
このチュートリアルでは
- opencodeとは何か、どのような機能を提供するのか、なぜCrushと混同してはいけないのか。
- ウェブ・インタラクションやデータ抽出機能で拡張することで、どのようにさらにリソースを増やすことができるか。
- opencodeをCLIでBright Data MCPサーバーに接続し、強力なAIコーディングエージェントを作成する方法。
さあ、飛び込もう!
opencodeとは?
opencodeは、ターミナル用に構築されたオープンソースのAIコーディングエージェントです。特に、以下のように動作します:
- CLIのTUI(ターミナル・ユーザー・インターフェース)。
- Visual Studio CodeやCursorなどのIDE統合。
- GitHubエクステンション。
より詳細には、opencodeを使用すると、次のことができます:
- レスポンシブでテーマ設定可能なターミナルインターフェースの設定。
- LLMに正しいLSP(言語サーバプロトコル)をロードする。
- 同じプロジェクトで複数のエージェントを並行して実行する。
- 参照やデバッグのためにセッションへのリンクを共有する。
- Anthropicでログインし、Claude ProまたはMaxアカウントを使用することができます。また、Models.dev(ローカルモデルを含む)を介して他の75以上のLLMプロバイダと統合することもできます。
ご覧の通り、CLIはLLMに依存しません。このCLIは主にGoとTypeScriptで開発されており、GitHubではすでに2万以上のスターを獲得している。
注:このテクノロジーは、”opencode “というオリジナルの名前を持つ別のプロジェクト、Crushと混同してはならない。もしCrushをお探しなら、Bright Data Web MCPとCrushの統合に関するガイドをご覧ください。
Bright DataのWeb MCPをopencode TUIに統合する理由
最終的にどのLLMをopencodeに設定したとしても、それらはすべて同じ制限を共有しています。LLMの知識は静的なものであり、トレーニングされたデータはスナップショットであり、すぐに古くなります。これは、ソフトウェア開発のような動きの速い分野では特に当てはまります。
では、opencode CLIアシスタントに次のような能力を与えることを想像してみてください:
- 新鮮なチュートリアルやドキュメントを取り込む。
- コードを書きながらライブガイドを参照する。
- ローカルファイルをナビゲートするのと同じように、ダイナミックなウェブサイトを簡単にブラウズする。
これらの機能は、Bright DataのWeb MCPに接続することで実現できます。
Bright Data Web MCPは、リアルタイムのWebインタラクションとデータ収集のために設計された60以上のAI対応ツールへのアクセスを提供します。
Bright Data Web MCPで最も利用されている2つのツール(無料層でも利用可能)です:
| ツール | ツール |
|---|---|
scrape_as_markdown |
高度な抽出オプションで1つのウェブページからコンテンツをスクレイピングし、結果のデータをMarkdownで返します。ボット検知やCAPTCHAをバイパスすることができます。 |
サーチエンジン |
Google、Bing、Yandexから検索結果を抽出する。SERPデータをJSONまたはMarkdown形式で返す。 |
この2つに加えて、ウェブページと対話し(例えば、scraping_browser_click)、LinkedIn、Amazon、Yahoo Finance、TikTokなどの複数のドメインから構造化データを収集するための55以上の特化したツールがある。
Web MCPがopencodeの中でどのように機能するかをチェックする時間だ!
opencodeをBright DataのWeb MCPに接続する方法
ローカルにopencodeをインストールして設定し、Bright DataのWeb MCPサーバーと統合する方法をご紹介します。その結果、60以上のWebツールにアクセスできる拡張コーディングエージェントになります。そのCLIエージェントをサンプルタスクで使用します:
- LinkedInの製品ページをオンザフライでスクレイピングし、実世界のプロファイルデータを収集する。
- データをJSONファイルにローカルに保存する。
- Node.jsスクリプトを作成し、データをロードして処理する。
以下の手順に従ってください!
注:このチュートリアル・セクションは、CLI経由でopencodeを使用することに焦点を当てています。しかし、ドキュメントに記載されているように、IDEに直接統合するために同様のセットアップを使用することができます。
前提条件
始める前に、以下の環境があることを確認してください:
- macOSまたはLinux環境(WindowsユーザーはWSLを使用する必要があります)。
- Claude Pro または Max のサブスクリプション、または資金と API キーを持つ Anthropic アカウント(このチュートリアルでは Anthropic API キーを使用しますが、他のサポートされている LLM を設定することもできます)。
- ローカルにインストールされたNode.js(最新のLTSバージョンを推奨します)。
- Bright DataアカウントとAPIキーの準備。
Bright Dataのセットアップについては、次のステップで説明しますので、今は心配しないでください。
次に、オプションですが、あると便利な予備知識をご紹介します:
- MCPの仕組みについての一般的な理解。
- Bright DataのWeb MCPとそのツールにある程度精通していること。
ステップ#1: opencodeのインストール
以下のコマンドを使用して、Unixベースのシステムにopencodeをインストールします:
curl -fsSL https://opencode.ai/install | bashこれにより、https://opencode.ai/installからインストーラーがダウンロードされ、それを実行してマシンに opencode をセットアップします。他のインストール・オプションも試してみてください。
を使ってopencodeが動作することを確認してください:
opencodeもし “missing executable “や “unrecognized command “エラーが発生したら、マシンを再起動してもう一度試してください。
すべてが期待通りに動けば、このように表示されるはずです:

これでopencodeが使えるようになりました。
ステップ2:LLMの設定
opencodeは多くのLLMに接続できますが、推奨モデルはAnthropicのものです。Claude MaxまたはProサブスクリプション、またはAnthropicアカウントと資金、APIキーがあることを確認してください。
以下のステップでは、APIキーを介してAnthropicアカウントにopencodeを接続する方法を説明しますが、他のサポートされているLLMインテグレーションでも動作します。
exitコマンドでopencodeのウィンドウを閉じ、LLMプロバイダで認証を開始します:
opencode auth login AIモデルプロバイダの選択を求められます:

Enterキーを押して “Anthropic “を選択し、”Manually enter API key “オプションを選択します:

AnthropicのAPIキーを貼り付け、Enterキーを押します:

これでLLMの設定は完了です。opencodeを再起動し、/modelsコマンドを起動すると、Anthropicモデルを選択できるようになります。例えば、”Claude Opus 4.1 “を選択します:
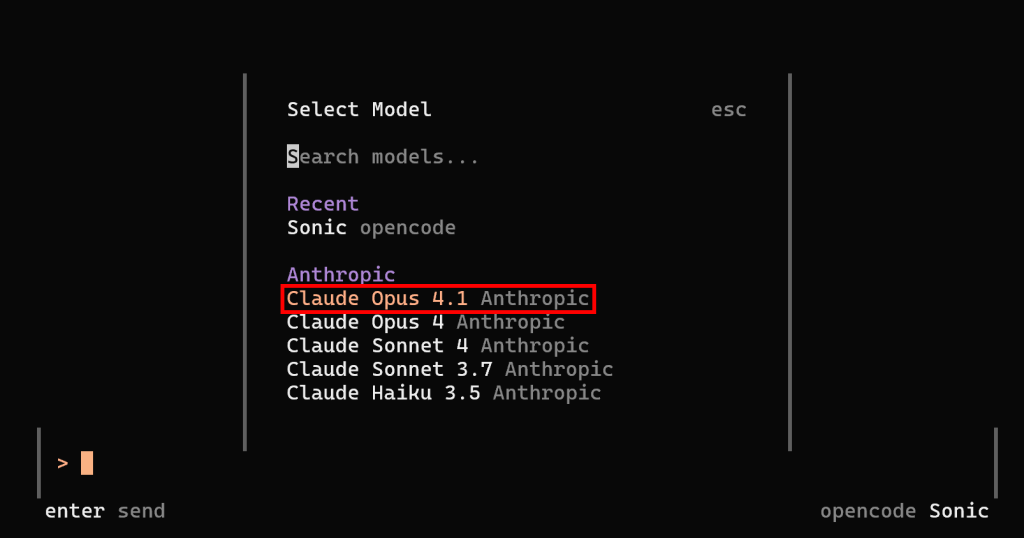
Enterを押してください:

opencodeが、設定されたAnthropic Claude Opus 4.1モデルを使ってどのように動作しているかに注目してください。よくできました!
ステップ3:opencodeプロジェクトを初期化する
cdコマンドを使ってプロジェクト・ディレクトリに移動し、そこでopencodeを起動します:
cd <path_to_your_project_folder>。
opencodeinitコマンドを実行して、opencodeプロジェクトを初期化します。出力はこのようになるはずです:

具体的には、/initコマンドはAGENTS.mdファイルを作成します。CLAUDE.mdや Cursorのルールと同様に、これはopencodeにカスタム命令を提供します。これらの命令はLLMのコンテキストに含まれ、特定のプロジェクト用に動作をカスタマイズします。
IDE(例えばVisual Studio Code)でAGENTS.mdファイルを開いてください:

プロジェクト・ディレクトリ内でAIコーディング・エージェントがどのように動作するかを指示するために、ニーズに応じてカスタマイズしてください。
ヒント:AGENTS.mdファイルは、プロジェクトフォルダの Git リポジトリにコミットしてください。
ステップ #4: Bright DataのWeb MCPをテストする
あなたのopencodeエージェントをBright Data Web MCPサーバーと統合する前に、このサーバーがどのように動作し、あなたのマシンで実行できるかを理解することが重要です。
まだの場合は、Bright Dataのアカウントを作成することから始めてください。すでにアカウントをお持ちの場合は、ログインしてください。簡単なセットアップのために、アカウントの “MCP “ページを見てください:

そうでなければ、以下の手順に従ってください。
Bright Data APIキーを生成してください。すぐに必要になりますので、安全な場所に保管してください。ここでは、統合がより簡単になるように、管理者権限を持つAPIキーを使用していると仮定します。
ターミナルで、@brightdata/mcpパッケージを使用してWeb MCPをグローバルにインストールします:
npm install -g @brightdata/mcp以下のBashコマンドで、ローカルのMCPサーバーが動作することを確認する:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpAPI_TOKEN="<YOUR_BRIGHT_DATA_API>“npx -y @brightdata/mcp.コマンドは必要なAPI_TOKEN環境変数を設定し、@brightdata/mcpパッケージを通してWeb MCPを起動します。
成功した場合、このようなログが表示されます:

初回起動時に、パッケージは自動的にBright Dataアカウントに2つのデフォルトゾーンを設定します:
mcp_unlocker:mcp_unlocker: Web Unlocker用のゾーンです。mcp_browser:mcp_unlocker: Web Unlocker用のゾーン。
これら2つのゾーンは、Web MCPが公開するすべてのツールを動かすために必要です。
上記2つのゾーンが作成されたことを確認するには、Bright Dataアカウントにログインします。ダッシュボードで“Proxies & Scraping Infrastructure” ページに移動します。そこに、テーブル内の2つのゾーンが表示されているはずです:

注意: API トークンに Admin 権限がない場合、これらのゾーンは自動的に作成されない可能性があります。その場合は、パッケージのGitHubページで説明されているように、ダッシュボードで手動で設定し、環境変数で名前を指定することができます。
デフォルトでは、MCPサーバーはsearch_engineと scrape_as_markdownツール(無料で使用できます!)のみを公開しています。
ブラウザの自動化や構造化データ・フィードの取得といった高度な機能をアンロックするには、Proモードを有効にする必要があります。そのためには、MCPサーバーを起動する前に環境変数PRO_MODE=trueを設定してください:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcp重要:Proモードを有効にすると、60以上のすべてのツールにアクセスできるようになります。一方、Proモードは無料ティアには含まれず、追加料金が発生します。
完璧です!Web MCPサーバーがあなたのマシンで動作することを確認しました。これからopencodeがサーバーを起動し、サーバーに接続するように設定するので、サーバープロセスを停止してください。
ステップ#5: Web MCPをopencodeに統合する
opencodeは設定ファイルのmcpエントリを介してMCPの統合をサポートしています。サポートされている設定方法は2つあることに注意してください:
- グローバルに:グローバルに
:~/.config/opencode/opencode.jsonのファイルを通して。グローバル設定はテーマ、プロバイダー、キーバインドなどの設定に便利です。 - プロジェクトごと:プロジェクトのディレクトリにあるローカルの
opencode.jsonファイルを通して。
MCP統合をローカルで設定したいとします。まず、作業ディレクトリ内にopencode.jsonファイルを追加します。
そのファイルを開き、以下の行が含まれていることを確認してください:
{
"$schema":"https://opencode.ai/config.json"、
"mcp":{
"brightData":{
"type":"ローカル": true
"enabled": true、
"コマンド": [
"npx"、
"-y",
"@brightdata/mcp"
],
"environment":{
"API_TOKEN":"<your_bright_data_api_key>"、
"PRO_MODE":"true"
}
}
}
}<YOUR_BRIGHT_DATA_API_KEY>を、先ほど生成してテストしたBright Data APIキーに置き換えてください。
この構成では
mcpオブジェクトは、opencode に外部 MCP サーバの起動方法を指示します。brightDataエントリは、Web MCP を起動するために必要なコマンド(npx) と環境変数を指定します。(PRO_MODEはオプションですが、有効にすると利用可能なツールのフルセットがアンロックされます)。
言い換えると、上記のopencode.jsonコンフィギュレーションは、先に定義した環境変数で同じnpxコマンドを実行するようにCLIに指示します。これにより、opencode は Bright Data Web MCP サーバーを起動し、接続することができます。
この記事を書いている時点では、MCPサーバーの接続を確認する専用のコマンドや利用可能なツールはありません。それでは、テストに移りましょう!
ステップ#6: opencodeでタスクを実行する
強化されたopencodeコーディングエージェントのウェブ機能をチェックするには、以下のようなプロンプトを起動します:
https://it.linkedin.com/in/antonello-zanini "をスクレイピングし、結果のデータをローカルの "profile.json "ファイルに保存します。次に、JSON ファイルを読み込み、その内容を返す基本的な Node.js スクリプトをセットアップします。これは、実際のデータを収集し、それをNode.jsスクリプトで使用するという、実際のユースケースを表している。
opencodeを起動し、プロンプトを入力し、Enterキーを押して実行する。このような動作が表示されるはずだ:

GIFはスピードアップされていますが、これはステップ・バイ・ステップで起こることです:
- クロード・オーパスのモデルはプランを定義する。
- プランの最初のステップは、リンクトインのデータを取得することです。これを行うために、LLMは適切なMCPツール
(web_data_linkedin_person_profile、CLIではBrightdata_web_data_linkedin_person_profileとして参照)をプロンプトから抽出された正しい引数で選択します(https://it.linkedin.com/in/antonello-zanini)。 - LLMはLinkedInスクレイピングツールを介してターゲットデータを収集し、プランを更新します。
- データはローカルの
profile.jsonファイルに保存される。 profile.jsonからデータを読み込んで印刷するNode.jsスクリプト(readProfile.js)が作成される。- 実行されたステップの概要と、作成された Node.js スクリプトを実行する指示が表示されます。
この例では、タスクが生成する最終出力はこのようになります:

インタラクションの最後には、作業ディレクトリに以下のファイルが含まれているはずです:
├── AGENTS.md
├── opencode.json
├── profile.json # <-- CLIによって作成される
└─ readProfile.js # <-- CLIによって作成されるすばらしい!それでは、生成されたファイルに意図したデータとロジックが含まれているかどうか確認してみましょう。
ステップ#7: 出力の確認とテスト
Visual Studio Codeでプロジェクトディレクトリを開き、profile.jsonファイルを調べることから始めましょう:

重要:profile.jsonのデータは、専用のweb_data_linkedin_person_profileMCPツールを介してBright DataLinkedIn Scraperが収集した本物のLinkedInデータです。幻覚や、クロードモデルによって生成されたでっち上げのコンテンツではありません!
プロンプトに記載されているLinkedInの公開プロフィールページを検査することで確認できるように、LinkedInのデータは正常に取得された:

注:LinkedInのスクレイピングは、その洗練されたアンチボットプロテクションのために悪名高く困難です。通常の LLM では、このタスクを確実に実行することはできません。これは、Bright Data Web MCP の統合により、コーディングエージェントがいかに強力になったかを示しています。
次に、readProfile.jsファイルを見てください:
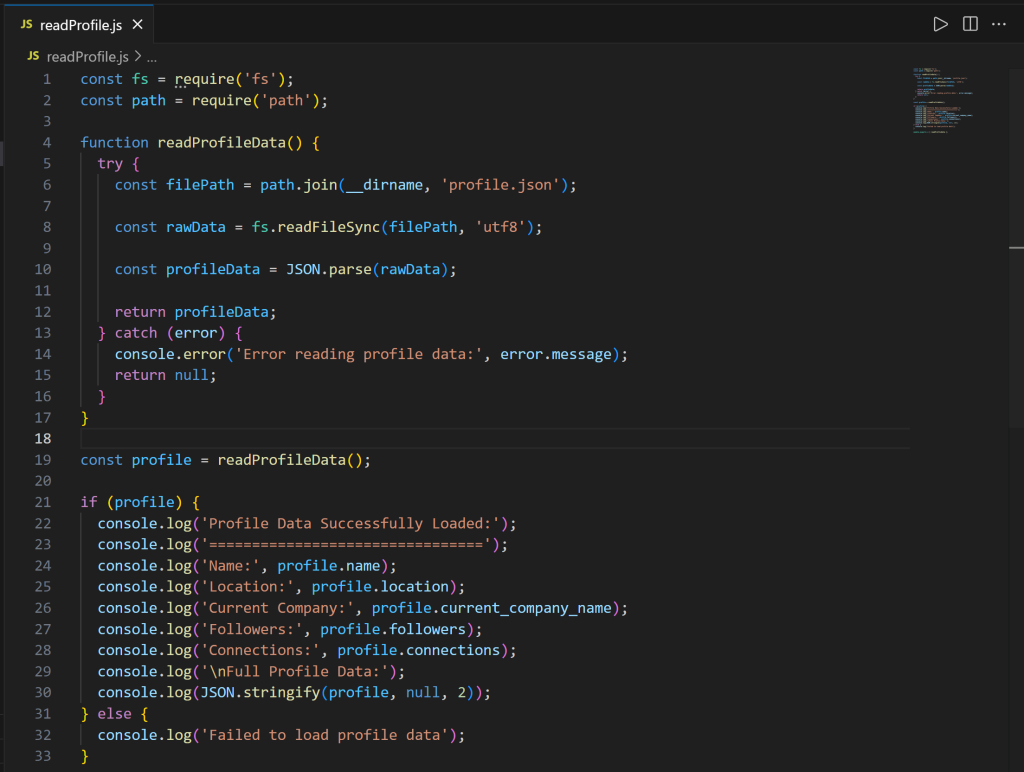
このコードでは、profile.jsonからLinkedInのプロフィールデータを読み込むために、readProfileData()関数が定義されていることに注目してください。この関数は、すべての詳細情報を含むプロフィールデータを表示するために呼び出されます。
スクリプトをテストします:
ノード readProfile.js出力されるはずです:

生成されたスクリプトが計画通りにLinkedInのスクレイピングされたデータをどのように表示するかを見てください。
ミッション完了!さまざまなプロンプトを試して、CLIで直接LLM駆動の高度なデータワークフローをテストしてください。
まとめ
この記事では、opencodeとBright DataのWeb MCP(現在、無料ティアを提供中!)を接続する方法を見た。その結果、ウェブからデータを抽出して対話することができる、ツール豊富なAIコーディングエージェントができました。
より複雑なAIエージェントを構築するには、Bright DataのAIインフラストラクチャで利用可能なあらゆるサービスや製品をご利用ください。これらのソリューションは、CLI統合を含め、様々なエージェントシナリオをサポートします。
Bright Dataに無料でサインアップして、AI対応ウェブツールの実験を始めてください!




