

このガイドでは、Bright Data Web MCPとLangGraphを連携させ、ライブウェブデータを検索・スクレイピング・推論できるAIリサーチエージェントを構築する方法を説明します。
このガイドでは以下の方法を学びます:
- – 推論ループを自律制御するLangGraphエージェントの構築
- – Bright DataWeb MCPの無料プランでエージェントにライブWebアクセスを提供する方法
- 検索・抽出ツールを実用エージェントに統合する方法
- Web MCPプレミアムツールを使用したブラウザ自動化で同じエージェントをアップグレードする方法
LangGraph入門
LangGraphでは、制御フローが明示的で容易に検証可能なLLMアプリケーションを構築できます。プロンプトや再試行の内部に埋もれることはありません。各ステップがノードとなり、各遷移はユーザーが定義します。
エージェントはループとして動作します。LLMモデルは現在の状態を読み取り、応答するかツールを要求します。ツール(ウェブ検索など)を呼び出した場合、結果は状態に追加され、モデルが再度判断します。十分な情報を得るとループは終了します。
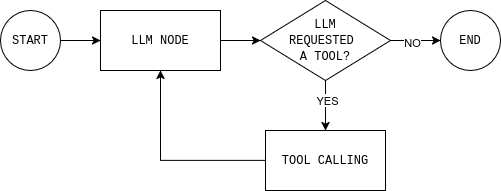
これがワークフローとエージェントの根本的な違いです。ワークフローは固定ステップを順守します。エージェントはループします:決定→実行→観察→再決定。このループはエージェント型RAGシステムでも用いられる基盤であり、固定ポイントではなく動的に検索が行われます。
LangGraphは、記憶機能、ツール呼び出し、明示的な停止条件を備えた、このループを構築するための構造化された方法を提供します。エージェントが行うすべての決定を確認し、停止タイミングを制御できます。
LangGraphでBright Data Web MCPを活用する理由
LLMは推論能力に優れますが、ウェブ上で現在起きている事象を把握できません。その知識は学習時点に限定されます。そのためエージェントが最新データが必要な場合、モデルは推測でそのギャップを埋めようとします。
Bright Data Web MCPは検索・抽出ツールを通じてエージェントにライブウェブデータへの直接アクセスを提供します。推測ではなく、モデルは回答を実際かつ最新のソースに裏付けます。
LangGraphは、このアクセスをエージェント環境で実用的にする技術です。エージェントは「十分な情報を得たか」「追加データが必要か」を判断する必要があります。
Web MCPでは、エージェントが質問に回答する際、記憶に頼るのではなく実際に使用した情報源を明示できます。これにより出力結果の信頼性とデバッグが容易になります。
Bright Data Web MCP を LangGraph エージェントに接続する方法
LangGraphはエージェントのループを制御します。Bright Data Web MCPはエージェントにライブWebデータへのアクセスを提供します。残る課題は、複雑さを増さずに両者を連携させることです。
このセクションでは、最小限のPythonプロジェクトを設定し、Web MCPサーバーに接続し、そのツールをLangGraphエージェントに公開します。
前提条件
このチュートリアルを実行するには以下が必要です:
- Python バージョン 3.11 以上
- Bright Dataアカウント
- OpenAI Platformアカウント
ステップ #1: OpenAI API キーの生成
エージェントが推論を行い、ツールの使用タイミングを決定するにはLLM APIキーが必要です。この設定では、そのキーはOpenAIから取得します。
OpenAI PlatformダッシュボードからAPIキーを作成します。「APIキー」ページを開き、「新しいシークレットキーを作成」をクリックします。
新しいウィンドウが開き、キーを設定できます。
デフォルト設定のまま、必要に応じてキーに名前を付け、「秘密鍵を作成」をクリックします。
生成されたキーをコピーし、安全に保管してください。次の手順でOPENAI_API_KEY環境変数に設定します。
このキーにより、LangGraphはLLMモデルを呼び出し、Web MCPツールをいつ呼び出すかを決定できます。
ステップ #2: Bright Data API トークンの生成
次に、Bright DataからAPIトークンを取得する必要があります。このトークンはエージェントをWeb MCPサーバーに認証し、検索ツールやスクレイピングツールを呼び出すことを可能にします。
Bright Dataダッシュボードでトークンを生成します。「アカウント設定」を開き、「ユーザーとAPIキー」に移動し、「+ キーを追加」をクリックします。
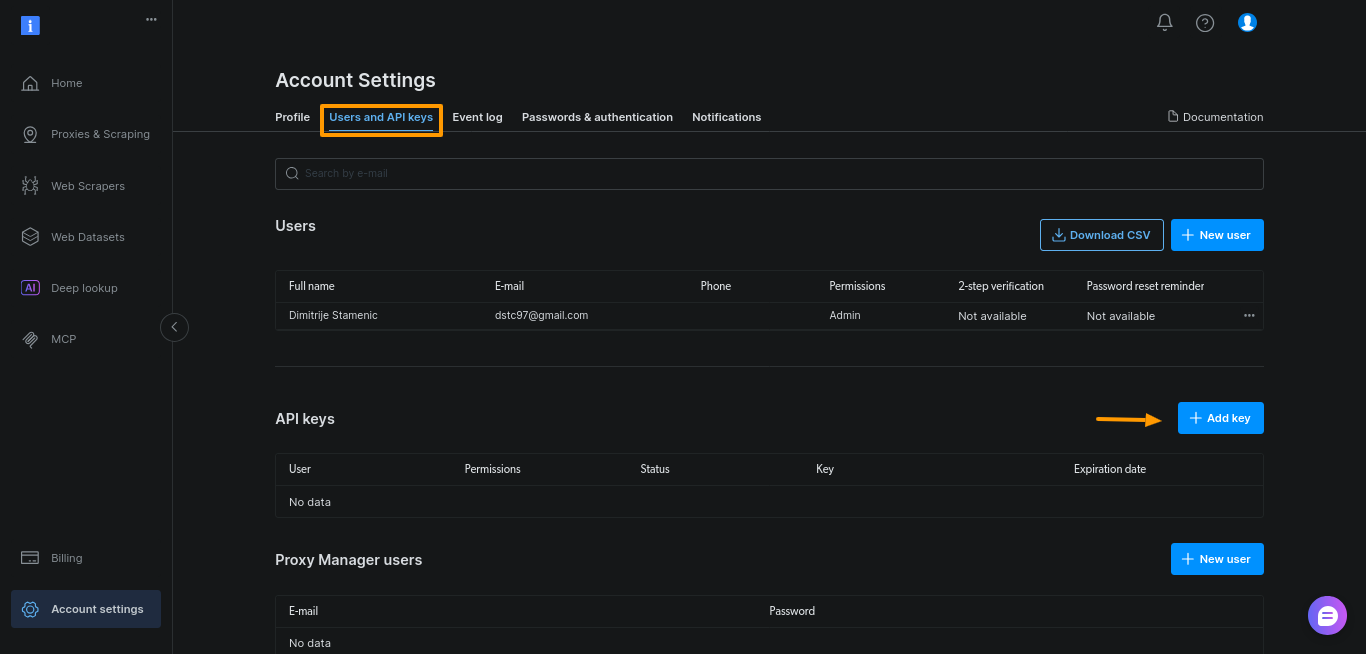
このガイドではデフォルト設定のまま「保存」をクリックしてください:
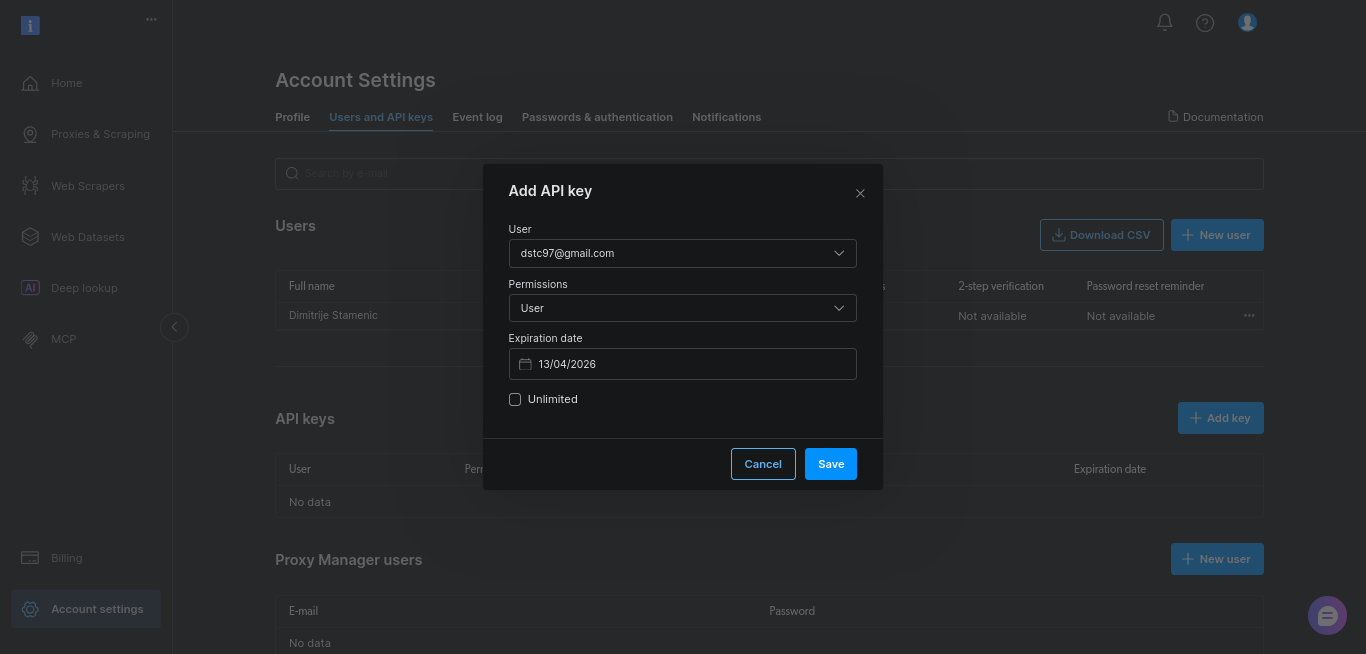
生成されたキーをコピーし、安全に保管してください。次の手順でBRIGHTDATA_TOKEN環境変数に追加します。
このトークンにより、エージェントはWeb MCP経由でライブWebデータにアクセスする権限を得ます。
ステップ #3: シンプルなPythonプロジェクトの設定
新しいプロジェクトディレクトリと仮想環境を作成します:
mkdir webmcp-langgraph-demo
cd webmcp-langgraph-demo
python3 -m venv webmcp-langgraph-venv 仮想環境を有効化します:
source webmcp-langgraph-venv/bin/activateこれにより依存関係が分離され、他のプロジェクトとの競合を回避できます。環境をアクティブにした状態で、必要な依存関係のみをインストールします。これらはBright DataのLangChainおよびLangGraph統合で共通して使用されるMCPアダプターと同じものです。これにより、エージェントが成長しても設定の一貫性が保たれます:
pip install
langgraph
langchain
langchain-openai
langchain-mcp-adapters
python-dotenvAPIキーを保存するための.envファイルを作成します:
touch .envOpenAI APIキーとBright Dataキーを.envファイルに貼り付けます:
OPENAI_API_KEY="your-openai-API-key"
BRIGHTDATA_TOKEN="your-brightdata-API-key"OPENAI_API_KEYの名前は変更しないでください。LangChain が自動的に読み込むため、コード内でキーを渡す必要はありません。
最後に、単一のPythonファイルを作成し、エージェントの役割・境界・ツール使用ルールを定義するシステムプロンプトを記述します:
# webmcp-langgraph-demo.py ファイル
SYSTEM_PROMPT = """あなたはウェブ調査アシスタントです。
タスク:
- Google検索結果と複数の情報源を用いてユーザーのトピックを調査する。
- 6~10個の簡潔な箇条書きを返す。
- 使用したURLのみを記載した短い「出典:」リストを追加する。
ツールの使用方法:
- まず検索ツールを呼び出しGoogle結果を取得
- 信頼性の高い結果を3~5件選択しスクレイピング
- スクレイピング失敗時は別の結果を試す
制約事項:
- 最大5件の情報源を使用
- 公式文書や一次資料を優先
- 迅速に処理:深掘りしない
"""ステップ #4: LangGraphノードの設定
これがエージェントの中核です。このループを理解すれば、他は実装の詳細に過ぎません。
コードを書く前に、構築しようとしているエージェントループを理解しておくと役立つ。図はシンプルなLangGraphエージェントループを示している:モデルは現在の状態を読み取り、外部データが必要かどうかを判断し、必要ならツールを呼び出し、結果を観察し、回答できるまで繰り返す。
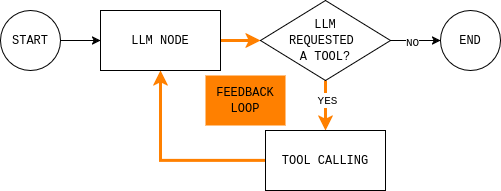
このループを実装するには、2つのノード(LLMノードとツール実行ノード)と、継続するか終了して最終応答を返すかを決定するルーティング関数が必要です。
LLMノードは現在の会話状態とシステムルールをモデルに送信し、応答またはツール呼び出しを返します。重要な点は、モデルの応答がすべてMessagesStateに追加されるため、後続のステップでモデルの決定内容とその理由を確認できることです。
def make_llm_call_node(llm_with_tools):
async def llm_call(state: MessagesState):
messages = [SystemMessage(content=SYSTEM_PROMPT)] + state["messages"]
ai_message = await llm_with_tools.ainvoke(messages)
return {"messages": [ai_message]}
return llm_callツール実行ノードは、モデルが要求したツールを実行し、その出力を観測値として記録します。この分離により、推論はモデル内で行われ、実行はコード内で行われます。
def make_tool_node(tools_by_name: dict):
async def tool_node(state: MessagesState):
last_ai_msg = state["messages"][-1]
tool_results = []
for tool_call in last_ai_msg.tool_calls:
tool = tools_by_name.get(tool_call["name"])
if not tool:
tool_results.append(
ToolMessage(
content=f"Tool not found: {tool_call['name']}",
tool_call_id=tool_call["id"],
)
)
continue
# MCPツールは通常非同期
observation = (
await tool.ainvoke(tool_call["args"])
if hasattr(tool, "ainvoke")
else tool.invoke(tool_call["args"])
)
tool_results.append(
ToolMessage(
content=str(observation),
tool_call_id=tool_call["id"],
)
)
return {"messages": tool_results}
return tool_node最後に、ルーティングルールはグラフがループを継続するか停止するかを決定します。実際には、単一の質問に答えます:モデルはツールを要求しましたか?
def should_continue(state: MessagesState) -> Literal["tool_node", END]:
last_message = state["messages"][-1]
if getattr(last_message, "tool_calls", None):
return "tool_node"
return ENDステップ #5: 全てを接続する
このステップのすべてはmain()関数内に記述されます。ここで認証情報を設定し、Web MCPに接続し、ツールをバインドし、グラフを構築し、クエリを実行します。
まず環境変数をロードし、BRIGHTDATA_TOKENを読み込みます。これにより認証情報をソースコードから分離し、トークンが欠落している場合に迅速に失敗処理を行います。
# .envから環境変数をロード
load_dotenv()
# Bright Dataトークンを読み込み
bd_token = os.getenv("BRIGHTDATA_TOKEN")
if not bd_token:
raise ValueError("BRIGHTDATA_TOKENが欠落しています")次に、MultiServerMCPClientを作成し、Web MCPエンドポイントを指します。このクライアントはエージェントをライブWebデータに接続します。
# Bright Data Web MCPサーバーに接続
client = MultiServerMCPClient({
"bright_data": {
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}",
"transport": "streamable_http",
}
})注:Web MCPはデフォルトでStreamable HTTPをトランスポートとして使用します。これは、従来のSSEベースの設定と比較してツールのストリーミングと再試行を簡素化します。このため、新しいMCP統合のほとんどがこのトランスポートを標準化しています。
次に利用可能なMCPツールを取得し、名前でインデックス付けします。ツール実行ノードはこのマップを使用して呼び出しをルーティングします。
# 利用可能な全MCPツール(検索、スクレイピングなど)を取得
tools = await client.get_tools()
tools_by_name = {tool.name: tool for tool in tools}LLMを初期化し、MCPツールをバインドします。これによりツール呼び出しが可能になります。
# LLMを初期化しMCPツール呼び出しを許可
llm = ChatOpenAI(model="gpt-4.1-mini", temperature=0)
llm_with_tools = llm.bind_tools(tools)先に示したLangGraphエージェントを構築します。StateGraph(MessagesState)を作成し、LLMノードとツールノードを追加し、ループに一致するようにエッジを接続します。
# LangGraphエージェントを構築
graph = StateGraph(MessagesState)
graph.add_node("llm_call", make_llm_call_node(llm_with_tools))
graph.add_node("tool_node", make_tool_node(tools_by_name))
# グラフフロー:
# START → LLM → (ツール?) → LLM → END
graph.add_edge(START, "llm_call")
graph.add_conditional_edges("llm_call", should_continue, ["tool_node", END])
graph.add_edge("tool_node", "llm_call")
agent = graph.compile()最後に、実際のプロンプトでエージェントを実行します。無限ループを防ぐため、recursion_limitを設定してください。
# 例:調査クエリ
topic = "Bright Data Web MCPとは何ですか?"
# エージェントの実行
result = await agent.invoke(
{
"messages": [
HumanMessage(content=f"このトピックを調査します:n{topic}")
]
},
# 無限ループ防止
config={"recursion_limit": 12})
# 最終応答を出力
print(result["messages"][-1].content)main() での実装例:
async def main():
# .envから環境変数をロード
load_dotenv()
# Bright Dataトークンを読み込み
bd_token = os.getenv("BRIGHTDATA_TOKEN")
if not bd_token:
raise ValueError("BRIGHTDATA_TOKENが不足しています")
# Bright Data Web MCPサーバーに接続
client = MultiServerMCPClient({
"bright_data": {
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}",
"transport": "streamable_http",
}
})
# 利用可能な全MCPツール(検索、スクレイピング等)を取得
tools = await client.get_tools()
tools_by_name = {tool.name: tool for tool in tools}
# LLMを初期化し、MCPツールを呼び出せるようにする
llm = ChatOpenAI(model="gpt-4.1-mini", temperature=0)
llm_with_tools = llm.bind_tools(tools)
# LangGraphエージェントを構築
graph = StateGraph(MessagesState)
graph.add_node("llm_call", make_llm_call_node(llm_with_tools))
graph.add_node("tool_node", make_tool_node(tools_by_name))
# グラフフロー:
# START → LLM → (ツール?) → LLM → END
graph.add_edge(START, "llm_call")
graph.add_conditional_edges("llm_call", should_continue, ["tool_node", END])
graph.add_edge("tool_node", "llm_call")
agent = graph.compile()
# 例:調査クエリ
topic = "Model Context Protocol (MCP) とは何か?LangGraphではどのように使用されるのか?"
# エージェントの実行
result = await agent.invoke(
{
"messages": [
HumanMessage(content=f"このトピックを調査してください:n{topic}")
]
},
# 無限ループ防止
config={"recursion_limit": 12}
)
# 最終応答を出力
print(result["messages"][-1].content)注:このエージェントの完全な実行可能バージョンは、このGitHubリポジトリで入手できます。リポジトリをクローンし、APIキーを
.envファイルに追加してスクリプトを実行すると、LangGraphとWeb MCPの連携ループが動作する様子を確認できます。
ブラウザ自動化によるウェブスクレイピング課題を克服するWeb MCP有料ツールの活用
静的スクレイピングは、サーバーレンダリングされたページを超えて、JavaScriptを多用したサイトやインタラクション駆動型サイトに移行すると機能しなくなります。これは、生のHTMLではなく実際のブラウザが必要なタイミングを決定する、静的 vs 動的の境界と同じものです。
また、実際のユーザー操作を必要とするページ(無限スクロール、ボタン駆動のページネーション)でも失敗し、ブラウザ自動化が唯一の信頼できる選択肢となります。
Web MCPはブラウザ自動化と高度なウェブスクレイピングをMCPツールとして提供します。エージェントにとっては、簡易ツールが不十分な場合の追加オプションに過ぎません。
Web MCPでブラウザ自動化ツールを有効化する
Web MCPのブラウザ自動化ツールは無料プランに含まれないため、まず左サイドバーの「Billing」メニューでBright Dataアカウントに資金を追加する必要があります。
次に、MCP設定でブラウザ自動化ツール群を有効化します。「MCP」セクションを開き、「編集」をクリック:
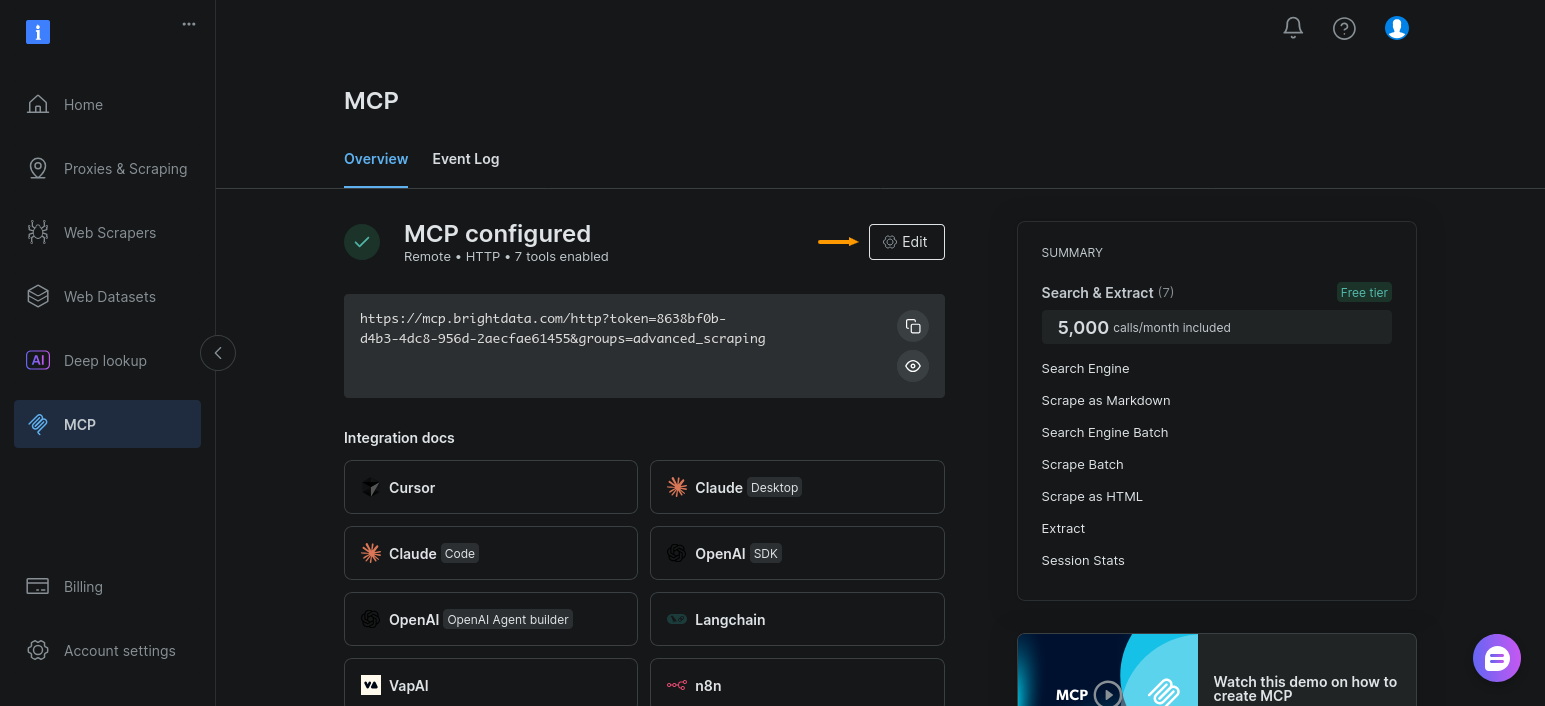
「ブラウザ自動化」を有効化し、「設定を続行」をクリック:
デフォルト設定のまま「コピー&閉じる」をクリック:
有効化後、エージェントがclient.get_tools() を呼び出すと、これらのツールは検索ツールやスクレイピングツールと共に表示されます。
既存のLangGraphエージェントをブラウザ自動化ツール用に拡張する
重要な点は単純です:LangGraphのアーキテクチャを変更する必要はありません。
エージェントは既に以下の機能を備えています:
- ツールを動的に検出
- それらをモデルにバインド
- 同じ
LLM→ツール→観察ループを通じて実行をルーティングする
ブラウザ自動化ツールの追加は、利用可能なツールの種類を変えるだけです。
実際の変更点はMCP接続URLのみです。基本エンドポイントではなく、高度なスクレイピングブラウザとブラウザ自動化ツール群をリクエストしてください:
# 高度なスクレイピングとブラウザ自動化を有効化
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}&groups=advanced_scraping,browser"スクリプトを再実行すると、client.get_tools()が追加のブラウザベースツールを返します。静的スクレイピングで結果が乏しい場合や不完全な場合に、モデルがこれらを選択できます。
結論
LangGraphは、状態・ルーティング・停止条件を制御可能な明確で検証可能なエージェントループを提供します。Web MCPは、ウェブスクレイピングロジックをプロンプトやコードに押し込まずに、そのループが実際のWebデータに確実にアクセスできるようにします。
結果として、関心の明確な分離が実現されます。モデルは実行すべき内容を決定し、LangGraphはループの実行方法を決定します。Bright Dataは検索、抽出、ブロック問題の処理を担当します。何かが失敗した場合、どこで、なぜ失敗したかを確認できます。
同様に重要なのは、この構成が行き止まりに縛られない点です。迅速な調査には基本のWeb MCPツールから始め、ウェブスクレイピングが機能しなくなったら有料ツールに移行できます。エージェントのアーキテクチャは変わらず、エージェントの到達範囲だけが拡大するのです。






