデルの検証に必要なすべてを提供します。
素晴らしい!これでSageMakerの特徴量エンジニアリングロジックを実装するためのすべての構成要素が揃いました。
ステップ5:入力ウェブデータを読み込む
最初のステップは、Bright DataからのGlassdoorウェブデータをSageMakerノートブックに読み込むことです。
左側の「Data Explorer」パネルで「Buckets」ドロップダウンを展開します。S3バケットを見つけてglassdoor-companies.jsonファイルを探します。ファイルの横にあるバーガーメニューをクリックして「Read as dataframe」オプションを選択します:
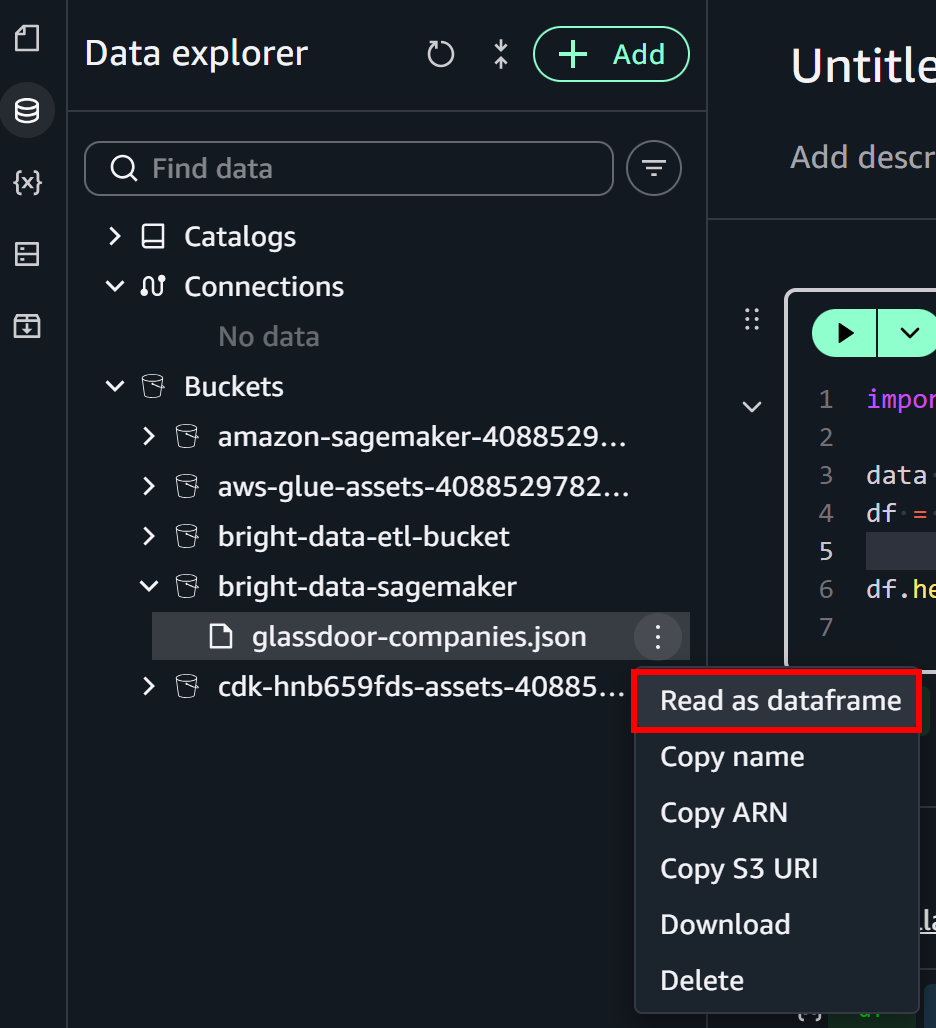
これにより、S3からファイルを読み込むロジックで最初のノートブックセルが自動入力されます:
import pandas as pd
data = pd.read_json("s3://bright-data-sagemaker/glassdoor-companies.json")注意:bright-data-sagemakerをS3バケットの名前に置き換えてください。
最初のセルのデータインポートロジックを次のように完成させます:
import pandas as pd
# S3バケットから入力データを読み込む
data = pd.read_json("s3://bright-data-sagemaker/glassdoor-companies.json")
# 構造化されたJSONフィールドを正規化する
df = pd.json_normalize(data.to_dict(orient="records"))
# 最初の10行を表示する
df.head(10)このコードスニペットは、PythonでS3バケットからJSONデータセットを読み込み、分析のための前処理を行います。pd.read_json()でファイルを読み込み、pd.json_normalize()でネストされたJSONフィールドを表形式のDataFrameに展開します。最後に、df.head(10)で最初の10行を表示し、構造化されたデータのクイックプレビューを提供します。
「▶」ボタンを押してセルを実行します。次のようなプレビューが表示されます:
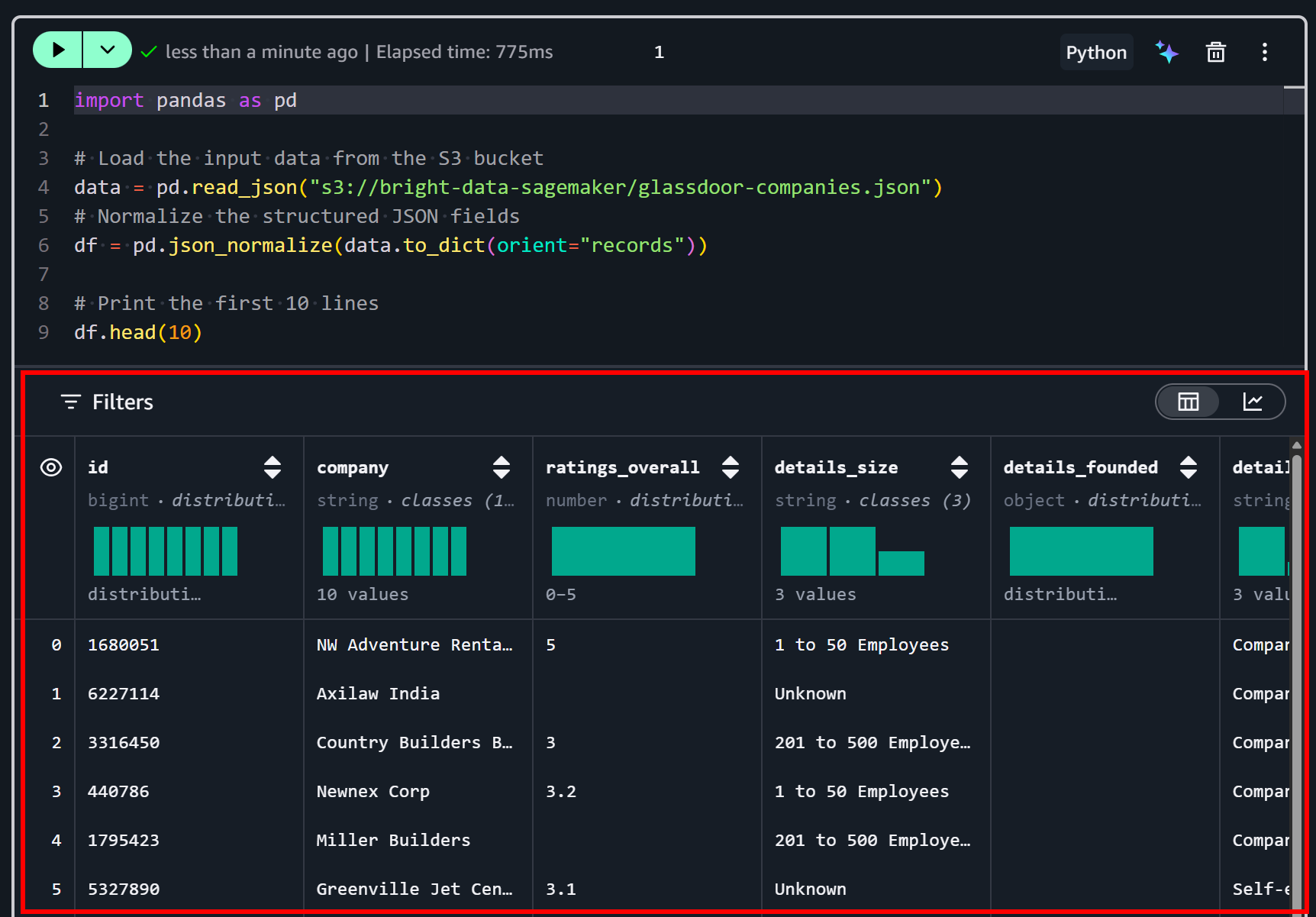
ご覧のように、データセットが正しく読み込まれました。これには50のデータフィールドが含まれており、Bright Dataのデータセットページの「Dictionary」タブに一覧表示されています:
特徴量エンジニアリングの準備ができた入力ウェブデータが揃いました。素晴らしい!
ステップ6:入力データを前処理する
データセットをノートブックにインポートしたので、次のステップは特徴量エンジニアリングのためにデータをクリーニングして準備することです。
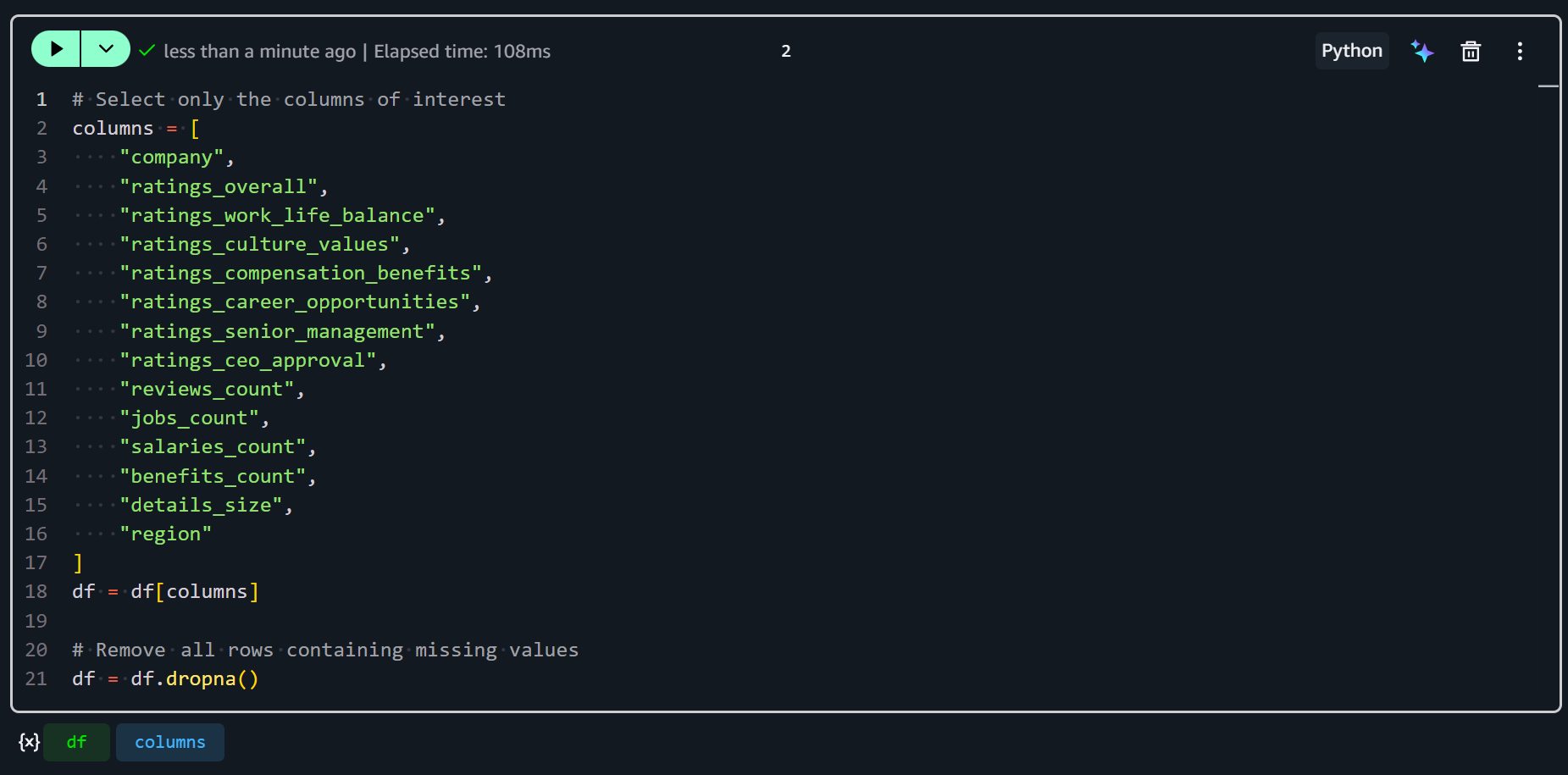
SageMakerノートブックに新しいセルを追加して、以下のコードを入力します:
# 対象の列のみを選択する
columns = [
"company",
"ratings_overall",
"ratings_work_life_balance",
"ratings_culture_values",
"ratings_compensation_benefits",
"ratings_career_opportunities",
"ratings_senior_management",
"ratings_ceo_approval",
"reviews_count",
"jobs_count",
"salaries_count",
"benefits_count",
"details_size",
"region"
]
df = df[columns]
# 欠損値を含むすべての行を削除する
df = df.dropna()このスニペットは、関連するメトリクスと識別子に焦点を当てるため、対象の列のみを選択します。次に、df.dropna()を使用して、選択した列に欠損値を含む行を削除します。これにより、特徴量エンジニアリングのためにデータがクリーンで一貫していることが保証されます。
新しいセルはこのようになります:
よくできました!入力データセットがSageMakerでの特徴量エンジニアリングの準備ができました。
ステップ7:特徴量を定義する
機械学習に使用する特徴量を定義する時が来ました。特徴量とは、生データを要約または変換して、根底にあるパターンをより適切に表す意味のあるメトリクスにした派生列であることを忘れないでください。
この例では、企業文化、報酬、人気度、成長活動を捉える特徴量を追加します。
まず、culture_score特徴量は、複数の関連評価を組み合わせて企業の全体的な文化環境を表す単一のメトリクスを作成します:
df["culture_score"] = (
df["ratings_culture_values"] +
df["ratings_work_life_balance"] +
df["ratings_senior_management"]
) / 33つの評価列を平均します:
ratings_culture_values:企業が掲げる価値観をどれだけ体現しているかを説明。ratings_work_life_balance:従業員のワークライフバランスの認識を評価。ratings_senior_management:リーダーシップと管理の認識を追跡。
3つの評価を合計して3で割ることで、正規化されたスコアが得られます。結果のスコアは元の評価と同じスケールを保ち、文化の各側面に等しい重みを与えます。
次に、compensation_score特徴量は、給与とキャリア成長に対する従業員満足度の複合的な見方を表します:
df["compensation_score"] = (
df["ratings_compensation_benefits"] +
df["ratings_career_opportunities"]
) / 2以下の要素が含まれます:
ratings_compensation_benefits:給与と福利厚生に対する従業員の満足度を評価。ratings_career_opportunities:キャリアアップの機会に対する従業員の満足度を追跡。
平均化することで、特徴量は両方の側面を均等にバランスするように他のスコアと一貫してスケールされます。
3つ目のreview_popularity特徴量は、Glassdoorで企業がどのくらいの頻度でレビューされているかを測定します:
df["review_popularity"] = df["reviews_count"].apply(lambda x: x ** 0.5)レビュー数に平方根変換を適用することで取得されます。なぜ平方根なのか?レビュー数は非常に偏っていることが多いためです(一部の企業は数千件のレビューを持ち、多くはほとんど持っていません)。平方根を取ることで、極端に高い値の影響を減らし、分散を安定させ、処理と分析が容易になります。
4つ目のhiring_intensity特徴量は、レビュー活動に対して企業がどれだけ積極的に採用しているかを推定します:
df["hiring_intensity"] = df["jobs_count"] / (df["reviews_count"] + 1)求人票数(jobs_count)をレビュー数+1(レビューがない企業のゼロ除算を避けるため)で割ることで計算されます。
高い値は、レビューを残す従業員数に比べて積極的に採用している企業を示します。これは成長や拡大活動の代理指標となり得ます。
すべてをまとめると、次のようになります:
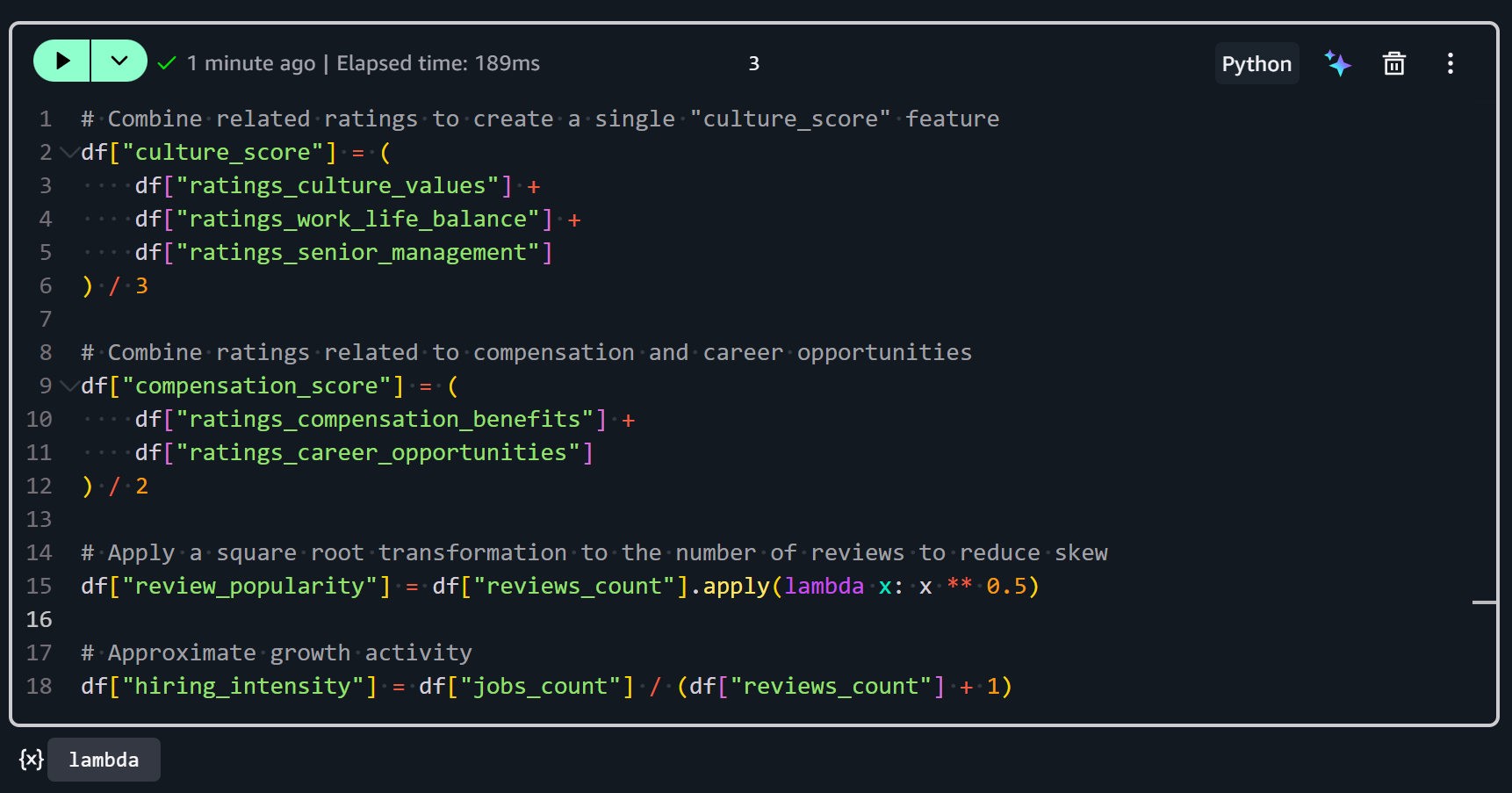
これらの変換を実行すると、データセットには生の評価と数値をより有益なメトリクスに組み合わせた派生特徴量が含まれるようになります。素晴らしい!
ステップ8:目的変数を設定する
特徴量が定義されたので、次のステップは機械学習タスクの目的変数を設定することです。目的変数は、モデルに予測させたい結果を表します。この場合、企業の従業員満足度が高いかどうかを予測します。
目的変数を設定するには、ノートブックに新しいセルを追加して、このコードを追加します:
# 目的変数を定義する
df["high_satisfaction"] = (df["ratings_overall"] >= 4).astype(int)これは、全体評価が4以上の企業をTrue(高満足度)、それ以外をFalse(低満足度)としてマークするブールフィールドを作成します。

多くの機械学習アルゴリズムは数値の目的変数を必要とします。満足度評価を二値の0/1ブールラベルに変換することで、分類タスクのモデルをトレーニングできます。これにより、作成した特徴量に基づいて、企業が高い従業員満足度を持つかどうかを予測できます。次のステップで実現しましょう!
ステップ9:満足度予測のためのMLモデルをトレーニングする
特徴量と目的変数が定義されたので、従業員満足度の高さを予測する機械学習モデルをトレーニングできます。
選択されたMLモデルはXGBoostで、表形式データと分類タスクで優れたパフォーマンスを発揮する勾配ブースティングアルゴリズムです。数値特徴量と派生特徴量を組み合わせてhigh_satisfaction変数を予測するのに適しています。
ノートブックに新しいセルを追加して、モデルをトレーニングするロジックを追加します:
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
# 予測に使用する特徴量を定義する
features = [
"culture_score",
"compensation_score",
"ratings_ceo_approval",
"review_popularity",
"hiring_intensity"
]
# 入力特徴量(X)と目的変数(y)を分離する
X = df[features]
y = df["high_satisfaction"]
# データをトレーニングセットとテストセットに分割する
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 適切なハイパーパラメータでXGBoostクラシファイアを初期化する
model = XGBClassifier(
n_estimators=500,
max_depth=5,
learning_rate=0.05,
eval_metric="logloss"
)
# トレーニングデータでモデルをトレーニングする
model.fit(X_train, y_train)上記のスニペットは、従業員満足度の高さを予測する機械学習モデルを準備してトレーニングします。エンジニアリングされた特徴量を選択し、データをトレーニングセットとテストセットに分割します。次に、調整されたハイパーパラメータでXGBoostクラシファイアを初期化し、最後にモデルをトレーニングデータに適合させます。
セルを実行して予測モデルを実際にトレーニングします:
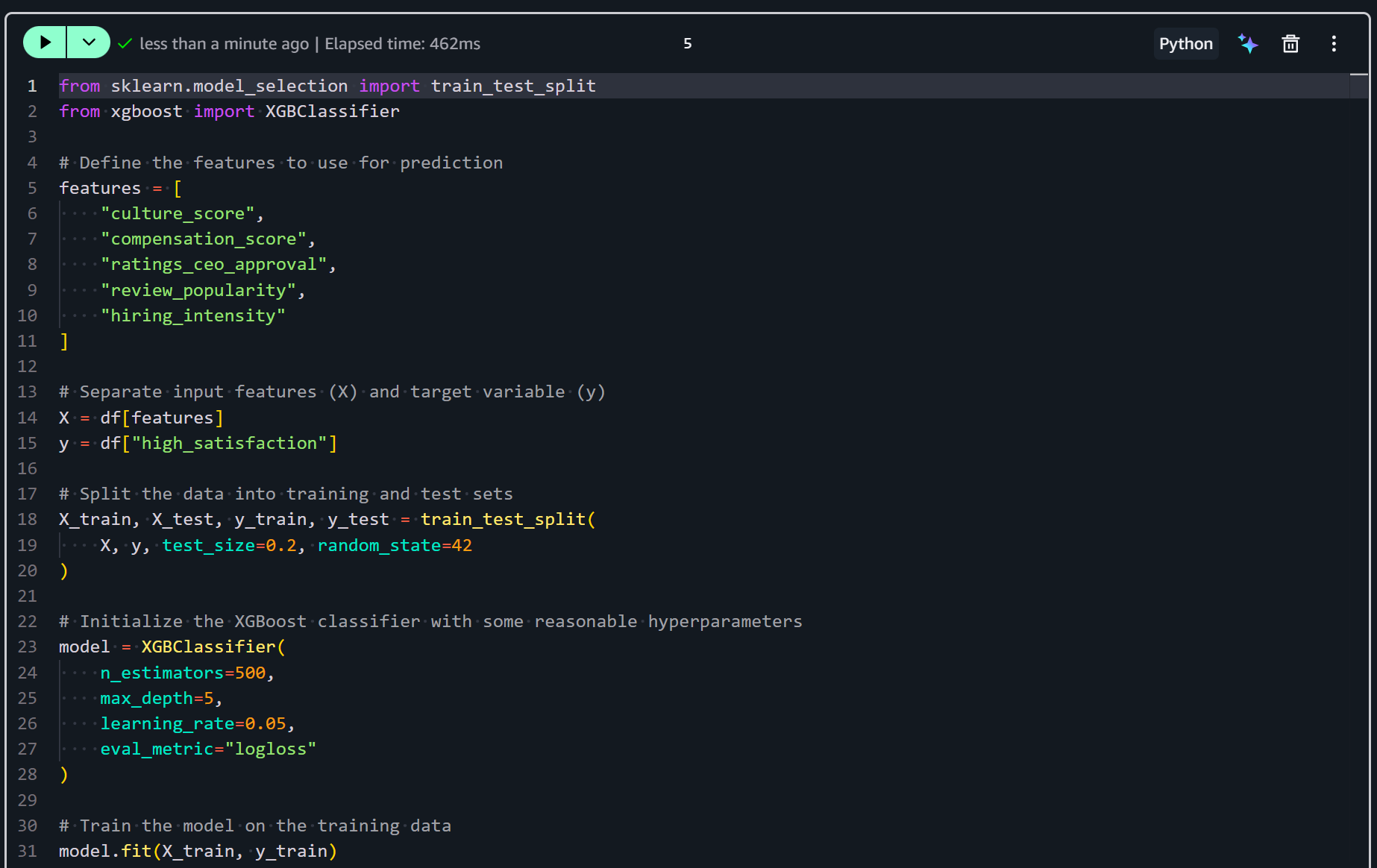
このステップの後、XGBoostクラシファイアがトレーニングされ、評価と予測の準備が整います。次のステップはパフォーマンスを評価することです!
ステップ10:モデルのパフォーマンスを評価する
最後のステップは、未見のデータに対してモデルがどれだけ機能するかを評価することです。このコードを使用してノートブックに新しいセルを追加します:
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix, roc_auc_score, accuracy_score
# トレーニング済みモデルを使用してテストセットのラベルを予測する
pred = model.predict(X_test)
print(classification_report(y_test, pred))
# 混同行列
cm = confusion_matrix(y_test, pred)
print("\n混同行列:\n", cm)
# ROC-AUCスコア
roc = roc_auc_score(y_test, model.predict_proba(X_test)[:,1])
print("\nROC-AUC:", roc)「Run All」ボタンを押してすべてのステップを実行し、メトリクスを計算します:

最後のセルが実行されると、次のような出力が表示されます:
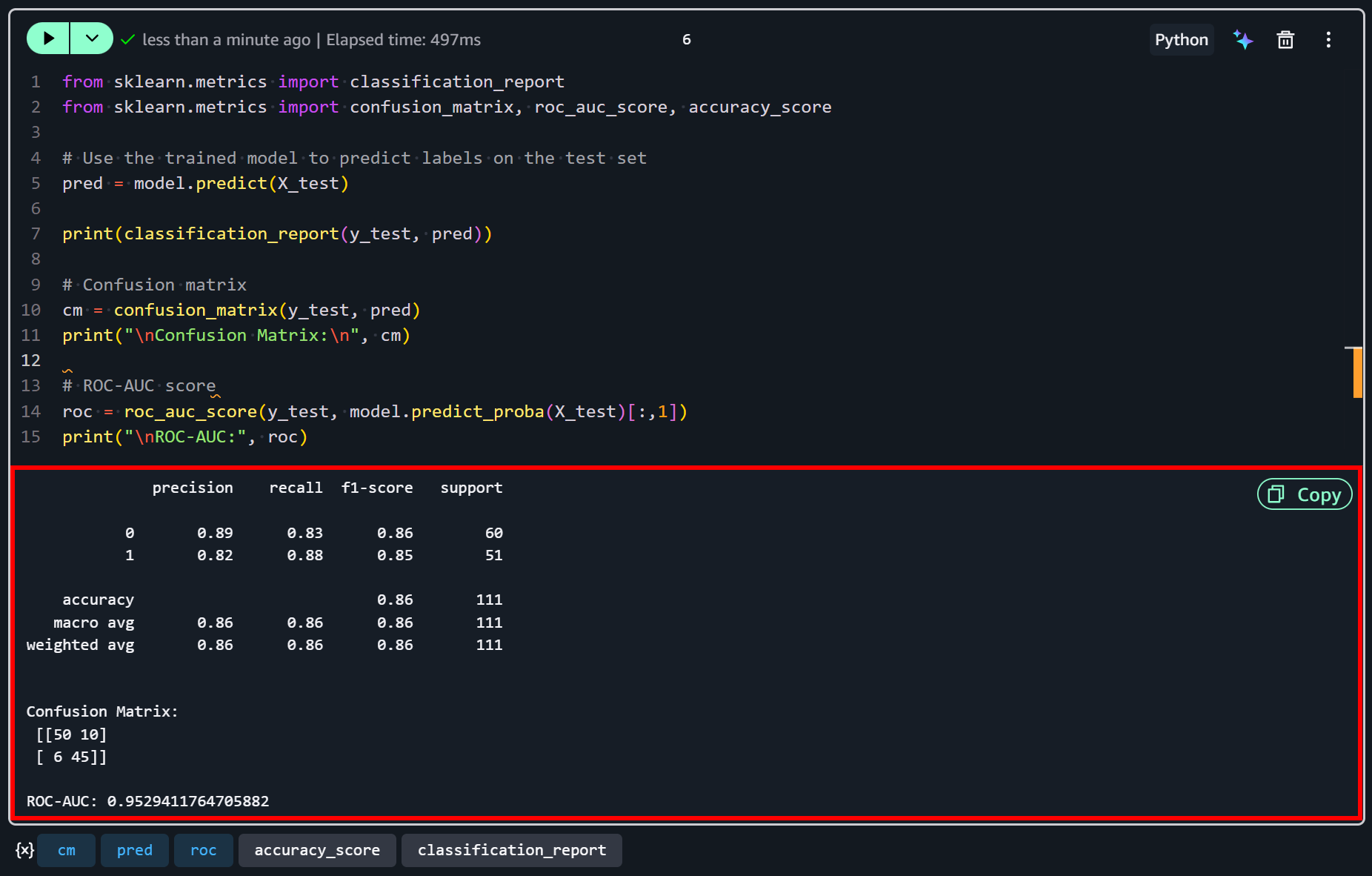
これらの結果は、このサンプルデータセットに対してモデルが適切なパフォーマンスを発揮していることを示しています。精度86%、ROC-AUCが0.95で、高満足度と低満足度の企業を区別する強い能力を示しています。
両クラスでバランスの取れた精度とリコールが示されており、モデルが高満足度の企業(1)と低満足度の企業(0)を正確に識別するのに同様に効果的であることを意味します。
ただし、いくつかの誤分類が残っています…混同行列に反映されているように、10社の低満足度企業が高満足度と誤って予測され、6社の高満足度企業が低満足度と誤って予測されました。
これは、モデルがデータの主要なパターンを捉えているものの、完璧ではなく、追加の特徴量(またはより多くのデータ)でさらに改善できることを示しています。
完成です!Bright Dataの入力ウェブデータセットのおかげで、Amazon SageMakerで特徴量エンジニアリングを実行し、予測モデルをトレーニングすることができました。これは、Bright Dataが提供する多様な構造化ウェブデータセットを活用して探索できる多くのユースケースの一つに過ぎません。
次のステップ
特徴量エンジニアリングで導出されたフィールドを使用して従業員満足度の高さを予測する現在のモデルは、まずまずの結果を達成しています。それでも、改善の余地があります。パフォーマンスを向上させるいくつかの方法があります:
- より多くの派生特徴量を作成する:既存の評価を新しい方法で組み合わせます。例えば、
ratings_senior_managementとratings_ceo_approvalからleadership_scoreを計算したり、給与とワークライフバランスのトレードオフを捉えるwork_life_compensation_ratioを作成したりできます。隠れたパターンを明らかにできる比率、差、または特徴量間の相互作用を探索してください。 - 歪んだ分布を変換する:
reviews_countやjobs_countなどの特徴量はしばしば歪んでいます。すでに平方根変換を適用しましたが、分散をさらに安定させるために対数変換やBox-Cox変換を検討してください。 - カテゴリカル特徴量を組み込む:現在、
regionとdetails_sizeは数値ではありません。ワンホットエンコーディングまたはターゲットエンコーディングでエンコードすることで、追加の予測シグナルが得られる可能性があります。 - 複数のデータポイントを集約する:過去のレビューや採用トレンドを取得できれば、時間経過による
jobs_countの平均成長率やculture_scoreの変化などの特徴量を作成することで、動的な企業行動を捉えることができます。 - 特徴量選択と重要度分析:トレーニング後、XGBoostの特徴量重要度を調査して、どの特徴量が予測に最も貢献しているかを特定します。最も予測力の高い特徴量にインスパイアされた新しい特徴量をエンジニアリングするかもしれません。
- 外部データエンリッチメント:他のBright Dataデータセットをマージして、よりリッチなコンテキスト特徴量を作成することを検討してください。
まとめ
このチュートリアルでは、Amazon SageMakerが機械学習シナリオにもたらすものを確認しました。具体的には、スクレイピングされたデータセットが特徴量エンジニアリングの優れたソースである理由と、予測MLモデルのトレーニングへの応用方法を学びました。
実証されたように、Bright Dataは数百のドメインと数十億のウェブデータレコードをカバーする豊富なデータセットマーケットプレイスを提供しています。これらのデータセットはウェブスクレイピングによって継続的に更新されており、機械学習とAIワークフローのサポートに理想的です。重要なことに、このガイドで示したように、Amazon SageMakerとシームレスに統合できます。
今すぐ無料のBright Dataアカウントを作成して、ウェブデータソリューションの探索を始めましょう!






