

この記事では、以下のことを学びます:
- Rufloとは何か、その主な機能と能力、そして最大の制限事項について。
- Bright DataのようなAI対応のWebデータインフラストラクチャソリューションを用いて、それらの制限に対処する方法。
- Bright DataとRufloをClaude CodeまたはOpenAI Codex環境に統合する2つの主な方法。
- ローカルのClaude Code搭載プロジェクトでRufloを設定し、使い始める方法。
- MCPを介して、Bright DataのエンタープライズレベルのWeb検索、データ取得、およびWebサイトとの対話をセットアップに追加する方法。
- Bright DataのClaudeスキルを使用して、同様の統合を実現する方法。
- このRuflo + Bright Dataのセットアップが、エージェント型コーディングアシスタントにどのような機能をもたらすか。
さっそく見ていきましょう!
Rufloの紹介:Claude向けエージェントオーケストレーションプラットフォーム
RufloとBright DataのWebデータ取得・検索機能を組み合わせる方法と理由については、後ほどご説明します。まずは、Rufloとは何か、そしてそれがどのような価値をもたらすのかを理解しましょう!
Rufloとは?
Ruflo(旧称:Claude Flow)は、Claude Code(およびOpenAI Codex)を機能豊富なマルチエージェント・オーケストレーション・フレームワークへと変えるために設計されたAIオーケストレーション・フレームワークです。
具体的には、エージェント型コーディングアシスタントに、約100種類の専門化されたAIエージェントからなる協調的なセットを装備し、それらを並行して動作させます。これにより、Claude CodeやOpenAI Codexは、インテリジェントなルーティング、共有メモリ、自己学習型ワークフローを通じて、複雑なソフトウェアタスクを処理できるようになります。
オープンソースプロジェクトとして、RufloはGitHubで2万7千以上のスターと6,000件以上のコミットを獲得しています。この急速な成長は、開発者コミュニティ内でRufloがいかに急速に支持を集めているかを如実に示しています。
RufloがAIエージェント型コーディングアシスタントを次のレベルへ引き上げる仕組み
大まかに言えば、Rufloが提供する主な機能は以下の通りです:
- 大規模なマルチエージェントオーケストレーション:複雑な開発タスクに対して並行して動作する約100の特化型AIエージェントを展開・調整します。
- スウォームベースのコラボレーション:エージェントは、階層的な調整、合意形成メカニズム、共有された目標を備えた構造化された「スウォーム」内で動作します。
- 自己学習と適応型ルーティング:過去の実行から学習し、パターン認識を用いてタスクを最も効果的なエージェントに動的に割り当てます。
- 永続的メモリとナレッジグラフ: ベクトル検索(HNSW)、共有メモリ、ナレッジグラフを組み合わせ、セッションをまたいでコンテキストを維持します。
- インテリジェントなコストおよびパフォーマンスの最適化:多層ルーティング(WASM + LLM)を使用して、レイテンシを低減し、APIコストを最大約75%削減します。
- フェイルオーバー機能付きマルチLLMサポート:Claude、GPT、Gemini、およびローカルモデルに対応し、タスクごとに最適なプロバイダーを自動的に選択します。
- 本番環境対応のセキュリティと拡張性:組み込みの保護機能(プロンプトインジェクション、検証)に加え、エージェント、フック、ワークフローを拡張するためのプラグインシステムを備えています。
これにより、Rufloを使用する場合と使用しない場合で、Claude Codeには大きな違いが生じます:
| Claude Codeのみ | Claude Code + Ruflo | |
|---|---|---|
| エージェント間の連携 | エージェントは独立して動作する | エージェントは共有メモリを用いて連携する |
| 調整 | 手動タスク管理 | 女王主導の階層構造と自動調整 |
| 集合知 | 利用不可 | エージェント間の集合知 |
| 合意形成 | マルチエージェントによる意思決定なし | 多数決ルールに基づく耐障害性のある投票 |
| メモリ | セッション限定 | 永続的ベクトルメモリ + ナレッジグラフ |
| ベクトルデータベース | なし | RuVector PostgreSQL、高速検索と高いQPS |
| ナレッジグラフ | フラットリスト | PageRankとコミュニティ検出を用いて重要な知見を抽出 |
| 集合的記憶 | 共有知識なし | エージェント間で共有される知識ベース |
| 学習 | 静的、適応なし | 迅速な適応と知見の移転を伴う自己学習 |
| エージェントのスコープ | 単一プロジェクトのみ | エージェント間での転送を伴う多階層メモリ(プロジェクト/ローカル/ユーザー) |
| タスクのルーティング | エージェントの手動選択 | 学習されたパターンに基づくインテリジェントなルーティング |
| 複雑なタスク | 手動での分割が必要 | 複数のドメインにわたる自動分解 |
| バックグラウンドワーカー | なし | ファイルの変更やパターンなどのトリガーによる自動ディスパッチ |
| LLMプロバイダー | Anthropicのみ | フェイルオーバーとコスト最適化機能を備えた複数プロバイダー |
| セキュリティ | 標準的な保護機能 | 強化済み:検証、暗号化、CVE対策 |
| パフォーマンス | ベースライン | 並列スウォームとスマートルーティングによる高速化 |
最大の制約と対処法
Rufloの約100体のエージェントや全体的な機能がどれほど豊富で多才であっても、根本的な制限が存在します。それはLLM(大規模言語モデル)そのものの性質に起因します。これらのモデルは特定の時点での静的なデータセットで学習されているため、その知識には本質的な限界があります。
確かに、Rufloにはウェブ検索、対話、データ抽出のための専用のブラウザ自動化エージェントが搭載されています。しかし、今日ほとんどのウェブサイトには、自動化されたリクエストをブロックするアンチボットシステムが導入されています。これには、AI駆動のブラウザエージェントからのリクエストも含まれます。そのため、Rufloによる知識の取得が失敗したり、必要なコンテンツの一部にしかアクセスできなかったりすることがあります。
これは重大な問題です。なぜなら、正確で最新かつ文脈に沿った知識こそが、マルチエージェントシステムを真に効果的なものにするからです。この問題を克服するには、AIコーディングアシスタントに、リアルタイムのウェブ検索、データ抽出、およびブロックされないウェブ操作のために特別に設計されたツールが必要です。
まさにそれが、Bright Dataが提供するものです!
解決策としてのBright DataのWebデータツール
市場をリードするWebデータプラットフォームとして、Bright Dataは次のようなAIエージェント対応ツールを提供しています:
- SERP API:Google、Bingなどの検索エンジン結果を集め、情報に基づいた応答を可能にします。
- Web Unlocker API:CAPTCHA、IPブロック、ボット対策などを回避し、あらゆるサイトの生のHTMLやMarkdownにアクセスします。
- Browser API:リモートブラウザをプログラムで制御し、あらゆるサイトとの自動化された制限のないやり取りを実現します。
- ウェブスクレイピングAPI:Amazon、Instagram、LinkedIn、Yahoo Financeなど、多数のプラットフォームから構造化データを収集します。
- Crawl API:ウェブサイト全体を構造化されたデータセットに変換し、下流のAIワークフローに活用します。
Bright Dataの最大の特徴は、エンタープライズグレードのインフラストラクチャです。195カ国にまたがる4億以上のIPアドレスから成るグローバルプロキシネットワークを基盤としており、99.99%の稼働率と99.95%の成功率を維持しながら、無制限のスケーラビリティを実現します。
Bright DataはRufloと連携し、エージェント型コーディングシステムに、ライブWebデータの探索、取得、推論を行う能力を提供します。これらすべてを、大規模かつブロックに遭遇することなく実現します!
Bright DataとRufloを組み合わせる方法:2つのアプローチ
技術的には、プラグインSDKを使用してBright DataをRufloに直接統合することも可能です。その場合、使用したい各Bright Data製品に接続するカスタムツールを定義する必要があります。しかし、それは最も効率的なアプローチではありません!
一から作り直すよりも、以下を活用する方がはるかに簡単です:
- Bright Data Web MCP:ブロックを使わずにウェブ検索、ナビゲーション、データ抽出、インタラクションを行うための60以上のツールを提供する、オールインワンのオープンソースサーバー。
- Bright Dataスキル:AIを活用したスクレイピング、検索、構造化データの取得方法をコーディングエージェントに教える、あらかじめ構築された機能です。これにはWeb MCPへの接続機能も含まれています。
これらをClaude Code(またはOpenAI Codex)に直接追加することで、RufloとBright Dataの両方を組み合わせた統合的なコーディング環境が実現します。これにより、基盤となるLLMは両ソリューションのツールを協調的かつ相乗的に活用できるようになります。
注:以下の例では Claude Code を使用していますが、OpenAI Codex にも簡単に適応させることができます。
それでは、MCPまたはスキルを使用して、Bright DataとRufloでClaude Codeを拡張する方法を見ていきましょう。その前に、まずRufloを設定しましょう!
Rufloの始め方
以下の手順に従って、コーディングプロジェクトでRufloを設定する方法を確認してください。
前提条件
このセクションの手順を実行するには、以下の環境が整っていることを確認してください:
- Claude Codeがローカルにインストールされ、設定済みであること。
- Node.js 20 以降がローカルにインストールされていること(最新の LTS バージョンを推奨)。
ステップ #1: Ruflo の設定
コーディングプロジェクト用の新しいフォルダを作成します(例:bright-data-ruflo-project)。このフォルダ内で Ruflo を初期化します。次に、ターミナルでそのフォルダに移動します:
mkdir bright-data-ruflo-project
cd bright-data-ruflo-project注:既存のプロジェクトフォルダから開始することも可能です。ほとんどの場合、この方法で行います。Rufloの機能を活用するために、プロジェクトにRufloを追加します。
ターミナルで次のコマンドを実行し、npm 経由で Ruflo のインストールウィザードを起動します:
npx ruflo@latest init --wizardrufloパッケージのインストールには数分かかる場合がありますので、しばらくお待ちください。
以下のような出力が表示されるはずです: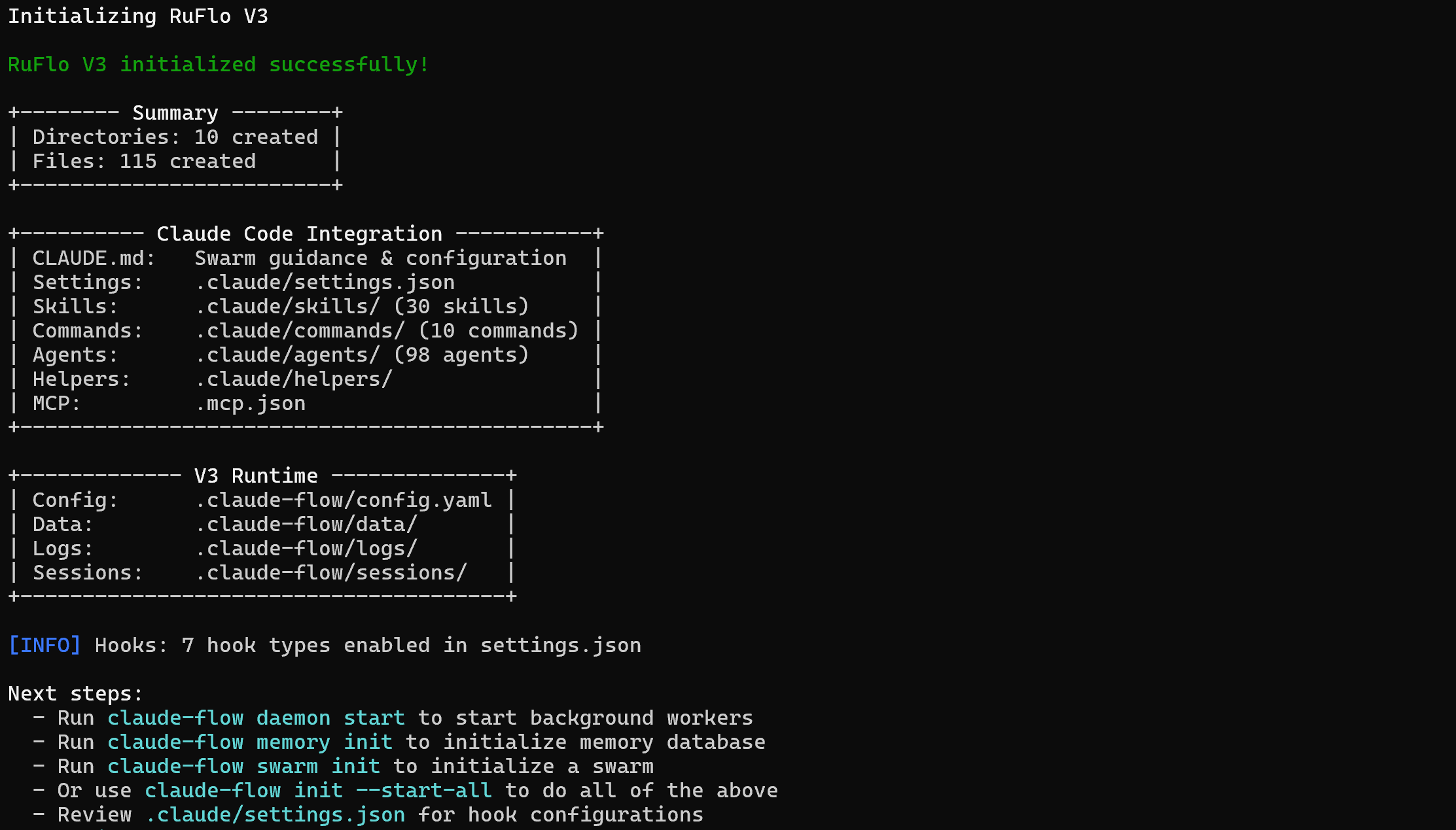
注:CLI の出力には、バックエンドサービス、メモリデータベース、またはスウォームを初期化するためにclaude-flowコマンドを使用するよう示唆されている場合があります。しかし、それは正確ではありません。npm 経由で Ruflo をインストールする場合、正しい基本コマンドは次のとおりです:
npx ruflo@latestプロジェクトフォルダには以下の内容が含まれるようになります:
bright-data-ruflo-project/
├─── .claude/
│ ├─── agents/
│ ├─── commands/
│ ├─── helpers/
│ └─── skills/
├─── .claude-flow/
├─── .swarm/
├─── .mcp.json
└─── CLAUDE.md基本的に、bright-data-ruflo-project には 、新しいスキル、コマンド、エージェントにプロジェクトレベルでアクセスするために Claude Code が必要とするすべてのファイルが含まれています。つまり、Ruflo はローカルの Claude Code 環境に完全に統合されたことになります。よくできました!
ステップ #2: Ruflo を起動する
Ruflo によって、いくつかのエージェント、コマンド、スキルが追加されました。しかし、Claude Code でそれらを実行するには、まず Ruflo を起動する必要があります。以下のコマンドで起動してください:
npx ruflo@latest start次のような出力が表示されるはずです: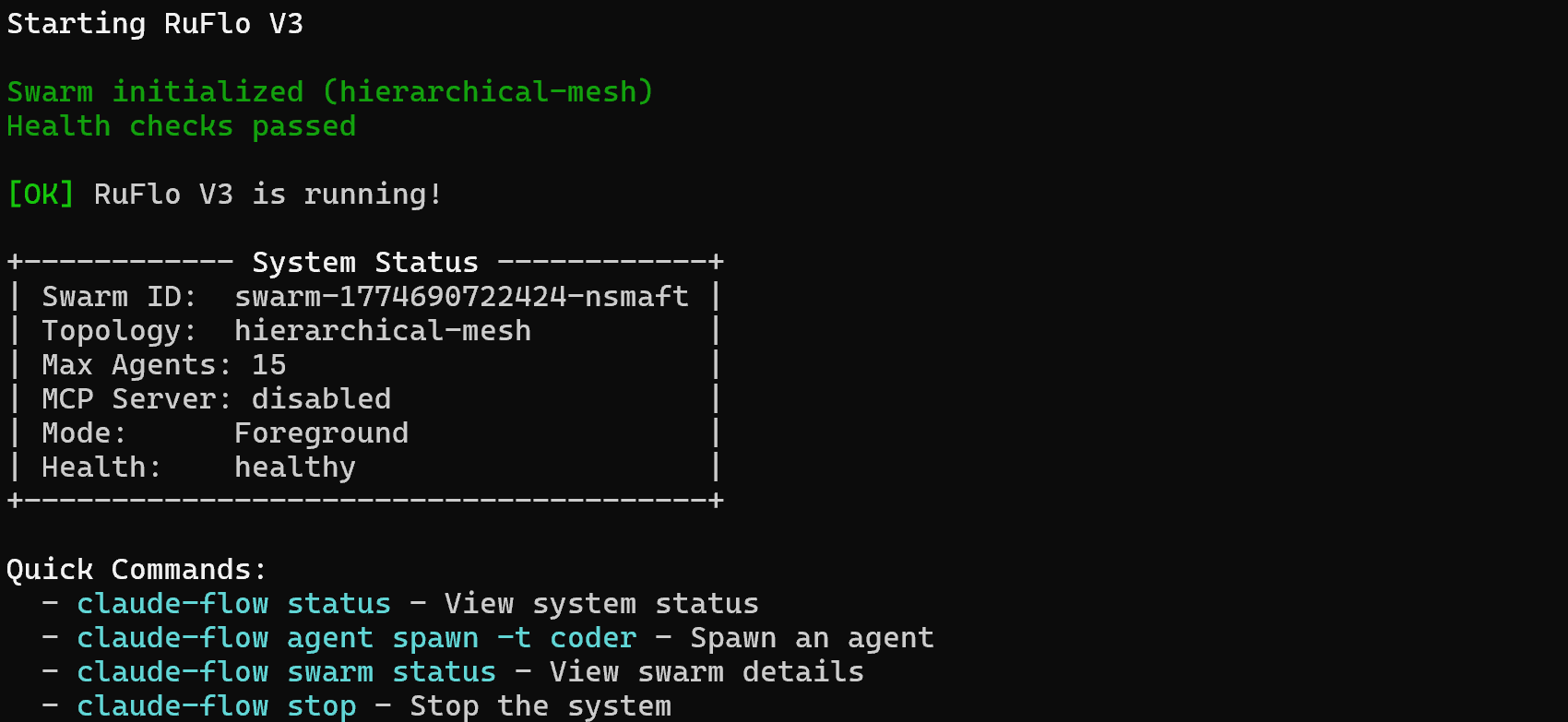
素晴らしい!これで、あなたの Claude Code 環境は Ruflo が提供する拡張機能を活用できるようになりました。
ステップ 3: 統合の確認
プロジェクトディレクトリで、Claude Code を起動します:
claude次のようなメッセージが表示される場合があります:
オプション1またはオプション2を選択してください。これにより、Claude Codeは起動時にRuflo MCPサーバーを起動し、接続します。
次に、Claude CodeでRufloが利用可能であることを明確に示すログが表示されます: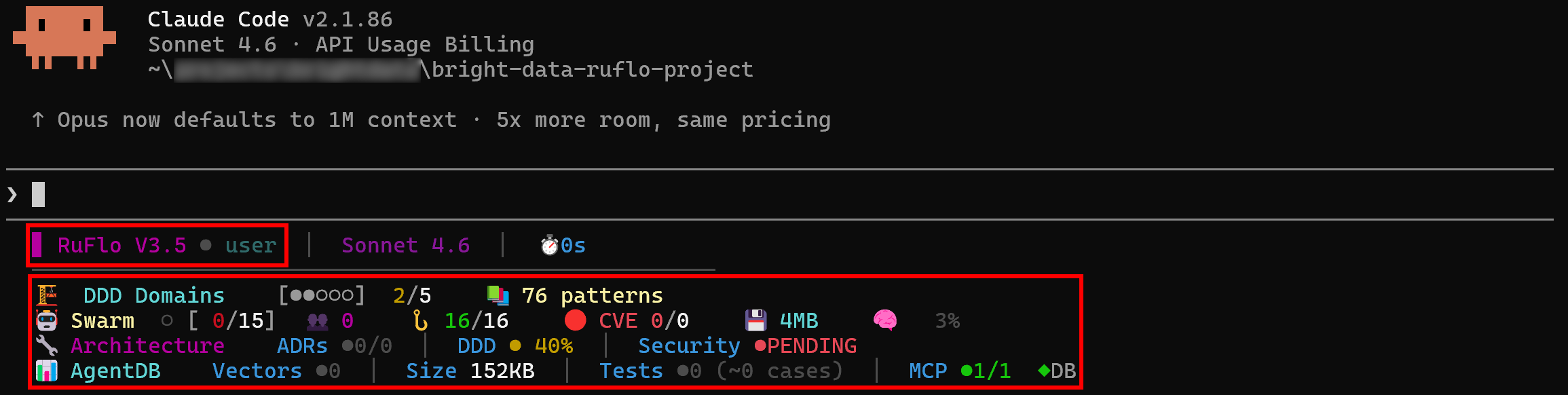
「/agent」と入力すると、Rufloの追加コマンドの一部が表示されます:
素晴らしい!Claude CodeがRufloに正常に接続され、統合が機能していることが確認されました。
統合アプローチ #1: Ruflo MCP + Bright Data MCP
このセクションでは、MCPを介してClaude Codeの設定にRufloとBright Dataの両方の機能を追加する方法について説明します。
前提条件
このセクションを簡潔にするため、Bright Data Web MCPがすでにClaude Codeの設定に統合されていることを前提とします。
まだ行っていない場合は、詳細なチュートリアル「Claude CodeとBright DataのWeb MCPの統合」またはドキュメントガイド「Claude Code MCPサーバーの統合」に従ってください。initコマンドの実行時にRufloによって作成されたローカルの.mcp.jsonファイルに、必要な設定を追加することを忘れないでください。
また、MCPの仕組みや、MCPサーバーをClaude Codeに接続する方法について理解していることも、重要な前提条件となります。
ステップ #1: 利用可能な MCP サーバーを確認する
デフォルトでは、ローカルの.mcp.jsonファイルに Ruflo MCP サーバーが設定されています。このファイルには、Bright Data Web MCP に接続するための設定も含まれている必要があります。
通常、Claude Codeは両方のMCPサーバーを自動的に検出して接続します。これを確認するには、プロジェクトフォルダ内でClaude Codeを起動し、/mcpコマンドを実行してください:
次のような表示がされるはずです:
bright-data-web-mcp(または.mcp.json設定で Bright Data Web MCP に付けた名前)。claude-flow(Ruflo MCPサーバーの名前)。
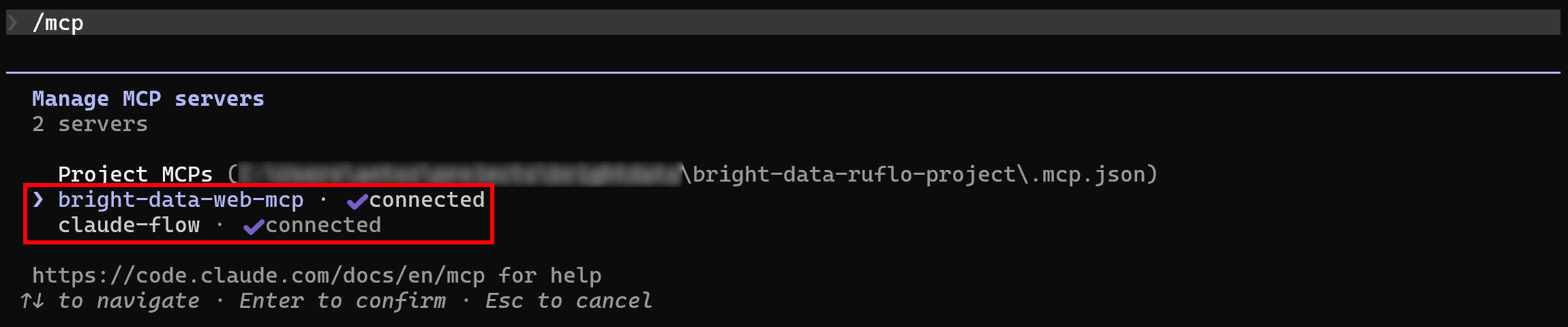
素晴らしい!これで、Claude Codeは期待どおり両方のMCPサーバーに接続されました。
ステップ #2: Bright Data Web MCP サーバーを確認する
「bright-data-web-mcp」エントリ(または任意の名前)を選択します:
「View tools」オプションを選択して、利用可能なすべてのツールを表示します。Proモードで設定している場合、65以上のすべてのツールが表示されます:
それ以外の場合は、4つのツール(scrape_as_markdown、search_engine、およびそれらの2つのバッチバージョン)のみが表示されます。
素晴らしい!Bright Data Web MCPは、期待通りにツールを公開しています。
ステップ #3: Ruflo MCP サーバーの確認
上記と同じ手順を、claude-flowMCPに対して繰り返してください。次のような画面が表示されるはずです:
Ruflo MCPが合計254ものツールを公開していることに注目してください。すごい!
統合アプローチ #2: Rufloスキル + Bright Dataスキル
ここでは、スキルを通じて、Claude Codeの設定にRufloとBright Dataの機能を追加する手順を解説します。
前提条件
このセクションを進めるには、以下の環境が整っていることを確認してください:
- Unixベースのオペレーティングシステム(macOS、Linux、またはWSL)上でClaude Codeがセットアップされていること。
- ローカルにGitがインストールされていること。
- Web Unlockerゾーンが設定され、APIキーが構成済みのBright Dataアカウント。
- Claudeスキルとは何か、およびClaude Codeでの設定方法に関する基本的な知識。
- Bright Dataの公式Claudeスキルリポジトリで利用可能なスキルについて、ある程度把握していること。
注:Bright Dataアカウントの設定については、次のステップで手順が説明されるため、現時点では心配する必要はありません。
次に、Bright Data Claudeスキルに必要な2つの前提条件であるcurlと jqをインストールします。macOSでは、以下のコマンドを実行してください:
brew install curl jq同様に、Linux では以下を実行してください:
sudo apt-get install curl jqデフォルトでは、ローカルプロジェクトに Ruflo をセットアップした後、Claude Code にはすでに 118 のスキルが一覧表示されています。/skillsコマンドを実行して、これを確認してください: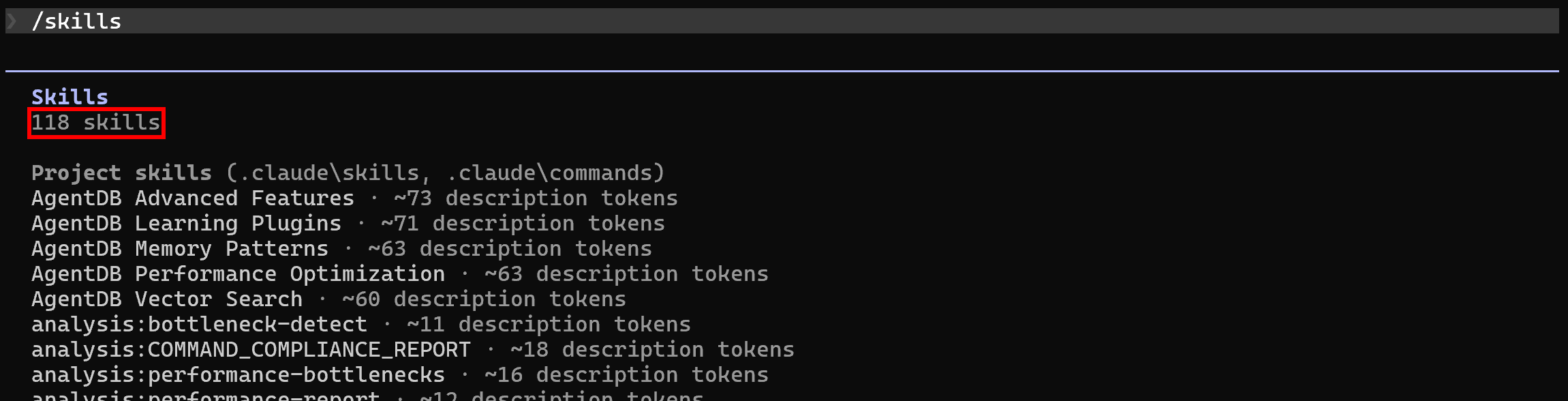
ステップ #1: Bright Data アカウントの設定
ドキュメントで説明されているように、Bright Data Claudeスキルを使用するには、以下の2つのシークレットをグローバル環境変数として設定する必要があります:
BRIGHTDATA_API_KEY: あなたの Bright Data API キー。BRIGHTDATA_UNLOCKER_ZONE: アカウントで設定された Web Unlocker ゾーンの名前。
手順については、「Bright DataのWeb Unlocker APIクイックスタートガイド」のドキュメントページを参照してください。または、以下の手順に従ってください。
Bright Dataアカウントをお持ちでない場合は、新規作成してください。すでにアカウントをお持ちの場合は、ログインしてください。コントロールパネルにアクセスし、「Proxies & Scraping」ページに移動します。「My Zones」テーブルを確認してください: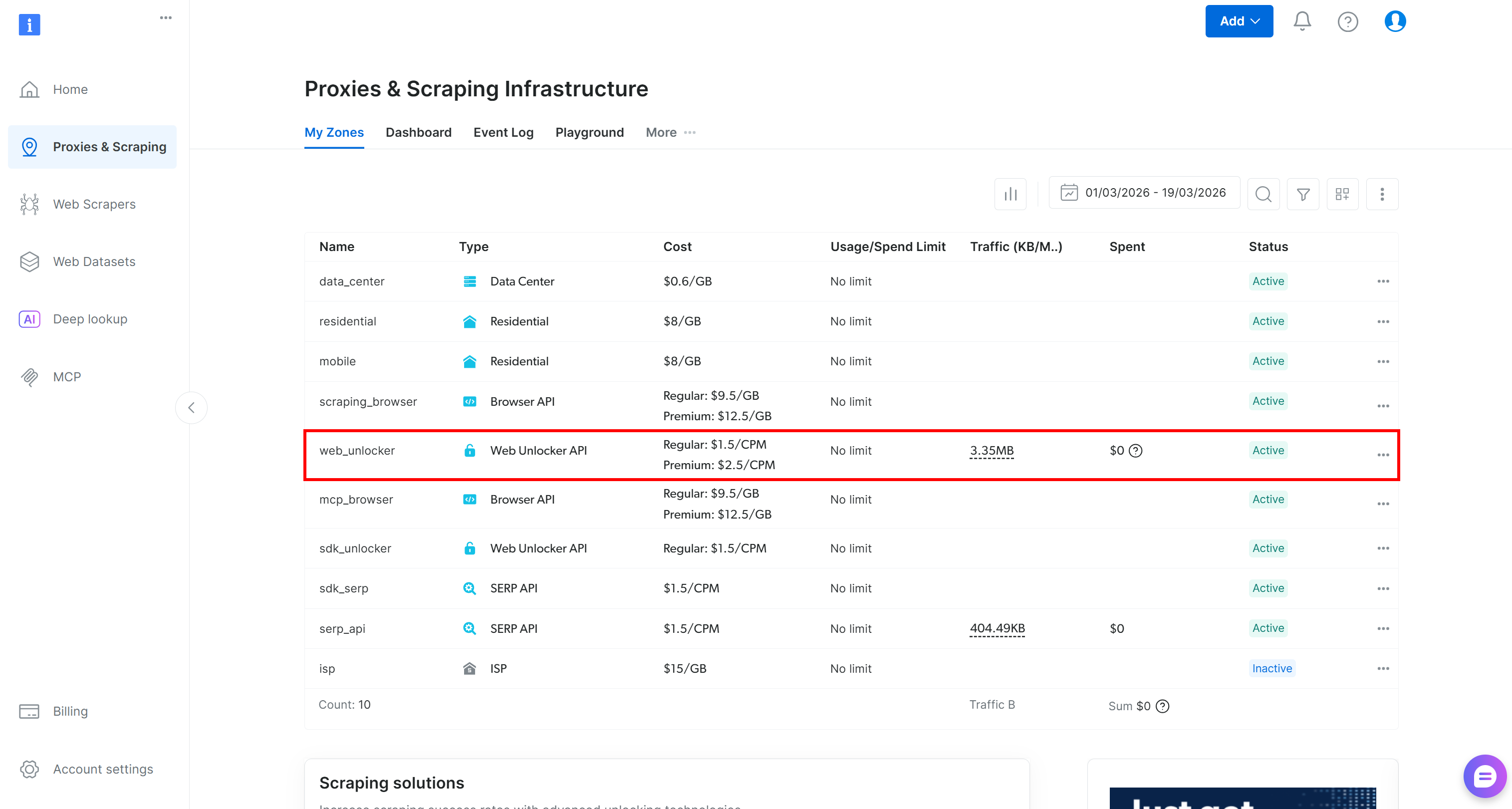
Web Unlocker APIゾーン(例:web_unlocker)が存在する場合は、APIキーの定義に進んでください。
存在しない場合は、新しいゾーンを作成してください。作成するには、「Unblocker API」カードまでスクロールし、「Create zone」をクリックして、ウィザードの手順に従ってください。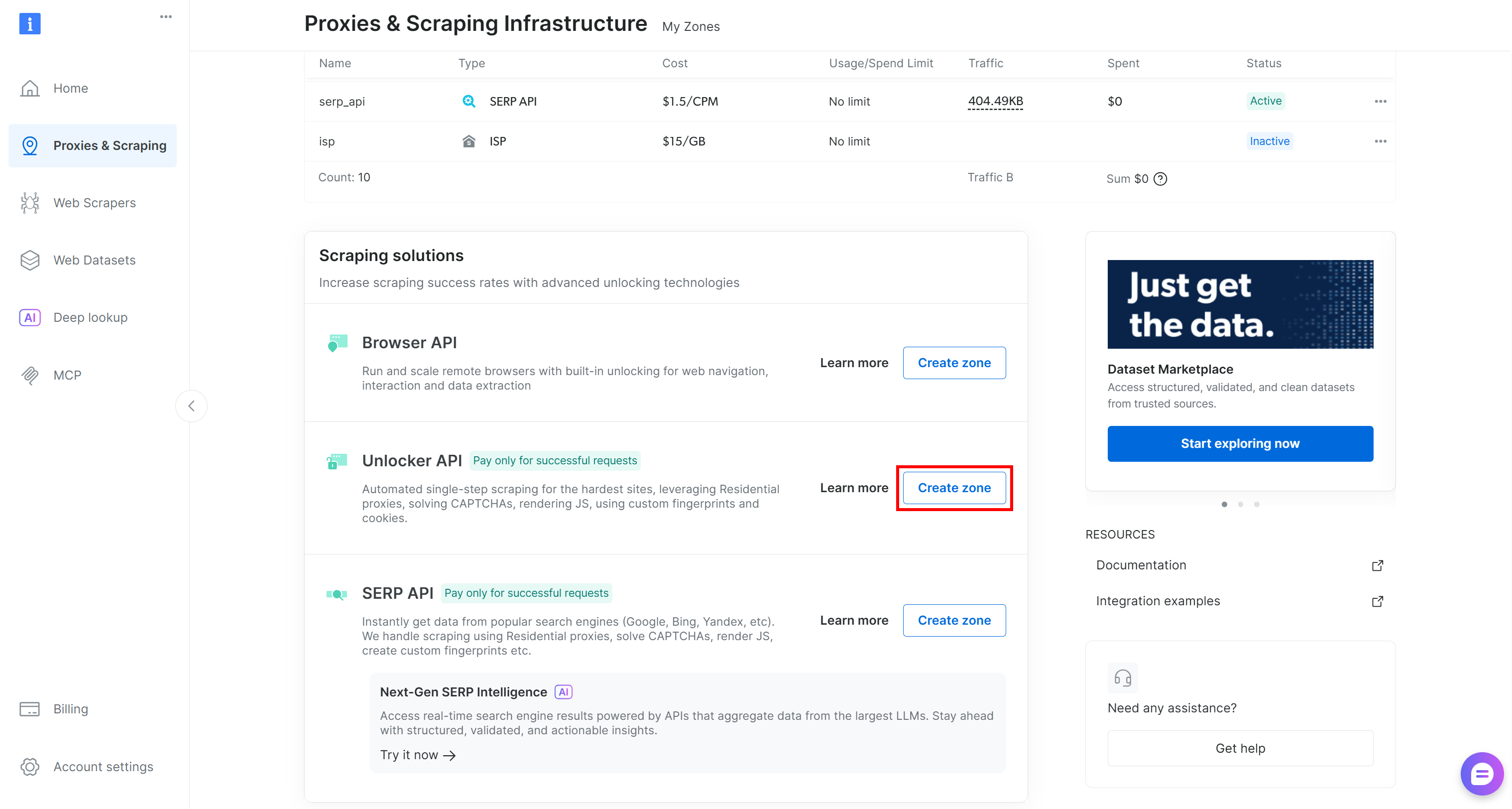
ウィザードの指示に従い、ゾーンにわかりやすい名前(例:web_unlocker)を付けます。
最後に、Bright Data APIキーを生成します。APIトークンとゾーン名が用意できたら、次のように2つのグローバル環境変数を定義します:
export BRIGHTDATA_API_KEY="<YOUR_BRIGHTDATA_API_KEY>"
export BRIGHTDATA_UNLOCKER_ZONE="<YOUR_BRIGHTDATA_UNLOCKER_ZONE>"素晴らしい!これで、Bright Data Claudeスキルがアカウントに接続し、正常に動作するようになりました。
ステップ #2: Bright Data スキルの取得
セットアップに新しいスキルを追加するには、それらのフォルダをローカルの.claude/skillsディレクトリにコピーします。
まず、Bright Data Claude Skills リポジトリを任意のフォルダにクローンします:
git clone https://github.com/brightdata/skillsクローンされたディレクトリ構造は次のようになります:
skills/
├── .claude-plugin
├── skills/
│ ├── bright-data-best-practices/
│ ├── bright-data-mcp/
│ ├── brightdata-cli/
│ ├── data-feeds/
│ ├── design-mirror/
│ ├── python-sdk-best-practices/
│ ├── scrape/
│ ├── scraper-builder/
│ └── search/
├── .gitignore
├── LICENSE
└── README.mdBright DataのClaudeスキルは以下の通りです:
search: Googleを検索し、タイトル、リンク、説明を含む構造化されたJSON結果を返します。scrape: ボット検出を自動的に回避しながら、任意のウェブページをクリーンなMarkdown形式で抽出します。data-feeds: 自動ポーリングと更新機能により、40以上のウェブサイトから構造化データを取得します。bright-data-mcp: 検索、スクレイピング、構造化データの抽出、ブラウザ自動化のための60以上のBright Data MCPツールを統合します。scraper-builder: サイト分析、API 選択、セレクター、ページネーション、実装を含む、本番環境対応のスクレイパーを構築します。bright-data-best-practices: Web Unlocker、SERP、Webスクレイパー、およびブラウザ API のリファレンス。python-sdk-best-practices:brightdata-sdkPython パッケージのガイド:非同期/同期クライアント、スクレイパー、データセット、エラー処理、およびパターン。brightdata-cli: Bright Data CLI のターミナルガイド:スクレイピング、検索、データ抽出、プロキシゾーンの管理、アカウントの確認。design-mirror: 一貫性のある高品質な UI 実装のための、デザインシステムトークンおよびコンポーネントの複製。
skills/内のフォルダ(bright-data-best-practices/、bright-data-mcp/ など)を、プロジェクトディレクトリ内のローカル.claude/skillsにコピーします。手動で行うか、次のコマンドを使用してください:
cp -r skills/skills/* <PATH_TO_YOUR_PROJECT>/.claude/skills/完了です!Bright Data Claudeスキルがプロジェクトに追加されました。
ステップ #3: 利用可能なスキルを確認する
プロジェクトフォルダ内で Claude Code を再度起動し、/skillsコマンドを実行してください: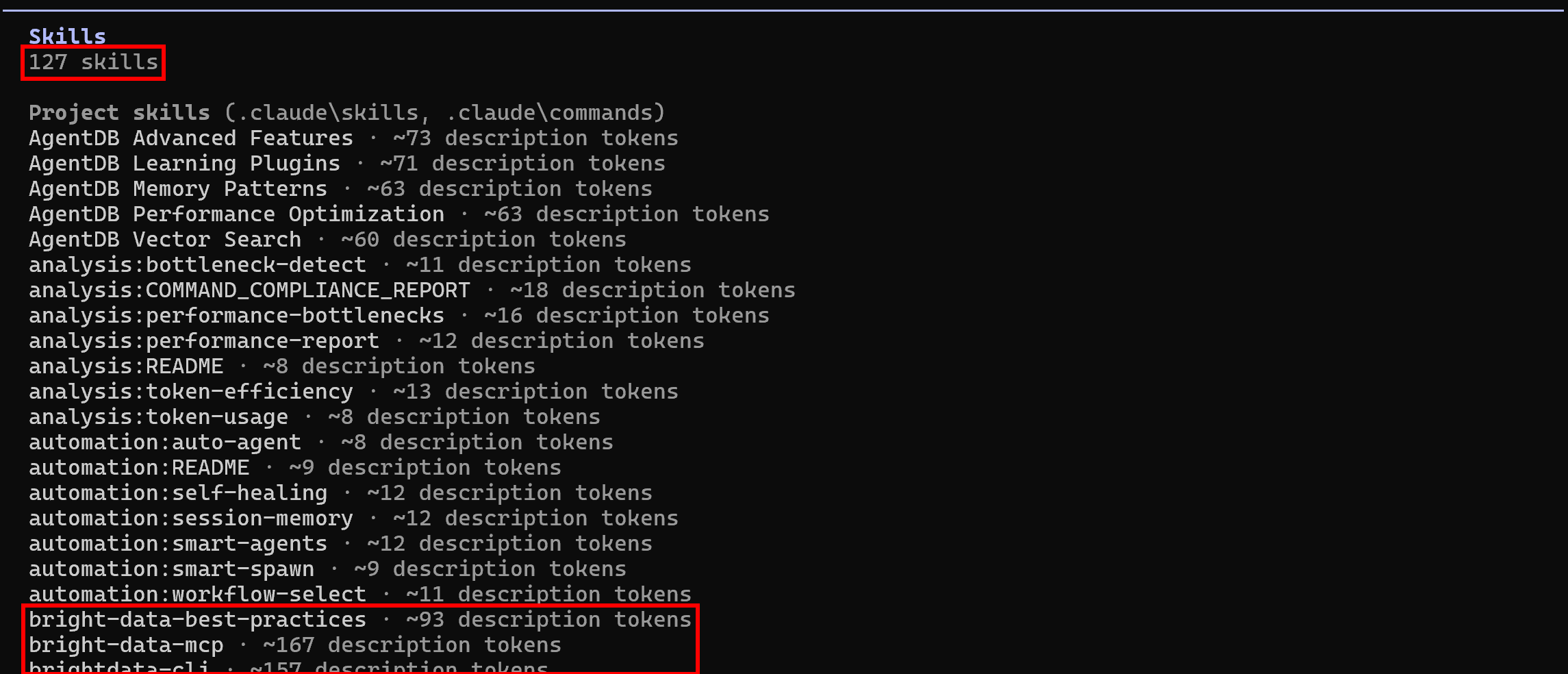
これで、利用可能なスキル数が127(当初の118から増加)になっているはずです。これは、Bright Dataのスキルが正常に読み込まれていることを示しています。ミッション完了です!これで、エージェント型コーディングシステムが、プログラムによるWebデータ抽出やWeb探索など、さまざまな用途でBright Dataのスキルを活用できるようになりました。
Ruflo + Bright Data:すべてを統合する
これで、Claude Code環境では300以上のMCPツール、あるいは125以上のスキルを利用できるようになりました。これらにより、協調的なコーディング作業が可能になるだけでなく、エージェントが自律的にウェブを検索し、データをスクレイピングし、ウェブページとやり取りできるようになります。これらはすべて、ブロックやスケーラビリティの制限なしに実現されます。
これにより、以下のような多くの新たな可能性が開かれます:
- 検索エンジンのリアルタイム検索結果(SERP)を取得し、
README.mdやその他のドキュメントページに文脈に応じたリンクを埋め込む。 - 現在のコーディングタスクに基づいて関連するチュートリアルやドキュメントを見つけ出し、コードベースを効率的に改善する。
- ウェブサイトから最新の公開データをスクレイピングし、モックアップ、分析、またはさらなる処理のためにローカルに保存する。
これらの例は、Claude Code / OpenAI Codex環境においてBright DataとRufloを併用することによる相乗効果を示しています。この統合により、Rufloのすでに充実した機能セットがさらに拡張されるだけでなく、Bright Dataのインフラストラクチャのおかげでエンタープライズレベルのユースケースにも対応可能になります。
まとめ
このブログ記事では、Ruflo(旧称:Claude Flow)とは何か、そしてそれがClaude CodeやOpenAI Codexにおけるエージェント体験をどのように変革するかについてご理解いただけたと思います。約100のエージェントが並列で動作するエンタープライズグレードのインフラストラクチャにより、Rufloは速度、トークン効率、出力品質を含むパフォーマンスを劇的に向上させます。
しかし、これらのツールには、Webデータの取得、Web検索、およびWebサイトとのプログラムによるやり取りを行うための、エンタープライズ対応のソリューションが欠けています。そこで登場するのがBright Dataです。専用のWeb MCPサーバーと 公式のClaude Skillsセットにより、AI向けに構築されたBright Dataのツール、サービス、インフラストラクチャのフルスイートへの接続が簡単になります。
ここでは、コーディング支援の効率と効果を最大化するために、Claude Codeで強力なRuflo + Bright Data環境を構築する方法について学びました。
今すぐ無料でBright Dataアカウントを作成し、AI対応のWebデータソリューションをぜひお試しください!




