

この記事では、以下の内容を学びます:
- OracleジェネレーティブAIエージェントサービスとは何か、そしてそれが提供するもの。
- エンタープライズAIエージェントがコンテキスト的な市場インサイトのためにライブウェブデータへのアクセスを必要とする理由、およびBright Dataがそれを可能にする方法。
- Bright Dataのカスタムツールを使用して、ウェブアクセス機能を持つOracleジェネレーティブAIエージェントを構築する方法。
早速始めましょう!
OracleジェネレーティブAIエージェントサービスとは?
OracleジェネレーティブAIエージェントは、AIエージェントを構築・デプロイするためのフルマネージドOCI(Oracle Cloud Infrastructure)サービスです。これらのエージェントは自然言語を理解し、会話のコンテキストを保持し、ツールをオーケストレーションし、エンタープライズデータにアクセスし、複雑なワークフローを自動化できます。
主なユースケースには、カスタマーサポート、技術的なトラブルシューティング、法律・財務調査、コンテンツ作成、教育的チュータリング、サプライチェーン分析、不動産インサイト、旅行支援などがあります。
主な機能
OracleジェネレーティブAIエージェントが提供するコア機能は以下の通りです:
- シンプルなエージェントセットアップ:インフラを管理することなく、ガイド付きのフルマネージドセットアッププロセスを通じてAIエージェントを作成・デプロイします。
- マルチターン会話:複数のメッセージにわたってコンテキストを意識したインタラクションで、自然で人間らしい会話をサポートします。
- コンテキスト保持:以前の会話ターンを記憶し、パーソナライズされた一貫性のある関連性の高い応答を提供します。
- カスタム指示:設定可能な指示を通じて、エージェントの動作、トーン、目標、ルーティングロジックを定義します。
- 組み込みガードレール:プロンプトインジェクション攻撃からの保護、コンテンツのモデレーション、機密PII データの検出を支援します。
- ヒューマンインザループサポート:機密性の高いアクションやビジネスクリティカルな操作に対する人間のレビューと介入を可能にします。
- エンタープライズのスケーラビリティとセキュリティ:エンタープライズグレードの信頼性とガバナンスを備えたOCIのセキュアでスケーラブルなインフラ上で動作します。
- 組み込みおよびカスタムツール:SQL、RAG、エージェント間オーケストレーション、ファンクションコーリング、カスタムAPI統合でエージェントを拡張します。
詳細は公式ドキュメントをご覧ください。
エンタープライズOracleのAIエージェントにウェブアクセスが必要な理由
ビジネスに即した意思決定を行うために、エンタープライズAIエージェントは外部市場データへのアクセスが必要です。これには現在のトレンド、競合他社の活動、顧客センチメント、速報ニュース、規制の更新が含まれます。
課題は、LLMがデフォルトではライブウェブに接続されていないことです。その結果、2つの主要な制限に直面します:
- リアルタイム情報へのアクセスなし:LLMはネイティブに最新のウェブコンテンツを取得できません。
- ウェブサイトへのアクセスが限定的:多くのウェブサイトは、自動化されたシステムによるデータ収集を防ぐアンチボット技術を採用しています。
これらの制約は、AIエージェントを外部ツールや統合で拡張することで克服できます。
これがまさにOracleジェネレーティブAIエージェントが複数のツールオプションをサポートする理由です。特に、APIエンドポイント呼び出しツールにより、Bright DataなどのAPIベースの外部サービスに安全に接続できます。
解決策としてのBright Data
Bright Dataは、業界をリードするエンタープライズグレードのAI対応ウェブデータプラットフォームです。包括的な製品スイートを通じて、公開ウェブデータを倫理的に大規模に収集、構造化、分析することができます。
主な製品には以下が含まれます:
- Unlocker API:CAPTCHA、アンチボットシステム、ウェブサイトのブロックを回避して、あらゆるウェブページからデータを取得します。
- SERP API:Google、Bing、Yandex、その他の主要な検索エンジンから構造化されたリアルタイムの検索エンジン結果を提供します。
- Discover API:ライブウェブからAIがランク付けした関連URLのリストを返し、さらなる処理に対応します。
- Crawl API:大規模なウェブサイトクローリングと自動データ抽出をサポートします。
- スクレイパーAPI:120以上の人気ウェブサイトやプラットフォームから構造化されたデータ抽出を提供します。
Bright Dataが際立っているのは、195カ国にまたがる4億以上のレジデンシャルIPのネットワークです。このインフラにより、高度にスケーラブルで地理的に分散したウェブデータ収集が可能になり、98.50%の成功率とSLAに裏付けられた99.99%の稼働時間を達成しています。また、GDPRやCCPAを含むすべての主要なプライバシーおよびセキュリティフレームワークに準拠しています。
APIエンドポイント呼び出しツールを通じてBright Dataを統合することで、OracleジェネレーティブAIエージェントはウェブを検索し、新鮮なオンライン情報にアクセスし、ウェブサイトからデータを取得し、実世界のコンテキストを応答に組み込むことができます。これにより、より正確で最新の実用的な結果が得られます。
Bright DataとOracleジェネレーティブAIエージェントの統合
このステップバイステップのセクションでは、Bright Dataと統合されたOracleジェネレーティブAIエージェントの構築方法を学びます。具体的には、Bright DataのWeb Unlocker APIとSERP APIに接続するための2つのカスタムAPIエンドポイント呼び出しツールの定義方法を説明します。
SERP APIによりエージェントは新しいソースを発見でき、Web Unlocker APIによりそれらのソースのコンテンツにアクセスできます。これらを組み合わせることで、強力なサーチアンドエクストラクトパターンが実現します。これにより、エージェントはリアルタイムで検証可能なコンテキスト的ウェブデータに基づいて自律的に応答を生成し、より事実に基づいたエンタープライズグレードの結果を生み出すことができます。
以下の手順に従ってください!
前提条件
このセクションを進めるには、以下が必要です:
- Oracleクラウドアカウント(無料ティアアカウントで十分です)。
- APIキーが設定されたBright Dataアカウント。Bright Data APIキーの設定については公式ガイドをご覧ください。
ステップ#1:VCNのセットアップ
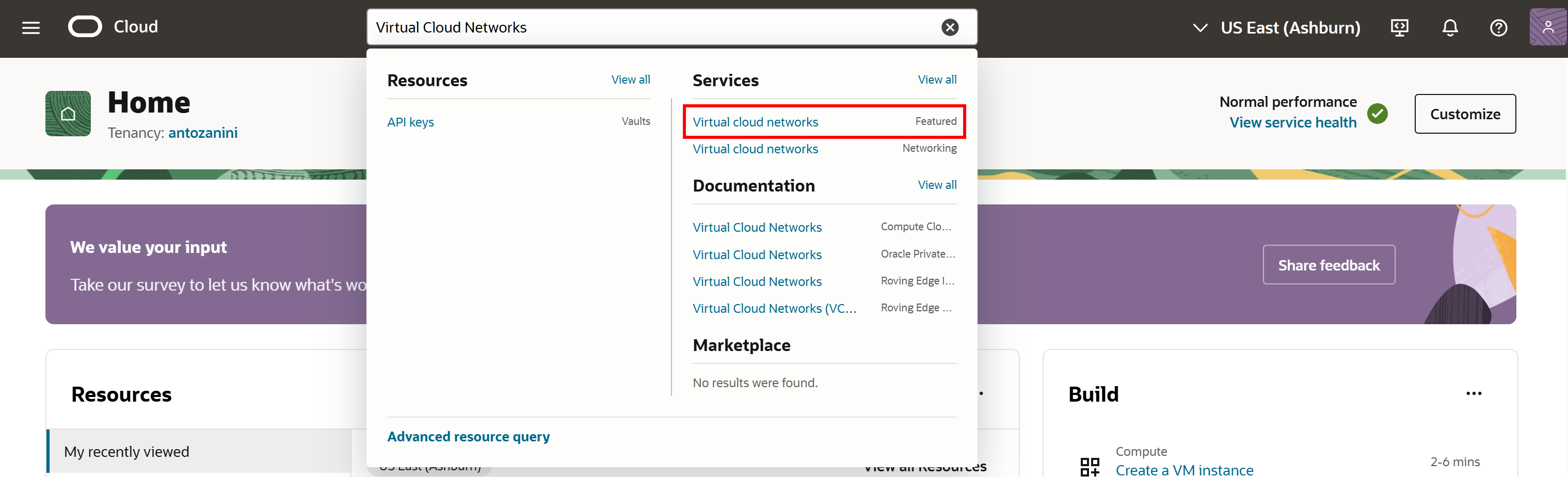
Oracleアカウントにログインし、「Virtual Cloud Networks」を検索して、対応するサービスを選択します:
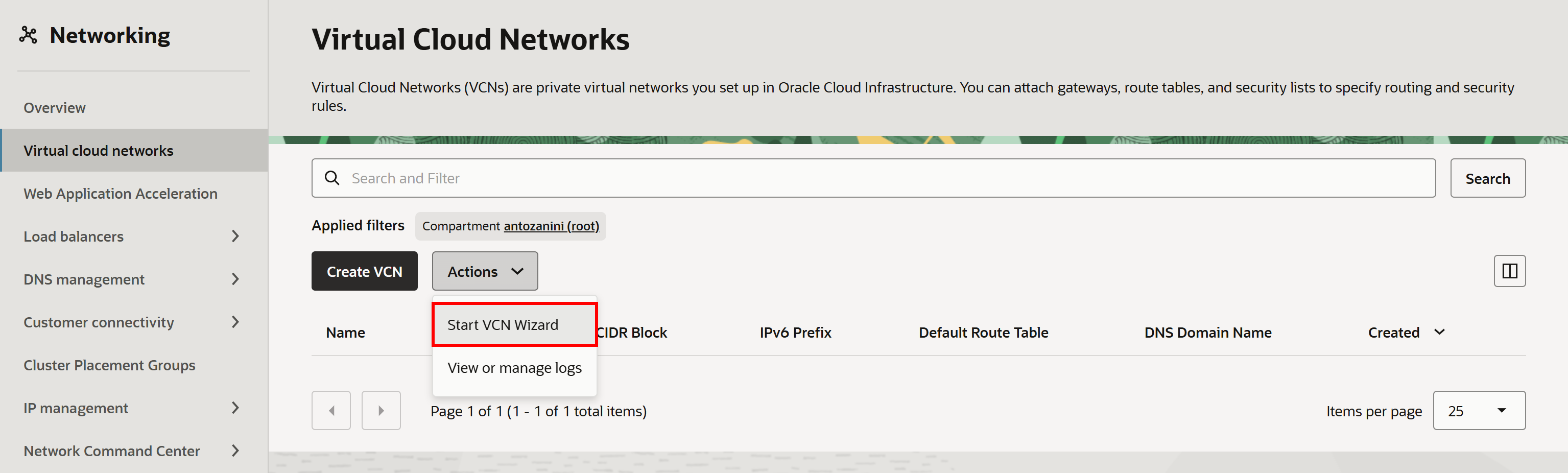
「Virtual Cloud Networks」ページで「Actions」ドロップダウンを開き、「Start VCN Wizard」を選択します:
次に、「Create VCN with Internet Connectivity」オプションを選択し、セットアップウィザードに従います:
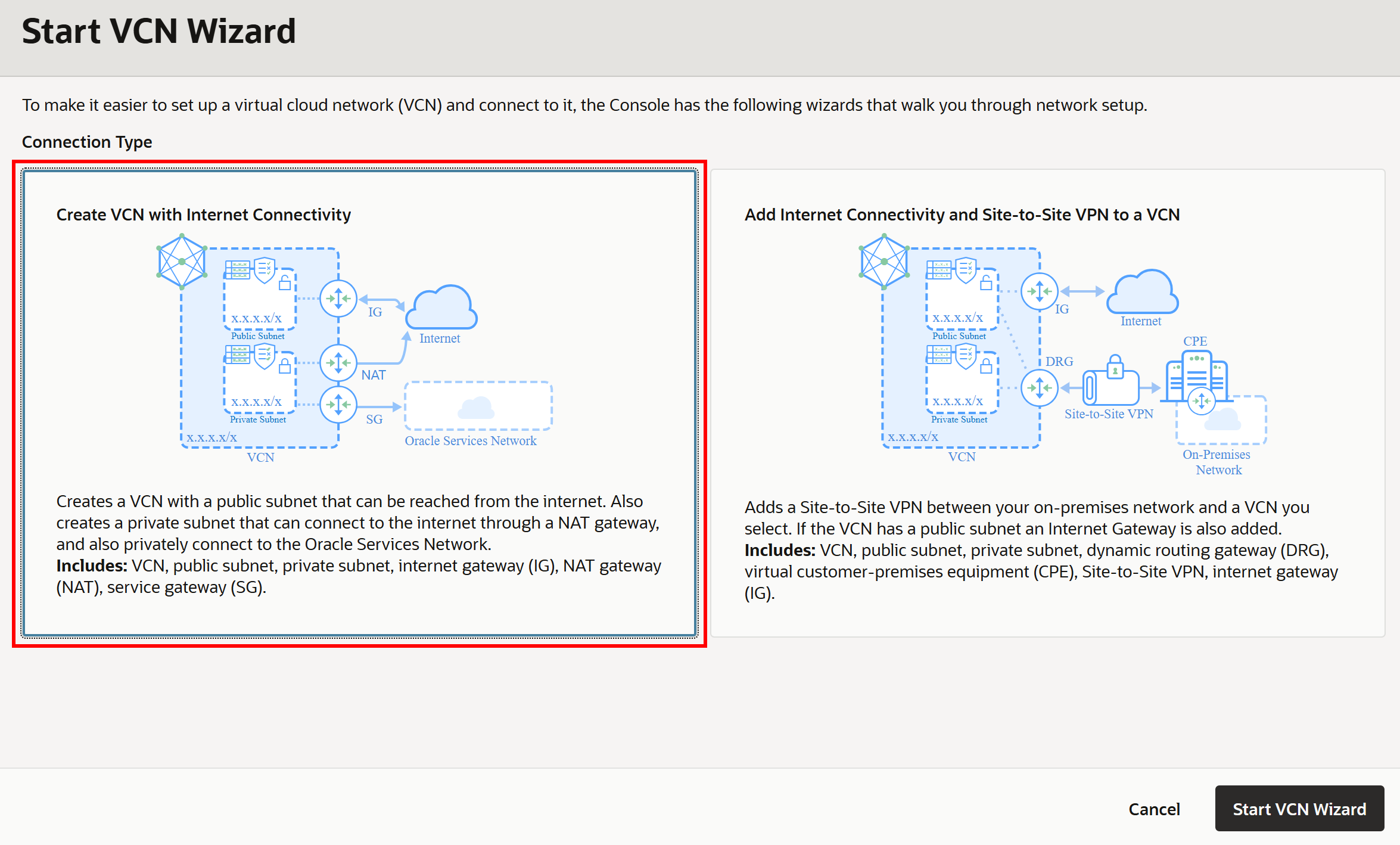
VCNに名前(例:「ai」)を付け、ウィザードを続けます。デフォルト設定はこのセットアップで問題ありません。
注意:サブネットの「DNS解決」機能を有効にする必要があります。そうしないと、カスタムツールが外部エンドポイントを呼び出せなくなります。ただし、OCIネットワーキングウィザードを使用する場合、この機能はデフォルトで有効になっているため、特に心配する必要はありません。
VCNが作成されると、次のような画面が表示されます:
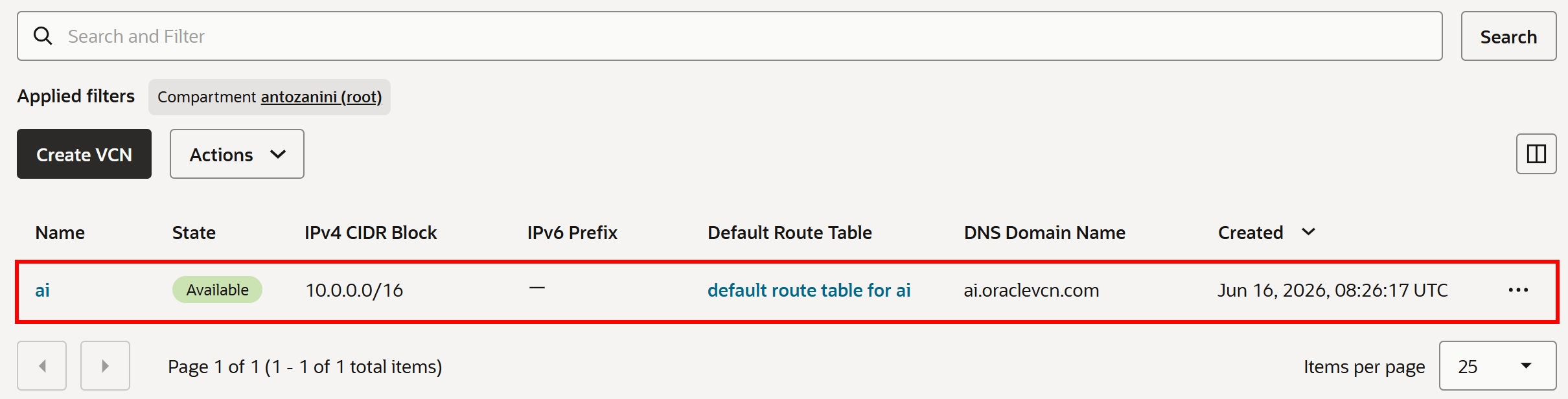
これで、Bright DataツールがHTTPトラフィックをルーティングするために使用できるサブネットを持つOCI仮想クラウドネットワーク(VCN)が完成しました。
ステップ#2:Bright Data APIキーをOracle Vaultに保存する
まず、Oracleの公式ガイドに従ってOracle Vaultをセットアップします(暗号化キーを含む)。次に、Oracleアカウントで「Secret Management」を検索してサービスを開きます。「Create secret」ボタンをクリックします:

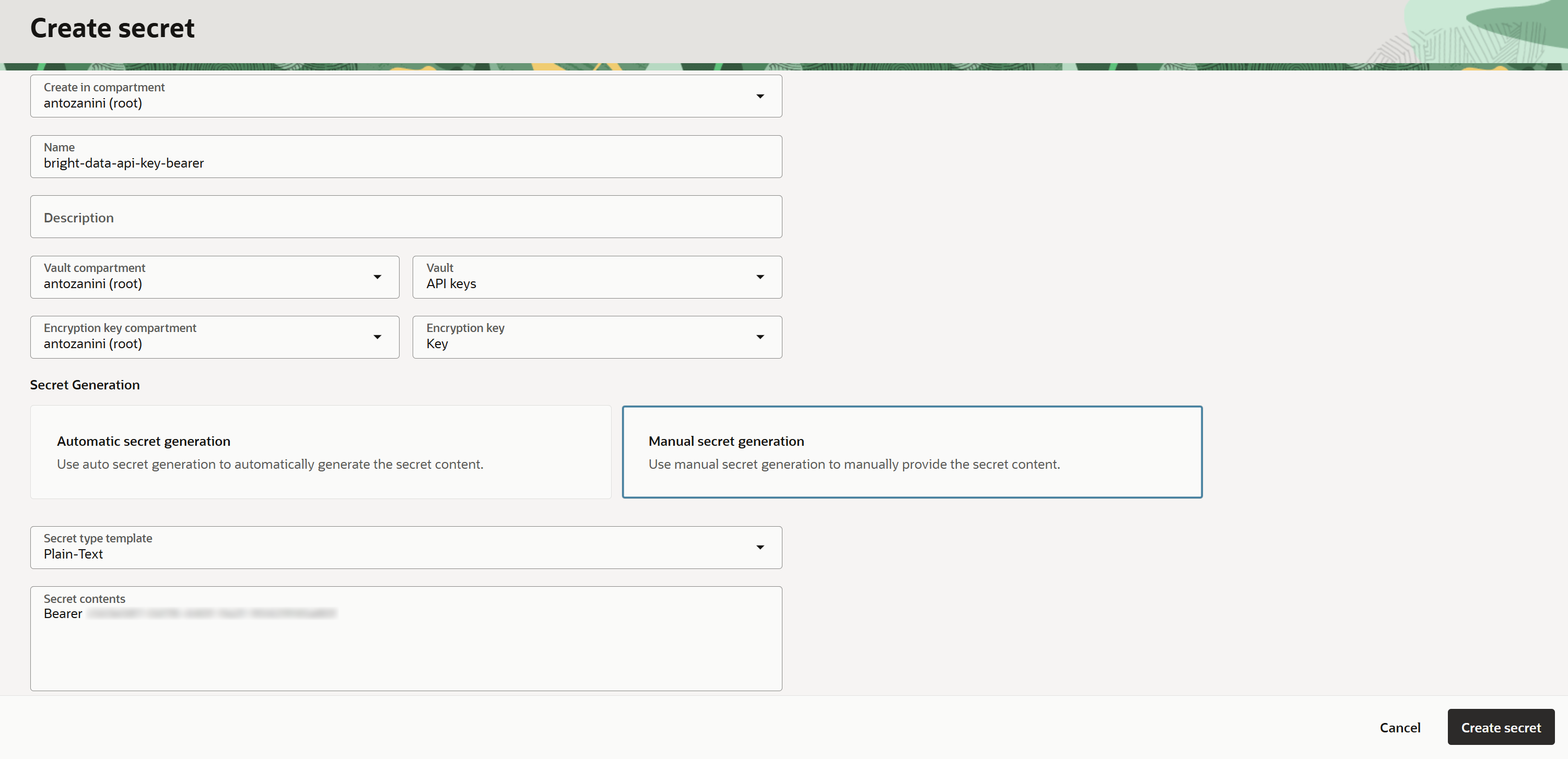
「Create secret」フォームで、シークレットに名前(例:「bright-data-api-key-bearer」)を付け、Oracle VaultとEncryptionキーを選択し、「Manual secret generation」オプションを選択します。以下の形式でシークレット値を入力します:
Bearer <BRIGHT_DATA_API_KEY><BRIGHT_DATA_API_KEY>プレースホルダーを実際のBright Data APIキーに置き換えてください。
注意:APIキーの前の「Bearer」プレフィックスは必須です。これは標準的なトークンベースの形式であり、Bright Data APIの認証のためにAuthorizationヘッダーに設定する必要があります。
「Create secret」を押してシークレットの作成を完了します。「Secrets」ページにシークレットが表示されるはずです:
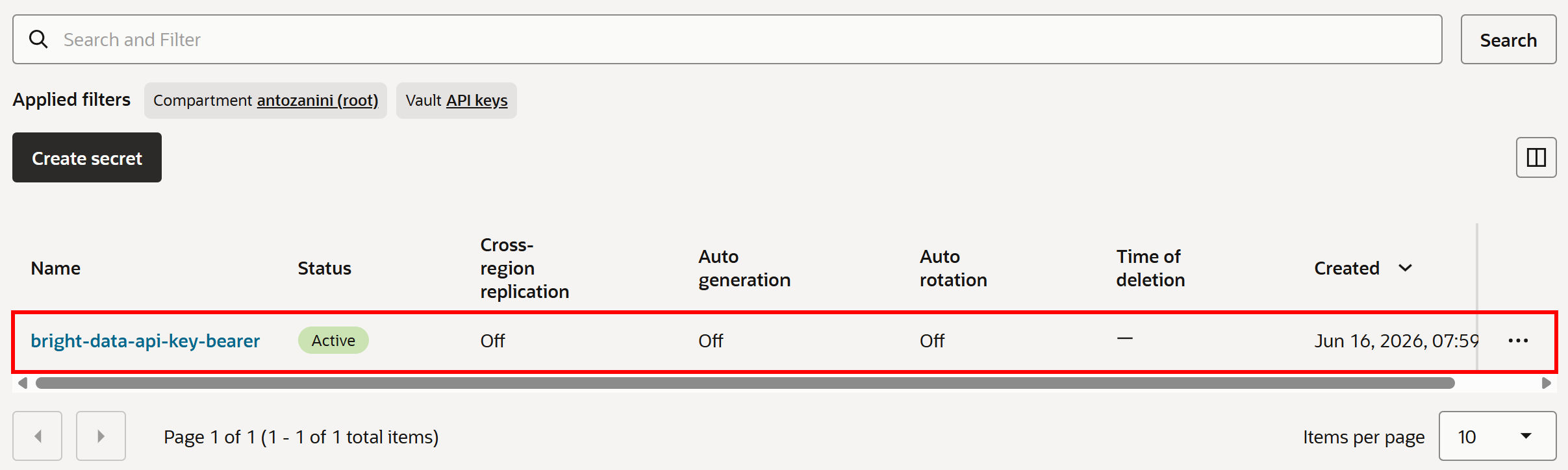
このシークレットは、カスタムエージェントツールがBright Data APIに対して行うリクエストの認証に使用されます。
ステップ#3:必要なIAMポリシーの追加
デフォルトでは、OracleジェネレーティブAIサービスはVaultに保存されたシークレットへのアクセス権を持っていません。これを有効にするには、正しいIAMポリシーを追加する必要があります。
OCIコンソールで「Policies」を検索し、対応するページを開きます。次に「Create Policy」をクリックします:
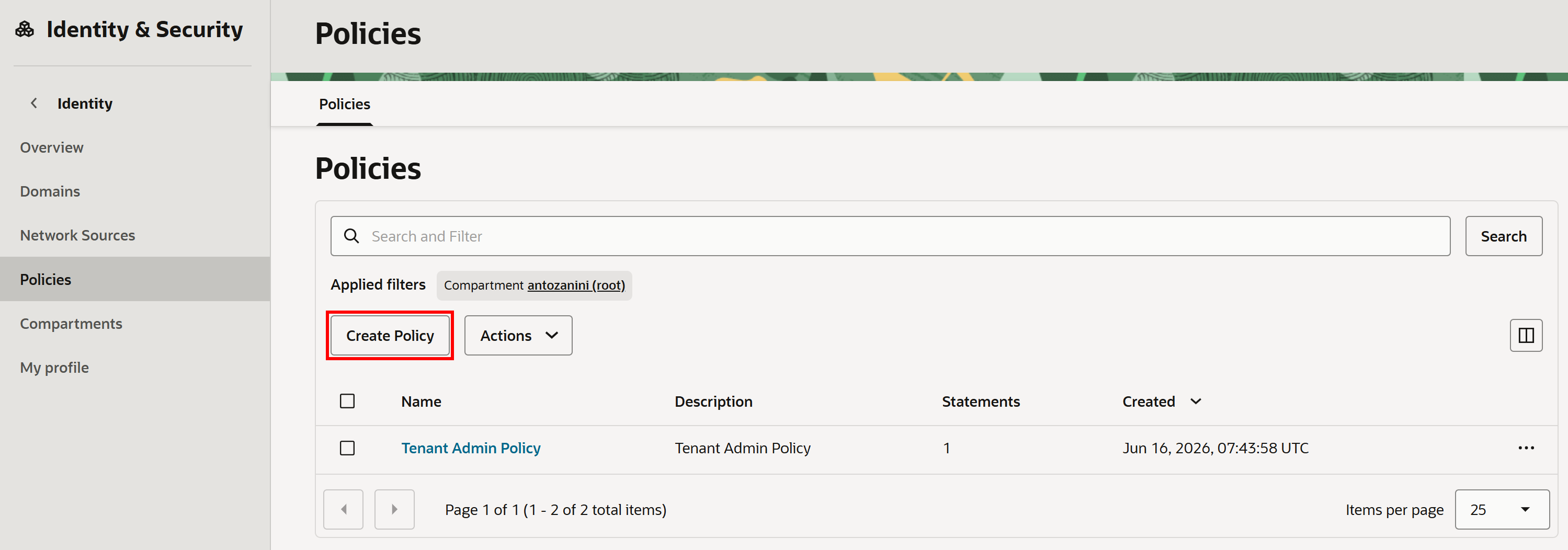
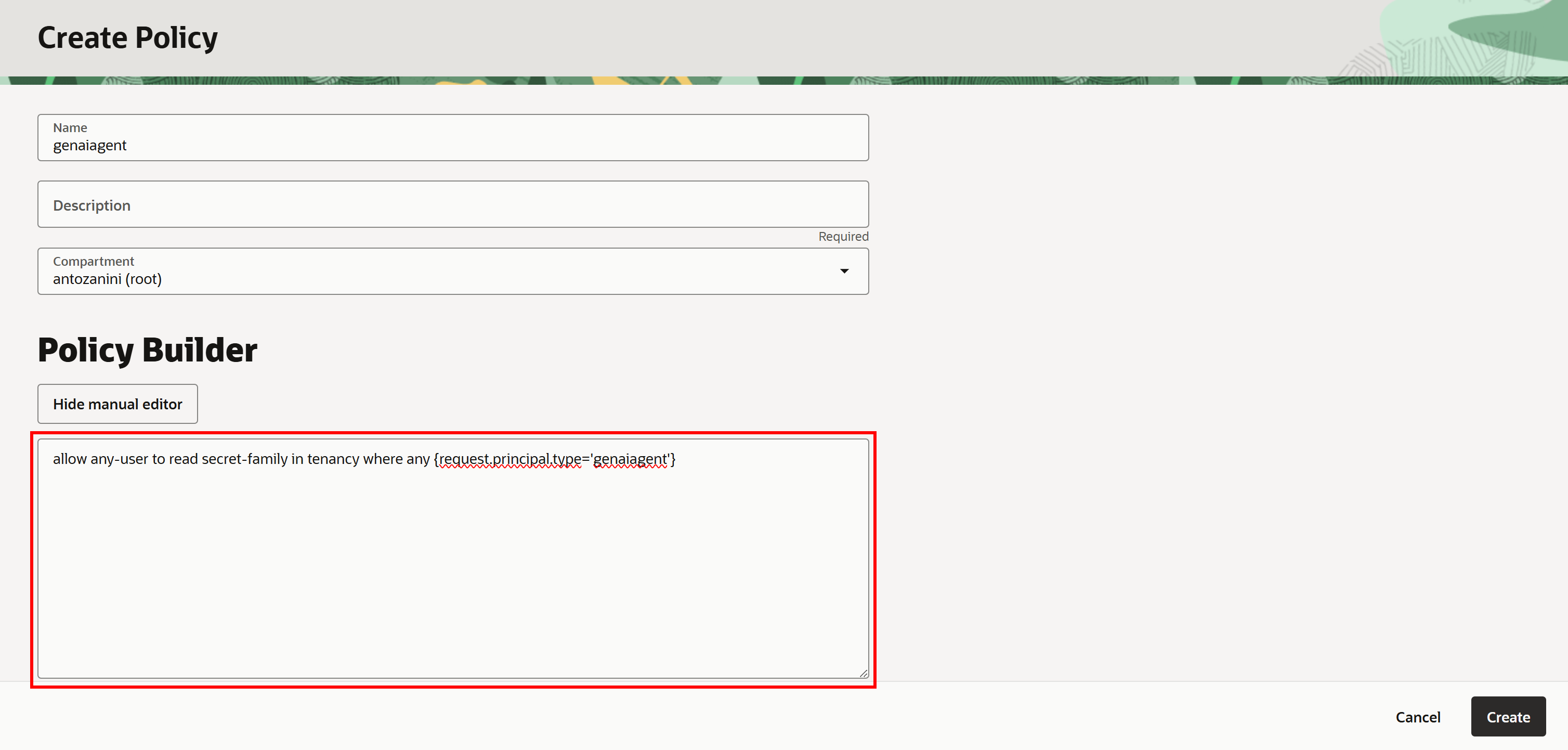
「Create Policy」フォームで、ポリシーに名前(例:「genaiagent」)を付けます。次に「Show manual editor」をクリックし、以下のIAMポリシーを貼り付けます:
allow any-user to read secret-family in tenancy where any {request.principal.type='genaiagent'}このポリシーにより、すべてのジェネレーティブAIエージェントがテナンシー全体のOCI Vaultインスタンスに保存されたシークレット(先ほど作成した「bright-data-api-key-bearer」シークレットを含む)を読み取ることができます。
「Create」をクリックしてポリシーの作成を確定します:
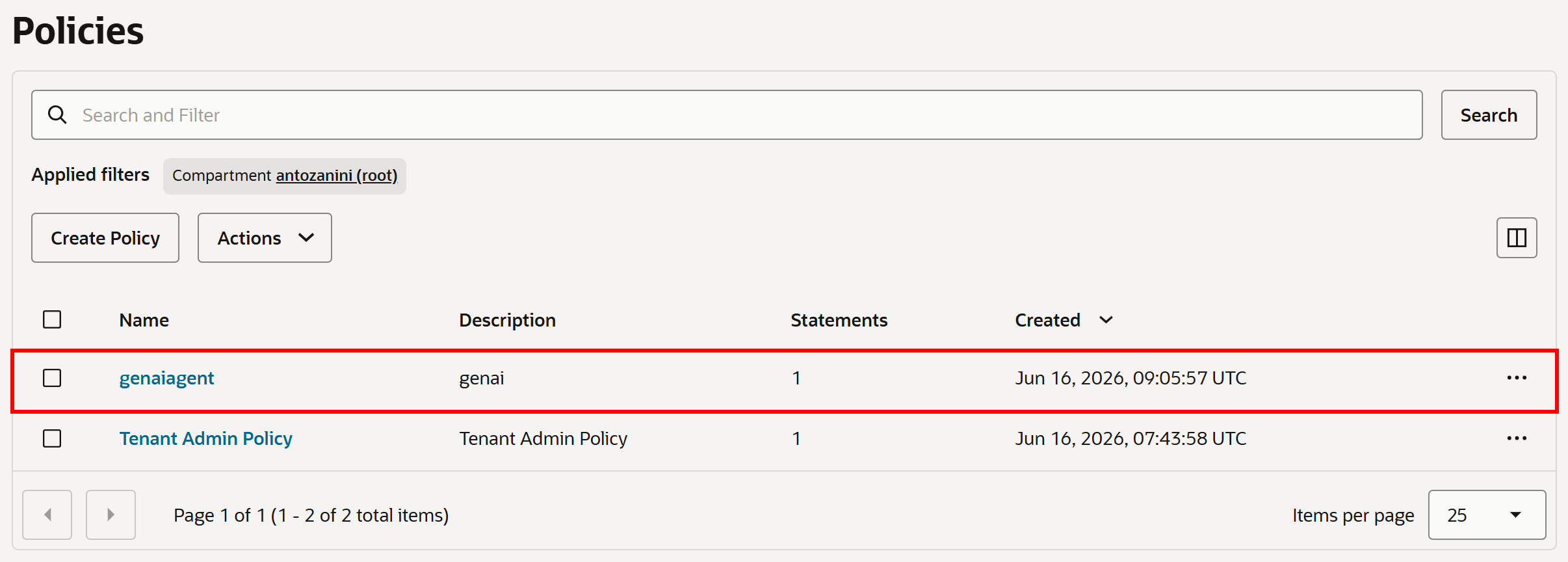
作成後、ポリシーは「Policies」ページに表示されます:
また、同じ目標を達成するために動的グループを設定する公式ガイドに従うこともできます。
これで、カスタムツールを介してBright Dataに接続できるOracleジェネレーティブAIエージェントを構築するために必要なすべての構成要素が揃いました。
ステップ#4:ウェブアクセスエージェントの初期化
「Agents」を検索し、「Generative AI Agents」サービスの対応するページを開きます:
「Create agent」ボタンを押して続けます:

エージェント作成ウィザードが起動します。フォームを以下のように入力します:
- 名前:
Web Access AI Agent - 説明:
You are a web agent with web access powered by the Bright Data integration - ルーティング指示:
When asked to search the web, retrieve online data, or scrape web pages, use the Bright Data tools
次に、エージェントのブレインとして好みのLLMを選択します。この場合、デフォルトのLlama 3.3 70Bモデルで十分です。
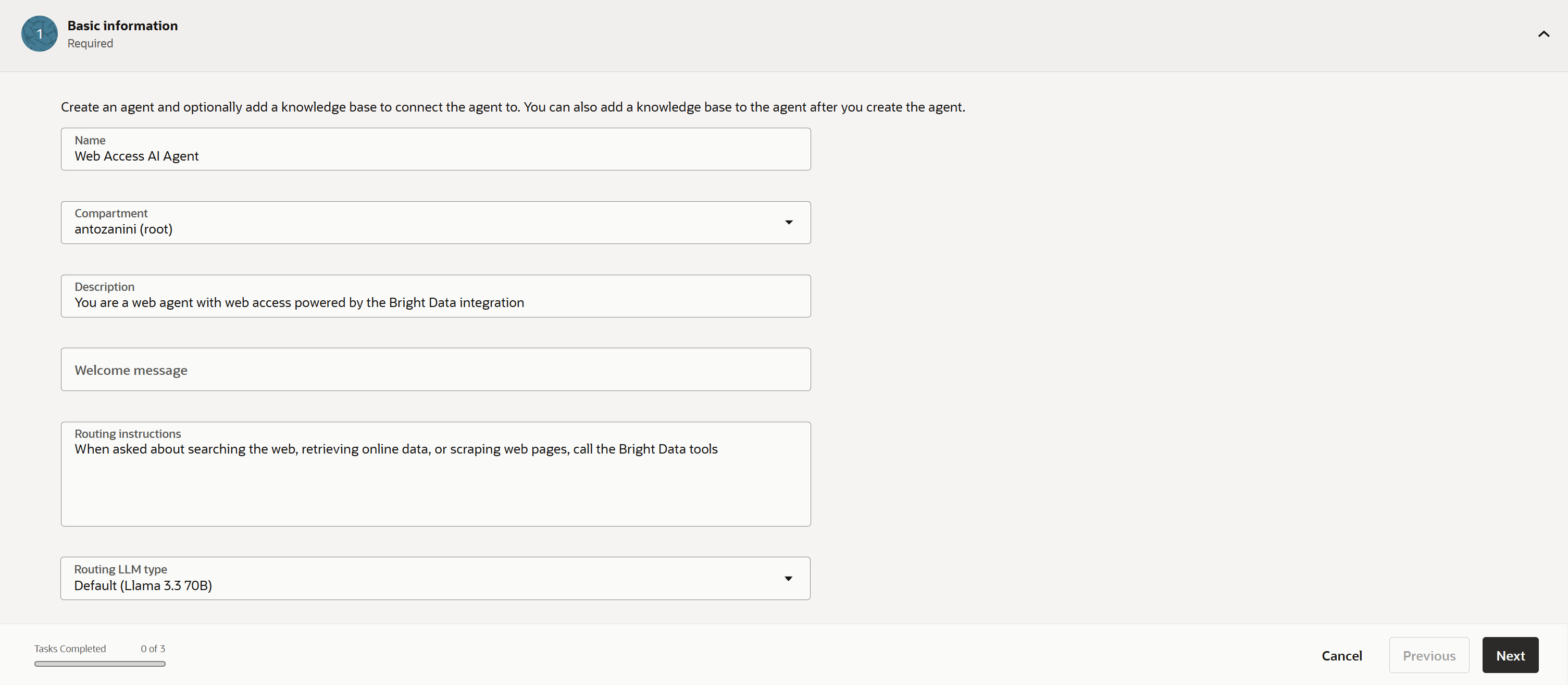
「Next」をクリックしてウィザードの「Tools」セクションに進みます。Bright Data統合ツールを定義する前に、準備を整えましょう。
ステップ#5:Bright DataのUnlocker APIとSERP APIの準備
Bright DataアカウントでUnlocker APIとSERP APIを作成する時が来ました。クイックセットアップのために、公式ドキュメントページを参照してください:
または、以下の手順に従ってください。
まだの場合は、Bright Dataアカウントを作成してください。すでにお持ちの場合は、ログインしてコントロールパネルを開きます:
次に、左側のメニューから「Web Access > Web Access API」に移動します:
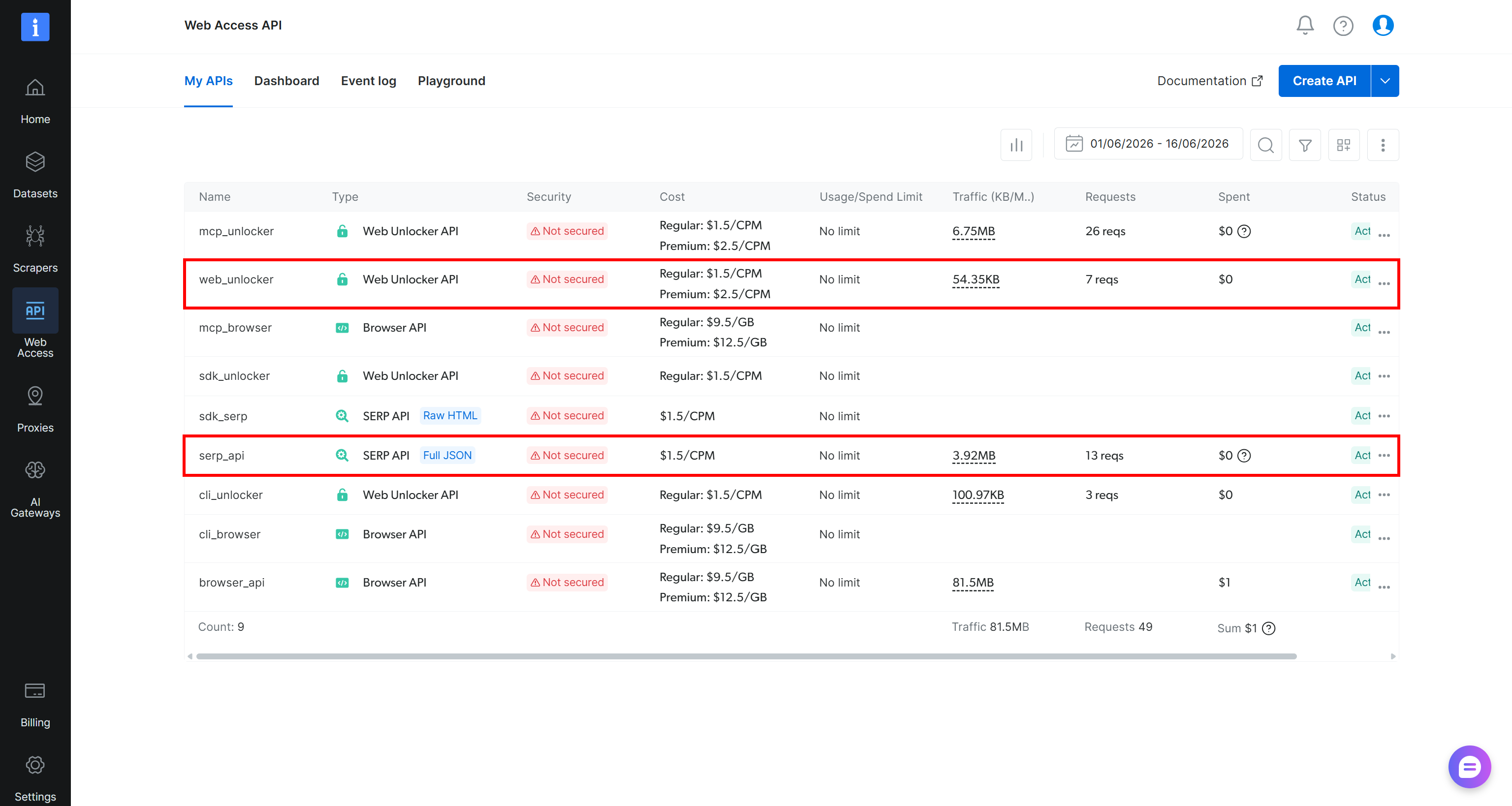
「My APIs」テーブルに「Web Unlocker API」と「SERP API」のエントリが既に表示されている場合は、準備完了です:
そうでない場合は、「Create API」ボタンのドロップダウンをクリックして「Unlocker API」(または「SERP API」を作成する場合はそちら)を選択します:
Unlocker/SERP APIのセットアップウィザードが起動します。APIに名前(例:unlocker_api/serp_api)を付け、必要に応じてAPIを設定します:
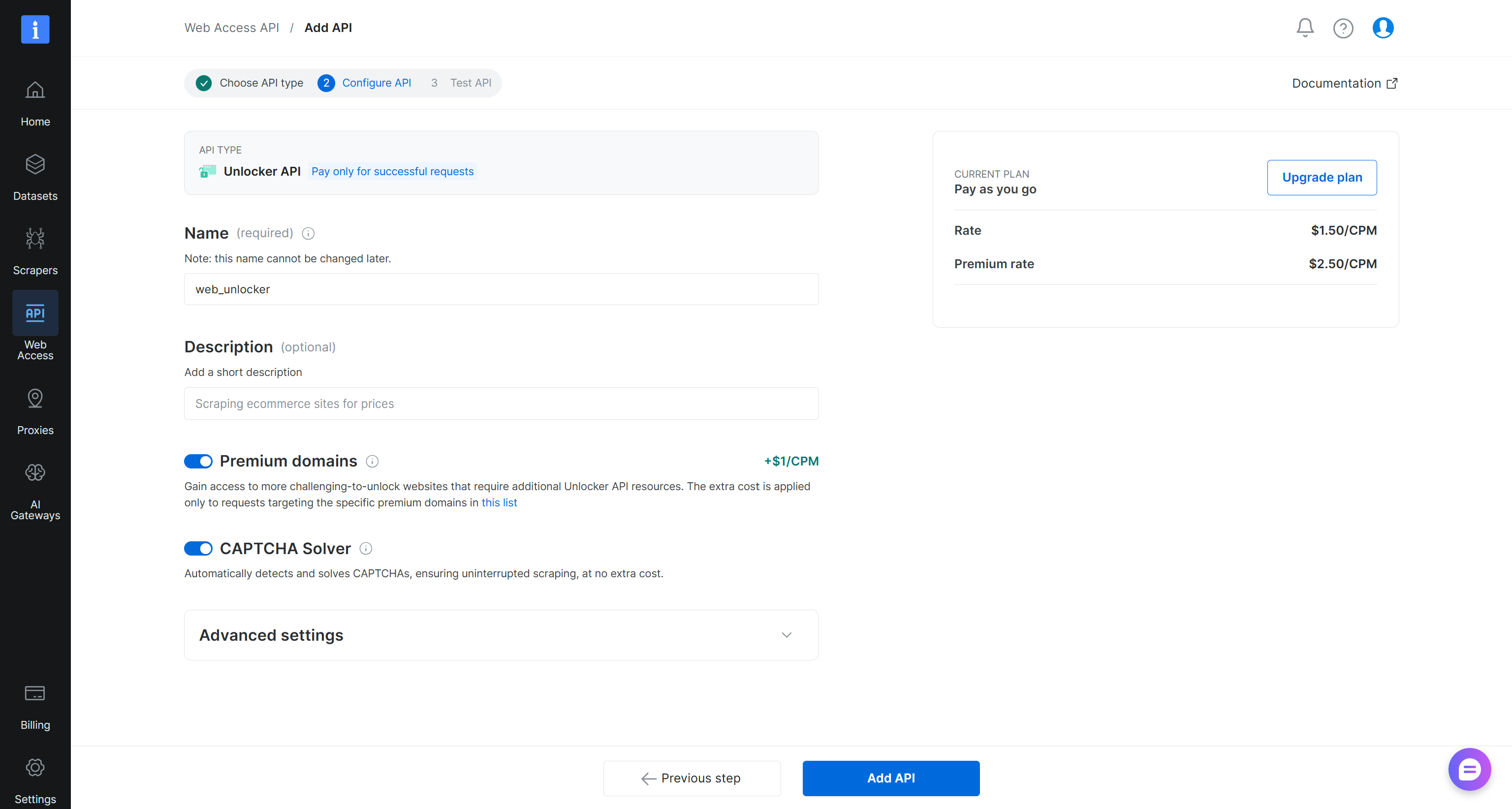
完了したら「Add API」をクリックします。以降、次のAPI名を設定したと仮定します:
- Bright Data Unlocker APIには
unlocker_api。 - Bright Data SERP APIには
serp_api。
これらのAPIに接続するカスタムAPIエンドポイント呼び出しツールを定義する準備が整いました。
ステップ#6:Web Unlocker API統合用カスタムツールの作成
ジェネレーティブAIエージェント作成ウィザードに戻ります。Toolsセクションで「Add tool」をクリックします。
Unlocker API統合用ツールを作成するには、「Custom tool」オプションを選択します。次にフォームを以下のように入力します:
- 名前:
Web Unlocker API - 説明:
An automated web scraping tool that extracts content from web pages and bypasses anti-bot protections
「Tool configuration」セクションで、「API endpoint calling (agent execution)」オプションを選択します:
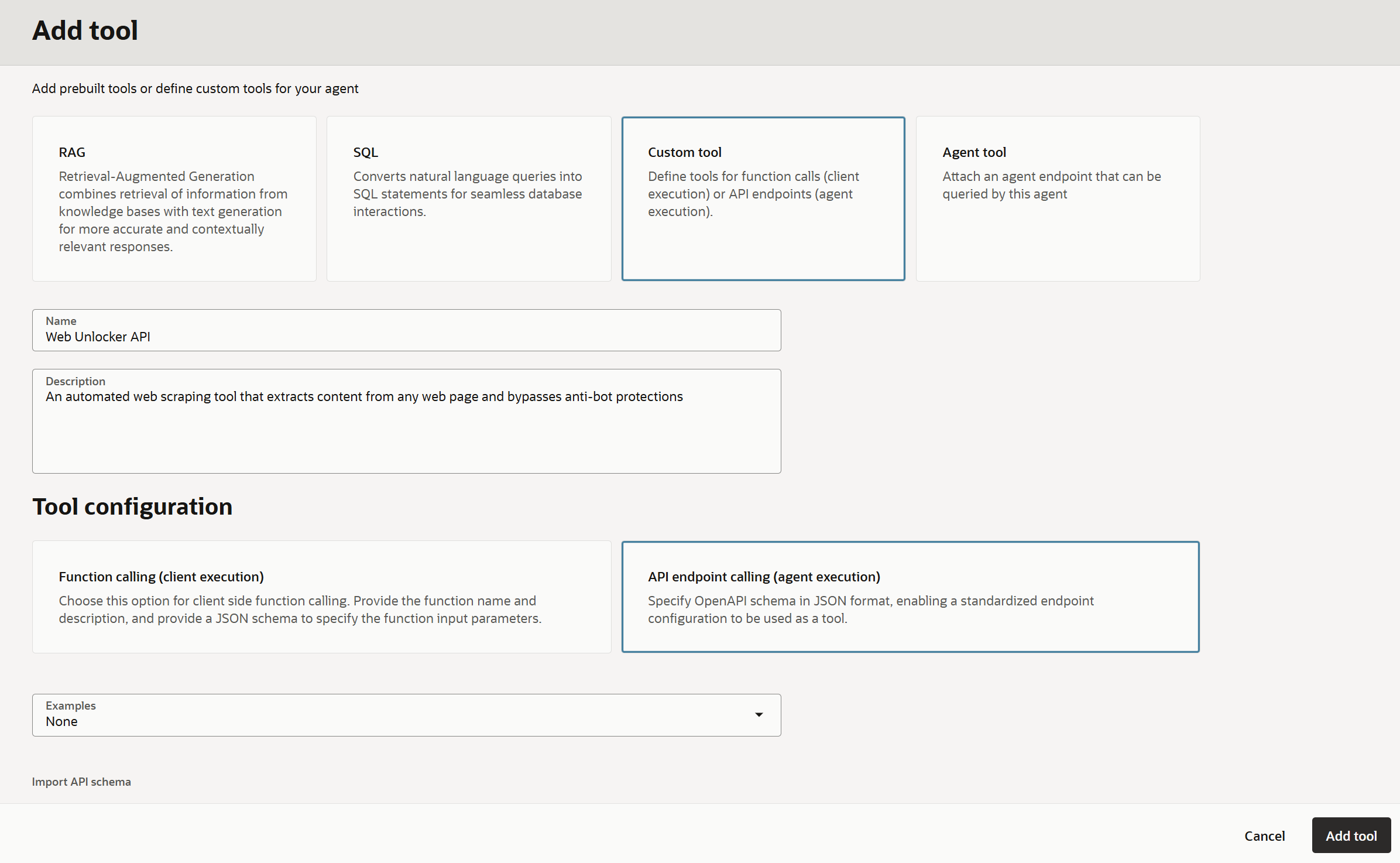
「Examples」セクションで「None」を選択して白紙の状態から始め、以下のOpenAPI仕様を貼り付けます:
{
"openapi": "3.0.4",
"info": {
"title": "Bright Data Web Unlocker API",
"version": "1.0.0",
"description": "Bright Data Unlocker API enables you to bypass anti-bot measures. It manages proxies and solves CAPTCHAs automatically for easier web data collection.\n\n\[Web Unlocker API documentation\](https://docs.brightdata.com/scraping-automation/web-unlocker/introduction)\n"
},
"servers": [
{
"url": "https://api.brightdata.com"
}
],
"paths": {
"/request": {
"post": {
"operationId": "sendWebUnlockerRequest",
"summary": "Send a Web Unlocker API request",
"description": "Submit a Web Unlocker API request using your Bright Data Web Unlocker API zone.\n\n\[Web Unlocker API `/request` documentation\](https://docs.brightdata.com/api-reference/rest-api/unlocker/unlock-website)\n",
"requestBody": {
"required": true,
"content": {
"application/json": {
"schema": {
"type": "object",
"required": ["zone", "url", "format"],
"properties": {
"zone": {
"type": "string",
"description": "Your Web Unlocker zone name.",
"default": "unlocker_api"
},
"url": {
"type": "string",
"description": "The target website URL to unlock and fetch.",
"example": "https://example.com/products"
},
"format": {
"type": "string",
"description": "Response format.\nAllowed values:\n- raw: Returns the response immediately in the body.\n- json: Returns the response as a structured JSON object.",
"default": "raw"
},
"method": {
"type": "string",
"description": "HTTP method used when fetching the target URL.",
"example": "GET"
},
"country": {
"type": "string",
"description": "Country code for proxy location (ISO 3166-1 alpha-2 format).",
"example": "us"
}
}
}
}
}
},
"responses": {
"200": {
"description": "Successful response containing search results."
},
"400": {
"description": "Invalid request (missing required fields or invalid parameters)."
},
"401": {
"description": "Unauthorized (invalid or missing Bright Data API key)."
}
}
}
}
}
}これはBright Data Web UnlockerのOpenAPI仕様に対応しています。詳細については、「OpenAPI Specs: AI Integration with SERP & Unlocker APIs」ガイドをお読みください。
重要:zoneプロパティの下の"default": "unlocker_api"フィールドに注目してください。これはAIエージェントにBright Data Unlocker APIの呼び出し方法を指示するために不可欠です。"unlocker_api"を実際のUnlocker API名に置き換えてください。
認証方法を設定するには、フォームを以下のように入力します:
- 認証タイプ:
API key - キーの場所:
Header - キー名:
Authorization - シークレット値:
bright-data-api-key-bearer(または保存したBright Data APIキーシークレットの名前) - VCN:
ai(またはOracle VCNの名前) - サブネット:
private-subnet-ai(重要:プライベートサブネットを選択してください。そうしないと、すべてのツール呼び出しが500エラーで失敗します)
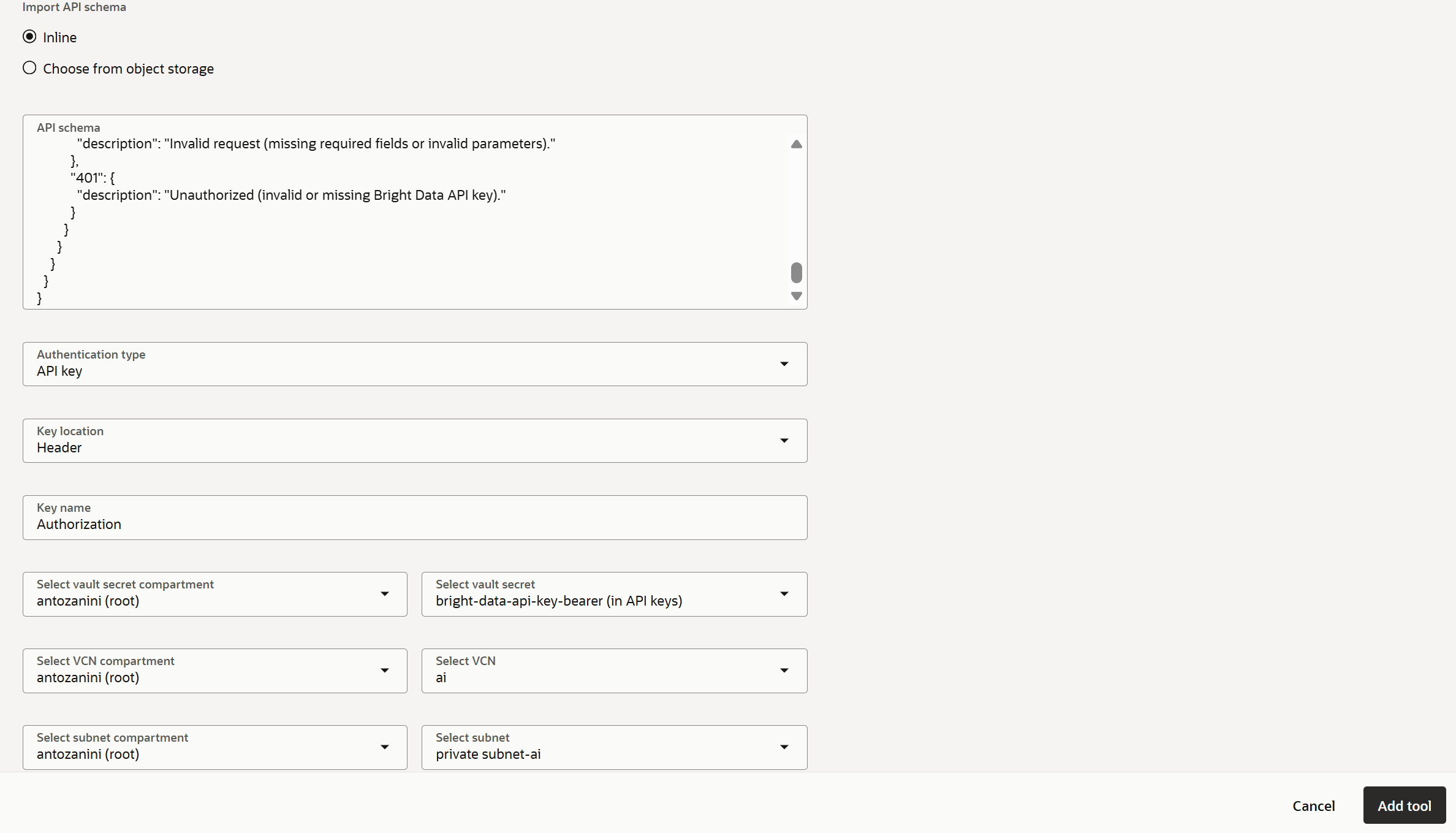
これにより、Bright Dataが必要とする認証方法でカスタムツールが設定されます。また、Unlocker APIへのAPI呼び出しがOCI VCNプライベートサブネットを通じて実行されることが保証されます。
最後に「Add tool」をクリックしてセットアップを完了します。Bright Dataが提供するウェブスクレイピングツールがエージェントで利用可能になります。
ステップ#7:SERP APIツールの作成
スクレイピング機能だけを持つエージェントは、ウェブコンテンツを自律的に発見する能力なしでは制限されます。ここでBright Data SERP APIの出番です!
再度「Add tool」をクリックし、前と同じプロセスを繰り返します。今回は以下のようにフォームを入力します:
- 名前:
SERP API - 説明:
An endpoint that provides real users'search results at high volume across major search engines, including Google
次に、以下の仕様を貼り付けます:
{
"openapi": "3.0.4",
"info": {
"title": "Bright Data SERP API",
"version": "1.0.0",
"description": "Extract search engine results using Bright Data SERP API. Extract structured data from major search engines, including Google, Bing, Yandex, DuckDuckGo, and more. \nGet organic results, paid ads, local listings, shopping results, and other SERP features.\n\[SERP API documentation\](https://docs.brightdata.com/scraping-automation/serp-api/introduction)\n"
},
"servers": [
{
"url": "https://api.brightdata.com"
}
],
"paths": {
"/request": {
"post": {
"operationId": "sendSerpRequest",
"summary": "Send a SERP API request",
"description": "Submit a SERP API request using your Bright Data SERP API zone. \n\n\[SERP API `/request` documentation\](https://docs.brightdata.com/api-reference/rest-api/serp/scrape-serp)\n",
"requestBody": {
"required": true,
"content": {
"application/json": {
"schema": {
"type": "object",
"required": [
"zone",
"url",
"format"
],
"properties": {
"zone": {
"type": "string",
"description": "The name of your SERP API zone.",
"default": "serp_api"
},
"url": {
"type": "string",
"description": "The search engine URL to query (e.g., `https://www.google.com/search?q=<search_query>`).",
"example": "https://www.google.com/search?q=pizza&hl=en&gl=us"
},
"format": {
"type": "string",
"description": "Response format. \nAllowed values: \n- `raw`: Returns the response immediately in the body. \n- `json`: Returns the response as a structured JSON object. \n",
"default": "raw",
"enum": [
"raw",
"json"
]
},
"country": {
"type": "string",
"description": "Country code for proxy location (ISO 3166-1 alpha-2 format). \n",
"example": "us"
}
}
}
}
}
},
"responses": {
"200": {
"description": "Successful response containing search results."
},
"400": {
"description": "Invalid request (missing required fields or invalid parameters)."
},
"401": {
"description": "Unauthorized (invalid or missing Bright Data API key)."
}
}
}
}
}
}重要:前述のように、zoneプロパティのdefaultフィールドがSERP API名と一致していることを確認してください。
このツールを追加すると、次のような画面が表示されます:
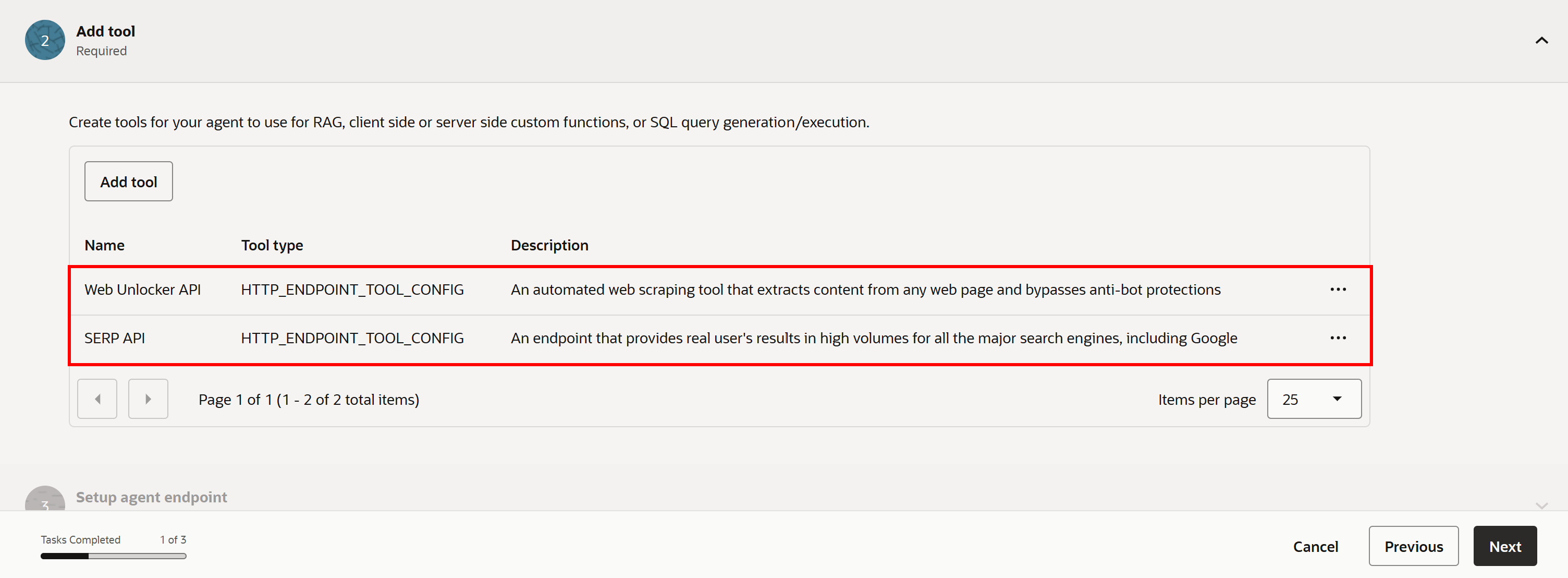
注意:同様の方法で、他のすべてのAPIベースのBright Dataソリューションを接続できます。
あとは最終的な仕上げをするだけです。
ステップ#8:エージェント作成の完了
「Next」をクリックしてエージェントエンドポイントのセットアップに進みます。これはエージェントのテストに必要です。次に、すべてのエージェント情報を確認し、「Create agent」をクリックして、Llama 3ライセンス契約に同意します。
「Agents」ページにリダイレクトされ、ステータスが「Creating」の「Web Access AI Agent」エントリが表示されます。プロビジョニングプロセスには数分かかる場合がありますので、しばらくお待ちください。
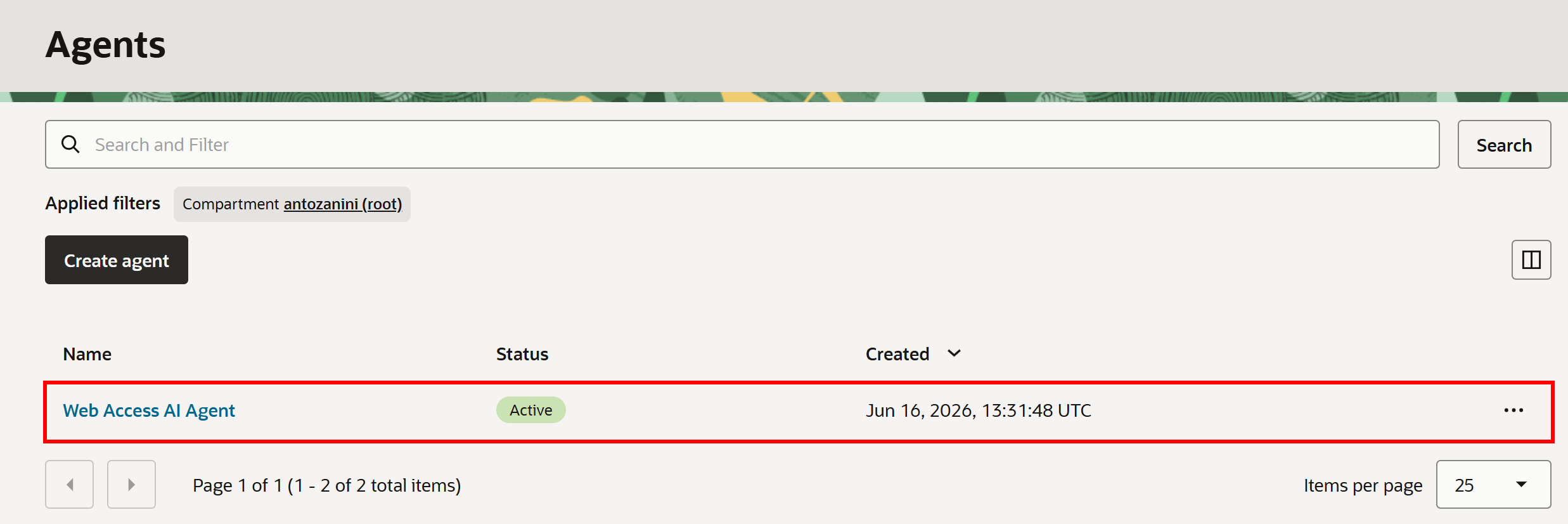
しばらくすると、ステータスが「Active」に変わり、Bright Data統合を持つOracleジェネレーティブAIエージェントの準備が完了します!
ステップ#8:エージェントのテスト
エージェント名をクリックすると、次のページにリダイレクトされます:
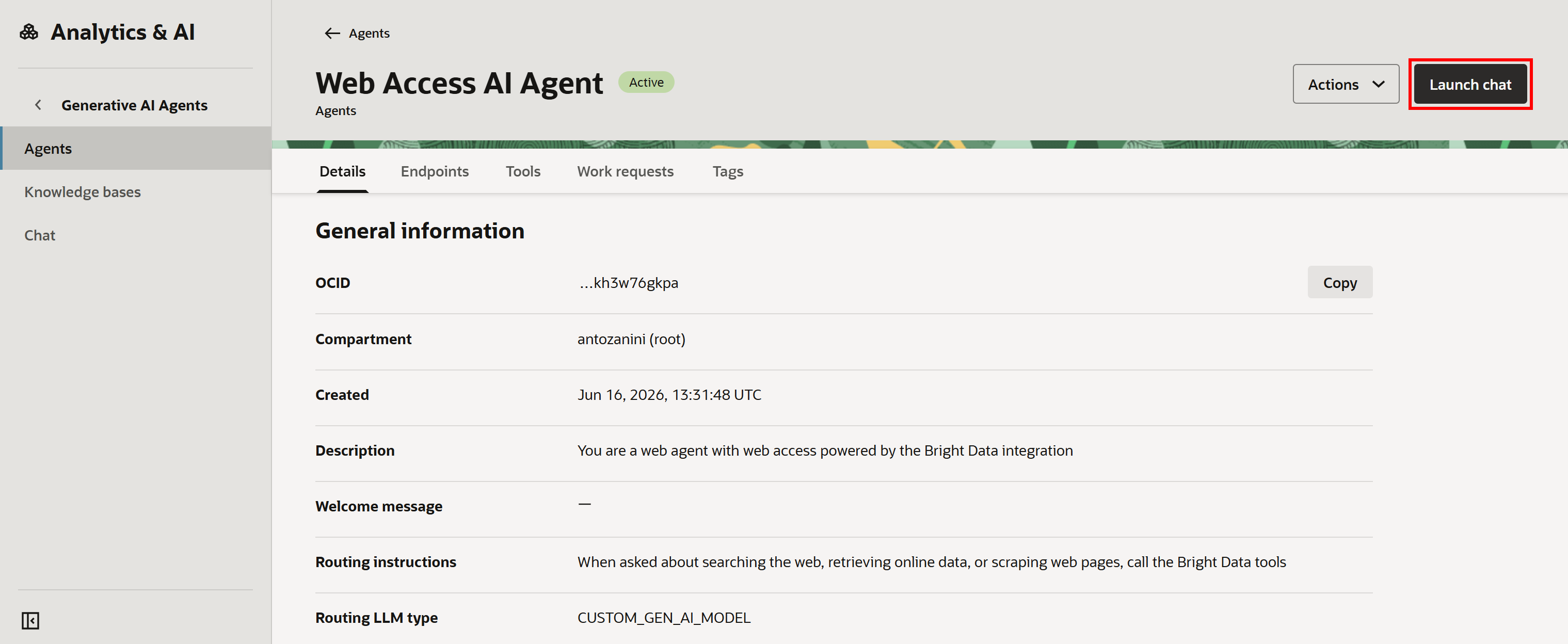
ここで「Launch chat」を押してエージェントをテストできます。
AIエージェントと関連エンドポイントが選択されていることを確認し、次のようなプロンプトを貼り付けます:
Search Google for the latest news about SpaceX stock, review the content from the 2,3 most relevant sources, and provide a report summarizing the most important informationこれはBright Data統合がウェブ検索とスクレイピングの両方のタスクを処理できることを検証するため、理想的なテストです。
「Chat」ページでプロンプトを実行します。次のような結果が表示されるはずです:
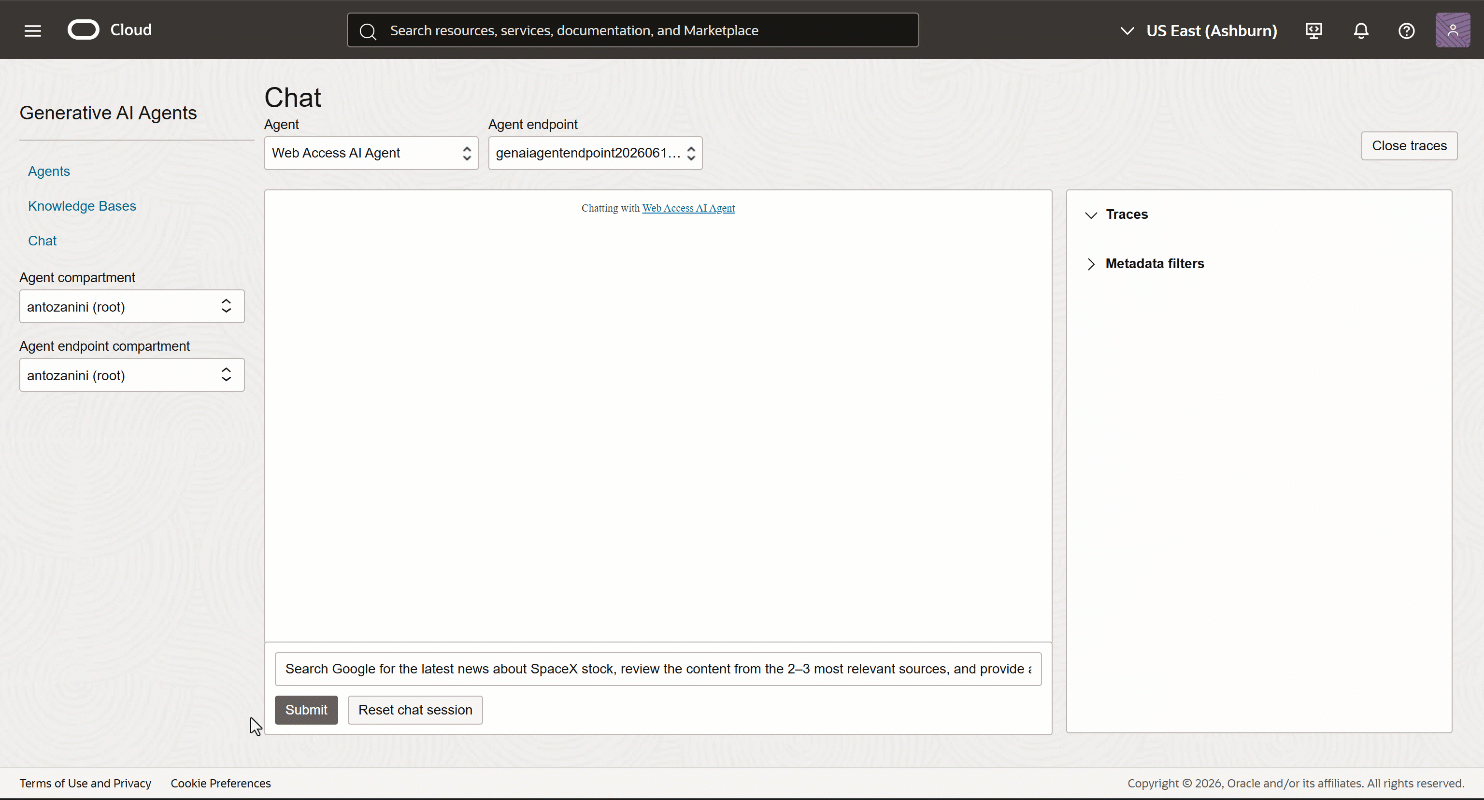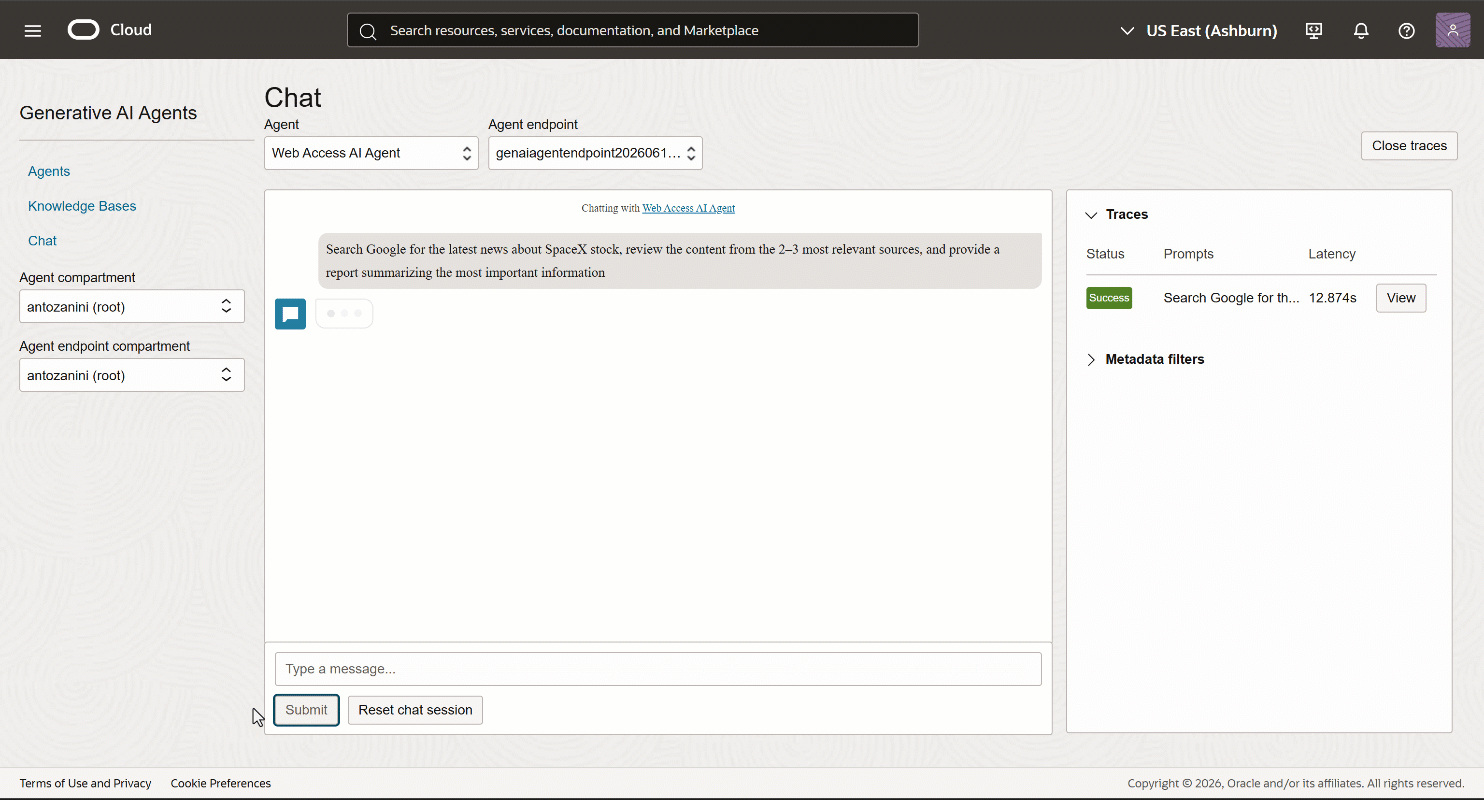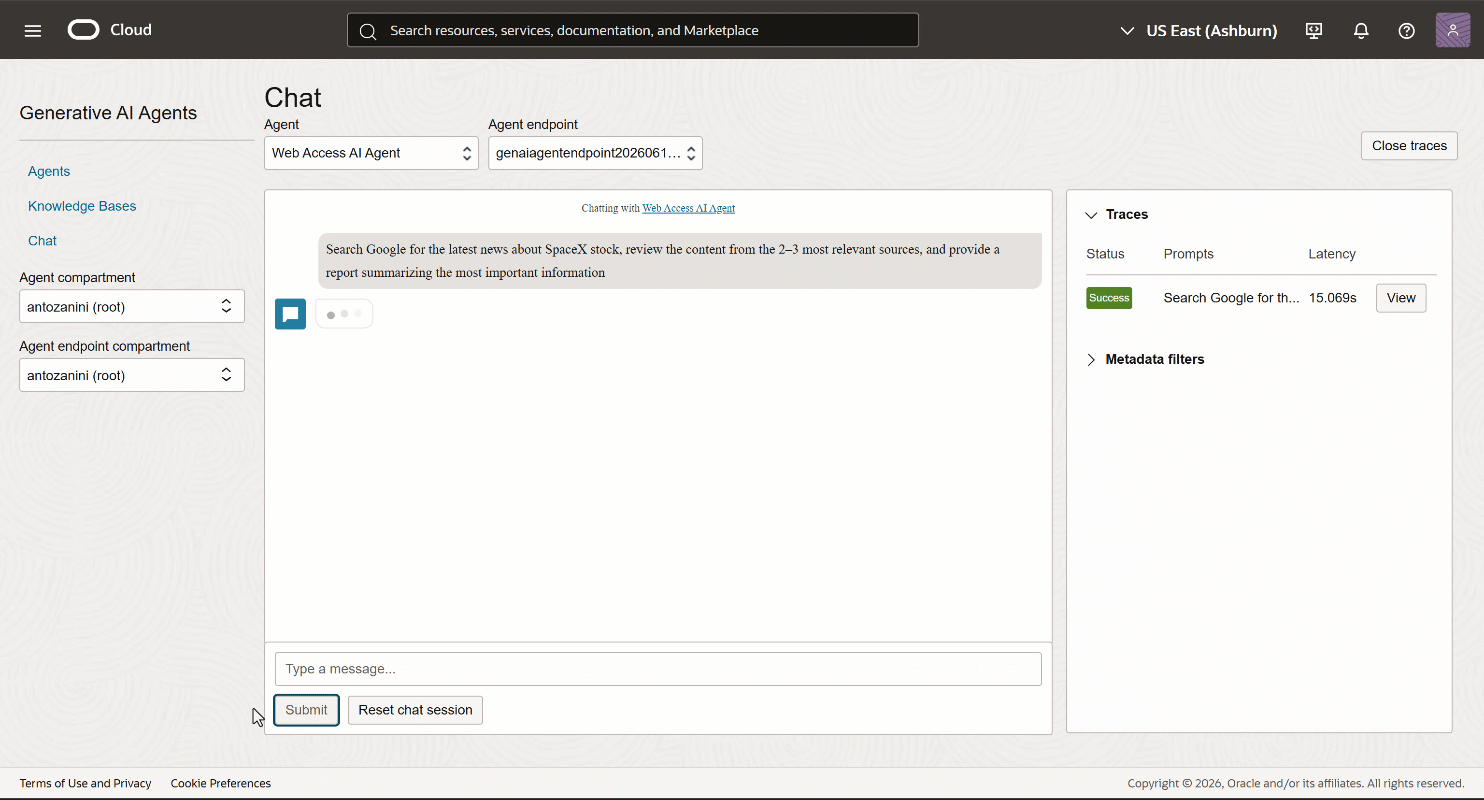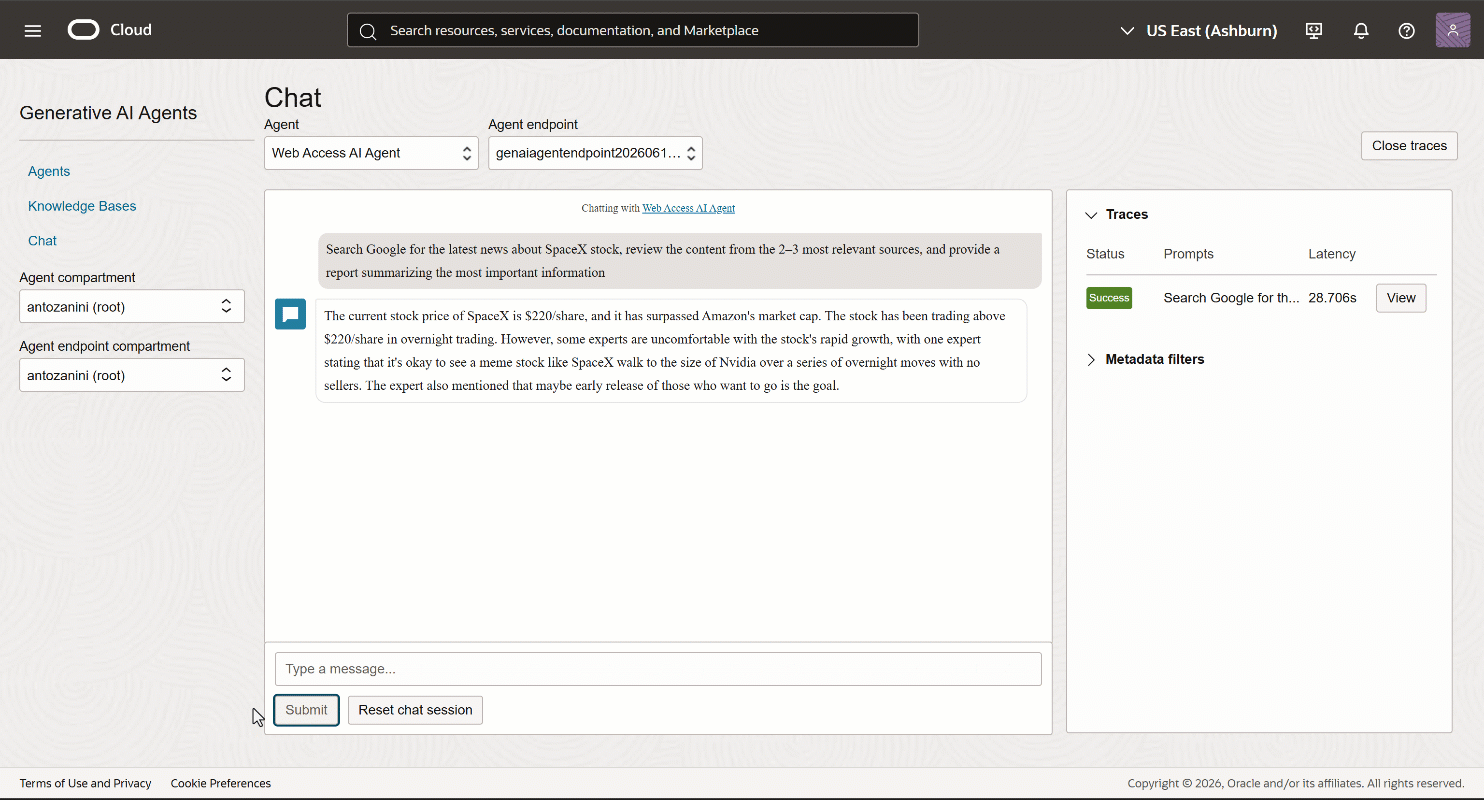
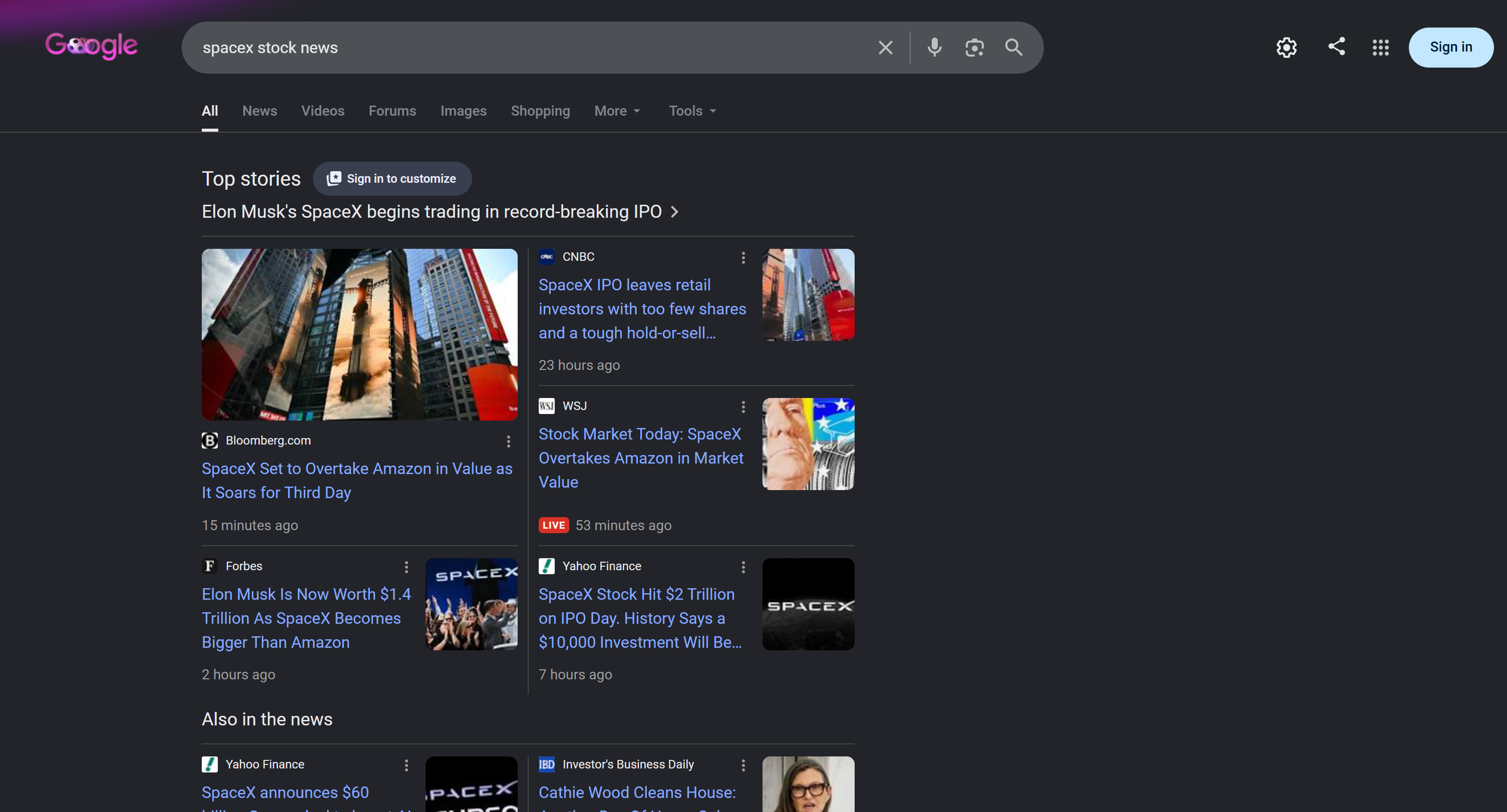
ご覧の通り、AIエージェントはSpaceXの株に関するコンテキスト情報を返しました。SpaceXが数時間前(執筆時点)に上場したばかりであるため、これは非常に最新の情報です。
標準的なLLMはこれを提供できません。なぜなら静的なデータセットで学習されているからです。Bright Dataツールが呼び出されたこと(そして結果がハルシネーションではないこと)を確認するには、「Traces」ドロップダウンを展開し、右側の「View」ボタンをクリックします。
ここで、エージェントの計画と実行ステップを確認できます。SpaceX株のニュースに関するGoogle検索のためにSERP APIツールが呼び出されたことが分かります:
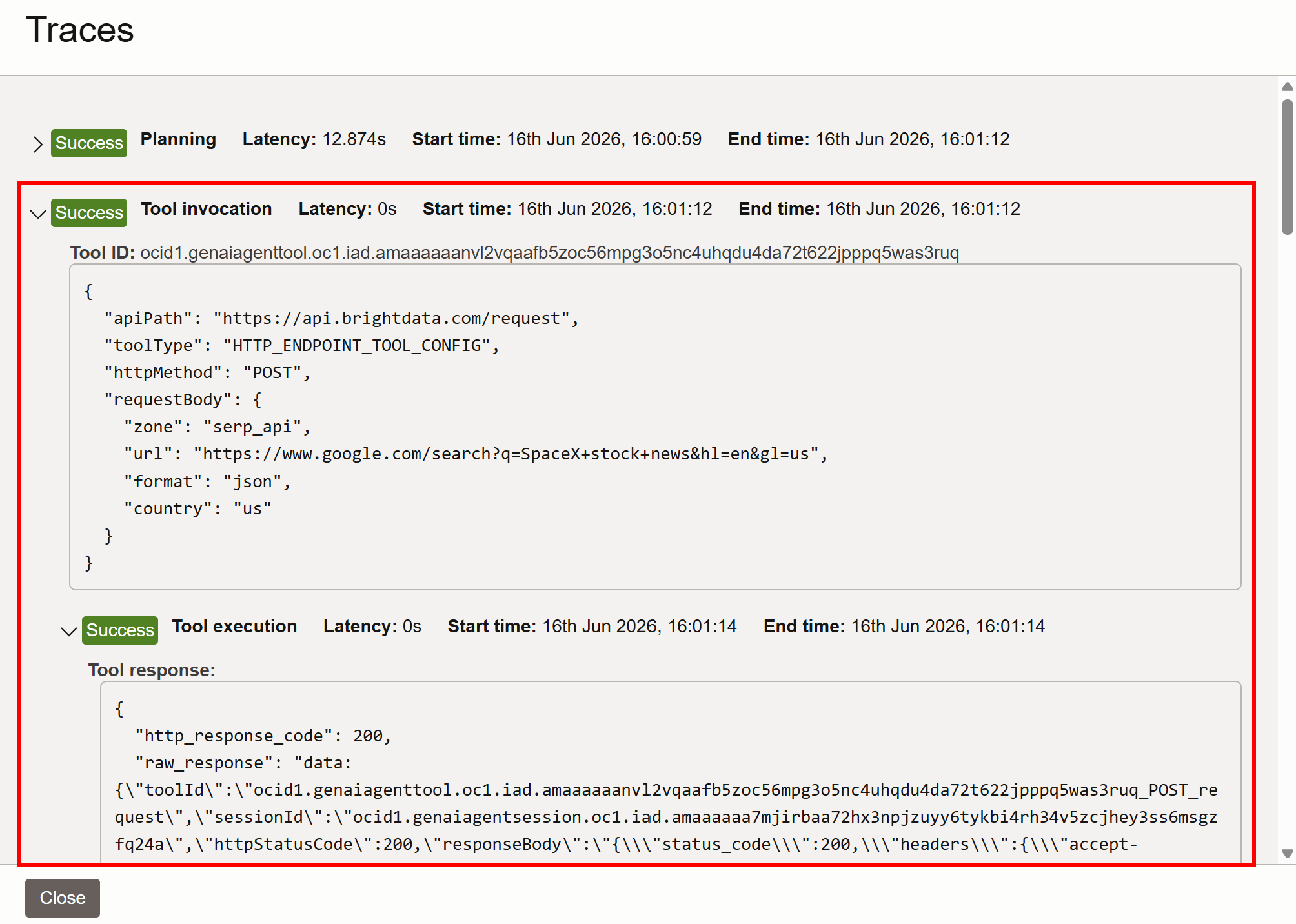
内部では、エージェントツールがBright Data SERP APIを呼び出し、このGoogle SERPのJSON版を返します:
発見されたURLから、エージェントは最も関連性の高いソースを選択し、それらをスクレイピングして、取得したすべての情報を最終的なコンテキスト結果に集約します。
これで完了です!この簡単な例は、Bright Dataが提供するウェブ検索とスクレイピング機能のおかげで、OracleジェネレーティブAIエージェントがいかに根拠のある正確な情報を提供できるかを示しています。さまざまなプロンプトを試して、サポートされているその他のエンタープライズユースケースを探索してみてください。
まとめ
このチュートリアルでは、OracleジェネレーティブAIエージェントサービスとは何か、そしてそれが提供する機能について学びました。また、AIエージェントの制限と、Bright Data APIを通じてエンタープライズシナリオでそれらに対処する方法についても探求しました。
Bright Dataエンドポイントを呼び出すカスタムツールを持つOracleジェネレーティブAIエージェントの定義を通じてガイドされました。結果として、人間がするようにウェブを探索して情報を取得できるAIエージェントが完成しました。
これはBright Data統合によって実現される多くのユースケースの一例に過ぎません。実装のサポートが必要な場合や、他の可能なシナリオを探索したい場合は、24時間365日のサポートチームにお問い合わせください。
今すぐ無料でBright Dataアカウントを作成し、ウェブデータソリューションの探索を始めましょう!






