

この記事では以下を学びます:
- LibreChatとは何か、その特長は何か。
- Bright DataのWeb MCPをLibreChatに統合する真の価値
- Web MCPをLibreChatに接続し、対応AIモデルと併用する方法
さっそく見ていきましょう!
LibreChatとは?
LibreChatは、Danny Avilesによって開発されたオープンソースのWebベースチャットアプリケーションで、GitHubスター数が3万以上(増加中!)です。
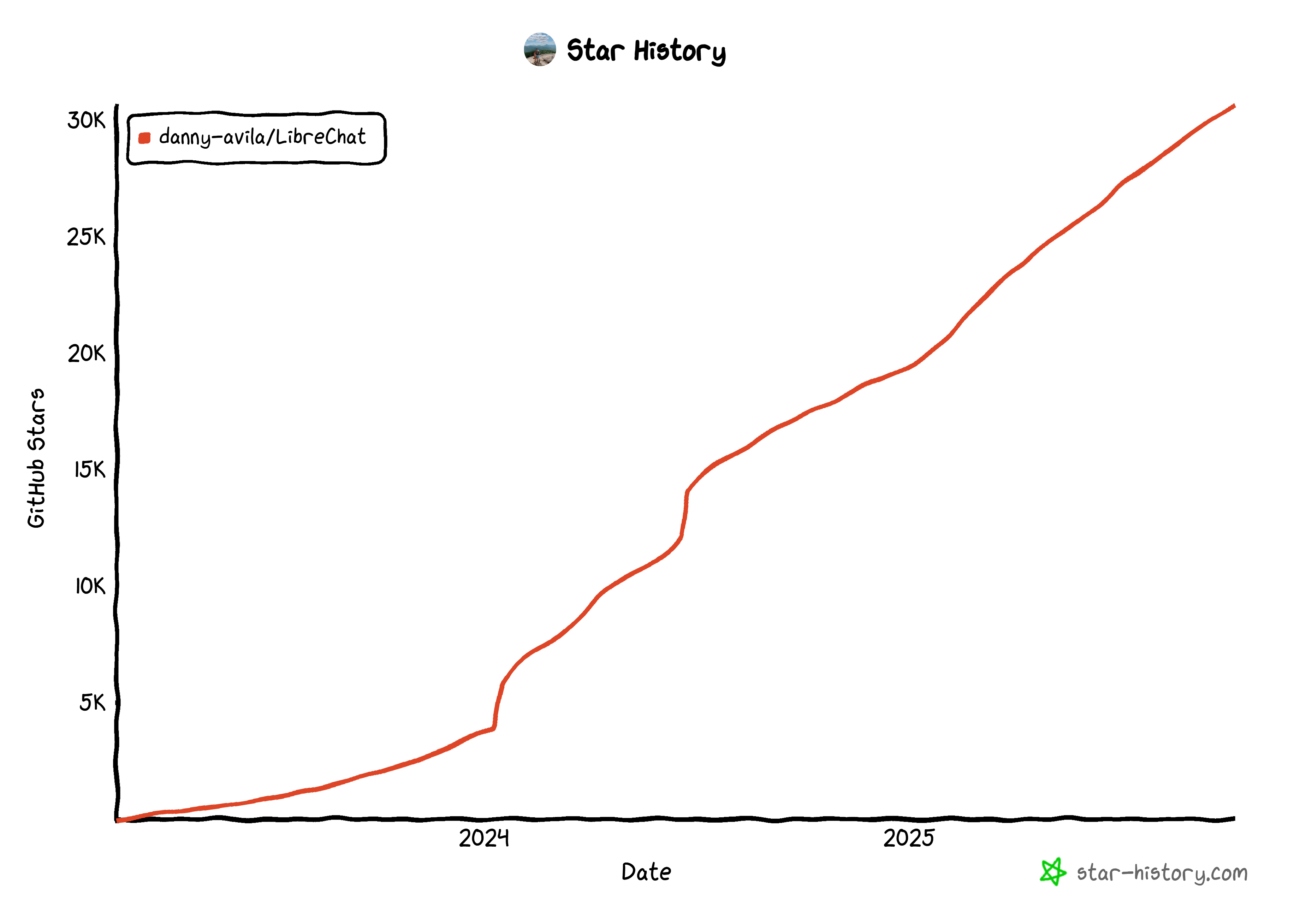
このアプリケーションは、複数のAIモデルと対話するための中央インターフェースとして機能し、オールインワンのオープンソースAIハブとしての役割を果たします。
LibreChatは、ChatGPTに着想を得たインターフェースを組み合わせた点が特徴です。OpenAIやAnthropicからGoogle、Ollamaに至るまで、ほぼすべての主要なAIプロバイダーとカスタムエンドポイントをサポートしています。同じUIから、マルチモーダルな会話やAIエージェントの構築が可能で、認証やモデレーション機能などのセキュリティ機能も備えています。
Bright DataのWeb MCPでLibreChatのAIモデルを拡張する理由
LibreChatではMCPサーバーをアプリケーションに接続し、そのツールをAIモデルが利用可能にできます。設定はアプリケーションレベルで一度行うだけで、その後は設定済みのあらゆるLLMモデルからアクセス可能になります。これによりMCPツールの使用が真にシームレスになります。
あるLLMの出力が満足できない場合、数クリックで別のモデルに切り替えるだけで、追加設定なしでMCPサーバーへのアクセスを維持できます。これがLibreChatの真価です!
では、絶対に検討すべきMCPサーバーとは?答えは単純です:AIモデルの最大の限界、すなわち知識の陳腐化とウェブ検索・閲覧不能を克服するサーバーです。
Bright DataのWeb MCPサーバー「Web MCP」は、まさにこの目的のために構築されています。オープンソースパッケージと リモートサーバーの両方で利用可能で、AIモデルがリアルタイムのウェブデータを取得し、人間のようにウェブページと対話することを可能にします。
具体的には、Web MCPはBright Dataのウェブインタラクション・データ収集インフラを活用した60以上のAI対応ツールを提供します。
無料プランでも、2つの画期的なツールを利用できます:
| ツール | 説明 |
|---|---|
search_engine |
Google、Bing、Yandexの検索結果をJSONまたはMarkdown形式で取得します。 |
scrape_as_markdown |
ボット検出やCAPTCHAを回避し、任意のウェブページをクリーンなMarkdown形式にスクレイピングします。 |
これら2つに加え、Web MCPにはクラウドベースのブラウザ自動化ツールや、YouTube、Amazon、LinkedIn、TikTok、Google Maps、Yahoo Financeなど多数のプラットフォームからの構造化データ抽出ツールが含まれます。
LibreChatでWeb MCPの動作を確認!
LibreChatをWeb MCPに接続する方法
このガイドセクションでは、LibreChatでWeb MCPを使用する方法を学びます。この設定により、どのLLMを設定しても強化されたAI体験が得られます。
これから体験していただくように、設定されたAIモデルはMCPサーバーが公開するツールを活用して株式分析を実行します。これは、この統合によってサポートされる数多くのユースケースのほんの一例に過ぎません。
注:同じ手順で、LibreChat AIエージェントでもWeb MCPツールを有効化できます。
以下の手順に従ってください!
前提条件
このチュートリアルを実行するには、以下の環境が整っていることを確認してください:
- ローカルにGitがインストールされていること。
- ローカルにDockerがインストールされていること。
- サポートされているプロバイダーのいずれかから取得したLLM APIキー(ここではGeminiを使用するため、Google APIキーが必要です)。
- APIキー付きのBright Dataアカウント。
Bright Dataアカウントの設定は現時点では心配不要です。後続の手順でガイドします。MCPの仕組みと Bright Data Web MCPで利用可能なツールに関する知識も役立ちます。
ステップ #1: LibreChat の開始
LibreChatのローカル環境構築を最も簡単に行う方法は、Docker経由で起動することです。プロジェクトのリポジトリを以下のコマンドでクローンしてください:
git clone https://github.com/danny-avila/LibreChat.git次に、お好みのIDE(Visual Studio CodeやIntelliJ IDEAなど)でLibreChat/ディレクトリを開きます。
クローンしたリポジトリ内には.env.exampleファイルがあります。これは LibreChat に必要な環境設定ファイルの例です。これをコピーして.env として貼り付けます:
.env.exampleファイルの単純なコピーで十分ですが、詳細については公式の.envファイル設定ガイドを参照してください。
次に、プロジェクト内にdocker-compose.ymlファイルが含まれていることに注意してください。これにより Docker 経由でアプリケーションを実行できます。次のコマンドで Docker 経由でアプリケーションを起動します:
docker compose up -dターミナルに以下のような出力が表示されるはずです:

必要なイメージがすべて取得され起動されたことを確認してください。LibreChatはhttp://localhost:3080(.envファイルで設定済み)で待機中です。ブラウザでこのページを開いてください。
LibreChatにはローカル認証システムが組み込まれているため、以下のような画面が表示されます:
「サインアップ」リンクからローカルアカウントを作成してください。ログイン後、以下のチャット画面にアクセスできます:
完了! LibreChatが起動しました。
ステップ #2: LLMの設定
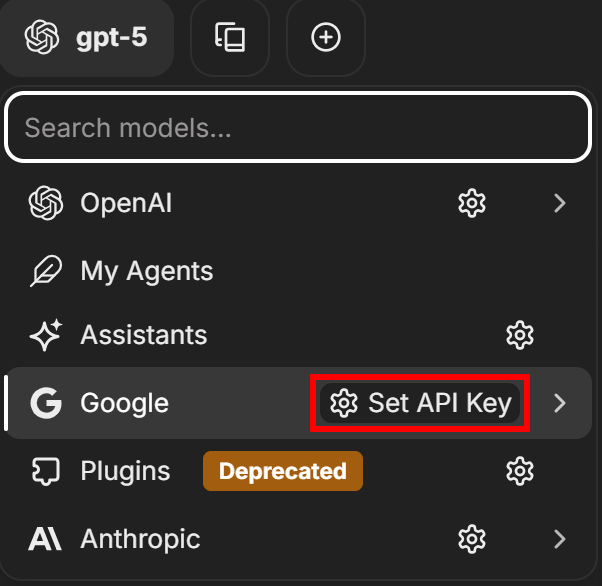
執筆時点では、LibreChatはデフォルトでGPT-5をLLMとして使用するように設定されています。これを変更するには、左上隅の「gpt-5」ラベルをクリックし、LLMプロバイダー(この例では「Google」)を選択し、「Set API Key」ボタンを押します:
すると、Google APIキーを入力するための以下のようなモーダルが表示されます:
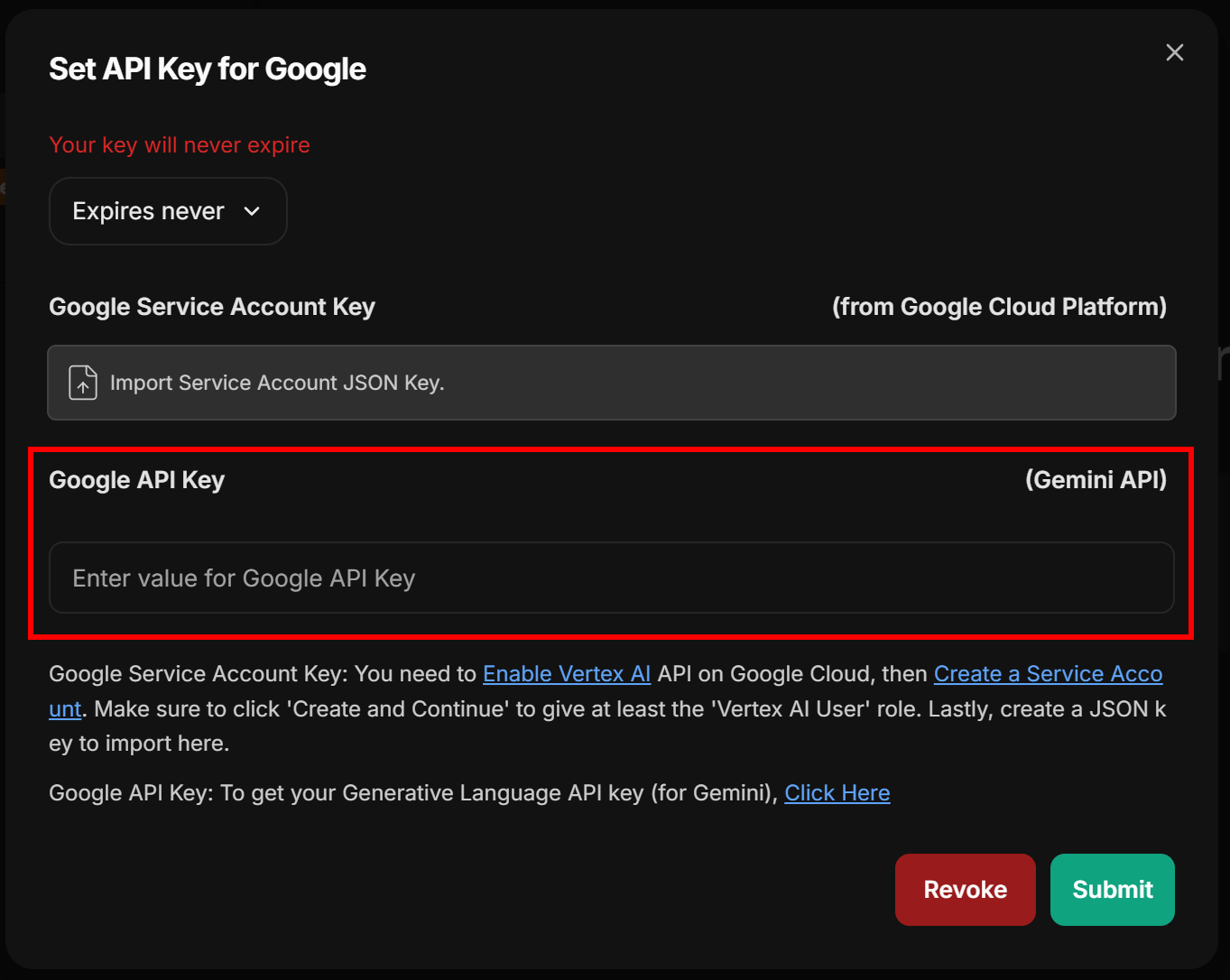
Google/Gemini APIキーを貼り付け、「送信」ボタンを押して確認します。これで、利用可能なGoogle AIモデル(例:gemini-2.5-pro)から選択できます:
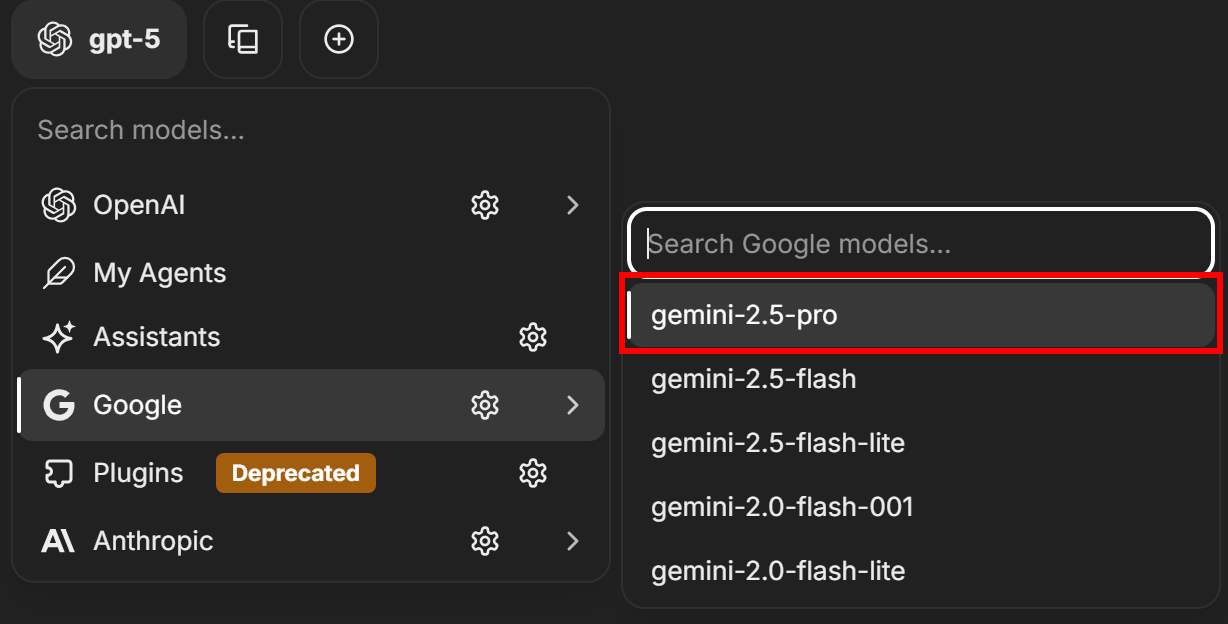
Gemini 2.5 Proには、追加料金なしで1日あたり10,000件のグラウンデッドプロンプトが含まれていることにご留意ください。
注:他のサポート対象AIモデルも同様の手順で設定可能です。
これでLibreChatで使用可能なLLMの準備が整いました。
ステップ #3: Bright DataのWeb MCPをローカルでテスト
LM StudioをBright DataのWeb MCPに接続する前に、ローカルマシンでMCPサーバーを実行できることを確認してください。これは、Web MCPサーバーへのローカル接続を実演するため重要です。SSE経由でリモートサーバーを使用する場合も、同様の設定が適用可能です。
まず、Bright Dataアカウントを作成してください。既にアカウントをお持ちの場合はログインしてください。迅速なセットアップには、アカウントの「MCP」セクションに記載されている手順に従ってください:
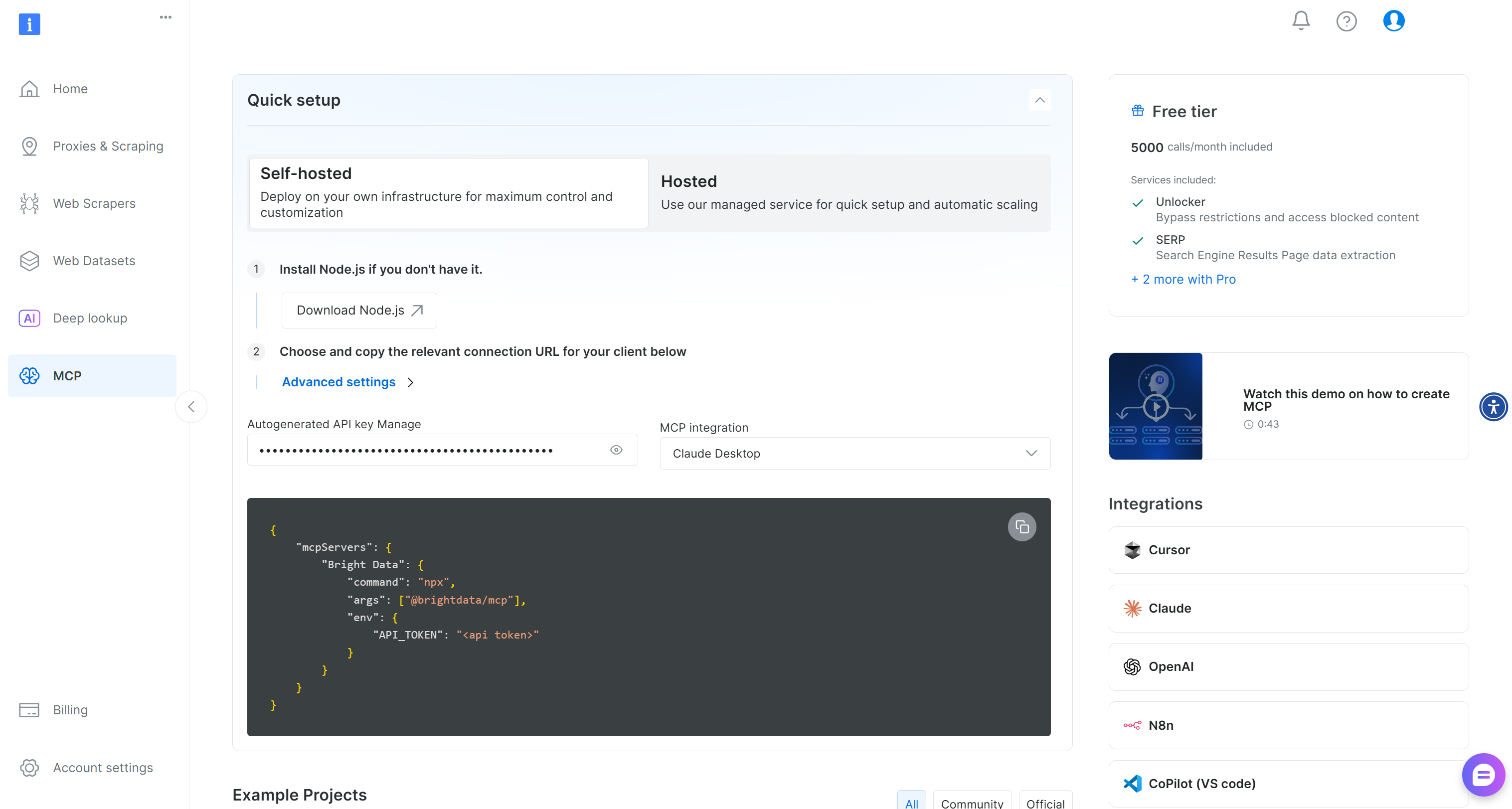
詳細な手順については、以下の説明を参照してください。
まず、Bright Data APIキーを取得します。次のステップで必要となるため、安全な場所に保管してください。Web MCP統合プロセスを簡略化するため、APIキーには管理者権限が付与されているものと仮定します。
次に、以下の npm コマンドで Web MCP をマシンにグローバルインストールします:
npm install -g @brightdata/mcpローカル環境でMCPサーバーが動作することを確認します:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpまたは、PowerShellで同等の操作を実行します:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp<YOUR_BRIGHT_DATA_API>プレースホルダーを、ご自身の Bright Data API トークンに置き換えてください。これら 2 つの(同等の)コマンドは、必要なAPI_TOKEN環境変数を設定し、@brightdata/mcpパッケージを実行して Web MCP をローカルで起動します。
正常に実行されると、以下のような出力が表示されます:

ご覧の通り、初回起動時にWeb MCPはBright Dataアカウント内に自動的に2つのデフォルトゾーンを作成します:
mcp_unlocker:Web Unlocker用ゾーンmcp_browser:ブラウザAPI用のゾーン。
Web MCPは60以上のツールを動作させるため、これら2つのBright Dataサービスに依存しています。
ゾーンが作成されたことを確認するには、Bright Dataダッシュボードの「プロキシ&スクレイピングインフラ」ページにアクセスしてください。テーブルに2つのゾーンが表示されるはずです:
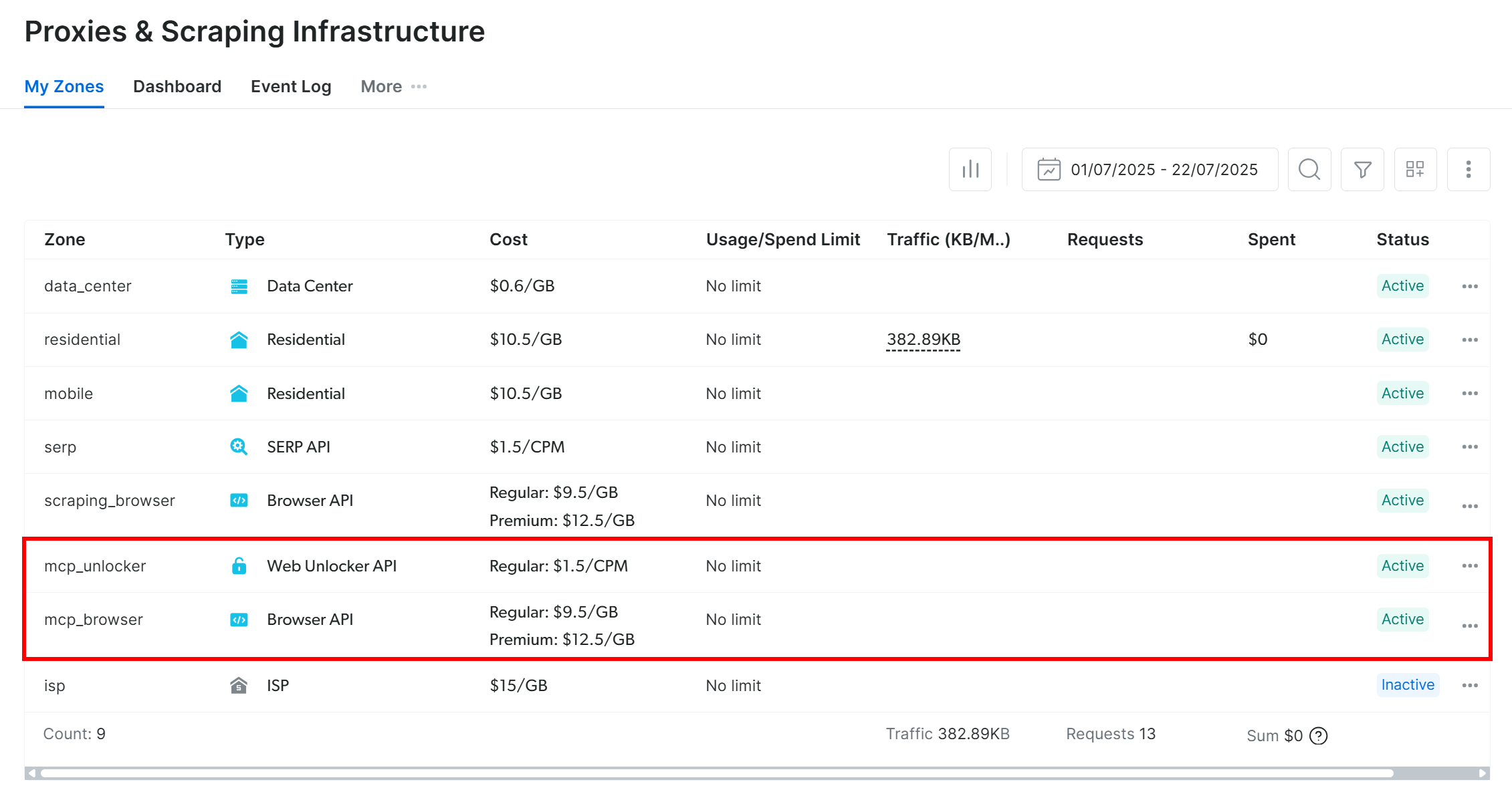
注: APIトークンに管理者権限がない場合、2つのゾーンは設定されません。その場合は、GitHubに示されているように、手動で定義し環境変数経由で設定する必要があります。
Web MCPの無料プランでは、MCPサーバーが公開するのはsearch_engineと scrape_as_markdownツール(およびそれらのバッチ版)のみです。全ツールを利用するには、PRO_MODE="true"環境変数を設定してProモードを有効化する必要があります:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpWindowsの場合:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpプロモードでは60以上のツールがすべて利用可能になりますが、無料プランには含まれず追加料金が発生します。
素晴らしい!これでWeb MCPサーバーがご自身のマシンで動作することを確認できました。MCPプロセスを停止し、LibreChatを接続する設定に進みましょう。
ステップ #4: Web MCP を LibreChat に統合
LibreChatでのMCP統合は、librechat.yaml設定ファイルを通じて利用可能です。.envファイルと同様に、このファイルはクローンしたリポジトリには含まれていません。作成はユーザーのタスクであり、librechat.example.yamlの例を参照できます:
デフォルトのlibrechat.example.yamlには多くの設定が含まれています。この例ではほとんど必要ありません。簡素化するため、以下の通りlibrechat.yamlを定義してください:
version: "1.3.0"
mcpServers:
bright-data:
type: stdio
command: npx
args:
- -y
- "@brightdata/mcp"
env:
API_TOKEN: "<YOUR_BRIGHT_DATA_API_KEY>"
PRO_MODE: "true" # オプション
timeout: 300000 # 5分この設定は、環境変数を認証情報および設定として使用する、先にテストしたnpxコマンドを反映したものです:
API_TOKENは必須です。事前に取得した Bright Data API キーを設定してください。PRO_MODEはオプションです。Proモードを有効化しない場合は削除してください。
ツール実行のタイムアウトは300000ミリ秒(5分)に設定されています。処理に時間がかかるツールでタイムアウトエラーが発生する場合は、この値を増やす必要があるかもしれません。
次に、Docker 設定を再読み込みします:
docker compose -f ./deploy-compose.yml downプロジェクトを再実行するには以下を実行してください:
docker compose -f ./deploy-compose.yml upアプリケーションが再読み込みされたら、ブラウザでhttp://localhost:3080 にアクセスしてください。チャットテキストエリアに「MCP Servers」ドロップダウンが表示されるはずです。これを開くと、上記で設定した「bright-data」MCP オプションが表示されます。これをクリックすると、LibreChat に Web MCP ツールが読み込まれます:
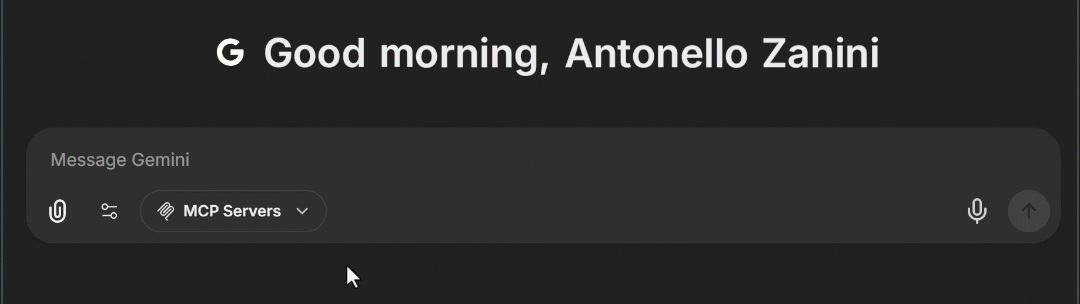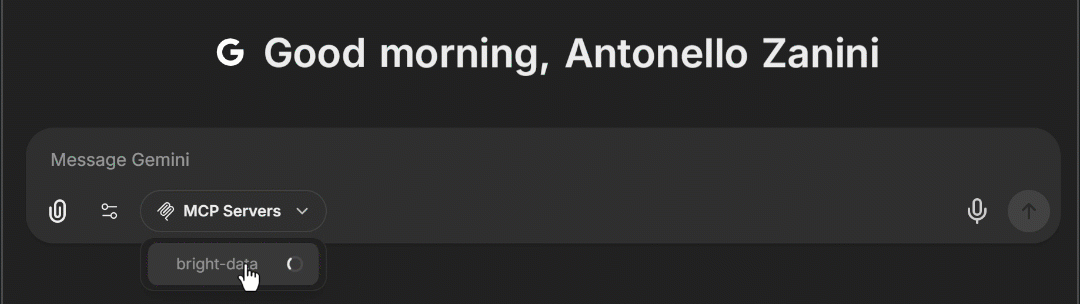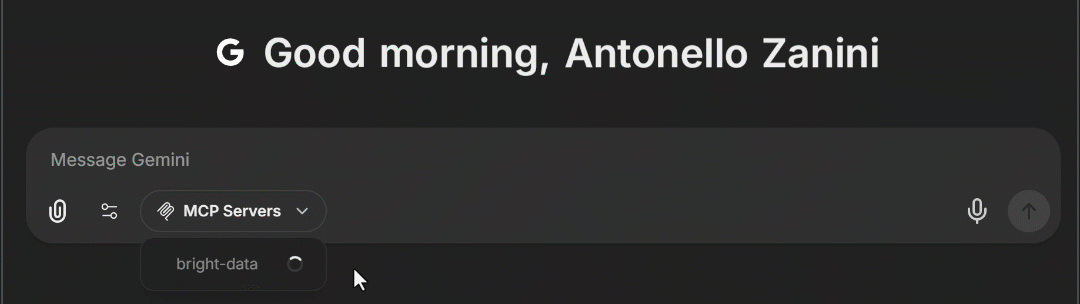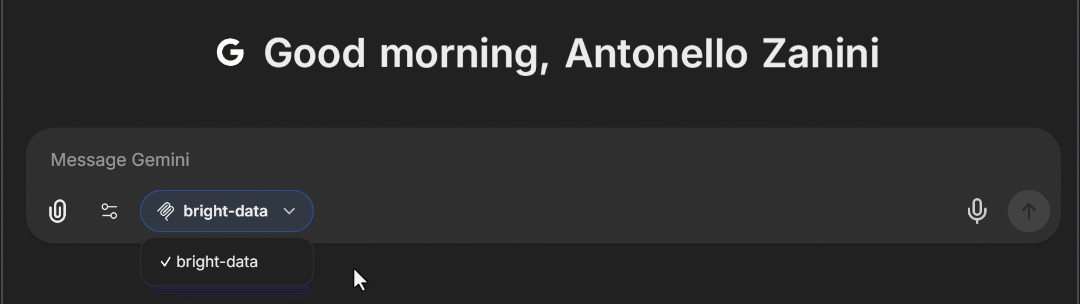
素晴らしい!これでLibreChatへのBright Data Web MCP統合が完了しました。
注: LibreChatはSmithery経由のMCP統合もサポートしています。詳細はドキュメントを参照し、Smithery上のWeb MCPサーバーもご確認ください。
ステップ #5: MCPツールの利用可能性を確認する
LibreChatでWeb MCPサーバーを有効化し読み込みが完了すると、設定済みのAIモデルがすべての公開ツールにアクセス可能になります。確認のため、以下のようなプロンプトを実行してください:
Bright DataのWeb MCPからどのツールにアクセスできますか?プロモードの場合は60以上の全ツールリスト、非プロモードの場合は4/5の無料ツールリストが表示されるはずです:
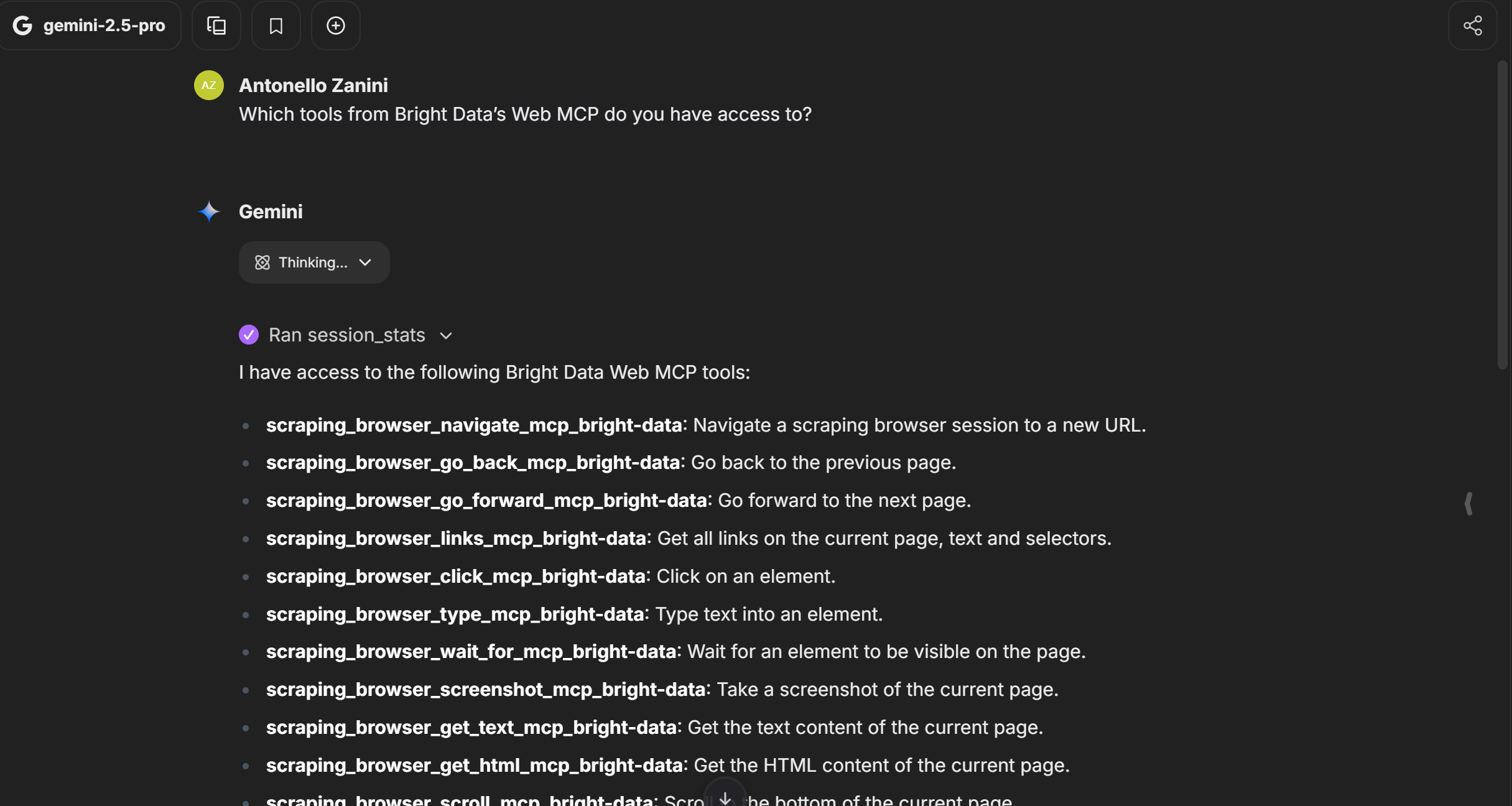
出力結果は、上記画像に示すように、選択したモード(Proか否か)に基づいてWeb MCPが公開するツール一覧と一致する必要があります。
ステップ #6: MCPサーバーが公開するWeb機能をテストする
LibreChatで設定されたAIモデルは、Web MCPが提供する全てのウェブデータ取得・操作機能にアクセス可能になりました。
これをテストするため、興味深い銘柄を特定し、さらに詳しく知りたいと仮定します。これはWeb検索とYahoo FinanceスクレイピングのWeb MCPツールをテストする絶好の機会です。
例えば、以下のようなプロンプトを考えてみましょう:
Yahoo Financeから以下の企業に関する主要情報をすべて提供してください:
"https://finance.yahoo.com/quote/IONQ/"
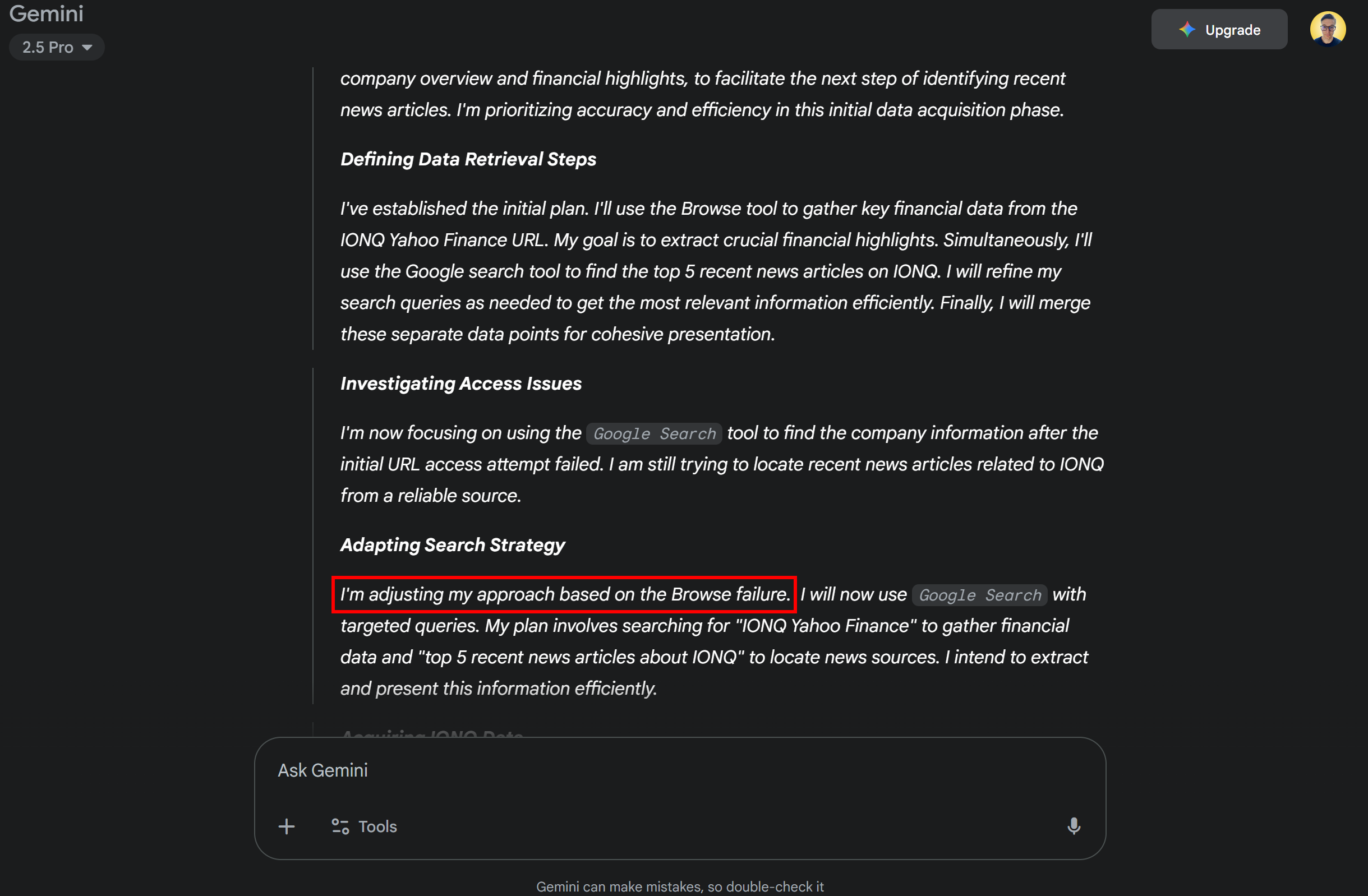
その後、同社に関する直近のニュース記事トップ5をウェブ検索し、タイトルとリンクのリストを返してください。標準のGeminiモデルではこのタスクを実行できない点に注意してください。Yahoo Financeのボット検知システムがスクレイピングを困難にしているためです。結果として、標準GeminiモデルはYahoo Financeから企業データを取得できず、別の手法に切り替わります:
一方、Web MCPとの連携により、LibreChat上の同一モデルでは目標を達成可能です。MCPサーバーをProモードで設定し、LibreChatでプロンプトを実行して確認してください。
Geminiモデルがタスク完了に必要な2つのツール「web_data_yahoo_finance_business」と「search_engine」を検出し、並列実行する様子をご覧ください。これらのツールの説明は以下の通りです:
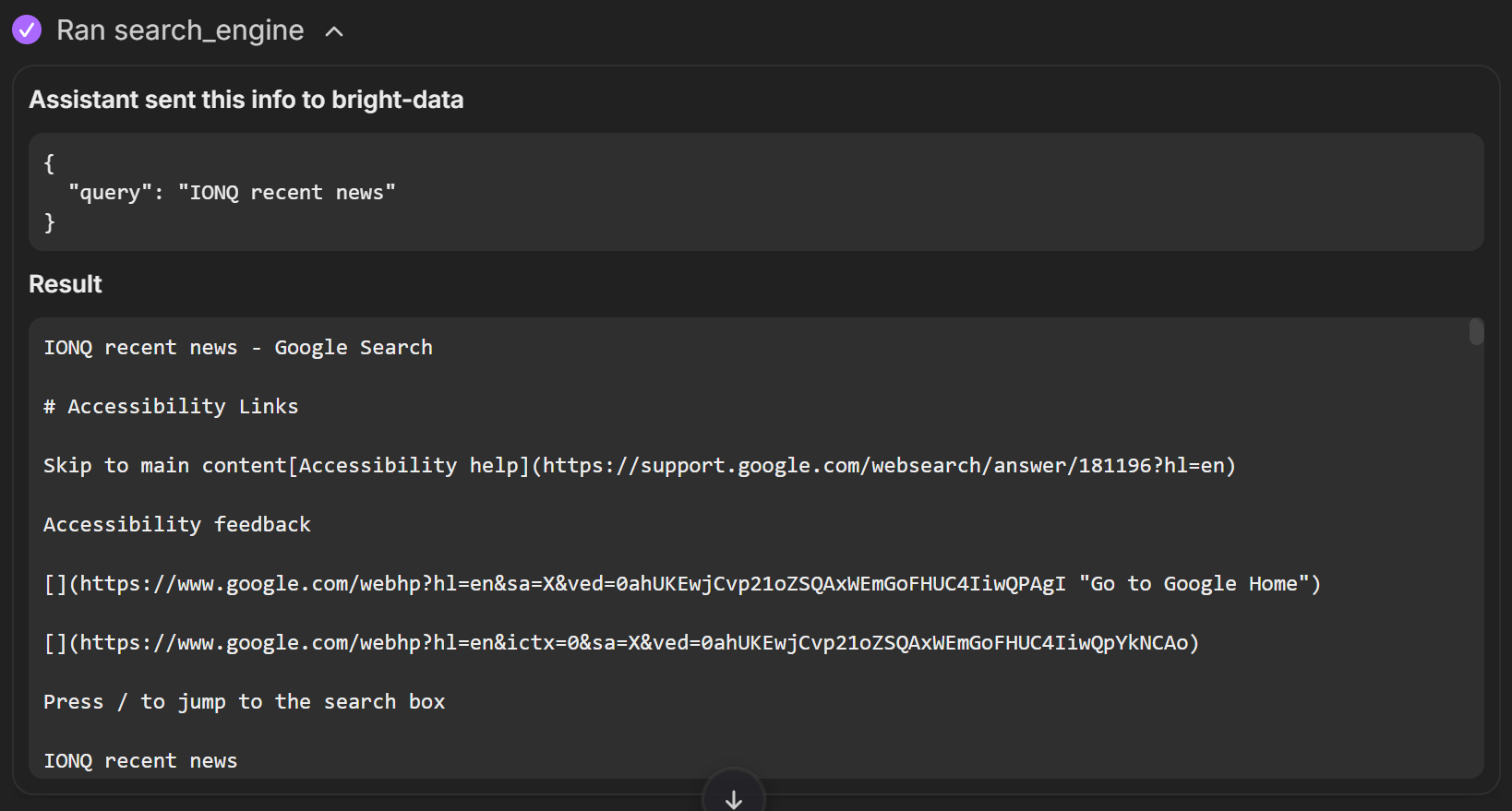
web_data_yahoo_finance_business: 構造化されたYahoo Financeビジネスデータを高速読み込み。有効なYahoo FinanceビジネスURLが必要。キャッシュ検索が可能で、スクレイピングより信頼性が高い。search_engine: Google、Bing、Yandexから検索結果をスクレイピングします。SERP結果をマークダウン形式(URL、タイトル、説明)で返します。
したがって、このタスクに完璧に適合します!
ドロップダウンを展開すると返されるデータを確認できます:
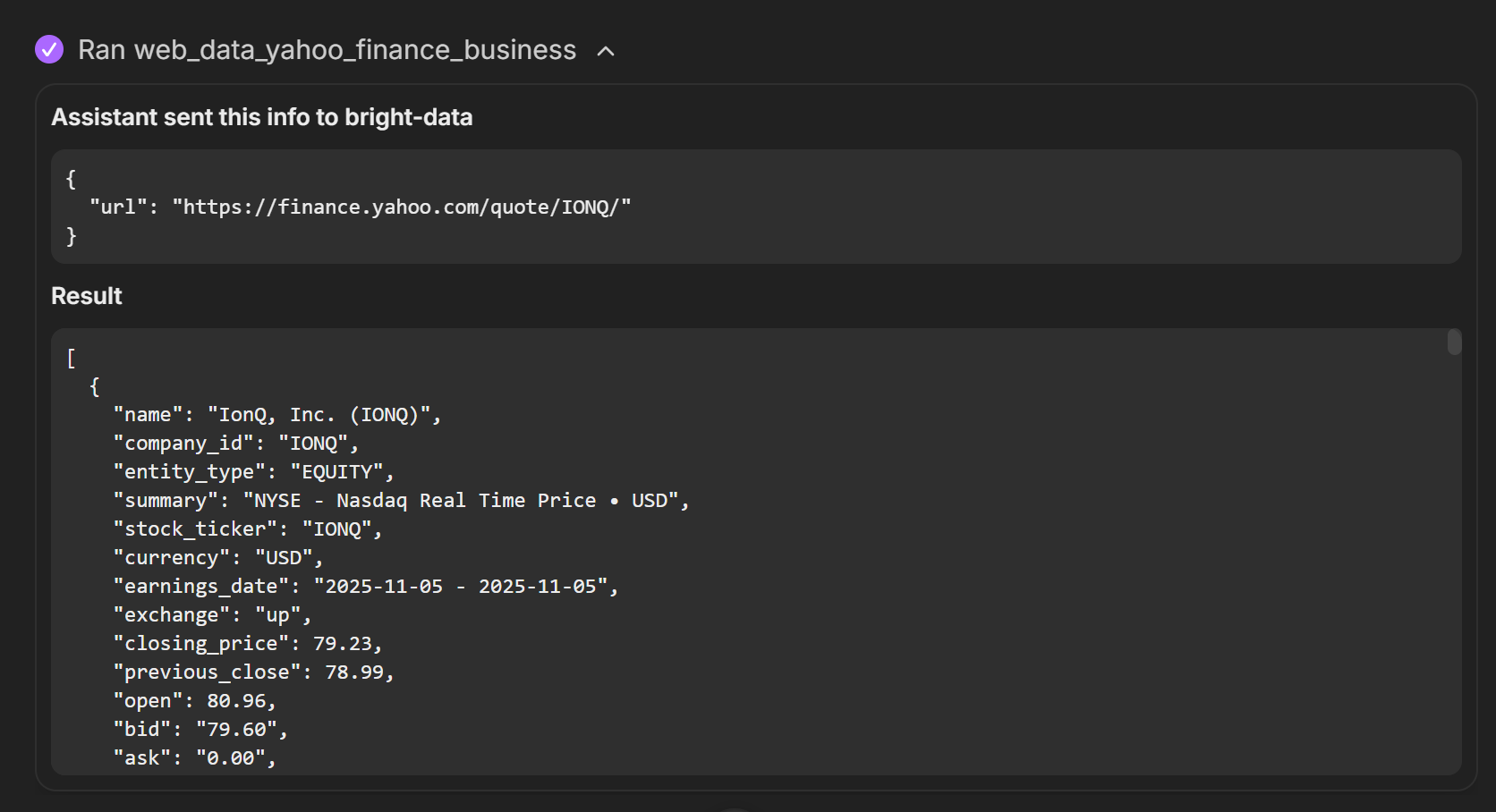
web_data_yahoo_finance_businessがYahoo Financeの構造化データを返す点に注目してください。これはツールがバックグラウンドでYahoo Finance Scraperを呼び出すためです。これはBright Dataのインフラで利用可能なYahoo Finance専用ウェブデータスクレイパーです。
一方、search_engineツールはGoogleで「IONQ recent news」のようなクエリを実行し、結果のSERPをMarkdown形式で返します:
各ツールが返した入力データをもとに、AIが以下のレポートに集約しました。関連情報が全て含まれています:

企業説明がYahoo Financeページの情報と一致している点に注目してください:
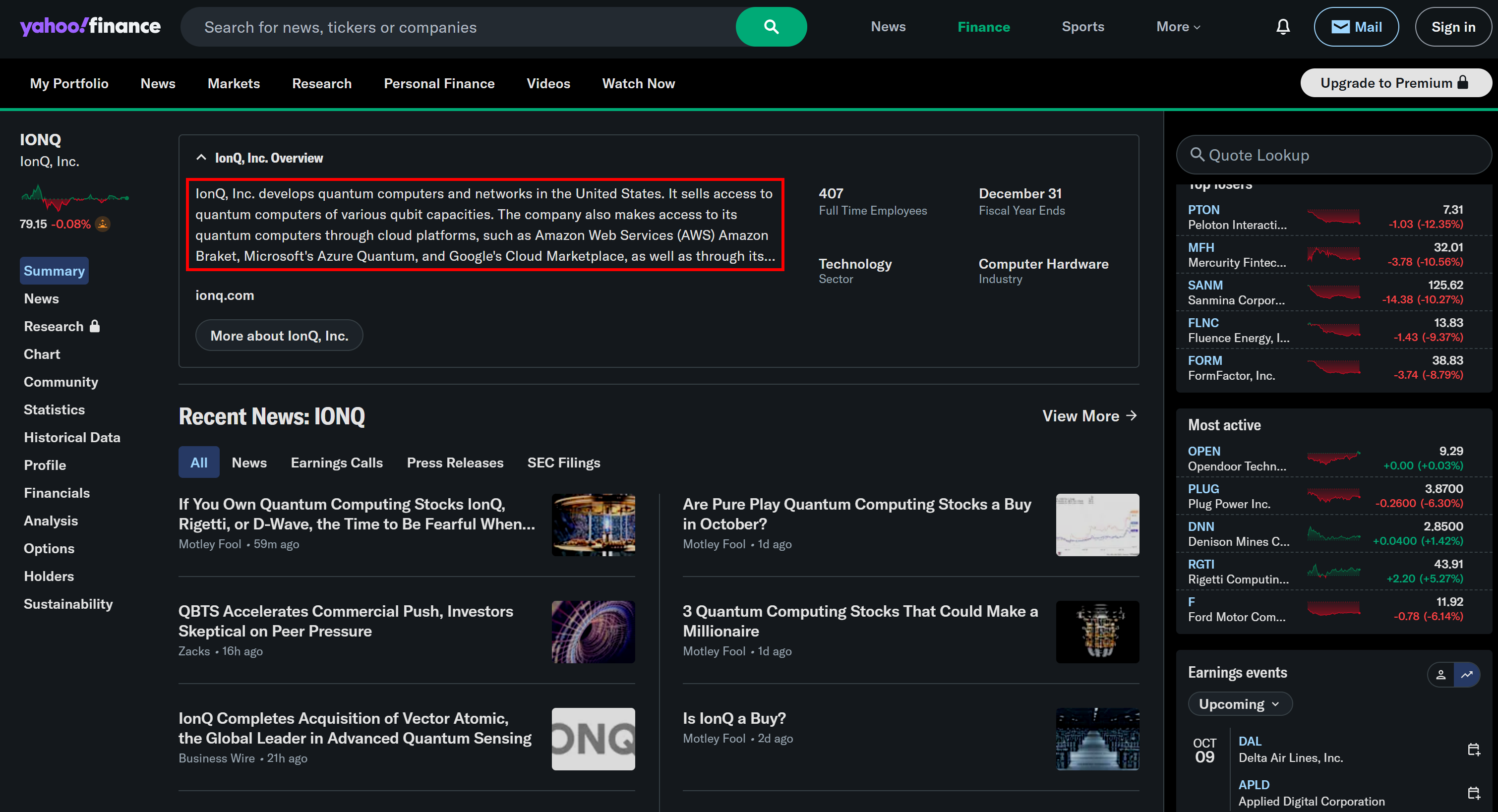
同様に、リンクはGoogleニュースから抽出された当該企業の最新ニュースを指しています。素晴らしい!ミッション完了です。
これはあくまで一例であることをお忘れなく。様々なプロンプトで自由に実験してください。Bright Data Web MCPツールの幅広いラインナップを活用すれば、他にも多くのシナリオに対応できます。
さあ、これでLibreChatとBright Data Web MCPを連携させる威力を体感いただきました。
まとめ
本ブログ記事では、LibreChatにおけるMCP統合の活用方法を学びました。具体的には、Bright DataのWeb MCPツールを用いて人気AIモデルを拡張する手法を詳細に確認しました。
ここで実証した通り、LibreChatの柔軟性により、選択したLLMはWeb MCPサーバーが公開する全ツールに自動的にアクセス可能となります。
この統合により、ウェブ検索、構造化データ抽出、ライブウェブデータフィード、自動化されたウェブインタラクションといった高度な機能がモデルに付与されます。複雑なAIワークフローを構築するには、Bright DataのAIエコシステム内で利用可能なAI対応サービスの全範囲を探索してください。
今すぐBright Dataの無料アカウントを作成し、当社のウェブデータツールを探索しましょう!





