

このガイドでは以下を学びます:
- サードパーティリスク管理(TPRM)とは何か、手動スクリーニングが失敗する理由
- ベンダーのネガティブメディアを調査する自律型AIエージェントの構築方法
- 信頼性が高く最新のデータ収集を実現するBright DataのSERP APIとWeb Unlockerの統合方法
- – エージェント用スクリプト生成にOpenHands SDKを、リスク分析にOpenAIを活用する方法
- 裁判所記録などの複雑なシナリオに対応するため、Browser APIでエージェントを強化する方法
さあ始めましょう!
手動によるベンダー審査の問題点
企業コンプライアンスチームは、ウェブ全体にわたる数百のサードパーティベンダーのリスクシグナルを監視するという不可能な課題に直面しています。従来のアプローチには以下が含まれます:
- 各ベンダー名と「訴訟」「破産」「詐欺」などのキーワードを組み合わせて手動でGoogle検索
- ニュース記事や裁判記録にアクセスする際の有料壁やCAPTCHAの壁
- 調査結果を記録する標準化されたプロセスがなく、文書化が不統一
- 継続的な監視がなく、ベンダー審査はオンボーディング時に一度行われるだけで、その後は二度と実施されない
この手法が失敗する3つの重大な理由:
- 規模:1人のアナリストが1日に徹底調査できるベンダーはせいぜい5~10社
- アクセス:裁判所記録や有料ニュースサイトなどの保護された情報源は自動アクセスをブロック
- 継続性:オンボーディング時点での評価では、その後発生するリスクを見逃す
解決策:自律型TPRMエージェント
TPRMエージェントは3つの専門レイヤーでベンダー調査ワークフロー全体を自動化:
- 発見(SERP API):訴訟、規制措置、財務的苦境などの危険信号をGoogleで検索
- アクセス(Web Unlocker):有料コンテンツやCAPTCHAで保護された関連結果に対し、エージェントが障壁を迂回して全文を抽出
- アクション(OpenAI + OpenHands SDK):エージェントはOpenAIでコンテンツのリスク深刻度を分析し、OpenHands SDKを用いてPython監視スクリプトを生成。これにより毎日新たなネガティブメディアをチェック
このシステムにより、数時間かかっていた手動調査が数分の自動分析に短縮されます。
前提条件
開始前に以下の環境を確認してください:
- Python 3.12 以上(OpenHands SDK に必須)
- APIアクセス権限付きのBright Dataアカウント(無料トライアルあり)
- リスク分析用のOpenAI APIキー
- OpenHands Cloudアカウント、またはエージェントスクリプト生成用の独自のLLM APIキー
- PythonおよびREST APIの基本的な知識
プロジェクトアーキテクチャ
TPRMエージェントは3段階のパイプラインに従います:
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 発見 │────▶│ アクセス │────▶│ アクション │
│ (SERP API) │ │ (Web Unlocker) │ │ (OpenAI + SDK) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │ │
Google検索 ペイウォールの回避 リスク分析
レッドフラグの検出 およびCAPTCHA スクリプト生成以下のプロジェクト構造を作成:
tprm-agent/
├── src/
│ ├── __init__.py
│ ├── config.py # 設定
│ ├── discovery.py # SERP API 統合
│ ├── access.py # Web Unlocker 統合
│ ├── actions.py # OpenAI + OpenHands SDK
│ ├── agent.py # メインオーケストレーション
│ └── browser.py # ブラウザAPI(拡張機能)
├── api/
│ └── main.py # FastAPIエンドポイント
├── scripts/
│ └── generated/ # 自動生成モニタリングスクリプト
├── .env
├── requirements.txt
└── README.md
環境設定
仮想環境を作成し、必要な依存関係をインストールします:
python -m venv venv
source venv/bin/activate # Windows: venvScriptsactivate
pip install requests fastapi uvicorn python-dotenv pydantic openai beautifulsoup4 playwright openhands-sdk openhands-tools
API認証情報を保存する.envファイルを作成:
# Bright Data API トークン (SERP API 用)
BRIGHT_DATA_API_TOKEN=your_api_token
# Bright Data SERP ゾーン
BRIGHT_DATA_SERP_ZONE=your_serp_zone_name
# Bright Data Web Unlocker 認証情報
BRIGHT_DATA_CUSTOMER_ID=your_customer_id
BRIGHT_DATA_UNLOCKER_ZONE=your_unlocker_zone_name
BRIGHT_DATA_UNLOCKER_PASSWORD=your_zone_password
# OpenAI (リスク分析用)
OPENAI_API_KEY=your_openai_api_key
# OpenHands (エージェントスクリプト生成用)
# OpenHands Cloudを使用: openhands/claude-sonnet-4-5-20260929
# または独自モデル: anthropic/claude-sonnet-4-5-20260929
LLM_API_KEY=your_llm_api_key
LLM_MODEL=openhands/claude-sonnet-4-5-20260929Bright Dataの設定
ステップ1: Bright Dataアカウントの作成
Bright Dataにサインアップし、ダッシュボードに移動します。
ステップ2: SERP APIゾーンの設定
- プロキシ&スクレイピングインフラに移動
- 「追加」をクリックし、SERP APIを選択
- ゾーンに名前を付けます(例:
tprm_serp) - 設定>APIトークンからゾーン名とAPIトークンをコピーしてメモしてください
SERP APIはGoogleからブロックされずに構造化された検索結果を返します。解析済みJSON出力を得るには、検索URLにbrd_json=1を追加してください。
ステップ3: Web Unlockerゾーンの設定
- [追加]をクリックし、Web Unlockerを選択
- ゾーンに名前を付けます(例:
tprm_unlocker) - ゾーン認証情報をコピー(ユーザー名形式:
brd-customer-CUSTOMER_ID-zone-ZONE_NAME)
Web Unlockerはプロキシエンドポイントを通じてCAPTCHA、フィンガープリンティング、IPローテーションを自動的に処理します。
ディスカバリー層の構築(SERP API)
ディスカバリーレイヤーはSERP APIを使用してベンダーに関するネガティブメディアをGoogleで検索します。src/discovery.pyを作成:
import requests
from typing import Optional
from dataclasses import dataclass
from urllib.parse import quote_plus
from config import settings
@dataclass
class SearchResult:
title: str
url: str
snippet: str
source: str
class DiscoveryClient:
"""Bright Data SERP API (Direct API) を使用して不利なメディアを検索します。"""
RISK_CATEGORIES = {
"litigation": ["訴訟", "訴訟", "訴えられた", "裁判", "法的措置"],
"financial": ["破産", "債務超過", "債務", "財政難", "債務不履行"],
"fraud": ["詐欺", "詐欺行為", "調査", "起訴", "スキャンダル"],
"regulatory": ["違反", "罰金", "制裁", "コンプライアンス", "規制当局"],
"operational": ["recall", "safety issue", "supply chain", "disruption"],
}
def __init__(self):
self.api_url = "https://api.brightdata.com/request"
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {settings.BRIGHT_DATA_API_TOKEN}",
}
def _build_queries(self, vendor_name: str, categories: Optional[list] = None) -> list[str]:
"""各リスクカテゴリの検索クエリを構築します。"""
categories = categories or list(self.RISK_CATEGORIES.keys())
queries = []
for category in categories:
keywords = self.RISK_CATEGORIES.get(category, [])
keyword_str = " OR ".join(keywords)
query = f'"{vendor_name}" ({keyword_str})'
queries.append(query)
return queries
def search(self, query: str) -> list[SearchResult]:
"""Bright Data SERP APIを使用して単一の検索クエリを実行します。"""
try:
# パース済みJSON用brd_json=1付きGoogle検索URLを構築
encoded_query = quote_plus(query)
google_url = f"https://www.google.com/search?q={encoded_query}&hl=en&gl=us&brd_json=1"
payload = {
"ゾーン": settings.BRIGHT_DATA_SERP_ゾーン,
"url": google_url,
"format": "raw",
}
response = requests.post(
self.api_url,
headers=self.headers,
json=payload,
timeout=30,
)
response.raise_for_status()
data = response.json()
results = []
organic = data.get("organic", [])
for item in organic:
results.append(
SearchResult(
title=item.get("title", ""),
url=item.get("link", ""),
snippet=item.get("description", ""),
source=item.get("displayed_link", ""),
)
)
return results
except Exception as e:
print(f"検索エラー: {e}")
return []
def discover_adverse_media(
self,
vendor_name: str,
categories: Optional[list] = None,
) -> dict[str, list[SearchResult]]:
"""すべてのリスクカテゴリにわたる悪意のあるメディアを検索します。"""
queries = self._build_queries(vendor_name, categories)
category_names = categories or list(self.RISK_CATEGORIES.keys())
categorized_results = {}
for category, query in zip(category_names, queries):
print(f" 検索中: {category}...")
results = self.search(query)
categorized_results[category] = results
return categorized_results
def filter_relevant_results(
self, results: dict[str, list[SearchResult]], vendor_name: str
) -> dict[str, list[SearchResult]]:
"""関連性のない結果を除外する。"""
filtered = {}
vendor_lower = vendor_name.lower()
for category, items in results.items():
relevant = []
for item in items:
if (
vendor_lower in item.title.lower()
or vendor_lower in item.snippet.lower()
):
relevant.append(item)
filtered[category] = relevant
return filtered
SERP APIはオーガニック検索結果を構造化されたJSON形式で返すため、各検索結果のタイトル、URL、スニペットを簡単にパースできます。
アクセス層の構築(Web Unlocker)
ディスカバリー層が関連URLを発見すると、アクセス層はWeb Unlocker APIを使用して完全なコンテンツを取得します。src/access.pyを作成:
import requests
from bs4 import BeautifulSoup
from dataclasses import dataclass
from typing import Optional
from config import settings
@dataclass
class ExtractedContent:
url: str
title: str
text: str
publish_date: Optional[str]
author: Optional[str]
success: bool
error: Optional[str] = None
class AccessClient:
"""Bright Data Web Unlocker (APIベース)を使用して保護されたコンテンツにアクセスします。"""
def __init__(self):
self.api_url = "https://api.brightdata.com/request"
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {settings.BRIGHT_DATA_API_TOKEN}",
}
def fetch_url(self, url: str) -> ExtractedContent:
"""Web Unlocker APIを使用してURLからコンテンツを取得・抽出します。"""
try:
payload = {
"ゾーン": settings.BRIGHT_DATA_UNLOCKER_ZONE,
"url": url,
"format": "raw",
}
response = requests.post(
self.api_url,
headers=self.headers,
json=payload,
timeout=60,
)
response.raise_for_status()
# Web Unlocker APIはHTMLを直接返す
html_content = response.text
content = self._extract_content(html_content, url)
return content
except requests.Timeout:
return ExtractedContent(
url=url,
title="",
text="",
publish_date=None,
author=None,
success=False,
error="Request timed out",
)
except Exception as e:
return ExtractedContent(
url=url,
title="",
text="",
publish_date=None,
author=None,
success=False,
error=str(e),
)
def _extract_content(self, html: str, url: str) -> ExtractedContent:
"""HTMLから記事コンテンツを抽出する"""
soup = BeautifulSoup(html, "html.parser")
# 不要な要素を除去
for element in soup(["script", "style", "nav", "footer", "header", "aside"]):
element.decompose()
# タイトルを抽出
title = ""
if soup.title:
title = soup.title.string or ""
elif soup.find("h1"):
title = soup.find("h1").get_text(strip=True)
# メインコンテンツを抽出
article = soup.find("article") or soup.find("main") or soup.find("body")
text = article.get_text(separator="n", strip=True) if article else ""
# テキストの長さを制限
text = text[:10000] if len(text) > 10000 else text
# 公開日を取得する
publish_date = None
date_meta = soup.find("meta", {"property": "article:published_time"})
if date_meta:
publish_date = date_meta.get("content")
# 著者を抽出しようとする
author = None
author_meta = soup.find("meta", {"name": "author"})
if author_meta:
author = author_meta.get("content")
return ExtractedContent(
url=url,
title=title,
text=text,
publish_date=publish_date,
author=author,
success=True,
)
def fetch_multiple(self, urls: list[str]) -> list[ExtractedContent]:
"""複数のURLを順次取得する。"""
results = []
for url in urls:
print(f" 取得中: {url[:60]}...")
content = self.fetch_url(url)
if not content.success:
print(f" エラー: {content.error}")
results.append(content)
return results
Web UnlockerはCAPTCHA、ブラウザフィンガープリント、IPローテーションを自動的に処理します。プロキシ経由でリクエストをルーティングするだけで、残りはすべて処理されます。
アクションレイヤーの構築 (OpenAI + OpenHands SDK)
アクションレイヤーは、OpenAIでリスクの深刻度を分析し、OpenHands SDKでBrightData Web Unlocker APIを利用する監視スクリプトを生成します。OpenHands SDKはエージェント機能を提供します:エージェントは推論、ファイル編集、コマンド実行を行い、本番環境対応のスクリプトを作成できます。
src/actions.py を作成:
import os
import json
from datetime import datetime, UTC
from dataclasses import dataclass, asdict
from openai import OpenAI
from pydantic import SecretStr
from openhands.sdk import LLM, Agent, Conversation, Tool
from openhands.tools.terminal import TerminalTool
from openhands.tools.file_editor import FileEditorTool
from config import settings
@dataclass
class RiskAssessment:
vendor_name: str
category: str
severity: str
summary: str
key_findings: list[str]
sources: list[str]
recommended_actions: list[str]
assessed_at: str
@dataclass
class MonitoringScript:
vendor_name: str
script_path: str
urls_monitored: list[str]
check_frequency: str
created_at: str
class ActionsClient:
"""OpenAIでリスクを分析し、OpenHands SDKで監視スクリプトを生成する。"""
def __init__(self):
# リスク分析用 OpenAI
self.openai_client = OpenAI(api_key=settings.OPENAI_API_KEY)
# エージェント型スクリプト生成用 OpenHands
self.llm = LLM(
model=settings.LLM_MODEL,
api_key=SecretStr(settings.LLM_API_KEY),
)
self.workspace = os.path.join(os.getcwd(), "scripts", "generated")
os.makedirs(self.workspace, exist_ok=True)
def analyze_risk(
self,
vendor_name: str,
category: str,
content: list[dict],
) -> RiskAssessment:
"""OpenAIを使用して抽出されたコンテンツのリスク深刻度を分析する。"""
content_summary = "nn".join(
[f"ソース: {c['url']}nタイトル: {c['title']}nコンテンツ: {c['text'][:2000]}" for c in content]
)
prompt = f"""サードパーティリスク評価のため、"{vendor_name}"に関する以下のコンテンツを分析してください。
カテゴリ: {category}
コンテンツ:
{content_summary}
以下のJSON形式で応答してください:
{{
"severity": "low|medium|high|critical",
"summary": "調査結果の概要(2~3文)",
"key_findings": ["調査結果1", "調査結果2", ...],
"recommended_actions": ["推奨措置1", "推奨措置2", ...]
}}
考慮事項:
- 深刻度は潜在的なビジネス影響に基づくこと
- 重大 = 即時対応が必要(進行中の不正、破産申請)
- 高 = 調査が必要な重大なリスク
- 中 = 監視に値する顕著な懸念
- 低 = 軽微な問題または過去の事象
"""
response = self.openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"},
)
response_text = response.choices[0].message.content
try:
result = json.loads(response_text)
except (json.JSONDecodeError, ValueError):
result = {
"severity": "medium",
"summary": "リスク評価をパースできませんでした",
"key_findings": [],
"recommended_actions": ["手動レビューが必要です"],
}
return RiskAssessment(
vendor_name=vendor_name,
category=category,
severity=result.get("severity", "medium"),
summary=result.get("summary", ""),
key_findings=result.get("key_findings", []),
sources=[c["url"] for c in content],
recommended_actions=result.get("recommended_actions", []),
assessed_at=datetime.now(UTC).isoformat(),
)
def generate_monitoring_script(
self,
vendor_name: str,
urls: list[str],
check_keywords: list[str],
) -> MonitoringScript:
"""OpenHands SDK エージェントを使用した Python 監視スクリプトを生成します。"""
script_name = f"monitor_{vendor_name.lower().replace(' ', '_')}.py"
script_path = os.path.join(self.workspace, script_name)
prompt = f"""{script_path} に以下の機能を持つ Python 監視スクリプトを作成します:
1. 毎日これらの URL をチェックし、新規コンテンツを確認: {urls[:5]}
2. 以下のキーワードを検索: {check_keywords}
3. 関連する新規コンテンツが見つかった場合、アラートを送信(コンソールに出力)
4. 全てのチェック結果を'monitoring_log.json'という名前のJSONファイルに記録
スクリプトは必ずBright Data Web Unlocker APIを使用してペイウォールとCAPTCHAを回避すること:
- APIエンドポイント: https://api.brightdata.com/request
- Bearerトークンには環境変数BRIGHT_DATA_API_TOKENを使用
- ゾーン名には環境変数BRIGHT_DATA_UNLOCKER_ZONEを使用
- JSONペイロード付きPOSTリクエストを送信: {{"zone": "zone_name", "url": "target_url", "format": "raw"}}
- ヘッダーを追加: "Authorization": "Bearer <token>"
- ヘッダーを追加: "Content-Type": "application/json"
スクリプトは以下を実行する:
- python-dotenvを使用して環境変数からBright Data認証情報を読み込む
- 全てのHTTPリクエストにBright Data Web Unlocker APIを使用(単純なrequests.getではない)
- try/exceptでエラーを適切に処理
- 直接実行可能なmain()関数を実装
- cronによるスケジュール実行をサポート
- 変更検出のためのコンテンツハッシュを保存
完全なスクリプトを{script_path}に記述してください。
"""
# ターミナルとファイルエディタツールを備えたOpenHandsエージェントを作成
agent = Agent(
llm=self.llm,
tools=[
Tool(name=TerminalTool.name),
Tool(name=FileEditorTool.name),
],
)
# エージェントを実行してスクリプトを生成
conversation = Conversation(agent=agent, workspace=self.workspace)
conversation.send_message(prompt)
conversation.run()
return MonitoringScript(
vendor_name=vendor_name,
script_path=script_path,
urls_monitored=urls[:5],
check_frequency="daily",
created_at=datetime.now(UTC).isoformat(),
)
def export_assessment(self, assessment: RiskAssessment, output_path: str) -> None:
"""リスク評価をJSONファイルにエクスポートする。"""
with open(output_path, "w") as f:
json.dump(asdict(assessment), f, indent=2)OpenHands SDKを単純なプロンプトベースのコード生成よりも使用する主な利点は、エージェントが作業を反復できる点です。スクリプトをテストし、エラーを修正し、正しく動作するまで改良を重ねることができます。
エージェントのオーケストレーション
それではすべてを組み合わせてみましょう。src/agent.pyを作成します:
from dataclasses import dataclass
from datetime import datetime, UTC
from typing import Optional
from discovery import DiscoveryClient, SearchResult
from access import AccessClient, ExtractedContent
from actions import ActionsClient, RiskAssessment, MonitoringScript
@dataclass
class InvestigationResult:
vendor_name: str
started_at: str
completed_at: str
total_sources_found: int
total_sources_accessed: int
risk_assessments: list[RiskAssessment]
monitoring_scripts: list[MonitoringScript]
errors: list[str]
class TPRMAgent:
"""サードパーティリスク管理調査のための自律エージェント。"""
def __init__(self):
self.discovery = DiscoveryClient()
self.access = AccessClient()
self.actions = ActionsClient()
def investigate(
self,
vendor_name: str,
categories: Optional[list[str]] = None,
generate_monitors: bool = True,
) -> InvestigationResult:
"""ベンダーの完全な調査を実行する。"""
started_at = datetime.now(UTC).isoformat()
errors = []
risk_assessments = []
monitoring_scripts = []
# ステージ1: 発見 (SERP API)
print(f"[発見] {vendor_name}に関するネガティブメディアを検索中...")
try:
raw_results = self.discovery.discover_adverse_media(vendor_name, categories)
filtered_results = self.discovery.filter_relevant_results(raw_results, vendor_name)
except Exception as e:
errors.append(f"調査失敗: {str(e)}")
return InvestigationResult(
vendor_name=vendor_name,
started_at=started_at,
completed_at=datetime.now(UTC).isoformat(),
total_sources_found=0,
total_sources_accessed=0,
risk_assessments=[],
monitoring_scripts=[],
errors=errors,
)
total_sources = sum(len(results) for results in filtered_results.values())
print(f"[Discovery] 関連ソース {total_sources} 件を発見")
# ステージ2: アクセス (Web Unlocker)
print(f"[Access] ソースからコンテンツを抽出中...")
all_urls = []
url_to_category = {}
for category, results in filtered_results.items():
for result in results:
all_urls.append(result.url)
url_to_category[result.url] = category
try:
extracted_content = self.access.fetch_multiple(all_urls)
successful_extractions = [c for c in extracted_content if c.success]
except Exception as e:
error_msg = f"アクセス失敗: {str(e)}"
print(f"[アクセス] {error_msg}")
errors.append(error_msg)
successful_extractions = []
print(f"[アクセス] {len(successful_extractions)} 件のソースを正常に抽出しました")
# ステージ3: アクション - リスク分析 (OpenAI)
print(f"[アクション] リスク分析中...")
category_content = {}
for content in successful_extractions:
category = url_to_category.get(content.url, "unknown")
if category not in category_content:
category_content[category] = []
category_content[category].append({
"url": content.url,
"title": content.title,
"text": content.text,
})
for category, content_list in category_content.items():
if not content_list:
continue
try:
assessment = self.actions.analyze_risk(vendor_name, category, content_list)
risk_assessments.append(assessment)
except Exception as e:
errors.append(f"{category} のリスク分析に失敗しました: {str(e)}")
# ステージ 3: アクション - 監視スクリプトの生成
if generate_monitors and successful_extractions:
print(f"[アクション] 監視スクリプトを生成中...")
try:
urls_to_monitor = [c.url for c in successful_extractions[:10]]
keywords = [vendor_name, "lawsuit", "bankruptcy", "fraud"]
script = self.actions.generate_monitoring_script(
vendor_name, urls_to_monitor, keywords
)
monitoring_scripts.append(script)
except Exception as e:
errors.append(f"スクリプト生成失敗: {str(e)}")
completed_at = datetime.now(UTC).isoformat()
print(f"[Complete] 調査完了")
return InvestigationResult(
vendor_name=vendor_name,
started_at=started_at,
completed_at=completed_at,
total_sources_found=total_sources,
total_sources_accessed=len(successful_extractions),
risk_assessments=risk_assessments,
monitoring_scripts=monitoring_scripts,
errors=errors,
)
def main():
"""使用例。"""
agent = TPRMAgent()
result = agent.investigate("Acme Corp")
print(f"n{'='*50}")
print(f"調査完了: {result.vendor_name}")
print(f"検出ソース数: {result.total_sources_found}")
print(f"アクセス済みソース数: {result.total_sources_accessed}")
print(f"リスク評価数: {len(result.risk_assessments)}")
print(f"監視スクリプト数: {len(result.monitoring_scripts)}")
for assessment in result.risk_assessments:
print(f"n[{assessment.category.upper()}] 深刻度: {assessment.severity}")
print(f"概要: {assessment.summary}")
if __name__ == "__main__":
main()
エージェントは3つのレイヤーすべてを調整し、エラーを適切に処理して包括的な調査結果を生成します。
設定
アプリケーションを正常に実行するために必要なすべてのシークレットとキーを設定するため、src/config.pyを作成します:
import os
from dotenv import load_dotenv
load_dotenv()
class Settings:
# SERP API
BRIGHT_DATA_API_TOKEN: str = os.getenv("BRIGHT_DATA_API_TOKEN", "")
BRIGHT_DATA_SERP_ZONE: str = os.getenv("BRIGHT_DATA_SERP_ZONE", "")
# Web Unlocker
BRIGHT_DATA_CUSTOMER_ID: str = os.getenv("BRIGHT_DATA_CUSTOMER_ID", "")
BRIGHT_DATA_UNLOCKER_ZONE: str = os.getenv("BRIGHT_DATA_UNLOCKER_ZONE", "")
BRIGHT_DATA_UNLOCKER_PASSWORD: str = os.getenv("BRIGHT_DATA_UNLOCKER_PASSWORD", "")
# OpenAI (リスク分析用)
OPENAI_API_KEY: str = os.getenv("OPENAI_API_KEY", "")
# OpenHands(エージェントスクリプト生成用)
LLM_API_KEY: str = os.getenv("LLM_API_KEY", "")
LLM_MODEL: str = os.getenv("LLM_MODEL", "openhands/claude-sonnet-4-5-20260929")
settings = Settings()APIレイヤーの構築
FastAPIを使用して、RESTエンドポイント経由でエージェントを公開するapi/main.pyを作成します:
from fastapi import FastAPI, HTTPException, BackgroundTasks
from pydantic import BaseModel
from typing import Optional
import uuid
import sys
sys.path.insert(0, 'src')
from agent import TPRMAgent, InvestigationResult
app = FastAPI(
title="TPRM Agent API",
description="自律型サードパーティリスク管理エージェント",
version="1.0.0",)
investigations: dict[str, InvestigationResult] = {}
agent = TPRMAgent()
class InvestigationRequest(BaseModel):
vendor_name: str
categories: Optional[list[str]] = None
generate_monitors: bool = True
class InvestigationResponse(BaseModel):
investigation_id: str
status: str
message: str
@app.post("/investigate", response_model=InvestigationResponse)
def start_investigation(
request: InvestigationRequest,
background_tasks: BackgroundTasks,
):
"""新規ベンダー調査を開始します。"""
investigation_id = str(uuid.uuid4())
def run_investigation():
result = agent.investigate(
vendor_name=request.vendor_name,
categories=request.categories,
generate_monitors=request.generate_monitors,
)
investigations[investigation_id] = result
background_tasks.add_task(run_investigation)
return InvestigationResponse(
investigation_id=investigation_id,
status="started",
message=f"{request.vendor_name} の調査を開始しました",
)
@app.get("/investigate/{investigation_id}")
def get_investigation(investigation_id: str):
"""調査結果を取得します。"""
if investigation_id not in investigations:
raise HTTPException(status_code=404, detail="調査が見つかりません、またはまだ進行中です")
return investigations[investigation_id]
@app.get("/reports/{vendor_name}")
def get_reports(vendor_name: str):
"""ベンダーの全レポートを取得します。"""
vendor_reports = [
result
for result in investigations.values()
if result.vendor_name.lower() == vendor_name.lower()
]
if not vendor_reports:
raise HTTPException(status_code=404, detail="このベンダーのレポートが見つかりません")
return vendor_reports
@app.get("/health")
def health_check():
"""ヘルスチェックエンドポイント。"""
return {"status": "healthy"}APIをローカルで実行:
python -m uvicorn API.main:app --reloadインタラクティブなAPIドキュメントを閲覧するにはhttp://localhost:8000/docsにアクセスしてください。
Browser API(スクレイピングブラウザ)による機能強化
フォーム送信が必要な裁判所登録システムやJavaScript多用サイトなど複雑なシナリオでは、Bright DataのBrowser API(スクレイピングブラウザ)でエージェントを強化できます。Web Unlocker APIやSERP APIと同様の方法で設定可能です。
Browser APIは、Chrome DevTools Protocol(CDP)を介したPlaywright経由で制御可能なクラウドホスト型ブラウザを提供します。これは以下のような場合に有用です:
- フォーム送信やナビゲーションを必要とする裁判所登録検索
- 動的コンテンツ読み込みを伴うJavaScript多用サイト
- 多段階認証フロー
- コンプライアンス文書用のスクリーンショット取得
設定
.envにBrowser API認証情報を追加:
# Browser API
BRIGHT_DATA_BROWSER_USER: str = os.getenv("BRIGHT_DATA_BROWSER_USER", "")
BRIGHT_DATA_BROWSER_PASSWORD: str = os.getenv("BRIGHT_DATA_BROWSER_PASSWORD", "")ブラウザクライアントの実装
src/browser.py を作成:
import asyncio
from playwright.async_api import async_playwright
from dataclasses import dataclass
from typing import Optional
from config import settings
@dataclass
class BrowserContent:
url: str
title: str
text: str
screenshot_path: Optional[str]
success: bool
error: Optional[str] = None
class BrowserClient:
"""Bright Data Browser API (スクレイピングブラウザ) を使用して動的コンテンツにアクセスします。
以下の用途に使用します:
- 完全なレンダリングが必要な JavaScript ヘビーなサイト
- 複数ステップのフォーム (例: 裁判所登録検索)
- クリック、スクロール、またはインタラクションが必要なサイト
- コンプライアンス文書用のスクリーンショット取得
"""
def __init__(self):
# CDP接続用WebSocketエンドポイント構築
auth = f"{settings.BRIGHT_DATA_BROWSER_USER}:{settings.BRIGHT_DATA_BROWSER_PASSWORD}"
self.endpoint_url = f"wss://{auth}@brd.superproxy.io:9222"
async def fetch_dynamic_page(
self,
url: str,
wait_for_selector: Optional[str] = None,
take_screenshot: bool = False,
screenshot_path: Optional[str] = None,
) -> BrowserContent:
"""Browser APIを使用して動的ページからコンテンツを取得します。"""
async with async_playwright() as playwright:
try:
print(f"Bright Data スクレイピングブラウザに接続中...")
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
print(f"{url} に移動中...")
await page.goto(url, timeout=120000)
# 指定されたセレクタを待機(指定されている場合)
if wait_for_selector:
await page.wait_for_selector(wait_for_selector, timeout=30000)
# ページコンテンツを取得
title = await page.title()
# テキストを抽出
text = await page.evaluate("() => document.body.innerText")
# スクリーンショットを要求された場合取得
if take_screenshot and screenshot_path:
await page.screenshot(path=screenshot_path, full_page=True)
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=screenshot_path if take_screenshot else None,
success=True,
)
finally:
await browser.close()
except Exception as e:
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
async def fill_and_submit_form(
self,
url: str,
form_data: dict[str, str],
submit_selector: str,
result_selector: str,
) -> BrowserContent:
"""フォームに入力し結果を取得 - 裁判所の登録業務に有用"""
async with async_playwright() as playwright:
try:
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
await page.goto(url, timeout=120000)
# フォームフィールド入力
for selector, value in form_data.items():
await page.fill(selector, value)
# フォーム送信
await page.click(submit_selector)
# 結果待ち
await page.wait_for_selector(result_selector, timeout=30000)
title = await page.title()
text = await page.evaluate("() => document.body.innerText")
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=None,
success=True,
)
finally:
await browser.close()
except Exception as e:
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
async def scroll_and_collect(
self,
url: str,
scroll_count: int = 5,
wait_between_scrolls: float = 1.0,
) -> BrowserContent:
"""無限スクロールページを処理する。"""
async with async_playwright() as playwright:
try:
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
await page.goto(url, timeout=120000)
# 複数回スクロールダウン
for i in range(scroll_count):
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
await asyncio.sleep(wait_between_scrolls)
title = await page.title()
text = await page.evaluate("() => document.body.innerText")
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=None,
success=True,
)
finally:
await browser.close()
except Exception as e:
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
# 裁判所登録検索の使用例
async def example_court_search():
client = BrowserClient()
# 例: 裁判所記録を検索
result = await client.fill_and_submit_form(
url="https://example-court-registry.gov/search",
form_data={
"#party-name": "Acme Corp",
"#case-type": "civil",
},
submit_selector="#search-button",
result_selector=".search-results",
)
if result.success:
print(f"裁判記録が見つかりました: {result.text[:500]}")
else:
print(f"エラー: {result.error}")
if __name__ == "__main__":
asyncio.run(example_court_search())ブラウザAPIとWeb Unlockerの使い分け
| シナリオ | 使用例 |
|---|---|
| シンプルなHTTPリクエスト | Web Unlocker |
| 静的HTMLページ | Web Unlocker |
| 読み込み時のCAPTCHA | Web Unlocker |
| JavaScriptでレンダリングされたコンテンツ | ブラウザ API |
| フォーム送信 | ブラウザ API |
| マルチステップナビゲーション | ブラウザ API |
| スクリーンショットが必要 | ブラウザ API |
Railway を使用したデプロイ
TPRMエージェントは、大規模な依存関係を持つPythonアプリケーションをサポートするRailwayまたはRenderを使用して本番環境にデプロイできます。
Railwayは、OpenHands SDKのような重い依存関係を持つPythonアプリケーションをデプロイする最も簡単な選択肢です。これを利用するには、サインアップしてアカウントを作成する必要があります。
ステップ1: Railway CLIをグローバルにインストール
npm i -g @railway/cliステップ2:Procfileファイルを追加
アプリケーションのルートフォルダに新しいProcfileファイルを作成し、以下の内容を追加します。これはデプロイの構成または起動コマンドとして機能します。
web: uvicorn API.main:app --host 0.0.0.0 --port $PORTステップ3: プロジェクトディレクトリでRailwayにログインし初期化
railway login
railway initステップ4: デプロイ
railway up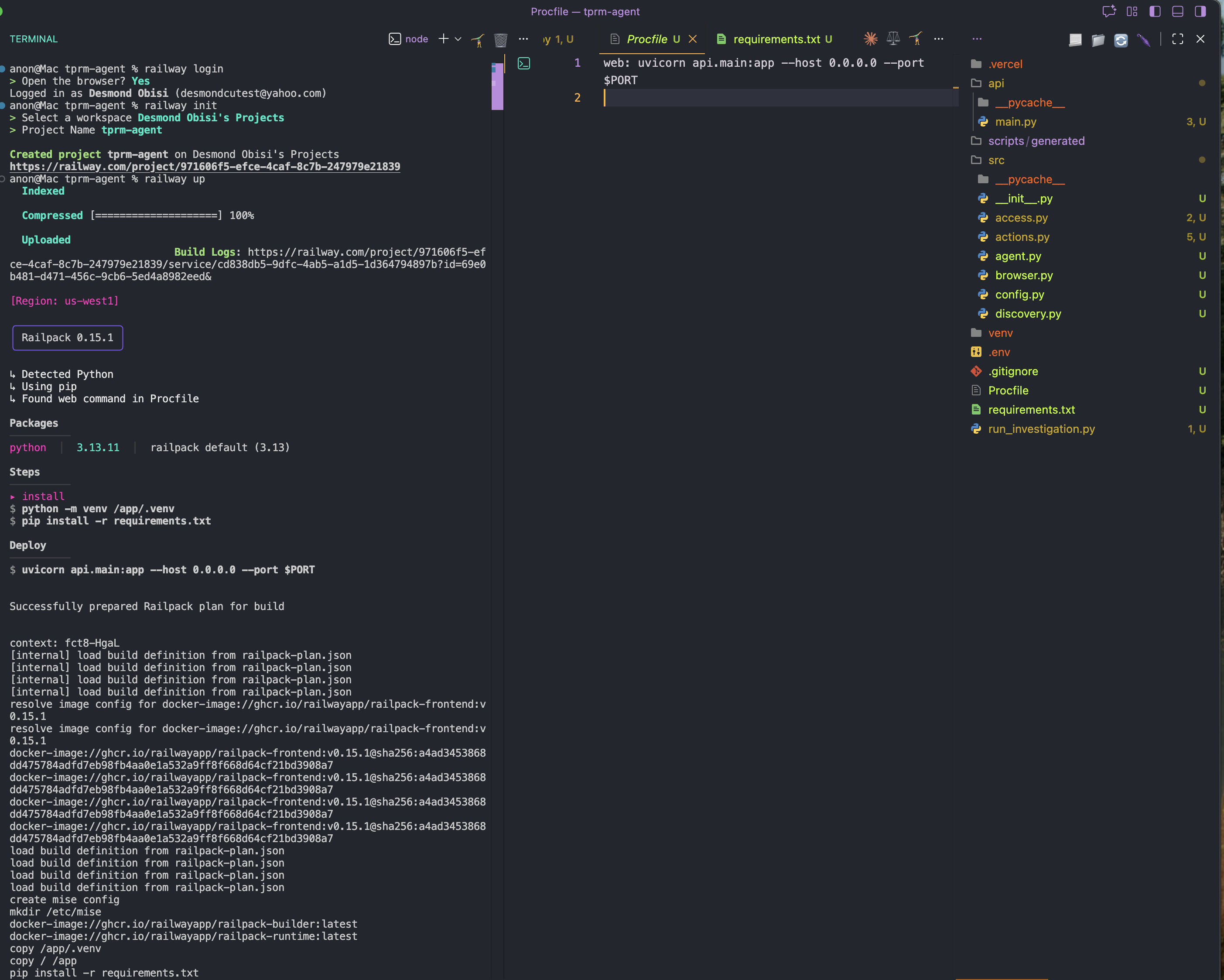
ステップ5: 環境変数の追加
Railwayプロジェクトダッシュボード →[設定] →[共有変数] に移動し、以下の変数とその値を追加します:
BRIGHT_DATA_API_TOKEN
BRIGHT_DATA_SERP_ZONE
BRIGHT_DATA_UNLOCKER_ZONE
OPENAI_API_KEY
LLM_API_KEY
LLM_MODEL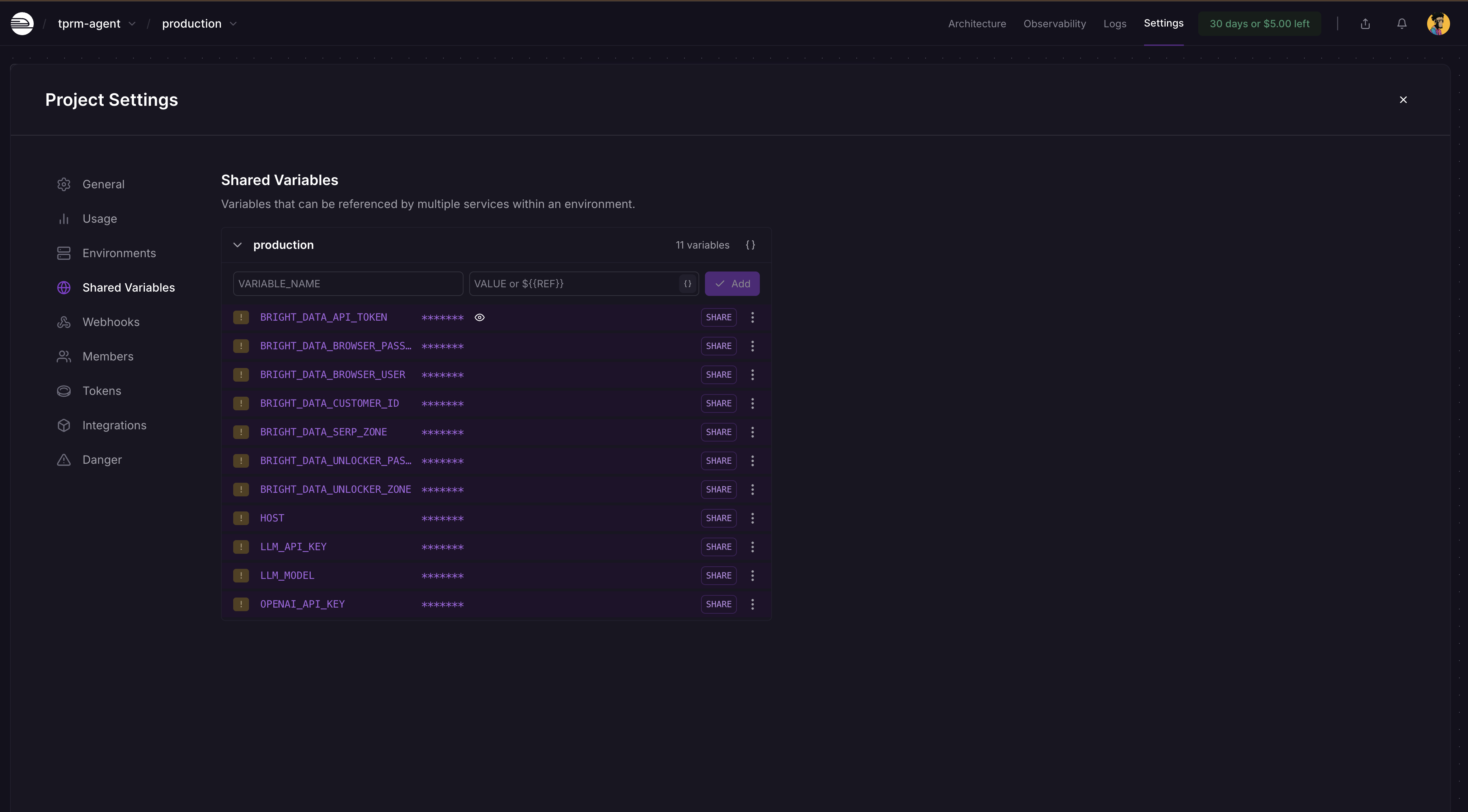
Railwayは変更を自動検出し、ダッシュボード上で再デプロイを促します。「デプロイ」をクリックすると、シークレットが適用されたアプリが更新されます。
再デプロイ後、サービスカードをクリックし「設定」を選択すると、サービスがまだ公開されていないためドメイン生成場所が表示されます。「ドメインを生成」をクリックして公開URLを取得してください。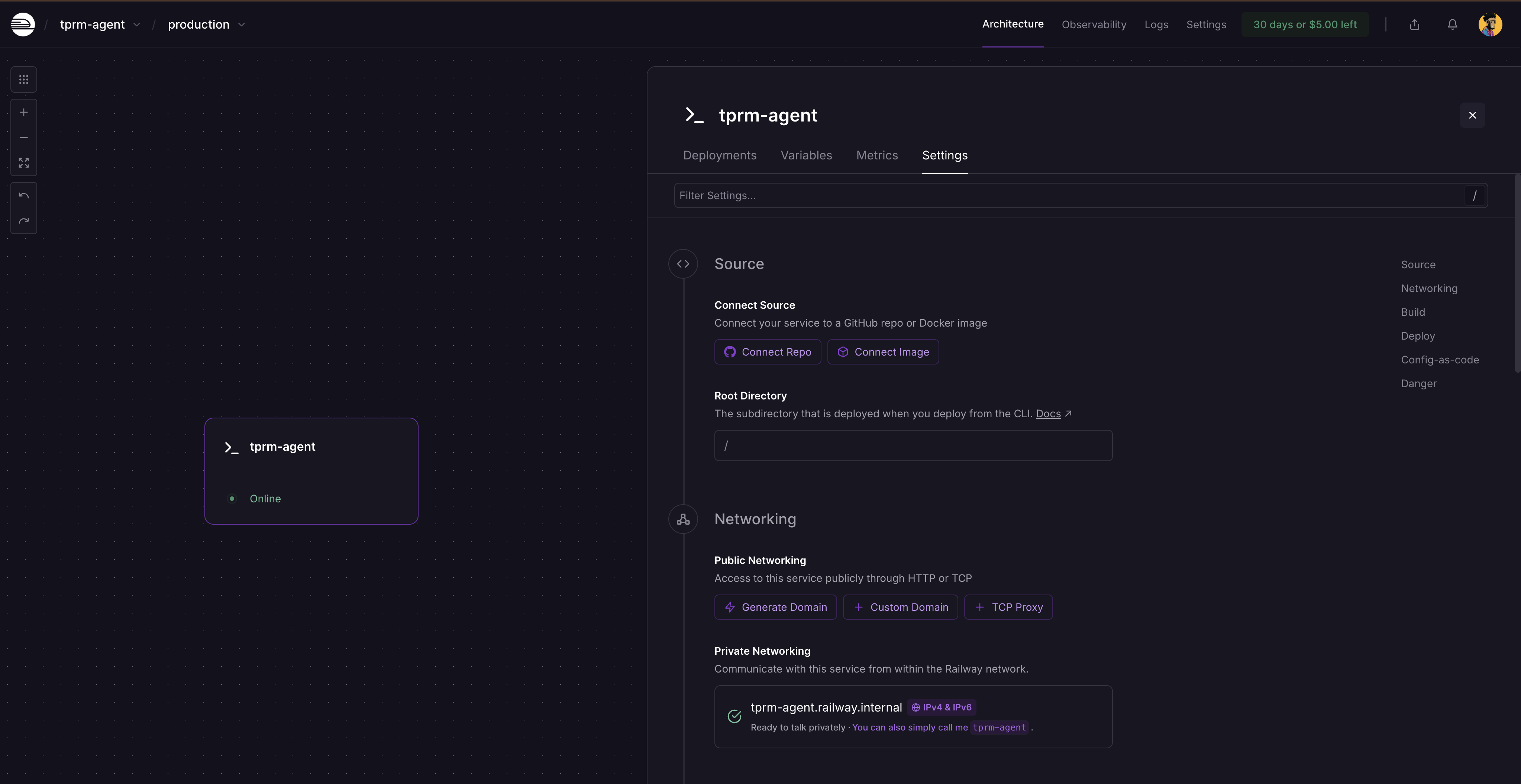
完全な調査の実行
curlを使用したローカル実行
FastAPIサーバーを起動:
# 仮想環境をアクティブ化
source venv/bin/activate # Windowsの場合: venvScriptsactivate
# サーバーを実行
python -m uvicorn api.main:app --reloadhttp://localhost:8000/docs にアクセスしてインタラクティブなAPIドキュメントを閲覧してください。
APIリクエストの実行
- 調査を開始:
curl -X POST "http://localhost:8000/investigate"
-H "Content-Type: application/json"
-d '{
"vendor_name": "Acme Corp",
"categories": ["litigation", "fraud"],
"generate_monitors": true
}'- これにより調査IDが返されます:
{
"investigation_id": "f6af2e0f-991a-4cb7-949e-2f316e677b5c",
"status": "started",
"message": "Acme Corp の調査が開始されました"
}- 調査ステータスの確認:
curl http://localhost:8000/investigate/f6af2e0f-991a-4cb7-949e-2f316e677b5cエージェントをスクリプトとして実行
プロジェクトルートにrun_investigation.pyというファイルを作成:
import sys
sys.path.insert(0, 'src')
from agent import TPRMAgent
def investigate_vendor():
"""ベンダーの完全な調査を実行します。"""
agent = TPRMAgent()
# 調査の実行
result = agent.investigate(
vendor_name="Acme Corp",
categories=["litigation", "financial", "fraud"],
generate_monitors=True,
)
# 概要の出力
print(f"n{'='*60}")
print(f"調査完了: {result.vendor_name}")
print(f"{'='*60}")
print(f"発見された情報源: {result.total_sources_found}")
print(f"アクセスされた情報源: {result.total_sources_accessed}")
print(f"リスク評価: {len(result.risk_assessments)}")
print(f"監視スクリプト: {len(result.monitoring_scripts)}")
# リスク評価を出力
for assessment in result.risk_assessments:
print(f"n{'─'*60}")
print(f"[{assessment.category.upper()}] 深刻度: {assessment.severity.upper()}")
print(f"{'─'*60}")
print(f"概要: {assessment.summary}")
print("n主な発見事項:")
for finding in assessment.key_findings:
print(f" • {finding}")
print("n推奨アクション:")
for action in assessment.recommended_actions:
print(f" → {action}")
# 監視スクリプト情報の出力
for script in result.monitoring_scripts:
print(f"n{'='*60}")
print(f"生成された監視スクリプト")
print(f"{'='*60}")
print(f"パス: {script.script_path}")
print(f"監視対象URL数: {len(script.urls_monitored)}")
print(f"頻度: {script.check_frequency}")
# エラーがあれば出力
if result.errors:
print(f"n{'='*60}")
print("エラー:")
for error in result.errors:
print(f" ⚠️ {error}")
if __name__ == "__main__":
investigate_vendor()調査スクリプトを新しいターミナルで実行
# 仮想環境をアクティブ化
source venv/bin/activate # Windowsの場合: venvScriptsactivate
# 調査スクリプトを実行
python run_investigation.pyエージェントは以下を実行します:
- SERP APIを使用してGoogleでネガティブメディアを検索
- Web Unlockerを使用してソースにアクセス
- OpenAIを使用してコンテンツのリスク深刻度を分析
- OpenHands SDKを使用してPython監視スクリプトを生成(cronによるスケジュール設定可能)
自動生成された監視スクリプトの実行
調査完了後、監視スクリプトがscripts/generatedフォルダに生成されます:
cd scripts/generated
python monitor_acme_corp.pyこの監視スクリプトはBright Data Web Unlocker APIを使用して監視対象の全URLをチェックし、以下を出力します: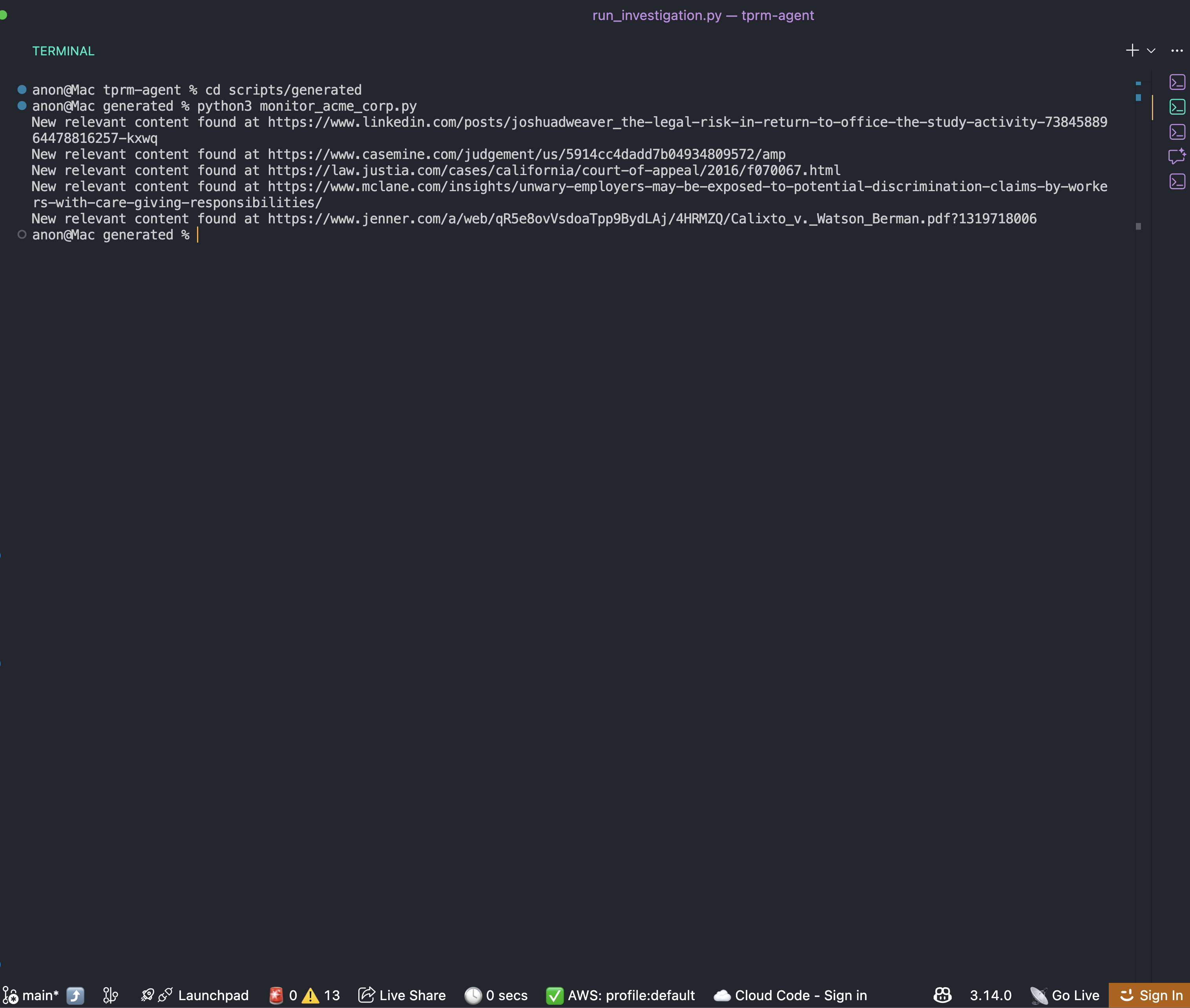
ビジネスに関する正確かつ最新の情報を常に取得するため、スクリプトのcronスケジュールを自由に設定できます。
まとめ
ベンダーのネガティブメディア調査を自動化するエンタープライズ向けTPRMエージェント構築の完全なフレームワークが完成しました。本システムは以下を実現します:
- Bright Data SERP APIを使用して複数カテゴリにわたるリスクシグナルを発見
- Bright Data Web Unlockerでコンテンツにアクセス
- OpenAIによるリスク分析とOpenHands SDKを用いた監視スクリプト生成
- 複雑なシナリオ向けにBrowser APIで機能を強化
モジュール式アーキテクチャにより拡張が容易です:
RISK_CATEGORIES辞書を更新して新たなリスクカテゴリを追加- APIレイヤーを拡張してGRCプラットフォームと連携
- バックグラウンドタスクキューで数千のベンダーに対応
- ブラウザAPI強化機能による裁判記録検索の追加
次のステップ
このエージェントをさらに改善するには、以下を検討してください:
- 追加データソースの統合:SEC提出書類、OFAC制裁リスト、法人登記情報
- データベース永続化の追加:調査履歴をPostgreSQLまたはMongoDBに保存
- Webhook通知の実装:高リスクベンダーを検出した際にSlackやTeamsへ通知
- ダッシュボード構築:ベンダーリスクスコアを可視化するReactフロントエンドを作成
- 自動スキャンのスケジュール設定:定期的なベンダー監視にCeleryまたはAPSchedulerを使用





