

このガイドでは、以下について学びます:
- GitHub Copilot CLIとは何か、そして何を提供するか。
- ウェブアクセスで拡張することで、なぜ次のレベルへと引き上げられるのか。
- Bright DataがどのようにGitHub Copilot CLIとのウェブスクレイピング、検索、ディスカバリー、ブラウザ自動化のための統合を実現するか。
- MCPを使用してBright DataをGitHub Copilot CLIに接続する方法。
- Agent SkillsでCopilot CLIにBright Dataの知識を装備する方法。
- GitHub Copilot CLI + Bright Dataの統合で何が可能になるか、完全な例とともに。
さっそく始めましょう!
GitHub Copilot CLIとは?
GitHub Copilot CLIは、オープンソースのAI搭載コーディングエージェントで、Copilotをターミナルに直接導入し、コマンドラインを離れることなく自然言語によるコーディング、デバッグ、GitHubとのやり取りを可能にします。
GitHubで1万以上のスターを獲得しており、グローバルな開発者コミュニティからの強い信頼とサポートを反映しています。なお、このプロジェクトはGitHubチームによって構築・維持されています。
GitHub Copilot CLIの主な機能は次のとおりです:
- 自然言語プログラミング:平易な英語でタスクを説明して、CLI上でコードを直接生成、修正、またはデバッグできます。
- GitHub統合:認証済みのGitHubコンテキストを使用して、リポジトリ、イシュー、プルリクエストと連携します。
- エージェント型実行モデル:ユーザーのコントロールを維持しながら、複数ステップのコーディングタスクを自律的に計画・実行できます。
- インタラクティブ+プログラマティックモード:会話形式のセッションや、CLIフラグによる単一コマンド自動化をサポートします。
- MCP拡張性:Model Context Protocolサーバーと統合して、外部ツールやデータソースで機能を拡張します。
- カスタムエージェントサポート:異なるワークフローやエンジニアリング標準に合わせた専門的なAI動作を可能にします。
- 安全性と承認システム:ファイルの実行・変更やシェルコマンドの実行前に明示的な許可を必要とします。
- モデルの柔軟性:異なるAIモデルを切り替えたり、外部プロバイダー(OpenAI互換、Azure、Anthropic、ローカルモデル)に接続したりできます。
- LSP(言語サーバープロトコル)サポート:外部LSPサーバーを介した診断、ホバー情報、定義へのジャンプなどの機能でコードインテリジェンスを強化します。
詳細については、ドキュメントをご確認ください。
動的なウェブデータの取得とディスカバリーでGitHub Copilotを拡張する理由
GitHub Copilot CLIに設定されたLLMがどれほど優れていても、普遍的な制約に直面します:情報の陳腐化です。大規模言語モデルはトレーニングデータに基づいて出力を生成するため、本質的に過去の静的なスナップショット内で動作します。
急速に変化する技術的な環境において、このタイムラグは大きなボトルネックです。オフラインのCLIエージェントは、非推奨のライブラリ構文を提案したり、最近のセキュリティパッチを考慮できなかったりする可能性があります。これらの障害を克服するには、AIツールにリアルタイムのウェブ統合が必要です。そこでBright Dataの出番です!
Bright DataのAI対応インフラにより、GitHub Copilot CLIエージェントはトレーニングデータを超えて自律的に以下のことができます:
- ライブ検索の実行:GoogleやほかのSERPをクエリして最新のドキュメントを見つけ、コマンドが最新のソフトウェアバージョンと互換性があることを確認します。
- 精度の検証:Stack OverflowのスレッドやGitHub Issuesと照合し、幻覚や古いコードに遭遇した際に自己修正します。
- 構造化データの取り込み:ライブのウェブコンテンツをスクレイピングして、ローカルデータベースへの入力やテスト用の正確なモックデータを生成します。
- ドキュメントの充実:
README.mdファイルや社内ウィキに有効で権威あるリンクを提案します。 - その他多数…
Bright Dataを際立たせるのは、195カ国にわたる4億以上のレジデンシャルIPからなる巨大なグローバルネットワークです。この基盤は無制限のスケーラビリティ、99.99%の稼働率、99.95%の成功率を提供します。その結果、本番環境対応の信頼性が高く堅牢なAI駆動の開発環境が実現します。
ウェブスクレイピングと検索機能でGitHub Copilot CLIを拡張する方法
Bright DataはGitHub Copilot CLIを2つの補完的な統合でサポートします:
- Bright Data Web MCP:Bright DataのAPIベースの製品とサービスとやり取りするための70以上のツールを公開する公式MCPサーバー。
- Bright Dataスキル:Copilotが検索、スクレイピング、データ抽出のためにBright Dataのツールを適切に使用する方法を教えるAgent Skillsのセット。
重要:これらの2つのアプローチは代替手段ではなく、相乗効果があります。具体的には、Bright DataスキルはAIコーディングエージェントがWeb MCPツールを最大限に活用するための特定のスキルを提供します。
Bright Data Web MCP
Bright Data Web MCPは70以上のツールを公開しており、自動ウェブデータ収集、構造化抽出、ブラウザ操作に対応しています。
無料ティアでも、以下のようなコアツールにアクセスできます:
| ツール | 説明 |
|---|---|
search_engine |
Google、Bing、またはYandexの結果をJSONまたはMarkdown形式で取得 |
scrape_as_markdown |
ボット保護を回避しながら任意のウェブページをクリーンなMarkdownに変換 |
discover |
ランク付けされた関連性の高い結果でAI搭載のウェブ検索を実行 |
search_engineとscrape_as_markdownのバッチバージョンも利用できます。
それでも、[Proモード](https://github.com/brightdata/brightdata-mcp?tab=readme-ov-file#-pricing, modes)はWeb MCPの真の可能性を解き放ちます。GitHub、NPM、Amazon、LinkedIn、Yahoo Finance、YouTube、TikTok、Zillow、Google Mapsなどのプラットフォームからの構造化抽出のための高度なツールが含まれます。さらに、ブラウザ自動化機能も利用できます。
Bright Dataスキル
Bright Dataスキルには以下が含まれます:
| スキル | 説明 |
|---|---|
search |
ページネーションとクリーンなJSON出力を備えた構造化Google検索 |
scrape |
ボット回避、CAPTCHA処理、JSレンダリングを備えた任意のウェブページのMarkdownスクレイピング |
data-feeds |
40以上のプラットフォーム(Amazon、LinkedIn、TikTok、YouTube、eBay、Walmartなど)からの事前構築済み構造化データセット |
bright-data-mcp |
検索、スクレイピング、抽出、自動化のためのMCPツールのオーケストレーション |
brightdata-cli |
スクレイピング、検索、プロキシ、抽出、監視のためのCLI使用法 |
scraper-builder |
分析から実装まで、本番環境対応スクレイパーの作成をガイド |
competitive-intel |
リアルタイムの競合情報(価格、レビュー、採用、SEOシグナル) |
design-mirror |
UIパターン、トークン、デザインシステムを複製 |
bright-data-best-practices |
Web Unlocker、SERP API、Scraper API、Browser APIのベストプラクティス |
python-sdk-best-practices |
Bright Data SDKの使用ガイド(同期/非同期、データセット、エラーなど) |
共通ステップ
次の2つの章では、MCPとAgent Skillsを使用してBright DataをGitHub Copilot CLIに統合する方法をそれぞれ説明します。まず、開始前に完了しておく必要のある共通の予備ステップに焦点を当てましょう。
前提条件
このチュートリアルに従うには、以下が必要です:
- Node.js 22以上がローカルにインストールされていること。
- GitHubアカウント、理想的にはCopilotプランが設定済みであること(無料プランでも動作します)。
- APIキーが設定されたBright Dataアカウント。
Bright Data APIキーを生成するには、公式ガイドに従ってください。
ステップ#1:GitHub Copilot CLIのインストール
以下のコマンドを実行して、@github/copilot npmパッケージ経由でGitHub Copilot CLIをインストールします:
npm install -g @github/copilot注意:GitHub Copilot CLIはHomebrewやWinGetでもインストールできます。ドキュメントで説明されています。
インストールが完了したら、以下のコマンドでCopilot CLIを実行できます:
copilot以上です!GitHub Copilot CLIがシステムに正常にインストールされました。
ステップ#2:セットアップの完了
ターミナルからプロジェクト用のフォルダを作成(または既存のフォルダに移動)します。この例では、github-copilot-cli-bright-data-exampleというディレクトリを使用します:
mkdir github-copilot-cli-bright-data-example
cd github-copilot-cli-bright-data-exampleプロジェクトフォルダ内で、GitHub Copilot CLIを起動します:
copilotツールを初めて実行すると、次のような画面が表示されます:
クイックスタートを完了するには、以下を実行します:
/loginこれにより、ローカルのGitHub Copilot CLIがGitHubアカウントに接続されます。まず、ログインするGitHubアカウントを選択します:

ブラウザでGitHubページが開き、デバイスを認証するためのコードの入力を求められます。次に、Copilot CLIをGitHubアカウントに接続し、必要な権限を付与するよう求められます:
権限を確認して「Authorize github」を押して確定します。
すでにCopilotプランをお持ちの場合は、そのまま進めます。そうでない場合は、Copilot無料プランを開始するよう求められます:

承認すると、次のような画面が表示されます:
この時点で、ログイン済みでCopilotプランがアクティブであることを確認する成功メッセージが表示されます。
よくできました!GitHub Copilot CLIのセットアップが正常に完了しました。
Web MCPを通じてBright DataをGitHub Copilot CLIに接続する
このセクションでは、GitHub Copilot CLIでBright Data Web MCPのローカルインスタンスを設定する方法を説明します。
前提条件
より理解しやすくするために、以下の知識があることをお勧めします:
- MCPの仕組みの基本的な理解。
- Bright Data Web MCPが公開するツールへの習熟。
また、「共通ステップ」の章に記載されている前提条件もここに適用されることを忘れないでください。
ステップ#1:Bright DataのWeb MCPのセットアップ
Bright DataのWeb MCPをCopilot CLIプロジェクトに追加する前に、MCPサーバーがマシン上で正しく動作することを確認してください。Bright Data Web MCPへのリモート接続を設定する予定の場合は、このステップをスキップしてください。
まず、Bright Dataアカウントにログインします。クイックセットアップのために、コントロールパネルの「MCP」セクションのウィザードに従ってください:
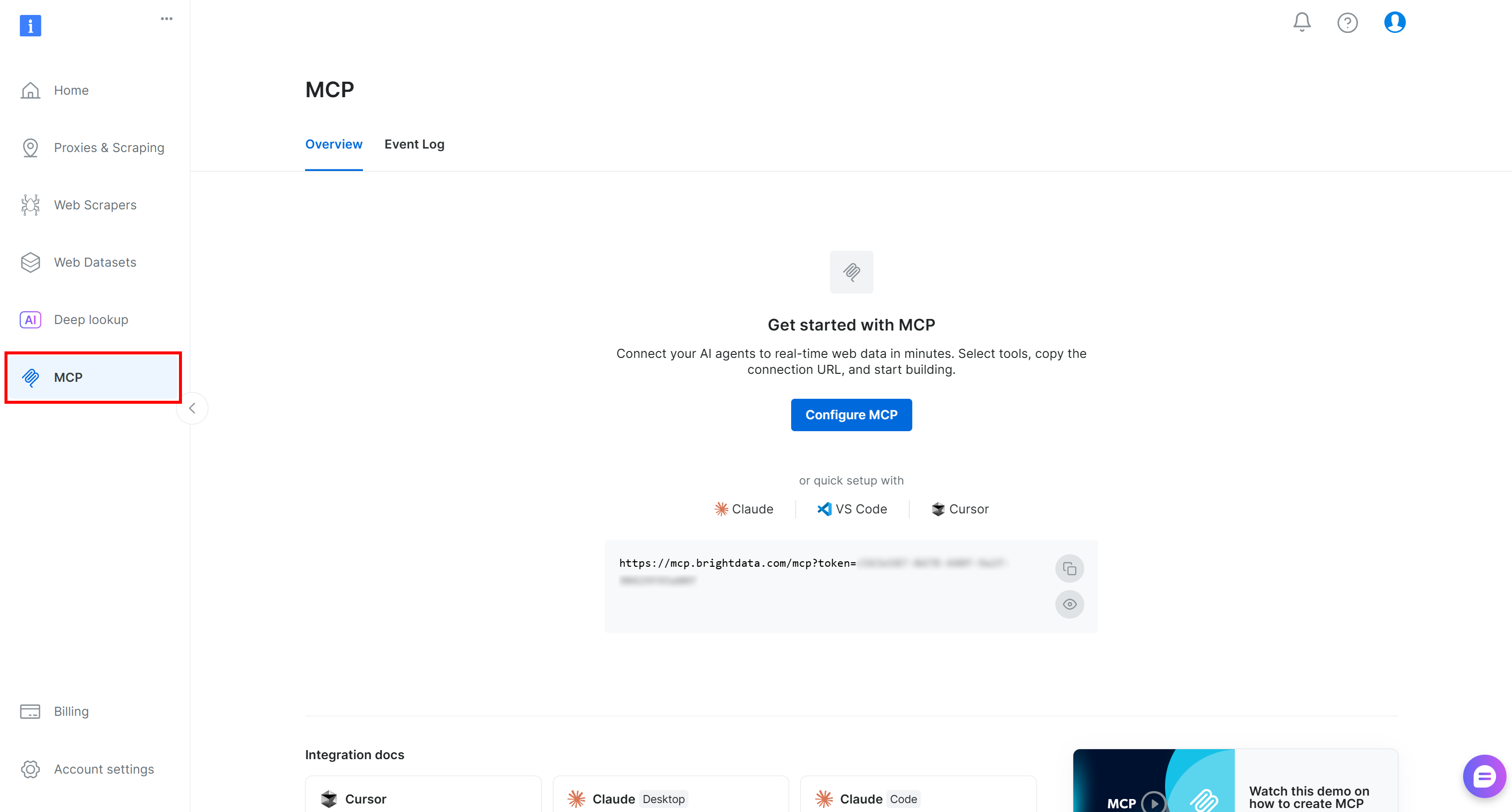
または、以下の手順に従ってください。
まず、@brightdata/mcpパッケージを追加してWeb MCPをグローバルにインストールします:
npm install -g @brightdata/mcp次に、MCPサーバーがローカルで起動することを確認します:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpまたは、PowerShellで同等のコマンド:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp<YOUR_BRIGHT_DATA_API>プレースホルダーを実際のBright Data APIキーに置き換えてください。このコマンドは必要なAPI_TOKEN環境変数を設定し、Web MCPサーバーをローカルで起動します。
すべてが正しく動作している場合、次のような出力が表示されます:

初回実行時、@brightdata/mcpパッケージはBright Dataアカウントに2つのゾーンを自動的に作成します:
mcp_unlocker:Web Unlocker用のゾーン。mcp_browser:Browser API用のゾーン。
これらのゾーンはWeb MCPで利用可能な60以上のツールを動かします。必要に応じてカスタムゾーンも設定できます。ドキュメントに記載されています。
デフォルトゾーンが作成されたことを確認するには、Bright Dataコントロールパネルの「プロキシ&スクレイピングインフラ」ページに移動します。両方のゾーンが一覧表示されているはずです:
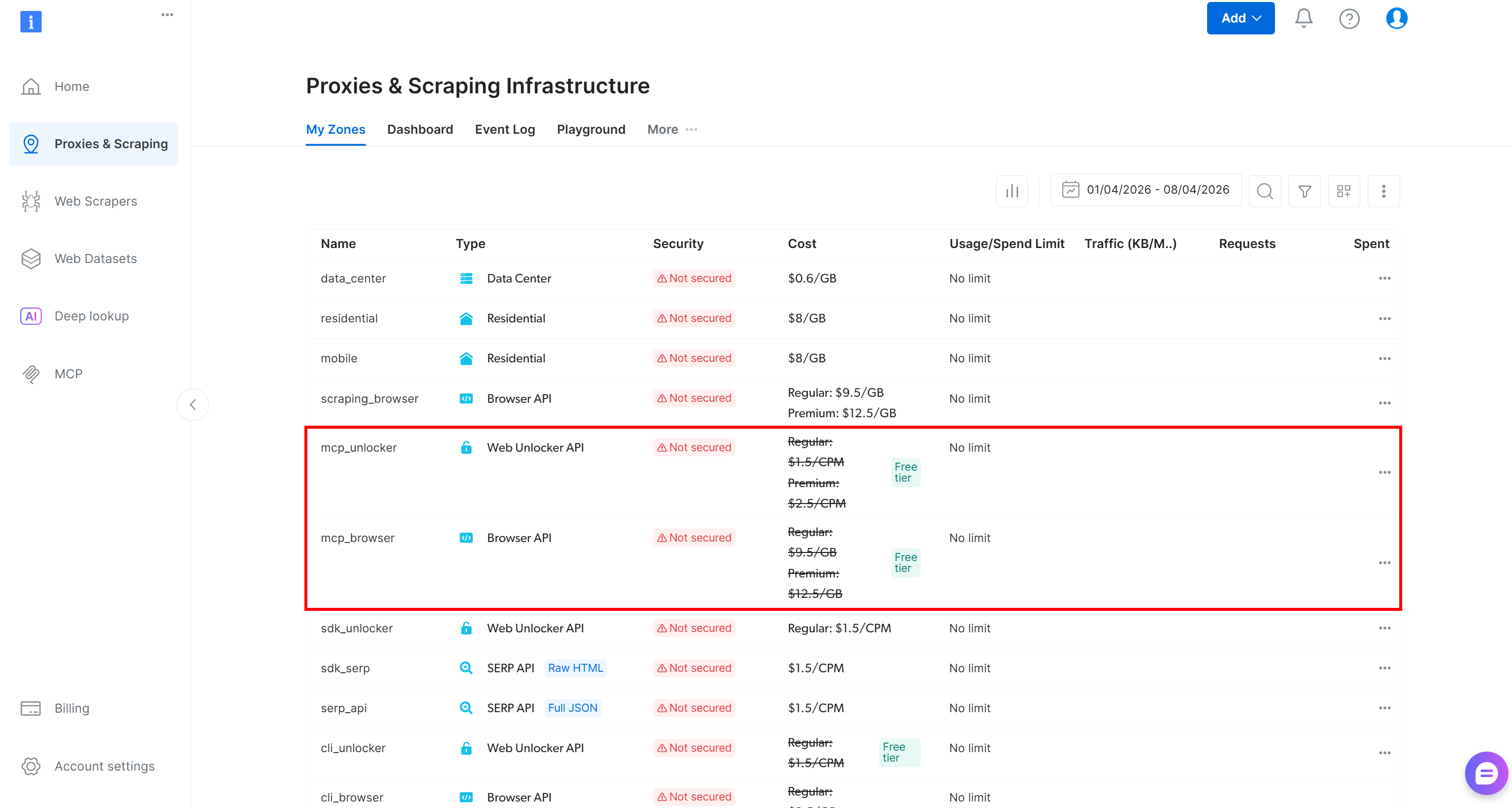
Web MCP無料ティアでは、利用可能なツールのセットが限られています:search_engine、scrape_as_markdown(およびそれらのバッチバージョン)とdiscoverツールです。
60以上のツールすべてをアンロックするには、PRO_MODE="true"環境変数を設定してProモードを有効化します:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpまたはWindowsの場合:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcp注意:Proモードは無料ティアには含まれておらず、[追加料金が発生します](https://github.com/brightdata/brightdata-mcp?tab=readme-ov-file#-pricing, modes)。
よくできました!Bright Data Web MCPがマシン上で動作することを確認しました。次に、GitHub Copilot CLIがサーバーを自動的に起動して接続するよう設定します。
ステップ#2:Web MCPの追加
GitHub Copilot CLIにMCPサーバー接続を追加するには、次のコマンドを実行します:
/mcp add必要な接続情報の入力を求められます。Tabキーでフィールド間を移動し、以下のように情報を入力します:
- MCP名:
bright-data-web-mcp(注意:名前にスペースは使用できません) - コマンド:
npx @brightdata/mcp - 環境変数:
{"API_TOKEN":"<YOUR_BRIGHT_DATA_API_KEY>", "PRO_MODE":"true"}(JSONキーと値のオブジェクトとして提供する必要があります) - ツール:
*(すべてのツールを有効にするため)
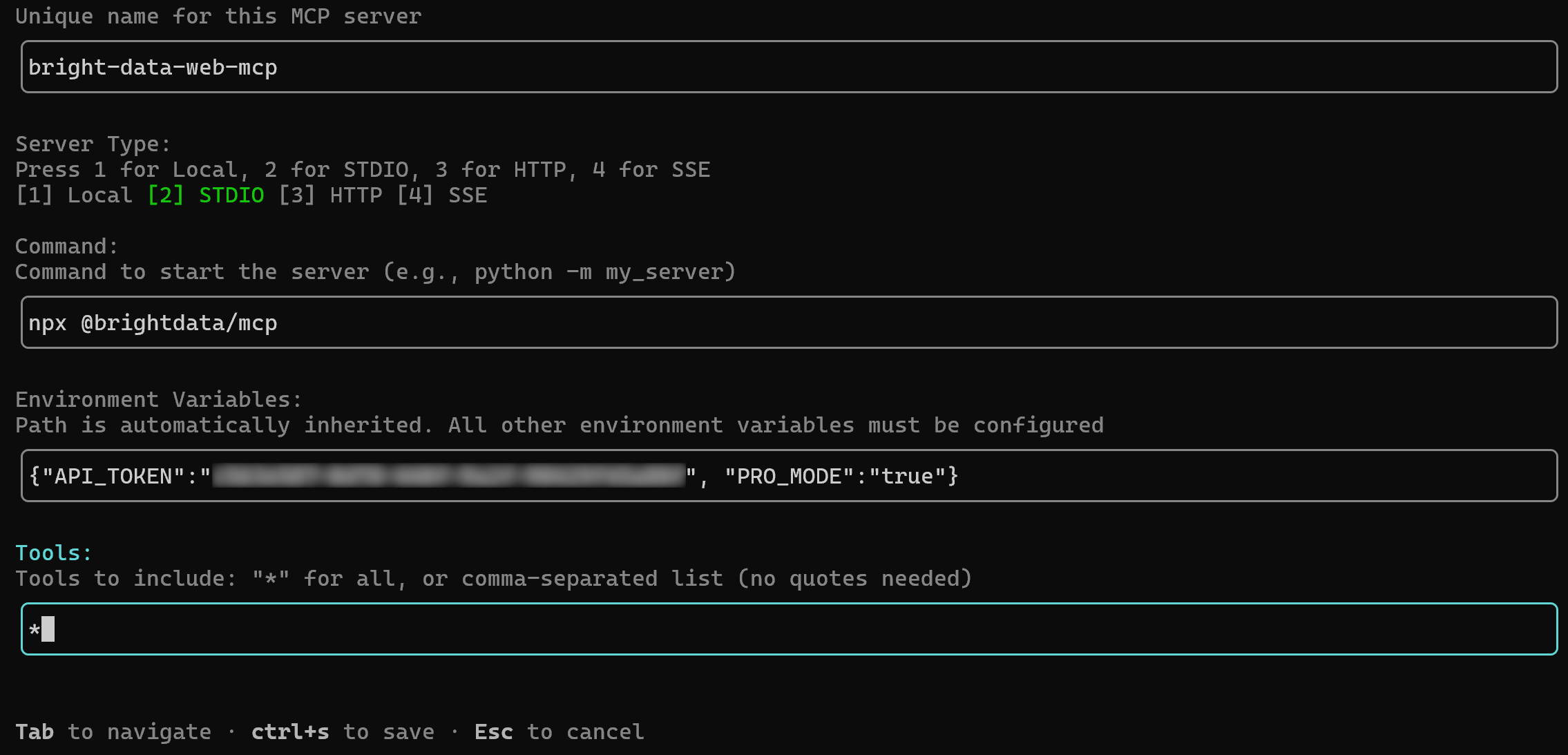
完了したら、Ctrl+Sを押して保存します。
上記の設定は、先ほどテストしたnpxコマンドを反映しており、認証情報とセットアップに環境変数を使用しています:
API_TOKEN:必須。Bright Data APIキーに設定します。PRO_MODE:オプション。Proモードを有効にしたくない場合は削除(または"false"に設定)します。
これでGitHub Copilot CLIは指定したnpxコマンドを使用してMCPサーバーを起動し、自動的に接続します。2つの確認メッセージが表示されます:

少なくとも2つのサーバーが表示されます。(1つは組み込みのgithub-mcp-server、もう1つは新しく設定されたBright Data Web MCPです。)
MCPサーバーの設定はグローバルの~/.copilot/mcp-config.json設定ファイルに保存されます。
代替アプローチ:~/.copilot/mcp-config.jsonファイルを直接編集して、以下の内容を含めます:
{
"mcpServers": {
"bright-data-web-mcp": {
"type": "stdio",
"command": "npx",
"tools": [
"*"
],
"args": [
"@brightdata/mcp"
],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
}
}
}ファイルを保存した後、GitHub Copilot CLIセッション内で以下のコマンドを実行します:
/mcp reloadいずれの方法でも、GitHub Copilot CLIのセットアップはBright Data Web MCPのローカルインスタンスに接続されます。すばらしい!
ステップ#3:接続の動作確認
/mcp addコマンドを実行して成功メッセージを確認した直後、次のような画面が表示されます:
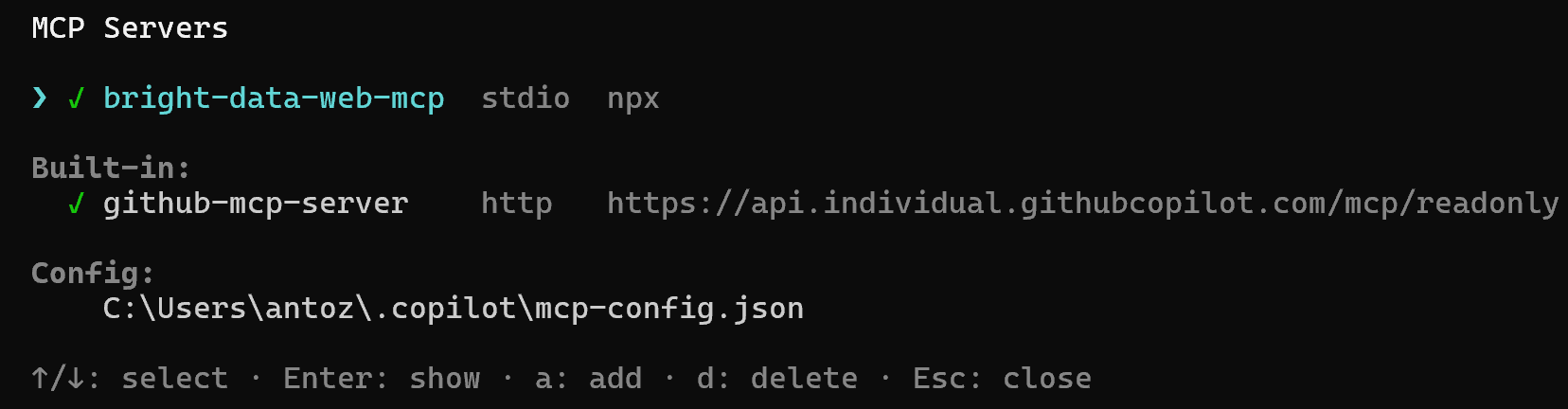
注意:その画面は/mcp showコマンドの出力に対応しています。表示されない場合は、コマンドからアクセスしてください。
bright-data-web-mcpオプションを選択してEnterを押します。利用可能なすべてのツールのリストが表示されます。Proモードでは、70以上のツールが含まれます:
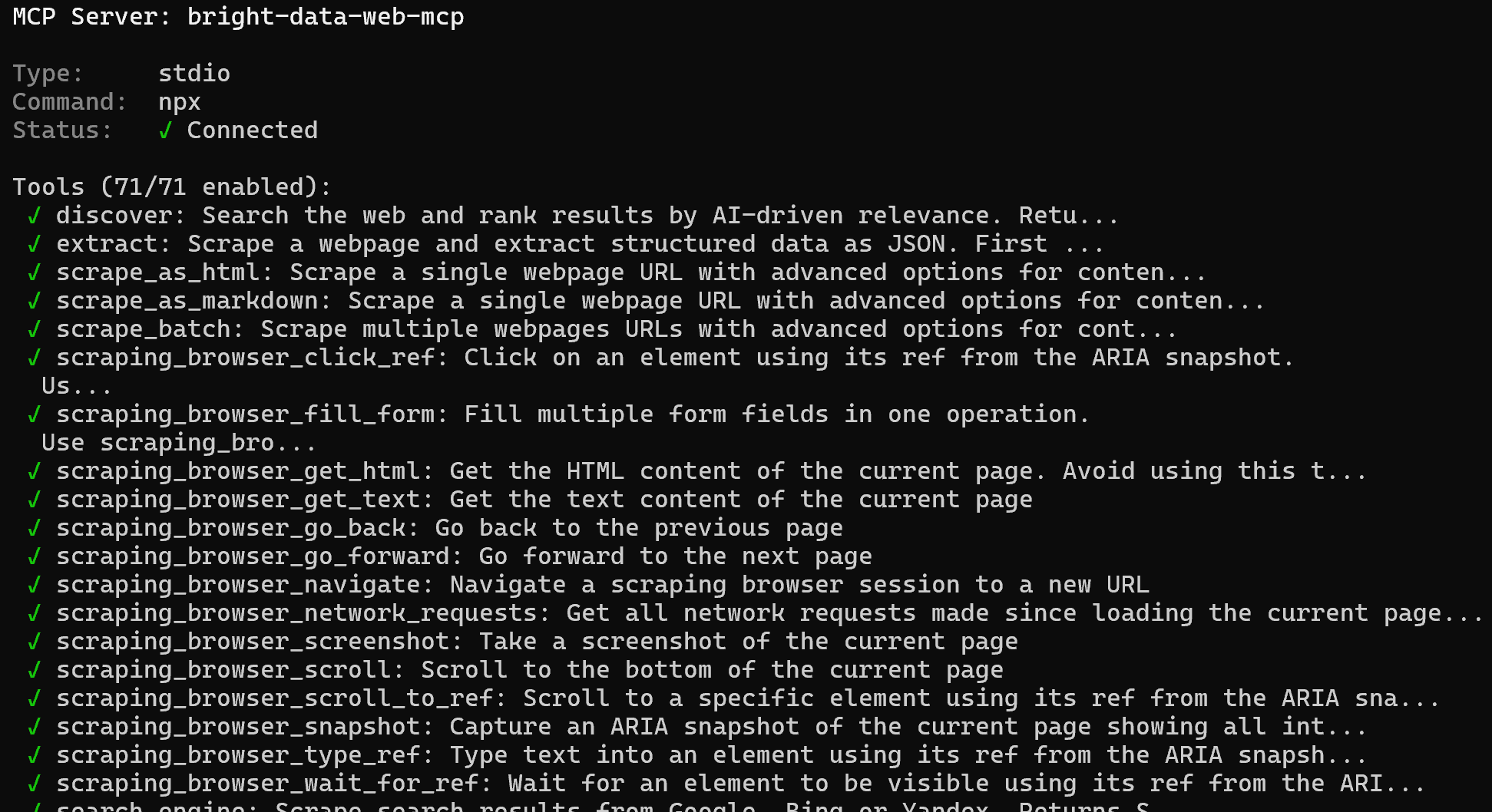
おめでとうございます!これにより、Bright Data Web MCPがGitHub Copilot CLIにツールを正しく公開していることが確認されます。このブログ記事の後半では、Bright DataスキルとともにWeb MCPの動作を実際に体験します。
GitHub Copilot CLIにBright Dataスキルを追加する
この章では、GitHub Copilot CLIプロジェクトにBright Dataスキルを追加する方法を説明します。これはVercelのskillsツールが提供するガイド付きワークフローを使用して実現します。
クイック手動セットアップ:手動セットアップを希望する場合は、Bright Data Skillsリポジトリをクローンしてください。次に、skills/skills/フォルダの内容をプロジェクトの~/.copilot/skills(または~/.agents/skills/skills/)ディレクトリにコピーします:
git clone https://github.com/brightdata/skills
cp -r skills/skills/* ~/.copilot/skills/ただし、以下のガイド付きアプローチの方がシンプルで信頼性が高いため、そちらを進めましょう!
前提条件
このセクションを完了するには、以下が必要です:
- Linux、macOS、またはWindows上のWSLなど、Unixベースのオペレーティングシステム。(注意:執筆時点では、これはまだ要件ですが、Bright DataスキルのWindowsサポートは近日公開予定です。)
- Agent Skillsスタンダードの基本的な理解。
- AIエージェントスキルを管理するためのVercelの
skillsCLIツールへの習熟。 - Bright Dataスキルの基本的な知識。
「共通ステップ」の章の前提条件に加えて、以下も必要です:
- Bright Dataアカウントに設定されたWeb Unlocker APIゾーン。
- ローカルにインストールされた
jqパッケージ。
Debianベースのオペレーティングシステムにjq(sedに似た軽量JSONプロセッサ)をインストールするには、以下を実行します:
sudo apt-get install curl jqmacOSの場合は、以下を実行します:
brew install curl jqWeb Unlocker APIゾーンのクイックセットアップについては、「最初のUnlocker APIを作成する」ガイドを参照してください。または、以下のステップを続けてください。
ステップ#1:Web Unlocker APIゾーンの追加
Bright Dataアカウントにログインして、「プロキシ&スクレイピングインフラ」ページに移動します。次に「マイゾーン」テーブルを確認します:
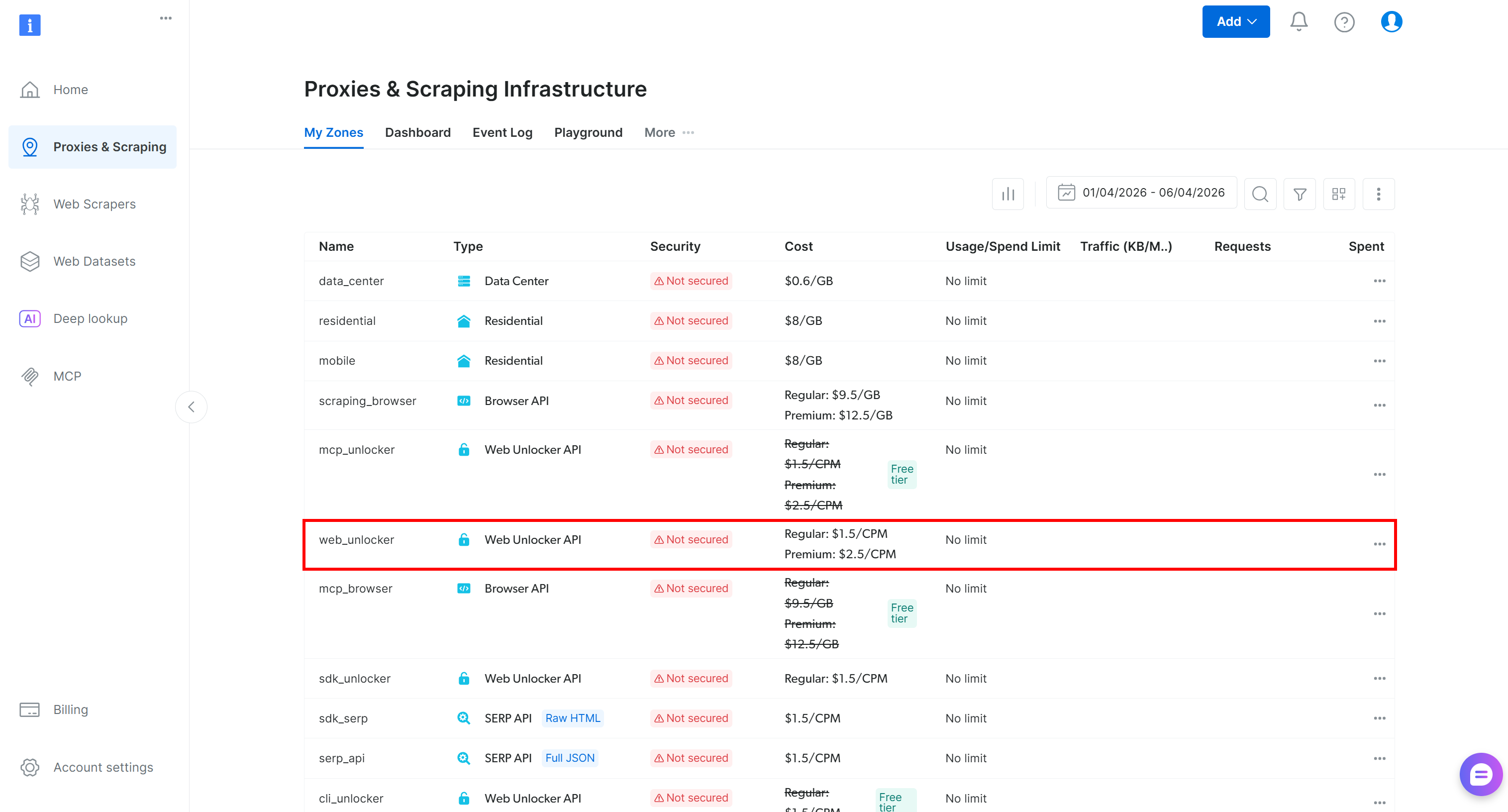
Web Unlockerゾーン(例:web_unlocker)がすでに存在する場合は、このステップをスキップできます。
存在しない場合は、「Unblocker API」カードまでスクロールして「ゾーンを作成」をクリックして作成します:
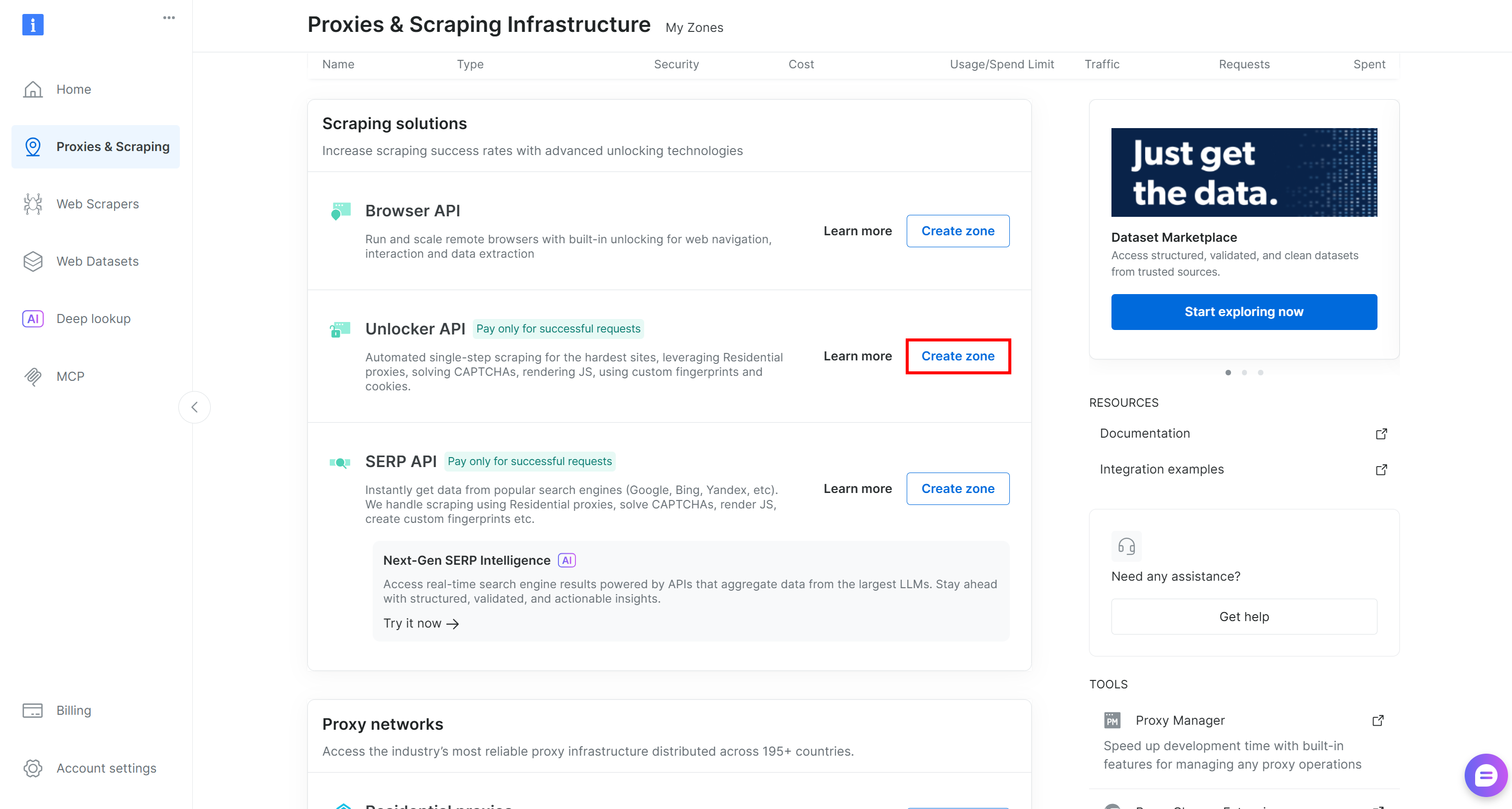
ゾーンにわかりやすい名前を選択し、ゾーンがアクティブになるまでセットアップウィザードを完了します。すばらしい!
ステップ#2:セットアップの完了
Bright Dataスキルが動作するには、以下の2つの環境変数が必要です:
BRIGHTDATA_API_KEY:Bright Data APIへのリクエストを認証するために使用されます。BRIGHTDATA_UNLOCKER_ZONE:Web Unlocker APIゾーンを指定し、ウェブスクレイピングと検索機能を有効にします(SERP APIとしても機能できます)。
ターミナルで必要な環境変数を以下のように設定します:
export BRIGHTDATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"
export BRIGHTDATA_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_API_ZONE_NAME>"プレースホルダーを実際の値に置き換えてください。設定が完了したら、Bright Dataスキルを使用する準備が整いました!
ステップ#3:Bright Dataスキルのインストール
GitHub Copilot CLIにBright Dataスキルをインストールするには、以下のコマンドを実行します:
npx skills add brightdata/skills -a github-copilotこのコマンドはskillsパッケージをインストールしてセットアッププロセスを開始します。これにより:
- 公式Agent Skillsディレクトリからのブライトデータスキルのダウンロード。
- GitHub Copilot CLIで使用するための設定。
最初に、インストールするスキルを選択できる画面が表示されます:
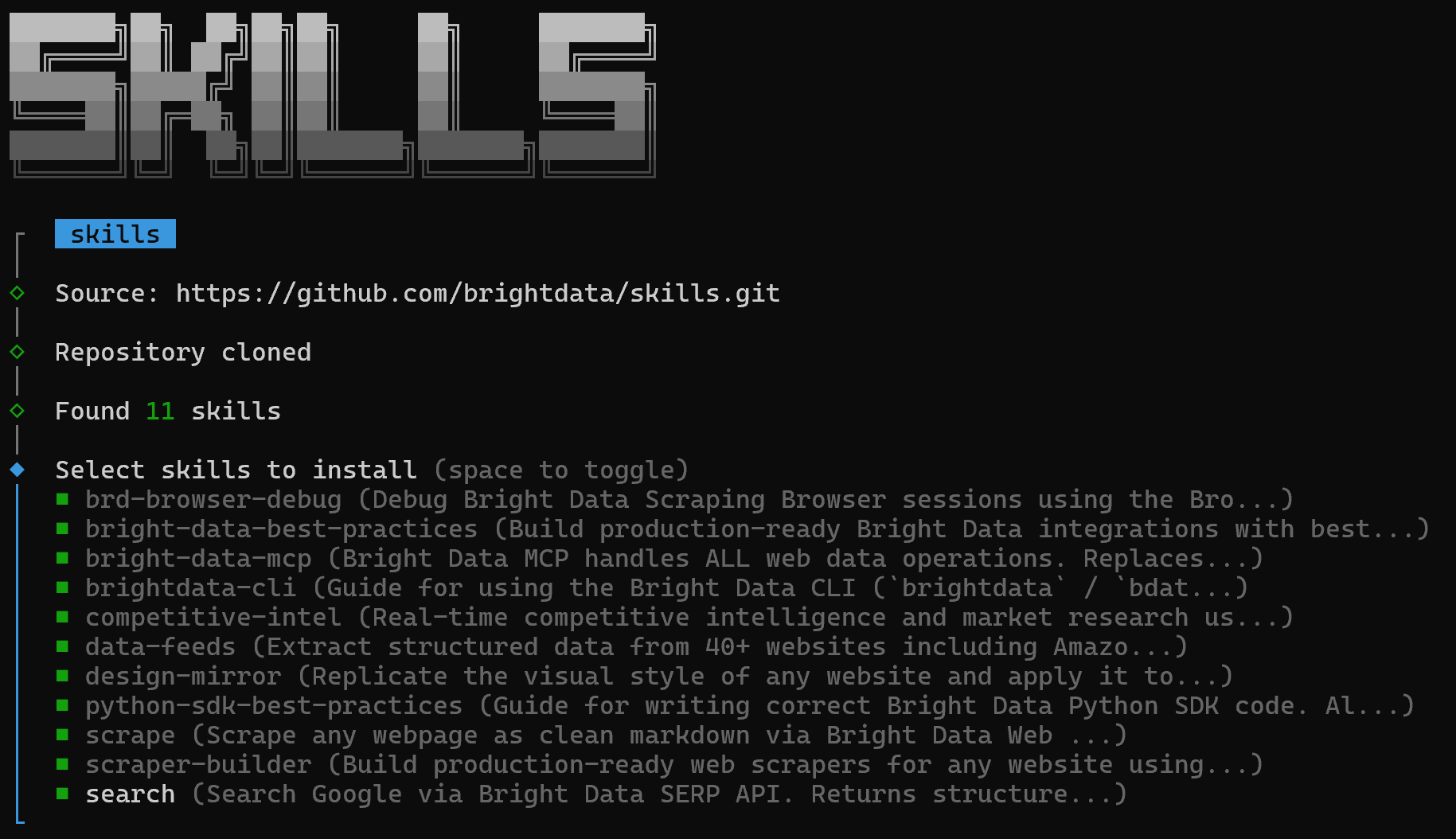
すべてインストールするには、スペースバーで各スキルを選択してからEnterを押します。
次に、インストールスコープの選択を求められます。Web MCP統合がグローバルに設定されているため、Bright Dataスキルもグローバルにインストールするのが理にかなっています。「グローバル」オプションを選択します:

「インストールサマリー」と「セキュリティリスク評価」セクションが表示されます。両方を注意深く確認してEnterを押して確定します。最後に、次のような確認メッセージが表示されます:
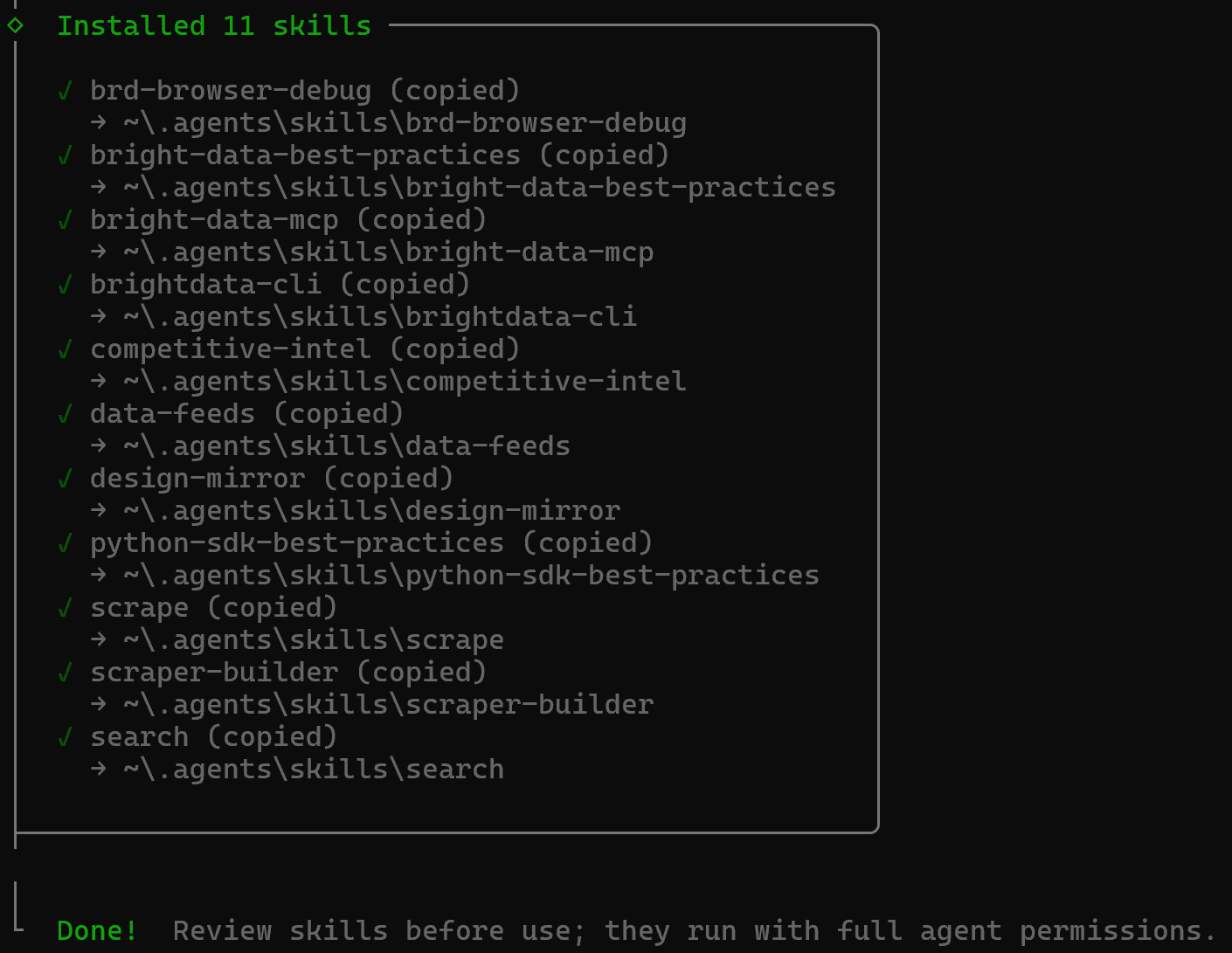
Bright Data Skillsは~/.agents/skillsディレクトリ(または~/.copilot/skills、~/.claude/skills)にコピーされます。
すばらしい!Bright DataスキルがCopilot CLIにインストールされ、利用可能になりました。
ステップ#4:スキルが利用可能であることを確認する
GitHub Copilot CLIセッションで、以下のコマンドですべてのスキルをリロードします:
/skills reload次のような結果が表示されます:

スキルの合計数は12です(11のBright Dataスキル+組み込みのcustomize-cloud-agentスキル)。
次に、利用可能なすべてのスキルを以下のコマンドで一覧表示します:
/skills list出力は次のようになります:

一覧表示されたスキルはBright Dataのスキル名と一致しており、正しくインストールされたことを確認しています。
ミッション完了!次の章では、GitHub Copilot CLIでBright Data Web MCPとAgent Skillsのセットアップを完全に活用する方法を体験します。
GitHub Copilot CLI + Bright Data:次世代AIコーディングアシスタンス
MCPとスキルの両方を通じてBright DataをCopilot CLIに統合したので、このセットアップが何を可能にするかを探る時です。実践的な実世界の例を見ていきます。他にも多くのユースケースが可能です。
GitHub Copilot CLIを最大限に活用する方法(プロンプトテクニック、ベストプラクティスなど)と、それを拡張する方法(エージェント、スキルなど)についてのリソースを学びたいとします。手動で何十ものソースを検索して確認する代わりに、コーディングアシスタントに以下のMarkdownレポートの生成を依頼してみましょう:
Search online for the best GitHub Copilot repositories and official GitHub Copilot CLI best practices. Scrape the top pages and generate a `.md` file containing the main instructions on how to get the most out of GitHub Copilot CLI, along with useful resources for extensions (agents, skills, etc.). Include contextual links discovered from the scraped pages.明らかに、標準的なAIコーディングエージェントはこのタスクに苦労するでしょう。ウェブ検索、ディスカバリー、スクレイピング機能のためのツールが必要だからです。
プロンプトを実行すると、次のような結果が得られます:
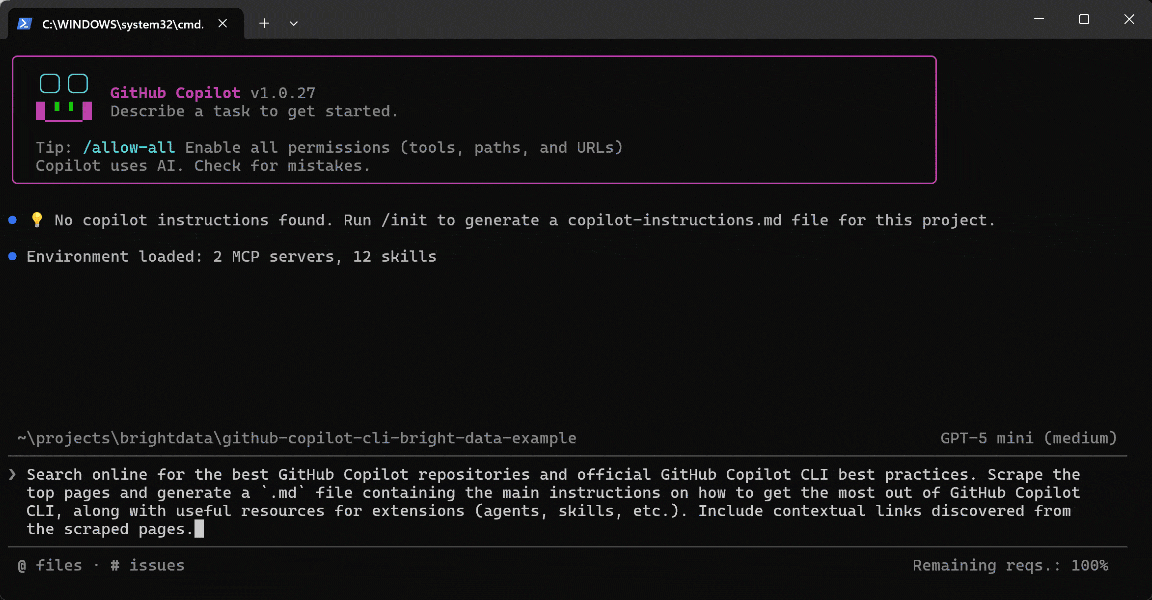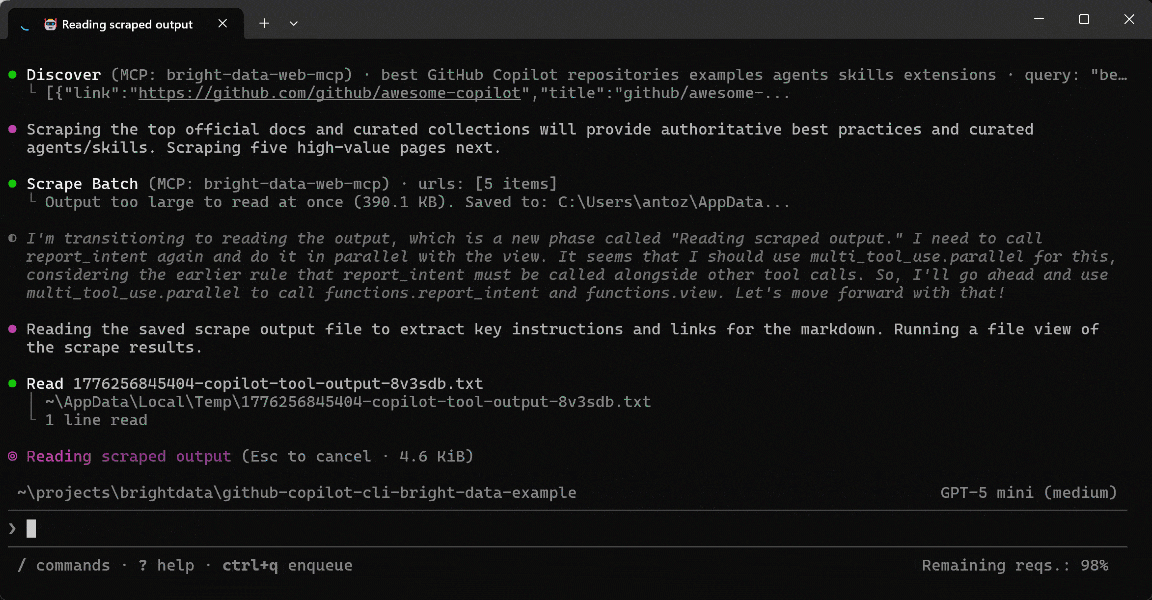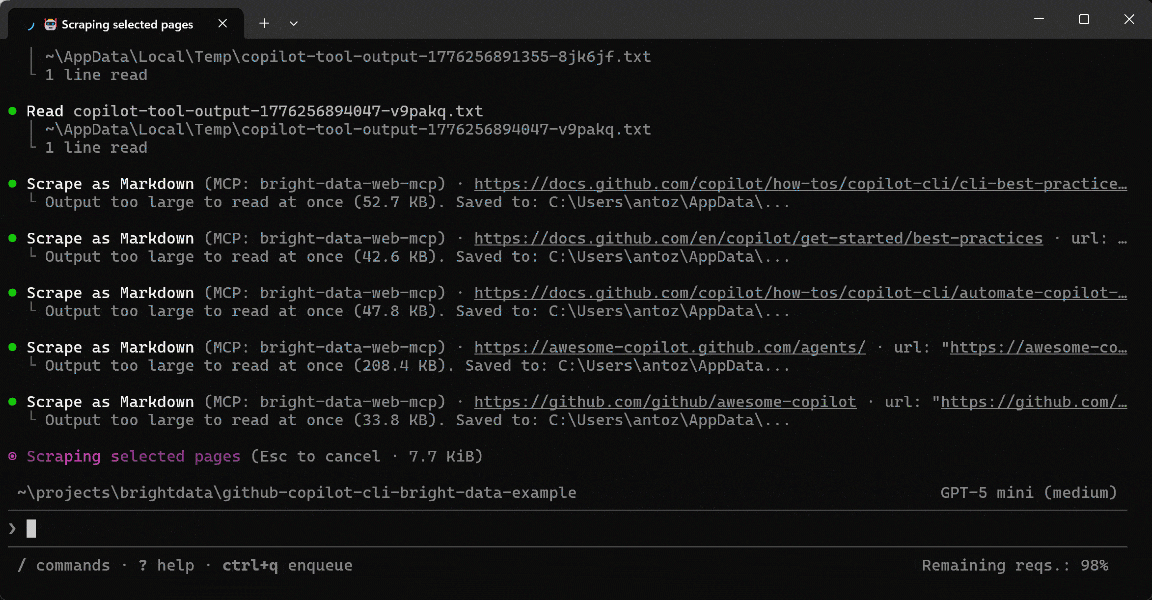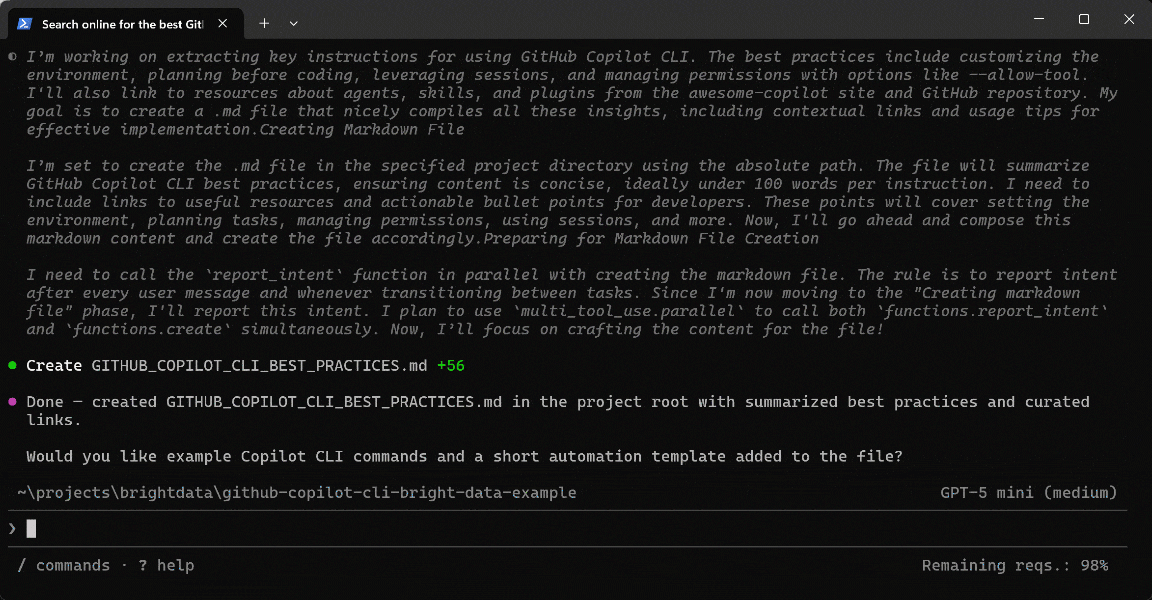
GitHub Copilot CLIエージェントが実際に行ったことは次のとおりです:
discoverツールを呼び出して複数のクエリを実行し、ベストプラクティスとリポジトリに関するランク付けされた関連ページを取得しました(Bright DataのWeb Discovery API経由)。- 権威ある高品質なソースを優先するために最も関連性の高いURLを選択しました。
scrape_batch(Web Unlocker APIを使用)を使用して、1回のリクエストで複数のページからコンテンツを効率的に抽出しました。- 追加のネットワーク呼び出しなしに主要なセクションを識別するために、スクレイピングした出力をローカルで処理しました。
- ターゲットを絞った検索(例:
grep)を適用して、関連するベストプラクティスを分離し、さらに分析するページを絞り込みました。 scrape_as_markdownツールを使用して、選択したページをクリーンで構造化されたMarkdownに変換しました。- ドキュメント用の構造化データセットにインサイトとコンテキストリンクを集約しました。
- ベストプラクティス、リソース、リンクを含む最終的な
.mdファイルを生成しました。
注意:Copilot CLIは各ステップに最適なBright Dataツールを自動的に選択しました。これはBright Dataスキルによって可能になり、エージェントの意思決定をガイドします。
生成された出力は以下のGITHUB_COPILOT_CLI_BEST_PRACTICES.mdファイルです:
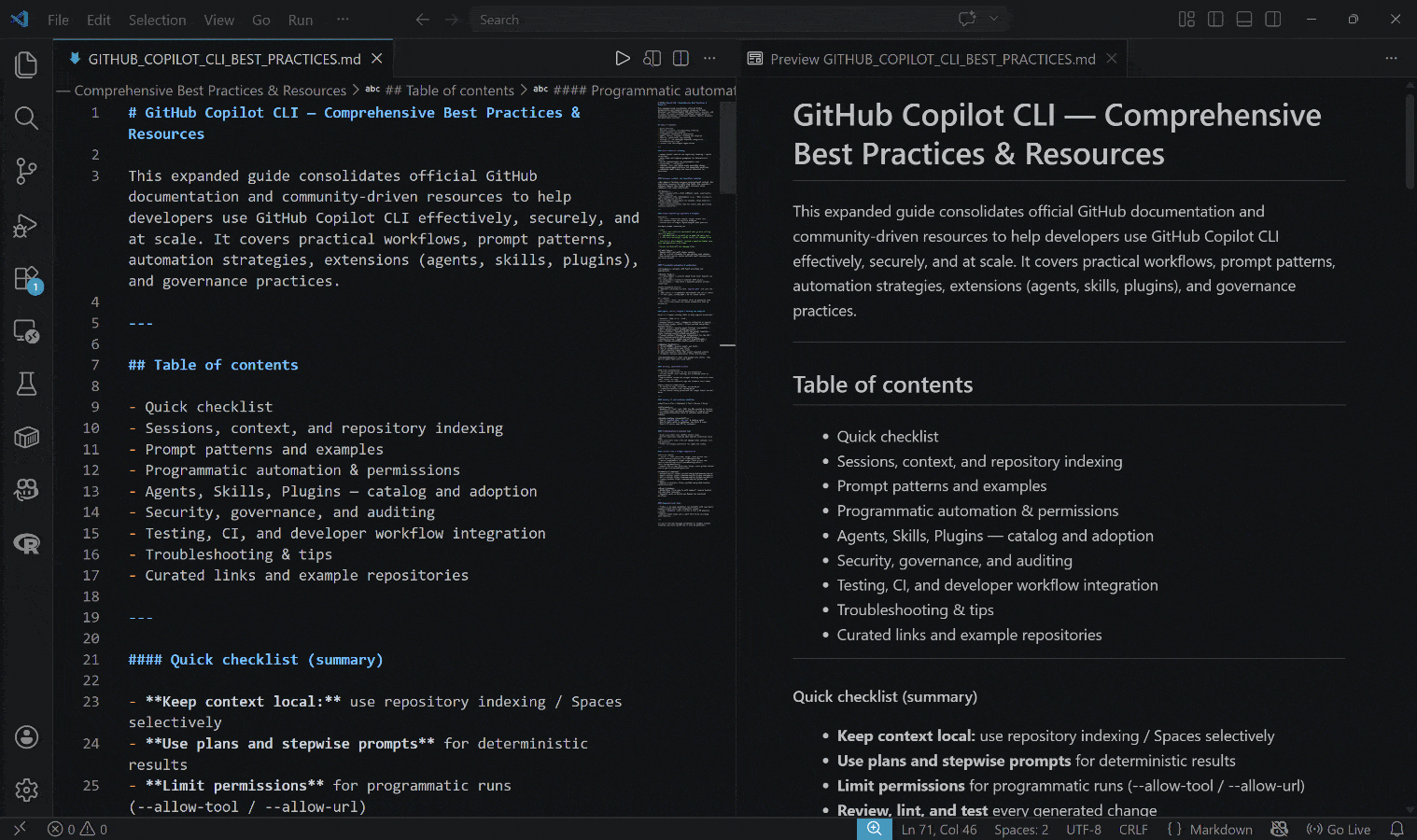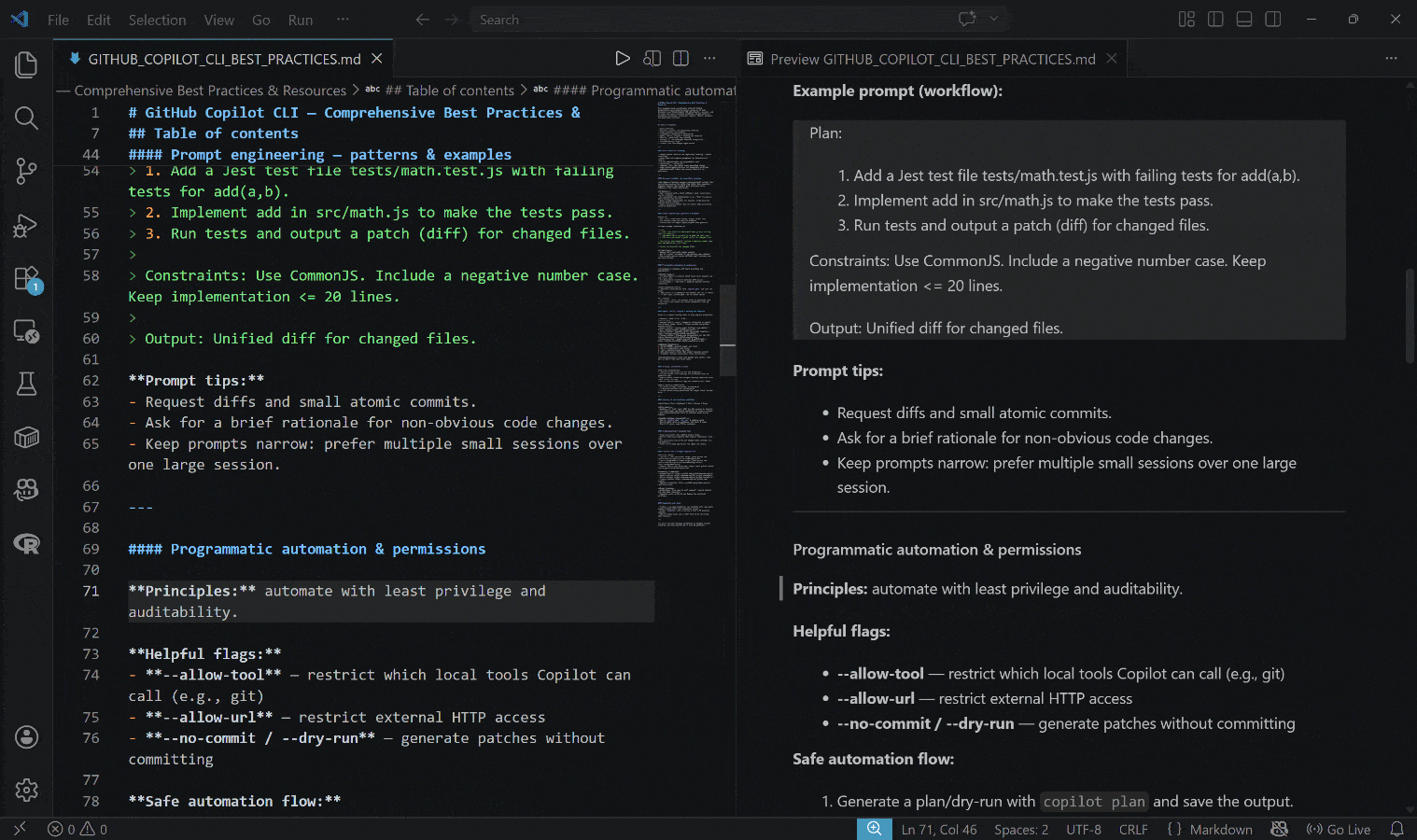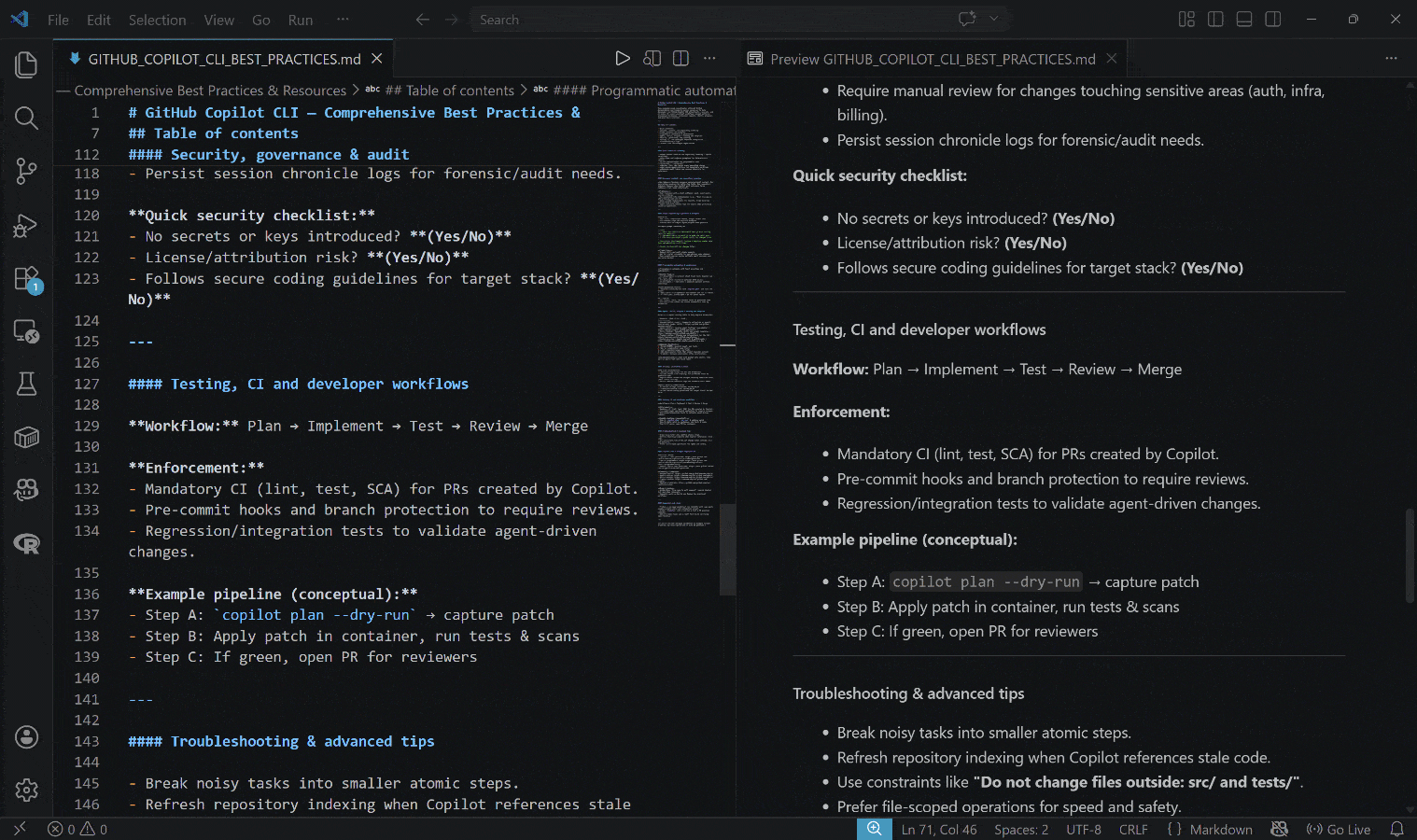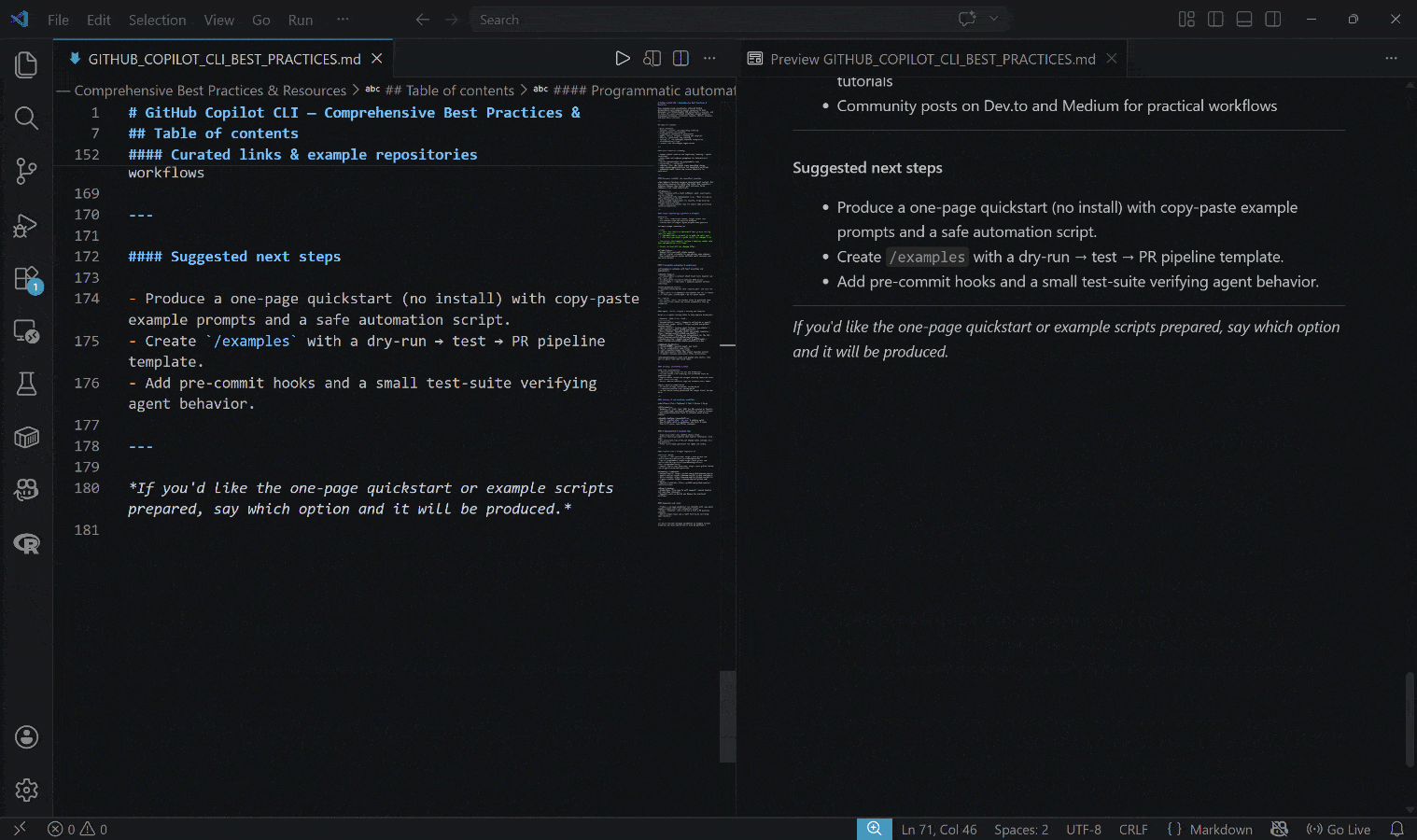
結果には実際のリンクと実践的な例に裏付けられた、リアルタイムのコンテキスト情報が含まれていることに注目してください。
これで完成です!このシンプルな例は、Bright DataをGitHub Copilot CLIと統合する力を示しています。他のプロンプトを試して、コーディングエージェントがより正確な結果のためにウェブと積極的にやり取りするようにしましょう。
まとめ
この記事では、GitHub Copilot CLIとは何か、そして何をもたらすかを理解しました。具体的には、Web MCPと公式スキルを介してBright Dataに接続することで、なぜ、どのようにそれを拡張するかを見ました。
この統合により、Copilot CLIのコーディング体験がまったく新しいレベルに引き上げられます。基盤となるAIコーディングエージェントが、ウェブ検索、ウェブディスカバリー、構造化データ抽出、自動化されたウェブインタラクションなどの強力な新機能を獲得するためです。
さらに高度なワークフローについては、Bright DataエコシステムのAI対応サービスの全範囲をご覧ください。
今すぐ無料でBright Dataアカウントを作成して、ウェブデータツールをお試しください!





