
このブログ記事では
- Ctushとは何か、なぜAIコーディング支援用のCLIアプリケーションとして愛されているのか。
- Ctushをウェブインタラクションとデータ抽出で拡張することで、より効果的になる方法。
- Crush CLIとBright Data Web MCPサーバーを接続し、AIコーディングエージェントを作成する方法。
さあ、飛び込もう!
Crushとは?
CrushはオープンソースのAIコーディングエージェントです。特に、Crush CLIはGoベースのCLIアプリケーションで、ターミナル環境に直接AIアシスタンスをもたらします。コーディング、デバッグ、その他の開発作業を支援するために、いくつかのLLMと対話するためのTUI(ターミナル・ユーザー・インターフェース)を提供します。
具体的には、これがCrushを特別なものにしている:
- クロスプラットフォーム:macOS、Linux、Windows(PowerShellとWSL)、FreeBSD、OpenBSD、NetBSDのすべての主要なターミナルで動作する。
- マルチモデルのサポート:幅広いLLMから選択、OpenAIまたはAnthropic互換のAPIを介して独自のものを統合、またはローカルモデルに接続。
- セッションベースのエクスペリエンス:プロジェクトごとに複数の作業セッションとコンテキストを維持します。
- 高い柔軟性:コンテキストを保持したまま、セッションの途中でLLMを切り替えることが可能。
- LSP対応:Crushは、最新のIDEのように、追加のコンテキストとインテリジェンスのためのLSP(言語サーバープロトコル)をサポートしています。
- 拡張性:MCP(HTTP、stdio、SSE)によるサードパーティ機能との統合をサポート。
このプロジェクトは、すでにGitHubで10k以上のスターを獲得しており、35人以上の貢献者がいる活気ある開発者コミュニティによって活発にメンテナンスされている。
Web MCPでCrush CLIのLLM知識ギャップを克服する
すべてのLLMに共通する課題は、知識の切り口を持つことです。Crush CLIで設定するLLMも同様です。これらのモデルは固定されたデータセットで学習されるため、その知識は過去の静的なスナップショットです。つまり、最近の出来事や動向を知らない。
これは、めまぐるしく変化するテクノロジーの世界では重要な欠点だ。最新の知識ベースがなければ、LLMは非推奨のライブラリや時代遅れのプログラミング手法を提案するかもしれないし、単に新しい機能やツールを知らないだけかもしれない。
では、もしあなたのCrush AIコーディングアシスタントが、古い情報を呼び出す以上のことができるとしたらどうだろう?最新のドキュメント、記事、ガイドをウェブで検索し、そのリアルタイムのデータを使って、より良い、より正確な支援を提供できることを想像してみてください。
LLMにウェブアクセスとデータ検索のパワーを与えるソリューションにCrushを接続することで、それを実現することができます。ブライトデータのウェブMCPサーバーは、まさにそれを実現します。このオープンソースサーバー(現在、無料ティアがあります!)は、ウェブインタラクションとデータ収集のための60以上のAI対応ツールを装備しています。
Bright Data Web MCPインテグレーション
以下は、MCPサーバーにある主なツールの2つです:
search_engine:SERPAPIに接続し、Google、Bing、またはYandexで検索を実行し、検索エンジンの結果ページデータをHTMLまたはMarkdown形式で返す。scrape_as_markdown:Web Unlockerを利用して、1つのウェブページのコンテンツをスクレイピングする。高度な抽出オプションをサポートし、ボット検知システムを回避し、CAPTCHAを解決してくれる。
これら以外にも、ウェブページと対話したり(scraping_browser_clickなど)、Amazon、LinkedIn、TikTokなど様々なドメインから構造化データフィードを収集するための55以上の特化したツールがある。例えば、web_data_amazon_productツールは、商品URLを使ってAmazonから直接、詳細で構造化された商品情報を引き出すことができる。
これらのツールを使って、Bright Data Web MCPをCrushで活用する方法をいくつかご紹介します:
- Yahoo Financeの株価やEコマースサイトの商品詳細など、プロジェクトに必要な最新情報を取得します。そのデータをローカルファイルに保存し、分析、テスト、モッキングなどに利用できます。
- AIに、使用しているライブラリやフレームワークの最新ドキュメントを取得させ、AIが提案するコードが最新で非推奨でないことを確認する。
- コンテキストを意識したリンクを収集し、それらのリソースをMarkdownファイル、ドキュメント、その他のアウトプットに統合します。
Web MCPがあなたのCrush CLIエージェントをどのように強化できるかをご覧ください!
CrushをBright DataのWeb MCPに接続する方法
このチュートリアルでは、Crushをローカルにインストールして設定し、Bright DataのWeb MCPと統合する方法を学びます。このチュートリアルでは、Crushをローカルにインストールして設定し、Bright DataのWeb MCPと統合する方法を学びます:
- Amazonの商品ページをオンザフライでスクレイピング。
- データをローカルのJSONファイルに保存。
- そのデータをロードして処理するNode.jsスクリプトの作成。
以下の手順に従ってください!
前提条件
始める前に、以下があることを確認してください:
- Node.jsがローカルにインストールされていること(最新のLTSバージョンを推奨)。
- サポートされているLLMプロバイダーのAPIキー(このガイドでは、Google Geminiを使用します)。
- APIキーが準備されているBright Dataアカウント(まだお持ちでない場合は、作成方法を説明しますのでご安心ください)。
また、オプションですが、役立つ予備知識として
- MCPの仕組みについての一般的な理解
- Bright Data Web MCP サーバーとそのツールに精通していること。
- CLIコーディングエージェントの動作と、それらがファイルシステムとどのように相互作用するかについての知識。
ステップ#1: Crushのインストールと設定
charmland/crushのnpmパッケージを使って、Crush CLIをシステムにグローバルにインストールする:
npm install -g @charmland/crushnpm経由でCLIをインストールしたくない場合は、他のインストールオプションを見つける。
これでCrushを起動できる:
クラッシュ下のようなLLMの選択画面が表示されるはずだ:
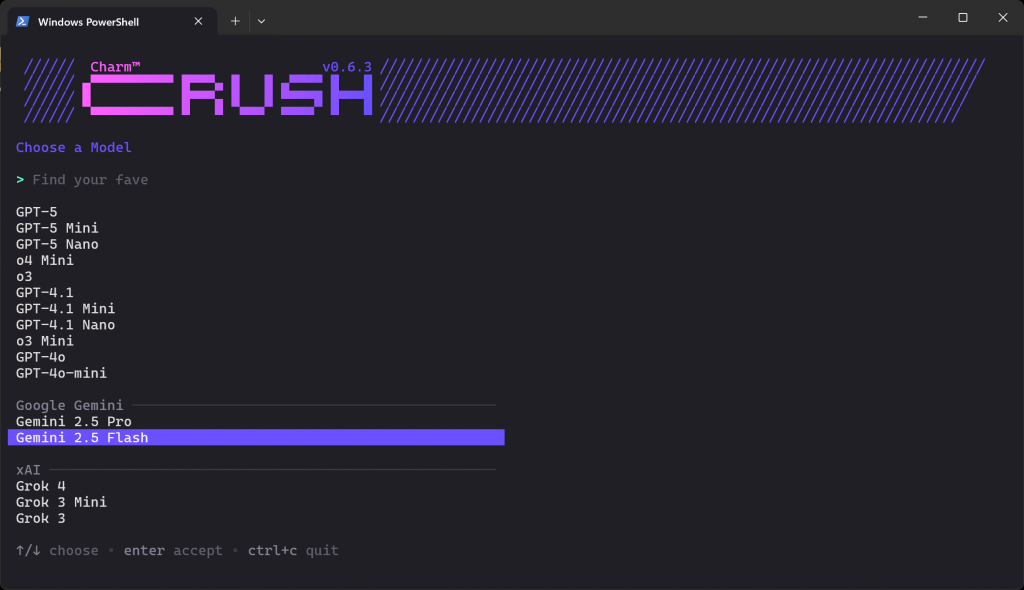
数十のプロバイダーと数百のモデルから選ぶことができます。矢印キーを使って、APIキーを持っているプロバイダーから欲しいモデルを見つけるまでナビゲートする。この例では、”Gemini 2.5 Flash“(API経由で基本的に無料で使用可能)を選択します。
次に、APIキーの入力を求められます。それを貼り付けてEnterキーを押します:
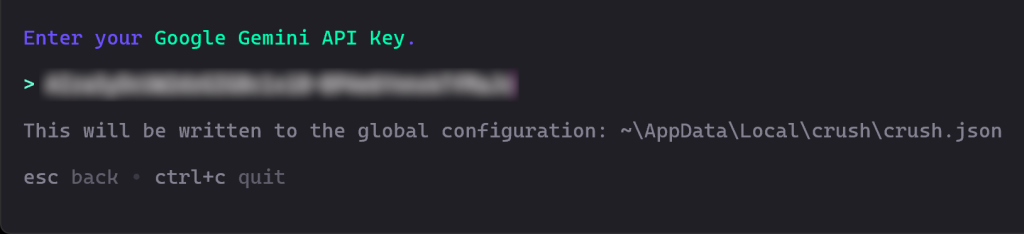
この場合、GoogleStudio AIから無料で取得できるGoogle Gemini APIキーを貼り付けます。
その後、CrushがAPIキーのバリデーションを行い、正常に動作することを確認します。
バリデーションが完了すると、このように表示されます:
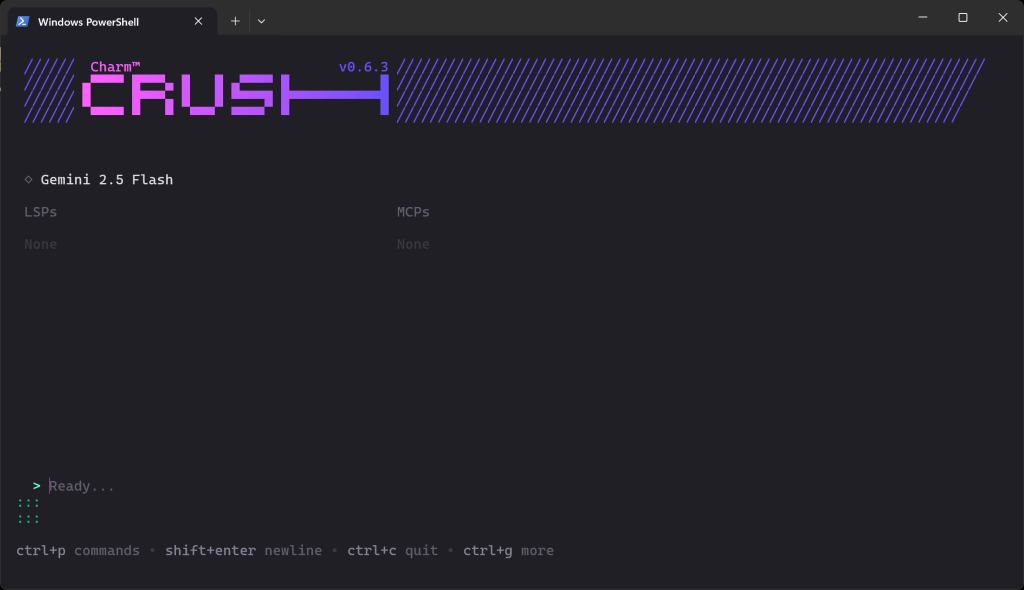
Ready… “セクションで、プロンプトを入力できます。
注意: Crush CLIを再度起動すると、LLM接続のセットアップを再度要求されることはありません。これは、設定されたLLMキーが自動的にグローバル設定$HOME/.config/crush/crush.jsonに保存されるためです(Windowsの場合は、%USERPROFILE%ApplicationData/Local/crush/crush.json)。
Visual Studio Code(またはお好みのIDE)でグローバルcrush.json設定ファイルを開いて検査します:
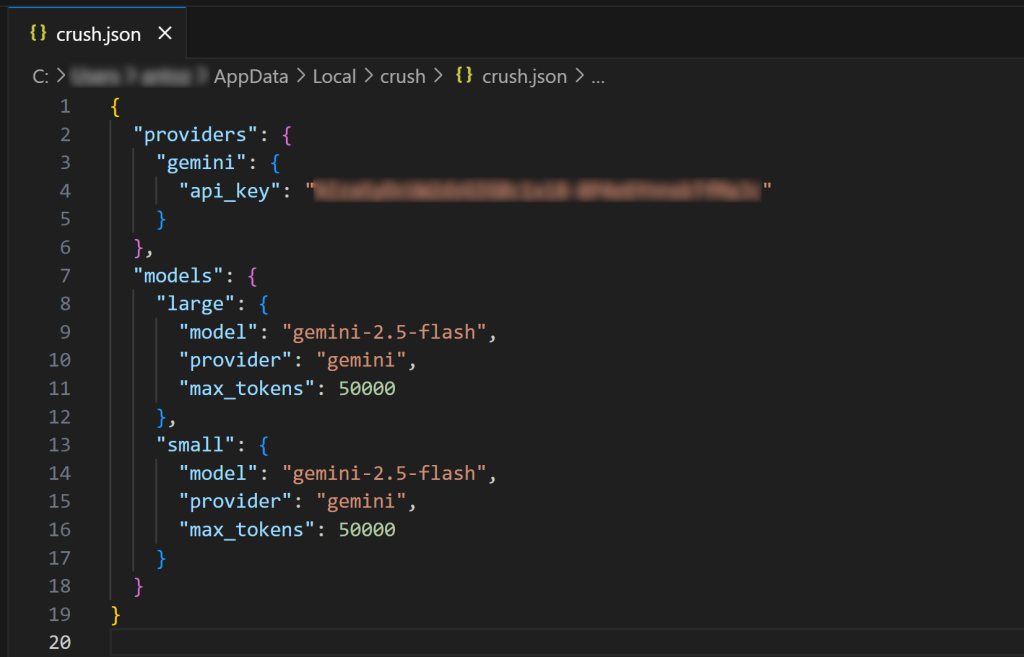
ご覧のように、crush.jsonファイルには、選択したモデルの設定とともにAPIキーが含まれています。これは、LLMを選択したときにCrush CLIによって入力されました。このファイルを編集して、他のAIモデル(ローカルモデルでも)を設定することもできます。
同様に、プロジェクトディレクトリ内にローカルのcrush.jsonまたは.crush.jsonファイルを作成して、グローバル設定を上書きすることもできます。詳細については、公式ドキュメントを参照してください。
驚いた!これでCrush CLIがあなたのシステムにインストールされ、動作するようになりました。
ステップ2: Bright DataのWeb MCPをテストする
まだアカウントをお持ちでない場合は、Bright Dataアカウントを作成してください。そうでなければ、既存のアカウントにログインしてください。
次に、公式の指示に従ってBright Data APIキーを生成してください。すぐに必要になりますので、安全な場所に保管してください。ここでは簡単のため、Admin権限を持つAPIキーを使用すると仮定します。
brightdata/mcpパッケージを使用して、Web MCP をグローバルにインストールします:
npm install -g @brightdata/mcp次に、以下のBashコマンドでサーバーが動作することを確認します:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpまたは、Windows PowerShellでも同様です:
Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp<YOUR_BRIGHT_DATA_API>プレースホルダーを、先ほど生成した実際のBright Data APIトークンに置き換えます。上記のコマンドは、必要なAPI_TOKEN環境変数を設定し、@brightdata/mcpnpmパッケージを通してMCPサーバーを起動します。
すべてが正しく動作すれば、このようなログが表示されるはずです:

最初の起動で、MCPサーバーは自動的にBright Dataアカウントに2つのゾーンを作成します:
mcp_unlocker:mcp_unlocker:Web Unlocker用のゾーン。mcp_browser:mcp_unlocker: Web Unlocker用のゾーン。
これらのゾーンは、MCPサーバーのすべてのツールを使用するために必要です。
これらのゾーンが作成されたことを確認するには、Bright Dataのダッシュボードにログインし、”Proxies & Scraping Infrastructure“ページに進みます。2つのゾーンが表示されているはずです:
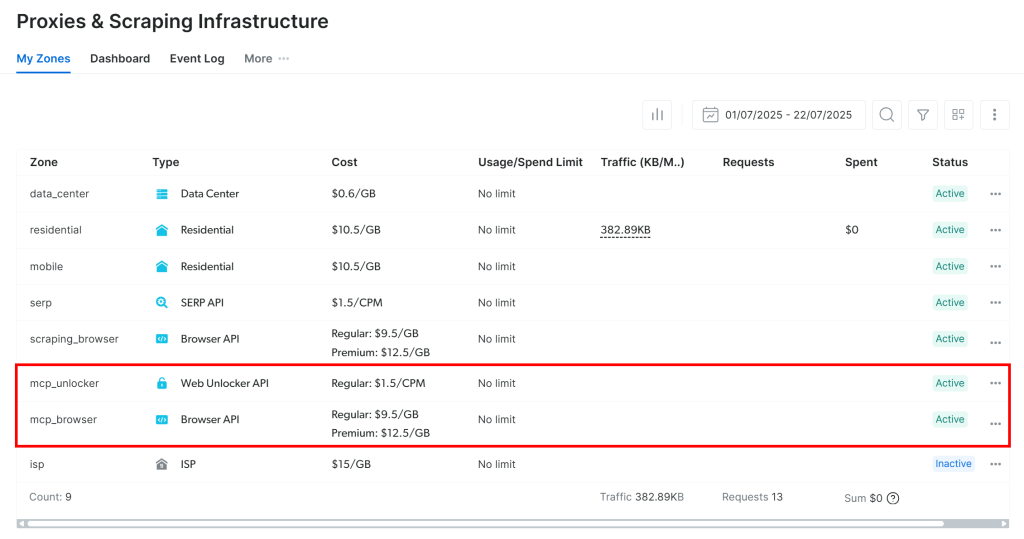
注意: APIトークンに管理者権限がない場合、これらのゾーンは作成されないかもしれません。その場合、公式ドキュメントに示されているように、手動で設定し、環境変数を使って名前を指定することができる。
覚えておいてください:デフォルトでは、MCPサーバーはsearch_engineと scrape_as_markdownツールだけを公開しています。
ブラウザ自動化と構造化データフィードのための高度なツールをアンロックするには、Proモードを有効にする必要があります。これを行うには、MCPサーバーを起動する前にPRO_MODE=true環境変数を設定します:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpまたは、Windowsの場合
Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcp重要: Proモードでは、60以上のすべてのツールにアクセスできます。ただし、Proモードの追加ツールは無料層には含まれず、料金が発生します。
Bright DataのWeb MCPサーバーの詳細については、公式ドキュメントをご覧ください。
完璧です!お使いのマシンでWeb MCPサーバーが正しく動作していることが確認できました。次のステップではCrushを起動し、起動時にサーバーに接続するように設定します。
ステップ#3: CrushでWeb MCPを設定する
Crushはローカルまたはグローバルのcrush.json設定ファイルの mcpエントリを通してMCP統合をサポートします。
この例では、Bright DataのWeb MCPをCrush CLI環境でグローバルに設定したいとします。そこで、グローバル設定ファイルを開きます:
- Linux/macOSの場合:
$HOME/.config/crush/crush.json。 - Windowsの場合:
%USERPROFILE%AppDataのLocalのCrushのCrushのCrushのCrushのCrushのCrush.json。
以下の内容が含まれていることを確認する:
"mcp":{
"brightData":{
"type":"stdio"、
"command":"npx"、
"args": [
"-y",
"@brightdata/mcp"
],
"env":{
"API_TOKEN":"<your_bright_data_api_key>"、
"PRO_MODE":"true"
}
}
}この設定では
mcpエントリは、外部MCPサーバーの起動方法をCrushに伝えます。brightDataエントリは、Web MCPを実行するために必要なコマンドと環境変数を定義します。(覚えておいてください:PRO_MODEの設定はオプションですが、推奨します。また、<YOUR_BRIGHT_DATA_API_KEY>をBright Data APIキーに置き換えてください)。
つまり、この設定はbrightDataというカスタムMCPサーバーを追加します。Crushは、このファイルで設定した環境変数を使用し、指定したnpxコマンド(前のステップで示したコマンドに対応する)でサーバーを起動します。簡単に言うと、CrushはローカルのWeb MCPプロセスを起動し、スタートアップ時に接続することができる。
素晴らしい!Crush CLIでMCPの統合をテストしてみましょう。
ステップ#4: MCP接続の確認
実行中のCrushインスタンスをすべて終了し、再度起動します:
クラッシュ MCP接続が期待通りに機能していれば、”MCPs “セクションにbrightDataのエントリーが表示されているはずです:
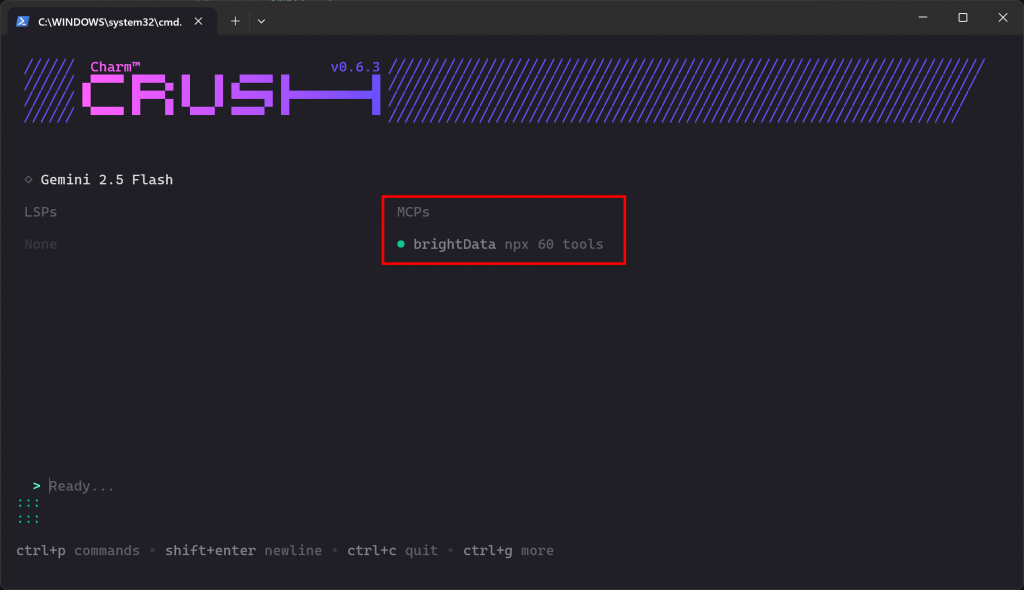
CLIは、60のツールが利用可能であることを示しています。これは、Proモードで実行するように設定したためです。そうでなければ、2つのツール(scrape_as_markdownと search_engine)しか利用できません。よくできました!
ステップ #5: Crushでタスクを実行する
CrushのCLIセットアップで新しい機能を確認するために、以下のようなプロンプトを実行してみてください:
https://www.amazon.com/Microfiber-Cleaning-Cloth-Performance-Washes/dp/B08BRJHJF9/"からデータをスクレイピングし、ローカルの "product.json "ファイルに保存し、Node.jsの "script.js "スクリプトを定義して、ファイルをロードし、ターミナルにその内容を表示する。このテストケースは、Bright DataのWeb MCPで公開されているツールを使用して達成されるはずの新鮮な商品データの取得を要求しているため、素晴らしいテストケースです。さらに、データ分析プロジェクトのモックやセットアップの際に使用する現実的なワークフローを示しています。
プロンプトをCrushに貼り付け、Enterを押して実行してください。このようなものが表示されるはずだ:
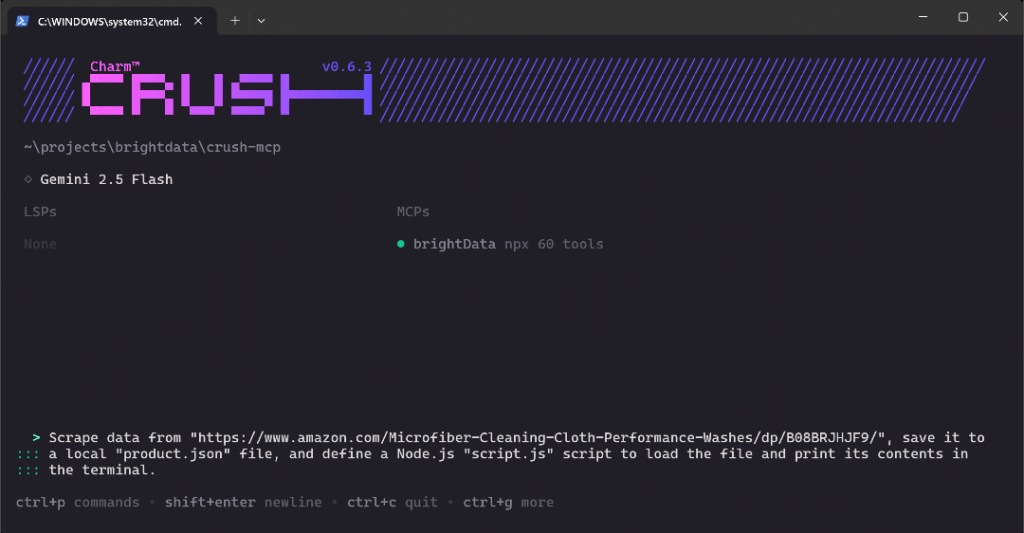
上のGIFはスピードアップされているが、これはステップバイステップで起こることである:
- Crushは
web_data_amazon_productツール(CLIではmcp_brightData_web_data_amazon_productとして参照される)をタスクに適したものとして識別し、実行の許可を求める。 - 承認されると、スクレイピング・タスクはMCP統合を介して実行されます。
- 結果のJSON商品データがターミナルに表示されます。
- Crushは、このデータを
product.jsonという名前のローカルファイルに保存できるかどうかを尋ねます。 - 承認後、ファイルが作成され、スクレイピングされたデータで満たされます。
- その後、Crush CLIは
script.jsのJavaScriptロジックを生成し、script.jsはJSONコンテンツをロードして表示します。 - 承認すると、
script.jsファイルが作成されます。 - Node.jsスクリプトの実行許可を求めるプロンプトが表示されます。
- 許可を与えると、
script.js が実行され、製品データがターミナルに出力されます。
明示的に要求していないにもかかわらず、CLI が生成された Node.js スクリプトの実行を要求していることに注意してください。この動作は意図的なもので、テスト(およびエラー時の修正)を容易にし、ワークフローに付加価値を与えるからです。
最後に、作業ディレクトリには以下の2つのファイルがあるはずだ:
├──prodcut.json
└── script.jsVSコードでproduct.jsonを開いてください:
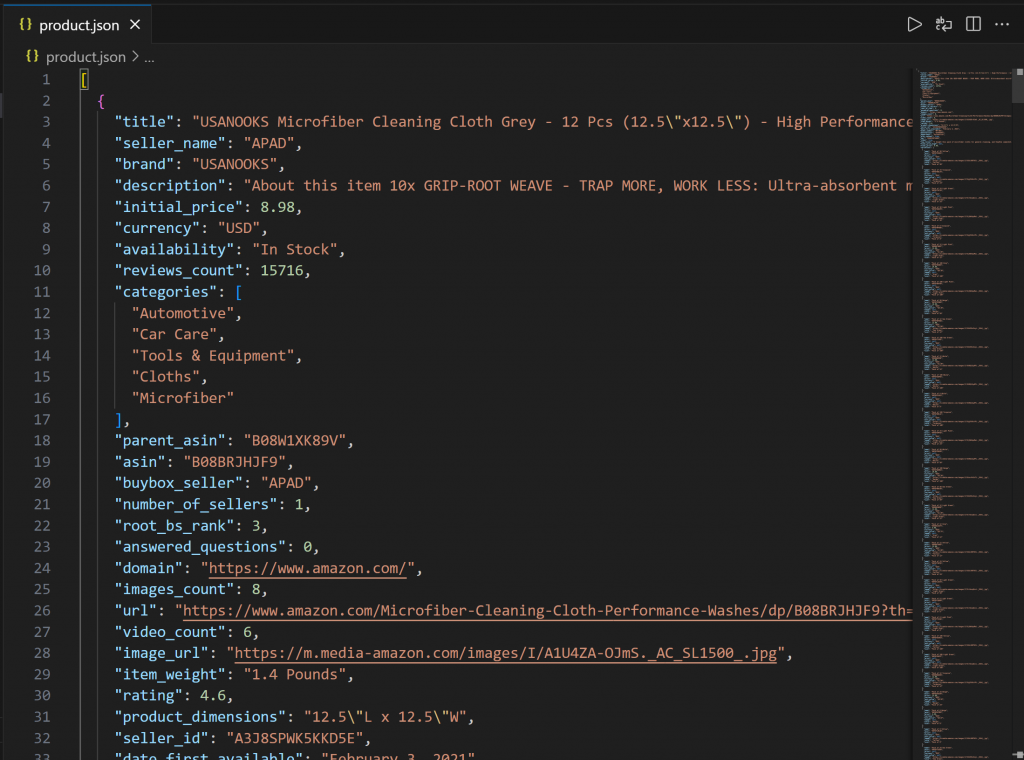
このファイルには、Bright DataのWeb MCP経由でAmazonからスクレイピングされた実際の商品データが含まれている。
次に、script.jsを開いてください:
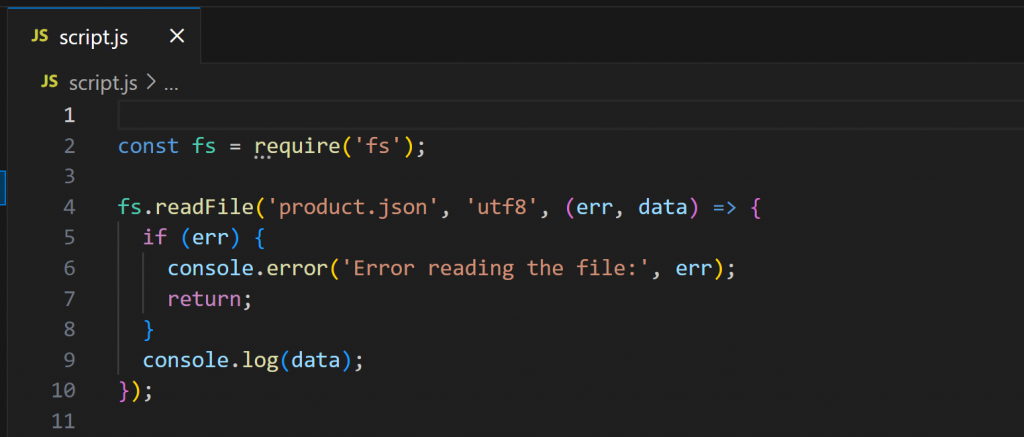
このスクリプトはNode.jsを使ってproduct.jsonの内容を読み込み、表示します。次のように実行します:
node script.js出力はこうなるはずだ:
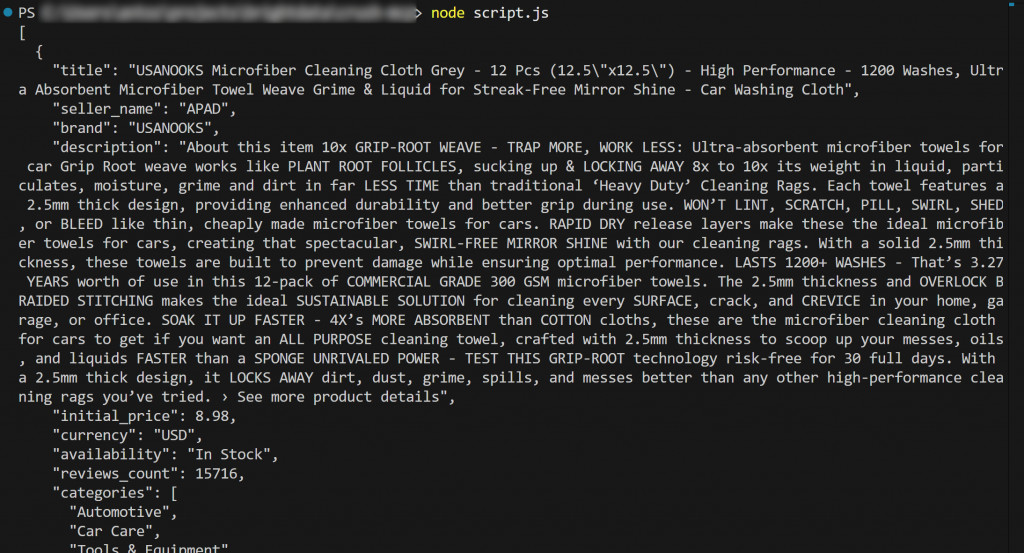
はい、できました!ワークフローは成功した。
詳細には、product.jsonからロードされ、ターミナルに出力されたコンテンツは、オリジナルのAmazon商品ページにある実際のデータと一致している。
重要:product.jsonは本物のスクレイピングされたデータを含んでいる。アマゾンのスクレイピングは、その高度なボット対策(例えば、アマゾンCAPTCHAのため)により、悪名高く難しいので、これは指摘すべき基本的なことである。したがって、通常のLLMだけではこの目標を達成することはできない!
この例は、CrushとBright DataのMCPサーバーを組み合わせることの真の力を示しています。今すぐ新しいプロンプトを試して、CLIで直接LLM駆動のより高度なデータワークフローを探求してみてください!
まとめ
このチュートリアルでは、CrushとBright DataのWeb MCP(現在は無料版も提供されています!)を接続する方法をご紹介しました。その結果、ウェブにアクセスして対話できる強力なCLIコーディングエージェントができました。この統合は、Crush CLIがMCPサーバーをビルトインでサポートしているおかげで可能になりました。
このガイドのタスク例は、意図的にシンプルにした。しかし、この統合により、より複雑なユースケースに取り組むことができることを忘れないでください。結局のところ、Bright Data Web MCP ツールは、様々なエージェントシナリオをサポートしています。
より高度なエージェントを作成するには、Bright Data AIインフラストラクチャで利用可能なすべてのサービスをご覧ください。
無料のBright Dataアカウントにサインアップして、今すぐAI対応ウェブツールの実験を始めましょう!




