

このチュートリアルでは、以下の内容を学びます:
- Haystackとは何か、そしてBright Dataを統合することでAIパイプラインとエージェントがどのように進化するのか。
- 導入方法。
- カスタムツールを使用したHaystackとBright Dataの統合方法
- Web MCP経由で利用可能な60以上のツールにHaystackを接続する方法。
さっそく始めましょう!
Haystack:その概要とWebデータ取得ツールの必要性
Haystackは、LLMを用いた本番環境対応アプリケーション構築のためのオープンソースAIフレームワークです。モデル、ベクトルデータベース、ツールなどのコンポーネントをモジュール化されたワークフローに接続することで、RAGシステム、AIエージェント、高度なデータパイプラインの作成を可能にします。
Haystackは、AIプロジェクトを構想からデプロイまで進めるために必要な柔軟性、カスタマイズ性、スケーラビリティを提供します。これらすべてが、GitHubで23,000以上のスターを獲得したオープンソースライブラリで実現されています。
しかし、Haystackアプリケーションがどれほど洗練されていても、LLMの根本的な限界には直面します。静的なトレーニングデータによる知識の陳腐化と、ライブウェブアクセス機能の欠如です!
解決策は、Bright DataのようなAIのためのデータプロバイダーとの統合です。ウェブスクレイピング、検索、ブラウザ自動化などのツールを提供し、AIシステムの真の潜在能力を解き放ちます!
前提条件
このチュートリアルを実行するには以下が必要です:
- ローカルにインストールされたPython 3.9以上
- APIキーが設定済みのBright Dataアカウント。
- OpenAI APIキー(またはHaystackがサポートする他のLLMのAPIキー)。
まだ設定していない場合は、公式ガイドに従ってアカウントを設定し、Bright Data APIキーを生成してください。すぐに必要になるため、安全な場所に保管してください。
Bright Dataの製品・サービスに関する知識や、HaystackにおけるツールとMCP統合の基本的な理解があるとさらに役立ちます。
簡略化のため、仮想環境が設定済みのPythonプロジェクトが既に存在すると仮定します。以下のコマンドでHaystackをインストールしてください:
pip install haystack-aiこれでHaystackにおけるBright Data統合に必要な準備は完了です。ここでは2つのアプローチを解説します:
HaystackにおけるBright Data連携カスタムツールの定義
HaystackでBright Dataの機能を利用する方法の一つは、カスタムツールを定義することです。これらのツールはカスタム関数内のAPIを介してBright Data製品と連携します。
このプロセスを簡略化するため、Bright Data Python SDKを利用します。このSDKはPython APIを提供し、以下の機能を簡単に呼び出せます:
- Web Unlocker API: 単一リクエストで任意のウェブサイトをスクレイピングし、クリーンなHTMLまたはJSONを取得。プロキシ、ブロック解除、ヘッダー、CAPTCHA処理はすべて自動化されます。
- SERP API: Google、Bingなど多数の検索エンジンから大規模に検索結果を収集。ブロックを気にせず利用可能。
- ウェブスクレイピングAPI:Amazon、Instagram、LinkedIn、Yahoo Financeなど人気サイトから構造化・パース済みデータを取得。
- その他のBright Dataソリューション…
主要なSDKメソッドをHaystack対応ツールに変換し、あらゆるAIエージェントやパイプラインがBright Dataによるウェブデータ取得の恩恵を受けられるようにします!
ステップ #1: Bright Data Python SDK のインストールと設定
brightdata-sdkPyPIパッケージを通じてBright Data Python SDKをインストールすることから始めます:
pip install brightdata-sdkライブラリをインポートし、BrightDataClientインスタンスを初期化します:
import os
from brightdata import BrightDataClient
os.environ["BRIGHTDATA_API_TOKEN"] = "<YOUR_BRIGHT_DATA_API_KEY>" # Bright Data APIキーに置き換えてください
# Bright Data Python SDKクライアントを初期化
client = BrightDataClient(
token=BRIGHT_DATA_API_KEY,
)<YOUR_BRIGHT_DATA_API_KEY>プレースホルダーは、「前提条件」セクションで生成した API キーに置き換えてください。
本番環境向けのコードでは、スクリプト内にAPIキーをハードコーディングしないでください。Bright Data Python SDKはBRIGHTDATA_API_TOKEN環境変数からAPIキーを取得するため、環境変数をグローバルに設定するか、python-dotenvパッケージを使用して.envファイルから読み込んでください。
BrightDataClientは、Bright DataアカウントにデフォルトのWeb UnlockerゾーンとSERP APIゾーンを自動的に設定します: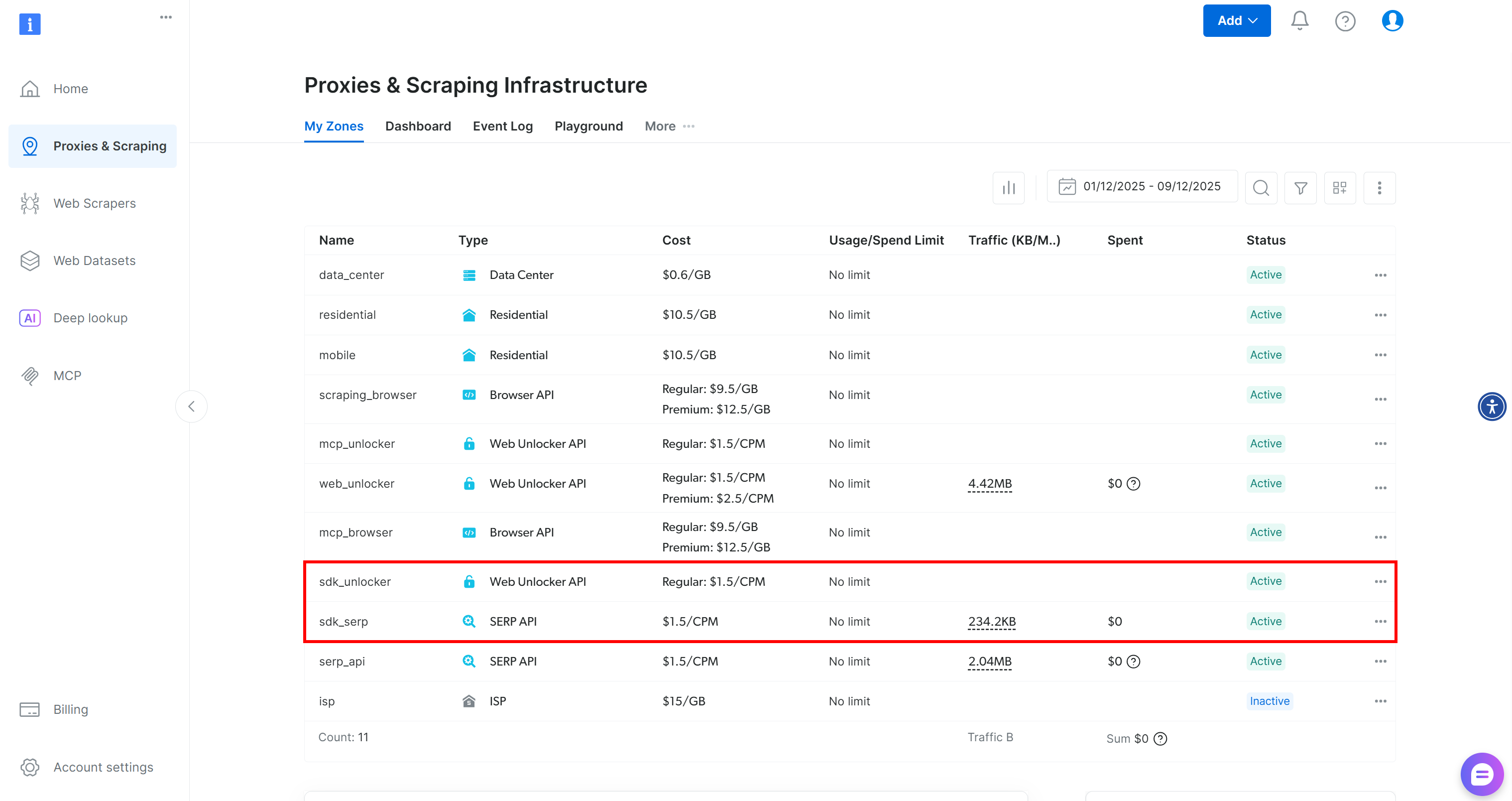
これらの2つのゾーンは、SDKが60以上のツールを提供するために必須です。
カスタムゾーンを既に設定済みの場合は、ドキュメントの説明に従って指定してください:
client = BrightDataClient(
serp_zone="serp_api", # 自身のSERP APIゾーン名に置き換えてください
web_unlocker_zone="web_unlocker", # 自身のWeb Unlocker APIゾーン名に置き換えてください
)素晴らしい!これでBright Data Python SDKメソッドをHaystackツールに変換する準備が整いました。
ステップ #2: SDK 関数をツールに変換する
このガイドセクションでは、Bright Data Python SDKのSERP APIおよびWeb UnlockerメソッドをHaystackツールに変換する方法を説明します。これを習得すれば、他のSDKメソッドや直接API呼び出しも簡単にHaystackツールに変換できるようになります。
まず、SERP APIメソッドをAI対応ツールとして実行できるように変換します:
from brightdata import SearchResult
from typing import Union, List
import json
from haystack.tools import Tool
parameters = {
"type": "object",
"properties": {
"query": {
"type": ["string", "array"],
"items": {"type": "string"},
"description": "Googleで検索を実行するクエリまたはクエリのリスト。"
},
"kwargs": {
"type": "object",
"description": "検索用の追加オプションパラメータ(例:location, language, device, num_results)"
}
},
"required": ["query"]
}
def serp_api_output_handler(results: Union[SearchResult, List[SearchResult]]) -> str:
if isinstance(results, list):
# SearchResultインスタンスのリストを処理
output = [result.data for result in results]
else:
# 単一のSearchResultを処理
output = results.data
return json.dumps(output)
serp_api_tool = Tool(
name="serp_api_tool",
description="Bright Data SERP APIを呼び出し、Googleからウェブ検索を実行してSERPデータを取得します。",
parameters=parameters,
function=client.search.google,
outputs_to_string={ "handler": serp_api_output_handler },
outputs_to_state= {
"documents": {"handler": serp_api_output_handler }
}
)上記のスニペットは、Bright Data SERP API用のHaystackツールを定義しています。ツールの構築には、名前、説明、入力パラメータに一致するJSONスキーマ、およびツールに変換する関数が必要です。
client.search.google()は特殊なオブジェクトを返します。そのため、関数の出力を文字列に変換するカスタム出力ハンドラーが必要です。このハンドラーは結果を JSON に変換し、文字列出力とエージェント状態の両方にマッピングします。
定義したツールは、AIエージェントやパイプラインがGoogle検索を実行し構造化SERPデータを取得するために使用できます。
同様に、Web Unlockerメソッドを呼び出すツールを作成します:
parameters = {
"type": "object",
"properties": {
"url": {
"type": ["string", "array"],
"items": {"type": "string"},
"description": "スクレイピング対象のURLまたはURLリスト。"
},
"country": {
"type": "string",
"description": "スクレイピングをローカライズするためのオプションの国コード。"
},
},
"required": ["url"]
}
def web_unlocker_output_handler(results: Union[ScrapeResult, List[ScrapeResult]]) -> str:
if isinstance(results, list):
# ScrapeResultインスタンスのリストを処理
output = [result.data for result in results]
else:
# 単一のScrapeResultを処理
output = results.data
return json.dumps(output)
web_unlocker_tool = Tool(
name="web_unlocker_tool",
description="Bright Data Web Unlocker APIを呼び出し、ウェブページをスクレイピングしてコンテンツを取得します。",
parameters=parameters,
function=client.scrape.generic.url,
outputs_to_string={"handler": web_unlocker_output_handler},
outputs_to_state={"scraped_data": {"handler": web_unlocker_output_handler}}
)この新しいツールにより、AIエージェントは、アンチスクレイピングやアンチボット対策で保護されている場合でも、ウェブページをスクレイピングし、そのコンテンツにアクセスできるようになります。
素晴らしい!これでBright Data Haystackツールが2つ利用可能になりました。
ステップ #3: ツールをHaystack AIエージェントに渡す
上記のツールは直接呼び出す、チャットジェネレーターに渡す、Haystackパイプラインで使用する、AIエージェントに統合するといった方法があります。ここではAIエージェントへの統合方法をご紹介しますが、ドキュメントに従えば他の3つの方法も簡単に試せます。
まず、Haystack AIエージェントにはLLMエンジンが必要です。この例ではOpenAIモデルを使用しますが、サポートされている他のLLMでも問題ありません:
from haystack.components.generators.chat import OpenAIChatGenerator
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # OpenAI APIキーに置き換えてください
# LLMエンジンの初期化
chat_generator = OpenAIChatGenerator(
model="gpt-5-mini"
)前述の通り、本番環境では環境変数からOpenAI APIキーを読み込んでください。ここではgpt-5-miniモデルを設定しましたが、ツール呼び出しをサポートするOpenAIモデルであればどれでも動作します。その他のサポートされているジェネレータも互換性があります。
次に、LLMエンジンとツールを組み合わせてHaystack AIエージェントを作成します:
from haystack.components.agents import Agent
agent = Agent(
chat_generator=chat_generator,
tools=[serp_api_tool, web_unlocker_tool], # Bright Dataツール
)2つのBright Dataツールがエージェントのtools引数に渡されている点に注目してください。これにより、OpenAI GPT-5 Miniで駆動されるAIエージェントがカスタムBright Dataツールを呼び出せるようになります。これで完了です!
ステップ #4: AIエージェントの実行
HaystackとBright Dataの連携をテストするため、ウェブ検索とウェブスクレイピングを伴うタスクを考えます。例えば、次のプロンプトを使用します:
Google社に関する最新株式市場ニュースを異なるトピックごとに上位3件特定し、記事にアクセスして各記事の要約を提供してください。 これにより、Googleへの投資に関心のある方への迅速な情報提供が可能になります。
以下のスニペットを使用して、Bright Data搭載のHaystackエージェントでこのプロンプトを実行します:
from haystack.dataclasses import ChatMessage
agent.warm_up()
prompt = """
Google社に関する異なるトピックの最新株式市場ニュース上位3件を特定し、記事にアクセスして各記事の要約を提供してください。
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])次に、AIエージェントが生成した応答とツール使用の詳細を以下のように出力します:
for msg in response["messages"]:
role = msg._role.value
if role == "tool":
# ツール出力をログ出力
for content in msg._content:
print("=== Tool Output ===")
print(json.dumps(content.result, indent=2))
elif role == "assistant":
# アシスタントの最終メッセージをログ出力
for content in msg._content:
if hasattr(content, "text"):
print("=== Assistant Response ===")
print(content.text)完璧です!あとは完全なコードを確認し、動作を検証するために実行するだけです。
ステップ #5: 完全なコード
Bright Dataツールに接続したHaystack AIエージェントの最終コードは以下の通りです:
# pip install haystack-ai brightdata-sdk
import os
from brightdata import BrightDataClient, SearchResult, ScrapeResult
from typing import Union, List
import json
from haystack.tools import Tool
from haystack.components.generators.chat import OpenAIChatGenerator
from haystack.components.agents import Agent
from haystack.dataclasses import ChatMessage
# 必要な環境変数を設定
os.environ["BRIGHTDATA_API_TOKEN"] = "<YOUR_BRIGHT_DATA_API_KEY>" # Bright Data APIキーに置き換えてください
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # OpenAI APIキーに置き換えてください
# Bright Data Python SDKクライアントを初期化
client = BrightDataClient(
serp_zone="serp_api", # 自身のSERP APIゾーン名に置き換える
web_unlocker_zone="web_unlocker", # 自身のWeb Unlocker APIゾーン名に置き換える
)
# Bright Data Python SDKのclient.search.google()をHaystackツールに変換
parameters = {
"type": "object",
"properties": {
"query": {
"type": ["string", "array"],
"items": {"type": "string"},
"description": "Google で実行する検索クエリまたはクエリのリストです。"
},
"kwargs": {
"type": "object",
"description": "検索用の追加オプションパラメータ(例:location, language, device, num_results)"
}
},
"required": ["query"]
}
def serp_api_output_handler(results: Union[SearchResult, List[SearchResult]]) -> str:
if isinstance(results, list):
# SearchResultインスタンスのリストを処理
output = [result.data for result in results]
else:
# 単一のSearchResultを処理
output = results.data
return json.dumps(output)
serp_api_tool = Tool(
name="serp_api_tool",
description="Bright Data SERP APIを呼び出し、Googleからウェブ検索を実行してSERPデータを取得します。",
parameters=parameters,
function=client.search.google,
outputs_to_string={ "handler": serp_api_output_handler },
outputs_to_state= {
"documents": {"handler": serp_api_output_handler }
})
# Bright Data Python SDKのclient.scrape.generic.url()をHaystackツールに変換
parameters = {
"type": "object",
"properties": {
"url": {
"type": ["string", "array"],
"items": {"type": "string"},
"description": "スクレイピング対象のURLまたはURLリスト。
},
"country": {
"type": "string",
"description": "スクレイピングをローカライズするためのオプションの国コード。"
},
},
"required": ["url"]
}
def web_unlocker_output_handler(results: Union[ScrapeResult, List[ScrapeResult]]) -> str:
if isinstance(results, list):
# ScrapeResultインスタンスのリストを処理
output = [result.data for result in results]
else:
# 単一のScrapeResultを処理
output = results.data
return json.dumps(output)
web_unlocker_tool = Tool(
name="web_unlocker_tool",
description="Bright Data Web Unlocker APIを呼び出し、ウェブページをスクレイピングしてコンテンツを取得します。",
parameters=parameters,
function=client.scrape.generic.url,
outputs_to_string={"handler": web_unlocker_output_handler},
outputs_to_state={"scraped_data": {"handler": web_unlocker_output_handler}}
)
# LLMエンジンの初期化
chat_generator = OpenAIChatGenerator(
model="gpt-5-mini")
# Haystack AIエージェントの初期化
agent = Agent(
chat_generator=chat_generator,
tools=[serp_api_tool, web_unlocker_tool], # Bright Dataツール
)
## エージェントを実行
agent.warm_up()
prompt = """
Google社に関する最新株式市場ニュースを異なるトピックごとに上位3件特定し、記事にアクセスして各記事の要約を提供してください。
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])
## ツール使用情報を付加した構造化形式で出力
for msg in response["messages"]:
role = msg._role.value
if role == "tool":
# ツール出力をログ出力
for content in msg._content:
print("=== Tool Output ===")
print(json.dumps(content.result, indent=2))
elif role == "assistant":
# アシスタントの最終メッセージをログ出力
for content in msg._content:
if hasattr(content, "text"):
print("=== Assistant Response ===")
print(content.text)さあ、完成です!わずか130行ほどのコードで、ウェブ検索やウェブスクレイピングを行い、幅広いタスクを遂行し、複数のユースケースをカバーできるAIエージェントを構築しました。
ステップ #6: 統合のテスト
スクリプトを実行すると、次のような結果が表示されるはずです: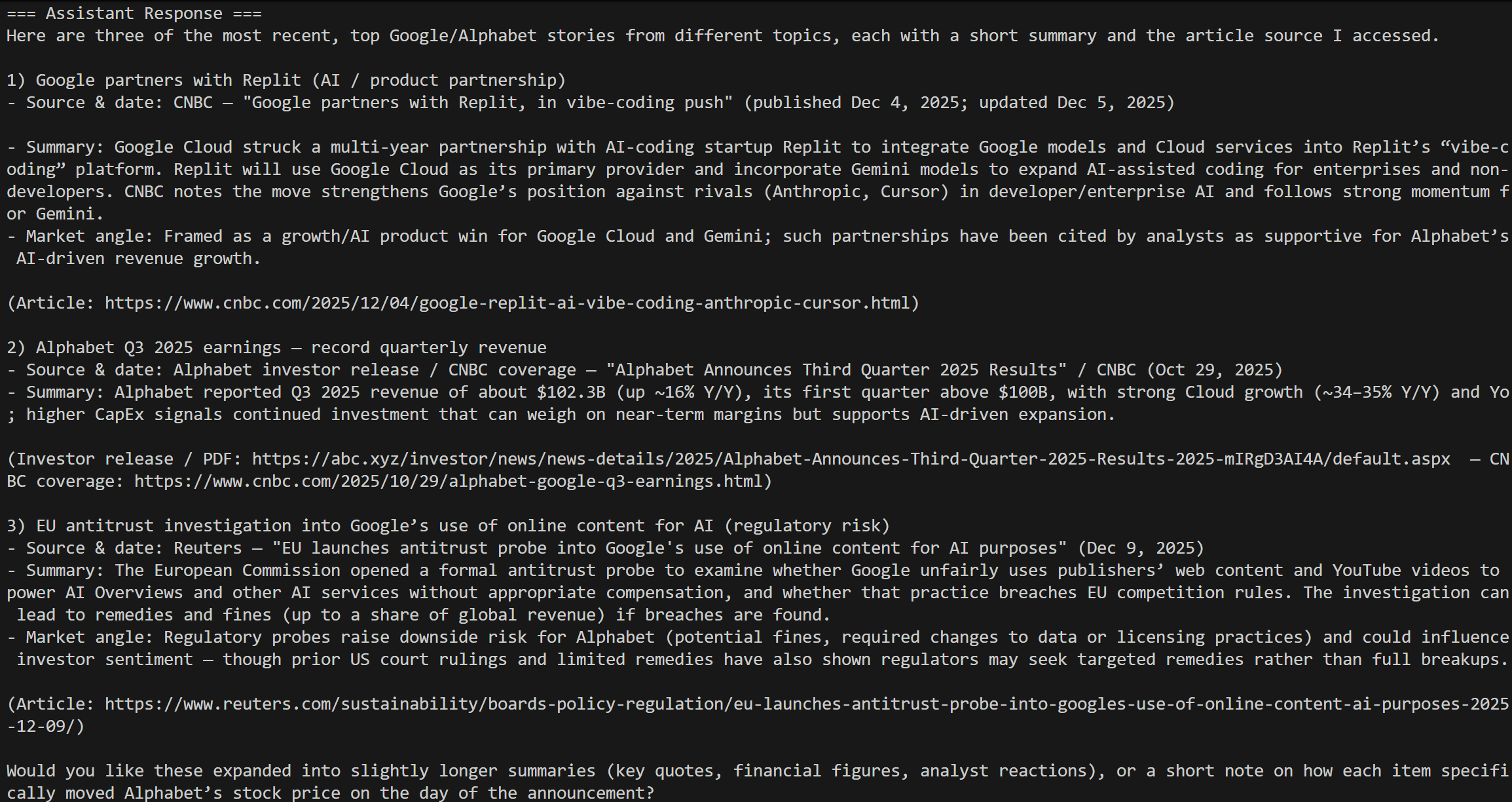
これは今日の「Google 株価ニュース」クエリに対する結果であり、期待通りです!
標準的なAIエージェントだけではこれを実現できません。汎用LLMは外部ツールなしではライブウェブや検索エンジンに直接アクセスできません。組み込みのグラウンディングツールも通常は制限が多く、遅く、Bright Dataのようにあらゆるウェブサイトにアクセスするスケーラビリティを持ちません。
ログにはSERP API呼び出しの詳細が全て記録されます: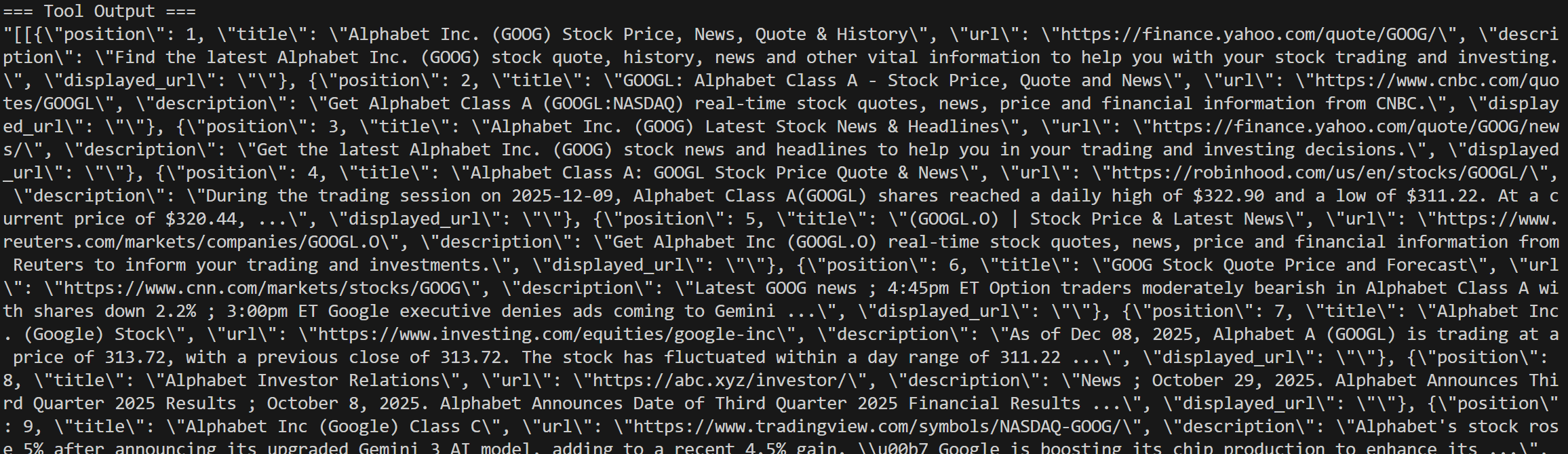
Google検索結果から選択したニュース記事に対するWeb Unlocker呼び出しも確認できます: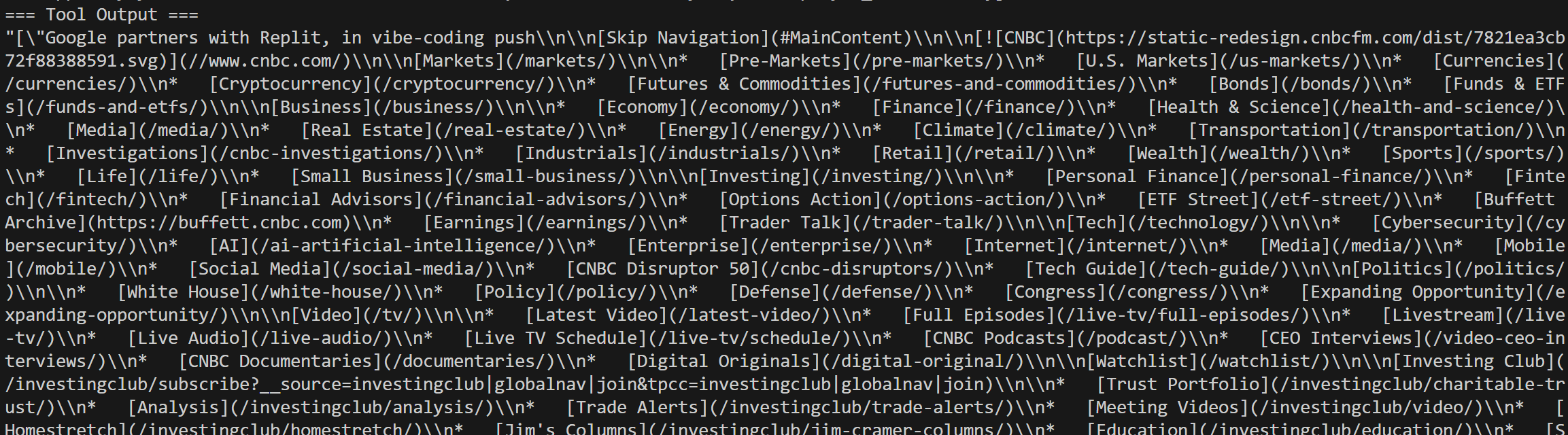
これで完成です! Bright Dataツールと完全に統合されたHaystack AIエージェントが利用可能になりました。
HaystackにおけるBright Data Web MCP統合
HaystackとBright Dataを接続する別の方法はWeb MCP経由です。このMCPサーバーは、Bright Dataの最も強力な機能の多くを、AI対応ツールの大規模なコレクションとして公開しています。
Web MCPには、Bright Dataのウェブ自動化およびデータ収集インフラストラクチャを基盤に構築された60以上のツールが含まれています。無料プランでも、以下の2つの非常に有用なツールにアクセスできます:
| ツール | 説明 |
|---|---|
search_engine |
Google、Bing、Yandexの検索結果をJSONまたはMarkdown形式で取得します。 |
scrape_as_markdown |
あらゆるウェブページを、ボット対策機能を回避しながらクリーンなMarkdown形式にスクレイピングします。 |
さらに、プレミアムティア(Proモード)を有効にすると、Web MCPはAmazon、Zillow、LinkedIn、YouTube、TikTok、Google Mapsなど主要プラットフォームの構造化データ抽出を可能にします。加えて、自動化されたブラウザ操作のためのツールも付属しています。
Haystack内でBright DataのWeb MCPを活用する方法を見ていきましょう!
前提条件
オープンソースのWeb MCPパッケージはNode.js上で構築されています。つまり、Web MCPをローカルで実行し、Haystack AIエージェントを接続するには、マシンにNode.jsがインストールされている必要があります。
あるいは、ローカル環境のセットアップが一切不要なリモートWeb MCPインスタンスに接続することも可能です。
ステップ #1: MCP–Haystack 統合のインストール
Pythonプロジェクトで以下のコマンドを実行し、MCP–Haystack統合をインストールします:
pip install mcp-haystackこのパッケージは、ローカルまたはリモートのMCPサーバーに接続するためのクラスにアクセスするために必要です。
ステップ #2: Web MCP のローカルテスト
HaystackをBright DataのWeb MCPに接続する前に、ローカルマシンでMCPサーバーをローカル実行できることを確認してください。
注: Web MCPはリモートサーバーとしても利用可能です(SSEおよびストリーム対応HTTP経由)。このオプションはエンタープライズグレードのシナリオに適しています。
まずBright Dataアカウントを作成してください。既にアカウントをお持ちの場合はログインしてください。迅速なセットアップには、ダッシュボードの「MCP」セクションの手順に従ってください: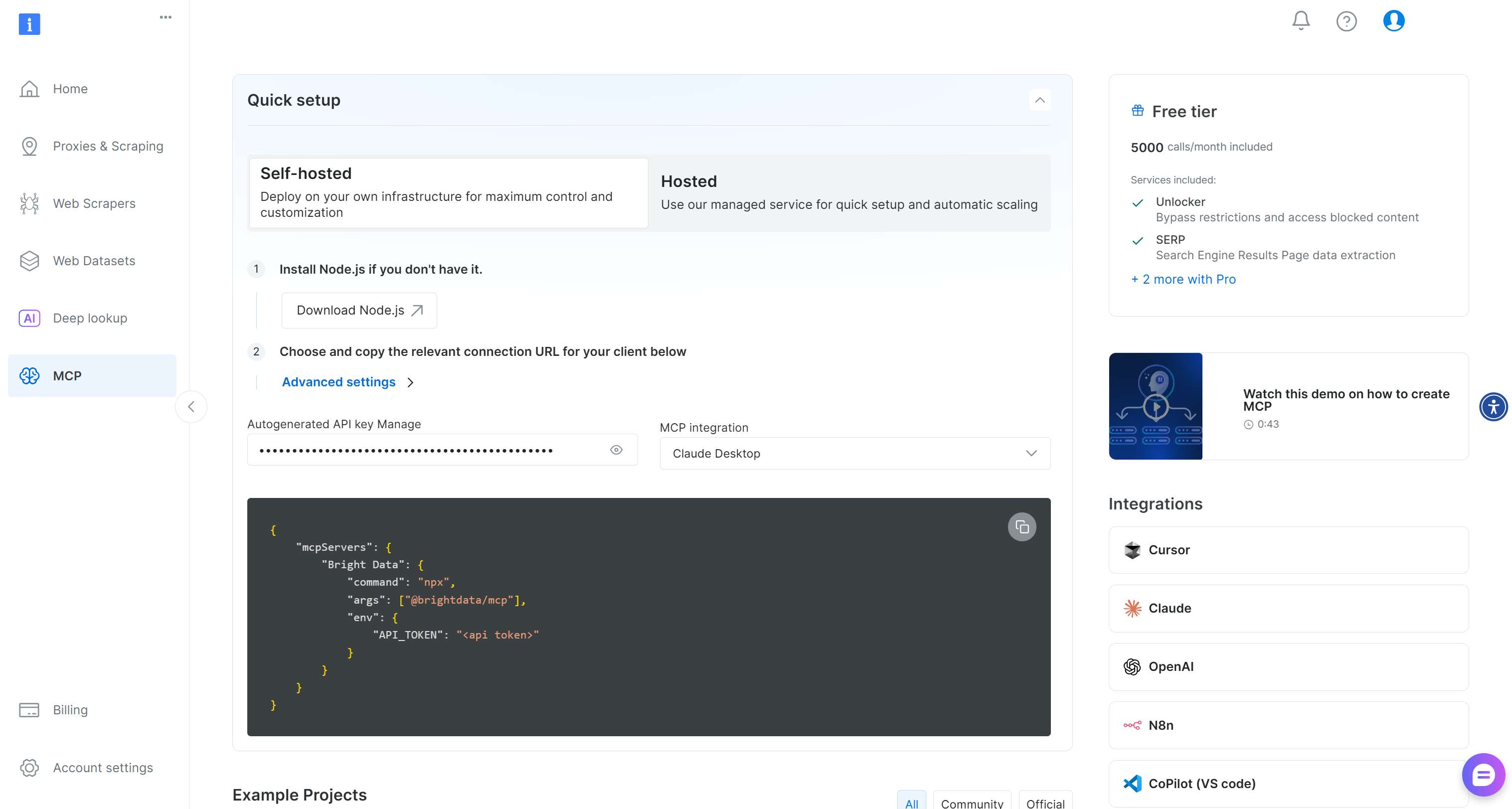
追加のガイダンスが必要な場合は、以下の手順を参照してください。
まず、Bright Data APIキーを生成します。ローカルWeb MCPインスタンスの認証にすぐに必要となるため、安全な場所に保管してください。
次に、@brightdata/mcpパッケージを使用して Web MCP をマシンにグローバルインストールします:
npm install -g @brightdata/mcpMCPサーバーが動作することを確認するため、以下を実行してください:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpまたは、PowerShellで同等の操作を実行します:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp<YOUR_BRIGHT_DATA_API>プレースホルダーを Bright Data API キーに置き換えてください。これら 2 つの(同等の)コマンドは、必要なAPI_TOKEN環境変数を設定し、Web MCP サーバーを起動します。
成功した場合、以下のようなログが表示されます:
初回起動時、Web MCPはBright Dataアカウント内に以下の2つのゾーンを作成します:
mcp_unlocker:Web Unlocker 用のゾーン。mcp_browser:ブラウザAPI用のゾーン。
これらの2つのサービスは、Web MCPが60以上のツールを動作させるために必要です。
ゾーンが作成されたことを確認するには、ダッシュボードの「プロキシとスクレイピングインフラ」ページにアクセスしてください。テーブルに両方のゾーンがリストされていることを確認できます:
なお、Web MCPの無料プランではsearch_engineとscrape_as_markdownツールのみが利用可能です。
全ツールを解放するには、環境変数PRO_MODE="true"を設定して Pro モードを有効化してください:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpWindowsの場合:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpProモードでは60以上のツールがすべて利用可能になりますが、無料プランには含まれず追加料金が発生する可能性があります。
完了!これでWeb MCPサーバーがローカルで正常に動作することを確認できました。Haystackの設定でサーバーをローカル起動し接続するため、プロセスを終了させてください。
ステップ #3: Haystack で Web MCP に接続する
Web MCPに接続するには以下のコードを使用します:
from haystack_integrations.tools.mcp import StdioServerInfo, MCPToolset
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Bright Data APIキーに置き換えてください
# STDIO経由でWeb MCPサーバーに接続するための設定
web_mcp_server_info = StdioServerInfo(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Proツールを有効化(オプション)
}
)上記のStdioServerInfoオブジェクトは、以前にテストしたnpxコマンドを反映していますが、Haystack が使用できる形式でラップしています。また、Web MCP サーバーを設定するために必要な環境変数も含まれています:
API_TOKEN: 必須。先に生成したBright Data APIキーを設定してください。PRO_MODE: オプション。無料プランのまま検索エンジンとマークダウン形式スクレイピングツールのみを利用する場合は削除してください。
次に、Web MCPが公開する全ツールにアクセスするには以下を実行します:
web_mcp_toolset = MCPToolset(
server_info=web_mcp_server_info,
invocation_timeout=180 # 3分
)すべてのツールを読み込み情報を出力して統合が機能することを確認します:
web_mcp_toolset.warm_up()
for tool in web_mcp_toolset.tools:
print(f"Name: {tool.name}")
print(f"Description: {tool.name}n")Proモードを使用している場合、60以上の全ツールが利用可能であることが確認できるはずです:
これで完了です!HaystackにおけるBright Data Web MCPの統合は完璧に機能しています。
ステップ #4: 統合のテスト
すべてのツールの設定が完了したら、AIエージェント(前述のデモ参照)またはHaystackパイプラインでそれらを使用します。例えば、AIエージェントに次のプロンプトを処理させたい場合:
以下のCrunchbase企業URLから有用なインサイトを含むMarkdownレポートを返す:
"https://www.crunchbase.com/organization/apple"これはWeb MCPツールを必要とするタスクの一例です。
エージェントで以下のように実行します:
agent = Agent(
chat_generator=chat_generator,
tools=web_mcp_toolset, # Bright Data Web MCPツール
)
## エージェントの実行
agent.warm_up()
prompt = """
以下のCrunchbase企業URLから有用なインサイトを含むMarkdownレポートを返す:
"https://www.crunchbase.com/organization/apple"
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])結果は次のようになります: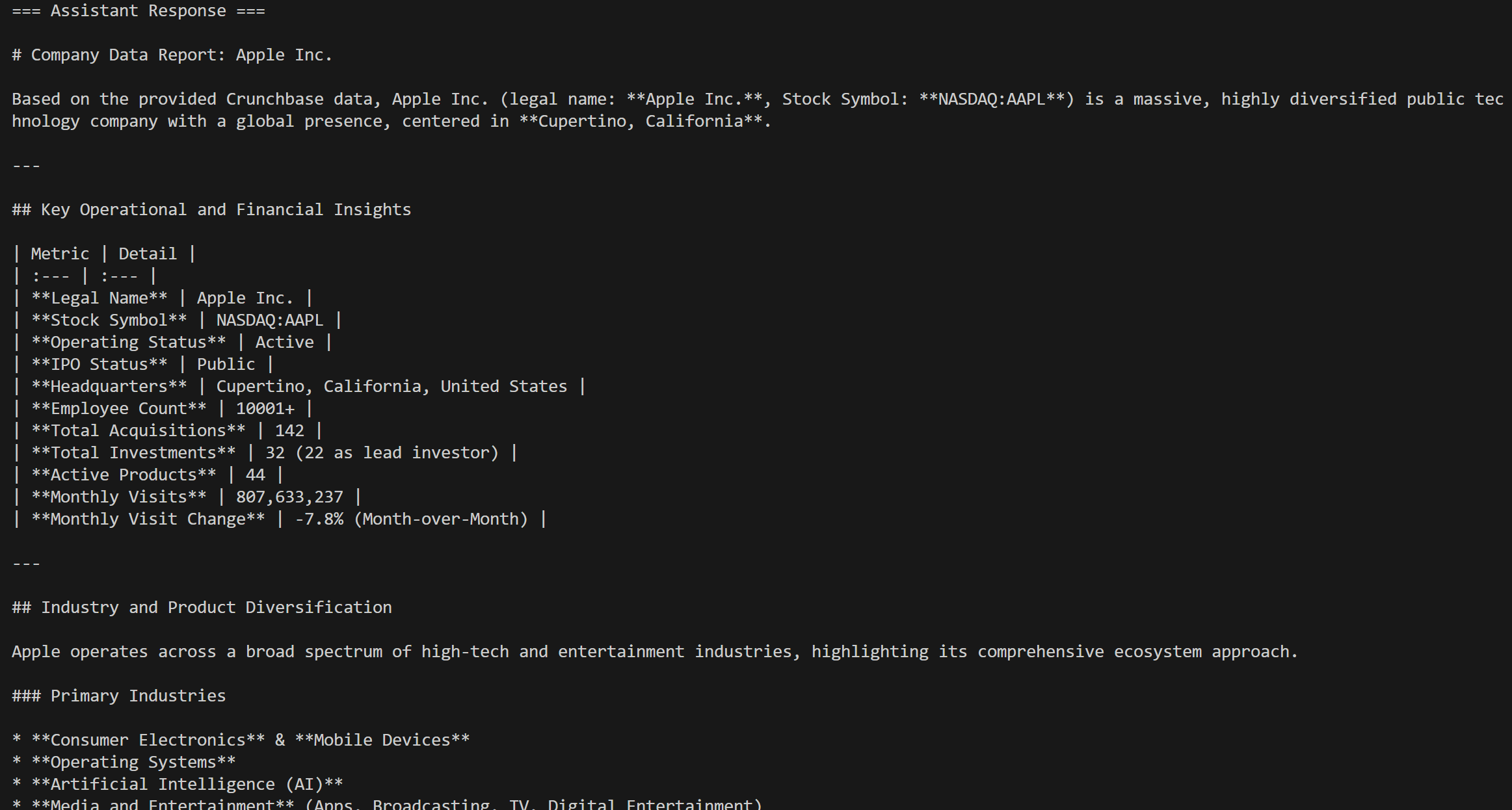
呼び出されるツールはweb_data_crunchbase_companyプロツールです: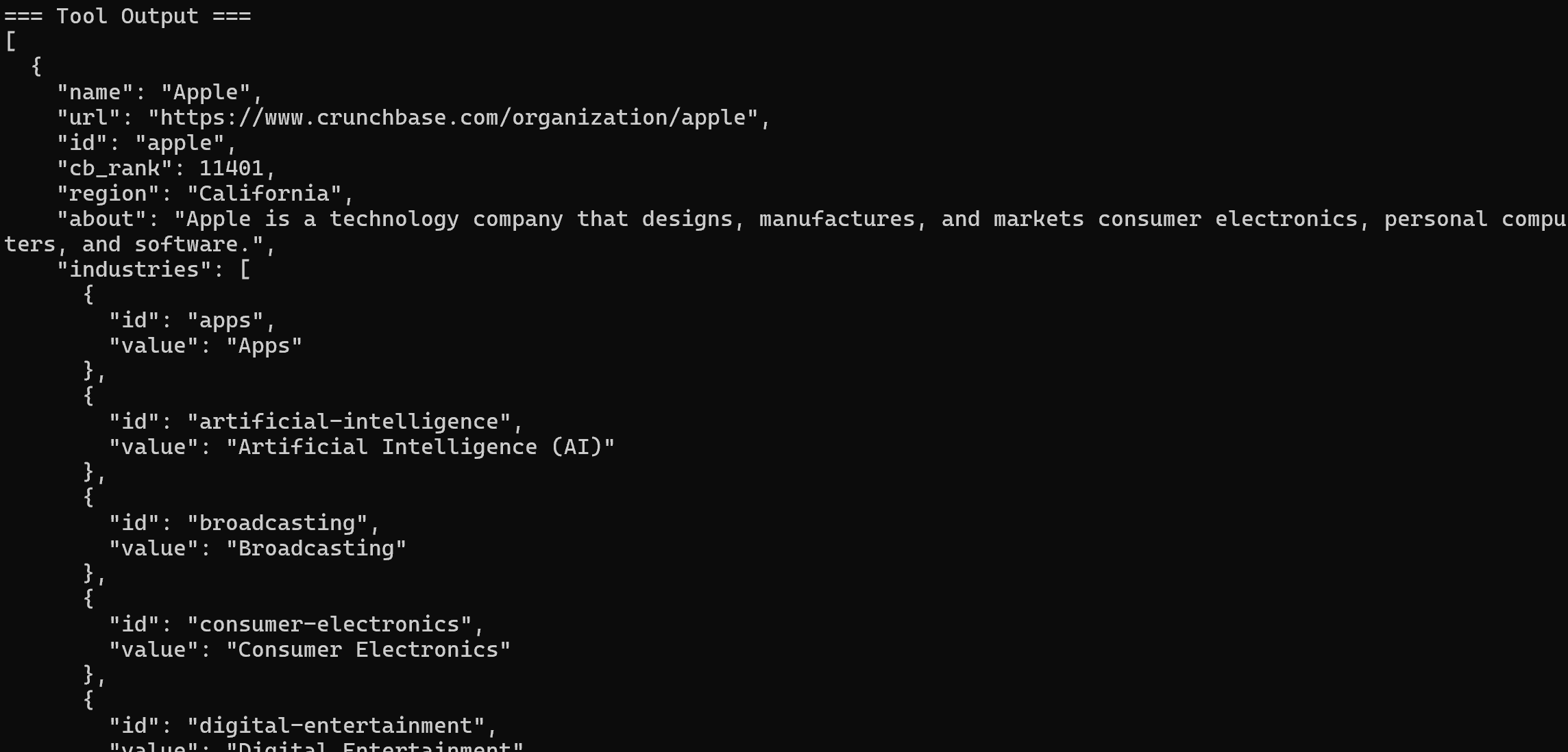
内部では、このツールは指定されたCrunchbaseページから構造化された情報を抽出するためにBright Data Crunchbaseスクレイパーに依存しています。
Crunchbaseのスクレイピングは、通常のLLMだけでは絶対に処理できません!これは、HaystackのWeb MCP統合が持つ力を証明しており、数多くのユースケースをサポートしています。
ステップ #5: 完全なコード
HaystackでBright Data Web MCPを接続する完全なコードは以下の通りです:
# pip install haystack-ai mcp-haystack
from haystack_integrations.tools.mcp import StdioServerInfo, MCPToolset
import os
from haystack.components.generators.chat import OpenAIChatGenerator
from haystack.components.agents import Agent
from haystack.dataclasses import ChatMessage
import json
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Bright Data APIキーに置き換えてください
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Bright Data APIキーに置き換えてください
# STDIO経由でWeb MCPサーバーに接続するための設定
web_mcp_server_info = StdioServerInfo(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Proツールを有効化(オプション)
})
# Web MCPサーバーが公開する利用可能なMCPツールを読み込み
web_mcp_toolset = MCPToolset(
server_info=web_mcp_server_info,
invocation_timeout=180, # 3分
tool_names=["web_data_crunchbase_company"]
)
# LLMエンジンを初期化
chat_generator = OpenAIChatGenerator(
model="gpt-5-mini")
# Haystack AIエージェントを初期化
agent = Agent(
chat_generator=chat_generator,
tools=web_mcp_toolset, # Bright Data Web MCPツール
)
## エージェントを実行
agent.warm_up()
prompt = """
以下のCrunchbase企業URLから有用なインサイトを含むMarkdownレポートを返す:
"https://www.crunchbase.com/organization/apple"
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])
## ツール使用情報を含む構造化形式で出力を表示
for msg in response["messages"]:
role = msg._role.value
if role == "tool":
# ツール出力をログ出力
for content in msg._content:
print("=== Tool Output ===")
print(json.dumps(content.result, indent=2))
elif role == "assistant":
# アシスタントの最終メッセージをログ出力
for content in msg._content:
if hasattr(content, "text"):
print("=== Assistant Response ===")
print(content.text)結論
本ガイドでは、カスタムツールまたはMCPを介したBright DataのHaystack統合活用方法を学びました。
この設定により、Haystackエージェントやパイプライン内のAIモデルがウェブ検索を実行し、構造化データを抽出、ライブウェブデータフィードにアクセス、ウェブインタラクションを自動化できるようになります。これらすべては、Bright DataのAI向けエコシステムが提供する包括的なサービス群によって実現されています。
Bright Dataアカウントを無料で作成し、強力なAI対応ウェブデータツールの探索を始めましょう!






